On personalization: how a Hungarian émigré used conditional probability to protect airplanes from enemy fire in World War II, and how today’s tech firms are using the same math to make personalized suggestions for films, music, news stories—even cancer drugs.
NETFLIX HAS COME so far, so fast, that it’s hard to remember that it started out as a “machine learning by mail” company. As recently as 2010, the company’s core business involved filling red envelopes with DVDs that would incur “no late fees, ever!” Each envelope would come back a few days after it had been sent out, along with the subscriber’s rating of the film on a 1-to-5 scale. As that ratings data accumulated, Netflix’s algorithms would look for patterns, and over time, subscribers would get better film recommendations. (This kind of AI is usually called a “recommender system”; we also like the term “suggestion engine.”)
Netflix 1.0 was so focused on improving its recommender system that in 2007, to great fanfare among math geeks the world over, it announced a public machine-learning contest with a prize of $1 million. The company put some of its ratings data on a public server, and it challenged all comers to improve upon Netflix’s own system, called Cinematch, by at least 10%—that is, by predicting how you’d rate a film with 10% better accuracy than Netflix could. The first team to meet the 10% threshold would win the cash.
Over the ensuing months, thousands of entries flooded in. Some came tantalizingly close to the magic 10% threshold, but nobody beat it. Then in 2009, after two years of refining their algorithm, a team calling themselves BellKor’s Pragmatic Chaos finally submitted the million-dollar piece of code, beating Netflix’s engine by 10.06%. And it’s a good thing they didn’t pause to watch an extra episode of The Big Bang Theory before hitting the submit button. BellKor reached the finish line of the two-year race just 19 minutes and 54 seconds ahead of a second team, The Ensemble, who submitted an algorithm also reaching 10.06% improvement—just not quite fast enough.
In retrospect, the Netflix Prize was a perfect symbol of the company’s early reliance on a core machine-learning task: algorithmically predicting how a subscriber would rate a film. Then, in March of 2011, three little words changed the future of Netflix forever: House of Cards.
House of Cards was the first “Netflix Original Series,” the company’s first try at producing TV rather than merely distributing it. The production team behind House of Cards originally went to all the major networks with their idea, and every single one was interested. But they were all cautious—and they all wanted to see a pilot first. The show, after all, is a tale of lies, betrayal, and murder. You can almost imagine the big networks asking themselves, “How can we be sure that anyone will watch something so sinister?” Well, Netflix could. According to the show’s producers, Netflix was the only network with the courage to say, “We believe in you. We’ve run our data, and it tells us that our audience would watch this series. We don’t need you to do a pilot. How many episodes do you want to do?”1
We’ve run our data, and we don’t need a pilot. Think of the economic implications of that statement for the television industry. In the year before House of Cards premiered, the major TV networks commissioned 113 pilots, at a total cost of nearly $400 million. Of those, only 35 went on the air, and only 13—one show in nine—made it to season two. Clearly the networks had almost no idea what would succeed.
So what did Netflix know in March of 2011 that the major networks didn’t? What made its people so confident in their assessment that they were willing to move beyond recommending personalized TV and start making personalized TV?
The pat answer is that Netflix had data on its subscriber base. But while data was important, this explanation is far too simple. The networks had lots of data, too, in the form of Nielsen ratings and focus groups and countless thousands of surveys—and big budgets for gathering more data, if they believed in its importance.
The data scientists at Netflix, however, had two things that the networks did not, things that were just as important as the data itself: (1) the deep knowledge of probability required to ask the right questions of their data, and (2) the courage to rebuild their entire business around the answers they got. The result was an astonishing transformation for Netflix: from a machine-learning-powered distribution network to a new breed of production company in which data scientists and artists come together to make awesome television. As Ted Sarandos, Netflix’s chief content officer, famously put it in an interview with GQ: “The goal is to become HBO faster than HBO can become us.”2
Today, few organizations use AI for personalization better than Netflix, and the approach it pioneered now dominates the online economy. Your digital trail yields personalized suggestions for music on Spotify, videos on YouTube, products on Amazon, news stories from The New York Times, friends on Facebook, ads on Google, and jobs on LinkedIn. Doctors can even use the same approach to give you personalized suggestions for cancer therapy, based on your genes.
It used to be that the most important algorithm in your digital life was search, which for most of us meant Google. But the key algorithms of the future are about suggestions, not search. Search is narrow and circumscribed; you have to know what to search for, and you’re limited by your own knowledge and experience. Suggestions, on the other hand, are rich and open ended; they draw on the accumulated knowledge and experience of billions of other people. Suggestion engines are like “doppelgänger software” that might someday come to know your preferences better than you do, at least consciously. How long will it be, for example, before you can tell Alexa, “I’m feeling adventurous; book me a weeklong holiday,” and expect a brilliant result?
There’s obviously a lot of sophisticated math behind these suggestion engines. But if you’re math-phobic, there’s also some very good news. It turns out that there’s really only one key concept you need to understand, and it’s this: to a learning machine, “personalization” means “conditional probability.”
In math, a conditional probability is the chance that one thing happens, given that some other thing has already happened. A great example is a weather forecast. If you were to look outside this morning and see gathering clouds, you might assume that rain is likely and bring an umbrella to work. In AI, we express this judgment as a conditional probability—for example, “the conditional probability of rain this afternoon, given clouds this morning, is 60%.” Data scientists write this a bit more compactly: P(rain this afternoon | clouds this morning) = 60%. P means “probability,” and that vertical bar means “given” or “conditional upon.” The thing on the left of the bar is the event we’re interested in. The thing on the right of the bar is our knowledge, also called the “conditioning event”: what we believe or assume to be true.
