
Top texture: © Laguna Design / Science Source;
CHAPTER 15: Transposable Elements and Retroviruses
Edited by Damon Lisch
Chapter Opener: © Laguna Design/Getty Images.
15.1 Introduction
A major cause of variation in nearly all genomes is provided by transposable elements, or transposons. These are discrete sequences in the genome that are mobile; that is, they are able to transport themselves to other locations within the genome. The mark of a transposon is that it does not utilize an independent form of the element (such as phage or plasmid DNA), but rather moves directly from one site in the genome to another. Unlike most other processes involved in genome restructuring, transposition does not rely on any relationship between the sequences at the donor and recipient sites. Transposons are restricted to moving themselves, and sometimes additional sequences, to new sites elsewhere within the same genome; they are, therefore, an internal counterpart to the vectors that can transport sequences from one genome to another. They can be a major source of mutations in the genome, as shown in FIGURE 15.1, and have had a significant impact on the overall size of many genomes, including our own, about half of which consist of transposable elements. Transposon content in eukaryotes varies over a wide range, from 4% in yeast to 70% or more in some amphibians and plants. Plants are particularly rich in these elements; for example, in Zea mays (maize) transposable elements make up 85% of the genome.

FIGURE 15.1 A major cause of sequence change within a genome is the movement of a transposon to a new site. This may have direct consequences on gene expression. Further, unequal crossing over between related sequences causes rearrangements. Copies of transposons can provide targets for such events.
Transposons fall into two general classes: (1) those that are able to directly manipulate DNA so as to propagate themselves within the genome (class II elements, or DNA-type elements) and (2) those whose source of mobility is the ability to make DNA copies of their RNA transcripts, which are then integrated at new sites in the genome (class I elements, or retroelements).
Transposons that mobilize via DNA are widespread in both prokaryotes and eukaryotes. Each transposon carries gene(s) that encode the enzyme activities required for its own transposition, although it may also require ancillary products of the genome in which it resides (such as DNA polymerase or DNA gyrase).
Transposition that involves an obligatory intermediate of RNA is primarily confined to eukaryotes. Transposons that employ an RNA intermediate all use some form of reverse transcriptase to translate RNA into DNA. Some of these elements are closely related to retroviral proviruses in their general organization and mechanism of transposition. As a class, these elements are called long terminal repeat (LTR) retrotransposons, or simply retrotransposons. Members of a second class of elements that also use reverse transcriptase but lack LTRs, and that employ a distinct mode of transposition, are referred to as non-LTR retrotransposons, or simply retroposons. (The nomenclature of transposable elements is somewhat confusing in the literature, but this system of distinguishing elements by the presence or absence of the LTR reflects the modern understanding of both the evolution and the transposition mechanisms of these elements.)
Like any other reproductive cycle, the cycle of a retrovirus or retrotransposon is continuous; it is arbitrary to consider the point at which we interrupt it a “beginning.” Our perspectives of these elements are biased, though, by the forms in which we usually observe them. The interlinked cycles of retroviruses and retrotransposons are depicted in FIGURE 15.2. Retroviruses were first observed as infectious virus particles that were capable of transmission between cells, and so the intracellular cycle (involving duplex DNA) is thought of as the means of reproducing the RNA virus. Retrotransposons were discovered as components of the genome, and the RNA forms have been mostly characterized for their functions as mRNAs and transposition intermediates. Thus, we think of retrotransposons as genomic (duplex DNA) sequences and retroviruses as RNA–protein complexes, but this obscures the close relationship between these elements. Indeed, recent phylogenetic evidence suggests that retroviruses as a class are simply retrotransposons that have acquired envelope proteins, the inverse of the previously assumed relationship.
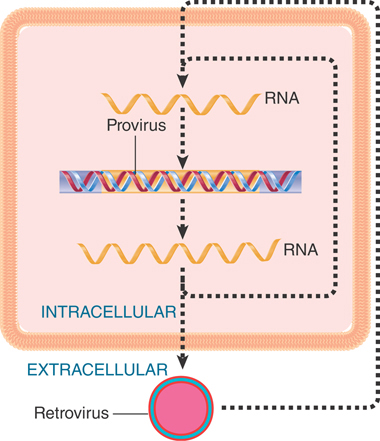
FIGURE 15.2 The reproductive cycles of retroviruses and retrotransposons alternate reverse transcription from RNA to DNA with transcription from DNA to RNA. Only retroviruses can generate infectious particles. Retrotransposons are confined to an intracellular cycle.
A genome may contain both functional and nonfunctional (defective) elements of either class of element. In most cases the majority of elements in a eukaryotic genome are defective and have lost the ability to transpose independently, although they may still be recognized as substrates for transposition by the enzymes produced by functional transposons. A eukaryotic genome contains a large number and variety of transposons. The relatively small fly genome has 1,572 identified transposons belonging to 96 distinct families. Larger genomes, such as those of maize and humans, can harbor hundreds of thousands of transposons. Each of these species has a genome composed of 50% to 85% transposons.
Transposable elements of all kinds can promote rearrangements of the genome directly or indirectly:
The transposition event itself may cause deletions or inversions or lead to the movement of a host sequence to a new location.
Transposons serve as substrates for cellular recombination systems by functioning as “portable regions of homology”; two copies of a transposon at different locations (even on different chromosomes) may provide sites for aberrant reciprocal recombination. Such exchanges result in deletions, insertions, inversions, or translocations.
The intermittent activities of a transposon seem to provide a somewhat nebulous target for natural selection. This view has prompted suggestions that most transposable elements confer neither advantage nor disadvantage on the phenotype, but could constitute “selfish DNA”—DNA concerned only with its own propagation. Indeed, in considering transposition as an event that is distinct from other cellular recombination systems we tacitly accept the view that the transposon is an independent entity that resides in the genome.
Such a relationship of the transposon to the genome would resemble that of a parasite with its host. Presumably the propagation of an element by transposition is balanced by the harm done if a transposition event inactivates a necessary gene or if the number of transposons becomes a burden on cellular systems. Yet we must remember that any transposition event conferring a selective advantage—for example, a genetic rearrangement—will lead to preferential survival of the genome carrying the active transposon.
15.2 Insertion Sequences Are Simple Transposition Modules
Transposable elements were first identified at the molecular level in the form of spontaneous insertions in bacterial operons. Such an insertion prevents transcription and/or translation of the gene in which it is inserted. Many different types of transposable elements have now been characterized in both prokaryotes and eukaryotes (they are far more abundant in the latter), but the basic principles and biochemistry of elements first described in bacteria apply to DNA-type elements in many species.
The simplest bacterial transposons are called insertion sequence (IS) elements (reflecting the way in which they were detected). Each type is given the prefix “IS,” followed by a number that identifies the type. (The original classes were numbered IS1 to IS4; later classes have numbers reflecting the history of their isolation, but not corresponding to the more than 700 elements so far identified!)
The IS elements are normal constituents of bacterial chromosomes and plasmids. A standard strain of Escherichia coli is likely to contain several (fewer than 10) copies of any one of the more common IS elements. To describe an insertion into a particular site, a double colon is used; thus λ::IS1 describes an IS1 element inserted into phage lambda. Most IS elements insert at a variety of sites within host DNA. Some, though, show varying degrees of preference for particular hotspots.
The IS elements are autonomous units, each of which encodes only the proteins needed to sponsor its own transposition. Each IS element is different in sequence, but there are some common features in organization. The structure of a generic transposon before and after insertion at a target site is illustrated in FIGURE 15.3, which also summarizes the details of some common IS elements.
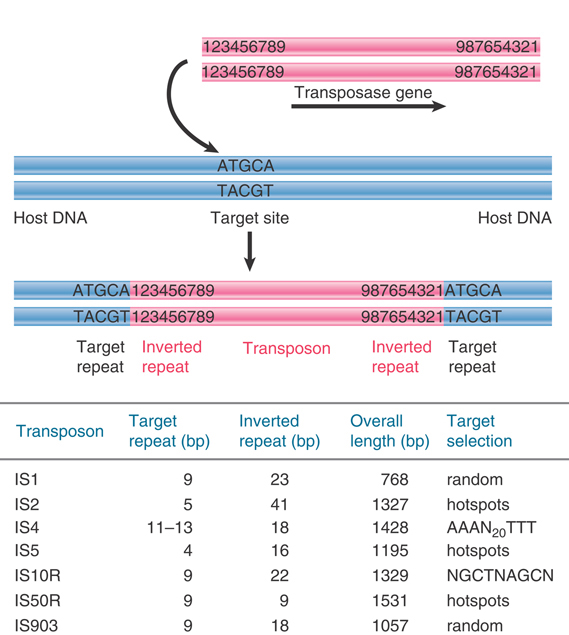
FIGURE 15.3 IS elements have inverted terminal repeats and generate direct repeats of flanking DNA at the target site. In this example, the target is a 5-bp sequence. The ends of the transposon consist of inverted repeats of 9 bp, where the numbers 1 through 9 indicate a sequence of base pairs.
An IS element ends in short inverted terminal repeats; usually the two copies of the repeat are closely related rather than identical. As illustrated in Figure 15.3, the presence of the inverted terminal repeats means that the same sequence is encountered proceeding toward the element from the flanking DNA on either side of it.
When an IS element transposes, a sequence of host DNA at the site of insertion is duplicated. The nature of the duplication is revealed by comparing the sequence of the target site before and after an insertion has occurred. Figure 15.3 shows that at the site of insertion the IS DNA is always flanked by very short direct repeats. (In this context, “direct” indicates that two copies of a sequence are repeated in the same orientation, not that the repeats are adjacent.) In the original gene (prior to insertion), however, the target site has the sequence of only one of these repeats. In the figure, the target site consists of the sequence 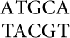 . After transposition, one copy of this sequence is present on either side of the transposon. The sequence of the direct repeat varies among individual transposition events undertaken by a transposon, but the length is constant for any particular IS element (a reflection of the mechanism of transposition).
. After transposition, one copy of this sequence is present on either side of the transposon. The sequence of the direct repeat varies among individual transposition events undertaken by a transposon, but the length is constant for any particular IS element (a reflection of the mechanism of transposition).
An IS element therefore displays a characteristic structure in which its ends are identified by the inverted terminal repeats, whereas the adjacent ends of the flanking host DNA are identified by the short direct repeats. When observed in a sequence of DNA, this type of organization is taken to be diagnostic of a transposon and suggests that the sequence originated in a transposition event.
The inverted repeats define the ends of a transposon. Recognition of the ends is common to transposition events sponsored by all types of DNA-type transposon. cis-acting mutations that prevent transposition are located in the ends, which are recognized by a protein(s) responsible for transposition. The protein is called a transposase.
Many of the IS elements contain a single, long coding region, which starts just inside the inverted repeat at one end and terminates just before or within the inverted repeat at the other end. This region encodes the transposase. Some elements have a more complex organization. IS1, for instance, has two separate reading frames; the transposase is produced by making a frameshift during translation to allow both reading frames to be used.
The frequency of transposition varies among different elements. Under most circumstances the overall rate of transposition is 10–3 to 10–4 per element per generation. Insertions in individual targets occur at a level comparable with the spontaneous mutation rate, usually 10–5 to 10–7 per generation. Reversion (by precise excision of the IS element) is usually infrequent, with a range of rates of 10–6 to 10–10 per generation, which is 103 times less frequent than insertion.
15.3 Transposition Occurs by Both Replicative and Nonreplicative Mechanisms
The insertion of a transposon into a new site is illustrated in FIGURE 15.4. It consists of making staggered breaks in the target DNA, joining the transposon to the protruding single-stranded ends, and filling in the gaps. The generation and filling of the staggered ends explain the occurrence of the direct repeats of target DNA at the site of insertion. The stagger between the cuts on the two strands determines the length of the direct repeats; thus, the target repeat characteristic of each transposon reflects the geometry of the enzyme involved in cutting target DNA.
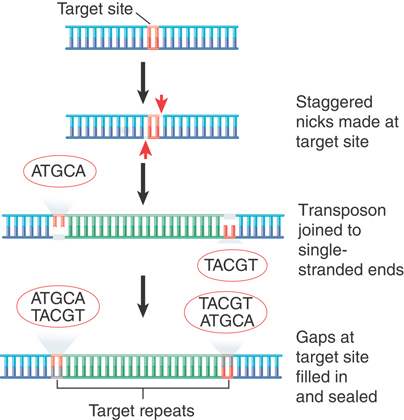
FIGURE 15.4 The direct repeats of target DNA flanking a transposon are generated by the introduction of staggered cuts whose protruding ends are linked to the transposon.
The use of staggered ends is common to most means of transposition, but we can distinguish two major types of mechanisms by which a transposon moves:
In replicative transposition, the element is duplicated during the reaction so that the transposing entity is a copy of the original element. FIGURE 15.5 summarizes the results of such a transposition. The transposon is copied as part of its movement. One copy remains at the original site, whereas the other inserts at the new site. Thus, transposition is accompanied by an increase in the number of copies of the transposon. Replicative transposition involves two types of enzymatic activity: a transposase that acts on the ends of the original transposon and a resolvase that acts on the duplicated copies. Although one group of transposons moves only by replicative transposition (see the section in this chapter titled Replicative Transposition Proceeds Through a Cointegrate), true replicative transposition is relatively rare among transposons in general.
In nonreplicative transposition, the transposing element moves as a physical entity directly from one site to another and is conserved. The insertion sequences and composite transposons (Tn), Tn10 and Tn5 (as well as many eukaryotic transposons), use the mechanism shown in FIGURE 15.6, which involves the release of the transposon from the flanking donor DNA during transfer. This type of mechanism, often referred to as “cut-and-paste,” requires only a transposase. Another mechanism utilizes the connection of donor and target DNA sequences and shares some steps with replicative transposition. Both mechanisms of nonreplicative transposition cause the element to be inserted at the target site and lost from the donor site. What happens to the donor molecule after a nonreplicative transposition? Its survival requires that host repair systems recognize the double-strand break and repair it (as described in the chapter titled Repair Systems).

