7How to Design Our Organization and Architecture with Conway’s Law in Mind
In the previous chapters, we identified a value stream to start our DevOps transformation and established shared goals and practices to enable a dedicated transformation team to improve how we deliver value to the customer.
In this chapter, we will start thinking about how to organize ourselves to best achieve our value stream goals. After all, how we organize our teams affects how we perform our work. Dr. Melvin Conway performed a famous experiment in 1968 with a contract research organization that had eight people who were commissioned to produce a COBOL and an ALGOL compiler. He observed, “After some initial estimates of difficulty and time, five people were assigned to the COBOL job and three to the ALGOL job. The resulting COBOL compiler ran in five phases, the ALGOL compiler ran in three.”
These observations led to what is now known as Conway’s Law, which states that “organizations which design systems...are constrained to produce designs which are copies of the communication structures of these organizations….The larger an organization is, the less flexibility it has and the more pronounced the phenomenon.” Eric S. Raymond, author of the book The Cathedral and the Bazaar: Musings on Linux and Open Source by an Accidental Revolutionary, crafted a simplified (and now, more famous) version of Conway’s Law in his Jargon File: “The organization of the software and the organization of the software team will be congruent; commonly stated as ‘if you have four groups working on a compiler, you’ll get a 4-pass compiler.’”
In other words, how we organize our teams has a powerful effect on the software we produce, as well as our resulting architectural and production outcomes. In order to get fast flow of work from Development into Operations, with high quality and great customer outcomes, we must organize our teams and our work so that Conway’s Law works to our advantage. Done poorly, Conway’s Law will prevent teams from working safely and independently; instead, they will be tightly-coupled together, all waiting on each other for work to be done, with even small changes creating potentially global, catastrophic consequences.
An example of how Conway’s Law can either impede or reinforce our goals can be seen in a technology that was developed at Etsy called Sprouter. Etsy’s DevOps journey began in 2009, and is one of the most admired DevOps organizations, with 2014 revenue of nearly $200 million and a successful IPO in 2015.
Originally developed in 2007, Sprouter connected people, processes, and technology in ways that created many undesired outcomes. Sprouter, shorthand for “stored procedure router,” was originally designed to help make life easier for the developers and database teams. As Ross Snyder, a senior engineer at Etsy, said during his presentation at Surge 2011, “Sprouter was designed to allow the Dev teams to write PHP code in the application, the DBAs to write SQL inside Postgres, with Sprouter helping them meet in the middle.”
Sprouter resided between their front-end PHP application and the Postgres database, centralizing access to the database and hiding the database implementation from the application layer. The problem was that adding any changes to business logic resulted in significant friction between developers and the database teams. As Snyder observed, “For nearly any new site functionality, Sprouter required that the DBAs write a new stored procedure. As a result, every time developers wanted to add new functionality, they would need something from the DBAs, which often required them to wade through a ton of bureaucracy.” In other words, developers creating new functionality had a dependency on the DBA team, which needed to be prioritized, communicated, and coordinated, resulting in work sitting in queues, meetings, longer lead times, and so forth. This is because Sprouter created a tight coupling between the development and database teams, preventing developers from being able to independently develop, test, and deploy their code into production.
Also, the database stored procedures were tightly-coupled to Sprouter—any time a stored procedure was changed, it required changes to Sprouter too. The result was that Sprouter became an ever-larger single point of failure. Snyder explained that everything was so tightly-coupled and required such a high level of synchronization as a result, that almost every deployment caused a mini-outage.
Both the problems associated with Sprouter and their eventual solution can be explained by Conway’s Law. Etsy initially had two teams, the developers and the DBAs, who were each responsible for two layers of the service, the application logic layer and stored procedure layer. Two teams working on two layers, as Conway’s Law predicts. Sprouter was intended to make life easier for both teams, but it didn’t work as expected—when business rules changed, instead of changing only two layers, they now needed to make changes to three layers (in the application, in the stored procedures, and now in Sprouter). The resulting challenges of coordinating and prioritizing work across three teams significantly increased lead times and caused reliability problems.
