 Two-Minute Drill
Two-Minute Drill• Search, Parse, and Build Strings (Including Scanner, StringTokenizer, StringBuilder, String, and Formatter)
• Search, Parse, and Replace Strings by Using Regular Expressions, Using Expression Patterns for Matching Limited to . (dot), * (star), + (plus),?, \d, \D, \s, \S, \w, \W, \b, \B, [], and ()
• Format Strings Using the Formatting Parameters %b, %c, %d, %f, and %s in Format Strings
• Read and Set the Locale Using the Locale Object
• Build a Resource Bundle for Each Locale
• Call a Resource Bundle from an Application
• Format Dates, Numbers, and Currency Values for Localization with the NumberFormat and DateFormat Classes (Including Number Format Patterns)
• Describe the Advantages of Localizing an Application
• Define a Locale Using Language and Country Codes
Two-Minute Drill
Q&A Self Test
This chapter focuses on the exam objectives related to searching, formatting, and parsing strings; formatting dates, numbers, and currency values; and using resource bundles for localization and internationalization tasks. Many of these topics could fill an entire book. Fortunately, you won’t have to become a total regex guru to do well on the exam. The intention of the exam team was to include just the basic aspects of these technologies, and in this chapter, we cover more than you’ll need to get through the related objectives on the exam.
5.1 Search, parse, and build strings (including Scanner, StringTokenizer, StringBuilder, String, and Formatter).
The OCA 7 exam covers the basics of building and using Strings and StringBuilders. While most of the OCP 7 String and StringBuilder questions will focus on searching and parsing, you might also get more basic questions, similar to those found on the OCA 7 exam. We recommend that you refresh your String and StringBuilder knowledge (the stuff we covered in Chapter 5), before taking the OCP 7 exam.
We’re going to start this chapter with date and number formatting and such, and we’ll return to parsing and tokenizing later in the chapter.
12.1 Read and set the locale using the Locale object.
12.4 Format dates, numbers, and currency values for localization with the NumberFormat and DateFormat classes (including number format patterns).
12.5 Describe the advantages of localizing an application.
12.6 Define a locale using language and country codes.
The Java API provides an extensive (perhaps a little too extensive) set of classes to help you work with dates, numbers, and currency. The exam will test your knowledge of the basic classes and methods you’ll use to work with dates and such. When you’ve finished this section, you should have a solid foundation in tasks such as creating new Date and DateFormat objects, converting Strings to Dates and back again, performing Calendaring functions, printing properly formatted currency values, and doing all of this for locations around the globe. In fact, a large part of why this section was added to the exam was to test whether you can do some basic internationalization (often shortened to “i18n”).
Note: In this section, we’ll introduce the Locale class. Later in the chapter, we’ll be discussing resource bundles, and you’ll learn more about Locale then.
If you want to work with dates from around the world (and who doesn’t?), you’ll need to be familiar with at least four classes from the java.text and java.util packages. In fact, we’ll admit it right up front: You might encounter questions on the exam that use classes that aren’t specifically mentioned in the Oracle objective. Here are the five date-related classes you’ll need to understand:

java.util.Date Most of this class’s methods have been deprecated, but you can use this class to bridge between the Calendar and DateFormat class. An instance of Date represents a mutable date and time, to a millisecond.
java.util.Calendar This class provides a huge variety of methods that help you convert and manipulate dates and times. For instance, if you want to add a month to a given date or find out what day of the week January 1, 3000, falls on, the methods in the Calendar class will save your bacon.
java.text.DateFormat This class is used to format dates, not only providing various styles such as “01/01/70” or “January 1, 1970,” but also dates for numerous locales around the world.
java.text.NumberFormat This class is used to format numbers and currencies for locales around the world.
java.util.Locale This class is used in conjunction with DateFormat and NumberFormat to format dates, numbers, and currency for specific locales. With the help of the Locale class, you’ll be able to convert a date like “10/10/2005” to “Segunda-feira, 10 de Outubro de 2005” in no time. If you want to manipulate dates without producing formatted output, you can use the Locale class directly with the Calendar class.
When you work with dates and numbers, you’ll often use several classes together. It’s important to understand how the classes we described earlier relate to each other and when to use which classes in combination. For instance, you’ll need to know that if you want to do date formatting for a specific locale, you need to create your Locale object before your DateFormat object, because you’ll need your Locale object as an argument to your DateFormat factory method. Table 8-1 provides a quick overview of common date-and number-related use cases and solutions using these classes. Table 8-1 will undoubtedly bring up specific questions about individual classes, and we will dive into specifics for each class next. Once you’ve gone through the class-level discussions, you should find that Table 8-1 provides a good summary.
TABLE 8-1 Common Use Cases When Working with Dates and Numbers

The Date class has a checkered past. Its API design didn’t do a good job of handling internationalization and localization situations. In its current state, most of its methods have been deprecated, and for most purposes, you’ll want to use the Calendar class instead of the Date class. The Date class is on the exam for several reasons: You might find it used in legacy code; it’s really easy if all you want is a quick and dirty way to get the current date and time; it’s good when you want a universal time that is not affected by time zones; and finally, you’ll use it as a temporary bridge to format a Calendar object using the DateFormat class.
As we mentioned briefly earlier, an instance of the Date class represents a single date and time. Internally, the date and time are stored as a primitive long. Specifically, the long holds the number of milliseconds (you know, 1000 of these per second) between the date being represented and January 1, 1970.
Have you ever tried to grasp how big really big numbers are? Let’s use the Date class to find out how long it took for a trillion milliseconds to pass, starting at January 1, 1970:

On our JVM, which has a U.S. locale, the output is
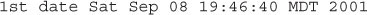
Okay, for future reference, remember that there are a trillion milliseconds for every 31 and 2/3 years.
Although most of Date’s methods have been deprecated, it’s still acceptable to use the getTime and setTime methods, although, as we’ll soon see, it’s a bit painful. Let’s add an hour to our Date instance, d1, from the previous example:

which produces (again, on our JVM):

Notice that both setTime() and getTime() used the handy millisecond scale… if you want to manipulate dates using the Date class, that’s your only choice. While that wasn’t too painful, imagine how much fun it would be to add, say, a year to a given date.
We’ll revisit the Date class later on, but for now, the only other thing you need to know is that if you want to create an instance of Date to represent “now,” you use Date’s no-argument constructor:

(We’re guessing that if you call now.getTime(), you’ll get a number somewhere between one trillion and two trillion.)
We’ve just seen that manipulating dates using the Date class is tricky. The Calendar class is designed to make date manipulation easy! (Well, easier.) While the Calendar class has about a million fields and methods, once you get the hang of a few of them, the rest tend to work in a similar fashion.
When you first try to use the Calendar class, you might notice that it’s an abstract class. You can’t say

In order to create a Calendar instance, you have to use one of the overloaded getInstance() static factory methods:

When you get a Calendar reference like cal, from earlier, your Calendar reference variable is actually referring to an instance of a concrete subclass of Calendar. You can’t know for sure what subclass you’ll get (java.util.GregorianCalendar is what you’ll almost certainly get), but it won’t matter to you. You’ll be using Calendar’s API. (As Java continues to spread around the world, in order to maintain cohesion, you might find additional, locale-specific subclasses of Calendar.)
Okay, so now we’ve got an instance of Calendar, let’s go back to our earlier example and find out what day of the week our trillionth millisecond falls on, and then let’s add a month to that date:

This produces something like

Let’s take a look at this program, focusing on the five highlighted lines:
1. We assign the Date d1 to the Calendar instance c.
2. We use Calendar’s SUNDAY field to determine whether, for our JVM, SUNDAY is considered to be the first day of the week. (In some locales, MONDAY is the first day of the week.) The Calendar class provides similar fields for days of the week, months, the day of the month, the day of the year, and so on.
3. We use the DAY_OF_WEEK field to find out the day of the week that the trillionth millisecond falls on.
4. So far, we’ve used “setter” and “getter” methods that should be intuitive to figure out. Now we’re going to use Calendar’s add() method. This very powerful method lets you add or subtract units of time appropriate for whichever Calendar field you specify. For instance:

5. Convert c’s value back to an instance of Date.
The other Calendar method you should know for the exam is the roll() method. The roll() method acts like the add() method, except that when a part of a Date gets incremented or decremented, larger parts of the Date will not get incremented or decremented. Hmmm… for instance:

The output would be something like this:

Notice that the year did not change, even though we added nine months to an October date. In a similar fashion, invoking roll() with HOUR won’t change the date, the month, or the year.
For the exam, you won’t have to memorize the Calendar class’s fields. If you need them to help answer a question, they will be provided as part of the question.
Having learned how to create dates and manipulate them, let’s find out how to format them. So that we’re all on the same page, here’s an example of how a date can be formatted in different ways:

which on our JVM produces

Examining this code, we see a couple of things right away. First off, it looks like DateFormat is another abstract class, so we can’t use new to create instances of DateFormat. In this case, we used two factory methods: getInstance() and getDateInstance(). Notice that getDateInstance() is overloaded; when we discuss locales, we’ll look at the other version of getDateInstance() that you’ll need to understand for the exam.
Next, we used static fields from the DateFormat class to customize our various instances of DateFormat. Each of these static fields represents a formatting style. In this case, it looks like the no-arg version of getDateInstance() gives us the same style as the MEDIUM version of the method, but that’s not a hard-and-fast rule. (More on this when we discuss locales.) Finally, we used the format() method to create strings representing the properly formatted versions of the Date we’re working with.
The last method you should be familiar with is the parse() method. The parse() method takes a string formatted in the style of the DateFormat instance being used and converts the string into a Date object. As you might imagine, this is a risky operation because the parse() method could easily receive a badly formatted string. Because of this, parse() can throw a ParseException. The following code creates a Date instance, uses DateFormat.format() to convert it into a string, and then uses DateFormat.parse() to change it back into a Date:

which on our JVM produces

Note: If we’d wanted to retain the time along with the date, we could have used the getDateTimeInstance()method, but it’s not on the exam.

The API for DateFormat.parse() explains that, by default, the parse() method is lenient when parsing dates. Our experience is that parse() isn’t very lenient about the formatting of strings it will successfully parse into dates; take care when you use this method!
Earlier, we said that a big part of why this objective exists is to test your ability to do some basic internationalization tasks. Your wait is over; the Locale class is your ticket to worldwide domination. Both the DateFormat class and the NumberFormat class (which we’ll cover next) can use an instance of Locale to customize formatted output to be specific to a locale. You might ask how Java defines a locale. The API says a locale is “a specific geographical, political, or cultural region.” The two Locale constructors you’ll need to understand for the exam are

The language argument represents an ISO 639 Language code, so, for instance, if you want to format your dates or numbers in Walloon (the language sometimes used in southern Belgium), you’d use “wa” as your language string. There are over 500 ISO Language codes, including one for Klingon (“tlh”), although, unfortunately, Java doesn’t yet support the Klingon locale. We thought about telling you that you’d have to memorize all these codes for the exam… but we didn’t want to cause any heart attacks. So rest assured, you won’t have to memorize any ISO Language codes or ISO Country codes (of which there are about 240) for the exam.
Let’s get back to how you might use these codes. If you want to represent basic Italian in your application, all you need is the language code. If, on the other hand, you want to represent the Italian used in Switzerland, you’d want to indicate that the country is Switzerland (yes, the country code for Switzerland is “CH”), but that the language is Italian:

Using these two locales on a date could give us output like this:

Now let’s put this all together in some code that creates a Calendar object, sets its date, and then converts it to a Date. After that, we’ll take that Date object and print it out using locales from around the world:

This, on our JVM, produces

Oops! Our machine isn’t configured to support locales for India or Japan, but you can see how a single Date object can be formatted to work for many locales.

There are a couple more methods in Locale (getDisplayCountry() and getDisplayLanguage()) that you’ll have to know for the exam. These methods let you create strings that represent a given locale’s country and language in terms of both the default locale and any other locale:

This, on our JVM, produces

Given that our JVM’s locale (the default for us) is US, the default for the country Brazil is Brazil, and the default for the Danish language is Danish. In Brazil, the country is called Brasil, and in Denmark, the language is called dansk. Finally, just for fun, we discovered that in Italy, the Danish language is called danese.
We’ll wrap up this objective by discussing the NumberFormat class. Like the DateFormat class, NumberFormat is abstract, so you’ll typically use some version of either getInstance() or getCurrencyInstance() to create a NumberFormat object. Not surprisingly, you use this class to format numbers or currency values:

This, on our JVM, produces

Don’t be worried if, like us, you’re not set up to display the symbols for francs, pounds, rupees, yen, baht, or drachmas. You won’t be expected to know the symbols used for currency: If you need one, it will be specified in the question. You might encounter methods other than the format() method on the exam. Here’s a little code that uses getMaximumFractionDigits(), setMaximumFractionDigits(), parse(), and setParseIntegerOnly():

This, on our JVM, produces

Notice that in this case, the initial number of fractional digits for the default NumberFormat is three, and that the format() method rounds f1’s value—it doesn’t truncate it. After changing nf’s fractional digits, the entire value of f1 is displayed. Next, notice that the parse() method must run in a try/catch block and that the setParseIntegerOnly() method takes a boolean and, in this case, causes subsequent calls to parse() to return only the integer part of strings formatted as floating-point numbers.
As we’ve seen, several of the classes covered in this objective are abstract. In addition, for all of these classes, key functionality for every instance is established at the time of creation. Table 8-2 summarizes the constructors or methods used to create instances of all the classes we’ve discussed in this section.
TABLE 8-2 Instance Creation for Key java .text and java.util Classes

5.1 Search, parse, and build strings (including Scanner, StringTokenizer, StringBuilder, String, and Formatter).
5.2 Search, parse, and replace strings by using regular expressions, using expression patterns for matching limited to . (dot), * (star), + (plus),?, \d, \D, \s, \S, \w, \W, \b, \B, [], and ().
5.3 Format strings using the formatting parameters %b, %c, %d, %f, and %s in format strings.
We’re going to start with yet another disclaimer: This small section isn’t going to morph you from regex newbie to regex guru. In this section, we’ll cover three basic ideas:
Finding stuff You’ve got big heaps of text to look through. Maybe you’re doing some screen scraping; maybe you’re reading from a file. In any case, you need easy ways to find textual needles in textual haystacks. We’ll use the java.util.regex.Pattern, java.util.regex.Matcher, and java .util.Scanner classes to help us find stuff.
Tokenizing stuff You’ve got a delimited file that you want to get useful data out of. You want to transform a piece of a text file that looks like “1500.00,343.77,123.4” into some individual float variables. We’ll show you the basics of using the String.split() method and the java.util.Scanner class to tokenize your data.
Formatting stuff You’ve got a report to create and you need to take a float variable with a value of 32500.000f and transform it into a string with a value of “$32,500.00”. We’ll introduce you to the java.util.Formatter class and to the printf() and format() methods.
Whether you’re looking for stuff or tokenizing stuff, a lot of the concepts are the same, so let’s start with some basics. No matter what language you’re using, sooner or later you’ll probably be faced with the need to search through large amounts of textual data, looking for some specific stuff.
Regular expressions (regex for short) are a kind of language within a language, designed to help programmers with these searching tasks. Every language that provides regex capabilities uses one or more regex engines. Regex engines search through textual data using instructions that are coded into expressions. A regex expression is like a very short program or script. When you invoke a regex engine, you’ll pass it the chunk of textual data you want it to process (in Java, this is usually a string or a stream), and you pass it the expression you want it to use to search through the data.
It’s fair to think of regex as a language, and we will refer to it that way throughout this section. The regex language is used to create expressions, and as we work through this section, whenever we talk about expressions or expression syntax, we’re talking about syntax for the regex “language.” Oh, one more disclaimer… we know that you regex mavens out there can come up with better expressions than what we’re about to present. Keep in mind that for the most part, we’re creating these expressions using only a portion of the total regex instruction set, thanks.
For our first example, we’d like to search through the following source String
abaaaba
for all occurrences (or matches) of the expression
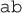
In all of these discussions, we’ll assume that our data sources use zero-based indexes, so if we display an index under our source String, we get
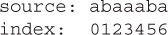
We can see that we have two occurrences of the expression ab: one starting at position 0 and the second starting at position 4. If we sent the previous source data and expression to a regex engine, it would reply by telling us that it found matches at positions 0 and 4. Below is a program (which we’ll explain in a few pages) that you can use to perform as many regex experiments as you want to get the feel for how regex works. We’ll use this program to show you some of the basics that are covered in the exam:

