
Top texture: © Laguna Design / Science Source;
CHAPTER 12: Extrachromosomal Replicons

Chapter Opener: © Tim Vernon/Science Source.
12.1 Introduction
A bacterium can be a host for independently replicating genetic units in addition to its chromosome. These extrachromosomal genomes fall into two general types: plasmids and bacteriophages (phages). Some plasmids, and all phages, have the ability to transfer from a donor bacterium to a recipient by an infective process. An important distinction between them is that plasmids exist only as free DNA genomes, whereas bacteriophages are viruses that package a nucleic acid genome into a protein coat and are released from the bacterium at the end of an infective cycle.
Plasmids are self-replicating circular molecules of DNA that are maintained in the cell in a stable and characteristic number of copies; that is, the average number remains constant from generation to generation. Low-copy number plasmids are maintained at a constant quantity relative to the bacterial host chromosome, often between 1 and 10 per bacterium, depending on the plasmid. As with the host chromosome, they rely on a specific apparatus to be segregated equally at each bacterial division. Multicopy plasmids exist in many copies per unit bacterium and can be segregated to daughter bacteria stochastically (meaning that there are enough copies to ensure that each daughter cell always gains some by a random distribution).
Plasmids and phages are defined by their ability to reside in a bacterium as independent genetic units. Certain plasmids, and some phages, can also exist as sequences integrated within the bacterial genome, though. In this case, the same sequence that constitutes the independent plasmid or phage genome is inherited like any other bacterial gene. Phages that are found as part of the bacterial chromosome are said to show lysogeny; plasmids that also have the ability to integrate into the chromosome are called episomes. All episomes are plasmids, but not all plasmids are episomes. Related processes are used by phages and episomes to insert into and excise from the bacterial chromosome.
A parallel between lysogenic phages and plasmids and episomes is that they maintain a selfish possession of their bacterium and often make it impossible for another element of the same type to become established. This effect is called immunity, although the molecular basis for plasmid immunity is different from lysogenic immunity, and is a consequence of the replication control system.
Several types of genetic units can be propagated in bacteria as independent genomes. Lytic phages can have genomes of any type of nucleic acid; they transfer between cells by release of infective particles. Lysogenic phages have double-stranded DNA genomes, as do plasmids and episomes. Some plasmids transfer between cells by a conjugative process (with direct contact between donor and recipient cells). A feature of the transfer process in both cases is that on occasion some bacterial host genes are transferred with the phage or plasmid DNA, so these events play a role in allowing exchange of genetic information between bacteria.
The key feature in determining the behavior of each type of unit is how its origin is used. An origin in a bacterial or eukaryotic chromosome is used to initiate a single replication event that extends across the replicon. Replicons, however, can also be used to sponsor other forms of replication. The most common alternative is used by the small, independently replicating units of viruses. The objective of a viral replication cycle is to produce many copies of the viral genome before the host cell is lysed to release them. Some viruses replicate in the same way as a host genome, with an initiation event leading to production of duplicate copies, each of which then replicates again, and so on. Others use a mode of replication in which many copies are produced as a tandem array following a single initiation event. A similar type of event is triggered by episomes when an integrated plasmid DNA ceases to be inert and initiates a replication cycle.
Many prokaryotic replicons are circular, and this indeed is a necessary feature for replication modes that produce multiple tandem copies. Some extrachromosomal replicons are linear, though, and in such cases researchers need to account for the ability to replicate the end of the replicon. (Of course, eukaryotic chromosomes are linear, so the same problem applies to the replicons at each end. These replicons, however, have a special system for resolving the problem.)
12.2 The Ends of Linear DNA Are a Problem for Replication
None of the replicons examined in this book so far have a linear end: Either they are circular (as in the Escherichia coli genome), or they are part of longer segregation units (as in eukaryotic chromosomes). Linear replicons do occur, though—in some cases as single extrachromosomal units, and at the ends, or telomeres, of eukaryotic chromosomes.
The ability of all known nucleic acid polymerases, DNA or RNA, to proceed only in the 5′→3′ direction poses a problem for synthesizing DNA at the end of a linear replicon. Consider the two parental strands depicted in FIGURE 12.1. The lower strand presents no problem: It can act as a template to synthesize a daughter strand that runs right up to the end, where presumably the polymerase falls off. To synthesize a complement at the end of the upper strand, however, synthesis must begin right at the very last base, or else this strand would become shorter in successive cycles of replication.

FIGURE 12.1 Replication could run off the 3′ end of a newly synthesized linear strand, but could it initiate at a 5′ end?
Researchers do not know whether initiation right at the end of a linear DNA is feasible. A polymerase is usually considered as binding at a site surrounding the position at which a base is to be incorporated. Thus, a special mechanism must be employed for replication at the ends of linear replicons. Several types of solutions may be imagined to accommodate the need to copy a terminus:
The problem can be circumvented by converting a linear replicon into a circular or multimeric molecule. Phages such as T4 or lambda use such mechanisms (see the section Rolling Circles Produce Multimers of a Replicon later in this chapter).
The DNA might form an unusual structure—for example, by creating a hairpin at the terminus, so that there is no free end. Formation of a crosslink is involved in replication of the linear mitochondrial DNA of Paramecium.
Instead of being precisely determined, the end might be variable. Eukaryotic chromosomes might adopt this solution, in which the number of copies of a short repeating unit at the end of the DNA changes (see the chapter Chromosomes). A mechanism to add or remove units makes it unnecessary to replicate right up to the very end.
A protein can intervene to make initiation possible at the actual terminus. Several linear viral nucleic acids have proteins that are covalently linked to the 5′ terminal base. The best characterized examples are adenovirus DNA, phage Ф29 DNA, and poliovirus RNA.
12.3 Terminal Proteins Enable Initiation at the Ends of Viral DNAs
An example of initiation at a linear end is provided by adenovirus and Ф29 DNAs, which actually replicate from both ends using the mechanism of strand displacement illustrated in FIGURE 12.2. The same events can occur independently at either end. Synthesis of a new strand starts at one end, displacing the homologous strand that was previously paired in the duplex. When the replication fork reaches the other end of the molecule, the displaced strand is released as a free single strand. It is then replicated independently; this requires the formation of a duplex origin by base pairing between some short complementary sequences at the ends of the molecule.
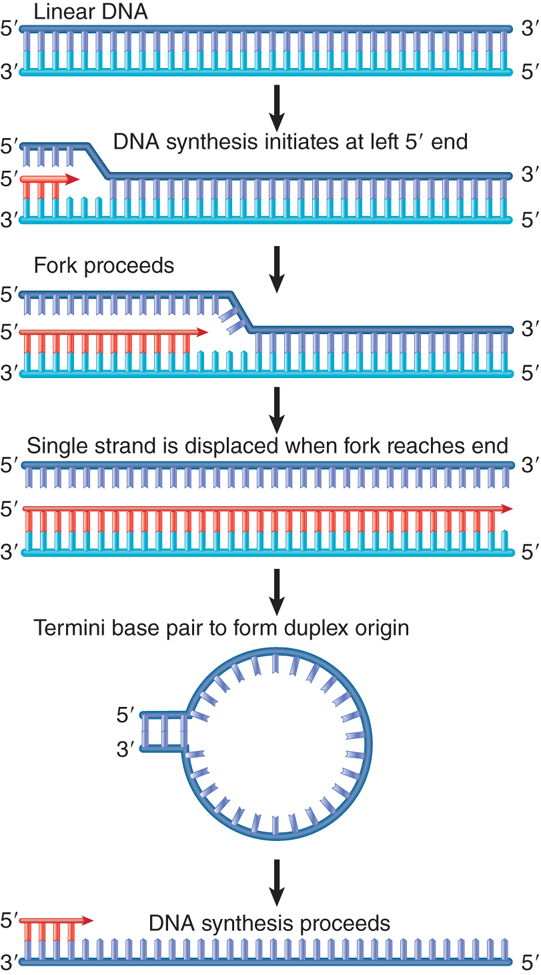
FIGURE 12.2 Adenovirus DNA replication is initiated separately at the two ends of the molecule and proceeds by strand displacement.
In several viruses that use such mechanisms, a protein is found covalently attached to each 5′ end. In the case of adenovirus, a terminal protein is linked to the mature viral DNA via a phosphodiester bond to serine, as indicated in FIGURE 12.3.

FIGURE 12.3 The 5′ terminal phosphate at each end of adenovirus DNA is covalently linked to serine in the 55-kD Ad-binding protein.
How does the attachment of the protein overcome the initiation problem? The terminal protein has a dual role: It carries a cytidine nucleotide that provides the primer –OH, and it is associated with DNA polymerase. In fact, linkage of terminal protein to a nucleotide is undertaken by DNA polymerase in the presence of adenovirus DNA. This suggests the model illustrated in FIGURE 12.4. The complex of polymerase and terminal protein, bearing the priming C nucleotide, binds to the end of the adenovirus DNA. The free 3′–OH end of the C nucleotide is used to prime the elongation reaction by the DNA polymerase. This generates a new strand whose 5′ end is covalently linked to the initiating C nucleotide. (The reaction actually involves displacement of protein from DNA rather than binding de novo. The 5′ end of adenovirus DNA is bound to the terminal protein that was used in the previous replication cycle. The old terminal protein is displaced by the new terminal protein for each new replication cycle.)

