Chapter 5
Classifying Speech Sounds: Your Gateway to Phonology
In This Chapter
![]() Taking a closer look at features
Taking a closer look at features
![]() Noting odd things with markedness
Noting odd things with markedness
![]() Keying in on consonant and vowel classification
Keying in on consonant and vowel classification
![]() Grasping the important concepts of phonemes and allophones
Grasping the important concepts of phonemes and allophones
Naming is knowledge. If you classify a speech sound, you know what its voicing source is, where it is produced in the vocal tract, and how the sound was physically made. This chapter introduces you to how speech sounds are described in phonetics. I discuss some of the traditional ways that phoneticians use to classify vowels and consonants — ways that are used somewhat differently across these two sound classes. I dedicate a major part of this chapter to the concepts of phoneme and allophone, important building blocks needed to understand the phonology (sound systems and rules) of any language.
Focusing on Features
A phonetic feature is a property used to define classes of sounds. More specifically, a feature is the smallest part of sound that can affect meaning in a language. In early work on feature theory, phoneticians defined features as the smallest units that people listened to when telling meaningful words apart, such as “dog” versus “bog.” As work in this area progressed, phoneticians also defined features by the role they played in phonological rules, which are broader sound patterns in language (refer to Chapters 8 and 9 for more on these rules). The following sections discuss the four types of phonetic features.
Binary: You’re in or out!
You may be familiar with the term binary from computers, meaning having two values, 0 or 1. Think of flipping a light switch either on or off. Because binary values are so (blessedly) straightforward, engineers and logicians all over the world love them. Phonologists use binary features because of their simplicity and because they can be easily used in computers and telephone and communication systems.
An example of a binary feature is voicing. A sound is either voiced (coded as + in binary features) or voiceless (coded as –). Another example is aspiration, whether a stop consonant is produced with a puff of air after its release. Using binary features, phoneticians classify stop consonants as being “+/– aspiration.”
To see how binary features are typically used for consonants and vowels, Figure 5-1 shows a binary feature matrix for the sounds in the word “needs,” written in IPA as /nidz/.
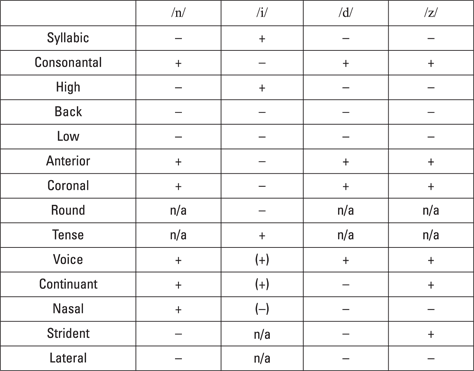
Illustration by Wiley, Composition Services Graphics
Figure 5-1: The word “needs” represented in a binary feature matrix.
In this figure, the sound features of each phoneme (/n/, /i/, /d/, and /z/) are listed as binary (+/–) values of features, detailed in the left-most column. For example, /n/ is a consonant (+ consonantal) that doesn’t make up the nucleus of a syllable (– syllabic). The next three features refer to positions of the tongue body relative to a neutral position, such as in production of the vowel /ə/ for “the”. The consonant /n/ is negative for these three features. Because /n/ is produced at the alveolar ridge, it’s considered + anterior and + coronal (sounds made with tongue tip or blade). Because /n/ isn’t a vowel, the features “round” and “tense” don’t apply. /n/ is produced with an ongoing flow of air and is thus + continuant. It’s + nasal (produced with airflow in the nasal passage), not made with noisy hissiness (– strident) nor with airflow around the sides of the tongue (– lateral).
If you’re an engineer, you can immediately see the usefulness of this kind of information. Binary features, which are necessary for many kinds of speech and communication technologies, break the speech signal into the smallest bits of information needed, and then discard and eliminate the less useful information.
