Two-Minute Drill
Two-Minute Drill• Describe the Interfaces that Make Up the Core of the JDBC API (Including the Driver, Connection, Statement, and ResultSet Interfaces and Their Relationship to Provider Implementations)
• Identify the Components Required to Connect to a Database Using the DriverManager Class (Including the JDBC URL)
• Submit Queries and Read Results from the Database (Including Creating Statements; Returning Result Sets; Iterating Through the Results; and Properly Closing Result Sets, Statements, and Connections)
• Use JDBC Transactions (Including Disabling Auto-commit Mode, Committing and Rolling Back Transactions, and Setting and Rolling Back to Savepoints)
• Construct and Use RowSet Objects Using the RowSetProvider Class and the RowSetFactory Interface
• Create and Use PreparedStatement and CallableStatement Objects
Two-Minute Drill
Q&A Self Test
This chapter covers the JDBC API that was added for the Java SE 7 exam. The exam developers have long felt that this API is truly a core feature of the language, and being able to demonstrate proficiency with JDBC goes a long way toward demonstrating your skills as a Java programmer.
Interestingly, JDBC has been a part of the language since JDK version 1.1 (1997) when JDBC 1.0 was introduced. Since then, there has been a steady progression of updates to the API, roughly one major release for each even-numbered JDK release, with the last major update being JDBC 4.0, released in 2006 with Java SE 6. In Java SE 7, JDBC got some minor updates, and is now at version 4.1, which we’ll discuss a little later in the chapter. While the focus of the exam is on JDBC 4.x, there are some questions about the differences between loading a driver with a JDBC 3.0 and JDBC 4.x implementation, so we’ll talk about that as well.
The good news is that the exam is not going to test your ability to write SQL statements. That would be an exam all by itself (maybe even more than one—SQL is a BIG topic!). But you will need to recognize some basic SQL syntax and commands, so we’ll start by spending some time covering the basics of relational database systems and enough SQL to make you popular at database parties. If you feel you have experience with SQL and understand database concepts, you might just skim the first section or skip right to the first exam objective and dive right in.
When you think of organizing information and storing it in some easily understood way, a spreadsheet or a table is often the first approach you might take. A spreadsheet or a table is a natural way of categorizing information: The first row of a table defines the sort of information that the table will hold, and each subsequent row contains a set of data that is related to the key we create on the left. For example, suppose you wanted to chart your monthly spending for several types of expenses (Table 15-1).
TABLE 15-1 Chart of Expenses

From the data in the chart, we can determine that your overall expenses are increasing month to month in the first three months of this year. But notice that without the table, without a relationship between the month and the data in the columns, you would just have a pile of receipts with no way to draw out important conclusions, such as
 Assuming you drove the same number of miles per month, gas is getting pricey—maybe it is time to get a Prius.
Assuming you drove the same number of miles per month, gas is getting pricey—maybe it is time to get a Prius.
You are eating out more month to month (or the price of eating out is going up)—maybe it’s time to start doing some meal planning.
And maybe you need to be a little less social—that phone bill is high.
The point is that this small sample of data is the key to understanding a relational database system. A relational database is really just a software application designed to store and manipulate data in tables. The software itself is actually called a Relational Database Management System (RDBMS), but many people shorten that to just “database”—so know that going forward, when we refer to a database, we are actually talking about an RDBMS (the whole system). What the relational management system adds to a database is the ability to define relationships between tables. It also provides a language to get data in and out in a meaningful way.
Looking at the simple table in Table 15-1, we know that the data in the columns, Gas, EatingOut, Utilities, and Phone, are grouped by the months January, February, and so on. The month is unique to each row and identifies this row of data. In database parlance, the month is a “primary key.” A primary key is generally required for a database table to identify which row of the table you want, and to make sure that there are no duplicate rows.
Extending this a little further, if the data in Table 15-1 were stored in a database, I could ask the database (write a query) to give me all of the data for the month of January (again, my primary key is “month” for this table). I might write something like:
“Give me all of my expenses for January.”
The result would be something like:
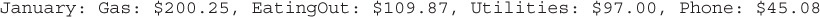
This kind of query is what makes a database so powerful. With a relatively simple language, you can construct some really powerful queries in order to manipulate your data to tell a story. In most RDBMSs, this language is called the Structured Query Language (SQL). The same query we wrote out in a sentence earlier, would be expressed like this in SQL:
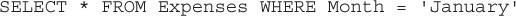
which can be translated to “select all of the columns (*) from my table named ‘Expenses’ where the month column is equal to the string ‘January’.” Let’s look a bit more at how we “talk” to a database and what other sorts of queries we can make with tables in a relational database.
There are three important concepts when working with a database:
Creating a connection to the database
Creating a statement to execute in the database
Getting back a set of data that represents the results
Let’s look at these concepts in more detail.
Before we can communicate with the software that manages the database, before we can send it a query, we need to make a connection with the RDBMS itself. There are many different types of connections, and a lot of underlying technology to describe the connection itself, but in general, to communicate with an RDBMS, we need to open a connection using an IP address and port number to the database. Once we have established the connection, we need to send it some parameters (such as a username and password) to authenticate ourselves as a valid user of the RDBMS. Finally, assuming all went well, we can send queries through the connection. This is like logging into your online account at a bank. You provide some credentials, a username and password, and a connection is established and opened between you and the bank. Later in the chapter, when we start writing code, we’ll open a connection using a Java class called the DriverManager, and in one request, pass in the database name, our username, and password.
Once we have established a connection, we can use some type of application (usually provided by the database vendor) to send query statements to the database, have them executed in the database, and get a set of results returned. A set of results can be one row, as we saw before when we asked for the data from the month of January, or several rows. For example, suppose we wanted to see all of the Gas expenses from our Expenses table. We might query the database like this:
“Show me all of my Gas Expenses”

The set of results that would “return” from my query would be three rows, and each row would contain one column.
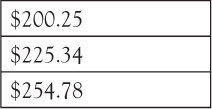
An important aspect of a database is that the data is presented back to you exactly the same way that it is stored. Since Gas expense is a column, the query will return three rows (one for January, one for February, and one for March). Note that because we did not ask the database to include the Month column in the results, all we got was the Gas column. The results do preserve the fact that Gas is a column and not a row, and in general, presents the data in the same row-and-column order that it is stored in the database.
Let’s look a bit more at the syntax of SQL, the language used to write queries in a database. There are really four basic SQL queries that we are going to use in this chapter, and that are common to manipulating data in a database. In summary, the SQL commands we are interested in are used to perform CRUD operations.
Like most terms presented in all caps, CRUD is an acronym, and means Create, Read, Update, and Delete. These are the four basic operations for data in a database. They are represented by four distinct SQL commands, detailed in Table 15-2.
TABLE 15-2 Example SQL CRUD Commands

Here is a quick explanation for the examples in Table 15-2:
INSERT Add a row to the table Expenses, and set each of the columns in the table to the values expressed in the parentheses.
SELECT with WHERE You have already seen the SELECT clause with a WHERE clause, so you know that this SQL statement returns a single row identified by the primary key—the Month column. Think of this statement as a refinement to Read—more like a Find or Find by primary key.
SELECT When the SELECT clause does not have a WHERE clause, we are asking the database to return every row. Further, because we are using an asterisk (*) following the SELECT, we are asking for every column. Basically, it is a dump of the data shown in Table 15-1. Think of this statement as a Read All.
UPDATE Change the data in the Phone and EatingOut cells to the new data provided for February.
DELETE Remove a row altogether from the database where the Month is April.
Really, this is all the SQL you need to know for this chapter. There are many other SQL commands, but this is really the core set. If we need to go beyond this set of four commands in the chapter, we will cover them as they come up. Now, let’s look at a more detailed database example that we will use as the example set of tables for this chapter, using the data requirements of a small bookseller, Bob’s Books.

SQL commands, like SELECT, INSERT, UPDATE, and so on, are case insensitive. So it is largely by convention (and one we will use in this chapter) to use all capital letters for SQL commands and key words, such as WHERE, FROM, LIKE, INTO, SET, and VALUES. SQL table names and column names, also called identifiers, can be case sensitive or case insensitive, depending upon the database. The example code shown in this chapter uses a case-insensitive database, so again, just for convention, we will use upper camel case, that is, the first letter of each noun capitalized and the rest in lowercase.
One final note about case—all databases preserve case when a string is delimited—that is, when they are enclosed in quotes. So a SQL clause that uses single or double quotation marks to delimit an identifier will preserve the case of the identifier.
In this section, we’ll describe a small database with a few tables and a few rows of data. As we work through the various JDBC topics in this chapter, we’ll work with this database.
Bob is a small bookseller who specializes in children’s books. Bob has designed his data around the need to sell his books online using a database (which one doesn’t really matter) and a Java application. Bob has decided to use the JDBC API to allow him to connect to a database and perform queries through a Java application.
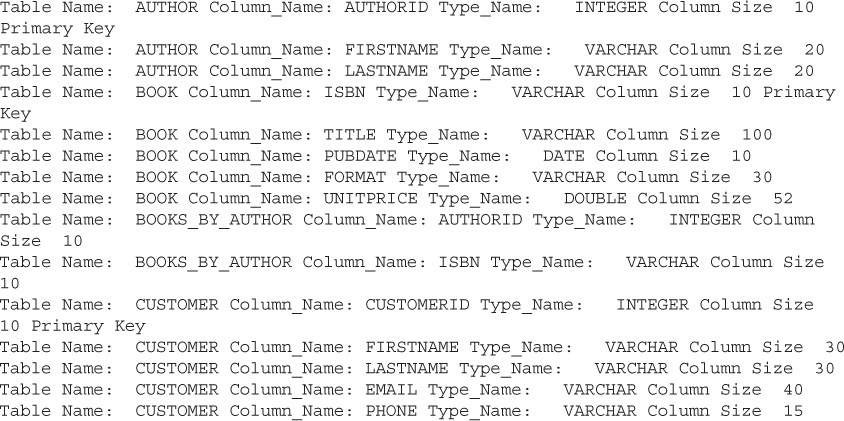
To start, let’s look at the organization of Bob’s data. In a database, the organization and specification of the tables is called the database schema (Figure 15-1). Bob’s is a relatively simple schema, and again, for the purposes of this chapter, we are going to concentrate on just four tables from Bob’s schema.
FIGURE 15-1 Bob’s BookSeller database schema

This is a relatively simple schema that represents a part of the database for a small bookstore. In the schema shown, there is a table for Customer (Table 15-3). This table stores data about Bob’s customers—a customer ID, first name and last name, an e-mail address, and phone number. Address and other information could be stored in another table.
TABLE 15-3 Bob’s Books Customer Table Sample Data

The next three tables we will look at represent the data required to store information about books that Bob sells. Because a book is a more complex set of data than a customer, we need to use one table for information about books, one for information about authors, and a third to create a relationship between books and authors.
Suppose that you tried to store a book in a single table with a column for the ISBN (International Standard Book Number), title, and author name. For many books, this would be fine. But what happens if a book has two authors? Or three authors? Remember that one requirement for a database table is a unique primary key, so you can’t simply repeat the ISBN in the table. In fact, having two rows with the same primary key will violate a key constraint in relational database design: The primary key of every row must be unique.

Instead, there needs to be a way to have a separate table of books and authors and some way to link them together. Bob addressed this issue by placing Books in one table (Table 15-4) and Authors (Table 15-5) in another. The primary key for Books is the ISBN number, and therefore, each Book entry will be unique. For the Author table, Bob is creating a unique AuthorID for each author in the table.
TABLE 15-4 Bob’s Books Sample Data for the “Books” Table
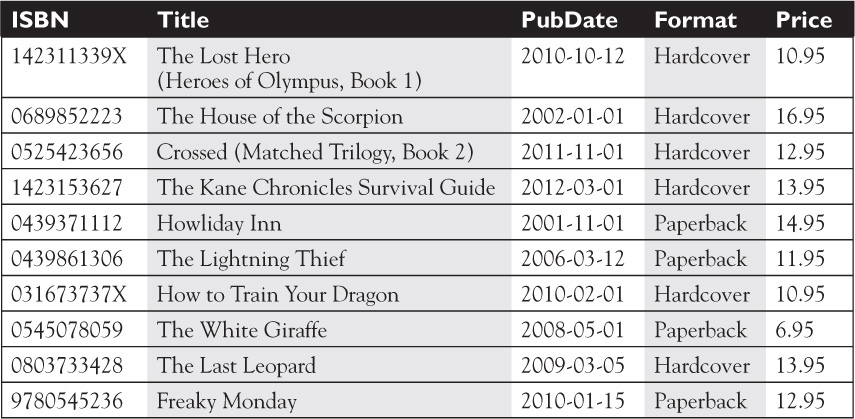
TABLE 15-5 Bob’s Books Author Table Sample Data for the “Authors” Table
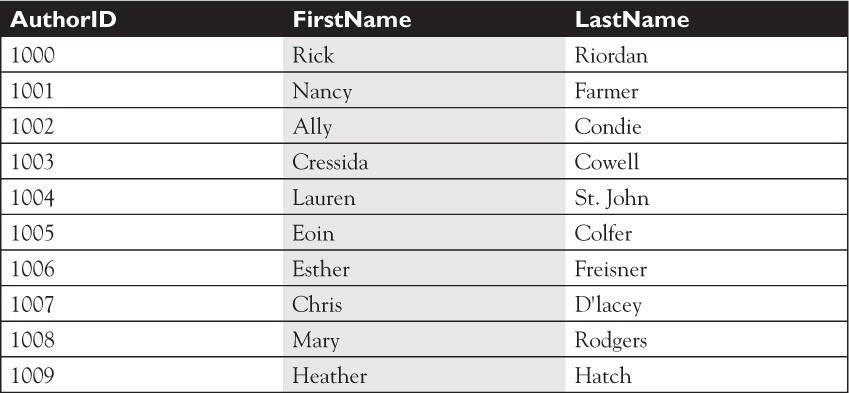
To tie Authors to Books and Books to Authors, Bob has created a third table called Books_by_Author. This is a unique table type in a relational database. This table is called a jointable. In a join table, there are no primary keys—instead, all the columns represent data that can be used by other tables to create a relationship. These columns are referred to as foreign keys—they represent a primary key in another table. Looking at the last two rows of this table, you can see that the Book with the ISBN 9780545236 has two authors: author id 1008 (Mary Rodgers) and 1009 (Heather Hatch). Using this join table, we can combine the two sets of data without needing duplicate entries in either table. We’ll return to the concept of a join table later in the chapter.
A complete Bob’s Books database schema would include tables for publishers, addresses, stock, purchase orders, and other data that the store needs to run its business. But for our purposes, this part of the schema is sufficient. Using this schema, we can write SQL queries using the SQL CRUD commands you learned earlier.
To summarize, before looking at JDBC, you should now know about connections, statements, and result sets:
A connection is how an application communicates with a database.
A statement is a SQL query that is executed on the database.
A result set is the data that is returned from a SELECT statement.
Having these concepts down, we can use Bob’s Books simple schema to frame some common uses of the JDBC API to submit SQL queries and get results in a Java application.
9.1 Describe the interfaces that make up the core of the JDBC API (including the Driver, Connection, Statement, and ResultSet interfaces and their relationship to provider implementations).
As we mentioned in the previous section, the purpose of a relational database is really threefold:
To provide storage for data in tables
To provide a way to create relationships between the data—just as Bob did with the Authors, Books, and Books_by_Author tables
To provide a language that can be used to get the data out, update the data, remove the data, and create new data
The purpose of JDBC is to provide an application programming interface (API) for Java developers to write Java applications that can access and manipulate relational databases and use SQL to perform CRUD operations.
Once you understand the basics of the JDBC API, you will be able to access a huge list of databases. One of the driving forces behind JDBC was to provide a standard way to access relational databases, but JDBC can also be used to access file systems and object-oriented data sources. The key is that the API provides an abstract view of a database connection, statements, and result sets. These concepts are represented in the API as interfaces in the java.sql package: Connection, Statement, and ResultSet, respectively. What these interfaces define are the contracts between you and the implementing class. In truth, you may not know (nor should you care) how the implementation class works. As long as the implementation class implements the interface you need, you are assured that the methods defined by the interface exist and you can invoke them.
The java.sql.Connection interface defines the contract for an object that represents the connection with a relational database system. Later, we will look at the methods of this contract, but for now, an instance of a Connection is what we need to communicate with the database. How the Connection interface is implemented is vendor dependent, and again, we don’t need to worry so much about the how—as long as the vendor follows the contract, we are assured that the object that represents a Connection will allow us to work with a database connection.
The Statement interface provides an abstraction of the functionality needed to get a SQL statement to execute on a database, and a ResultSet interface is an abstraction functionality needed to process a result set (the table of data) that is returned from the SQL query when the query involves a SQL SELECT statement.
The implementation classes of Connection, Statement, ResultSet, and a number of other interfaces we will look at shortly are created by the vendor of the database we are using. The vendor understands their database product better than anyone else, so it makes sense that they create these classes. And, it allows the vendor to optimize or hide any special characteristics of their product. The collection of the implementation classes is called the JDBC driver. A JDBC driver (lowercase “d”) is the collection of classes required to support the API, whereas Driver (uppercase “D”) is one of the implementations required in a driver.
A JDBC driver is typically provided by the vendor in a JAR or ZIP file. The implementation classes of the driver must meet a minimum set of requirements in order to be JDBC compliant. The JDBC specification provides a list of the functionality that a vendor must support and what functionality a vendor may optionally support.
Here is a partial list of the requirements for a JDBC driver. For more details, please read the specification (JSR-221). Note that the details of implementing a JDBC driver are NOTon the exam.
Fully implement the interfaces: java.sql.Driver, java.sql .DatabaseMetaData, java.sql.ResultSetMetaData.
Implement the java.sql.Connection interface. (Note that some methods are optional depending upon the SQL version the database supports—more on SQL versions later in the chapter.)
Implement the java.sql.Statement, java.sql.PreparedStatement.
Implement the java.sql.CallableStatement interfaces if the database supports stored procedures. Again, more on this interface later in the chapter.
Implement the java.sql.ResultSet interface.
9.2 Identify the components required to connect to a database using the DriverManager class (including the JDBC URL)
Not all of the types defined in the JDBC API are interfaces. One important class for JDBC is the java.sql.DriverManager class. This concrete class is used to interact with a JDBC driver and return instances of Connection objects to you. Conceptually, the way this works is by using a design pattern called Factory. Next, we’ll look at DriverManager in more detail.

