The more complete the database the better the chance of detecting criminals, both those guilty of crimes past and those whose crimes are yet to be committed.
—Lord Brown, House of Lords, British Parliament1
Forensic DNA data banks have been the subject of many narratives, but none more forceful in its advocacy and more universally held than the one that claims that, ceteris paribus, the larger the data banks, the more crimes will be solved and the more crimes will be prevented. When the New York State Senate was debating whether to expand the state’s forensic DNA databases to arrestees, then Senator Joseph L. Bruno said, “Expanding the scope of the DNA databank means expanding the ability of our law enforcement officials to solve both new crimes and old ones.”2
There are certainly intuitive aspects to this narrative. Forensic DNA data banks of felons overall have been a good thing for law enforcement, both in prosecutions of murder-rapists who might have escaped being caught were it not for DNA evidence and in early DNA exclusions of suspects who otherwise might have run up high investigative costs. But is more of a good thing necessarily better? Examples abound in daily life where this is not the case. Sometimes “more” can go hand in hand with “more complicated,” resulting in diminishing returns and increasing inefficiencies. We all like choices when we go to the grocery store, but the more choices we have, the more time we spend making our way down the aisle. Sometimes expanding the good beyond the boundaries of its initial intent can have unforeseen consequences. Soon after estrogen therapy proved successful in helping women who lacked normal estrogen levels to conceive, physicians began using estrogen as a replacement therapy for women who lost estrogen in the aging process under the theory that, since estrogen was important for women’s health, more of it would make women healthier. Instead, this continuous, long-term use3 of synthetic estrogen proved to carry with it substantial risks, requiring special medical oversight. Similar fallacies have been made in law enforcement. Few would deny that police should be adequately armed against violent criminals. But the fact that an armed police force is a good thing does not imply that more powerful arms, such as a 12-gauge shotgun or an AK-47 rifle, makes for better policing and would not result in the abuse of deadly force.
This leads us to the central question of this chapter: what is the relationship of the size of a country’s forensic DNA database to its rate of solving crimes? As noted, it is frequently argued that the larger the database, the greater the opportunity police have to solve new crimes and to clear their cold-case files of unsolved crimes. Is there any evidence that supports these claims? And if there is evidence, does it apply to databases that have been expanded to include arrestees who have not been convicted of a crime and volunteers who gave a DNA sample to police (so-called elimination samples) to rule themselves out as suspects in a highly publicized case?
Are there any reasons that expanded forensic DNA databases might impede law enforcement? Are there diminishing marginal returns for criminal justice in the expansion of DNA data banks? If there are errors in DNA analysis that may lead to false convictions, is there reason to believe that the rate of false convictions could increase by expanding DNA databases to arrestees who have not been convicted of a crime or to those convicted of minor offenses?
Current Standards for Measuring Database Success
The U.S. Combined DNA Index System (CODIS) database currently holds more than 8 million “offender” profiles (including over 100,000 profiles from arrestees)4 and over 300,000 forensic profiles from crime scenes.5 The FBI measures the success of the database by the number of matches or “hits” made against the database, as well as the number of “investigations aided,” defined as criminal investigations where CODIS has added value to the investigative process. As of March 2010 CODIS had produced 114,300 hits assisting in 112,300 investigations.6
Neither of these pieces of information—number of “hits” or “investigations aided”—is particularly helpful in determining the efficacy of the database. A “hit” is only a match; it tells us nothing about whether those hits were followed up, how many resulted in arrests, and how many arrests resulted in convictions. The fact that an individual’s DNA is found at a crime scene does not tell us whether his or her DNA was left at the time the crime was committed, let alone whether he or she was responsible for the crime in question. There have also been reported cases of a DNA cold hit leading to a suspect who was found to be too young (e.g., an infant) at the time of the crime.7 The match was most likely the result of cross-contamination in the forensic laboratory. In addition, multiple “hits” can occur for single cases or investigations. Likewise, “investigations aided” include those cases where an offender was already a suspect and would have been convicted regardless of DNA evidence; they might even include cases where the individual identified turned out not to have been related to the crime in question at all and just happened to have his or her DNA at the scene of the crime. These cumulative figures also tell us nothing about whether the rate of “hits” or “investigations aided” has increased in proportion to the growth of the database. Last, it is not possible to know from these figures what the actual contribution of the database has been to crime investigations overall; for example, what proportion of investigations conducted consists of those involving “hits” that occurred through the DNA database?
