There are around 50 standard LINQ operators. The rest of this chapter describes the most important operators, broken down by the main areas of functionality. We’ll show how to use them both from a query expression (where possible) and with an explicit method call.
Note
Sometimes it’s useful to call the LINQ query operator methods
explicitly, rather than writing a query expression. Some operators offer
overloads with advanced features that are not available in a query
expression. For example, sorting strings is a locale-dependent
operation—there are variations on what constitutes alphabetical ordering
in different languages. The query expression syntax for ordering data
always uses the current thread’s default culture for ordering. If you
need to use a different culture for some reason, or you want a
culture-independent order, you’ll need to call an overload of the
OrderBy operator explicitly instead
of using an orderby clause in a query
expression.
There are even some LINQ operators that don’t have an equivalent in a query expression. So understanding how LINQ uses methods is not just a case of looking at implementation details. It’s the only way to access some more advanced LINQ features.
You already saw the main filtering feature of LINQ. We
illustrated the where clause and the
corresponding Where operator in Example 8-2 and Example 8-3, respectively. Another filter
operator worth being aware of is called OfType. It has no query expression equivalent,
so you can use it only with a method call. OfType is useful when you have a collection
that could contain a mixture of types, and you only want to look at the
elements that have a particular type. For example, in a user interface
you might want to get hold of control elements (such as buttons),
ignoring purely visual elements such as images or drawings. You could
write this sort of code:
var controls = myPanel.Children.OfType<Control>();
If myPanel.Children is a
collection of objects of some kind, this code will ensure that controls is an enumeration that only returns
objects that can be cast to the Control type.
Although OfType has no
equivalent in a query expression, that doesn’t stop you from using it in
conjunction with a query expression—you can use the result of OfType as the source for a query:
var controlNames = from control in myPanel.Children.OfType<Control>()
where !string.IsNullOrEmpty(control.Name)
select control.Name;This uses the OfType operator
to filter the items down to objects of type Control, and then uses a where clause to further filter the items to
just those with a nonempty Name
property.
Query expressions can contain an orderby clause, indicating the order in which
you’d like the items to emerge from the query. In queries with no
orderby clause, LINQ does not, in
general, make any guarantees about the order in which items emerge. LINQ
to Objects happens to return items in the order in which they emerge
from the source enumeration if you don’t specify an order, but other
LINQ providers will not necessarily define a default order. (In
particular, database LINQ providers typically return items in an
unpredictable order unless you explicitly specify an order.)
So as to have some data to sort, Example 8-10 brings back the
CalendarEvent class from Chapter 7.
Example 8-10. Class representing a calendar event
class CalendarEvent
{
public string Title { get; set; }
public DateTimeOffset StartTime { get; set; }
public TimeSpan Duration { get; set; }
}When examples in this chapter refer to an events variable, assume that it was
initialized with the data shown in Example 8-11.
Example 8-11. Some example data
List<CalendarEvent> events = new List<CalendarEvent>
{
new CalendarEvent
{
Title = "Swing Dancing at the South Bank",
StartTime = new DateTimeOffset (2009, 7, 11, 15, 00, 00, TimeSpan.Zero),
Duration = TimeSpan.FromHours(4)
},
new CalendarEvent
{
Title = "Saturday Night Swing",
StartTime = new DateTimeOffset (2009, 7, 11, 19, 30, 00, TimeSpan.Zero),
Duration = TimeSpan.FromHours(6.5)
},
new CalendarEvent
{
Title = "Formula 1 German Grand Prix",
StartTime = new DateTimeOffset (2009, 7, 12, 12, 10, 00, TimeSpan.Zero),
Duration = TimeSpan.FromHours(3)
},
new CalendarEvent
{
Title = "Swing Dance Picnic",
StartTime = new DateTimeOffset (2009, 7, 12, 15, 00, 00, TimeSpan.Zero),
Duration = TimeSpan.FromHours(4)
},
new CalendarEvent
{
Title = "Stompin' at the 100 Club",
StartTime = new DateTimeOffset (2009, 7, 13, 19, 45, 00, TimeSpan.Zero),
Duration = TimeSpan.FromHours(5)
}
};Example 8-12 shows a LINQ query that orders these events by start time.
Example 8-12. Ordering items with LINQ
var eventsByStartTime = from ev in events
orderby ev.StartTime
select ev;By default, the items will be sorted into ascending order. You can be explicit about this if you like:
var eventsByStartTime = from ev in events
orderby ev.StartTime ascending
select ev;And, of course, you can sort into descending order too:
var eventsByStartTime = from ev in events
orderby ev.StartTime descending
select ev;The expression in the orderby
clause does not need to correspond directly to a property of the source
object. It can be a more complex expression. For example, we could
extract just the time of day to produce the slightly confusing result of
events ordered by what time they start, regardless of date:
var eventsByStartTime = from ev in events
orderby ev.StartTime.TimeOfDay
select ev;You can specify multiple criteria. Example 8-13 sorts the events: first by date (ignoring the time) and then by duration.
