There are several decisions that must be made about how to structure a large Rails application. Issues arise with how to manage multiple branches of development, a team of developers, and external or vendor software. In this section, we cover some of the most common choices.
Subversion usually needs a little bit of configuration to work with Rails. There are some
"volatile" files that change from development to production or within
a deployment. These files should be kept out of version control. In
Subversion, a file is ignored within a directory by setting a pattern
matching the file as the value of the svn:ignore property on the parent directory.
For most Rails applications, the following ignores are typically
used:
$ svn propset svn:ignore database.yml config/
$ svn propset svn:ignore "*" log/ tmp/{cache,pids,sessions,sockets}There is a Subversion client configuration that sets up many of
these settings, and will ignore those volatile files without the need
for svn:ignore. It also sets up
autoprops, which sets the MIME type on files in
the repository automatically. If you work mainly with Rails projects,
this can be a good choice. The config file is available from http://3spoken.wordpress.com/rails-subversion-tng-config-file.
As a rule, configuration specific to a particular Rails environment (excluding database connection specifications, which are more specific to the developer and his environment) should not be ignored, but rather should be placed in environment-specific blocks. This allows the configuration to be versioned while still remaining environment-specific.
The svn importcommand is
designed to place a directory (and its subdirectories) under version
control. Unfortunately, it is only an import, not a checkout. It
does not turn the imported directory into a working copy, which is
usually the behavior you want when importing a project that is already under
development.
There is a neat Subversion trick to add an existing directory tree "in place" to an empty repository. You can use this when putting an existing application under version control:
$ svn mkdir svn://repo/my_app/trunk $ cd my_app $ svn co svn://repo/my_app/trunk . $ svn add * $ svn ci
To add only certain directories without their contents, pass
the -N (--non-recursive) flag to svn add. This is very useful when setting
contents of certain directories to be ignored; for example, these
commands will add the
public/attachmentsdirectory while ignoring its
contents:
$ svn add -N public $ svn add -N public/attachments $ svn propset svn:ignore "*" public/attachments
Subversion has an externals facility for pulling in code from other repositories. When a folder is designated as an external, it is paired with a remote repository. When updating the working copy, code will be pulled from that repository in addition to the main project repository.
In Rails, there are two reasons you would want to do this. The
first is to lock Rails to a certain version (or to track edge Rails).
The second is for plugins: you may want to follow updates to a
plugin's Subversion repository, so you can lock
vendor/plugins/ plugin_name to the plugin's
development repository. The script/plugincommand even provides a flag
that adds the plugin as an external rather than downloading it:
$ script/plugin install -x some_plugin
This works for small-scale applications, but the dependencies
can quickly become a mess. Most of the time, you will not want to
follow the bleeding edge of Rails or a plugin, but instead lock to a
known-stable version. Although svn:externals has a feature to do that, it
can get messy. The biggest problem is that any local changes you make
to the external code are not versioned. In addition, updates are slow
as they must query each external server.
The best solution at this point is François Beausoleil's Piston
(http://piston.rubyforge.org). Rather than
pulling a copy of the code from the remote Subversion server, Piston
stores a copy locally, in your project's own Subversion repository. It
uses properties on the folder to track the current version at the
remote repo. To Subversion, the directory is just another set of files
in your project. This means that updates are fast, as they only talk
to one server. You also only get external updates when you ask for
them (piston update).
First, install Piston and convert your existing svn:externalsto Piston-locked
directories:
$ sudo gem install --include-dependencies piston $ piston convert
You can now lock to edge Rails:
$ piston import http://svn.rubyonrails.org/rails/trunk vendor/rails
Installing plugins is simple if you know the repository URL:
$ piston import \ http://activemerchant.googlecode.com/svn/trunk/active_merchant \ vendor/plugins/active_merchant
Remember to manually execute the commands in
install.rb if it does anything special; script/plugin would do this for you, but
Piston doesn't know or care that you are installing a Rails
plugin.
Piston-controlled directories can be updated all at once with
piston update, or one at a time
with piston update
vendor/plugins/active_merchant.
If a Rails distribution is unpacked in
vendor/rails under the application root, it will
be used. If vendor/railsis not present, Rails
will look for an installed rails
gem matching the specified RAILS_GEM_VERSION(usually specified in
config/environment.rb). It is usually best, for
the sake of predictability, to have the Rails code unpacked in
vendor/rails. Although it takes up a little more
room in the repository and on the server, it ensures that everyone is
on the same page and developing against the exact same
version.
Nothing says that you have to use edge Rails; for the stable branch of Rails 1.2, use Piston to lock vendor/rails to http://svn.rubyonrails.org/rails/branches/1-2-stable.
As Rails has matured, the environment.rb configuration file has been shifting in purpose and style. Originally, it started out as a procedural language where every little bit of configuration was included, and you would just "throw something at the bottom" to have it run upon Rails initialization. Now, its purpose is more focused, to the point that it almost seems to be a domain-specific language for configuring Rails. The mechanics of starting up Rails have been moved to boot.rb, and what is left has been cleaned up.
However, sometimes we just need a place to put initialization routines. In edge Rails, these have been given a new place. If you have (or create) a config/initializers directory, any Ruby files there will be executed after the environment is configured.
