CHAPTER 3
Computation
In the previous chapter we set up a Hadoop integrated storage system, where we stored huge amounts of data to be used by a distributed computation engine. Hadoop MapReduce is the major distributed computation framework that has been used for a long time. Hadoop MapReduce is an actual open source implementation of MapReduce, supported by various types of companies and individuals. The reliability and results of Hadoop MapReduce for enterprise usage is outstanding among many of the distributed computation frameworks.
In this chapter, we will introduce the basic concept of MapReduce, and the details of implementing Hadoop MapReduce. Hadoop MapReduce is easily understood by engineers who are familiar with distributed computation or high performance computing. If you have sufficient knowledge in that area, please skip this first section about the basics of MapReduce.
BASICS OF HADOOP MAPREDUCE
Hadoop MapReduce is an open source version of a distributed computational framework originally introduced by Google. MapReduce enables you to easily write general distributed applications on Hadoop, and the MapReduce computational model is so general that you can write almost any type of process logic used in enterprise. Here we will explain the basic concepts and purposes of the MapReduce framework needed to write a MapReduce application. We will then introduce the concrete architecture of Hadoop MapReduce.
Concept
There are three primary features that MapReduce is trying to solve:
- High scalability
- High fault tolerance
- High level interface to achieve these two points
MapReduce does not achieve high scalability with distributed processing and high fault tolerance at the same time. Distributed computation is often a messy thing, so it is difficult to write a reliable distributed application by yourself. There are various kinds of failures that are introduced when distributed applications are running: Some servers might fail abruptly, whereas some disks may get out of order. Keep in mind that writing code to handle failures by yourself is very time consuming and can also cause new bugs in your application.
Hadoop MapReduce, however, can take care of fault tolerance. When your application fails, the framework can handle the cause of failure and retry it or abort. Thanks to this feature, the application can complete its tasks while overcoming failures.
Hadoop MapReduce is integrated with HDFS, which was introduced in Chapter 2. The MapReduce framework handles the input and output between your application and HDFS. You don't have to write I/O code between these two frameworks. HDFS can also handle block failure, and as long as you use HDFS with MapReduce, you don't have to pay attention to storage layer failure. On the contrary, you should not use a storage system that doesn't take disk failure or node failure into consideration with the MapReduce framework. Otherwise, the reliability and scalability of your application will worsen.
The MapReduce application is divided into several phases, which are described in the following list and illustrated in Figure 3.1. The tasks you must write are map and reduce, but the other tasks are managed by the MapReduce framework.
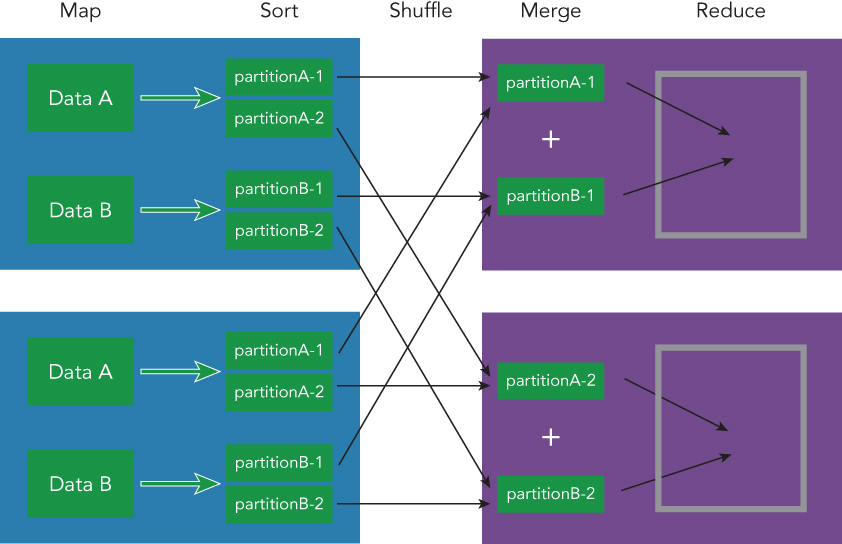
- map: Read the data from a storage system such as HDFS.
- sort: Sort the input data from the map task according to their keys.
- shuffle: Divide the sorted data and repartitioning among cluster nodes.
- merge: Merge the input data sent from mapper on each node.
- reduce: Read the merged data and integrate them into one result.