FIGURE 12.4 Adenovirus terminal protein binds to the 5′ end of DNA and provides a C–OH end to prime synthesis of a new DNA strand.
Terminal protein binds to the region located between 9 and 18 bp from the end of the DNA. The adjacent region, between positions 17 and 48, is essential for the binding of a host protein, nuclear factor I, which is also required for the initiation reaction. The initiation complex may therefore form between positions 9 and 48, a fixed distance from the end of the DNA.
12.4 Rolling Circles Produce Multimers of a Replicon
The structures generated by replication depend on the relationship between the template and the replication fork. The critical features are whether the template is circular or linear, and whether the replication fork is engaged in synthesizing both strands of DNA or only one.
Replication of only one strand is used to generate copies of some circular molecules. A nick opens one strand, and then the free 3′–OH end generated by the nick is extended by the DNA polymerase. The newly synthesized strand displaces the original parental strand. The ensuing events are depicted in FIGURE 12.5.

FIGURE 12.5 The rolling circle generates a multimeric single-stranded tail.
This type of structure is called a rolling circle, because the growing point can be envisaged as rolling around the circular template strand. It could in principle continue to do so indefinitely. As it moves, the replication fork extends the outer strand and displaces the previous partner. An example is shown in the electron micrograph of FIGURE 12.6.

FIGURE 12.6 A rolling circle appears as a circular molecule with a linear tail by electron microscopy.
Photo courtesy of Ross B. Inman, Institute of Molecular Virology, Bock Laboratory and Department of Biochemistry, University of Wisconsin, Madison, Wisconsin, USA.
The newly synthesized material is covalently linked to the original material, and as a result the displaced strand has the original unit genome at its 5′ end. The original unit is followed by any number of unit genomes, synthesized by continuing revolutions of the template. Each revolution displaces the material synthesized in the previous cycle.
The rolling circle is put to several uses in vivo. FIGURE 12.7 depicts some pathways that are used to replicate DNA.

FIGURE 12.7 The fate of the displaced tail determines the types of products generated by rolling circles. Cleavage at unit length generates monomers, which can be converted to duplex and circular forms. Cleavage of multimers generates a series of tandemly repeated copies of the original unit. Note that the conversion to double-stranded form could occur earlier, before the tail is cleaved from the rolling circle.
Cleavage of a unit length tail generates a copy of the original circular replicon in linear form. The linear form can be maintained as a single strand or can be converted into a duplex by synthesis of the complementary strand (which is identical in sequence to the template strand of the original rolling circle).
The rolling circle provides a means for amplifying the original (unit) replicon. This mechanism is used to generate amplified ribosomal DNA (rDNA) in the Xenopus oocyte. The genes for ribosomal RNA (rRNA) are organized as a large number of contiguous repeats in the genome. A single repeating unit from the genome is converted into a rolling circle. The displaced tail, which contains many units, is converted into duplex DNA; later it is cleaved from the circle so that the two ends can be joined together to generate a large circle of amplified rDNA. The amplified material therefore consists of a large number of identical repeating units.
12.5 Rolling Circles Are Used to Replicate Phage Genomes
Replication by rolling circles is common among bacteriophages. Unit genomes can be cleaved from the displaced tail, generating monomers that can be packaged into phage particles or used for further replication cycles. FIGURE 12.8 provides a more detailed view of a phage replication cycle that is centered on the rolling circle.
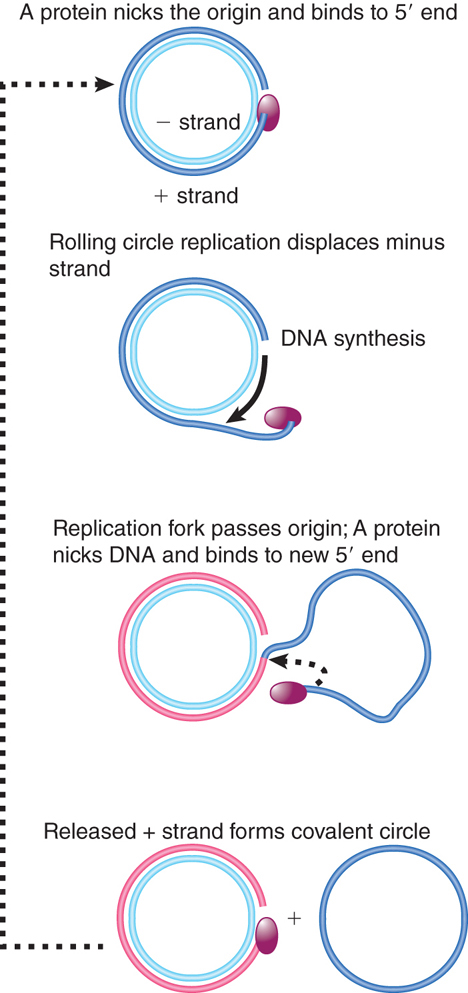
FIGURE 12.8 ФX174 RF DNA is a template for synthesizing single-stranded viral circles. The A protein remains attached to the same genome through indefinite revolutions, each time nicking the origin on the viral (+) strand and transferring to the new 5′ end. At the same time, the released viral strand is circularized.
Phage ФX174 consists of a single-stranded circular DNA known as the plus (+) strand. A complementary strand, called the minus (−) strand, is synthesized. This action generates the duplex circle shown at the top of Figure 12.8, which is then replicated by a rolling circle mechanism.
The duplex circle is converted to a covalently closed form, which becomes supercoiled. A protein encoded by the phage genome, the A protein, nicks the (+) strand of the duplex DNA at a specific site that defines the origin for replication. After nicking the origin, the A protein remains connected to the 5′ end that it generates, while the 3′ end is extended by DNA polymerase.
The structure of the DNA plays an important role in this reaction, for the DNA can be nicked only when it is negatively supercoiled (i.e., wound around its axis in space in the opposite sense from the handedness of the double helix; supercoiling is discussed in the chapter titled Genes Are DNA and Encode RNAs and Polypeptides). The A protein is able to bind to a single-stranded decamer fragment of DNA that surrounds the site of the nick. This suggests that the supercoiling is needed to assist the formation of a single-stranded region that provides the A protein with its binding site. (An enzymatic activity in which a protein cleaves duplex DNA and binds to a released 5′ end is sometimes called a relaxase.) The nick generates a 3′–OH end and a 5′–phosphate end (covalently attached to the A protein), both of which have roles to play in ФX174 replication.
Using the rolling circle, the 3′–OH end of the nick is extended into a new chain. The chain is elongated around the circular (−) strand template until it reaches the starting point and displaces the origin. Now the A protein functions again. It remains connected with the rolling circle as well as to the 5′ end of the displaced tail, and is therefore in the vicinity as the growing point returns past the origin. Thus, the same A protein is available again to recognize the origin and nick it, now attaching to the end generated by the new nick. The cycle can be repeated indefinitely.
Following this nicking event, the displaced single (+) strand is freed as a circle. The A protein is involved in the circularization. In fact, the joining of the 3′ and 5′ ends of the (+) strand product is accomplished by the A protein as part of the reaction by which it is released at the end of one cycle of replication, and starts another cycle.
The A protein has an unusual property that may be connected with these activities. It is cis-acting in vivo. (This behavior is not reproduced in vitro, as can be seen from its activity on any DNA template in a cell-free system.) The implication is that in vivo the A protein synthesized by a particular genome can attach only to the DNA of that genome. Researchers do not know how this is accomplished. Its activity in vitro, however, shows how it remains associated with the same parental (−) strand template. The A protein has two active sites; this might allow it to cleave the “new” origin while still retaining the “old” origin. It then ligates the displaced strand into a circle.
The displaced (+) strand can follow either of two fates after circularization. During the replication phase of viral infection, it might be used as a template to synthesize the complementary (−) strand. The duplex circle can then be used as a rolling circle to generate more progeny. During phage morphogenesis, the displaced (+) strand is packaged into the phage virion.
12.6 The F Plasmid Is Transferred by Conjugation Between Bacteria
Another example of a connection between replication and the propagation of a genetic unit is provided by bacterial conjugation, in which a plasmid genome or part of a host chromosome with an integrated episome is transferred from one bacterium to another.
Conjugation is mediated by the F plasmid, which is the classic example of an episome—an element that can exist as a free circular plasmid, or that can become integrated into the bacterial chromosome as a linear sequence (like a lysogenic bacteriophage). The F plasmid is a large, circular DNA approximately 100 kilobases (kb) in length.
The F plasmid can integrate at numerous sites in the E. coli chromosome, often by a recombination event involving certain sequences (called IS sequences; see the chapter titled Transposable Elements and Retroviruses) that are present on both the host chromosome and F plasmid. In its free (plasmid) form, the F plasmid utilizes its own replication origin (oriV) and control system, and is maintained at a level of one copy per bacterial chromosome. When it is integrated into the bacterial chromosome, this system is suppressed, and F DNA is replicated as a part of the chromosome.
The presence of the F plasmid, whether free or integrated, has important consequences for the host bacterium. Bacteria that are F-positive are able to conjugate (or mate) only with bacteria that are F-negative. Conjugation involves direct, physical contact between donor (F-positive) and recipient (F-negative) bacteria; contact is followed by one-way transfer of the F plasmid from the donor to the recipient (but never the other way). If the F plasmid exists as a free plasmid in the donor bacterium, it is transferred as a plasmid and the infective process converts the F-negative recipient into an F-positive state. If the F plasmid is present in an integrated form in the donor, the transfer process might also cause some or (rarely) all of the bacterial chromosome to be transferred. Many plasmids have conjugation systems that operate in a generally similar manner, but the F plasmid was the first to be discovered and remains the paradigm for this type of genetic transfer.
A large (about 33 kb) region of the F plasmid called the transfer region is required for conjugation. It contains roughly 40 genes that are required for the transmission of DNA; FIGURE 12.9 summarizes their organization. The genes are arranged in loci named tra and trb. Most of them are expressed coordinately as part of a single polycistronic 32-kb transcription unit (the traY-I unit). traM and traJ are expressed separately. traJ is a regulator that turns on both traM and traY-I. On the opposite strand, finP is a regulator that codes for a small antisense RNA that turns off traJ. Its activity requires expression of another gene, finO. Only four of the tra and trb genes, traD, traI, traM, and traY, in the major transcription unit are concerned directly with the transfer of DNA; most of these genes encode proteins that form a large membrane-spanning protein complex called a type 4 secretion system (T4SS). These systems are common in bacteria, where they have been shown to be involved in the transport of various proteins and DNA across the bacterial cell envelope and are responsible for maintaining contacts between mating bacteria.

