The difference between text strings and byte strings, and between text files and binary files.
The concept of encoding and decoding to get back and forth between text and byte representation.
The importance of overlaying a file-like view on a set of data acquired over a network.
Access an HTTP result, both as raw bytes and as a character string.
Be able to change the encoding for interpretation of the raw bytes as a string.
For these collections of binary data bytes and string-based result data, overlay a file-like interface to enable better access to the data.
Combine the above to be able to transform the data into the structures for the different formats of data (CSV, JSON, XML) explored in Part II of the book.
In Chap. 20, we learned the syntax of HTTP, and how to use the requests module to issue GET and POST request messages that allow us to obtain results from a web server. In this chapter, we explore variations of taking the results and transforming the data into an in-memory structure usable in our client programs.
In Chaps. 6 and 15 and in Sect. 2.4, we used local files as our data source to get CSV-, XML-, and JSON-formatted data into pandas, into an element tree, and into a dictionary/list composite structure, respectively. Now this same format data is being acquired over the network and arrives at our client application in the body of an HTTP request. We need to process and obtain the same in-memory structure of a pandas data frame from CSV-formatted data, an lxml element tree from XML-formatted data, or the Python data structure from JSON-formatted data. To do this correctly, we will often require understanding of the encoding, by which the characters of the data at the server are mapped to the bytes transmitted over the network.
21.1 Encoding and Decoding
Recall from Sect. 2.2.2 that the term encoding (aka codec ) defines a translation from a sequence of characters (i.e., a string or text) to the set of bytes that are used to represent that character sequence. Given an encoding, then, for each character, there is a specific translation of that character into its byte representation. Some encodings are limited in the set of characters that they are able to encode, and thus the alphabets and languages they can support. Other encodings allow the full Unicode character set as their input and can adapt to many alphabets and languages. In the reverse direction, given a set of bytes representing a character sequence, along with knowledge of the specific encoding used, we use the term decoding for the process of converting a sequence of bytes back into its original character sequence.
Common encodings
Encoding | Bytes per Char | Notes |
|---|---|---|
ASCII | Exactly 1 | One of the most limited encodings, only supporting the English alphabet, and including A-Z, a-z, 0-9, and basic keyboard special characters |
UTF-8 | 1 to 4, but using 1 whenever possible | Supports full Unicode but is backwardly compatible to ASCII for the one byte characters supported there. This encoding accounts for 95% of the web |
UTF-16 | 2 to 4, with 2 the most dominant | Supports full Unicode and is used more on Windows platforms, where it started as always 2 bytes, until it needed to be expanded. Variations include UTF-16BE and UTF-16LE that make explicit the ordering of multibyte units |
ISO-8859-1 | Exactly 1 | Latin character set, starting from ASCII, but adding common European characters and diacritics. Also known as LATIN_1 |
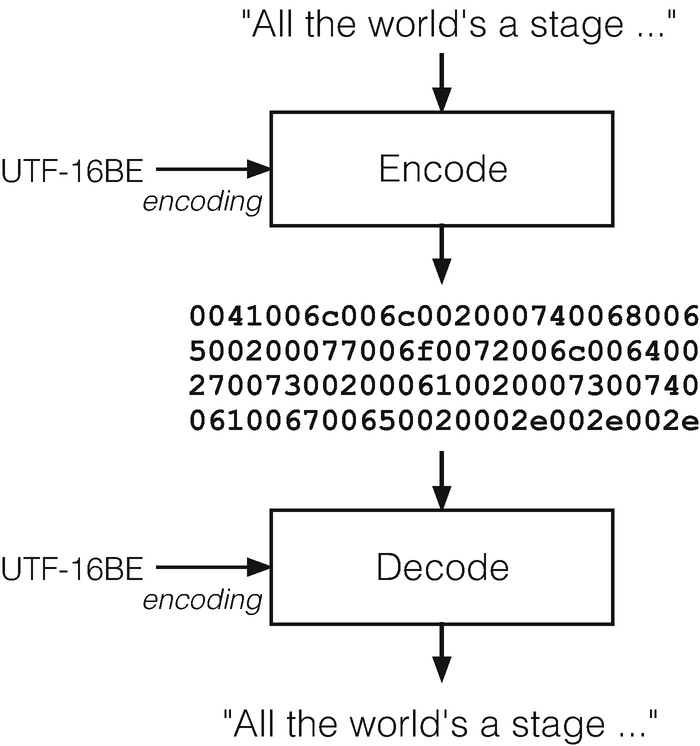
Encoding and decoding process
Relative to this book, there are three contexts within which we should be aware of encoding. First, within our Python programs, we may have character strings from which we need to explicitly generate a raw bytes representation, or vice versa. Second, every local file is actually stored as a sequence of bytes. If it is a text file, we need to ensure that, whether reading from a text file or writing to a text file, we are able to specify a desired encoding as appropriate. Third, when we are acquiring data over the network, the body of an HTTP response message is also conveyed over the TCP reliable byte-stream as a sequence of raw bytes. So we want to be able to decode those bytes into their original character sequence when the contents of the message are, in fact, text.
We address the first context, encoding and decoding explicitly in our Python program, here in this section. Encoding and decoding when interacting with files have already been covered in Sect. 2.2.2 and will not be repeated here, but we will give file-based examples in Sects. 21.2 through 21.4. The third context is directly related to the main goals of this chapter and will also be illustrated in Sects. 21.2 to 21.4.
21.1.1 Python Strings and Bytes
The characters of Python strings allow for the full Unicode character set and thus can support a spectrum of alphabets and languages. Further, Python, by default, uses the UTF-8 encoding. These defaults of character set and encoding are often sufficient when our programs are not interacting with text data from outside sources. In this case, we rarely have to do explicit translations, or to specify encodings as we open and use files. But when text data originates from some outside source, and if that outside source might use a different encoding, we must have the tools to interpret the data.
In Python, we represent sequences of characters as a string data type, and the type name is str. Individual characters do not have a separate type and are represented as str whose length is one. Python also has a class bytes that is used to represent a set of raw bytes. This data type can be used both for the result of an encode( ) operation on a string and for non-string types of binary data. A Python value of the bytes data type can be created using a constant syntax similar to that of strings, but prefixed with a b character. For instance, b'Hello!' defines a bytes value that is the UTF-8 encoding of the string that follows the b character. But this value should not be mistakenly thought of as a str value.
21.1.1.1 The Encode Operation: A String to Bytes



