
It’s a big world out there, and one that your web application can’t afford to ignore. Perhaps more importantly, you’d rather the world not ignore your web application. One excellent way to tune the world in to your web application is to make its data available for syndication, which means users can subscribe to your site’s content instead of having to visit your web site directly to find new info. Not only that, your application can interface to other applications through web services and take advantage of other people’s data to provide a richer experience.
One of the big problems facing any web site is keeping people coming back. It’s one thing to snare a visitor, but quite another to get them to come back again. Even sites with the most engaging content can fall off a person’s radar simply because it’s hard to remember to go visit a web site regularly. Knowing this, Owen wants to offer an alternative means of viewing alien abduction reports—he wants to “push” the reports to people, as opposed to them having to visit his site on a regular basis.

By pushing alien abduction content to users, Owen effectively creates a virtual team of people who can help him monitor abduction reports. With more people on the case, the odds of identifying more Fang sightings and hopefully homing in on Fang’s location increase.
Pushing web content to users is a great way to help gain more exposure for a web site.

The idea behind posting HTML content to the Web is that it will be viewed by people who visit a web site. But what if we want users to receive our web content without having to ask for it? This is possible with RSS, a data format that allows users to find out about web content without actually having to visit a site.
RSS is kinda like the web equivalent of a digital video recorder (DVR). DVRs allow you to “subscribe” to certain television shows, automatically recording every episode as it airs. Why flip channels looking for your favorite show when you can just let the shows come to you by virtue of the DVR? While RSS doesn’t actually record anything, it is similar to a DVR in that it brings web content to you instead of you having to go in search of it.
By creating an RSS feed for his alien abduction data, Owen wants to notify users when new reports are posted. This will help ensure that people stay interested, resulting in more people combing through the data. The cool thing is that the same database can drive both the web page and the RSS feed.
HTML is for viewing; RSS is for syndicating.

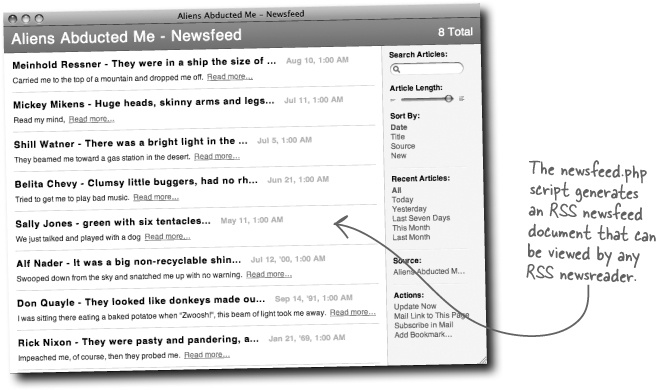
RSS offers a view on web data that is delivered to users automatically as new content is made available. An RSS view on a particular set of data is called an RSS feed, or newsfeed. Users subscribe to the feed and receive new content as it is posted to the web site—no need to visit the site and keep tabs.
To view an RSS feed, all a person needs is an RSS newsreader. Most popular web browsers and email clients can subscribe to RSS feeds. You just provide the newsreader with the URL of the feed, and it does all the rest.
RSS is like HTML in that it is a plain text markup language that uses tags and attributes to describe content. RSS is based on XML, which is a general markup language that can be used to describe any kind of data. XML’s power comes from its flexibility—it doesn’t define any specific tags or attributes; it just sets the rules for how tags and attributes are created and used. It’s up to specific languages such as HTML and RSS to establish the details regarding what tags and attributes can be used, and how.
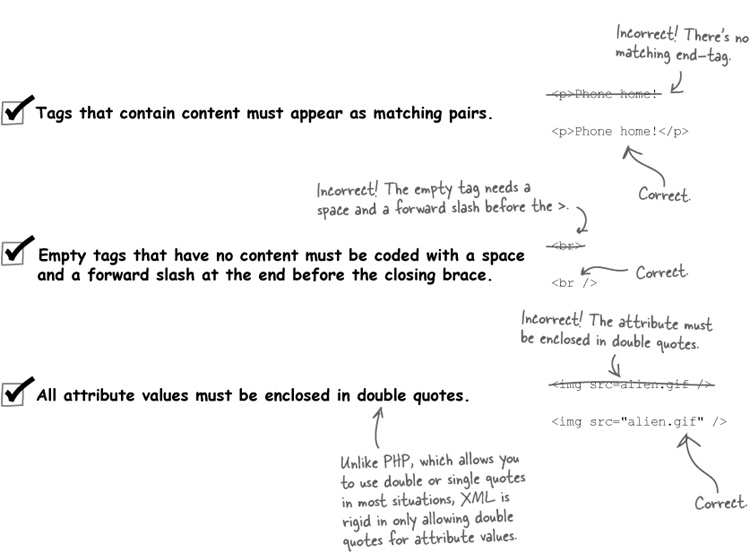
In order to be proficient with RSS, you must first understand the ground rules of XML. These rules apply to all XML-based languages, including RSS and the modern version of HTML known as XHTML. These rules are simple but important—your XML (RSS) code won’t work if you violate them! Here goes:
RSS is a markup language used to describe web content for syndication.
XML is a markup language used to describe any kind of data.
Exercise Solution
Below is RSS code for an Aliens Abducted Me news feed. Annotate the highlighted code to explain what you think each tag is doing.


