This book relies heavily on a firm understanding of Ruby. This section will explain some aspects of Ruby that are often confusing or misunderstood. Some of this may be familiar, but these are important concepts that form the basis for the metaprogramming techniques covered later in this chapter.
Classes and modules are the foundation of object-oriented programming in Ruby. Classes facilitate encapsulation and separation of concerns. Modules can be used as mixins—bundles of functionality that are added onto a class to add behaviors in lieu of multiple inheritance. Modules are also used to separate classes into namespaces.
In Ruby, every class name is a constant. This is why Ruby
requires class names to begin with an uppercase letter. The constant
evaluates to the class object, which is an object
of the class Class. This is
distinct from the Class object, which represents
the actual class Class. [3] When we refer to a "class object" (with a lowercase C),
we mean any object that represents a class (including Class itself). When we refer to the "Class
object" (uppercase C), we mean the class Class, which is the superclass of all class
objects.
The class Class inherits from
Module; every class is also a
module. However, there is an important distinction. Classes cannot be
mixed in to other classes, and classes cannot extend objects; only
modules can.
Method lookup in Ruby can be very confusing, but it is quite regular. The easiest way to understand complicated situations is to visualize the data structures that Ruby creates behind the scenes.
Every Ruby object[4] has a set of fields in memory:
klassA pointer to the class object of this object. (It is
klassinstead ofclassbecause the latter is a reserved word in C++ and Ruby; if it were calledclass, Ruby would compile with a C compiler but not with a C++ compiler. This deliberate misspelling is used everywhere in Ruby.)iv_tbl"Instance Variable Table," a hashtable containing the instance variables belonging to this object.
flagsA bitfield of Boolean flags with some status information, such as the object's taint status, garbage collection mark bit, and whether the object is frozen.
Every Ruby class or module has the same fields, plus two more:
m_tbl"Method Table," a hashtable of this class or module's instance methods.
superA pointer to this class or module's superclass.
These fields play a huge role in method lookup, and it is
important that you understand them. In particular, you should pay
close attention to the difference between the klass and super pointers of a class object.
The method lookup rules are very simple, but they depend on an understanding of how Ruby's data structures work. When a message is sent to an object, [5] the following steps occur:
Ruby follows the receiver's
klasspointer and searches them_tblof that class object for a matching method. (The target of aklasspointer will always be a class object.)If no method is found, Ruby follows that class object's
superpointer and continues the search in the superclass'sm_tbl.Ruby progresses in this manner until the method is found or the top of the
superchain is reached.If the method is not found in any object on the chain, Ruby invokes
method_ missingon the receiver of the original method. This starts the process over again, this time looking formethod_missingrather than the original method.
These rules apply universally. All of the interesting things
that method lookup involves (mixins, class methods, and singleton
classes) are consequences of the structure of the klass and super pointers. We will now examine this
process in detail.
The method lookup process can be confusing, so we'll start simple. Here is the simplest possible class definition in Ruby:
class A end
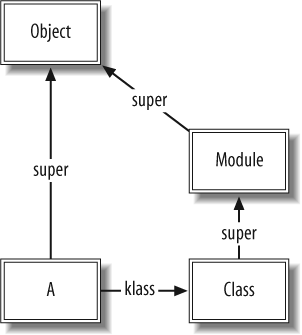
This code generates the following data structures in memory (see Figure 1-1).
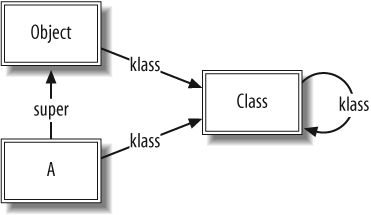
The double-bordered boxes represent class objects—objects
whose klass pointer points to the
Class object. A's super pointer refers to the Object class object, indicating that
A inherits from Object. For clarity, from now on we will
omit default klass pointers to
Class, Module, and Object where there is no ambiguity.