Hadoop MapReduce defines all sort, shuffle, and merge operations in advance. You must write the map and reduce operations, which are defined by Mapper and Reducer. Hadoop MapReduce prepares a sufficient abstraction for the distributed programming model. Basically, the data type MapReduce can manipulate is a tuple that contains a key and a value. You can use any type of key or value as long as they are serializable, but you must pass the data between Mapper and Reducer in the tuple format. Mapper converts an input record into a tuple that has a key and a value, and you can define which part needs to be extracted from the input data by Mapper. Mapper has a method named map for converting input data. Keep in mind that the output tuple data type from the Mapper class is not necessarily the same as the input data type.
The outputs from the Mapper class are transferred to Reducers. Tuples that have the same key are all transferred to the same Reducer. Therefore, if a tuple has a “Dog” text as a key and is transferred to reducer1, the next tuple that has a “Dog” as its key must be transferred to reducer1 (see Figure 3.2). If it is necessary to aggregate some type of value, you should set the same key in the Mapper class. For example, if you want to count the number of appearances of each word in text, a key should be the word itself in the Mapper class. The same words are transferred to the same Reducer, and the Reducer can take the sum of the total tuples transferred from Mappers.
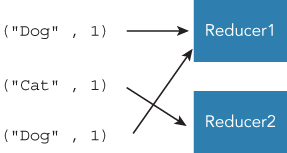
Figure 3.3 shows the overall abstraction of data flow in MapReduce. As you can see, the important notion in the MapReduce data flow is a key-value tuple. Once a record in the storage system is converted into a key-value tuple by Mapper, the MapReduce system manipulates the data according to the key-value tuple abstraction as described in Figure 3.3.
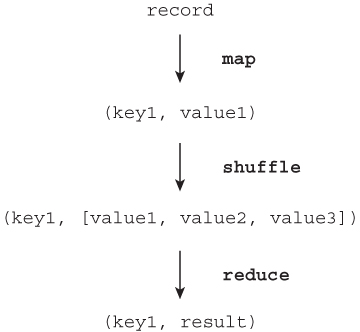
You may think that this programming model is not powerful and flexible, given that the only things you can define are how to convert input data into key-value tuples, and how to get results from aggregated tuples. But, you can write many types of applications that are needed for daily data analysis. This has certainly been proven by Hadoop use cases in many companies. A concrete MapReduce application will be written later in this chapter.
Architecture
Hadoop MapReduce currently runs on YARN, which is a resource manager developed by the Hadoop project. YARN manages the whole resource of your Hadoop cluster, as well as the scheduling of each application submitted by each user. YARN is a general resource management framework, which is not specific to the MapReduce application. Recently, a lot of framework applications such as Spark, Storm, and HBase are able to run on YARN. An overview of YARN and the MapReduce application is shown in Figure 3.4.
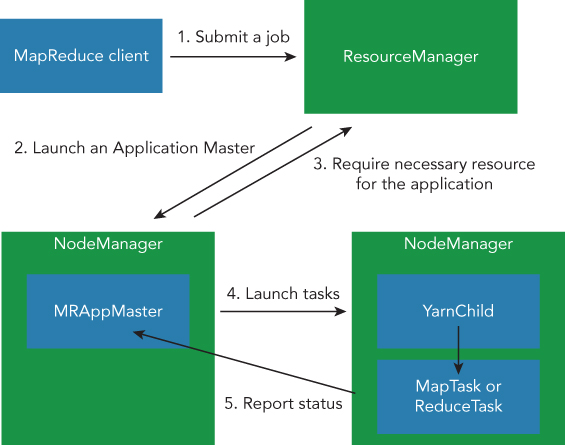
Figure 3.4 illustrates the use of both YARN and the MapReduce framework. YARN components are permanent daemons that keep running after applications have finished. Let's examine ResourceManager and NodeManager:
- ResourceManager: ResourceManager manages whole memory and CPU cores of the YARN cluster. ResourceManager decides how much memory and how many CPU cores can be given to each application. After finishing the application, ResourceManager collects log files generated through each task so that you can find the cause of any failures in your application. ResourceManager is a master server of the YARN cluster, and there is usually one ResourceManager in one YARN cluster.
- NodeManager: NodeManager manages concrete tasks. After requesting to launch a process called a container for each task from the application master, NodeManager will do this same thing on each node. NodeManager is a slave server in a YARN cluster. Increasing servers in a YARN cluster often means increasing servers managed by NodeManager. The total capacity of YARN clusters in terms of memory and CPU cores is determined by the number of slaves managed by NodeManagers.
Components shown in Figure 3.4 are temporary, and are necessary only when an application is running. They are diminished after an application has successfully finished. The flow of submitting a MapReduce application on YARN is also described in Figure 3.4.
