THE WEB IS THE WORLD’S LARGEST ONLINE INFORMATION SYSTEM, scaling to billions of devices and users. Hypermedia
documents connect a near limitless number of resources, most of which are
designed to be read, not modified. At a grand scale, structural hypermedia
rules, helped by the safe, idempotent properties of the ubiquitous
GET method, and to a lesser extent some
of the other cacheable verbs.
From a programmatic web perspective, the infrastructure that has evolved on the Web—particularly around information retrieval—solves many integration challenges. In this chapter, we look at how we can use that infrastructure and some associated patterns to build scalable, fault-tolerant enterprise applications.
According to the HTTP specification, GET
is used to retrieve the representation of a resource. Example 6-1 shows a consumer
retrieving a representation of an order resource from a Restbucks
service by sending an HTTP GET
request to the server where the resource is located.
Example 6-1. A GET request using a relative URI
GET /order/1234 HTTP/1.1 Connection: keep-alive Host: restbucks.com
The value of the Host
header plus the relative path that follows GET together give the complete URI of the
resource being requested—in this case, http://restbucks.com/order/1234. In HTTP 1.1, servers
must also support absolute URIs, in which case the Host header is not necessary, as shown in
Example 6-2.
The response to either of these two requests is shown in Example 6-3.
Example 6-3. A response to a GET request
HTTP/1.1 200 OK
Content-Length: ...
Content-Type: application/vnd.restbucks+xml
Date: Fri, 26 Mar 2010 10:01:22 GMT
Last-Modified: Fri, 26 Mar 2010 09:55:15 GMT
Cache-Control: max-age=3600
ETag: "74f4be4b"
<order xmlns="http://schemas.restbucks.com">
<location>takeaway</location>
<item>
<drink>latte</drink>
<milk>whole</milk>
<size>large</size>
</item>
</order>As well as the payload, the response includes some headers, which help consumers and any intermediaries on the network process the response. Importantly, we can use some of these headers to control the caching behavior of the order representation.
As we discussed in Chapter 3,
GET is both safe and idempotent. We
use GET simply to
retrieve a resource’s state representation, rather
than deliberately modify that state.
Note
If we don’t want the entire representation of a resource, but
just want to inspect the HTTP headers, we can use the HEAD verb. HEAD allows us to decide how to make forward
progress based on the processing context of the identified resource,
without having to pay the penalty of transferring its entire
representation over the network.
Because GET has no impact on
resource state, it is possible to optimize the network to take advantage
of its safe and idempotent characteristics. If we see a GET request, we immediately understand that
the requestor doesn’t want to modify anything. For these requests, it
makes sense to store responses closer to consumers, where they can be
reused to satisfy subsequent requests. This optimization is baked into
the Web through caching.
Caching is the ability to store copies of frequently accessed data in several places along the request-response path. When a consumer requests a resource representation, the request goes through a cache or a series of caches toward the service hosting the resource. If any of the caches along the request path has a fresh copy of the requested representation, it uses that copy to satisfy the request. If none of the caches can satisfy the request, the request travels all the way to the service (or origin server as it is formally known).
Origin servers control the caching behavior of the representations
they issue. Using HTTP headers, an origin server indicates whether a
response can be cached, and if so, by whom, and for how long. Caches
along the response path can take a copy of a response, but only if the
caching metadata allows them to do so. The caches can then use these
copies to satisfy subsequent requests. Cached copies of a resource
representation can be used to satisfy subsequent requests so long as
they remain fresh. A cached representation remains
fresh for a specific period of time, which is called its
freshness lifetime. When the age of a cached object
exceeds its freshness lifetime, the object is said to be
stale. Caches will often add an Age response header to a cached response. The
Age header indicates how many seconds
have passed since the representation was generated at the origin
server.
A stale representation must be revalidated with the origin server before it can be used to satisfy any further requests. If the revalidation reveals that the stale representation is in fact still valid, the cached copy can be reused. If, however, the resource has changed since the stale representation was first issued, the cached copy must be invalidated and replaced. Representations can become invalid during their freshness lifetime without the cache knowing. Unless the consumer specifically asks for a revalidation or a new copy from the origin server, the cache will continue to use these invalid (but fresh) representations until they become stale.
Optimizing the network using caching improves the overall quality-of-service characteristics of a distributed application. Caching significantly benefits four areas of systems operation, allowing us to:
- Reduce bandwidth
By reducing the number of network hops required to retrieve a representation, caching reduces network traffic and conserves bandwidth.
- Reduce latency
Because caches store copies of frequently accessed information nearer to where the information is used, caching reduces the time it takes to satisfy a request.
- Reduce load on servers
Because they are able to serve a percentage of requests from their own stores, caches reduce the number of requests that reach an origin server.
- Hide network failures
Caches can continue to serve cached content even if the origin server that issued the content is currently unavailable or committed to an expensive processing task that prevents it from generating a response. In this way, caches provide fault tolerance by masking intermittent failures and delays from consumers.
Ordinarily, we’d have to make a substantial investment in development effort and middleware in order to achieve these benefits. However, the Web’s existing caching infrastructure means we don’t have to; the capability is already globally deployed.
One of the Web’s key architectural tenets is that servers and services should not preserve application state. The statelessness constraint helps make distributed applications fault-tolerant and horizontally scalable. But it also has its downsides. First, because application state is not persisted on the server, consumers and services must exchange application state information with each request and response, which adds to the size of the message and the bandwidth consumed by the interaction. Second, because the constraint requires services to forget about clients between requests, it prevents the use of the classical publish-subscribe pattern (which requires the service to retain subscriber lists). To receive notifications, consumers must instead frequently poll services to determine whether a resource has changed, adding to the load on the server.
Caching helps mitigate the consequences of applying the statelessness constraint.[62] It reduces the amount of data sent over the network by storing representations closer to where they are needed, and it reduces the load on origin servers by having caches satisfy repeated requests for the same data.
Note
In fact, polling is what allows the Web to scale. By repeatedly polling a cacheable resource, a consumer “warms” all of the caches between it and the origin server, pulling data from the origin server into the network where other consumers can rapidly access it. Furthermore, once the caches are warm, any requests they can satisfy mean less traffic to the origin server, no matter how hard a consumer polls. This is the classic latency/scalability trade-off that the Web provides. By making representations cacheable, we get massive scale, but introduce latency between the resource changing and those changes becoming visible to consumers. Of course, individual caches can themselves become overloaded by requests; in such circumstances, we may have to consider clustered or hierarchical caching topologies.