In the United Kingdom more information is routinely published by the government that sheds some light on database efficacy, although these data are also limited. Official reports from the United Kingdom offer evidence that the collection of DNA samples at crime scenes has contributed to crime detection. As noted by Helen Wallace, “Detections are crimes that have been recorded as ‘cleared up’ by the police. This includes crimes where [a] person has been charged, cautioned or warned, and some crimes that are not proceeded against (for example, because the victim is unwilling to give evidence).”8 The “crime-detection rate” is defined as the percentage of crimes recorded by police that are cleared up. Police in the United Kingdom have reported that the clear-up rates for crimes where DNA evidence is available are significantly higher than for those crime scenes where no DNA is found. In 2004 clear-up rates for crimes where DNA was successfully recovered were between 38 and 43 percent, compared with the overall detection rate of 23.5 percent.9
One might argue that efficacy ends at detection. However, conviction is the standard endpoint for success of criminal justice techniques. If DNA can only lead to a suspect but plays little or no role in conviction, then the efficacy of DNA, despite the Crime Scene Investigation (CSI) effect, is diminished. It is difficult to isolate the role of DNA exclusively as a contributor to conviction rates since DNA is rarely the only or even the primary factor in a conviction (indeed, it should not be).
What is of additional interest is whether the growth in the database has improved crime-solving capacity. According to data presented by Carole Mc-Cartney, the proportion of matches resulting in a successful detection in the United Kingdom rose from 37 percent (1999–2000) to 48 percent (2000–2001) but then fell in 2002–2003 to 42 percent.10 The size of the United Kingdom’s DNA database rose significantly from 1999 to 2003, but the proportion of matches has not followed that trend.
Another factor to consider in evaluating the use of DNA databases to solve crimes is the number of crime scenes that produce DNA evidence. A report by the United Kingdom’s National DNA Database (NDNAD) stated that a mere 0.85 percent (85 in 10,000) of all recorded crimes produce a DNA sample that can be tested.11 In other words, in more than 99 out of 100 cases, DNA cannot be collected from the crime scene and uploaded to the database in the first place. McCartney concludes: “Objective assessment of the ‘success’ or otherwise of the DNA Expansion Programme on the basis of crime detection rates is therefore near impossible. Even some police officers concede that perhaps the ability of DNA to solve the crime problem has been overstated.”12
Another factor British criminologists look at to measure the impact of the database is the “match rate,” which is simply the proportion of crime-scene profiles that are found to match profiles of individuals in the database. The “match rate” is considered a useful indicator for determining whether enlarging the databases will yield more cold hits when crime-scene data are loaded into the national database. The “match rate” is defined as 100 times the number of crime-scene profile matches made when profiles are entered into the database divided by the number of crime-scene profiles collected in that year. In the United Kingdom, between 2004 and 2006 the match rate rose slightly but then flattened out, even though the total number of profiles retained in the database rose each month. As of March 2006 the match rate was reported as 52 percent, up 4 percent from the previous year.13
Although the match rate is often used to promote data-bank expansion, it does not give us insight into the efficacy of DNA data banks. Suppose that for a particular year there were 1,000 crime-scene profiles, and 600 of them were matched to a profile in the national forensic DNA database. That would yield a “match rate” of 60 percent. But this indicator does not take account of the size of the database. Suppose that the database doubled and the “match rate” remained the same even though one expects more matches in a larger database. “Match rate” is not a surrogate for efficacy.
The U.K. NDNAD report for 2005–2006 stated: “Of the 200,300 or so profiles on the NDNAD that have been retained under the CJPA 2001 [profiles mainly of arrestees] and would previously had to have been removed, approximately 8,500 profiles from some 6,290 individuals have been linked with crime scene sample profiles from some 4,000 offenses.”14 The claim seems to be that were it not for the expansion of the database to arrestees, these individuals would not have been connected with these crimes. However, these figures do not tell us how many of these “matches” were followed up, resulted in convictions, or were associated with crimes that otherwise would not have been solved. They also do not tell us how many individuals linked to crimes were convicted for other offenses and thus would have been linked regardless at the point where their DNA was entered into the database upon conviction. Moreover, again, it does not tell us whether these additional matches are in proportion to the increase in the database over this period.
