14 BUILDING, MANAGING AND DEPLOYING CODE INTO ENTERPRISE ENVIRONMENTS
‘The most powerful tool we have as developers is automation.’
– Scott Hanselman
As mentioned previously, few mid- to large-scale projects are completed by individuals in the modern software development industry – it’s just become far too complex to work in this way. As such, developments need to be undertaken in environments where multiple individuals can contribute productively and collaboratively.
Creating a modern software development process involves adopting certain approaches, tools and techniques. In this chapter we will look at some of the more recent developments. But first, a bit of history.
PREVIOUSLY IN SOFTWARE DEVELOPMENT…
Many years ago, the different teams involved in the development of a new software project could be quite isolated and rarely interacted, instead focusing on their own jobs and responsibilities. For example, developers rarely talked to quality assurance (doing the testing) and didn’t tend to interact a great deal with operations (who eventually deployed and monitored the solution) – that is, until things went wrong, of course.
As you might have guessed, this isn’t a great model. There’s no teamwork, no collective responsibility, and precious little communication or co-operation.
The solution to this is to modify your techniques by working together more effectively.
DEVOPS
As the name suggests, DevOps is the operational combination of ‘developer’ and ‘operations’, plus quality assurance (see Figure 14.1).
By improving communication through collaborative working in DevOps, the natural outcome is better-quality software, written more quickly and working more reliably. Toolchains are standardised and the focus is firmly placed on constant testing and continuous delivery, ideally meeting the requirements of an Agile delivery framework.
There are other advantages to DevOps, such as faster deployments and lower costs (bugs tend to be identified and fixed earlier in the cycle, and teams generally engage more with the process, which improves underlying productivity). DevOps also encourages three adjacent practices:
Figure 14.1 DevOps exists at the heart of three disciplinary areas
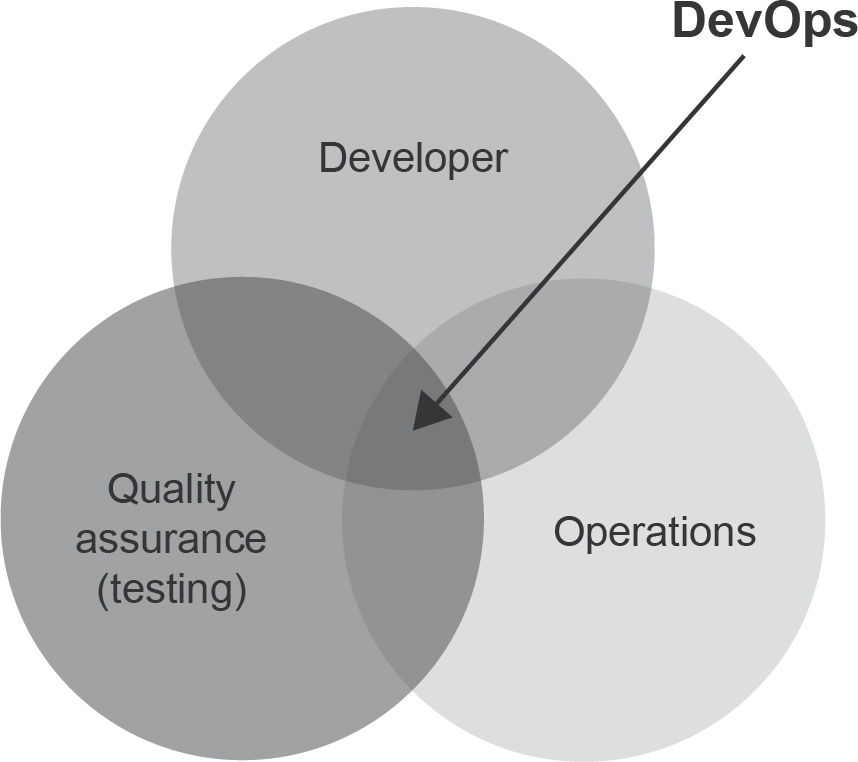
- Continuous integration: developers merge their code into the shared repository more often.
- Continuous development: software is produced in shorter cycles, permitting more frequent releases.
- Continuous deployment: as above, but releases are made automatically through an automated production pipeline.
But still, something is missing: security.
