10
MUSIC AND LANGUAGE
Ray Jackendoff
Formulating the issues
A fundamental question that has animated a great deal of thought and research over the years is: What does music share with language that makes them distinct from other human activities?
This question emphasizes similarities between language and music (see, for example, Patel 2008), sometimes leading to a belief that they are (almost) the same thing. For instance, the prospectus for a 2008 conference in Dijon entitled “Musique Langage Cerveau” (“Music Language Brain”) states: “The similarities between these two activities are therefore not superficial: music and language could be two expressions of the same competence for human communication” (my translation). However, the divergences between music and language are also quite striking. So we should also ask:
- How are language and music different?
- Insofar as language and music are the same, are they distinct from other human activities?
The emphasis of this chapter will be on these latter two questions.
These questions are sharpened by the “Chomskyan turn” in linguistics, which focuses on how language is instantiated in speakers’ minds, such that they can produce and understand utterances in unlimited profusion, and on how speakers acquire this ability. Lerdahl and Jackendoff’s A Generative Theory of Tonal Music (GTTM, 1983) advocates a similar approach to music: its central issue is what constitutes musical understanding, such that individuals can understand an unlimited number of pieces of music in a style with which they are experienced, and how individuals acquire fluency in a musical style through experience.
Through this lens, music and language can be compared in the following terms:
- Every normal individual has knowledge of language and music.
- Everyone learns the local variant(s) of both language and music. Normal adults achieve full linguistic competence, but are more variable in musical ability, depending on exposure and talent.
Then the important question becomes: What cognitive capacities are involved in acquiring and using a language, and what capacities are involved in acquiring and using a musical idiom? The question is the same for both capacities, but this does not mean the answer is the same.
The issue of particular interest here is: What cognitive capacities are shared by language and music, but not by other cognitive domains?
Similar issues arise with other human capacities; for example, the capacity for social and cultural interaction (Jackendoff 2007). Like languages and musical idioms, cultures differ widely, and an individual’s ability to function in a culture requires considerable learning and the use of multiple cognitive capacities. Moreover, the use of language and music is embedded in social and cultural interaction, but that does not entail that the capacity for either language or music is simply a subset of the social/cultural capacity.
A major dispute in the theory of language, of course, is how much of the language acquisition capacity is special-purpose. Many people (e.g. Christiansen and Chater 2008; Tomasello 2003) think that language is acquired through general- purpose learning plus abilities for social interaction. This view is explicitly in opposition to the claims made by generative grammarians up to the late 1990s to the effect that there must be a rich innate language-specific Universal Grammar (Chomsky 1965, 1981). In between these two extremes are all manner of intermediate views (Hauser, Chomsky, and Fitch 2002; Jackendoff 2002; Pinker and Jackendoff 2005).
The parallel issue in music cognition and acquisition arouses less vehement dispute, partly because claims for an innate music capacity have been less highly politicized – and partly because claims that music is an adaptation favored by natural selection are considerably weaker than those for language. At one extreme we find Pinker’s hypothesis that music is “auditory cheesecake,” constructed adventitiously from parts of other capacities (1997: 534); at the other might be the fairly rich claims of GTTM. In between is, for example, Patel’s view that music is a social construction, but that the capacity for pitch discrimination and formation of tonally oriented scales is nevertheless specific to music (2008).
General capacities shared by language and music
Some similarities between language and music are easily enumerated.
- Although many animals have communication systems, no non-humans have language or music in the human sense, and there are no obvious evolutionary precursors for either in non-human primates.
- Language and music both involve sound production (although notice that language also exists in the signed modality and music does not).
- Every culture has a local variant of language, and every culture has a local variant of music. The differences among local variants are, moreover, quite striking; this contrasts with other species, whose communication systems show very limited variation at best.
- In every culture (I believe), language and music can be combined in song.
Looking more cognitively, the acquisition and processing of both language and music call for certain capacities that are shared with other cognitive domains. Here are seven.
First, both language and music require substantial memory capacity for storing representations – words in language (tens of thousands) and recognizable melodies in music (number unknown; my informal estimate easily runs into the thousands). But this is not specific to music and language. Massive storage is also necessary for encoding the appearance of familiar objects, the detailed geography of one’s environment, the actions appropriate to thousands of kinds of artifacts (Jackendoff 2007: ch. 4), and one’s interactions with thousands of people – not just what they look like but also their personalities and their roles in one’s social milieu (Jackendoff 2007: ch. 5).
