2
Sound It Out
In Chapter 1 we concluded that writing is meant to preserve and communicate thoughts, but does so indirectly. It's a workaround, a cheat, because it doesn't communicate thought, it communicates the sound of spoken language. That means reading what someone has written requires three things. You need to be able to differentiate one symbol (i.e., letter) from another. You must be able to differentiate one sound from another, to hear the difference between b and p. And you must know what sound a letter or group of letters is associated with. Those challenges exist for experienced readers, but they are easiest to appreciate when they are fresh. So in this chapter I will use many examples of studies that have examined children learning to read.
Challenge 1: The Letters
If you were inventing an alphabet from scratch, how would you design the letters? I've just prompted you to think that it might be wise to create letters that would be easy to distinguish, so readers would not confuse them. Then again, it might be helpful to create letters that are easy to draw, for the sake of writers. That's logical enough, but alphabets respect neither principle.
Letters from the Environment
Mark Changizi and his colleagues analyzed 96 writing systems to determine which shapes they commonly used.1 Then they examined a large set of photographs of natural scenes, to determine whether the shapes found in the alphabets also tended to appear in natural scenes. For example, “L” shapes and “T” shapes are very commonly observed in the environment because the former is created when two edges of an object meet, and the latter is formed when an object overlaps another object (Figure 2.1).

Figure 2.1. Natural scene with T's and L's. T shapes and L shapes are commonly observed in the outlines of objects.
Original version © Dragan Milovanovic, Shutterstock
The researchers then looked for a relationship between the frequency that a shape was used by a writing system and the frequency that that shape was observed in the photographs of natural scenes. The researchers found that the most common letter shapes match the shapes that people most frequently encounter in their daily visual worlds.
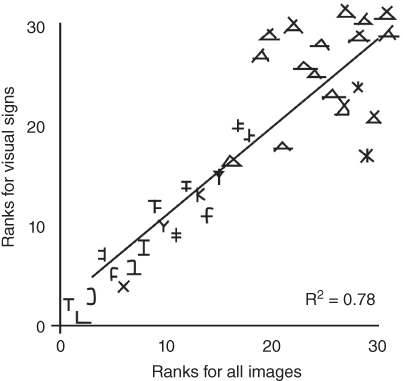
Figure 2.2 Alphabetic shapes. This graph shows that alphabets use shapes commonly seen in the natural environment. The vertical axis shows the frequency that a particular shape is observed in alphabets. The horizontal axis shows the frequency that the shape is observed in a large set of photographs of natural scenes.
Redrawn from Changizi, Zhang, Ye, & Shimojo (2006)
A reasonable hypothesis is that the visual system has been tuned over time (either evolutionary time, or the lifetime of an individual, or both) to best perceive shapes that appear most frequently in the environment. People who invented alphabets unconsciously capitalized on that property of the visual system. The shapes that people see most easily were judged to make nice letters. It's a good example of what we mean when we say that the brain is not designed for reading and writing—rather, we co‐opt existing mental mechanisms to make literacy work.
There are other design properties that alphabets lack. Letters are not designed to be easily written. Letters vary in how many hand movements they require. An “L” requires two hand movements. An “X” requires three, even though the letter is composed of just two strokes. If the Roman alphabet were designed to minimize work for writers, most letters would take just one or two strokes: for example, l, /, \,—, and J. But we have “E” and “H,” each of which require five strokes.
Letter Confusability
Even though letters tend to be shapes that our visual system purportedly sees well, those shapes are often confusable. Many of our letters use a vertical line with a semicircle to the right: “B,” “D,” “P,” “R.” The letters “E,” “F,” and “H” differ by just one stroke, as do “I,” “J,” and “L.” Some pairs are mirror images, like “M” and “W” or “b” and “d.” If the goal were to make letters look really different from one another, why not use some characters that have unconnected line segments, e.g., “ ” or “
” or “ ”? Why not have some closed figures that are not rounded, e.g., “∆” or “ ▪ ”? Letters of our Roman alphabet are at least modestly confusable, and when children learn to read, they do indeed mix up letters that look similar, a phenomenon also observed with alphabets other than the Roman (Figure 2.3).2–4
”? Why not have some closed figures that are not rounded, e.g., “∆” or “ ▪ ”? Letters of our Roman alphabet are at least modestly confusable, and when children learn to read, they do indeed mix up letters that look similar, a phenomenon also observed with alphabets other than the Roman (Figure 2.3).2–4

Figure 2.3. Letter confusion matrix. Preschool children were shown a letter and were asked to name it. The rows show the letter presented, and the columns show what the child said, with the numbers showing how often each response was offered. Thus, the diagonal (the large numbers) represents correct responses. As you can see, “b” and “d” were highly confusable for these children.