The U.K. NDNAD also publishes data about the match rate as they relate to the number of “subject” profiles (offenders, arrestees, and others qualified for database inclusion). Data from 2004 to 2006 actually show a decline in the crime-to-subject match rate; as additional subject profiles were added to the database, the match rate actually went down from about 2 percent to 1.2 percent.15 Although it is difficult to tease out the factors that might have contributed to this pattern,16 it certainly does not support the notion that expanding the database necessarily leads to more effective or efficient crime solving.
Evaluating DNA Database Efficacy
In evaluating the efficacy of DNA databases for solving crimes, one has to go beyond simply looking at the number of “hits,” “investigations aided,” “detection rate,” or “match rate” and explore, to begin with, the following factors.
The percentage of crime scenes that are screened for DNA. DNA profiles can contribute to solving crimes only if crime scenes are screened for DNA evidence. Therefore, the effectiveness of the database will, in part, depend on the extent to which DNA is collected at crime scenes.
The number of crime-scene DNA samples with complete profiles that are loaded into the database. The fact that crime scenes are screened for DNA samples does not necessarily mean that there will be one or more viable DNA profiles obtained that meet the criteria for uploading them to the database. The DNA might be too degraded, or there might be mixtures that cannot be individuated into discrete profiles.
The number of uploaded crime-scene DNA profiles that match identified profiles already in the DNA data bank. The matches of crime-scene DNA profiles with profiles in the database must produce one or more suspects who can be investigated for the crime in question.
The number of detections (people charged with a crime) based on those matches. When a match is found between a crime-scene DNA profile and a person whose profile has been entered into the national data bank, the police may have a suspect, but they have not solved the crime. There may be several explanations of why that individual’s DNA was left at the scene of the crime. This is why, at least in the United Kingdom, additional corroborating evidence is required before an individual can be charged with a crime.17 It is imperative that we know how many of these matches result in individuals who are charged with a crime if we are to evaluate the efficacy of enlarging these databases.
The number of convictions based on the DNA crime-scene matches. The true test of the efficacy of DNA data banks is measured by how effective they are in contributing to convictions. Moreover, in how many cases is the DNA match a necessary condition for a conviction, as opposed to ancillary or secondary evidence?
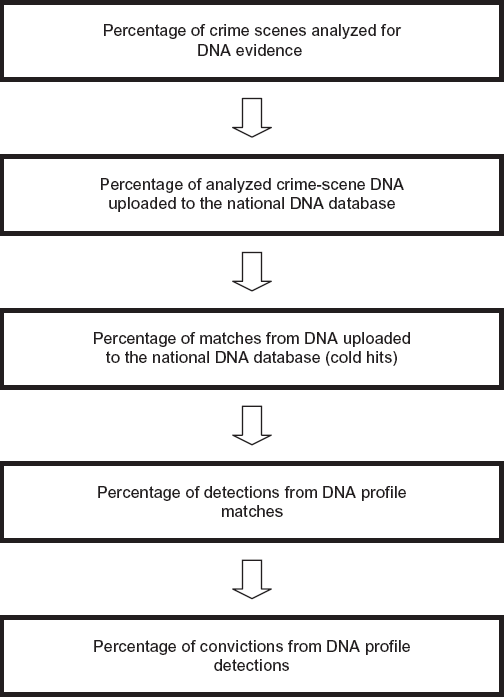
For an overall index of DNA database efficacy with respect to solving all reportable crimes, we construct the following indicator that we call the DNA Crime-Solving Efficacy (CSE) Index (see figure 17.1 for components of the CSE Index).