Let’s take this opportunity to see the Factory design pattern we discussed in Chapter 10 in use.
As you recall, in a factory pattern, a concrete class with static methods is used to create instances of objects that implement an interface. For example, suppose we wanted to create an instance of a Vehicle object:

We need an implementation of Vehicle in order to use this contract. So we design a Car:

In order to use the Car, we could create one:

However, here it would be better to use a factory—that way, we need not know anything about the actual implementation, and, as we will see later with DriverManager, we can use methods of the factory to dynamically determine which implementation to use at runtime.

The factory in this case could create a different car based on the string passed to the static getVehicle() method; something like this:

DriverManager uses this factory pattern to “construct” an instance of a Connection object by passing a string to its getConnection() method.
The DriverManager class is a concrete class in the JDBC API with static methods. You will recall that static or class methods can be invoked by other classes using the class name. One of those methods is getConnection(), which we look at next.
The DriverManager class is so named because it manages which JDBC driver implementation you get when you request an instance of a Connection through the getConnection() method.
There are several overloaded getConnection methods, but they all share one common parameter: a String URL. One pattern for getConnection is
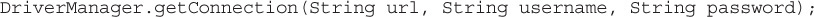
For example:

In this example, we are creating a connection to a Derby database, on a network, at a localhost address (on the local machine), at port number 1521, to a database called “BookSellerDB”, and we are using the credentials, “bookguy” as the user id, and “$3lleR” as the password. Don’t worry too much about the syntax of the URL right now—we’ll cover that soon.
It’s a horrible idea to hard-code a username and password in the getConnection() method. Obviously, anyone reading the code would then know the username and password to the database. A more secure way to handle database credentials would be to separate the code that produces the credentials from the code that makes the connection. So in some other class, you would use some type of authentication and authorization code to produce a set of credentials to allow access to the database.
For simplicity in the examples in the chapter, we’ll hard-code the username and password, but just keep in mind that on the job, this is not a best practice.
When you invoke the DriverManager’s getConnection() method, you are asking the DriverManager to try passing the first string in the statement, the driver URL, along with the username and password to each of the driver classes registered with the DriverManager in turn. If one of the driver classes recognizes the URL string, and the username and password are accepted, the driver returns an instance of a Connection object. If, however, the URL is incorrect, or the username and/or password are not correct, then the method will throw a SQLException. We’ll spend some time looking at SQLException later in this chapter.
Because this part of the JDBC process is important to understand, and it involves a little Java magic, let’s spend some time diagramming how driver classes become “registered” with the DriverManager, as shown in Figure 15-2.
Figure 15-2 How JDBC drivers self-register with DriverManager
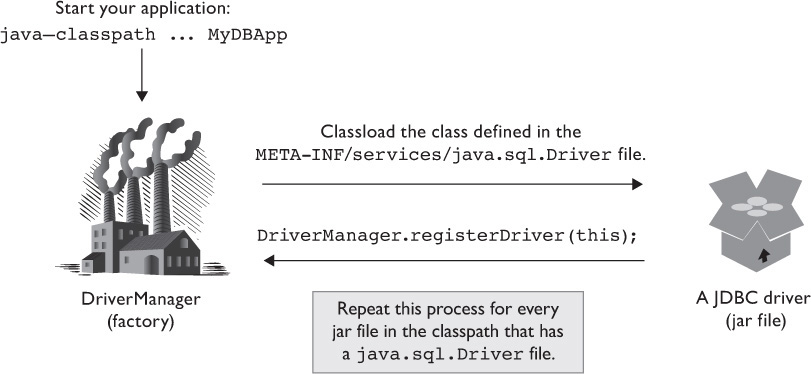
First, one or more JDBC drivers, in a JAR or ZIP file, are included in the classpath of your application. The DriverManager class uses a service provider mechanism to search the classpath for any JAR or ZIP files that contain a file named java.sql.Driver in the META-INF/services folder of the driver jar or zip. This is simply a text file that contains the full name of the class that the vendor used to implement the jdbc.sql.Driver interface. For example, for a Derby driver, the full name is org.apache.derby.jdbc.ClientDriver.
The DriverManager will then attempt to load the class it found in the java.sql.Driver file using the class loader:
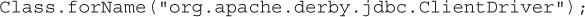
When the driver class is loaded, its static initialization block is executed. Per the JDBC specification, one of the first activities of a driver instance is to “self-register” with the DriverManager class by invoking a static method on DriverManager. The code (minus error handling) looks something like this:

This registers (stores) an instance of the Driver class into the DriverManager.
Now, when your application invokes the DriverManager.getConnection() method and passes a JDBC URL, username, and password to the method, the DriverManager simply invokes the connect() method on the registered Driver. If the connection was successful, the method returns a Connection object instance to DriverManager, which, in turn, passes that back to you.
If there is more than one registered driver, the DriverManager calls each of the drivers in turn and attempts to get a Connection object from them, as shown in Figure 15-3.
FIGURE 15-3 How the DriverManager gets a Connection
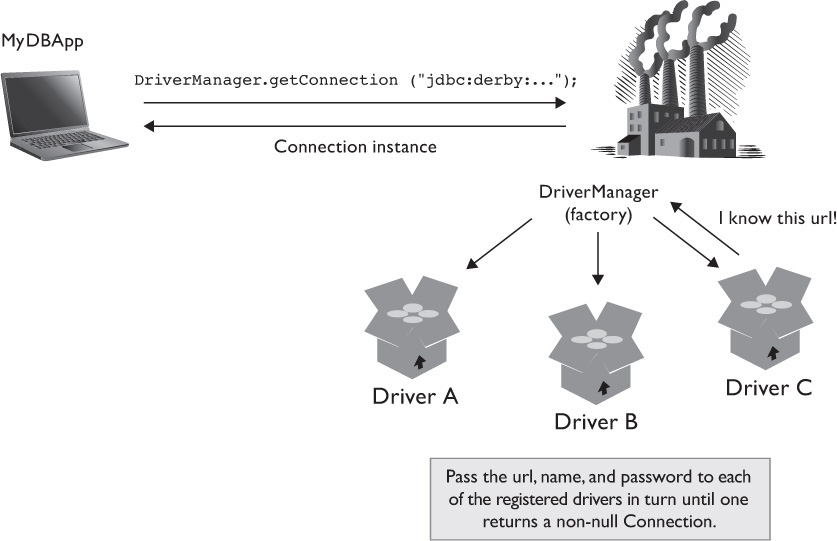
The first driver that recognizes the JDBC URL and successfully creates a connection using the username and password will return an instance of a Connection object. If no drivers recognize the URL, username, and password combination, or if there are no registered drivers, then a SQLException is thrown instead.
To summarize:
The JVM loads the DriverManager class, a concrete class in the JDBC API.
The DriverManager class loads any instances of classes it finds in the META-INF/services/java.sql.Driver file of JAR/ZIP files on the classpath.
Driver classes call DriverManager.register(this) to self-register with the DriverManager.
When the DriverManager.getConnection(String url) method is invoked, DriverManager invokes the connect() method of each of these registered Driver instances with the URL string.
The first Driver that successfully creates a connection with the URL returns an instance of a Connection object to the DriverManager.getConnection method invocation.
Let’s look at the JDBC URL syntax next.
The JDBC URL is what is used to determine which driver implementation to use for a given Connection. Think of the JDBC URL (uniform resource locator) as a way to narrow down the universe of possible drivers to one specific connection. For example, suppose you need to send a package to someone. In order to narrow the universe of possible addresses down to a single unique location, you would have to identify the country, the state, the city, the street, and perhaps a house or address number on your package:
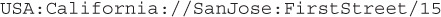
This string indicates that the address you want is in the United States, California State, San Jose city, First Street, number 15.
JDBC URLs follow this same idea. To access Bob’s Books, we might write the URL like this:
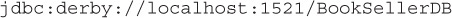
The first part, jdbc, simply identifies that this is a JDBC URL (versus HTTP or something else). The second part indicates that driver vendor is derby driver. The third part indicates that the database is on the localhost of this machine (IP address 127.0.0.1), at port 1521, and the final part indicates that we are interested in the BookSellerDB database.
Just like street addresses, the reason we need this string is because JDBC was designed to work with multiple databases at once. Each of the JDBC database drivers will have a different URL, so we need to be able to pass the JDBC URL string to the DriverManager and ensure that the Connection returned was for the intended database instance.
Unfortunately, other than a requirement that the JDBC URL begin with “jdbc,” there is very little standard about a JDBC URL. Vendors may modify the URL to define characteristics for a particular driver implementation. The format of the JDBC URL is
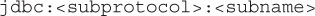
In general, subprotocol is the vendor name; for example:

The subname field is where things get a bit more vendor specific. Some vendors use the subname to identify the hostname and port, followed by a database name. For example:

Other vendors may use the subname to identify additional context information about the driver. For example:
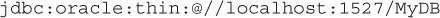
In any case, it is best to consult the documentation for your specific database vendor’s JDBC driver to determine the syntax of the URL.
We talked about how the DriverManager will scan the classpath for JAR files that contain the META-INF/services/java.sql.Driver file and use a classloader to load those drivers. This feature was introduced in the JDBC 4.0 specification. Prior to that, JDBC drivers were loaded manually by the application.
If you are using a JDBC driver that is an earlier version, say, a JDBC 3.0 driver, then you must explicitly load the class provided by the database vendor that implements the java.sql.Driver interface. Typically, the database vendor’s documentation would tell you what the driver class is. For example, if our Apache Derby JDBC driver were a 3.0 driver, you would manually load the Driver implementation class before calling the getConnection() method:

Note that using the Class.forName() method is compatible with both JDBC 3.0 and JDBC 4.0 drivers. It is simply not needed when the driver supports 4.0.
Here is a quick summary of what we have discussed so far:
Before you can start working with JDBC, creating queries and getting results, you must first establish a connection.
In order to establish a connection, you must have a JDBC driver.
If your JDBC driver is a JDBC 3.0 driver, then you are required to explicitly load the driver in your code using Class.forName() and the fully qualified path of the Driver implementation class.
If your JDBC driver is a JDBC 4.0 driver, then simply include the driver (jar or zip) in the classpath.
9.3 Submit queries and read results from the database (including creating statements; returning result sets; iterating through the results; and properly closing result sets, statements, and connections).
In this section, we’ll explore the JDBC API in much greater detail. We will start by looking at a simple example using the Connection, Statement, and ResultSet interfaces to pull together what we’ve learned so far in this chapter. Then we’ll do a deep dive into Statements and ResultSets.
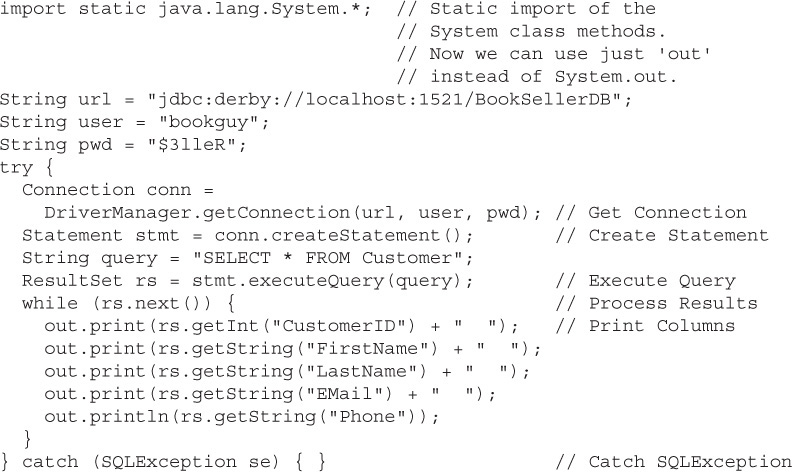
Probably one of the most used SQL queries is SELECT * FROM <Table name>, which is used to print out or see all of the records in a table. Assume that we have a Java DB (Derby) database populated with data from Bob’s Books. To query the database and return all of the Customers in the database, we would write something like the example shown next.
Note that to make the code listing a little shorter, going forward, we will use out.println instead of System.out.println. Just assume that means that we have included a static import statement, like the one at the top of this example:
Again, we’ll dive into all of the parts of this example in greater detail, but here is what is happening:
Get connection We are creating a Connection object instance using the information we need to access Bob’s Books Database (stored on a Java DB Relational database, BookSellerDB, and accessed via the credentials “bookguy” with a password of “$3lleR”).
Create statement We are using the Connection to create a Statement object. The Statement object handles passing Strings to the database as queries for the database to execute.
Execute query We are executing the query string on the database and returning a ResultSet object.
Process results We are iterating through the result set rows—each call to next() moves us to the next row of results.
Print columns We are getting the values of the columns in the current result set row and printing them to standard out.
Catch SQLException All of the JDBC API method invocations throw SQLException. A SQLException can be thrown when a method is used improperly, or if the database is no longer responding. For example, a SQLException is thrown if the JDBC URL, username, or password is invalid. Or we attempted to query a table that does not exist. Or the database is no longer reachable because the network went down or the database went offline. We will look at SQLException in greater detail later in the chapter.
The output of the previous code will look something like this:

We’ll take a detailed look at the Statement and ResultSet interfaces and methods in the next two sections.
Once we have successfully connected to a database, the fun can really start. From a Connection object, we can create an instance of a Statement object (or, to be precise, using the Connection instance we received from the DriverManager, we can get an instance of an object that implements the Statement interface). For example:

The primary purpose of a Statement is to execute a SQL statement using a method and return some type of result. There are several forms of Statement methods: those that return a result set, and those that return an integer status. The most commonly used Statement method performs a SQL query that returns some data, like the SELECT call we used earlier to fetch all the Customer table rows.
To start, let’s look at the base Statement, which is used to execute a static SQL query and return a result. You’ll recall that we get a Statement from a Connection and then use the Statement object to execute a SQL statement, like a query on the database. For example:

Because not all SQL statements return results, the Statement object provides several different methods to execute SQL commands. Some SQL commands do not return a result set, but instead return an integer status. For example, SQL INSERT, UPDATE, and DELETE commands, or any of the SQL Data Definition Language (DDL) statements, like CREATE TABLE, return either the number of rows affected by the query or 0.
Let’s look at each of the execute methods in detail.
public ResultSet executeQuery(String sql) throws SQLException This is the most commonly executed Statement method. This method is used when we know that we want to return results—we are querying the database for one or more rows of data. For example:

Assuming there is data in the Customer table, this statement should return all of the rows from the Customer table into a ResultSet object—we’ll look at ResultSet in the next section. Notice that the method declaration includes “throws SQLException.” This means that this method must be called in a try-catch block, or must be called in a method that also throws SQLException. Again, one reason that these methods all throw SQLException is that a connection to the database is likely to a database on a network. As with all things on the network, availability is not guaranteed, so one possible reason for SQLException is the lack of availability of the database itself.
public int executeUpdate(String sql) throws SQLException This method is used for a SQL operation that affects one or more rows and does not return results—for example, SQL INSERT, UPDATE, DELETE, and DDL queries. These statements do not return results, but do return a count of the number of rows affected by the SQL query. For example, here is an example method invocation where we want to update the Book table, increasing the price of every book that is currently priced less than 8.95 and is a hardcover book:

When this query executes, we are expecting some number of rows will be affected. The integer that returns is the number of rows that were updated.
Note that this Statement method can also be used to execute SQL queries that do not return a row count, such as CREATE TABLE or DROP TABLE and other DDL queries. For DDL queries, the return value is 0.
public boolean execute(String sql) throws SQLException This method is used when you are not sure what the result will be—perhaps the query will return a result set, and perhaps not. This method can be used to execute a query whose type may not be known until runtime—for example, one constructed in code. The return value is true if the query resulted in a result set and false if the query resulted in an update count or no results.
However, more often, this method is used when invoking a stored procedure (using the CallableStatement, which we’ll talk about later in the chapter). A stored procedure can return a single result set or row count, or multiple result sets and row counts, so this method was designed to handle what happens when a single database invocation produces more than one result set or row count.
You might also use this method if you wrote an application to test queries—something that reads a String from the command line and then runs that String against the database as a query. For example:

Because this statement may return a result set or may simply return an integer row count, there are two additional statement commands you can use to get the results or the count based on whether the execute method returned true (there is a result set) or false (there is an update count or there was no result). The getResultSet() is used to retrieve results when the execute method returns true, and the getUpdateCount() is used to retrieve the count when the execute method returns false. Let’s look at these methods next.
It is generally a very bad idea to allow a user to enter a query string directly in an input field, or allow a user to pass a string to construct a query directly. The reason is that if a user can construct a query or even include a freeform string into a query, they can use the query to return more data than you intended or to alter the database table permissions.
For example, assume that we have a query where the user enters their e-mail address and the string the user enters is inserted directly to the query:

The user of this code could enter a string like this:
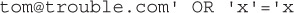
The resulting query executed by the database becomes:
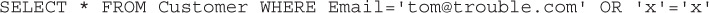
Because the OR statement will always return true, the result is that the query will return ALL of the customer rows, effectively the same as the query:
And now this user of your code has a list of the e-mail addresses of every customer in the database.
This type of attack is called a SQL injection attack. It is easy to prevent by carefully sanitizing any string input used in a query to the database and/or by using one of the other Statement types, PreparedStatement and CallableStatement. Despite how easy it is to prevent, it happens frequently, even to large, experienced companies like Yahoo!.
public ResultSet getResultSet() throws SQLException If the boolean value from the execute() method returns true, then there is a result set. To get the result set, as shown earlier, call the getResultSet() method on the Statement object. Then you can process the ResultSet object (which we will cover in the next section). This method is basically foolproof—if, in fact, there are no results, the method will return a null.
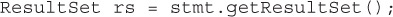
public int getUpdateCount() throws SQLException If the boolean value from the execute() method returns false, then there is a row count, and this method will return the number of rows affected. A return value of –1 indicates that there are no results.