© Daniel Willingham, data from Courrieu & De Falco (1989)
That said, we shouldn't think this problem is worse than it is. There simply aren't that many letters to be learned. So even children who have received no reading instruction often learn a bit about letters simply through observation. Parents may notice that their child seems to read familiar signs like “McDonalds” or “Taco Bell.” In truth, they are probably just recognizing the logo, but when a logo is not available they still may show letter learning, as when they recognize friends' names on their cubbies at preschool.5
And although similar letters may be confusing when they are first learned, with practice, telling them apart is not a problem. Children learn the critical features that differentiate letters. In one experiment, researchers presented two nonword letter strings and asked children to say whether the two were identical (e.g., “BMWQ BMWQ”) or different (e.g., “BMWQ BWMQ”). The letters were quite large, so kids had to move their eyes around to see them. Where a kindergartener looked was somewhat unpredictable, but third‐graders looked at the parts of letters that tend to differ—those are the parts that carry the most information.6
But what about dyslexia? Isn't letter reversal at the heart of that reading problem? The hypothesis that dyslexia is rooted in visual problems goes back to at least the 1920s and was current until the 1970s. At that time some surprisingly simple experiments were conducted, showing that vision is usually not the problem. One experiment simply counted the number of errors dyslexic readers made that could be due to reversals and found they are relatively infrequent.7 In another clever experiment, researchers flashed words on a screen one at a time and asked dyslexic readers to copy what they had seen, without trying to read the words aloud. They made very few errors, so the reading problem was not visual.8
Dealing with Letter Differences
What about the problem raised in the Introduction? How do readers deal with differences in fonts, type size, and typographical emphasis? I noted that this is a type of problem that your visual system has to solve all the time—all dogs must be identified as dogs, even if they look different—but how does that happen?
An influential approach is to think of letters as composed of constituents like horizontal lines, vertical lines, semicircles, and so on (Figure 2.4).

Figure 2.4. Letter features. These features are basic constituents of letters. “L” contains a horizontal line, vertical line, and a corner. “P” contains a vertical line and a semi‐circle, and so on. More features would be needed to capture all the letters in the Roman alphabet.
© Daniel Willingham
Now imagine a network (Figure 2.5, Time 1). You can see there are two rows of circles, which we'll call nodes. Imagine that a node can have energy associated with it, as though it's vibrating, or has a voltage. When a letter appears out in the world, the visual system evaluates it for its constituent features: does it contain a horizontal line, a vertical line, a semicircle? If the letter contains the letter constituent, then the corresponding node becomes energized. In the example, the person sees the letter “L,” and so three of the letter constituents are active, which is symbolized by the thicker border of those nodes (Figure 2.5, Time 2). If the three constituents of the letter “L” are all active, they pass the energy to the “L” node, and it becomes active. The “M” node becomes somewhat active, because a vertical line is one of its constituents too. The system decides which letter is present simply by selecting the letter node with the greatest activity (Figure 2.5, Time 3).9
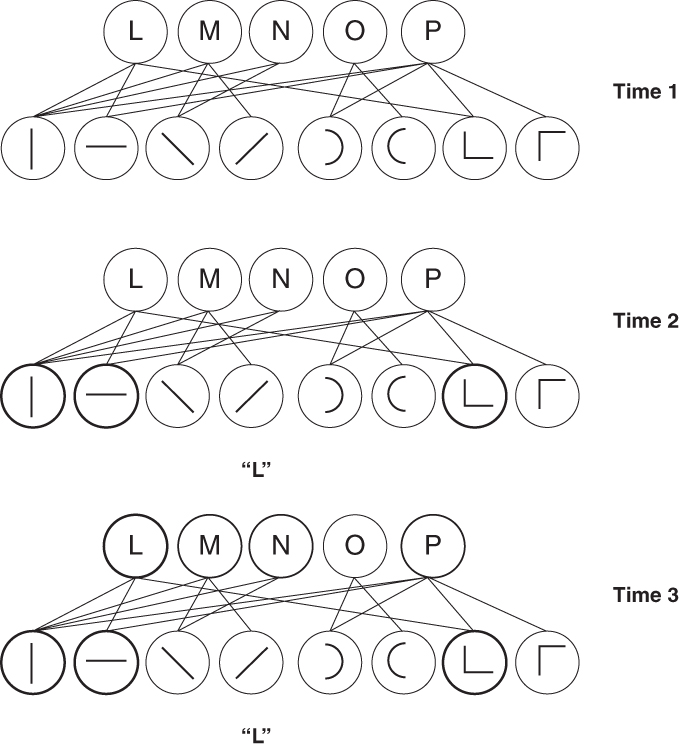
Figure 2.5. Letter identification network. Letters are composed of constituents shown as activated nodes in this model of visual letter recognition.
© Daniel Willingham
This model of how people identify letters is very successful. For one thing, it greatly reduces the too‐many‐fonts problem because most letters in different fonts or sizes still share the same features. In addition, we see why letters that share lots of features (e.g., “b” and “d”) would be much more likely to be confused than letters that share no features (e.g., “b” and “w”). Furthermore, there is evidence that there are groups of cells in the visual system that do exactly this sort of constituent feature detection.10
In sum, even though alphabets were not created to ensure minimum confusability of letters, that doesn't seem to pose a problem. Good readers and struggling readers are more similar than different when it comes to differentiating “P” from “D.” That's not the case, however, when it comes to hearing the sounds associated with each letter.
Challenge 2: The Sounds
Being able to hear the sounds associated with letters doesn't seem like it ought to be that hard. Isn't it obvious that a child can do that if she can hear the difference between big and dig in everyday speech? But that's not quite the same task because in order to learn to read and write, the child must be aware of what differentiates big and dig, so she can think Aha, there's the letter ‘d,’ I know what sound that makes! Many mental processes lie outside of awareness, and some seem destined to remain so. For example, you obviously know how to shift your weight to stay upright on a bicycle, but that knowledge is accessible only to the parts of the brain that control movement. You can't examine that knowledge or describe it. Other types of knowledge are unconscious, but can become conscious. For example, most people speak grammatically—even if they violate some rules taught in school, they speak in accordance with others in their linguistic community. People are unaware of these rules, but can consciously learn them. Hearing individual speech sounds is analogous. Any speaker can hear that big and dig differ and although people aren't born with the ability to describe the difference, most can learn to do so.
