Table 25.1 Cache Structure
What the ancients called a clever fighter is one who not only wins, but excels in winning with ease.
—Sun Tzu
What is the best way to handle large volumes of traffic? This is, of course, a trick question and at this point in the book we hope you answered something like “Establish the right organization, implement the right processes, and follow the right architectural principles to ensure the system can scale.” That’s a great answer. An even better answer is to say, “Not to handle it at all.” While this may sound too good to be true, it can be accomplished. The guideline of “Don’t handle the traffic if you can avoid it” should be a mantra of your architects and potentially even an architectural principle. The key to achieving this goal is pervasive use of caches.
In this chapter, we will cover caching and explore how it can be one of the best tools in your scalability toolbox. Caching is built into most of the tools we employ, from CPU caches to DNS caches to Web browser caches. Understanding cache approaches will allow you to build better, faster, and more scalable products.
This chapter covers the three levels of caching that are most under your control from an architectural perspective. We will start with a simple primer on caching and then discuss object caches, application caches, and content delivery networks (CDNs), considering how to leverage each for your product.
Cache is an allocation of memory by a device or application for the temporary storage of data that is likely to be used again. This term was first used in 1967 in the publication IBM Systems Journal to label a memory improvement described as a high-speed buffer.1 Don’t be confused by this point: Caches and buffers have similar functionality but differ in purpose. Both buffers and caches are allocations of memory and have similar structures. A buffer is memory that is used temporarily for access requirements, such as when data from disk must be moved into memory for processor instructions to utilize it. Buffers can also be used for performance, such as when reordering of data is required before writing to disk. A cache, in contrast, is used for the temporary storage of data that is likely to be accessed again, such as when the same data is read over and over without the data changing.
1. According to the caching article in Wikipedia: http://en.wikipedia.org/wiki/Cache.
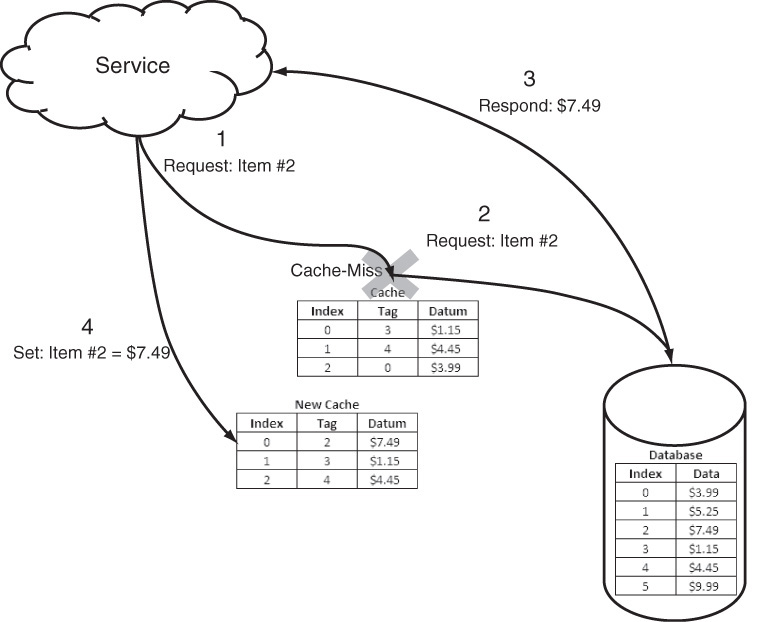
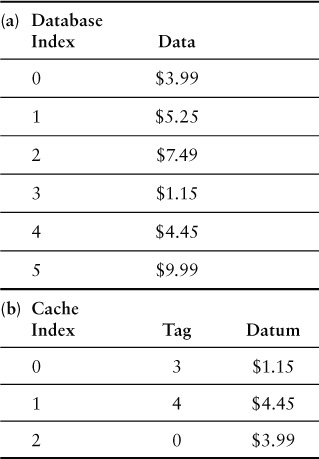
The structure of a cache is similar to the array data structure implemented with key–value pairs. In a cache, these tuples or entries are called tags and datum. The tag specifies the identity of the datum, and the datum is the actual data being stored. The data stored in the datum is an exact copy of the data stored in either a persistent storage device, such as a database, or as calculated by an executable application. The tag is the identifier that allows the requesting application or user to find the datum or determine that it is not present in the cache. In Table 25.1, the cache has three items cached from the database—items with tags 3, 4, and 0. The cache can have its own index that could be based on recent usage or other indexing mechanism to speed up the reading of data.