FIGURE 15.5 Replicative transposition creates a copy of the transposon, which inserts at a recipient site. The donor site remains unchanged, so both donor and recipient have a copy of the transposon.
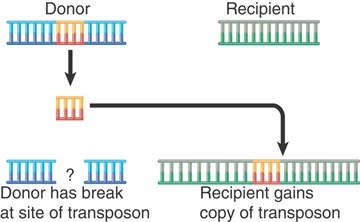
FIGURE 15.6 Nonreplicative transposition allows a transposon to move as a physical entity from a donor to a recipient site. This leaves a break at the donor site, which is lethal unless it can be repaired.
Some bacterial transposons use only one type of pathway for transposition, whereas others may be able to use multiple pathways. The elements IS1 and IS903 use both nonreplicative and replicative pathways, and the ability of phage Mu to turn to either type of pathway from a common intermediate has been well characterized.
The same basic types of reaction are involved in all classes of transposition events. The ends of the transposon are disconnected from the donor DNA by cleavage reactions that generate 3′–OH ends. The exposed ends are then joined to the target DNA by transfer reactions, involving transesterification in which the 3′–OH end directly attacks the target DNA. These reactions take place within a nucleoprotein complex that contains the necessary enzymes and both ends of the transposon. Transposons differ as to whether the target DNA is recognized before or after the cleavage of the transposon itself, and whether one or both strands at the ends of the transposon are cleaved prior to integration.
The choice of target site is in effect made by the transposase, sometimes in conjunction with accessory proteins. In some cases, the target is chosen virtually at random. In others, there is specificity for a consensus sequence or for some other feature in the target. The feature can take the form of a structure in DNA, such as bent DNA, or a protein–DNA complex. In the latter case, the nature of the target complex can cause the transposon to insert at specific promoters (such as Ty1 or Ty3, which select pol III promoters in yeast), inactive regions of the chromosome, or replicating DNA.
15.4 Transposons Cause Rearrangement of DNA
In addition to the “simple” intermolecular transposition that results in insertion at a new site, transposons promote other types of DNA rearrangements. Some of these events are consequences of the relationship between the multiple copies of the transposon. Others represent alternative outcomes of the transposition mechanism, and they leave clues about the nature of the underlying events.
Rearrangements of host DNA may result when a transposon inserts a copy at a second site near its original location. Host systems may undertake reciprocal recombination between the two copies of the transposon; the consequences are determined by whether the repeats are in direct or inverted orientation.
FIGURE 15.7 illustrates the general rule that recombination between any pair of direct repeats will delete the material between them. The intervening region is excised as a circle of DNA (which is lost from the cell); the chromosome retains a single copy of the direct repeat. A recombination between the directly repeated IS1 modules of the composite transposon Tn9 would replace the transposon with a single IS1 module.

FIGURE 15.7 Reciprocal recombination between direct repeats excises the material between them; each product of recombination has one copy of the direct repeat.
Deletion of sequences adjacent to a transposon could therefore result from a two-stage process; transposition generates a direct repeat of a transposon, and recombination occurs between the repeats. The majority of deletions that arise in the vicinity of transposons, however, probably result from a variation in the pathway followed in the transposition event itself.
FIGURE 15.8 depicts the consequences of a reciprocal recombination between a pair of inverted repeats. The region between the repeats becomes inverted; the repeats themselves remain available to sponsor further inversions. A composite transposon whose modules are inverted is a stable component of the genome, although the direction of the central region with regard to the modules could be inverted by recombination.
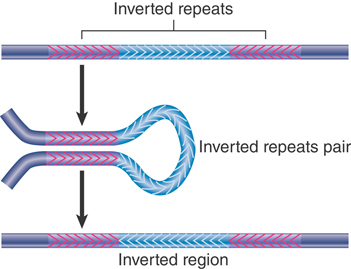
FIGURE 15.8 Reciprocal recombination between inverted repeats inverts the region between them.
Excision in this case is not supported by transposons themselves, but occurs when bacterial enzymes recognize homologous regions in the transposons. This is important because the loss of a transposon may restore function at the site of insertion. Precise excision requires removal of the transposon, plus one copy of the duplicated sequence. This is rare; it occurs at a frequency of approximately 10–6 for Tn5 and 10–9 for Tn10. It probably involves a recombination between the duplicated target sites.
Imprecise excision leaves a remnant of the transposon. The remnant may be sufficient to prevent reactivation of the target gene, but it may be insufficient to cause polar effects in adjacent genes so that a change of phenotype occurs. Imprecise excision occurs at a frequency of 10–6 for Tn10. It involves recombination between sequences of 24 bp in the IS10 modules; these sequences are inverted repeats, but because the IS10 modules themselves are inverted, they form direct repeats in Tn10.
The greater frequency of imprecise excision compared with precise excision probably reflects the increase in the length of the direct repeats (24 bp as opposed to 9 bp). Neither type of excision relies on transposon-encoded functions, but the mechanism is not known. Excision is RecA independent and could occur by some cellular mechanism that generates spontaneous deletions between closely spaced repeated sequences.
Both precise and imprecise excisions can also arise as a consequence of transposition of cut-and-paste elements in eukaryotes. In this case, the outcome depends on the nature of the repair of the double-stranded DNA break introduced by excision of the element. This break can be repaired using the homologous chromosome or the sister chromatid, resulting in a transfer of DNA from those templates. Repair using a chromosome that lacks the transposon insertion can result in precise restoration of sequences surrounding the original insertion. Repair using the sister chromatid results in restoration of the transposon insertion. Incomplete repair can result in deletions, either of sequences flanking the insertion or of portions of the transposon. Alternatively, the break can be repaired using nonhomologous end joining, which results in the addition or deletion of short stretches of DNA.
15.5 Replicative Transposition Proceeds Through a Cointegrate
The basic structures involved in replicative transposition are illustrated in FIGURE 15.9: The 3′ ends of the strand transfer complex are used as primers for replication. This generates a structure called a cointegrate, which represents a fusion of the two original molecules. The cointegrate has two copies of the transposon, one at each junction between the original replicons, oriented as direct repeats. The crossover is formed by the transposase. Its conversion into the cointegrate requires host replication functions.
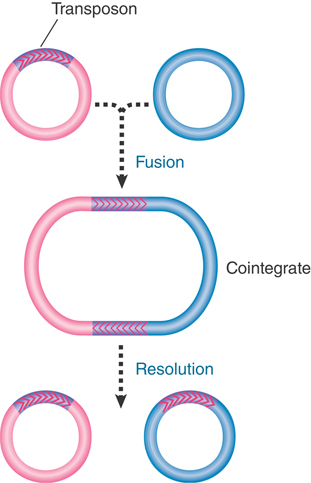
FIGURE 15.9 Transposition may fuse a donor and recipient replicon into a cointegrate. Resolution releases two replicons, each containing a copy of the transposon.
Homologous recombination between the two copies of the transposon releases two individual replicons, each of which has a copy of the transposon. One of the replicons is the original donor replicon. The other is a target replicon that has gained a transposon flanked by short direct repeats of the host target sequence. The recombination reaction is called resolution; the enzyme activity responsible is called the resolvase.
The reactions involved in generating a cointegrate have been defined in detail for phage Mu and are illustrated in FIGURE 15.10. The process starts with the formation of the strand transfer complex (sometimes called a crossover complex). The donor and target strands are ligated so that each end of the transposon sequence is joined to one of the protruding single strands generated at the target site. The strand transfer complex generates a crossover-shaped structure held together at the duplex transposon. The fate of the crossover structure determines the mode of transposition.
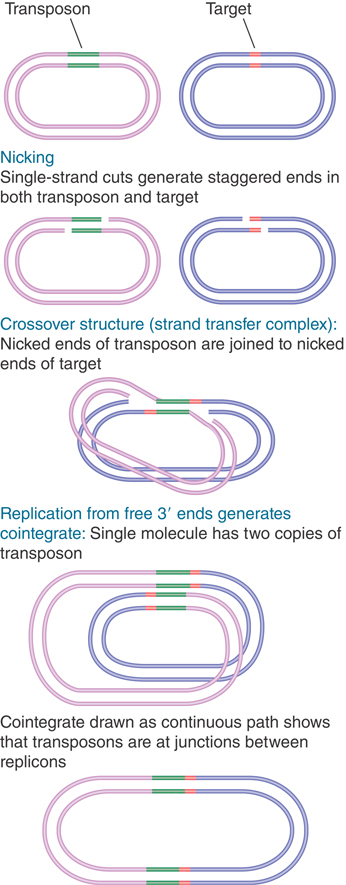
FIGURE 15.10 Mu transposition generates a crossover structure, which is converted by replication into a cointegrate.
The principle of replicative transposition is that replication through the transposon duplicates it, which creates copies at both the target and donor sites. The product is a cointegrate.
The crossover structure contains a single-stranded region at each of the staggered ends. These regions are pseudoreplication forks that provide a template for DNA synthesis. (Use of the ends as primers for replication implies that the strand breakage must occur with a polarity that generates a 3′–OH terminus at this point.)
If replication continues from both of the pseudoreplication forks, it will proceed through the transposon, separating its strands and terminating at its ends. Replication is accomplished by host-encoded functions. At this juncture, the structure has become a cointegrate, possessing direct repeats of the transposon at the junctions between the replicons (as can be seen by tracing the path around the cointegrate).
15.6 Nonreplicative Transposition Proceeds by Breakage and Reunion
The crossover structure can also be used in nonreplicative transposition. The principle of nonreplicative transposition by this mechanism is that a breakage and reunion reaction allows the target to be reconstructed with the insertion of the transposon; the donor remains broken. No cointegrate is formed.
FIGURE 15.11 shows the cleavage events that generate nonreplicative transposition of phage Mu. Once the unbroken donor strands have been nicked, the target strands on either side of the transposon can be ligated. The single-stranded regions generated by the staggered cuts must be filled in by repair synthesis. The product of this reaction is a target replicon in which the transposon has been inserted between repeats of the sequence created by the original single-strand nicks. The donor replicon has a double-strand break across the site where the transposon was originally located.
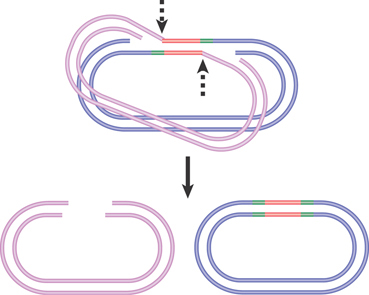
FIGURE 15.11 Nonreplicative transposition results when a crossover structure is released by nicking. This inserts the transposon into the target DNA, flanked by the direct repeats of the target, and the donor is left with a double-strand break.
Nonreplicative transposition can also occur by an alternative pathway in which nicks are made in target DNA, but a double-strand break is made on either side of the transposon, releasing it entirely from flanking donor sequences (as envisaged in Figure 15.6). This cut-and-paste pathway is used by Tn10 and by many eukaryotic transposons and is illustrated in FIGURE 15.12.

FIGURE 15.12 Both strands of Tn10 are cleaved sequentially, and then the transposon is joined to the nicked target site.
A simple experiment to prove that Tn10 transposes nonreplicatively made use of an artificially constructed heteroduplex of Tn10 that contained single-base mismatches. If transposition involves replication, the transposon at the new site will contain information from only one of the parent Tn10 strands. If, however, transposition takes place by physical movement of the existing transposon, the mismatches will be conserved at the new site. This proves to be the case.
The basic difference in Figure 15.11 from the model of Figure 15.12 is that both strands of Tn10 are cleaved before any connection is made to the target site. The first step in the reaction is recognition of the transposon ends by the transposase, forming a proteinaceous structure within which the reaction occurs. At each end of the transposon, the strands are cleaved in a specific order: The transferred strand (the one to be connected to the target site) is cleaved first, followed by the other strand. (This is the same order as in the Mu transposition of Figure 15.10 and Figure 15.11.)
Tn5 also transposes by nonreplicative transposition. FIGURE 15.13 shows the interesting cleavage reaction that separates the transposon from the flanking sequences. First, one DNA strand is nicked. The 3′–OH end that is released then attacks the other strand of DNA. This releases the flanking sequence and joins the two strands of the transposon in a hairpin. An activated water molecule then attacks the hairpin to generate free ends for each strand of the transposon.