Why Speech Sounds Are Hard to Describe
We are not born with the ability to hear individual speech sounds, but the challenge is even greater than that. Young children have difficulty understanding where one spoken word ends and another begins. That's important for reading—you need to know which sounds are supposed to clump together to form a word. But kids don't hear individual words as well as adults do. In a standard test of this ability, an experimenter gives a child a short sentence to keep in mind—say, “I like yellow bananas.” The child is given a small basket of blocks and asked to make a line of blocks, one for each word in the sentence. There's no guarantee that the child will pick four blocks for the sentence. It might be three, it might be five, it might be seven. They are just not sure where words begin and end.11
That's hard to believe, but this confusion actually reflects the physical stimulus of speech—it's more or less continuous. Our mind may perceive breaks between words, and we might assume that perception is due to very brief periods of silence; but those periods are actually infrequent, and are as likely to occur in the middle of a word as between words! (Figure 2.6)
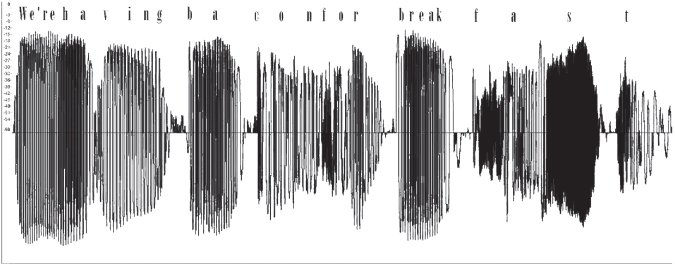
Figure 2.6. Visual representation of the sound of a spoken sentence. The author is saying “We're having bacon for breakfast.” Time moves left to right, and the vertical axis shows sound intensity. You can see the words “We're” and “having” blend together, and there is a break in the middle of the word “bacon.”
© Daniel Willingham
Brief pauses between words don't really exist in the speech stimulus, but rather are created by our minds as part of speech perception. To further persuade yourself that's so, think of what it sounds like when someone speaks a foreign language you don't understand. You don't hear any breaks.
There is a fairly standard progression by which children develop the ability to hear speech sounds: they learn to hear separate words, then words within compound words (scarecrow includes the words scare and crow), then individual syllables (table includes the syllables tey and buhl), and finally, individual speech sounds (sat includes three sounds: s, æ, and t). Hearing words, syllables, and speech sounds can be harder or easier depending on the particular task, and children needn't gain full expertise in one before starting to learn the other, but this rough order is typically observed.12 Obviously, it's learning to hear speech sounds that is of greatest concern for reading, especially because that ability is less likely to develop spontaneously, and more likely to require some special activities on the part of parents and teachers.
Why is hearing individual speech sounds so hard? One problem is that people pronounce differently what we tell children ought to be same speech sound. That is, people have regional accents, and two people ostensibly saying the same thing can produce quite different speech sounds. So I'm supposed to understand that “b” goes with the final sound in the name Bob, but people with certain accents actually pronounce it Bop (Figure 2.7).

Figure 2.7. Comparison of accents. The George Mason University speech accent archive (www.accent.gmu.edu) maintains a database of English speakers with different backgrounds, each uttering the same paragraph, shown at the left. The center panel shows the phonetic transcription of a 37‐year‐old Glasgow native, and at right, a Russian of the same age who has been learning English for one year. I've highlighted a few of the differences.
Composite of screenshots from www.accent.gmu.edu
But the problems in identifying individual speech sounds don't end with the fact that different people say them differently. An individual speaker also says them differently, depending on the context. People produce about 10 speech sounds per second, so it's no great surprise that the positions your lips, tongue, and vocal cords were in when you produced the last speech sound will influence the way the next one sounds. In fact, you also produce a speech sound differently because you anticipate the next sound you're going to say. For example, try this. Put your hand in front of your mouth and say pot. You feel the puff of air when you say the p. Now do the same thing, saying spot. The puff is stronger for pot than spot. So there's not a single sound associated with the letter “p.” The same person says it a little differently, depending on the context.
For some speech sounds, the problem is still worse. Consider the letter “p” again. You actually can't say it aloud. You might think of it as puh—that's what parents often tell children—but that's two sounds: the sound associated with the letter “p” and then a vowel sound after it, uh. The sound associated with the letter “p” is simply a plosion of air. In fact, that's the same plosion of air you make for the letter “b.” The only difference is that when you say bee your vocal chords vibrate to make the vowel sound at the same time you make the plosion of air, whereas when you say pee the vocal chords only start to vibrate about 0.04 seconds after the plosion. Yup. The difference between pee and bee hinges on this 0.04 second difference in timing. So asking “What sound does the letter ‘p’ make?” is nonsensical. The very definition of the sound that is supposed to go with the letter depends on its relationship to neighboring sounds. It's actually impossible to say p in isolation.
