Ruby 1.8 has less-than-ideal Unicode support, when compared to its contemporaries such as Java and the .NET languages. To Ruby, strings are just sequences of 8-bit bytes, while the character and string types of the Java runtime and .NETCLR are based on Unicode code points. While Ruby's approach simplifies the language, most developers at this point in time need Unicode support. Luckily, Ruby is flexible enough that we can tack support for Unicode onto the language in a relatively friendly way.
It is not surprising that Ruby's Unicode support is lacking. During the time of Ruby's genesis in Japan (the mid-1990s), Unicode was first being developed. In Unicode's early stages, its supporters were mainly American and European, with less East Asian involvement.
Many Japanese people opposed the process of Han unification, or collapsing most of the Han characters common to CJKV languages into a single set of code points. The unified Han characters tended to appeal more to Chinese speakers than Japanese speakers. The people involved in Han unification (primarily Westerners) tended to collapse characters that were similar, but not identical, across Asian languages. In the early days of Unicode, rendering software would get confused and display similar, but incorrect, glyphs for the Han-unified characters. This was at best disconcerting; at worst, offensive.
There are technical solutions to all of these problems today, but Unicode was a slow starter in Japan. Other character sets such as Shift_JIS gained more currency in Japan at the time, which actually may have contributed somewhat to the problem; having more extant character sets leads to more conversion issues. [76]
Ruby 1.9 will support multilingualization (m17n). Rather than a built-in Unicode assumption, Ruby 1.9 will support interoperability between multiple character sets. This is more flexible than assuming that all string literals are Unicode, and it is a more general approach to character set handling. To use UTF-8 for all string and regex literals, the following pragma can be used:
# coding: utf-8
In lieu of complete multibyte character support in Ruby 1.8, Rails has created a workaround. We touched on this solution, ActiveSupport::Multibyte, back in Chapter 2. Here, we will explore it in more detail.
Recall that the global variable $KCODE determines the current character
encoding, and thus influences how Ruby treats your strings. In Rails
1.2 and later, Initializer sets $KCODE to 'u', so all processing is assumed to be in
UTF-8 unless otherwise specified.
Rails includes a library called ActiveSupport::Multibyte that
provides a way to deal with multibyte characters on top of Ruby. At
this time, only UTF-8 is supported. The encoding is derived from the
current value of $KCODE.
Multibyte adds a String#chars
instance method, which returns a proxy (of type ActiveSupport::Multibyte::Chars) to that
string. This proxy delegates to a handler, depending on the current
encoding. (Right now, the only handlers are a UTF-8 handler for
$KCODE='u' and a pass-through
handler for everything else.) The Chars object uses method_missing to trap unknown calls and
send them to the handler. If the handler cannot deal with them, they
are sent to the original String.
The most important feature Multibyte provides is the ability to
split strings on character boundaries, rather than byte boundaries.
All you need to do is call the String#chars method and optionally convert
back to a String when you are
done:
$KCODE = 'u' str = "résumé" # => "résumé" str[0..1] # => "r\303" str.chars[0..1].to_s # => "ré"
Multibyte also provides case conversion, which can differ vastly among languages:
str.upcase # => "RéSUMé" str.chars.upcase.to_s # => "RÉSUMÉ"
And method calls to chars can be chained, as the Chars methods return a Chars object rather than Strings. Even methods that are proxied back
to the original String have their
String return values converted to Chars objects.
str.chars[0..1].upcase.to_s # => "RÉ"
The implementation of Multibyte is itself fascinating; the
tables of composition maps, codepoints, case maps, and other details
are generated automatically from tables at the Unicode Consortium web site and stored in
active_support/values/unicode_tables.dat
. The generator can be found in
active_support/multibyte/generators/generate_tables.rb.
As with any increasingly complicated encoding, normalization and canonicalization are important issues with Unicode. One representation on paper (or screen) may map to multiple encodings. In some cases, it may be more desirable to treat those sequences identically, but in other cases we may need to treat them differently.
One complicating issue is character composition. Unicode provides multiple versions of some characters, for various reasons. For example, the ö in the German word schön can be encoded as either ö (U+00F6 LATIN SMALL LETTER O WITH DIAERESIS) or as the combination of o (U+006F LATIN SMALL LETTER O) and (U+0308 COMBINING DIAERESIS). The two representations use different byte sequences, and therefore they would not compare as equivalent to a byte-oriented procedure.