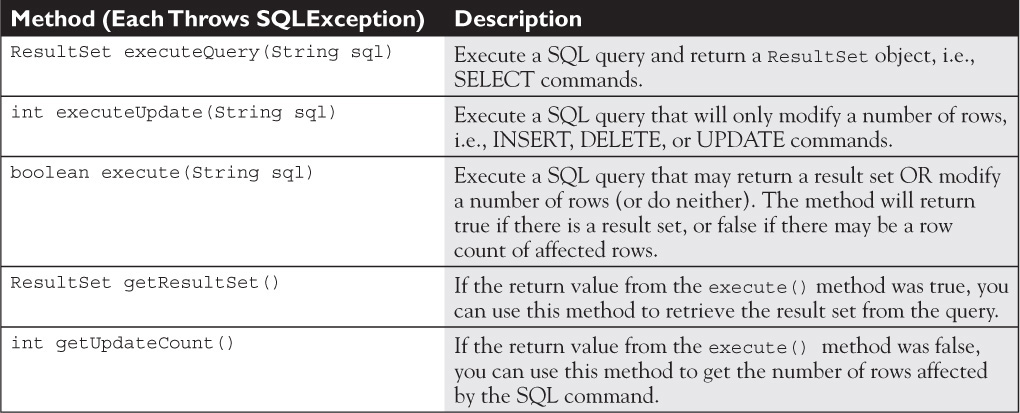
Table 15-6 summarizes the Statement methods we just covered.
TABLE 15-6 Important Statement Methods
When a query returns a result set, an instance of a class that implements the ResultSet interface is returned. The ResultSet object represents the results of the query—all of the data in each row on a per-column basis. Again, as a reminder, how data in a ResultSet are stored is entirely up to the JDBC driver vendor. It is possible that the JDBC driver caches the entire set of results in memory all at once, or that it uses internal buffers and gets only a few rows at a time. From your point of view as the user of the data, it really doesn’t matter much. Using the methods defined in the ResultSet interface, you can read and manipulate the data, and that’s all that matters.
One important thing to keep in mind is that a ResultSet is a copy of the data from the database from the instance in time when the query was executed. Unless you are the only person using the database, you need to always assume that the underlying database table or tables that the ResultSet came from could be changed by some other user or application.
Because ResultSet is such a comprehensive part of the JDBC API, we are going to tackle it in sections. Table 15-7 summarizes each section so you can reference these later.
TABLE 15-7 ResultSet Sections

The best way to think of a ResultSet object is visually. Assume that in our BookSellerDB database we have several customers whose last name begins with the letter “C.” We could create a query to return those rows “like” this:
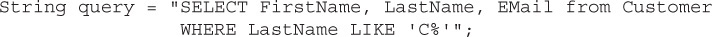
The SQL operator LIKE treats the string that follows as a pattern to match, where the % indicates a wildcard. So, LastName LIKE ‘C%’ means “any LastName with a C, followed by any other character(s).”
When we execute this query using the executeQuery() method, the ResultSet returned will contain the FirstName, LastName, and EMail columns where the customer’s LastName starts with the capital letter “C”:
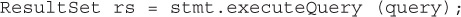
The ResultSet object returned contains the data from the query as shown in Figure 15-4.
FIGURE 15-4 A ResultSet after the executeQuery
Note in Figure 15-4 that the ResultSet object maintains a cursor, or a pointer, to the current row of the results. When the ResultSet object is first returned from the query, the cursor is not yet pointing to a row of results—the cursor is pointing above the first row. In order to get the results of the table, you must always call the next() method on the ResultSet object to move the cursor forward to the first row of data. By default, a ResultSet object is read-only (the data in the rows cannot be updated), and you can only move the cursor forward. We’ll look at how to change this behavior a little later on.
So the first method you will need to know for ResultSet is the next() method.
public boolean next() The next() method moves the cursor forward one row and returns true if the cursor now points to a row of data in the ResultSet. If the cursor points beyond the last row of data as a result of the next()method (or if the ResultSet contains no rows), the return value is false.
So in order to read the three rows of data in the table shown in Figure 15-4, we need to call the next() method, read the row of data, and then call next()again twice more. When the next()method is invoked the fourth time, the method will return false. The easiest way to read all of the rows from first to last is in a while loop:

Moving the cursor forward through the ResultSet is just the start of reading data from the results of the query. Let’s look at the two ways to get the data from each row in a result set.
When a ResultSet is returned, and you have dutifully called next() to move the cursor to the first actual row of data, you can now read the data in each column of the current row. As illustrated in Figure 15-4, a result set from a database query is like a table or a spreadsheet. Each row contains (typically) one or more columns, and the data in each column is one of the SQL data types. In order to bring the data from each column into your Java application, you must use a ResultSet method to retrieve each of the SQL column values into an appropriate Java type. So SQL INTEGER, for example, can be read as a Java int primitive, SQL VARCHAR can be read as a Java String, SQL DATE can be read as a java.sql.Date object, and so on. ResultSet defines several other types as well, but whether or not the database or the driver supports all of the types defined by the specification depends on the database vendor. For the exam, we recommend you focus on the most common SQL data types and the ResultSet methods shown in Table 15-7.
SQL has been around for a long time. The first formalized, American National Standards Institute (ANSI)–approved version was adopted in 1986 (SQL-86). The next major revision was in 1992, SQL-92, which is widely considered the “base” release for every database. SQL-92 defined a number of new data types, including DATE, TIME, TIMESTAMP, BIT, and VARCHAR strings. SQL-92 has multiple levels; each level adds a bit more functionality to the previous level. JDBC drivers recognize three ANSI SQL-92 levels: Entry, Intermediate, and Full.
SQL-1999, also known as SQL-3, added LARGE OBJECT types, including BINARY LARGE OBJECT (BLOB) and CHARACTER LARGE OBJECT (CLOB). SQL-1999 also introduced the BOOLEAN type and a composite type, ARRAY and ROW, to store collections directly into the database. In addition, SQL-1999 added a number of features to SQL, including triggers, regular expressions, and procedural and flow control.
SQL-2003 introduced XML to the database, and importantly, added columns with auto-generated values, including columns that support identity, like the primary key and foreign key columns. Believe or not, other standards have been proposed, including SQL-2006, SQL-2008, and SQL-2011.
The reason this matters is because the JDBC specification has attempted to be consistent with features from the most widely adopted specification at the time. Thus, JDBC 3.0 supports SQL-92 and a part of the SQL-1999 specification, and JDBC 4.0 supports parts of the SQL-2003 specification. In this chapter, we’ll try to stick to the most widely used SQL-92 features and the most commonly supported SQL-1999 features that JDBC also supports.
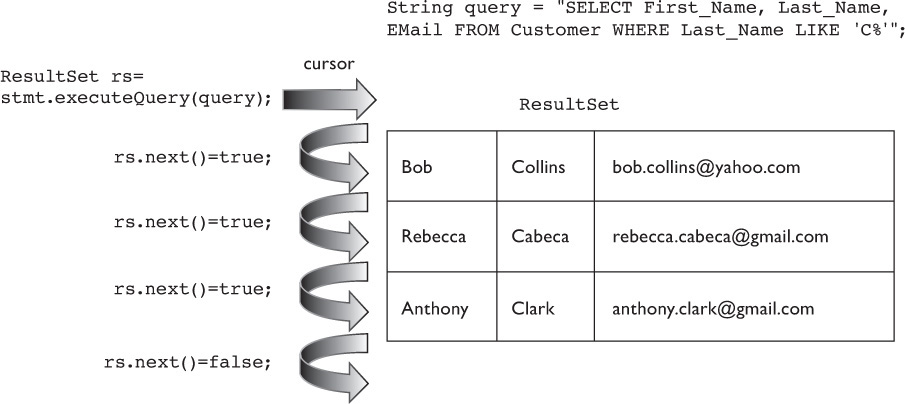
One way to read the column data is by using the names of the columns themselves as string values. For example, using the column names from Bob’s Book table (Table 15-4), in these ResultSet methods, the String name of the column from the Book table is passed to the method to read the column data type:
Note that although here the column names were retrieved from the ResultSet row in the order they were requested in the SQL query, they could have been processed in any order.
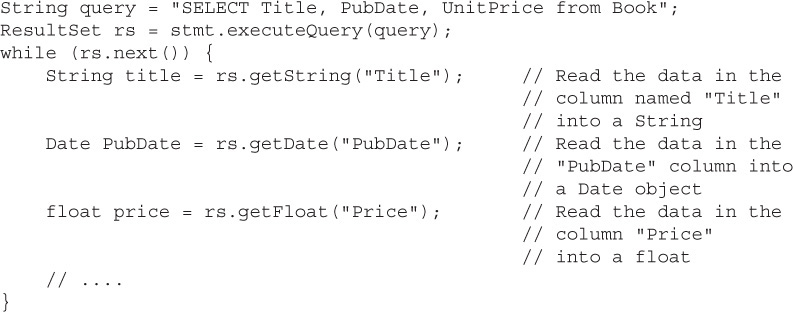
ResultSet also provides an overloaded method that takes an integer index value for each of the SQL types. This value is the integer position of the column in the result set, numbered from 1 to the number of columns returned. So we could write the same statements earlier like this:
Using the positional methods shown earlier, the order of the column in the ResultSet does matter. In our query, Title is in position 1, PubDate is in position 2, and Price is in position 3.
What the database stores as a type, the SQL type, and what JDBC returns as a type are often two different things. It is important to understand that the JDBC specification provides a set of standard mappings—the best match between what the database provides as a type and the Java type a programmer should use with that type. Rather than repeating what is in the specification, we encourage you to look at Appendix B of the JDBC (JSR-221) specification.
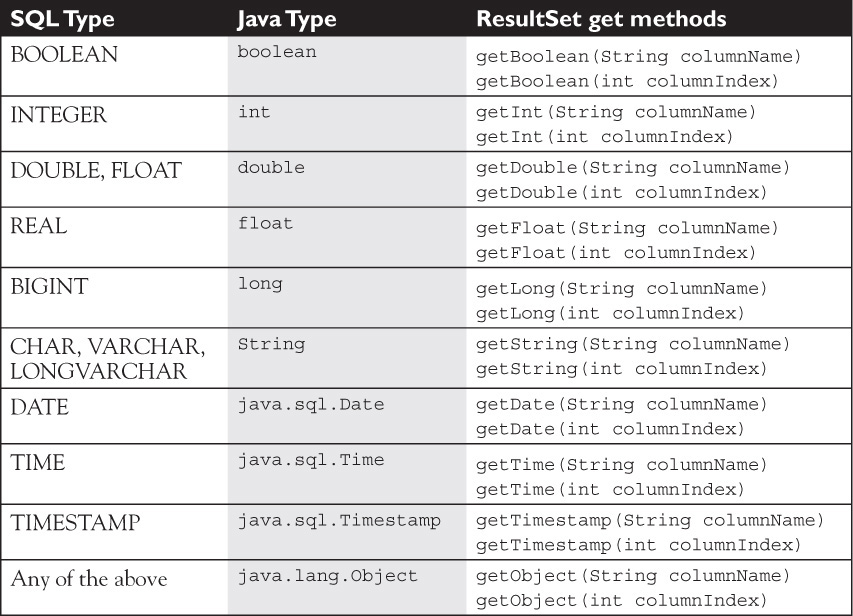
The most commonly used ResultSet get methods are listed next. Let’s look at these methods in detail.
public boolean getBoolean(String columnLabel) This method retrieves the value of the named column in the ResultSet as a Java boolean. Boolean values are rarely returned in SQL queries, and some databases may not support a SQL BOOLEAN type, so check with your database vendor. In this contrived example here, we are returning employment status:

public double getDouble(String columnLabel) This method retrieves the value of the column as a Java double. This method is recommended for returning the value stored in the database as SQL DOUBLE and SQL FLOAT types.
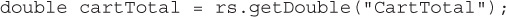
public int getInt(String columnLabel) This method retrieves the value of the column as a Java int. Integers are often a good choice for primary keys. This method is recommended for returning values stored in the database as SQL INTEGER types.
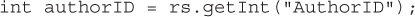
public float getFloat(String columnLabel) This method retrieves the value of the column as a Java float. It is recommended for SQL REAL types.
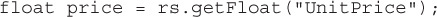
public long getLong(String columnLabel) This method retrieves the value of the column as a Java long. It is recommended for SQL BIGINT types.
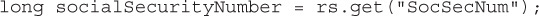
public java.sql.Date getDate(String columnLabel) This method retrieves the value of the column as a Java Date object. Note that java.sql.Date extends java.util.Date. The most interesting difference between the two is that the toString() method of java.sql.Date returns a date string in the form: “yyyy mm dd.” This method is recommended for SQL DATE types.
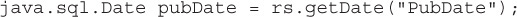
public java.lang.String getString(String columnLabel) This method retrieves the value of the column as a Java String object. It is good for reading SQL columns with CHAR, VARCHAR, and LONGVARCHAR types.
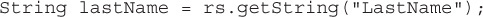
public java.sql.Time getTime(String columnLabel) This method retrieves the value of the column as a Java Time object. Like java.sql.Date, this class extends java.util.Date, and its toString() method returns a time string in the form: “hh:mm:ss.” TIME is the SQL type that this method is designed to read.
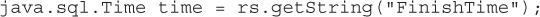
public java.sql.Timestamp getTimestamp(String columnLabel) This method retrieves the value of the column as a Timestamp object. Its toString() method formats the result in the form: yyyy-mm-dd hh:mm:ss.fffffffff, where ffffffffff is nanoseconds. This method is recommended for reading SQL TIMESTAMP types.
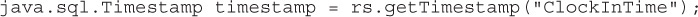
public java.lang.Object getObject(String columnLabel) This method retrieves the value of the column as a Java Object. It can be used as a general-purpose method for reading data in a column. This method works by reading the value returned as the appropriate Java wrapper class for the type and returning that as a Java Object object. So, for example, reading an integer (SQL INTEGER type) using this method returns an object that is a java.lang.Integer type. We can use instanceof to check for an Integer and get the int value:

Table 15-8 lists the most commonly used methods to retrieve specific data from a ResultSet. For the complete and exhaustive set of ResultSet get methods, see the Java documentation for java.sql.ResultSet.
TABLE 15-8 SQL Types and JDBC Types
When you write a query using a string, as we have in the examples so far, you know the name and type of the columns returned. However, what happens when you want to allow your users to dynamically construct the query? You may not always know in advance how many columns are returned and the type and name of the columns returned.
Fortunately, the ResultSetMetaData class was designed to provide just that information. Using ResultSetMetaData, you can get important information about the results returned from the query, including the number of columns, the table name, the column name, and the column class name—the Java class that is used to represent this column when the column is returned as an Object. Here is a simple example, and then we’ll look at these methods in more detail:

Running this code using the BookSeller database (Bob’s Books) produces the following output:

ResultSetMetaData is often used to generate reports, so here are the most commonly used methods. For more information and more methods, check out the JavaDocs.
public int getColumnCount() throws SQLException This method is probably the most used ResultSetMetaData method. It returns the integer count of the number of columns returned by the query. With this method, you can iterate through the columns to get information about each column.