FIGURE 15.13 Cleavage of Tn5 from flanking DNA involves nicking, interstrand reaction, and hairpin cleavage.
In the next step, the cleaved donor DNA is released, and the transposon is joined to the nicked ends at the target site. The transposon and the target site remain constrained in the proteinaceous structure created by the transposase (and other proteins). The double-strand cleavage at each end of the transposon precludes any replicative-type transposition and forces the reaction to proceed by nonreplicative transposition, thus giving the same outcome as in Figure 15.12, but with the individual cleavage and joining steps occurring in a different order.
The Tn5 and Tn10 transposases both function as dimers. Each subunit in the dimer has an active site that successively catalyzes the double-strand breakage of the two strands at one end of the transposon, and then catalyzes staggered cleavage of the target site. FIGURE 15.14 illustrates the structure of the Tn5 transposase bound to the cleaved transposon. Each end of the transposon is located in the active site of one subunit. One end of the subunit also contacts the other end of the transposon. This controls the geometry of the transposition reaction. Each of the active sites will cleave one strand of the target DNA. It is the geometry of the complex that determines the distance between these sites on the two target strands (9 bp in the case of Tn5).

FIGURE 15.14 Each subunit of the Tn5 transposase has one end of the transposon located in its active site and also makes contact at a different site with the other end of the transposon.
15.7 Transposons Form Superfamilies and Families
Most eukaryotic genomes contain multiple superfamilies of DNA-based (class II) transposons. Transposon superfamilies are defined by the sequences of their encoded transposases. Transposons may occupy a significant part of the genome; for example, the maize genome has roughly doubled in overall size in the last 6 million years due to transposon activity, and transposons occupy 25% of the genome of the frog Xenopus tropicalis. In humans, only 3% of the genome is composed of DNA-based transposons (our genome contains many more class I elements), but the 3% represents nearly 400,000 individual transposable elements.
The members of transposon families can be divided into two classes:
Autonomous transposons have the ability to excise and transpose. As a result of the continuing activity of an autonomous transposon, its insertion at any locus creates an unstable, or “mutable,” allele. Loss of the autonomous transposon itself, or of its ability to transpose, converts a mutable allele to a stable allele.
Nonautonomous transposons are stable; they do not transpose or suffer other spontaneous changes in condition. They become unstable only when an autonomous member of the same family is present elsewhere in the genome. When complemented in trans by an autonomous element, a nonautonomous element displays the usual range of activities associated with autonomous elements, including the ability to transpose to new sites. Nonautonomous transposons are derived from autonomous transposons by loss of trans-acting functions needed for transposition.
Within the superfamilies, families of transposons consist of a single type of autonomous element accompanied by a variety of nonautonomous elements. A nonautonomous element is placed in a family by its ability to be activated in trans by the autonomous elements. The relationship between active transposons and nonautonomous partners is depicted in FIGURE 15.15. Different plant and animal species have differing numbers of active transposons, but in general only a limited number of transposons, if any, are known to be active in a given species. Very few endogenous DNA-based transposons are currently active in vertebrates, whereas plants harbor a large number of active elements.

FIGURE 15.15 Each transposon family has both autonomous and nonautonomous members. Autonomous elements are capable of transposition. Nonautonomous elements are deficient in transposition.
Transposon superfamilies also have differing distributions in nature. Some are highly species restrictive, whereas others are able to move between quite distantly related hosts. For example, P elements (see the section in this chapter titled The Role of Transposable Elements in Hybrid Dysgenesis) are restricted to the Drosophila genus, whereas transposons in the Tc1/mariner superfamily (originally identified in Caenorhabditis elegans and Drosophila mauritiana) are remarkably widespread and have been identified in fungi, ciliates, plants, and animals. These promiscuous elements have been adapted for use as transgene vectors in vertebrates (most notably the versatile Sleeping Beauty element), and seem able to function in nearly any species due to their lack of dependence on specific host factors for transposition. One of the only autonomous DNA transposons known in vertebrates, Tol1 (a member of the hAT superfamily discovered in medaka fish), also appears to be active when transferred to other species, including mammals.
Characterized at the molecular level, most transposons share the usual form of organization—inverted repeats at the ends and short direct repeats in the adjacent target DNA—but otherwise vary in size and coding capacity. All families of transposons share the same type of relationship between the autonomous and nonautonomous elements. The autonomous elements have open reading frames between the terminal repeats, whereas the nonautonomous elements do not code for functional proteins. Sometimes the internal sequences are related to those of autonomous elements; at other times they are composed of fragments of genes that have been captured between transposon-inverted repeats. Some examples of transposon families are described in the paragraphs that follow.
The first transposons were originally identified in maize, which contains a number of active transposons. The Mutator transposon is the most active and mutagenic of all maize transposons. The autonomous element MuDR contains the genes mudrA (which encodes the MURA transposase) and mudrB (which encodes MURB, an accessory protein required for integration). The ends of the elements are marked by 200-bp inverted repeats. Nonautonomous Mutator elements—basically any units that have the inverted repeats, but that may not have any internal sequence relationship to MuDR—are also mobilized by MURA and MURB. Mutator elements in maize are the founding members of the MULE (Mu-like element) superfamily of transposons, which are present in bacteria, fungi, plants, and animals.
The prototypical transposons, also originally found in maize, are members of the Ac/Ds family, first discovered by Barbara McClintock in the 1940s (and for which she received the Nobel Prize in 1983). FIGURE 15.16 summarizes their structures. Their molecular characteristics are described further here to illustrate some of the typical relationships between autonomous and nonautonomous family members. Although this example is from maize, the principles apply to transposon families in any species. Most of the length of the autonomous Ac (Activator) element is occupied by a single gene consisting of five exons. The product is the transposase. The element itself ends in inverted repeats of 11 bp, and a target sequence of 8 bp is duplicated at the site of insertion.

FIGURE 15.16 The Ac element has five exons (pink) that encode a transposase; Ds elements have internal deletions (gray).
Ds (Dissociator) elements vary in both length and sequence, but are related to Ac. They end in the same 11-bp inverted repeats. They are shorter than Ac, and the length of deletion varies. At one extreme, the element Ds9 has a deletion of only 194 bp. In a more extensive deletion, the Ds6 element retains a length of only 2 kb, representing 1 kb from each end of Ac. A complex double Ds element has one Ds6 sequence inserted in reverse orientation into another.
Nonautonomous elements lack internal sequences but possess the terminal inverted repeats (and possibly other sequence features). Some nonautonomous elements are derived from autonomous elements by deletions (or other changes) that inactivate the trans-acting transposase but leave the sites (including the termini) on which the transposase acts intact. Their structures range from minor (but inactivating) mutations of Ac to sequences that have major deletions or rearrangements.
At another extreme, the Ds1 family members comprise short sequences whose only relationship to Ac lies in the possession of terminal inverted repeats. Elements of this class need not be directly derived from Ac, but could be derived by any event that generates the inverted repeats. Their existence suggests that the transposase recognizes only the terminal inverted repeats or possibly the terminal repeats in conjunction with some short internal sequence.
Ds1 elements are just one example of a widespread form of DNA-type elements called MITEs (miniature inverted repeat transposable elements). These are very short derivatives of autonomous elements found in many eukaryotes that can be present in tens or hundreds of thousands of copies in a given genome. They range from 300 to 500 bp, and generate 2- to 3-bp target site duplications. Unlike many other classes of transposons in plants, MITEs are often found in or near genes.
Transposition of Ac/Ds occurs by a nonreplicative cut-and-paste mechanism that involves double-stranded breaks followed by integration of the released element. The mechanism of transposition is similar to that described for Tn5 and Tn10 (see the section in this chapter titled Nonreplicative Transposition Proceeds by Breakage and Reunion). It is accompanied by its disappearance from the donor location. Transposition of Ac/Ds almost always occurs soon after the donor element has been replicated. These features resemble transposition of the bacterial element Tn10. The cause is the same: Transposition does not occur when the DNA of the transposon is methylated on both strands (the typical state before replication); it is activated when the DNA is hemimethylated (the typical state immediately after replication). The recipient site is frequently on the same chromosome as the donor site, and often is quite close to it. Note that if transposition is from a replicated region of a chromosome into an unreplicated region, the transposition event will result in a net increase in the copy number of the element; one chromatid will carry a single copy of the transposon, and the second chromatid will carry two copies. This ensures that elements such as Ac can increase their copy number, even though transposition is not duplicative.
Replication generates two copies of a potential Ac/Ds donor, but usually only one copy actually transposes. What happens to the donor site? The rearrangements that are found at sites from which controlling elements have been lost can be explained in terms of the consequences of a chromosome break. Based on the sequence of the donor site following excision, the majority of the breaks caused by Ac excision appear to be repaired using nonhomologous end joining, which usually creates sequence alterations, or “transposon footprints,” at the excision sites. If the resulting transposon footprint restores functionality to the gene in which the Ac element had been inserted, the result is a reversion event. Otherwise, the result is a stable, nonfunctional gene. In contrast, the mode of Mu element transposition appears to vary depending on the tissue type. Late during somatic development, transposition is similar to that observed for Ac. In germinal tissues, though, the vast majority of transposition events are effectively replicative, perhaps due to gap repair using the sister chromatid as a template.
Autonomous and nonautonomous elements are subject to a variety of changes in their condition. Some of these changes are genetic; others are epigenetic. The major change is (of course) the conversion of an autonomous element into a nonautonomous element, but further changes may occur in the nonautonomous element. cis-acting defects may render a nonautonomous element impervious to autonomous elements. Thus, a nonautonomous element may become permanently stable because it can no longer be activated to transpose.
Autonomous elements are subject to “changes of phase,” which are heritable (but often unstable) alterations in their properties. These may take the form of a reversible inactivation in which the element cycles between an active and inactive condition during plant development, or they may result in stably inactive elements.
Phase changes in both the Ac and Mu types of autonomous element are associated with changes in the methylation of DNA. The inactive forms of all elements are methylated at cytosine residues. In most cases, it is not known what triggers this loss of activity, but in the case of MuDR epigenetic silencing can be triggered by a derivative of MuDR that is duplicated and inverted relative to itself. This rearrangement results in the production of a hairpin RNA, in which two parts of the transcript are perfect complements to each other. The resulting double-stranded RNA is processed by cellular factors into small RNAs that, in turn, trigger methylation and transcriptional gene silencing of the MuDR element (see the Regulatory RNA chapter).
The effect of methylation is common generally among transposons in plants and other organisms that methylate their DNA. The best demonstration of the effect of methylation on activity comes from observations made with the Arabidopsis mutant ddm1, which causes a genome-wide loss of methylation. Among the targets that lose methyl groups is a family of transposons related to MuDR. Direct analysis of genome sequences shows that the demethylation and associated modification of histone tails (see the Chromatin and Eukaryotic Transcription Regulation chapters) allow transposition events to occur. Methylation is probably the major mechanism that is used to prevent transposons from damaging the genome by transposing too frequently. Transposons appear to be targeted for methylation because they are far more likely to produce double-stranded or otherwise aberrant transcripts that can be used to guide sequence-specific DNA methylation using small RNA produced from those transcripts. In addition, a class of small RNAs expressed in germ cells is enriched in transposable elements and other repetitive sequences, and their expression results in transposon repression. The first RNAs described in this class are the piwi-interacting RNAs (piRNAs; see the Regulatory RNA chapter) of Drosophila and are proposed to protect the germline against sterilizing transposition events; homologs in mice appear to play the same role during spermatogenesis. Once methylation of a transposon has been established, it can be heritably maintained over many generations. In plants and animals that methylate their DNA, the vast majority of transposons are epigenetically silenced in this way.
Transposition may be self-regulating, analogous to the immunity effects displayed by bacterial transposons. An increase in the number of Ac elements in the genome decreases the frequency of transposition. The Ac element may code for a repressor of transposition; the activity could be carried by the same protein that provides transposase function. Additionally, derivatives of some transposons, such as those of P elements in Drosophila, encode truncated proteins that can repress the activity of autonomous elements in somatic tissue (see the section in this chapter titled P Elements Are Activated in the Germline).
15.8 The Role of Transposable Elements in Hybrid Dysgenesis
Certain strains of D. melanogaster encounter difficulties in interbreeding. When flies from two of these strains are crossed, the progeny display “dysgenic traits”—a series of defects including mutations, chromosomal aberrations, distorted segregation at meiosis, and reduced fertility. The appearance of these correlated defects is called hybrid dysgenesis.
Two systems responsible for hybrid dysgenesis have been identified in D. melanogaster. In the first, flies are divided into the types I (inducer) and R (reactive). Reduced fertility is seen in crosses of I males with R females, but not in the reverse direction. In the second system, flies are divided into the two types, P (paternal contributing) and M (maternal contributing). FIGURE 15.17 illustrates the asymmetry of the system; a cross between a P male and an M female causes dysgenesis, but the reverse cross does not.
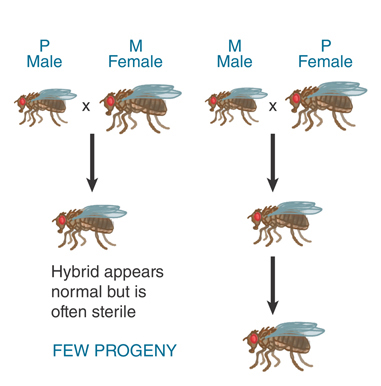
FIGURE 15.17 Hybrid dysgenesis is asymmetrical; it is induced by P male × M female crosses, but not by M male × P female crosses.
Dysgenesis is principally a phenomenon of the germ cells. In crosses involving the P-M system, the F1 hybrid flies have normal somatic tissues. Their gonads, however, do not develop normally, and the hybrids are often sterile, particularly at higher temperatures. The morphological defect in gamete development dates from the stage at which rapid cell divisions commence in the germline.
Any one of the chromosomes of a P male can induce dysgenesis in a cross with an M female. The construction of recombinant chromosomes shows that several regions within each P chromosome are able to cause dysgenesis. This suggests that a P male has sequences at many different chromosomal locations that can induce dysgenesis. The locations differ between individual P strains. The P-specific sequences are absent from chromosomes of M flies.
The nature of the P-specific sequences was first identified by mapping the DNA of w mutants found among the dysgenic hybrids. All the mutations result from the insertion of DNA into the white (w) locus. (The insertion inactivates the gene, which is required for red eye color, causing the white-eye phenotype for which the locus is named.) The inserted sequence is called the P element.
The P element insertions form a classic transposable system. Individual elements vary in length but are homologous in sequence. All P elements possess inverted terminal repeats of 31 bp and generate direct repeats of target DNA of 8 bp upon transposition. The longest P elements are about 2.9 kb long and have four open reading frames. The shorter elements arise, apparently rather frequently, by internal deletions of a full-length P factor. Some of the shorter P elements have lost the capacity to produce the transposase, but they may be activated in trans by the enzyme coded by a complete P element.
A P strain carries 30 to 50 copies of the P element, about one-third of which are full length. The elements are absent from M strains. In a P strain the elements are carried as inert components of the genome, but they become activated to transpose when a P male is crossed with an M female.
Chromosomes from P-M hybrid dysgenic flies have P elements inserted at many new sites. The insertions inactivate the genes in which they are located and often cause chromosomal breaks. The result of the transpositions is therefore to dramatically alter the genome.
15.9 P Elements Are Activated in the Germline
Activation of P elements is tissue specific: It occurs only in the germline. P elements are transcribed, though, in both germline and somatic tissues. Tissue specificity is conferred by a change in the splicing pattern.
FIGURE 15.18 depicts the organization of the element and its transcripts. The primary transcript extends for 2.5 or 3.0 kb, the difference probably reflecting merely the leakiness of the termination site. Two protein products can be produced:
In somatic tissues, only the first two introns are excised, creating a coding region of ORF0-ORF1-ORF2. Translation of this RNA yields a protein of 66 kD. This protein is a repressor of transposon activity.
In germline tissues, an additional splicing event occurs to remove intron 3. This connects all four open reading frames into an mRNA that is translated to generate a protein of 87 kD. This protein is the transposase.