- Requesting to submit an application using ResourceManager. When the request finishes successfully, the job client uploads resource files such as any JARs and configurations on HDFS.
- ResourceManager submits a request to a NodeManager to launch a container for the application master that manages the whole progress of this application. In the case of the MapReduce framework, MRAppMaster plays a role as an application master.
- MRAppMaster requests the ResourceManager to provide the necessary resources. ResourceManager replies with the number of containers and the list of available NodeManagers.
- According to the given resource from ResourceManager, MRAppMaster launches containers on NodeManagers. NodeManagers launch a process called YarnChild in a MapReduce application, and YarnChild runs a concrete task such as Mapper or Reducer.
- While the application is running, MapTask and ReduceTask report the progress to MRAppMaster. MRAppMaster knows the whole progress of the application thanks to the given status report from each task. The progress can be seen with the ResourceManager web UI, because ResourceManager knows where MRAppMaster is running.
After the application finishes, MRAppMaster, and each task process, will clean up temporary data generated from the running application. The log files are collected by the YARN framework or the history server (which will be explained in the following section) and archived on HDFS. It is necessary to investigate the cause of any failures introduced by your application, which is the overview of the whole process of the MapReduce application on YARN. You know the importance of resource management in distributed applications such as MapReduce. The number of memory and CPU cores must be shared successfully among applications running on one YARN cluster. This resource distribution is managed by the scheduler in ResourceManager. Currently there are two implementations of scheduler on YARN:
- Fair scheduler: Fair scheduler tries to distribute the same resource to each user in a fixed span. It does not mean that a user who submits more jobs than other users can obtain more resources than other average users. Each user has a resource pool for their own jobs, which are put in the resource pool. If a resource pool can't receive sufficient resources, the Fair scheduler can kill a task that uses too many resources and gives the resources to the resource pool that cannot receive enough resources in a span.
- Capacity scheduler: Capacity scheduler prepares job queues for all users. Each queue is a priority FIFO (First In First Out). The queues have a hierarchical structure, so a queue might be a child of another queue. Thanks to assigning each queue to an organization, you can make the utilization of a maximum cluster guarantee sufficient capacity for each organization's SLA. Users or organizations can regard a queue as a separated cluster for their own workload. In addition to this, Capacity scheduler can also provide free resources to any queue beyond its capacity. Applications can be assigned to a queue running below capacity at the future time by the scheduler. You write
capacity-scheduler.xmlto configure the scheduler settings. Therootqueue is a pre-defined queue, and all queues are children of therootqueue.
The root queue has a full capacity for your cluster. The children of the root queue divide the capacity according to each assignment set by capacify-scheduler.xml. You can make queues under the root like the following:
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>a,b,c</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.b.queues</name>
<value>b1,b2,b3</value>
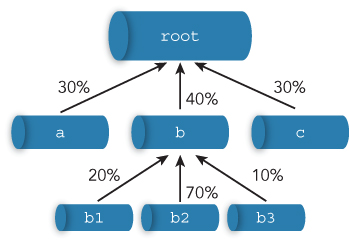
</property>As you know, when you want to make a queue a under root queue, you have to set yarn.scheduler.capacity.root.queues=a. The name of queues can be set hierarchically, so you can set the child of queue a like yarn.scheduler.capacity.root.a.queues=a1,a2. The resource capacity of a queue can also be set with yarn.scheduler.capacity.<queue-path>.capacity. The total capacity of the same layer queues must be 100% as shown in Figure 3.5. In this description, queue b2 can be assigned 0.4(40%) * 0.7(70%) = 0.28(28%) resources of the whole cluster. You can set the maximum and minimum resource for each queue. Capacity scheduler can guarantee minimum resources for each organization to satisfy their SLA (Service Level Agreement).
Later in this chapter we will cover the MapReduce architecture, which describes the shuffle and sort mechanism that is a core system of MapReduce. MapReduce guarantees that all inputs to reducer are sorted by key. This is done in a shuffle phase between map and reduce phases. A shuffle phase often affects the whole performance of the MapReduce application. Understanding the detail of the shuffle is useful for optimizing your MapReduce application.
The MapReduce application needs to read an input file from a filesystem such as HDFS. Hadoop MapReduce uses a class called InputFormat to define how each map task reads the input file. Each map task processes a segment of the input file defined by InputFormat. The segment is called InputSplit, and InputSplit is processed by a map task. InputSplit has a length of a segment in a byte unit, and a list of hostnames where the InputSplit is located. InputSplit is transparently generated by InputFormat, and you don't have to pay attention to the implementation of InputSplit in many cases, given how InputSplit can be had by InputFormat#getSplits. This is called by a job client, which creates the split meta information on HDFS. An application master fetches the split meta information from the HDFS directory after launch. The application master passes the split meta information to each map task to read the corresponding field. The flow of the split info is described in Figure 3.6.
