Table 5.1 Example Leadership and Management Activities
In respect of the military method, we have, firstly, Measurement; secondly, Estimation of quantity; thirdly, Calculation; fourthly, Balancing of chances; fifthly, Victory.
—Sun Tzu
Scott Cook cofounded Intuit with Tom Proulx in 1983. Scott’s experience at Proctor & Gamble made him realize that personal computers would ultimately replace pencil-and-paper accounting.1 That realization, coupled with a desire to create something to help his wife with the mundane task of “paying the bills,” became the inspiration for the company’s first product, the home finance software solution Quicken.2 As Intuit grew, the company continued to improve Quicken, which competed against other consumer financial packages like Microsoft’s Money. In 1992, the company launched QuickBooks—a peer to Quicken focused on small- and medium-sized business bookkeeping. In 1993, the company went public and then merged with Chipsoft, the makers of TurboTax, through a stock swap.3 Since 1993, the company has made dozens of acquisitions focused on both consumer and small-business financial solutions. As of 2014, Intuit was a highly successful global company with revenues of $4 billion, net income of $897 million, and 8,000 employees.
1. S. Taylor and K. Schroeder. Inside Intuit. Cambridge, MA: Harvard Business Review Press, September 4, 2003.
2. “6 Ways Wealth Made This Billionaire an Amazing Human Being.” NextShark, March 15, 2014. http://nextshark.com/6-ways-wealth-made-this-billionaire-an-amazing-human-being/.
3. “Intuit and Chipsoft to Merge.” The New York Times, September 2, 1993. http://www.nytimes.com/1993/09/02/business/intuit-and-chipsoft-to-merge.html.
Experience tells us that at the heart of every success story are a number of critical moments—moments where leaders, managers, and teams either do or do not rise to and capitalize on the challenges and opportunities with which they are presented. Intuit’s story begins with shifts in consumer purchase behaviors in the late 1990s. Intuit’s first offerings were all desktop- and laptop-based products, but by the late 1990s consumer behavior started to change: Users began to expect the products they once ran on their systems to instead be delivered as a service online (Software as a Service). Identifying this trend early, Intuit developed Web-enabled versions of many of its products, including Quicken, TurboTax, and QuickBooks.
While Intuit’s business shifted toward SaaS, its development practices remained stagnant. The Product and Technology group, led by senior VP and CTO Tayloe Stansbury, was a growing team of individuals who were responsible for defining the infrastructure upon which software solutions would run. The company continued to develop online solutions in this fashion until 2013.
“Then we had a bit of an epiphany,” stated Stansbury. “We were doing rather well in several dimensions, but we seemed to have the same types of small but nevertheless painful problems occurring over and over again. The software and the infrastructure folks were glaring at each other across this chasm and then it hit us—the world had changed around us but we really hadn’t changed the way we produced our products. We were still building software but we were selling services. We really needed to change our approach to recognize that in the new world order, software and hardware are the raw materials consumed to create a service. We needed to rethink our organization, processes, incentives, and project management.”
As mentioned previously, great companies and great managers, when presented with significant challenges and opportunities, rise to the occasion. Intuit is still around and thriving, so how did it address this opportunity? This chapter outlines how to take a vision (an element of leadership) and break it down into the concrete tasks necessary for implementation (management). We’ll discuss staff teams for success and explore how to coach them across the goal line of a compelling vision, whether to meet the scalability challenges associated with incredible growth or for nearly any other reason.
In this chapter, we define management and outline characteristics of great managers. We also describe the need for continually improving and upgrading one’s team, and provide a conceptual framework to accomplish that task. In addition, we illustrate the importance of metrics and provide a tool to tie metrics to the creation of shareholder wealth (the ultimate metric). We end the chapter by emphasizing the need for management to remove obstacles for teams so that they can reach their objectives.
Merriam-Webster Dictionary defines management as “the conducting or supervising of something” and as the “judicious use of means to accomplish an end.” We’ll make a minor modification to this definition and add ethics to the mix, ending with “the judicious and ethical use of means to accomplish an end.” Why ethics? How can ethics negatively influence scalability? Consider cases where intellectual property is pirated, licenses for third-party products duplicated, and erroneous public statements about the scalability and viability of a platform are made. Each of these cases involves an ethical issue—the commission of theft and lies intended to garner personal gain at the expense of someone else. Ethics plays a role in how we treat our people, how we incent them, and how we accomplish our mission. If we tell an underperformer that he is performing acceptable work, we are behaving unethically; we are cheating both the shareholders and the employee because he deserves to know how he is performing. The way in which a mission is accomplished is every bit as important as the actual accomplishment of that mission.