We’ve discussed several of the benefits of caching. But there are at least four situations in which we might not want to cache data:
When
GETrequests generate server-side side effects that have a business impact on the service. Remember,GETis safe, but it can still generate side effects for which the consumer cannot be held responsible. These effects may range from simply logging traffic (which is then used to generate business metrics) to incrementing a counter that determines whether a particular class of customer is within a certain usage threshold for the service to which the request is being directed. If these kinds of internal side effects are important, we may want to prevent or limit caching.When consumers cannot tolerate any discrepancy between the state of a resource as conveyed in a response and the actual state of that resource at the moment the request was satisfied. As we discuss later in this chapter, caching exacerbates the weak consistency of the Web; the longer a representation of a volatile resource is cached, the more likely it is that a response returned from a cache no longer reflects the state of the resource at the origin server. This is particularly problematic when two or more overlapping resources manipulate the same underlying domain entity. Consider, for example, a service that exposes order and completion resources, where both an order and a completion are associated with the same underlying order domain entity.
POSTing a completion changes the state of an order entity. Because of this change, cached order representations no longer reflect the state of the underlying domain entity. Consumers that act on these cached order representations may commit themselves to business transactions that are no longer valid.When a response contains sensitive or personal data particular to a consumer. Security and caching can coexist to a certain extent: first, local and proxy caches can sometimes cache encrypted responses; second, as we show later, it is possible to cache responses in a way that requires the cache to authorize them with the origin server with every request. But in many circumstances, regulatory or organizational requirements will dictate that responses must not be cached.
When the data changes so frequently that caching and revalidating a response adds more overhead than the origin server simply generating a fresh response with each request.
A whole ecosystem of proxy servers has grown up around GET and its safe and idempotent semantics.
Proxy servers are common intermediaries between consumers and origin
servers, which we recognize from our human use of the Web. While they
can perform various operations on HTTP requests and
responses, such as information filtering and security checks, they are
most commonly used for caching.
Many of us are familiar with application caches and database caches—two types of caches that can reside behind service boundaries. Nowadays, many systems also explicitly route requests through distributed in-memory caches. But the kinds of caches we’re talking about here are those that are already part of the installed infrastructure of the Web:
- Local cache
A local cache stores representations from many origin servers on behalf of a single user agent, application, or machine. A consumer may have a local cache so that frequently accessed resources are stored locally and served immediately. Local caches can be held in memory or persisted to disk.
- Proxy cache
A proxy cache stores representations from many origin servers on behalf of many consumers. Proxies can be hosted both inside the corporate firewall and outside. An organization may deploy caches of its own so that the applications running within its boundaries don’t necessarily hit the Internet when accessing cacheable resources. Network providers (e.g., ISPs), organizations with their own virtual networks, and even entire countries may also introduce proxies in order to speed up access to frequently accessed web resources.
- Reverse proxy
A reverse proxy, or accelerator, stores representations from one origin server on behalf of many consumers. Reverse proxies are located in front of an application or web server. Clusters of reverse proxies improve redundancy and prevent popular resources from becoming server hotspots. Reverse proxy implementations include Squid,[63] Varnish,[64] and Apache Traffic Server.[65]
Figure 6-1 shows the many places in which these caches appear on the Web.
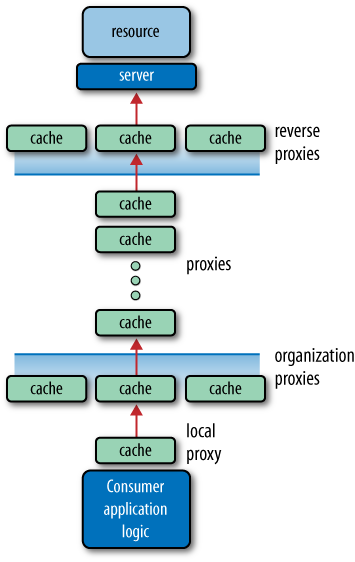
Caches can be arranged in complex topologies. They can be clustered to improve reliability or arranged in hierarchies. Caches in a cache hierarchy forward requests for which they do not have a cached representation to other caches farther up the hierarchy, until a cached representation is found or the request is finally passed to the origin server.
Warning
A request reaching an origin server is the most expensive operation on the Web. Not only will the request have consumed network bandwidth, but also, once it reaches the server, it may cause computation to occur and data to be retrieved. These are not cheap options at web scale: contention for computational and data resources will be fierce for a typical service. Caching acts as a buffer between the finite resources of a service and the myriad consumers of those resources on the Web.
Given that caches are designed around the retrieval of resource
representations, it shouldn’t come as a surprise to learn that they
mostly (but not exclusively) work with GET requests. Responses to GET requests are cacheable by
default.[66] Responses to POST
requests are not cacheable by default, but can be made cacheable if
either an Expires header, or a
Cache-Control header with a directive
that explicitly allows caching, is added to the response. Responses to PUT and DELETE requests are not cacheable at
all.
The more a service supports GET
and the appropriate caching headers, the more the Web’s infrastructure can
help with scalability. Imagine a situation in which a very inquisitive
Restbucks customer repeatedly asks a barista for the status of his
coffee. If the barista spends a lot of her time answering questions, her
overall output will diminish. Given that the answer stays the same for
relatively long periods (e.g., “I’m preparing your medium skim-milk
latte”), a lot of effort is wasted for very little benefit. Deploying a cache between the consumer and
the Restbucks barista frees the barista from having to answer the same
question over and over again. As a result, the overall coffee output of
the Restbucks service improves.
There are two main HTTP response headers that we can use to control caching behavior:
ExpiresThe
ExpiresHTTP header specifies an absolute expiry time for a cached representation. Beyond that time, a cached representation is considered stale and must be revalidated with the origin server. A service can indicate that a representation has already expired by including anExpiresvalue equal to theDateheader value (the representation expires now), or a value of0. To indicate that a representation never expires, a service can include a time up to one year in the future.Cache-ControlThe
Cache-Controlheader can be used in both requests and responses to control the caching behavior of the response. The header value comprises one or more comma-separated directives. These directives determine whether a response is cacheable, and if so, by whom, and for how long.
If we can determine an absolute expiry time for a cached
response, we should use an Expires
header. If it’s more appropriate to indicate how long the response can
be considered fresh once it has left the origin server, we should use
a Cache-Control header, adding a
max-age or s-maxage directive to specify a relative
Time to Live (TTL).