The next-simplest case is inheritance from one class. Class
inheritance simply follows the super pointers. For example, we will
create a B class that descends
from A:
class B < A end
The resulting data structures are shown in Figure 1-2.
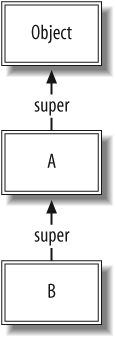
The super keyword always
delegates along the method lookup chain, as in the following
example:
class B def initialize logger.info "Creating B object" super end end
The call to super in
initialize will follow the
standard method lookup chain, beginning with A#initialize.
Now we get a chance to see how method lookup is performed. We
first create an instance of class B:
obj = B.new
This creates a new object, and sets its klass pointer to B's class object (see Figure 1-3).
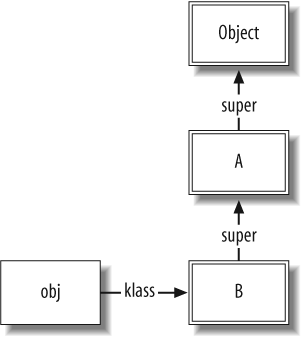
The single-bordered box around obj represents a plain-old object
instance. Note that each box in this diagram is an object instance.
However, the double-bordered boxes represent objects that are
instances of the Class class
(hence their klass pointer points
to the Class object).
When we send obj a
message:
obj.to_s
this chain is followed:
obj's klasspointer is followed toB; B's methods (inm_tbl) are searched for a matching method.No methods are found in
B. B'ssuperpointer is followed, andAis searched for methods.No methods are found in
A. A'ssuperpointer is followed, andObjectis searched for methods.The
Objectclass contains ato_smethod in native code (rb_any_to_s). This is invoked, yielding a value like "#<B:0x1cd3c0>". Therb_any_to_smethod examines the receiver'sklasspointer to determine what class name to display; therefore,Bis shown even though the method invoked resides inObject.
Things get more complicated when we start mixing in modules.
Ruby handles module inclusion with ICLASSes,[6] which are proxies for modules. When you include a
module into a class, Ruby inserts an ICLASS representing the
included module into the including class object's super chain.
For our module inclusion example, let's simplify things a bit
by ignoring B for now. We define
a module and mix it in to A,
which results in data structures shown in Figure 1-4:
module Mixin def mixed_method puts "Hello from mixin" end end class A include Mixin end
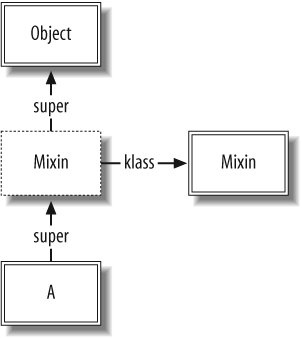
Here is where the ICLASS comes into play. The super link pointing from A to Object is intercepted by a new ICLASS
(represented by the box with the dashed line). The ICLASS is a proxy
for the Mixin module. It contains
pointers to Mixin's iv_tbl (instance variables) and m_tbl (methods).
From this diagram, it is easy to see why we need proxy
classes: the same module may be mixed in to any number of different
classes—classes that may inherit from different classes (thus having
different super pointers). We
could not directly insert Mixin
into the lookup chain, because its super pointer would have to point to two
different things if it were mixed in to two classes with different
parents.
When we instantiate A, the
structures are as shown in Figure 1-5:
objA = A.new
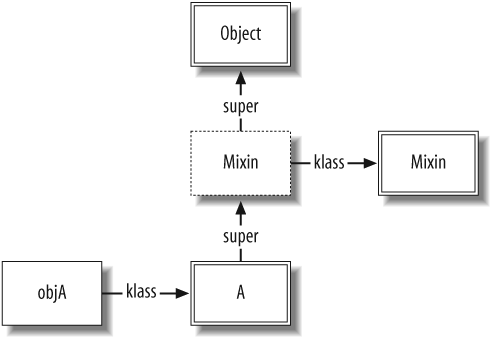
We invoke the mixed_method
method from the mixin, with objA
as the receiver:
objA.mixed_method # >> Hello from mixin
The following method-lookup process takes place:
objA's class,A, is searched for a matching method. None is found.A'ssuperpointer is followed to the ICLASS that proxiesMixin. This proxy object is searched for a matching method. Because the proxy'sm_tblis the same asMixin'sm_tbl, themixed_methodmethod is found and invoked.