Example 8-13. Multiple sort criteria
var eventsByStartDateThenDuration = from ev in events
orderby ev.StartTime.Date, ev.Duration
select ev;Four LINQ query operator methods correspond to the orderby clause. Most obviously, there’s
OrderBy, which takes a
single ordering criterion as a lambda:
var eventsByStartTime = events.OrderBy(ev => ev.StartTime);
That code has exactly the same effect as Example 8-12. Of course, like most LINQ
operators, you can chain this together with other ones. So we could
combine that with the Where
operator:
var longEvents = events.OrderBy(ev => ev.StartTime).
Where(ev => ev.Duration > TimeSpan.FromHours(2));This is equivalent to the following query:
var longEvents = from ev in events
orderby ev.StartTime
where ev.Duration > TimeSpan.FromHours(2)
select ev;You can customize the comparison mechanism used to sort the items
by using an overload that accepts a comparison object—it must implement
IComparer<TKey>[18] where TKey is the type
returned by the ordering expression. So in these examples, it would need
to be an IComparer<DateTimeOffset>, since that’s
the type of the StartTime property
we’re using to order the data. There’s not a lot of scope for discussion
about what order dates come in, so this is not a useful example for
plugging in an alternate comparison. However, string comparisons do vary
a lot—different languages have different ideas about what order letters
come in, particularly when it comes to letters with accents. The .NET
Framework class library offers a StringComparer class that can provide an
IComparer<string>
implementation for any language and culture supported in .NET. The
following example uses this in conjunction with an overload of the
OrderBy operator to sort the events
by their title, using a string sorting order appropriate for the
French-speaking Canadian culture, and configured for case
insensitivity:
CultureInfo cult = new CultureInfo("fr-CA");
// 2nd argument is true for case insensitivity
StringComparer comp = StringComparer.Create(cult, true);
var eventsByTitle = events.OrderBy(ev => ev.Title, comp);There is no equivalent query expression—if you want to use
anything other than the default comparison for a type, you must use this
overload of the OrderBy
operator.
The OrderBy operator method
always sorts in ascending order. To sort in descending order, there’s an
OrderByDescending operator.
If you want to use multiple sort criteria, as in Example 8-13, a different operator comes into
play: you need to use either ThenBy
or ThenByDescending. This is because
the OrderBy and OrderByDescending operators discard the order
of incoming elements and impose the specified order from scratch—that’s
the whole point of those operators. Refining an ordering by adding
further sort criteria is a different kind of operation, hence the
different operators. So the method-based equivalent of Example 8-13 would look like this:
var eventsByStartTime = events.OrderBy(ev => ev.StartTime).
ThenBy(ev => ev.Duration);Ordering will cause LINQ to Objects to iterate through the whole source collection before returning any elements—it can only sort items once it has seen all of the items.
Sometimes you’ll end up wanting to combine two sequences
of values into one. LINQ provides a very straightforward operator for
this: Concat. There is no equivalent
in the query expression syntax. If you wanted to combine two lists of
events into one, you would use the code in Example 8-14.
Note that this does not modify the inputs. This builds a new
enumeration object that returns all the elements from existingEvents, followed by all the elements
from newEvents.
So this can be safer than the List<T>.AddRange
method shown in Chapter 7, because this
doesn’t modify anything. (Conversely, if you were expecting Example 8-14 to modify existingEvents, you will be
disappointed.)
Note
This is a good illustration of how LINQ uses the functional style described earlier.
Like mathematical functions, most LINQ operators calculate their outputs without
modifying their inputs. For example, if you have two int variables called x and y,
you would expect to be able to calculate x+y without that calculation changing either
x or y. Concatenation works the same way—you can
produce a sequence that is the concatenation of two inputs without
changing those inputs.
As with most LINQ operators, concatenation uses deferred
evaluation—it doesn’t start asking its source enumerations for elements
in advance. Only when you start to iterate through the contents of
allEvents will this start retrieving
items from existingEvents. (And it
won’t start asking for anything from newEvents until it has retrieved all the
elements from existingEvents.)
LINQ provides the ability to take flat lists of data and
group them. As Example 8-15 shows, we could
use this to write a LINQ-based alternative to the GetEventsByDay method shown in Chapter 7.
Example 8-15. Simple LINQ grouping
var eventsByDay = from ev in events
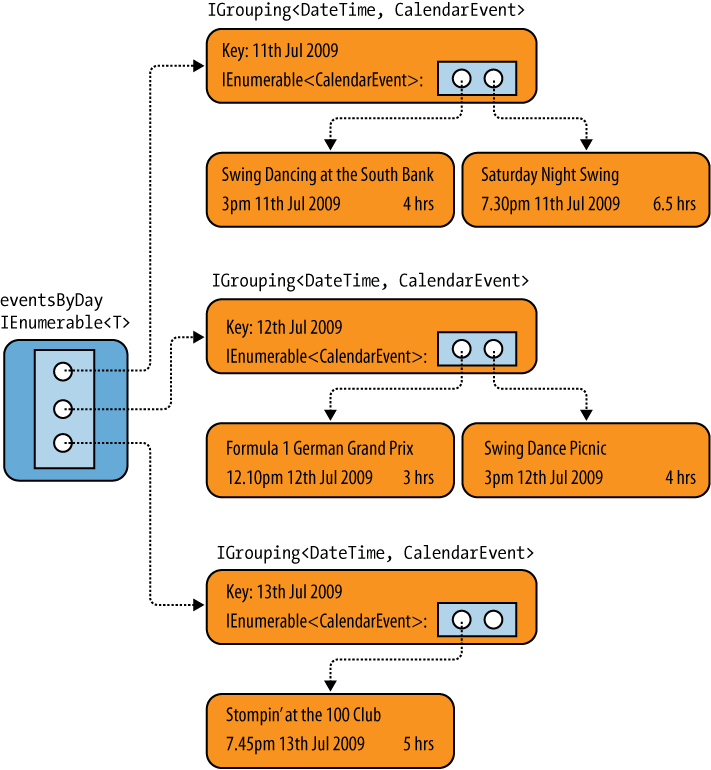
group ev by ev.StartTime.Date;This will arrange the objects in the events source into one group for each
day.