A cache hit occurs when the requesting application finds the data for which it is asking in the cache. When the data is not present in the cache (a cache miss), the application must go to the primary source to retrieve the data. The ratio of cache hits to requests is called the cache ratio or hit ratio. This ratio describes the effectiveness of the cache in removing requests from the primary source. Low cache ratios indicate poorly performing caches that may negatively impact performance due to the duplicative requests for data.
A few different methods are available for updating or refreshing data in a cache. The first is an offline process that periodically reads data from the primary source and completely updates the datum in the cache. There are a variety of uses for such a refresh method. One of the most common uses is to populate an empty cache for initial use, such as on startup of a system or product. Another is to recalculate and distribute large segments of data. This latter case may be arise with solutions such as yield optimization or retargeting information for advertising engines.
Another method of updating or refreshing data in a cache is to do so when a cache miss occurs. Here, the application or service requesting the data retrieves it from the primary data source and then stores it in the cache. Assuming the cache is filled, meaning that all memory allocated for the cache is full of data, storing the newly retrieved data requires some other piece of data to be ejected from the cache. Decisions about which piece of data to eject are the subject of an entire field of study. The algorithms that are used to make this determination are known as caching algorithms. One of the algorithms most commonly used in caching is the least recently used (LRU) heuristic, which removes the data that has been accessed furthest in the past.
In Figure 25.1, the service has requested Item #2 (step 1), which is not present in the cache and results in a cache miss. The request is reiterated to the primary source, the database (step 2), where it is retrieved (step 3). The application then must update the cache (step 4); it does so, creating the new cache by ejecting the least recently used item (index 2 tag 0 datum $3.99). This is a sample of a cache miss with update based on the least recently used algorithm.
Another algorithm is the exact opposite of LRU—that is, the most recently used (MRU). LRU is relatively commonsensical, in that it generally makes sense that something not being used should be expunged to make room for something needed right now. The MRU at first take seems nonsensical, but in fact it has a use. If the likelihood that a piece of data will be accessed again is most remote when it first has been read, MRU works best. Let’s return to our price_recalc batch job example. This time, we don’t have room in our cache to store all the item prices, and the application accessing the price cache is a search engine bot. After the search engine bot has accessed the page to retrieve the price, it marks it off the list and is not likely to revisit this page or price again until all others have been accessed. In this situation, the MRU algorithm might be the most appropriate choice.
As we mentioned earlier, there is an entire field of study dedicated to caching algorithms. Some very sophisticated algorithms take a variety of factors, such as differences in retrieval time, size of data, and user intent, into account when determining which data stays and which data goes.
Thus far, we’ve focused on reading the data from the cache and assumed that only reads were being performed on the data. What happens when that data is manipulated and must be updated to ensure that if it is accessed again it is correct? In this case, we need to write data into the cache and ultimately get the data in the original data store updated as well. There are a variety of ways to achieve this. One of the most popular methods is a write-through policy, in which the application manipulating the data writes it into the cache and into the data store. With this technique, the application has responsibility for ensuring integrity between the stores.
In an alternative method, known as write-back, the cache stores the updated data until a certain point in the future. In this case, the data is marked as dirty so that it can be identified and understood that it has changed from the primary data source. Often, the future event that causes the write-back is the data being ejected from the cache. With this technique, the data is retrieved by a service and changed. This changed data is placed back into the cache and marked as dirty. When there is no longer room in the cache for this piece of data, it is expelled from the cache and written to the primary data store. Obviously, the write-back method eliminates the burden of writing to two locations from the service, but—as you can imagine—it also increases the complexity of many situations, such as when shutting down or restoring the cache.