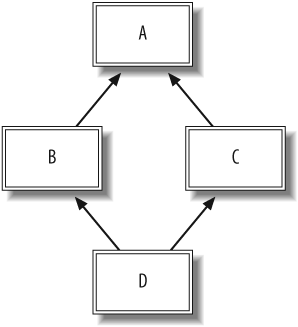
Many languages with multiple inheritance suffer from the diamond problem, which is ambiguity in resolving method calls on objects whose classes have a diamond-shaped inheritance graph, as shown in Figure 1-6.
Given this diagram, if an object of class D calls a method defined in class A that has been overridden in both
B and C, there is ambiguity about which method
should be called. Ruby resolves this by linearizing the order of
inclusion. Upon a method call, the lookup chain is
searched linearly, including any ICLASSes that have been inserted
into the chain.
First of all, Ruby does not support multiple inheritance;
however, multiple modules can be mixed into classes and other
modules. Therefore, A, B, and
C must be modules. We see that
there is no ambiguity here; the method chosen is the latest one that
was inserted into the lookup chain:
module A def hello "Hello from A" end end
module B include A def hello "Hello from B" end end module C include A def hello "Hello from C" end end class D include B include C end D.new.hello # => "Hello from C"
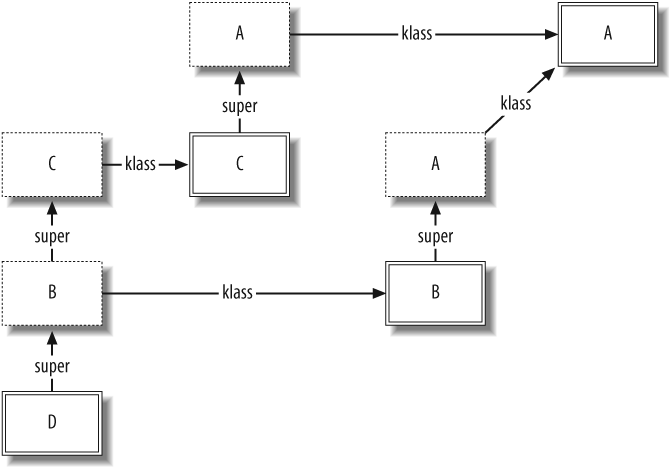
And if we change the order of inclusion, the result changes correspondingly:
class D include C include B end D.new.hello # => "Hello from B"
In this last example, where B is included last, the object graph looks
like Figure 1-7
(for simplicity, pointers to Object and Class have been elided).
Singleton classes (also metaclasses or eigenclasses; see the upcoming sidebar, "Single-ton Class Terminology") allow an object's behavior to be different from that of other objects of its class. You've probably seen the notation to open up a singleton class before:
class A end objA = A.new objB = A.new objA.to_s # => "#<A:0x1cd0a0>" objB.to_s # => "#<A:0x1c4e28>" class <<objA # Open the singleton class of objA def to_s; "Object A"; end end objA.to_s # => "Object A" objB.to_s # => "#<A:0x1c4e28>"
The class <<objA
notation opens objA's singleton
class. Instance methods added to the singleton class function as
instance methods in the lookup chain. The resulting data structures are shown
in Figure 1-8.
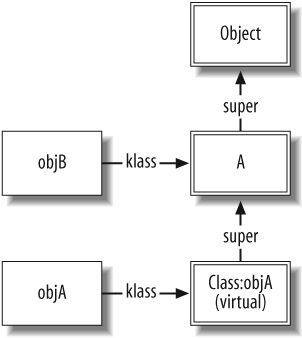
The objB instance is of
class A, as usual. And if you ask
Ruby, it will tell you that objA
is also of class A:
objA.class # => A
However, something different is going on behind the scenes.
