Example 4.36
Consider an arbitrary connected graph (see Section 3.6 for definitions) having a number 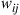 associated with arc (
associated with arc ( ) for each arc. One instance of such a graph is given by Figure 4.1. Now consider a particle moving from node to node in this manner: If at any time the particle resides at node
) for each arc. One instance of such a graph is given by Figure 4.1. Now consider a particle moving from node to node in this manner: If at any time the particle resides at node  , then it will next move to node
, then it will next move to node 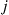 with probability
with probability 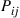 where
where
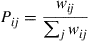
and where  is 0 if (
is 0 if ( ) is not an arc. For instance, for the graph of Figure 4.1,
) is not an arc. For instance, for the graph of Figure 4.1, 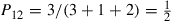 .
.
The time reversibility equations

reduce to

or, equivalently, since 
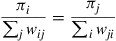
which is equivalent to

or

or, since 

Because the 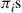 given by this equation satisfy the time reversibility equations, it follows that the process is time reversible with these limiting probabilities.
given by this equation satisfy the time reversibility equations, it follows that the process is time reversible with these limiting probabilities.
For the graph of Figure 4.1 we have that


If we try to solve Equation (4.22) for an arbitrary Markov chain with states  , it will usually turn out that no solution exists. For example, from Equation (4.22),
, it will usually turn out that no solution exists. For example, from Equation (4.22),

implying (if 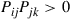 ) that
) that

which in general need not equal 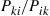 . Thus, we see that a necessary condition for time reversibility is that
. Thus, we see that a necessary condition for time reversibility is that
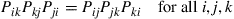 (4.25)
(4.25)
which is equivalent to the statement that, starting in state  , the path
, the path 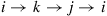 has the same probability as the reversed path
has the same probability as the reversed path  . To understand the necessity of this, note that time reversibility implies that the rate at which a sequence of transitions from
. To understand the necessity of this, note that time reversibility implies that the rate at which a sequence of transitions from  to
to  to
to 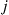 to
to  occurs must equal the rate of ones from
occurs must equal the rate of ones from  to
to  to
to 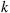 to
to 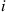 (why?), and so we must have
(why?), and so we must have

implying Equation (4.25) when  .
.
In fact, we can show the following.
Theorem 4.2
An ergodic Markov chain for which  whenever
whenever  is time reversible if and only if starting in state
is time reversible if and only if starting in state 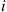 , any path back to
, any path back to 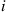 has the same probability as the reversed path. That is, if
has the same probability as the reversed path. That is, if
 (4.26)
(4.26)
for all states  .
.
Proof
We have already proven necessity. To prove sufficiency, fix states  and
and  and rewrite (4.26) as
and rewrite (4.26) as

Summing the preceding over all states  yields
yields
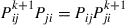
Letting  yields
yields
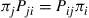
which proves the theorem. ■
Example 4.37
Suppose we are given a set of 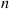 elements, numbered 1 through
elements, numbered 1 through  , which are to be arranged in some ordered list. At each unit of time a request is made to retrieve one of these elements, element
, which are to be arranged in some ordered list. At each unit of time a request is made to retrieve one of these elements, element  being requested (independently of the past) with probability
being requested (independently of the past) with probability  . After being requested, the element then is put back but not necessarily in the same position. In fact, let us suppose that the element requested is moved one closer to the front of the list; for instance, if the present list ordering is 1, 3, 4, 2, 5 and element 2 is requested, then the new ordering becomes 1, 3, 2, 4, 5. We are interested in the long-run average position of the element requested.
. After being requested, the element then is put back but not necessarily in the same position. In fact, let us suppose that the element requested is moved one closer to the front of the list; for instance, if the present list ordering is 1, 3, 4, 2, 5 and element 2 is requested, then the new ordering becomes 1, 3, 2, 4, 5. We are interested in the long-run average position of the element requested.
For any given probability vector  , the preceding can be modeled as a Markov chain with
, the preceding can be modeled as a Markov chain with  ! states, with the state at any time being the list order at that time. We shall show that this Markov chain is time reversible and then use this to show that the average position of the element requested when this one-closer rule is in effect is less than when the rule of always moving the requested element to the front of the line is used. The time reversibility of the resulting Markov chain when the one-closer reordering rule is in effect easily follows from Theorem 4.2. For instance, suppose
! states, with the state at any time being the list order at that time. We shall show that this Markov chain is time reversible and then use this to show that the average position of the element requested when this one-closer rule is in effect is less than when the rule of always moving the requested element to the front of the line is used. The time reversibility of the resulting Markov chain when the one-closer reordering rule is in effect easily follows from Theorem 4.2. For instance, suppose  and consider the following path from state (1, 2, 3) to itself:
and consider the following path from state (1, 2, 3) to itself:

The product of the transition probabilities in the forward direction is

whereas in the reverse direction, it is

Because the general result follows in much the same manner, the Markov chain is indeed time reversible. (For a formal argument note that if  denotes the number of times element
denotes the number of times element 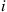 moves forward in the path, then as the path goes from a fixed state back to itself, it follows that element
moves forward in the path, then as the path goes from a fixed state back to itself, it follows that element  will also move backward
will also move backward  times. Therefore, since the backward moves of element
times. Therefore, since the backward moves of element 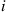 are precisely the times that it moves forward in the reverse path, it follows that the product of the transition probabilities for both the path and its reversal will equal
are precisely the times that it moves forward in the reverse path, it follows that the product of the transition probabilities for both the path and its reversal will equal
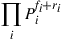
where  is equal to the number of times that element
is equal to the number of times that element  is in the first position and the path (or the reverse path) does not change states.)
is in the first position and the path (or the reverse path) does not change states.)
For any permutation  of
of  , let
, let 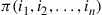 denote the limiting probability under the one-closer rule. By time reversibility we have
denote the limiting probability under the one-closer rule. By time reversibility we have
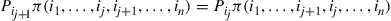 (4.27)
(4.27)
for all permutations.
Now the average position of the element requested can be expressed (as in Section 3.6.1) as

Hence, to minimize the average position of the element requested, we would want to make 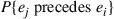 as large as possible when
as large as possible when  and as small as possible when
and as small as possible when 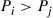 . Under the front-of-the-line rule we showed in Section 3.6.1,
. Under the front-of-the-line rule we showed in Section 3.6.1,
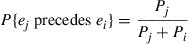
(since under the front-of-the-line rule element  will precede element
will precede element  if and only if the last request for either
if and only if the last request for either  or
or  was for
was for  ).
).
Therefore, to show that the one-closer rule is better than the front-of-the-line rule, it suffices to show that under the one-closer rule
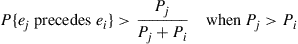
Now consider any state where element  precedes element
precedes element 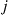 , say, (
, say, ( ). By successive transpositions using Equation (4.27), we have
). By successive transpositions using Equation (4.27), we have
 (4.28)
(4.28)
For instance,

Now when 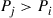 , Equation (4.28) implies that
, Equation (4.28) implies that

Letting  , we see by summing over all states for which
, we see by summing over all states for which 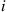 precedes
precedes 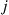 and by using the preceding that
and by using the preceding that
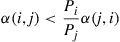
which, since  , yields
, yields