In the spring of 2009, as part of what Snyder called “the great Etsy cultural transformation,” Chad Dickerson joined as their new CTO. Dickerson put into motion many things, including a massive investment into site stability, having developers perform their own deployments into production, as well as beginning a two-year journey to eliminate Sprouter.
To do this, the team decided to move all the business logic from the database layer into the application layer, removing the need for Sprouter. They created a small team that wrote a PHP Object Relational Mapping (ORM) layer,† enabling the front-end developers to make calls directly to the database and reducing the number of teams required to change business logic from three teams down to one team.
As Snyder described, “We started using the ORM for any new areas of the site and migrated small parts of our site from Sprouter to the ORM over time. It took us two years to migrate the entire site off of Sprouter. And even though we all grumbled about Sprouter the entire time, it remained in production throughout.”
By eliminating Sprouter, they also eliminated the problems associated with multiple teams needing to coordinate for business logic changes, decreased the number of handoffs, and significantly increased the speed and success of production deployments, improving site stability. Furthermore, because small teams could independently develop and deploy their code without requiring another team to make changes in other areas of the system, developer productivity increased.
Sprouter was finally removed from production and Etsy’s version control repositories in early 2001. As Snyder said, “Wow, it felt good.”‡
As Snyder and Etsy experienced, how we design our organization dictates how work is performed, and, therefore, the outcomes we achieve. Throughout the rest of this chapter we will explore how Conway’s Law can negatively impact the performance of our value stream, and, more importantly, how we organize our teams to use Conway’s Law to our advantage.
ORGANIZATIONAL ARCHETYPES
In the field of decision sciences, there are three primary types of organizational structures that inform how we design our DevOps value streams with Conway’s Law in mind: functional, matrix, and market. They are defined by Dr. Roberto Fernandez as follows:
- Functional-oriented organizations optimize for expertise, division of labor, or reducing cost. These organizations centralize expertise, which helps enable career growth and skill development, and often have tall hierarchical organizational structures. This has been the prevailing method of organization for Operations (i.e., server admins, network admins, database admins, and so forth are all organized into separate groups).
- Matrix-oriented organizations attempt to combine functional and market orientation. However, as many who work in or manage matrix organizations observe, matrix organizations often result in complicated organizational structures, such as individual contributors reporting to two managers or more, and sometimes achieving neither of the goals of functional or market orientation.
- Market-oriented organizations optimize for responding quickly to customer needs. These organizations tend to be flat, composed of multiple, cross-functional disciplines (e.g., marketing, engineering, etc.), which often lead to potential redundancies across the organization. This is how many prominent organizations adopting DevOps operate—in extreme examples, such as at Amazon or Netflix, each service team is simultaneously responsible for feature delivery and service support.§
With these three categories of organizations in mind, let’s explore further how an overly functional orientation, especially in Operations, can cause undesired outcomes in the technology value stream, as Conway’s Law would predict.
PROBLEMS OFTEN CAUSED BY OVERLY FUNCTIONAL ORIENTATION (“OPTIMIZING FOR COST”)
In traditional IT Operations organizations, we often use functional orientation to organize our teams by their specialties. We put the database administrators in one group, the network administrators in another, the server administrators in a third, and so forth. One of the most visible consequences of this is long lead times, especially for complex activities like large deployments where we must open up tickets with multiple groups and coordinate work handoffs, resulting in our work waiting in long queues at every step.
Compounding the issue, the person performing the work often has little visibility or understanding of how their work relates to any value stream goals (e.g., “I’m just configuring servers because someone told me to.”). This places workers in a creativity and motivation vacuum.
The problem is exacerbated when each Operations functional area has to serve multiple value streams (i.e., multiple Development teams) who all compete for their scarce cycles. In order for Development teams to get their work done in a timely manner, we often have to escalate issues to a manager or director, and eventually to someone (usually an executive) who can finally prioritize the work against the global organizational goals instead of the functional silo goals. This decision must then get cascaded down into each of the functional areas to change the local priorities, and this, in turn, slows down other teams. When every team expedites their work, the net result is that every project ends up moving at the same slow crawl.
