Hot site This is a site that has everything needed and is ready to go live.
Hot site This is a site that has everything needed and is ready to go live.Redundant Arrays of Inexpensive Disks
As we’ll see in the next chapter, any number of disasters can put a company at risk of not being able to do business. Fires, blizzards, earthquakes, or something as simple as a primary server failing could threaten the capability of an organization to function. An important part of protecting a business from potential threats is redundancy planning.
Redundancy planning refers to looking at potential threats to the capability of an organization to do business and a network’s capability to function, and implements measures that reduce the risk to a minimum. As we’ll see in the sections that follow, this involves setting up facilities to use if a disaster occurs, installing duplicate systems that take over if the primary systems fail, and using devices that will provide power and other functions in cases of emergency.
Alternate sites are important to certain companies, so they can experience minimal downtime or almost no downtime at all. In a disaster, it’s possible that the facilities, servers, or other network devices are damaged or destroyed. In such a case, the company would require a temporary location in which data can be restored to servers, and business functions can resume. Without such a facility, the company would need to find a new business location, purchase new equipment, set it up, and then go live. The time that it would take to do this could be so long that the disaster could put them out of business. Alternate sites get the business up-and-running quicker, allowing the business to continue running until their existing facilities are repaired or a new permanent site is established.
As we’ll see in the sections that follow, there are different types of alternate sites that can be used, with each having its own benefits and drawbacks. They are as follows:
Hot site This is a site that has everything needed and is ready to go live.
Warm site This is a site in which some equipment and services need to be set up, and data needs to be restored from backups before going live.
Cold site This is a site that is the least expensive to maintain but requires the most amount of preparation before going live.
Creating alternate or backup sites can take considerable planning. Companies need to identify what equipment needs to be available, and how fast they need backup systems to go live after a disaster. When deciding on appropriate locations for such sites, it is important that they be in different geographical locations. If the alternate site is not at a significant distance from the primary site, it can fall victim to the same disaster. Imagine having an alternate site across the road from a company when an earthquake occurs. Both sites would experience the same disaster, so now there would be no alternate site available to resume business. However, you don’t want the alternate site so far away that it will significantly add to downtime. If the information technology staff needs to travel long distances to get to the site, this can increase the downtime and result in additional losses. Designate a site that is close enough to work from, but not so near that it will become a major issue when a disaster occurs.
Notes from the Field |
September 11 and Business Continuity
The terrorist activities of September 11, 2001, which resulted in the destruction of the World Trade Center in New York City, caused many companies to seriously consider their business continuity plans. Companies may have planned for a localized disaster (such as a fire) affecting their business, but the decimation caused as a result of airliners slamming into the buildings was something no one had accounted for. A large-scale disaster resulting in the loss and inaccessibility of employees, facilities, and other assets wasn’t something that many considered.
According to a report by the U.S. Securities and Exchange Commission entitled Summary of “Lessons Learned” from Events of September 11 and Implications for Business Continuity, the businesses that did have alternate sites had them too close to their primary facility. As a result, when the twin towers collapsed and the area was shut down for the emergency, they were cut off from their alternate sites that were in nearby buildings. For further information on the findings of the U.S. Securities and Exchange Commission, you can visit www.sec.gov/divisions/marketreg/lessonslearned.htm.
A hot site is a facility that has the necessary hardware, software, phone lines, and network connectivity to allow a business to resume normal functions almost immediately. This can be a branch office or data center, but it must be online and connected to the production network. A copy of data is held on a server at that location, so little or no data is lost. Replication of data from production servers may occur in real time, so that an exact duplicate of the system is ready when needed. In other instances, the bulk of data is stored on servers, so only a minimal amount of data needs to be restored. This allows business functions to resume very quickly, with almost zero downtime.
A hot site is the optimum solution in a disaster. However, while every company would like a hot site for their alternate site, companies may decide against them due to budget concerns. The hot site has equipment that matches the configuration of the production network, which means that any changes to equipment need to be duplicated at the alternate site. However, if the business expects significant losses (in terms of money and customers) from the network going down for any great length of time, a hot site would be seen as a necessary investment.
A warm site is not as equipped as a hot site, but it has part of the necessary hardware, software, and other office needs to restore normal business functions. Such a site may have most of the equipment necessary, but it will still need work to bring it online and support the needs of the business. With such a site, the bulk of data will need to be restored to servers, and additional work (such as activating phone lines or other services) will need to be done. No data is replicated to the server, so backup tapes must be restored so that data on the servers is recent.