Context‐Free Sounds and Reading
I've described three difficulties in hearing speech sounds: people pronounce them differently, the same individual pronounces them differently depending on context, and in some cases the sound itself depends on the neighboring sounds. The critical thing to notice is that each of these three challenges describes ways that context is important for understanding individual speech sounds. When someone is speaking you have that context available. But when you are learning which sounds go with which letters of the alphabet, that's context‐free. The problem lies in isolating all the different ways you hear a sound in spoken speech, and then abstracting some ideal version of that sound so you can associate it with a letter (Figure 2.8).
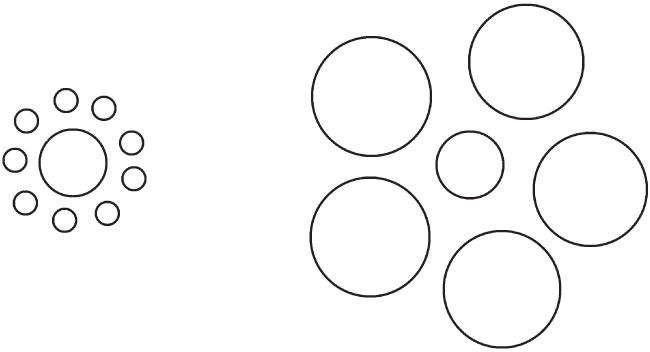
Figure 2.8. Visual illusion. You've likely seen this illusion before, the point being that the central circles appear to be different sizes because of the surrounding circles. In a similar fashion, context influences how we evaluate speech sounds, so thinking about them in isolation is very difficult.
© Daniel Willingham
The ability to hear individual speech sounds is called phonemic awareness. (Phonological awareness is the term for hearing any sort of speech sound, e.g., separate words, or separate syllables.) It is tested with several different tasks. Children might be asked to name the sound at the beginning of a word. They might be asked if two words begin with the same sound, or end with the same sound. In more challenging tasks, they might be asked to change a word by adding, removing, or manipulating sounds, e.g., if I took the word top and added a ssss at the beginning, what word would it make?
We would guess that phonological awareness would be important to learning to read. If reading is a code between symbols and speech sounds, it's going to be hard to learn the code if you can't hear the speech sounds. Lots of research indicates that this reasonable supposition is right. Children who have trouble learning to read often have difficulty with phonological awareness tasks.13 At the other end of the spectrum, children who more or less teach themselves to read turn out to perform quite well on these tasks.14 More generally, measures of phonological awareness and of letter knowledge show strong relationships with reading measures, not just in elementary school but continuing through high school.15,16 This relationship between phonological awareness and reading is not unique to learning to read English—you see it across languages.17,18
But of course these studies just show a correlation. They can't support the stronger conclusion that phonological awareness is required for learning to read. Training studies are more persuasive. Children can be given practice in phonological awareness by, for example, playing games with rhyme (Who knows a bird's name that rhymes with luck?) or alliteration (Five fantastic falcons fanned four flipping foxes!). Training tasks tend to be quite similar to those used to measure phonological awareness, but include practice and feedback. We'd expect that children who get phonological awareness training would show improvements in learning to read compared to kids who don't get the training. They do.19–21
Some children get incidental training at home. That is, their parents play rhyming and alliteration games with them as a matter of course, for example, through read‐alouds; Mother Goose, Dr. Seuss, and other children's favorites are packed with such wordplay. And research shows that children who encounter this sort of wordplay at home develop phonemic awareness and later find it easier to learn to read.22
Still, we might question whether sound is necessary for learning to read. Perhaps teachers make sound necessary by virtue of the way they teach reading. They emphasize the sound‐based nature of the code and so it's no surprise that training students to hear sounds helps. What if a child had to bypass sound when learning to read because she cannot hear? The letters may signify sound, but the pattern of letters for each word is still unique (or nearly so). Would she learn to read by matching word spellings—their visual appearances—directly to their meaning?
It turns out that sound is difficult to bypass. Some deaf children try to match words to their American Sign Language counterparts, but that's tough to do—you're trying to match an alphabetic word to a symbol that corresponds to a meaning unit.23,24 If you bypass sound, you're forced to focus on the visual aspect of the letters to differentiate words, and you're back to one of the problems with a logographic code—there is a huge number of symbols to memorize. Little wonder that many or most deaf readers code phonologically, and that's true even for beginning readers.25 That's hard, obviously, and it results in poor reading performance; deaf high school graduates read, on average, at a fourth grade level.26
I've made it sound as though there's a strict order to these two mental processes: gain phonemic awareness, then learn to read. The processes are better characterized as reciprocal. It's hard to learn to read without some degree of phonemic awareness, but that awareness may be pretty crude—it improves with reading experience. One of the more dramatic demonstrations of this phenomenon came in an experiment of Portuguese adults who could not read. They had a terrible time with phonemic awareness tests. But once they learned how to read, their phonemic awareness improved dramatically.27
Challenge 3: The Mapping
The third challenge inherent in reading English is that you must learn the alphabetic principle; the idea that letters correspond to sounds. Perceiving that idea is not intuitive, and children don't effortlessly learn it via exposure, the way they learn grammar by listening. They may learn that letters correspond to names or words (as in the cubby example above), but that's different than understanding that individual letters signify speech sounds.
For example, in one experiment children who could not yet read were taught to recognize the printed words “mat” and “sat.” Once they could do so the experimenters showed them the words “mow” and “sow” to see whether the children could differentiate them. If so, that would indicate that they understood that individual letters signify individual sounds. The only children who could extend “mat/sat” knowledge to “mow/sow” were those who had good phonological awareness and who had learned the graphic symbols “m” and “s.” The alphabetic principle—the idea of an association between letters and sounds—doesn't come naturally. The auditory and the visual pieces must be in place.