Another class object has been inserted into the lookup chain. This object is the singleton class of
objA.We refer to it as "Class:objA" in this documentation. Ruby
calls it a similar name: #<Class:#<A:0x1cd0a0>>. Like
all classes, the singleton class's klass pointer (not shown) points to the
Class object.
The singleton class is marked as a virtual
class (one of the flags is used to indicate that a class is
virtual). Virtual classes cannot be instantiated, and we
generally do not see them from Ruby unless we take pains to do so.
When we ask Ruby for objA's
class, it traverses the klass and
super pointers up the hierarchy
until it finds the first nonvirtual class.
Therefore, it tells us that objA's class is A. This is important to remember: an object's
class (from Ruby's perspective) may not match the object pointed to
by klass.
Singleton classes are called singleton for a reason: there can only be one
singleton class per object. Therefore, we can refer unambiguously to
"objA's singleton class" or
Class:objA. In our code, we can
assume that the singleton class exists; in reality, for efficiency,
Ruby creates it only when we first mention it.
Ruby allows singleton classes to be defined on any object
except Fixnums or symbols.
Fixnums and symbols are
immediate values (for efficiency, they're
stored as themselves in memory, rather than as a pointer to a data
structure). Because they're stored on their own, they don't have
klass pointers, so there's no way
to alter their method lookup chain.
You can open singleton classes for true, false, and nil, but the singleton class returned will
be the same as the object's class. These values are singleton
instances (the only instances) of TrueClass, FalseClass, and NilClass, respectively. When you ask for
the singleton class of true, you
will get TrueClass, as the
immediate value true is the only possible instance of that class. In
Ruby:
true.class # => TrueClass class << true; self; end # => TrueClass true.class == (class << true; self; end) # => true
Here is where it gets complicated. Keep in mind the basic rule
of method lookup: first Ruby follows an object's klass pointer and searches for methods; then Ruby keeps following super pointers all the way up the chain
until it finds the appropriate method or reaches the top.
The important thing to remember is that classes are
objects, too. Just as a plain-old object can have a
singleton class, class objects can also have their own singleton
classes. Those singleton classes, like all other classes, can have
methods. Since the singleton class is accessed through the klass pointer of its owner's class object,
the singleton class's instance methods are class methods of the
singleton's owner.
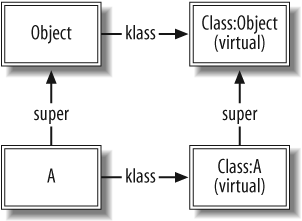
The full set of data structures for the following code is shown in Figure 1-9:
class A end
Class A inherits from
Object. The A class object is of type Class. Class inherits from Module, which inherits from Object. The methods stored in A's m_tbl are instance methods of A. So what happens when we call a class
method on A?
A.to_s # => "A"
The same method lookup rules apply, with A as the receiver. (Remember, A is a constant that evaluates to A's class object.) First, Ruby follows
A's klass pointer to Class. Class's m_tbl is searched for a function named
to_s. Finding none, Ruby follows
Class's super pointer to Module, where the to_s function is found (in native code,
rb_mod_to_s).
This should not be a surprise. There is no magic here. Class methods are found in the exact same way as instance methods—the only difference is whether the receiver is a class or an instance of a class.
Now that we know how class methods are looked up, it would
seem that we could define class methods on any class by defining
instance methods on the Class
object (to insert them into Class's m_tbl). Indeed, this works:
class A; end # from Module#to_s A.to_s # => "A" class Class def to_s; "Class#to_s"; end end A.to_s # => "Class#to_s"
That is an interesting trick, but it is of very limited utility. Usually we want to define unique class methods on each class. This is where singleton classes of class objects are used. To open up a singleton class on a class, simply pass the class's name as the object to the singleton class notation:
class A; end class B; end class <<A def to_s; "Class A"; end end A.to_s # => "Class A" B.to_s # => "B"
The resulting data structures are shown in Figure 1-10. Class B is omitted for brevity.