DEVSECOPS
In the 21st century, it’s no longer good enough to develop a solution that solves a set problem – it must also be secure. Simply put, this is because cyberattacks occur frequently at the application layer.
This is mostly because applications can be soft targets (they can be poorly programmed or use compromised components). This provides an attacker with a useful attack vector that they can use as an entry point before quickly escalating their privileges (e.g. by compromising user accounts, accessing databases or changing file permissions) on a now vulnerable infrastructure.
Obviously, vulnerable software that is easily exploited has exposed critical infrastructure, leading to worrying implications for data protection (GDPR; see Chapter 11) and financial implications for the organisation concerned (commercial and reputational damage).
The problem generally with DevOps is that traditional security models don’t work particularly well. This has led to the concept of ‘security as code’ and the introduction of an even more tightly interwoven model of software production: DevSecOps (see Figure 14.2).
Figure 14.2 DevSecOps exists at the heart of four disciplinary areas
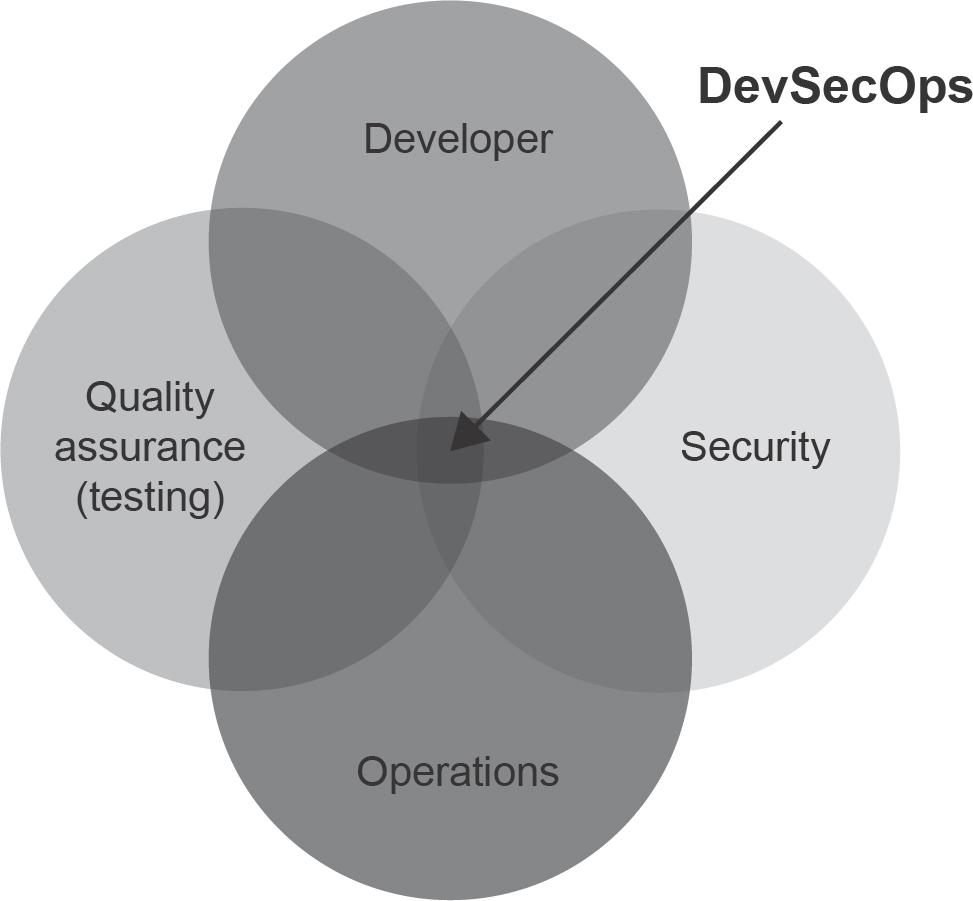
In this model, security is ever present throughout the development pipeline, being ‘shifted to the left’ (see Figures 15.1 and 15.2) rather than relegated to a pre-release penetration test. This allows security issues and common vulnerabilities (insecure libraries, embedded credentials etc.) to be identified and fixed early in the development process, further reducing costs and ensuring a more secure product. Automated pipelines are again the favoured applications used to manage this process.