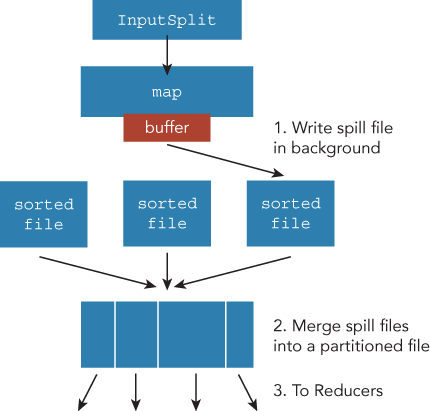
A map task reads a split of the input file. Split is a segment of the whole input file, as described earlier. The size of split is usually the same as the size of the block size of the filesystem, such as HDFS. You can write your own InputFormat class if you want to use the new text file format Hadoop MapReduce does not yet support. When a buffer is filled beyond a configured threshold (mapreduce.map.sort.spill.percent), the buffer content will be output on a disk. The file is called a spill file (see Figure 3.6). The writing on the disk can be done in the background, so it does not block map processing unless the memory buffer is not filled. Just before writing the spill file, the records are sorted for making partitions to distribute the next reducers. The spill files are merged into one file, if there are several spill files, before sending the output to reducers. The merged file is also sorted and separated into partitions, which will be sent to a corresponding reducer.
It is also efficient to compress map output, because it reduces the time to write map output on the disk and to transfer to reducers. You can enable map output compressed with mapreduce.map.output.compress=true. The default value is false, and the codec used by the map output compression can be set with mapreduce.map.output.compress.codec.
A reducer must fetch all of the output from mappers to complete the application, and the reduce task has threads for copying output data from mapper to the local disk. The number of threads can be controlled by mapreduce.reduce.shuffle.parallel.copies. The default value is 5, and the copy phase is conducted in parallel. When an output of the mapper is sufficiently small, which can be stored in the memory buffer, it will be stored in memory. Otherwise, it will be written to disk (see Figure 3.7). After finishing the copying of all data from mapper, the reduce task starts its merge phase. All map output that is in memory or on disks should be converted to a format that the reducer can read. Records have already been sorted by map tasks. In the merge phase, reduce tasks merge into one file. But the final file passed to reducer is not necessarily one file, nor even one disk. The input of reducer can be on both disk or memory if the overhead of merging to the last file is larger than the overhead of passing the data as it is to reducer. The input to reducer can be controlled by mapreduce.task.io.sort.factor. This value represents the number of open files when the merging starts at the same time. If the output of mappers are 50 and io.sort.factor is 10, the count of the merging cycle can be 5 (50 / 10 = 5). The reduce task tries to merge files with as few cycles as possible.
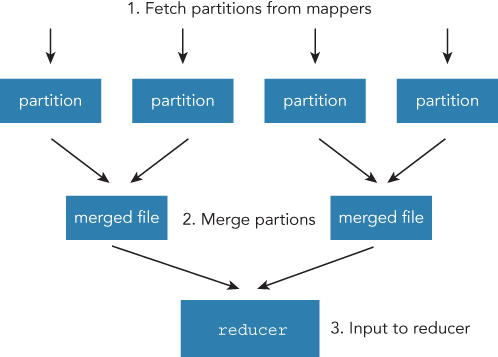
Shuffle is the most resource consuming process in the MapReduce application. Making shuffle phases more efficient often means directly making efficient MapReduce applications. Understanding the overview of the architecture of the MapReduce application will help you when tuning your MapReduce application.
HOW TO LAUNCH A MAPREDUCE JOB
We will now cover how to write a concrete MapReduce application based on the knowledge shown in previous sections. Hadoop MapReduce is a simple Java program. It is necessary to understand the basic knowledge of writing Java programs and compiling them, except for the MapReduce architecture described in previous sections, in order to develop a MapReduce application. The actual MapReduce applications are included in the Hadoop project under hadoop-mapreduce-examples. If you installed Hadoop correctly, you can find the JAR file for examples under $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-*-.jar. You can see the example application with the JAR command.