In this brief overview of caching, we have covered the tag–datum structure of caches; the concepts of cache hit, cache miss, and hit ratio; the cache refreshing methodologies of batch and upon cache miss; caching algorithms such as LRU and MRU; and write-through versus write-back methods of manipulating the data stored in cache. Armed with the information from this brief tutorial, we are now ready to begin our discussion of three types of caches: object, application, and CDN.
Object caches are used to store objects for the application to be reused. These objects usually either come from a database or are generated by calculations or manipulations of the application. The objects are almost always serialized objects, which are marshalled or deflated into a serialized format that minimizes the memory footprint. When retrieved, the objects must be converted into their original data type (a process typically called unmarshalling). Marshalling is the process of transforming the memory representation of an object into a byte-stream or sequence of bytes so that it can be stored or transmitted. Unmarshalling is the process of decoding from the byte representation into the original object form. For object caches to be used, the application must be aware of them and have implemented methods to manipulate the cache.
The basic methods of manipulation of a cache include a way to add data into the cache, a way to retrieve it, and a way to update the data. These methods are typically called set for adding data, get for retrieving data, and replace for updating data. Depending on the particular cache that is chosen, many programming languages already have built-in support for the most popular caches. For example, Memcached is one of the most popular caches in use today. It is a “high-performance, distributed memory object caching system, generic in nature, but intended for use in speeding up dynamic Web applications by alleviating database load.”2 This particular cache is very fast, using nonblocking network input/output (I/O) and its own slab allocator to prevent memory fragmentation, and thereby guaranteeing allocations to be O(1) or able to be computed in constant time and thus not bound by the size of the data.3
2. The description of Memcached comes from the Web site http://www.danga.com/memcached/.
3. See the “Big O notation” entry in Wikipedia: http://en.wikipedia.org/wiki/Big_O_notation.
As indicated in the description of Memcached, this cache is primarily designed to speed up Web applications by alleviating requests to an underlying database. This makes sense because the database is almost always the slowest retrieval device in the application tiers. The overhead of implementing ACID (atomicity, consistency, isolation, and durability) properties in a relational database management system can be relatively large, especially when data has to be written and read from disk. However, it is completely normal and advisable in some cases to use an object caching layer between other tiers of the system.
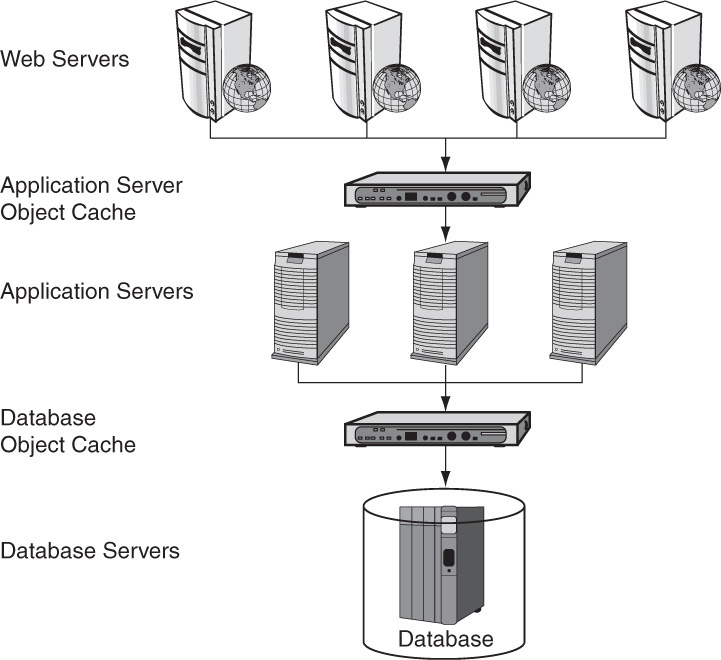
An object cache fits into the typical two- or three-tier architecture by being placed in front of the database tier. As indicated earlier, this arrangement is used because the database is usually the slowest overall performing tier and often the most expensive tier to expand. Figure 25.2 depicts a typical three-tier system stack consisting of a Web server tier, an application server tier, and a database tier. Instead of just one object cache, there are two. One cache is found in between the application servers and the database, and one is found between the Web servers and the application servers. This scheme makes sense if the application server is performing a great deal of calculations or manipulations that are cacheable. It prevents the application servers from having to constantly recalculate the same data, by allowing data to be cached and thereby relieving the load on the application servers. Just as with the database, this caching layer can help scale the tier without additional hardware. It is very likely that the objects being cached are a subset of the total data set from either the database or the application servers. For example, the application code on the Web servers might make use of the cache for user permission objects but not for transaction amounts, because user permissions are rarely changed and are accessed frequently; whereas a transaction amount is likely to be different with each transaction and accessed only once.