Yes, sort of. But you don’t typically create XML code by hand, and it often doesn’t get stored in files.
It’s true that XML can and often does get stored in files. But with RSS we’re talking about dynamic data that is constantly changing, so it doesn’t make sense to store it in files—it would quickly get outdated and we’d have to continually rewrite the file. Instead, we want XML code that is generated on-the-fly from a database, which is how the HTML version of the main Aliens Abducted Me page already works. So we want to use PHP to dynamically generate RSS (XML) code and return it directly to an RSS newsreader upon request.
In order to provide a newsfeed for alien abduction data, Owen needs to dynamically generate RSS code from his MySQL database. This RSS code forms a complete RSS document that is ready for consumption by RSS newsreaders. So PHP is used to format raw alien abduction data into the RSS format, which is then capable of being processed by newsreaders and made available to users. The really cool part of this process is that once the newsfeed is made available in RSS form, everything else is automatic—it’s up to newsreaders to show updated news items as they appear.
An RSS newsreader is designed to consume the data made available by an RSS newsfeed.

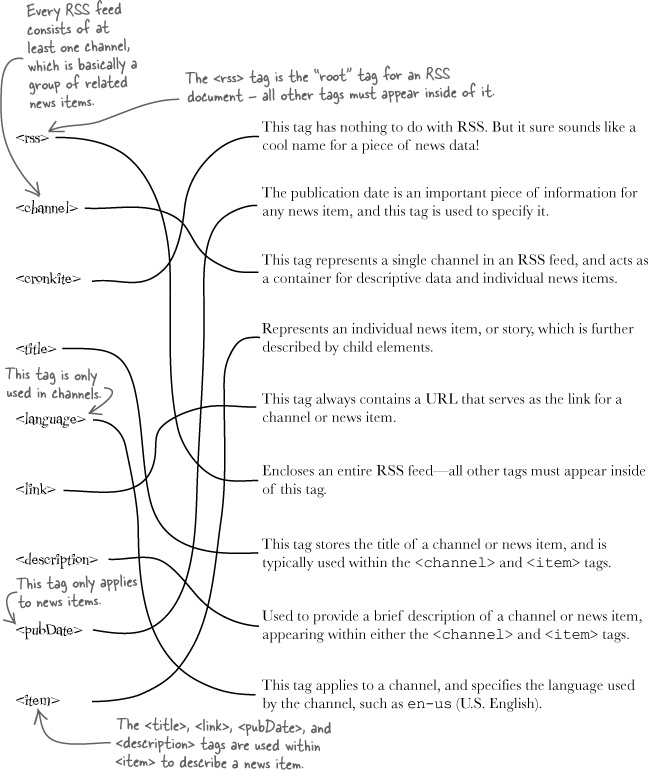
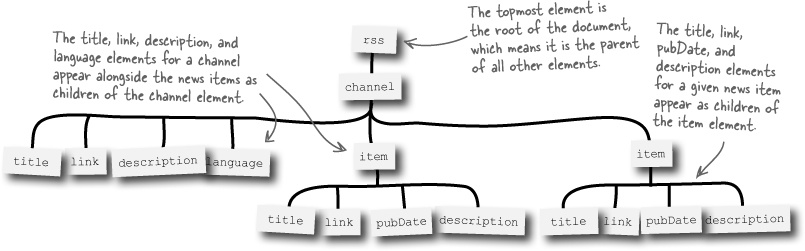
You already learned that XML code consists of tags, which are also sometimes referred to as elements, that form parent-child relationships within the context of a complete XML document. It is very helpful to be able to visualize this parent-child relationship as you work with XML code. As an example, the RSS document on the facing page can be visualized as a hierarchy of elements, kind of like a family tree for newsfeed data, with parent elements at the top fanning out to child elements as you work your way down.
Exercise
Below is a brand-new alien abduction report that has been added to the aliens_abduction database. Write the XML code for an RSS <item> tag for this abduction report, making sure to adhere to the RSS format for newsfeeds.