$ $HADOOP_HOME/bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-↲
3.0.0-SNAPSHOT.jarAn example program must be given as the first argument. Valid program names are:
aggregatewordcount: An Aggregate based map/reduce program that counts the words in the input files.aggregatewordhist: An Aggregate based map/reduce program that computes the histogram of the words in the input files.bbp: A map/reduce program that uses Bailey-Borwein-Plouffe to compute exact digits of Pi.dbcount: An example job that counts the pageview count from a database.distbbp: A map/reduce program that uses a BBP-type formula to compute exact bits of Pi.grep: A map/reduce program that counts the matches of a regex in the input.join: A job that effects a join over sorted, equally partitioned datasets.
We will describe a transitional hello world program of MapReduce: the word count application. The word count application counts the number of appearances of each word found in documentation. In other words, we expect the output of this application to look like the following:
"wordA" 1
"wordB" 10
"wordC" 12Let's continue by writing the map task.
Writing a Map Task
The input file is assumed to be a simple text file. One thing to do in map task is to conduct a morphological analysis. English text can be separated with the Java StringTokenizer.
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.StringTokenizer;
public class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one
= new IntWritable(1);
private Text word = new Text();
@Override
protected void map(Object key, Text value, Context context) throws ↲
IOException, InterruptedException {
StringTokenizer iterator
= new StringTokenizer(value.toString());
while (iterator.hasMoreTokens()) {
word.set(iterator.nextToken());
context.write(word, one);
}
}
}Map task must inherit the Mapper class in Hadoop MapReduce. Mapper receives the key and value type of input and output as generics. Hadoop MapReduce uses TextInputFormat as the default InputFormat, and TextInputFormat makes splits in bytes. Each record is a key-value tuple whose keys are offset from the start of the file, with text values, except for terminal characters. For example, take a look at this example:
My name is Kai Sasaki. I'm a software
engineer living in Tokyo. My favorite
things are programming and scuba diving.
Every summer I go to Okinawa to dive into the blue
ocean. I'm looking forward to the beautiful summer.This text is passed to Mapper through TextInputFormat with 5 tuples.
(0, "My name is Kai Sasaki. I'm a software")
(38, "engineer living in Tokyo. My favorite")
(75, "things are programming and scuba diving.")
(115, "Every summer I go to Okinawa to dive into the blue")
(161, "ocean. I'm looking forward to the beautiful summer.")Each key is an offset from the start position of the file. This is not the line number of the file. TokenizerMapper defines the input key and value as Object and Text.
Map task in this case only records the appearance of a word. Map output is a tuple that has a word itself as a key and the count 1 as a value. The output of the TokenizerMapper task looks like this:
("My", 1)
("name", 1)
("is", 1)
("Kai", 1)
… The outputs are sent to reduce task as described in the previous section. Tuples that have the same keys are collected by a reducer, and same word tuples are all collected by one reducer. It is necessary to aggregate all tuples that have the same word key in one machine to calculate the total count. Although some types of application don't need to reduce a task, the workload that is doing aggregation requires a reduce task after a map task.
Writing a Reduce Task
Just like the map task that is an inherited Mapper class, the reduce task class inherits the Reducer class. Reducer also receives the generics to specify the key and value type of input and output.
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class CountSumReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key,
Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
result.set(sum);
context.write(key, result);
}
}Reduce task receives a key and a list of values, so reduce is called for the same key. The input to the reduce task can be written like this:
("My", [1, 1, 1, 1, 1, 1])All that reduce task has to do is calculate the sum of the list of values. The output is also a tuple whose key is a word (Text), and value is a total count of appearance (IntWritable). The output is written with Context#write. To store results IntWritable is reused in the reduce task because it is resource consuming to re-create the IntWritable object over the time the reduce method is called.
We have now finished writing a map task and a reduce task class. The last thing to write is the Job class to submit an application on the Hadoop cluster.
Writing a MapReduce Job
The Job class has a setting for referring a map task, a reduce class, and the configuration values and input/output path.
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static void main(String[] args)
throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Word Count");
job.setJarByClass(WordCount.class);
// Setup Map task class
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(CountSumReducer.class);
// Setup Reduce task class
job.setReducerClass(CountSumReducer.class);
// This is for output of reduce task
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// Set input path of an application
FileInputFormat
.addInputPath(job, new Path("/input"));
// Set output path of an application
FileOutputFormat
.setOutputPath(job, new Path("/output"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}The Job class can be instantiated by the Job.getInstance static method. The Hadoop MapReduce runtime has to find the classes for executing the MapReduce application on the distributed cluster. The classes needed to run the application are archived in a JAR format, and the Job#setJarByClass method specifies the JAR file including the WordCount class. The Hadoop MapReduce runtime finds the necessary class path automatically with this setting. Map task and reduce task classes are set with setMapperClass and setReducerClass. Combiner is a class used often in the merge phase between map task and reduce task. It is enough to set the reduce class as a combiner class, because it contributes mainly optimization for compressing output of the map task. The result must not be different, regardless of whether or not you set the combiner class. The input and output of a MapReduce application is specified as a filesystem directory, so the input directory can include multiple input files that are normal text files in a WordCount application. The output directory includes the result file and the status of an application.
