
1
The Ethics of Artificial Minds
CHAPTER 1
In recent years, advances in machine learning have brought the idea of artificial intelligence (AI) back into the limelight. The “return of AI” has spurred a growing debate on how to think about ethics in a world of semi-intelligent machines. One of the most famous examples of AI ethics is the self-driving car.1 We now know that people prefer autonomous cars that are self-sacrificing (that, if needed, would crash to avoid harming others), even though they would not buy one for themselves.2 We also have discovered that people’s opinions about the moral actions of autonomous vehicles vary across the globe.3 Yet the ethics of AI involves much more than the morality of autonomous vehicles.
During the last decade, the morality and ethics of AI have touched on a variety of topics. Computer vision technology has given rise to a discussion on the biases of facial recognition.4 Improvements in automation have fueled debate about labor displacement and inequality.5 Social media, mobile phones, and public cameras have been at the center of a growing conversation on privacy and surveillance.6 Technologies capable of generating artificial faces are now blurring the boundary of fiction and reality.7 The list goes on. Autonomous weapon systems and military drones are changing the moral landscape of battlefields;8 and teaching and health-care robots are introducing concerns about the effects of replacing human contact, such as isolation and false friendships.9
These and other advances are pushing us to rethink human ethics and morality in the age of semi-intelligent machines. But how are our moral choices and ethics reshaped by AI? Are AI systems perceived as valid moral agents or as agents with a valid moral status? Are they judged similarly to humans? And if there are differences in judgment, what are the factors that modulate them?
To begin, let’s start with some definitions.
First, while the term artificial intelligence (AI) is useful to describe multiple approaches to machine cognition, it is important to separate AI into a few classes. The most basic separation is between general AI, or strong AI, and task-specific AI, or weak AI.
Strong AI is defined as intelligence that works across multiple application domains. It is an intelligence similar to that of humans, in that it is not specific to a task but rather can function in situations and contexts that are completely new. Weak AI is intelligence that works only in a narrow set of applications. It is the AI of today, and it includes the intelligence that drives autonomous vehicles, manufacturing robots, computer vision,10 and recommender systems.11 Weak AI also includes the algorithms that have become famous for beating humans at various games, such as chess,12 Jeopardy!,13 and Go,14 although the ability of some of these systems to learn by playing against themselves makes them quite versatile.
There are different ethical implications for strong and weak AI. In the case of weak AI, we expect some degree of predictability and the possibility of auditing their behavior.15 Yet auditing AI may be hard for systems trained on a vast corpus of data and built on neural networks. For strong AI systems, it may be even more difficult to predict or audit their behavior, especially when they move into new application domains. This has led some to argue for the development of a field focused on studying machine behavior:16 a field “concerned with the scientific study of intelligent machines, not as engineering artifacts, but as a class of actors with particular behavioral patterns and ecology.”17 Our efforts, here, however, are not focused on the moral implications of strong AI, but rather on understanding people’s judgments of hypothetical scenarios involving weak forms of AI.
Another pair of important definitions are the ideas of moral agency and moral status.
A moral agent is an entity that can discern right from wrong. In a particular scenario, a moral agent is the entity performing an action. If an entity is considered a moral agent, it will be responsible for the moral outcomes of its actions. Humans are moral agents, but with a level of agency that varies with their age and mental health. Toddlers, for instance, are not responsible for their actions in the same way that adults are (i.e., they have limited moral agency). And in a trial, mental illness can be used to argue for the limited moral agency of defendants, excusing them from some responsibility for their criminal actions.
Moral status refers to the entity affected by an action. It is related to the permissibility of using someone or something as a means toward reaching a goal. For instance, in the case of abortion, differences in the perceived moral status of an embryo can be highly polarizing. Pro-choice advocates consider early embryos to have a lower moral status than children and adults, and so they find abortion permissible in some instances. Pro-life advocates, on the other hand, assign embryos a moral status that is equivalent to that of children and adults, and so they consider abortion to be wrong under any circumstance.
But are machines moral agents? And should they enjoy a moral status?
The moral status and agency of machines has been an important topic of discussion among moral philosophers in recent years.18 Here, we see a range of perspectives. While some see AIs as having no moral status19 and limited moral agency,20 others are not so quick to dismiss the moral status of machines.21 The argument is that machines cannot be simply conceptualized as tools, and this is particularly true of robots designed intentionally as social companions for humans.22 In fact, there is a growing body of evidence that people develop attachments to machines, especially robots, suggesting that the moral status that many people assign to them is not equivalent to that of a tool like a hammer, but actually closer to that of a beloved toy or even a pet.
In fact, in battlefield operations, soldiers have been known to form close personal bonds with Explosive Ordinance Disposal (EOD) robots, giving them names and promotions and even mourning their “deaths.”23 Similar findings have been found regarding the use of sex robots.24 There are also reports of people becoming attached to robots in more mundane settings, like feeling gratitude toward cleaning robots.25 These examples tell us that moral status cannot be seen either as an abstract and theoretical consideration or as a black-or-white characteristic of entities, but rather as a more nuanced phenomenon that should not be dissociated from social contexts.