We can also encode a string s into byte form using b = bytes( s, encoding = 'ascii') , which returns a byte version of the string (e.g., if s = "Ben" then b = b"Ben").
The important takeaway through all these examples is that encoding is operating on a string or a character (type str), and the result is one or more bytes (type bytes).
21.1.1.2 The Decode Operation: Bytes to a String
The decode operation translates a byte sequence back into its original sequence of characters, based on the encoding. As long as the encoding used in the decode operation is the same one used by a prior encode operation, the resulting string will be the same one we started with. In similar fashion to the examples above, we can see decode for a multiple character sequence or for a single character.

We see that although b16 and b8 were clearly not the same bytes value, after decoding, s16 and s8 have the same original character sequence.
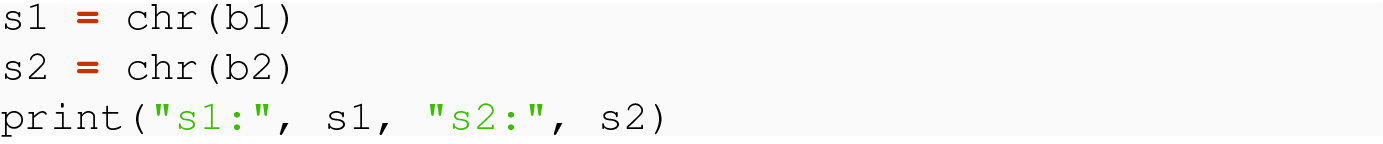
We can also use the conversion capability of the str( ) function, with a first argument that is the encoded bytes value, and can specify an encoding= named parameter to control the conversion to use the specified encoding. So str( b16, encoding='UTF-16BE') yields the same result as b16.decode( 'UTF-16BE') .
The important takeaway through these examples is that decoding is operating on a bytes or int value, and the result is a string (type str).
21.1.2 Prelude to Format Examples
Sections 21.2 through 21.4 will focus on each of the primary formats of CSV, JSON, and XML, with the goal of demonstrating translations of both local files and HTTP response messages into structures usable in our client applications.
In local files, we often know the encoding, but when data is retrieved through the body of an HTTP response message , we cannot assume that the encoding will be ASCII, or UTF-8, or ISO-8559-1. It is important to remember that the bytes of the data files are reaching us via a byte-stream (TCP), which does not mandate textual data, nor require a particular encoding. Furthermore, many different encodings are possible, such as UTF-16BE, which stands for “big endian 16 bits,” which results in two raw bytes per character to be encoded. We will discuss this further in the sections below.
For illustration, we will use the following files, both locally, and as retrieved over the network, for our examples.
It will be important to keep in mind the distinction between strings and byte strings, and between text files and binary files, in the discussion to come. We now discuss a sequence of vignettes, with how to acquire data in the formats CSV, JSON, and XML.
Example files in various formats and multiple encodings
UTF-8 Encoded | UTF-16BE Encoded | Description |
|---|---|---|
ind2016.csv | ind2016_16.csv | Six country indicators from year 2016 in CSV format |
ind0.json | ind0_16.json | Indicator data of pop and gdp for three countries for two different years in JSON format |
ind0.xml | ind0_16.xml | Indicator data of pop and gdp for three countries for two different years in XML format |
Response.content: the raw bytes version of the data,
Response.text: the decoded translation of the raw bytes into a sequence of characters.
The latter uses an assumed/inferred encoding, which can be found through the attribute Response.encoding. We will give examples of extracting this information so that it can be used by our code. We will also show how to read both types of data (i.e., either the text data from Response.text or the underlying byte data from Response.content).
In common amongst the set of network examples, we use our custom util.buildURL( ) function to construct a string url prior to each requests invocation. This, along with helper functions to print results, is documented in Appendix A, in Sect. A.1. For buildURL( ) , we specify the desired resource-path in the first argument and the host location in the second argument.