In addition to long queues and long lead times, this situation results in poor handoffs, large amounts of re-work, quality issues, bottlenecks, and delays. This gridlock impedes the achievement of important organizational goals, which often far outweigh the desire to reduce costs.¶
Similarly, functional orientation can also be found with centralized QA and Infosec functions, which may have worked fine (or at least, well enough) when performing less frequent software releases. However, as we increase the number of Development teams and their deployment and release frequencies, most functionally-oriented organizations will have difficulty keeping up and delivering satisfactory outcomes, especially when their work is being performed manually. Now we’ll study how market oriented organizations work.
ENABLE MARKET-ORIENTED TEAMS (“OPTIMIZING FOR SPEED”)
Broadly speaking, to achieve DevOps outcomes, we need to reduce the effects of functional orientation (“optimizing for cost”) and enable market orientation (“optimizing for speed”) so we can have many small teams working safely and independently, quickly delivering value to the customer.
Taken to the extreme, market-oriented teams are responsible not only for feature development, but also for testing, securing, deploying, and supporting their service in production, from idea conception to retirement. These teams are designed to be cross-functional and independent—able to design and run user experiments, build and deliver new features, deploy and run their service in production, and fix any defects without manual dependencies on other teams, thus enabling them to move faster. This model has been adopted by Amazon and Netflix and is touted by Amazon as one of the primary reasons behind their ability to move fast even as they grow.
To achieve market orientation, we won’t do a large, top-down reorganization, which often creates large amounts of disruption, fear, and paralysis. Instead, we will embed the functional engineers and skills (e.g., Ops, QA, Infosec) into each service team, or provide their capabilities to teams through automated self-service platforms that provide production-like environments, initiate automated tests, or perform deployments.
This enables each service team to independently deliver value to the customer without having to open tickets with other groups, such as IT Operations, QA, or Infosec.**
MAKING FUNCTIONAL ORIENTATION WORK
Having just recommended market-orientated teams, it is worth pointing out that it is possible to create effective, high-velocity organizations with functional orientation. Cross-functional and market-oriented teams are one way to achieve fast flow and reliability, but they are not the only path. We can also achieve our desired DevOps outcomes through functional orientation, as long as everyone in the value stream views customer and organizational outcomes as a shared goal, regardless of where they reside in the organization.
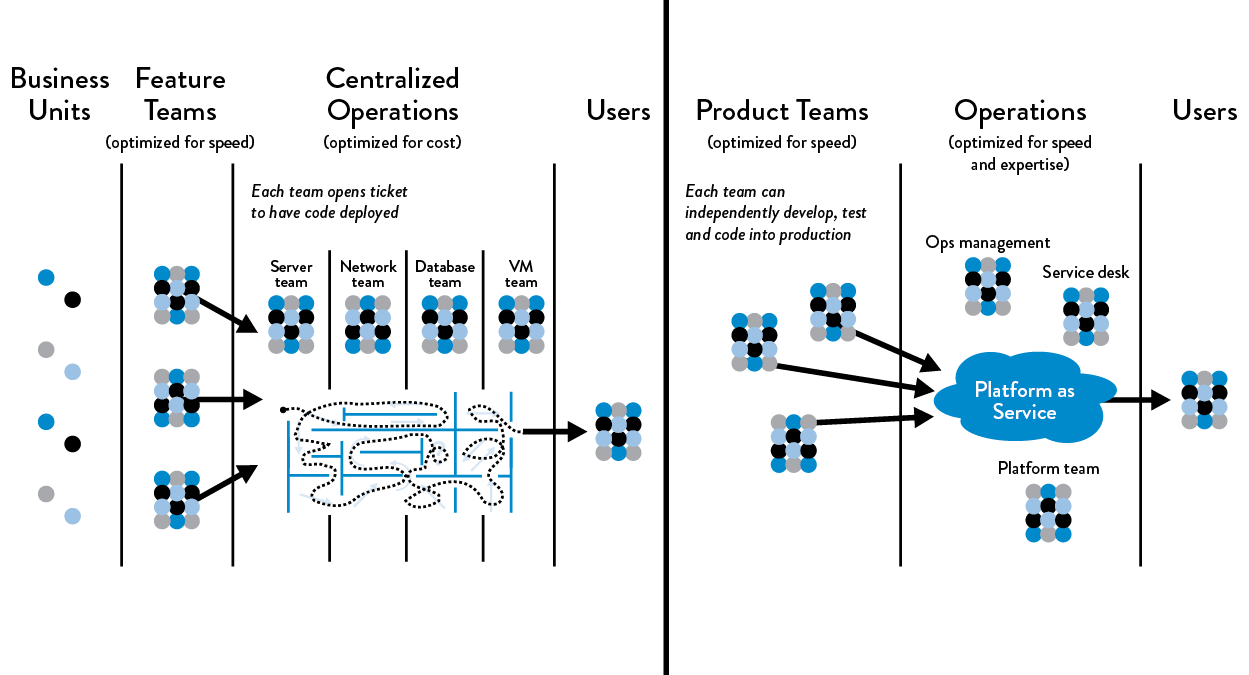 Figure 12: Functional vs. market orientation
Figure 12: Functional vs. market orientation
Left: Functional orientation: all work flows through centralized IT Operations; Right: Market orientation: all product teams can deploy their loosely-coupled components self-service into production. (Source: Humble, Molesky, and O’Reilly, Lean Enterprise, Kindle edition, 4523 & 4592.)