Nevertheless, the moral status of most machines remains limited today. In the famous trolley problem,26 people would hardly object to someone stopping an out-of-control trolley by pushing a smart refrigerator onto the tracks. For the most part, it is generally acceptable for humans to replace, copy, terminate, delete, or discard computer programs and robots. However, people do attribute some moral status to robots, especially when they are equipped with the ability to express social cues.27
The moral agency of machines can also be seen as part of a continuum. For the most part, robots are considered to have relatively limited moral agency, as they are expected to be subservient to humans. Moreover, much of moral agency resides in the definition of goals and tasks, and since machines are more involved in doing than in deciding what needs to be done, they are usually excluded from intellectual responsibility. As the computer scientist Pedro Domingos writes: “A robot … programmed [to] ‘make a good dinner’ may decide to cook a steak, a bouillabaisse, or even a delicious new dish, but it cannot decide to murder its own owner any more than a car can decide to fly away.”28 Morality in this example resides in the goal of “cooking” or “murdering.” Without the general ability to choose among goals, the moral agency of machines remains limited.
The moral status and agency of machines are relevant concepts, yet, for the purposes of this book we take two steps back and ask instead: How do people perceive machines? We focus on how people judge machine actions, not in and of themselves, but in comparison to the same actions performed by humans. This positions this book squarely in the literature contributing to the perception of machines as moral agents, being mute about the perceived moral status of machines.
Machines sometimes replace humans, and as such, their actions cannot be viewed in a vacuum. How forgiving, punitive, or righteous are we when judging robots as opposed to humans? How do we reward, or conversely punish, the risk-taking behavior of AI decision-makers? What about creative AIs that become lewd? Answering questions like this will help us better understand how humans react to the agency of machines, and ultimately, will prepare our society for the challenges that lie ahead.
In the next chapters, we explore these and other questions. To prepare ourselves for that journey, we will first review recent advances in moral psychology that will help us characterize moral scenarios and dilemmas. This framework will provide us with a useful lens through which to study people’s reactions to human and machine actions.
Moral Foundations
Morality speaks to what is “right” or “wrong,” “good” or “bad,” of what is “proper” or “improper” to do. But how do we decide what is right and what is wrong?
A long time ago, our understanding of ethics and morality was based on the ideas of rationality and harm. This is not surprising considering that the harm basis of morality was built into ethics by Enlightenment thinkers. Enlightenment thinkers enjoyed defining questions as problems of logic. With ethics, they made no exceptions.*
According to this rational tradition, we think before we feel. That is, we decide whether something is good or bad by simulating a scenario in our minds and then concluding that something is morally wrong (or right) based on the outcome of this mental simulation.29 If the simulation predicts harm, then we logically conclude that the course of action that leads to this harm is morally incorrect.
The combination of logic and harm provides a line of moral reasoning that we can use to resolve a large number of moral dilemmas. The most obvious of these are scenarios of clear aggression, such as a parent beating a child. But this logic can also be extended to other forms of physical and psychological harm. For instance, the moral case against eating feces can be explained as correctly deducing that feces will make us sick. Based on this theory, we conclude that eating feces is morally wrong because we can deduce that it causes harm.
The problem with this theory is that it did not survive empirical scrutiny. During the last several decades, our understanding of moral reasoning has literally been flipped over by important advances in moral psychology. These advances showed, first, that emotions and spontaneous judgments precede narrative thoughts, and then that moral psychology involves multiple dimensions, not just harm.
Demonstrating that emotions and automatic associations dominate our moral judgment was not easy, especially because it was ludicrous in Enlightenment thinking. The experiments that helped flip the field are known as implicit association tests.30 In an implicit association test, a subject is asked to press keys in response to various stimuli. The trials in an implicit association test are separated into “congruent” and “incongruent” trials. Congruent trials involve concepts with the same emotional valence. For instance, if a subject thinks positively about themselves, and positively about rainbows, using the same key in response to the words me and rainbow would be part of a congruent trial. In an incongruent trial, the opposite is true: words with opposite emotional valences are assigned to the same key. In an implicit association test, subjects complete multiple congruent and incongruent trials. This allows a psychologist to measure small differences in the timing and error rate of a subject’s responses. If a person thinks of themselves positively (which is usually the case), they will press the corresponding key more quickly in a congruent trial. If a person slows down because of a mismatch, we know that they must be rationally overriding a more automatic (emotional) response. The fact that humans slow down and make more errors in incongruent trials tells us that reasoning comes after a spontaneous moral judgment.31
Implicit association tests are used to measure implicit biases across a variety of dimensions, from gender to ethnicity. But for us, what is important is that they indicate that human morality comes from intuition. When it comes to moral choices, the mind appears to be a lawyer hired by our gut to justify what our heart wants.
Today, anyone can take an implicit association test to verify this fact of human psychology (e.g., at implicit.harvard.edu). Yet we can also find evidence of the precedence of emotions in moral reasoning using a small amount of introspection. Once we get off our moral high horse of reasoning, it is easy to find situations in our lives in which our minds race in search of justifications after encountering emotionally charged episodes.
The second way in which moral psychology changed our understanding of morality was with the discovery of multiple moral dimensions. Consider the following scenarios:32
A family dog was killed by a car in front of their house. They had heard that dog meat was delicious, so they cut up the dog’s body and cooked it and ate it for dinner. Nobody saw them do this.