CSE (DNA crime-solving efficacy) = P × Q × R × S × T,
where
P = Rate of crime scenes analyzed for DNA
Q = Rate of crime-scene DNA profiles loaded into the DNA database per crime scenes analyzed
R = Rate of matches per loaded DNA profiles
S = Rate of detection per matches
T = Rate of conviction per unit of detection
The rate of crime scenes analyzed is simply the number of crime scenes (from all recorded crimes) analyzed for DNA divided by the total number of recorded crimes. In the United Kingdom 17 percent of crime scenes are examined for DNA evidence.18 Not all the crime scenes investigated for DNA will yield viable profiles that can be uploaded to the national database, as discussed earlier; in the United Kingdom, of the 17 percent of crimes scenes that are examined for DNA evidence, only 5 percent result in a successful DNA sample being collected, profiled, and loaded into the database. Taken together, this means that a testable DNA sample is obtained in only 0.85 percent of all recorded crimes.19
The third factor in the equation is the rate of matches for all the crime-scene profiles loaded into the database. We are assuming in this case that the matches are determined through the database, as opposed to a preexisting suspect. Obviously, many crimes are solved by matching the DNA at the crime scene with the DNA of a suspect, where the national DNA database is not involved. If we are seeking an indicator of DNA efficacy, then we will include detections both with and without the database. On the other hand, if we are seeking an indicator of DNA database efficacy, we will include only the matches obtained by uploading crime-scene DNA to the database (so-called cold hits). The match rate in the United Kingdom was reported at 52 percent as of March 2006; in general it averaged around 50 percent over the course of that year.
The fourth factor is the rate of detection (charges filed) per matches. For this indicator, we make the distinction between “detection” and “conviction.” As discussed earlier, the detection rates for crimes involving DNA matches in the United Kingdom ranged from 37 percent to 48 percent for the period 1999–2003. For illustration purposes, we estimate this at 50 percent.
FIGURE 17.1. Flowchart of the components of the Crime-Solving Efficacy Index (CSE) from crime scenes analyzed to convictions. Source: Authors.
The fifth and final factor is the rate of conviction from the number of detections. The fact that someone’s DNA profile in the database is matched with crime-scene DNA by no means necessarily results in a conviction. Someone’s DNA may have been left at the scene before the criminal event, or, as in some notable cases, the DNA match arose from contamination of the evidence. With no reliable data, for the purpose of this example, let us assume that the conviction rate is 50 percent.
From the numerical values of these percentages, we can calculate the values for the CSE Index and assess the role of DNA databases in solving recordable offenses as follows:
CSE = .17 × .05 × .50 × .50 × .50 = .0010625, or 0.1 percent.
This tells us that the role DNA plays in convictions of all crimes is minuscule—DNA plays a role in only about 1 out of every 1,000 convictions.
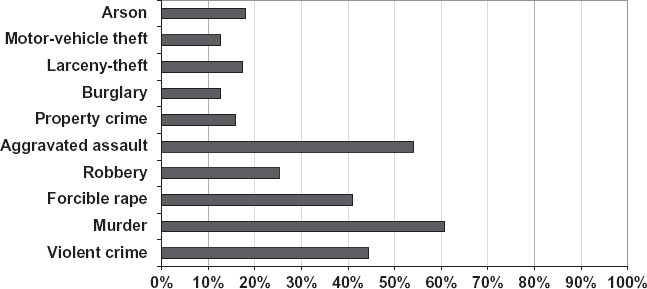
But is it fair to compare minor robberies, where DNA is not even sought, with the efficacy of DNA in solving violent crimes? Shouldn’t we define efficacy of DNA data banks in terms only of those crime scenes that have been examined for DNA? We can begin with the assumption that there will be DNA screenings in all serious crimes. Thus factor P will be 100 percent (P = 1). Overall detection rates in the United Kingdom are about 23 percent, whereas detection rates for violent crimes are about 50 percent, about the same as the rate for cases involving DNA. These rates are similar to those in the United States. Figure 17.2 shows that the clearing rates for forcible rape and murder in the United States in 2006 are just over 40 and 60 percent, respectively.
For purposes of illustration, assuming P = 1 and using the same values as in the previous example (Q = .05; R = .50; S = .50; T = .50), the four factors will yield a Crime-Solving Efficacy Index of 0.63 percent, still less than 1 percent. The number of cold-hit matches does provide some indication of the role of DNA data banks. Disaggregated national data on cold-hit matches versus suspect-to-crime-scene profile matches are not always available. If we exclude from the “frequency of matches” those that arise from preexisting suspects and leave only cold hits, then we have a better indicator of the efficacy of the data bank by itself.
