Recognize independent and dependent variables and how they are typically displayed graphically
Explain the importance of the different types of control, including positive and negative controls
Distinguish between accuracy and precision:
Basic scienceresearch—the kind conducted in a laboratory, and not on people—is generally the easiest to
design because the experimenter has the most control. Often a causal relationship
is being examined because the hypothesis generally states a condition and an outcome.
In order to make generalizations about our experiments, we must make sure that the
outcome of interest would not have occurred without our intervention, and therefore,
we use controls. We must also demonstrate causality, which is relatively simple in
basic science research, but less so in other research areas.
Controls
In basic science research, conditions can be applied to multiple trials of the same
experiment that are as near to identical as possible. In this way, a control or standard acts as a method of verifying results. Consider the following experiment: a scientist
has an unknown concentration of a basic ammonia solution and wishes to determine the
concentration experimentally. He takes a standardized solution of hydrochloric acid
(made by comparison to a potassium hydrogen phthalate [KHP] standard) and titrates
the basic solution in the presence of the same calibrated pH meter he used for the
hydrochloric acid standardization. He then determines the ammonia concentration from
the results of the titration. Because the concentration of the acid used to determine
the ammonia concentration was verified against a standard, he can be confident that
the calculated ammonia concentration is accurate.
Real World
The use of controls also allows investigators to check for contamination of reagents.
Controls can also be separate experimental conditions altogether. For example, when
testing the reaction of a tissue culture to an antibiotic, a separate culture is generally
grown and administered an equal quantity of a compound known to be inert, like water
or saline. The control corrects for any impact that the simple addition of volume
might have had on the experiment. Some experiments have both positive and negative
controls for points of comparison or a group of controls that can be used to create
a curve of known values. Positive controls are those that ensure a change in the dependent variable when it is expected. In
the development of a new assay for detection of HIV, for example, administering the
test to a group of blood samples known to contain HIV could constitute a positive
control. Negative controls, in contrast, ensure no change in the dependent variable when no change is expected.
With the same assay, administering the test to a group of samples known not to contain
the HIV virus could constitute a negative control. In drug trials, a negative control
group is often used to assess for the placebo effect—an observed or reported change when an individual is given a sugar pill or sham intervention.
Causality
The other big advantage to being able to manipulate all of the relevant experimental
conditions is that basic science researchers can often establish causality. Causality
is an if–then relationship, and is often the hypothesis being tested. In basic science
research, we manipulate an independent variable, and measure or observe a dependent variable. When there is a theoretical or known mechanism that links the independent and dependent
variables, a causal relationship can be investigated. If the change in the independent
variable always precedes the change in the dependent variable, and the change in the
dependent variable does not occur in the absence of the experimental intervention,
the relationship is said to be causal.
Key Concept
The independent variable is the one that the experimenter is manipulating, and the
dependent or outcome variable is the one that is being observed. On a graph the independent
variable belongs on the x-axis and the dependent variable belongs on the y-axis.
Error Sources
In basic science research, experimental bias is usually minimal. The most likely way
for an experimenter’s personal opinions to be incorporated is through the generation
of a faulty hypothesis from incomplete early data and resource collection. However,
there can be manipulation of the results by eliminating trials without appropriate
background, or by failing to publish works that contradict the experimenter’s own
hypothesis.