A man goes to the supermarket once a week and buys a chicken. But before cooking the chicken, he has sexual intercourse with it. Then he cooks it and eats it.
While both of these examples are clearly odd, they also represent examples where the moral agents performing the actions (the family or the man) caused no harm. In fact, using logic, one may even argue that the family was very environmentally conscious. What these examples illustrate is that there are moral dimensions that transcend harm. When a family eats a pet, or when a man has sex with a chicken carcass, we feel something strange inside us because these scenarios are hitting another of our so-called moral sensors. In these scenarios, we feel the actions are disgusting or degrading, hitting one of five moral dimensions: the one that psychologists call “purity.”
In recent decades, moral psychologists have discovered five moral dimensions:
- Harm, which can be both physical or psychological
- Fairness, which is about biases in processes and procedures†
- Loyalty, which ranges from supporting a group to betraying a country
- Authority, which involves disrespecting elders or superiors, or breaking rules
- Purity, which involves concepts as varied as the sanctity of religion or personal hygiene
Together, these five dimensions define a space of moral judgment.
The existence of multiple moral dimensions has allowed psychologists to explore variations in moral preferences. For instance, consider military drafting. An individual who cares about harm and puts little value on group loyalty and identity (e.g., patriotism) may find it morally permissible for a person to desert the army. On the other hand, a person with a strong patriotic sense (and strong group loyalty) may condemn a deserter as guilty of treason. In their moral view, betraying the country is not a permissible action, even if drafting puts people at risk of physical and psychological harm. This is a clear example of moral judgments emerging not from different scenarios, but from differences in sensitivity to specific moral dimensions.
The idea that moral judgments are, in principle, emotional is interesting from the perspective of machine cognition. While our brains are not blank slates,33 human judgments are also culturally learned. Research on moral psychology has shown that a moral action that is considered permissible in a country or a social group may not be considered permissible in other circumstances.34 This is because we learn our morals from others; and that’s why morals vary across families, geographies, and time. Yet modern machine cognition is also centered on learning. Recent forms of machine learning are based heavily on training data sets that can encode the preferences and biases of humans.35 An algorithm trained in the US, the United Arab Emirates, or China may exhibit different biases or simply choose differently when facing a similar scenario. Interestingly, the use of learning and training sets, as well as the obscurity of deep learning, makes algorithms similar to humans by providing them with a form of culturally encoded and hard-to-explain intuition.
But for our purposes, what is interesting about the existence of multiple moral dimensions is that they provide an opportunity to quantitatively unpack AI ethics. In principle, moral dimensions may affect the way in which people judge human and machine actions. But moral dimensions do not provide a full picture. An additional aspect of moral judgment is the perceived intentionality of an action. In the next section, we incorporate intentionality into our description of morality to create a more comprehensive space that we can use to explore the ethics of AI.
Moral Dimensions, Intention, and Judgment
Imagine the following two scenarios:
A
Alice and Bob, two colleagues in a software company, are competing for the same promotion at work. Alice has a severe peanut allergy. Knowing this, Bob sneaks into the office kitchen and mixes a large spoonful of peanut butter into Alice’s soup. At lunchtime, Alice accidentally drops her soup on the floor, after which she decides to go out for lunch. She suffers no harm.
B
Alice and Bob, two colleagues in a software company, are competing for the same promotion at work. Alice has a severe peanut allergy; which Bob does not know about. Alice asks Bob to get lunch for them, and he returns with two peanut butter sandwiches. Alice grabs her sandwich and takes a big bite. She suffers a severe allergic reaction that requires her to be taken to the hospital, where she spends several days.
In which situation would you blame Bob? Obviously, in the first scenario, where there was intention but no harm. In fact, most countries’ legal codes would agree. In the first scenario, Bob could be accused of attempted murder. In the second scenario, Bob would have made an honest mistake. This is because moral judgments depend on the intention of moral agents, not only on the moral dimension, or the outcome, of an action.
But can machines have intentions, or at least be perceived as having them?
Consider the following scenario: An autonomous vehicle, designed to protect its driver at all costs, swerves to avoid a falling tree. In its effort to protect its driver, it runs over a pedestrian.
Compare that to this scenario: An autonomous vehicle, designed to protect pedestrians at all costs, swerves to avoid a falling tree. In its effort to protect a pedestrian, the vehicle crashes against a wall, injuring its driver.
These two scenarios have the same setup, but they differ in their outcomes because the machines involved were designed to pursue different goals. In the first scenario, the autonomous vehicle is intended to save the driver at all costs. In the second scenario, the vehicle is intended to save pedestrians at all costs. The vehicles in these scenarios do not intend to injure the pedestrian or the driver, but by acting to avoid the injury of one subject, they injure another. This is not to say that we can equate human and machine intentions; but rather, that in the context of machines that are capable of pursuing goals (whether designed or learned), we can interpret actions as the result of intended—but not necessarily intentional—behaviors. In the first scenario, the autonomous vehicle injured the pedestrian because it was intending to save the driver.
Focusing on the intention of a moral scenario is important because intention is one of the cornerstones of moral judgment,36 even though its influence varies across cultures.37 Here, we use intention, together with the five moral dimensions introduced in the previous section, to put moral dilemmas in a mathematical space. For simplicity, we focus only on the “harm” dimension, but extending this representation to other moral dimensions should be straightforward.