The use of an object cache makes sense if a piece of data, either in the database or in the application server, gets accessed frequently but is updated infrequently. The database is the first place to look to offset load because it is generally the slowest and most expensive of your application tiers. But don’t stop there: Consider other tiers or pools of servers in your system for an object cache. Another very likely candidate for an object cache is a centralized session management cache. If you make use of session data, we recommend that you first eliminate session data as much as possible. Completely do away with sessions if possible. Sessions are costly within your infrastructure and architecture. If it is not possible to eliminate sessions, consider a centralized session management system that allows requests to come to any Web server and the session be moved from one server to another without disruption. This way, you can make more efficient use of the Web servers through a load-balanced solution, and in the event of a failure, users can be moved to another server with minimal disruption. Continue to look at your application for more candidates for object caches.
Application caches are another common type of cache found in products. There are two varieties of application caching: proxy caching and reverse proxy caching. Before we dive into the details of each, let’s cover the concepts behind application caching in general. The basic premise is that you want to either speed up perceived performance or minimize the resources used. What do we mean by speeding up perceived performance? End users care only about how quickly the product responds and that they achieve their desired utility from a product. End users do not care which device answers their request, or how many requests a server can handle, or how lightly utilized a device may be.
How do you speed up response time and minimize resource utilization? The way to achieve this goal is not to have the application or Web servers handle the requests. Let’s start out by looking at proxy caches. Internet service providers (ISPs), universities, schools, or corporations usually implement proxy caches. The terms forward proxy cache and proxy server are sometimes used to be more descriptive. The idea is that instead of the ISP having to transmit an end user’s request through its network to a peer network to a server for the URL requested, the ISP can proxy these requests and return them from a cache without ever going to the URL’s actual servers. Of course, this saves a lot of resources on the ISP’s network from being used as well as speeds up the processing. The caching is done without the end user knowing that it has occurred; to her, the return page looks and behaves as if the actual site had returned her request.
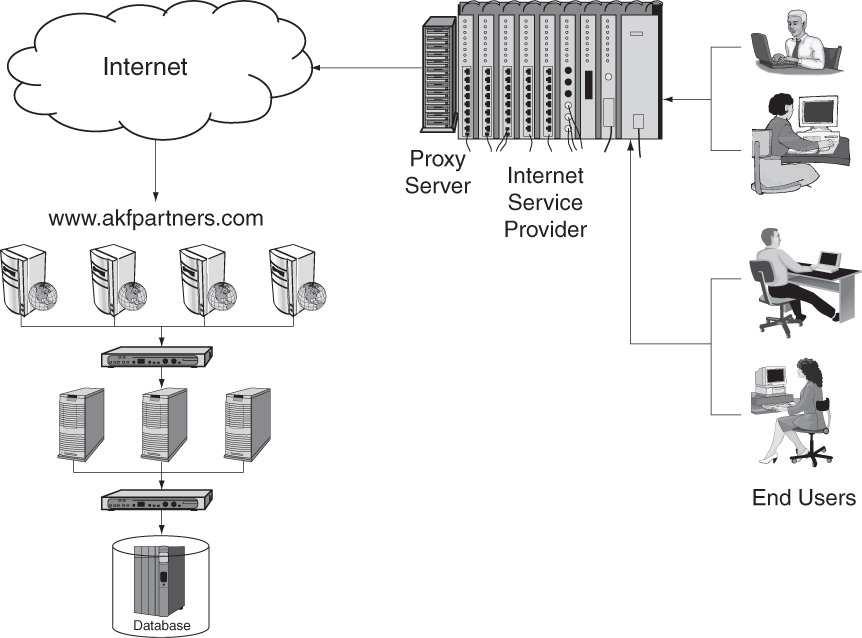
Figure 25.3 shows an implementation of a proxy cache at an ISP. The ISP has implemented a proxy cache that handles requests from a limited set of users for an unlimited number of applications or Web sites. The limited number of users can be the entire subscriber population or—more likely—subsets of subscribers who are geographically colocated. All of these grouped users make requests through the cache. If the data is present, it is returned automatically; if the data is not present, the authoritative site is requested and the data is potentially stored in cache in case some other subscriber requests it. The caching algorithm that determines whether a page or piece of data gets updated/replaced can be customized for the subset of users who are using the cache. It may make sense for caching to occur only if a minimum number of requests for that piece of data is seen over a period of time. This way, the most requested data is cached and sporadic requests for unique data do not replace the most viewed data.