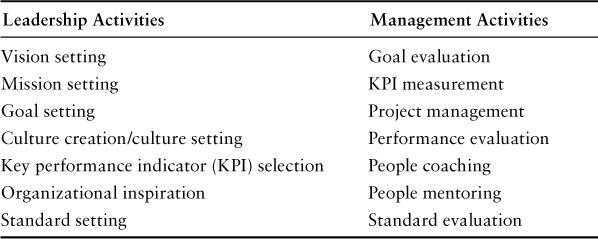
As we’ve previously stated, management and leadership differ in many ways, but both are important. If leadership is a promise, then management is action. If leadership is a destination, then management is the direction. If leadership is inspiration, then management is motivation. Leadership pulls and management pushes. Both are necessary to be successful in maximizing shareholder wealth. Recall the comparison of leadership and management from Chapter 1, revisited in Table 5.1
Management includes the activities of measuring, goal evaluation, and metric creation. It also includes the personnel responsibilities of staffing, personnel evaluation, and team construction (including skills and other characteristics of team members). Finally, management includes all the activities one might typically consider “project management,” such as driving the team to work completion, setting aggressive dates, and so on.
Good managers get projects done on time and on budget, and meet the expectations of shareholder value creation in the completion of their projects. Great managers do the same thing even in the face of adversity. Both achieve their goals by decomposing them into concrete supporting tasks. They then enlist appropriate help both inside and outside the organization and continually measure progress. Although this isn’t a book on project management, and we won’t go into great detail about how to effectively manage scale projects, it is important to understand the necessary actions in those projects to be successful.
Let’s return to our Intuit story and see how the CTO, Tayloe Stansbury, and his team broke down the opportunity of changing the business into the component tasks necessary to be successful. Intuit’s epiphany that it was building software but selling services led to a reorganization that moved the internal corporate technology teams under the purview of the CTO. Furthermore, infrastructure individual contributors, such as storage engineers and database administrators, were divided up and allocated to become part of the product teams with which they worked. Product infrastructure professionals were expected to think of themselves as part of the product teams. Each business-oriented product team shared goals including revenue generation, availability, and time to market regardless of whether it was software or hardware focused. Hardware and software teams would now work together. “No more ‘you are a customer of mine’ mindset,” explained Stansbury. “One team, one Intuit, one customer.”
The teams further determined that they weren’t paying attention to all of the metrics they should be monitoring. A by-product of the “software mindset” was that Intuit wasn’t as focused on the availability of its products as many other SaaS companies. Under Stansbury’s leadership, this situation quickly changed. The combined teams started a morning service delivery call to jointly discuss the quality of service from the previous day and any open issues across the product lines. Problems associated with incidents were aggressively tracked down and resolved. The teams started reporting on a number of new metrics across the enterprise, including the mean time to resolve incidents, the mean time to repair problems, and the average time to identify incidents in production. Aggressive availability and end-user response time targets were created for each team and shared between the software and infrastructure disciplines. Stansbury’s view: “Shared goals are critical to the success of creating a one team, one Intuit, one customer mindset.”
Stansbury and his team also felt that Intuit’s past organizational structure and approach had left the company with large amounts of technical debt: “When two teams that are necessary to build a product don’t collaborate from the beginning in the creation of that product, you can imagine that you don’t always get the best designs.” Stansbury believed that certain elements of the holistic product were overbuilt, whereas others were underbuilt relative to the individual product needs: “We needed to move our holistic product architecture to more purpose-built designs—designs wherein the software and infrastructure leverage the other’s strengths and mitigate the other’s weaknesses.” In turn, Stansbury and his team planned and budgeted to redesign each product group of services, beginning with the tax division. Incorporating elements of fault-isolative architectures, products would be capable of operating independently of each other and in so doing incorporate software and hardware specific to their needs and desired outcomes. Precise project plans were created and daily meetings held to identify barriers to success within the plans.
While not an all-inclusive list, Intuit’s activities are indicative of what it takes to be successful in managing teams toward a vision. Stansbury and his team identified the gap in approach necessary to be successful and broke it down into its component parts. Teams weren’t working as well together as they could, so they reorganized to create cross-functional, product-oriented teams. This endeavor reflects the management aspect of executing the organizational structures described in Chapter 3, Designing Organizations. Collectively, Intuit’s teams weren’t as focused on availability as they could be, so the company created metrics and structure around availability, including a daily review of performance. Lastly, the combined teams identified architectural improvements around service offerings; in turn, they created structure, budget, and project plans and assigned owners to ensure the successful delivery of those new solutions.