FIGURE 15.18 The P element has four exons. The first three are spliced together in somatic expression; all four are spliced together in germline expression.
Two types of experiments have demonstrated that splicing of the third intron is needed for transposition. First, if the splicing junctions are mutated in vitro and the P element is reintroduced into flies, its transposition activity is abolished. Second, if the third intron is deleted, so that ORF3 is constitutively included in the mRNA in all tissues, transposition occurs in somatic tissues as well as the germline. Thus, whenever ORF3 is spliced to the preceding reading frame, the P element becomes active. This is the crucial regulatory event, and usually it occurs only in the germline.
What is responsible for the tissue-specific splicing? Somatic cells contain a protein that binds to sequences in exon 3 to prevent splicing of the last intron (see the RNA Splicing and Processing chapter). The absence of this protein in germline cells allows splicing to generate the mRNA that encodes the transposase.
Transposition of a P element requires about 150 bp of terminal DNA. The transposase binds to 10-bp sequences that are adjacent to the 31-bp inverted repeats. Transposition occurs by a nonreplicative cut-and-paste mechanism resembling that of Tn10. It contributes to hybrid dysgenesis in two ways: Insertion of the transposed element at a new site may cause mutations, and the break that is left at the donor site (see Figure 15.6) can have a deleterious effect.
It is interesting that, in a significant proportion of cases, the break in donor DNA is repaired by using the sequence of the homologous chromosome. If the homolog has a P element, the presence of a P element at the donor site may be restored (so the event resembles the result of a replicative transposition). If the homolog lacks a P element, repair may generate a sequence lacking the P element, thus apparently providing a precise excision (an unusual event in other transposable systems).
The dependence of hybrid dysgenesis on the origin of the female in a cross shows that the cytoplasm is important, as are the P factors themselves. The contribution of the cytoplasm is described as the cytotype; a line of flies containing P elements has P cytotype, whereas a line of flies lacking P elements has M cytotype. Hybrid dysgenesis occurs only when chromosomes containing P factors find themselves in M cytotype; that is, when the male parent has P elements and the female parent does not.
Cytotype shows an inheritable cytoplasmic effect; when a cross occurs through P cytotype (the female parent has P elements), hybrid dysgenesis is suppressed for several generations of crosses with M female parents. Thus, something in P cytotype, which can be diluted out over some generations, suppresses hybrid dysgenesis.
The effect of cytotype has been a particularly puzzling phenomenon. All explanations assume that a repressor molecule is deposited into the egg cell cytoplasm, as illustrated in FIGURE 15.19. The repressor is provided as a maternal factor in the egg. In a P line, sufficient repressor must be present to prevent transposition from occurring, even though the P elements are present. In any cross involving a P female, its presence prevents either synthesis or activity of the transposase. When the female parent is M type, though, no repressor is present in the egg, and the introduction of a P element from the male parent results in activity of transposase in the germline. The ability of P cytotype to exert an effect through more than one generation suggests that there must be enough repressor protein in the egg, and that it must be stable enough, to be passed on through the adult to be present in the eggs of the next generation.

FIGURE 15.19 Hybrid dysgenesis is determined by the interactions between P elements in the genome and repressors in the cytotype.
For many years, the best candidate for the repressor was the 66-kD protein. However, some strains of flies lack P elements capable of producing a 66-kD repressor protein and yet still exhibit the P cytotype. More recent evidence has implicated small RNAs in P element repression; genes important in processing small RNAs derived from P element transcripts (and those of several other transposons as well) are also required for efficient transposon silencing. This observation has led to a model in which P cytotype is conditioned by P elements at particular positions that produce transcripts that are processed into a specific class of small RNAs called piRNAs (see the Regulatory RNA chapter). In this case, it is the presence of these small RNAs in the cytoplasm that are responsible for P element cytotype repression. Like the small RNAs involved in RNA interference, piRNAs are hypothesized to direct the degradation of P element transcript. An appealing feature of this model is that it suggests that P element cytotype repression is a particular example of a widespread mechanism by which transposon activity is repressed in plants, fungi, and animals.
Remarkably, P elements have only been detectable in the D. melanogaster genome for a few decades. They came from a second species of Drosophila, D. willisoni, through a horizontal transfer of P element sequence. Subsequent to that transfer, P elements rapidly spread throughout the worldwide population of D. melanogaster. Analysis of P elements in a variety of Drosophila species reveals that horizontal transfer of this transposon has occurred repeatedly throughout its history. This propensity to move between species has been documented among a number of transposons, leading to the suggestion that an important component to the transposon life cycle is the ability to regularly invade “naïve” genomes that lack sequences (such as those that produce piRNAs) that can repress transposon activity.
15.10 The Retrovirus Life Cycle Involves Transposition-Like Events
Retroviruses have genomes of single-stranded RNA that are replicated through a double-stranded DNA intermediate. The life cycle of the virus involves an obligatory stage in which the double-stranded DNA is inserted into the host genome by a transposition-like event that generates short direct repeats of target DNA. This similarity is not surprising, given evidence that new retroviruses have arisen repeatedly over evolutionary time as a consequence of the capture by retrotransposons of genes encoding envelope proteins, which makes infection possible.
The significance of this integration reaction extends beyond the perpetuation of the virus. Some of the consequences are as follows:
A retroviral sequence that is integrated into the germline remains in the cellular genome as an endogenous provirus. Like a lysogenic bacteriophage, a provirus behaves as part of the genetic material of the organism.
Cellular sequences occasionally recombine with the retroviral sequence and then are transposed with it; these sequences may be inserted into the genome as duplex sequences in new locations.
Cellular sequences that are transposed by a retrovirus may change the properties of a cell that becomes infected with the virus.
The particulars of the retroviral life cycle are expanded in FIGURE 15.20. The crucial steps are that the viral RNA is converted into DNA, the DNA becomes integrated into the host genome, and then the DNA provirus is transcribed into RNA. The enzyme responsible for generating the initial DNA copy of the RNA is reverse transcriptase. The enzyme converts the RNA into a linear duplex of DNA in the cytoplasm of the infected cell. The DNA also is converted into circular forms, but these do not appear to be involved in reproduction.

FIGURE 15.20 The retroviral life cycle proceeds by reverse transcribing the RNA genome into duplex DNA, which is inserted into the host genome, in order to be transcribed into RNA.
The linear DNA makes its way to the nucleus. One or more DNA copies become integrated into the host genome. A single enzyme called integrase is responsible for integration. Retroviral integrases are related by sequence, structure, and function to the transposases encoded by transposons. The provirus is transcribed by the host machinery to produce viral RNAs, which serve both as mRNAs and as genomes for packaging into virions. Integration is a normal part of the life cycle and is necessary for transcription.
Two copies of the RNA genome are packaged into each virion, making the individual virus particle effectively diploid. When a cell is simultaneously infected by two different but related viruses, it is possible to generate heterozygous virus particles carrying one genome of each type. The diploidy may be important in allowing the virus to acquire cellular sequences. The enzyme’s reverse transcriptase and integrase are carried with the genome in the viral particle.
15.11 Retroviral Genes Code for Polyproteins
A typical retroviral sequence contains three or four “genes.” (In this context, the term gene is used to identify coding regions, each of which actually gives rise to multiple proteins by processing reactions.) A typical retrovirus genome with three genes is organized in the sequence gag-pol-env, as indicated in FIGURE 15.21.

FIGURE 15.21 The genes of the retrovirus are expressed as polyproteins that are processed into individual products.
Retroviral mRNA has a conventional structure; it is capped at the 5′ end and polyadenylated at the 3′ end. It is represented in two mRNAs. The full-length mRNA is translated to give the Gag and Pol polyproteins. The Gag product is translated by reading from the initiation codon to the first termination codon. This termination codon must be bypassed to express Pol.
Different mechanisms are used in different viruses to proceed beyond the gag termination codon, depending on the relationship between the gag and pol reading frames. When gag and pol follow continuously, suppression by a glutamyl-tRNA that recognizes the termination codon allows a single protein to be generated. When gag and pol are in different reading frames, a ribosomal frameshift occurs to generate a single protein. Usually the readthrough is about 5% efficient, so Gag protein outnumbers Gag-Pol protein about 20-fold.
The Env polyprotein is expressed by another means: Splicing generates a shorter subgenomic mRNA that is translated into the Env product.
The gag gene gives rise to the protein components of the nucleoprotein core of the virion. The pol gene encodes proteins with functions in nucleic acid synthesis and recombination. The env gene encodes components of the envelope of the particle, which also sequesters components from the cellular cytoplasmic membrane.
Both the Gag or Gag-Pol and the Env products are polyproteins that are cleaved by a protease to release the individual proteins that are found in mature virions. The protease activity is encoded by the virus in various forms: It may be part of Gag or Pol, and at times it takes the form of an additional independent reading frame.
The production of a retroviral particle involves packaging the RNA into a core, surrounding it with capsid proteins, and pinching off a segment of membrane from the host cell. The release of infective particles by such means is shown in FIGURE 15.22. The process is reversed during infection: A virus infects a new host cell by fusing with the plasma membrane and then releasing the contents of the virion.