__________________________________________
__________________________________________
__________________________________________
__________________________________________
__________________________________________
__________________________________________

Understanding the RSS data format is all fine and good, but Owen still needs a newsfeed to take alien abduction reports to the people. It’s time to break out PHP and dynamically generate a newsfeed full of alien abduction data that has been plucked from Owen’s MySQL database. Fortunately, this can be accomplished by following a series of steps:
The resulting newsfeed isn’t stored in a file but it is an XML document.
Set the content type of the document to XML.
Generate the XML directive to indicate that this is an XML document.
Generate the static RSS code that doesn’t come from the database, such as the <rss> tag and the channel information.
Query the aliens_abduction database for alien abduction data.
Loop through the data generating RSS code for each news item.
Generate the static RSS code required to finish up the document, including closing </channel> and </rss> tags.
</channel> </rss>


PHP & MySQL & XML Magnets
Owen’s Aliens Abducted Me RSS newsfeed script (newsfeed.php) is missing some important code. Carefully choose the appropriate magnets to finish the code and dynamically generate the newsfeed.

PHP & MySQL & XML! Magnets Solution
Owen’s Aliens Abducted Me RSS newsfeed script (newsfeed.php) is missing some important code. Carefully choose the appropriate magnets to finish the code and dynamically generate the newsfeed.

Test Drive
Add the RSS Newsfeed script to Aliens Abducted Me.
Create a new text file named newsfeed.php, and enter the code for Owen’s RSS Newsfeed script from the Magnets exercise a few pages back (or download the script from the Head First Labs site at www.headfirstlabs.com/books/hfphp).
Upload the script to your web server, and then open it in a newsreader. Most web browsers and some email clients allow you to view newsfeeds, so you can try those first if you don’t have a stand-alone newsreader application. The Newsfeed script should display the latest alien abductions pulled straight from the Aliens Abducted Me database.
Note
If your browser has trouble viewing the newsfeed, try using feed:// in the URL instead of http://.

Just provide a link to it from the home page.
Don’t forget that newsfeed.php is nothing more than a PHP script. The only difference between it and most of the other PHP scripts you’ve seen throughout the book is that it generates an RSS document instead of an HTML document. But you still access it just as you would any other PHP script—just specify the name of the script in a URL. What Owen is missing is a way to share this URL with people who visit his site. This is accomplished with very little effort by providing a syndication link, which is just a link to the newsfeed.php script on Owen’s server.
It’s important to provide a prominent link to the newsfeed for a web site because a lot of users will appreciate that you offer such a service. To help aid users in quickly finding an RSS feed for a given site, there is a standard icon you can use to visually call out the feed. We can use this icon to build a newsfeed link at the bottom of Owen’s home page (index.php).


After a newsfeed subscriber alerted Owen to a YouTube video with a dog in it that resembles Fang, Owen realized that he’s going to have to use additional technology to expand his search for Fang. But how? If Owen could incorporate YouTube videos into Aliens Abducted Me, his users could all be on the lookout for Fang. Not only that, but he really needs to come up with a way to avoid constantly doing manual video searches on YouTube.

Try this!
Visit Owen’s YouTube videos at www.youtube.com/user/aliensabductedme.
Watch a few of the alien abduction videos that Owen has found. Do you think the dog in the videos is Fang?

The idea behind an RSS newsfeed is that it pushes your content to others so that they don’t have to constantly visit your web site for new content. This is a great way to make it more convenient for people to keep tabs on your site, as Owen has found out. But there’s another side to the web syndication coin, and it involves pulling content from another site to place on your site. So you become the consumer, and someone else acts as the content provider. In Owen’s case of showing YouTube videos on his site, YouTube becomes the provider.
YouTube is the provider of videos.
Aliens Abducted Me is the consumer of videos.