21.1.3 Reading Questions
How many characters can be encoded in ASCII, and what are some examples of “basic keyboard special characters”? Use a web search to answer this if you have never seen ASCII before.
What does it mean that UTF-8 is “backwardly compatible” to ASCII?
How many characters can be encoded with ISO-8859-1 and is it backwardly compatible with ASCII? You are encouraged to use a web search if this is your first exposure to ISO-8859-1.
The reading points out that “every local file is actually stored as a sequence of bytes.” Have you ever had the experience of trying to open a local file in a program (e.g., a text editor), and seeing something very strange display? This probably had to do with your computer using the wrong decoding scheme. Describe your experience when this happened.
Is the body of a response to an HTTP GET always text? Justify your answer or give a counterexample.
What do you notice about the hex byte sequence representations for the two “Hello!” encode( ) examples? Why is this?
Conceptually, why do you think there are so many different encoding schemes, and why is it important to keep them compatible?
As the files ind2016.csv and ind2016_16.csv are stored on the book web page, please go and download them, then try to open them in the most naive program possible (i.e., a simple text editor). Describe what you see.
Please refer back to an HTTP GET request you made in the previous chapter using the requests module and use the .content and .text attributes to look at the data. Investigate these two quantities using print( ) and type( ) and report what you find.
Please refer back to an HTTP GET request you made in the previous chapter using the requests module and determine the encoding using the .encoding attribute of the response. What did you find?
21.1.4 Exercises
One of the reasons for the existence of Unicode is its ability to use strings that go beyond the limitations of the keyboard. Relative to the discussion in the chapter, Unicode is about the strings we can use in our programs, and the issue of how they translate/map to a sequence of bytes (i.e., their encoding) is a separate concept.
which of the hex representations is longer?
give explicit lengths for b8, b16, and for the two hex( ) transformations.
how does this compare to the length of s?
Write a function
whose parameter, letter, should be a single character. If the character is between "A" and "Z", the function returns an uppercase character n positions further along, and “wrapping” if the + n mapping goes past "Z". Likewise, it should map the lower case characters between "a" and "z". If the parameter letter is anything else, or not of length 1, the function should return letter.
Hint: review functions ord( ) and chr( ) from the section, as well as the modulus operator % .
Building on the previous exercise, write a function
that performs a shiftLetter for each of the letters in plaintext and accumulates and returns the resultant string.
Write a function
that takes its argument, s, and determines whether or not all the characters in s can be encoded by a single byte. The function should return the Boolean True if so, and False otherwise.
Suppose you have, in your Python program, a variable that refers to a bytes data type, like mystery refers to the bytes constant literal as given here:
“UTF-8,”
“UTF-16BE,”
“cp037,”
“latin_1.”
Write code to convert the byte sequence to a character string and determine the correct encoding.
21.2 CSV Data
We have seen that the CSV format is ubiquitous in the world of tidy data. A working data scientist will often work with both local CSV files and CSV files obtained over a network.
21.2.1 CSV from File Data