Hence, the average position of the element requested is indeed smaller under the one-closer rule than under the front-of-the-line rule. ■
The concept of the reversed chain is useful even when the process is not time reversible. To illustrate this, we start with the following proposition whose proof is left as an exercise.
Proposition 4.9
Consider an irreducible Markov chain with transition probabilities 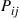 . If we can find positive numbers
. If we can find positive numbers  , summing to one, and a transition probability matrix
, summing to one, and a transition probability matrix 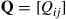 such that
such that
 (4.29)
(4.29)
then the 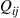 are the transition probabilities of the reversed chain and the
are the transition probabilities of the reversed chain and the 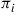 are the stationary probabilities both for the original and reversed chain.
are the stationary probabilities both for the original and reversed chain.
The importance of the preceding proposition is that, by thinking backward, we can sometimes guess at the nature of the reversed chain and then use the set of Equations (4.29) to obtain both the stationary probabilities and the  .
.
Example 4.38
A single bulb is necessary to light a given room. When the bulb in use fails, it is replaced by a new one at the beginning of the next day. Let  equal
equal  if the bulb in use at the beginning of day
if the bulb in use at the beginning of day 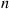 is in its
is in its 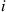 th day of use (that is, if its present age is
th day of use (that is, if its present age is 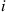 ). For instance, if a bulb fails on day
). For instance, if a bulb fails on day  , then a new bulb will be put in use at the beginning of day
, then a new bulb will be put in use at the beginning of day  and so
and so 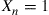 . If we suppose that each bulb, independently, fails on its
. If we suppose that each bulb, independently, fails on its 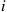 th day of use with probability
th day of use with probability  , then it is easy to see that
, then it is easy to see that 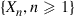 is a Markov chain whose transition probabilities are as follows:
is a Markov chain whose transition probabilities are as follows:
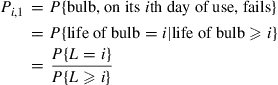
where 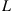 , a random variable representing the lifetime of a bulb, is such that
, a random variable representing the lifetime of a bulb, is such that 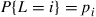 . Also,
. Also,
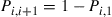
Suppose now that this chain has been in operation for a long (in theory, an infinite) time and consider the sequence of states going backward in time. Since, in the forward direction, the state is always increasing by 1 until it reaches the age at which the item fails, it is easy to see that the reverse chain will always decrease by 1 until it reaches 1 and then it will jump to a random value representing the lifetime of the (in real time) previous bulb. Thus, it seems that the reverse chain should have transition probabilities given by
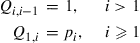
To check this, and at the same time determine the stationary probabilities, we must see if we can find, with the 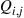 as previously given, positive numbers
as previously given, positive numbers 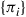 such that
such that
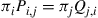
To begin, let  and consider the resulting equations:
and consider the resulting equations:
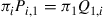
This is equivalent to

or
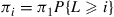
Summing over all  yields
yields

and so, for the preceding  to represent the reverse transition probabilities, it is necessary for the stationary probabilities to be
to represent the reverse transition probabilities, it is necessary for the stationary probabilities to be

To finish the proof that the reverse transition probabilities and stationary probabilities are as given, all that remains is to show that they satisfy

which is equivalent to
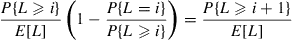
and which is true since  . ■
. ■
4.9 Markov Chain Monte Carlo Methods
Let  be a discrete random vector whose set of possible values is
be a discrete random vector whose set of possible values is  . Let the probability mass function of
. Let the probability mass function of  be given by
be given by  , and suppose that we are interested in calculating
, and suppose that we are interested in calculating
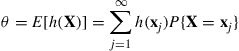
for some specified function 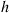 . In situations where it is computationally difficult to evaluate the function
. In situations where it is computationally difficult to evaluate the function  , we often turn to simulation to approximate
, we often turn to simulation to approximate  . The usual approach, called Monte Carlo simulation, is to use random numbers to generate a partial sequence of independent and identically distributed random vectors
. The usual approach, called Monte Carlo simulation, is to use random numbers to generate a partial sequence of independent and identically distributed random vectors 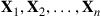 having the mass function
having the mass function 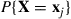 ,
,  (see Chapter 11 for a discussion as to how this can be accomplished). Since the strong law of large numbers yields
(see Chapter 11 for a discussion as to how this can be accomplished). Since the strong law of large numbers yields
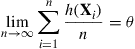 (4.30)
(4.30)
it follows that we can estimate 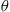 by letting
by letting 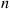 be large and using the average of the values of
be large and using the average of the values of 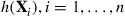 as the estimator.
as the estimator.
It often, however, turns out that it is difficult to generate a random vector having the specified probability mass function, particularly if  is a vector of dependent random variables. In addition, its probability mass function is sometimes given in the form
is a vector of dependent random variables. In addition, its probability mass function is sometimes given in the form  , where the
, where the 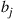 are specified, but
are specified, but  must be computed, and in many applications it is not computationally feasible to sum the
must be computed, and in many applications it is not computationally feasible to sum the 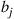 so as to determine
so as to determine 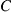 . Fortunately, however, there is another way of using simulation to estimate
. Fortunately, however, there is another way of using simulation to estimate 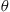 in these situations. It works by generating a sequence, not of independent random vectors, but of the successive states of a vector-valued Markov chain
in these situations. It works by generating a sequence, not of independent random vectors, but of the successive states of a vector-valued Markov chain 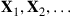 whose stationary probabilities are
whose stationary probabilities are 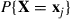 ,
,  . If this can be accomplished, then it would follow from Proposition 4.7 that Equation (4.30) remains valid, implying that we can then use
. If this can be accomplished, then it would follow from Proposition 4.7 that Equation (4.30) remains valid, implying that we can then use 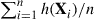 as an estimator of
as an estimator of  .
.
We now show how to generate a Markov chain with arbitrary stationary probabilities that may only be specified up to a multiplicative constant. Let 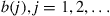 be positive numbers whose sum
be positive numbers whose sum 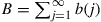 is finite. The following, known as the Hastings–Metropolis algorithm, can be used to generate a time reversible Markov chain whose stationary probabilities are
is finite. The following, known as the Hastings–Metropolis algorithm, can be used to generate a time reversible Markov chain whose stationary probabilities are