It’s important to understand that Owen doesn’t just want to embed a specific YouTube video or a link to a video. That’s easy enough to accomplish by simply cutting and pasting HTML code from YouTube. He wants to actually perform a search on YouTube videos and display the results of that search. So Aliens Abducted Me needs to perform a real-time query on YouTube data, and then dynamically display the results. This allows Owen and his legion of helpful Fang searchers to keep up-to-the-minute tabs on alien abduction videos that have been posted to YouTube.
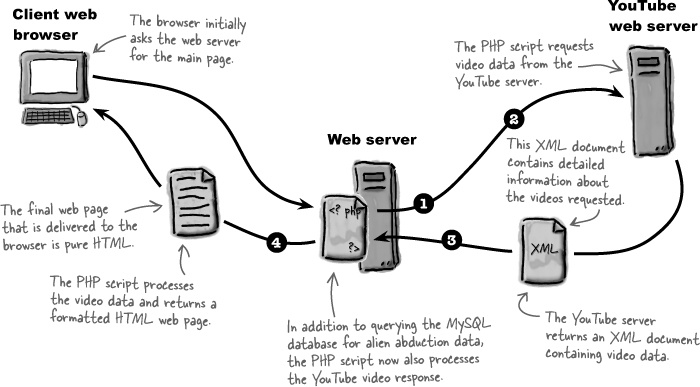
In order to source videos from YouTube, we must learn exactly how YouTube makes videos available for syndication. YouTube offers videos for syndication through a request/response communication process where you make a request for certain videos and then receive information about those videos in a response from YouTube’s servers. You are responsible for both issuing a request in the format expected by YouTube and handling the response, which includes sifting through response data to get at the specific video data you need (video title, thumbnail image, link, etc.).
Following are the steps required to pull videos from YouTube and display them:
Syndicating videos from YouTube involves issuing requests and handling responses.
Build a request for YouTube videos.
Issue the video request to YouTube.
Receive YouTube’s response data containing information about the videos.
Process the response data and format it as HTML code.
Pulling videos from YouTube and incorporating them into your own web pages begins with a request. YouTube expects videos to be queried through the use of a REST request, which is a custom URL that leads to specific resources, such as YouTube video data. You construct a URL identifying the videos you want, and then YouTube returns information about them via an XML document.
The details of the URL for a YouTube request are determined by what videos you want to access. For example, you can request the favorite videos of a particular user. In Owen’s case, the best approach is probably to perform a keyword search on all YouTube videos. The URL required for each of these types of video REST requests varies slightly, but the base of the URL always starts like this:

Requesting the favorite videos for a particular YouTube user involves adding onto the base URL, and also providing the user’s name on YouTube.

To request the favorite videos for the user elmerpriestley, use the following URL:

 Request videos with a keyword search
Request videos with a keyword search
A more powerful and often more useful YouTube video request is to carry out a keyword search that is independent of users. You can use more than one keyword as long as you separate them by forward slashes at the end of the URL.

To request the favorite videos for the keywords “elvis” and “impersonator,” use the following URL:

BE the YouTube REST Request
Your job is to get inside the mind of YouTube and become a video REST request. Use the magnets below to assemble video REST requests for the following YouTube videos, and then try them out in your web browser.
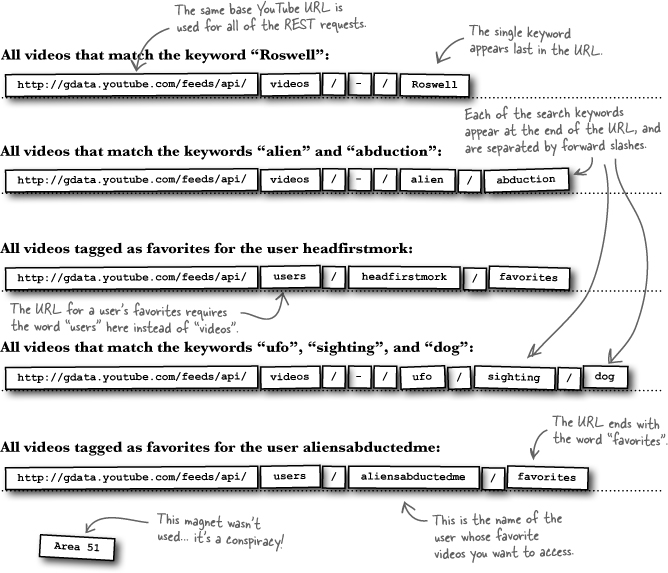
All videos that match the keyword “Roswell”:
__________________________________________
All videos that match the keywords “alien” and “abduction”:
__________________________________________
All videos tagged as favorites for the user headfirstmork:
__________________________________________
All videos that match the keywords “ufo”, “sighting”, and “dog”:
__________________________________________
All videos tagged as favorites for the user aliensabductedme:
__________________________________________
Since Owen’s goal is to scour YouTube for alien abduction videos that might have Fang in them, a keyword search makes the most sense as the type of REST request to submit to YouTube. There are lots of different keyword combinations that could be used to search for possible Fang videos, but one in particular will help home in on videos related specifically to Fang:

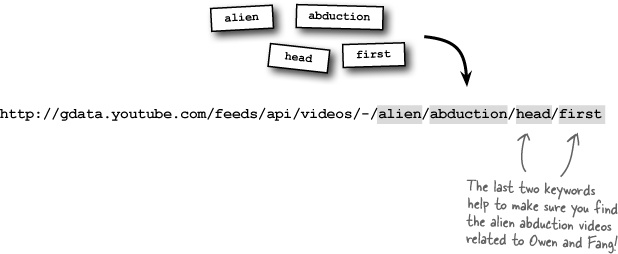
While you probably wouldn’t reference the title of a book series when carrying out a normal YouTube video search, it just so happens to be a good idea in this particular case. Let’s just say it’s a coincidence that a lot of alien abduction videos have been made by Head First fans! With a REST request URL in hand, Owen can scratch off Step 1 of the YouTube video syndication process.
Build a request for YouTube videos.
Issue the video request to YouTube.
Receive YouTube’s response data containing information about the videos.
Process the response data and format it as HTML code.
Test Drive
Try out Owen’s YouTube request URL.
Enter Owen’s YouTube request URL in a web browser:
http://gdata.youtube.com/feeds/api/videos/-/alien/abduction/head/first
What does the browser show? Try viewing the source of the page to take a look at the actual code returned by YouTube.
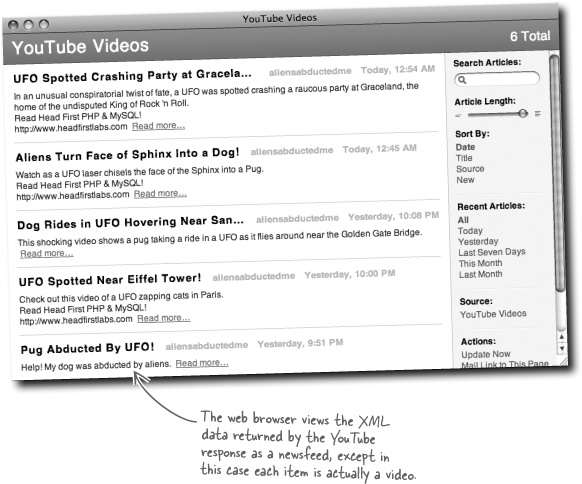

We can, we just need a PHP function that allows us to submit a REST request and receive a response.
Note
The SimpleXML extension to PHP, which offers the simplexml_load_file() function, was added to PHP in version 5. So prior versions of PHP don’t have built-in support for XML processing.
The built-in PHP function simplexml_load_file() lets us submit REST requests that result in XML responses, such as YouTube requests/responses. The function actually loads an XML document into a PHP object, which we can then use to drill down into the XML data and extract whatever specific information is needed. So how does that impact Owen’s YouTube video request? Check out this code, which creates a constant to hold a YouTube URL, and then issues a REST request using the simplexml_load_file() function:


Relax
Don’t sweat it if you don’t know what an object is, especially in the context of PHP.
A PHP object is a special data type that allows data to be packaged together with functions in a single construct. All you need to know for now is that it’s much easier to process XML data in PHP by using objects. You’ll learn more about how this is possible in just a bit.


Oh, but there is! The XML code returned by YouTube isn’t really as messy as it looks... you just have to know where to look.
The video response from YouTube isn’t exactly a DVD packaged up in a shiny box and delivered to your front door. No, it’s an XML document containing detailed information about the videos you requested, not the videos themselves.
YouTube responds to video requests with XML data that describes the videos.

Sharpen your pencil Solution
Study the highlighted XML code for the YouTube response in YouTube speaks XML and answer the following questions. You might just know more about YouTube’s video XML format than you thought at first glance!


The unusual XML code uses namespaces and entities, which help organize tags and encode special characters.
When you see an XML tag that has two names separated by a colon, you’re looking at a namespace, which is a way of organizing a set of tags into a logical group. The purpose of namespaces is to keep tags with the same name from clashing when multiple XML vocabularies are used in the same document. As an example, consider the following two XML tags:

Without the media namespace in the second <title> tag, it would be impossible to tell the two tags apart if they appeared in the same XML code. So you can think of a namespace as a surname for tags—it helps keep an XML document full of “first names” from clashing by hanging a “last name” on related tags. The YouTube response code uses several different namespaces, which means it is using several different XML languages at once—namespaces allow us to clearly tell them apart.
To ensure uniqueness, an XML namespace is always associated with a URL. For example, the media namespace used in YouTube XML data is established within the <feed> tag like this:
Namespaces are named groups of XML tags, while entities are used to encode special characters within XML documents.