Another example is compatibility characters, or characters that were introduced into Unicode for compatibility with older encodings. One area where this occurs is typo-graphical ligatures (see Figure 8-2).
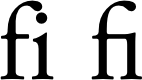
The text on the left does not use a ligature. For typographical reasons, the style on the right is usually used for the combination of f and i. The original intent of Unicode was that a smart rendering system would replace the consecutive code points f and i with the appropriate ligature. However, many systems turned out not to be capable of this advanced rendering (Mac OS X being a notable exception). Therefore, common ligatures were given their own code points, so that they could be embedded in a body of text and rendered (with a suitable font including those ligatures) with a dumb client. In this case, the ligature "fi" is U+FB01 LATIN SMALL LIGATURE FI.
To support character composition on platforms with less complex rendering systems, Unicode includes precomposed characters, such as the ö shown earlier (U+00F6 LATIN SMALL LETTER O WITH DIAERESIS). Compatibility characters such as the typographical ligatures are often precomposed. In order to properly compare and collate strings that may include both combining characters and precomposed characters, the strings must be canonicalized, or reduced to a well-known form such that two strings that are "the same" (by some definition) will always map to the same sequence of code points.
To canonicalize sequences of code points, we must first determine what our notion of equivalence is. Unicode defines two types of equivalence: the narrow canonical equivalence and the broader compatibility equivalence. Canonical equivalence is limited to characters that are equal in both form and function—the standard example being the decomposed ö (the two code points o and ") versus the precomposed character ö (one code point). Two sequences of code points, such as those, that are canonically equivalent are identical in appearance and usage, and can in nearly all cases be substituted for each other.
Compatibility equivalence is a broader concept. Compatibility equivalence includes all canonically equivalent characters, plus characters that may have different semantics but are rendered similarly. Examples include the characters f and i versus the fi ligature, or the superscript 2 versus the ordinary numeral 2.
There are four methods of Unicode normalization: D, C, KD, and KC. (They are also referred to as NFD, NFC, NFKD, and NFKC, with NF standing for Normalization Form.) The D forms leave the string in a decomposed form, while the C forms leave the string canonically composed (by first decomposing, and then recomposing by canonical equivalence). The K forms decompose by compatibility equivalence, while those without a K decompose by canonical equivalence. (All composition is done under canonical equivalence to ensure a consistent composition.)
ActiveSupport provides methods on the UTF-8 handler for Unicode normalization, supporting all four forms. The following code shows the differences between the four forms as applied to the string final piñata. The first word includes the fi ligature, which is compatibility equivalent (but not canonically equivalent) to the separated characters fi. The second word includes the character ñ, which is both compatibility equivalent and canonically equivalent to the code points n and ˜.
$KCODE = 'u' str = "final piñata".chars str.normalize(:d).to_s # => "final pin˜ata" str.normalize(:c).to_s # => "final piñata" str.normalize(:kd).to_s # => "final pin˜ata" str.normalize(:kc).to_s # => "final piñata"
Although you may be UTF-8 clean through your entire system (UTF-8 text can be entered anywhere and is displayed identically upon output), you are still at risk of problems if you just accept user-provided strings as UTF-8. Users can provide invalid UTF-8 text (not all byte sequences correspond to valid sequences of UTF-8 code points). Users will even provide maliciously malformed UTF-8 text in an attempt to crash or exploit your string-processing functions.
Paul Battley wrote an article addressing the issue of filtering untrusted UTF-8 strings. [77] As with most other hard problems in Rails, we cheat. In this case, the iconv library can clean up UTF-8 strings for us:
require 'iconv'
ic = Iconv.new('UTF-8//IGNORE', 'UTF-8')
valid_string = ic.iconv(untrusted_string + ' ')[0..-2]The Iconv.new line creates a
new Iconv object to translate
potentially invalid UTF-8 data into UTF-8 data with invalid characters
ignored. The next line works around an Iconv bug: it will not detect an invalid
byte at the end of a string. Therefore, we add a space (a known-valid
byte) and chop it off after performing the conversion.