To begin, let  be any specified irreducible Markov transition probability matrix on the integers, with
be any specified irreducible Markov transition probability matrix on the integers, with  representing the row
representing the row  column
column  element of
element of 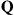 . Now define a Markov chain
. Now define a Markov chain  as follows. When
as follows. When 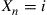 , generate a random variable
, generate a random variable 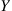 such that
such that  . If
. If 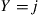 , then set
, then set 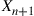 equal to
equal to  with probability
with probability 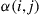 , and set it equal to
, and set it equal to  with probability
with probability 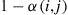 . Under these conditions, it is easy to see that the sequence of states constitutes a Markov chain with transition probabilities
. Under these conditions, it is easy to see that the sequence of states constitutes a Markov chain with transition probabilities 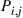 given by
given by
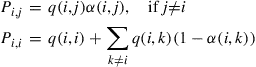
This Markov chain will be time reversible and have stationary probabilities 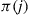 if
if
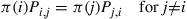
which is equivalent to
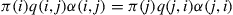 (4.31)
(4.31)
But if we take  and set
and set
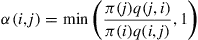 (4.32)
(4.32)
then Equation (4.31) is easily seen to be satisfied. For if
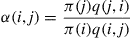
then 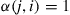 and Equation (4.31) follows, and if
and Equation (4.31) follows, and if 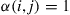 then
then
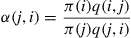
and again Equation (4.31) holds, thus showing that the Markov chain is time reversible with stationary probabilities  . Also, since
. Also, since 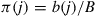 , we see from (4.32) that
, we see from (4.32) that
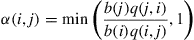
which shows that the value of 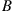 is not needed to define the Markov chain, because the values
is not needed to define the Markov chain, because the values  suffice. Also, it is almost always the case that
suffice. Also, it is almost always the case that  will not only be stationary probabilities but will also be limiting probabilities. (Indeed, a sufficient condition is that
will not only be stationary probabilities but will also be limiting probabilities. (Indeed, a sufficient condition is that 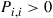 for some
for some  .)
.)
Example 4.39
Suppose that we want to generate a uniformly distributed element in 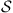 , the set of all permutations
, the set of all permutations  of the numbers
of the numbers  for which
for which  for a given constant
for a given constant 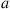 . To utilize the Hastings–Metropolis algorithm we need to define an irreducible Markov transition probability matrix on the state space
. To utilize the Hastings–Metropolis algorithm we need to define an irreducible Markov transition probability matrix on the state space 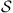 . To accomplish this, we first define a concept of “neighboring” elements of
. To accomplish this, we first define a concept of “neighboring” elements of  , and then construct a graph whose vertex set is
, and then construct a graph whose vertex set is  . We start by putting an arc between each pair of neighboring elements in
. We start by putting an arc between each pair of neighboring elements in  , where any two permutations in
, where any two permutations in 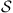 are said to be neighbors if one results from an interchange of two of the positions of the other. That is, (1, 2, 3, 4) and (1, 2, 4, 3) are neighbors whereas (1, 2, 3, 4) and (1, 3, 4, 2) are not. Now, define the
are said to be neighbors if one results from an interchange of two of the positions of the other. That is, (1, 2, 3, 4) and (1, 2, 4, 3) are neighbors whereas (1, 2, 3, 4) and (1, 3, 4, 2) are not. Now, define the 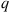 transition probability function as follows. With
transition probability function as follows. With 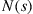 defined as the set of neighbors of
defined as the set of neighbors of  , and
, and  equal to the number of elements in the set
equal to the number of elements in the set 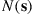 , let
, let