For example, high performance with a functional-oriented and centralized Operations group is possible, as long as service teams get what they need from Operations reliably and quickly (ideally on demand) and vice-versa. Many of the most admired DevOps organizations retain functional orientation of Operations, including Etsy, Google, and GitHub.
What these organizations have in common is a high-trust culture that enables all departments to work together effectively, where all work is transparently prioritized and there is sufficient slack in the system to allow high-priority work to be completed quickly. This is, in part, enabled by automated self-service platforms that build quality into the products everyone is building.
In the Lean manufacturing movement of the 1980s, many researchers were puzzled by Toyota’s functional orientation, which was at odds with the best practice of having cross-functional, market-oriented teams. They were so puzzled it was called “the second Toyota paradox.”
As Mike Rother wrote in Toyota Kata, “As tempting as it seems, one cannot reorganize your way to continuous improvement and adaptiveness. What is decisive is not the form of the organization, but how people act and react. The roots of Toyota’s success lie not in its organizational structures, but in developing capability and habits in its people. It surprises many people, in fact, to find that Toyota is largely organized in a traditional, functional-department style.” It is this development of habits and capabilities in people and the workforce that are the focus of our next sections.
TESTING, OPERATIONS, AND SECURITY AS EVERYONE’S JOB, EVERY DAY
In high-performing organizations, everyone within the team shares a common goal—quality, availability, and security aren’t the responsibility of individual departments, but are a part of everyone’s job, every day.
This means that the most urgent problem of the day may be working on or deploying a customer feature or fixing a Severity 1 production incident. Alternatively, the day may require reviewing a fellow engineer’s change, applying emergency security patches to production servers, or making improvements so that fellow engineers are more productive.
Reflecting on shared goals between Development and Operations, Jody Mulkey, CTO at Ticketmaster, said, “For almost 25 years, I used an American football metaphor to describe Dev and Ops. You know, Ops is defense, who keeps the other team from scoring, and Dev is offense, trying to score goals. And one day, I realized how flawed this metaphor was, because they never all play on the field at the same time. They’re not actually on the same team!”
He continued, “The analogy I use now is that Ops are the offensive linemen, and Dev are the ‘skill’ positions (like the quarterback and wide receivers) whose job it is to move the ball down the field—the job of Ops is to help make sure Dev has enough time to properly execute the plays.”
A striking example of how shared pain can reinforce shared goals is when Facebook was undergoing enormous growth in 2009. They were experiencing significant problems related to code deployments—while not all issues caused customer-impacting issues, there was chronic firefighting and long hours. Pedro Canahuati, their director of production engineering, described a meeting full of Ops engineers where someone asked that all people not working on an incident close their laptops, and no one could.
One of the most significant things they did to help change the outcomes of deployments was to have all Facebook engineers, engineering managers, and architects rotate through on-call duty for the services they built. By doing this, everyone who worked on the service experienced visceral feedback on the upstream architectural and coding decisions they made, which made an enormous positive impact on the downstream outcomes.