So this invocation:

produces

In a few pages, we’re going to show you a lot more regex code, but first we want to go over some more regex syntax. Once you understand a little more regex, the code samples will make a lot more sense. Here’s a more complicated example of a source and an expression:

How many occurrences do we get in this case? Well, there is clearly an occurrence starting at position 0 and another starting at position 4. But how about starting at position 2? In general in the world of regex, the aba string that starts at position 2 will not be considered a valid occurrence. The first general regex search rule is
In general, a regex search runs from left to right, and once a source’s character has been used in a match, it cannot be reused.
So in our previous example, the first match used positions 0, 1, and 2 to match the expression. (Another common term for this is that the first three characters of the source were consumed.) Because the character in position 2 was consumed in the first match, it couldn’t be used again. So the engine moved on and didn’t find another occurrence of aba until it reached position 4. This is the typical way that a regex matching engine works. However, in a few pages, we’ll look at an exception to the first rule we stated earlier.
So we’ve matched a couple of exact strings, but what would we do if we wanted to find something a little more dynamic? For instance, what if we wanted to find all of the occurrences of hex numbers or phone numbers or ZIP codes?
As luck would have it, regex has a powerful mechanism for dealing with the cases we described earlier. At the heart of this mechanism is the idea of a metacharacter. As an easy example, let’s say that we want to search through some source data looking for all occurrences of numeric digits. In regex, the following expression is used to look for numeric digits:

If we change the previous program to apply the expression \d to the following source string, we’d see:

regex will tell us that it found digits at positions 1, 2, 4, 6, 7, and 8. (If you want to try this at home, you’ll need to “escape” the compile method’s \d argument by making it ” \\d”; more on this a little later.)
Regex provides a rich set of metacharacters that you can find described in the API documentation for java.util.regex.Pattern. We won’t discuss them all here, but we will describe the ones you’ll need for the exam:
\d A digit (0–9) \D A non-digit (anything BUT 0–9)
\s A whitespace character (e.g. space, \t, \n, \f, \r) \S A non-whitespace character
\w A word character (letters (a–z and A–Z), digits, or the “_” [underscore]) \W A non-word character (everything else)
\b A word “boundary” (ends of the string and between \w and not \w—more soon)
\B A non-word “boundary” (between two \w’s or two not \w’s)
So, for example, given

regex will return positions 0, 2, 4, 5, 7, and 8. The only characters in this source that don’t match the definition of a word character are the whitespaces. (Note: In this example, we enclosed the source data in quotes to clearly indicate that there was no whitespace at either end.)
Character Matching The first six (\d, \D, \s, \S, \w, \W), are fairly straightforward. Regex returns the positions where occurrences of those types of characters (or their opposites occur). Here’s an example of an “opposites” match:

Here you can see that regex matched on everything BUT whitespace.
Boundary Matching The last two (\b and \B) are a bit different. In these cases, regex is looking for a specific relationship between two adjacent characters. When it finds a match, it returns the position of the second character. Also note that the ends of the strings are considered to be “non-word” characters. Let’s look at a few examples:

First, let’s recall that “word characters” are A–Z, a–z, and 0–9. It’s not too tricky to understand the matches at positions 3, 4, 5, and 9. Regex is telling us that characters 2 and 3 are a boundary between a word character and a non-word character. Remembering that order doesn’t matter, it’s easy to see that positions 4, 5, and 9 are similar “boundaries” between the two classes of characters—the character specified and the one preceding it.
But the matches on positions 0 and 11 are a bit confusing. For the sake of the exam, just imagine that for \b and \B, there is a hidden, non-word character at each end of the string that you can see. Let’s look at an example of using \b and then \B against the same string:

In this case, the matches should be intuitive; they mark the second character in a pair of characters that represent a boundary (word versus non-word). But here:

in this case, assuming invisible, non-word characters at each end of the string, we see places where there are NOT word boundaries (i.e., where two-word characters abut or where two non-word characters abut).
You can also specify sets of characters to search for using square brackets and ranges of characters to search for using square brackets and a dash:
[abc] Searches only for a’s, b’s, or c’s
[a-f] Searches only for a, b, c, d, e, or f characters
In addition, you can search across several ranges at once. The following expression is looking for occurrences of the letters a-f or A-F; it’s NOT looking for an fA combination:
[a-fA-F]Searches for the first six letters of the alphabet, both cases.
So, for instance,

returns positions 0, 1, 4, 5, 6.
In addition to the capabilities described for the exam, you can apply the following attributes to sets and ranges within square brackets: “^” to negate the characters specified, nested brackets to create a union of sets, and “&&” to specify the intersection of sets. While these constructs are not on the exam, they are quite useful, and good examples can be found in the API for the java.util.regex.Pattern class.
Let’s say that we want to create a regex pattern to search for hexadecimal literals. As a first step, let’s solve the problem for one-digit hexadecimal numbers:

The preceding expression could be stated:
Find a set of characters in which the first character is a "0", the second character is either an "x" or an "X", and the third character is a digit from "0" to "9", a letter from "a" to "f", or an uppercase letter from "A" to "F".
Using the preceding expression and the following data:

regex would return 6 and 11. (Note: 0x and 0xg are not valid hex numbers.)
As a second step, let’s think about an easier problem. What if we just wanted regex to find occurrences of integers? Integers can be one or more digits long, so it would be great if we could say “one or more” in an expression. There is a set of regex constructs called quantifiers that let us specify concepts such as “one or more.” In fact, the quantifier that represents “one or more” is the “+” character. We’ll see the others shortly.
The other issue this raises is that when we’re searching for something whose length is variable, getting only a starting position as a return value is of limited use. So, in addition to returning starting positions, another bit of information that a regex engine can return is the entire match, or group, that it finds. We’re going to change the way we talk about what regex returns by specifying each return on its own line, remembering that now for each return we’re going to get back the starting position AND then the group. Here’s the revised code:

So, if we invoke GroupTest like this:

you can read this expression as saying: “Find one or more digits in a row.” This expression produces this regex output:

You can read this as “At position 0, there’s an integer with a value of 1; then at position 3, there’s an integer with a value of 12; then at position 6, there’s an integer with a value of 234.” Returning now to our hexadecimal problem, the last thing we need to know is how to specify the use of a quantifier for only part of an expression. In this case, we must have exactly one occurrence of 0x or 0X, but we can have from one to many occurrences of the hex “digits” that follow. The following expression adds parentheses to limit the “+” quantifier to only the hex digits:

The parentheses and “+” augment the previous find-the-hex expression by saying in effect: “Once we’ve found our 0x or 0X, you can find from one to many occurrences of hex digits.” Notice that we put the “+” quantifier at the end of the expression. It’s useful to think of quantifiers as always quantifying the part of the expression that precedes them.
The other two quantifiers we’re going to look at are
* Zero or more occurrences
? Zero or one occurrence
Let’s say you have a text file containing a comma-delimited list of all the filenames in a directory that contains several very important projects. (BTW, this isn’t how we’d arrange our directories. :)) You want to create a list of all the files whose names start with proj1. You might discover .txt files, .java files, .pdf files—who knows? What kind of regex expression could we create to find these various proj1 files? First, let’s take a look at what a part of this text might look like:
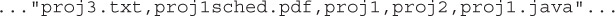
To solve this problem, we’re going to use the regex ^ (carat) operator, which we mentioned earlier. The regex ^ operator isn’t on the exam, but it will help us create a fairly clean solution to our problem. The ^ is the negation symbol in regex. For instance, if you want to find anything but a’s, b’s, or c’s in a file, you could say
[^abc]
So, armed with the ^ operator and the * (zero or more) quantifier, we can create the following:

If we apply this expression to just the portion of the text file we listed earlier, regex returns

The key part of this expression is the “give me zero or more characters that aren’t a comma.”
The last quantifier example we’ll look at is the? (zero or one) quantifier. Let’s say that our job this time is to search a text file and find anything that might be a local seven-digit phone number. We’re going to say, arbitrarily, that if we find seven digits in a row, or three digits followed by a dash, or a space followed by four digits, that we have a candidate. Here are examples of “valid” phone numbers:

The key to creating this expression is to see that we need “zero or one instance of either a space or a dash” in the middle of our digits:

In addition to the \s, \d, and \w metacharacters that we discussed, you have to understand the “.” (dot) metacharacter. When you see this character in a regex expression, it means “any character can serve here.” For instance, the following source and pattern:

will produce the output

The “.” was able to match both the “b” and the ” ” in the source data.
When you use the *, +, and ? quantifiers, you can fine-tune them a bit to produce behavior that’s known as “greedy,” “reluctant,” or “possessive.” Although you need to understand only the greedy quantifier for the exam, we’re also going to discuss the reluctant quantifier to serve as a basis for comparison. First, the syntax:
? is greedy, ?? is reluctant, for zero or once
*is greedy, *? is reluctant, for zero or more
+ is greedy, +? is reluctant, for one or more
What happens when we have the following source and pattern:

First off, we’re doing something a bit different here by looking for characters that prefix the static (xx) portion of the expression. We think we’re saying something like: “Find sets of characters that end with xx“. Before we tell what happens, we at least want you to consider that there are two plausible results… can you find them? Remember we said earlier that in general, regex engines worked from left to right and consumed characters as they went. So, working from left to right, we might predict that the engine would search the first four characters (0–3), find xx starting in position 2, and have its first match. Then it would proceed and find the second xx starting in position 6. This would lead us to a result like this:

A plausible second argument is that since we asked for a set of characters that ends with xx, we might get a result like this:
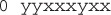
The way to think about this is to consider the name greedy. In order for the second answer to be correct, the regex engine would have to look (greedily) at the entire source data before it could determine that there was an xx at the end. So, in fact, the second result is the correct result because in the original example we used the greedy quantifier *. The result that finds two different sets can be generated by using the reluctant quantifier *?. Let’s review:
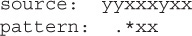
is using the greedy quantifier * and produces


we’re now using the reluctant qualifier *?, and we get the following:

The greedy quantifier does, in fact, read the entire source data and then it works backward (from the right) until it finds the rightmost match. At that point, it includes everything from earlier in the source data, up to and including the data that is part of the rightmost match.
There are a lot more aspects to regex quantifiers than we’ve discussed here, but we’ve covered more than enough for the exam. Oracle has several tutorials that will help you learn more about quantifiers and turn you into the go-to person at your job.
So far, we’ve been talking about regex from a theoretical perspective. Before we can put regex to work, we have to discuss one more gotcha. When it’s time to implement regex in our code, it will be quite common that our source data and/or our expressions will be stored in strings. The problem is that metacharacters and strings don’t mix too well. For instance, let’s say we just want to do a simple regex pattern that looks for digits. We might try something like
String pattern = "\d"; // compiler error!
This line of code won’t compile! The compiler sees the \ and thinks, “Okay, here comes an escape sequence; maybe it’ll be a new line!” But no, next comes the d and the compiler says, “I’ve never heard of the \d escape sequence.” The way to satisfy the compiler is to add another backslash in front of the \d:
String pattern = "\\d"; // a compilable metacharacter
The first backslash tells the compiler that whatever comes next should be taken literally, not as an escape sequence. How about the dot (.) metacharacter? If we want a dot in our expression to be used as a metacharacter, no problem, but what if we’re reading some source data that happens to use dots as delimiters? Here’s another way to look at our options:
A similar problem can occur when you hand metacharacters to a Java program via command-line arguments. If we want to pass the \d metacharacter into our Java program, our JVM does the right thing if we say

But your JVM might not. If you have problems running the following examples, you might try adding a backslash (i.e., \\d) to your command-line metacharacters. Don’t worry—you won’t see any command-line metacharacters on the exam!
The Java language defines several escape sequences, including
\n = linefeed (which you might see on the exam)
\b = backspace
\t = tab
And others, which you can find in the Java Language Specification. Other than perhaps seeing a \n inside a string, you won’t have to worry about Java’s escape sequences on the exam.
At this point, we’ve learned enough of the regex language to start using it in our Java programs. We’ll start by looking at using regex expressions to find stuff, and then we’ll move to the closely related topic of tokenizing stuff.
Over the last few pages, we’ve used a few small Java programs to explore some regex basics. Now we’re going to take a more detailed look at the two classes we’ve been using: java.util.regex.Pattarn and java.util.regex.Matcher. Once you know a little regex, using the java.util.regex.Pattern (Pattern) and java.util.regex.Matcher (Matcher) classes is pretty straightforward. The Pattern class is used to hold a representation of a regex expression so that it can be used and reused by instances of the Matcher class. The Matcher class is used to invoke the regex engine, with the intention of performing match operations. The following program shows Pattern and Matcher in action, and, as we’ve seen, it’s not a bad way for you to do your own regex experiments. Note, once you’ve read about the Console class in Chapter 9, you might want to modify the following class by adding some functionality from the Console class. That way, you’ll get some practice with the Console class, and it’ll be easier to run multiple regex experiments.