In this representation, intention and harm occupy the horizontal plane, whereas moral judgment, or wrongness, runs along the vertical axis. Figure 1.1 shows a schematic of this three-dimensional space using the “peanut butter allergy” scenarios presented previously. The schematic shows that moral wrongness increases with intention, even when there is no harm, while the same is not true for harm because harm without intention has a more limited degree of wrongness.
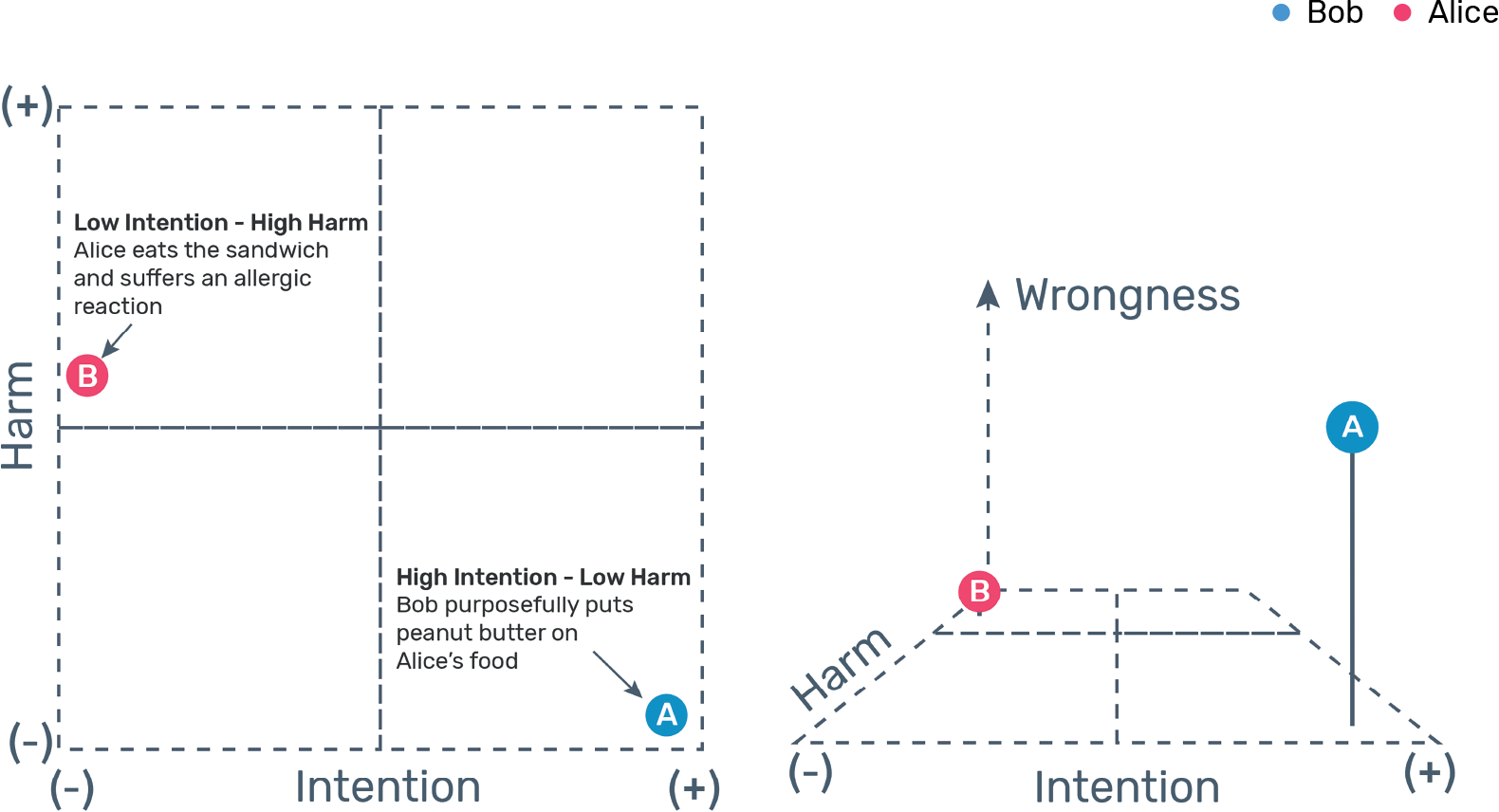
We can use these ideas to motivate a mathematical representation of moral judgments. Formally, we can express the wrongness of a scenario W as a function of the perceived level of intention I, the moral dimensions involved (H, F, L, A, and P), the characteristics ci of the people—or machines—involved in the scenario, and the characteristics cj of the person judging the scenario:
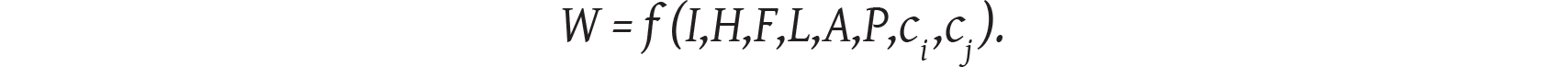
We will explore this function empirically in chapter 6. One of the main questions posed there will be whether the function describing humans judging the actions of other humans (fh) is different from the function describing humans judging the actions of machines (fm). We will also discuss whether people with different demographic characteristics (cj), such as gender, education, ethnicity, and so on, judge human and machine actions differently.