Second, in order for novel stimuli to be perceived and comprehended, both language and music require the ability to integrate stored representations combinatorially in working memory by means of a system of rules or structural schemata. Again, this characteristic is not specific to language and music. Understanding a complex visual environment requires a capacity to integrate multiple objects into a structured scene; and creating a plan for complex action requires hierarchical integration of more elementary action schemata, in many cases bringing in complex social information as well. (See Jackendoff and Pinker 2005, who argue against Hauser, Chomsky, and Fitch’s (2002) hypothesis that the use of recursion is what makes language unique. All cognitive capacities of any complexity have recursion.)
Third (as stressed by Patel (2008)), the processing of both language and music involves creating expectations of what is to come. But visual perception involves expectation, too: if we see a car heading for a tree, we expect a crash.
Fourth, producing both language and music requires fine-scale voluntary control of vocal production. No other faculties place similar demands on vocal production per se. However, voluntary control of vocal production is plausibly a cognitive extension of our species’ enhanced voluntary control of the hands, crucial for tool-making and tool use (Calvin 1990; Wilkins 2005), not to mention for signed language and playing musical instruments.
Fifth, learning to produce both language and music relies on an ability – and desire – to imitate others’ vocal production. In the case of music, one may imitate other sound-producing actions as well (e.g. drumming, birdsong). This ability to incorporate others’ inventions enables both language and music to build a culturally shared repertoire of words and songs. However, this is not specific to language and music either: the richness of human culture is a consequence of the ability to imitate and integrate others’ actions (not just others’ words) into one’s own repertoire.
Sixth, there must be some individuals who can invent new items – words or tunes – that others can imitate. This too extends to cultural practices, be they tools, food, types of clothing, or praxis (customs, trade, games, rituals, etc.).
Seventh, individuals must be able to engage in jointly intended actions – actions understood not just as me doing this and you doing that, but as us two doing something together, each with a particular role (Bratman 1999; Gilbert 1989; Searle 1995). This ability lies behind the human ability for widespread cooperation (Boyd and Richerson 2005; Tomasello et al. 2005), and it is necessary in language use for holding conversations (Clark 1996) and in music for any sort of group singing, playing, dancing, or performing for an audience.
The only capacity on this list not shared with other domains is fine-scale voluntary vocal production, which of course is not necessary for either signed languages or instrumental music. Other primates arguably possess the first three – large-scale memory, combinatoriality, and expectation – though not in their communication systems. The last three – imitation, innovation, and joint action – are not shared with other primates, but are generally necessary for all sorts of cultural cognition and culturally guided action. The point is that these general abilities alone do not specifically determine the form of either language or music.
Differences in ecological function
One fundamental difference between language and music concerns their ecological functions in human life. In brief, language conveys propositional thought, and music enhances affect. (I prefer the broader term affect to the more usual emotion; see Jackendoff and Lerdahl 2006.) Although this point is hardly new, it is worth expanding in order to make clear the extent of the difference.
Language is essentially a mapping between sound and “propositional” or “conceptual” thought. The messages it conveys can be about people, objects, places, actions, or any manner of abstraction. Language can convey information about the past and the future, visible and invisible things, and what is not the case. Linguistic utterances can be used to offer information, make requests for action, ask questions, give instructions and orders, negotiate, undertake obligations (including promises), assert authority, and construct arguments about the differences between language and music. Linguistic messages distinguish information taken to be new to the hearer (“focus”) from information taken to be shared with the hearer (“common ground”), and they can incorporate social distinctions between speaker and hearer (as in French tu versus vous or Japanese honorifics). The gist of a linguistic utterance can be translated from any language into any other, given appropriate vocabulary.
Music can satisfy none of these functions. In particular, linguistic utterances cannot be translated into music. (Even if various drumming and whistling languages use media more commonly deployed for musical purposes, they are codes for language and are not forms of music.)
Consider now the functions of music. Probably furthest from its evolutionary roots are the uses in which people sit and passively listen to a performance. Many different uses of music in traditional cultures have been proposed as the original adaptive function of music (see, for example, the essays in Wallin, Merker, and Brown 2000), but actual evidence is scanty. What the different uses of music have in common is the enhancement of affect associated with an activity. If this is considered “musical meaning” (e.g. Raffman 1993), it still bears no relation to “propositional” linguistic meaning.
