Toward Segment-Based Machine Translation
The IBM models have been subjected to numerous enhancements. The most significant improvement was to take into consideration the notion of segments (or sequences of words) in order to overcome the limitation of a simple word-for-word translation. Among the other improvements, the notion of double alignment is worth mentioning, since it greatly increases the quality of the search for translations at word level in bilingual corpora.
Double Alignment
The IBM models are able to recognize correspondences such that, for one word in the source language, there is 0, 1, or n words in the target language. However, the original IBM models, because of their formal basis, do not make it possible to obtain the opposite correspondences (in other words, one word from the target language cannot correspond to a multiword expression in the source language, for example). This is a strong limitation of these models that has no linguistic basis, since multiword expressions clearly exist in every language. It therefore seemed necessary to overcome this limitation imposed by the IBM models in order to allow for m-n alignments (where any number of words from the source language corresponds to any number of words in the target language).
The original IBM article specifically mentioned the example shown in figure 17, which the models proposed in 1993 were unable to handle.
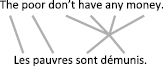
Figure 17 Example of an alignment that is impossible to obtain from IBM models. The sequence “don’t have any money” corresponds to the group “sont démunis” in French: this is an example of an m-n correspondence (here, m=4 and n=2 such that four English words correspond to two French words, if we consider “don’t” as a single word).
One way of overcoming this problem is to first calculate the alignments from the source language into the target language, then repeat the operation in the opposite direction (from the target language into the source language). The shared alignments are kept, namely those concerning words that have been aligned in both directions. The alignments obtained using this technique are generally precise but provide a low coverage of the bi-texts. Globally, this method has two major defects: first, the process is more complex than a simple alignment, and is therefore more costly in terms of computation time; second, at the end of the process, a large number of words are no longer aligned because the constraints imposed by the double-direction analysis cause numerous alignments identified in a single direction to be rejected. Various heuristics then have to be used to expand the alignments to neighboring words in order to compensate for the coverage problems incurred (the double alignments, or “symmetric alignments,” can be seen as “islands of confidence”; see chapter 7).
It has been shown that this method improves the results of the original IBM models. However, in order to obtain a good coverage of the data with these models, it is necessary to have huge quantities of data, which makes them impractical in some circumstances.
The Generalizations of Segment-Based Machine Translation
We have seen that the double alignment approach helps to identify m-n translational equivalences, such as “don’t have any money” ⇔ “sont démunis” (where four English words amount to two French words). In fact, it is possible to generalize the approach so to consider the problem of translation as an alignment problem at the level of sequences of words, and not at the level of isolated words only. The goal is to translate at the phrase level (i.e., sequences of several words): this would enable the context to be better taken into account and would thus offer translations of better quality than simple word-for-word equivalences.
It is possible to generalize the approach so as to consider the problem of translation as an alignment problem at the level of sequences of words, and not at the level of isolated words only.
Several research groups have tackled this problem since the late 1990s, and various strategies have been explored. One strategy is to systematically symmetrize the alignments (see the previous section) in order to identify all the possible m-n alignments. Other researchers have tried to directly identify linguistically coherent sequences in texts, through rules describing syntactic phrases for example (this can be seen as a first attempt to introduce a light syntactic analysis in the translation process). A last line of research tried to import some techniques from the example-based paradigm (see chapter 8), the idea being to make the alignment process both more robust and more precise by aligning from tags and not from word forms. For example, the following two sentences may seem very different for a computer, since several words are different: “In September 2008, the crisis …” and “In October 2009, the crisis … .” However, if the system is able to recognize date expressions, it is possible to recognize the structure “In <DATE>, the crisis” in both sentences: they can thus be aligned successfully. This technique can significantly improve the quality of the alignment.
The results obtained by these models show a clear improvement in comparison to the more complex IBM models, notably IBM model 4. However, the results are still very dependent on the training data: the more data there are, the more accurate the models will be. Moreover, segment models require a lot more training data than models based only on word alignment. Finally, it should be noted that the notion of segments does not generally correspond to the notion of phrases. A closer look at the results obtained shows that the segments obtained by training from large bilingual corpora correspond to frequent but fragmentary groups of words (for example, “table of” or “table based on”). On the contrary, limiting the analysis to linguistically coherent phrases (for example, “the table” or “on the table”) seriously affects the results. In other words, if one forces the system to focus on linguistically coherent sequences corresponding to syntactically complete groups, the results are not as good as with a purely mechanical approach that does not take syntax into account.
The most challenging part of segment-based translation is for the system to produce a relevant sentence from scattered pieces of translation. Figure 18 gives a simplified but typical view of the situation after the selection of translation fragments (this view is simplified, because here the sentence to be translated is short, the number of segments to be taken into account is limited, and in real systems all fragments have a probability score).

Figure 18 Segment-based translation: different segments have been found corresponding to isolated words or to longer sequences of words. The system then has to find the most probable translation from these different pieces of translation. It is probable that “les pauvres n’ont pas d’argent” will be preferred to “les pauvres sont démunis,” but this would be acceptable since the goal of automatic systems is to provide a literal translation, not a literary one.
It is clear from figure 18 that only the careful selection of some fragments can lead to a meaningful translation. The language model of the target language helps in finding the most probable sequence in the target language; in other words, it tries to separate linguistically correct sentences from incorrect ones (independently from the source sentence at this stage).
As one can easily imagine, these models are much more complex than the original IBM models based on simple words. Thus, they may require considerable processing time compared to the original IBM models. The increasing computational power of computers somewhat compensates for this problem. From a linguistic point of view, it should be noted that these models fail to identify discontinuous phrases (where one word in the source language corresponds to two noncontiguous words in the target language), which are crucial in languages such as French or German (English: “I bought the car” ⇔ German: “Ich habe das Auto gekauft”; English: “I don’t want” ⇔ French: “Je ne veux pas”).
The recent developments we have described in this section have, however, helped improve the IBM models and can still be considered currently as the state of the art in machine translation.