Conditional probability is how AI systems express judgments in a way that reflects their partial knowledge:
You just gave Sherlock a high rating. What’s the conditional probability that you will like The Imitation Game or Tinker Tailor Soldier Spy?
Yesterday you listened to Pharrell Williams on Spotify. What’s the conditional probability that you’ll want to listen to Bruno Mars today?
You just bought organic dog food. What’s the conditional probability that you will also buy a GPS-enabled dog collar?
You follow Cristiano Ronaldo (@cristiano) on Instagram. What’s the conditional probability that you will respond to a suggestion to follow Lionel Messi (@leomessi) or Gareth Bale (@garethbale11)?
Personalization runs on conditional probabilities, all of which must be estimated from massive data sets in which you are the conditioning event. In this chapter, you’ll learn a bit of the magic behind how this works.
Abraham Wald, World War II Hero
The core idea behind personalization is a lot older than Netflix, older even than television itself. In fact, if you want to understand the last decade’s revolution in the way that people engage with popular culture, then the best place to start isn’t in Silicon Valley, or in the living room of a cord-cutting millennial in Brooklyn or Shoreditch. Rather, it’s in 1944, in the skies over occupied Europe, where one man’s mastery of conditional probability saved the lives of an untold number of Allied bomber crews in the largest aerial campaign in history: the bombardment of the Third Reich.
During World War II, the size of the air war over Europe was truly staggering. Every morning, vast squadrons of British Lancasters and American B-17s took off from bases in England and made their way to their targets across the Channel. By 1944, the combined Allied air forces were dropping over 35 million pounds of bombs per week. But as the air campaign escalated, so too did the losses. On a single mission in August of 1943, the Allies dispatched 376 bombers from 16 different air bases, in a joint bombing raid on factories in Schweinfurt and Regensburg in Germany. Sixty planes never came back—a daily loss of 16%. The 381st Bomb Group, flying out of RAF Ridgewell, lost 9 of its 20 bombers that day.3
World War II airmen were painfully aware that each mission was a roll of the dice. But in the face of these bleak odds, the bomber crews had at least three defenses.
1. Their own tail and turret gunners, to ward off attackers.
2. Their fighter escorts: the Spitfires and P-51 Mustangs sent along to defend the bombers from the Luftwaffe.
3. A Hungarian-American statistician named Abraham Wald.
Abraham Wald never shot down a Messerschmitt or even saw the inside of a combat aircraft. Nonetheless, he made an outsized contribution to the Allied war effort using an equally potent weapon: conditional probability. Specifically, Wald built a recommender system that could make personalized survivability suggestions for different kinds of planes. At its heart, it was just like a modern AI-based recommender system for TV shows. And when you understand how he built it, you’ll also understand a lot more about Netflix, Hulu, Spotify, Instagram, Amazon, YouTube, and just about every tech company that’s ever made you an automatic suggestion worth following.
Wald’s Early Years
Abraham Wald was born in 1902 to a large Orthodox Jewish family in Kolozsvár, Hungary, which became part of Romania and changed its name to Cluj after World War I. His father, who worked at a bakery in town, created a home atmosphere of learning and intellectual curiosity for his six children. The young Wald and his siblings grew up playing the violin, solving math puzzles, and listening to stories at the feet of their grandfather, a famous and beloved rabbi. Wald attended the local university, graduating in 1926. He then went on to the University of Vienna, where he studied mathematics under a distinguished scholar named Karl Menger.4
By 1931, when he finished his PhD, Wald had emerged as a rare talent. Menger called his pupil’s dissertation a “masterpiece of pure mathematics,” describing it as “deep, beautiful, and of fundamental importance.” But no university in Austria would hire a Jew, no matter how talented, and no matter how strongly his famous advisor recommended him. So Wald looked for other options. In fact, he told Menger that he was happy to take any job that would let him make ends meet; all he wanted to do was keep proving theorems and attending math seminars.
At first, Wald worked as the private math tutor for a wealthy Austrian banker named Karl Schlesinger, to whom Wald remained forever grateful. Then in 1933 he was hired as a researcher at the Austrian Institute for Business Cycle Research, where yet another famous scholar found himself impressed by Wald: economist Oskar Morgenstern, the coinventor of game theory. Wald worked side by side with Morgenstern for five years, analyzing seasonal variation in economic data. It was there at the institute that Wald first encountered statistics, a subject that would soon come to define his professional life.
But dark clouds were gathering over Austria. As Wald’s advisor Menger put it, “Viennese culture resembled a bed of delicate flowers to which its owner refused soil and light, while a fiendish neighbor was waiting for a chance to ruin the entire garden.” The spring of 1938 brought disaster: Anschluss. On March 11, Austria’s elected leader, Kurt Schuschnigg, was deposed by Hitler and replaced by a Nazi stooge. Within hours, 100,000 troops from the German Wehrmacht marched unopposed across the border. By March 15 they were parading through Vienna. In a bitter omen, Karl Schlesinger, Wald’s benefactor from the lean years of 1931–32, took his own life that very day.