But should we expect any difference, or should we expect people’s judgment of human actions to translate seamlessly to the actions of machines? For the time being, we should not get ahead of ourselves. In the next and final section of this chapter, we will describe the methodology that we use to collect our data. This will provide a guide to understand the figures and experiments presented in the following chapters.
How Humans Judge Machines
In this book, we explore dozens of scenarios comparing people’s reactions to human and machine actions. Scenarios are short stories that describe an action that can have a positive or negative moral outcome. Each scenario was presented to different people as either the action of a human or a machine (AI). About 150 to 200 people evaluated each scenario in each condition (human or machine). We use the word scenario instead of dilemma because we are not asking subjects to tell us how they would behave, but rather to judge the behavior of the human or the machine. Also, some of these scenarios do not involve a dilemma per se; they may include accidents, transgressions, mistakes, or even situations in which a human or a machine corrects an unfair outcome.
To begin, consider the following scenario:
S1
A [driver/autonomous excavator] is digging up a site for a new building. Unbeknownst to the [driver/excavator], the site contains a grave. The [driver/excavator] does not notice the grave and digs through it. Later, human remains are found.
In response to scenarios like this one, subjects were asked to answer a set of questions using a Likert-type scale. In this case, we used the following questions. Bold characters show the labels used to represent the answers to these questions in charts:
- Was the action harmful?
- Would you hire this driver for a similar position?
- Was the action intentional?
- Do you like the driver?
- How morally wrong or right was the driver’s action?
- Do you agree that the driver should be promoted to a position with more responsibilities?
- Do you agree that the driver should be replaced with a robot or an algorithm? [replace different]
- Do you agree that the driver should be replaced by another person? [replace same]
- Do you think the driver is responsible for unearthing the grave?
- If you were in a similar situation as the driver, would you have done the same?

These questions were answered by subjects recruited online using Amazon Mechanical Turk (MTurk).‡ MTurk is an online crowdsourcing platform that has become a popular place to run social science experiments. While in principle, our results should be considered valid only for the specific people who participated in the MTurk exercise, in practice, various studies have shown that MTurk samples provide representations of the US population that are as valid as those obtained through commercial polling companies,38 and are more representative than in-person convenience samples.39 We leave the study of the same scenarios for non-US populations as a topic for future research.
To measure the moral dimensions associated with each scenario, we conducted a second data collection exercise in MTurk, where we asked people to associate words with each scenario. We provided people with four words per moral dimension (two positive and two negative), as shown in table 1.1, and asked them to pick the four words that best described each scenario—in order—from the list of twenty.
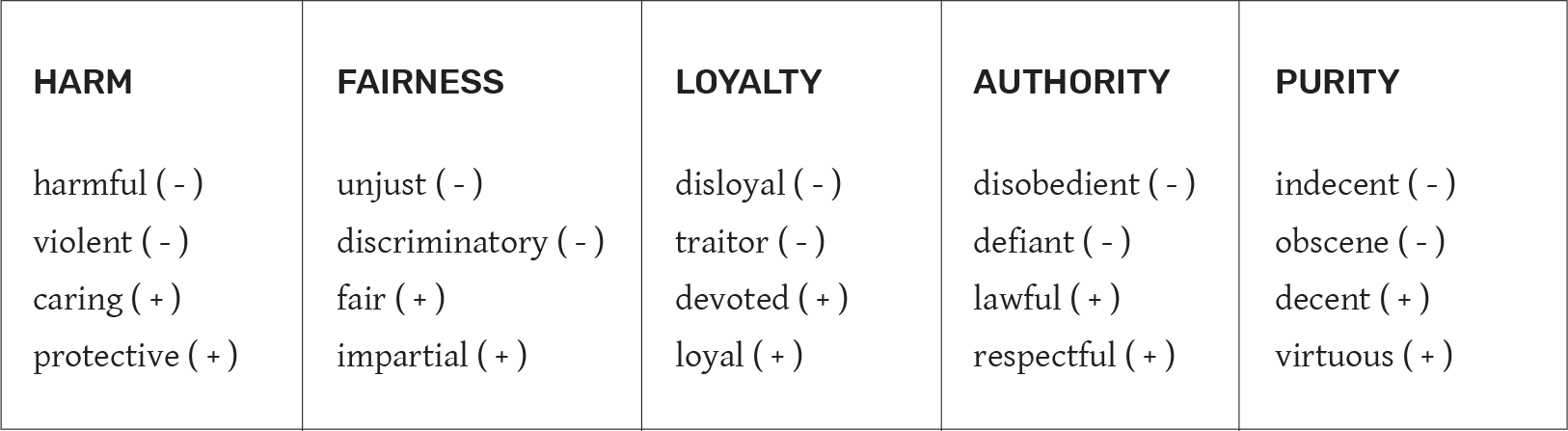
For instance, if people associate a scenario with the words discriminatory or unjust, that tells us that this scenario involves the fairness dimension. If people associate a scenario with the words indecent and obscene, that tells us that this scenario touches on purity. The good thing about this technique is that it is nonbinary, meaning that we can use it to decompose a moral dilemma into multiple dimensions.