FIGURE 12.9 The tra region of the F plasmid contains the genes needed for bacterial conjugation.
F-positive bacteria possess surface appendages called pili (singular pilus) that are encoded by the F plasmid. The gene traA codes for the single subunit protein, pilin, that is polymerized into the pilus extending from the inner to the outer membrane at the T4SS. At least 12 tra genes are required for the modification and assembly of pilin into the pilus and the stabilization of the T4SS. The F-pili are hairlike structures, 2 to 3 μm long, that protrude from the bacterial surface. A typical F-positive cell has two to three pili. The pilin subunits are polymerized into a hollow cylinder, about 8 nm in diameter, with a 2-nm axial hole.
Mating is initiated when the tip of the F-pilus contacts the surface of the recipient cell. FIGURE 12.10 shows an example of E. coli cells beginning to mate. A donor cell does not contact other cells carrying the F plasmid, because the genes traS and traT encode “surface exclusion” proteins that make the cell a poor recipient in such contacts. This effectively restricts donor cells to mating with F-negative cells. (The presence of F-pili has secondary consequences; they provide the sites to which RNA phages and some single-stranded DNA phages attach, so F-positive bacteria are susceptible to infection by these phages, whereas F-negative bacteria are resistant.)

FIGURE 12.10 Mating bacteria are initially connected when donor F-pili contact the recipient bacterium.
Photo courtesy of Emeritus Professor Ron Skurray, School of Biological Sciences, University of Sydney.
The initial contact between donor and recipient cells is easily broken, but other tra genes act to stabilize the association; this brings the mating cells closer together. The F-pili are essential for initiating pairing, but retract or disassemble as part of the process by which the mating cells are brought into close contact. It is proposed that the T4SS provides the channel through which DNA is transferred. TraD is a so-called coupling protein encoded by F plasmids that is necessary for recruitment of plasmid DNA to the T4SS, and it may associate with the T4SS to be involved in the actual plasmid transfer.
12.7 Conjugation Transfers Single-Stranded DNA
Transfer of the F plasmid is initiated at a site called oriT, the origin of transfer, which is located at one end of the transfer region. The transfer process may be initiated when TraM recognizes that a mating pair has formed. TraY then binds near oriT and causes TraI to bind to form the relaxosome in conjunction with host-encoded DNA-binding proteins called integration host factor (IHF). TraI is a relaxase, like ФX174 A protein. TraI nicks oriT at a unique site (called nic), and then forms a covalent link to the 5′ end that has been generated. TraI also catalyzes the unwinding of approximately 200 base pairs (bp) of DNA and remains attached to the DNA 5′ end throughout the conjugation process (this is a helicase activity). The TraI-bound DNA is then transferred to the T4SS by the coupling protein TraD, where it is exported to the recipient cell. FIGURE 12.11 shows that the relaxase-bound 5′ end leads the way into the recipient bacterium. The transferred single strand is circularized and a complement strand is synthesized in the recipient bacterium, which as a result is converted to the F-positive state.

FIGURE 12.11 Transfer of DNA occurs when the F plasmid is nicked at oriT and a single strand is led by the 5′ end bound to TraI into the recipient. Only one unit length is transferred. Complementary strands are synthesized to the single strand remaining in the donor and to the strand transferred into the recipient.
A complementary strand must be synthesized in the donor bacterium to replace the strand that has been transferred. If this happens concomitantly with the transfer process, the state of the F plasmid will resemble the rolling circle of Figure 12.5. DNA synthesis could occur instantly, using the freed 3′ end as a starting point. Conjugating DNA usually appears like a rolling circle, but replication as such is not necessary to provide the driving energy, and single-strand transfer is independent of DNA synthesis. Only a single unit length of the F plasmid is transferred to the recipient bacterium. This implies that some feature (perhaps TraI) terminates the process after one revolution, after which the covalent integrity of the F plasmid is restored. TraI might also be involved in recircularization of the transferred DNA to which a complementary strand is then synthesized.
When an integrated F plasmid initiates conjugation, the orientation of transfer is directed away from the transfer region and into the bacterial chromosome. FIGURE 12.12 shows that, following a short leading sequence of F DNA, bacterial DNA is transferred. The process continues until it is interrupted by the breaking of contacts between the mating bacteria. It takes 100 minutes to transfer the entire bacterial chromosome, and under standard conditions contact is often broken before the completion of transfer.

FIGURE 12.12 Transfer of chromosomal DNA occurs when an integrated F plasmid is nicked at oriT. Transfer of DNA starts with a short sequence of F DNA and continues until prevented by loss of contact between the bacteria.
Donor DNA that enters a recipient bacterium is converted to double-stranded form and may recombine with the recipient chromosome. (Note that two recombination events are required to insert the donor DNA in order to avoid converting the circular chromosome to a linear form.) Thus, conjugation affords a means to exchange genetic material between bacteria, a contrast to their usual asexual growth (hence the original name Fertility factor or F factor). A strain of E. coli with an integrated F plasmid supports such recombination at relatively high frequencies (compared to strains that lack integrated F plasmids); such strains are described as high-frequency recombination (Hfr). Each position of integration for the F plasmid gives rise to a different Hfr strain, with a characteristic pattern of transferring bacterial markers to a recipient chromosome.
Contact between conjugating bacteria is usually broken before transfer of DNA is complete. As a result, the probability that a region of the bacterial chromosome will be transferred depends on its distance from oriT. Bacterial genes located close to the site of F integration (in the direction of transfer) enter recipient bacteria first, and are therefore found at greater frequencies than those that are located farther away and enter later. This gives rise to a gradient of transfer frequencies around the chromosome, declining from the position of F integration. Marker positions on the donor chromosome can be assayed in terms of the time at which transfer occurs; this gave rise to the standard description of the E. coli chromosome as a map divided into 100 minutes. The map refers to transfer times from a particular Hfr strain; the starting point for the gradient of transfer is different for each Hfr strain because it is determined by the site where the F plasmid has integrated into the bacterial genome.
12.8 Single-Copy Plasmids Have a Partitioning System
The type of system that a plasmid uses to ensure that it is distributed to both daughter cells at division depends upon its type of replication system. Each type of plasmid is maintained in its bacterial host at a characteristic copy number:
Single-copy control systems resemble that of the bacterial chromosome and result in one replication per cell division. A single-copy plasmid effectively maintains parity with the bacterial chromosome.
Multicopy control systems allow multiple initiation events per cell cycle, with the result that there are several copies of the plasmid per bacterium. Multicopy plasmids exist in a characteristic number (typically 10 to 20) per bacterial chromosome.
Copy number is primarily a consequence of the type of replication control mechanism. The system responsible for initiating replication determines how many origins can be present in the bacterium. Each plasmid consists of a single replicon, and as a result the number of origins is the same as the number of plasmid molecules.
Single-copy plasmids have a system for replication control whose consequences are similar to those of the system for replication governing the bacterial chromosome. A single origin can be replicated once, and then the daughter origins are segregated to the different daughter cells.
Multicopy plasmids have a replication system that allows a pool of origins to exist. If the number is great enough (in practice, fewer than 10 per bacterium), an active segregation system becomes unnecessary, because even a statistical distribution of plasmids to daughter cells will result in the loss of plasmids at frequencies of less than 10−6.
Plasmids are maintained in bacterial populations with very low rates of loss (less than 10−7 per cell division is typical, even for a single-copy plasmid). The systems that control plasmid segregation can be identified by mutations that increase the frequency of loss, but that do not act upon replication itself. Several types of mechanisms are used to ensure the survival of a plasmid in a bacterial population. It is common for a plasmid to carry several systems, often of different types, all acting independently to ensure its survival. Some of these systems act indirectly, whereas others are concerned directly with regulating the partition event. In terms of evolution, however, all serve the same purpose—to help ensure perpetuation of the plasmid to the maximum number of progeny bacteria.
Single-copy plasmids require partition systems to ensure that the duplicate copies find themselves on opposite sides of the septum at cell division and are therefore segregated to a different daughter cell. In fact, functions involved in partition were first identified in plasmids. FIGURE 12.13 summarizes the components of a common system. Typically, there are two trans-acting loci (usually called parA and parB) and a cis-acting element (usually called parS) located next to the two genes. ParA is a partition ATPase. It binds to ParB, which binds to the parS site on DNA. Deletions of any of the three loci prevent proper partition of the plasmid. Systems of this type have been characterized for the plasmids F, P1, and R1. Partition systems generally fall into two major classes that depend on properties of the system’s ATPase. In one group, such as the system in plasmid R1, the ATPase resembles actin and acts via polymerization (discussed further in subsequent paragraphs). The other group, which includes plasmids P1 and F, has a different type of ATPase (based on protein sequence homologies). These ParAs use the bacterial nucleoid for positioning plasmids, although the mechanisms by which this is accomplished are not yet clear.