How Confusing is the Mapping in English?
The principle may not come naturally, but surely we could make the particulars easier. If you were creating an alphabet for English from scratch, you would probably create 44 letters and match each speech sound with one letter. We'd call that a one‐to‐one matching. Written English, alas, was not created from scratch. Our language is a mongrel: Germanic origins, heavily influenced by the Norman invasion and later by the adoption of Latinate and Greek words. That's a problem because when we borrowed words, we frequently retained the spelling conventions of the original language. The result is that English uses a many‐to‐many matching. One letter (or letter combination) can signify many sounds, as the letter “e” does: red, flower, bee. Then too, the same sound might be spelled via different letters or letter combinations, as in “boat,” “doe,” and “row.” This complexity has caused misery among generations of school children, although it has provided fodder for light rimers.28
| When the English tongue we speak. | And think of goose and yet with choose |
| Why is break not rhymed with freak? | Think of comb, tomb and bomb, |
| Will you tell me why it's true | Doll and roll or home and some. |
| We say sew but likewise few? | Since pay is rhymed with say |
| And the maker of the verse, | Why not paid with said I pray? |
| Cannot rhyme his horse with worse? | Think of blood, food and good. |
| Beard is not the same as heard | Mould is not pronounced like could. |
| Cord is different from word. | Wherefore done, but gone and lone |
| Cow is cow but low is low | Is there any reason known? |
| Shoe is never rhymed with foe. | To sum up all, it seems to me |
| Think of hose, dose, and lose | Sound and letters don't agree. |
And yet things are not as bad as you might first think. English pronunciation looks more consistent when we take context into account. A well‐known example of the anything‐goes sensibility of English spelling is the invented word “ghoti,” to be pronounced fish—provided one pronounces “gh” as in the word enough, “o” as in the word women, and “ti” as in the word motion. Cute, but there's a reason most would pronounce “ghoti” as goatee. The context of each letter matters. When “gh” appears at the start of a word, it's pronounced as a hard g (e.g., ghastly, ghost). In the middle of a word it's silent (e.g., daughter, taught). It's only pronounced as f at the end of a word (laugh, tough).
How much does context help constrain pronunciation? Researchers Brett Kessler and Becky Treiman analyzed the spelling and pronunciation of 3,117 single‐syllable words. They found that consonants at the start of a word were pronounced consistently about 90% of the time. And the 10% of the time that the beginning consonants were not consistent, looking at the vowel that followed sometimes helped the reader figure out how to pronounce that initial consonant. For example, “c” is pronounced as s when it precedes “e,” “i,” or “y” (e.g., cent, cinch, or cycle), and “c” is pronounced as k when followed by other vowels (e.g., cat, collar, or culprit.) Final consonants were pronounced consistently about 94% of time. But context was of little help for those few inconsistencies.
Context helps even more when we consider vowels. But then again, vowels need more help because they are more often inconsistent; in Kessler and Treiman's analysis fully 40% of vowel sounds were exceptions. The initial consonant was never any help in predicting the pronunciation, but the final consonant was about 80% of the time. So for example, the vowel string “oo” is usually pronounced as in the word boot, but sometimes it's pronounced as in the word book. Well, it turns out that “oo” only has the latter pronunciation when it's followed by “k” or “r” (book, brook, crook, shook, poor, door, floor).
Of course, there are out‐and‐out rule violations in English spelling—enough that some educators suggest it makes more sense to use the term spelling patterns, rather than rules. Even for exceptions to the patterns, we can take heart. These are often high‐frequency words—that is, they appear very often in the language.29 “Gone,” “give,” “are,” “were,” and “done” all violate the pattern when a word ends with ‘e’, the vowel sound is long. (Hence, “give” should rhyme with “hive.”) Although these violate the pattern, they appear so commonly they are good candidates simply to be memorized as exceptions.
So in the end just how many letter‐sound pairings must children learn? It depends on whether you include only the words that seven‐year‐olds are likely to encounter, or all English words. The lowest estimate would be at least 200 pairings.
Learning the Mapping
A couple hundred letter‐sound pairings does seem like a lot to learn. It's also not the type of learning that humans find easiest, but we're not terrible at it, either. Psychologists call it arbitrary paired‐associate learning; we're supposed to know that “A” and “B” go together. If I see “A”, I think of “B”, and vice versa, but there's no special rhyme or reason as to why “A” goes with “B” instead of going with “C”. It's arbitrary. In the same way, there's no reason that the shape “c” goes with the sounds it does.
We do this sort of learning all the time, for example, associating people's names and faces, or associating the names of sports teams with the cities they play in. If you follow football in the fall and baseball in the summer, that's 62 city‐team associations you know. So the idea of children learning a couple of hundred associations seems . . . well, frustrating, given that there are 44 speech sounds, but not insurmountable.