Luckily for Wald, his work on economic statistics had earned attention abroad. The previous summer, in 1937, he’d been invited to America by an economics research institute in Colorado Springs. Although pleased by the recognition, Wald had initially been hesitant to leave Vienna. But Anschluss changed his mind, as he witnessed the Jews of Austria falling victim to a terrible orgy of murder and theft and betrayal. Their shops were plundered, their homes vandalized, their roles in public life stripped by the Nuremberg Laws—including Wald’s role, at the Institute for Business Cycle Research. Wald was sad to say good-bye to Vienna, his second home, but he could see the winds of madness blowing stronger every day.
So in the summer of 1938, at great peril, he snuck across the border into Romania and traveled onward to America, dodging guards on the lookout for Jews fleeing the country. The decision to leave probably saved his life. Remaining in Europe were Wald’s parents, his grandparents, and his five brothers and sisters—and all but one, his brother Hermann, were murdered in the Holocaust. By then Wald was living in America. He was safe and hard at work, married and with two children, and he took solace in the joys of his new life. Yet he would remain so stricken by grief over the fate of his family that he never again played the violin.
Wald in America
Abraham Wald would, however, do more than his fair share to make sure that Hitler faced the music.
The 35-year-old Wald arrived in America in the summer of 1938. Although he missed Vienna, he immediately liked his new home. Colorado Springs echoed the Carpathian foothills of his youth, and his new colleagues received him with warmth and affection. He didn’t stay in Colorado for long, though. Oskar Morgenstern, who had fled to America himself and was now in Princeton, was telling his math friends all up and down the East Coast about his old colleague Wald, whom he described as a “gentle man” with “exceptional gifts and great mathematical power.” Wald’s reputation kept growing, and it soon caught the attention of an eminent statistics professor in New York named Harold Hotelling. In the fall of 1938, Wald accepted an offer to join Hotelling’s group at Columbia University. He began as a research associate, but he flourished so rapidly as both a teacher and scholar that he was soon offered a permanent position on the faculty.
By late 1941, Wald had been in New York for three years, and the stakes of what was happening across the water were obvious to all but the willfully blind. For two of those years Britain had been fighting the Nazis alone, fighting, as Churchill put it, “to rescue not only Europe but mankind.” Yet for those two long years, America had stood aside. It took the bombing of Pearl Harbor to rouse the American people from their torpor, but roused they were at last. Young men surged forward to enlist. Women joined factories and nursing units. And scientists rushed to their labs and chalkboards, especially the many émigrés who’d fled the Nazis in terror: Albert Einstein, John von Neumann, Edward Teller, Stanislaw Ulam, and hundreds of other brilliant refugees who gave American science a decisive boost during the war.
Abraham Wald, too, was eager to answer the call. He was soon given the chance, when his colleague W. Allen Wallis invited him to join Columbia’s Statistical Research Group. The SRG had been started in 1942 by four statisticians who met periodically in a dingy room in Rockefeller Center, in midtown Manhattan, to provide statistical consulting to the military. As academics, they were initially unaccustomed to giving advice under pressure. Sometimes this led to episodes revealing comically poor perspective on the demands of war. In the SRG’s early days, one mathematician complained resentfully about being forced by a secretary to save paper by writing his equations on both sides of the page.
But their gomer days didn’t last long. By 1944, the Statistical Research Group had matured into a team of 16 statisticians and 30 young women from Hunter and Vassar Colleges who handled the computing work. The team became an indispensable source of technical advice to the military’s Office of Scientific Research and Development, and their guidance was sought at the highest levels of command—and they got results. The statisticians at Columbia developed nothing so fearsome or famous as the teams gathered in Los Alamos or Bletchley Park at the same time. But their remit was broader, and their effect on the war was profound. They studied rocket propellants, torpedoes, proximity fuses, the geometry of aerial combat, the vulnerability of merchant vessels—anything involving math that would advance the war effort. As Wallis, the group’s director, later reminisced:
During the Battle of the Bulge in December 1944, several high-ranking Army officers flew to Washington from the battle, spent a day discussing the best settings on proximity fuses for air bursts of artillery shells against ground troops, and flew back to the battle.… This kind of responsibility, although rarely spoken of, was always in the atmosphere and exerted a powerful, pervasive, and unremitting pressure.5
Fortunately, it was a team of some of the best mathematical minds in the country, many of whom would go on to lead their chosen fields. Two became university presidents. Four served as president of the American Statistical Association. Mina Rees became the first female president of the American Association for the Advancement of Science. Milton Friedman and George Stigler received the Nobel Prize in Economics.
And on this team of all-stars, Abraham Wald was like LeBron James: the man who did everything. Only the hardest problems ever found their way to his desk, for even his fellow geniuses recognized that, in the words of the group’s director, “Wald’s time was too valuable to be wasted.”
Wald and the Missing Airplanes
Wald’s most famous contribution to the group’s work was a paper that invented a branch of data analysis known as sequential sampling. His mathematical insights showed factories how they could produce fewer defective tanks and planes, just by implementing smarter inspection protocols. When this paper was declassified by the military, it made Wald an academic celebrity, and it changed the course of twentieth-century statistics, as researchers everywhere rushed to apply Wald’s mathematical insights in new areas—especially in clinical trials, where those insights are still used today.
But our story here, about the exponential growth of Netflix-style personalization, relates to a different and almost universally misunderstood contribution of Abraham Wald’s: his method for devising personalized survivability recommendations for aircraft.