FIGURE 12.13 A common segregation system consists of genes parA and parB and the target site parS.
parS plays a role for the plasmid that is equivalent to the centromere of a eukaryotic chromosome. Binding of the ParB protein to it creates a structure that segregates the plasmid copies to opposite daughter cells. In some plasmids, such as P1, a bacterial protein, IHF, also binds at this site to form part of the structure. The complex of ParB (and IHF in some cases) with parS is called the partition complex. Formation of this initial complex enables further molecules of ParB to bind cooperatively, forming a very large protein–DNA complex. These complexes hold daughter plasmids together in pairs until ready to interact with ParA. The activity of ParA is necessary to position the plasmids in the cell so that at least one copy is on each side of the dividing cell septum.
The partition ATPase of plasmid R1, called ParM in this system, acts as a cytoskeletal element. The structure of ParM resembles eukaryotic actin and bacterial MreB protein (see the chapter titled Replication Is Connected to the Cell Cycle) and polymerizes into filamentous structures in the presence of ATP. In the R1 system, the partition site is called parC and the ParB-like protein is called ParR. Binding of ParM to the ParR/parC partition complexes stimulates the polymerization of ParM between complexes on daughter plasmids, effectively pushing the plasmids apart and to opposite ends of the dividing cell (see FIGURE 12.14).

FIGURE 12.14 The partition of plasmid R1 involves polymerization of the ParM ATPase between plasmids.
In the other, nonactin class of partition ATPases, it is not known how these ParA proteins work to position plasmids. There are no sequences or structural similarities with ParM. It is possible that ParA proteins of plasmids such as P1 and F also act via polymerization. These ParA proteins do share some sequence similarities with the MinD ATPase that helps position the septum (see the chapter titled Replication Is Connected to the Cell Cycle). Intriguingly, some ParAs have been shown to oscillate over the bacterial nucleoid. The role of this oscillation is still a mystery, but these properties suggest that dynamic behavior of the ParA proteins is necessary for the partition reaction.
Proteins related to ParA and ParB are found in several bacteria. In Bacillus subtilis, they are called Soj and Spo0J, respectively. Mutations in these loci prevent sporulation because of a failure to segregate one daughter chromosome into the forespore. Mutations in the spo0J gene cause a 100-fold increase in the frequency of anucleate cells in vegetatively growing cells, suggesting that wild-type Spo0J contributes to chromosome segregation in normal cell cycles as well as during sporulation. Spo0J binds to a parS sequence that is present in multiple copies that are dispersed over about 20% of the chromosome in the vicinity of the origin. It is possible that Spo0J binds both old and newly synthesized origins, maintaining a status equivalent to chromosome pairing until the chromosomes are segregated to the opposite poles. In Caulobacter crescentus, ParA and ParB localize to the poles of the bacterium and ParB binds sequences close to the origin, thus localizing the origin to the pole. These results suggest that a specific apparatus is responsible for localizing the origin to the pole. The next stage of the analysis will be to identify the cellular components with which this apparatus interacts.
The importance to the plasmid of ensuring that all daughter cells gain replica plasmids is emphasized by the existence of multiple, independent systems in individual plasmids that ensure proper partition. Addiction systems, which operate on the basis of “we hang together or we hang separately,” ensure that a bacterium carrying a plasmid can survive only as long as it retains the plasmid. There are several ways to ensure that a cell dies if it is “cured” of a plasmid, all of which share the principle illustrated in FIGURE 12.15 that the plasmid produces both a poison and an antidote. The poison is a killer substance that is relatively stable, whereas the antidote consists of a substance that blocks killer action but is relatively short lived. When the plasmid is lost the antidote decays, and then the killer substance causes the death of the cell. Thus, bacteria that lose the plasmid inevitably die, and the population is condemned to retain the plasmid indefinitely. These systems take various forms. One specified by the F plasmid consists of killer and blocking proteins. The plasmid R1 has a killer that is the mRNA for a toxic protein; the antidote is a small antisense RNA that prevents expression of the mRNA.

FIGURE 12.15 Plasmids might ensure that bacteria cannot live without them by synthesizing a long-lived killer and a short-lived antidote.
12.9 Plasmid Incompatibility Is Determined by the Replicon
The phenomenon of plasmid incompatibility is related to the regulation of plasmid copy number and segregation. A compatibility group is defined as a set of plasmids whose members are unable to coexist in the same bacterial cell. The reason for their incompatibility is that they cannot be distinguished from one another at some stage that is essential for plasmid maintenance. DNA replication and segregation are stages at which this may apply.
The negative control model for plasmid incompatibility follows the idea that copy number control is achieved by synthesizing a repressor that measures the concentration of origins. (Formally, this is the same as the titration model for regulating replication of the bacterial chromosome.)
The introduction of a new origin in the form of a second plasmid of the same compatibility group mimics the result of replication of the resident plasmid; two origins now are present. Thus, any further replication is prevented until after the two plasmids have been segregated to different cells to create the correct prereplication copy number, as illustrated in FIGURE 12.16.

FIGURE 12.16 Two plasmids are incompatible (they belong to the same compatibility group) if their origins cannot be distinguished at the stage of initiation. The same model could apply to segregation.
A similar effect would be produced if the system for segregating the products to daughter cells could not distinguish between two plasmids. For example, if two plasmids have the same cis-acting partition sites, competition between them would ensure that they would be segregated to different cells, and therefore could not survive in the same line.
The presence of a member of one compatibility group does not directly affect the survival of a plasmid belonging to a different group. Only one replicon of a given compatibility group (of a single-copy plasmid) can be maintained in the bacterium, but it does not interact with replicons of other compatibility groups.
12.10 The ColE1 Compatibility System Is Controlled by an RNA Regulator
The best characterized copy number and incompatibility system is that of the plasmid ColE1, a multicopy plasmid that is maintained at a steady level of about 20 copies per E. coli cell. The system for maintaining the copy number depends on the mechanism for initiating replication at the ColE1 origin, as illustrated in FIGURE 12.17.
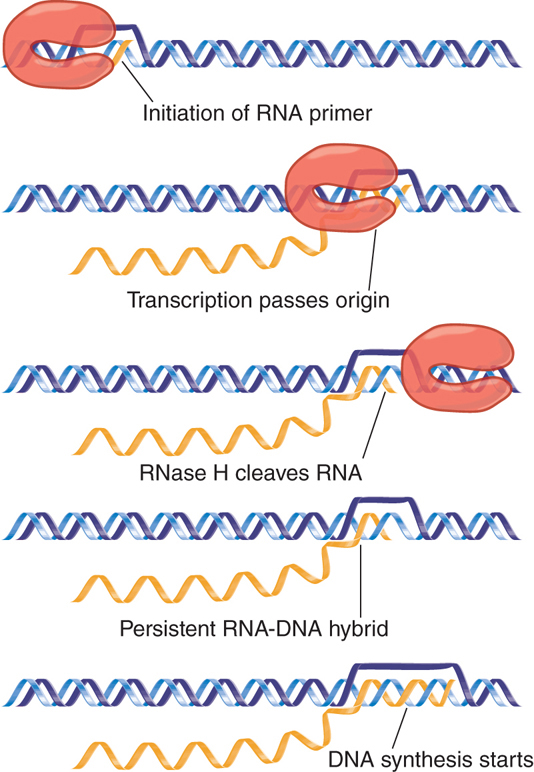
FIGURE 12.17 Replication of ColE1 DNA is initiated by cleaving the primer RNA to generate a 3′–OH end. The primer forms a persistent hybrid in the origin region.
Replication starts with the transcription of an RNA that initiates 555 bp upstream of the origin. Transcription continues through the origin. The enzyme RNase H (whose name reflects its specificity for a substrate of RNA hybridized with DNA) cleaves the transcript at the origin. This generates a 3′–OH end that is used as the “primer” at which DNA synthesis is initiated (the use of primers is discussed in more detail in the chapter titled DNA Replication). The primer RNA forms a persistent hybrid with the DNA. Pairing between the RNA and DNA occurs just upstream of the origin (around position −20) and also farther upstream (around position −265).
Two regulatory systems exert their effects on the RNA primer. One involves synthesis of an RNA complementary to the primer; the other involves a protein encoded by a nearby locus.
The regulatory species RNA I is a molecule of about 108 bases and is encoded by the opposite strand from that specifying primer RNA. The relationship between the primer RNA and RNA I is illustrated in FIGURE 12.18. The RNA I molecule is initiated within the primer region and terminates close to the site where the primer RNA initiates. Thus, RNA I is complementary to the 5′–terminal region of the primer RNA. Base pairing between the two RNAs controls the availability of the primer RNA to initiate a cycle of replication.