The eventsByDay variable here
ends up with a slightly different type than anything we’ve seen before.
It’s an IEnumerable<IGrouping<DateTimeOffset,
CalendarEvent>>. So eventsByDay is an enumeration, and it
returns an item for each group found by the group clause. Example 8-16 shows one way of using
this. It iterates through the collection of groupings, and for each
grouping it displays the Key
property—the value by which the items have been grouped—and then
iterates through the items in the group.
Example 8-16. Iterating through grouped results
foreach (var day in eventsByDay)
{
Console.WriteLine("Events for " + day.Key);
foreach (var item in day)
{
Console.WriteLine(item.Title);
}
}This produces the following output:
Events for 7/11/2009 12:00:00 AM Swing Dancing at the South Bank Saturday Night Swing Events for 7/12/2009 12:00:00 AM Formula 1 German Grand Prix Swing Dance Picnic Events for 7/13/2009 12:00:00 AM Stompin' at the 100 Club
This illustrates that the query in Example 8-15 has successfully grouped the events by
day, but let’s look at what returned in a little more detail. Each group
is represented as an IGrouping<TKey,
TElement>, where TKey is
the type of the expression used to group the data—a DateTimeOffset in this case—and TElement is the type of the elements making up
the groups—CalendarEvent in this
example. IGrouping<TKey,
TElement> derives from IEnumerable<TElement>, so you can
enumerate through the contents of a group like you would any other
enumeration. (In fact, the only thing IGrouping<TKey, TElement> adds is the
Key property, which is the grouping
value.) So the query in Example 8-15 returns
a sequence of sequences—one for each group (see Figure 8-1).
While a LINQ query expression is allowed to end with a group clause, as Example 8-15 does, it doesn’t have to finish there.
If you would like to do further processing, you can add an into keyword on the
end, followed by an identifier. The continuation of the query after a
group ... into clause will iterate over the groups, and
the identifier effectively becomes a new range variable. Example 8-17 uses this to convert
each group into an array. (Calling ToArray on an IGrouping effectively discards the Key, and leaves you with just an array
containing that group’s contents. So this query ends up producing an
IEnumerable<CalendarEvent[]>—a
collection of arrays.)
Example 8-17. Continuing a grouped query with into
var eventsByDay = from ev in events
group ev by ev.StartTime.Date into dayGroup
select dayGroup.ToArray();Like the ordering operators, grouping will cause LINQ to Objects to evaluate the whole source sequence before returning any results.
The select clause’s job is
to define how each item should look when it comes out of the query. The
official (if somewhat stuffy) term for this is
projection. The simplest possible kind of
projection just leaves the items as they are, as shown in Example 8-18.
Earlier, you saw this kind of trivial select clause collapsing away to nothing.
However, that doesn’t happen here, because this is what’s called a
degenerate query—it contains nothing
but a trivial projection. (Example 8-2 was different, because it
contained a where clause in addition
to the trivial select.) LINQ never
reduces a query down to nothing at all, so when faced with a degenerate
query, it leaves the trivial select
in place, even though it appears to have nothing to do. So Example 8-18 becomes a call to the Select LINQ operator method:
var projected = events.Select(ev => ev);
But projections often have work to do. For example, if we want to pick out event titles, we can write this:
var projected = from ev in events
select ev.Title;Again, this becomes a call to the Select LINQ operator method, with a slightly
more interesting projection lambda:
var projected = events.Select(ev => ev.Title);
We can also calculate new values in the select clause. This calculates the end time of
the events:
var projected = from ev in events
select ev.StartTime + ev.Duration;You can use any expression you like in the select clause. In fact, there’s not even any
obligation to use the range variable, although it’s likely to be a bit
of a waste of time to construct a query against a data source if you
ultimately don’t use any data from that source. But C# doesn’t care—any
expression is allowed. The following slightly silly code generates one
random number for each event, in a way that is entirely unrelated to the
event in question:
Random r = new Random();
var projected = from ev in events
select r.Next();You can, of course, construct a new object in the select clause. There’s one interesting
variation on this that often crops up in LINQ queries, which occurs when
you want the query to return multiple pieces of information for each
item. For example, we might want to display calendar events in a format
where we show both the start and the end times. This is slightly
different from how the CalendarEvent
class represents things—it stores the duration rather than the end time.
We could easily write a query that calculates the end time, but it
wouldn’t be very useful to have just that time. We’d want all the
details—the title, the start time, and the end time.
In other words, we’d be transforming the data slightly. We’d be
taking a stream of objects where each item contains Title, StartTime, and Duration properties, and producing one where
each item contains a Title, StartTime, and EndTime. Example 8-19 does
exactly this.