The other type of application caching is the reverse proxy cache. With proxy caching, the cache handles the requests from a limited number of users for a potentially unlimited number of sites or applications. A reverse proxy cache works in the opposite direction: It caches for an unlimited number of users or requestors and for a limited number of sites or applications.
Another term for reverse proxy cache is gateway cache. System owners often implement gateway caches to offload the requests on their Web servers. Instead of every single request coming to the Web server, another tier is added for all or part of the set of available requests in front of the Web servers. Requests that are being cached can be returned immediately to the requestor without processing on the Web or application servers. The cached item can be anything from entire static pages to static images to parts of dynamic pages. The configuration of the specific application will determine what can be cached.
Just because your service or application is dynamic, it does not mean that you cannot take advantage of application caching. Even on the most dynamic sites, many items can be cached.
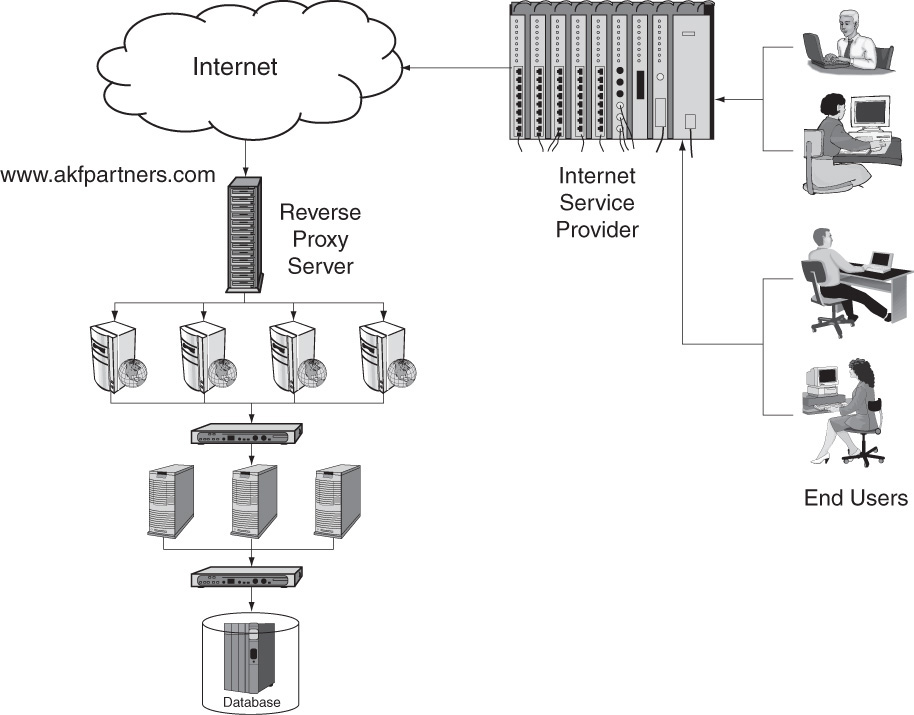
Figure 25.4 shows an implementation of a reverse proxy cache in front of a site’s Web servers. The reverse proxy server handles some or all of the requests until the pages or data that is stored in them is out of date or until the server receives a request for which it does not have data (a cache miss). When this occurs, the request is passed through to a Web server to fulfill the request and to refresh the cache. Any users that have access to make the requests for the application can be serviced by the cache. This is why a reverse proxy cache is considered the opposite of the proxy cache—a reverse proxy cache handles any number of users for a limited number of sites.