-rw-r—r-- 1 root supergroup 0 2016-01-01 23:04 /output/_SUCCESS
-rw-r--r-- 1 root supergroup 1306 2016-01-01 23:04 /output/part-r-00000The result file is part-r-XXXXX.
It is better to use Apache Maven to compile the Hadoop MapReduce application. The dependency needed to import is hadoop-client. It is necessary to write below the dependency in your pom.xml file.
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
</dependencies>Next, compile using the maven command.
$ mvn clean package -DskipTestsThe necessary file to run your MapReduce application is the JAR archive, including all of the classes that you wrote. The JAR archive must be uploaded on a client or a master node of the Hadoop cluster. You can run the application with the hadoop jar command.
$ $HADOOP_HOME/bin/hadoop jar \
/path/to/my-wordcount-1.0-SNAPSHOT.jar \
my.package.WordCountConfigurations
The MapReduce application has a lot of configurations. Some of them are for optimizing performance, and some of them are the host name or port number of each component. It is usually beneficial to change the configuration in order to improve the performance of the application. Although it is often enough to use the default value for the ordinal workload, let's go over how to change the configurations for each application.
Hadoop prepares a utility interface for giving configuration values from the command line. The interface is Tool, and it has an interface to run an override method. The interface is necessary to run the MapReduce application using ToolRunner, which can handle parsing command line arguments and options. By combining with the Configured class, the ToolRunner set up configuration object is automatically based on the given configuration from the command line. The sample WordCount application implemented with ToolRunner is written here.
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WordCountTool
extends Configured implements Tool {
public int run(String[] strings) throws Exception {
Configuration conf = this.getConf();
// Obtain input path and output path from
// command line options
String inputPath
= conf.get("input_path", "/input");
String outputPath
= conf.get("output_path", "/output");
Job job = Job
.getInstance(conf, conf.get("app_name"));
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(CountSumReducer.class);
job.setReducerClass(CountSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat
.addInputPath(job, new Path(inputPath));
FileOutputFormat
.setOutputPath(job, new Path(outputPath));
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args)
throws Exception {
int exitCode
= ToolRunner.run(new WordCountTool(), args);
System.exit(exitCode);
}
}The configurations can be given by using the -D property=value format on the command line. WordCountTool requires the application name, input path and output path. You can pass these configurations with the hadoop jar command.
$ $HADOOP_HOME/bin/hadoop jar \
/path/to/hadoop-wordcount-1.0-SNAPSHOT.jar \
your.package.WordCountTool \
-D input_path=/input \
-D output_path=/output \
-D app_name=myappThe configuration can be restored from every task by using the Context#getConfiguration method. The necessary information to run your application can be set on the Configuration object. Therefore, almost all configurations must be passed with the Configuration object. But there may be times when you want to pass a relatively large resource for your application, such as binary data, rather than a string. This data can be passed from the command line correctly, but so too can a large configuration that pressures a task in JVM memory. It is wasteful to pass custom resources to each task, and the solution to this problem will be introduced in the next section.
ADVANCED FEATURES OF MAPREDUCE
Let's now examine some of the advanced MapReduce features that you can tap into.
Distributed Cache
Distributed cache distributes read-only data to slave nodes for each task that can use the data. The distributed data is archived in slave nodes. The copy process runs only once to save network bandwidth inside the cluster, and ToolRunner can specify the files to be distributed in a cluster using the -files option.
$ $HADOOP_HOME/bin/hadoop jar \
/path/to/hadoop-wordcount-1.0-SNAPSHOT.jar \
your.package.WordCountTool \
-files /path/to/distributed-file.txtThe distributed file can be put on any filesystem that is integrated in Hadoop, such as the local filesystem, HDFS, and S3. If you do not specify the schema, the distributed file is automatically found on the local filesystem. You can specify archive files such as JAR, ZIP, TAR, and GZIP files by using the -archives option. You can also add classes on the task JVM class path by using the -libjars option.