Cacheable responses (whether to a GET or to a POST request) should also include a
validator—either an ETag or a Last-Modified header:
ETagIn Chapter 4, we said that an
ETagvalue is an opaque string token that a server associates with a resource to uniquely identify the state of the resource over its lifetime. When the resource changes, the entity tag changes accordingly. Though we usedETagvalues for concurrency control in Chapter 4, they are just as useful for validating the freshness of cached representations.Last-ModifiedWhereas a response’s
Dateheader indicates when the response was generated, theLast-Modifiedheader indicates when the associated resource last changed. TheLast-Modifiedvalue cannot be later than theDatevalue.
Example 6-4 shows a response
containing Expires, ETag,
and Last-Modified
headers.
Example 6-4. A response with an absolute expiry time
Request:GET /product-catalog/9876 Host: restbucks.comResponse:HTTP/1.1 200 OK Content-Length: ... Content-Type: application/vnd.restbucks+xml Date: Fri, 26 Mar 2010 09:33:49 GMTExpires: Sat, 27 Mar 2010 09:33:49 GMTLast-Modified: Fri, 26 Mar 2010 09:33:49 GMTETag: "cde893c4"<product xmlns="http://schemas.restbucks.com/product"> <name>Sumatra Organic Beans</name> <size>1kg</size> <price>12</price> </product>
This response can be cached and will remain fresh until the date
and time specified in the Expires
header. To revalidate a response, a cache uses the ETag header value or the Last-Modified header value to do a
conditional GET.[67] If a consumer wants to revalidate a response, it should
include a Cache-Control: no-cache
directive in its request. This ensures that the conditional request
travels all the way to the origin server, rather than being satisfied
by an intermediary.
Example 6-5 shows
a response containing a Last-Modified header, an ETag header, and a Cache-Control header with a max-age directive.
Example 6-5. A response with a relative expiry time
Request:GET /product-catalog/1234 Host: restbucks.comResponse:HTTP/1.1 200 OK Content-Length: ... Content-Type: application/vnd.restbucks+xml Date: Fri, 26 Mar 2010 12:07:22 GMTCache-Control: max-age=3600Last-Modified: Fri, 26 Mar 2010 11:45:00 GMTETag: "59c6dd9f"<product xmlns="http://schemas.restbucks.com/product"> <name>Fairtrade Roma Coffee Beans</name> <size>1kg</size> <price>12</price> </product>
This response is cacheable and will remain fresh for up to one
hour. As with the previous example, a cache can revalidate the
representation using either the Last-Modified value or the ETag value.
Cache-Control directives
serve three functions when used in a response. Some make normally
uncacheable responses cacheable. Others make normally cacheable
responses uncacheable. Finally, there are some Cache-Control directives that do not affect
the cacheability of a response at all; rather, they determine the
freshness of an already cacheable response. An individual directive
can serve one or more of these functions.
max-age=<delta-seconds>This directive controls both cacheability and freshness. It makes a response capable of being cached by local and shared caches (proxies and reverse proxies), as well as specifying a freshness lifetime in seconds. A
max-agevalue overrides anyExpiryvalue supplied in a response.s-maxage=<delta-seconds>Like
max-age, this directive serves two functions: it makes responses cacheable, but only by shared caches, and it specifies a freshness lifetime in seconds.publicThis directive makes a response capable of being cached by local and shared caches, but doesn’t determine a freshness value. Importantly,
publictakes precedence over authorization headers. Normally, if a request includes anAuthorizationheader, the response cannot be cached. If, however, the response includes apublicdirective, it can be cached. You should exercise care, however, when making responses that require authorization cacheable.privateThis directive makes a response capable of being cached by local caches only (i.e., within the consumer implementation). At the same time, it prevents normally cacheable responses from being cached by shared caches.
privatedoesn’t determine a freshness value.must-revalidateThis directive makes normally uncacheable responses cacheable, but requires caches to revalidate stale responses with the origin server. Only if the stale response is successfully validated with the origin server can the cached content be used to satisfy the request.
must-revalidateis enormously useful in balancing consistency with reduced bandwidth and computing resource consumption. While it forces a revalidation request to travel all the way to the origin server, an efficient validation mechanism on the server side will prevent the core service logic from being invoked for a large percentage of requests—all for the cost of a measly304 Not Modifiedresponse.proxy-revalidateThis directive is similar to
must-revalidate, but it only applies to shared caches.no-cacheThis directive requires caches to revalidate a cached response with the origin server with every request. If the request is successfully validated with the origin server, the cached content can be used to satisfy the request. The directive only works for responses that have been made cacheable using another header or directive (i.e., it doesn’t make uncacheable responses cacheable). Unfortunately, different caches behave in different ways with regard to
no-cache: some caches treatno-cacheas an instruction to not cache a response (as per an old draft of HTTP 1.1); some treat it correctly, as a requirement to always revalidate a cached response.no-storeThis directive makes normally cacheable content uncacheable by all caches.
The HTTP Stale Controls Informational RFC recently added two new directives to this list, which together enable us to make trade-offs between latency, availability, and consistency.[68] These directives are:
stale-while-revalidate=<delta-seconds>In situations where a cache is able to release a stale response, this directive allows the cache to release the response immediately, but instructs it to also revalidate it in the background (i.e., in a nonblocking fashion). This directive favors reduced latency (caches release stale responses immediately, even as they revalidate them) over consistency. If a stale representation is not revalidated before
delta-secondshave passed, however, the cache should stop serving it.stale-if-error=<delta-seconds>This directive allows a cache to release a stale response if it encounters an error while contacting the origin server. If a response is staler than the stale window specified by
delta-seconds, it should not be released. This directive favors availability over consistency.
Squid 2.7 currently supports these last two directives; support is forthcoming in later versions of Squid and Apache Traffic Server.
The directives we’ve looked at so far can be mixed in interesting and useful ways, as the following examples demonstrate. Example 6-6 shows how we can make a representation cacheable by local caches for up to one hour.
Example 6-7 is more interesting, in that it allows caching of representations that require authorization.
public makes the response
cacheable by both local and shared caches, while max-age=0 requires a cache to revalidate a
cached representation with the origin server (using a conditional
GET request) before releasing it.
(Ideally, we’d use no-cache, but
because some caches treat no-cache
as an instruction to not cache at all, we’ve opted for max-age=0 instead.) This combination is
useful when we want to authorize each request, but still take
advantage of the bandwidth savings offered by the caching infrastructure, as we see in Figure 6-2.
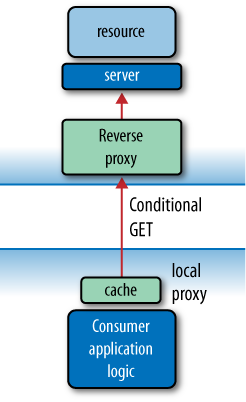
In revalidating each request with the server, the cache will
pass on the contents of the Authorization header supplied by the
consumer. If the origin server replies 401
Unauthorized, the cache will refuse to release the cached
representation. The combination public,
max-age=0 differs from must-revalidate in that it allows caching of responses to requests that contain Authorization headers.