We see now that the pandas data frame df2 now correctly contains the data.
21.2.2 CSV from Network Data




If the data presented above were in a file, instead of being in a memory structure of a Response object, we could use our file-based techniques from Sect. 3.4 to iterate over the lines and compose the data into a native Python data structure. Otherwise, we would have to manually extract the data. Further, the ability to layer a file-like view of a set of data where the bytes or characters reside in memory would allow pandas, lxml, and json to perform parsing and interpretation the same way they do for files.
io.StringIO( ) : takes a string buffer and returns an object that operates in the same way as a file object returned from an open( ) call. Like a file object, this object has a notion of a current location that advances as we read (using read( ) , readline( ) , etc.) through the characters of the object.
io.BytesIO( ) ∖index{BytesIO( ) constructor}: takes a bytes buffer and returns an object that operates in the same way as a file object returned from an open( ) call and opened in binary mode. Like a file object, this object has a notion of a current location that advances as we perform read( ) operations over the bytes of the object.
We will use these constructors, passing either Response.text or Response.content, as appropriate, to allow much easier processing of HTTP response message as we consider CSV as well as JSON and XML parsing and interpretation in the sections that follow.
21.2.2.1 Option 1: From String Text







We have seen how to read string text into a pandas data frame. We turn now to the case where we use the body from request.get( ) as byte data.
21.2.2.2 Option 2: From Underlying Bytes
In the example above, changes in response.encoding and the resultant difference in response.text did not change the underlying bytes data, available in response.content. While it is more complex, particularly across non-standard encoding, to use the bytes data and direct file type operations to construct a data frame, the pandas read_csv( ) can take its input from a file-like object containing bytes data and can perform the decoding itself.