FIGURE 15.22 Retroviruses (HIV) bud from the plasma membrane of an infected cell.
Photos courtesy of Matthew A. Gonda, Ph.D., Partner at Power Ten Medical Ventures, Inc.
15.12 Viral DNA Is Generated by Reverse Transcription
Retroviruses are called plus-strand viruses, because the viral RNA itself codes for the protein products. As its name implies, reverse transcriptase is responsible for converting the genome (plus-strand RNA) into a complementary DNA strand, which is called the minus-strand DNA. Reverse transcriptase also catalyzes subsequent stages in the production of duplex DNA. It has a DNA polymerase activity, which enables it to synthesize a duplex DNA from the single-stranded reverse transcript of the RNA. The second DNA strand in this duplex is called the plus-strand DNA. As a necessary adjunct to this activity, the enzyme has an RNase H activity, which can degrade the RNA part of the RNA–DNA hybrid. All retroviral reverse transcriptases share considerable similarities of amino acid sequence, and homologous sequences can be recognized in all other retroelements.
The structures of the DNA forms of the virus are compared with the RNA in FIGURE 15.23. The viral RNA has direct repeats at its ends. These R segments vary in different strains of virus, ranging from 10 to 80 nucleotides. The sequence at the 5′ end of the virus is R-U5, and the sequence at the 3′ end is U3-R. The R segments are used during the conversion from the RNA to the DNA form to generate the more extensive direct repeats that are found in linear DNA, as shown in FIGURE 15.24 and FIGURE 15.25. The shortening of 2 bp at each end in the integrated form is a consequence of the mechanism of integration (see Figure 15.27).
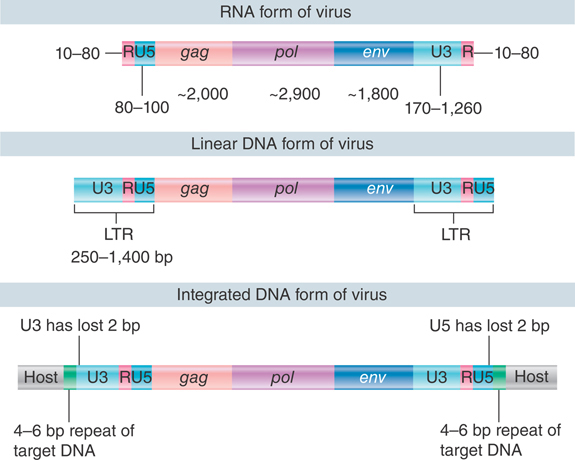
FIGURE 15.23 Retroviral RNA ends in direct repeats (R), the free linear DNA ends in LTRs, and the provirus ends in LTRs that are shortened by two bases each.

FIGURE 15.24 Minus-strand DNA is generated by switching templates during reverse transcription.
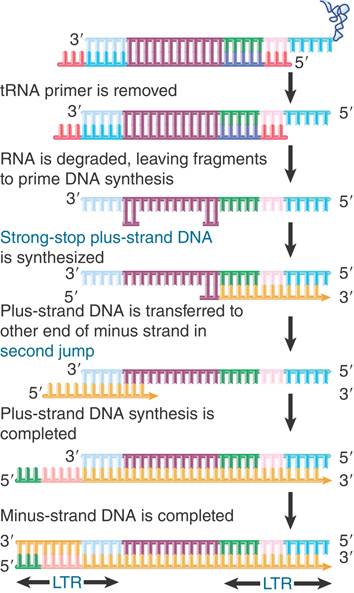
FIGURE 15.25 Synthesis of plus-strand DNA requires a second jump.
Like other DNA polymerases, reverse transcriptase requires a primer. For retroviruses, the native primer is tRNA. An uncharged host tRNA is present in the virion. A sequence of 18 bases at the 3′ end of the tRNA is base paired to a site 100 to 200 bases from the 5′ end of one of the viral RNA molecules. The tRNA may also be base paired to another site near the 5′ end of the other viral RNA, thus assisting in dimer formation between the viral RNAs.
Here is a dilemma: Reverse transcriptase starts to synthesize DNA at a site only 100 to 200 bases downstream from the 5′ end. How can DNA be generated to represent the intact RNA genome? (This is an extreme variant of the general problem in replicating the ends of any linear nucleic acid; see the Extrachromosomal Replicons chapter.)
Synthesis in vitro proceeds to the end, generating a short DNA sequence called strong-stop minus DNA. This molecule is not found in vivo because synthesis continues by the reaction illustrated in Figure 15.25. Reverse transcriptase switches templates, carrying the nascent DNA with it to the new template. This is the first of two jumps between templates.
In this reaction, the R region at the 5′ terminus of the RNA template is degraded by the RNase H activity of reverse transcriptase. Its removal allows the R region at a 3′ end to base pair with the newly synthesized DNA. Reverse transcription then continues through the U3 region into the body of the RNA.
The source of the R region that pairs with the strong-stop minus DNA can be either the 3′ end of the same RNA molecule (intramolecular pairing) or the 3′ end of a different RNA molecule (intermolecular pairing). The switch to a different RNA template is used in the figure because evidence suggests that the sequence of the tRNA primer is not inherited in a retroposon life cycle. (If intramolecular pairing occurred, we would expect the sequence to be inherited, because it would provide the only source for the primer binding sequence in the next cycle. Intermolecular pairing allows another retroviral RNA to provide this sequence.)
The result of the switch and extension is to add a U3 segment to the 5′ end. The stretch of sequence U3-R-U5 is called the long terminal repeat (LTR) because a similar series of events adds a U5 segment to the 3′ end, giving it the same structure of U3-R-U5. Its length varies from 250 to 1,400 bp (see Figure 15.23).
We now need to generate the plus strand of DNA and to generate the LTR at the other end. The reaction is shown in Figure 15.25. Reverse transcriptase primes synthesis of plus-strand DNA from a fragment of RNA that is left after degrading the original RNA molecule. A strong-stop plus-strand DNA is generated when the enzyme reaches the end of the template. This DNA is then transferred to the other end of a minus strand, where it is probably released by a displacement reaction when a second round of DNA synthesis occurs from a primer fragment farther upstream (to its left in the figure). It uses the R region to pair with the 3′ end of a minus-strand DNA. This double-stranded DNA then requires completion of both strands to generate a duplex LTR at each end.
Each retroviral particle carries two RNA genomes. This makes it possible for recombination to occur during a viral life cycle. In principle this could occur during minus-strand synthesis and/or during plus-strand synthesis:
The intermolecular pairing shown in Figure 15.24 allows a recombination to occur between sequences of the two successive RNA templates when minus-strand DNA is synthesized. Retroviral recombination is mostly due to strand transfer at this stage, when the nascent DNA strand is transferred from one RNA template to another during reverse transcription.
Plus-strand DNA may be synthesized discontinuously, in a reaction that involves several internal initiations. Strand transfer during this reaction can also occur, but is less common.
The common feature of both events is that recombination results from a change in the template during the act of DNA synthesis. This is a general example of a mechanism for recombination called copy choice. For many years this was regarded as a possible mechanism for general recombination. It is unlikely to be employed by cellular systems, but it is a common basis for recombination during infection by RNA viruses, including those that replicate exclusively through RNA forms, such as poliovirus.
Strand switching occurs with a certain frequency during each cycle of reverse transcription; that is, in addition to the transfer reaction that is forced at the end of the template strand. The principle is illustrated in FIGURE 15.26, although not much is known about the precise mechanism. Reverse transcription in vivo occurs in a ribonucleoprotein complex, in which the RNA template strand is bound to virion components, including the major protein of the capsid. In the case of human immunodeficiency virus (HIV), addition of this protein (NCp7) to an in vitro system causes recombination to occur. The effect is probably indirect: NCp7 affects the structure of the RNA template, which, in turn, affects the likelihood that reverse transcriptase will switch from one template strand to another.

FIGURE 15.26 Copy choice recombination occurs when reverse transcriptase releases its template and resumes DNA synthesis using a new template. Transfer between template strands probably occurs directly, but is shown here in separate steps to illustrate the process.
15.13 Viral DNA Integrates into the Chromosome
The organization of the integrated provirus resembles that of the linear DNA. The LTRs at each end of the provirus are identical. The 3′ end of U5 consists of a short inverted repeat relative to the 5′ end of U3, so the LTR itself ends in short inverted repeats. The integrated proviral DNA is like a transposon: The proviral sequence ends in inverted repeats and is flanked by short direct repeats of target DNA.
The provirus is generated by directly inserting a linear DNA into a target site. In addition to linear DNA, circular forms of the viral sequences also occur. One has two adjacent LTR sequences generated by joining the linear ends. The other has only one LTR—presumably generated by a recombination event and actually comprising the majority of circles. For a long time it appeared that the circle might be an integration intermediate (by analogy with the integration of lambda DNA). It is now known, though, that the linear form is used for integration.
Integration of linear DNA is catalyzed by a single viral product, the integrase. The integrase acts on both the retroviral linear DNA and the target DNA. The reaction is illustrated in FIGURE 15.27.
The ends of the viral DNA are important, just as they are for transposons. The most conserved feature is the presence of the dinucleotide sequence CA close to the end of each LTR. This CA dinucleotide is conserved among all retroviruses, viral retrotransposons, and many DNA transposons as well. The integrase brings the ends of the linear DNA together in a ribonucleoprotein complex and then converts the blunt ends into recessed ends by removing the bases beyond the conserved CA. In general, this involves a loss of two bases.

FIGURE 15.27 Integrase is the only viral protein required for the integration reaction, in which each LTR loses 2 bp and is inserted between 4-bp repeats of target DNA.
Target sites are chosen at random with respect to sequence. The integrase makes staggered cuts at a target site. In the example of Figure 15.27, the cuts are separated by 4 bp. The length of the target repeat depends on the particular virus; it may be 4, 5, or 6 bp. Presumably, it is determined by the geometry of the reaction of integrase with target DNA.
The 5′ ends generated by the cleavage of target DNA are covalently joined to the 3′ recessed ends of the viral DNA. At this point, both termini of the viral DNA are joined by one strand to the target DNA. The single-stranded region is repaired by enzymes of the host cell, and in the course of this reaction the protruding two bases at each 5′ end of the viral DNA are removed. The result is that the integrated viral DNA has lost 2 bp at each LTR; this corresponds to the loss of 2 bp from the left end of the 5′ terminal U3 and to the loss of 2 bp from the right end of the 3′ terminal U5. There is a characteristic short direct repeat of target DNA at each end of the integrated retroviral genome.
The viral DNA integrates into the host genome at randomly selected sites. A successfully infected cell gains 1 to 10 copies of the provirus. An infectious virus enters the cytoplasm, of course, but the DNA form becomes integrated into the genome in the nucleus. Some retroviruses can replicate only in proliferating cells, because entry into the nucleus requires the cell to pass through mitosis, when the viral genome gains access to the nuclear material. Others, such as HIV, can be actively transported into the nucleus even in the absence of cell division.
The U3 region of each LTR carries a promoter. The promoter in the left LTR is responsible for initiating transcription of the provirus. Recall that the generation of proviral DNA is required to place the U3 sequence at the left LTR; thus, we see that the promoter is in fact generated by the conversion of the RNA into duplex DNA.
Sometimes (probably rather rarely), the promoter in the right LTR sponsors transcription of the host sequences that are adjacent to the site of integration. The LTR also carries an enhancer (a sequence that activates promoters in the vicinity) that can act on cellular as well as viral sequences. Integration of a retrovirus can be responsible for converting a host cell into a tumorigenic state when certain types of genes are activated in this way.
We have dealt thus far with retroviruses in terms of the infective cycle, in which integration is necessary for the production of further copies of the RNA. When a viral DNA integrates in a germline cell, though, it becomes an inherited “endogenous provirus” of the organism. Endogenous viruses usually are not expressed, but sometimes they are activated by external events, such as infection with another virus.
15.14 Retroviruses May Transduce Cellular Sequences
An interesting light on the viral life cycle is cast by the occurrence of transducing viruses, which are variants that have acquired cellular sequences in the form illustrated in FIGURE 15.28. Part of the viral sequence has been replaced by the v-onc gene. Protein synthesis generates a Gag-v-Onc protein instead of the usual Gag, Pol, and Env proteins. The resulting virus is replication defective; it cannot sustain an infective cycle by itself. It can, however, be perpetuated in the company of a helper virus that provides the missing viral functions.
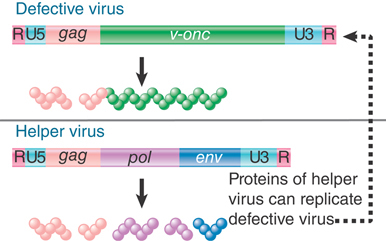
FIGURE 15.28 Replication-defective transforming viruses have a cellular sequence substituted for part of the viral sequence. The defective virus may replicate with the assistance of a helper virus that carries the wild-type functions.
Onc is an abbreviation for oncogenesis, the ability to transform cultured cells so that the usual regulation of growth is released to allow unrestricted division. Both viral and cellular onc genes may be responsible for creating tumorigenic cells.
A v-onc gene confers upon a virus the ability to transform a certain type of host cell. Loci with homologous sequences found in the host genome are called c-onc genes. How are the onc genes acquired by the retroviruses? A revealing feature is the discrepancy in the structures of c-onc and v-onc genes. The c-onc genes usually are interrupted by introns, whereas the v-onc genes are uninterrupted. This suggests that the v-onc genes originate from spliced RNA copies of the c-onc genes.
A model for the formation of transforming viruses is illustrated in FIGURE 15.29. A retrovirus has integrated near a c-onc gene. A deletion occurs to fuse the provirus to the c-onc gene; transcription then generates a joint RNA, which contains viral sequences at one end and cellular onc sequences at the other end. Splicing removes the introns in the cellular parts of the RNA. The RNA has the appropriate signals for packaging into the virion, which will be present if the cell also contains another intact copy of the provirus. At this point, some of the diploid virus particles may contain one fused RNA and one viral RNA.