Let’s see how Restbucks can take advantage of caching to improve
the distribution of its menu. The Restbucks menu is an XML document that
is consumed by third-party applications such as coffee shop price
comparators and customers. The menu resource is dynamically created from
the Restbucks product database. Every time the menu service receives a
GET request for the menu, it must
perform some logic and database access.
Restbucks would like to ensure that its menu service isn’t overwhelmed by thousands of requests from external services. But instead of deploying more servers or paying for more bandwidth, Restbucks decides to make use of the Web’s caching infrastructure.
This caching infrastructure includes reverse proxies and proxy caches, as well as local caches. Some consumers of Restbucks’ menu service may opt to use their local caches to speed up their systems, knowing that consistency with Restbucks’ data isn’t always guaranteed. Doing so is easy: Example 6-8 shows some simple .NET HTTP client code that uses the WinINet cache provided by Microsoft Windows Internet Services. The WinINet cache is the same local cache that Internet Explorer uses, and so has a large installed base.
To take advantage of local caching, we need only add a RequestCachePolicy instance to our request.
The policy is initialized with a RequestCacheLevel.Default enum value, which
ensures that the local cache is used to try to satisfy the request. If
the local cache can’t satisfy the request, the request will be
forwarded to the origin server (or to any intervening shared
caches).
Example 6-8. Using the WinINet local cache from consumer code
Uri uri = new Uri("http://restbucks.com/product-catalog/1234");
HttpWebRequest webRequest = (HttpWebRequest) WebRequest.Create(uri);
webRequest.Method = "GET";
webRequest.CachePolicy = new RequestCachePolicy(RequestCacheLevel.Default);
HttpWebResponse webResponse = (HttpWebResponse) webRequest.GetResponse();On the server side, the menu service is implemented using an
instance of the .NET Framework’s HttpListener class.[69] Example 6-9 shows the code that
creates and starts the listener.
Example 6-9. A simple web server
private static void Main(string[] args)
{
Console.WriteLine("Server started...");
Console.WriteLine();
HttpListener listener = new HttpListener();
listener.Prefixes.Add("http://localhost./");
listener.Start();
listener.BeginGetContext(new AsyncCallback(GetMenu), listener);
Console.ReadKey();
}When it receives a request, the listener calls its GetMenu(…) method, passing it an HttpListenerContext object, which encapsulates
the request and response context. Each request is handled on a separate
thread taken from the .NET thread pool. The implementation of GetMenu(…) is shown in Example 6-10.
Example 6-10. GetMenu(…) satisfies an HTTP GET request
public void GetMenu(HttpListenerContext context)
{
context.Response.ContentType = "application/xml";
XDocument menu = menuRepository.Get();
using (Stream stream = context.Response.OutputStream)
{
using (XmlWriter writer = new XmlTextWriter(stream, Encoding.UTF8))
{
menu.WriteTo(writer);
}
}
}First, GetMenu(…) sets the
ContentType of the response to
application/xml. Then it gets an
XDocument representation of the menu
from a repository and writes it to the response stream.
This implementation produces the response shown in Example 6-11. Every time a
consumer attempts to GET the
Restbucks menu, the request is handled by this code. In other words,
every request consumes processor time. This is because there are no
caching headers in the response that would allow any web
proxies on the request path to cache the response and directly serve it in the
future.
Example 6-11. Response to a GET request for the Restbucks menu
HTTP/1.1 200 OK Content-Type: application/xml Date: Sun, 27 Dec 2009 01:30:51 GMT Content-Length: ... ... <!-- Content omitted -->
According to the HTTP specification, a web proxy can cache a
200 OK response even if the response
doesn’t include any specific caching metadata.[70] Still, it’d be helpful if the service explicitly stated
whether a response can be cached. Doing so helps to ensure that the
caching infrastructure is used to its full potential.
Example 6-12 shows how we
can change the implementation of GetMenu(…) to include some caching
metadata.
Example 6-12. Adding a Cache-Control header to the response
public void GetMenu(HttpListenerContext context)
{
context.Response.ContentType = "application/xml";
context.Response.AddHeader("Cache-Control", "public, max-age=604800");
XDocument menu = Database.GetMenu();
using (Stream stream = context.Response.OutputStream)
{
using (XmlWriter writer = new XmlTextWriter(stream, Encoding.UTF8))
{
menu.WriteTo(writer);
}
}
}As Example 6-12
shows, we only need to add a single line in order to make the response cacheable. Because we don’t expect the menu to change more
than once per week, we inform caches that they can consider the response
fresh for up to 604,800 seconds. We also indicate that the
representation is public, meaning
both local and shared caches can cache it. As a result of this
change, the response now contains a Cache-Control header, as shown in Example 6-13.
Example 6-13. The response now includes a Cache-Control header
HTTP/1.1 200 OK Cache-Control: public, max-age=604800 Content-Type: application/xml Date: Sun, 27 Dec 2009 01:30:51 GMT Content-Length: ... ... <!-- Content omitted -->
That one line of code has the potential to dramatically reduce Restbucks’ infrastructure and operational costs. Our menu’s representation now gets distributed at various caches around the Web, as Figure 6-3 illustrates.
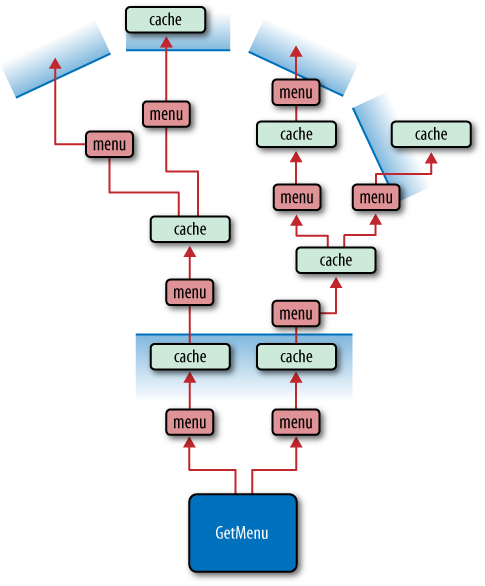
Caching doesn’t just work for public-facing services.
Using these same web caching techniques, we can also improve the
scalability and fault-tolerance characteristics of services we deploy
within the boundaries of an organization. If we write our applications
with caching in mind, and expose most of our business logic
through domain application protocols using GET and caching headers, we can offload much
of the processing and bandwidth load to caches without any special coding or middleware.