ENABLE EVERY TEAM MEMBER TO BE A GENERALIST
In extreme cases of a functionally-oriented Operations organization, we have departments of specialists, such as network administrators, storage administrators, and so forth. When departments over-specialize, it causes siloization, which Dr. Spear describes as when departments “operate more like sovereign states.” Any complex operational activity then requires multiple handoffs and queues between the different areas of the infrastructure, leading to longer lead times (e.g., because every network change must be made by someone in the networking department).
Because we rely upon an ever increasing number of technologies, we must have engineers who have specialized and achieved mastery in the technology areas we need. However, we don’t want to create specialists who are “frozen in time,” only understanding and able to contribute to that one area of the value stream.
One countermeasure is to enable and encourage every team member to be a generalist. We do this by providing opportunities for engineers to learn all the skills necessary to build and run the systems they are responsible for, and regularly rotating people through different roles. The term full stack engineer is now commonly used (sometimes as a rich source of parody) to describe generalists who are familiar—at least have a general level of understanding—with the entire application stack (e.g., application code, databases, operating systems, networking, cloud).
Table 2: Specialists vs. Generalists vs. “E-shaped” Staff (experience, expertise, exploration, and execution)
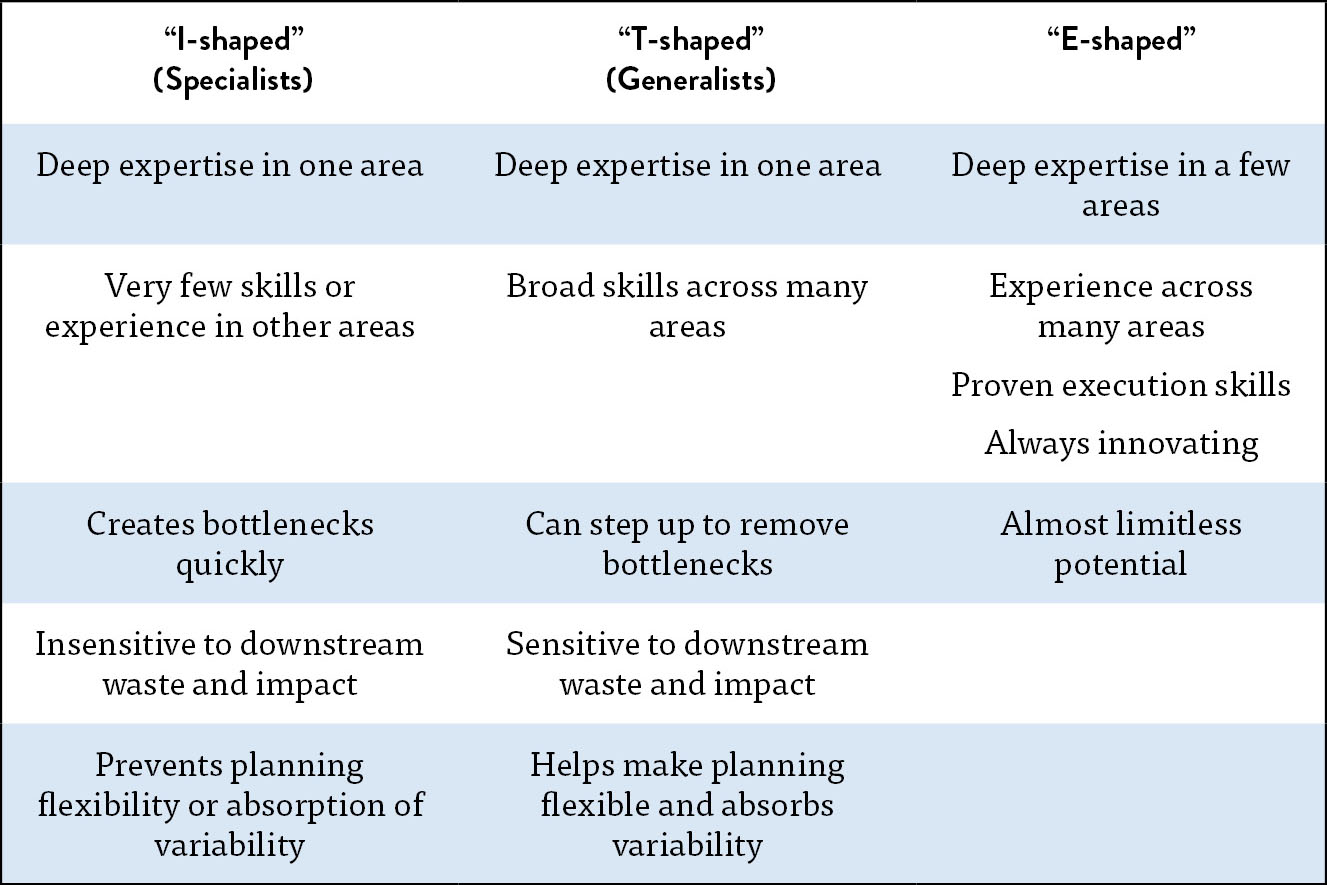
(Source: Scott Prugh, “Continuous Delivery,” ScaledAgileFramework.com, February 14, 2013, http://scaledagileframework.com/continuous-delivery/.)