Phoneticians only want to work with the most needed features. For instance, because most stop consonants are oral stops (sounds made by blocking airflow in the mouth, refer to Chapter 6 for more information), you don’t usually need to state the oral features for /p/, /t/, /k/, /b/, /d/, and /ɡ/. However, the nasal feature (describing sounds made with airflow through the nasal passage) is added to the description of the (less common) English nasal stop consonants /m/, /n/, and /ŋ/. Here are some examples of reducing this feature redundancy (repetition) to make phonetic description more streamlined and complete:
/b/: This sound is typically described as a voiced bilabial stop. You don’t need to further specify “oral” because it’s understood by default.
/m/: This sound is typically described as a voiced bilabial nasal or a voiced bilabial nasal stop. Because nasals are less common sounds and are distinguished from the more typical oral stops by their nasality, it’s important to note “nasal” in their description.
Here is another example. In Figure 5-1, the last 5 features (voice, continuant, nasal, strident, lateral) apply chiefly to consonants. Thus, the vowel /i/ (as in “eat”), doesn’t need to be marked with these (+ voice, + continuant, and so on). For this reason, I’ve placed the values in parentheses or marked them as “n/a” (not applicable).
Graded: All levels can apply
Other properties of spoken language don’t divide up as neatly as the cases of voicing and aspiration, as the previous section shows. Phoneticians typically use graded (categorized) representations for showing various melodic patterns across different intended meanings or emotions. Suprasegmental (larger than the individual sound segment) properties (such as stress, length, and intonation) indicate gradual change over the course of an utterance.
For example, try saying “Oh, really?” several times, first in a surprised, then in a bored voice. You probably produced rather different melodic patterns across the two intended emotions. Marking these changes with any kind of simple binary feature would be difficult. That’s why using graded representations is better. Here is this graded example:
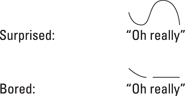
 To represent the melody of these utterances, you have a couple of different options. You can draw one of the following two:
To represent the melody of these utterances, you have a couple of different options. You can draw one of the following two:
 Pitch contour: A pitch contour is a line that represents the fundamental frequency of the utterance. Figure 5-2 provides an example.
Pitch contour: A pitch contour is a line that represents the fundamental frequency of the utterance. Figure 5-2 provides an example.
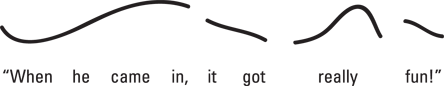
Illustration by Wiley, Composition Services Graphics
Figure 5-2: A pitch contour example.
Numeric categorization scheme: In such a representation (as this), numeric levels of pitch (where 1 is low, 2 is mid, and 3 is high) and thespacing between numbers representing juncture (the space between words) provide a graded representation of the information.
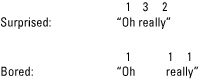
There is no one correct method for transcribing suprasegmental information described in the IPA. However, refer to Chapters 10 and 11 for some recommendations.
Articulatory: What your body does
Articulatory features refer to the positions of the moving speech articulators (the tongue, lips, jaw, and velum). In the old days, articulatory features also referred to the muscular settings of the vocal tract (tense and lax). The old phoneticians got a lot right; the positions of the speech articulators are a pretty good way of classifying consonant sounds. However, this muscular setting hypothesis for vowels was wrong. Phoneticians now know the following:
For consonant sounds: Articulatory features can point to the tongue itself, such as apical (made by the tip), coronal (made by the blade), as well as the regions on the lips, teeth, and vocal tract where consonantal constrictions take place (bilabial, labiodental, dental, alveolar, post-alveolar, retroflex, palatal, uvular, pharyngeal, and glottal).
For vowels: Articulatory descriptions of vowels consider the height and backness of the tongue. Tongue position refers to high, mid, or low (also known as having the mouth move from close to open) and back, central, or front in the horizontal direction. Figure 5-3 shows this common expression in a diagram known as a vowel chart, or vowel quadrilateral.
Vowel charts also account for the articulatory feature of rounding (lip protrusion), listing unrounded and rounded versions of vowels side by side. For instance, the high front rounded vowel /y/, as found in the French word “tu” (meaning you informal), would appear next to the high front vowel /i/. English doesn’t have rounded and unrounded vowel pairs. Instead, the four vowels with some lip rounding are circled in Figure 5-3. The arrows show movement for diphthongs (vowels with more than one quality). Chapter 7 provides further information about vowels, diphthongs, and the vowel quadrilateral.