Because the Web is loosely coupled, weak consistency is a feature
of all web-based distributed applications. As a result of the
statelessness constraint, a service has no way of notifying consumers
when a resource changes. In consequence, consumers sometimes act on
stale data. In an attempt to keep up-to-date, many consumers will
repeatedly GET (poll) a resource
representation to discover whether it has changed recently. But this
strategy is only as good as the polling frequency. In general, we must
assume that a consumer’s understanding of the state of a resource lags
the service’s view of the same resource.
Caching only exacerbates the situation. The moment we introduce caching, we should assume that consumers will become inconsistent with services, and just deal with it. While there are several techniques for increasing the degree of consistency among consumers, caches, and services, the fact remains that different web actors will often have different copies of a resource representation.
The three techniques for improving consistency are:
- Invalidation
Invalidation involves notifying consumers and caches of changes to resources for which they hold cached representations. With server-driven invalidation, the server must maintain a list of recipients to be contacted whenever a resource changes. This goes against the requirement that services not maintain application state.
- Validation
To ensure that they have an up-to-date resource representation, consumers and caches can verify a local copy with the origin server. This approach requires the consumer to make a validation request of the service, which uses bandwidth and places some load on the server. Services must be able to respond to validation requests. Unlike server-driven invalidation, however, servers do not have to maintain a list of consumers to be contacted whenever a resource changes. Despite the fact that requests have to travel all the way to the origin server, validation is a relatively efficient, low-bandwidth way of keeping data up-to-date. Validation helps improve scalability and performance, and reduce latency. In so doing, it drives down per-request costs.
- Expiration
Expiration-based consistency involves specifying an explicit TTL for each cacheable representation. Cached representations older than this TTL are considered stale, and must usually be revalidated or replaced. HTTP implements expiration-based consistency using
ExpiresHTTP headers andCache-Controldirectives.
Expiration raises a couple of issues. On the one hand, a long TTL increases the likelihood that at some point a cached representation will no longer reflect the current state of the resource on the origin server, even though it is still fresh in the cache. That is, fresh representations can become invalid. Consumers of such cached representations must be able to tolerate a degree of latency between a resource changing and its being updated in a cache. On the other hand, representations that have become stale in the cache, but whose resources haven’t changed since they were issued, will in fact prove to be still valid; revalidating such representations, though necessary, is suboptimal in terms of network and server resource usage.
Expiration and validation can be used separately or in combination. With
a pure validation-based approach (using, for example, a no-cache directive), consumers and caches
revalidate with every request, thereby ensuring that they always have an
up-to-date version of a representation. With this strategy, we must
assess the trade-offs between increased consistency and the resultant rise in bandwidth and load
on the server.
In contrast, an exclusively expiration-based approach reduces
bandwidth usage and the load on the origin server, but at the risk of
there being newer versions of a resource on the server while older (but
still fresh) representations are being served from caches. After a
cached representation has expired, a subsequent GET will result in a full representation being
returned along the response path, even if the version hasn’t in fact
changed on the server.
By using expiration and validation together, we get the best of both worlds. Cached representations are used while they remain fresh. When they become stale, the cache or consumer revalidates the representation with the origin server. This approach helps reduce bandwidth usage and server load. There’s still the possibility, however, that representations that remain fresh in a cache become inconsistent with resource state on the origin server.
A cache can determine whether a resource has changed by
revalidating a cached representation with the origin server. In Chapter 4, we used ETag values with If-Match and If-None-Match headers (and Last-Modified values with If-Unmodified-Since and If-Modified-Since headers) to do conditional
updates and deletes. Validation is accomplished using the same headers
and values, but with conditional GETs.
A conditional GET tries
to conserve bandwidth by sending and receiving just HTTP headers rather than headers and
entity bodies. A conditional GET
only exchanges entity bodies when a cached resource representation is
out of date. In simple terms, the conditional GET pattern says to a server: “Give me a new
resource representation only if the resource has changed substantially
since the last time I asked for it. Otherwise, just give me the
headers I need to keep my copy up-to-date.”
Conditional GETs are useful
only when the client making the request has previously fetched and
held a copy of a resource representation (and the attached ETag or Last-Modified value). To revalidate a
representation, a consumer or cache uses a previously received
ETag value with an If-None-Match header, or a previously
supplied Last-Modified value with
an If-Modified-Since header. If the
resource hasn’t changed (its ETag
or Last-Modified value is the same
as the one supplied by the consumer), the service replies with
304 Not Modified (plus any ETag or Location headers that would normally have
been included in a 200 OK
response). If the resource has changed, the service sends back a full
representation with a 200 OK status
code.
When a service replies with 304 Not
Modified, it can also include Expires, Cache-Control, and Vary headers. Caches can update their cached
representation with any new values in these headers. A 304 Not Modified response should also
include any ETag or Location headers that would ordinarily have
been sent in a 200 OK response;
including these headers ensures that as well as the cached resource
state, the consumer’s cached metadata is also kept
up-to-date.
Note
The Vary header is used to
list the request headers a service uses to generate different
representations of a resource. Caches store and release responses
based on the values of these request headers. Vary: Accept-Encoding, for example,
indicates that requests with different Accept-Encoding header values will
generate significantly different representations. If the responses
can be cached, each variation will be stored separately so that it
can be used to satisfy subsequent requests with the same Accept-Encoding value. Be careful using
Vary: careless use of the
Vary header can easily overload a
cache with multiple representations of the same resource.
Example 6-14
shows two request-response interactions: a GET, which returns an entity body, and then
a revalidation, which uses the Last-Modified value from the first response
with an If-Modified-Since header.
The revalidation says “execute this request only if the
entity has changed since the Last-Modified time supplied in this
request.”
Example 6-14. Revalidation using If-Modified-Since with a previous Last-Modified value
Request:GET /order/1234 HTTP/1.1 Host: restbucks.comResponse:HTTP/1.1 200 OK Content-Length: ... Content-Type: application/vnd.restbucks+xml Date: Fri, 26 Mar 2010 10:01:22 GMT Last-Modified: Fri, 26 Mar 2010 09:55:15 GMT ETag: "74f4be4b" <order xmlns="http://schemas.restbucks.com"> <location>takeaway</location> <item> <drink>latte</drink> <milk>whole</milk> <size>large</size> </item> </order>Request:GET /order/1234 HTTP/1.1 Host: restbucks.com If-Modified-Since: Fri, 26 Mar 2010 09:55:15 GMTResponse:HTTP/1.1 304 Not Modified
Example 6-15
shows a similar pair of interactions, but this time the revalidation uses an If-None-Match header with an ETag value. This revalidation says “execute this request only if the
ETag belonging to the entity is
different from the ETag value
supplied in the request.”