Example 8-19. Select clause with anonymous type
var projected = from ev in events
select new
{
Title = ev.Title,
StartTime = ev.StartTime,
EndTime = ev.StartTime + ev.Duration
};This constructs a new object for each item. But while the
new keyword is there,
notice that we’ve not specified the name of a type. All we have is the
object initialization syntax to populate various properties—the list of
values in braces after the new
keyword. We haven’t even defined a type anywhere in these examples that
has a Title, a StartTime, and an EndTime property. And yet this compiles. And
we can go on to use the results as shown in Example 8-20.
Example 8-20. Using a collection with an anonymous item type
foreach (var item in projected)
{
Console.WriteLine("Event {0} starts at {1} and ends at {2}",
item.Title, item.StartTime, item.EndTime);
}These two examples are using the anonymous type feature added in C# 3.0.
If we want to define a type to represent some information in our
application, we would normally use the class or struct keyword as described in Chapter 3. Typically, the
type definition would live in its own source file, and in a real
project we would want to devise unit tests to ensure that it works as
expected. This might be enough to put you off the idea of defining a
type for use in a very narrow context, such as having a convenient
container for the information coming out of a query. But it’s often
useful for the select clause of a
query just to pick out a few properties from the source items,
possibly transforming the data in some way to get it into a convenient
representation.
Note
Extracting just the properties you need can become important
when using LINQ with a database—database providers are typically
able to transform the projection into an equivalent SQL SELECT statement. But if your LINQ query
just fetches the whole row, it will end up fetching every column
whether you need it or not, placing an unnecessary extra load on the
database and network.
There’s a trade-off here. Is the effort of creating a type worth the benefits if you’re only going to use it to hold the results of a query? If your code immediately does further processing of the data, the type will be useful to only a handful of lines of code. But if you don’t create the type, you have to deal with a compromise—you might not be able to structure the information coming out of your query in exactly the way you want.
C# 3.0 shifts the balance in favor of creating a type in this scenario, by removing most of the effort required, thanks to anonymous types. This is another language feature added mainly for the benefit of LINQ, although you can use it in other scenarios if you find it useful. An anonymous type is one that the C# compiler writes for you, based on the properties in the object initializer list. So when the compiler sees this expression from Example 8-19:
new
{
Title = ev.Title,
StartTime = ev.StartTime,
EndTime = ev.StartTime + ev.Duration
};it knows that it needs to supply a type, because we’ve not
specified a type name after the new
keyword. It will create a new class definition, and will define
properties for each entry in the initializer. It will work out what
types the properties should have from the types of the expressions in
the initializer. For example, the ev.Title expression evaluates to a string,
so it will add a property called Title of type string.
Note
Before generating a new anonymous type, the C# compiler checks to see if it has already generated one with properties of the same name and type, specified in the same order elsewhere in your project. If it has, it just reuses that type. So if different parts of your code happen to end up creating identical anonymous types, the compiler is smart enough to share the type definition. (Normally, the order in which properties are defined has no significance, but in the case of anonymous types, C# considers two types to be equivalent only if the properties were specified in the same order.)
The nice thing about this is that when we come to use the items in a collection based on an anonymous type (such as in Example 8-20) IntelliSense and compile-time checking work exactly as they always do—it’s just like working with a normal type, but we didn’t have to write it.
From the point of view of the .NET Framework, the type generated by the C# compiler is a perfectly ordinary type like any other. It neither knows nor cares that the compiler wrote the class for us. It’s anonymous only from the point of view of our C# code—the generated type does in fact have a name, it’s just a slightly odd-looking one. It’ll be something like this:
<>f__AnonymousType0`3
The C# compiler deliberately picks a name for the type that would be illegal as a C# class name (but which is still legal as far as .NET is concerned) in order to stop us from trying to use the class by its name—that would be a bad thing to do, because the compiler doesn’t guarantee to keep the name the same from one compilation to the next.
The anonymity of the type name means that anonymous types are
only any use within a single method. Suppose you wanted to return an
anonymous type (or an IEnumerable<SomeAnonymousType>) from a
method—what would you write as the return type if the type in question
has no name? You could use Object,
but the properties of the anonymous type won’t be visible. The best
you could do is use dynamic, which
we describe in Chapter 18. This would make it possible
to access the properties, but without the aid of compile-time type
checking or IntelliSense. So the main purpose of anonymous types is
simply to provide a convenient way to get information from a query to
code later in the same method that does something with that
information.
Anonymous types would not be very useful without the var keyword, another
feature introduced in C# 3.0. As we saw earlier, when you declare a
local variable with the var
keyword, the compiler works out the type from the expression you use
to initialize the variable. To see why we need this for anonymous
types to be useful, look at Example 8-19—how would you declare
the projected local variable if we
weren’t using var? It’s going to be
some sort of IEnumerable<T>,
but what’s T here? It’s an
anonymous type, so by definition we can’t write down its name. It’s
interesting to see how Visual Studio reacts if we ask it to show us
the type by hovering our mouse pointer over the variable—Figure 8-2 shows the
resultant data tip.
Visual Studio chooses to denote anonymous types with names such
as 'a, 'b, and so forth. These are not legal
names—they’re just placeholders, and the data tip pop up goes on to
show the structure of the anonymous types they represent.