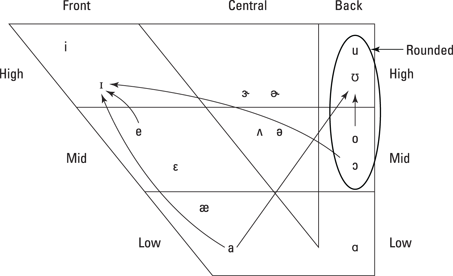
Illustration by Wiley, Composition Services Graphics
Figure 5-3: Vowel quadrilateral showing rounded vowels and diphthongs.
Acoustic: The sounds themselves
Although specifying more or less where the tongue is during vowel production is okay for a basic classification of vowels, doing so doesn’t cover everything. Phoneticians agree that acoustic (sound-based) features give a more precise definition, especially for vowels. These acoustic features have to do with specific issues, such as how high or low the frequencies of the sounds are in different parts of the sound spectrum, and the duration (length) of the sounds.
The tongue makes many different shapes when you say vowels, and a more critical determining factor in what creates a vowel sound is the shape of the tube in your throat. Refer to the top part of Figure 5-4 for a sample of these tube shapes.
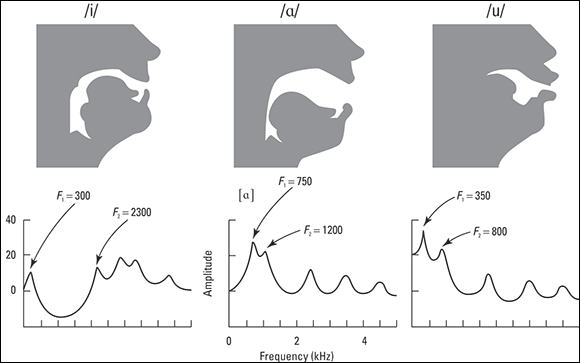
Illustration by Wiley, Composition Services Graphics
Figure 5-4: Three cross-sectional heads showing different tube shapes and the corresponding vowel spectra.
To work with acoustic features, phoneticians analyze speech by computer and look for landmarks. One such important landmark for vowels is called formant frequencies, which are peaks in the spectrum which determine vowel sound quality. Chapter 12 explains more about acoustic features and formant frequencies.
Marking Strange Sounds
The number of possible features for any given speech sound can become, well, many! As a phonetician considers the numerous sounds in language, it becomes important to keep track of which are the more common sounds, those likely to be universal across the world’s languages, and which sounds are rare — that is, the oddballs of the phonetics world.
To do so, the unusual sound or process is considered marked, whereas the rather common one is unmarked. Here are some examples:
Stop consonants made at the lips (such as /p/ and /b/) are relatively common across the world’s languages, and are thus rather unmarked. However, the first sound in the Japanese word “Fuji” is a voiceless bilabial fricative made by blowing air sharply through the two lips. This fricative (classified with the Greek character “phi,” /ф/ in IPA) is relatively rare in the world’s languages, and is thus considered marked.
The vowels /i/, /u/, and /a/ are highly unmarked, because they’re some of the most likely vowels to be found in any languages in the world. In contrast, the rounded vowels /y/, /ø/, and /ɶ/ are more marked, because they only tend to appear if a language also has a corresponding unrounded series /i/, /e/, and /a/.
How a phonetician determines whether a sound is marked or unmarked is a pretty sophisticated way of viewing language. Saying that a sound or process is marked means that it’s less commonly distributed among the world’s languages, perhaps because a certain sound is relatively difficult to hear or is effortful to produce (or both).
However, remember that a phonetician talking about markedness is quite different than people saying that a certain language is difficult. The idea of a language being difficult is usually a value judgment: It depends on where you’re coming from. When deciding whether a language is simple or complex, be careful about making value judgments about other languages. For example, Japanese may seem like a “difficult” language for an English speaker, but perhaps not so much for a native speaker of Korean because Japanese and Korean share many phonological, syntactic, and writing similarities that English doesn’t share.