SOFTWARE VERSIONING
In industry it is rare, but not unknown, for programmers to work in isolation on a software project. When they do, maintaining revisions of their program code is not an overly difficult task – they are completely aware of all the changes they make to their closed codebase. However, when programmers work in parallel on a project, keeping track of different contributions can be problematic; a version control system (VCS) is needed. When you start working as a developer, it is highly likely you will encounter one of these, so having some familiarity with them beforehand is a good idea.
Many popular VCSs exist (e.g. Concurrent Versions System, Subversion and Perforce), but perhaps the most ubiquitous is called Git.
Git was created in 2005 by Linus Torvalds as he worked on the Linux kernel with other programmers. It has subsequently exploded in popularity and become the preferred workflow-management tool for many organisations (and individual programmers) worldwide. Git is free and open source software, distributed under the GNU General Public License (GNU GPL) version 2.
Before you start thinking about Git, it is worthwhile remembering that projects are typically organised into a project structure, one that groups together related aspects of the solution. Understanding the structure of your project will enable you to quickly navigate its components when using a versioning system such as Git. An example project structure is shown in Figure 14.3.
Figure 14.3 A simple web project’s structure
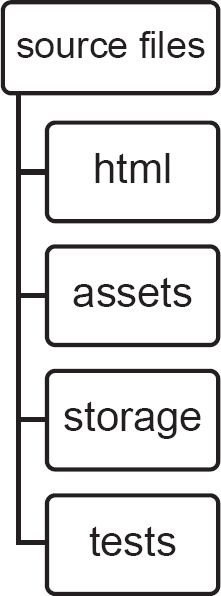
Git is freely downloadable and can be used to create a new local repository (containing your project) or clone from a public or private remote repository, although for the latter you need appropriate credentials.
How Git works
Unlike many other versioning systems, Git uses a ‘snapshot’ technique rather than keeping track of individual modifications in source code files. The snapshot contains state information about a folder.
The three areas of a Git project are shown in Figure 14.4. These areas all exist on your local computer.
Figure 14.4 Git projects