Every day, the Allied air forces sent massive squadrons of airplanes to attack Nazi targets, and many planes returned having taken damage from enemy fire. At some point, someone in the navy had the clever idea of analyzing the distribution of hits on these returning planes. The thinking was simple: if you could find patterns in where the planes were taking fire, then you could recommend where to reinforce them with extra armor. These recommendations, moreover, could be personalized to each plane, since the threats to a nimble P-51 fighter were very different from the threats to a lumbering B-17 bomber.
The naïve strategy would be to put more armor wherever you saw lots of bullet holes on the returning planes. But this would be a bad idea, because the navy didn’t have any data on the planes that got shot down. To see why this is so important, consider an extreme example. Suppose that a bomber could be shot down by a single hit to the engine, but that it was invulnerable to hits on the fuselage. If that were true, then the navy’s data analysts would see hundreds of bombers coming back with harmless bullet holes on the fuselage—but not a single one coming back with holes around the engine, since every such plane would have crashed. Under this scenario, if you simply added armor where you saw the bullet holes—on the fuselage—then you’d actually be handicapping the bombers, adding weight that “protected” them from a nonexistent danger.
This example illustrates an extreme case of survivorship bias. Although the real world is much less extreme—bullets to the engine are not 100% lethal, nor are bullets to the fuselage 100% harmless—the statistical point remains: the pattern of damage on the returning planes had to be analyzed carefully.
At this juncture, we must pause to make two important side points. First, the internet bloody loves this story. Second, just about everyone who’s ever told it—with the notable exception of an obscure, highly technical paper published in the Journal of the American Statistical Association in 1984—gets it wrong.6
Try Googling “Abraham Wald” and “World War II” yourself and see what you find: one blog post after another about how a mathematical crusader named Wald prevented those navy blockheads from making a terrible blunder and slapping a bunch of unnecessary armor on the fuselages of airplanes. We’ve read dozens of these things, and we have spared you the same dreary task by creating the following composite sketch.
During World War II, the navy found a striking pattern of damage to planes returning from bombing runs in Germany, in which most of the bullet holes were on the fuselage. The navy guys reached the obvious conclusion: put more armor on the fuselage. Nonetheless, they gave their data to Abraham Wald, just to double-check. Wald’s little gray cells went to work. And then a thunderbolt. “Wait!” Wald exclaims. “That’s wrong. We don’t see any damage to the engines because the planes that are hit in the engine never return. You need to add armor to the engine, not the fuselage.” Wald had pointed out the crucial flaw in the navy’s thinking: survivorship bias. His final, life-saving advice ran exactly counter to that of bthe other so-called experts: put the armor where you don’t see the bullet holes.
We can see why this version of the story is so irresistible: the path of counterintuition eventually turns a full 360 degrees. Imagine asking any person off the street, “Where should we put extra armor on airplanes to help them survive enemy fire?” While we haven’t done this survey, we suspect that “the engine” would be a popular response. But a naïve interpretation of the data initially seems to suggest otherwise: if the returning planes have taken damage on the fuselage, then by God, let’s put the armor there instead. Only a genius like Wald, the story goes, can see to the heart of the matter, leading us back to our initial, intuitive conclusion.
Alas, as far as we can tell from the historical record, this account has little basis in fact. Worse still, this embellished version, in which the moral of the story is about survivorship bias, misses the truly important thing about Abraham Wald’s contribution to the Allied war effort. Survivorship bias in the data was obviously the problem, and everybody knew it. Otherwise there would have been no reason to call the Statistical Research Group in the first place; the navy didn’t need a bunch of math professors just to count bullet holes. Their question was more specific: how to estimate the conditional probability of an aircraft surviving an enemy hit in a particular spot, despite the fact that much of the relevant data was missing. The navy folks didn’t know how to do this. They were really smart, but it is no insult to say that they weren’t as smart as Abraham Wald.
Wald’s real contribution was far subtler and more interesting than delivering some survivorship-bias boom-shakalaka to a cartoonish dolt of a navy commander. His masterstroke wasn’t to identify the problem but to invent a solution: a “survivability recommender system,” or a method that could provide military commanders with bespoke suggestions about how to improve survivability for any model of aircraft, using data on combat damage. Wald’s algorithm was, in the words of the Statistical Research Group’s director, an “ingenious piece of work by one of the greatest figures in the history of American statistics.” Although Wald’s algorithm wasn’t published until the 1980s, it was used behind the scenes in World War II and for many years thereafter.7 In the Vietnam War, the navy used Wald’s algorithm on the A-4 Skyhawk; years later, the air force used it to improve the armor on the B-52 Stratofortress, the longest-serving aircraft in U.S. military history.
Missing Data: What You Don’t Know Can Fool You
As you can now appreciate, Abraham Wald’s problem of improving aircraft survivability was a whole lot like Netflix’s problem of making personalized film suggestions. But there’s a catch, and it’s a big one.
U.S. Navy, in 1943: “We want to estimate the conditional probability that a plane will crash, given that it takes enemy fire in a particular location, in light of the damage data from all other planes. This will allow us to personalize survivorship recommendations for each model of plane. But much of the data is missing: the planes that crash never return.”
Netflix, 70 years later: “We want to estimate the conditional probability that a subscriber will like a film, given his or her particular viewing history, in light of the ratings data from all other subscribers. This will allow us to personalize film recommendations for each viewer. But much of the data is missing: most subscribers haven’t watched most films.”