Also, before making a judgment of difficulty, think about what part of the language is supposed to be difficult. Linguists talk about languages in terms of their phonology, morphology (way of representing chunks of meaning), syntax (way of marking who did what to whom), semantics (phrase and sentence level meaning), and writing systems, assuming the language has a written form (most languages in the world don’t have a written form). It’s very typical for languages to be complex in some areas and not in others. For instance, Japanese has a rather simple sound inventory, a relatively straightforward syntax, but a very complicated writing system. In contrast, Turkish has a fairly simple writing system but a rather complex phonology and syntax.
Introducing the Big Three
In order to grasp a basic tenet of phonetics, you need to know about the Big Three — the three types of articulatory features that allow you to classify consonants. For phonetics, the three are voicing, place, and manner, which create the acronym VPM. Here is a bit more about these three and what you need to know:
Voicing: This term refers to whether or not the vocal folds are buzzing during speech. If there is voicing, buzzing occurs and speech is heard as voiced, such as the consonants in “bee” (/bi/) and “zoo” (/zu/). If there is no buzzing, a sound is voiceless, such as the consonants in “pit” (/pɪt/) or “shy” (/ʃaɪ/). All vowels and about half of the consonants are normally produced voiced, unless you’re whispering.
Places of articulation: This term relates to the location of consonant production. They’re the regions of the vocal tract where consonant constriction takes place. Refer to Table 5-1 for the different places.
Table 5-1 Where English Consonants Are Produced
|
Feature |
Location |
IPA |
|
Bilabial |
At the two lips |
/p/, /b/, /m/ |
|
Labiodental |
Lower lip to teeth |
/f/, /v/ |
|
Dental |
Teeth |
/θ/, /ð/ |
|
Alveolar |
Ridge on palate behind teeth |
/s/, /z/, /t/, /d/, /ɹ/, /l/, /n/ |
|
Post-alveolar (also known as palato-alveolar) |
Behind the alveolar ridge |
/ʧ/, /ʤ/, /ʃ/, /ʒ/ |
|
Palatal |
At the hard palate |
/j/ |
|
Velar |
At the soft palate |
/k/, /ɡ/, /ŋ/ |
|
Labio-velar |
With lips and soft palate |
/w/ |
|
Glottal |
Space between vocal folds |
/Ɂ/, /h/ |
Manner of Articulation: This term refers to the how of consonant production, specifically, the nature of the consonantal constriction. Table 5-2 lists the major manner types for English.
Table 5-2 How English Consonants Are Produced
|
Name |
Construction Type |
IPA |
|
Stop |
Complete blockage – by default, oral |
/p/, /t/, /k/, /b/, /d/, /ɡ/, |
|
Nasal |
Nasal stop – oral cavity stopped, air flows out nasal cavity |
/m/, /n/, /ŋ/ |
|
Fricative |
Groove or narrow slit to produce hissing |
/θ/, /ð/, /ʃ/, /ʒ/, /s/, /z/, /h/, /f/, /v/ |
|
Affricate |
Combo of stop and fricative |
/ʧ/, /ʤ/ |
|
Approximant |
Articulators approximate each other, come together for a “wa-wa” effect |
/w/, /ɹ/, /l/, /j/ |
|
Tap |
Brief complete blockage |
/ɾ/ |
|
Glottal stop |
Complete blockage at the glottal source |
/Ɂ/ |
Every time you encounter a consonant, think of VPM and be prepared to determine its voicing, place, and manner features.
 Making flashcards is a great way to master consonants and vowels, with a word or sound on one side, and the features on the other.
Making flashcards is a great way to master consonants and vowels, with a word or sound on one side, and the features on the other.
Moving to the Middle, Moving to the Sides
Most speech sounds are made with central airflow, through the middle of the oral cavity, which is the default or unmarked case. However for some sounds, like the “l” sound, a lateral (sideways) airflow mechanism is used, which involves air flowing around the sides of the tongue.
In English, you can find an important central versus lateral distinction for the voiced alveolar approximants /ɹ/ and /l/. You can hear these two sounds in the minimal pair “leap” and “reap” (/lip/ and /ɹip/). For /l/, air is produced with lateral movement around the tongue.