As with our earlier programs, this program uses the first command-line argument (args[0]) to represent the regex expression you want to use, and it uses the second argument (args[1]) to represent the source data you want to search. Here’s a test run:
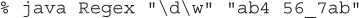
produces the output

(Remember, if you want this expression to be represented in a string, you’d use \\d\\w.) Because you’ll often have special characters or whitespace as part of your arguments, you’ll probably want to get in the habit of always enclosing your argument in quotes. Let’s take a look at this code in more detail. First off, notice that we aren’t using new to create a Pattern; if you check the API, you’ll find no constructors are listed. You’ll use the overloaded, static compile() method (which takes String expression) to create an instance of Pattern. For the exam, all you’ll need to know to create a Matcher is to use the Pattern.matcher() method (which takes String sourceData).
The important method in this program is the find() method. This is the method that actually cranks up the regex engine and does some searching. The find() method returns true if it gets a match and remembers the start position of the match. If find() returns true, you can call the start() method to get the starting position of the match, and you can call the group() method to get the string that represents the actual bit of source data that was matched.
To provide the most flexibility, Matcher.find(), when coupled with the greedy quantifiers ? or *, allows for (somewhat unintuitively) the idea of a zero-length match. As an experiment, modify the previous Regex class and add an invocation of m.end() to the System.out.print (S.O.P.) in the while loop. With that modification in place, the invocation

should produce something very similar to this:

The lines of output 1 1 and 3 3 are examples of zero-length matches. Zero-length matches can occur in several places:
After the last character of source data (the 3 3 example)
In between characters after a match has been found (the 1 1 example)
At the beginning of source data (try java Regex “a?” “baba”)
At the beginning of zero-length source data
A common reason to use regex is to perform search-and-replace operations. Although replace operations are not on the exam, you should know that the Matcher class provides several methods that perform search-and-replace operations. See the appendReplacement(), appendTail(), and replaceAll() methods in the Matcher API for more details.
The Matcher class allows you to look at subsets of your source data by using a concept called regions. In real life, regions can greatly improve performance, but you won’t need to know anything about them for the exam.
Searching Using the Scanner Class Although the java.util.scanner class is primarily intended for tokenizing data (which we’ll cover next), it can also be used to find stuff, just like the Pattern and Matcher classes. While Scanner doesn’t provide location information or search-and-replace functionality, you can use it to apply regex expressions to source data to tell you how many instances of an expression exist in a given piece of source data. The following program uses the first command-line argument as a regex expression and then asks for input using System .in. It outputs a message every time a match is found:

The invocation and input

produce the following:

Tokenizing is the process of taking big pieces of source data, breaking them into little pieces, and storing the little pieces in variables. Probably the most common tokenizing situation is reading a delimited file in order to get the contents of the file moved into useful places, like objects, arrays, or collections. We’ll look at two classes in the API that provide tokenizing capabilities: String (using the split() method) and Scanner, which has many methods that are useful for tokenizing.
When we talk about tokenizing, we’re talking about data that starts out composed of two things: tokens and delimiters. Tokens are the actual pieces of data, and delimiters are the expressions that separate the tokens from each other. When most people think of delimiters, they think of single characters, like commas or backslashes or maybe a single whitespace. These are indeed very common delimiters, but strictly speaking, delimiters can be much more dynamic. In fact, as we hinted at a few sentences ago, delimiters can be anything that qualifies as a regex expression. Let’s take a single piece of source data and tokenize it using a couple of different delimiters:

If we say that our delimiter is a comma, then our four tokens would be

If we use the same source but declare our delimiter to be \d, we get three tokens:
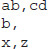
In general, when we tokenize source data, the delimiters themselves are discarded and all that we are left with are the tokens. So in the second example, we defined digits to be delimiters, so the 5, 6, and 4 do not appear in the final tokens.
The String class’s split() method takes a regex expression as its argument and returns a String array populated with the tokens produced by the split (or tokenizing) process. This is a handy way to tokenize relatively small pieces of data. The following program uses args[0] to hold a source string, and args[1] to hold the regex pattern to use as a delimiter:

Everything happens all at once when the split() method is invoked. The source string is split into pieces, and the pieces are all loaded into the tokens String array. All the code after that is just there to verify what the split operation generated. The following invocation

produces

(Note: Remember that to represent “\” in a string, you may need to use the escape sequence “\\“. Because of this, and depending on your OS, your second argument might have to be “\\d” or even “\\\\d“.)
We put the tokens inside > < characters to show whitespace. Notice that every digit was used as a delimiter and that contiguous digits created an empty token.
One drawback to using the String.split() method is that often you’ll want to look at tokens as they are produced, and possibly quit a tokenization operation early when you’ve created the tokens you need. For instance, you might be searching a large file for a phone number. If the phone number occurs early in the file, you’d like to quit the tokenization process as soon as you’ve got your number. The Scanner class provides a rich API for doing just such on-the-fly tokenization operations.
Because System.out.println() is so heavily used on the exam, you might see examples of escape sequences tucked in with questions on most any topic, including regex. Remember that if you need to create a string that contains a double quote (”) or a backslash (\), you need to add an escape character first:

This prints

But what if you need to search for periods (.) in your source data? If you just put a period in the regex expression, you get the “any character” behavior. But what if you try “\.”? Now the Java compiler thinks you’re trying to create an escape sequence that doesn’t exist. The correct syntax is

The java.util.Scanner class is the Cadillac of tokenizing. When you need to do some serious tokenizing, look no further than Scanner—this beauty has it all. In addition to the basic tokenizing capabilities provided by String.split(), the Scanner class offers the following features:
Scanners can be constructed using files, streams, or strings as a source.
Tokenizing is performed within a loop so that you can exit the process at any point.
Tokens can be converted to their appropriate primitive types automatically.
Let’s look at a program that demonstrates several of Scanner’s methods and capabilities. Scanner’s default delimiter is whitespace, which this program uses. The program makes two Scanner objects: s1 is iterated over with the more generic next() method, which returns every token as a String, while s2 is analyzed with several of the specialized nextXxx() methods (where Xxx is a primitive type):

If this program is invoked with
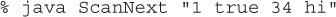
it produces

Of course, we’re not doing anything with the tokens once we’ve got them, but you can see that s2’s tokens are converted to their respective primitives. A key point here is that the methods named hasNextXxx() test the value of the next token but do not actually get the token, nor do they move to the next token in the source data. The nextXxx() methods all perform two functions: They get the next token, and then they move to the next token.
The Scanner class has nextXxx() (for instance, nextLong()) and hasNextXxx() (for instance, hasNextDouble()) methods for every primitive type except char. In addition, the Scanner class has a useDelimiter() method that allows you to set the delimiter to be any valid regex expression.
The java.util.StringTokenizer class is the rusty old Buick of tokenizing. These days, when you want to do tokenizing, the Scanner class and String.split()are the preferred approaches. In fact, in the API docs, the StringTokenizer class is not recommended. The reason it’s on the exam is because you’ll often find it in older code, and when you do, you’ll want to understand how it works. The following list of features summarizes the capabilities of StringTokenizer and relates them to the Scanner class:
StringTokenizer objects are constructed using strings as a source.
StringTokenizer objects use whitespace characters by default as delimiters, but they can be constructed with a custom set of delimiters (which are listed as a string).
Tokenizing is performed within a loop so that you can exit the process at any point.
The loop used for tokenizing uses the Enumerator interface, and typically uses the hasMoreTokens() and nextToken() methods, which are very similar to Scanner’s next() and hasNext() methods. (Note: These days, the Iterator interface is recommended instead of Enumerator.)
Let’s look at a program that demonstrates several of StringTokenizer’s methods and capabilities:

which produces the output:

To recap, the first StringTokenizer, st, uses whitespace as its delimiter, and the second StringTokenizer, st2, uses “a” as its delimiter. In both cases, we surrounded the tokens with “> <” characters to show any whitespace included in tokens. We also used the countTokens() method to display how many tokens were Enumerator-able before and after each enumeration loop.
There are a few more details in the StringTokenizer class, but this is all you’ll need for the exam.
What fun would accounts receivable reports be if the decimal points didn’t line up? Where would you be if you couldn’t put negative numbers inside of parentheses? Burning questions like these caused the exam creation team to include formatting as a part of the exam. The format() and printf() methods were added to java.io .PrintStream in Java 5. These two methods behave exactly the same way, so anything we say about one of these methods applies to both of them. (The rumor is that printf() was added just to make old C programmers happy.)
Behind the scenes, the format() method uses the java.util.Formatter class to do the heavy formatting work. You can use the Formatter class directly if you choose, but for the exam, all you have to know is the basic syntax of the arguments you pass to the format() method. The documentation for these formatting arguments can be found in the Formatter API. We’re going to take the “nickel tour” of the formatting String syntax, which will be more than enough to allow you to do a lot of basic formatting work AND ace all the formatting questions on the exam.
Let’s start by paraphrasing the API documentation for format strings (for more complete, way-past-what-you-need-for-the-exam coverage, check out the java.util.Formatter API):