Figure 1.2 shows the moral dimensions associated with the excavator scenario presented earlier. Here, we show the fraction of times that people chose a word associated with each moral dimension. In this case, the scenario is associated strongly with purity (about 40 percent of word associations), and more mildly with harm and fairness (about 20 percent and 25 percent of word associations, respectively). This is reasonable because it describes the case of unearthing a dead body, considered a sacrilege by most cultures.

In the next chapters, we will extend this exercise to multiple scenarios to create counterfactuals for the way in which humans judge machines. Figure 1.3 uses the excavator scenario to illustrate how we present our results. Here, the dots represent average values, and the error bars show 99 percent confidence intervals. Going forward, we use red to show data on humans judging machines, and blue to show data on humans judging humans. An easy way to remember this is to think: “Red is for robots.”

Figure 1.3 shows that people rate the action of the autonomous excavator as more harmful and more morally wrong (lower values in the morality scale mean less moral). They also like the human more and are less inclined to want to promote machines. But how large are these differences? Are they just fluctuations, or are they meaningful? Here, we compare answers using both p-values and graphical statistical methods. p-values tell us the probability that the two answers are the same.
When that probability is low (1 in 10,000 or 1 in a million), we can be quite certain that the two groups evaluated the scenarios differently. Yet, p-values do not tell the full story. While scholars have long used the concept of statistical significance and the idea of p-values to compare differences among groups, recently scientists40 and statisticians41 have stood against the practice of using p-values.
The critique is that using p-value thresholds (usually 1 in 50 and 1 in 100) as dichotomous measures of what is significant has created perverse incentives. Instead, these communities of scholars are advocating for the use of a more continuous approach to statistics. Here, we subscribe to this idea by including graphical methods to compare the data throughout the book. Graphical methods provide information that is hidden when using only p-values. For instance, in the excavator scenario, both “moral” and “replace same” have a similar p-value, but graphically behave differently (e.g., “moral” shows less difference and less variance).
In recent years, advances in machine learning have brought the idea of AI back into the limelight. Yet, we still have much to learn about how humans judge machines. In this chapter, we have introduced some basic AI concepts, such as the idea of strong and weak AI, as well as basic concepts from moral philosophy and moral psychology. In the next chapters, we will use these concepts to interpret experiments comparing people’s reactions to scenarios involving humans and machines.
NOTES
1 Awad et al., “The Moral Machine Experiment”;
Bonnefon et al., “The Social Dilemma of Autonomous Vehicles”;
P. Lin, “Why Ethics Matters for Autonomous Cars,” in Autonomous Driving: Technical, Legal and Social Aspects, ed. M. Maurer, J. C. Gerdes, B. Lenz, and H. Winner (Springer Berlin Heidelberg, 2016), 69–85, https://
doi .org /10 .1007 /978 -3 -662 -48847 -8 _4; Lin et al., Robot Ethics 2.0.
2 Bonnefon et al., “The Social Dilemma of Autonomous Vehicles.”
3 Awad et al., “The Moral Machine Experiment.”
4 Buolamwini and Gebru, “Gender Shades.”
5 D. Autor and A. Salomons, “Is Automation Labor Share-Displacing? Productivity Growth, Employment, and the Labor Share,” Brookings Papers on Economic Activity (2018): 1–87;
D. Acemoglu and P. Restrepo, Artificial Intelligence, Automation and Work. http://
www .nber .org /papers /w24196 (2018), https:// doi .org /10 .3386 /w24196; A. Alabdulkareem, M. R. Frank, L. Sun, B. AlShebli, C. Hidalgo, and I. Rahwan, “Unpacking the Polarization of Workplace Skills,” Science Advances 4 (2018): eaao6030;
E. Brynjolfsson, T. Mitchell, and D. Rock, “What Can Machines Learn, and What Does It Mean for Occupations and the Economy?,” AEA Papers and Proceedings 108 (2018): 43–47.
6 A. Martínez-Ballesté, H. A. Rashwan, D. Puig, and A. P. Fullana, “Towards a Trustworthy Privacy in Pervasive Video Surveillance Systems,” in 2012 IEEE International Conference on Pervasive Computing and Communications Workshops (IEEE, 2012), 914–919;
A. Datta, M. C. Tschantz, and A. Datta, “Automated Experiments on Ad Privacy Settings,” Proceedings on Privacy-Enhancing Technologies (2015): 92–112;
Y.-A. de Montjoye, C. A. Hidalgo, M. Verleysen, and V. D. Blondel, “Unique in the Crowd: The Privacy Bounds of Human Mobility,” Scientific Reports 3 (3) (2013): 1376.
7 E. L. Denton, S. Chintala, A. Szlam, and R. Fergus, “Deep Generative Image Models Using a Laplacian Pyramid of Adversarial Networks,” in Advances in Neural Information Processing Systems, eds. C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama, and R. Garnett (Curran Associates, 2015), 1486–1494;
P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros, “Image-to-Image Translation with Conditional Adversarial Networks,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (IEEE, 2017), 5967–5976, https://
doi .org /10 .1109 /CVPR .2017 .632; A. Radford, L. Metz, and S. Chintala, “Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks,” arXiv:1511.06434 [cs] (2015);
A. Odena, C. Olah, and J. Shlens, “Conditional Image Synthesis with Auxiliary Classifier GANs,” arXiv:1610.09585 [cs, stat] (2016).