Naturally, some people are a little better at it than others, and there is evidence that children who are good at learning paired‐associates learn to read faster.30 Interestingly, you only see the advantage if children are good at the very specific type of association called for in reading, namely, learning a verbal response to a visual stimulus. For example, you show children an arbitrary shape, and ask them to learn that it's called a maluma. When the association goes in the other direction—I say maluma and you have to pick out the shape—learning is unrelated to reading. 31–33
It's little wonder we use the word “decode” to refer to the process of translating print to sounds. Print is a code. And although the code may not be as haphazard as it first appears, it's definitely a problem for beginning readers, a problem that kids learning to read more consistent spelling systems don't face. Finnish, Spanish, and Italian, for example, are very consistent, with a near one‐to‐one mapping between letters and speech sounds and very few exception words. Kids learn to decode quite quickly in those countries. In a matter of months, almost all children can read aloud one or two syllable words with few errors. English‐speaking children lag far behind (Figure 2.9).
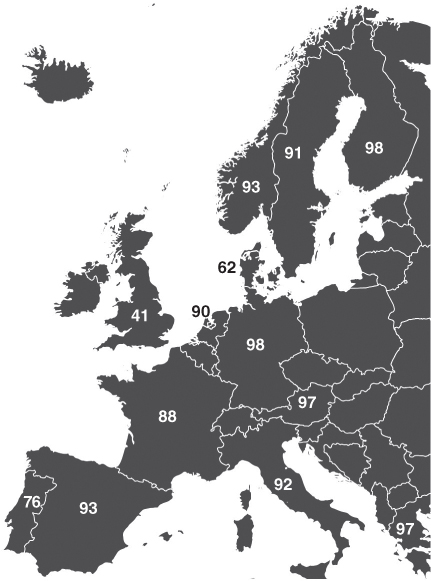
Figure 2.9. First‐grade reading proficiency in European countries. The numbers are the average percentages of one‐syllable words that children could read correctly at the end of first grade. Portuguese, French, and Danish, like English, have less consistent mappings between sounds and letters than other languages do.
Map of Europe: modified, original © hektoR, Shutterstock; data from Seymour, Aro, & Erskine (2003)
First‐graders do have a hard time in countries where the sound of the language maps inconsistently to writing. But most of the children learn the mapping, complex though it may be. By the time they reach fourth grade, the difficulty of the mapping is no longer the primary reason that children read well or poorly (Figure 2.10).
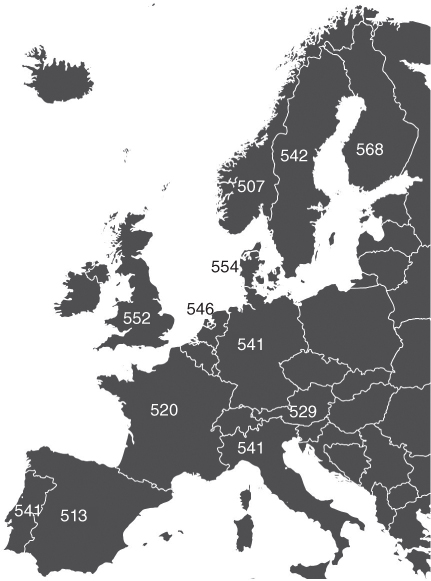
Figure 2.10. Average results from the Progress in International Reading Literacy Study (PIRLS) administered to 10‐year‐olds around the world. The scale goes from 0‐1,000, with higher numbers reflecting better performance. The fourth‐graders in England, Portugal, and Denmark score quite well, even though first‐graders in those countries struggle with the difficult letter‐sound mapping. These results show that most children are able to learn the mapping.
Map of Europe: modified, original © hektoR, Shutterstock; data from Mullis, Martin, Foy, & Drucker (2012)
All right, most children learn the letter‐sound mappings in English, despite the difficulty. But must it be so difficult? Why not simplify English spelling?
This seemingly obvious idea has not been enacted because there are some non‐obvious obstacles. First, such a movement could not be universal due to differences in pronunciation. If you really tried to respect pronunciation, you'd have different spellings of the same word in many of the countries that use English as an official language: Australia, Cameroon, Canada, England, Gambia, Malawi, Scotland, and so on. Second, simplified spelling would carry some costs. English has a lot of homophones: “I” and “eye,” “bear” and “bare,” and so on. The different spellings are troublesome to learn, but once you know them, they make reading easier. If these were spelled the same way, readers would have to use context to know which sense was meant. Third, it has proven harder than you might think to develop an accepted list of spelling patterns. The problem is that our current list of patterns is a mish‐mash of those found in German, French, Latin, and Greek. Schemes to simplify spelling tend to privilege one of these four languages, so the number of words affected ends up being huge.
A goal more modest than the complete regularization of spelling might be achievable: reduce redundancies. The letter “x” could be replaced by “ks.” Hard “c” could be replaced by “k,” and soft “c” could be replaced by “s.” Even this less ambitious goal has little chance of realization, as attempts at spelling simplification have historically encountered strong public opposition. English, unlike many other languages, does not have a central regulatory body with the authority to dictate changes, so public enthusiasm (or at least, acquiescence) would be essential.
Summing Up
In Chapter 1 we noted that English writing—and all other writing—codes sound, not meaning. In the case of our alphabetic system, that means that children must learn to discriminate only a small number of visual symbols, namely the letters of the Roman alphabet. That visual discrimination is relatively easy. More difficult is learning the mapping between letters and sounds. It's more complicated than it needs to be, but the mind is not ill equipped to learn this sort of association, so with time and practice, children catch on. The hardest aspect of learning to decode is the hearing of individual speech sounds. That your brain is not designed to do, and although some children pick up this skill with ease, many do not. It's the weak spot in learning to decode, the aspect of reading that is most likely to give kids trouble.