Scott Prugh writes that CSG International has undergone a transformation that brings most resources required to build and run the product onto one team, including analysis, architecture, development, test, and operations. “By cross-training and growing engineering skills, generalists can do orders of magnitude more work than their specialist counterparts, and it also improves our overall flow of work by removing queues and wait time.” This approach is at odds with traditional hiring practices, but, as Prugh explains, it is well worth it. “Traditional managers will often object to hiring engineers with generalist skill sets, arguing that they are more expensive and that ‘I can hire two server administrators for every multi-skilled operations engineer.’” However, the business benefits of enabling faster flow are overwhelming. Furthermore, as Prugh notes, “[I]nvesting in cross training is the right thing for [employees’] career growth, and makes everyone’s work more fun.”
When we value people merely for their existing skills or performance in their current role rather than for their ability to acquire and deploy new skills, we (often inadvertently) reinforce what Dr. Carol Dweck describes as the fixed mindset, where people view their intelligence and abilities as static “givens” that can’t be changed in meaningful ways.
Instead, we want to encourage learning, help people overcome learning anxiety, help ensure that people have relevant skills and a defined career road map, and so forth. By doing this, we help foster a growth mindset in our engineers—after all, a learning organization requires people who are willing to learn. By encouraging everyone to learn, as well as providing training and support, we create the most sustainable and least expensive way to create greatness in our teams—by investing in the development of the people we already have.
As Jason Cox, Director of Systems Engineering at Disney, described, “Inside of Operations, we had to change our hiring practices. We looked for people who had ‘curiosity, courage, and candor,’ who were not only capable of being generalists but also renegades...We want to promote positive disruption so our business doesn’t get stuck and can move into the future.” As we’ll see in the next section, how we fund our teams also affects our outcomes.
FUND NOT PROJECTS, BUT SERVICES AND PRODUCTS
Another way to enable high-performing outcomes is to create stable service teams with ongoing funding to execute their own strategy and road map of initiatives. These teams have the dedicated engineers needed to deliver on concrete commitments made to internal and external customers, such as features, stories, and tasks.
Contrast this to the more traditional model where Development and Test teams are assigned to a “project” and then reassigned to another project as soon as the project is completed and funding runs out. This leads to all sorts of undesired outcomes, including developers being unable to see the long-term consequences of decisions they make (a form of feedback) and a funding model that only values and pays for the earliest stages of the software life cycle—which, tragically, is also the least expensive part for successful products or services.††
Our goal with a product-based funding model is to value the achievement of organizational and customer outcomes, such as revenue, customer lifetime value, or customer adoption rate, ideally with the minimum of output (e.g., amount of effort or time, lines of code). Contrast this to how projects are typically measured, such as whether it was completed within the promised budget, time, and scope.
DESIGN TEAM BOUNDARIES IN ACCORDANCE WITH CONWAY’S LAW
As organizations grow, one of the largest challenges is maintaining effective communication and coordination between people and teams. All too often, when people and teams reside on a different floor, in a different building, or in a different time zone, creating and maintaining a shared understanding and mutual trust becomes more difficult, impeding effective collaboration. Collaboration is also impeded when the primary communication mechanisms are work tickets and change requests, or worse, when teams are separated by contractual boundaries, such as when work is performed by an outsourced team.