FIGURE 15.29 Replication-defective viruses may be generated through integration and deletion of a viral genome to generate a fused viral–cellular transcript that is packaged with a normal RNA genome. Nonhomologous recombination is necessary to generate the replication-defective transforming genome.
A recombination between these sequences could generate the transforming genome, in which the viral repeats are present at both ends. Recombination occurs by various means at a high frequency during the retroviral infective cycle. We do not know anything about its demands for homology in the substrates, but we assume that the nonhomologous reaction between a viral genome and the cellular part of the fused RNA proceeds by the same mechanisms responsible for viral recombination.
The common features of the entire retroviral class suggest that it may be derived from a single ancestor. This is supported by phylogenetic analysis of reverse transcriptases from a wide variety of retroelements, including both retrotransposons and retroviruses. The fact that this class of elements has features common to both DNA-type transposons (integrase/transposase) and non-LTR retroposons (reverse transcriptase) has led to the suggestion that LTR retrotransposons arose as a consequence of a fusion between these two, more ancient element classes. Other functions, such as Env proteins and transforming genes, would have been incorporated later. (There is no reason to suppose that the mechanism is involved in acquisition of env and onc genes; viruses carrying these genes may have a selective advantage, though.)
15.15 Retroelements Fall into Three Classes
Retroelements are defined by their use of mechanisms for transposition that involve reverse transcription of RNA into DNA. Three classes of retroelements are distinguished in TABLE 15.1: LTR retrotransposons, non-LTR retroposons, and the nonautonomous short-interspersed nuclear elements (SINEs).
TABLE 15.1 Retroelements can be divided into LTR retrotransposons, non-LTR retroposons, and the nonautonomous SINEs.
| LTR Retrotransposons | Non-LTR Retroposons | SINEs | |
|---|---|---|---|
| Common types | Ty (S. cerevisiae) Copia (D. melanogaster) Tnt1A (N. tabacum) |
L1 (human) Cin4 (Z. mays) |
Alu elements (human) B1, B2 ID, B4 (mouse) Pseudogenes of pol III transcripts |
| Termini | Long terminal repeats | No repeats | No repeats |
| Target repeats | 4–6 bp | 7–21 bp | 7–21 bp |
| Enzyme activities | Reverse transcriptase and/or integrase | Reverse transcriptase/endonuclease | None (or none coding for transposon products) |
| Organization | May contain introns (removed in subgenomic mRNA) | One or two uninterrupted ORFs | No introns |
LTR retrotransposons, or simply retrotransposons, have LTRs and encode reverse transcriptase and integrase activities. They reproduce in the same manner as retroviruses but differ from them in not passing through an independent infectious form. They are best characterized in the Ty, copia, and Tos17 elements of yeast, flies, and rice, respectively.
The non-LTR retrotransposons, or retroposons, also have reverse transcriptase activity but constitute a phylogenetically distinct family of elements that employ a distinct transposition mechanism. Unlike retrotransposons and retroviruses, retroposons lack LTRs and use a different mechanism from retroviruses to prime the reverse transcription reaction. They are derived from RNA polymerase II transcripts. Only a few of the elements in a given genome are fully functional and can transpose autonomously; others have mutations, and thus can only transpose as the result of the action of a trans-acting autonomous element. The most common elements of this class in the human genome are the long-interspersed nuclear elements, or LINEs.
In addition to LTR retrotransposons and non-LTR retroposons, many genomes contain large numbers of sequences whose external and internal features suggest that they originated in RNA sequences. In these cases, though, we can only speculate about how a DNA copy was generated. We assume that they were targets for a transposition event by an enzyme system coded elsewhere—that is, they are always nonautonomous—and that they originated in cellular transcripts. They do not code for proteins that have transposition functions. The most prominent components of this family are called short-interspersed nuclear elements (SINEs). These elements are derived from RNA polymerase III transcripts, usually 7SL RNAs, 5S rRNAs, and tRNAs. Many of these elements also include portions of a cognate LINE, leading to the hypothesis that SINEs can use the enzymatic machinery of LINEs for replication.
FIGURE 15.30 shows the organization and sequence relationships of elements that encode reverse transcriptase. Like retroviruses, the LTR retrotransposons can be classified into groups according to the number of independent reading frames for gag, pol, and int and the order of the genes. In spite of these superficial differences of organization, the common features are the presence of LTRs as well as reverse transcriptase and integrase activities. In contrast, non-LTR retroposons such as the mammalian LINEs lack LTRs. They have two reading frames; one codes for a nucleic acid–binding protein, and the other codes for reverse transcriptase and endonuclease activity.

FIGURE 15.30 Retrotransposons that are closely related to retroviruses have a similar organization, but non-LTR retroposons such as LINEs share only the reverse transcriptase activity and lack LTRs.
LTR-containing elements can vary from integrated retroviruses to retrotransposons that do not have the capacity to generate infectious particles. Yeast and fly genomes have the Ty and copia elements that cannot generate infectious particles. Mammalian genomes have some endogenous retroviruses that, when active, can generate infectious particles. The mouse genome has several active endogenous retroviruses that are able to generate particles that propagate horizontal infections. By contrast, almost all endogenous retroviruses lost their activity some 50 million years ago in the human lineage, and the genome now has mostly inactive remnants of the endogenous retroviruses.
LINEs and SINEs comprise a major part of the animal genome. They were defined originally by the existence of a large number of relatively short sequences that are related to one another. They are described as interspersed sequences or interspersed repeats because of their common occurrence and widespread distribution. In many higher eukaryotic genomes, particularly metazoans, LINEs and SINEs can make up half of the total DNA. In contrast, in plant genomes LTR retrotransposons tend to predominate.
FIGURE 15.31 summarizes the distribution of the different types of transposons that constitute almost half of the human genome. Except for the SINES, which never encode functional proteins, the other types of elements all consist of functional elements and elements that have suffered deletions that eliminated parts of the reading frames that code for the protein(s) needed for transposition. The relative proportions of these types of transposons are generally similar in the mouse genome.

FIGURE 15.31 Four types of transposable elements constitute almost half of the human genome.
The most common LINE in mammalian genomes is called L1. The typical member is about 6,500 bp long and terminates in a tract rich in adenine. The two open reading frames of a full-length element are called ORF1 and ORF2. The number of full-length elements is usually small (around 50), and the remainder of the copies are truncated. Transcripts can be found. As implied by its presence in repetitive DNA, the LINE family shows sequence variation among individual members. The members of the family within a species, however, are relatively homogeneous compared to the variation shown between species. L1 is the only member of the LINE family that has been active in either the mouse or human lineages. It seems to have remained highly active in the mouse, but has declined in the human lineage.
Only one SINE has been active in the human lineage: the common Alu element. The mouse genome has a counterpart to this element (B1) and also other SINES (B2, ID, B4) that have been active. Human Alu and mouse B1 SINEs are probably derived from the 7SL RNA (see the section later in this chapter titled The Alu Family Has Many Widely Dispersed Members). The other mouse SINEs appear to have originated from reverse transcripts of tRNAs. The transposition of the SINES probably results from their recognition as substrates by an active L1 element.
15.16 Yeast Ty Elements Resemble Retroviruses
Ty elements comprise a family of dispersed repetitive DNA sequences that are found at different sites in different strains of yeast. Ty is an abbreviation for “transposon yeast.” Five types of Ty elements in yeast (Ty1–Ty5) have been identified. All are LTR retrotransposons, with characteristic LTRs and gag and pol genes with homology to those encoded by retroviruses. These elements are representative of two of the major classes of retrotransposons in eukaryotes, the Ty1/copia class (Ty1, Ty2, Ty4, and Ty5) and the Ty3/gypsy class. Each class is phylogenetically distinct, and each contains a characteristic order of open reading frames.
In the yeast Saccharomyces cerevisiae, Ty1 is the most abundant and the most well-characterized retroelement. A Ty1 transposition event creates a characteristic footprint: 5 bp of target DNA are repeated on either side of the inserted Ty1 element. Under most circumstances the frequency of Ty1 transposition is lower than that of most bacterial transposons, about 10–7 to 10–8, but it can be increased by a variety of factors that stress the organism, such as mutagens and nutrient depletion.
The general organization of Ty1 elements is illustrated in FIGURE 15.32. Each element is 5.9 kb long; the last 334 bp at each end constitute LTRs, called delta (δ) for historical reasons but referred to here simply as LTRs. Individual Ty1 elements have many changes from the prototype of their class, including base-pair substitutions, insertions, and deletions. The typical yeast genome has about 30 copies of Ty1 and 13 copies of the closely related Ty2. In addition, there are around 180 independent solo Ty1/Ty2 LTRs.

FIGURE 15.32 Ty elements terminate in short direct repeats and are transcribed into two overlapping RNAs. They have two reading frames, with sequences related to the retroviral gag and pol genes.
The LTR sequences also show considerable heterogeneity, although the two repeats of an individual Ty1 element are often identical or at least very closely related. The LTR sequences associated with Ty1 elements show greater conservation of sequence than the solo LTRs. This is because transposition of Ty1 elements, like replication of retroviruses, involves duplication of the LTRs (discussed in the following paragraphs). Thus, recently inserted elements carry identical LTRs, but solo LTRs diverge over time due to random mutations.
The Ty1 element is transcribed into two poly(A)+ RNA species, which constitute as much as 8% of the total mRNA of a haploid yeast cell. Both species initiate within a promoter in the LTR at the left end. One terminates after 5 kb; the other terminates after 5.7 kb, within the LTR sequence at the right end.
The sequence of the Ty1 element has two open reading frames. These frames are expressed in the same direction, but are read in different phases and overlap by 13 amino acids. TyA is related to retroviral gag genes and encodes a capsid protein. TyB contains regions that have homologies with reverse transcriptase, protease, and integrase sequences of retroviruses.
The organization and functions of TyA and TyB are analogous to the behavior of the retroviral gag and pol functions. The reading frames TyA and TyB are expressed in two forms. The TyA protein represents the TyA reading frame and terminates at its end. The TyB reading frame, however, is expressed only as part of a joint protein, in which the TyA region is fused to the TyB region by a specific frameshift event that allows the termination codon to be bypassed. (This is analogous to gag-pol translation in retroviruses.)
Recombination between Ty1 elements seems to occur in bursts; when one event is detected, the probability of finding others is increased. Gene conversion occurs between Ty1 elements at different locations, with the result that one element is “replaced” by the sequence of the other.
Ty elements can be deleted via homologous recombination between the directly repeated LTR sequences. The large number of solo LTR elements may be footprints of such events. A deletion of this nature may be associated with reversion of a mutation caused by the insertion of Ty; the level of reversion may depend on the exact LTR sequences left behind and the nature of the insertion site.
A paradox is that both LTRs have the same sequence, yet a promoter is active in the LTR at one end and a terminator is active in the LTR at the other end. (A similar feature is found in other transposable elements, including the retroviruses.)
Ty elements are classic retrotransposons in that they transpose through an RNA intermediate. An ingenious protocol used to detect this event is illustrated in FIGURE 15.33. An intron was inserted into an element to generate a unique Ty sequence. This sequence was placed under the control of a GAL promoter on a plasmid and introduced into yeast cells. Transposition results in the appearance of multiple copies of the transposon in the yeast genome, but the copies all lack the intron.