Intuit’s service availability increased significantly as a result of its focus on purpose-built designs, implementation of aggressive goals with respect to availability, and rigorous problem and incident management. None of this, however, would have been possible without multiple levels of management focused on decomposing goals into their component parts and the organizational realignment of teams to service offerings.
Here we will transition briefly to a discussion of one of the most often-overlooked aspects of project management—a focus on contingencies. Helmut Von Moltke was a Prussian general famous for several versions of the phrase, “No plan survives contact with the enemy.” Nowhere is this phrase more correct than in the management of complex product development. Myriad things can go wrong in the delivery of complex products, including delays in equipment delivery, problems with the interaction of complex components and software, and critical staff members falling ill or leaving in the middle of a project. In our entire careers, we have never seen a project run exactly as initially envisioned within the first iteration of a project plan. The initial delivery dates may have been met, but the path taken toward those dates was never the original path laid out with such optimism by the planners of the project.
This experience has taught us that while project planning is important, the value it creates lies not in the initial plan but rather in the exercise of thinking through the project and the possible paths. Unfortunately, too many of our clients see the original plan as the only path to success, rather than as just one of many possible paths. Moltke’s quote warns us away from this focus on initial plan execution and moves us toward recognition of the value of contingency planning. Instead of adopting a laser-like focus on the precision of our plan, we should instead consider how we might take any one of a number of paths to project success. As such, we at AKF practice what we call the “5-95 Rule”: Spend 5% of your time developing an adequate, defensible, and detailed plan—but also recognize that this plan will not survive contact with the enemy and devote the remaining 95% of your time to “war gaming” the plan to come up with contingencies. What will you do when network equipment does not arrive on time for your data center build-out? How will you handle the case in which your most critical resource calls in sick during a launch date? What happens when your data access object hasn’t included an important resource necessary for correct execution of an application?
The real value in project plans lies in the cerebral exercise of understanding your options in execution on the path to shareholder value creation. Remember the AKF 5-95 Rule and spend 5% of your time planning and 95% of your time addressing contingencies.
Professional football team coaches know that having the right team to accomplish the mission is critical to reaching the Super Bowl in any given season. Furthermore, they understand that the right team today might not be the right team for next season: Rookie players enter the sport stronger and faster than ever before; offensive strategies and needs change; injuries plague certain players; and salary caps create downward pressure on the total value of talent that can exist within any team in any year.
Managing team skill sets and experience levels in professional sports is a dynamic job requiring the continual upgrading of talent, movement of personnel, management of depth and bench strength, selection of team captains, recruiting new talent, and coaching for skills.
Imagine a coach or general manager who is faced with the difficult task of recruiting a new player to fill a specific weakness in the team and whose collective team salaries are already at or near the designated salary cap. The choices in this case are to release an existing player, renegotiate one or more players’ contracts to make room for the new player’s salary, or not hire the necessary player for the critical position. What do you think would happen to the coach who decides to take no action and not hire the new player? If the team owners find out, they are likely to fire the coach. If they don’t find out sooner or later, the team is likely to atrophy and consistently turn out substandard seasons, resulting in lower ticket sales and unhappy shareholders (owners).
Our jobs as managers and executives are really no different than the jobs of coaches of professional football teams. Our salary caps are the budgets that are developed by the executive management team and are reviewed and approved by our boards of directors. To ensure that work is completed cost-effectively with the highest possible levels of throughput and quality, we must constantly look for the best talent available at a price that we can afford. Yet most of us don’t actively manage the skills, people, and composition of our teams, ultimately short-changing our company and our shareholders. Scalability in professional sports means scaling the output of individuals. Professional football, for instance, will not allow teams to add a twelfth player to the on-field personnel. In your organization, scaling individuals might mean the same thing. The output of your organization depends on both individual output and the team size. Efficiency—a component of cost-effective scaling—is a measurement of getting more for the same amount of money or (better yet) more for less money. Scaling with people, then, is a function both of the individual people, the number of people, and the organization of people.
Consider a coach who refused to spend time improving the team’s players. Can you imagine such a coach keeping his or her job? Similarly, can you imagine walking into your next board of directors meeting and stating that part of your job is not to grow and maintain the best team possible? Think about that last point for a minute. In Chapter 4, Leadership 101, we made the case that everything you do needs to be focused on creating shareholder value. Here, we have just identified a test to help you know when you are not creating shareholder value. With any major action that you take, would you be prepared to present it to the board of directors as something that must be done? Remember that a decision to not do something is the same as deciding to do something. Furthermore, ignoring something that should be done is a decision not to do it. If you have not spent time with the members of your team for weeks on end, you have decided not to spend time with them. That course of action is absolutely inexcusable and not something that you would likely feel comfortable discussing with your board of directors.