In some sorts of music, one person directs music at another: lullabies convey a sense of soothing intimacy; love songs convey affection and passion; ballads convey the emotional impact of a story. Other sorts of music are meant to be sung or played together. Work songs convey the coordinated rhythm of work and the affect of coordinated action. Marches convey the coordinated action of walking, often militaristically or ceremonially. Religious music conveys transcendence and spirituality, with affect anywhere from meditative to frenzied. Dance tunes stimulate affective or expressive body movement. Songs for collective situations such as campfires and bars seem to instill a sense of fellowship. Another genre is children’s songs, including nursery tunes; it is not clear to me what their function is. Still other sorts of music, such as muzak and café music, are meant to be perceived subliminally. Their function is evidently to enhance mood. This genre also includes film music, whose effects can be quite powerful. There is no comparable subliminal use of language.
Of course, language can be put to affective use. For instance, utterances such as “You are an idiot” and “I love you” convey affect, though in a different way from music. Language also borrows a wide range of rhetorical devices from music. Poetry (especially “folk” poetry) makes use of isochrony or strict rhythm, which brings linguistic utterances closer to the metrical character of music. Poetic rhyme parallels the rhythmic patterns of harmonic/melodic expectation in music (Lerdahl 2003). Poetry’s appeal – even to children – partly comes from the affect of such rhythmic patterning. Similarly, call and response patterns (as in certain styles of preaching) evoke strong affect, paralleling the experience of choral singing. More generally, combinations of music and language are ubiquitous – in song, where language follows musical rhythms, in chant (e.g. recitative), where melody follows speech rhythms, and in rap, where words without melody follow musical rhythms. Lerdahl (2003) suggests that these are all hybrids: poetry is the result of superimposing musical principles on linguistic utterances. Thus poetic form conveys affect because it invokes principles of musical perception that are not normally associated with language.
Interestingly, poetry in signed languages makes use of alliteration (such as deliberate choice of parallel handshapes), rhythmic patterning, and – unlike spoken poetry – counterpoint (overlapping of signs) (Klima and Bellugi 1979: 340–72). Again, arguably musical types of structure are superimposed on language.
Language and music also both convey affect through tone of voice. However, this does not show that the two capacities are the same: they have each incorporated some of the character of mammalian call systems. Mammalian calls do convey both affect (like music) and some very limited sort of conceptual information (like language). But it does not follow that language and music evolved as a single capacity that later split (Brown’s (2000) “musilanguage” hypothesis). They could equally be independent evolutionary specializations of primate communication. The next section enumerates differences that favor the latter hypothesis.
To sum up this brief survey: aside from the use of tone of voice shared by language and music, and aside from the mixture of language and music in poetry, the specialization of language to conceptual information and music to affect is actually quite extreme.
Similarities and differences in formal structure
Next consider the formal devices out of which language and music are constructed.
Pitch
Unlike other cognitive capacities, both language and music involve a sequence of discrete sounds: speech sounds in language, tones or pitch events in music. This is one reason to believe they are alike. But the resemblance ends there. The repertoire of speech sounds forms a structured space of timbres that is governed by how consonants and vowels are articulated in the vocal tract. Speech sounds can also be distinguished by length (the shortest differing from the longest by a factor of two or so).
By contrast, tones in music form a structured space of pitches and differ over a broad range of lengths (shortest to longest differing by a factor of sixteen or more). In all traditional musical genres that use pitch, the organization of sound is built around a tonal pitch space, a fixed collection of pitches whose stability is determined in relation to a tonic pitch. It is well established that the structure of tonal systems is explained only in part by psychoacoustics; the rest is culture-specific (see Jackendoff and Lerdahl 2006 and references therein).
The characteristics of tonal pitch spaces are mostly not shared with language. There are a number of possible parallels. For instance, prosodic contours in lan- guage tend to go down at the end, and so do melodies. But both probably inherit this from the form of human and mammalian calls (and possibly from physiology – the drop in air pressure as the lungs are emptied). Thus this common characteristic could be the result of independent inheritance from a common ancestor.
Moreover, only melodies have discrete pitches, while prosodic contours usually involve a continuous rise and fall. Of course there are mixtures. On the one hand, many vocal and instrumental traditions incorporate bending of pitches and sliding between them. And intonation (in many languages) is commonly analyzed in terms of high and low pitches anchored on prominent accents and ends of breath-groups (Pierrehumbert 1980). Thus intonation in language might be fundamentally a two-pitch tonal system, modulated by continuous transitions between the anchoring pitches. However, the high and low pitches are not fixed in frequency throughout an utterance, unlike the fixed dominant and tonic in musical pitch space. So the analogy between intonational systems and tonal pitch spaces is strained at best.