Suppose that for one year 100 percent of all violent crimes had DNA samples taken (P = 1), 20 percent of all crime-scene DNA was loaded into the database (Q = .2), 40 percent of the DNA loaded yielded cold matches (R = .4), 30 percent of the matches resulted in charges filed (detection) (S = .3), and 20 percent of those charged were convicted (T = .2). The Crime-Solving Efficacy Index for the database would be given by
CSE = 1 × .20 × .40 × .30 × .20 = .0048, or 0.48 percent.
We still need a factor that accounts for the size of the data bank. If the data bank expands by 100 percent but the CSE rises by 5 percent, then the increased size of the data bank is not having a major impact on the match, detection, and conviction rates, or at the very least there are diminishing marginal returns from the expansion of the DNA database. We can choose a base year for setting the size of the database NB. Let the database for any other year be designated as N. Our modified indicator of DNA database efficacy would be given as follows:
CSE = P × Q × R × S × T × NB/N.
Thus, if in one year the number of DNA cold-hit convictions (T) goes up 20 percent, while the database increases twofold (100 percent or N = 2NB), then the efficacy for crime solving as determined by our index would go by about 40 percent from what it was when the database was half its present size. Our index for efficacy of DNA data banks grows when DNA plays a stronger role in cold-hit convictions and shrinks when a larger database does little to improve the conviction rate. This indicator tells us that when all the factors of the index remain constant (P, Q, R, S, and T) while the size of the database grows, the efficacy of the DNA data bank decreases.
Size of a DNA Data Bank Versus Solving Crimes
Why would a larger database not necessarily lead to more crimes being solved more efficiently? As previously noted, it is taken for granted by many police authorities that the larger the database, the more crimes will be solved. As an example, consider the following statement published in the annual report of the U.K. NDNAD for 2005–2006: “The additional CJ [criminal justice] arrestee sample profiles to the NDNAD have brought significant benefits, including direct police savings through speedier investigations, quicker apprehension of offenders, earlier elimination of suspects and greater victim reassurance.”20
There are many reasons that a larger database does not necessarily deliver more crime control. First, as we have seen from the previous exercise, the factor currently limiting database efficacy is the number of crime-scene profiles, not the number of offender or subject profiles. Although numbers of subject profiles have increased exponentially in both the United States and the United Kingdom from 2000 to 2010, the number of crime-scene samples added to the database has risen gradually (see figures 17.3 and 17.4). To improve the efficacy of DNA databases in solving crimes, one has to increase the number of crime-scene DNA profiles loaded into the database in the first place.
This is not an easy undertaking. The proportion of crime scenes where DNA has been recovered has increased since 1988 from 4.5 percent to 17 percent in the United Kingdom.21 However, there are limitations on crime-scene profiling that are likely to prevent this number from getting much higher. First, DNA is most readily obtainable from scenes of violent crimes—crimes where biological evidence is likely to be left behind in the form of blood, semen, or skin cells. The majority of crimes that are committed, however, are property crimes. This is true even for the most serious crimes, which are tallied annually by the FBI in its “Crime Index.” Out of the 11.9 million index offenses reported to the FBI in 2002, 1.4 million constituted violent crimes, while 10.5 million were property crimes.22 To look for DNA where it is not obviously present requires painstaking and costly crime-scene investigation, during which forensic technicians scour the scene looking for trace evidence that may or may not carry the DNA of the perpetrator. Moreover, DNA found in these situations may not be of sufficient quality and quantity to permit testing.
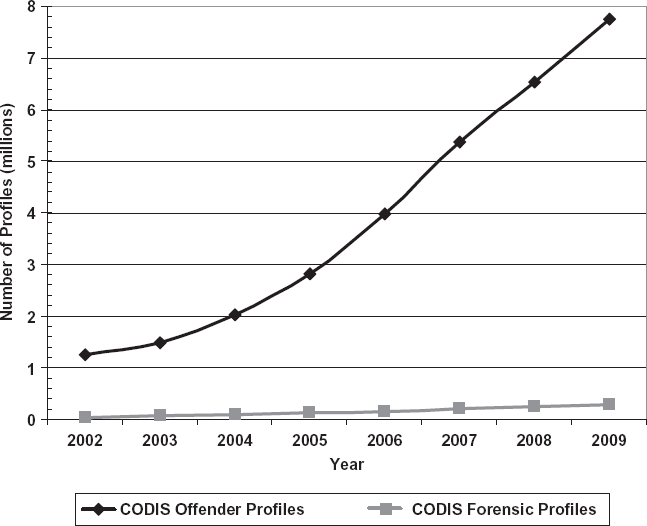
FIGURE 17.3. Diminishing returns: CODIS offender profiles (in millions) relative to forensic profiles. Source: CODIS Combined DNA Index System (FBI brochure); CODIS Program Office, FBI, personal communication. Compiled by Tania Simoncelli, Harry G. Levine, and John Gettman, March 2008. Updated by the authors May 2010.