The parallels in professional sports to the responsibilities of team building for corporate executives are clear but all too commonly ignored. To get our jobs done, we must have the best talent (i.e., the best people) possible given our board-authorized budgets. We must constantly evaluate and coach our team to ensure that each member is adding value appropriate to his or her level of compensation, find new and higher-performing talent, and coach the great people we have to achieve even higher levels of performance.
Even a novice gardener knows that gardening is about more than just raking some soil, throwing some seeds, and praying for rain. Unfortunately, rake, throw, and pray is exactly what most managers do with their teams. Our team is a garden, and our garden expects more of us than having manure thrown on it from time to time. Just as importantly, the scalability of our organization (as we described in our sports metaphor) is largely tied to how great our talent is on a per-person basis and how consistent their behaviors are with our corporate culture.
Gardens should be thoughtfully designed, and the same is true of our teams. Designing our teams means finding the right talent that matches the needs of the organization’s vision and mission. Before planting new seeds or inserting new seedlings in our garden, we evaluate how the different plants and flowers will interact. We should do the same with our teams. Will certain team members steal too many nutrients? Will the soil (our culture) properly support their needs? Should the garden be full of only bright and brilliant flowers or will it be more pleasing with robust and healthy foliage to support the flowers?
Managers in hyper-growth companies often spend a lot of time interviewing and selecting candidates, but usually very little time on a per-candidate basis. Even worse, these managers often don’t take the time to determine where they’ve gone wrong with past hiring decisions and what they’ve done well in certain decisions. Finding the right individual for a particular job requires paying attention to and correcting past failures and repeating past hiring successes. All too often, though, we interview for skills but overlook critical items like cultural or team fit. Ask yourself these questions: Why have you had to remove people? Why have people decided to leave?
Candidate selection also requires paying attention to the needs of the organization from a productivity and quality perspective. Do you need another engineer or product manager, or do inefficiencies in the company’s operations indicate the need for additional process definition, tools engineers, or quality assurance personnel?
All too often, we try to make hiring decisions after we’ve spent a mere 30 to 60 minutes with a candidate. We encourage you to spend as much time as possible with the candidate and try to make a good hire the first time. Seek help in interviewing by adding people whom you trust and who have great interviewing skills. Call previous managers and peers of the candidates, and be mindful to ask and prod for weaknesses of individuals in your background checks. Pay attention to more than just the skills—determine whether you and your team will like spending a lot of time with the individual. Interview the person to make certain that he or she will be a good fit with your culture and that the individual’s behaviors are consistent with the behavioral expectations of the company.
Feeding your garden means spending time growing your team. Of all the practices involved in tending to your team, this is the one that is most often overlooked for lack of time. We might spend time picking new flowers (though not enough on a per-flower basis), but we often forget about the existing flowers needing nourishment within our garden.
The intent of feeding is to grow the members of your team who are producing to the expectations of your shareholders. Feeding consists of coaching, praising, correcting technique or approach, adjusting compensation and equity, and anything else that creates a stronger and more productive employee.
Feeding your garden also means taking individuals who might not be performing well in a certain position and putting them into positions where they can thrive. However, if you find yourself moving an employee more than once, it is likely that you are avoiding the appropriate action of weeding.
Finally, feeding your garden means raising the bar on the team overall and helping employees achieve greater levels of success. Great teams enjoy aggressive but achievable challenges, and it is your job as a manager to challenge them to be the best they can be.
Although you should invest as much as possible in seeding and feeding, we all know that underperforming and nonperforming individuals choke team productivity, just as surely as weeds steal vital nutrients from the flowers within your garden. The nutrients in this case are the time that you spend attempting to coach underperforming individuals to an acceptable performance level and the time your team spends compensating for an underperforming individual’s poor results. Weeding our gardens is often the most painful activity for most managers and executives, and as a result it is often the one to which we tend last.
Although you must abide by your company’s practices regarding the removal of people who are not performing (legal requirements vary by country and state), it is vital that you find ways to quickly remove personnel who are keeping you and the rest of your team from achieving your objectives. The sooner you remove the poor performers, the sooner you can find appropriate replacements and get your team moving forward.