Warm sites cost less than hot sites, which makes them an attractive alternative. However, they also lack a number of the features required for them to go online quickly. Unlike a hot site, a duplicate of the data is not held on servers. The alternate site may be used as a facility to store backups of data from production servers, which are used in a disaster to restore data to the warm site’s servers. To delay matters further, the site may require additional equipment before it can go live. Because hot sites allow an immediate switchover, it can be up in hours, but a warm site may require days of setup.
A cold site requires the most work to set up, as it is neither online nor part of the production network. It may have all or part of the necessary equipment and resources needed to resume business activities, but installation is required and data needs to be restored to servers. Additional work (such as activating phone lines and other services) will also need to be done. The major difference between a cold site and hot site is that a hot site can be used immediately when a disaster occurs, whereas a cold site must be built from scratch.
A cold site is the least expensive type of alternate site, but isn’t an option for companies that can’t afford to wait for servers and equipment to be set up. Generally, this is an empty facility that has some network capabilities, but doesn’t have any servers or other network equipment. In a disaster, the company would need to purchase equipment, or scavenge and salvage their own equipment from other offices. This can mean that the company is unable to resume business for weeks. Also, because the site can’t be tested prior to its use, there may be significant issues with equipment not working properly and having poor initial performance.
TEST DAY TIP The exam will expect you to know the difference between cold, warm, and hot sites. Don’t get too stressed out trying to remember all of the features of each site. A quick and dirty way of keeping them straight is to remember that a hot site is active and functional, a cold site is offline and nonfunctional, and a warm site is an intermediate. |
A single point of failure can be the heel of Achilles that brings down a system. Imagine a single road with a bridge that provides the only way to enter or exit a town. If the bridge fell down, no one would be able to enter or leave the town. Just like the bridge, which provides a single point of failure that can cut off people from the outside world, a single point of failure in a system can sever the capability of a company to perform normal business functions.
High availability is the capability of a network to keep systems operating and to keep services available in the event of an outage. How this is provided is through redundant systems and fault tolerance. Redundancy is a duplication of services and systems. If the primary method used to store data, transfer information, or other operations fails, then a secondary method is used to continue providing the services. Fault tolerance refers to a systems capability to continue working in the event of such a failure. If one component stops working, it will fail over to another component. This ensures that systems are always available in one way or another, with minimal downtime so that people are not prevented from doing their jobs. By providing high availability to a network, the business is able to continue functioning with minimal impact from a system failure.
TEST DAY TIP Don’t get confused between the terms high availability, redundancy, and fault tolerance. High availability means that things are up-and-running most of the time, regardless of a problem. Redundancy means that services and systems are duplicated, so if one goes down, the other can still be used. Fault tolerance means the capability of a system to continue working even if a component or service fails. These terms will probably appear on your exam, so you should be familiar with each of them. |
There are many ways of providing fault tolerance and redundancy in servers, which involves duplicate components or duplicate servers. For example, a server may have multiple network cards installed on it, so that if one of the cards fails, the data on that server can still be accessed through the second card. A server that provides important services or runs critical programs may use a failover server. The failover server duplicates the services and data of the primary server, and checks at regular intervals that the primary server is running. If the failover server doesn’t receive a response during one of these checks, it will then take over the role of the primary server and provides services to users. From the user’s point of view, there is little to no breakdown in service.
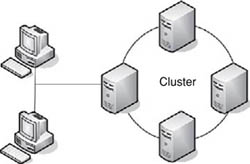
Many operating systems (OSes) provide the capability to cluster servers together. Server clusters are groups of independent servers that are connected together, so that if one fails the others will continue to provide the services. Windows Server, Novell Open Enterprise Server, and Linux support clustering, and are often used for servers providing file and print services, applications, databases, or messaging. In the event of a failure, a user’s request for a resource is redirected from the failed server to another server that is still operating.
As seen in Figure 13.1, each of the servers runs independently on the network but is connected together. Each server handles its own local resources and has a copy of the services and applications that run on other servers in the cluster. In many clusters, the servers share a single disk system, and appear on the network as a single entity. When a user makes a request for a resource, it is sent to the cluster. If one of these servers failed, the others in the cluster would still function and be able to take over processing requests from the network, and provide services. This is invisible to the user, who would be unaware that a failure event occurred.