FIGURE 12.18 The sequence of RNA I is complementary to the 5′ region of primer RNA.
An RNA molecule such as RNA I that functions by virtue of its complementarity with another RNA encoded in the same region is called a countertranscript. This type of mechanism is another example of the use of antisense RNA (see the chapter titled Regulatory RNA).
Mutations that reduce or eliminate incompatibility between plasmids can be obtained by selecting plasmids of the same group for their ability to coexist. Incompatibility mutations in ColE1 map in the region of overlap between RNA I and primer RNA. This region is represented in two different RNAs, so either or both might be involved in the effect.
When RNA I is added to a system for replicating ColE1 DNA in vitro, it inhibits the formation of active primer RNA. The presence of RNA I, however, does not inhibit the initiation or elongation of primer RNA synthesis. This suggests that RNA I prevents RNase H from generating the 3′ end of the primer RNA. The basis for this effect lies in base pairing between RNA I and primer RNA.
Both RNA molecules have the same potential secondary structure in this region, with three duplex hairpins terminating in single-stranded loops. Mutations reducing incompatibility are located in these loops, which suggests that the initial step in base pairing between RNA I and primer RNA is contact between the unpaired loops.
How does pairing with RNA I prevent cleavage to form primer RNA? A model is illustrated in FIGURE 12.19. In the absence of RNA I, the primer RNA forms its own secondary structure (involving loops and stems). When RNA I is present, though, the two molecules pair and become completely double-stranded for the entire length of RNA I. The new secondary structure prevents the formation of the primer, probably by affecting the ability of the RNA to form the persistent hybrid.

FIGURE 12.19 Base pairing with RNA I may change the secondary structure of the primer RNA sequence and thus prevent cleavage from generating a 3′–OH end.
The model resembles the mechanism involved in attenuation of transcription, in which the alternative pairings of an RNA sequence permit or prevent formation of the secondary structure needed for termination by RNA polymerase (see the chapter titled The Operon). The action of RNA I is exercised by its ability to affect distant regions of the primer precursor.
Formally, the model is equivalent to postulating a control circuit involving two RNA species. A large RNA primer precursor is a positive regulator and is needed to initiate replication. The small RNA I is a negative regulator that is able to inhibit the action of the positive regulator.
In its ability to act on any plasmid present in the cell, RNA I provides a repressor that prevents newly introduced DNA from functioning. This is analogous to the role of the lambda lysogenic repressor (see the chapter titled Phage Strategies). Instead of a repressor protein that binds the new DNA, an RNA binds the newly synthesized precursor to the RNA primer.
Binding between RNA I and primer RNA can be influenced by the Rom protein, which is coded by a gene located downstream of the origin. Rom enhances binding between RNA I and primer RNA transcripts of more than 200 bases. The result is to inhibit formation of the primer.
How do mutations in the RNAs affect incompatibility? FIGURE 12.20 shows the situation when a cell contains two types of RNA I/primer RNA sequence. The RNA I and primer RNA made from each type of genome can interact, but RNA I from one genome does not interact with primer RNA from the other genome. This situation would arise when a mutation in the region that is common to RNA I and primer RNA occurred at a location involved in the base pairing between them. Each RNA I would continue to pair with the primer RNA encoded by the same plasmid, but might be unable to pair with the primer RNA coded by the other plasmid. This would cause the original and the mutant plasmids to behave as members of different compatibility groups.

FIGURE 12.20 Mutations in the region coding for RNA I and the primer precursor need not affect their ability to pair, but they may prevent pairing with the complementary RNA encoded by a different plasmid.
12.11 How Do Mitochondria Replicate and Segregate?
Mitochondria must be duplicated during the cell cycle and segregated to the daughter cells. Researchers understand some of the mechanics of this process, but not its regulation.
At each stage in the duplication of mitochondria—DNA replication, DNA segregation to duplicated mitochondria, and organelle segregation to daughter cells—the process appears to be stochastic, governed by a random distribution of each copy. The theory of distribution in this case is analogous to that of multicopy bacterial plasmids, with the same conclusion that about 10 copies are required to ensure that each daughter gains at least one copy. When there are mtDNAs with allelic variations in the same cell, called heteroplasmy (either because of inheritance from different parents or because of mutation), the stochastic distribution may generate cells that have only one of the alleles.
Replication of mtDNA might be stochastic because there is no control over which particular copies are replicated, so that in any cycle some mtDNA molecules might replicate more times than others. The total number of copies of the genome might be controlled by titrating mass in a way similar to that of bacteria (see the chapter titled Replication Is Connected to the Cell Cycle).
A mitochondrion divides by developing a ring around the organelle that constricts to pinch it into two halves. The mechanism is similar in principle to that involved in bacterial division. The apparatus that is used in plant cell mitochondria is similar to that used in bacteria and uses a homolog of the bacterial protein FtsZ (see the chapter titled Replication Is Connected to the Cell Cycle). The molecular apparatus is different in animal cell mitochondria and uses the protein dynamin, which is involved in formation of membranous vesicles. An individual organelle may have more than one copy of its genome.
Researchers do not know whether there is a partition mechanism for segregating mtDNA molecules within the mitochondrion, or whether they are simply inherited by daughter mitochondria according to which half of the mitochondrion in which they happen to lie. FIGURE 12.21 shows that the combination of replication and segregation mechanisms can result in a stochastic assignment of DNA to each of the copies; that is, so that the distribution of mitochondrial genomes to daughter mitochondria does not depend on their parental origins.

FIGURE 12.21 Mitochondrial DNA replicates by increasing the number of genomes in proportion to mitochondrial mass, but without ensuring that each genome replicates the same number of times. This can lead to changes in the representation of alleles in the daughter mitochondria.
The assignment of mitochondria to daughter cells at mitosis also appears to be random. Indeed, it was the observation of somatic variation in plants that first suggested the existence of genes that could be lost from one of the daughter cells because they were not inherited according to Mendel′s laws (see the chapter titled The Content of the Genome).
In some situations a mitochondrion has both paternal and maternal alleles. This has two requirements: that both parents provide alleles to the zygote (which of course is not the case when there is maternal inheritance; see the chapter titled The Content of the Genome), and that the parental alleles are found in the same mitochondrion. For this to happen, parental mitochondria must have fused.
The size of the individual mitochondrion might not be precisely defined. Indeed, there is a continuing question about whether an individual mitochondrion represents a unique and discrete copy of the organelle or whether it is in a dynamic flux in which it can fuse with other mitochondria. Researchers know that mitochondria can fuse in yeast, because recombination between mtDNAs can occur after two haploid yeast strains have mated to produce a diploid strain. This implies that the two mtDNAs must have been exposed to one another in the same mitochondrial compartment. Researchers have made attempts to test for the occurrence of similar events in animal cells by looking for complementation between alleles after two cells have been fused, but the results are not clear.
12.12 D Loops Maintain Mitochondrial Origins
The origins of replicons in both prokaryotic and eukaryotic chromosomes are static structures: They comprise sequences of DNA that are recognized in duplex form and used to initiate replication at the appropriate time. Initiation requires separating the DNA strands and commencing bidirectional DNA synthesis. A different type of arrangement is found in mitochondria.
Replication begins at a specific origin in the circular duplex DNA. Initially, though, only one of the two parental strands (the H strand in mammalian mitochondrial DNA) is used as a template for synthesis of a new strand. Synthesis proceeds for only a short distance, displacing the original partner (L) strand, which remains single-stranded, as illustrated in FIGURE 12.22. The condition of this region gives rise to its name as the displacement loop, or D loop.