The to_s method has been added to A's singleton class, or Class:A. Now, when A.to_s is called, Ruby will follow
A's klass pointer to Class:A and invoke the appropriate method
there.
There is one more wrinkle in method definition. In a class or
module definition, self always
refers to the class or module object:
class A self # => A end
So, inside A's class
definition, class<<A can
also be written class<<self, since inside that
definition A and self refer to the same object. This idiom
is used everywhere in Rails to define class methods. This example shows all of the ways to define
class methods:
class A def A.class_method_one; "Class method"; end def self.class_method_two; "Also a class method"; end class <<A def class_method_three; "Still a class method"; end end class <<self def class_method_four; "Yet another class method"; end end end def A.class_method_five "This works outside of the class definition" end class <<A def A.class_method_six "You can open the metaclass outside of the class definition" end end # Print the result of calling each method in turn %w(one two three four five six).each do |number| puts A.send(:"class_method_#{number}") end # >> Class method # >> Also a class method # >> Still a class method # >> Yet another class method # >> This works outside of the class definition # >> You can open the metaclass outside of the class definition
This also means that inside a singleton class definition—as in
any other class definition—self
refers to the class object being defined. When we remember that the
value of a block or class definition is the value of the last
statement executed, we can see that the value of class <<objA; self; end is objA's singleton class. The class <<objA construct opens up the
singleton class, and self (the
singleton class) is returned from the class definition.
Putting this together, we can open up the Object class and add an instance method to
every object that returns that object's singleton class:
class Object def metaclass class <<self self end end end
This method forms the basis of Metaid, which is described shortly.
After all of that confusion, method_missing is remarkably simple. There
is one rule: if the whole method lookup procedure fails all the way up to Object, method lookup is tried again,
looking for a method_missing
method rather than the original method. If the method is found, it
is called with the same arguments as the original method, with the
method name prepended. Any block given is also passed
through.
The default method_missing
function in Object
(rb_method_missing) raises an exception.
why the lucky stiff has created a tiny library for Ruby metaprogramming called metaid.rb. This snippet is useful enough to include in any project in which meta-programming is needed:[7]
class Object # The hidden singleton lurks behind everyone def metaclass; class << self; self; end; end def meta_eval &blk; metaclass.instance_eval &blk; end # Adds methods to a metaclass def meta_def name, &blk meta_eval { define_method name, &blk } end # Defines an instance method within a class def class_def name, &blk class_eval { define_method name, &blk } end end
This library defines four methods on every object:
metaclassRefers to the singleton class of the receiver (self).
meta_evalThe equivalent of
class_evalfor singleton classes. Evaluates the given block in the context of the receiver's singleton class.meta_defDefines a method within the receiver's singleton class. If the receiver is a class or module, this will create a class method (instance method of the receiver's singleton class).
class_defDefines an instance method in the receiver (which must be a class or module).
Metaid's convenience lies in its brevity. By using a shorthand
for referring to and augmenting metaclasses, your code will become
clearer rather than being littered with constructs like class << self; self; end. The shorter
and more readable these techniques are, the more likely you are to use
them appropriately in your programs.
This example shows how we can use Metaid to examine and simplify our singleton class hacking:
class Person def name; "Bob"; end def self.species; "Homo sapiens"; end end
Class methods are added as instance methods of the singleton class:
Person.instance_methods(false) # => ["name"] Person.metaclass.instance_methods - Object.metaclass.instance_methods # => ["species"]
Using the methods from Metaid, we could have written the method definitions as:
Person.class_def(:name) { "Bob" }
Person.meta_def(:species) { "Homo sapiens" }There are four types of variables in Ruby: global variables, class variables, instance variables, and local variables.[8] Global variables are stored globally, and local variables are stored lexically, so neither of them is relevant to our discussion now, as they do not interact with Ruby's class system.