When considering performance as a reason for termination, you should always include an evaluation of the person’s behaviors. Sometimes one individual within an organization may create more and get more done than any other team member, yet exhibit actions and behaviors that bring down total team output. This is typically fairly obvious when an employee is creating a hostile work environment, but less so when an employee simply does not work well with others. For instance, an employee might get a lot done, but in such a manner that absolutely no one wants to work with him. The result might be that you spend a great deal of time soothing hurt feelings or finding out how to assign the employee tasks that do not require teamwork. If the employee’s actions limit the output of the team, then ultimately they limit scalability, and you should act immediately to rectify the situation.
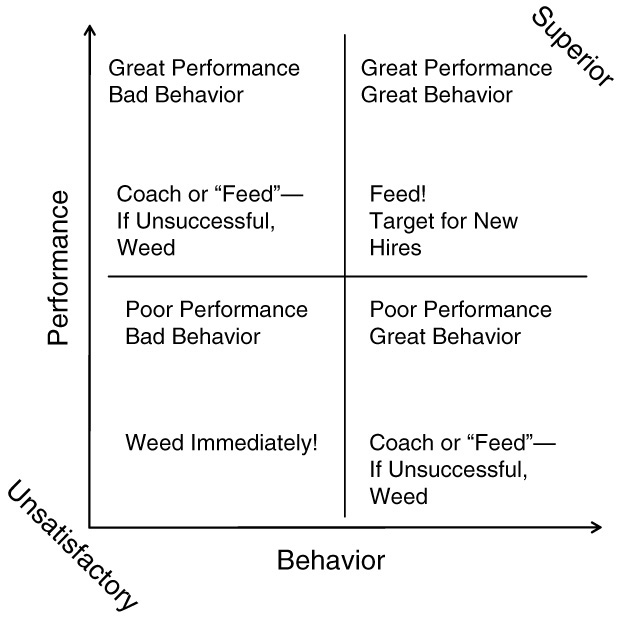
To assess these kinds of tradeoffs, it’s often useful to use the concept of a two-dimensional axis with defined actions, such as that depicted in Figure 5.1. The x-axis here is the behavior of the employee and the y-axis is the employee’s performance. Many employee reviews, when done properly, identify the actions on the y-axis, but they may not consider the impact of the behavioral x-axis. The idea here is that the employees you want to keep are in the upper-right portion of the graph. Those who should be immediately “weeded” are in the bottom-left portion of the graph. You should coach those individuals in the upper-left and lower-right portions of the graph, but be prepared to weed them if they do not respond to coaching. And of course, you want all of your seeds or new employees to be targeted in the upper-right portion of the graph.
One thing that we have learned over time is that you will always wish you had acted earlier in removing underperformers. There are a number of reasons why you can’t act quickly enough, including company travel, competing requests, meetings, and so on. Don’t waste time agonizing over whether you are acting too quickly—that never happens. You will always wish you had acted even sooner when you have completed the termination.
We’re not certain who first said it, but one of our favorite sayings is “You can’t improve that which you do not measure.” Amazingly, we’ve found ourselves in a number of arguments regarding this statement. These arguments range from “Measurement is too expensive” to “I know intuitively whether I’ve improved something.” You can get away with both of these statements if you are the only shareholder of your company, although we would still argue that your results will be suboptimal. If you happen to be a manager in a company with external shareholders, however, you must be able to prove that you are creating shareholder value, and the only way to do so is through measurement.
We believe in creating cultures that support measurement of nearly everything related to the creation of shareholder value. With respect to scale, however, we believe in bundling our measurements thematically. The themes we most often recommend to track scale are cost, availability/response times, engineering productivity and efficiency, and quality.
As we’ve previously indicated, cost has a direct impact on the scalability of your platform. You undoubtedly will either be given or have helped develop a budget for the company’s engineering initiatives. Ideally, a portion of that budget in a growth company will be dedicated to the scalability of the organization’s platform or services. This percentage alone is an interesting value to monitor over time, as we would expect good managers to be able to reduce the cost of scaling their platforms over time—potentially as measured by the cost per transaction. Let’s assume that you inherit a platform with scalability problems that manifest themselves as availability issues. You might decide that you need to spend 30% to 50% of your engineering time and a significant amount of capital to fix a majority of these issues in the first 2 to 24 months of your job. However, something is wrong if you can’t slowly start giving more time back to the business for business initiatives (customer features) over time. Consequently, we recommend measuring the cost of scale as both a percentage of total engineering spending and a cost per transaction.