FIGURE 12.22 The D loop maintains an opening in mammalian mitochondrial DNA, which has separate origins for the replication of each strand.
DNA polymerases cannot initiate synthesis, but require a priming 3′ end (see the chapter DNA Replication). Replication at the H-strand origin is initiated when RNA polymerase transcribes a primer. The 3′ ends are generated in the primer by an endonuclease that cleaves the DNA–RNA hybrid at several discrete sites. The endonuclease is specific for the triple structure of DNA–RNA hybrid plus the displaced DNA single strand. The 3′ end is then extended into DNA by the DNA polymerase.
A single D loop is found as an opening of 500 to 600 bases in mammalian mitochondria. The short strand that maintains the D loop is unstable and turns over; it is frequently degraded and resynthesized to maintain the opening of the duplex at this site. Some mitochondrial DNAs possess several D loops, reflecting the use of multiple origins. The same mechanism is employed in chloroplast DNA, where (in complex plants) there are two D loops.
To replicate mammalian mitochondrial DNA, the short strand in the D loop is extended. The displaced region of the original L strand becomes longer, expanding the D loop. This expansion continues until it reaches a point about two-thirds of the way around the circle. Replication of this region exposes an origin in the displaced L strand. Synthesis of an H strand initiates at this site, which is used by a special primase that synthesizes a short RNA. The RNA is then extended by DNA polymerase, proceeding around the displaced single-stranded L template in the opposite direction from L-strand synthesis.
As a result of the lag in its start, H-strand synthesis has proceeded only a third of the way around the circle when L-strand synthesis finishes. This releases one completed duplex circle and one gapped circle, the latter of which remains partially single-stranded until synthesis of the H strand is completed. Finally, the new strands are sealed to become covalently intact.
The existence of D loops exposes a general principle: An origin can be a sequence of DNA that serves to initiate DNA synthesis using one strand as a template. The opening of the duplex does not necessarily lead to the initiation of replication on the other strand. In the case of mitochondrial DNA replication, the origins for replicating the complementary strands lie at different locations. Origins that sponsor replication of only one strand are also found in the rolling circle mode of replication (see the discussion in the section Rolling Circles Produce Multimers of a Replicon earlier in this chapter).
12.13 The Bacterial Ti Plasmid Causes Crown Gall Disease in Plants
Most events in which DNA is rearranged or amplified occur within a genome, but the interaction between bacteria and certain plants involves the transfer of DNA from the bacterial genome to the plant genome. Crown gall disease, shown in FIGURE 12.23, can be induced in most dicotyledonous plants by the soil bacterium Agrobacterium tumefaciens. The bacterium is a parasite that effects a genetic change in the eukaryotic host cell, with consequences for both parasite and host: It improves conditions for survival of the parasite and causes the plant cell to grow as a tumor.

FIGURE 12.23 An Agrobacterium carrying a Ti plasmid of the nopaline type induces a teratoma, in which differentiated structures develop.
Photo courtesy of the estate of Jeff Schell. Used with permission of the Max Planck Institute for Plant Breeding Research, Cologne.
Agrobacteria are required to induce tumor formation, but the tumor cells do not require the continued presence of bacteria. As with animal tumors, the plant cells have been transformed into a state in which new mechanisms govern growth and differentiation. Transformation is caused by the expression within the plant cell of genetic information transferred from the bacterium.
The tumor-inducing principle of Agrobacterium resides in the Ti plasmid, which is perpetuated as an independent replicon within the bacterium. The plasmid carries genes involved in various bacterial and plant cell activities, including those required to generate the transformed state, and a set of genes concerned with synthesis or utilization of opines (novel derivatives of arginine).
Ti plasmids (and thus the Agrobacteria in which they reside) can be divided into four groups, according to the types of opine that are made:
Nopaline plasmids carry genes for synthesizing nopaline in tumors and for utilizing it in bacteria. Nopaline tumors can differentiate into shoots with abnormal structures. They have been called teratomas by analogy with certain mammalian tumors that retain the ability to differentiate into early embryonic structures.
Octopine plasmids are similar to nopaline plasmids, but the relevant opine is different. Octopine tumors are usually undifferentiated, however, and do not form teratoma shoots.
Agropine plasmids carry genes for agropine metabolism; the tumors do not differentiate, and they develop poorly and die early.
Ri plasmids can induce hairy root disease on some plants and crown gall on others. They have agropine-type genes, and can have segments derived from both nopaline and octopine plasmids.
The types of genes carried by a Ti plasmid are summarized in TABLE 12.1. Genes utilized in the bacterium encode proteins for plasmid replication and incompatibility, transfer between bacteria, sensitivity to phages, and synthesis of other compounds, some of which are toxic to other soil bacteria. Genes used in the plant cell encode proteins for transfer of DNA into the plant, induction of the transformed state, and shoot and root induction.
TABLE 12.1 Ti plasmids carry genes involved in both plant and bacterial functions.
| Locus | Function | Ti Plasmid |
|---|---|---|
| Vir | DNA transfer into plant | All |
| Shi | Shoot induction | All |
| Roi | Root induction | All |
| Nos | Nopaline synthesis | Nopaline |
| Noc | Nopaline catabolism | Nopaline |
| Ocs | Octopine synthesis | Octopine |
| Occ | Octopine catabolism | Octopine |
| Tra | Bacterial transfer genes | All |
| Lnc | Incompatibility genes | All |
| oriV | Origin for replication | All |
The specificity of the opine genes depends on the type of plasmid. Genes needed for opine synthesis are linked to genes whose products catabolize the same opine; thus, each strain of Agrobacterium causes crown gall tumor cells to synthesize opines that are useful for survival of the parasite. The opines can be used as the sole carbon and/or nitrogen source for the inducing Agrobacterium strain. The principle is that the transformed plant cell synthesizes those opines that the bacterium can use.
12.14 T-DNA Carries Genes Required for Infection
FIGURE 12.24 illustrates the interaction between Agrobacterium and a plant cell. The bacterium does not enter the plant cell, but rather it transfers part of the Ti plasmid to the plant nucleus. The transferred part of the Ti genome is called T-DNA. It becomes integrated into the plant genome, where it expresses the functions needed to synthesize opines and to transform the plant cell.
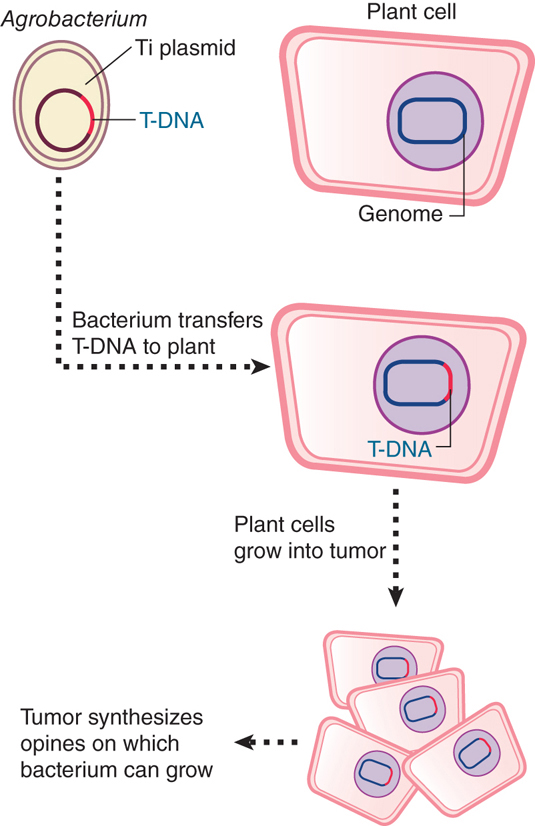
FIGURE 12.24 T-DNA is transferred from Agrobacterium carrying a Ti plasmid into a plant cell, where it becomes integrated into the nuclear genome and expresses functions that transform the host cell.
Transformation of plant cells requires three types of function carried in the Agrobacterium:
Three loci on the Agrobacterium chromosome, chvA, chvB, and pscA, are required for the initial stage of binding the bacterium to the plant cell. They are responsible for synthesizing a polysaccharide on the bacterial cell surface.
The vir region carried by the Ti plasmid outside the T-DNA region is required to release and initiate transfer of the T-DNA.
The T-DNA is required to transform the plant cell.
FIGURE 12.25 illustrates the organization of the major two types of Ti plasmid. About 30% of the approximately 200 kb Ti genome is common to nopaline and octopine plasmids. The common regions include genes involved in all stages of the interaction between Agrobacterium and a plant host, but considerable rearrangement of the sequences has occurred between the plasmids.