The catch is that both Abraham Wald and Netflix needed to estimate a conditional probability, but both faced the problem of missing data. And sometimes what’s missing can be very informative.
Consider, for example, something that happened when one of your authors (Polson, a Brit) visited the other (Scott, a Texan) down in Austin for the first time. On a walk to a local coffee shop, we noticed a large white van parked on the street that read:
ARMADILLO
PET CARE
Imagine Polson’s bemusement at the idea of a flourishing local business devoted to the needs of these very non-British creatures. What were armadillos like as pets? Did they learn their names? And why such a big van?
But then a delivery guy moved a trolley stacked high with packages from beside the van, and the quotidian truth was revealed:
ARMADILLO
CARPET CARE
Sometimes the missing part of the data changes the entire story.
It was just the same with Abraham Wald’s data on aircraft survivability. Although his raw figures are lost to history, we can use his published navy report to hypothesize what he might have seen. Let’s imagine following in Wald’s footsteps as he examines the data on the Schweinfurt–Regensburg raid in August of 1943, where the Allies lost 60 of their 376 planes in a single day. The raw reports from the field would have looked something like this, where a question mark means “missing data”:
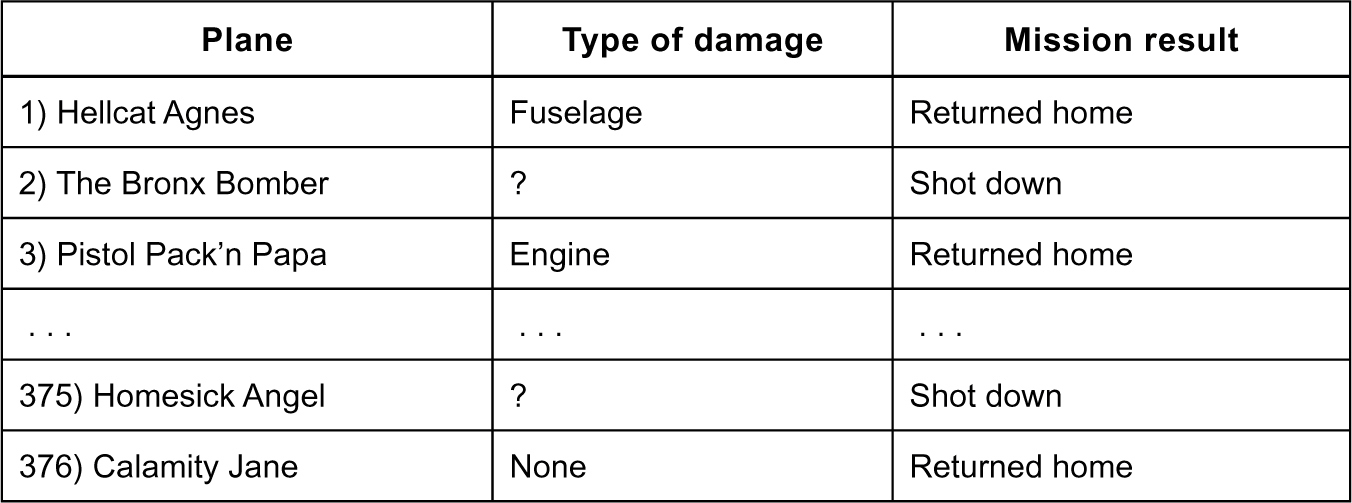
From these reports, Wald could have cross-tabulated the planes according to damage type and mission result.* This would have produced the following table:

Of the 316 planes making it back home, 105 have taken damage on the fuselage. This fact would have allowed Wald to estimate the conditional probability that a plane has taken damage on the fuselage, given that it returns safely:
P(damage on fuselage | returns safely) = 105/316 ≈ 32%.
But that’s the right answer to the wrong question. Instead, what we want to know is the exact inverse: the conditional probability that a plane returns safely, given that it has taken damage on the fuselage. This might be a very different number.
This brings us to an important rule about conditional probabilities: they are not symmetric. Just because Wald knew P(damage on fuselage | returns safely), he didn’t necessarily know the inverse probability, P(returns safely | damage on fuselage). To illustrate why not, consider a simple example:
• All NBA players practice basketball, which means that P(practices basketball | plays in NBA) is nearly 100%.
• A vanishingly small fraction of those who practice basketball will make the NBA, which means P(plays in NBA | practices basketball) is nearly 0%.
So P(practices basketball | plays in NBA) does not equal P(plays in NBA | practices basketball). When thinking about probabilities, it’s very important to be clear about which event is on the left side of the bar, and which event is on the right side of the bar.
Wald knew this. He knew that to calculate a probability like P(plane returns safely | damage on fuselage), he needed to estimate how many planes had taken damage to the fuselage and never made it home. His task was to put actual numbers in place of those question marks in the table above: that is, to fill in the missing data by reconstructing the statistical signature of the downed planes. Data scientists call this process “imputation.” It’s usually a lot better than “amputation,” which means just chopping off the missing data.
Wald’s attempt at imputation all came down to his modeling assumptions. He had to re-create the typical encounter of a B-17 with the enemy, using only the mute testimony of the bullet holes on the planes that had made it back, coupled with a hypothetical model of an aerial battle. To ensure that his modeling assumptions were as realistic as possible, Wald set to work like a forensic scientist. He analyzed the likely attack angle of enemy fighters. He chatted with engineers. He studied the properties of a shrapnel cloud from a flak gun. He even suggested that the army fire thousands of dummy bullets at a plane so that he could tabulate the hits.