The other strange thing in the YouTube XML code is &, which is XML’s way of representing the ampersand character (&). This is an XML entity, a symbolic way of referencing a special character, such as &, <, or >, all of which have special meaning within XML code. Following are the five predefined XML entities that you will likely encounter as you delve deeper into XML code:
Once you get to know the structure of a YouTube response, extracting the video data you need is pretty straightforward. In addition to understanding what tags and attributes store what data, it’s also important to understand how the tags relate to one another. If you recall from earlier in the chapter when analyzing an RSS feed, an XML document can be viewed as a hierarchy of elements. The same is true for the XML data returned in a YouTube video response.
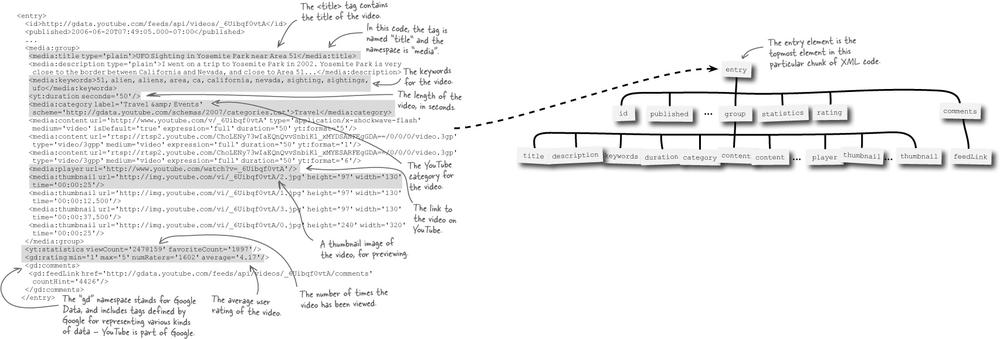
One important clue toward understanding the video data buried in this XML code is the different namespaces being used. The media namespace accompanies most of the tags specifically related to video data, while the yt namespace is used solely with the <statistics> tag. Finally, comments are enclosed within the <comments> tag, which falls under the gd namespace. These namespaces will matter a great deal when you begin writing PHP code to find specific tags and their data.
Earlier in the chapter when working with RSS code, it was revealed that an XML document can be visualized as a hierarchy of elements (tags) that have a parent-child relationship. This relationship becomes increasingly important as you begin to process XML code and access data stored within it. In fact, it can be an invaluable skill to be able to look at an XML document and immediately visualize the relationship between the elements. Just remember that any element enclosed within another element is a child, and the enclosing element is its parent. Working through the XML code for the YouTube video on the facing page results in the following visualization.
An element is just an abstract way of thinking of an XML tag and the data it contains.
The significance of this hierarchy of elements is that you can navigate from any element to another by tracing its path from the top of the hierarchy. So, for example, if you wanted to obtain the title of the video, you could trace its path like this:

There are lots of different ways to work with XML data with PHP, and one of the best involves objects. An object is a special PHP data type that combines data and functions into a single construct. But what does that have to do with XML? The entire hierarchy of elements in an XML document is contained within a single variable, an object. You can then use the object to drill down into the data and access individual elements. Objects also have methods, which are functions that are tied to an object, and let us further manipulate the object’s data. For an object that contains XML data, methods let us access the collection of child elements for an element, as well as its attributes.
Objects are a special PHP data type that combine data and functions together.
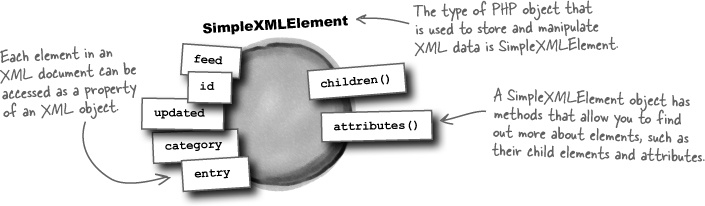
You’ve already seen how to create this XML object for Owen’s alien abduction YouTube keyword search:

This code results in a variable named $xml that contains all of the XML YouTube video data packaged into a PHP object. To access the data you use object properties, which are individual pieces of data stored within an object. Each property corresponds to an XML element. Take a look at the following example, which accesses all of the entry elements in the document:

This code accesses all the entry elements in the XML data using a property. Since there are multiple entry elements in the data, the $entries variable stores an array of objects that you can use to access individual video entries. And since we’re now dealing with an array, each video <entry> tag can be accessed by indexing the array. For example, the first <entry> tag in the document is the first item in the array, the second tag is the second item, etc.