Pitch in language is also used for tone in tone languages such as Chinese and many West African languages. In such languages, the tones form a fixed set that might seem analogous to tonal pitch space. However, since the tones used are determined by the words being used, no tone can function as a tonic – the point of maximum stability at which melodies typically come to rest. Moreover, tones are superimposed on an overall intonation contour. As a breath group continues, all tones drift down, and the intervals between them get smaller (Ladd 1996) – an entirely different use of pitch than in musical pitch spaces. Finally, evidence from tone deafness and amusia (Peretz and Coltheart 2003) suggests that linguistic intonation and musical pitch are controlled by distinct brain areas.
Thus language has no convincing analogue to the musical use of pitch space, despite their making use of the same motor capacities in the vocal tract.
Rhythm
GTTM shows that phonology and music are both structured rhythmically by similar metrical systems, based on a hierarchical metrical grid. This is a parallel perhaps shared by only music and language. However, the domains use the grid differently. The minimal metrical unit in phonology is the syllable, a sequence of speech sounds which corresponds to a beat in the metrical grid. The metrical grid in language usually is not performed isochronously (Patel 2008: 97–154). By contrast, a single note in music can subtend multiple beats, and a beat can be subdivided by multiple notes. And within certain degrees of tolerance (depending on the style), the metrical grid is isochronous, which makes syncopation possible.
The second component of musical rhythm is grouping, which segments the musical stream recursively into motives, phrases, and sections. Musical grouping parallels visual segmentation, which configures multiple objects in space and segments objects into parts. Though grouping structure is recursive, musical groups simply contain a collection of individual notes or smaller groups. There is no distinguished element in a group that functions as “head,” parallel to the heads of syntactic constituents in language (see below). If there is a linguistic analogue to musical grouping, it is probably intonational phrasing. But intonational phrasing forms a relatively flat structure, unlike musical grouping, which extends recursively from small motivic units to an entire piece. Moreover, intonational phrases are made up of smaller prosodic constituents such as phonological words and phonological phrases, each with its own specific properties (Selkirk 1984). Music lacks such differentiation of grouping units into distinct types.
In the rhythmic domain, then, the metrical grid may well be a genuine capacity unique to language and music; musical grouping is shared more with vision than with language, and linguistic intonation contours are partly specific to language.
Words
Beyond the sound system, language and music diverge more radically. Linguistic utterances are built up from words and syntax; pieces of music are built up from individual tones, some formulaic patterns, and prolongational structure. Consider the possible parallels here.
Words are conventionalized sound patterns associated in long-term memory with pieces of meaning (or concepts). Sentences are composed of words plus “grammatical glue” such as agreement, grammatical gender, and case. Musical idioms do incorporate some conventionalized sound patterns such as stylistic clichés and standard cadences, plus larger patterns such as 12-bar blues and sonata form. But these patterns are not associated with concepts. Moreover, melodies are usually not made up exclusively of conventionalized patterns in the way in which sentences are made up of words. (There are exceptions, though, such as much Jewish liturgical chant (Binder 1959).)
The function of conventionalized patterns in music more closely resembles the function of linguistic “prefabs” – clichés, idioms, and figures of speech. Like musical formulas, prefabs are frequent, but utterances are not exclusively made of them: there is still plenty of free choice of words. However, if musical formulas are parallel to prefabs, then words have no musical parallel. And of course musical formulas do not carry conceptual meaning in any event.
Syntax
Language can serve as such an expressive mode of communication because of syntactic structure, a hierarchical structure in which each node belongs to a syntactic category such as noun or adjective phrase. Music has no counterpart to these categories. Syntactic structure is headed: one element of most constituents is designated as its head. The category of a phrase is determined by the category of its head: a noun phrase is headed by a noun, a prepositional phrase by a preposition, and so on. This is the fundamental “X-bar” principle of phrase structure (Chomsky 1970; Jackendoff 1977). Each syntactic category has a characteristic configuration. For example, English verb phrases contain a head verb followed by up to two noun phrases, followed by prepositional phrases, adverbs, and subordinate clauses.