The working directory, or tree, usually starts in a completely unmodified state; this is often referred to as having a ‘clean working tree’. As you add, delete or modify code in your source files, the tree state changes. Git considers all files to be either ‘tracked’ or ‘untracked’:
- tracked file: a file that Git knows about;
- untracked file: a file that Git does not know about.
A git add command is used to begin tracking a new file, effectively moving the modified file into the ‘staging area’ (it is now ready to be committed).
Unsurprisingly, a git commit command is used to commit your tracked changes to the local Git repository (any untracked changes you have are not included). It is considered good practice to include a Git comment which describes the nature of the commit you have made – a short but meaningful note can help project managers to track changes and identify the purpose of the commit.
At this point the required changes have only been made to your local Git repository. Eventually, a git push command can be used to ‘share’ your changes with the remote repository (often called the ‘origin’). This is known as pushing your work ‘upstream’.
Sometimes your push may be rejected because another programmer has pushed upstream just before you. When this happens, you must issue a git fetch or git pull to combine their changes with yours and then try again. Figure 14.5 summarises these processes.
Figure 14.5 Git repositories
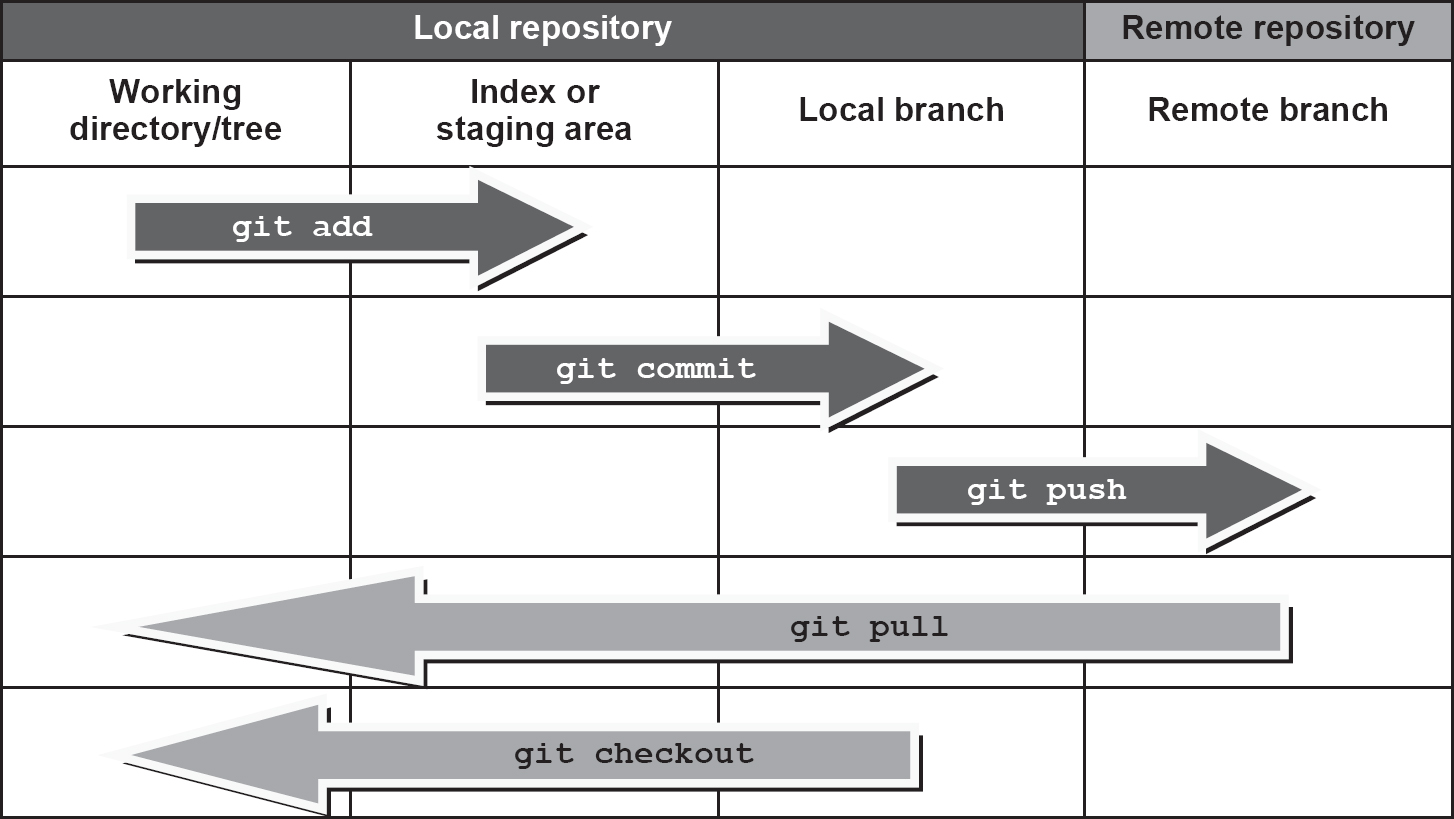
Other programmers can then pull your changes from the remote repository down to their local git repository and see the changes you have made.
Branches
Developers often need to work on independent parts of a project which may not immediately impact others. To keep their work free of changes from other developers, they can work individually or collectively (in small teams) on separate ‘branches’ of a repository, rather than the traditional master branch.
Commits can be made to the new branch without affecting any other. When completed, each named branch can be merged back into the main codebase once it has been successfully tested (see Figure 14.6).