When all was said and done, Wald had invented a method for reconstructing the full table. Based on his model of aerial battles, his estimates would have looked something like this:

From a filled-in data set like this one, it is now straightforward to estimate the conditional probabilities that Wald needed. For example, of 113 planes with hits to the fuselage, 105 of them returned home, and an estimated 8 didn’t. Thus the conditional probability of returning safely, given damage to the fuselage, is

According to this estimate, a B-17 was very likely to survive a hit on the fuselage.
On the other hand, of the 60 planes that took damage to the engine, only 29 returned safely. Therefore

The bombers were much more likely to get shot down if they took damage to the engine.
These, finally, were the kind of numbers the navy could use. But more than just the numbers for a specific plane, it could also use Wald’s approach to personalize the survivability recommendations for any plane. Conditional probability plus careful modeling of missing data proved to be a lifesaving combination.
Missing Bombers, Missing Ratings
Seventy years later, these same ideas would play a fundamental role in the way that Netflix reinvented itself as a company.
It all started from Netflix 1.0’s recommender system, which we’ll explain here in broad strokes. Imagine that you face the daunting task of designing this system yourself. As an input, the system must accept a subscriber’s viewing history, and as an output, it must produce a prediction about whether that subscriber will like a particular show. You decide to start with an easy case inspired by Wald: assessing how probable it is that a subscriber will like the film Saving Private Ryan, given that he or she liked the HBO series Band of Brothers. This seems like a good bet: both are epic dramas about the Normandy invasion and its aftermath.
For this particular pair of shows, fine: recommend away. Keep in mind, however, that you want to be able to do this automatically. It would surely not be cost-effective to place a huge team of human annotators into the recommendation loop here, laboriously tagging all possible pairs of movies for similarities. But now recall that you have access to the entire Netflix database showing which customers have liked which films. Your goal is to leverage this vast data resource to automate the recommender system.
The key insight is to frame the problem in terms of conditional probability. Suppose that, for some pair of films A and B, the probability P(random subscriber likes film A | same random subscriber likes film B) is high—say, 80%. Now we learn from Linda’s viewing history that she liked film B but hasn’t yet seen film A. Wouldn’t film A be a good recommendation? Based on her liking of B, there’s an 80% chance she’ll like A.
But how can we learn a number like P(subscriber likes Saving Private Ryan | subscriber likes Band of Brothers)? This is where your database comes in handy. To keep the numbers simple, let’s say there are 100 people in your database, and every one of them has seen both films. Their viewing histories come in the form of a big “ratings matrix,” where the rows correspond to subscribers and the columns to films:

Next, you cross-tabulate the data from the ratings matrix by counting how many subscribers had a specific combination of preferences for these two films:

From this table, we can easily work out the conditional probability that your recommender system needs:
• 70 subscribers liked Band of Brothers (56 + 14).
• Of these 70 subscribers, 56 of them liked Saving Private Ryan, and 14 didn’t.
This allows you to calculate the conditional probability that someone who liked Band of Brothers will like Saving Private Ryan:

The key thing that makes this approach work so well is that it’s automatic. Computers aren’t very good (yet) at automatically scanning films for thematic content. But they’re brilliant at counting—that is, cross-tabulating vast databases of subscribers’ movie-watching histories from a ratings matrix to estimate conditional probabilities.
The real problem that Netflix faces is much harder than this toy example, for at least three reasons. The first is scale. Netflix doesn’t have 100 subscribers, it has 100 million, and it doesn’t have ratings data on two shows, but on more than 10,000. As a result, the ratings matrix has more than a trillion possible entries.
The second issue is “missingness.” Most subscribers haven’t watched most films, so most of those trillion-plus entries in the ratings matrix are missing. Moreover, as in the case of the World War II bombers, that missingness pattern is informative. If you haven’t watched Fight Club, maybe you just haven’t gotten around to it—but then again, maybe films about nihilism just do nothing for you.
The final issue is combinatorial explosion. Or, if you’d rather stick with Fight Club and philosophy over mathematics: each Netflix subscriber is a beautiful and unique phenomenological snowflake. In a database with only two films, millions of users will share identical like/dislike experiences, since only four such experiences are possible: liked both, liked neither, or liked one but not the other. Not so in a database with 10,000 films. Consider your own film-watching history. No one else’s history is exactly the same as yours, and no one else’s ever will be, because there are too many ways to differ. Even in a database with only 300 films in it, there would be vastly more possible combinations of liking or disliking those films (2300) than there are atoms in the universe (about 2272). Long before you get to 210,000, you might as well stop counting—the varieties of film-liking experience are, for all practical purposes, infinite.
This raises an important question. How can Netflix make a recommendation on the basis of your viewing history, using other people’s viewing histories, when yours is unprecedented and theirs will never be repeated?
The solution to all three issues is careful modeling. Just as Wald solved his missing-data problem by building a model of a B-17’s encounter with an enemy fighter, Netflix solved its problem by building a model of a subscriber’s encounter with a film. And while Netflix’s current model is proprietary, the million-dollar model built by team BellKor’s Pragmatic Chaos, winner of the Netflix Prize, is posted for free on the web.8 Here’s the gist of how it works. (Remember, Netflix predicts ratings on a 1-to-5 scale, from which a like/dislike prediction can be made using a simple cutoff, e.g., four stars.)