Whether or not you’re using anonymous types in your projections, there’s an alternative form of projection that you will sometimes find useful when dealing with multiple sources.

Earlier, Example 8-15 used a
groupby clause to add
some structure to a list of events—the result was a list containing
one group per day, with each group itself containing a list of events.
Sometimes it can be useful to go in the opposite direction—you may
have structured information that you would like to flatten into a
single list. You can do this in a query expression by writing multiple
from clauses, as Example 8-21 shows.
Example 8-21. Flattening lists using multiple from clauses
var items = from day in eventsByday
from item in day
select item;You can think of this as having roughly the same effect as the following code:
List<CalendarEvent> items = new List<CalendarEvent>();
foreach (IGrouping<DateTime, CalendarEvent> day in eventsByDay)
{
foreach (CalendarEvent item in day)
{
items.Add(item);
}
}That’s not exactly how it works, because the LINQ query will use
deferred execution—it won’t
start iterating through the source items until you start trying to
iterate through the query. The foreach loops, on the other hand, are
eager—they build the entire flattened list as soon as they run. But
lazy versus eager aside, the set of items produced is the same—for
each item in the first source, every item in the second source will be
processed.
Note
Notice that this is very different from the concatenation
operator shown earlier. That also works with two sources, but it
simply returns all the items in the first source, followed by all
the items in the second source. But Example 8-21 will iterate
through the source of the second from clause once for every item in the
source of the first from clause.
(So concatenation and flattening are as different as addition and
multiplication.) Moreover, the second from clause’s source expression typically
evaluates to a different result each time around.
In Example 8-21,
the second from clause uses the
range variable from the first from
clause as its source. This is a common technique—it’s what enables
this style of query to flatten a grouped structure. But it’s not
mandatory—you can use any LINQ-capable source you like; for example,
any IEnumerable<T>. Example 8-22 uses the same
source array for both from
clauses.
Example 8-22. Alternative use of multiple from clauses
int[] numbers = { 1, 2, 3, 4, 5 };
var multiplied = from x in numbers
from y in numbers
select x * y;
foreach (int n in multiplied)
{
Console.WriteLine(n);
}The source contains five numbers, so the resultant multiplied sequence contains 25 elements—the
second from clause counts through
all five numbers for each time around the first from clause.
The LINQ operator method for flattening multiple sources is
called SelectMany. The
equivalent of Example 8-22 looks like
this:
var multiplied = numbers.SelectMany(
x => numbers,
(x, y) => x * y);The first lambda is expected to return the collection over which
the nested iteration will be performed—the collection for the second
from clause in the LINQ query. The
second lambda is the projection from the select clause in the query. In queries with
a trivial final projection, a simpler form is used, so the equivalent
of Example 8-21
is:
var items = days.SelectMany(day => day);
Whether you’re using a multisource SelectMany or a simple single-source
projection, there’s a useful variant that lets your projection know
each item’s position, by passing a number into the projection.
The Select and
SelectMany LINQ operators both
offer overloads that make it easy to number items. Example 8-23 uses this to build a list of numbered
event names.
Example 8-23. Adding item numbers
var numberedEvents = events.
Select((ev, i) => string.Format("{0}: {1}", i + 1, ev.Title));If we iterate over this, printing out each item:
foreach (string item in numberedEvents)
{
Console.WriteLine(item);
}the results look like this:
1: Swing Dancing at the South Bank 2: Formula 1 German Grand Prix 3: Swing Dance Picnic 4: Saturday Night Swing 5: Stompin' at the 100 Club
This illustrates how LINQ often makes for much more concise code
than was possible before C# 3.0. Remember that in Chapter 7, we wrote a function that takes an array
of strings and adds a number in a similar fashion. That required a
loop with several lines of code, and it worked only if we already
happened to have a collection of strings. Here we’ve turned a
collection of CalendarEvents into a
collection of numbered event titles with just a single method
call.
As you get to learn LINQ, you’ll find this happens quite a lot—situations in which you might have written a loop, or a series of loops, can often turn into fairly simple LINQ queries.
The Zip operator is
useful when you have two related sequences, where each element in one
sequence is somehow connected with the element at the same position in
the other sequence. You can unite the two sequences by
zipping them back into one. Obviously, the name has
nothing to do with the popular ZIP compression format. This operator is
named after zippers of the kind used in clothing.
This might be useful with a race car telemetry application of the kind we discussed in Chapter 2. You might end up with two distinct series of data produced by two different measurement sources. For example, fuel level readings and lap time readings could be two separate sequences, since such readings would likely be produced by different instruments. But if you’re getting one reading per lap in each sequence, it might be useful to combine these into a single sequence with one element per lap, as Example 8-24 shows.
Example 8-24. Zipping two sequences into one
IEnumerable<TimeSpan> lapTimes = GetLapTimes();
IEnumerable<double> fuelLevels = GetLapFuelLevels();
var lapInfo = lapTimes.Zip(fuelLevels, (time, fuel) =>
new
{
LapTime = time,
FuelLevel = fuel
});You invoke the Zip operator on
one of the input streams, passing in the second stream as the first
argument. The second argument is a projection function—it’s similar to
the projections used with the Select
operator, except it is passed two arguments, one for each stream. So the
lapInfo sequence produced by Example 8-24 will contain one item per
lap, where the items are of an anonymous type, containing both the
LapTime and the FuelLevel in a single item.