Cost of scale as a percentage of engineering time should decrease over time. Of course, it’s easy to “game” this number. Suppose that in year 1 you have a team of 20 engineers and dedicate 10 to scalability initiatives; in this year, you are spending 50% of your engineering headcount-related budget on scalability. Next suppose that in year 2 you hire 10 more engineers but dedicate only the original 10 to scale issues; you are now spending only 33% of your budget on scalability. Although the percentages would suggest that you’ve reduced the cost of scale, you’ve really kept it constant, which could argue for measuring and reporting on the relative and absolute costs of scale.
Rather than reporting the absolute cost of scale (e.g., 10 engineers, $1.2 million per annum), we often recommend normalizing this value based on the activities that create shareholder value. If your organization is a Software as a Service platform (SaaS) provider and makes money on a per-transaction basis, either through advertising or by charging transaction fees, this normalization might be accomplished by reporting the cost of scale on a per-transaction basis. For instance, if your company completes 1.2 million transactions each year and spends $1.2 million in headcount on scale initiatives, its cost of scale would be $1/transaction. Ouch! That’s really painful if you don’t make at least a dollar per transaction!
Availability is another obvious choice when figuring out what to measure. If a primary goal of your scalability initiatives is eliminating downtime, you must measure availability and report on how much of your organization’s downtime is associated with scalability problems within its platforms or systems. The intent here is to eliminate lost opportunity associated with users not being able to complete their transactions. In the Internet world, this factor most often has a real impact on revenue; in contrast, in the back-office information technology world, it might result in a greater cost of operations because people are required to work overtime to complete jobs when systems become available again.
Closely related to availability is response time. In most systems, increasing response times often escalate to brownouts, which are then followed by blackouts or downtime for the system. Brownouts are typically caused by systems performing so slowly that most users abandon their efforts, whereas blackouts are a result of a system that completely fails under high demand. The measurement of response times should be compared to the absolute service level agreement (SLA), even if the agreement remains unpublished. Ideally, the measurement should be performed using actual end-user transactions rather than proxies for their interactions. In addition to the absolute measurement against internal or external service levels, relative measurement against past-month values should be tracked over time for critical transactions. This data can later be used to justify scalability projects if a slowing of any given critical transaction proves to be tightly correlated with revenues associated with that transaction, abandon rates, and so on.
Engineering productivity and efficiency is another important measurement. Consider an organization that measures and improves the productivity of its engineers over time versus one that has no such measurements. You would expect that the former will start to produce more products and complete more initiatives at an equivalent cost to the latter, or that it will start to produce the same products at a lower cost. Both of these outcomes will help us in our scalability initiatives: If we produce more, by allocating an equivalent percentage of our engineering team, we can get more done more quickly and thereby reduce future scale demands on the engineering team. Also, if we can produce the same number of products at lower cost, we will increase shareholder value, because the net decrease in cost structure to produce a scalable platform means greater profitability for the company.
The real trick in figuring out how to measure engineering productivity and efficiency is to split it up into at least two components. The first part addresses whether your engineering teams are using as much of the available engineering days as possible for engineering-related tasks. To measure this component, assume that an engineer is available for 200 days per year minus your company’s sick time, vacation time, training time, and so on. Perhaps your company allows 15 days of paid time off per year and expects engineers to be in 10 days of training per year, resulting in 175 engineering days/engineer. This becomes the denominator within our equation. Then, subtract from this denominator all of the hours and days spent “blocked” on issues related to unavailable build environments, nonworking test environments, broken tools or build environments, missing source code or documentation, and so on. If you haven’t measured such value destroyers in the past, you might be astonished to discover that you are making use of only 60% to 70% of your engineering days.
The second part of engineering productivity and efficiency focuses on measuring how much you get out of each of your engineering days. This is a much harder exercise, as it requires you to choose among a set of unattractive options. These options range from measuring thousands of lines of code (KLOC) produced by an engineer, to stories, function points, or use cases produced. All of these options are unattractive because they all have “failures” within their implementation. For instance, you might produce 100 lines of code per engineer per day, but what if you really need to write only 10 lines to get the same job done? Function points, by comparison, are difficult and costly to calculate. Stories and use cases are largely subjective; as such, they all sound like bad options. Of course, an even worse option is to not measure this area at all. Training programs, after all, are intended to help increase individual output, and without some sort of measurement of their effectiveness, there is no way to prove to a shareholder that the money spent on training was well spent.