Figure 14.6 Branch example
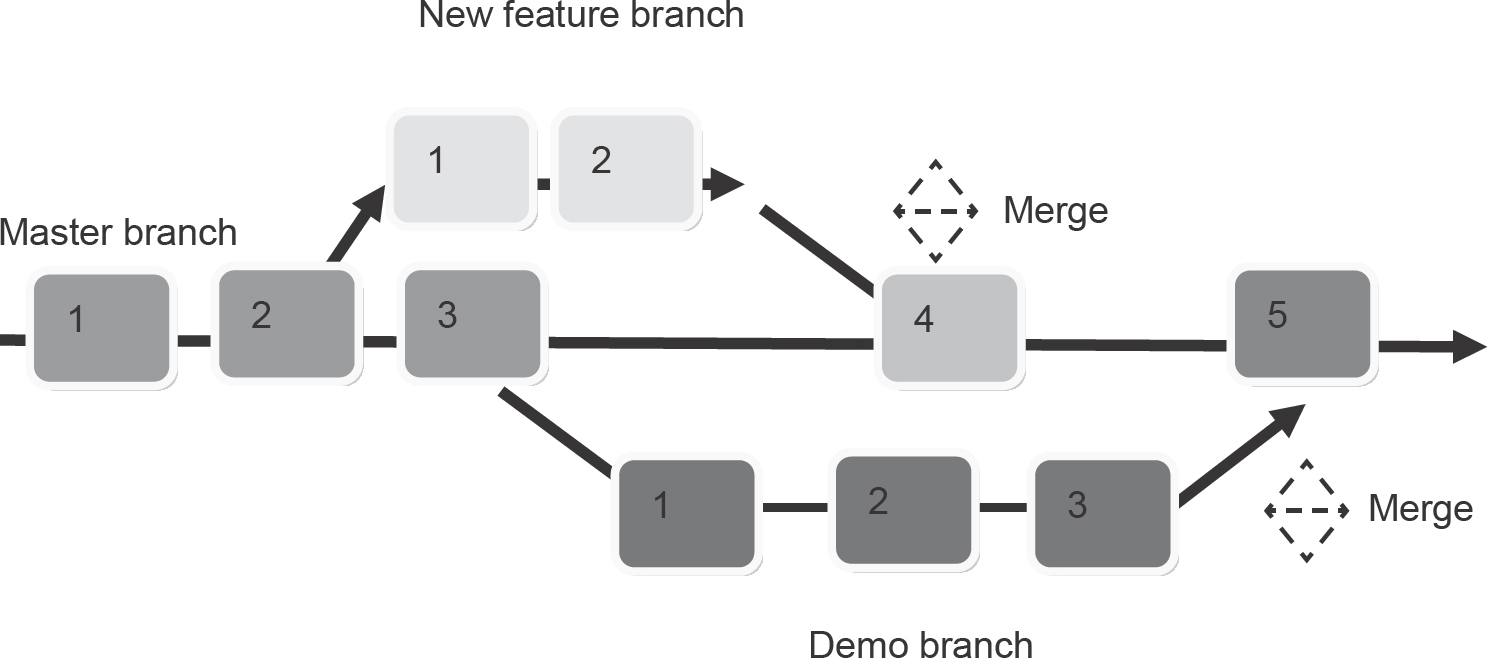
Branches are often used to test new ideas or experiment with problem-solving approaches without risking polluting the master branch, which is typically the one used in production.
Occasionally, having multiple branches can cause problems when the same source file has been modified separately by two programmers and their respective changes cannot be automatically reconciled by Git (typically they will each make different changes to the same code). When this happens, it is necessary for a programmer to perform a manual merge. This involves resolving flagged conflicts using an editor and then re-committing and pushing the combined changes back to the master branch on the remote repository.
Advantages of Git
Advantages of Git include:
- It provides a long-term history of every single file in a system which contains every change ever made. This includes:
- file creation (including renaming and moving in the project structure);
- file modification;
- file deletion (including renaming and moving in the project structure).
- It provides accountability, as tracking every code change to a software project enables managers to easily identify:
- annotation of each change (why it was done);
- date of each change (when it was done);
- developer commit signature (who did it).
This can provide a project manager with important information which helps them to attribute project workloads and resolve problems or bugs that have been introduced in a recent (or historical) commit.
- It has good data integrity: SHA1 (Secure Hash Algorithm 1) is a cryptographic hash which provides a checksum (a value derived arithmetically from data that uniquely identifies it) that makes it simple to detect corruption.
- Git is a distributed VCS. This means that programmers can work independently on a project and choose which aspects of their work are uploaded for others to see. This also allows work to continue offline, if required.
- Problematic changes can be undone by inverting the changes made in the identified commit and appending a new commit with the necessary fixes.
- It works well as part of an Agile workflow; Git branches can be thought of as Agile tasks.
- Branches can be tested individually.
Disadvantages of Git
Disadvantages of Git include:
- Operation can vary between different operating systems.
- There are many different commands to learn (although admittedly a developer could survive with a core of 10–20 that are frequently used).
- It can require more steps than other VCSs to achieve the same goals – for example, making a change to a project is simpler in Subversion than in Git.
- Command usage can be a little inconsistent and therefore harder to learn.
- Git’s first-party documentation can be a little impenetrable for the novice developer (for example, see https://git-scm.com/docs/git-push).