As we saw in the Etsy Sprouter example at the beginning of this chapter, the way we organize teams can create poor outcomes, a side effect of Conway’s Law. These include splitting teams by function (e.g., by putting developers and testers in different locations or by outsourcing testers entirely) or by architectural layer (e.g., application, database).
These configurations require significant communication and coordination between teams, but still results in a high amount of rework, disagreements over specifications, poor handoffs, and people sitting idle waiting for somebody else.
Ideally, our software architecture should enable small teams to be independently productive, sufficiently decoupled from each other so that work can be done without excessive or unnecessary communication and coordination.
CREATE LOOSELY-COUPLED ARCHITECTURES TO ENABLE DEVELOPER PRODUCTIVITY AND SAFETY
When we have a tightly-coupled architecture, small changes can result in large scale failures. As a result, anyone working in one part of the system must constantly coordinate with anyone else working in another part of the system they may affect, including navigating complex and bureaucratic change management processes.
Furthermore, to test that the entire system works together requires integrating changes with the changes from hundreds, or even thousands, of other developers, which may, in turn, have dependencies on tens, hundreds, or thousands of interconnected systems. Testing is done in scarce integration test environments, which often require weeks to obtain and configure. The result is not only long lead times for changes (typically measured in weeks or months) but also low developer productivity and poor deployment outcomes.
In contrast, when we have an architecture that enables small teams of developers to independently implement, test, and deploy code into production safely and quickly, we can increase and maintain developer productivity and improve deployment outcomes. These characteristics can be found in service-oriented architectures (SOAs) first described in the 1990s, in which services are independently testable and deployable. A key feature of SOAs is that they’re composed of loosely-coupled services with bounded contexts.‡‡
Having architecture that is loosely-coupled means that services can update in production independently, without having to update other services. Services must be decoupled from other services and, just as important, from shared databases (although they can share a database service, provided they don’t have any common schemas).
Bounded contexts are described in the book Domain Driven Design by Eric J. Evans. The idea is that developers should be able to understand and update the code of a service without knowing anything about the internals of its peer services. Services interact with their peers strictly through APIs and thus don’t share data structures, database schemata, or other internal representations of objects. Bounded contexts ensure that services are compartmentalized and have well-defined interfaces, which also enables easier testing.
Randy Shoup, former Engineering Director for Google App Engine, observed that “organizations with these types of service-oriented architectures, such as Google and Amazon, have incredible flexibility and scalability. These organizations have tens of thousands of developers where small teams can still be incredibly productive.”
KEEP TEAM SIZES SMALL (THE “TWO-PIZZA TEAM” RULE)
Conway’s Law helps us design our team boundaries in the context of desired communication patterns, but it also encourages us to keep our team sizes small, reducing the amount of inter-team communication and encouraging us to keep the scope of each team’s domain small and bounded.
As part of its transformation initiative away from a monolithic code base in 2002, Amazon used the two-pizza rule to keep team sizes small—a team only as large as can be fed with two pizzas—usually about five to ten people.
This limit on size has four important effects:
- It ensures the team has a clear, shared understanding of the system they are working on. As teams get larger, the amount of communication required for everybody to know what’s going on scales in a combinatorial fashion.
- It limits the growth rate of the product or service being worked on. By limiting the size of the team, we limit the rate at which their system can evolve. This also helps to ensure the team maintains a shared understanding of the system.
- It decentralizes power and enables autonomy. Each two-pizza team (2PT) is as autonomous as possible. The team’s lead, working with the executive team, decides on the key business metric that the team is responsible for, known as the fitness function, which becomes the overall evaluation criteria for the team’s experiments. The team is then able to act autonomously to maximize that metric.§§
- Leading a 2PT is a way for employees to gain some leadership experience in an environment where failure does not have catastrophic consequences. An essential element of Amazon’s strategy was the link between the organizational structure of a 2PT and the architectural approach of a service-oriented architecture.