When it comes to XML data and PHP objects, you’re really dealing with a collection of objects. Remember that stuff about visualizing an XML document as a hierarchy of elements? Well, that same hierarchy is realized as a collection of objects in PHP. Take a look:

This element hieararchy/object collection stuff forms the basis of understanding how to dig through XML data in PHP. With the relationship between individual pieces of XML data in mind, it becomes possible to write code that navigates through the data. Then we can isolate the content stored in a particular tag or attribute down deep in an XML document.
Getting back to Owen, our goal is to pull out a few pieces of information for videos that are returned as part of the XML YouTube response. We know how to retrieve the XML data into a PHP object using the simplexml_load_file() function, but most of the interesting data is found down deeper in this data. How do we navigate through the collection of objects? The answer is the -> operator, which is used to reference a property or method of an object. In the case of an XML object, the -> operator accesses each child object. So this code displays the title of a video entry stored in a variable named $entry:

This code relies heavily on the relationship between the title, group, and entry objects, which form a parent-child relationship from one to the next.
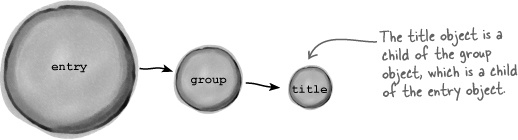
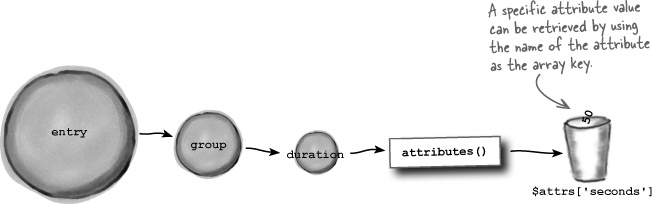
The -> operator references a child object from a parent object. So title is a child of group, which is a child of entry. Remember that the -> operator can be used to access both properties and methods. One method that comes in particularly handy is the attributes() method, which is able to pluck out the value of an XML attribute for a given element.

This code drills down to the duration element and then grabs all of its attributes and stores them in the $attrs variable, which is an array of all the attributes. The value of the seconds attribute is then retrieved from the array.
There’s a small problem with the code on the facing page that accesses XML data using objects, and it has to do with namespaces. If you recall, namespaces act as surnames for tags by organizing them into meaningful collections. So in a YouTube response, the <duration> tag is actually coded as <yt:duration>, and the title for a video is coded as <media:title>, not <title>. When an element is associated with a namespace, you can’t just reference it by tag name in PHP code. Instead, you have to first isolate it by namespace by calling the children() method on the parent object.
Namespaces make it a bit trickier to access elements within XML data.

This code retrieves all the child objects of the video entry whose namespace is http://search.yahoo.com/mrss/. But that’s the URL for a namespace, not the namespace itself. This URL is located in the <feed> tag at the start of the XML document. This is where you’ll find all the namespaces being used.

This code reveals how each namespace is associated with a URL. More specifically, it shows how the media and yt namespaces are specified for use in the document. This is all you need to find tags related to these two namespaces.
Once you’ve isolated the child elements for a particular namespace by calling the children() method on the parent element, you can then resume accessing child objects with the -> operator. For example, this code obtains the video title from the <media:group> tag:
Use the children() method to isolate all elements associated with a namespace.
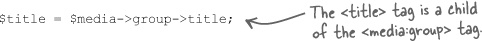

While Owen has been busy brushing up on XML and figuring out how to communicate with YouTube, Fang has been busy. Numerous video sightings have turned up with the little guy apparently serving as a tour guide for his alien abductors. Owen is ready to finish up the YouTube script, get some videos showing on the Aliens Abducted Me home page, and find his lost dog.