Instance variables are specific to a certain object. They are
prefixed with one @ symbol:
@price is an instance variable.
Because every Ruby object has an iv_tbl structure, any object can have
instance variables.
Since a class is also an object, a class can have instance variables. The following code accesses an instance variable of a class:
class A @ivar = "Instance variable of A" end A.instance_variable_get(:@ivar) # => "Instance variable of A"
Instance variables are always resolved based on the object
pointed to by self. Because
self is A's class object in the class A … end definition, @ivar belongs to A's class object.
Class variables are different. Any instance of a class can
access its class variables (which start with @@). Class variables can also be referenced
from the class definition itself. While class variables and instance
variables of a class are similar, they're not the same:
class A @var = "Instance variable of A" @@var = "Class variable of A" def A.ivar @var end def A.cvar @@var end end A.ivar # => "Instance variable of A" A.cvar # => "Class variable of A"
In this code sample, @var and
@@var are stored in the same place:
in A's iv_tbl. However, they are different
variables, because they have different names (the @ symbols are included in the variable's
name as stored). Ruby's functions for accessing instance variables and
class variables check to ensure that the names passed are in the
proper format:
A.instance_variable_get(:@@var) # ~> -:17:in 'instance_variable_get': '@@var' is not allowed as an instance variable name (NameError)
Class variables can be somewhat confusing to use. They are shared all the way down the inheritance hierarchy, so subclasses that modify a class variable will modify the parent's class variable as well.
>> class A; @@x = 3 end => 3 >> class B < A; @@x = 4 end => 4 >> class A; @@x end => 4
This may be useful, but it may also be confusing. Generally, you either want class instance variables—which are independent of the inheritance hierarchy—or the class inheritable attributes provided by ActiveSupport, which propagate values in a controlled, well-defined manner.
One powerful feature of Ruby is the ability to work with pieces of code as objects. There are three classes that come into play, as follows:
ProcA Procrepresents a code block: a piece of code that can be called with arguments and has a return value.UnboundMethodThis is similar to a
Proc; it represents an instance method of a particular class. (Remember that class methods are instance methods of a class object, soUnboundMethodscan represent class methods, too.) AnUnboundMethodmust be bound to a class before it can be invoked.MethodMethodobjects areUnboundMethodsthat have been bound to an object withUnboundMethod#bind. Alternatively, they can be obtained withObject#method.
Let's examine some ways to get Proc and Method objects. We'll use the Fixnum#+ method as an example. We usually
invoke it using the dyadic syntax:
3 + 5 # => 8
However, it can be invoked as an instance method of a Fixnum object, like any other instance
method:
3.+(5) # => 8
We can use the Object#method
method to get an object representing this instance method. The method
will be bound to the object that method was called on, 3.
add_3 = 3.method(:+) add_3 # => #<Method: Fixnum#+>
This method can be converted to a Proc, or called directly with
arguments:
add_3.to_proc # => #<Proc:0x00024b08@-:6> add_3.call(5) # => 8 # Method#[] is a handy synonym for Method#call. add_3[5] # => 8
There are two ways to obtain an unbound method. We can call
instance_method on the class
object:
add_unbound = Fixnum.instance_method(:+) add_unbound # => #<UnboundMethod: Fixnum#+>
We can also unbind a method that has already been bound to an object:
add_unbound == 3.method(:+).unbind # => true add_unbound.bind(3).call(5) # => 8
We can bind the UnboundMethod
to any other object of the same class:
add_unbound.bind(15)[4] # => 19
However, the object we bind to must be an
instance of the same class, or else we get a TypeError:
add_unbound.bind(1.5)[4] # => # ~> -:16:in 'bind': bind argument must be an instance of Fixnum (TypeError) # ~> from -:16
We get this error because + is defined in Fixnum; therefore, the UnboundMethod object we receive must be
bound to an object that is a kind_of?(Fixnum). Had the + method been
defined in Numeric (from which both
Fixnum and Float inherit), the preceding code would have returned 5.5.