Having a separate place for initializers helps you to separate them by function. Here is a sample file for custom inflections:
# config/initializers/inflections.rb # inflect.uncountable(["data"]) doesn't catch "something_data" Inflector.inflections do |inflect| inflect.plural(/(data)$/i, '\1') inflect.singular(/(data)$/i, '\1') end
The last trick for initialization is the after_initialize block. Included as part of
the configuration, it will be run at the end of initialization
(immediately before the initializers mentioned previously). The block
is specified thus:
config.after_initialize do # some initialization code... end
Unfortunately, you only get one after_initialize block per
initialization—you can't have one in
environment.rb and another in
production.rb. So, choose wisely where you need
it. My recommendation: use it in your environment-specific
configuration files, and use the initializers directory for your
generic initialization.
When deploying to a new machine, it can be frustrating to make sure all of the dependencies are in order. RubyGems are typically the main culprit here. One way to ensure you have gem dependencies under your control is to include them in the project tree. This idea, from Chris Wanstrath,[88] is the natural extension of keeping Rails and plugins within the project.
To include gems in the project, we will create a directory to hold
them, then unpack a gem there using the gem
unpack command (you may need to update Ruby Gems for this command to work):
$ mkdir vendor/gems $ cd vendor/gems $ gem unpack hpricot Unpacked gem: 'hpricot-0.4'
Now we need to ensure that the directory we have created is
added to the load path. In the environment.rb file, inside the
Rails::Initializer.run block, add
the following:
config.load_paths += Dir["#{RAILS_ROOT}/vendor/gems/**"].map do |dir|
File.directory?(lib = "#{dir}/lib") ? lib : dir
endThere are plenty of nuances to this trick, so be sure to check the aforementioned blog post and its comments for the full story.
For large projects, sometimes multiple Rails applications need to be grouped together. Multiple applications that need to share code can be grouped in the same version control tree. This is a good use for Subversion externals; externals can point to other parts of the repository that they live in.
Under this setup, bits of shared code are kept in the repository at the top level of their branch or trunk (at the same level as the Rails applications). Subversion externals are used to pull shared folders into each of the Rails projects. A typical directory structure looks like Figure 10-5.
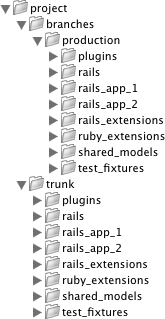
Under this directory layout, you would issue commands like the following to import each directory from the shared tree:
$ cd project
$ svn propset svn:externals "models(repo)/trunk/shared_models" \
trunk/rails_app_{1,2}/appThat command tells Subversion to source trunk/rails_app_1/app/models and trunk/ rails_app_2/app/models from trunk/shared_models. When you update either of the Rails applications, they will grab code from shared_models. When you commit code into the applications' model directories, Subversion will push the code into shared_models.
There is one caveat to this approach. Subversion will not commit to two repositories at once, and it sees an external as a separate repository. So, if you make changes to both the models and some other part of an application at the same time, you must check those changes in separately. This can take some getting used to, but it quickly becomes second nature.
Depending on your situation, you may want to keep any or all of these shared between two or more Rails applications:
- Rails codebase
Usually, you want all of the applications within a project to be locked to the same version of Rails.With a project maintained under Subversion, using Piston to source the vendor code offers an advantage; you can maintain local changes to the Rails tree independently of what happens upstream. Using Piston, you can lock Rails to a certain branch (stable or edge) and update when you feel like it.
You can pull changes from the upstream Rails repository and sync them throughout
trunkwith the following commands:$ cd project/trunk $ piston update rails $ svn up
- Plugins
Like the Rails source, plugins usually come in from an upstream repository. Often you will need them synchronized across projects. Here, Piston is a great help again, as you can update across your project and only pull changes from upstream when you are ready.You have two options for structuring the source tree: you can either pull the plugins directory as a whole(into vendor/plugins), or you can cherry-pick the plugins you need for each application.
- RubyGems
Maintaining gem dependencies between development environments, staging, and production servers can be a hassle. The most consistent solution is to "vendor everything"—create a vendor/gems directory, carry your gem dependencies around with the project code, and modify Rails to look there before your installed RubyGems.
Chris Wanstrath came up with this solution (http://errtheblog.com/post/2120), and Dr.Nic Williams packaged it into a gem itself,
gemsonrails(http://gemsonrails.rubyforge.org). Kyle Maxwell has a Rails plugin that allows the "vendor everything" approach to be used for gems that require building native extensions (http://svn.kylemaxwell.com/rails_plugins/vendor_everything_extensions).- Ruby and Rails extensions
Any project of reasonable size usually accumulates a series of extensions, annotations, and utility functions that supplement the Ruby and Rails core. Examples of Ruby extensions:
class String # "Frequently - Asked Questions!" => "frequently_asked_questions_" def to_slug self.downcase.gsub(/[^a-z0-9]+/, "_") end # 12345678.to_s.with_commas => "12,345,678" def with_commas self.reverse.gsub(/\d{3}/,"\\&,").reverse.sub(/^,/,"") end endBecause these utility functions are usually widely applicable, it is useful to share them between projects.Iusually keep them under lib/extensions and
requirethem from an initializer.- ActiveRecord models
Some situations call for two or more separate applications sharing the same data.While this is usually accomplished with one Rails application and judicious separation of concerns, occasionally the purposes for the applications will diverge and it will make sense to split them up. In that case, the models can be placed in a shared_models directory and shared out among the applications.
- Test fixtures
If you share a data model between applications, you will usually want to share any test fixtures you have between those applications as well.