Example 6-15. Revalidation using If-None-Match with an entity tag value
Request:GET /order/1234 HTTP/1.1 Host: restbucks.comResponse:HTTP/1.1 200 OK Content-Length: ... Content-Type: application/vnd.restbucks+xml Date: Fri, 26 Mar 2010 10:01:22 GMT Last-Modified: Fri, 26 Mar 2010 09:55:15 GMT ETag: "74f4be4b" <order xmlns="http://schemas.restbucks.com"> <location>takeaway</location> <item> <drink>latte</drink> <milk>whole</milk> <size>large</size> </item> </order>Request:GET /order/1234 HTTP/1.1 Host: restbucks.com If-None-Match: "74f4be4b"Response:HTTP/1.1 304 Not Modified
When developing services, we have to decide the best way of
calculating entity tags on a case-by-case basis. Consumers, however,
should always treat ETags as opaque
string tokens—they don’t care how they’re generated, so long as the
tag discriminates between changed representations.
There are two things to consider when implementing ETags in a service: computation and storage.
If an entity tag value can be computed on the fly in a relatively
cheap manner, there’s very little point in storing the value with the
resource—we can just compute it with each request. If, however,
generating an entity tag value is a relatively expensive operation,
it’s worth persisting the computed value with the resource.
Computationally cheap ETag
values can be generated using quoted string versions of timestamps, as we discussed in Chapter 4. This is generally a “good enough”
solution for entities that don’t change very often. When a consumer
includes an entity tag value generated using this method in a
conditional request, evaluating the conditional request is often as
simple as comparing the supplied value against a file or database row
timestamp. For collections, we can use the timestamp of the most
recently updated member of the collection. Using a timestamp in an
ETag header rather than—as is more
usual—a Last-Modified header allows
us to evolve the service validation strategy without requiring corresponding
changes in consumers. For example, we might choose to use a
timestamp-based strategy in an early version of a service because the
business context ensures that resources change relatively
infrequently. If the business process later evolves such that
resources change twice or more during a single second, we can safely
change the service-side entity tag generation and validation strategy without consumers having to evolve
in lockstep. If we’d initially used a Last-Modified header, consumers would have
to switch to using ETags.
The most expensive ETag
values tend to be those that are computed using a hash of a
representation. Hashes can be computed from just the entity body, or
they can include headers and header values as well. If hashing headers, avoid
including header values containing machine identity. This is to avoid
problems when scaling out, where many machines serve identical
representations. If a representation’s ETag value encodes something host-specific,
caches will end up with multiple copies of a representation differing
only by origin server. Similarly, if we generate ETag values based on a hash of the headers
as well as the entity body, we should avoid using the Expires, Cache-Control, and Vary headers, which can sometimes be used to
update a cached representation after revalidating with the origin
server.
Note
Of course, we should remember that before we can hash a
resource, we must assemble its representation. When used in response
to a conditional GET, this
strategy requires the server to do everything it would do to satisfy
a normal request, except send the full-blown representation back
across the wire. We’ll still save bandwidth, but we’ll continue to
pay a high computational cost—because hashes tend to be expensive
algorithms. If assembling a representation is expensive, it may be
better to use version numbers, even if it involves fetching them
from a backing store. Alternatively, we might simply indicate that
an entity has changed by generating a universally unique identifier value (a UUID), which we then store with the entity. If in
doubt as to the best strategy, implement some representative test
cases, measure the results, and then choose.
As an optimization, we might consider caching precomputed entity tag values in an in-memory
structure. Once again, load-balanced, multimachine scenarios introduce
additional complexity here, but if computing the value on the fly is especially expensive,
or accessing a persisted, precomputed value becomes a bottleneck in
the system, a distributed, in-memory cache of ETag values might just be the thing we need
to help save precious computing resources.
Most of the work of implementing conditional GET takes place in the service code, which
has to look for the If-Modified-Since and If-None-Match headers, evaluate their
conditions, and construct a 200 OK
or 304 Not Modified response as
appropriate. Services that don’t set caching headers, or that
incorrectly handle conditional GETs, can have a detrimental effect on the
behavior of the system.
The bandwidth, latency, and scalability benefits of using
conditional GET should be clear by
now, but at what expense? It might seem as though to realize these
benefits we have quite a bit of work to do on the client and the
server—storing entity tags, adding If-Modified-Since and If-None-Match headers to requests, and
updating store representations with response header values.
But guess what? Most caches handle this behavior for us for
free. Consumer applications don’t need to take any notice of ETag and Last-Modified values: validations are dealt with by the underlying caching
infrastructure.
We’ve already seen how a service can control the expiration of a
representation using the Expires
header and certain Cache-Control
directives in a response. Consumers, too, can influence cache
behavior. By sending Cache-Control
directives in requests, consumers can express their preference for
representations that fall within particular freshness bounds, or their
tolerance for stale representations.
max-age=<delta-seconds>Indicates that the consumer will only accept cached representations that are not older than the specified age,
delta-seconds. If the consumer specifiesmax-age=0, the request causes an end-to-end revalidation all the way to the origin server.max-stale=<delta-seconds>Indicates that the consumer is prepared to accept representations that have been stale for up to the specified number of seconds. The
delta-secondsvalue is optional; by omitting this value, the consumer indicates it is prepared to accept a stale response of any age.min-fresh=<delta-seconds>Indicates that the consumer wants only cached representations that will still be fresh when the current age of the cached object is added to the supplied
delta-secondsvalue.only-if-cachedTells a cache to return only a cached representation. If the cache doesn’t have a fresh representation of the requested resource, it returns
504 Gateway Timeout.no-cacheInstructs a cache not to use a cached representation to satisfy the request, thereby generating an end-to-end reload. An end-to-end reload causes all intermediaries on the response path to obtain fresh copies of the requested representation (whereas an end-to-end revalidation—using
max-age=0—allows intermediaries to update cached representations with headers in the response).no-storeRequires caches not to store the request or the response, and not to return a cached representation.
These Cache-Control
directives allow a consumer to make trade-off decisions around
consistency and latency. Consider, for example, an
application that has been optimized for latency (by making the
majority of representations cacheable). Consumers that require a
higher degree of consistency can use max-age or min-stale to obtain representations with
stricter freshness bounds, but at the expense of the cache
revalidating with the origin server more often than dictated by the
server. In contrast, consumers that care more about latency than consistency can choose to relax
freshness constraints, and accept stale representations from nearby
caches, using max-stale or only-if-cached.