Adequately covering even a portion of the caching software that is available both from vendors and from the open source communities is beyond the scope of this chapter. However, some points will be covered to guide you in your search for the right caching software for your company’s needs.
The first point is that you should thoroughly understand your application and user demands. Running a site with multiple gigabytes per second of traffic requires a much more robust and enterprise-class caching solution than does a small site serving 10MB per second of traffic. Are you projecting a doubling of requests or users or traffic every month? Are you introducing a brand-new video product line that will completely change the type of and need for caching? These are the types of questions you need to ask yourself before you start shopping the Web for a solution, or you could easily fall into the trap of making your problem fit the solution.
The second point addresses the difference between add-on features and purpose-built solutions and is applicable to both hardware and software solutions. To understand the difference, let’s discuss the life cycle of a typical technology product. A product usually starts out as a unique technology that garners sales and gains traction, or is adopted in the case of open source, as a result of its innovation and benefit within its target market. Over time, this product becomes less unique and eventually commoditized, meaning everyone sells essentially the same product with the primary differentiation being price. High-tech companies generally don’t like selling commodity products because the profit margins continue to get squeezed each year. Open source communities are usually passionate about their software and want to see it continue to serve a purpose. The way to prevent the margin squeeze or the move into the history books is to add features to the product. The more “value” the vendor adds, the more likely it is that the vendor can keep the price high. The problem with this strategy is that these add-on features are almost always inferior to purpose-built products designed to solve this one specific problem.
An example of this can be seen in comparing the performance of mod_cache in Apache as an add-on feature with that of the purpose-built product Memcached. This is not to belittle or take away anything from Apache, which is a very common open source Web server that is developed and maintained by an open community of developers known as the Apache Software Foundation. The application is available for a wide variety of operating systems and has been the most popular Web server on the World Wide Web since 1996. The Apache module, mod_cache, implements an HTTP content cache that can be used to cache either local or proxied content. This module is one of hundreds available for Apache, and it absolutely serves a purpose—but when you need an object cache that is distributed and fault tolerant, better solutions are available, such as Memcached.
Application caches are extensive in their types, implementations, and configurations. You should first become familiar with the current and future requirements of your application. Then, you should make sure you understand the differences between add-on features and purpose-built solutions. With these two pieces of knowledge, you will be ready to make a good decision when it comes to the ideal caching solution for your application.
The last type of caching that we will cover in this chapter is the content delivery network. This level of caching is used to push any of your content that is cacheable closer to the end user. The benefits of this approach include faster response time and fewer requests on your servers. The implementation of a CDN varies, but most generically can be thought of as a network of gateway caches located in many different geographic areas and residing on many different Internet peering networks. Many CDNs use the Internet as their backbone and offer their servers to host your content. Others, to provide higher availability and differentiate themselves, have built their own point-to-point networks between their hosting locations.
The advantages of CDNs are that they speed up response time, offload requests from your application’s origin servers, and possibly lower delivery cost, although this is not always the case. The concept is that the total capacity of the CDN’s strategically placed servers can yield a higher capacity and availability than the network backbone. The reason for this is that if there is a network constraint or bottleneck, the total throughput is limited. When these obstacles are eliminated by placing CDN servers on the edge of the network, the total capacity increases and overall availability increases as well.
With this strategy, you use the CDN’s domain as an alias for your server by including a canonical name (CNAME) in your DNS entry. A sample entry might look like this:
ads.akfpartners.com CNAME ads.akfpartners.akfcdn.net
Here, we have our CDN, akfcdn.net, as an alias for our subdomain ads.akfpartners.com. The CDN alias could then be requested by the application. As long as the cache was valid, it would be served from the CDN and not our origin servers for our system. The CDN gateway servers would periodically make requests to our application origin servers to ensure that the data, content, or Web pages that they have in cache is up-to-date. If the cache is out-of-date, the new content is distributed through the CDN to their edge servers.