The value of df2 is identical. Having demonstrated how to read CSV data, we turn now to reading JSON data.
21.2.3 Reading Questions
The first example involves specifying the correct encoding for ind2016_16.csv. The reading shows what happens if you specify no encoding. What do the results look like if you specify the wrong encoding? Investigate (using the local file ind2016_16.csv that you should have downloaded) with at least three encodings.
Please carry out the requests.get( csv_url) block of code and experiment with setting different encodings. Try with both naive encodings like ASCII and also more advanced encodings like UTF-16. Also try with a bytes encoding like UTF-16BE. Describe the results of util.print_text( ) in each case.
Recall that when you open( ) a file you can choose various modes, e.g., for reading versus writing. What mode would you use to create a bytes file?
In the code to process response.text into a LoL, please explain the purpose of strip( ) , split( ) , and astype( ) . You might want to refer back to earlier chapters.
Investigate the read_csv( ) method of reading response.text into a data frame. Are the entries floating point numbers or strings?
In the approach to reading from response.content into a data frame, did we need to set a value for response.encoding? Why or why not?
21.2.4 Exercises
The purpose of io.StringIO( ) is to create a file-like object from any string in a Python program. The object created “acts” just like an open file would.
Consider the following single Python string, s, composed over multiple continued lines:
determine the length of s,
find the start and end indices of the substring "dark" within s,
create string s2 by replacing "embark" with "disembark".
Now, create a file-like object from s and perform a first readline( ) , assigning to variable line1 and then write a for loop to use the file-like object as an iterator to accumulate into lines a list of the remaining lines, printing each.
Practice with io.StringIO( ) by using a for loop to print the numbers 1 through 100 into a file-like object, one per line. Then, iterate through this object and confirm that read( ) yields a string representing the entire data, while readline( ) yields one line at a time, and keeps track of the location in the file-like object. Provide your code.
Repeat the previous problem but with io.BytesIO( ) . Note that you can convert the numbers yielded by your loop into bytes using the bytes( ) function from the previous section. Provide your code.
for the top 10 name applications of each sex to the US Social Security Administration for the year 2015.
“UTF-8,”
“UTF-16BE,”
“UTF-16LE,”
“cp037,”
“latin_1.”
acquire the file from the web server,
ensure the status_code is 200,
assign to content_type the value of the Content-Type header line of the response,
determine the correct encoding and assign to real_encoding,
set the .encoding attribute of the response to real_encoding,
assign to csv_body the string text for the body of the response.
In this question, you will start with a string and create a Dictionary of Lists representation of the data entailed in the string. It is suggested to use the result of the previous problem, csv_ body, as the starting point. But to start independently, you can use the following string literal constant assignment to get to the same starting point:
Construct a file-like object from csv_body and then use file object operations to create a dictionary of lists representation of the tab-separated data. Note that there is no header line in the data, so you can name the columns malename, malecount, femalename, and femalecount.
Use pandas to obtain a data frame named df by using a file-like object based on csv_body and use read_csv( ) . Name your resultant data frame df. Make sure you have reasonable column names.
Be careful to call read_csv so that the separators are tabs, not commas.
21.3 JSON Data
Recall from Chaps. 2 and 15 that JSON is a light-weight format for transmitting simple data types.
21.3.1 JSON from File
When we acquire JSON through a file, we use the json.load( ) function. This function uses an open file object (or file-like object) as an argument. Therefore, to deal with a different encoding, we simply need to specify the encoding as we open the file.



21.3.2 JSON from Network

We next show how to get from response1 and response2 to in-memory data structures.
21.3.2.1 JSON from String Data in Response


We see that as soon as the correct encoding is specified, the field response.text is legible. We are ready to read the data into memory.
Use json.loads( ) , which takes a string and returns the in-memory data structure.
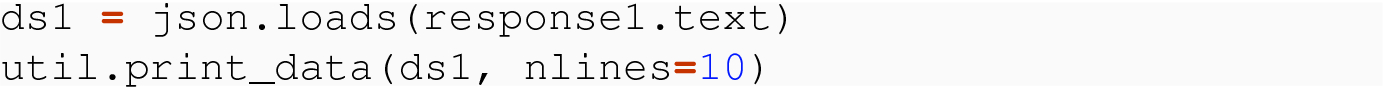
We achieve a Python dictionary in memory.
Create a file-like object, and then use json.load( ) .

We achieve a Python dictionary in memory.
Use requests .json( ) method of a response object.
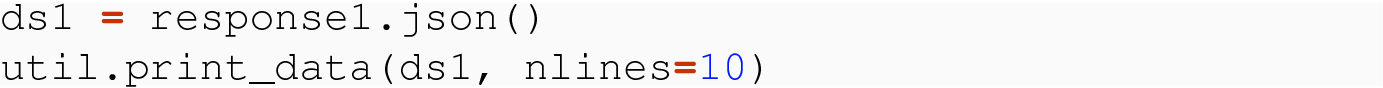
In all three of these examples, we have been provided JSON data in string form. We consider now the case of JSON data in byte form.
21.3.2.2 JSON from Bytes Data in Response Body
Because of its alternate encoding resulting in a different set of bytes for the sequence of characters, we use the bytes data of response2 in our examples demonstrating bytes data conversion into JSON-derived data structure.
A Request for Comments (RFC) documents a given Internet Standard. The RFC standard for JSON explicitly allows all three of UTF-8, UTF-16, and UTF-32 to be used in data formatted as JSON. This means that the json module will recognize the bytes data directly, as if it were already a decoded string, greatly simplifying our lives.
Use json.loads( ) , which takes bytes data in UTF-8, UTF-16, or UTF-32 and returns the in-memory data structure.
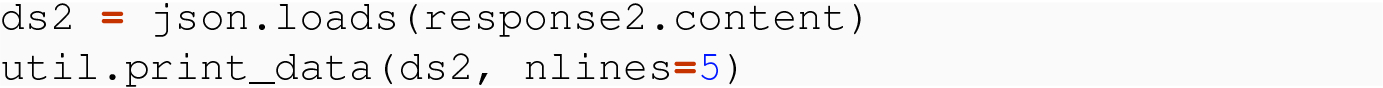
The result is still a Python data structure in memory.
Create a bytes file-like object and then use json.load( ) .