Syntax also contains multiple devices for encoding the dependencies among its constituents, such as agreement, case, reflexivity (and other anaphora), ellipsis, and long-distance dependencies (for instance, when who functions as direct object of meet in Who does Joe think he will meet at the party?). Words often are further differentiated into morphosyntactic structure: affixal structures that affect meaning and syntactic category. Sometimes this structure is recursive (as in antidisestablishmentarianism), and sometimes templatic (for instance, the underlined French object clitics in Je le lui ai donné, ‘I gave it to him’).
None of this structure has a counterpart in music. It all serves to code meaning relations among words in a fashion fit for phonological expression, namely, linear order and affixation. Of course, meaning expression is absent in music as well.
Prolongational structure
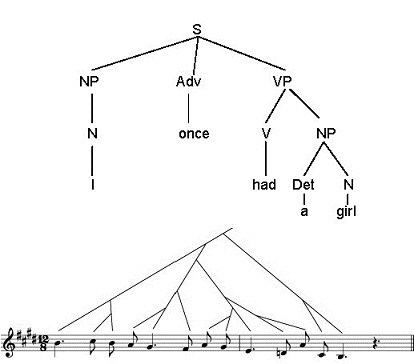
The closest musical counterpart to syntax is GTTM’s prolongational structure, originally inspired by the reductional hierarchy of Schenkerian theory (Schenker 1979). Prolongational structure is a recursive hierarchy, in which each constituent has a head, and other dependents modify or elaborate the head. But in other respects it diverges from syntax. It has no parts of speech: the tonic/dominant distinction, for instance, is not formally analogous to either noun/verb or subject/ predicate/object. The category of a constituent is determined by its head, but it does not parallel X-bar structure in language. For instance, a phrase headed by the note G or by a G major chord is not a “G-phrase,” but simply an elaborated G. The difference between the two structures is illustrated in Figure 10.1.
Prolongational relations do not express the regimentation of conceptual relations; rather, they encode the relative stability of pitch-events in local and global contexts. Prolongational structure creates patterns of tensing and relaxing as the music moves away from stability and back toward a new point of stability. GTTM and, in much more detail, Lerdahl (2001) argue that these patterns of tensing and relaxation have a great deal to do with affect in music. Language has no counterpart to this function. Thus, on both formal and functional grounds, syntax and prolongational structure have little in common beyond both being headed hierarchies.
Following the general intuition that the components of music ought not to be sui generis, one would hope for a stronger analogue of prolongational structure in some other cognitive capacity. However, evaluating the strength of potential parallels with other capacities requires a detailed analysis and comparison of faculties. At the moment, this is impossible: not enough is known about the formal structure of mental representations for any other cognitive capacity.
However, a candidate comparison has recently emerged. Jackendoff (2007: 111–43), drawing in part on work in robotics, suggests that, like syntax and prolongational structure, the formulation and execution of complex actions – actions as ordinary as shaking hands or making coffee – invokes a recursive headed hierarchical structure that integrates and modulates many subactions stored in long-term memory. Patel (2003, 2008) presents experimental evidence that the hierarchical structures of language and music, although formally distinct, are integrated by the same part of the brain, roughly Broca’s area. If so, this invites a conjecture that complex action structures are, too. That this area is usually considered premotor would add some plausibility to such speculation. In fact, the integration and execution of complex action might be a strong candidate for a more general, evolutionarily older function that could be appropriated by both language and music, quite possibly independently.
Conclusion
Language and music share a considerable number of general characteristics and one detailed formal one, namely, metrical structure. They also share some brain areas. However, most of what they share does not indicate a particularly close relation that makes them distinct from other cognitive domains. Many of their shared characteristics prove to be domain-general; for instance, recursion, the use of memory, and the need for learning and for a social context. Moreover, the fact that language and music are both conveyed through the auditory–vocal modality, though it places constraints on both of them, does not have much to do with their formal structure. This is pointed up especially by the alternative signed modality for language, which preserves most of the standard formal properties of language. Finally, language and music differ substantially in their use of pitch, in their rhythmic structure, in their “meaning” (propositional versus affective), and in the form and function of their hierarchical structures.
The conclusion, then, is to urge caution in drawing strong connections between language and music, both in the contemporary human brain and in their evolutionary roots. This is not to say we should not attempt to draw such connections. For example, Patel (2008), surveying much the same evidence as this chapter, concludes the glass is half full rather than half (or three-quarters) empty. But if one wishes to draw connections, it is important to do so on the basis of more than speculation. In particular, at the moment we do not have a properly laid out account of even one other capacity against which to compare language and music. It is an interesting question when and how cognitive science will approach such accounts, in order eventually to have a fair basis for comparison.