It is possible that DNA technology will continue to change in ways that will allow us to detect even smaller amounts of DNA. But improved DNA detection will not contribute to solving property crimes, where multiple sources of DNA will be found at the same crime scene, and regardless of the technology it will not be possible to sort out which samples belong to the perpetrator. In fact, a concern with overreliance on DNA in criminal investigations is that by attempting to increase the input of crime-scene samples to generate more “hits,” we may end up generating higher numbers of spurious matches. This may in turn decrease the crime-detection and conviction rates and also runs the risk of leading to more wrongful convictions.
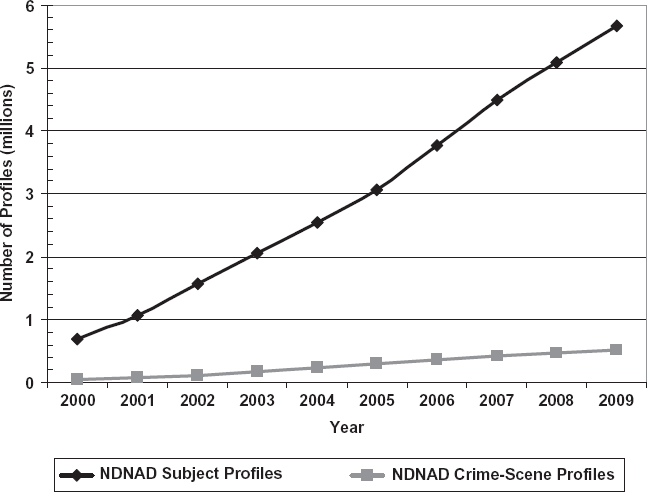
FIGURE 17.4. NDNAD offender profiles (in millions) relative to forensic profiles. The number of subject profiles held on NDNAD includes profiles from arrested individuals as well as volunteers and is higher than the number of individuals represented in the database because some of the profiles are replicates. The National DNA Database Annual Report 2007–09 estimates that 13.5 percent of the subject profiles are replicates, such that the number of individuals in the database was approximately 4.9 million as of March 2009. Similarly, the number of crime-scene profiles reported here do not reflect those that have been removed from the database. As of March 2009 there were a total of approximately 350,000 crime-scene profiles retained on the NDNAD (Annual Report, p. 25). Source: Authors. Date Source: National DNA Database Annual Report 2007–09, http://www.npia.police.uk/en/docs/NDNAD07-09-LR.pdf (accessed May 14, 2010).
Even within the category of violent crime the use of DNA is limited. In most cases of rape the rapist is known to the victim. DNA is seldom useful in those cases, since what is most often in dispute is whether the act was forced or consensual (see chapter 8).