The result is a Python data structure in memory. Having demonstrated how to acquire JSON data, we turn to XML data.
21.3.3 Reading Questions
Please download ind0_16.json as a local file and experiment with setting different encodings in open( ) , and the try/except block of code given. Explain what happens.
In the previous question, we explored errors associated with the JSON load( ) function when the encoding is wrong. Please do the same now with the loads( ) function and describe what happens when the encoding is wrong. You may use the code provided to read JSON data from the book web page.
In JSON Option 2 for response.text, does this assume the encoding has already been specified?
In JSON Option 3 for response.text, does this assume the encoding has already been specified?
When extracting JSON from bytes data, do we need to specify response.encoding before applying json.loads( ) to response. content?
Why were there three options for extracting in-memory data structures from string data but only two options for bytes data?
21.3.4 Exercises
In many of the following exercises, we will show a curl incantation that obtains JSON-formatted text data from the Internet. Your task will be to translate the incantation into the equivalent requests module programming steps, and to obtain the parsed JSON-based data structure from the result, assigning to variable data. In some cases, we will ask for a specific method from those demonstrated in the section.
Using any method, get the JSON data from school0.json:
Using the bytes data in .content, a file-like object, and json.load( ) , get the JSON data from school0.json.
Write a function
that makes a request to location for resource with the specified protocol, then uses the bytes data in the .content of the response, with a file-like object, and json.load( ) , to get the JSON data. On success, return the data. On failure of either the request or the parse of the data, return None.
Where in your code did the encoding of “utf-32” come into play? Can you explain why? What does this mean for the getJSONdata( ) function you wrote previously?
Use any method you wish to obtain the JSON data associated with the following POST request. Make sure you faithfully translate the -H and -d options of the curl into their requests equivalent.
21.4 XML Data
Recall from Chap. 15 that XML is a format used for hierarchical data. When an XML file is well formed, we can parse it to map it onto the tree it represents, and can extract the root Element containing the data of the entire tree. This process of turning an XML file into a tree, and finding the root, uses the lxml library and the etree module within it.
In the examples that follow, when we have parsed a tree, we print out the tag of the root Element. Since, for all these examples, the data is the indicators data set, and the tree is structured so that the root Element has tag, indicators, we are successful when this is the result we print. Also, the parse( ) function raises an exception when it encounters a problem, so we place our examples in try-except blocks to help show when such problems occur.
21.4.1 XML from File Data





