In this chapter, we’ll look at technical issues involving entities outside your organization that you need to consider if you hope to offer a reliable web service.
The most powerful technique for providing a reliable service is redundancy: using multiple systems, Internet connections, routes, web servers, and locations to protect your services from failure. Let’s look at what can happen if you don’t provide sufficient redundancy.
It was Monday, July 10, and all of Martha’s Vineyard was full of vacation cheer. But for Simson Garfinkel, who had spent the weekend on the Massachusetts island, things were not so good. At 9:30 a.m., Simson was in the middle of downloading his email when suddenly IP connectivity between his house on Martha’s Vineyard and his house on the mainland was interrupted. No amount of pinging, traceroutes, or praying, for that matter, would make it come back.
What had happened to the vaunted reliability of the Walden network that we described in Chapter 2? In a word, it was gone. The Walden network had been decommissioned on June 30, when Simson moved from Cambridge to Belmont. Because Belmont’s telephone central office was wired for DSL, Simson was able to move his Megapath Networks DSL line, but Belmont’s cable plant had not been upgraded for data, so he had to leave his cable modem behind. So long, redundancy! On the plus side, with the money that Simson saved by canceling the cable modem, he was able to upgrade the DSL line from 384 Kbps to 1.1 Mbps without incurring an additional monthly fee. Moving from 384 Kbps to 1.1 Mbps offered a huge improvement in performance. But the new setup also represented an increase in risk: Simson now only had one upstream provider. Simson had taken a gamble, trading redundancy for performance . . . and he had lost.
Simson caught a 10:45 a.m. ferry from Oak Bluffs to Woods Hole, then drove up to Belmont. With a few more detours and delays, he made it to Belmont at 4:00 p.m. Then he called Megapath Networks, his ISP, and waited on hold for more than 30 minutes. Finally, at 4:45 p.m. a technician answered the phone. The technician’s advice was straightforward: turn off the DSL router, wait a minute, then turn it back on. When that didn’t work, the technician put Simson on hold and called Rhythms, the CLEC that Megapath had contracted with to provide Simson’s DSL service. After another 30 minutes on hold, a Rhythms technician picked up the phone. That engineer did a line test, asked Simson to unplug his DSL router from the phone line, then did another line test. At last the verdict was in: “It seems that your DSL line recently got a whole lot shorter,” the engineer said.
How could a telephone line suddenly get shorter? Quite easily, it turns out. Sometimes, when a telephone installer working for the incumbent local exchange company (the ILEC) is looking for a pair of wires to run a telephone circuit from one place to another, the linesman will listen to the line with a telephone set to see if it is in use or not. This sort of practice is especially common in neighborhoods like Cambridge and Belmont, where the telephone wires can be decades old and the telephone company’s records are less than perfect. If the telephone installer hears a dial tone or a telephone conversation on a pair of wires, he knows that the pair is in use. But DSL lines don’t have dial tones or conversations—they simply have a hiss of data. In all likelihood, a linesman needed a pair for a new telephone that was being installed, clicked onto Simson’s DSL line, heard nothing, and reallocated the pair to somebody else.
Two hours later, Simson called Megapath back, which in turn called Rhythms. “Good thing you called!” he was told. Apparently nothing had been done—one of the companies, either Megapath or Rhythms, had a policy of not escalating service outage complaints until the subscriber called back a second time. Rhythms finally made a call to Verizon and was told that a new line would be installed within 48 hours.
Fortunately, things went better the next day. An installer from Verizon showed up at 10 a.m. that morning. That installer discovered that the DSL line had been cut by a junior Verizon employee who was installing Simson’s fax line. By 2 p.m. the DSL line was back up. Unfortunately, by that time, Simson’s email had already started to bounce, because many ISPs configure their mail systems to return email to the sender if the destination computer is unavailable for more than 24 hours.
What’s the lesson of this story?
If your Internet service provider promises “99% uptime,” you should probably look for another ISP. With 365 days in a year, 99% uptime translates to 3 days, 15 hours and 36 minutes of downtime every year. Much better is a commitment of “5 nines” reliability, or 99.999%—that translates to only 5 minutes and 15 seconds of downtime in a year. For many users, 5 minutes of downtime each year is an acceptable level of performance.