FIGURE 15.33 A unique Ty element, engineered to contain an intron, transposes to give copies that lack the intron. The copies possess identical terminal repeats, which are generated from one of the termini of the original Ty element.
We know of only one way to remove introns: RNA splicing. This suggests that transposition occurs by the same mechanism as with retroviruses. The Ty element is transcribed into an RNA that is recognized by the splicing apparatus. The spliced RNA is recognized by a reverse transcriptase and regenerates a duplex DNA copy, which is then integrated back into the genome using the integrase protein.
The analogy with retroviruses extends further. The original Ty1 element has a difference in sequence between its two LTRs. The transposed elements possess identical delta sequences, however, which are derived from the 5′ delta of the original element. Just as shown for retroviruses in Figures 15.23, 15.24, and 15.25, the complete LTR is regenerated by adding a U5 to the 3′ end and a U3 to the 5′ end.
Transposition is controlled by genes within the Ty1 element. The GAL promoter used to control transcription of the marked Ty1 element is inducible: It is turned on by the addition of galactose. Induction of the promoter has two effects. It is necessary to activate transposition of the marked element, and its activation also increases the frequency of transposition of the other Ty1 elements on the yeast chromosome. This implies that the products of the Ty1 element can act in trans on other elements (actually on their RNAs).
The Ty element does not give rise to infectious particles; instead, virus-like particles (VLPs) with icosahedral features accumulate within the cells in which transposition has been induced. The particles contain full-length RNA, double-stranded DNA, reverse transcriptase activity, and a TyB product with integrase activity and are associated with RNA processing bodies (P bodies). The TyA product is cleaved like a gag precursor to produce the mature core proteins of the VLP.
Not all of the Ty1 elements in any yeast genome are active: Some have lost the ability to transpose (and are analogous to inert endogenous proviruses). These “dead” elements retain LTRs, though, and as a result they provide targets for transposition in response to the proteins synthesized by an active element.
15.17 The Alu Family Has Many Widely Dispersed Members
The most prominent SINE comprises a single family. Its short length and high degree of repetition make it comparable to simple sequence (satellite) DNA, except that the individual members of the family are dispersed around the genome instead of being confined to tandem clusters. Again, there is significant similarity between the members within a species compared with variation between species.
In the human genome, a large part of the moderately repetitive DNA exists as sequences of ~300 bp that are interspersed with nonrepetitive DNA. At least half of the renatured duplex material is cleaved by the restriction enzyme AluI at a single site located 170 bp along the sequence. The cleaved sequences all are members of a single family known as the Alu family, after the means of its identification. The human genome has about 1 million members (equivalent to 1 member per 3 kb of DNA). The individual Alu sequences are widely dispersed. A related sequence family is present in the mouse (where the approximately 350,000 members are called the B1 family), in the Chinese hamster (where it is called the Alu-equivalent family), and in other mammals.
The individual members of the Alu family are related rather than identical. The human family seems to have originated by means of a 130-bp tandem duplication, with an unrelated sequence of 31 bp inserted in the right half of the dimer. The two repeats are sometimes called the “left half” and the “right half” of the Alu sequence. The individual members of the Alu family have an average identity with the consensus sequence of 87%. The mouse B1 repeating unit is 130 bp long and corresponds to a monomer of the human unit. It has 70% to 80% homology with the human sequence.
The Alu sequence is related to 7SL RNA, a component of the signal-recognition particle involved in protein targeting to the endoplasmic reticulum, and Alu elements are likely derived from 7SL RNA transcripts. The 7SL RNA corresponds to the left half of an Alu sequence with an insertion in the middle. Thus, the ninety 5′ terminal bases of 7SL RNA are homologous to the left end of Alu, the central 160 bases of 7SL RNA have no homology to Alu, and the 3′ terminal bases of 7SL RNA are homologous to the right end of Alu. Like 7SL RNA genes, active Alu elements contain a functional internal RNA polymerase III promoter and are actively transcribed by this enzyme.
The members of the Alu family resemble transposons in being flanked by short direct repeats. They display, however, the curious feature that the lengths of the repeats are different for individual members of the family.
A variety of properties have been found for the Alu family, and its ubiquity has prompted many suggestions for its function. It is not yet possible, though, to discern its true role, if any (it may simply be a particularly successful selfish DNA). At least some members of the family can be transcribed into independent RNAs. In the Chinese hamster, some (though not all) members of the Alu-equivalent family appear to be transcribed in vivo. Transcription units of this sort are found in the vicinity of other transcription units.
Members of the Alu family may be included within structural gene transcription units, as seen by their presence in long nuclear RNA. The presence of multiple copies of the Alu sequence in a single nuclear molecule can generate secondary structure. In fact, the presence of Alu family members in the form of inverted repeats is responsible for most of the secondary structure found in mammalian nuclear RNA.
15.18 LINEs Use an Endonuclease to Generate a Priming End
LINEs, like all retroposons, do not terminate in the LTRs that are typical of retroviral elements. This poses the question: How is reverse transcription primed? It does not involve the typical reaction, in which a tRNA primer pairs with the LTR. The open reading frames in these elements lack many of the retroviral functions, such as protease or integrase domains, but typically have reverse transcriptase–like sequences and code for an endonuclease activity. In the human LINE L1, ORF1 is a DNA-binding protein and ORF2 has both reverse transcriptase and endonuclease activities; both products are required for transposition.
FIGURE 15.34 shows how these activities support transposition. A nick is made in the DNA target site by an endonuclease activity encoded by the retroposon. The RNA product of the element associates with the protein bound at the nick. The nick provides a 3′–OH end that primes synthesis of cDNA on the RNA template. A second cleavage event is required to open the other strand of DNA, and the RNA–DNA hybrid is linked to the other end of the gap either at this stage or after it has been converted into a DNA duplex. A similar mechanism is used by some mobile introns (see the Catalytic RNA chapter).