Amazon CTO Werner Vogels explained the advantages of this structure to Larry Dignan of Baseline in 2005. Dignan writes:
“Small teams are fast...and don’t get bogged down in so-called administrivia….Each group assigned to a particular business is completely responsible for it….The team scopes the fix, designs it, builds it, implements it and monitors its ongoing use. This way, technology programmers and architects get direct feedback from the business people who use their code or applications—in regular meetings and informal conversations.”
Another example of how architecture can profoundly improve productivity is the API Enablement program at Target, Inc.
Case Study
API Enablement at Target (2015)
Target is the sixth-largest retailer in the US and spends over $1 billion on technology annually. Heather Mickman, a director of development for Target, described the beginnings of their DevOps journey: “In the bad old days, it used to take ten different teams to provision a server at Target, and when things broke, we tended to stop making changes to prevent further issues, which of course makes everything worse.”
The hardships associated with getting environments and performing deployments created significant difficulties for development teams, as did getting access to data they needed. As Mickman described:
The problem was that much of our core data, such as information on inventory, pricing, and stores, was locked up in legacy systems and mainframes. We often had multiple sources of truths of data, especially between e-commerce and our physical stores, which were owned by different teams, with different data structures and different priorities....The result was that if a new development team wanted to build something for our guests, it would take three to six months to build the integrations to get the data they needed. Worse, it would take another three to six months to do the manual testing to make sure they didn’t break anything critical, because of how many custom point-to-point integrations we had in a very tightly-coupled system. Having to manage the interactions with the twenty to thirty different teams, along with all their dependencies, required lots of project managers, because of all the coordination and handoffs. It meant that development was spending all their time waiting in queues, instead of delivering results and getting stuff done.
This long lead time for retrieving and creating data in their systems of record was jeopardizing important business goals, such as integrating the supply chain operations of Target’s physical stores and their e-commerce site, which now required getting inventory to stores and customer homes. This pushed the Target supply chain well beyond what it was designed for, which was merely to facilitate the movement of goods from vendors to distribution centers and stores.
In an attempt to solve the data problem, in 2012 Mickman led the API Enablement team to enable development teams to “deliver new capabilities in days instead of months.” They wanted any engineering team inside of Target to be able to get and store the data they needed, such as information on their products or their stores, including operating hours, location, whether there was as Starbucks on-site, and so forth.
Time constraints played a large role in team selection. Mickman explained that:
Because our team also needed to deliver capabilities in days, not months, I needed a team who could do the work, not give it to contractors—we wanted people with kickass engineering skills, not people who knew how to manage contracts. And to make sure our work wasn’t sitting in queue, we needed to own the entire stack, which meant that we took over the Ops requirements as well....We brought in many new tools to support continuous integration and continuous delivery. And because we knew that if we succeeded, we would have to scale with extremely high growth, we brought in new tools such as the Cassandra database and Kafka message broker. When we asked for permission, we were told no, but we did it anyway, because we knew we needed it.
In the following two years, the API Enablement team enabled fifty-three new business capabilities, including Ship to Store and Gift Registry, as well as their integrations with Instacart and Pinterest. As Mickman described, “Working with Pinterest suddenly became very easy, because we just provided them our APIs.”
In 2014, the API Enablement team served over 1.5 billion API calls per month. By 2015, this had grown to seventeen billion calls per month spanning ninety different APIs. To support this capability, they routinely performed eighty deployments per week.
These changes have created major business benefits for Target—digital sales increased 42% during the 2014 holiday season and increased another 32% in Q2. During the Black Friday weekend of 2015, over 280k in-store pickup orders were created. By 2015, their goal is to enable 450 of their 1,800 stores to be able to fulfill e-commerce orders, up from one hundred.
“The API Enablement team shows what a team of passionate change agents can do,” Mickman says. “And it help set us up for the next stage, which is to expand DevOps across the entire technology organization.”
CONCLUSION
Through the Etsy and Target case studies, we can see how architecture and organizational design can dramatically improve our outcomes. Done incorrectly, Conway’s Law will ensure that the organization creates poor outcomes, preventing safety and agility. Done well, the organization enables developers to safely and independently develop, test, and deploy value to the customer.