Since the two sequences are of equal length here—the number of
laps completed—it’s clear how long the output sequence will be, but what
if the input lengths differ? The Zip
operator stops as soon as either one of the input sequences stops, so
the shorter of the two determines the length. Any spare elements in the
longer stream will not be used.
Sometimes you won’t want to work with an entire collection. For
example, in an application with limited screen space, you might want to
show just the next three events on the user’s calendar. While there is
no way to do this directly in a query expression, LINQ defines a
Take operator for this purpose. As
Example 8-25 shows, you
can still use the query syntax for most of the query, using the Take operator as the final stage.
Example 8-25. Taking the first few results of a query
var eventsByStart = from ev in events
orderby ev.StartTime
where ev.StartTime > DateTimeOffset.Now
select ev;
var next3Events = eventsByStart.Take(3);LINQ also defines a Skip operator which
does the opposite of Take—it drops the first
three items (or however many you ask it to drop) and then returns all
the rest.
If you’re interested in only the very first item, you may find the
First operator more convenient. If
you were to call Take(1), the method
would still return a collection of items. So this code would not
compile:
CalendarEvent nextEvent = eventsByStart.Take(1);
You’d get the following compiler error:
CS0266: Cannot implicitly convert type 'System.Collections.Generic.IEnumerable< CalendarEvent>' to CalendarEvent'. An explicit conversion exists (are you missing a cast?)
In other words, Take always
returns an IEnumerable<CalendarEvent>, even if we
ask for only one object. But this works:
CalendarEvent nextEvent = eventsByStart.First();
First gets the first element
from the enumeration and returns that. (It then abandons the
enumerator—it doesn’t iterate all the way to the end of the
sequence.)
You may run into situations where the list might be empty. For
example, suppose you want to show the user’s next appointment for
today—it’s possible that there are no more appointments. If you call
First in this scenario, it will throw
an exception. So there’s also a FirstOrDefault operator, which returns the
default value when there are no elements (e.g., null, if you’re dealing with a reference
type). The Last and LastOrDefault operators
are similar, except they return the very last element in the sequence,
or the default value in the case of an empty sequence.
A yet more specialized case is where you are expecting a sequence
to contain no more than one element. For example, suppose you modify the
CalendarEvent class to add an
ID property intended to be used as a
unique identifier for the event. (Most real calendar systems have a
concept of a unique ID to provide an unambiguous way of referring to a
particular calendar entry.) You might write this sort of query to find
an item by ID:
var matchingItem = from ev in events
where ev.ID == theItemWeWant
select ev;If the ID property is meant to
be unique, we would hope that this query returns no more than one item.
The presence of two or more items would point to a problem. If you use
either the First or the FirstOrDefault operator, you’d never notice
the problem—these would pick the first item and silently ignore any
more. As a general rule, you don’t want to ignore signs of trouble. In
this case, it would be better to use either Single or SingleOrDefault. Single would be the right choice in cases
where failure to find a match would be an error, while SingleOrDefault would be appropriate if you do
not necessarily expect to find a match. Either will throw an InvalidOperationException if the sequence
contains more than one item. So given the previous query, you could use
the following:
CalendarEvent item = matchingItem.SingleOrDefault();
If a programming error causes multiple different calendar events
to end up with the same ID, this code will detect that problem. (And if
your code contains no such problem, this will work in exactly the same
way as FirstOrDefault.)
You may need to discover at runtime whether certain characteristics are true about any or every element in a collection. For example, if the user is adding a new event to the calendar, you might want to warn him if the event overlaps with any existing items. First, we’ll write a helper function to do the date overlap test:
static bool TimesOverlap(DateTimeOffset startTime1, TimeSpan duration1,
DateTimeOffset startTime2, TimeSpan duration2)
{
DateTimeOffset end1 = startTime1 + duration1;
DateTimeOffset end2 = startTime2 + duration2;
return (startTime1 < startTime2) ?
(end1 > startTime2) :
(startTime1 < end2);
}Then we can use this to see if any events overlap with the proposed time for a new entry:
DateTimeOffset newEventStart = new DateTimeOffset(2009, 7, 20, 19, 45, 00,
TimeSpan.Zero);
TimeSpan newEventDuration = TimeSpan.FromHours(5);
bool overlaps = events.Any(
ev => TimesOverlap(ev.StartTime, ev.Duration,
newEventStart, newEventDuration));The Any operator looks to
see if there is at least one item for which the condition is true, and
it returns true if it finds one and
false if it gets to the end of the
collection without having found a single item that meets the condition.
So if overlaps ends up false here, we
know that events didn’t contain any
items whose time overlapped with the proposed new event time.
There’s also an All operator that
returns true only if all of the items
meet the condition. We could also have used this for our overlap
test—we’d just need to invert the sense of the test:
bool noOverlaps = events.All(
ev => !TimesOverlap(ev.StartTime, ev.Duration,
newEventStart, newEventDuration));Warning
The All operator returns
true if you apply it to an empty
sequence. This surprises some people, but it’s difficult to say what
the right behavior is—what does
it mean to ask if some fact is true about all the elements if there
are no elements? This operator’s definition takes the view that it
returns false if and only if at
least one element does not meet the condition. And while there is some
logic to that, you would probably feel misled if a company told you
“All our customers think our widgets are the best they’ve ever seen”
but neglected to mention that it has no customers.