See also Music, philosophy, and cognitive science (Chapter 54), Psychology of music (Chapter 55), Rhythm, melody, and harmony (Chapter 3), and Understanding music (Chapter 12).
References
Binder, A. W. (1959) Biblical Chant, New York: Philosophical Library.
Boyd, R. and Richerson, P.J. (2005) The Origin and Evolution of Cultures, Oxford: Oxford University Press.
Bratman, M.E. (1999) Faces of Intention, Cambridge: Cambridge University Press.
Brown, S. (2000) “The ‘Musilanguage’ Model of Music Evolution,” in Wallin, Merker, and Brown, pp. 271–300.
Calvin, W. (1990) The Cerebral Symphony, New York: Bantam Books.
Chomsky, N. (1965) Aspects of the Theory of Syntax, Cambridge: MIT Press.
—— (1970) “Remarks on Nominalizations,” in R. Jacobs and P. Rosenbaum (eds) Readings in English Transformational Grammar, Waltham: Ginn, pp. 184–221.
—— (1981) Lectures on Government and Binding, Dordrecht: Foris.
Christiansen, M. and Chater, N. (2008) “Language as Shaped by the Brain,” Behavioral and Brain Sciences 31: 537–58.
Clark, H.H. (1996) Using Language, Cambridge: Cambridge University Press.
Gilbert, M. (1989) On Social Facts, Princeton: Princeton University Press.
Hauser, M.D., Chomsky, N. and Fitch, W.T. (2002) “The Faculty of Language: What is it, Who has it, and How did it Evolve?” Science 298: 1569–79.
Jackendoff, R. (1977) X-bar Syntax, Cambridge: MIT Press.
—— (2002) Foundations of Language, Oxford: Oxford University Press.
—— (2007) Language, Consciousness, Culture, Cambridge: MIT Press.
Jackendoff, R. and Lerdahl, F. (2006) “The Capacity for Music: What’s Special about it?” Cognition 100: 33–72.
Jackendoff, R. and Pinker, S. (2005) “The Nature of the Language Faculty and its Implications for the Evolution of Language (Reply to Fitch, Hauser, and Chomsky),” Cognition 97: 211–25.
Klima, E. and Bellugi, U. (1979) The Signs of Language, Cambridge: Harvard University Press.
Ladd, R. (1996) Intonational Phonology, Cambridge: Cambridge University Press.
Lerdahl, F. (2001) Tonal Pitch Space, New York: Oxford University Press.
—— (2003) “The Sounds of Poetry Viewed as Music,” in J. Sundberg, L. Nord, and R. Carlson (eds) Music, Language, Speech and Brain, London: Macmillan, pp. 34–47.
Lerdahl, F. and Jackendoff, R. (1983) A Generative Theory of Tonal Music, Cambridge: MIT Press.
Patel, A. D. (2003) “Language, Music, Syntax, and the Brain,” Nature Neuroscience 6: 674–81.
—— (2008) Music, Language, and the Brain, Oxford: Oxford University Press.
Peretz, I. and Coltheart, M. (2003) “Modularity of Music Processing,” Nature Neuroscience 6: 688–91.
Pierrehumbert, J. (1980) “The Phonetics and Phonology of English Intonation”, Ph.D. diss. Massachusetts Institute of Technology. (Published by Indiana University Linguistics Club, 1987.)
Pinker, S. (1997) How the Mind Works, New York: Norton.
Pinker, S. and Jackendoff, R. (2005) “The Faculty of Language: What’s Special about it?” Cognition 95: 201–36.
Raffman, D. (1993) Language, Music, and Mind, Cambridge: MIT Press.
Schenker, H. (1979 [1935]) Free Composition, trans. E. Oster, New York: Longman.
Searle, J. (1995) The Construction of Social Reality, New York: Free Press.
Selkirk, E.O. (1984) Phonology and Syntax: The Relation between Sound and Structure, Cambridge: MIT Press.
Tomasello, M. (2003) Constructing a Language, Cambridge: Harvard University Press.
Tomasello, M. et al. (2005) “Understanding and Sharing Intentions: The Origins of Cultural Cognition,” Behavioral and Brain Sciences 28: 675–91.
Wallin, N.L., Merker, B. and Brown, S. (eds) (2000) The Origins of Music, Cambridge: MIT Press.
Wilkins, W.K. (2005) “Anatomy Matters,” The Linguistic Review 22: 271–88.