Another situation where these request directives are useful is
after a failed conditional PUT or
POST. If a conditional operation
fails, it’s normal for the consumer to GET the current state of the resource before
retrying the operation. In these circumstances, it is advisable to use
a Cache-Control: no-cache directive
with the request, to force an end-to-end reload that returns the
current state of the resource on the server, rather than a still fresh
but now invalid representation from a cache.
There are two types of invalidation: consumer-driven invalidation and server-driven invalidation. Server-driven invalidation falls outside HTTP’s capabilities, whereas a form of consumer-driven invalidation is intrinsic to HTTP.
Let’s look at consumer-driven invalidation first. According to
the HTTP specification, DELETE,
PUT, and POST requests
should invalidate any cached representations belonging to the request
URI. In addition, if the response contains a Location or Content-Location header, representations
associated with either of these header values should also be
invalidated.
Note
Unfortunately, many caches do not invalidate cached content
based on the Location and
Content-Location header values.
Invalidations based on the unsafe methods just listed are, however,
common.
At first glance, it would appear that a consumer could
invalidate a cached representation using a DELETE, PUT, or POST request, and thereafter be confident
that this same representation won’t be returned in subsequent GETs. But we must remember that this
technique can only guarantee to invalidate caches on the immediate
request path. Caches that are not on the request path will not
necessarily be invalidated. Once again, we are reminded of the need to
deal with the weak consistency issues inherent in the Web’s
architecture.
In contrast to the necessarily weak consistency model of consumer-driven invalidation, server-driven invalidation would appear to offer stronger consistency guarantees. With server-driven invalidation, the service sends invalidation notices to the caches and consumers it knows are likely to have a cached representation of a particular resource. With this approach, all interested parties—both those on and those off the request-response path—will be invalidated when a resource changes.
But this is not the way the Web usually works. For such an approach to be successful, a service would have to maintain a list of consumers and caches to be contacted when a resource changes. In other words, the service would have to maintain application state. And holding application state on the server undermines scalability.
Server-driven invalidation only works for caches the server knows about. Moreover, its strong consistency guarantees only hold while the caches that need to be notified of an invalidation event are connected to the service. If a network problem disconnects a cache, causing it to miss one or more invalidation messages, the overall distributed application will be in an inconsistent state—at least temporarily.
It should be clear by now that server-driven invalidation can only partly mitigate the weak consistency issues that come with adopting the Web as an integration platform. Because of the generally web-unfriendly nature of server-driven invalidation, expiration and validation are by far the most common methods of ensuring eventual consistency between services and consumers on the Web.
Once we have determined that a resource’s representations can be cached, we will have to decide which caches to target, together with the freshness lifetimes of the cacheable representations.
When deciding on the freshness lifetime of a representation, we must balance server control with scalability concerns. With short expiration values, the service retains a relatively high degree of control over the representations it releases, but this control comes at the expense of frequent reloads and revalidations, both of which use network resources and place load on the origin server. Longer expiration values, on the other hand, conserve bandwidth and reduce the number of requests that reach the origin server; at the same time, however, they increase the likelihood that a cached representation will become inconsistent with resource state on the server over the course of its freshness lifetime.
Being able to invalidate cached representations would help here; we could specify a long freshness lifetime for each representation, but then invalidate cached entries the moment a resource changes. Unfortunately, the Web doesn’t support a general invalidation mechanism.
There is, however, one way we can work with the Web to make representations as cacheable as possible, but no more. Instead of seeking to invalidate entries, we can extend their freshness lifetime.
Cache channels implement a technique for extending the freshness lifetimes of cached representations.[71] Caches that don’t understand the cache channel protocol will continue to expire representations the moment they become stale. Caches that do understand the protocol, however, are entitled to treat a normally stale representation as still fresh, until they hear otherwise.
Cache channels use two new Cache-Control extensions. Caches that
understand these directives can use cache channels to extend the
freshness lifetime of cached representations. These
extensions are:
channelThe
channelextension supplies the absolute URI of a channel that a cache can subscribe to in order to fetch events associated with a cached representation.groupThe
groupextension supplies an absolute URI that can be used to group multiple cached representations. Events that apply to a group ID can be applied to all the cached representations belonging to that group.
Example 6-16
shows a request for a product from Restbucks’ product catalog. The
response includes a Cache-Control
header containing both cache channel extensions.
Example 6-16. The channel and group extensions allow caches to subscribe to a cache channel
Request:GET /product-catalog/1234 Host: restbucks.comResponse:HTTP/1.1 200 OKCache-Control: max-age=3600, channel="http://internal.restbucks.com/product-catalog/cache-channel/", group="urn:uuid:1f80b2a1-660a-4874-92c4-45732e03087b"Content-Length: ... Content-Type: application/vnd.restbucks+xml Last-Modified: Fri, 26 Mar 2010 09:33:49 GMT Date: Fri, 26 Mar 2010 09:33:49 GMT ETag: "d53514da9e54" <product xmlns="http://schemas.restbucks.com/product"> <name>Fairtrade Roma Coffee Beans</name> <size>1kg</size> <price>10</price> </product>
The max-age directive
specifies that this representation will remain fresh for up to an
hour, after which it must be revalidated with the origin server. But
any cache on the response path that understands the channel and group extensions can continue to extend the
freshness lifetime of this representation as long as two
conditions hold:
The cache continues to poll the channel at least as often as a precision value specified by the channel itself.
The channel doesn’t issue a “stale” event for either the URI of the cached representation or the
groupURI with which the representation is associated.
If a cache performs a GET on
the channel specified in the channel extension, it receives the cache
channel feed shown in Example 6-17.
Example 6-17. An empty cache channel feed
HTTP/1.1 200 OK
Cache-Control: max-age=300
Content-Length: ...
Content-Type: application/atom+xml
Last-Modified: Fri, 26 Mar 2010 09:00:00 GMT
Date: Fri, 26 Mar 2010 09:42:02 GMT
<feed xmlns="http://www.w3.org/2005/Atom"
xmlns:cc="http://purl.org/syndication/cache-channel">
<title>Invalidations for restbucks.com</title>
<id>urn:uuid:d2faab5a-2743-44b1-a979-8e60248dcc8e</id>
<link rel="self"
href="http://internal.restbucks.com/product-catalog/cache-channel/"/>
<updated>2010-03-26T09:00:00Z</updated>
<author>
<name>Product Catalog Service</name>
</author>
<cc:precision>900</cc:precision>
<cc:lifetime>86400</cc:lifetime>
</feed>This is an Atom feed that has been generated by the origin
server. In the next chapter, we discuss Atom feeds in detail and use
them to build event-driven systems. For now, all we need to understand
is that this is an empty feed—it doesn’t contain any channel events.