Having reviewed how to open and parse XML files locally, we turn to data obtained over the network.
21.4.2 From Network
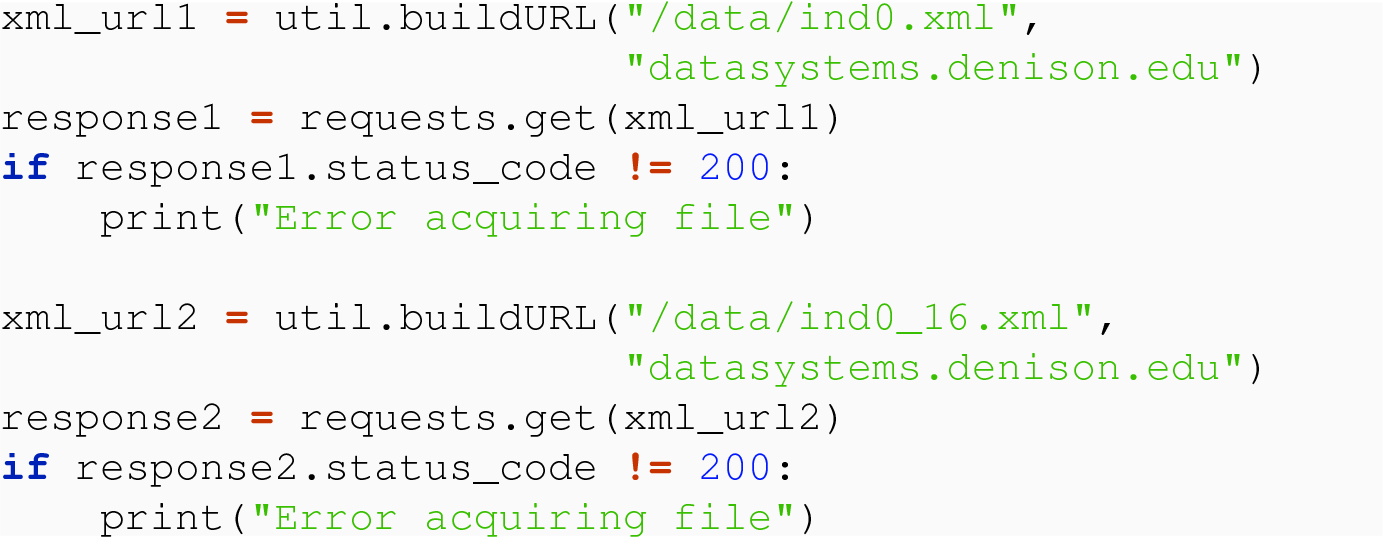

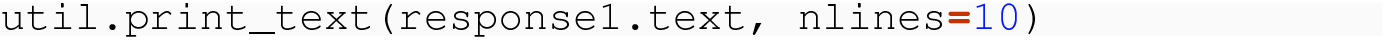


In both cases, we have achieved XML data in the text field of response. We now discuss how to parse this XML data.
21.4.2.1 Using parse on Bytes
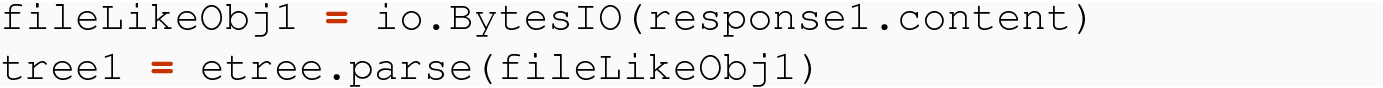
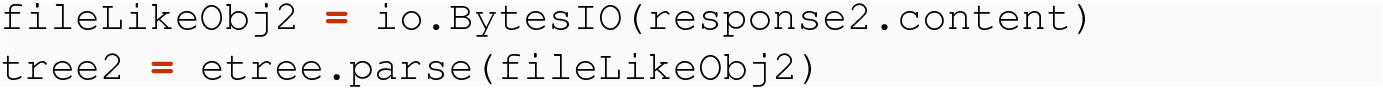


We turn now to an alternative way to get the root Element that avoids the need for the parse( ) function.
21.4.2.2 Using fromstring( ) with Bytes and Strings
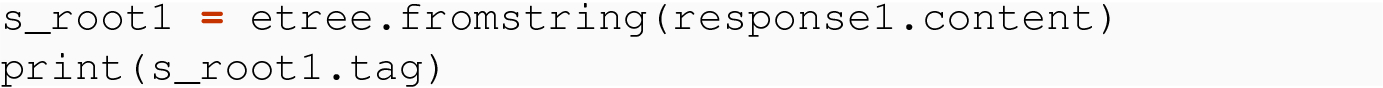
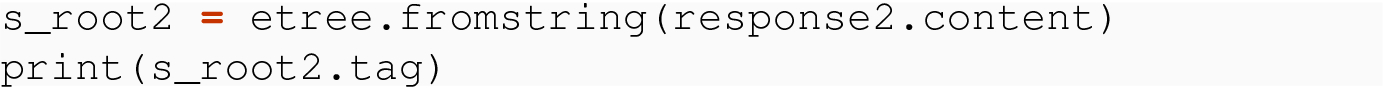
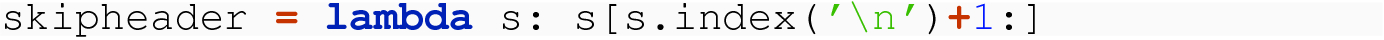
We note here that the header we are skipping is a prolog part of the test of the XML data and is unrelated to the headers that come from the requests module. The header we are skipping is entirely contained in the body of the response we begin with.