The good news is that Owen is almost finished with the YouTube script. In fact, all that’s left is to finish processing the XML data and format it as HTML code.
Build a request for YouTube videos.
Issue the video request to YouTube.
Receive YouTube’s response data containing information about the videos.
Process the response data and format it as HTML code.
Draw how you would format YouTube response data as videos along the bottom of the main Aliens Abducted Me page:
The idea behind the youtube.php script is that it will be included in the main index.php script for Aliens Abducted Me. This means that the youtube.php script needs to take care of submitting a video request, processing the XML response, and formatting the individual videos so that they are displayed via HTML in such a way that they can coexist with the alien abduction reports that are already on the main page. A good way to accomplish this is to arrange the videos horizontally along the bottom of the page.
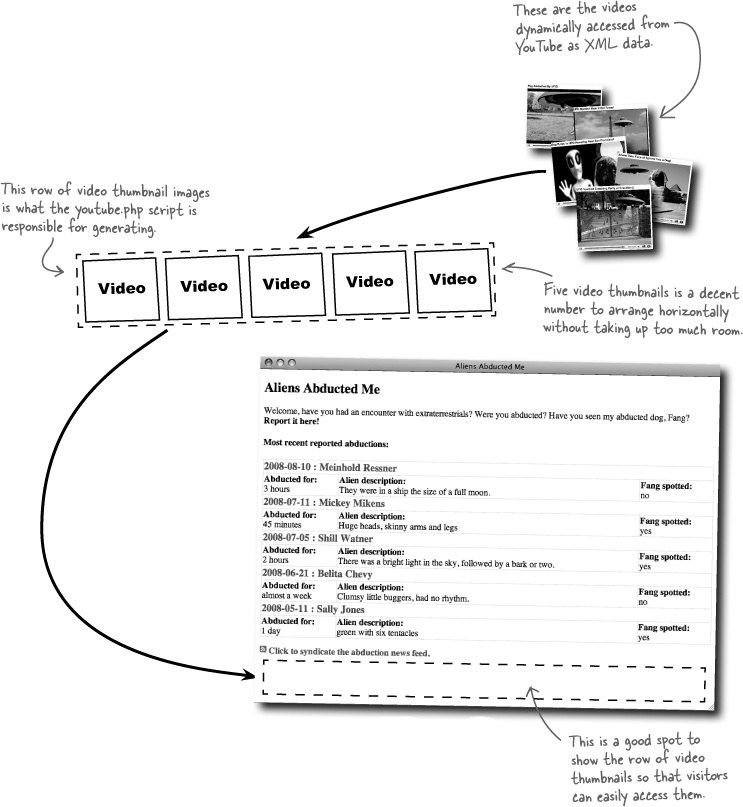
The youtube.php script will be included so that the videos appear just below the alien abduction reports.
Arranging the videos horizontally on the main page keeps them from detracting too much from the alien abduction reports. Also, we’re talking about arranging the video thumbnail images, not the videos themselves, so users will have to click a thumbnail to visit YouTube and see the actual video. It would eat up too much screen real estate to attempt to show multiple videos large enough to be embedded directly on the Aliens Abducted Me page.
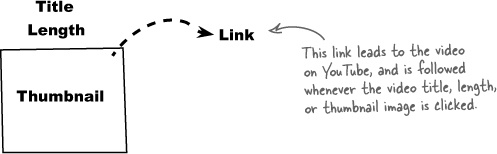
Although a video thumbnail image is certainly one of the most important pieces of information when assessing whether or not a video is worth watching, it isn’t the only data useful for Owen’s YouTube script. For example, the title of a video could hold some important information about the nature of the video—like whether it might include a dog. The length of the video could also be helpful. And of course, we need the URL of the video link to YouTube so that the user can click on a video thumbnail to actually view a video. So the following information is what we need to extract from the XML data in the YouTube response:

This data forms the basis for the HTML code that displays a horizontal row of videos. In fact, each video in the row ends up looking like this:
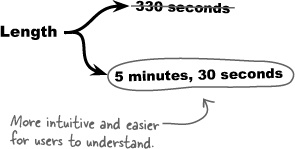
In the YouTube response data, the length of a video is specified in the seconds attribute of the <yt:duration> tag. Unfortunately, most people don’t think in terms of total seconds because we’re accustomed to times being specified in minutes and seconds. For example, it isn’t immediately obvious that 330 seconds is a five-and-a-half-minute video—you have to do the math for the value to make sense as a length of time. Knowing this, it’s a good idea to go ahead and do the math for users when displaying the length of a video, converting seconds into minutes and seconds.
Geek Bits
It isn’t necessary to factor in hours in the video length calculation because YouTube doesn’t currently allow videos longer than 10 minutes to be posted.
That is, unless you’re part of the YouTube Director program, in which case you can post videos longer than 10 minutes.

Exercise Solution
The youtube.php script uses PHP code to grab the top five matches for an alien abduction YouTube video search. It then displays thumbnail images for those videos in a horizontal row, with links to the actual videos on YouTube. Fill in the missing code for the script, using the example YouTube XML video response data on the facing page as a guide.


Test Drive
Add the YouTube script to Aliens Abducted Me.
Create a new text file named youtube.php, and enter the code for Owen’s YouTube script from the previous two pages (or download the script from the Head First Labs site at www.headfirstlabs.com/books/hfphp). You still need to plug the script into the index.php script to turn YouTube videos loose on the main Aliens Abducted Me page. Here are the two lines of PHP code to do it:

Upload the scripts to your web server, and then open index.php in a web browser. The bottom of the page should show a dynamically generated row of YouTube video links that are related to alien abductions.