There are two forms of server clusters that can be used on a network: active/ active and active/passive. An active/active cluster has all of the servers actively responding to requests, so that if one server fails, all of the other servers in the cluster can continue processing requests. This type of cluster provides high availability, because in the event of a failure, there is no loss in the availability of services.
An active/passive cluster has servers that are only used if the active server fails. In this type of cluster, the active server processes the requests, whereas the other only becomes active if the first one fails. When a failure occurs, the passive node then begins taking over the role of responding to requests, until such time that the original server’s issue has been taken care of and can become active again.
FIGURE 13.1
Server Clustering
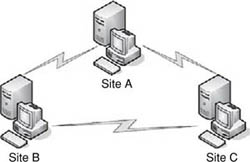
Redundancy is often found in networks, such as when multiple links are used to connect sites on a wide area network (WAN). Network lines may be used to connect two sites, with a separate network line set up in case the first link goes down. If this first link fails, the network can be switched over to use the second link. In other instances, additional lines may be set up in other ways to provide redundancy. For example, site A is connected to site B, which is connected to site C. These two links connect the three sites together, but if either of them fails, one of the sites will be unable to communicate with the others, and vice versa. To provide high availability, a third link can be set up between sites A and C. As shown in Figure 13.2, the additional link allows the three sites to communicate with one another if any one link fails.
Exam WarninG Multiple connections between sites allow a network to function, even if one of the links between the sites fails. If a connection between one site and another failed, the lower priority link could then be used to transfer data. |
Many companies depend on Internet connectivity almost as much as network connectivity. In some cases, such as e-commerce businesses, they depend on it more. A redundant Internet Service Provider (ISP) can be used to provide connectivity when an organization’s primary ISP’s service becomes unavailable. The link to the secondary ISP can be configured as a low-priority route, whereas the primary ISP is advertised as high priority. Such a configuration will have users using the primary ISP for normal usage, but automatically switching over to the low-priority connection, when the first one fails. If a secondary ISP is not desired, the administrator should ensure that the ISP uses two different points of presence. A point of presence is an access point to the Internet, therefore having multiple points of presence will allow access to the Internet if one goes down.
FIGURE 13.2
Multiple Connections Used to Provide Redundancy on a Network
Data is a commodity of any business, so it’s important to ensure that it is always available to those who need it. Redundant arrays of inexpensive disks (RAID) technology was developed to prevent the loss of data and/or improve the performance. RAID provides several methods of writing data across multiple disks, and writing to several disks at once. Rather than losing a single disk and all the information, administrators can replace the damaged disk and regenerate the data quickly. When determining which level of RAID to use, it is important to remember that some RAID levels only increase performance, some only prevent loss of data, but not all will do both. The different levels of RAID available include the following:
RAID 0 (Disk striping) In this level, the data is written (striped) across two or more disks, but no copies of the data are made. This improves the performance because the data is read from multiple disks, but there is no fault tolerance if a disk fails.
RAID 0+1 (Disk striping -with mirroring) This level combines the features of RAID 0 and RAID 1. It allows four or more disks to be used as a set, but provides full redundancy and the same fault tolerance as RAID 5.
RAID 1 (Mirroring or duplexing) In this level, the data that is written to one disk is also written to another, so that each drive has an exact copy of the data. In other words, the data of one disk is a mirror image of the other. Additional fault tolerance is achieved by using separate disk controllers for each disk, which is called duplexing. If one of the disks fails or (in the case of duplexing) a controller fails, the data can still be available through the other disk in the pair. Because data from one disk is mirrored to another, a minimum of two disks must be used to implement RAID 1. Novell Netware systems commonly use mirroring for fault tolerance.
RAID 1+0 This level is also referred to as RAID 10. This level of RAID uses both striping and mirroring. In using this method, the disks are configured as a striped set of mirrored subsets or a mirrored set of striped subsets.
RAID 2 This level is similar to RAID 0, except that error correction codes are used for drives that do not have built-in error detection.
RAID 3 In this level, the data is striped across three or more drives, but one drive is used to store the parity bits for each byte that is written to the other disks. When a disk fails, it can be replaced and the data can be restored to it from the parity information. If two or more disks in the set fail, data cannot be recovered.
RAID 4 This level is similar to RAID 3, but stripes the data in larger blocks. As with RAID 3, if one disk fails, data can be recovered. However, if more than one disk fails, data cannot be recovered. Three or more hard disks are required to implement RAID 4.