FIGURE 15.34 Retrotransposition of non-LTR retroposons occurs by nicking the target to provide a primer for cDNA synthesis on an RNA template. The arrowheads indicate 3′ ends.
One of the reasons why LINEs are so effective lies with their method of propagation. When a LINE mRNA is translated, the protein products show a cis-preference for binding to the mRNA from which they were translated. FIGURE 15.35 shows that the ribonucleoprotein complex then moves to the nucleus, where the proteins insert a DNA copy into the genome. Reverse transcription often does not proceed fully to the end, resulting in a truncated and inactive element. The potential exists, however, for insertion of an active copy, because the proteins are acting in cis on a transcript of the original active element.
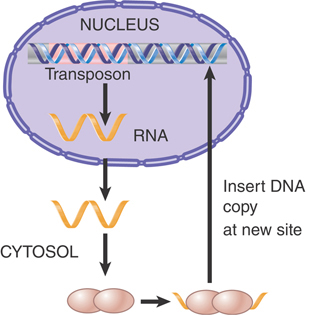
FIGURE 15.35 A LINE is transcribed into an RNA that is translated into proteins that assemble into a complex with the RNA. The complex translocates to the nucleus, where it inserts a DNA copy into the genome.
By contrast, the proteins produced by the DNA transposons must be imported into the nucleus after being synthesized in the cytoplasm, but they have no means of distinguishing full-length transposons from inactive deleted transposons. FIGURE 15.36 shows that instead of distinguishing these two types of transposons, the proteins will indiscriminately recognize any element by virtue of the repeats that mark the ends. This greatly reduces their chance of acting on a full-length element as opposed to one that has been deleted, resulting in an inability to replicate the autonomous elements efficiently. This can potentially lead to extinction of the entire family of elements.
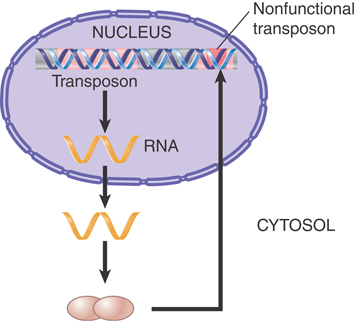
FIGURE 15.36 A transposon is transcribed into an RNA that is translated into proteins that move independently to the nucleus, where they act on any pair of inverted repeats with the same sequence as the original transposon.
Are transposition events of retroelements currently occurring in these genomes, or are we seeing only the footprints of ancient systems? This varies with the species. Only a few transposons are currently active in the human genome, but several active transposons are known in the mouse genome. This explains the fact that spontaneous mutations caused by LINE insertions occur at a rate of about 3% in mice, but only 0.1% in humans. It appears that 80 to 100 LINEs are active in the human genome. Some human diseases can be pinpointed as the result of transposition of L1 into genes, and others result from unequal crossing-over events involving repeated copies of L1. A model system in which LINE transposition occurs in tissue culture cells suggests that a transposition event can introduce several types of collateral damage as well as inserting into a new site; the damage includes chromosomal rearrangements and deletions. Such events may be viewed as agents of genetic change. Neither DNA transposons nor retroviral-like retrotransposons seem to have been active in the human genome for 40 to 50 million years, but several active examples of both are found in the mouse.
Note that for transpositions to survive, they must occur in the germline. Similar events occur in somatic cells, but do not survive beyond one generation.
Summary
Prokaryotic and eukaryotic cells contain a variety of transposons that mobilize by moving or copying DNA sequences. The transposon can be identified only as an entity within the genome; its mobility does not involve an independent form. The transposon could be selfish DNA, concerned only with perpetuating itself within the resident genome; if it conveys any selective advantage upon the genome, this must be indirect. All transposons have systems to limit the extent of transposition, because unbridled transposition is presumably damaging, but the molecular mechanisms are different in each case.
The archetypal transposon has inverted repeats at its termini and generates direct repeats of a short sequence at the site of insertion. The simplest types are the bacterial insertion sequence (IS) elements, which consist essentially of the inverted terminal repeats flanking a coding frame(s) whose product(s) provide transposition activity.
The generation of target repeats flanking a transposon reflects a common feature of transposition. The target site is cleaved at points that are staggered on each DNA strand by a fixed distance (often 5 or 9 bp). The transposon is, in effect, inserted between protruding single-stranded ends generated by the staggered cuts. Target repeats are generated by filling in the single-stranded regions.
IS elements, composite transposons, P elements, and the “controlling elements” in maize mobilize by nonreplicative transposition, in which the element moves directly from a donor site to a recipient site. A single transposase enzyme undertakes the reaction. It occurs by a cut-and-paste mechanism in which the transposon is separated from flanking DNA. Cleavage of the transposon ends, nicking of the target site, and connection of the transposon ends to the staggered nicks all occur in a nucleoprotein complex containing the transposase. Loss of the transposon from the donor creates a double-strand break whose fate can vary depending on the host repair mechanisms and the timing of excision. In the case of Tn10, transposition becomes possible immediately after DNA replication, when sites recognized by the dam methylation system are transiently hemimethylated. This imposes a demand for the existence of two copies of the donor site, which may enhance the cell’s chances for survival.
Phage Mu can undergo either replicative or nonreplicative transposition. In replicative transposition, after the transposon at the donor site becomes connected to the target site, replication generates a cointegrate molecule that has two copies of the transposon. A resolution reaction that involves recombination between two particular sites then frees the two copies of the transposon, so that one remains at the donor site and one appears at the target site. Two enzymes coded by the transposon are required: Transposase recognizes the ends of the transposon and connects them to the target site, and resolvase provides a site-specific recombination function. Mu can also can use its cointegrate intermediate to transpose by a nonreplicative mechanism. The difference between this reaction and the nonreplicative transposition of IS elements is that the cleavage events occur in a different order.
Transposons are grouped into superfamilies based on transposase sequences. Within superfamilies, different families of transposable elements each contain a single type of autonomous element that is analogous to bacterial transposons in its ability to mobilize. A family typically also contains many different nonautonomous elements that are derived by mutations of the autonomous element. The nonautonomous elements lack the ability to transpose, but display transposition activity and other abilities of the autonomous element when an autonomous element is present to provide the necessary trans-acting functions.
Transposition of the majority of eukaryotic elements is nonreplicative, and in many cases requires only the enzymes coded by the element. Transposition occurs preferentially after replication of the element. A number of mechanisms limit the frequency of transposition. Advantageous rearrangements of some genome may have been connected with the presence of the elements.
P elements in D. melanogaster are responsible for hybrid dysgenesis. A cross between a male carrying P elements and a female lacking them generates hybrids that are sterile. A P element has four open reading frames, which are separated by introns. Splicing of the first three ORFs generates a 66-kD repressor and occurs in somatic cells. Splicing of all four ORFs to generate the 87-kD transposase occurs only in the germline by a tissue-specific splicing event. P elements mobilize when exposed to cytoplasm lacking the repressor. The burst of transposition events inactivates the genome by random insertions. Only a complete P element can generate transposase, but defective elements can be mobilized in trans by the enzyme.
Reverse transcription is the unifying mechanism for reproduction of retroviruses and perpetuation of retroelements. The cycle of each type of element is in principle similar, although retroviruses are usually regarded from the perspective of the free viral (RNA) form, whereas retrotransposons are regarded from the stance of the genomic (duplex DNA) form.
Retroviruses have genomes of single-stranded RNA that are replicated through a double-stranded DNA intermediate. An individual retrovirus contains two copies of its genome. The genome contains the gag, pol, and env genes, which are translated into polyproteins, each of which is then cleaved into smaller functional proteins. The Gag and Env components are concerned with packing RNA and generating the virion; the Pol components are concerned with nucleic acid synthesis.
Reverse transcriptase is the major component of Pol and is responsible for synthesizing a DNA (minus-strand) copy of the viral (plus-strand) RNA. The DNA product is longer than the RNA template; by switching template strands, reverse transcriptase copies the 3′ sequence of the RNA to the 5′ end of the DNA and the 5′ sequence of the RNA to the 3′ end of the DNA. This generates the characteristic LTRs of the DNA. A similar switch of templates occurs when the plus strand of DNA is synthesized using the minus strand as a template. Linear duplex DNA is inserted into a host genome by the integrase enzyme. Transcription of the integrated DNA from a promoter in the left LTR generates further copies of the RNA sequence.
Switches in template during nucleic acid synthesis allow recombination to occur by copy choice. During an infective cycle, a retrovirus may exchange part of its usual sequence for a cellular sequence; the resulting virus is usually replication defective, but can be perpetuated in the course of a joint infection with a helper virus. Many of the defective viruses have gained an RNA version (v-onc) of a cellular gene (c-onc). The onc sequence may be any one of a number of genes whose expression in v-onc form causes the cell to be transformed into a tumorigenic phenotype.
The integration event generates direct target repeats (like transposons that mobilize via DNA). An inserted provirus therefore has direct terminal repeats of the LTRs, flanked by short repeats of target DNA. Mammalian and avian genomes have endogenous (inactive) proviruses with such structures. Other elements with this organization have been found in plants, animals, and fungi. Ty elements of yeast have coding sequences with homology to reverse transcriptase and mobilize via an RNA form. They may generate particles resembling viruses, but do not have infectious capability. The LINE sequences of mammalian genomes are further removed from the retroviruses, but retain enough similarities to suggest a common origin. They use a different type of priming event to initiate reverse transcription, in which an endonuclease activity associated with the reverse transcriptase makes a nick that provides a 3′–OH end for priming synthesis on an RNA template. The frequency of LINE transposition is increased because its protein products are cis-acting; they associate with the mRNA from which they were translated to form a ribonucleoprotein complex that is transported into the nucleus.
The members of another class of retroelements have the hallmarks of transposition via RNA, but have no coding sequences (or at least none resembling retroviral functions). They may have originated as passengers in a retroviral-like transposition event, in which an RNA was a target for a reverse transcriptase. A particularly prominent family that appears to have originated from a processing event is represented by SINEs; it includes the human Alu family. Some snRNAs, including 7SL snRNA (a component of the signal recognition particle, SRP), are related to this family.
References
15.1 Introduction
Reviews
Craig, N. L., Craigie, R., Gellert, M., and Lambowitz, A., eds. (2002). Mobile DNA II. Washington, DC: American Society for Microbiology Press.
Deininger, P. L., and Roy-Engel, A. M. (2002). Mobile elements in animal and plant genomes. In Craig, N. L., Craigie, R., Gellert, M., and Lambowitz, A., eds. Mobile DNA II. Washington, DC: American Society for Microbiology Press, pp. 1074–1092.
Feschotte C., and Pritham E. J. (2007). DNA transposons and the evolution of eukaryotic genomes. Ann. Rev. Genet. 41, 331–368.
15.2 Insertion Sequences Are Simple Transposition Modules
Reviews
Chandler, M., and Mahillon, J. (2002). Bacterial insertion sequences revisited. In Craig, N. L., Craigie, R., Gellert, M., and Lambowitz, A., eds. Mobile DNA II. Washington, DC: American Society for Microbiology Press, pp. 305–366.
Craig, N. L. (1997). Target site selection in transposition. Annu. Rev. Biochem. 66, 437–474.
Research
Grindley, N. D. (1978). IS1 insertion generates duplication of a 9 bp sequence at its target site. Cell 13, 419–426.
15.3 Transposition Occurs by Both Replicative and Nonreplicative Mechanisms
Reviews
Craig, N. L. (1997). Target site selection in transposition. Annu. Rev. Biochem. 66, 437–474.
Grindley, N. D., and Reed, R. R. (1985). Transpositional recombination in prokaryotes. Annu. Rev. Biochem. 54, 863–896.
Haren, L., Ton-Hoang, B., and Chandler, M. (1999). Integrating DNA: transposases and retroviral integrases. Annu. Rev. Microbiol. 53, 245–281.
15.6 Nonreplicative Transposition Proceeds by Breakage and Reunion
Review
Reznikoff, W. S. (2008). Transposon Tn5. Annu. Rev. Genet. 42, 269–286.
Research
Bender, J., and Kleckner, N. (1986). Genetic evidence that Tn10 transposes by a nonreplicative mechanism. Cell 45, 801–815.
Bolland, S., and Kleckner, N. (1996). The three chemical steps of Tn10/IS10 transposition involve repeated utilization of a single active site. Cell 84, 223–233.
Davies, D. R., Goryshin, I. Y., Reznikoff, W. S., and Rayment, I. (2000). Three-dimensional structure of the Tn5 synaptic complex transposition intermediate. Science 289, 77–85.
Haniford, D. B., Benjamin, H. W., and Kleckner, N. (1991). Kinetic and structural analysis of a cleaved donor intermediate and a strand transfer intermediate in Tn10 transposition. Cell 64, 171–179.
Kennedy, A. K., Guhathakurta, A., Kleckner, N., and Haniford, D. B. (1998). Tn10 transposition via a DNA hairpin intermediate. Cell 95, 125–134.
15.7 Transposons Form Superfamilies and Families
Reviews
Feschotte, C, Jiang, N., and Wessler, S. R. (2002). Plant transposable elements: where genetics meets genomics. Nat. Rev. Genet. 3, 329–341.
Gierl, A., Saedler, H., and Peterson, P. A. (1989). Maize transposable elements. Annu. Rev. Genet. 23, 71–85.
Kunz, R., and Weil, C. F. (2002). The hAT and CACTA superfamilies of plant transposons. In Craig, N. L., Craigie, R., Gellert, M., and Lambowitz, A., eds. Mobile DNA II. Washington, DC: American Society for Microbiology Press, pp. 400–600.
Plasterk, R. H. A., Izsvak, Z., and Ivics, Z. (1999). Resident aliens: the Tc1/mariner superfamily of transposable elements. Trends Genet. 15, 326–332.
Research
Benito, M. I., and Walbot, V. (1997). Characterization of the maize Mutator transposable element MURA transposase as a DNA-binding protein. Mol. Cell Biol. 17, 5165–5175.
Jiang, N., Bao, Z., Zhang, X., Hirochika, H., Eddy, S. R., McCouch, S. R., and Wessler, S. R. (2004). An active DNA transposon family in rice. Nature 421, 163–167.
Koga A., Shimada A., Kuroki T., Hori H., Kusumi J., Kyono-Hamaguchi Y., and Hamaguchi S. (2007). The Tol1 transposable element of the medaka fish moves in human and mouse cells. J. Hum. Genet. 52, 628–35.
Ros, F., and Kunze, R. (2001). Regulation of activator/dissociation transposition by replication and DNA methylation. Genetics 157, 1723–1733.
Singer, T., Yordan, C., and Martienssen, R. A. (2001). Robertson’s Mutator transposons in A. thaliana are regulated by the chromatin-remodeling gene decrease in DNA Methylation (DDM1). Genes Dev. 15, 591–602.
Slotkin, K. R., Freeling, M., and Lisch, D. (2005). Heritable silencing of a transposon family is initiated by a naturally occurring inverted repeat derivative. Nature Genet. 137, 641–644.
Yuan Y.-W., and Wessler, S. R. (2011). The catalytic domain of all eukaryotic cut-and-paste transposase superfamilies. Proc. Natl. Acad. Sci. USA 108, 7884–7889.
Zhou, L., Mitra, R., Atkinson, P. W., Hickman, A. B., Dyda, F., and Craig, N. L. (2004). Transposition of hAT elements links transposable elements and V(D)J recombination. Nature 432, 960–961.
15.8 The Role of Transposable Elements in Hybrid Dysgenesis
Reviews
Engels, W. R. (1983). The P family of transposable elements in Drosophila. Annu. Rev. Genet. 17, 315–344.
Rio, D. C. (2002). P transposable elements in Drosophila melanogaster. In Craig, N. L., Craigie, R., Gellert, M., and Lambowitz, A., eds. Mobile DNA II. Washington, DC: American Society for Microbiology Press, pp. 484–518.
Research
Daniels, S. B., Peterson, K. R., Strausbaugh, L. D., Kidwell, M. G., and Chovnick, A. (1990). Evidence for horizontal transmission of the P transposable element between Drosophila species. Genetics 124, 339–355.
Engels, W. R., Johnson-Schlitz, D. M., Eggleston, W. B., and Sved, J. (1990). High-frequency P element loss in Drosophila is homolog dependent. Cell 62, 515–525.
15.9 P Elements Are Activated in the Germline
Research
Brennecke J., Malone C. D., Aravin, A. A., Sachidanandam, R., Stark, A., and Hannon, G. J. (2008). An epigenetic role for maternally inherited piRNAs in transposon silencing. Science 322, 1387–1392.
Laski, F. A., Rio, D. C., and Rubin, G. M. (1986). Tissue specificity of Drosophila P element transposition is regulated at the level of mRNA splicing. Cell 44, 7–19.
15.10 The Retrovirus Life Cycle Involves Transposition-Like Events
Review
Varmus, H. E., and Brown, P. O. (1989). Retroviruses. In Howe, M. M., and Berg, D. E., eds., Mobile DNA. Washington, DC: American Society for Microbiology, pp. 53–108.
Research
Baltimore, D. (1970). RNA-dependent DNA polymerase in virions of RNA tumor viruses. Nature 226, 1209–1211.
Temin, H. M., and Mizutani, S. (1970). RNA-dependent DNA polymerase in virions of Rous sarcoma virus. Nature 226, 1211–1213.
15.12 Viral DNA Is Generated by Reverse Transcription
Reviews
Katz, R. A., and Skalka, A. M. (1994). The retroviral enzymes. Annu. Rev. Biochem. 63, 133–173.
Lai, M. M. C. (1992). RNA recombination in animal and plant viruses. Microbiol. Rev. 56, 61–79.
Negroni, M., and Buc, H. (2001). Mechanisms of retroviral recombination. Annu. Rev. Genet. 35, 275–302.
Research
Hu, W. S., and Temin, H. M. (1990). Retroviral recombination and reverse transcription. Science 250, 1227–1233.
Negroni, M., and Buc, H. (2000). Copy-choice recombination by reverse transcriptases: reshuffling of genetic markers mediated by RNA chaperones. Proc. Natl. Acad. Sci. USA 97, 6385–6390.
15.13 Viral DNA Integrates into the Chromosome
Reviews
Craigie, R. (2002). Retroviral integration. In Craig, N. L., Craigie, R., Gellert, M., and Lambowitz, A., eds. Mobile DNA II. Washington, DC: American Society for Microbiology Press, pp. 613–630.
Craigie, R., Fujiwara, T., and Bushman, F. (1990). The IN protein of Moloney murine leukemia virus processes the viral DNA ends and accomplishes their integration in vitro. Cell 62, 829–837.
15.15 Retroelements Fall into Three Classes
Reviews
Deininger, P. L. (1989). SINEs: short interspersed repeated DNA elements in higher eukaryotes. In Howe, M. M., and Berg, D. E., eds. Mobile DNA. Washington, DC: American Society for Microbiology, pp. 619–636.
Moran, J., and Gilbert, N. (2002). Mammalian LINE-1 retrotransposons and related elements. In Craig, N. L., Craigie, R., Gellert, M., and Lambowitz, A., eds. Mobile DNA II. Washington, DC: American Society for Microbiology Press, pp. 836–869.
Research
Chinwalla, A. T., et al. (2002). Initial sequencing and comparative analysis of the mouse genome. Nature 420, 520–562.
Dewannieux, M., Esnault, C., and Heidmann, T. (2003). LINE-mediated retrotransposition of marked Alu sequences. Nature Genet. 35, 41–48.
Loeb, D. D., Padgett, R. W., Hardies, S. C., Shehee, W. R., Comer, M. B., Edgell, M. H., Hutchison, C. A., 3rd. (1986). The sequence of a large L1Md element reveals a tandemly repeated 5′ end and several features found in retrotransposons. Mol. Cell Biol. 6, 168–182.
Sachidanandam, R., et al. (2001). A map of human genome sequence variation containing 1.42 million single nucleotide polymorphisms. Nature 409, 928–933.
15.16 Yeast Ty Elements Resemble Retroviruses
Research
Beliakova-Bethell, N., Beckham, C., Giddings, T. H., Jr., Winey, M., Parker, R., and Sandmeyer, S. (2006). Virus-like particles of the Ty3 retrotransposon assemble in association with P-body components. RNA 12, 94–101.
Boeke, J. D., Garfinkel, D. J., Styles, C. A., and Fink, G. R. (1985). Ty elements transpose through an RNA intermediate. Cell 40, 491–500.
Kuznetsov, Y. G., Zhang, M., Menees, T. M., McPherson, A., and Sandmeyer, S. (2005). Investigation by atomic force microscopy of the structure of Ty3 retrotransposon particles. J Virol 79, 8032–8045.
Lauermann, V., and Boeke, J. D. (1994). The primer tRNA sequence is not inherited during Ty1 retrotransposition. Proc. Natl. Acad. Sci. USA 91, 9847–9851.
15.18 LINEs Use an Endonuclease to Generate a Priming End
Review
Ostertag, E. M., and Kazazian, H. H. (2001). Biology of mammalian L1 retrotransposons. Annu. Rev. Genet. 35, 501–538.
Research
Feng, Q., Moran, J. V., Kazazian, H. H., and Boeke, J. D. (1996). Human L1 retrotransposon encodes a conserved endonuclease required for retrotransposition. Cell 87, 905–916.
Gilbert, N., Lutz-Prigge, S., and Moran, J. V. (2002). Genomic deletions created upon LINE-1 retrotransposition. Cell 110, 315–325.
Luan, D. D., Korman, M. H., Jakubczak, J. L., and Eickbush, T. H. (1993). Reverse transcription of R2Bm RNA is primed by a nick at the chromosomal target site: a mechanism for non-LTR retrotransposition. Cell 72, 595–605.
Moran, J. V., Holmes, S. E., Naas, T. P., DeBerardinis, R. J., Boeke, J. D., and Kazazian, H. H. (1996). High frequency retrotransposition in cultured mammalian cells. Cell 87, 917–927.
Symer, D. E., Connelly, C., Szak, S. T., Caputo, E. M., Cost, G. J., Parmigiani, G., and Boeke, J. D. (2002). Human l1 retrotransposition is associated with genetic instability in vitro. Cell 110, 327–338.