Ilya Grigorik shows how to use the Oniguruma regular expression
engine to filter out control characters (of the Cx classes). [78] Note that the Oniguruma engine is standard in Ruby 1.9,
but is also available for Ruby 1.8 (gem
install oniguruma).
require 'oniguruma'
# Finall all Cx category graphemes
reg = Oniguruma::ORegexp.new("\p{C}", {:encoding => Oniguruma::ENCODING_UTF8})
# Erase the Cx graphemes from our validated string
filtered_string = reg.gsub(validated_string, '')Proper i18n requires that your character set be correctly processed in the application and correctly stored in the database. For most Rails applications, this means setting up the database and connection to be UTF-8 clean. Since Rails 1.2, ActiveRecord correctly processes UTF-8 data and is ready for UTF-8 storage over supported connections. The specifics differ among database engines, so we'll examine MySQL and PostgreSQL here.
To properly store UTF-8 data in a MySQL database, two things need to be in place. First, the database and tables need to be configured with the proper encoding. Secondly, the client connection between ActiveRecord and MySQL needs to use UTF-8.
MySQL ships with Latin1 (ISO-8859-1) as the default character set. Thus, all of the string operations are by default byte-oriented. You can change the default character set and collation for the entire database server with the following commands in the MySQL configuration file (my.cnf):
character-set-server=utf8 default-collation=utf8_unicode_ci
The Rails create_database
schema definition method will attempt to do the right thing. If you
use create_database to create
your databases, they will default to UTF-8:
>> ActiveRecord::Schema.define do ?> create_database :test_db >> end -- create_database(:test_db) SQL (0.000585) CREATE DATABASE `test_db` DEFAULT CHARACTER SET `utf8` -> 0.0008s => nil
However, the create_table
method does not specify a character set, but you can provide an
:options parameter that specifies
any table creation options, including a character set. (Bear in
mind, though, that by specifying DBMS-specific table creation
syntax, you lose portability between DBMSs.)
>> ActiveRecord::Schema.define do
?> create_table :test do end
>> end
-- create_table(:test)
SQL (0.028168) CREATE TABLE `test` (`id` int(11) DEFAULT NULL
auto_increment PRIMARY KEY) ENGINE=InnoDB
-> 0.1264s
=> nil
>> ActiveRecord::Schema.define do
?> create_table :test2, :options =>
'ENGINE=InnoDB DEFAULT CHARSET=utf8' do end
>> end
-- create_table(:test2, {:options=>"ENGINE=InnoDB DEFAULT CHARSET=utf8"})
SQL (0.028386) CREATE TABLE `test2` (`id` int(11) DEFAULT NULL
auto_increment PRIMARY KEY) ENGINE=InnoDB
DEFAULT CHARSET=utf8
-> 0.0287s
=> nilHowever, none of these methods will handle preexisting
databases. Chances are, if you have created databases and tables
without specifying CHARACTER SET
utf8, the tables are treating the data as Latin1. If the
data is actually Latin1 (and you are now converting the entire
application to Unicode at once), the conversion is simple, though it
must be done once for each table:
ALTER TABLE table_name CONVERT TO CHARACTER SET utf8;
If your only need is straight data conversion, this will work. If you are using ActiveRecord migrations, Graeme Mathieson has written a migration that will perform this conversion for every table in your database. It is available from http://woss.name/ 2006/10/25/migrating-your-rails-application-to-unicode/.
Be very careful converting a table that has existing data. If you have been using Rails 1.2 or later (which support UTF-8 by default) and have not converted your tables to UTF-8, you may have UTF-8 data stored in the database as Latin1. If you then convert the table to UTF-8, the conversion will be performed twice, which will corrupt your data. The standard procedure in this case is to dump the data as Latin1, piping the dump through sed to change the output character set to UTF-8:
mysqldump -uusername -p --default-character-set=latin1 mydb \ | sed -e 's/SET NAMES latin1/SET NAMES utf8/g' \ | sed -e 's/CHARSET=latin1/CHARSET=utf8/g' >mydb.sql
Then, load the dump back into MySQL as UTF-8:
mysql -uusername -p –default-character-set=utf8 <mydb.sql
The last step in this process is to set up the client connection to support UTF-8. Even if all of the data is properly configured and using UTF-8, if MySQL thinks the client wants Latin1 data, that is what it will send. The SQL command to set the client encoding in MySQL is the following:
SET NAMES utf8;
The Rails MySQL connection adapter has an encoding option that sets the client
encoding as well; in lieu of sending the preceding command, just add
the following to your database.yml:
production: adapter: mysql (...) encoding: utf8
At this time, MySQL does not support 4-byte UTF-8 characters. This is generally not a problem, as characters in the Basic Multilingual Plane can always be encoded in three or fewer bytes.