The fundamental equation here is
Predicted Rating = Overall Average + Film Offset + User Offset + User-Film Interaction.
The first three pieces of this equation are easy to explain.
• The overall average rating across all films is 3.7 stars.
• Every film has its own offset. Schindler’s List and Shakespeare in Love have positive offsets because they’re popular, while Daddy Day Care and Judge Dredd have negative offsets because they’re not.
• Every user has an offset, because some users are more or less critical than average. Maybe Vladimir is a cynic and rates every film harshly (negative offset), while Donald thinks all films are terrific and rates them highly (positive offset).
These three terms provide a baseline rating for a given user/film pair. For example, imagine recommending The Spy Who Loved Me (film offset = 0.4) to Vlad the curmudgeon (user offset = −0.2). Vlad’s baseline rating would be 3.7 + 0.4 − 0.2 = 3.9.
But that’s just the baseline. It ignores the user-film interaction, which is where most of the data-science action happens. To estimate this interaction, the prizewinning team built something called a “latent feature” model. (“Latent feature” just means something not directly measured.) The idea here is that a person’s ratings of similar films exhibit patterns because those ratings are all associated with latent features of that person. Each person’s latent features can be estimated from prior ratings and used to make predictions about as-yet-unseen data. This same idea comes up everywhere, under many different names:
• Survey respondents give similar answers to questions about their job and education. Both are related to a latent feature, “socioeconomic status,” that can also be used to predict a respondent’s answer to a question about income. Social scientists call this “factor analysis.”
• Senators vote in similar ways on taxes and health-care policy. Both are related to a latent feature, “ideology,” that can also be used to predict a senator’s vote on defense spending. Political scientists call this an “ideal point model.”
• SAT test takers give similar patterns of answers to questions about geometry and algebra. Both are related to a latent feature, “math skill,” that can also be used to predict a student’s answer to a question about trigonometry. Test designers call this “item-response theory.”
• Netflix subscribers rate 30 Rock and Arrested Development in similar ways. Both are related to a latent feature—let’s call it “affinity for witty oddball comedies”—that can also be used to predict a user’s rating for Parks and Recreation. Data scientists call this “user-based collaborative filtering.”
Of course, there’s not just one latent feature to describe Netflix subscribers, but dozens or even hundreds. There’s a “British murder mystery” feature, a “gritty character-driven crime drama” feature, a “cooking show” feature, a “hipster comedy films” feature, and so on. These features form the coordinate axes of a giant multidimensional space in which every user occupies a unique position, corresponding to the user’s unique mix of preferences. Love Poirot but can’t handle the violence of Narcos? Maybe you’re a +2.5 on the British-murder-mystery axis and a −2.1 on the crime-drama axis. Adore The Royal Tenenbaums but find The Great British Baking Show a snooze? Maybe you’re a 3.1 on hipster comedy and a −1.9 on cooking shows.
The coolest part about this whole process is that the latent features defining these axes aren’t decided upon ahead of time. Instead, they are discovered organically by AI, using the patterns of correlation in tens of millions of user ratings. The data—not a critic or a human annotator—determines which shows go together.
The Hidden Features Tell the Story
We can now, at last, finish our story of personalization in AI. It is the story of how subscriber-level latent features, discovered from massive data sets using conditional probability, were the hidden force behind Netflix’s strategic transformation from distributor to producer. It is also the story of how these latent features are the magic elixir of the digital economy—a special brew of data, algorithms, and human insight that represents the most perfect tool ever conceived for targeted marketing. The people who run Netflix realized this. They decided to use that tool to start making television shows themselves, and they never looked back.
Think about what makes Netflix different as a content producer. Unlike the major TV networks, Netflix doesn’t care how old you are, what ethnicity you are, or where you live. It doesn’t care about your job, your education, your income, or your gender. And it certainly doesn’t care what the advertisers think, because there aren’t any. The only thing Netflix cares about is what TV shows you like—something it understands in extraordinary detail, based on its estimates of your latent features.
Those features allow Netflix to segment its subscriber base according to hundreds of different criteria. Do you like dramas or comedies? Are you a sports fan? Do you like cooking shows? Do you like musicals? Do you like films with a more diverse cast? Do you watch every second of action films, or do you fast-forward when the violent parts come on? Do you watch cartoons? The patterns in your own viewing history, together with those learned from everyone else’s history, give a mathematically precise answer to each of these questions, and to hundreds more. Your precise combination of latent features—your tiny little corner of a giant multidimensional Euclidean space—makes you a demographic of one.
And that’s how Netflix invented its new business model of commissioning fantastic stories from world-class artists—some of them aimed at one miniaudience, and some at another. A great example is The Crown, an opulent, layered drama about the early life of Queen Elizabeth II. As of 2017, The Crown was the most expensive TV series ever made: $130 million for 10 episodes. Included in that budget were 7,000 period costumes, most famously a $35,000 royal wedding dress. It may sound as though Netflix is spending money like a drunken sailor on new programs. But remember those gory statistics from a single year of network television: $400 million commissioning 113 pilots, of which only 13 shows made it to a second season. When the standard industry practice is to blow hundreds of millions of dollars on shows destined for irrelevance, even a wedding dress that costs 300 annual Netflix subscriptions starts to look like a bargain. So rather than a drunken sailor, the better metaphor is a fortune-teller with a crystal ball—a data-driven, probabilistic crystal ball capable of telling the folks at Netflix exactly what kind of program their subscribers would pay $130 million for. Once they’ve figured that out, they trust the artists to do the rest.