Distributed files can be private or public, and this designation determines how the distributed files are used on the slave nodes. A private version of distributed files is cached onto the local directory, and is only used by a user who submits an application with the distributed file. These files cannot be accessed by applications submitted by other users. So, the public version of a distributed file is put in the global directory that can be accessed by all users, and this accessibility is achieved by the HDFS permissions system.
Distributed files are then accessed by each task, and the restore can be done with a relative file path. In the above case, the filename is distributed-file.txt. You can obtain this resource file using the ordinal reading of a text file:
new File("distributed-file.txt")ToolRunner (correctly GenericOptionsParser) automatically handles the distributed cache mechanism. You can use the distributed cache API specifically for your application, and there are two types of APIs for distributed cache. One is an API for adding distributed cache to your application. The other is an API for referring a distributed cache data from each task. The former can be set with the Job class, and the latter can be set with the JobContext class.
public void Job#addCacheFile(URI)
public void Job#addCacheArchive(URI)
public void Job#setCacheFiles(URI[])
public void Job#setCacheArchives(URI[])
public void Job#addFileToClassPath(Path)
public void Job#addArchiveToClassPath(Path)In the list, the addCacheFile and setCacheFiles methods add the files to the distributed cache. These methods do the same to the -files option on the command line. addCacheArchive and setCacheArchives do the same to the -archives option from the command line, just as addFileToClassPath does the same to the -libjars option. One major difference between using options on the command line and the Java API shown above is that the Java API does not copy a distributed file on HDFS from the local filesystem. So, if you specify a file with the -files option, ToolRunner automatically copies the file on HDFS. But, you have to always specify the HDFS (or S3, etc.) path, because the Java API cannot find the distributed file on the local file system by itself.
These APIs are for referring distributed cache data:
public Path[] Context#getLocalCacheFiles()
public Path[] Context#getLocalCacheArchives()
public Path[] Context#getFileClassPath()
public Path[] Context#getArchiveClassPath()These APIs return the distributed file paths of corresponding files, and they are used from the Context class, and passed to the map task and reduce task respectively. Mapper and Reduce have a setup method to initialize objects used in each task. The setup method is called once before the map function.
String data = null;
@Override
protected void setup(Context context)
throws IOException, InterruptedException {
Path[] localPaths = context.getLocalCacheFiles();
if (localPaths.length > 0) {
File localFile = new File(localPaths[0].toString());
data = new String(Files.readAllBytes(localFile.toPath()));
}
}With Hadoop 2.2.0, getLocalCacheFiles and getLocalCacheArchives are deprecated. It is recommended to use getCacheFiles and getCacheArchives instead.
Counter
It is necessary to obtain custom metrics as the need arises in order to tune your application. For example, it is necessary to know the number of read/write operations in order to reduce I/O overload, and the total number of splits and records are useful to optimize input data size. Counter provides a functionality to collect any type of metrics to measure the performance of your application, and you can set application-specific counters. It is useful to know how many invalid records are included in the data set for improving data set quality. In this section we will describe how to use pre-defined counters and user-defined counters.
Here are some types of pre-defined counters in Hadoop MapReduce.
- File System counters: The metrics around filesystem operations. This counter includes like number of bytes read, number of bytes written, number of read operations, and number of write operations.
- Job counters: The metrics about job execution. This counter includes the number of launched map tasks, launched reduce tasks, rack-local map tasks, and total time spent by all map tasks.
- MapReduce framework counters: The metrics are managed mainly by the MapReduce framework. This counter includes the number of combined input records, spent CPU time, and elapsed garbage collection time.
- Shuffle errors counter: The metrics count the number of errors that occurred in the shuffle phase such as BAD_ID, IO_ERROR, WRONG_MAP, and WRONG_REDUCE.
- File input format counters: The metrics about InputFormat used by an application. This counter includes the bytes read by each task.
- File output format counters: The metrics about OutputFormat used by an application. This counter includes the bytes written by each task.
These counters are counted by each task and the total of the job. These counter values are automatically calculated by the MapReduce framework.
In addition to these counters, you can also define custom counters by yourself. Counter has a group name and a counter name, and counters can be used through the Context#getCounter method.
context.getCounter("WordCounter", "total word count").increment(1)The output can be confirmed by the console just after the job has finished, or the web UI of the Job history server that is described in the next section.
WordCounter
total word count=179You can also obtain counter values from the command line: hadoop job -counter.