That is, the candidate next state from  is equally likely to be any of its neighbors. Since the desired limiting probabilities of the Markov chain are
is equally likely to be any of its neighbors. Since the desired limiting probabilities of the Markov chain are 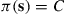 , it follows that
, it follows that 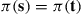 , and so
, and so

That is, if the present state of the Markov chain is  then one of its neighbors is randomly chosen, say,
then one of its neighbors is randomly chosen, say,  . If
. If  is a state with fewer neighbors than
is a state with fewer neighbors than  (in graph theory language, if the degree of vertex
(in graph theory language, if the degree of vertex 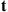 is less than that of vertex
is less than that of vertex  ), then the next state is
), then the next state is 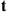 . If not, a uniform (0,1) random number
. If not, a uniform (0,1) random number 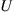 is generated and the next state is
is generated and the next state is  if
if 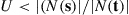 and is
and is  otherwise. The limiting probabilities of this Markov chain are
otherwise. The limiting probabilities of this Markov chain are 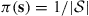 , where
, where 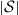 is the (unknown) number of permutations in
is the (unknown) number of permutations in  . ■
. ■
The most widely used version of the Hastings–Metropolis algorithm is the Gibbs sampler. Let  be a discrete random vector with probability mass function
be a discrete random vector with probability mass function  that is only specified up to a multiplicative constant, and suppose that we want to generate a random vector whose distribution is that of
that is only specified up to a multiplicative constant, and suppose that we want to generate a random vector whose distribution is that of 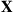 . That is, we want to generate a random vector having mass function
. That is, we want to generate a random vector having mass function
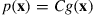
where 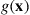 is known, but
is known, but 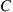 is not. Utilization of the Gibbs sampler assumes that for any
is not. Utilization of the Gibbs sampler assumes that for any 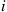 and values
and values 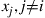 , we can generate a random variable
, we can generate a random variable 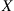 having the probability mass function
having the probability mass function
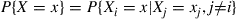
It operates by using the Hasting–Metropolis algorithm on a Markov chain with states 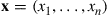 , and with transition probabilities defined as follows. Whenever the present state is x, a coordinate that is equally likely to be any of
, and with transition probabilities defined as follows. Whenever the present state is x, a coordinate that is equally likely to be any of  is chosen. If coordinate
is chosen. If coordinate  is chosen, then a random variable
is chosen, then a random variable  with probability mass function
with probability mass function 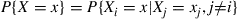 is generated. If
is generated. If  , then the state
, then the state  ) is considered as the candidate next state. In other words, with x and y as given, the Gibbs sampler uses the Hastings–Metropolis algorithm with
) is considered as the candidate next state. In other words, with x and y as given, the Gibbs sampler uses the Hastings–Metropolis algorithm with
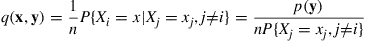
Because we want the limiting mass function to be  , we see from Equation (4.32) that the vector
, we see from Equation (4.32) that the vector 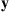 is then accepted as the new state with probability
is then accepted as the new state with probability
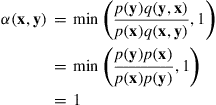
Hence, when utilizing the Gibbs sampler, the candidate state is always accepted as the next state of the chain.
Example 4.40
Suppose that we want to generate  uniformly distributed points in the circle of radius 1 centered at the origin, conditional on the event that no two points are within a distance
uniformly distributed points in the circle of radius 1 centered at the origin, conditional on the event that no two points are within a distance 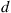 of each other, when the probability of this conditioning event is small. This can be accomplished by using the Gibbs sampler as follows. Start with any