The format string can contain both normal string-literal information that isn’t associated with any arguments and argument-specific formatting data. The clue to determining whether you’re looking at formatting data is that formatting data will always start with a percent sign (%). Let’s look at an example, and don’t panic, we’ll cover everything that comes after the % next:

This produces
456 + 123
Let’s look at what just happened. Inside the double quotes there is a format string, then a +, and then a second format string. Notice that we mixed literals in with the format strings. Now let’s dive in a little deeper and look at the construction of format strings:

The values within [ ] are optional. In other words, the only required elements of a format string are the % and a conversion character. In the previous example, the only optional values we used were for argument indexing. The 2$ represents the second argument, and the 1$ represents the first argument. (Notice that there’s no problem switching the order of arguments.) The d after the arguments is a conversion character (more or less the type of the argument). Here’s a rundown of the format string elements you’ll need to know for the exam:
arg_index An integer followed directly by a $, this indicates which argument should be printed in this position.
flags While many flags are available, for the exam, you’ll need to know:
- Left-justify this argument
+ Include a sign (+ or -) with this argument
0 Pad this argument with zeroes
, Use locale-specific grouping separators (i.e., the comma in 123, 456)
( Enclose negative numbers in parentheses
width This value indicates the minimum number of characters to print. (If you want nice, even columns, you’ll use this value extensively.)
precision For the exam, you’ll only need this when formatting a floating-point number, and in the case of floating-point numbers, precision indicates the number of digits to print after the decimal point.
conversion The type of argument you’ll be formatting. You’ll need to know:
b boolean
c char
d integer
f floating point
s string
Let’s see some of these formatting strings in action:

This produces:

(We added the > and < literals to help show how minimum widths, zero padding, and alignments work.) Finally, it’s important to remember that—barring the use of booleans—if you have a mismatch between the type specified in your conversion character and your argument, you’ll get a runtime exception:


12.2 Build a resource bundle for each object.
12.3 Call a resource bundle from an application.
12.5 Describe the advantages of localizing an application.
Earlier, we used the Locale class to display numbers and dates for basic localization. For full-fledged localization, we also need to provide language and country-specific strings for display. There are only two parts to building an application with resource bundles:
Locale You can use the same Locale we used for DateFormat and NumberFormat to identify which resource bundle to choose.
ResourceBundle Think of a ResourceBundle as a map. You can use property files or Java classes to specify the mappings.
Let’s build up a simple application to be used in Canada. Since Canada has two official languages, we want to let the user choose her favorite language. Designing our application, we decided to have it just output “Hello Java” to show off how cool it is. We can always add more text later.
We are going to externalize everything language specific to special files called resource bundles. They’re just property files that contain keys and string values to display. Here are two simple resource bundle files:
A file named Labels_en.properties that contains a single line of data:

A second file named Labels_fr.properties that contains a single line of data:
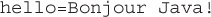
Using a resource bundle has three steps: obtaining the Locale, getting the ResourceBundle, and looking up a value from the resource bundle. First, we create a Locale object. To review, this means one of the following:

Next, we need to create the resource bundle. We need to know the “title” of the resource bundle and the locale. Then we pass those values to a factory, which creates the resource bundle. The getBundle() method looks in the classpath for bundles that match the bundle name (“Labels”) and the provided locale.
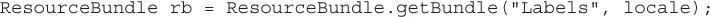
Finally, we use the resource bundle like a map and get a value based on the key:
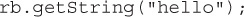
Putting this together and adding java.util imports, we have everything we need in order to read from a resource bundle:

Running the code twice, we get:

The Java API for java.util.ResourceBundle lists three good reasons to use resource bundles. Using resource bundles “allows you to write programs than can
Be easily localized, or translated, into different languages
Handle multiple locales at once
Be easily modified later to support even more locales”
If you encounter any questions on the exam that ask about the advantages of using resource bundles, this quote from the API will serve you well.
The most common use of localization in Java is web applications. You can get the user’s locale from information passed in the request rather than hard-coding it.
Let’s take a closer look at the property file. Aside from comments, a property file contains key/value pairs:

As you can see, comments are lines beginning with #. A key is the first string on a line. Keys and values are separated by an equal sign. If you want to break up a single line into multiple lines, you use a backslash:

If you actually want a line break, you use the standard Java \n escape sequence:

You can mix and match these to your heart’s content. Java helpfully ignores any whitespace before subsequent lines of a multiline property. This is so you can use indentation for clarity:

Almost everyone uses # for comments and = to separate key/value pairs. There are alternative syntax choices, though, which you should understand if you come across them.
Property files can use two styles of commenting:

or

Property files can define key/value pairs in any of the following formats:

These few rules are all you need to know about the PropertyResourceBundle. While property files are the most common format for resource bundles, what happens if we want to represent types of values other than String? Or if we want to load the resource bundles from a database?
When we need to move beyond simple property file key to string value mappings, we can use resource bundles that are Java classes. We write Java classes that extend ListResourceBundle. The class name is similar to the one for property files. Only the extension is different.

We implement ListResourceBundle’s one required method that returns an array of arrays. The inner array is key/value pairs. The outer array accumulates such pairs. Notice that now we aren’t limited to String values. We can call getObject() to get a non-String value:

Which prints “from Java”.
What do you think happens if we call ResourceBundle.getBundle (“Labels”) without any locale? It depends. Java will pick the resource bundle that matches the locale the JVM is using. Typically, this matches the locale of the machine running the program, but it doesn’t have to. You can even change the default locale at runtime. Which might be useful if you are working with people in different locales so you can get the same behavior on all machines.
Exploring the API to get and set the default locale:

which on our computer prints:

For the first and last line, you may get different output depending on where you live. The key is that the middle of the program executes as if it were in Germany, regardless of where it is actually being run. It is good practice to restore the default unless your program is ending right away. That way, the rest of your code works normally—it probably doesn’t expect to be in Germany.
There are two main ways to get a resource bundle:

Luckily, ResourceBundle.getBundle(baseName)is just shorthand for ResourceBundle.getBundle(baseName, Locale.getDefault())and you only have to remember one set of rules. There are a few other overloaded signatures for getBundle(), such as taking a ClassLoader. But don’t worry—these aren’t on the exam.
Now on to the rules. How does Java choose the right resource bundle to use? In a nutshell, Java chooses the most specific resource bundle it can while giving preference to Java ListResourceBundle.
Going back to our Canadian application, we decide to request the Canadian French resource bundle:

Java will look for the following files in the classpath in this order:

If none of these files exist, Java gives up and throws a MissingResourceException. While this is a lot of things for Java to try, it is pretty easy to remember. Start with the full Locale requested. Then fall back to just language. Then fall back to the default Locale. Then fall back to the default bundle. Then cry.
Make sure you understand this because it is about to get more complicated.
You don’t have to specify all the keys in all the property files. They can inherit from each other. This is a good thing, as it reduces duplication.