RAID 5 (Disk striping with parity) In this level, the data is striped across three or more disks, but parity information is stored across multiple drives. It is a preferred method for fault tolerance on Windows servers.
RAID 5+1 This level uses a combination of methods to achieve fault tolerance. RAID 5+1 uses mirroring (or duplexing) and block striping with distributed parity.
RAID 6 This level is similar to RAID 5 except that it uses two parity blocks that are distributed across all of the disks in the striped set.
RAID 10 This level allows four or more drives to be used in an array, and has data striped across them with the same fault tolerance as RAID 1.
RAID 53 This level allows a minimum of five disks to be used in an array, but provides the same fault tolerance as RAID 3.
RAID is available through hardware or software. Hardware RAID generally supports more levels of RAID, and provides higher performance. This type of RAID can also support hot swapping (discussed in the next section), in which a disk can be removed from the server without having to take the server down.
Software RAID is provided through OSes, such as Windows. When RAID is provided through the software, the levels of RAID supported may be limited. For example, Windows servers will only support RAID 0, 1, and 5. RAID levels 0, 1, 3, and 5 are most commonly implemented, with others rarely found on networks. Also, it takes a higher toll on the system, as RAID functions must run through the OS running on the machine. Because of this, hot swapping is often unsupported, so you will need to take down the system to replace a disk.
TEST DAY TIP RAID 0, 1, 3, and 5 are the most commonly used levels of RAID. Although there are other levels of RAID that could possibly be used on a network, these four RAID levels are the ones most likely to appear on your exam. Focus studying on RAID 0, 1, 3, and 5.
Spare parts refer to additional hardware components that are necessary for servers or other network devices to operate. If a network card or power supply on a server failed, having an extra component on hand makes it possible to replace the defective part and get the server up-and-running. By having the parts stored on the site, you don’t need to spend time ordering a replacement for the faulty component and waiting for it to be delivered.
Determining how many spare parts are necessary for your organization will often depend on how critical it is for there to be little to no wait time to replace the faulty components. It is possible for a company to have an extra part for every component, but this is obviously expensive. By having one extra component for all of the ones used on servers, you can replace a faulty component on one server at any given time. Another strategy is to use the N + 1 equation, where N is the number of components. For example, if you had six servers that were of the same model, you would have seven (6 + 1) of each of the power supplies, network cards, and so forth that are used in those servers.
Hardware components may provide features that improve the ease and speed of replacing faulty hardware. The following allow you to replace a faulty component without having to completely shut down the system:
Hot swap
Warm swap
Hot spare
Hot swapping refers to the ability to replace hardware components without having to shut down the computer. If a component fails, you don’t need to power off the machine. As we mentioned earlier, when we discussed RAID, a hard disk or other hardware that supports hot swapping can be inserted or removed while the computer remains online, meaning that there is no interruption to service.
Warm swapping is similar to hot swapping, as the computer doesn’t need to be completely shut down. However, the computer does need to be put into a suspended state (such as hibernate) while the hardware is being inserted or removed. This means that any services that a server provides are temporarily suspended while the work is being done. Once the faulty component has been replaced, the system is taken out of a suspended state, allowing normal operations to resume.
TEST DAY TIP Remember that hot swapping doesn’t require powering down the computer, or even setting it into a suspended state. Think of universal serial bus devices that you can insert and remove without any changes to the state of the computer, when you think of hot swapping. Warm swapping also doesn’t require completely shutting down the computer, but does require putting the computer into a suspended state.
A hot spare is different from the earlier methods, as it doesn’t require physically removing and inserting a spare part in the case of a failure. It is a redundant component that is used in situations when the system needs to fail over. A hot spare is installed on the system, but isn’t used until the primary component fails. When the component fails, the system might be configured to detect this and automatically switch over to the hot spare. For example, additional drives may be used in a RAID array and held in standby mode. Once a failure occurs, these additional drives are taken out of standby mode and become actively used.
EXAM WARNING Don’t confuse a hot spare with some of the other “hot” topics we’ve discussed in this chapter. A hot spare is installed in the computer, and is only used when the primary component fails.
Even if administrators are comfortable with the internal measures that they have taken to protect data and other assets, outside sources may still have an impact on systems. Utility companies supply essential services, such as electricity and communication services. In some disasters, such as major storms or earthquakes, these services may become unavailable. Without them, servers and other vital systems are left without power, and unable to phone for assistance to bring them back online when power is restored. To continue doing normal business functions, administrators need to implement equipment that will provide these services when the utility companies cannot.