 To test it, try the phonetician’s cool air trick. To use this test, produce a speech sound you wish to investigate, freeze the position, and suck in air. Your articulators can sense the cool incoming air, and you should be able to get a better sensation of where your tongue, lips, and jaw are during the production of the sound. For this example, to do this test, follow along:
To test it, try the phonetician’s cool air trick. To use this test, produce a speech sound you wish to investigate, freeze the position, and suck in air. Your articulators can sense the cool incoming air, and you should be able to get a better sensation of where your tongue, lips, and jaw are during the production of the sound. For this example, to do this test, follow along:
1. Say “reap,” holding the initial consonant (/ɹ/).
2. Suck in some cool air to help feel where your tongue is and where the air flows.
3. Say “leap,” doing the same thing while sensing tongue position and airflow for the initial /l/.
You should be able to feel airflow around the sides of the tongue for /l/. You may also notice a bit of a duck-like, slurpy quality to the air as it flows around the sides of the tongue. This is a well-known quality, also found as a feature in some of the languages that have slightly different lateral sounds than are found in English. Chapter 16 provides more information on these unusual lateral sounds.
Sounding Out Vowels and Keeping Things Cardinal
Knowing what phoneticians generally think about when classifying vowels is important. In fact, phonetics has a strong tradition, dating back to 19th century British phonetician Daniel Jones, of using the ear to determine vowel quality. An important technique for relying on the ear depends on using cardinal vowels, vowels produced at well-defined positions in articulatory space and used as a reference against which other vowels can be heard.
Figure 5-5 shows how cardinal vowels work. Plotted are the cardinal vowels, as originally defined by Jones and still used by many phoneticians today. These vowels aren’t necessarily the vowels of any given language, although many lie close to vowels found in many languages (for instance, cardinal vowel /i/ is quite close to the high front unrounded vowel of German). The relative tongue position for each vowel is shown on the sides of the figure.
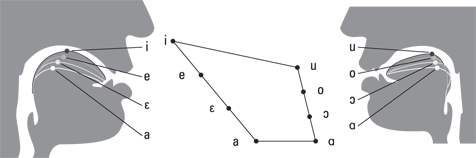
Illustration by Wiley, Composition Services Graphics
Figure 5-5: English cardinal vowels and associated tongue positions.
To make cardinal vowel /i/, make a regular English /i/ and then push your tongue higher and more front — that is, make the most extreme /i/ possible for you to make. This point vowel, or extreme articulatory case, is a very pure /i/ against which other types of “/i/-like” vowels may be judged. With such an extremely /i/-sounding reference handy, a phonetician can describe how the high front sounds of, say, English, Swedish, and Japanese differ.
The same type of logic holds true for the other vowels in this figure, such as the low front vowel /a/ or the high back vowel /u/. Just like with the regular IPA chart (see Chapter 3), this set of cardinal vowels also has rounded and unrounded (either produced with the lips protruded or not) vowels. Jones called the rounded series the secondary cardinal vowels.
To hear Daniel Jones producing 18 cardinal vowels (from an original 1956 Linguaphone recording), go to www.youtube.com/watch?v=haJm2QoRNKo.
Tackling Phonemes
A phoneme is the smallest unit of sound that contributes to a meaning in a language. Knowing about phonemes is important and frequently overlooked by beginning students of phonetics because they can seem so obvious and, well, boring. However, phonemes aren’t boring. In fact, they’re essential to many fields, such as speech language pathology, psycholinguistics, and child language acquisition.
In simple terms, a phoneme is psychological. If you want to talk about a speech sound in general, it’s a phone, not a phoneme. A sound becomes a phoneme when it’s considered a meaningful sound in a language. Phoneticians talk about phonemes of English or Russian or Tagalog. That is, to be a phoneme means to be a crucial part of a particular language, not language in general.
Furthermore, one person’s phoneme isn’t necessarily another person’s phoneme. If I were to suddenly drop you among speakers of a very different-sounding language, and these people tried to teach you their language’s sound system, you would probably have a difficult time telling certain sounds apart. This is because the sound boundaries in your mind (based on the phonemes of your native language) wouldn’t work well for the new language I have dumped you in.