Quality rounds out our scalability management measurement suite. Quality can have a positive or negative impact on many other measurements. Poor product quality can cause scalability issues in the production environment and, as a result, can increase downtime and decrease availability. Poor product quality increases cost and reduces productivity and efficiency because rework is needed to meet the appropriate scalability needs. Although you obviously need to look at such typical metrics as bugs, KLOC in production and KLOC per release, absolute bug numbers for your entire product, and the cost of your product quality initiatives, we also recommend further breaking these elements out into the issues that affect scale. For example, how many defects cause scalability (response time or availability) problems for your team? How many of these defects do you release per major or minor release of your code, and how are you getting this number to trend downward over time? How many of these defects are caught by quality assurance versus found in production? You can almost certainly think of even more possible subdivisions.
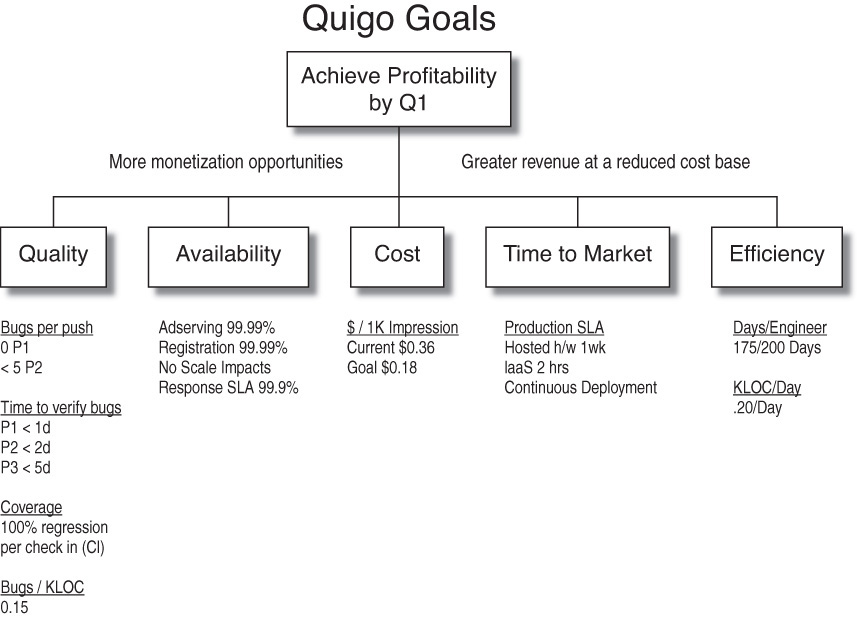
One easy way to map organizational goals to company goals is through a goal tree. A goal tree takes as its root one or more company or organizational goals and breaks it down into the subordinate goals to achieve that major goal. We’ll use a modified goal tree that we created when we were at the advertising technology company Quigo (Figure 5.2). In 2005, the company had a desire to be profitable by the first quarter of 2006. In keeping with this aim, we entered the goal of “Achieve Profitability by Q1” as the root of our tree. We felt that the two ways the product team could impact profitability were by creating more monetization opportunities and by generating greater revenues at reduced costs.
Quality and availability both affected our opportunity to monetize the product. Unavailability means lost monetization opportunities. Many defects have a similar effect: We can’t monetize an ad placement if a defect forces us to serve the wrong ad or credit the wrong publisher, for example. From an availability perspective, we focused on achieving greater than 99.99% availability from the ad serving and registration systems, having no impacts on availability from scale-related issues, and achieving the desired response-time service levels (less than 1 second for each ad delivered) 99.9% of the time. Our quality metrics covered how quickly we would fix different priority levels of bugs, how many bugs we would release of each type, and how many defects per thousand lines of code we had in our production environment.
From a cost perspective, we focused on reducing the cost per thousand pages delivered by more than 50% (while the focus was real, the numbers given here are completely fictitious—if you have your own advertising solution, you won’t gain any insights here!). We also wanted to reduce time to market (TTM) and decrease our cost of delivery.
So far, we’ve painted a picture of a manager as being equal parts taskmaster, tactician, gardener, and measurement guru. But a manager’s job isn’t done there. Besides being responsible for ensuring the team is up to the job, deciding which path to take to a goal, and measuring progress, a manager must make sure that the path to that goal is bulldozed and paved. A manager who allows a team to struggle unnecessarily over rough terrain on the way to an objective when he or she can easily pave the way reduces the output of the team. This reduction in output means the team can’t scale efficiently, as less work is applied to the end goal. Less efficiency means lower shareholder return for an investment.
Bulldozed is a rather aggressive term, of course. In this context, we don’t mean to imply that a manager should act as a fullback attempting to lay out a linebacker so that a halfback can make a touchdown. Although that type of aggressive play might be required from time to time, employing it will likely damage your reputation as a desirable and cooperative colleague. Additionally, such behavior may be absolutely unacceptable in some cultures. Instead, we mean that managers are responsible for removing obstacles in the road to the success of an organization and its objectives.