In the overall scheme of solving crimes, Wallace notes, “The number of cases that can be solved using DNA will always be limited by the number of crime scenes from which DNA profiles can be collected and the need for corroborating evidence.”23 She adds that even if the DNA match rate (number of DNA matches per crime-scene sample) were 100 percent (for example, if the database were truly universal), the DNA detection rate (or conviction rate) would never be that high.24
There are other reasons to be skeptical about the notion that a larger database is a better one. When DNA databases are expanded to include samples and profiles taken from petty criminals or arrestees who are not charged with a crime, they are including individuals who are less likely to go on to commit future crimes, especially the types of crimes where DNA can be collected. Some argue that adding arrestees to databases will either hinder the conviction rate or not help at all. In 2005 the police liaison officer of the Scottish DNA Database was quoted as saying, “It is arguable that the general retention of profiles from the un-convicted has not been shown to significantly enhance criminal intelligence or detection.”25
Beyond this, there are ways in which DNA expansions can even interfere with or undermine crime-solving efficiency. DNA database expansions create backlogs of unprocessed crime-scene DNA samples, which may remain in a queue for months or even years. As a result, when serious crimes are committed, the crime-scene DNA samples await their turn to be profiled. In 2003 the National Institute of Justice estimated that more than 350,000 rape and homicide cases awaited DNA testing and that crime labs were deluged with analysis requests for convicted-offender samples.26 If we add to the convicted felons individuals arrested but not charged or those detained by federal agencies, the backlog could inhibit the role of DNA in convicting serious felons. As an example, in 2001 police in Wyoming took a DNA sample from an individual convicted of kidnapping. The sample languished in the laboratory without being processed or uploaded to the national database. When it was finally processed, it matched the profile found at a 1997 murder of a University of Colorado student. This case reveals that when biological samples are taken from too many people and scheduled to be processed and uploaded to the forensic DNA database, fewer crimes are actually solved. This may sound counterintuitive. As P. Solomon Banda explained, “The nation’s DNA tracking system is beset with a huge backlog that could take years to clear. And in the meantime, law enforcement officials say, crimes are going unsolved.”27
DNA expansions also are likely to result in more errors in profiling, labeling, and transcription of samples that will add to administrative costs, needless lawsuits, and human hardships for people falsely accused and perhaps even convicted by DNA. Indeed, errors of these types have already occurred, and some have been attributed to the problem of mounting backlogs.28 The error rate will undoubtedly increase as the backlog of DNA profiles rises. Cross-contamination of samples, which has explained past errors and remains a serious quality-control problem in sequencing DNA samples, is more likely to occur when lab technicians are under increased pressure to speed up processing.
The larger the database, the more opportunity there is for a person to be falsely accused and incriminated for a crime. As the database grows, so too does its potential use as a resource for criminals to frame others for crimes by obtaining and planting DNA evidence from others. Already there have been cases where criminals have planted or tampered with evidence or paid inmates to take DNA tests as a way of confusing investigators or evading prosecution (see the case of Anthony Turner, discussed in chapter 16). Unfortunately, it is not only criminals who might plant DNA in an attempt to frame someone for a crime; there have been a surprising number of police frame-ups reported over the last 10 to 15 years (see chapter 16 for a discussion of Philadelphia police who pleaded guilty to planting illegal drugs on suspects). William C. Thompson notes, “If your profile is in a DNA database you face a higher risk than other citizens of being falsely linked to a crime. You are at higher risk of false incrimination by coincidental DNA matches, by laboratory error and by intentional planting of DNA.”29
The expansion of DNA databases to include DNA profiles of petty criminals and innocent people requires resources, which may come at the expense of traditional criminal investigation techniques. In other words, a transfer of resources takes place from shoe-leather investigations to DNA profiling and database matches. Jenny Rushlow argues that “all of the resources devoted to DNA testing and database management, which are extremely costly and time-intensive, diverts necessary resources away from other aspects of investigations, like tracking down witnesses, victims and suspects.”30 Rockne Harmon, a senior deputy district attorney from Alameda County, California, has complained that the costs associated with building California’s database as a result of the passage of Proposition 69 have taken away resources that are needed to place officers on the streets.31
Finally, thus far we have been discussing the efficacy of DNA data banking in solving crimes. It has also been argued that DNA data banks will prevent or deter crimes from taking place. The presumed conventional wisdom is that people who are in the database will be deterred from committing a crime out of a fear of getting caught. This argument does not apply to the vast majority of innocent people who have not yet and may never commit any serious crimes. Also, there is no evidence that crime rates have declined as a result of the growth of the DNA databases. Furthermore, there is no reason to think that crimes of passion will be deterred by having one’s profile on a DNA data bank. Finally, sophisticated criminals will not be deterred from committing crimes; rather, they will seek to confound the criminal justice system, for example, by introducing foreign DNA into the crime scene.
We return to an earlier discussion of efficacy. By overextending the function of a reliable technology, we can undermine its efficacy. When DNA profiling and data banking are used in connection with violent crimes, there is ample evidence that they can be efficacious and cost effective for generating suspects and evidence that an individual was at the crime scene. However, when the technology is extended to petty crimes or innocent and suspicionless individuals, the evidence leads to the conclusion that there will be a rapid decline in efficacy; the marginal benefits of loading names into a national database decline rapidly. Moreover, there is no evidence that posting people’s DNA profiles on a national database will deter or prevent crimes.