If you’re a native English speaker, you’d be in this plight if you were trying to hear the sound of the Thai consonant /t/ at the beginning of a syllable. For example, the clear spicy Thai soup “tom yum” may sound to you as if it were pronounced “dom yum,” instead of having an unaspirated /t/ at the beginning. Native Thai speakers may be surprised and even amused at your inability to hear this word pronounced correctly.
Determining whether speech breaks down at the phonemic level is important in understanding language disorders such as aphasia, the language loss in adults after brain damage, and in studying child language acquisition. The following sections take a closer look at phonemes.
Defining phonemes
To investigate the sound system of a language, you search for a phoneme. To be a phoneme, a sound must pass two tests:
It must be able to form a minimal pair. A minimal pair is formed whenever two words differ by one sound, such as “bat” versus “bag” (/bæt/ and /bæɡ/), or “eat” versus “it” (/it/ and/ɪt/). In the first pair, consonant voicing (/t/ versus /ɡ/) makes the difference. In the second pair, vowel quality (/i/ versus /ɪ/) makes the difference. However, in both cases a single phoneme causes a meaningful distinction between two words. Phoneticians consider minimal pairs a test for a distinctive feature because the feature contributes to an important, sound-based meaning in a language.
It should be in free (or contrastive) distribution. The term free distribution means a sound can be found in the same environment with a change in meaning. For example, the minimal pair “bay” versus “pay” (/be/ and /pe/) show that English /b/ and /p/ are in free distribution.
Notice that phonemes in a language (such as the English consonants /s/, /t/, /ɡ/, and the vowels /i/, /ɑ/, and /u/) can appear basically anywhere in a word and change meaning in pretty much the same fashion. The same kind of sound-meaning relationships hold true even when these sounds are in different syllabic positions, such as “toe” versus “go” (initial position) or “seat” versus “seed” (final position).
Complementary distribution: Eyeing allophones
Complementary distribution is when sounds don’t distribute freely, but seem to vary systematically (suggesting some kind of interesting, underlying reason). Complementary distribution is the opposite of free distribution, a property of phonemes. The systematically varying sounds that result from complimentary distribution are called allophones, a group of possible stand-ins for a phoneme. It’s kind of like Clark Kent and Superman — they’re really the same guy, but the two are never seen in the same place together. One can stand in for the other.
The prefix allo- means a systematic variant of something, and -phone is a language sound. Therefore, an allophone is a systematic variant of a phoneme in language. In this case, a language has one phoneme of something (such as a “t” in English), but this phoneme is realized in several different ways, depending on the context.
English has just one meaningful “t”. At the level of meaning, the “t” in “Ted” is the same as the “t” in “bat,” in “Betty,” and in “mitten.” They all represent some kind of basic “t” in your mind. However, what may surprise you is that each of the “t” sounds for these four words is pronounced quite differently, as in the following:
|
Word |
IPA Transcription (narrow) |
The “t” Used (Allophone) |
|
Ted |
[tʰɛd] |
aspirated t |
|
bat |
[bæt] |
unaspirated t |
|
Betty |
[ˈbɛɾɪ] |
alveolar tap |
|
mitten |
[ˈmɪɁn̩] |
glottal stop |
Each of these words only has one meaningful “t” sound, but depending on the context, each word has its own realized but different kind of “t” sound.
To put it another way, you understand just one phoneme /t/, but actually speak and hear four different allophones. These include aspirated t, unaspirated t, alveolar tap, and glottal stop. Each of these allophones is a systematic variant of the phoneme /t/ in General American English. Note: Although phonemes are written in slash brackets (/t/), allophones are written in square brackets, ([t]).
Sleuthing Some Test Cases
Making sure you have the concepts of phoneme and allophone is important and one way to do so is to examine other languages. In these sections, I conduct a brief phonological analysis of English and contrast these patterns with those of with Spanish and Thai. I also provide an American indigenous language example.
Comparing English with Thai and Spanish
Here I make a quick comparison of how two other languages treat their stop consonants, in comparison to English. Table 5-3 focuses on the voiceless, bilabial stop (/p/ in IPA) and compares English with Thai and Spanish examples.