PostgreSQL is in a similar situation; both the database encoding and client encoding must be specified. The default encoding is SQL_ASCII. This is a special byteoriented compatibility encoding; the low-ASCII bytes (0x00 through 0x7F) are treated as ASCII characters, and the rest (0x80 through 0xFF) are left alone. Because of the design of UTF-8, the SQL_ASCII encoding is safe to use with UTF-8. However, it is not optimal, as the database server will not validate any input data.
A new database can be created with UTF-8 encoding, using
either the -E option to createdb or the SQL WITH ENCODING clause:
$ createdb -E UTF-8 new_database -or => CREATE DATABASE new_database WITH ENCODING 'UTF-8';
Existing databases that were created with another encoding can be dumped and reloaded to convert them, as with MySQL.
The ActiveRecord PostgreSQL adapter also respects the encoding option to control client
encoding, so remember to set it to UTF-8:
production: adapter: postgresql (...) encoding: UTF-8
Properly serving UTF-8 is a matter of telling the browser that you are using UTF-8. This is done in two ways:
- HTTP
Content-typeheader with a charset parameter This is the preferred way to set the encoding. The server should be configured to spit out a header like:
Content-Type: text/html; charset=UTF-8
Rails takes care of this for us. As of Rails 1.2, the encoding automatically defaults to UTF-8.
- HTML
<meta>tag This method is often used by those who are not able to change their server's configuration to add a proper header. The <meta> tag takes the place of the HTTP header. Put this inside of the <head> tag on your layouts for the same effect as the header specified previously:
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
When used by itself, setting a <meta> tag is less than ideal. This is because once a browser reaches this tag, it must reparse the document from the beginning if its initial assumption about the encoding was incorrect. (This method works because the characters likely to be used in an HTML document before the <meta> tag have the same representation in all of the common encodings—they are the low ASCII characters.)
However,
<meta>tags are helpful when used in conjunction with proper server headers. They allow the browser to determine the proper encoding even if the file is saved locally (thus removing the header information).
Note that, in the Content-type header, the name "charset" is
misleading, as this parameter really specifies the encoding.
You must consider the issue of data you receive from external sources in non-UTF-8 encodings. If you serve HTML in UTF-8, the data you receive through form posts will be UTF-8. But there are other external sources as well:
Forms from third-party sites pointed at your server may not be encoded in UTF-8. These forms will post their data in the original character set.
When interacting with other systems through web services or messaging, a character set and encoding must be agreed upon.
When retrieving data from the Web (with net/http or open-uri), you must be sure to convert text from its source encoding into your working encoding.
To remedy this situation, you can use the iconv library, which
is part of the Ruby standard library. We have seen this earlier; it
was used to strip invalid characters out of our UTF-8. To convert a
string from one encoding to another, create an Iconv object, providing the source and
destination encodings, and call its iconv instance method:
require 'iconv'
# Latin-1 (ISO-8859-1) equivalent of "café"
# Latin-1 E9 == "é"
cafe_latin1 = "caf#{"E9".hex.chr}"
ic = Iconv.new("utf-8", "iso-8859-1") # to_encoding, from_encoding
cafe_utf8 = ic.iconv(cafe_latin1)We can play with the $KCODE variable to change how we see the output. If we set $KCODE to "U", the string is interpreted as UTF-8 and we see the properly converted "café." If $KCODE is "A", the string is interpreted as a series of bytes, and so we see the unprintable characters escaped:
cafe_latin1 # => "caf\351" $KCODE = "U" cafe_utf8 # => "café" $KCODE = "A" cafe_utf8 # => "caf\303\251"
As usual, we can see the byte length of each string with
String#length:
cafe_latin1.length # => 4 cafe_utf8.length # => 5
There is one important thing to remember if you use JavaScript
to URI-encode text in a UTF-8 environment: always encode data using
encodeURI() or encodeURIComponent(); do not use escape().The encodeURI forms follow RFC 3986,
converting the text to UTF-8 and percent-encoding each byte. This
makes things much easier on the server end.
The escape() function, on
the other hand, escapes one character at a time, using nonstandard
constructs such as %u1234
(corresponding to the code point U+1234). It escapes extended-ASCII
characters as Latin-1, even on a page served as UTF-8:
>>> document.characterSet
"UTF-8"
>>> escape("café")
"caf%E9"
>>> encodeURI("café")
"caf%C3%A9"[76] Matz expresses this sentiment in an interview available at http://blog.grayproductions.net/articles/the_ruby_vm_episode_iv.