There’s an overload of the Any
operator that doesn’t take a condition. You can use this to ask the
question: is there anything in this sequence? For example:
bool doIHaveToGetOutOfBedToday = eventsForToday.Any();
Note
The Any and All operators are technically known as
quantifiers. More specifically,
they are sometimes referred to as the existential quantifier and the
universal quantifier, respectively.
You may also have come across the common mathematical notation for
these.
The existential quantifier is written as a backward E (∃), and is conventionally pronounced “there exists.”
This corresponds to the Any operator—it’s true if at least one item
exists in the set that meets the condition.
The universal quantifier is written as an upside down A (∀), and is conventionally pronounced “for all.” It
corresponds to the All operator,
and is true if all the elements in some set meet the condition. The
convention that the universal quantifier is true for any empty set
(i.e., that All returns true when you give it no elements,
regardless of the condition) has a splendid mathematical name: it is
called a vacuous truth.
Quantifiers are special cases of a more general operation called aggregation—aggregation operators perform calculations across all the elements in a set. The quantifiers are singled out as special cases because they have the useful property that the calculation can often terminate early: if you’re testing to see whether something is true about all the elements in the set, and you find an element for which it’s not true, you can stop right there. But for most whole-set operations that’s not true, so there are some more general-purpose aggregation operators.
Aggregation operators perform calculations that involve every
single element in a collection, producing a single value as the result.
This can be as simple as counting the number of elements—this involves
all the elements in the sense that you need to know how many elements
exist to get the correct count. And if you’re dealing with an IEnumerable<T>, it
is usually necessary to iterate through the whole collection because in
general, enumerable sources don’t know how many items they contain in
advance. So the Count operator
iterates through the entire collection, and returns the number of
elements it found.
Note
LINQ to Objects has optimizations for some special cases. It
looks for an implementation of a standard ICollection<T>
interface, which defines a Count property. (This
is distinct from the Count
operator, which, like all LINQ operators, is a method, not a
property.) Collections such as arrays and List<T> that know how many items they
contain implement this interface. So the Count operator may be able to avoid having
to enumerate the whole collection by using the Count property. And more generally, the
nature of the Count operator
depends on the source—database
LINQ providers can arrange for the database to calculate the correct
value for Count, avoiding the need
to churn through an entire table just to count rows. But in cases
where there’s no way of knowing the count up front, such as the file
enumeration in Example 8-1, Count can take a long time to
complete.
LINQ defines some specialized aggregation operators for numeric
values. The Sum operator returns the
sum of the values of a given expression for all items in a collection.
For example, if you want to find out how many hours of meetings you have
in a collection of events, you could do this:
double totalHours = events.Sum(ev => ev.Duration.TotalHours);
Average calculates the same
sum, but then divides the result by the number of items, returning the
mean value. Min and Max return the lowest and highest of the
values calculated by the expression.
There’s also a general-purpose aggregation operator called
Aggregate. This lets you perform any
operation that builds up some value by performing some calculation on
each item in turn. In fact, Aggregate
is all you really need—the other aggregation operators are simply more
convenient.[19] For instance, Example 8-26 shows how to implement
Count using Aggregate.
The first argument here is a seed value—it’s
the starting point for the value that will be built up as the
aggregation runs. In this case, we’re building up a count, so we start
at 0. You can use any value of any type here—Aggregate is a generic method that lets you
use whatever type you like.
The second argument is a delegate that will be invoked once for each item. It will be passed the current aggregated value (initially the seed value) and the current item. And then whatever this delegate returns becomes the new aggregated value, and will be passed in as the first argument when that delegate is called for the next item, and so on. So in this example, the aggregated value starts off at 0, and then we add 1 each time around. The final result is therefore the number of items.
Example 8-26 doesn’t look
at the individual items—it just counts them. If we wanted to implement
Sum, we’d need to add a value from
the source item to the running total instead of just adding 1:
double hours = events.Aggregate(0.0,
(total, ev) => total + ev.Duration.TotalHours);Calculating an average is a little more involved—we need to
maintain both a running total and the count of the number of elements
we’ve seen, which we can do by using an anonymous type as the
aggregation value. And then we can use an overload of Aggregate that lets us provide a separate
delegate to be used to determine the final value—that gives us the opportunity to
divide the total by the count:
double averageHours = events.Aggregate(
new { TotalHours = 0.0, Count = 0 },
(agg, ev) => new
{
TotalHours = agg.TotalHours + ev.Duration.TotalHours,
Count = agg.Count + 1
},
(agg) => agg.TotalHours / agg.Count);Obviously, it’s easier to use the specialized Count, Sum,
and Average operators, but this
illustrates the flexibility of Aggregate.
Note
While LINQ calls this mechanism Aggregate, it is often known by other names.
In functional programming languages, it’s sometimes called
fold or reduce. The latter
name in particular has become slightly better known in recent years
thanks to Google’s much-publicized use of a programming system called
map/reduce. (LINQ’s name for map is Select, incidentally.) LINQ’s names weren’t
chosen to be different for the sake of it—they are more consistent
with these concepts’ names in database query languages. Most
professional developers are currently likely to have rather more
experience with SQL than, say, Haskell or LISP.