Job History Server
The Job history server aggregates log files generated from each task in your application. It is necessary to see log files to debug the application and ensure it is running correctly. The log files of an application usually are removed when the application has finished, but it is necessary to collect log files before they are removed, and the Job history server does this. The server aggregates all logs for each application and stores them in HDFS. You can see the logs of past applications through the web UI (see Figure 3.8). The default post number of the Job history server is 19888. You can access http://<Resource Manager hostname>:19888.
The log files are stored in the path configured by mapreduce.jobhistory.intermediate-done-dir and mapreduce.jobhistory.done-dir. Log files are categorized into two types: intermediate files and done files. Intermediate files are unfinished application logs. These log files are for the application running right now. Done files are for applications that are finished. After the application has finished, the Job history server moves intermediate files to the done directory.
The Job history server provides a REST API to enable users to get the overall information and statuses about applications. Table 3.1 contains the list of APIs for obtaining MapReduce related information.
Table 3.1 APIs for MapReduce information
| Available info | REST API URI |
| List Jobs | http://<Job history server hostname>/ws/v1/history/mapreduce/jobs |
| Job information | http://<Job history server hostname>/ws/v1/history/mapreduce/jobs/<Job ID> |
| Configuration of Job | http://<Job history server hostname>/ws/v1/history/mapreduce/jobs/<Job ID>/conf |
| List Tasks | http://<Job history server hostname>/ws/v1/history/mapreduce/jobs/<Job ID>/tasks |
| Task information | http://<Job history server hostname>/ws/v1/history/mapreduce/jobs/<Job ID>/tasks/<Task ID> |
| List Task Attempts | http://<Job history server hostname>/ws/v1/history/mapreduce/jobs/<Job ID>/tasks/<Task ID>/attempts |
| Task Attempts information | http://<Job history server hostname>/ws/v1/history/mapreduce/jobs/<Job ID>/tasks/<Task ID>/attempts/<Attempt ID> |
The Attempts ID specifies the actual execution of each task. One task might have several attempts where some failures have occurred. There are more APIs provided by the Job history server, and all of the APIs are listed in the official document here: (http://hadoop.apache.org/docs/current/hadoop-mapreduce-client/hadoop-mapreduce-client-hs/HistoryServerRest.html).
You can also check the counter values incremented by your application tasks. Next we'll take a look at Apache Spark and see briefly how it compares to Hadoop MapReduce.
THE DIFFERENCE FROM A SPARK JOB
Apache Spark is a next generation framework for distributed processing. Spark improves some disadvantages that Hadoop MapReduce originally faced. Launching JVMs for operating each task, and writing intermediate files on distributed filesystem between each task, often causes a huge overhead. The overhead cannot fit with the machine learning workload that is doing the calculations. Spark was introduced as a new general on-memory distributed computational engine, but Spark is now a unique ecosystem and community. The main difference between Hadoop MapReduce and Spark job is shown here in Table 3.2.
Table 3.2 Differences between Hadoop MapReduce and Spark job
| Hadoop MapReduce | Spark Job |
| Write intermediate data on HDFS | On-memory processing |
| Java API and Hadoop streaming | Scala, Java, Python, and R |
| Running on YARN | Running on YARN, Mesos, and Standalone |
| Set only map task and reduce task | Flexible abstraction of tasks |
The main advantage of Spark jobs is the sophisticated API and the workload speed that is has. The number of core lines you have to write in a Spark job are usually smaller than those for a MapReduce application. Although writing a Spark application in Scala or Python requires some knowledge about closure or lambda functions, it can enable you to write distributed applications more easily. This is the example of an application of counting words that we wrote in a previous section.
val wordCounts = textFile
.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey((a, b) => a + b)
wordCounts.collectThis is one of the biggest reasons why Spark gets so much attention from data scientists and data engineers. But one thing to note here is that Spark is a relatively new platform compared to Hadoop MapReduce. In terms of scalability and reliability, Hadoop MapReduce often defeats a Spark application, so it is best to decide which platform to use based on your workload.
SUMMARY
In this chapter, we explained the basics of Hadoop MapReduce. Understanding the basic architecture of Hadoop MapReduce helps you develop better applications. Hadoop MapReduce relies on other distributed frameworks such as HDFS or YARN. Although omitted here, MapReduce can also run on new frameworks. Apache Tez and Apache Spark can also work as an execution engine supporting a MapReduce application, so the number of users of the MapReduce framework continues to grow.
We also covered how to write a MapReduce application, showing how MapReduce is a simple framework, but it can provide sufficient flexibility to develop and to write any kind of distributed platform applications.
Finally, in order to compare and know the difference between MapReduce and a relatively new platform, we examined Apache Spark, which is currently under active development, and is worthwhile paying attention to.