Outputs:

The common “ride.in” property comes from the parent noncountry-specific bundle “RB_en.properties.” The “elevator” property is different by country and comes from the UK version that we specifically requested.
The parent hierarchy is more specific than the search order. A bundle’s parent always has a shorter name than the child bundle. If a parent is missing, Java just skips along that hierarchy. ListResourceBundles and PropertyResourcesBundles do not share a hierarchy. Similarly, the default locale’s resource bundles do not share a hierarchy with the requested locale’s resource bundles. Table 8-3 shows examples of bundles that do share a hierarchy.
TABLE 8-3 Resource Bundle Lookups

Remember that searching for a property file uses a linear list. However, once a matching resource bundle is found, keys can only come from that resource bundle’s hierarchy.
One more example to make this clear. Think about which resource bundles will be used from the previous code if I use the following code to request a resource bundle:

First, Java looks for RB_fr_FR.java and RB_fr_FR.properties. Since neither is found, Java falls back to using RB_fr.java. Then as we request keys from rb, Java starts looking in RB_fr.java and additionally looks in RB.java. Java started out looking for a matching file and then switched to searching the hierarchy of that file.
Dates, Numbers, and Currency Remember that the objective is a bit misleading and that you’ll have to understand the basics of five related classes: java.util.Date, java.util.Calendar, java.util.Locale, java.text .DateFormat, and java.text.NumberFormat. A Date is the number of milliseconds since January 1, 1970, stored in a long. Most of Date’s methods have been deprecated, so use the Calendar class for your date-manipulation tasks. Remember that in order to create instances of Calendar, DateFormat, and NumberFormat, you have to use static factory methods like getInstance(). The Locale class is used with DateFormat and NumberFormat to generate a variety of output styles that are language and/or country specific.
Parsing, Tokenizing, and Formatting To find specific pieces of data in large data sources, Java provides several mechanisms that use the concepts of regular expressions (regex). Regex expressions can be used with the java.util.regex package’s Pattern and Matcher classes, as well as with java.util.Scanner and with the String.split() method. When creating regex patterns, you can use literal characters for matching or you can use metacharacters that allow you to match on concepts like “find digits” or “find whitespace.” Regex provides quantifiers that allow you to say things like “find one or more of these things in a row.” You won’t have to understand the Matcher methods that facilitate replacing strings in data.
Tokenizing is splitting delimited data into pieces. Delimiters are usually as simple as a comma, but they can be as complex as any other regex pattern. The java .util.Scanner class provides full tokenizing capabilities using regex and allows you to tokenize in a loop so that you can stop the tokenizing process at any point. String.split() allows full regex patterns for tokenizing, but tokenizing is done in one step; hence, large data sources can take a long time to process. The java.util .StringTokenizer class is almost deprecated, but you might find it in old code. It’s similar to Scanner.
Formatting data for output can be handled by using the Formatter class, or more commonly, by using the new PrintStream methods format() and printf(). Remember format() and printf() behave identically. To use these methods, you create a format string that is associated with every piece of data you want to format.
Resource Bundles Finally, resource bundles allow you to move locale-specific information (usually strings) out of your code and into external files where they can easily be amended. This provides an easy way for you to localize your applications across many locales.
TWO-MINUTE DRILLHere are some of the key points from the certification objectives in this chapter.
 The classes you need to understand are
The classes you need to understand are java.util.Date, java.util.Calendar, java.text.DateFormat, java.text.NumberFormat, and java.util.Locale.
Most of the Date class’s methods have been deprecated.
A Date is stored as a long, the number of milliseconds since January 1, 1970.
Date objects are go-betweens for the Calendar and DateFormat classes.
The Calendar provides a powerful set of methods to manipulate dates, performing tasks such as getting days of the week or adding some number of months or years (or other increments) to a date.
Create Calendar instances using static factory methods (getInstance()).
The Calendar methods you should understand are add(), which allows you to add or subtract various pieces (minutes, days, years, and so on) of dates, and roll(), which works like add() but doesn’t increment a date’s bigger pieces. (For example, adding ten months to an October date changes the month to August, but doesn’t increment the Calendar’s year value.)
DateFormat instances are created using static factory methods (getInstance() and getDateInstance()).
There are several format “styles” available in the DateFormat class.
DateFormat styles can be applied against various Locales to create a wide array of outputs for any given date.
The DateFormat.format() method is used to create strings containing properly formatted dates.
The Locale class is used in conjunction with DateFormat and NumberFormat.
Both DateFormat and NumberFormat objects can be constructed with a specific, immutable Locale.
For the exam, you should understand creating Locales using either language or a combination of language and country.
Regex is short for regular expressions, which are the patterns used to search for data within large data sources.
Regex is a sublanguage that exists in Java and other languages (such as Perl).
Regex lets you create search patterns using literal characters or metacharacters. Metacharacters allow you to search for slightly more abstract data like “digits” or “whitespace.”
Study the \d, \s, \w, and . metacharacters.
Regex provides for quantifiers, which allow you to specify concepts like “look for one or more digits in a row.”
Study the ?, *, and + greedy quantifiers.
Remember that metacharacters and strings don’t mix well unless you remember to “escape” them properly. For instance, String s = “\\d”;.
The Pattern and Matcher classes have Java’s most powerful regex capabilities.
You should understand the Pattern compile() method and the Matcher matches(), pattern(), find(), start(), and group() methods.
You WON’T need to understand Matcher’s replacement-oriented methods.
You can use java.util.Scanner to do simple regex searches, but it is primarily intended for tokenizing.
Tokenizing is the process of splitting delimited data into small pieces.
In tokenizing, the data you want is called tokens, and the strings that separate the tokens are called delimiters.
Tokenizing should be done with the Scanner class or with String.split().
Delimiters are either single characters like commas or complex regex expressions.
The Scanner class allows you to tokenize data from within a loop, which allows you to stop whenever you want to.
The Scanner class allows you to tokenize strings or streams or files.
The old StringTokenizer class allows you to tokenize strings.
The String.split() method tokenizes the entire source data all at once, so large amounts of data can be quite slow to process.
As of Java 5 there are two methods used to format data for output. These methods are format() and printf(). These methods are found in the PrintStream class, an instance of which is the out in System.out.
The format() and printf() methods have identical functionality.
Formatting data with printf() (or format()) is accomplished using formatting strings that are associated with primitive or string arguments.
The format() method allows you to mix literals in with your format strings.
The format string values you should know are
Flags: -, +, 0, “,“, and (
Conversions: b, c, d, f, and s
Barring booleans, if your conversion character doesn’t match your argument type, an exception will be thrown.
A ListResourceBundle comes from Java classes, and a PropertyResourceBundle comes from .property files.
ResourceBundle.getBundle(name)uses the default Locale.
Locale.getDefault()returns the JVM’s default Locale . Locale.setDefault(locale)can change the JVM’s locale.
Java searches for resource bundles in this order: requested language/country, requested language, default locale language/country, default locale language, default bundle. Within each item, Java ListResourceBundle is favored over PropertyResourceBundle.
Once a ResourceBundle is found, only parents of that bundle can be used to look up keys.
Note: Both the OCA 7 and OCP 7 exams have objectives concerning Strings and StringBuilders. In Chapter 5, we discussed these two classes. This chapter’s self test includes questions about Strings and StringBuilders for the sake of preparing you for the OCP exam. If you need a refresher on Strings and Stringbuilders, head back to Chapter 5.
1. Given:

And the command line:
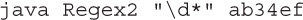
What is the result?
A. 234
B. 334
C. 2334
D. 0123456
E. 01234456
F. 12334567
G. Compilation fails
2. Given:

Assume the default Locale is Italian. If each of the following is the only resource bundle on the classpath and contains key=value, which will be used? (Choose all that apply.)
A. Flag.java
B. Flag_CA.properties
C. Flag_en.java
D. Flag_en.properties
E. Flag_en_CA.properties
F. Flag_fr_CA.properties
3. Given:

Which invocation(s) will produce the output: 0 2 4 8? (Choose all that apply.)
A. java Quetico “\b” “^23 *$76 bc”
B. java Quetico “\B” “^23 *$76 bc”
C. java Quetico “\S” “^23 *$76 bc”
D. java Quetico “\W” “^23 *$76 bc”
E. None of the above
F. Compilation fails
G. An exception is thrown at runtime
4. Given:

And two invocations:

What is the result? (Choose all that apply.)
A. In both cases, the count will be 5
B. In both cases, the count will be 6
C. In one case, the count will be 5, and in the other case, 6
D. Banana cannot be invoked because it will not compile
E. At least one of the invocations will throw an exception
5. Given three resource bundles and a Java class:

Which of the following, when made independently, will change the output to “ride underground”? (Choose all that apply.)
A. Add train=underground to Train_en.properties
B. Change line 1 to Locale.setDefault(new Locale(“en”, “UK”));
C. Change line 5 to Locale.ENGLISH);
D. Change line 5 to new Locale(“en”, “UK”));
E. Delete file Train_en_US.properties
6. Given that 1119280000000L is roughly the number of milliseconds from January 1, 1970, to June 20, 2005, and that you want to print that date in German, using the LONG style such that “June” will be displayed as “Juni,” complete the code using the following fragments. Note: You can use each fragment either zero or one times, and you might not need to fill all of the slots.
Code:

Fragments:

7. Given:

What is the result?
A. 0 8 abcdef78
B. 0 8 789abcde
C. 0 9 abcdef789
D. 0 9 789abcdef
E. Compilations fails
F. 0, followed by an exception
8. Given two files:

Which, inserted independently, will compile? (Choose all that apply.)
A. Object obj = rb.getInteger(“123”);
B. Object obj = rb.getInteger(123);
C. Object obj = rb.getObject(“123”);
D. Object obj = rb.getObject(123);
E. Object obj = rb.getString(“123”);
F. Object obj = rb.getString(123);
9. Given:

Which are true? (Choose all that apply.)
A. Compilation fails
B. The first line of output is abc abc true
C. The first line of output is abc abc false
D. The first line of output is abcd abc false
E. The second line of output is abcd abc false
F. The second line of output is abcd abcd true
G. The second line of output is abcd abcd false
10. Given:

What is the result?
A. >abcefh<
B. >efhabc<
C. >abc ef h<
D. \>>ef h abc<
E. >abc ef h <
11. Given:

Which are true? (Choose all that apply.)
A. The output is 987.12345 987.12345
B. The output is 987.12346 987.12345
C. The output is 987.12345 987.123456
D. The output is 987.12346 987.123456
E. The try/catch block is unnecessary
F. The code compiles and runs without exception
G. The invocation of parse() must be placed within a try/catch block
12. Given:

And given the command-line invocation:
java Archie "\d+" ab2c4d67
What is the result?
A. 0
B. 3
C. 4
D. 8
E. 9
F. Compilation fails
13. Given:

What is the result?
A. 1 2
B. 1 2 3 45 6
C. 1 2 3 4 5 6
D. 1 2 a 3 45 6
E. Compilation fails
F. 1 2 followed by an exception
1.  E is correct. The
E is correct. The \d is looking for digits. The * is a quantifier that looks for 0 to many occurrences of the pattern that precedes it. Because we specified *, the group()method returns empty strings until consecutive digits are found, so the only time group() returns a value is when it returns 34, when the matcher finds digits starting in position 2. The start() method returns the starting position of the previous match because, again, we said find 0 to many occurrences.
 A, B, C, D, F, and G are incorrect based on the above. (OCP Objective 5.2)
A, B, C, D, F, and G are incorrect based on the above. (OCP Objective 5.2)
2. A, C, D, and E are correct. The default Locale is irrelevant here since none of the choices use Italian. A is the default resource bundle. C and D use the language but not the country from the requested locale. E uses the exact match of the requested locale.
B is incorrect because the language code of CA does not match en. And CA isn’t a valid language code. F is incorrect because the language code “fr” does not match en. Even though the country code of CA does match, the language code is more important. (OCP Objectives 12.2 and 12.3)
3. B is correct. Remember that the boundary metacharacters (\b and \B), act as though the string being searched is bounded with invisible, non-word characters. Then remember that \B reports on boundaries between word to word or non-word to non-word characters.
A, C, D, E, F, and G are incorrect based on the above. (OCP Objective 5.2)
4. B is correct. In the second case, the first token is empty. Remember that in the first case, the delimiter is a space, and in the second case, the delimiter is any numeric digit.
A, C, D, and E are incorrect based on the above. (OCP Objectives 5.1 and 5.2)
5. D is correct. As is, the code finds resource bundle Train_en_US.properties, which uses Train_en.properties as a parent. Choice D finds resource bundle Train_en_UK.properties, which uses Train_en.properties as a parent.
A is incorrect because both the parent and child have the same property. In this scenario, the more specific one (child) gets used. B is incorrect because the default locale only gets used if the requested resource bundle can’t be found. C is incorrect because it finds the resource bundle Train_en.properties, which does not have any “train” key. E is incorrect because there is no “ride” key once we delete the parent. F is incorrect based on the above. (OCP Objectives 12.2 and 12.3)
6. Answer:
Notes: Remember that you must build DateFormat objects using static methods. Also, remember that you must specify a Locale for a DateFormat object at the time of instantiation. The getInstance() method does not take a Locale. (OCP Objective 12.4)
7. C is correct. The append()method appends to the end of the StringBuilder’s current value, and if you append past the current capacity, the capacity is automatically increased. Note: Invoking insert() past the current capacity will cause an exception to be thrown.
A, B, D, E, and F are incorrect based on the above. (OCP Objective 5.1)
8. C and E are correct. When getting a key from a resource bundle, the key must be a string. The returned result must be a string or an object. While that object may happen to be an integer, the API is still getObject(). E will throw a ClassCastException since 456 is not a string, but it will compile.
A, B, D, and F are incorrect because of the above. (OCP Objectives 12.2 and 12.3)
9. D and F are correct . While String objects are immutable, references to Strings are mutable. The code s1 += “d”; creates a new String object. StringBuffer objects are mutable, so the append() is changing the single StringBuffer object towhich both StringBuffer references refer.
A, B, C, E, and G are incorrect based on the above. (OCP Objective 5.1)
10. C is correct. The concat() method adds to the end of the String, not the front. The trickier part is the return statement. Remember that Strings are immutable. The String referred to by “s” in doStuff() is not changed by the trim() method. Instead, a new String object is created via the trim() method, and a reference to that new String is returned to main().
A, B, D, and E are incorrect based on the above. (OCP Objective 5.1)
11. D, F, and G are correct. The setMaximumFractionDigits() applies to the formatting, but not the parsing. The try/catch block is placed appropriately. This one might scare you into thinking that you’ll need to memorize more than you really do. If you can remember that you’re formatting the number and parsing the string, you should be fine for the exam.
A, B, C, and E are incorrect based on the above. (OCP Objective 12.4)
12. B is correct. The “\d” metacharacter looks for digits, and the + quantifier says look for “one or more” occurrences. The find() method will find three sets of one or more consecutive digits: 2, 4, and 67.
A, C, D, E, and F are incorrect based on the above. (OCP Objective 5.2)
13. F is correct. The nextXxx() methods are typically invoked after a call to a hasNextXxx(), which determines whether the next token is of the correct type.
A, B, C, D, and E are incorrect based on the above. (OCP Objective 5.1)