One downside to the current implementation of Ruby: blocks are
not always Procs, and vice versa.
Ordinary blocks (created with do…end or {}) must be attached to a method
call, and are not automatically objects. For example, you cannot say
code_ block ={puts"abc"}. This is
what the Kernel#lambda and
Proc.new functions are for:
converting blocks to Procs.
[9]
block_1 = lambda { puts "abc" } # => #<Proc:0x00024914@-:20>
block_2 = Proc.new { puts "abc" } # => #<Proc:0x000246a8@-:21>There is a slight difference between Kernel#lambda and Proc.new. Returning from a Proc created with Kernel#lambda returns the given value to
the calling function; returning from a Proc created with Proc.new attempts to return
from the calling function, raising a LocalJumpError if that is impossible. Here
is an example:
def block_test
lambda_proc = lambda { return 3 }
proc_new_proc = Proc.new { return 4 }
lambda_proc.call # => 3
proc_new_proc.call # =>
puts "Never reached"
end
block_test # => 4The return statement in lambda_proc returns the value 3 from the
lambda. Conversely, the return statement in proc_new_proc returns from the calling
function, block_test— thus, the
value 4 is returned from block_test. The puts statement is never
executed, because the proc_new_proc.call statement returns from
block_test first.
Blocks can also be converted to Procs by passing them to a function, using
& in the function's formal parameters:
def some_function(&b)
puts "Block is a #{b} and returns #{b.call}"
end
some_function { 6 + 3 }
# >> Block is a #<Proc:0x00025774@-:7> and returns 9Conversely, you can also substitute a Proc with & when a function expects a
block:
add_3 = lambda {|x| x+3}
(1..5).map(&add_3) # => [4, 5, 6, 7, 8]Closures are created when a block or
Proc accesses variables defined
outside of its scope. Even though the containing block may go out of
scope, the variables are kept around until the block or Proc referencing them goes out of scope. A
simplistic example, though not practically useful, demonstrates the
idea:
def get_closure
data = [1, 2, 3]
lambda { data }
end
block = get_closure
block.call # => [1, 2, 3]The anonymous function (the lambda) returned from get_closure references the local variable
data, which is defined outside of its scope. As long as the block variable is in scope, it will hold
its own reference to data, and
that instance of data will not be
destroyed (even though the get_closure function returns). Note that
each time get_closure is called,
data references a different
variable (since it is function-local):
block = get_closure block2 = get_closure block.call.object_id # => 76200 block2.call.object_id # => 76170
A classic example of closures is the make_counter function, which returns a
counter function (a Proc) that,
when executed, increments and returns its counter. In Ruby, make_counter can be implemented like
this:
def make_counter(i=0) lambda { i += 1 } end x = make_counter x.call # => 1 x.call # => 2 y = make_counter y.call # => 1 y.call # => 2
The lambda function creates
a closure that closes over the current value of the local variable
i. Not only can the variable be
accessed, but its value can be modified. Each closure gets a
separate instance of the variable (because it is a variable local to
a particular instantiation of make_counter). Since x and y
contain references to different instances of the local variable
i, they have different
state.
[3] If that weren't confusing enough, the Class object has class Class as well.
[4] Except immediate objects (Fixnums,
symbols, true, false, and nil); we'll get to those
later.
[5] Ruby often co-opts Smalltalk's message-passing
terminology: when a method is called, it is said that one is
sending a message. The receiver is the object that the
message is sent to.
[6] ICLASS is Mauricio Fernández's term for these proxy
classes. They have no official name but are of type T_ICLASS in the Ruby source.
[7] "Seeing Metaclasses Clearly." http://whytheluckystiff.net/articles/seeingMetaclassesClearly.html
[8] There are also constants, but they shouldn't vary. (They can, but Ruby will complain.)
[9] Kernel#proc is another
name for Kernel#lambda, but
its usage is deprecated.