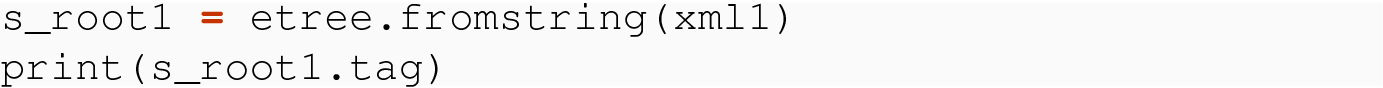
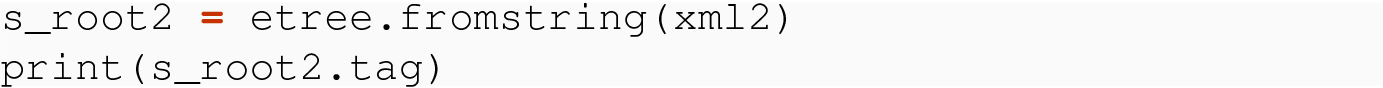
In all cases, we are able to retrieve the tree and root Element representing the XML data that comes to us either in local form or over the network.
21.4.3 Reading Questions
The first XML example does not specify an encoding but the second does. Could the second have gotten away without specifying encoding='UTF-8'? Justify your answer by actually running the code.
If the parse function is doing the decoding, why do we need to wrap our code in a try/except block? What could go wrong?
When reading XML file, how can you print the encoding, to see “UTF-8”? Hint: think back to how we did it for CSV and JSON.
Please experiment with response.text by purposely specifying the wrong encoding and seeing what is printed by util.print_text( ) for one of the XML files accessed over the network. Describe your results.
The reading shows how to use parse on Bytes. Can you also use parse( ) on response.text? Do you need to specify the encoding?
Consider the second block of code that invokes the fromstring( ) method. How does this demonstrate that encoding need not be specified?
Experiment to find out what happens if you purposely set the wrong encoding, e.g., with response2.encoding = 'ASCII' before invoking the fromstring( ) method on response2.content. Report your findings.
Explain the lambda function skipheader in detail. Why does this skip the header? Why is skipping the header important?
When feeding the fromstring( ) function text data, do we need to specify the encoding, e.g., with response1.encoding = 'UTF-8' before invoking skipheader( response1.text) ? Investigate by actually running the code, and report what you found.
21.4.4 Exercises
In many of the following exercises, we will show a curl incantation that obtains XML-formatted text data from the Internet. Your task will be to translate the incantation into the equivalent requests module programming steps and to obtain the parsed XML-based ElementTree structure from the result, assigning to variable root the root of the result. In some cases, we will ask for a specific method from those demonstrated in the section.
Using any method, get the XML data from school0.xml:
Using the bytes data in .content, a file-like object, and etree.parse( ) , get the XML data from school0.xml.
Write a function
that makes a request to location for resource with the specified protocol, and then uses the bytes data in the .content of the response, with a file-like object, and etree.parse( ) , to get the XML data. On success, return the root of the tree. On failure of either the request or the parse of the data, return None.
Repeat acquiring the school0_32.xml resource, encoded with utf-32be. This time, use the method of using the bytes data in .content, a file-like object, and etree.parse( ) .
Where in your code did the encoding of “utf-32be” come into play? Can you explain why? What does this mean for the getXMLdata( ) function you wrote previously?
Use any method you wish to obtain the XML data associated with the following GET request. Do not simply copy and paste the full url. Translate the set of query parameters into a dictionary to be used in the requests.get( ) invocation.