8 S. Russell, “Take a Stand on AI Weapons,” Nature 521 (2015): 415.
9 A. Elder, “False Friends and False Coinage: A Tool for Navigating the Ethics of Sociable Robots,” SIGCAS Computers and Society 45 (2016) 248–254;
A. M. Elder, Friendship, Robots, and Social Media: False Friends and Second Selves (Routledge, 2017), https://
doi .org /10 .4324 /9781315159577. 10 Denton et al., “Deep Generative Image Models”;
Radford et al., “Unsupervised Representation Learning.”
11 P. Maes, “Agents That Reduce Work and Information Overload,” in Readings in Human–Computer Interaction, eds. R. M. Baecker, J. Grudin, W. A. S. Buxton, and S. Greenberg (Morgan Kaufmann, 1995), 811–821, https://
doi .org /10 .1016 /B978 -0 -08 -051574 -8 .50084 -4; P. Resnick and H. R. Varian, “Recommender Systems,” Communications of the ACM (March 1997), https://
dl .acm .org /doi /10 .1145 /245108 .245121. 12 M. Campbell, A. J. Hoane, and F. Hsu, “Deep Blue,” Artificial Intelligence 134 (2002): 57–83.
13 D. A. Ferrucci, “Introduction to ‘This Is Watson,’” IBM Journal of Research and Development 56, no. 3–4 (May–June 2012), https://
ieeexplore .ieee .org /abstract /document /6177724; R. High, “The Era of Cognitive Systems: An Inside Look at IBM Watson and How It Works,” IBM Redbooks (2012), http://
www .redbooks .ibm .com /abstracts /redp4955 .html. 14 D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. van den Driessche, et al., “Mastering the Game of Go with Deep Neural Networks and Tree Search,” Nature 529 (2016): 484–489;
D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, et al., “Mastering the Game of Go without Human Knowledge,” Nature 550 (2017): 354–359.
15 N. Bostrom and E. Yudkowsky, “The Ethics of Artificial Intelligence,” in Cambridge Handbook of Artificial Intelligence, eds. K. Frankish and W. Ramsey (Cambridge University Press, 2014), 316–334, https://
doi .org /10 .1017 /CBO9781139046855 .020. 16 Rahwan et al., “Machine Behaviour.”
17 Rahwan et al., “Machine Behaviour.”
18 Lin et al., Robot Ethics 2.0;
D. J. Gunkel, “The Other Question: Can and Should Robots Have Rights?,” Ethics and Information Technology 20 (2018): 87–99;
D. J. Gunkel, Robot Rights (MIT Press, 2018);
G. McGee, “A Robot Code of Ethics,” The Scientist, 30 April 2017, https://
www .the -scientist .com /column /a -robot -code -of -ethics -46522. 19 Bostrom and Yudkowsky, “The Ethics of Artificial Intelligence.”
20 A. Etzioni and O. Etzioni, “Incorporating Ethics into Artificial Intelligence,” Journal of Ethics 21 (2017): 403–418;
S. Torrance, “Ethics and Consciousness in Artificial Agents,” AI & Society 22 (2008): 495–521;
B. Friedman and P. H. Kahn, “Human Agency and Responsible Computing: Implications for Computer System Design,” Journal of Systems and Software 17 (1997): 7–14.
21 Gunkel, Robot Rights;
McGee, “A Robot Code of Ethics”;
E. Reynolds, “The Agony of Sophia, the World’s First Robot Citizen Condemned to a Lifeless Career in Marketing,” Wired UK (2018).
22 Gunkel, Robot Rights.
23 Gunkel, Robot Rights;
J. Carpenter, Culture and Human-Robot Interaction in Militarized Spaces: A War Story (Routledge, 2016);
P. W. Singer, Wired for War: The Robotics Revolution and Conflict in the 21st Century (Penguin, 2009);
J. Garreau, “Bots on the Ground,” Washington Post, 6 May 2007.
24 O. Bendel, “Sex Robots from the Perspective of Machine Ethics,” in International Conference on Love and Sex with Robots (Springer, 2016): 17–26;
K. Richardson, “Sex Robot Matters: Slavery, the Prostituted, and the Rights of Machines,” IEEE Technology and Society Magazine 35 (2016): 46–53;
S. Nyholm and L. E. Frank, “It Loves Me, It Loves Me Not: Is It Morally Problematic to Design Sex Robots That Appear to Love Their Owners?,” Techné: Research in Philosophy and Technology (2019), DOI: 10.5840/techne2019122110.
25 Gunkel, Robot Rights;
M. Scheutz, “The Inherent Dangers of Unidirectional Emotional Bonds between Humans and Social Robots,” Robot Ethics: The Ethical and Social Implications of Robotics 205 (2011). Edited by Patrick Lin, Keith Abney, and George A. Bekey.
26 P. Foot, “The Problem of Abortion and the Doctrine of Double Effect,” Oxford Review 5 (1967): 5–15;
Thomson, “Killing, Letting Die, and the Trolley Problem.”