Web-based hosting services for Git
Commercial organisations may choose to host their own remote repository using Git or use one of the many different web-based services available. GitHub (acquired by Microsoft in 2018) is probably the most popular, having over 28 million users. It hosts millions of public open source and privately owned software projects. Bitbucket (owned by Atlassian) offers a similar service, including free accounts and various commercial hosting plans and support for other VCSs, such as Mercurial.
A popular feature of web-based VCS services such as GitHub is ‘forking’. You may encounter a fork in a project when the codebase is split, for example when a sub-team uses the current codebase as a starting point for another project which will typically not feed back into the main one.
Many web-based hosting services offer ‘webhook’ plug-ins for continuous integration and delivery of automation services such as Jenkins. Such webhooks can be used to trigger an automated project build whenever a programmer commits new code to a web-based hosting service. Similar webhooks exist for Agile project tracking software, such as Jira.
Useful examples of webhooks include:
- ensuring that the Jira task/issue reference is included in the commit message;
- warning programmers about pulling from a remote repository’s branch that contains known issues.
It is this flexibility that makes using a VCS a must-have skill for developers and a desirable trait that recruiters and potential employers will almost certainly seek out.
CHANGING DEVELOPMENTAL PRACTICES
Getting development practices right has always been a difficult proposition, principally because of the digital soup of different technologies which are typically required to form a modern software solution. For example, a developer may have their code working perfectly on their local development set-up but when it is being tested by others, the lack of an installed library or an inaccessible database could bring the application’s execution to a screeching halt. This can be problematic because testers may not have the technical expertise to fix this type of broken mess (nor feel it’s their responsibility to do so).
It can get much worse. For instance, it may be discovered during deployment that a client’s target environment is not compatible with key components of the solution, making further progress fraught with difficulties.
Fortunately, the use of virtualisation (virtual machines, or VMs) and various cloud-based services provides potential solutions to these development, management and deployment issues. Until recently the use of VMs proved to be the most popular option, but these are typically resource hungry as they require a platform to host another operating system. Containers, offering a far more lightweight and portable alternative, are becoming much more popular.
The role of containers in software development and implementation
Containers have quickly become an incredibly useful tool for software developers over the past few years, saving them both time and effort when setting up their development and test environments. Given their growing popularity, its highly likely you will encounter them in the workplace.
Let’s start by tackling the key question: what is a container? In simple terms, a container is a package of software that contains code and its dependencies. Dependencies are things a program needs in order to run successfully – for example, system and run-time libraries, and environment settings.
A traditional approach to hosting another operating system is to deploy a VM. However, a container differs from a VM because it attempts to virtualise the operating system, not the actual underlying hardware – there’s no attempt to create another machine, just an environment which the programmer can use to develop and test their code. This lightweight approach makes containers much more efficient to use, and they typically consume far less memory and backing storage than a VM.