FIGURE 12.25 Nopaline and octopine Ti plasmids carry a variety of genes, including T-regions that have overlapping functions.
The T-region occupies about 23 kb. Some 9 kb is the same in the two types of plasmid. The Ti plasmids carry genes for opine synthesis (Nos or Ocs) within the T-region; corresponding genes for opine catabolism (Noc or Occ) reside elsewhere on the plasmid. The plasmids encode similar, but not identical, morphogenetic functions, as seen in the induction of characteristic types of tumors.
Functions affecting oncogenicity—the ability to form tumors—are not confined to the T-region. Those genes located outside the T-region must be concerned with establishing the tumorigenic state, but their products are not needed to perpetuate it. They might be concerned with transfer of T-DNA into the plant nucleus or perhaps with subsidiary functions such as the balance of plant hormones in the infected tissue. Some of the mutations are host specific, preventing tumor formation by some plant species but not by others.
The virulence genes encode the functions required for the transfer of the T-DNA to the plant cell (whereas the proteins needed for conjugal transfer of the entire Ti plasmid to recipient bacteria are encoded by the tra region). Six loci (virA, -B, -C, -D, -E, and -G) reside in a 40-kb region outside the T-DNA. Each locus is transcribed as an individual unit; some contain more than one open reading frame (ORF). FIGURE 12.26 illustrates some of the most important components and their role in the transformation process.

FIGURE 12.26 A model for the Agrobacterium-mediated genetic transformation. The transformation process comprises 10 major steps and begins with recognition and attachment of the Agrobacterium to the host cell (1) and the sensing of specific plant signals by the Agrobacterium VirA-VirG two-component, signal-transduction system (2). Following activation of the vir gene region (3), a mobile copy of the T-DNA is generated by the VirD1-VirD2 protein complex (4) and delivered as a VirD2-DNA complex (immature T-complex), together with several other Vir proteins, into the host cell cytoplasm (5). Following the association of VirE2 with the T-strand, the mature T-complex forms, travels through the host-cell cytoplasm (6), and is actively imported into the host-cell nucleus (7). After it is inside the nucleus, the T-DNA is recruited to the point of integration (8), stripped of its escorting proteins (9), and integrated into the host genome (10).
Reprinted from Tzfira T., and Citovsky, V. 2006. “Agrobacterium-mediated genetic transformation of plants.” Curr Opin Biotechnol 17:147–154, with permission from Elsevier (http://www.sciencedirect.com/science/journal/09581669).
Researchers can divide the transforming process into (at least) two stages:
Agrobacterium contacts a plant cell, and the vir genes are induced.
vir gene products cause T-DNA to be transferred to the plant cell nucleus, where it is integrated into the genome.
The vir genes fall into two groups that correspond to these stages. Genes virA and virG are regulators that respond to a change in the plant by inducing the other genes. Thus, mutants in virA and virG are avirulent and cannot express the remaining vir genes. Genes virB, -C, -D, and -E code for proteins involved in the transfer of DNA. Mutants in virB and virD are avirulent in all plants, but the effects of mutations in virC and virE vary with the type of host plant.
virA and virG are expressed constitutively (at a rather low level). The signal to which they respond is provided by phenolic compounds generated by plants as a response to wounding. FIGURE 12.27 presents an example. Nicotiana tabacum (tobacco) generates the molecules acetosyringone and α-hydroxyacetosyringone. Exposure to these compounds activates virA, which acts on virG, which in turn induces the expression de novo of virB, -C, -D, and -E. This reaction explains why Agrobacterium infection succeeds only on wounded plants.
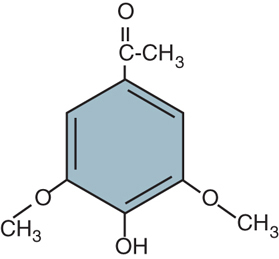
FIGURE 12.27 Acetosyringone (4-acetyl-2,6-dimethoxy-phenol) is produced by N. tabacum upon wounding and induces transfer of T-DNA from Agrobacterium.
VirA and VirG are an example of a classic type of bacterial system in which stimulation of a sensor protein causes autophosphorylation and transfer of the phosphate to the second protein. FIGURE 12.28 illustrates the relationship.

FIGURE 12.28 The two-component system of VirA-VirG responds to phenolic signals by activating transcription of target genes.
VirA forms a homodimer that is located in the inner membrane; it may respond to the presence of the phenolic compounds in the periplasmic space. Exposure to these compounds causes VirA to become autophosphorylated on histidine. The phosphate group is then transferred to an Asp residue in VirG. The phosphorylated VirG binds to promoters of the virB, -C, -D, and -E genes to activate transcription. When virG is activated, its transcription is induced from a new start point—a different one from the one used for constitutive expression—with the result that the amount of VirG protein is increased.
12.15 Transfer of T-DNA Resembles Bacterial Conjugation
The transfer process actually selects the T-region for entry into the plant. FIGURE 12.29 shows that the T-DNA of a nopaline plasmid is demarcated from the flanking regions in the Ti plasmid by repeats of 25 bp, which differ at only two positions between the left and right ends. When T-DNA is integrated into a plant genome, it has a well-defined right junction, which retains 1 to 2 bp of the right repeat. The left junction is variable; the boundary of T-DNA in the plant genome can be located at the 25-bp repeat or at one of a series of sites extending over about 100 bp within the T-DNA. At times multiple tandem copies of T-DNA are integrated at a single site.
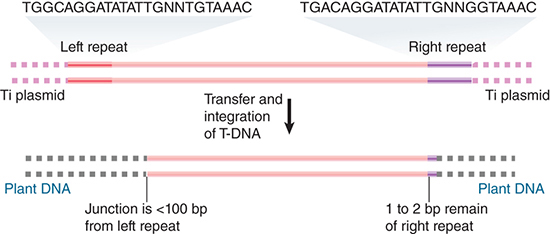
FIGURE 12.29 T-DNA has almost identical repeats of 25 bp at each end in the Ti plasmid. The right repeat is necessary for transfer and integration to a plant genome. T-DNA that is integrated in a plant genome has a precise junction that retains 1 to 2 bp of the right repeat, but the left junction varies and may be up to 100 bp short of the left repeat.
The virD locus has four ORFs. Two of the proteins encoded at virD—VirD1 and VirD2—provide an endonuclease that initiates the transfer process by nicking T-DNA at a specific site. FIGURE 12.30 illustrates a model for transfer. A nick is made at the right 25-bp repeat. It provides a priming end for synthesis of a DNA single strand. Synthesis of the new strand displaces the old strand, which is used in the transfer process. Transfer is terminated when DNA synthesis reaches a nick at the left repeat. This model explains why the right repeat is essential, and it accounts for the polarity of the process. If the left repeat fails to be nicked, transfer could continue farther along the Ti plasmid.