(Cache channels don’t have to be implemented as Atom feeds, but given
that there’s widespread support for Atom on almost all development
platforms it’s easy to build cache channels using the Atom format.)
The feed’s <cc:precision>
element specifies a precision in seconds, meaning that caches that
subscribe to this feed must poll it at least as often as every 15
minutes if they want to extend the freshness lifetimes of any representations associated
with this channel. The <cc:lifetime> element value indicates
that events in this feed will be available for at least a day after
they have been issued.
Note
As you can see from Example 6-17, the Atom feed can itself be cached. As we’ll learn in the next chapter, event feeds can take advantage of the Web’s caching infrastructure as much as any other representation.
As long as the cache continues to poll the channel at least every 15 minutes, it can continue to serve the cached product representation well beyond its original freshness lifetime of an hour. If the resource does change on the origin server, the very next time the cache polls the channel it will receive a response similar to the one shown in Example 6-18.
Example 6-18. A cache channel feed containing a stale event
HTTP/1.1 200 OK
Cache-Control: max-age=900
Content-Length: ...
Content-Type: application/atom+xml
Last-Modified: Fri, 26 Mar 2010 13:10:05 GMT
Date: Fri, 26 Mar 2010 13:15:42 GMT
<feed xmlns="http://www.w3.org/2005/Atom"
xmlns:cc="http://purl.org/syndication/cache-channel">
<title>Invalidations for restbucks.com</title>
<id>urn:uuid:d2faab5a-2743-44b1-a979-8e60248dcc8e</id>
<link rel="self"
href="http://internal.restbucks.com/product-catalog/cache-channel/"/>
<updated>2010-03-26T13:10:05Z</updated>
<author>
<name>Product Catalog Service</name>
</author>
<cc:precision>900</cc:precision>
<cc:lifetime>86400</cc:lifetime>
<entry>
<title>stale</title>
<id>urn:uuid:d8b4cd04-d448-4c26-85a6-b08363de8e87</id>
<updated>2010-03-26T13:10:05Z</updated>
<link href="urn:uuid:1f80b2a1-660a-4874-92c4-45732e03087b" rel="alternate"/>
<cc:stale/>
</entry>
</feed>The feed now contains a stale event entry whose alternate
<link> element associates it
with the group ID to which the product representation belongs
(urn:uuid:1f80b2a1-660a-4874-92c4-45732e03087b).
Each event has its own ID, which has nothing to do with the
identifiers of any cached representations; it’s the <link> element’s href value that associates the event with a
group or particular representation.
Note
In practice, we might expect to see additional entries—related to other groups and individual resource IDs—in the feed, with the most recent entries appearing first.
Seeing this event, the cache stops extending the freshness lifetime of any representations belonging to this group. The next time a consumer issues a request for http://restbucks.com/product-catalog/1234, the cache will revalidate its stale representation with the origin server.
Cache channels work with the Web because they don’t require origin servers to maintain application state in the form of lists of connected caches. Each cache is responsible for guaranteeing the delivery of stale events by polling the cache channel. If a cache can’t connect to the channel, it can no longer continue to extend the freshness lifetime of otherwise stale representations.
By associating cached representations with groups, cache
channels provide a powerful mechanism for canceling the extended
freshness of several related representations at the same
time. This is particularly useful when we decompose an application
protocol into several overlapping resources that together manipulate
the state of an underlying domain entity. POSTing a completion to http://restbucks.com/orders/1234/completion, for
example, may render any fresh representations of http://restbucks.com/orders/1234 invalid. This is the
kind of consistency issue traditional invalidation mechanisms seek to
address and precisely the kind of challenge the loosely coupled nature
of the Web makes difficult to solve. Using small freshness lifetimes
together with cache channels, we can reduce the time it takes for the
overall distributed application to reach a consistent state.
Note
Cache channels provide a clean separation of concerns. Cache management can be dealt with separately from designing the caching characteristics of individual resource representations. Cache channel servers can even be deployed on separate hardware from business services.
Of course, cache channels only work for caches that know how to
take advantage of the channel and
group extensions. Though the
HTTP Cache Channels Internet-Draft has now expired,
several reverse proxies, including Squid and Varnish, include
support for its freshness extension mechanism.[72] But in an environment where not all cache
implementations can be controlled by service implementers, the same
difficult truth emerges once again: the Web is weakly
consistent.
In this chapter, we saw how the safe and idempotent properties of
the most popular verb on the Web, GET, are key to building fault-tolerant and
scalable systems. The installed infrastructure of the Web includes a
caching substrate that we can use to bring frequently accessed
representations closer to consumers, thereby reducing latency,
conserving bandwidth, masking transient faults, and decreasing the load
on services. Services dictate the caching behaviors of the
representations they issue; consumers tighten or relax the expectations
they have of caches as they see fit.
We also considered the implications of the Web’s weak consistency model. No matter the expiration or validation mechanisms we choose to employ, we must always remember that we cannot guarantee that a representation of resource state as received by a consumer reflects the current state of the resource as held by the service.
In the last section, we looked at how cache channels allow us to extend the freshness lifetimes of cached representations. Our cache channels example used an Atom feed to communicate “stale” events to caches that understand the cache channels protocol.
In the next chapter, we look in more detail at the Atom feed
format. Knowing about GET and the
caching opportunities offered by the Web, we show how to put these
pieces together to create a scalable, fault-tolerant, event-driven
system.
[62] Benjamin Carlyle discusses this topic in more detail here: http://soundadvice.id.au/blog/2010/01/17/.
[66] The response should really have either an expiry time, or a validator, as we discuss shortly.
[67] Choosing between ETag
values and Last-Modified
timestamps depends on the granularity of updates to the resource.
Last-Modified is only as
accurate as a timestamp (to the nearest second), while ETags can be generated at any frequency.
Typically, however, timestamps are cheaper to generate.
[69] For this example, we host the HttpListener instance in a console
application. For production, we’d host it in IIS to take advantage
of management and fault-tolerance features.
[70] Additional responses that can be cached in this fashion
include 203 Non-Authoritative Information,
206 Partial Content, 300 Multiple Choices, 301 Moved
Permanently, and 410
Gone.
[71] Cache channels are the brainchild of Mark Nottingham; see http://www.mnot.net/blog/2008/01/04/cache_channels.