The value of columnCount for the Author table is 3. We can use this value to iterate through the columns using the methods illustrated next.
public String getColumnName(int column) throws SQLException This method returns the String name of this column. Using the columnCount, we can create an output of the data from the database in a report-like format. For example:

This example is somewhat rudimentary, as we probably need to do some better formatting on the data, but it will produce a table of output:
public String getTableName(int column) throws SQLException The method returns the String name of the table that this column belongs to. This method is useful when the query is a join of two or more tables and we need to know which table a column came from. For example, suppose that we want to get a list of books by author’s last name:

With a query like this, we might want to know which table the column data came from:

This code will print the name of the table, a colon, and the column name. The output might look something like this:
public int getColumnDisplaySize(int column) throws SQLException This method returns an integer of the size of the column. This information is useful for determining the maximum number of characters a column can hold (if it is a VARCHAR type) and the spacing that is required between columns for a report.
To make a prettier report than the one in the getColumnName method earlier, for example, we could use the display size to pad the column name and data with spaces. What we want is a table with spaces between the columns and headings that looks something like this when we query the Author table:

Using the methods we have discussed so far, here is code that produces a pretty report from a query:

A couple of things to note about the example code: first, the leftJustify method, which takes a string to print left-justified and an integer for the total number of characters in the string. The difference between the actual string length and the integer value will be filled with spaces. This method uses the String format() method and the “-” (dash) flag to return a String that is left-justified with spaces. The %1$ part indicates the flag should be applied to the first argument. What we are building is a format string dynamically. If the column display size is 20, the format string will be %1$-20s, which says “print the argument passed (the first argument) on the left with a width of 20 and use a string conversion.”
Note that if the length of the string passed in and the integer field length (n) are the same, we add one space to the length to make it look pretty:

Second, databases can store NULL values. If the value of a column is NULL, the object returned in the rs.getObject() method is a Java null. So we have to test for null to avoid getting a null pointer exception when we execute the toString() method.
Notice that we don’t have to use the next() method before reading the ResultSetMetaData—we can do that at any time after obtaining a valid result set. Running this code and passing it a query like “SELECT * FROM Author” returns a neatly printed set of authors:

So far, for all the result sets we looked at, we simply moved the cursor forward by calling next(). The default characteristics of a Statement are cursors that only move forward and result sets that do not support changes. The ResultSet interface actually defines these characteristics as static int variables: TYPE_FORWARD_ONLY and CONCUR_READ_ONLY. However, the JDBC specification defines additional static int types (shown next) that allow a developer to move the cursor forward, backward, and to a specific position in the result set. In addition, the result set can be modified while open and the changes written to the database. Note that support for cursor movement and updatable result sets is not a requirement on a driver, but most drivers provide this capability. In order to create a result set that uses positionable cursors and/or supports updates, you must create a Statement with the appropriate scroll type and concurrency setting, and then use that Statement to create the ResultSet object.
The ability to move the cursor to a particular position is the key to being able to determine how many rows are returned from a result set—something we will look at shortly. The ability to modify an open result set may seem odd, particularly if you are a seasoned database developer. After all, isn’t that what a SQL UPDATE command is for?
Consider a situation where you want to perform a series of calculations using the data from the result set rows, then write a change to each row based on some criteria, and finally write the data back to the database. For example, imagine a database table that contains customer data, including the date they joined as a customer, their purchase history, and the total number of orders in the last two months. After reading this data into a result set, you could iterate over each customer record and modify it based on business rules: set their minimum discount higher if they have been a customer for more than a year with at least one purchase per year, or set their preferred credit status if they have been purchasing more than $100 per month. With an updatable result set, you can modify several customer rows, each in a different way, and commit the rows to the database without having to write a complex SQL query or a set of SQL queries—you simply commit the updates on the open result set.
Let’s look at how to modify a result set in more detail. There are three ResultSet cursor types:
TYPE_FORWARD_ONLY The default value for a ResultSet—the cursor moves forward only through a set of results.
TYPE_SCROLL_INSENSITIVE A cursor position can be moved in the result forward or backward, or positioned to a particular cursor location. Any changes made to the underlying data—the database itself—are not reflected in the result set. In other words, the result set does not have to “keep state” with the database. This type is generally supported by databases.
TYPE_SCROLL_SENSITIVE A cursor can be changed in the results forward or backward, or positioned to a particular cursor location. Any changes made to the underlying data are reflected in the open result set. As you can imagine, this is difficult to implement, and is therefore not implemented in a database or JDBC driver very often.
JDBC provides two options for data concurrency with a result set:
CONCUR_READ_ONLY This is the default value for result set concurrency. Any open result set is read-only and cannot be modified or changed.
CONCUR_UPDATABLE A result set can be modified through the ResultSet methods while the result set is open.
Because a database and JDBC driver are not required to support cursor movement and concurrent updates, the JDBC provides methods to query the database and driver using the DatabaseMetaData object to determine if your driver supports these capabilities. For example:
Running this code on the Java DB (Derby) database, these are the results:

In order to create a ResultSet with TYPE_SCROLL_INSENSITIVE and CONCUR_UPDATABLE, the Statement used to create the ResultSet must be created (from the Connection) with the cursor type and concurrency you want. You can determine what cursor type and concurrency the Statement was created with, but once created, you can’t change the cursor type or concurrency of an existing Statement object. Also, note that just because you set a cursor type or concurrency setting, that doesn’t mean you will get those settings. As you will see in the section on exceptions, the driver can determine that the database doesn’t support one or both of the settings you chose and it will throw a warning and (silently) revert to its default settings if they are not supported. You will see how to detect these JDBC warnings in the section on exceptions and warnings.

Besides being able to use a ResultSet object to update results, which we’ll look at next, being able to manipulate the cursor provides a side benefit—we can use the cursor to determine the number of rows returned in a query. Although it would seem like there ought to be a method in ResultSet or ResultSetMetaData to do this, this method does not exist.
In general, you should not need to know how many rows are returned, but during debugging, you may want to diagnose your queries with a stand-alone database and use cursor movement to read the number of rows returned.
Something like this would work:

Of course, you may also want to have a more sophisticated method that preserves the current cursor position and returns the cursor to that position, regardless of when the method was called. Before we look at that code, let’s look at the other cursor movement methods and test methods (besides next) in ResultSet. As a quick summary, Table 15-9 lists the methods you use to change the cursor position in a ResultSet.
TABLE 15-9 ResultSet Cursor Positioning Methods
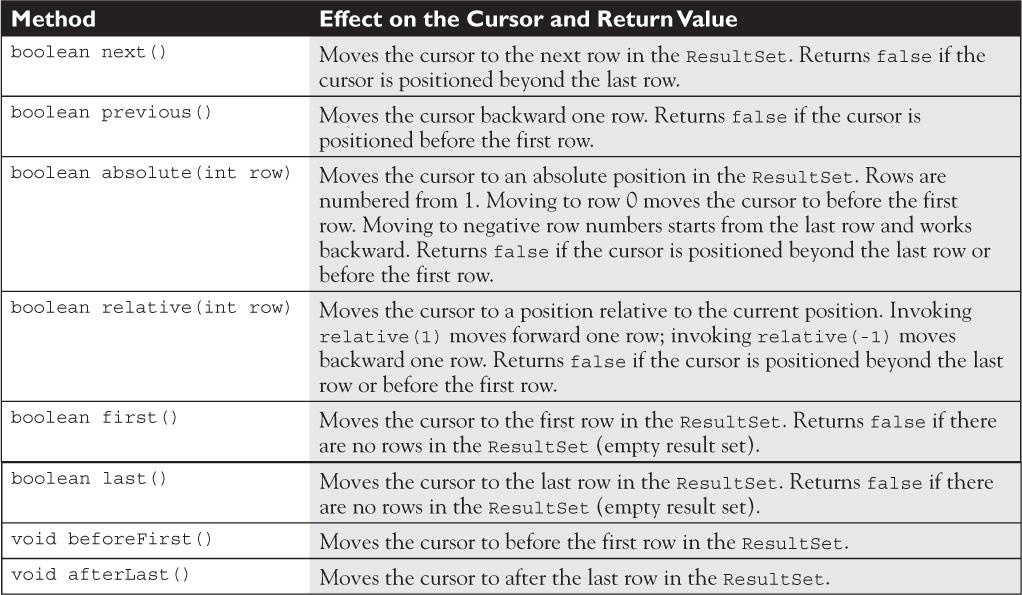
Let’s look at each of these methods in more detail.
public boolean absolute(int row) throws SQLException This method positions the cursor to an absolute row number. The contrasting method is relative. Passing 0 as the row argument positions the cursor to before the first row. Passing a negative value, like -1, positions the cursor to the position after the last row minus one—in other words, the last row. If you attempt to position the cursor beyond the last row, say at position 22 in a 19-row result set, the cursor will be positioned beyond the last row, the implications of which we’ll discuss next. Figure 15-5 illustrates how invocations of absolute() position the cursor.
FIGURE 15-5 Absolute cursor positioning
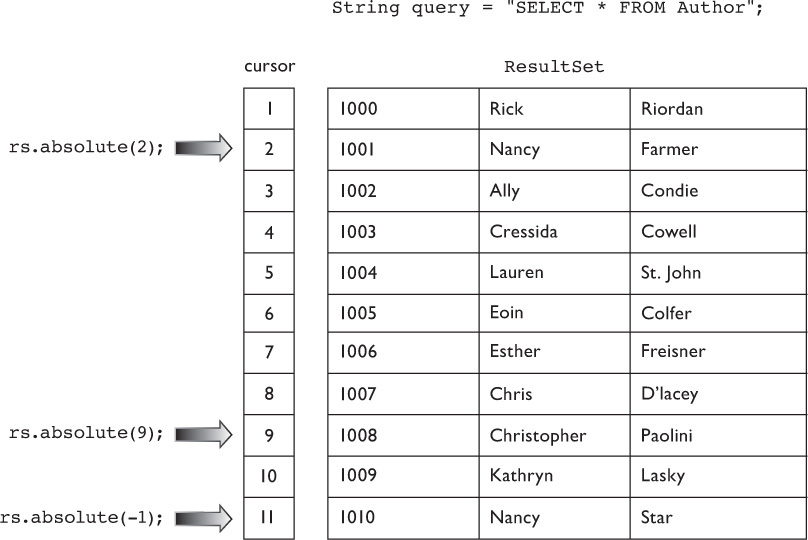
The absolute() method returns true if the cursor was successfully positioned within the ResultSet and false if the cursor ended up before the first or after the last row. For example, suppose that you wanted to process only every other row:

public int getRow() throws SQLException This method returns the current row position as a positive integer (1 for the first row, 2 for the second, and so on) or 0 if there is no current row—the cursor is either before the first row or after the last row. This is the only method of this set of cursor methods that is optionally supported for TYPE_FORWARD_ONLY ResultSets.
public boolean relative(int rows) throws SQLException The relative() method is the cousin to absolute. Get it, cousin? Okay, anyway, relative() will position the cursor either before or after the current position of the number of rows passed in to the method. So if the cursor is on row 15 of a 30-row ResultSet, calling relative(2) will position the cursor to row 17, and then calling relative(-5) positions the cursor to row 12. Figure 15-6 shows how the cursor is moved based on calls to absolute() and relative().
FIGURE 15-6 Relative cursor positioning (Circled numbers indicate order of invocation.)

Like absolute positioning, attempting to position the cursor beyond the last row or before the first row simply results in the cursor being after the last row or before the first row, respectively, and the method returns false. Also, calling relative with an argument of 0 does exactly what you might expect—the cursor remains where it is. Why would you use relative? Let’s assume that you are displaying a fairly long database table on a web page using an HTML table. You might want to allow your user to be able to page forward or backward relative to the currently selected row; maybe something like this:

public boolean previous() throws SQLException The previous() method works exactly the same as the next() method, only it backs up through the ResultSet. Using this method with the afterLast() method described next, you can move through a ResultSet in reverse order (from last row to first).
public void afterLast() throws SQLException This method positions the cursor after the last row. Using this method and then the previous() method, you can iterate through a ResultSet in reverse. For example:

Just like next(), when previous() backs up all the way to before the first row, the method returns false.
public void beforeFirst() throws SQLException This method will return the cursor to the position it held when the ResultSet was first created and returned by a Statement object.
public boolean first() throws SQLException The first() method positions the cursor on the first row. It is the equivalent of calling absolute(1). This method returns true if the cursor was moved to a valid row, and false if the ResultSet has no rows.

public boolean last() throws SQLException The last() method positions the cursor on the last row. This method is the equivalent of calling absolute(-1). This method returns true if the cursor was moved to a valid row, and false if the ResultSet has no rows.

A couple of notes on the exceptions thrown by all of these methods:
A SQLException will be thrown by these methods if the type of the ResultSet is TYPE_FORWARD_ONLY, if the ResultSet is closed (we will look at how a result set is closed in an upcoming section), or if a database error occurs.
A SQLFeatureNotSupportedException will be thrown by these methods if the JDBC driver does not support the method. This exception is a subclass of SQLException.
Most of these methods have no effect if the ResultSet has no rows—for example, a ResultSet returned by a query that returned no rows.
The following methods return a boolean to allow you to “test” the current cursor position without moving the cursor. Note that these are not on the exam, but are provided to you for completeness:
isBeforeFirst() True if the cursor is positioned before the first row
isAfterLast() True if the cursor is positioned after the last row
isFirst() True if the cursor is on the first row
isLast() True if the cursor is on the last row
So now that we have looked at the cursor positioning methods, let’s revisit the code to calculate the row count. We will create a general-purpose method to allow the row count to be calculated at any time and at any current cursor position. Here is the code:

Looking through the code, you notice that we took special care to preserve the current position of the cursor in the ResultSet. We called getRow() to get the current position, and if the value returned was 0, the current position of the ResultSet could be either before the first row or after the last row, so we used the isAfterLast() method to determine where the cursor was. If the cursor was after the last row, then we stored a -1 in the currRow integer.
We then moved the cursor to the last position in the ResultSet, and if that move was successful, we get the current position and save it as the rowCount (the last row and, therefore, the count of rows in the ResultSet). Finally, we use the value of currRow to determine where to return the cursor. If the value of the cursor is -1, we need to position the cursor after the last row. Otherwise, we simply use absolute() to return the cursor to the appropriate position in the ResultSet.
While this may seem like several extra steps, we will look at why preserving the cursor can be important when we look at updating ResultSets next.
If you have casually used JDBC, or are new to JDBC, you may be surprised to know that a ResultSet object can do more than just provide the results of a query to your application. Besides just returning the results of a query, a ResultSet object may be used to modify the contents of a database table, including update existing rows, delete existing rows, and add new rows. Please note that this section and the subsections that follow are not on the exam, and are provided to give you some insight into the power of using an object to represent relational data.
In a traditional SQL application, you might perform the following SQL queries to raise the price of all of the hardcover books in inventory that are currently 10.95 to 11.95 in price:
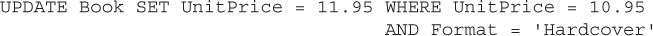
Hopefully by now you feel comfortable that you could create a Statement to perform this query using a SQL UPDATE:

But what if you wanted to do the updates on a book-by-book basis? You only want to increase the price of your best sellers, rather than every single book.
You would then have to get the values from the database using a SELECT, then store the values in an array indexed somehow—perhaps with the primary key—then construct the appropriate UPDATE command strings, and call executeUpdate() one row at a time. Another option is to update the ResultSet directly.
When you create a Statement with concurrency set to CONCUR_UPDATABLE, you can modify the data in a result set and then apply your changes back to the database without having to issue another query.
In addition to the getXXXX methods we looked at for ResultSet, methods that get column values as integers, Date objects, Strings, etc., there is an equivalent updateXXXX method for each type. And, just like the getXXXX methods, the updateXXXX methods can take either a String column name or an integer column index.
Let’s rewrite the previous update example using an updatable ResultSet:

Notice that after modifying the value of UnitPrice using the updateFloat() method, we called the method updateRow(). This method writes the current row to the database. This two-step approach ensures that all of the changes are made to the row before the row is written to the database. And, you can change your mind with a cancelRowUpdates() method call.
Table 15-10 summarizes methods that are commonly used with updatable ResultSets (whose concurrency type is set to CONCUR_UPDATABLE).
TABLE 15-10 Methods Used with Updatable ResultSets

Let’s look at the common methods used for altering database contents through the ResultSet in detail.
public void updateRow() throws SQLException This method updates the database with the contents of the current row of the ResultSet. There are a couple of caveats for this method. First, the ResultSet must be from a SQL SELECT statement on a single table—a SQL statement that includes a JOIN or a SQL statement with two tables cannot be updated. Second, the updateRow() method should be called before moving to the next row. Otherwise, the updates to the current row may be lost.
So the typical use for this method is to update the contents of a row using the appropriate updateXXXX() methods and then update the database with the contents of the row using the updateRow() method. For example, in this fragment, we are updating the UnitPrice of a row to $11.95:
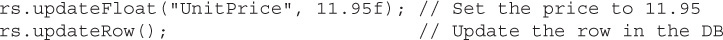
public boolean rowUpdated() throws SQLException This method returns true if the current row was updated. Note that not all databases can detect updates. However, JDBC provides a method in DatabaseMetaData to determine if updates are detectable, DatabaseMetaData.updatesAreDetected(int type), where the type is one of the ResultSet types—TYPE_SCROLL_INSENSITIVE, for example. We will cover the DatabaseMetaData interface and its methods a little later in this section.
public void cancelRowUpdates() throws SQLException This method allows you to “back out” changes made to the row. This method is important, because the updateXXXX methods should not be called twice on the same column. In other words, if you set the value of UnitPrice to 11.95 in the previous example and then decided to switch the price back to 10.95, calling the updateFloat() method again can lead to unpredictable results. So the better approach is to call cancelRowUpdates() before changing the value of a column a second time.

public void deleteRow() throws SQLException This method will remove the current row from the ResultSet and from the underlying database. The row in the database is removed (similar to the result of a DELETE statement).
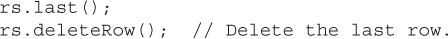
What happens to the ResultSet after a deleteRow() method depends upon whether or not the ResultSet can detect deletions. This ability is dependent upon the JDBC driver. When a ResultSet can detect deletions, the deleted row is removed from the ResultSet. When the ResultSet cannot detect deletions, the columns of the ResultSet row that was deleted are made invalid by setting each column to null.
The DatabaseMetaData interface can be used to determine if the ResultSet can detect deletions:

In general, to maintain an up-to-date ResultSet after a deletion, the ResultSet should be re-created with a query.
Deleting the current row does not move the cursor—it remains on the current row—so if you deleted row 1, the cursor is still positioned at row 1. However, if the deleted row was the last row, then the cursor is positioned after the last row. Note that there is no undo for deleteRow(), at least, not by default. As you will see a little later, we can “undo” a delete if we are using transactions.
public boolean rowDeleted() throws SQLException As described earlier, when a ResultSet can detect deletes, the rowDeleted() method is used to indicate a row has been deleted, but remains as a part of the ResultSet object. For example, suppose that we deleted the second row of the Customer table. Printing the results (after the delete) to the console would look like Figure 15-7.
FIGURE 15-7 A ResultSet after delete() is called on the second row
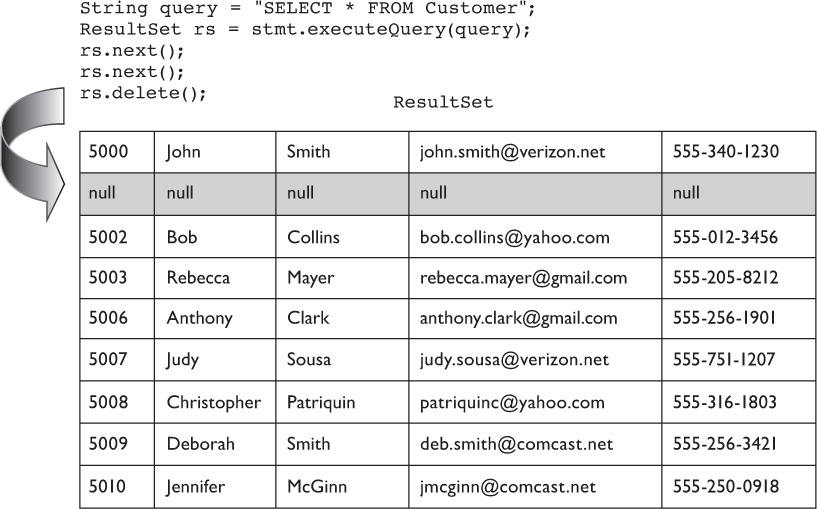
So if you are working with a ResultSet that is being passed around between methods and shared across classes, you might use rowDeleted() to detect if the current row contains valid data.
Updating Columns Using Objects An interesting aspect of the getObject() and updateObject() methods is that they retrieve a column as a Java object. And, since every Java object can be turned into a String using the object’s toString() method, you can retrieve the value of any column in the database and print the value to the console as a String, as we saw in the section “Printing a Report.”
Going the other way, toward the database, you can also use Strings to update almost every column in a ResultSet. All of the most common SQL types—integer, float, double, long, and date—are wrapped by their representative Java object: Integer, Float, Double, Long, and java.sql.Date. Each of these objects has a method valueOf() that takes a String.
The updateObject() method takes two arguments: the first, a column name (String) or column index, and the second, an Object. We can pass a String as the Object type, and as long as the String meets the requirements of the valueOf() method for the column type, the String will be properly converted and stored in the database as the desired SQL type.
For example, suppose that we are going to update the publish date (PubDate) of one of our books:

The String we passed meets the requirements for java.sql.Date, “yyyy-[m]m-[d]d,” so the String is properly converted and stored in the database as the SQL Date value: 2005-04-23. Note this technique is limited to those SQL types that can be converted to and from a String, and if the String passed to the valueOf() method for the SQL type of the column is not properly formatted for the Java object, an IllegalArgumentException is thrown.
In the last section, we looked at modifying the existing column data in a ResultSet and removing existing rows. In our final section on ResultSets, we’ll look at how to create and insert a new row. First, you must have a valid ResultSet open, so typically, you have performed some query. ResultSet provides a special row, called the insert row, that you are actually modifying (updating) before performing the insert. Think of the insert row as a buffer where you can modify an empty row of your ResultSet with values.
Inserting a row is a three-step process, as shown in Figure 15-8: First (1) move to the special insert row, then (2) update the values of the columns for the new row, and finally (3) perform the actual insert (write to the underlying database). The existing ResultSet is not changed—you must rerun your query to see the underlying changes in the database. However, you can insert as many rows as you like. Note that each of these methods throws a SQLException if the concurrency type of the result set is set to CONCUR_READ_ONLY. Let’s look at the methods before we look at example code.
FIGURE 15-8 The ResultSet insert row
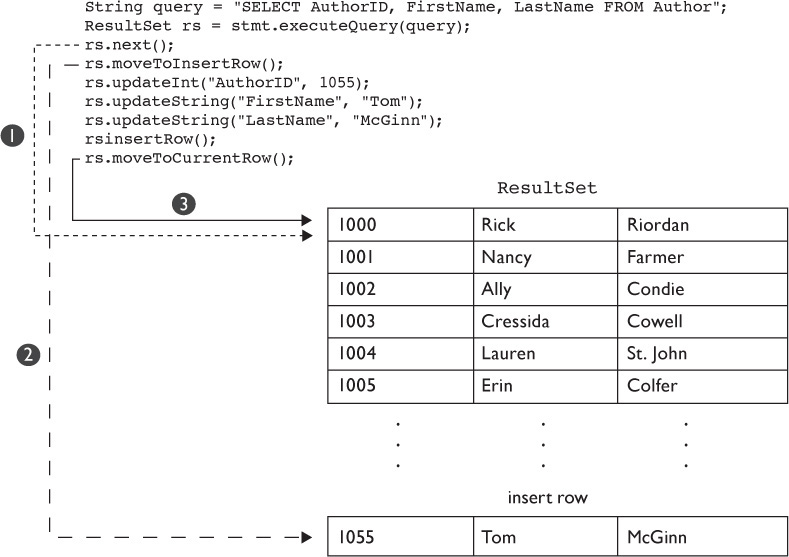
public void moveToInsertRow() throws SQLException This method moves the cursor to insert a row buffer. Wherever the cursor was when this method was called is remembered. After calling this method, the appropriate updater methods are called to update the values of the columns.

public void insertRow() throws SQLException This method writes the insert row buffer to the database. Note that the cursor must be on the insert row when this method is called. Also, note that each column must be set to a value before the row is inserted in the database or a SQLException will be thrown. The insertRow() method can be called more than once—however, the insertRow follows the same rules as a SQL INSERT command—unless the primary key is auto-generated, two inserts of the same data will result in a SQLException (duplicate primary key).
public void moveToCurrentRow() throws SQLException This method returns the result set cursor to the row the cursor was on before the moveToInsertRow() method was called.
Let’s look at a simple example, where we will add a new row in the Author table:

In the example we are using in this chapter, Bob’s Books, we know quite a lot about the tables, columns, and relationships between the tables because we had that nifty data model earlier. But what if that were not the case? This section covers DatabaseMetaData, an interface that provides a significant amount of information about the database itself. This topic is fairly advanced stuff and is not on the exam, but it is provided here to give you an idea about how you can use metadata to build a model of a database without having to know anything about the database in advance.
Recall that the Connection object we obtained from DriverManager is an object that represents an actual connection with the database. And while the Connection object is primarily used to create Statement objects, there are a couple of important methods to study in the Connection interface. A Connection can be used to obtain information about the database as well. This data is called “metadata,” or “data about data.”
One of Connection’s methods returns a DatabaseMetaData object instance, through which we can get information about the database, about the driver, and about transaction semantics that the database and JDBC driver support. We will spend more time looking at transactions in another section.
To obtain an instance of a DatabaseMetaData object, we use Connection’s getMetaData() method:
DatabaseMetaData is a comprehensive interface, and through an object instance, we can determine a great deal about the database and the supporting driver. Most of the time, as a developer, you aren’t coding against a database blindly and know the capabilities of the database and the driver before you write any code. Still, it is helpful to know that you can use getObject to return the value of the column, regardless of its type—very useful when all you want to do is create a report, and we’ll look at an example.
Here are a few methods we will highlight:
getColumns()Returns a description of columns in a specified catalog and schema
getProcedures() Returns a description of the stored procedures in a given catalog and schema
getDriverName()Returns the name of the JDBC driver
getDriverVersion()Returns the version number of the JDBC driver as a string
supportsANSI92EntryLevelSQL()Returns a boolean true if this database supports ANSI92 entry-level grammar
It is interesting to note that DatabaseMetaData methods also use ResultSet objects to return data about the database. Let’s look at these methods in more detail.
public ResultSet getColumns(String catalog, String schemaPattern, String tableNamePattern, String columnNamePattern) throws SQLException This method is one of the best all-purpose data retrieval methods for details about the tables and columns in your database. Before we look at a code sample, it might be helpful to define catalogs and schemas. In a database, a schema is an object that enforces the integrity of the tables in the database. The schema name is generally the name of the person who created the database. In our examples, the BookGuy database holds the collection of tables and is the name of the schema. Databases may have multiple schemas stored in a catalog.
In this example, using the Java DB database as our sample database, the catalog is null and our schema is “BOOKGUY”, and we are using a SQL catch-all pattern “%” for the table and column name patterns, like the “*” character you are probably used to with file systems like Windows. Thus, we are going to retrieve all of the tables and columns in the schema. Specifically, we are going to print out the table name, column name, the SQL data type for the column, and the size of the column. Note that here we used uppercase column identifiers. These are the column names verbatim from the JavaDoc, but in truth, they are not case sensitive either, so “Table_Name” would have worked just as well. Also, the JavaDoc specifies the column index for these column headings, so we could have also used rs.getString(3) to get the table name.

Running this code produces output something like this:
public ResultSet getProcedures(String catalog, String schemaPattern, String procedureNamePattern) throws SQLException Stored procedures are functions that are sometimes built into a database and often defined by a database developer or database admin. These functions can range from data cleanup to complex queries. This method returns a result set that contains descriptive information about the stored procedures for a catalog and schema. In the example code, we will use null for the catalog name and schema pattern. The null indicates that we do not wish to narrow the search (effectively, the same as using a catch-all “%” search). Note that this example is returning the name of every stored procedure in the database. A little later, we’ll look at how to actually call a stored procedure.

Note that the output from this code fragment is highly database dependent. Here is sample output from the Derby (JavaDB) database that ships with the JDK:

public String getDriverName() throws SQLException This method simply returns the name of the JDBC driver as a string. This method would be useful to log in the start of the application, as you’ll see in the next section.
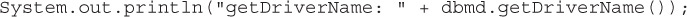
Obviously, the name of the driver depends on the JDBC driver you are using. Again, with the Derby database and JDBC driver, the output from this method looks something like this:
public String getDriverVersion() throws SQLException This method returns the JDBC driver version number as a string. This information and the driver name would be good to log in the start-up of an application.

Statements written to the log are generally recorded in a log file, but depending upon the IDE, they can also be written to the console. In NetBeans, for example, the log statements look something like this in the console:

public boolean supportsANSI92EntryLevelSQL() throws SQLException This method returns true if the database and JDBC driver support ANSI SQL-92 entry-level grammar. Support for this level (at a minimum) is a requirement for JDBC drivers (and therefore the database.)

Whenever you are working with a database using JDBC, there is a possibility that something can go wrong. A JDBC connection is typically through a socket to a database resource on the network. So already we have at least two possible points of failure—the network can be down and/or the database can be down. And that assumes that everything else you are doing with your database is correct, that all your queries are perfect! Like other Java exceptions, SQLException is a way for your application to determine what the problem is and take action if necessary.
Let’s look at the type of data you get from a SQLException through its methods.
public String getMessage() This method is actually inherited from java.lang.Exception, which SQLException extends from. But this method returns the detailed reason why the exception was thrown. Note that this is not the same message that is returned from the toString() method, i.e., the method called when you put the exception object instance into a System.out.println method. Often, the message content SQLState and error code provide specific information about what went wrong.
public String getSQLState() The String returned by getSQLState provides a specific code and related message. SQLState messages are defined by the X/Open and SQL:2003 standards; however, it is up to the implementation to use these values. You can determine which standard your JDBC driver uses (or if it does not) through the DatabaseMetaData.getSQLStateType() method. Your implementation may also define additional codes specific to the implementation, so in either case, it is a good idea to consult your JDBC driver and database documentation. Because the SQLState messages and codes tend to be specific to the driver and database, the typical use of these in an application is limited to either logging messages or debugging information.
public int getErrorCode() Error codes are not defined by a standard and are thus implementation specific. They can be used to pass an actual error code or severity level, depending upon the implementation.
public SQLException getNextException() One of the interesting aspects of SQLException is that the exception thrown could be the result of more than one issue. Fortunately, JDBC simply tacks each exception onto the next in a process called chaining. Typically, the most severe exception is thrown last, so it is the first exception in the chain.
You can get a list of all of the exceptions in the chain using the getNextException() method to iterate through the list. When the end of the list is reached, getNextException() returns a null. In this example, the SQLExceptions, SQLState, and vendor error codes are logged:

Although SQLWarning is a subclass of SQLException, warnings are silently chained to the JDBC object that reported them. This is probably one of the few times in Java where an object that is part of an exception hierarchy is not thrown as an exception. The reason is that a warning is not an exception per se. Warnings can be reported on Connection, Statement, and ResultSet objects.
For example, suppose that we mistakenly set the result set type to TYPE_SCROLL_SENSITIVE when creating a Statement object. This does not create an exception; instead, the database will handle the situation by chaining a SQLWarning to the Connection object and resetting the type to TYPE_FORWARD_ONLY (the default) and continue on. Everything would be fine, of course, until we tried to position the cursor, at which point a SQLException would be thrown. And, like SQLException, you can retrieve warnings from the SQLWarning object using the getNextWarning() method.

Connection objects will add warnings (if necessary) until the Connection is closed, or until the clearWarnings() method is called on the Connection instance. The clearWarnings() method sets the list of warnings to null until another warning is reported for this Connection object.
Statements and ResultSets also generate SQLWarnings, and these objects have their own clearWarnings() methods. Statement warnings are cleared automatically when a statement is reexecuted, and ResultSet warnings are cleared each time a new row is read from the result set.
The following sections summarize the methods associated with SQLWarnings.
SQLWarning getWarnings() throws SQLException This method gets the first SQLWarning object or returns null if there are no warnings for this Connection, Statement, or ResultSet object. A SQLException is thrown if the method is called on a closed object.
void clearWarnings() throws SQLException This method clears and resets the current set of warnings for this Connection, Statement, or ResultSet object. A SQLException is thrown if the method is called on a closed object.
In this chapter, we have looked at some very simple examples where we create a Connection and Statement and a ResultSet all within a single try block, and catch any SQLExceptions thrown. What we have not done so far is properly close these resources. The reality is that it is probably less important for such small examples, but for any code that uses a resource, like a socket, or a file, or a JDBC database connection, closing the open resources is a good practice.
It is also important to know when a resource is closed automatically. Each of the three major JDBC objects, Connection, Statement, and ResultSet, has a close() method to explicitly close the resource associated with the object and explicitly release the resource. We hope by now you also realize that the objects have a relationship with each other, so if one object executes close(), it will have an impact on the other objects. The following table should help explain this.

It is also a good practice to minimize the number of times you close and re-create Connection objects. As a rule, creating the connection to the database and passing the username and password credentials for authentication is a relatively expensive process, so performing the activity once for every SQL query would not result in highly performing code. In fact, typically, database connections are created in a pool, and connection instances are handed out to applications as needed, rather than allowing or requiring individual applications to create them.
Statement objects are less expensive to create, and as we’ll see in the next section, there are ways to precompile SQL statements using a PreparedStatement, which reduces the overhead associated with creating SQL query strings and sending those strings to the database for execution.
ResultSets are the least expensive of the objects to create, and as we looked at in the section on ResultSets, for results from a single table, you can use the ResultSet to update, insert, and delete rows, so it can be very efficient to use a ResultSet.
Let’s look at one of our previous examples, where we used a Connection, a Statement, and a ResultSet, and rewrite this code to close the resources properly.
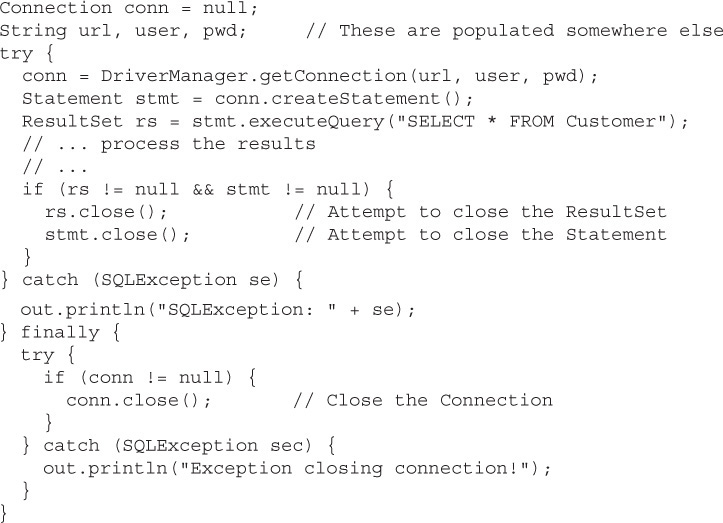
Notice all the work we have to go through to close the Connection—we first need to make sure we actually got an object and not a null, and then we need to try the close() method inside of another try inside of the finally block! Fortunately, there is an easier way….
As you’ll recall from Chapter 7, one of the most useful changes in Java SE 7 (JDK 7) was a number of small modifications to the language, including a new try statement to support the automatic resource management. This language change is called try-with-resources, and its longer name belies how much simpler it makes writing code with resources that should be closed. The try-with-resources statement will automatically call the close() method on any resource declared in the parentheses at the end of the try block.
There is a caveat: A resource declared in the try-with-resource statement must implement the AutoCloseable interface. One of the changes for JDBC in Java SE 7 (JDBC 4.1) was the modification of the API so that Connection, Statement, and ResultSet all implement the AutoCloseable interface and support automatic resource management. So we can rewrite our previous code example using try-with-resources:

Notice that we must include the object type in the declaration inside of the parentheses. The following will throw a compilation error:
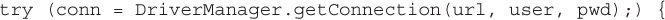
The try-with-resources can also be used with multiple resources, so you could include the Statement declaration in the try as well:

Note that when more than one resource is declared in the try-with-resources statement, the resources are closed in the reverse order of their declaration—so stmt.close() will be called first, followed by conn.close().
It probably makes sense that if there is an exception thrown from the try block, the exception will be caught by the catch statement, but what happens to exceptions thrown as a result of closing the resources in the try-with-resources statement? Any exceptions thrown as a result of closing resources at the end of the try block are suppressed if there was also an exception thrown in the try block. These exceptions can be retrieved from the exception thrown by calling the getSuppressed() method on the exception thrown.
For example:

9.5 Create and use PreparedStatement and CallableStatement objects.
So far, we used Statement object instances to pass queries as strings directly to the JDBC driver and then to the database. But as we mentioned earlier, the JDBC API provides two additional interfaces that JDBC driver vendors implement. These are PreparedStatement and CallableStatement. These interfaces extend the Statement interface and add functionality.
A PreparedStatement can improve the performance of a frequently executed query because the SQL part of the statement is precompiled in the database. In order to understand what precompiled means, we need to explain SQL execution at a high level. When a SQL string is sent to a database, the string goes through a number of processing steps. First, the string is parsed and all of the SQL keywords are checked for proper syntax. Next, the table and column names are checked against the schema to make sure they all exist (and are properly spelled). Next, the database creates an execution plan for the query, choosing between several options for the best overall performance. Finally, the chosen execution plan is run.
The steps leading up to the execution of a query plan can be done in advance using a PreparedStatement object. Parameters can be passed to a PreparedStatement, and these are inserted into the query just before execution. This is why PreparedStatement is a good choice for a frequently executed SQL statement.
Databases also provide the capability for developers to write small programs directly to the database. Each program is named, compiled, and stored in the database itself. These named programs are generally developed and added to the database when the tables are created. There are three types of these small programs: procedures, functions, and triggers. Because triggers are only invoked by the database itself and are not accessible by SQL queries or directly from an external application, we will not cover triggers. We will focus on stored procedures and functions.
The advantage of stored procedures and functions is that they are completely self-contained. You can think of a stored procedure as a method for a database. You call the stored procedure using its name and pass it arguments. The stored procedure may or may not return results, as you will see in the section on CallableStatements.
The CallableStatement is used to execute a named stored procedure or function. Unlike prepared statements, stored procedures and functions must exist before a CallableStatement can be executed on them. Like PreparedStatements, parameters can be passed to stored procedures and functions.
Because PreparedStatements are precompiled, they excel at reducing overall execution time for frequently executed SQL queries. For example, an online retailer like Bob’s Books may make frequent changes to price and quantity of the inventory based on seasonal demand and stock on hand. When the number of update operations with the database is in the thousands per day, the savings that a precompiled SQL statement affords is significant.
PreparedStatement objects are obtained from a Connection object in the same way that Statement objects are obtained, but through the prepareStatement() method instead of a createStatement() method. There are several forms of the prepareStatement method, including those that take the result set type and result set concurrency, just like Statement, so a ResultSet returned from a PreparedStatement can be scrollable and updatable as well.
One difference between the Statement and PreparedStatement is the execution sequence. Recall that for a Statement object, we created a Statement and then passed a String query to it to obtain a result, perform and update, or perform a general-purpose query. In order to construct a dynamic query using Statement, we had to carefully concatenate Strings to create the SQL query. Any parameters were added to the query before the String was passed as an argument to Statement’s execute method.
To create a PreparedStatement object instance, you pass a String query to the prepareStatement() method. The string passed as an argument is a parameterized query. A parameterized query looks like a standard SQL query, except the query takes an argument—for example, in the WHERE clause, we simply add a placeholder character, a question mark (?), as a parameter that will be filled in before we execute the query. Thus, the PreparedStatement object instance is constructed before the final query is executed, allowing you to modify the parameters of the query without having to construct a new Statement object every time.
Parameters passed into the query are referred to as IN parameters. In this example, we create a parameterized query to return the price of all books that have a title, such as the string we will pass into the query as a parameter:

Let’s take this apart. First, we created the PreparedStatement with a string that contained a parameter, indicated by the question mark in the string. The question mark represents a parameter that this query is expecting. Attempting to execute a query without setting a parameter will result in a SQLException.
The Java type of the parameter, String, int, float, etc., is entirely up to you. For this query, the type of the parameter expected is a String, so the PreparedStatement method used to insert a string value into the query is the setString() method. Note that we did not have to construct the String with single quotes, as you would typically have to do for a String query passed to a Statement:

This is an additional benefit of a PreparedStatement. Since the type expected by the setString() method is a String, the method replaces non-string characters by “escaping” them. Characters like ‘ (single quote) are converted to \’ (slash-single quote) in the string. Strings that could be executed as commands in SQL are converted to a single SQL string.
The setString() method takes two parameters: the index of the placeholder and the type expected by the set method. Just like the updateXXXX methods we looked at in ResultSet earlier, PreparedStatement has a setXXXX method for each of the Java types JDBC supports.
Again, as we mentioned earlier, the power of a PreparedStatement is that once the object is created with the parameterized query, the query is precompiled. When bind parameters are passed in the query, the query is stored in its post-plan state in the database. When parameters are received, the database simply has to substitute them into the plan and execute the query.
Where this makes the most sense is with a set of queries that is likely to be executed many times over the life of an application. For example, here is a PreparedStatement query used to add a record to the Purchase_Item table by adding another book to an existing customer’s order:
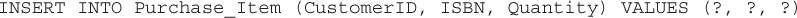
Queries like this one would be created by the application developer and used to create PreparedStatements available for execution at any point in the application lifecycle.
The CallableStatement extends the PreparedStatement interface to support calling a stored procedure or function using JDBC. By the way, the only difference between a stored procedure and a function is that a function is designed to return an argument. So for the rest of this chapter, we will refer to stored procedures and functions collectively as stored procedures.
Stored procedures offer a number of advantages over straight SQL queries. Most stored procedure languages are fairly sophisticated and support variables, branching, looping, and if-then-else constructs. A stored procedure can execute any SQL statement, so a single stored procedure can perform a number of operations in a single execution.
One use case for a stored procedure is to encapsulate specific tables in the database. Just like a Java class can encapsulate data by making a field private and then only providing access to the field through a method, a stored procedure can be used to prevent a user from having access to the data in a table directly. For example, imagine that an employee database contains very sensitive information, such as salary, Social Security numbers, and birth dates. To protect this information, a stored procedure can perform several checks on the user executing the stored procedure before making any changes or allowing access to the data.
There are two drawbacks to stored procedures. First, stored procedures are typically developed in a proprietary, database-specific language, requiring a developer to learn yet another set of commands and syntax. Second, once in the database, how they were written and what they actually do can be difficult to figure out since they are “compiled” into the database. And we all know how much developers like to create detailed documentation for their code!
Recently, more and more database vendors have moved to allowing Java to run in the database, making it easier to write stored procedures, although this doesn’t address the documentation issue. The bottom line from a performance standpoint is that stored procedures rule (just not so much from a maintainability standpoint). Regardless, how to write a stored procedure is really beyond the scope of this chapter, but some resources are available on the Internet—just do a search for “java stored procedures.”
Because stored procedures can be a proprietary language with a unique syntax, the JDBC API provides JDBC-specific escape syntax for executing stored procedures and functions. The JDBC driver takes care of converting the JDBC syntax to the database format. This syntax has two forms: one form for functions that return a result, and another form for stored procedures that do not return a result.
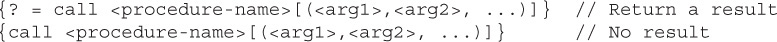
Like PreparedStatements, CallableStatements can pass arguments in to the stored procedure using an IN parameter. However, as shown in the first form earlier, functions return a value, as shown by the question mark to the left of the equals sign. The result of a function is returned to the caller as a parameter registered as an OUT parameter. Finally, stored procedures also support a third type of parameter that can be used to pass values into a stored procedure and return a result. These are called INOUT parameters. We will look at examples using these three types of parameters next.
CallableStatement objects are created using a Connection object instance and the prepareCall() method. Like PreparedStatement, the prepareCall() method takes a String as the first argument that describes the stored procedure call and uses one of the two forms shown earlier. Let’s look at an example. A stored procedure named “getBooksInRange” takes three arguments: a customer ID and two dates that represent the range to search between. The stored procedure returns all of the books purchased by a customer (the customer ID is used to identify the customer) between the two dates as a ResultSet.
Each of the parameters is an IN parameter and is inserted into the CallableStatement cstmt object using the appropriate setXXXX method before executing the stored procedure and returning the ResultSet:

Note that the executeQuery() command does not take a string (just like the PreparedStatement executeQuery() method). If you attempt to call executeQuery() on a CallableStatement with a String argument, a SQLException is thrown at runtime.
When a callable statement takes an OUT parameter, the parameter must also be registered as such before the call. For example, suppose we had a simple stored procedure that calculates the total of all orders placed by a customer. In this example, the stored procedure will return the result of the calculation as a SQL DOUBLE:

A stored procedure that takes a parameter that doubles as an INOUT parameter is passed the IN parameter first and then registered as an OUT parameter—for example, an imaginary stored procedure that takes the customer ID and simply counts the orders and returns them in the same parameter.

Because stored procedures are code that you, as a JDBC developer, may not have insight or control over, you may or may not know if a stored procedure returns a ResultSet. In fact, invoking executeQuery() on a stored procedure that does not return a ResultSet object will throw a SQLException. So if you are not sure, a good practice is to use the execute() method instead and test for a ResultSet after executing a stored procedure by using the method getMoreResults(); for example:

9.5 Construct and use RowSet objects using the RowSetProvider class and the RowSetFactory interface.
One of the changes for Java SE 7 was a minor update to JDBC. The version number of the API went from 4.0 to 4.1, and there were changes to the javax.sql.rowset package, including the addition of an interface, RowSetFactory, and a class, RowSetProvider. This interface and this class provide a convenient way for a developer to either use the default reference implementation of RowSet objects, or use a custom implementation using a factory pattern. These changes are referred to as RowSet 1.1.
What this means to you is two things: First, RowSetFactory and RowSetProvider are on the exam, and second, as a consequence, there is some coverage of RowSet interfaces on the exam as well. So this section will look at how to use RowSet interfaces.
First, know that a RowSet is a ResultSet. The RowSet interface extends the ResultSet interface. RowSet objects fall into two categories: those that are connected to the database and therefore stay in sync with the data in the database, and those that can be disconnected from a database and synchronized with the database later.
A connected RowSet provides you with the opportunity to keep state synchronized with data in a database table—so you might use a connected RowSet object to keep a shopping cart or other type of cache without needing to translate changes in your cart object into SQL update or insert queries. A disconnected RowSet is created with some initial state read from the database and can then be disconnected and passed to other objects and later synchronized with the database with changes.
Note there is no magic associated with data synchronization—a RowSet is a ResultSet, and therefore has the ability to update, remove, and insert new rows in the database. The difference between a ResultSet and RowSet is that a RowSet can maintain state so that when the underlying ResultSet object is changed, the data changes are reflected in the database—either synchronously, in the case of a connected RowSet, or asynchronously, in the case of a disconnected RowSet.
You might use a disconnected RowSet to pass an object containing a result set to a completely different application. For example, imagine that you have an application that builds a customer profile for an insurance policy using a workflow application. The initial data read may contain information about the customer: name, address, phone, and e-mail. This record is then passed as an object to another part of an application that fills in medical information: blood pressure, cholesterol, and blood sugar. When the disconnected RowSet object finally returns, it is synchronized with the database and any new and changed data is automatically written to the database without having to construct another SQL query.
Prior to RowSet 1.1, to create an instance of a RowSet object, you needed to know the full path name to the reference implementation class. So, to create an instance of a JdbcRowSet with the Sun reference implementation, you would need to include the full name of the implementation class (or make sure you imported the class) and include the implementation API in your classpath. For example:
Now, in Java SE 7, the RowSetProvider class, which is part of the core API, manages access to the reference implementation and returns a factory object (RowSetFactory) that can be used to generate instances of RowSet objects. Hopefully, this sounds very familiar to you—this factory pattern is similar to the one used to create Connection objects. The RowSetProvider class will return a reference to a RowSetFactory, which in turn can be used to create instances of RowSet objects. For example:

While this additional code may seem unnecessary, it allows you, the developer, to work with a well-defined factory interface in the API rather than a specialized implementation object. As a result, the implementation could be swapped out, and you would need only change one line of code:

The javax.sql package (and several subpackages) were introduced in Java SE 1.4 as an important part of supporting J2EE (Java EE 1.4). Although the bulk of the work for 1.4 was the introduction of DataSource as an alternative to DriverManager, Connection and Statement pooling in a J2EE container, and distributed transactions, what we are interested in in this section is RowSet.
The RowSet interface was developed to wrap a ResultSet as a JavaBeans component; in fact, the RowSet interface extends java.sql.ResultSet. So you may think of RowSet as a JavaBeans version of ResultSet. JavaBeans components have two important characteristics. One, they have a well-defined pattern for accessing fields in a class through getters and setters (properties), and two, they support and can participate in the JavaBeans event notification system.
Properties in a JavaBeans component are represented by a pair of methods, one to get the value of the property and one to set the value of the property. We often think of a property as a getter/setter pair for a class instance field, but the value of the property can also be computed. What is important about the getter/setter methods is consistency, because a requirement for a JavaBeans component is support for introspection. So, given these methods from the RowSet interface, we can infer that there is a String URL property associated with this component:
public String getUrl() throws SQLException
public void setUrl(String url) throws SQLException
The JavaBeans notification system allows RowSets to register themselves as listeners for events. A RowSet registers for an event by adding an instance of a class that implements the RowSetListener interface, which has three event methods that are invoked when one of the following events occurs on an instance of a RowSet object:
A change in the cursor location
A change to a row in this RowSet (inserted, updated, or deleted)
A change to the RowSet contents (a new RowSet)
As we mentioned earlier, RowSet objects come in two flavors: connected and disconnected. A connected RowSet maintains its connection to the underlying database. A disconnected RowSet can be connected to a database to get its initial information and then disconnected. While disconnected, changes can be made to the RowSet: Rows can be added, updated, or deleted and when reconnected to the database, the changes will be synchronized. Let’s look at each of these RowSet types.
The JdbcRowSet interface extends RowSet and provides a connected JavaBeans-styled ResultSet object. A JdbcRowSet instance is created from the RowSetFactory and then populated with a ResultSet returned from executing a SQL query. JdbcRowSet is a fairly thin wrapper around RowSet, so many of the methods shown in the examples are actually RowSet methods. Let’s start by creating a JdbdRowSet object:

Notice that we used the JdbcRowSet object to perform all of the tasks we did previously with a Connection, Statement, and ResultSet. Once we obtained the object from the factory, we simply set the values of the connection (URL, username, and password) and then execute the query statement. The JdbcRowSet object takes care of creating the connection, creating a statement, and executing the query. One of the nice features of a JdbcRowSet is that a number of characteristics are set by default. The default values and the setter methods are listed in the following table:

Once the execute statement completes, we have a connected JdbcRowSet. From there, the rest of the code should look familiar. We used next() to get to the next row in the result set and then printed the results to the console.
An important difference between how RowSet objects work and ResultSet objects work is evident in the execute() method. The execute() method is really the equivalent of executeQuery() and is intended to populate the JdbcRowSet object with data. There are no executeQuery() or executeUpdate() methods, and attempting to use the execute() method to perform an UPDATE, INSERT, or DELETE query will result in a SQLException. Instead, to perform an update, you simply need to update the data in your JdbcRowSet object. For example, assuming that we have populated the JdbcRowSet object jrs with all of the Author data, here we will change the first name of the last author in the set:

To delete a row, we move the cursor to the desired row and delete it. Here, for example, we will delete the fifth row of the current RowSet:

To insert a new row into the JdbcRowSet, the methods are similar to those in ResultSet. In this example, we will add a new author to the JdbcRowSet:

Note that like ResultSet, updating, deleting, and inserting affect the underlying database, but have varying effects on the current RowSet. Deleting a row from a RowSet leaves a gap in the current RowSet data, and inserting a row has no effect on the current RowSet data. The way to keep the data in the JdbcRowSet current is to re-execute the original query that populated the RowSet. You could simply add the execute command after every update, delete, or insert, like this:
But a more elegant way is to use the event model that JdbcRowSet implements. RowSet has a method to register a RowSetListener object:
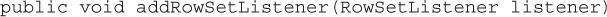
The RowSetListener interface has three methods that are invoked by the implementation, depending upon the event:
public void cursorMoved(RowSetEvent event) Receives an event for every movement of the cursor. This method is called a lot, for example, once for every invocation of next(), so be judicious of its use.
public void rowChanged(RowSetEvent event) Receives an event when a row is updated, inserted, or deleted. This is a good method to use to refresh the RowSet.
public void rowSetChanged(RowSetEvent event) Receives an event when the entire RowSet is changed, so for every invocation of execute().
Each of the methods listed here is passed a RowSetEvent object, which is simply a wrapper around the RowSet object that created the event. To create a listener that will automatically update our JdbcRowSet each time we delete, update, or insert a row, we need to create a class that implements RowSetListener and implement a rowChanged() method to refresh our RowSet:
Now we simply need to register this listener with our JdbcRowSet:
Now, whenever a row is updated, deleted, or inserted, the rowChanged() method in MyRowSetListener will be invoked and execute the current query set in the RowSet object to refresh the data in the RowSet.
There are several disconnected RowSets: WebRowSet, FilteredRowSet, and JoinRowSet. These RowSets are descendants of CachedRowSet, with some additional specialization in each. So once you understand CachedRowSet, we can describe the other interfaces in a few sentences. Working through each of the RowSets is really beyond the scope of this chapter, and is not covered on the exam.
A disconnected RowSet operates without requiring a connection to a database. Of course, in order to start with data, a disconnected RowSet typically does make a connection and gets a ResultSet, but immediately after, it is disconnected and can operate even if the database is offline. This is really the definition of a cache, after all—it is data held in memory and only synchronized with its data source when required.
To create a CachedRowSet, you create one from the RowSetFactory:
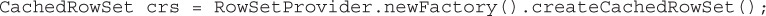
To initially load a CachedResultSet, you follow the same sequence as a JdbcRowSet: by setting the JDBC URL, username, password, and an execute query to populate the initial results:

Once you have made some changes (updated, inserted, or deleted) and are ready to push those changes to the database, you need to call the acceptChanges() method:
The difference between a connected RowSet, JdbcRowSet, and a disconnected RowSet is what happens behind the scenes for the execute() and acceptChanges() methods. CachedRowSet relies on another class, SyncProvider, to perform the synchronization with the underlying database. SyncProvider is implemented for you in the reference implementation. SyncProvider has two additional interfaces to perform reading (RowSetReader) and to perform writing (RowSetWriter). The implementation of these classes performs the following functions:
RowSetReader Makes a connection to the database, executes the query set in the RowSet, populates the CachedRowSet object with the data, and closes the connection.
RowSetWriter Makes a connection, updates the database with the changes made to the CachedRowSet object, and closes the connection.
If there are conflicts between the changes made to the disconnected RowSet object and the database (i.e., someone else altered the database while the CachedRowSet was disconnected), then SyncProvider will throw a SyncProviderException. You can use the exception thrown to get an instance of a class called SyncResolver to manage the conflicts. As your head is surely spinning by now, don’t worry—this is not on the exam and really beyond the scope of what this chapter is meant to cover.
Just to wrap up our discussion on the remaining RowSet objects, here is a summary of the RowSet objects in RowSet 1.1 and some benefits and features of each.