It is very easy for people to confuse this idea with the notion that “anything that stands in my way is an obstacle to my success and should be removed.” Sometimes the obstacles in your path serve to ensure that you are performing the correct functions. For instance, if you need to release something to your production environment, you might see the quality assurance organization as an obstacle. This observation is at odds with our definition of an obstacle, because the QA organization exists to help you ensure that you are meeting the shareholder’s needs for a higher-quality product. The obstacle in this case is actually you and your flawed perception.
Real obstacles are issues that arise and that the team is not equipped to handle. Examples might be a failure of a partner to deliver software or hardware in a time frame consistent with your needs or difficulties in getting testing support or capital freed up for a project. When you encounter these kinds of obstacles, remember that the team isn’t working for you but rather with you. You may be the captain of the team, but you are still a critical part of its success. Great managers actually get their hands dirty and “help” the team accomplish its goals.
Management is about execution and all of the activities necessary to realize the organization’s goals, objectives, and vision, while adhering to its mission. It should be thought of as a “judicious and ethical use of means to accomplish an end.” Succeeding at management, like thriving as a leader, requires a focus and commitment to learning and growth. It also necessitates respect for and caretaking of tasks, people, and measurements to accomplish the desired goals.
Project and task management is essential to successful management. This effort includes the disaggregation of goals into their associated projects and tasks, the assignment of individuals and organizations to those tasks, the measurement of progress, the communication of status, and the resolution of problematic issues. In larger projects, it will include the relationships between tasks, so as to determine which tasks should happen when and to establish timelines.
People management has to do with the composition and development of organizations and the hiring, firing, and development of individuals. We often spend too much time with our underperformers and wait too long to eliminate them from the team. As a consequence, we don’t spend enough time growing the folks who are truly adding value. In general, we need to devote more time to giving timely feedback to the individuals on our team to ensure that they have ample opportunities to contribute to shareholder value. We also spend a great deal of time interviewing new candidates in total, but often not enough on a per-candidate basis. All too often, our new team members have spent only 30 minutes to an hour with six to seven people before a hiring decision is made. Set aside enough time with people to be sure that you will be comfortable with welcoming them into your family.
Measurement is critical to management success. Without measurements and metrics, we cannot hope to improve, and if there is no hope for improvement, why employ people as managers? The “Measurement, Metrics, and Goal Evaluation” section provides a number of measurement suggestions, and we highly recommend a review of these from time to time as you develop your scalability program.
Managers need to help their team complete its tasks. This means preventing issues from occurring when possible and ensuring that any obstacles that do appear are resolved in a timely fashion. Good managers work to immediately remove barriers, and great managers keep them from arising in the first place.
• Management is the judicious and ethical use of means to accomplish an end.
• As with leadership, the pursuit of management excellence is a lifelong goal and as much a journey as it is a definition.
• Like leadership, management can be viewed as a function consisting of personal characteristics, skills, experiences, actions, and approaches. Increasing any aspect of these elements increases your management “quotient.”
• Forget about “management style” and instead learn to adapt to the needs of your team, your company, and your mission. Project and task management is critical to successful management. These activities require the ability to decompose a goal into component parts, determine the relationships among those parts, assign ownership with dates, and measure progress based on those dates.
• Spend 5% of your project management time creating detailed project plans and 95% of your time developing contingencies to those plans. Focus on achieving results in an appropriate time frame, rather than laboring to fit activities to the initial plan.
• People and organization management is broken into “seeding, feeding, and weeding.”
 Seeding is the hiring of people into an organization with the goal of getting better and better people. Most managers spend too little time on the interview process and don’t aim high enough. Cultural and behavioral interviewing should be included when looking to seed new employees.
Seeding is the hiring of people into an organization with the goal of getting better and better people. Most managers spend too little time on the interview process and don’t aim high enough. Cultural and behavioral interviewing should be included when looking to seed new employees.
Feeding is the development of people within an organization. We can never spend enough time giving quality feedback to our employees.
Weeding is the elimination of underperforming people within an organization. It is rarely done “soon enough,” although we should always feel obligated to give someone performance-related feedback first.
• We can’t improve what we don’t measure. Scalability measurements should include measurements of availability, response time, engineering productivity and efficiency, cost, and quality.
• Goal trees are effective for mapping organizational goals to company goals and help create a “causal roadmap to success.”
• Managers are responsible for paving the path to success. The most successful managers see themselves as critical parts of their teams working toward a common goal.