When power is out for lengthy periods of time, additional measures may be necessary to supply electricity to equipment. Power generators can run on gasoline, kerosene, or other fuels for an extended time, and provide energy to a building. Certain power outlets may be connected to the generator, so that any systems plugged into these outlets will receive power when normal power is lost.
Damage and Defense
Providing Power to a Power Generator
In August 2003, a major power outage affected parts of the United States and Ontario, Canada. An estimated 45 million Americans and 10 million Canadians were left without power for a day. Because of preparation for Y2K a few years before and other factors, a number of homes and businesses had various kinds of power generators. Unfortunately, people who owned gas generators and didn’t have a supply of gasoline on hand were faced with a surprising fact: gas pumps were electrically powered. Gas stations affected by the blackout had no way of powering the pumps to get the gas out of the ground, and had to close (even though there were plenty of potential customers driving around looking for fuel).
Preparing for a disaster requires identifying risks, and one of those risks is not having fuel to power a backup generator. Fuel used for backup generators should be stored in a secure facility that won’t pose a danger of fire or other types of ignition. If a power outage occurs, this fuel can be used to start up and run the generator. Without this fuel, you could be one of the many people looking at a nonfunctioning gas pump, wondering how you’re going to get fuel to run your generator.
Uninterruptible power supplies (UPSes) are power supplies that can switch over to a battery backup when power outages occur. Multiple devices can be plugged into a UPS similar to a power bar, and the UPS generally provides such functions as surge protection and noise filtering. When a drop in voltage occurs, the UPS detects it and switches over to battery backup. Components plugged into the UPS can then receive power for a limited amount of time (often ranging from 10 to 45 min), until normal power is restored or the system can shut down properly. This does not allow you to continue normal business functions, but it will protect data from corruption caused by sudden losses of power and improper shutdowns.
EXAM WARNING UPSes are used for short-term power, whereas backup generators are designed for providing power for longer periods of time.
In this chapter, we discussed a number of methods for providing redundancy of systems and preparing for potential threats that could impact on the capability of an organization to function. In cases where the business’s facility or networking capabilities are damaged or destroyed, alternate sites can be used. These sites can take various amounts of preparation to get up-and-running. Hot sites take little work to get online and have a copy of data on servers, warm sites require restoring backed-up data to servers and may require some equipment, while cold sites must be made from scratch.
Redundant systems can also be used to reduce the impact of potential threats, by having duplicate components or systems available in case one fails. This can include having servers clustered on a network, having spare components available to install or bring online when a failure occurs, or implementing RAID. These ensure that the servers have high availability, can fail over, or allow data to be restored if a disaster occurs.
Because power is so important to a business, methods of providing power during an outage must also be available on a network. UPSes can be used to provide power for short periods of time, allowing a computer to be shut down gracefully. For longer periods of power outages, backup generators can be used to provide power for hours or days at a time.
Together, redundancy in systems protects a business from a wide variety of threats. They allow systems to continue functioning throughout a disaster and allow companies to continue doing business.
Alternate sites should be identified to provide an area where business functions can be restored. There are three options for alternate sites: hot, warm, and cold.
A hot site is a facility that has the necessary hardware, software, phone lines, and network connectivity to allow a business to resume normal functions almost immediately.
A warm site is not as equipped as a hot site, but has part of the necessary hardware, software, and other office needs to restore normal business functions.
A cold site requires the most work to set up, as it is neither online nor part of the production network. It may have all or part of the necessary equipment and resources needed to resume business activities but installation is required and data needs to be restored to servers.
High availability is the capability of a network to keep systems operating and services available in the event of an outage. It is provided through redundant systems and fault tolerance.
Redundancy is a duplication of services and systems. If the primary method used to store data, transfer information, or other operations fails, then a secondary method is used to continue providing services.
Fault tolerance refers to the capability of a system to continue working in the event of such a failure. If one component stops working, it will fail over to another component.
Server clusters are groups of independent servers that are connected together, so that if one fails, the others will continue to provide the services.
In an active/active cluster, all of the servers are actively responding to requests. If one fails, there is no loss of availability because the other servers are already processing the requests.
In an active/passive cluster, one server actively responds to requests, whereas the other becomes active and processes requests only if the first one fails.
Companies may use more than one ISP, so that they can switch to the secondary ISP in the case of a failure.