The English /p/ has an aspirated form found at the beginning of syllables (such as “pet”) and an unaspirated form found elsewhere (like in “spot” and “nap”). Thai has two phonemes, aspirated /pʰ/, as in “forest” ([pʰa:]), and unaspirated /p/, as in “split” ([pa:]). Spanish has only one phoneme, unaspirated /p/, as in “but” ([ˈpeɾo]).
As a result, it’s no surprise that some English speakers may have trouble clearly hearing the /p/ of Thai [pa:] or Spanish [ˈpeɾo] as “p,” and not “b.”
You can also understand how people from one language may have difficulty learning the sounds of a new language; a language learner must mentally form new categories. They can experience phonemic misperception (hearing the wrong phoneme) when this kind of listening is not yet acquired (or if it goes wrong, such as in the case of language loss after brain damage).
Eyeing the Papago-Pima language
Papago-Pima (also known as O’odham) is a Uto-Aztecan language of the American Southwest. Approximately 10,000 people speak the Papago-Pima language, mostly in Arizona. Figure 5-6 shows a brief corpus selected to show how the sounds /t/ and /ʧ/ distribute.

Figure 5-6: Selected words from the Papago-Pima language.
From the data in Figure 5-6, determine if the /t/ and /ʧ/ are separate phonemes or if they’re allophones of a single underlying phoneme. If they’re phonemes, show why. If they’re allophones, describe their occurrence.
To do this problem, see how the sounds distribute. See if there are any minimal pairs. Look for free distribution versus complementary distribution. If the distribution is complementary, give the details of how the sounds distribute.
To solve this problem, follow these steps:
1. Check to see if the /t/ and /ʧ/ form any minimal pairs.
For instance, the word [ˈta:pan] means “split.” Can you find a word [ˈʧ a:pan] anywhere that means anything? If so, you can conclude these sounds are separate phonemes (and go on your merry way); however, you’ll see this is not the case. Thus, the first test of phoneme-hood fails, which means your work isn’t finished.
2. Begin to suspect allophones and check for complementary distribution.
You may first check along the lines of the syllable contexts, whether the sounds in question begin or end a syllable. That is, you may first be able to reason that [t] is found in one syllable position and [ʧ] in the other.
You can quickly see that such an explanation doesn’t work. For instance, a [t] is found in syllable initial position (such as in [ˈtaːpan]), as is [ʧ] (in [ˈʧɨkid] “vaccinate”). Both [t] and [ʧ] are also found in medial position, such as in [ˈtaːtam] and [ˈkiːʧud], and in final position, such as [ˈwiɖut] and [ˈɲumaʧ].
3. Try other left context cues.
Perhaps the vowels occurring in front of the [t] and [tʃ] may provide the answer. You see that [t] can have [a] or [u] to the left of it (as in [ˈgatwid] and [ˈwiɖut], and [tʃ] can also be preceded by [i] and [a], as in [ˈki:ʧud] and [ˈɲumaʧ]. These distributions suggest some overlap.
4. Because the left context isn’t working, you can next try looking to the right of the segment.
Here, you find the answer. The stop consonant [t] occurs before mid and low vowels (such as /o/ and /a/), the approximant /w/, and the end of a word. However, [ʧ] is only found before the high vowels /i/, /ɨ/, or /u/.
In other words, in Papago-Pima, [t] and [ʧ] are allophones of the phoneme, /t/. You can describe the allophones as “the palato-alveolar affricate occurs before high vowels; alveolar stops occur elsewhere.”
Congratulations! You worked out a phonological rule.
Many phonologists prefer to describe these processes more formally. Figure 5-7 shows the Papago-Pima rule.

Illustration by Wiley, Composition Services Graphics
Figure 5-7: The formalized Papago-Pima rule.
Chapter 9 reviews the phonological rules for English. With these rules, you can discover how to do a narrow transcription in IPA, including which diacritics to include where. You’ll be able to explain which sound processes take place in English and why, which is a highly valuable skill for language teaching and learning.