The low levels of bias introduced by the experimenter do not eliminate all error from
basic science research. Measurements are especially important in the laboratory sciences,
and the instruments may give faulty readings. Instrument error may affect accuracy,
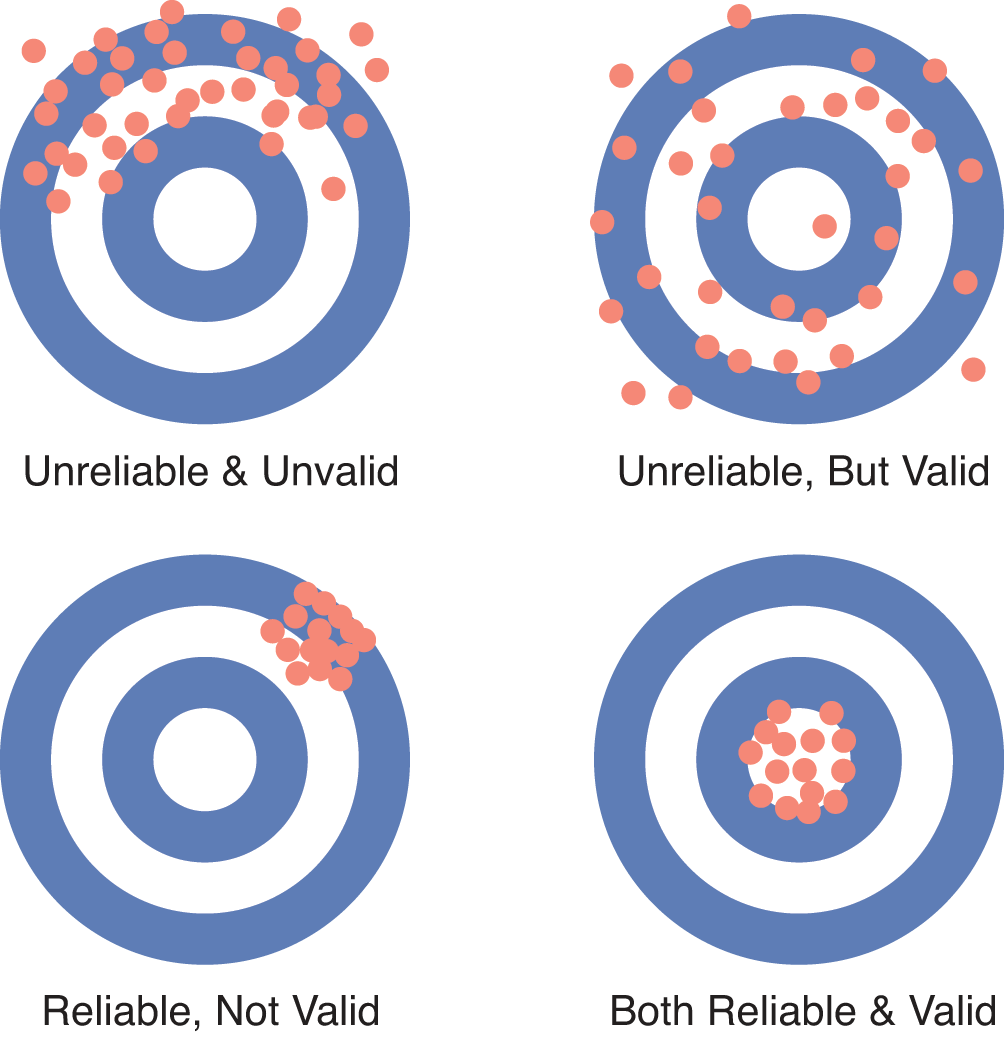
precision, or both. Accuracy, also called validity, is the ability of an instrument to measure a true value. For example, an accurate
scale should register a 170-pound person’s weight as 170 pounds. Precision, also called reliability, is the ability of the instrument to read consistently, or within a narrow range.
The same person standing on a scale that is accurate but imprecise may get readings
between 150 and 190 pounds. The same person standing on a scale that is inaccurate
but precise may get readings between 129 and 131 pounds, a relatively narrow range.
Accuracy and precision are represented in Figure 11.1. Because bias is a systematic error in data, only an inaccurate tool will introduce bias, but an imprecise tool will
still introduce error. Random chance can also introduce error into an experiment;
while random error is difficult to avoid, it is usually overcome by using a large
sample size.
Figure11.1.Accuracy (Validity) and Precision (Reliability) of Measurements