ISPs may provide more than one point of presence to ensure fault tolerance. A point of presence is an access point to the Internet. Multiple points of presence will allow access to the Internet if one goes down.
There are different levels of RAID that can be implemented, each with unique characteristics that provide increased performance and/or fault tolerance.
RAID 0 is disk striping, in which data is written across two or more disks, but no copies of the data are made.
RAID 0+1 allows four or more disks to be used as a set, but provides full redundancy and the same fault tolerance as RAID 5.
RAID 1 is mirroring or duplexing, in which data written to one disk is also written to another, so that each drive has an exact copy of the data.
RAID 2 is similar to RAID 0, except that error correction codes are used for drives that do not have built-in error detection.
RAID 3 involves data being striped across three or more drives, but one drive is used to store the parity bits for each byte that is written to the other disks.
RAID 4 is similar to RAID 3, but stripes data in larger blocks. Three or more hard disks are required to implement RAID 4.
RAID 5 is disk striping with parity, in which data is striped across three or more disks, but parity information is stored across multiple drives.
RAID 10 allows four or more drives to be used in an array and has data striped across them with the same fault tolerance as RAID 1.
RAID 53 allows a minimum of five disks to be used in an array but provides the same fault tolerance as RAID 3.
Spare parts refer to additional hardware components that are necessary for servers or other network devices to operate.
Hot swapping refers to the ability to replace hardware components without having to shut down the computer.
Warm swapping requires the computer to be put in a suspended state while a component is being inserted or removed.
A hot spare is different from the previous methods, as it doesn’t require physically removing and inserting a spare part in the case of a failure.
Even if administrators are comfortable with the internal measures that they have taken to protect data and other assets, outside sources may still have an impact on systems.
Preparing for a disaster requires identifying risks, and one of those risks is not having fuel to power a backup generator. Fuel used for backup generators should be stored in a secure facility that won’t pose a danger of fire or other types of ignition.
Backup generators are used to ensure that the business can continue functioning for longer periods of time after a power outage. As long as a company has enough fuel for the generator, it could be used to power the business for days at a time.
UPSes are power supplies that can switch over to a battery backup, when power outages occur.
UPSes can be used to ensure a business can continue functioning for a limited time after a power outage.
UPSes are used for short-term power, whereas backup generators are designed for providing power for longer periods of time.
Q: My company would like to have an alternate site available to use in cases of emergency, but our budget doesn’t allow renting an extra facility. How can we have an alternate site on a low budget?
A: If your company has branch offices, you could look at having an alternate site designated at one of those facilities. If this isn’t an option, you could develop a partnership with another business in a different location. Each organization would have their own servers and network equipment stored in the other company’s server room. If one of your facilities became unavailable due to a disaster, you could then bring the servers at the other location online and resume business functions.
Q: We want systems to be protected in the case of a power outage, but we can’t afford to install UPSes on every machine in the company. What can we do to protect systems from power outages?
A: If protecting every machine with a UPS isn’t an option, select the most critical systems to be plugged into a UPS. This would include servers, networking devices, and computers used for crucial business purposes.
Q: I’ve implemented RAID for fault tolerance through my Windows OS, but I still have to shut down the system to remove and replace a failed hard disk. Is there any way to implement RAID and not have to shut down the server when a disk needs replacing?
A: RAID can be implemented through hardware, which can support hot swapping, in which a disk can be removed from the server without having to take it down. RAID takes a higher toll on the system, as RAID functions must run through the OS running on the machine. Because of this, hot swapping is often unsupported through the OS, which is why you must take down the system to replace a disk.
1. Your company wants to set up an alternate site that can be used if a disaster damages servers or the network. A copy of the data will be held on servers at this location, with replication data from production servers being copied to it. Which of the following sites will you implement?
A. Hot site
B. Cold site
C. Warm site
D. Hot spare
2. Your company wants to set up an alternate site that can be used if a disaster damages servers or the network. The company has budgeted to have servers, some furniture, and other necessary equipment set up onsite. In the event of a disaster, these servers can be brought online. The site will also be used for storage, having backup tapes of the production servers stored there. This not only makes it cheaper, not having to pay a security company for storage of tapes, but also allows the data to be restored to servers quickly if a disaster occurs. What kind of site is this?
A. Hot site
B. Cold site
C. Warm site
D. Hot spare
3. Your company wants to set up an alternate site that can be used if a disaster damages servers or the network. Due to budget concerns, it doesn’t have the capabilities to provide much funding. Which of the following is the least expensive type of alternate site to implement?