Unfortunately, the problem with uptime commitments is that they are only promises—you can still have downtime. Even companies that offer so-called Service Level Agreements (SLAs) can’t prevent your network connection from going down if the line is physically cut by a backhoe; all they can do is refund your money or make some kind of restitution after an outage. If Internet connectivity is critical for your service’s continued operation, you should obtain redundant Internet connections from separate organizations or provide for backup services that will take over in the event that you are disconnected.
Deploying independent, redundant systems is the safest and ultimately the least expensive way to improve the reliability of your information services. Consider: instead of spending $1000/month for a T1 line that promises less than 6 hours of downtime a month, you could purchase three less-reliable DSL circuits for $200/month from providers that promise 48-hour response time. Not only would save you money, you would actually have a higher predicted level of reliability. In this case, if the T1 were actually down for 6 hours a month, then there would be a 0.83% chance of the line being down on any given hour. For each DSL line, the chance that it would be down on any given hour would be 6.6%. But if the DSL lines are truly independent—coming in from different providers, using different CLECs and different backbones—then the chance that they would all be down for the same hour is 0.029%, making the three DSL lines almost 30 times more reliable than the single T1. The three 1.1 Mbps DSL lines would also offer nearly twice the bandwidth of a single T1 when all are operating normally.
While redundancy is a powerful tool, deploying redundant systems can also be a difficult balancing act. Coordinating multiply redundant systems is both a technical and a managerial challenge. Testing the systems can also present problems. If you are going to deploy redundant systems, here are some things that you should consider:
Make sure your redundant systems are actually independent! There are many stories of companies that thought they had ordered redundant circuits from separate telecommunications providers, but later discovered that the providers had all partnered with each other and sent all of the circuits down a single fiber-optic conduit! Or you might order one Internet connection over company A’s metropolitan fiber ring and a second Internet connection from company B’s wireless network, only to later discover that company B was also using company A’s fiber ring to interconnect its wireless hubs.
If you decide to obtain DSL circuits from multiple providers, make sure that each DSL circuit is terminated by a different local carrier.
If you have multiple upstream Internet connections, you will either have a different set of IP addresses for each connection, or have your own block of IP addresses and use BGP (Border Gateway Protocol) to handle failover.
If you use multiple IP addresses, make sure that your DNS servers hand out the appropriate IP addresses depending on the network conditions. One approach is to use DNS round-robin to force users to try each IP address until they find one that works. Another approach is to register two DNS servers, one for each upstream provider, and have each one hand out an IP address on its own network.
If you use BGP, monitor your announcements from various parts of the Internet to make sure that your announcements are behaving properly. Remember that some ISPs will not listen to announcements that are smaller than /19 or /20—be sure that both upstream providers can reroute your packets in the event that a line goes down.
In either case, be aware that multiple upstream connections are for redundancy, and not for load balancing. Each circuit should be able to handle your entire network load on its own. If you have two DS3 circuits to two different upstream providers, and each DS3 circuit routinely runs at 80% of its capacity, then you do not have two redundant circuits—you simply have created two possibilities for catastrophic failure.
Don’t stop at multiple Internet connections: for the greatest reliability, you should have multiple routers, multiple web servers, and—ideally—multiple locations that are simultaneously serving up your content. Figure 18-1 shows various approaches to increasing reliability for web services. Of course, as reliability increases, so do complexity and operating costs.
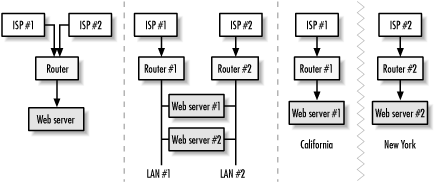
Figure 18-1. You can have multiple upstream providers enter into the same router, which is served by a single web server (left). For increased reliability, have each upstream connection served by its own router, with multiple web servers serving your content (middle). For highest reliability, have multiple, disconnected sites that serve your content to web visitors on the Internet (right).