I've emphasized sound so much you may well have concluded the story of decoding ends there. Print allows us to talk to ourselves, and that's reading. But there's more to it. For example, have a look at this passage:
How'd that go? I expect you could work out the meaning, probably helped by the fact that the story is familiar. But note how much more quickly you can read the same passage with standard spelling:
If reading is a matter of translating print to sound and mentally “listening” to what we've decoded, shouldn't the passage be easier to read? Why should “coddij” be harder to read than “cottage”? In laboratory experiments we see that it takes a little longer to reject as a nonword a letter string that sounds like a word (e.g., “chare”) compared to one that doesn't sound like a word (e.g., “pleck”).34
An obvious explanation is that we have had some practice reading “cottage” and “chair,” and none reading “coddij” or “pleck.” That may mean that reading is more than the application of spelling‐sound conversion rules—we know what words look like. But it may not mean that. It may be that some translation rules are used less often than others, we're slower to read when we use those unusual rules, and the “Liddle Rehd Rye Din Hood” paragraph used a lot of those unusual translation rules.
We consider these possibilities in the next chapter.
References
- 1. Changizi, M. A., Zhang, Q., Ye, H., & Shimojo, S. (2006). The structures of letters and symbols throughout human history are selected to match those found in objects in natural scenes. The American Naturalist, 167(5), E117–E139. http://doi.org/10.1086/502806.
- 2. Treiman, R., & Kessler, B. (2003). The role of letter names in the acquisition of literacy. In Advances in child development and behavior (Vol. 31, pp. 105–135). San Diego, CA: Academic Press.
- 3. Treiman, R., Kessler, B., & Pollo, T. C. (2006). Learning about the letter name subset of the vocabulary: Evidence from US and Brazilian preschoolers. Applied Psycholinguistics, 27, 211–227.
- 4. Treiman, R., Levin, I., & Kessler, B. (2012). Linking the shapes of alphabet letters to their sounds: the case of Hebrew. Reading and Writing, 25(2), 569–585. http://doi.org/10.1007/s11145‐010‐9286‐3.
- 5. Treiman, R., & Broderick, V. (1998). What's in a name: Children's knowledge about the letters in their own names. Journal of Experimental Child Psychology, 70(2), 97–116. http://doi.org/10.1006/jecp.1998.2448.
- 6. Nodine, C. F., & Lang, N. J. (1971). Development of visual scanning strategies for differentiating words. Developmental Psychology, 5(2), 221–232. http://doi.org/10.1037/h0031428.
- 7. Liberman, I. Y., Shankweiler, D., Orlando, C., Harris, K. S., & Berti, F. B. (1971). Letter confusions and reversals of sequence in the beginning reader: Implications for Orton's Theory of Developmental Dyslexia. Cortex, 7(2), 127–142. http://doi.org/10.1016/S0010‐9452(71)80009‐6.
- 8. Vellutino, F. R., Smith, H., Steger, J. A., & Kaman, M. (1975). Reading disability: Age differences and the perceptual‐deficit hypothesis. Child Development, 46(2), 487–493. Retrieved from www.jstor.org/stable/1128146.
- 9. Grainger, J., Rey, A., & Dufau, S. (2008). Letter perception: From pixels to pandemonium. Trends in Cognitive Sciences, 12(10), 381–387. http://doi.org/10.1016/j.tics.2008.06.006.
- 10. Hubel, D., & Wiesel, T. (1962). Receptive fields, binocular interaction and functional architecture in the cat's visual cortex. The Journal of Physiology, 160(1), 106–154. Retrieved from http://onlinelibrary.wiley.com/doi/10.1113/jphysiol.1962.sp006837/full/.
- 11. Holden, M. H., & MacGinitie, W. H. (1972). Children's conceptions of word boundaries in speech and print. Journal of Educational Psychology, 63(6), 551–557. Retrieved from http://psycnet.apa.orgjournals/edu/63/6/551.
- 12. Cunningham, A. E., & Zibulsky, J. (2014). Book smart. New York: Oxford University Press.
- 13. Melby‐Lervåg, M., Lyster, S. A. H., & Hulme, C. (2012). Phonological skills and their role in learning to read: A meta‐analytic review. Psychological Bulletin, 138(2), 322–52. http://doi.org/10.1037/a0026744.
- 14. Backman, J. (1983). The role of psycholinguistic skills in reading acquisition: A look at early readers. Reading Research Quarterly, 18(4), 466–479.
- 15. Storch, S. A., & Whitehurst, G. J. (2002). Oral language and code‐related precursors to reading: Evidence from a longitudinal structural model. Developmental Psychology, 38(6), 934–947. http://doi.org/10.1037//0012‐1649.38.6.934.
- 16. Calfee, R. C., Lindamood, P., & Lindamood, C. (1973). Acoustic‐phonetic skills and reading: Kindergarten through twelfth grade. Journal of Educational Psychology, 64(3), 293–298. Retrieved from www.ncbi.nlm.nih.gov/pubmed/4710951.
- 17. Anthony, J. L., & Francis, D. J. (2005). Development of phonological awareness. Current Directions in Psychological Science, 14(5), 255–259. http://doi.org/10.1111/j.0963‐7214.2005.00376.x.