LINQ provides operators for some common set-based
operations. If you have two collections, and you want to discover all
the elements that are present in both collections, you can use the
Intersect operator:
var inBoth = set1.Intersect(set2);
It also offers a Union
operator, which provides all the elements from both input sets, but when
it comes to the second set it will skip any elements that were already
returned because they were also in the first set. So you could think of
this as being like Concat, except it
detects and removes duplicates. In a similar vein, there’s the
Distinct operator—this works on a single
collection, rather than a pair of collections. Distinct ensures that it returns any
given element only once, so if your input collection happens to contain
duplicate entries, Distinct will skip
over those.
Finally, the Except operator
returns only those elements from the first set that do not also appear
in the second set.
LINQ supports joining of sources, in the sense typically associated with databases—given two sets of items, you can form a new set by combining the items from each set that have the same value for some attribute. This is a feature that tends not to get a lot of use when working with object models—relationships between objects are usually represented with references exposed via properties, so there’s not much need for joins. But joins can become much more important if you’re using LINQ with data from a relational database. (Although the Entity Framework, which we describe in a later chapter, is often able to represent relationships between tables as object references. It’ll use joins at the database level under the covers, but you may not need to use them explicitly in LINQ all that often.)
Even though joins are typically most useful when working with data structured for storage in a relational database, you can still perform joins across objects—it’s possible with LINQ to Objects even if it’s not all that common.
In our hypothetical calendar application, imagine that you want to add a feature where you can reconcile events in the user’s local calendar with events retrieved from his phone’s calendar, and you need to try to work out which of the imported events from the phone correspond to items already in the calendar. You might find that the only way to do this is to look for events with the same name that occur at the same time, in which case you might be able to use a join to build up a list of events from the two sources that are logically the same events:
var pairs = from localEvent in events
join phoneEvent in phoneEvents
on new { Title = localEvent.Title, Start = localEvent.StartTime }
equals new { Title = phoneEvent.Name, Start = phoneEvent.Time }
select new { Local = localEvent, Phone = phoneEvent };A LINQ join expects to be able to compare just a single object in
order to determine whether two items should be joined. But we want to
join items only when both the title and the time match. So this example
builds an anonymously typed object to hold both values in order to be
able to provide LINQ with the single object it expects. (You can use
this technique for the grouping operators too, incidentally.) Note that
this example also illustrates how you would deal with the relevant
properties having different names. You can imagine that the imported
phone events might use different property names because you might need
to use some third-party import library, so this example shows how the
code would look if it called the relevant properties Name and Time instead of Title and StartTime. We fix this by mapping the
properties from the two sources into anonymous types that have the same
structure.
Sometimes it’s necessary to convert the results of a LINQ
query into a specific collection type. For example, you might have code
that expects an array or a List<T>. You can still use LINQ queries
when creating these kinds of collections, thanks to the standard
ToArray and ToList operators. Example 8-17 used ToArray to convert a grouping into an array of
objects. We could extend that further to convert the query into an array
of arrays, just like the original example from Chapter 7:
var eventsByDay = from ev in events
group ev by ev.StartTime.Date into dayGroup
select dayGroup.ToArray();
CalendarEvent[][] arrayOfEventsByDay = eventsByDay.ToArray();In this example, eventsByDay is
of type IEnumerable<CalendarEvent[]>. The final
line then turns the enumeration into an array of arrays—a CalendarEvent[][].
Remember that LINQ queries typically use deferred execution—they
don’t start doing any work until you start asking them for elements. But
by calling ToList or ToArray, you will fully execute the query,
because it builds the entire list or array in one go.
As well as providing conversion operators for getting data out of
LINQ and into other data types, there are some operators for getting
data into LINQ’s world. Sometimes you will come across types that
provide only the old .NET 1.x-style nongeneric IEnumerable interface. This is
problematic for LINQ because there’s no way for it to know what kinds of
objects it will find. You might happen to know that a collection will
always contain CalendarEvent objects,
but this would be invisible to LINQ if you are working with a library
that uses old-style collections. So to work around this, LINQ defines a
Cast operator—you can use this to
tell LINQ what sort of items you believe are in the collection:
IEnumerable oldEnum = GetCollectionFromSomewhere();
var items = from ev in oldEnum.Cast<CalendarEvent>()
orderby ev.StartTime
select ev;As you would expect, this will throw an InvalidCastException if it discovers any
elements in the collection that are not of the type you said. But be
aware that like most LINQ operators, Cast uses deferred execution—it casts the
elements one at a time as they are requested, so any mismatch will not
be discovered at the point at which you call Cast. The exception will be thrown at the
point at which you reach the first nonmatching item while enumerating
the query.
[18] This is very similar to IComparable<T>, introduced in the
preceding chapter. But while objects that implement IComparable<T> can themselves be
compared with other objects of type T, an IComparer<T> compares two objects of
type T—the objects being compared
are separate from the comparer.
[19] That’s true for LINQ to Objects. However, database LINQ
providers may implement Sum,
Average, and so on using
corresponding database query features. They might not be able to do
this optimization if you use the general-purpose Aggregate operator.