A. Hot site
B. Cold site
C. Warm site
D. Hot spare
4. You are deciding on appropriate locations for a cold site that will be used in case of a disaster. You decide to set up the cold site in a nearby facility, which is used by the company to store equipment and office supplies. The building has an old Halon system for fire suppression in key areas, has air conditioning in all areas, and is dry. Should a disaster occur, the members of the organization will simply move down the street and set up operations at this location. Based on the features and location of the site, is it suitable to set up a cold site?
A. The facility is a perfect location for a cold site.
B. The fire suppression system, air conditioning, and other environmental conditions make it unsuitable for a cold site.
C. The physical proximity to the company makes it unsuitable for a cold site.
D. The fact that it is not part of the production network makes it unsuitable for a cold site.
5. A service runs on a network server that users access with an application on their workstations. The application is used to process requests and access data in a database. If the server or service fails, you still want users to be able to access this data. What method of fault tolerance will you use so that network users can still continue to work?
A. Install two network cards on the server, so that if one card fails, users can still access the data through the second card
B. Use server clustering to provide fault tolerance
C. Implement RAID
D. Connect the server to a UPS
6. You have decided to set up server clustering on your network, so that there is no loss of availability to data. Which of the following will you use?
A. Active/active clustering, so that all of the servers are able to become active if one of them fails
B. Active/active clustering, so that all of the servers are actively processing the requests
C. Active/passive clustering, so that if the active server fails, the passive server will become active and begin the processing of requests
D. Active/passive clustering, so that all of the servers are actively processing the requests
7. Your company relies on the Internet to make sales and run an e-commerce site. If the Internet was unavailable to users, it could cost the organization significant sales, and possibly result in a loss of customers. Which of the following are options that you could implement to ensure there is no loss of Internet connectivity to the network? Choose all that apply.
A. Ensure that the ISP uses two different points of presence
B. Use multiple links across the WAN of your network so that connectivity is always available if one of the links fails
C. Use a redundant ISP. Configure the normal ISP as a high-priority connection, and the redundant ISP as low-priority connection
D. Use a redundant ISP. Configure the redundant ISP as a high-priority connection, and the normal ISP as low-priority connection
8. You have decided to implement a RAID for fault tolerance, and want data to be striped across multiple disks with parity information stored on multiple drives. Which of the following levels of RAID will you use?
A. RAID 0
B. RAID 1
C. RAID 3
D. RAID 5
9. You have decided to implement disk duplexing on a Novell Netware server. You want the server to have 800 GB of storage space. How many of the following disks would you need to provide this amount of storage?
A. Four 200 GB hard disks
B. Two 400 GB hard disks
C. Four 400 GB hard disks
D. One 800 GB hard disk
10. You have a server that you plan to use to store backup files from other servers. An application backs up the data from these other servers and will store them on the backup server. Because of its purpose, fault tolerance isn’t an issue, but high performance is important. Which level of RAID will you use?
A. RAID 0
B. RAID 1
B. RAID 1
D. RAID 5
11. You have decided to purchase spare hardware components that you can replace on a server without having to shut down the computer. Which of the following is being used?
A. Hot swapping
B. Warm swapping
C. Hot spare
D. Hot site
12. You have purchased a spare hardware component that you can replace on a computer when it is put into a suspended state. Which of the following is being used?
A. Hot swapping
B. Warm swapping
C. Hot spare
D. Hot site
13. You have purchased a hardware component that is installed in a server, and it remains inactive until a fault occurs and it is needed. Once the primary component fails, the system switches over to this secondary component. Which of the following is being used?
A. Hot swapping
B. Warm swapping
C. Hot spare
D. Hot site
14. You have been experiencing intermittent brownouts and blackouts that can last upwards of a few minutes and are concerned that power outages will result in data being lost as the computers suddenly shutdown improperly. Which of the following can you use for these temporary outages?
A. UPS
B. Line conditioner
C. Power bar
D. Backup generator
15. You are developing a disaster recovery plan, and you are concerned that blackouts could cause power outages that could last hours or even days. To address the risk of this happening, which of the following should you implement in your company?
A. UPS
B. Line conditioner
C. Power bar
D. Backup generator
1. A
2. C
3. B
4. C
5. B
6. D
7. A, and C
8. D
9. C
10. A
11. A
12. B
13. B
14. A
15. D