Figure 14.7 differentiates the two approaches. In this example, multiple containers can run on the same container engine, sharing the same resources provided by the host operating system (such as binaries and libraries) and underlying hardware but running as isolated processes. In the contrasting VM solution, the hardware runs three separate guest operating systems, with each requiring its own configuration, duplicate resources and so on.
Figure 14.7 Containers versus virtual machines
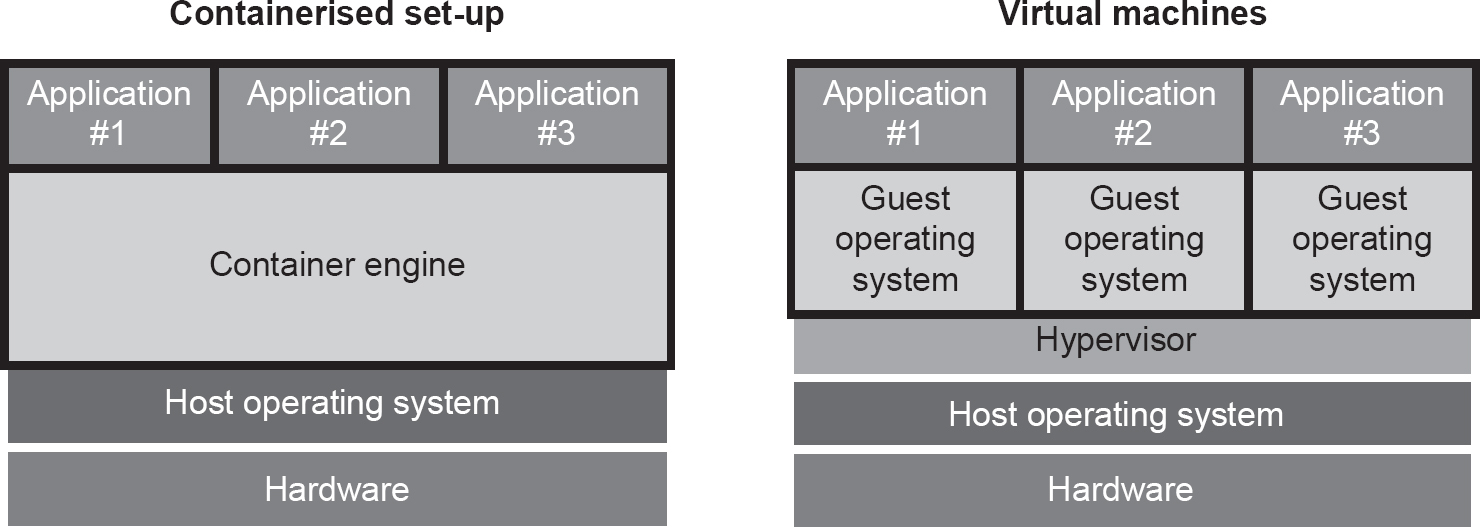
Probably the most well known container engine is Docker. It was introduced in 2013 and has subsequently helped to shape the industry standard through the donation of its container specification and run-time code to the Open Container Initiative.
Let’s consider a practical, real-world example. If you had a development role as a full-stack web developer, it is likely that you would need to set up (at the very least) the following software:
- web server, such as Apache HTTPD;
- relational database server and client, such as MySQL or MariaDB.
- server-side script engine, such as PHP;
- server-side MVC (model-view-controller) framework, such as Laravel;
- IDE, such as IBM NetBeans.
That’s at least five separate technologies which need to be installed and configured for use on a target operating system before any lines of code have been written. Of course, any variances between installation, configuration and usage in different operating systems, for instance Microsoft Windows vs Linux vs Apple macOS X, can only complicate matters further.
For example, case-sensitivity issues in some databases and programming languages are more important on Linux operating systems, which can cause nasty surprises for programmers developing on Microsoft Windows and then moving to a Linux staging environment for testing. Using a containerised solution for development makes things a lot easier as they tend to be Linux-based, so the issue typically does not occur – the programmer’s development environment already matches the staging and (very likely) production environments where the code will eventually run.
A further example may be beneficial here. The following practical steps are required to quickly set up a suitable Python development container on a Windows PC:
- Install Docker for Windows
- Pull (download) an image of the container type required (e.g. MariaDB, Python or Ubuntu), typically from Docker Hub (hub.docker.com):
C:\Users\Demo>docker pull python
Using default tag: latest
latest: Pulling from library/python
22dbe790f715: Pull complete
0250231711a0: Pull complete
6fba9447437b: Pull complete
c2b4d327b352: Pull complete
270e1baa5299: Pull complete
8dc8edf0ab44: Pull complete
86ded05de41b: Pull complete
1eac5266a8fa: Pull complete
61b3f1392c29: Pull complete
Digest: sha256:166ad1e6ca19a4b84a8907d41c985549d89e80ceed2f7eafd90dca3e328de23a
Status: Downloaded newer image for python:latest
- Run the container (with suitable options) and start the Python shell:
C:\Users\Demo>docker run -it python bash
root@39867802043b:/# python
Python 3.7.2 (default, Mar 5 2019, 06:22:51)
[GCC 6.3.0 20170516] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> print("Hello World")
Hello World
>>>
- You are now working within a Debian Linux container complete with an up-to-date version of Python. You can now start developing!
From a starting perspective, it is that simple. In practice, there’s a lot of deeper learning required to get the most out of containerisation and the broad range of options and configurations that are available. Of course, it’s also possible to build your own customised containers which you can share with others.
Deploying code into enterprise environments
One of the strongest aspects of the containerised approach is that it’s possible to package your application (code, required libraries and dependencies) and its native environment into a container and ‘ship’ it to a customer, knowing it will run practically anywhere that has a compatible container engine. This has huge ramifications for implementation and the portability of solutions.
No wonder industry heavyweights such as Google, Microsoft and Oracle have embraced the technology; it’s a game-changer.