of each other, when the probability of this conditioning event is small. This can be accomplished by using the Gibbs sampler as follows. Start with any 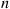 points
points 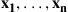 in the circle that have the property that no two of them are within
in the circle that have the property that no two of them are within 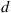 of the other; then generate the value of
of the other; then generate the value of  , equally likely to be any of the values
, equally likely to be any of the values  . Then continually generate a random point in the circle until you obtain one that is not within
. Then continually generate a random point in the circle until you obtain one that is not within  of any of the other
of any of the other  points excluding
points excluding  . At this point, replace
. At this point, replace 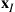 by the generated point and then repeat the operation. After a large number of iterations of this algorithm, the set of
by the generated point and then repeat the operation. After a large number of iterations of this algorithm, the set of 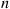 points will approximately have the desired distribution. ■
points will approximately have the desired distribution. ■
Example 4.41
Let  , be independent exponential random variables with respective rates
, be independent exponential random variables with respective rates 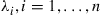 . Let
. Let 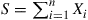 , and suppose that we want to generate the random vector
, and suppose that we want to generate the random vector  , conditional on the event that
, conditional on the event that  for some large positive constant
for some large positive constant  . That is, we want to generate the value of a random vector whose density function is
. That is, we want to generate the value of a random vector whose density function is
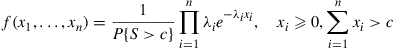
This is easily accomplished by starting with an initial vector 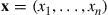 satisfying
satisfying 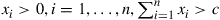 . Then generate a random variable
. Then generate a random variable  that is equally likely to be any of
that is equally likely to be any of  . Next, generate an exponential random variable
. Next, generate an exponential random variable 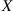 with rate
with rate 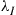 conditional on the event that
conditional on the event that  . This latter step, which calls for generating the value of an exponential random variable given that it exceeds
. This latter step, which calls for generating the value of an exponential random variable given that it exceeds 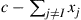 , is easily accomplished by using the fact that an exponential conditioned to be greater than a positive constant is distributed as the constant plus the exponential. Consequently, to obtain
, is easily accomplished by using the fact that an exponential conditioned to be greater than a positive constant is distributed as the constant plus the exponential. Consequently, to obtain  , first generate an exponential random variable
, first generate an exponential random variable 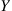 with rate
with rate  , and then set
, and then set
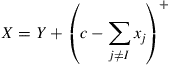
where  . The value of
. The value of 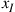 should then be reset as
should then be reset as 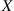 and a new iteration of the algorithm begun. ■
and a new iteration of the algorithm begun. ■
4.10 Markov Decision Processes
Consider a process that is observed at discrete time points to be in any one of 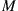 possible states, which we number by
possible states, which we number by  . After observing the state of the process, an action must be chosen, and we let
. After observing the state of the process, an action must be chosen, and we let  , assumed finite, denote the set of all possible actions.
, assumed finite, denote the set of all possible actions.
If the process is in state  at time
at time  and action
and action  is chosen, then the next state of the system is determined according to the transition probabilities
is chosen, then the next state of the system is determined according to the transition probabilities 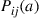 . If we let
. If we let  denote the state of the process at time
denote the state of the process at time 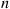 and
and 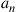 the action chosen at time
the action chosen at time 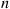 , then the preceding is equivalent to stating that
, then the preceding is equivalent to stating that