- 18. Hu, C.‐F., & Catts, H. W. (1998). The role of phonological processing in early reading ability: What we can learn from Chinese. Scientific Studies of Reading, 2(1), 55–79.
- 19. Bradley, L., & Bryant, P. E. (1983). Categorizing sounds and learning to read: A causal connection. Nature, 301, 419–421.
- 20. Ehri, L. C., Nunes, S. R., Stahl, S. a., & Willows, D. M. (2001). Systematic phonics instruction helps students learn to read: evidence from the National Reading Panel's Meta‐Analysis. Review of Educational Research, 71(3), 393–447. http://doi.org/10.3102/00346543071003393.
- 21. Bus, A. G., & van IJzendoorn, M. H. (1999). Phonological awareness and early reading: A meta‐analysis of experimental training studies. Journal of Educational Psychology, 91(3), 403–414.
- 22. Rodriguez, E. T., & Tamis‐Lemonda, C. S. (2011). Trajectories of the home learning environment across the first 5 years: Associations with children's vocabulary and literacy skills at prekindergarten.Child Development, 82(4), 1058–1075. http://doi.org/10.1111/j.1467‐8624.2011.01614.x.
- 23. Hanson, V. L., Liberman, I. Y., & Shankweiler, D. (1984). Linguistic coding by deaf children in relation to beginning reading success. Journal of Experimental Child Psychology, 37(2), 1984.
- 24. Morford, J. P., Wilkinson, E., Villwock, A., Piñar, P., & Kroll, J. F. (2011). When deaf signers read English: Do written words activate their sign translations? Cognition, 118(2), 286–292. http://doi.org/10.1016/j.cognition.2010.11.006.
- 25. Hanson, V. L., Goodell, E. W., & Perfetti, C. A. (1991). Tongue‐twister effects in the silent reading of hearing and deaf college students. Journal of Memory and Language, 30, 319–330.
- 26. Traxler, C. B. (2000). The Stanford Achievement Test, 9th edition: National norming and performance standards for deaf and Hard‐of‐Hearing Students. Journal of Deaf Studies and deaf education, 5(4), 337–348. http://doi.org/10.1093/deafed/5.4.337.
- 27. Morais, J., Luz, G., Alegria, J., & Bertels, P. (1979). Does awareness of speech as a sequence of phones arise spontaneously? Cognition, 7, 323–331.
- 28. Vaughn, J. S. (1902, August). Our strange language. The Spectator, 187.
- 29. Ziegler, J. C., Stone, G. O., & Jacobs, A. M. (1997). What is the pronunciation for ‐ough and the for computing spelling for /u /? A database for computing feedforward and feedback consistency in English. Behavior Research Methods, Instruments, & Computers, 29(4), 600–618.
- 30. Windfuhr, K. L., & Snowling, M. J. (2001). The relationship between paired associate learning and phonological skills in normally developing readers. Journal of Experimental Child Psychology, 80(2), 160–173. http://doi.org/10.1006/jecp.2000.2625.
- 31. Hulme, C., Goetz, K., Gooch, D., Adams, J., & Snowling, M. J. (2007). Paired‐associate learning, phoneme awareness, and learning to read. Journal of Experimental Child Psychology, 96(2), 150–166. http://doi.org/10.1016/j.jecp.2006.09.002.
- 32. Litt, R. A., de Jong, P. F., van Bergen, E., & Nation, K. (2013). Dissociating crossmodal and verbal demands in paired associate learning (PAL): What drives the PAL‐reading relationship? Journal of Experimental Child Psychology, 115(1), 137–149. http://doi.org/10.1016/j.jecp.2012.11.012.
- 33. Litt, R. A., & Nation, K. (2014). The nature and specificity of paired associate learning deficits in children with dyslexia. Journal of Memory and Language, 71(1), 71–88. http://doi.org/10.1016/j.jml.2013.10.005.
- 34. Coltheart, M., Davelaar, E., Jonasson, T., & Besner, D. (1977). Access to the internal lexicon. In Attention & Performance VI. London: Academic Press.
- 35. Liberman, I. Y. (1973). Segmentation of the spoken word and reading acquisition. Annals of Dyslexia, 23(1), 64–77; Stanovich, K. E. (1988). Explaining the differences between the dyslexic and the garden‐variety poor reader: The phonological‐core variable‐difference model. Journal of Learning Disabilities, 21(10), 590–604.
- 36. A highly readable introduction to dyslexia may be found in Mark Seidenberg's wonderful book, Language at the speed of sight (New York: Basic Books, 2016).
- 37. Justice, L. M., & Pullen, P. C. (2003). Promising interventions for promoting emergent literacy skills: Three evidence‐based approaches. Topics in Early Childhood Special Education, 23(3), 99–113.
- 38. Treiman, R., & Kessler, B. (2003). The role of letter names in the acquisition of literacy. Advances in Child Development and Behavior, 31, 105–138.
- 39. Share, D. L. (2004). Knowing letter names and learning letter sounds: A causal connection. Journal of Experimental Child Psychology, 88(3), 213–233.
- 40. Ellefson, M. R., Treiman, R., & Kessler, B. (2009). Learning to label letters by sounds or names: A comparison of England and the United States. Journal of Experimental Child Psychology, 102, 323–341.
- 41. Suggate, S. P., Schaughency, E. A. & Reese, E. (2013). Children learning to read later catch up to children reading earlier. Early Childhood Research Quarterly, 28, 33–48.