FIGURE 12.30 T-DNA is generated by displacement when DNA synthesis starts at a nick made at the right repeat. The reaction is terminated by a nick at the left repeat.
The transfer process involves production of a single molecule of single-stranded DNA in the infecting bacterium. It is transferred in the form of a DNA–protein complex, sometimes called the T-complex. The DNA is covered by the VirE2 single-strand binding protein, which has a nuclear localization signal and is responsible for transporting T-DNA into the plant cell nucleus. A single molecule of the D2 subunit of the endonuclease remains bound at the 5′ end. The virB operon codes for 11 products that are involved in the transfer reaction.
Outside T-DNA, immediately adjacent to the right border, is another short sequence called overdrive, which greatly stimulates the transfer process. Overdrive functions like an enhancer: It must lie on the same molecule of DNA, but enhances the efficiency of transfer even when located several thousand base pairs away from the border. VirC1, and possibly VirC2, may act at the overdrive sequence.
Octopine plasmids have a more complex pattern of integrated T-DNA than nopaline plasmids. The pattern of T-strands is also more complex, and several discrete species can be found, corresponding to elements of T-DNA. This suggests that octopine T-DNA has several sequences that provide targets for nicking and/or termination of DNA synthesis.
This model for transfer of T-DNA closely resembles the events involved in bacterial conjugation, when the E. coli chromosome is transferred from one cell to another in single-stranded form. The genes of the virB operon are homologous to the tra genes of certain bacterial plasmids (including the tra operons on Ti-plasmids) that are involved in conjugation (see the section Conjugation Transfers Single-Stranded DNA earlier in this chapter). Together with VirD4 (a coupling protein), the gene products of the virB genes form a T4SS.
The T strand, along with several other Vir proteins, is then exported into the plant cell by the T4SS, a step that requires interaction of the bacterial T-pilus with at least one host-specific protein. The T-strand molecule is coated with numerous VirE2 molecules when entering the plant-cell cytoplasm. These molecules confer to the T-DNA the structure and protection needed for its travel to the plant-cell nucleus (see Figure 12.26).
Researchers do not know how the transferred DNA is integrated into the plant genome. At some stage, the newly generated single strand must be converted into duplex DNA. Circles of T-DNA that are found in infected plant cells appear to be generated by recombination between the left and right 25-bp repeats, but researchers do not know if they are intermediates. The actual event is likely to involve nonhomologous recombination, because there is no homology between the T-DNA and the sites of integration.
What is the structure of the target site? Sequences flanking the integrated T-DNA tend to be rich in A-T base pairs (a feature displayed in target sites for some transposable elements). The sequence rearrangements that occur at the ends of the integrated T-DNA make it difficult to analyze the structure. Researchers do not know whether the integration process generates new sequences in the target DNA comparable to the target repeats created in transposition.
T-DNA is expressed at its site of integration. The region contains several transcription units, each of which probably contains a gene expressed from an individual promoter. Their functions are concerned with the state of the plant cell, maintaining its tumorigenic properties, controlling shoot and root formation, and suppressing differentiation into other tissues. None of these genes is needed for T-DNA transfer.
The Ti plasmid presents an interesting organization of functions. Outside the T-region, it carries genes needed to initiate oncogenesis; at least some are concerned with the transfer of T-DNA, and researchers would like to know whether others function in the plant cell to affect its behavior at this stage. Also outside the T-region are the genes that enable the Agrobacterium to catabolize the opine that the transformed plant cell will produce. Within the T-region are the genes that control the transformed state of the plant as well as the genes that cause it to synthesize the opines that will benefit the Agrobacterium that originally provided the T-DNA.
As a practical matter, the ability of Agrobacterium to transfer T-DNA to the plant genome makes it possible to introduce new genes into plants. The transfer/integration and oncogenic functions are separate; thus, it is possible to engineer new Ti plasmids in which the oncogenic functions have been replaced by other genes whose effect on the plant researchers wish to test. The existence of a natural system for delivering genes to the plant genome has greatly facilitated genetic engineering of plants.
Summary
The rolling circle is an alternative form of replication for circular DNA molecules in which an origin is nicked to provide a priming end. One strand of DNA is synthesized from this end; this displaces the original partner strand, which is extruded as a tail. Multiple genomes can be produced by continuing revolutions of the circle.
Rolling circles are used to replicate some phages. The A protein that nicks the ФX174 origin has the unusual property of cis action. It acts only on the DNA from which it was synthesized. It remains attached to the displaced strand until an entire strand has been synthesized, and then nicks the origin again; this releases the displaced strand and starts another cycle of replication.
Rolling circles also characterize bacterial conjugation, which occurs when an F plasmid is transferred from a donor to a recipient cell following the initiation of contact between the cells by means of the F-pili. A free F plasmid infects new cells by this means; an integrated F plasmid creates an Hfr strain that might similarly transfer chromosomal DNA. In conjugation, replication is used to synthesize complements to the single strand remaining in the donor and to the single strand transferred to the recipient, but does not provide the motive power.
Plasmids have a variety of systems that ensure or assist their stable inheritance in bacterial cells, and an individual plasmid can carry systems of several types. Plasmid localization is promoted by ParA and ParB partition proteins that act on a plasmid site called parS. The copy number of a plasmid describes whether it is present at the same level as the bacterial chromosome (one per unit cell) or in greater numbers. Plasmid incompatibility can be a consequence of the mechanisms involved in either replication or partition (for single-copy plasmids).
Agrobacteria induce tumor formation in wounded plant cells. The wounded cells secrete phenolic compounds that activate vir genes carried by the Ti plasmid of the bacterium. The vir gene products cause a single strand of DNA from the T-DNA region of the plasmid to be transferred to the plant-cell nucleus. Transfer is initiated at one boundary of T-DNA, but ends at variable sites. The single strand is converted into a double strand and integrated into the plant genome. Genes within the T-DNA transform the plant cell and cause it to produce particular opines (derivatives of arginine). Genes in the Ti plasmid allow Agrobacteria to metabolize the opines produced by the transformed plant cell. T-DNA has been used to develop vectors for transferring genes into plant cells.
References
12.4 Rolling Circles Produce Multimers of a Replicon
Research
Gilbert, W., and Dressler, D. (1968). DNA replication: the rolling circle model. Cold Spring Harbor Symp. Quant. Biol. 33, 473–484.
12.6 The F Plasmid Is Transferred by Conjugation Between Bacteria
Research
Ihler, G., and Rupp, W. D. (1969). Strand-specific transfer of donor DNA during conjugation in E. coli. Proc. Natl. Acad. Sci. USA 63, 138–143.
Lu, J., et al. (2008). Structural basis of specific TraD-TraM recognition during F plasmid-mediated bacterial conjugation. Mol. Microbiol. 70, 89–99.
12.7 Conjugation Transfers Single-Stranded DNA
Reviews
Frost, L. S., et al. (1994). Analysis of the sequence and gene products of the transfer region of the F sex factor. Microbiol. Rev. 58, 162–210.
Ippen-Ihler, K. A., and Minkley, E. G. (1986). The conjugation system of F, the fertility factor of E. coli. Annu. Rev. Genet 20, 593–624.
Lanka, E., and Wilkins, B. M. (1995). DNA processing reactions in bacterial conjugation. Annu. Rev. Biochem. 64, 141–169.
Willetts, N., and Skurray, R. (1987). Structure and function of the F factor and mechanism of conjugation. In Neidhardt, F. C., ed. Escherichia coli and Salmonella typhimurium. Washington, DC : American Society for Microbiology, pp. 1110–1133.
12.8 Single-Copy Plasmids Have a Partitioning System
Reviews
Ebersbach, G., and Gerdes, K. (2005). Plasmid segregation mechanisms. Annu. Rev. Genet 39, 453–479.
Hayes, F., and Barilla, D. (2006) The bacterial segrosome: a dynamic nucleoprotein machine for DNA trafficking and segregation. Nat. Rev. Microbiol. 4, 133–143.
Research
Ireton, K., et al. (1994). spo0J is required for normal chromosome segregation as well as the initiation of sporulation in Bacillus subtilis. J. Bacteriol. 176, 5320–5329.
Moller-Jensen, J., et al. (2003). Bacterial mitosis: ParM of plasmid R1 moves plasmid DNA by an actin-like insertional polymerization mechanism. Mol. Cell 12, 1477–1487.
Surtees, J. A., and Funnell, B. E. (2001). The DNA binding domains of P1 ParB and the architecture of the P1 plasmid partition complex. J. Biol. Chem. 276, 12385–12394.
12.9 Plasmid Incompatibility Is Determined by the Replicon
Reviews
Nordstrom, K., and Austin, S. J. (1989). Mechanisms that contribute to the stable segregation of plasmids. Annu. Rev. Genet 23, 37–69.
Scott, J. R. (1984). Regulation of plasmid replication. Microbiol. Rev. 48, 1–23.
12.10 The ColE1 Compatibility System Is Controlled by an RNA Regulator
Research
Masukata, H., and Tomizawa, J. (1990). A mechanism of formation of a persistent hybrid between elongating RNA and template DNA. Cell 62, 331–338.
Tomizawa, J. I., and Itoh, T. (1981). Plasmid ColE1 incompatibility determined by interaction of RNA with primer transcript. Proc. Natl. Acad. Sci. USA 78, 6096–6100.
12.11 How Do Mitochondria Replicate and Segregate?
Review
Birky, C. W. (2001). The inheritance of genes in mitochondria and chloroplasts: laws, mechanisms, and models. Annu. Rev. Genet 35, 125–148.
12.12 D Loops Maintain Mitochondrial Origins
Reviews
Clayton, D. (1982). Replication of animal mitochondrial DNA. Cell 28, 693–705.
Falkenberg, M., et al. (2007) DNA replication and transcription in mammalian mitochondria. Annu. Rev. Biochem. 76, 679–700.
Shadel, G. S., and Clayton, D. A. (1997). Mitochondrial DNA maintenance in vertebrates. Annu. Rev. Biochem. 66, 409–435.
12.15 Transfer of T-DNA Resembles Bacterial Conjugation
Reviews
Gelvin, S. B. (2006). Agrobacterium virulence gene induction. Methods Mol. Biol. 343, 77–84.
Lacroix, B., et al. (2006). Will you let me use your nucleus? How Agrobacterium gets its T-DNA expressed in the host plant cell. Can. J. Physiol. Pharmacol. 84, 333–345.
Research
Anand, A., et al. (2008). Arabidopsis VIRE2 INTERACTING PROTEIN2 is required for Agrobacterium T-DNA integration in plants. Plant Cell 19, 695–708.
Lacroix, B., et al. (2008). Association of the Agrobacterium T-DNA-protein complex with plant nucleosomes. Proc. Natl. Acad. Sci. USA 105, 15429–34.
Ulker, B., et al. (2008). T-DNA-mediated transfer of Agrobacterium tumefaciens chromosomal DNA into plants. Nat. Biotechnol. 26, 1015–1017.