Thus, the transition probabilities are functions only of the present state and the subsequent action.
By a policy, we mean a rule for choosing actions. We shall restrict ourselves to policies that are of the form that the action they prescribe at any time depends only on the state of the process at that time (and not on any information concerning prior states and actions). However, we shall allow the policy to be “randomized” in that its instructions may be to choose actions according to a probability distribution. In other words, a policy 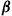 is a set of numbers
is a set of numbers 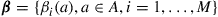 with the interpretation that if the process is in state
with the interpretation that if the process is in state 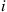 , then action
, then action  is to be chosen with probability
is to be chosen with probability  . Of course, we need have
. Of course, we need have

Under any given policy  , the sequence of states
, the sequence of states 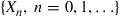 constitutes a Markov chain with transition probabilities
constitutes a Markov chain with transition probabilities  given by∗
given by∗
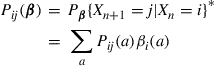
where the last equality follows by conditioning on the action chosen when in state  . Let us suppose that for every choice of a policy
. Let us suppose that for every choice of a policy 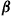 , the resultant Markov chain
, the resultant Markov chain 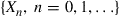 is ergodic.
is ergodic.
For any policy  , let
, let 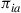 denote the limiting (or steady-state) probability that the process will be in state
denote the limiting (or steady-state) probability that the process will be in state  and action
and action  will be chosen if policy
will be chosen if policy  is employed. That is,
is employed. That is,

The vector  must satisfy
must satisfy
 (4.33)
(4.33)
Equations (i) and (ii) are obvious, and Equation (iii), which is an analogue of Theorem 4.1, follows as the left-hand side equals the steady-state probability of being in state  and the right-hand side is the same probability computed by conditioning on the state and action chosen one stage earlier.
and the right-hand side is the same probability computed by conditioning on the state and action chosen one stage earlier.
Thus for any policy  , there is a vector
, there is a vector 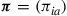 that satisfies (i)–(iii) and with the interpretation that
that satisfies (i)–(iii) and with the interpretation that 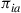 is equal to the steady-state probability of being in state
is equal to the steady-state probability of being in state 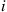 and choosing action
and choosing action 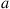 when policy
when policy 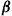 is employed. Moreover, it turns out that the reverse is also true. Namely, for any vector
is employed. Moreover, it turns out that the reverse is also true. Namely, for any vector 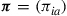 that satisfies (i)–(iii), there exists a policy
that satisfies (i)–(iii), there exists a policy 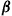 such that if
such that if 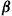 is used, then the steady-state probability of being in
is used, then the steady-state probability of being in 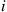 and choosing action
and choosing action 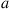 equals
equals  . To verify this last statement, suppose that
. To verify this last statement, suppose that 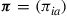 is a vector that satisfies (i)–(iii). Then, let the policy
is a vector that satisfies (i)–(iii). Then, let the policy  be
be

Now let  denote the limiting probability of being in
denote the limiting probability of being in  and choosing
and choosing 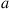 when policy
when policy 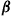 is employed. We need to show that
is employed. We need to show that  . To do so, first note that
. To do so, first note that  are the limiting probabilities of the two-dimensional Markov chain
are the limiting probabilities of the two-dimensional Markov chain  . Hence, by the fundamental Theorem 4.1, they are the unique solution of
. Hence, by the fundamental Theorem 4.1, they are the unique solution of

where ( ) follows since
) follows since

Because

we see that  is the unique solution of
is the unique solution of

Hence, to show that  , we need show that
, we need show that
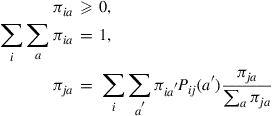
The top two equations follow from (i) and (ii) of Equation (4.33), and the third, which is equivalent to
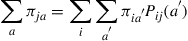
follows from condition (iii) of Equation (4.33).
Thus we have shown that a vector  will satisfy (i), (ii), and (iii) of Equation (4.33) if and only if there exists a policy
will satisfy (i), (ii), and (iii) of Equation (4.33) if and only if there exists a policy  such that
such that 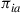 is equal to the steady-state probability of being in state
is equal to the steady-state probability of being in state  and choosing action
and choosing action 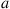 when
when  is used. In fact, the policy
is used. In fact, the policy  is defined by
is defined by 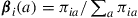 .
.
The preceding is quite important in the determination of “optimal” policies. For instance, suppose that a reward 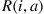 is earned whenever action
is earned whenever action 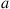 is chosen in state
is chosen in state  . Since
. Since  would then represent the reward earned at time
would then represent the reward earned at time 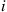 , the expected average reward per unit time under policy
, the expected average reward per unit time under policy 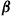 can be expressed as
can be expressed as
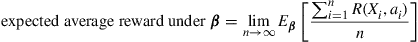
Now, if  denotes the steady-state probability of being in state
denotes the steady-state probability of being in state 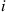 and choosing action
and choosing action 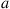 , it follows that the limiting expected reward at time
, it follows that the limiting expected reward at time 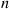 equals
equals

which implies that

Hence, the problem of determining the policy that maximizes the expected average reward is