PRODUCING A TECHNICAL GUIDE
All good development teams will produce a technical guide to support the development product. To ensure a technical guide is robust, the team should:
- Plan the content. The content should include some (or all) of the following, as appropriate:
- description of the software;
- systems requirements;
- diagrams of the final solution (flowcharts, data flow diagrams, system diagrams, UI mockups, wireframes, storyboards etc.) (see Chapter 11);
- annotated code;
- diverse and representative test data.
- Carefully consider using the output from auto-documenters, which will almost always produce far more information that you really need to include. Some auto-documenters can produce hundreds of pages for what is essentially a relatively straightforward program or database.
- Ensure that correct spelling and grammar are used. This makes your documentation more authoritative and avoids it looking sloppy, rushed or unprofessional.
- Think about who is going to use the guide. Because this will be a technical guide, you are free to use technical terms, although you should still provide a glossary.
- Try to be concise and, where appropriate, use images to support the text – particularly flowcharts, other diagrams and tables of information – rather than just long paragraphs of text.
- Ensure code is commented appropriately. Comments in your coding contribute to technical documentation if not the technical guide itself.
- Ensure the technical guide is peer reviewed by other developers, both those involved in the development and others with suitable experience.
To help your client comply with the requirements of the GDPR, you should consider extending the product documentation to demonstrate how the product meets the requirements laid out in the regulations.
PRODUCING A USER GUIDE
A user guide is simply a document written to support people when they are operating your software. Most real-world appliances come with one, so why shouldn’t your software?
Many users still prefer a physical user guide rather than an electronic one. This is because not every target user will have a dual-screen set-up, permitting simultaneous viewing of the guide and the software.
A user guide should include:
- an introduction including a concise description of the software’s purpose;
- an overview of all the functionality within the software;
- information on how to install, configure and remove the software correctly (if applicable);
- screen captures with step-by-step instructions to walk users through operational procedures;
- if the product replaces a previous version, a ‘before’ and ‘after’ comparison of the user interface may be appropriate to help communicate the changes implemented;
- a trouble-shooting section including error messages that might be encountered (and their meanings);
- FAQs (frequently asked questions) are sometimes useful;
- a glossary of technical terms for quick reference.
Tips for creating a user guide
- Ensure that the guide is written using language that will be suitable for the experience level of the expected user (the target audience). Be consistent in what you call things and, above all, avoid technical jargon.
- Be careful not to patronise users. However, you should also not assume that your user has any real experience.
- Consider an electronic format (for environmental reasons).
- Depending on the deployment of your software, you may need to consider other natural languages (e.g. French, German, Urdu).
- Ensure that the content of your guide is logically organised.
- Think about the design of the pages and try to be consistent; familiarity helps people to absorb information.
- Ensure the guide is as simple as possible. You may think that cross-referencing will save on page count, but it can be frustrating for new users who must constantly flip backwards and forwards between different parts of the guide’s content.
- Diagrams often help to explain complex ideas, and they certainly reduce the word count.
- Try to use ordered lists or bullet points rather than writing paragraphs of text.
- Use fonts consistently; many users prefer sans serif fonts such as Arial, Calibri or Helvetica because they are easier to read (particularly for on-screen documentation).
- User colour sparingly (apart from screenshots of the software, which benefit from being in colour).
- Ensure that there is sensible use of white space as a highly cluttered page can be frustrating for users.
TIPS FOR BUILDING, MANAGING AND DEPLOYING CODE INTO ENTERPRISE ENVIRONMENTS
Shown below are a few ideas for getting ready to work in a modern enterprise environment:
- Be familiar with VCSs: target popular ones such as Git and Subversion. You can always practise on personal projects by uploading these to remote repositories such as GitHub, where free accounts are available.
- Practise using VMs and containerised solutions to work in operating systems other than the host system you are familiar with (e.g. using a Linux container on a Windows PC to build and test software).
- Keep track of trends in software development processes (e.g. DevSecOps, continuous integration and continuous delivery).
- Remember that in a DevSecOps approach to software development you are likely to be communicating often with testers, hardware technicians and even network engineers; learn to speak their language.
In this chapter we have seen that software development is rarely an individual activity in a modern enterprise, relying on a combination of innovative approaches, tools and techniques.
In the next chapter we will explore modern trends in software testing.