9.4 Use JDBC transactions (including disabling auto-commit mode, committing and rolling back transactions, and setting and rolling back to savepoints).
Transactions are a part of our everyday life. The classic transaction example involves two parties attempting to alter the same piece of data at the same time. For example, using the Figure 15-9, imagine we have two hopeful concert-goers, both interested in seats at the nearly sold-out Coldplay concert. Person A, on the top computer, wants five seats, all together, as close to center stage as possible. So in step 1 in the figure, the system returns information that it read from the concert-seating database, that yes, there are five seats together in row 12!
FIGURE 15-9 A transaction problem
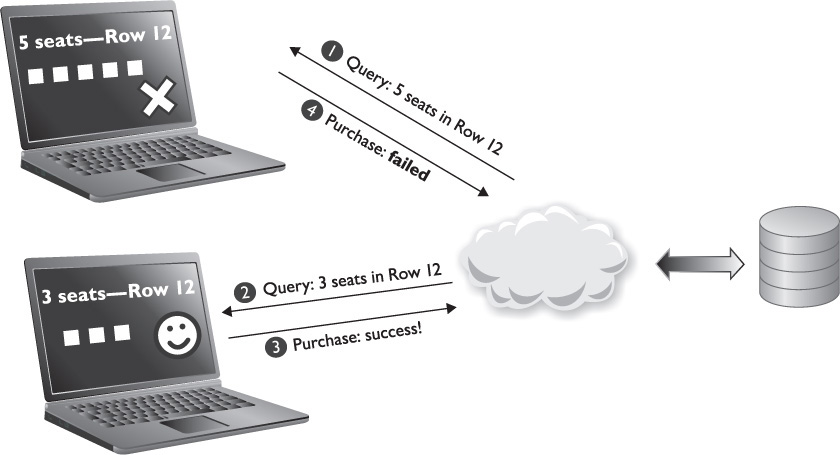
Person B on another computer (which looks suspiciously like Person A’s computer) is interested in three seats together, close to center stage. Again, in step 2, the database returns information that indicates that yes, there are three seats in row 12. So we arrive at the critical point—who will get the tickets?
Person B enters her credit card information and presses the buy button to purchase three tickets. The system begins a transaction to purchase the three seats. The system checks the credit card, gets a preliminary okay for the charge, updates the records of three seats to mark them unavailable, and charges the credit card. Finally, the transaction is committed and the system returns a confirmation message to Person B.
Meanwhile, Person A has finished entering his credit card information and started a transaction for the five seats. The system begins a transaction to purchase five seats. The system checks the credit card, gets a preliminary okay for the charge, and attempts to update the records of the five seats, but now three of the five seats are already marked taken. (By the way, as you will see a little later, this is called a dirty read.) At this point, the system must roll back the entire transaction, issue a credit request to the credit card, and return an error message to Person A.
This is the way transactions are supposed to work. What we would not want (or expect) to happen is that the system goes ahead and charges Person A for the five seats anyway, or conversely, for Person B to get the three seats even if her card was rejected. A transaction for the tickets is all or nothing—the desired seats have to be available, and the credit card must be valid and capable of being charged the amount of the tickets. This is the criteria for a successful transaction: all of them have to happen together, or none of them happens. And if any part of the transaction should fail—a bad credit card number or not enough seats—then everything must go back to the way it was before the transaction began. As it is, Person A may not be going to see Coldplay, but he is also not being charged for the tickets.
Fundamentally, in the world of transactions, it comes down to making sure that everything we wanted to happen in a transaction does, and that if there is a problem, everything goes back to the way it was before the transaction started.
JDBC support for transactions is a requirement for compliance with the specification. JDBC support for transactions includes three concepts:
All transactions are in auto-commit mode unless explicitly disabled.
Transactions have varying levels of isolation—that is, what data is visible to the code executing in a transaction.
JDBC supports the idea of a savepoint. A savepoint is a point within a transaction where the work that occurred up until that point is valid. A savepoint is useful when there are conditions in a transaction that you wish to preserve even if other parts of the transaction fail.
Let’s look at these three concepts in more detail in the next few sections.
Transactions are typically started with some type of begin statement. However, the JDBC API does not provide a begin() method for transactions, and by default, the JDBC driver or the database determines when to start a transaction and when to commit an existing transaction. When a SQL statement requires a transaction, the JDBC driver or database creates a transaction and commits the transaction when the statement ends. In order for you to control transactions with JDBC, you must first turn off this auto-commit mode:

Note the comment in the code—when you turn off auto-commit mode, you also explicitly begin a transaction.
A transaction includes all of the SQL queries you execute until either
You explicitly commit the current transaction.
You explicitly roll back the current transaction.
There is a failure that forces an automatic rollback.
As an example, we are going to add a book to Bob’s Bookstore. A book has a three-part relationship in our schema: There is an entry in the Authors table for the author’s name (first and last), and an entry in the Books table for the book, and a relationship between the two in the Books_by_Author table. If one of these three tables is not updated, we would end up with a phantom author or book. So when we add a book to Bob’s Bookstore, we need all three tables to be populated in a single transaction (all of the insert statements happen as a unit):

This is a perfect opportunity to use a set of prepared statements or, better yet, a stored procedure, since this is likely something that would happen a lot in a bookstore! As an application developer, if you find yourself cutting and pasting code, even if you are modifying it, think about being a DRY programmer. Andy Hunt and Dave Thomas formulated this principle in their book The Pragmatic Programmer (Addison-Wesley Professional, 1999). DRY stands for Don’t Repeat Yourself. What? I said, don’t… ah, you got me—very funny. Fundamentally, the DRY principle is about looking for every opportunity to apply code reuse by creating other methods or classes instead of copying and pasting. (As a counterpoint, programmers who cut and paste are sometimes called WET programmers: “Write Everything Twice,” or perhaps “We Enjoy Typing”?)
This example illustrates the concept of a transaction demarcation—where and when a transaction is started, and where and when a transaction is committed. Notice that we start a transaction on a Connection object by turning auto-commit off (false). This means that Connection can only have one transaction active at any one time. And without going into a lot of details about the different transaction models, this means that transactions in JDBC are flat. A flat transaction can include a number of different SQL statements, but there is only one transaction, and it only has one beginning and one end (at commit).
The other point is that as soon as the commit() method returns, we have started another transaction. Now what happens to our database if we don’t invoke the commit() method? If for, example, in the code fragment earlier, we left off the conn.commit() and just closed the Connection? Well, because invoking commit() changes the database, and JDBC is required to make sure that any statements are completely executed, the driver will not perform a commit implicitly, and the driver and database simply roll back the transaction as if nothing happened.
In the example we used to open this section on transactions, we mentioned that when Person A’s attempt to get five seats for Coldplay fails, the credit card transaction that was started is rolled back—in fact, short of remembering that he attempted to buy the tickets, there is no record of the credit transaction at all; it is as if it never happened.
A transaction rollback is simply a way to indicate, “These operations aren’t working out, I want everything back the way it was.” Transactions can be rolled back explicitly in code by invoking the rollback() method on the Connection object, or implicitly if a SQLException is thrown during any point of the transaction. As an example of an explicit rollback, in the code example where we added a new book to the database, we might want to check to make sure that each SQL INSERT was successful and, if there was a problem, roll back the entire transaction. The modified code looks like this:
Note that both commit() and rollback() are transaction methods, and if either of these methods is invoked when a Connection is not in a transaction (for example, when a Connection is in auto-commit mode), these methods will throw a SQLException.
One thing that is important to remember when using transactions is that it is extremely rare for an application to have only one user. As a result, there is a strong likelihood that two users will attempt to access the same data at the same time. An important aspect of transactions is isolation level—the visibility of one transaction to the changes being made by another transaction. Most databases (and therefore their drivers) have some default isolation level, and you can determine what isolation support is available using DatabaseMetaData and set the isolation level using the Connection setTransactionIsolation() method.
However, choosing the appropriate isolation level is an important task because with too little isolation, you run the risk of incorrect results, and with too much isolation, application performance suffers. Typically, you would work with your DBA to learn what the default isolation level is for your database and whether customizing the level would be appropriate for your application.
A savepoint is some point in a transaction where you want to place a virtual marker, indicating that everything is good up until this point. As a practical example of a transaction savepoint, imagine a situation in which a customer places an order for several books. The order application checks the availability of the requested books and finds that one of the books is out of stock. Rather than roll back the entire transaction, the application may place a savepoint on the order (for some limited amount of time) to allow the customer to decide if they want either the order all at once or a partial shipment now of the available titles and the rest later. If the customer agrees to receive a partial shipment, the transaction could then continue from the savepoint and ship part of the order.
In the JDBC API, a Savepoint is an object returned by a Connection in a transaction. A Savepoint object can be named or unnamed (created with a String name or not). The benefit of a Savepoint is that it represents a point in a transaction that you can roll back to. For example, let’s look at our sample code where we add a book to Bob’s Books. Suppose that we decide that while we must have an entry in the Book and Author table, we are okay if the entry in the join table fails, because we can make the connection between a book and its authors later.
We decide to use a Savepoint to identify that point when the Book and Author tables are set, and we can roll the transaction back to that point and commit it there if necessary:
There are a few important things to note about Savepoints:
When you set Savepoint A and then later set Savepoint B, if you roll back to Savepoint A, you automatically release and invalidate Savepoint B.
Support for Savepoints is not required, but you can check to see if your JDBC driver and database support Savepoints using the DatabaseMetaData .supportsSavePoints() method, which will return true if Savepoints are supported.
Because a Savepoint is an actual point-in-time state of a transaction context, the number of Savepoints supported by your JDBC driver and database may be limited. For example, the Java DB database does support Savepoints, but only one per transaction.
There is good news and bad news as well. The bad news is that there is no method to determine the number of Savepoints supported by your JDBC driver and database. The good news is that if you only get one, you can reuse it. Connection provides a releaseSavepoint() method, which takes a Savepoint object. After the Savepoint is released, you can set another Savepoint, sort of like moving your pebble forward in hopscotch!
Remember that the JDBC API is a set of interfaces with one important concrete class, the DriverManager class. You write code using the well-defined set of JDBC interfaces, and the provider of your JDBC driver writes code implementations of those interfaces. The key (and therefore required) interfaces a JDBC driver must implement include Driver, Connection, Statement, and ResultSet.
The driver provider will also implement an instance of DatabaseMetaData, which you use to invoke a method to query the driver for information about the database and JDBC driver. One important piece of information is if the database is SQL-92 compliant, and there are a number of methods that begin with “supports” to determine the capabilities of the driver. One important method is supportsResultSetType(), which is used to determine if the driver supports scrolling result sets.
The DriverManager is one of the few concrete classes in the JDBC API, and you will recall that the DriverManager is a factory class—using the DriverManager, you construct instances of Connection objects. In reality, the DriverManager simply holds references to registered JDBC drivers, and when you invoke the getConnection() method with a JDBC URL, the DriverManager passes the URL to each driver in turn. If the URL matches a valid driver, host, port number, username, and password, then that driver returns an instance of a Connection object. Remember that the JDBC URL is simply a string that encodes the information required to make a connection to a database.
How a JDBC driver is registered with the DriverManager is also important. In the current version of JDBC, 4.0, and later, the driver jar file simply needs to be on the classpath, and the DriverManager will take care of finding the driver’s Driver class implementation and load that. JDBC, 3.0, and earlier, require that the driver’s Driver class implementation be manually loaded using the Class.forName() method with the fully qualified class name of the class.
The most important use of a database is clearly using SQL statements and queries to create, read, update, and delete database records. The Statement interface provides the methods needed to create SQL statements and execute them. Remember that there are three different Statement methods to execute SQL queries: one that returns a result set, executeQuery(); one that returns an affected row count, executeUpdate(); and one general-purpose method, execute(), that returns a boolean to indicate if the query produced a result set.
ResultSet is the interface used to read columns of data returned from a query, one row at a time. ResultSet objects represent a snapshot (a copy) of the data returned from a query, and there is a cursor that points to just above the first row when the results are returned. Unless you created a Statement object using the Connection.createStatement(int, int) method that takes resultSetType and resultSetConcurrency parameters, ResultSets are not updatable and only allow the cursor to move forward through the results. However, if your database supports it, you can create a Statement object with a type of ResultSet.TYPE_SCROLL_INSENSITIVE and/or a concurrency of ResultSet.CONCUR_UPDATABLE, which allows any result set created with the Statement object to position the cursor anywhere in the results (scrollable) and allows you to change the value of any column in any row in the result set (updatable). Finally, when using a ResultSet that is scrollable, you can determine the number of rows returned from a query—and this is the only way to determine the row count because there is no “rowCount” method.
SQLException is the base class for exceptions thrown by JDBC, and because one query can result in a number of exceptions, the exceptions are chained. To determine all of the reasons a method call returned a SQLException, you must iterate through the exception by calling the getNextException() method. JDBC also keeps track of warnings for methods on Connection, Statement, and ResultSet objects using a SQLWarning exception type. Like SQLException, SQLWarning is silently chained to the object that caused the warning—for example, suppose that you attempt to create a Statement object that supports scrollable ResultSet, but the database does not support that type. A SQLWarning will be added to the Connection object (the Connection.createConnection(int, int) method creates a Statement object). The getWarnings() method is used to return any SQLWarnings.
One of the important additions to Java SE 7 is the try-with-resources statement, and all of the JDBC interfaces have been updated to support the new AutoCloseable interface. However, bear in mind that there is an order of precedence when closing Connections, Statements, and ResultSets. So when a Connection is closed, any Statement created from that Connection is also closed, and likewise, when a Statement is closed, any ResultSet created using that ResultSet is also closed. And attempting to invoke a method on a closed object will result in a SQLException!
SQL provides the ability to create a prepared statement query that is “precompiled.” This means that the syntax of the statement has been checked; any table names and column names are checked against the schema and, finally, an execution plan for the query is created. Note that JDBC’s PreparedStatement performs this precompilation during the first execution of the PreparedStatement. When you pass parameters to a prepared statement, the database substitutes the values you pass in for placeholders in the precompiled query. This makes the execution of the prepared query much faster than a regular query.
JDBC’s PreparedStatement object uses this mechanism to pass parameters into the precompiled query from your Java code. This approach makes it difficult to create a SQL injection attack because each PreparedStatement doesn’t allow strings passed in as parameters to contain non-string characters—these are “escaped” by prepending backslashes to them to make them into string characters.
Parameters passed into PreparedStatements are called IN parameters—these are set into the prepared statement and passed to the database for execution. Each IN type parameter corresponds to a specific placeholder (indicated by a question mark character).
CallableStatement is the JDBC object used to invoke database stored procedures. Unlike prepared statements, stored procedures use a database-dependent language that may or may not resemble SQL. Like prepared statements, stored procedures are compiled into the database and can accept parameters passed to them. However, stored procedures also allow values to be returned to the caller through OUT type parameters, using the same “?” syntax. Finally, parameters can be passed into a stored procedure and return a new value as a result through an INOUT type parameter.
Remember that as a result of a minor change to JDBC for version 4.1, the way that RowSet objects were created was changed, and thus, RowSetFactory and RowSetProvider are covered on the exam. Further, this means that you should understand the major differences between the various RowSet interfaces as well.
In previous versions of JDBC, an instance of a RowSet was created using the new keyword on a specific implementation, and you had to include the implementation in your classpath. In Java SE 7, using the RowSetProvider class and newFactory() method, you get an instance of a RowSetFactory object. Finally, RowSet objects are created using the factory. This approach hides the implementation details and eliminates changes in your code for different RowSet implementations.
The key to understanding RowSet objects is the difference between a connected and unconnected RowSet. A connected RowSet object, like JdbcRowSet, is created using an instance of RowSetFactory and then populated through a SQL query. Once populated, changes to a JdbcRowSet (updates, deletes, and inserts) are automatically reflected in the underlying database. To keep the JdbcRowSet in sync with the underlying database contents, you can re-execute the initial JdbcRowSet query or implement a RowSetListener to manage synchronization by tracking changes to the RowSet.
There are several disconnected RowSets, all descendants of CachedRowSet, so if you learn this one, you will be in good shape. Like connected RowSets, a disconnected RowSet is initially populated with a ResultSet. However, immediately after the RowSet is populated, it is disconnected from the database. Any changes made to the underlying results are cached (thus the aptly named class!). You are responsible for synching the changes you made with the underlying database by calling the acceptChanges() method.
The key takeaway for this certification objective is that JDBC transactions are in auto-commit mode by default, and you must explicitly start a transaction by calling Connection.setAutoCommit() with a boolean false parameter. This starts a transaction context. Within a transaction context, any changes made to the current ResultSet are not made to the underlying database until you explicitly call the commit() method. If you wish to undo changes made during a transaction, the transaction can be rolled back by calling the rollback() method. If a method invoked during a transaction results in a SQLException, the transaction is rolled back automatically. Finally, remember that the setAutoCommit() method is tricky—if you are in the middle of a transaction and call setAutoCommit(true), the equivalent of turning auto-commit back on, then the current transaction context is immediately committed.
Transactions in JDBC are flat, meaning there can be only one transaction context per Connection at any one time. However, some databases allow you to mark spots in your transaction called savepoints. If, partway through a transaction with multiple changes (inserts, deletes, updates), you create a Savepoint object by calling the setSavepoint() method, and if there is a problem further on in the transaction, you can roll the transaction back to your savepoint instead of all the way to the beginning.
Here are some of the key points from the certification objectives in this chapter.
 To be compliant with JDBC, driver vendors must provide implementations for the key JDBC interfaces:
To be compliant with JDBC, driver vendors must provide implementations for the key JDBC interfaces: Driver, Connection, Statement, and ResultSet.
DatabaseMetaData can be used to determine which SQL-92 level your driver and database support.
DatabaseMetaData provides methods to interrogate the driver for capabilities and features.
The JDBC API follows a factory pattern, where the DriverManager class is used to construct instances of Connection objects.
The JDBC URL is passed to each registered driver in turn in an attempt to create a valid Connection.
Identify the Java statements required to connect to a database using JDBC.
JDBC 3.0 (and earlier) drivers must be loaded prior to their use.
JDBC 4.0 drivers just need to be part of the classpath, and they are automatically loaded by the DriverManager.
The next() method must be called on a ResultSet before reading the first row of results.
When a Statement execute() method is executed, any open ResultSets tied to that Statement are automatically closed.
When a Statement is closed, any related ResultSets are also closed.
ResultSet column indexes are numbered from 1, not 0.
The default ResultSet is not updatable (read-only), and the cursor moves forward only.
A ResultSet that is scrollable and updatable can be modified, and the cursor can be positioned anywhere within the ResultSet.
ResultSetMetaData can be used to dynamically discover the number of columns and their type returned in a ResultSet.
ResultSetMetaData does not have a row count method. To determine the number of rows returned, the ResultSet must be scrollable.
ResultSet fetch size can be controlled for large data sets; however, it is a hint to the driver and may be ignored.
SQLExceptions are chained. You must iterate through the exception class thrown to get all of the reasons why an exception was thrown.
SQLException also contains database-specific error codes and status codes.
The executeQuery method is used to return a ResultSet (SELECT).
The executeUpdate method is used to update data, to modify the database, and to return the number of rows affected (INSERT, UPDATE, DELETE, and DDLs).
The execute method is used to perform any SQL command. A boolean true is returned when the query produced a ResultSet and false when there were no results, or if the result is an update count.
There is an order of precedence in the closing of Connections, Statements, and ResultSets.
Using the try-with-resources statement, you can close Connections, Statements, and ResultSets automatically (they implement the new AutoCloseable interface in Java SE 7).
When a Connection is closed, all of the related Statements and ResultSets are closed.
PreparedStatements are precompiled and can increase efficiency for frequently used SQL queries.
PreparedStatement is a good way to avoid SQL injection attacks.
PreparedStatement setXXXX methods are indexed from 1, not 0.
CallableStatements are executed using a stored procedure on the database.
The actual language used to create the stored procedure is database dependent.
JdbcRowSet provides a JavaBean view of a ResultSet (getters and setters).
Understand CachedRowSet, FilteredRowSet, JdbcRowSet, Joinable, JoinRowSet, Predicate, and WebRowSet.
RowSetProvider is a factory class used to obtain a RowSetFactory to generate RowSet object types.
RowSetFactory provides a way to create instances of RowSet objects. Prior to JDBC 4.1 (Java SE 7), the developer was required to provide the class name of the implementation of the RowSet interface.
Transactions in JDBC are flat—that is, there is only one transaction active at any one time per Connection instance.
All transactions in JDBC are in auto-commit mode by default—you must explicitly turn transactions on by calling Connection .setAutoCommit(false).
Invoking setAutoCommit(true) explicitly commits the current transaction (and reverts to auto-commit mode).
A rollback method throws an exception if Connection is set to auto-commit mode.
A savepoint is a point within a current transaction that can be referenced from a Connection.rollback() method.
A rollback to a savepoint only rolls the transaction back to the last savepoint created.
1. Given:

Assuming “org.gjt.mm.mysql.Driver” is a legitimate class, which line, when inserted at // INSERT CODE HERE, will correctly load this JDBC 3.0 driver?
A DriverManager.registerDriver(“org.gjt.mm.mysql.Driver”);
B. Class.forName(“org.gjt.mm.mysql.Driver”);
C. DatabaseMetaData.loadDriver(“org.gjt.mm.mysql.Driver”);
D. Driver.connect(“org.gjt.mm.mysql.Driver”);
E. DriverManager.getDriver(“org.gjt.mm.mysql.Driver”);
2. Given that you are working with a JDBC 4.0 driver, which three are required for this JDBC driver to be compliant?
A. Must include a META-INF/services/java.sql.Driver file
B. Must provide implementations of Driver, Connection, Statement, and ResultSet interfaces
C. Must support scrollable ResultSets
D. Must support updatable ResultSet s
E. Must support transactions
F. Must support the SQL99 standard
G. Must support PreparedStatement and CallableStatement
3. Which three are available through an instance of DatabaseMetaData?
A. The number of columns returned
B. The number of rows returned
C. The name of the JDBC driver
D. The default transaction isolation level
E. The last query used
F. The names of stored procedures in the database
G. The current Savepoint name
4. Given:

Assuming a Connection object has already been created (conn) and that the query produces a valid result, what is the result?
A. Compiler error at line X
B. Compiler error at line Y
C. No result
D. The first name from the first row that matches ‘Rand%’
E. SQLException
F. A runtime exception
5. Given the SQL query:
Assuming this is a valid SQL query and there is a valid Connection object (conn), which will compile correctly and execute this query?
A. Statement stmt = conn.createStatement();
stmt.executeQuery(query);
B. Statement stmt = conn.createStatement(query);
stmt.executeUpdate();
C. Statement stmt = conn.createStatement();
stmt.setQuery(query); stmt.execute();
D. Statement stmt = conn.createStatement();
stmt.execute(query);
E. Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeUpdate(query);
6. Given:

And assuming a valid Connection object (conn) and that the query will return results, what is the result?
A. The customer names will be printed out
B. Compiler error at line X
C. Illegal query
D. Compiler error at line Y
E. SQLException
F. Runtime exception
7. Given this code fragment:

Which query statements entered into <QUERY HERE> produce the output that follows the query string (in the following answer), assuming each query is valid? (Choose all that apply.)
A. “SELECT * FROM Customer” Results
B. “INSERT INTO Book VALUES (’1023456789’, ‘One Night in Paris’, ‘1984-10-20’, ‘Hardcover’, 13.95)” Update
C. “UPDATE Customer SET Phone = ‘555-234-1021’ WHERE CustomerID = 101” Update
D. “SELECT Author.LastName FROM Author” Results
E. “DELETE FROM Book WHERE ISBN = ‘1023456789’” Update
8. Given:

Assuming the table name and column names are valid, what is the result?
A. The last name of the customer with id 5001is set to “Smith”
B. Error – update failed
C. Exception
D. Compilation fails
9. Given:

And assuming that each pair of query elements in the array searchPair will return two rows and assuming a valid Connection object (conn), what is the result?
B. Yes Yes SQLException
C. Yes Yes Yes Yes
D. Compiler error at line X
E. Compiler error at line Y
F. Compiler error at line Z
10. Given:

If REMOVEBOOKS is a stored procedure that takes an INOUT integer parameter as its first argument and an IN String parameter as its second argument, which code blocks, when placed at the line // Code added here, could correctly execute the stored procedure and return a result?
11. Which creates a connected RowSet object?
A. WebRowSet wrs = RowSetProvider.newFactory().createWebRowSet();
B. CachedRowSet crs = RowSetProvider.newFactory().createCachedRowSet();
C. try(JdbcRowSet jrs = RowSetProvider.newFactory().createJdbcRowSet()) { // assume the rest of the try-catch is valid
D. try(RowSetFactory rsf = RowSetProvider.newFactory()) { RowSet rws = rsf.createRowSet(); // assume the rest of the try-catch is valid
E. JoinRowSet jrs = RowSetProvider.newFactory().createJoinRowSet();
F. ResultSet rs = Statement.execute(“SELECT * FROM Customer”); JdbcRowSet jrs = RowSetProvider.newFactory().setResultSet(rs);
12. Given:

Assuming that the query produced a result set in Line Q and that the database goes offline on or before the line OFFLINE and comes back online on or before the line ONLINE, which statements are true?
A. SQLException will print out due to Line V
B. SQLException will print out due to Line Z
C. SQLException will print out due to Line X
D. SQLException will print out due to Line Y
E. SQLException will print out due to Line W
F. One row is updated, one row is inserted, and one row is deleted
G. The database will be unchanged
13. Given:

And assuming the two queries are valid, what is the result of executing this fragment?
A. Query 1 and Query 2 are rolled back (no change to the database)
B. Query 1 is executed and Query 2 is rolled back
C. Query 1 is executed, Query 2 is executed, and SQLException
D. SQLException
E. A runtime exception is thrown
14. Given:

And given that the queries are valid, what is the result of executing this fragment?
A. Two new rows are added to the database
B. The row from query 1 is added to the database
C. The row from query 2 is added to the database
D. No rows are added to the database
E. A SQLException is thrown
15. Given:

Assuming that the Order table was empty before this code fragment was executed and that the database supports multiple savepoints and that all of the queries are valid, what rows does Order contain?
A. 23, 99.99, ‘Winter Boots’
B. 23, 99.99, ‘Winter Boots’ 25, 29.99, ‘Wool Scarf’
C. 23, 99.99, ‘Winter Boots’ 24, 39.99, ‘Fleece Jacket’
D. 24, 39.99, ‘Fleece Jacket’ 25, 29.99, ‘Wool Scarf’
E. No rows
1.  B is correct. Prior to JDBC 4.0, JDBC drivers were required to register themselves with the
B is correct. Prior to JDBC 4.0, JDBC drivers were required to register themselves with the DriverManager class by invoking DriverManager.register(this); after the driver was instantiated through a call from the classloader. The Class.forName() method calls the classloader, which in turn creates an instance of the class passed as a String to the method.
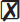 A is incorrect because this method is meant to be invoked with an instance of a
A is incorrect because this method is meant to be invoked with an instance of a Driver class. C is incorrect because DatabaseMetaData does not have a loadDriver method, and the purpose of DatabaseMetaData is to return information about a database connection. D is incorrect because, again, while the method sounds right, the arguments are not of the right types, and this method is actually the one called by DriverManager.getConnection to get a Connection object. E is incorrect because while this method returns a Driver instance, one has to be loaded and registered with the DriverManager first. (OCP Objective 9.2)
2. A,B, and E are correct. To be JDBC 4.0 compliant, a JDBC driver must support the ability to autoload the driver by providing a file, META-INF/services/java.sql.Driver, that indicates the fully qualified class name of the Driver class that DriverManager should load upon start-up. The JDBC driver must implement the interfaces for Driver, Connection, Statement, ResultSet, and others. The driver must also support transactions.
C and D are incorrect. It is not a requirement to support scrollable or updatable ResultSets, although many drivers do. If, however, the driver reports that through DatabaseMetaData it supports scrollable and updatable ResultSets, then the driver must support all of the methods associated with cursor movement and updates. F is incorrect. The JDBC requires that the driver support SQL92 entry-level grammar and the SQL command DROP TABLE (from SQL92 Transitional Level). G is not correct. While JDBC 4.0 drivers must support PreparedStatement, CallableStatement is optional, and only required if the driver returns true for the method DatabaseMetaData.supportsStoredProcedures. (OCP Objective 9.2)
3. C,D, and F are correct. DatabaseMetaData provides data about the database and the Connection object. The name, version, and other JDBC driver information are available, plus information about the database, including the names of stored procedures, functions, SQL keywords, and more. Finally, the default transaction isolation level and data about what transaction levels are supported are also available through DatabaseMetaData.
A and B are incorrect, as they are really about the result of a query with the database. Column count is available through a ResultSetMetaData object, but a row count requires that you, as the developer, move the cursor to the end of a result set and then evaluate the cursor position. E is incorrect. There is no method defined to return the last query in JDBC. G is not correct. The Savepoint information is accessed through a Savepoint instance and is part of a transaction. (OCP Objective 9.1)
4. E is correct. When the ResultSet returns, the cursor is pointing before the first row of the ResultSet. You must invoke the next() method to move to the next row of results before you can read any data from the columns. Trying to read a result using a getXXXX method will result in a SQLException when the cursor is before the first row or after the last row.
A, B, D, and F are incorrect based on the above. Note about C: the ResultSet returned from executeQuery will never be null. (OCP Objective 9.3)
5. D is correct.
Note that answer E is close, but will not compile because the executeUpdate(query) method returns an integer result. A will compile correctly, but throw a SQLException at runtime—the executeQuery method cannot be used on INSERT, UPDATE, DELETE, or DDL SQL queries. B will not compile because the createStatement method does not take a String argument for the query. C is incorrect because Statement does not have a setQuery method and this fragment will not compile. (OCP Objective 9.3)
6. E is correct. Recall that the try-with-resources statement on line X will automatically close the resource specified at the close of the try block (when the closing curly brace is reached), and closing the Statement object automatically closes any open ResultSets associated with the Statement. The SQLException thrown is that the ResultSet is not open. To fix this code, move the while statement into the try-with-resources block.
A, B, C, D, and F are incorrect based on the above. (OCP Objective 9.3)
7. All of the answers are correct (A, B, C, D, E). SELECT statements will produce a ResultSet even if there are no rows. INSERT, UPDATE, and DELETE statements all produce an update count, even when the number of rows affected is 0. (OCP Objective 9.3)
8. C is the correct answer. Parameters are numbered from 1, not 0. When the program executes, a SQLException will be thrown by Line X.
D is incorrect because the compiler cannot detect that the value of the method should be a 1 and not a zero. The compiler can only determine that the type of the argument is correct, and in this case, the type is correct as an integer. A and B are incorrect based on the above. (OCP Objective 9.6)
9. B is correct. In the first iteration of the for loop, i = 0 and the pstmt.setString method index (the first parameter) is 1 and the second index is 2. But in the second iteration of the loop, the index value is now 3 and 4, respectively. It would be better to hard-code these two values as 1 and 2, respectively.
A, C, D, E, and F are incorrect based on the above. (OCP Objective 9.6)
10. E is correct. Recall that to specify an IN parameter, you use a setXXXX method, and for an OUT parameter, you must register the parameter as an OUT before the call, and then use a getXXXX method to return the result from the stored procedure after executing the method.
A is incorrect because parameter indexes are numbered from 1, not from 0. B is incorrect because the executeQuery method includes the String query passed in as a parameter. This method will throw a SQLException. C is incorrect because the OUT parameter was not registered before the execute call, but after the execute method. D is incorrect because this stored procedure does not return a ResultSet. So while a ResultSet will be returned as a result of the executeQuery call, the call to rs.getInt will throw a SQLException. (OCP Objective 9.6)
11. C is the correct answer. This code fragment is creating an instance of a JdbcRowSet object—the only RowSet that is a connected RowSet object. This is the proper way to use the RowSetProvider static newFactory() method or obtain a RowSetFactory instance that is then used to create a JdbcRowSet instance.
A, B, and E are incorrect. These are disconnected RowSet objects, although the syntax to acquire these objects is correct. D is incorrect and will not compile. The reason is that RowSetFactory does not extend AutoCloseable; thus, the compiler will complain about the use of RowSetFactory in a try-with-resources. F is incorrect because this is not the proper way to initialize a RowSet object. The factory method is used to create an instance, and the instance must be used to execute a query and populate the RowSet with results. (OCP Objective 9.5)
12. G is correct. First, the database being offline at any point after the execute() method is invoked is irrelevant, since this is a disconnected RowSet object (CachedRowSet). Thus, the results are cached in the object and changes can be made to the results, regardless of the status of the database. However, there is a critical error in this code: to write the changes made to the data due to the update, insert, and delete, the acceptChanges() method must be called in order to make a connection to the database and reconcile the results in the CachedRowSet with the database. Since this line of code is missing, the changes were only made to the in-memory object and not reflected in the database.
A, B, C, D, E,and F are incorrect based on the above. (OCP Objective 9.5)
13. C is correct. Because the Connection object conn was never set to setAutoCommit(false), there is no transaction context to rollback. All transactions are in auto-commit mode, so the first transaction is executed and completed, the second transaction is executed and completed, and when the conn.rollback() method is executed on line Z, a SQLException is thrown because there is no transaction to rollback.
A, B, D, and E are incorrect based on the above. (OCP Objective 9.4)
14. D is correct. Because there is no commit statement, the Connection closes when the try block completes, and the transaction created by setting setAutoCommit to false is rolled back.
A, B, C,and E are incorrect based on the above. (OCP Objective 9.4)
15. B is correct. The statement conn.rollback(sp1); rolls back the insertion of the row that contains the ‘Fleece Jacket’. Then the transaction continues and processes the insertion of the row that contains ‘Wool Scarf’.
A, C, D, and E are incorrect based on the above. (OCP Objective 9.4)