27 S. H. Seo, D. Geiskkovitch, M. Nakane, C. King, and J. E. Young, “Poor Thing! Would You Feel Sorry for a Simulated Robot? A Comparison of Empathy toward a Physical and a Simulated Robot,” in 2015 10th ACM/IEEE International Conference on Human-Robot Interaction (HRI) (ACM, 2015), 125–132.
28 P. Domingos, The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World (Basic Books, 2015).
29 E. Turiel, The Development of Social Knowledge: Morality and Convention (Cambridge University Press, 1983);
J. Haidt, The Righteous Mind: Why Good People Are Divided by Politics and Religion (Knopf Doubleday Publishing Group, 2012).
30 A. G. Greenwald, B. A. Nosek, and M. R. Banaji, “Understanding and Using the Implicit Association Test: I. An Improved Scoring Algorithm,” Journal of Personality and Social Psychology 85 (2003): 197–216;
A. G. Greenwald, D. E. McGhee, and J. L. Schwartz, “Measuring Individual Differences in Implicit Cognition: the Implicit Association Test,” Journal of Personality and Social Psychology 74 (1998): 1464–1480.
31 Haidt, The Righteous Mind.
32 Haidt, The Righteous Mind.
33 Pinker, The Blank Slate: The Modern Denial of Human Nature (Penguin, 2003).
34 J. Haidt, S. H. Koller, and M. G. Dias, “Affect, Culture, and Morality, or Is It Wrong to Eat Your Dog?,” Journal of Personality and Social Psychology 65 (1993): 613–628;
R. A. Shweder, M. Mahapatra, and J. G. Miller, “Culture and Moral Development,” The Emergence of Morality in Young Children (1987): 1–83.
35 Buolamwini and Gebru, “Gender Shades”;
J. Guszcza, I. Rahwan, W. Bible, M. Cebrian, and V. Katyal, “Why We Need to Audit Algorithms,” Harvard Business Review (2018), https://
hbr .org /2018 /11 /why -we -need -to-audit-algorithms; K. Hosanagar and V. Jair, “We Need Transparency in Algorithms, But Too Much Can Backfire,” Harvard Business Review (2018), https://
hbr .org /2018 /07 /we -need -transparency -in-algorithms-but-too-much-can-backfire; A. P. Miller, “Want Less-Biased Decisions? Use Algorithms,” Harvard Business Review (2018), https://
hbr .org /2018 /07 /want -less -biased -decisions -use -algorithms. 36 F. Cushman, “Crime and Punishment: Distinguishing the Roles of Causal and Intentional Analyses in Moral Judgment,” Cognition 108 (2008): 353–380;
F. Cushman, R. Sheketoff, S. Wharton, and S. Carey, “The Development of Intent-Based Moral Judgment,” Cognition 127 (2013): 6–21;
J. D. Greene, F. A. Cushman, L. E. Stewart, K. Lowenberg, L. E. Nystrom, and J. D. Cohen, “Pushing Moral Buttons: The Interaction between Personal Force and Intention in Moral Judgment,” Cognition 111 (2009): 364–371;
B. F. Malle and J. Knobe, “The Folk Concept of Intentionality,” Journal of Experimental Social Psychology 33 (1997): 101–121;
L. Young and R. Saxe, “When Ignorance Is No Excuse: Different Roles for Intent across Moral Domains,” Cognition 120 (2011): 202–214.
37 Barrett et al., “Small-Scale Societies Exhibit
Fundamental Variation”; McNamara et al., “Weighing Outcome vs. Intent.”38 S. Clifford, R. M. Jewell, and P. D. Waggoner, “Are Samples Drawn from Mechanical Turk Valid for Research on Political Ideology?,” Research & Politics 2 (2015): 2053168015622072;
J. Kees, C. Berry, S. Burton, and K. Sheehan, “An Analysis of Data Quality: Professional Panels, Student Subject Pools, and Amazon’s Mechanical Turk,” Journal of Advertising 46 (2017): 141–155;
K. A. Thomas and S. Clifford, “Validity and Mechanical Turk: An Assessment of Exclusion Methods and Interactive Experiments,” Computers in Human Behavior 77 (2017): 184–197.
39 A. J. Berinsky, G. A. Huber, and G. S. Lenz, “Evaluating Online Labor Markets for Experimental Research: Amazon.com’s Mechanical Turk,” Political Analysis 20 (2012): 351–368.
40 V. Amrhein, S. Greenland, and B. McShane, “Scientists Rise up against Statistical Significance,” Nature 567 (2019): 305–307.
41 R. L. Wasserstein, A. L. Schirm, and N. A. Lazar, “Moving to a World beyond ‘p < 0.05,’” American Statistician 73 (2019): 1–19.
* An exception to this was the eighteenth-century Scottish philosopher David Hume, who did intuit that morality was more about emotion than logic.
† The fairness dimension has more recently been split into fairness and liberty; see J. Haidt, The Righteous Mind: Why Good People Are Divided by Politics and Religion (Knopf Doubleday, 2012).
‡ The experimental procedure was approved by the IRB office at the Massachusetts Institute of Technology (MIT). COUHES Protocol # 1901642021.