Today, CDNs offer a wide variety of services in addition to the primary service of caching your content closer to the end user. These services include DNS replacement; geo-load balancing, which is serving content to users based on their geographic locations; and even application monitoring. All of these services are becoming more commoditized as more providers enter into the market. In addition to commercial CDNs, more peer-to-peer (P2P) services are utilized for content delivery to end users to minimize the bandwidth and server utilization from providers.
The best way to handle large amounts of traffic is to avoid handling this traffic in the first place—ideally by utilizing caching. In this manner, caching can be one of the most valuable tools in your toolbox for ensuring scalability. Numerous forms of caching exist, ranging from CPU cache to DNS cache to Web browser caches. However, three levels of caching are most under your control from an architectural perspective: caching at the object, application, and content delivery network levels.
In this chapter, we offered a primer on caching in general and covered the tag–datum structure of caches and how they are similar to buffers. We also covered the terminology of cache hit, cache miss, and hit ratio. We discussed the various refreshing methodologies of batch and upon cache miss as well as caching algorithms such as LRU and MRU. We finished the introductory section with a comparison of write-through versus write-back methods of manipulating the data stored in cache.
Object caches are used to store objects for the application to be reused. Objects stored within the cache usually either come from a database or are generated by the application. These objects are serialized to be placed into the cache. For object caches to be used, the application must be aware of them and have implemented methods to manipulate the cache. The database is the first place to look to offset load through the use of an object cache, because it is generally the slowest and most expensive of your application tiers; however, the application tier is often a target as well.
Two varieties of application caching exist: proxy caching and reverse proxy caching. The basic premise of application caching is that you desire to speed up performance or minimize resources used. Proxy caching is used for a limited number of users requesting an unlimited number of Web pages. Internet service providers or local area networks such as in schools and corporations often employ this type of caching. A reverse proxy cache is used for an unlimited number of users or requestors and for a limited number of sites or applications. System owners most often implement reverse proxy caches to offload the requests on their application origin servers.
The general principle underlying content delivery networks is to push content that is cacheable closer to the end user. Benefits of this type of caching include faster response time and fewer requests on the origin servers. CDNs are implemented as a network of gateway caches in different geographic areas utilizing different ISPs.
No matter which type of service or application you provide, it is important to understand the various methods of caching so that you can choose the right type of cache. There is almost always a caching type or level that makes sense with SaaS systems.
• The most easily scalable traffic is the type that never touches the application because it is serviced by caching.
• There are many layers at which to consider adding caching, each with pros and cons.
• Buffers are similar to caches and can be used to boost performance, such as when reordering of data is required before writing to disk.
• The structure of a cache is very similar to that of data structures, such as arrays with key–value pairs. In a cache, these tuples or entries are called tags and datum.
• A cache is used for the temporary storage of data that is likely to be accessed again, such as when the same data is read over and over without the data changing.
• When the requesting application or user finds the data that it is asking for in the cache, the situation is called a cache hit.
• When the data is not present in the cache, the application must go to the primary source to retrieve the data. Not finding the data in the cache is called a cache miss.
• The number of hits to requests is called a cache ratio or hit ratio.
• The use of an object cache makes sense if you have a piece of data either in the database or in the application server that is accessed frequently but updated infrequently.
• The database is the first place to look to offset load because it is generally the slowest and most expensive application tier.
• A reverse proxy cache—also called a gateway cache—caches for an unlimited number of users or requestors and for a limited number of sites or applications.
• Reverse proxy caches are most often implemented by system owners to offload the requests on their Web servers.
• Many content delivery networks use the Internet as their backbone and offer their servers to host your content.
• Other content delivery networks, to provide higher availability and differentiate themselves, have built their own point-to-point networks between their hosting locations.
• The advantages of CDNs are that they lower delivery cost, speed up response time, and offload requests from your application’s origin servers.