The numbers are even starting to show that this approach works. Netflix doesn’t release viewership statistics, but we do have at least one metric, and that’s awards. In 2015, Netflix was in sixth place among TV networks for Emmy nominations. By 2017, it was in second place; its 91 nominations lagged behind only HBO’s haul of 110, and HBO is justifiably worried about what will happen when the wildly popular Game of Thrones ends its run. It seems only a matter of time before streaming services like Netflix dominate the awards circuit.
Either way, the Netflix approach to personalization already dominates the digital economy. If the future of digital life is about suggestions rather than search, as we believe it is, then the future is also, inevitably, about conditional probability.
The Mixed Legacy of Suggestion Engines
Suggestion engines have been a major area of research in AI for a decade or more, both in academia and industry. Even though that legacy is still unfolding, it’s worth reflecting on where we are now. The news is mixed.
The Dark Side of Targeted Marketing
First the bad news: these technologies haven’t only been used to make suggestions about fun stuff, like TV shows and music. Suggestion engines also have a dark side, one that’s been exploited in cynical, divisive ways. There’s no better example than Russian agents’ use of Facebook in the months leading up to America’s 2016 presidential election.
Facebook is popular among advertisers for the same reason Netflix is popular among TV watchers: it’s mastered the art of targeted marketing based on your digital trail. In ages past, when companies wanted to reach some demographic—college students, for example, or parents with school-age kids—those companies would buy ads in places where their target audience might be paying attention. Marketers made these ad-buying decisions using aggregate data on which people tended to watch this show or read that magazine. But they couldn’t target specific individuals. As the marketer’s old saw goes: half of all advertising dollars are wasted; we just don’t know which half.
But if an ad used to be a blunt instrument, today it is a laser beam. Marketers can now design an online ad for any target audience they can imagine, defined at a level of demographic and psychographic detail that would boggle your mind. If you came to Facebook’s sales team with a goal of targeting a vague group like “young professionals,” for example, you would probably be laughed at behind your back. Tell us who you really want to target, you’d be told. Do you want lawyers or bankers? Democrats or Republicans? Sports fans or opera connoisseurs? Black or white, man or woman, North or South, steak or salad—and if salad, iceberg or kale? The list goes on and on. Once you’ve decided upon your audience, Facebook’s algorithms can pick out exactly which users to target, and they can serve up an ad or a sponsored post to those users at exactly the moment when they’re most likely to be receptive to its message. This makes marketers giddy—and it’s why Facebook was, at the time of writing, worth over half a trillion dollars, more than the GDP of Sweden.
This kind of targeted marketing has been going on for a while, and judging by their behavior, most Facebook users have been willing to accept the “data for gossip” bargain implicit in their continued use of the platform. But for many people the alarm bells started to go off in the wake of the 2016 presidential election, when it became clear just how cleverly Russia had exploited Facebook’s ad-targeting system to sow discord among American voters. Russian agents, for example, zeroed in on a group of users who’d gone on Facebook to express solidarity with police officers in the wake of protests by the Black Lives Matter movement. They targeted these users with an ad containing a picture of a flag-draped coffin at a policeman’s funeral, along with the caption: “Another gruesome attack on police by a BLM movement activist. Our hearts are with those 11 heroes.” They targeted a group of conservative Christian users with a different ad: a photo of Hillary Clinton shaking hands with a woman in a headscarf, together with a caption rendered in pseudo-Arabic script, “Support Hillary. American Muslims.” The Russians made different ads for New Yorkers and for Texans, for LGBTQ advocates and for NRA supporters, for veterans and for civil rights activists—all of them targeted with ruthless algorithmic efficiency.9
We don’t know anyone, of any party or any profession, who isn’t appalled by the idea of a hostile foreign power weaponizing social media to influence an American election. And it is clear that the technology behind suggestion engines was at least one ingredient in this toxic cocktail of Russian money and identity politics. Once you move away from those points of near-universal agreement, however, the questions get a lot more complex. For example:
1. Did these activities change the outcome of the presidential election? We’ll probably never know, since we cannot reverse engineer the decision-making processes of the 138.8 million people who cast a ballot, or the tens of millions more who stayed home.
2. Would it be different if a U.S.-based actor—say, the Koch brothers on the right, or the Blue Dog PAC on the left—did something similar? If you think that would still be objectionable, and that Facebook or someone else should put a stop to it, would you trust your political opponents to decide exactly where the limits should be?
3. Are these digital-age techniques qualitatively more effective at influencing people than the techniques that other propagandists, from Leni Riefenstahl to talk radio, have been using for years? This is a simple empirical question: If people are targeted with hyperspecific digital ads based on what the data says about them, and if that data is very accurate, how many change their minds or behave differently? If the answer is that the ads don’t change any minds but just make people more likely to vote the positions they already hold—again, assuming an American ad buyer—is that good or bad for democracy?
4. What, exactly, should be done now? Algorithms surely played a role in the Russia/Facebook debacle, but so did our preexisting political culture, and so did our laws on advertising, especially paid political advertising. What is the right mix of legal and policy responses to keep this kind of thing from happening again? Going further, should this be a wake-up call on targeted digital marketing period, not just in politics?
We don’t know the answers to these questions, but we do believe that it’s possible to have an informed conversation about them. So in the service of that conversation, here are two things to consider.
First, we can think of no clearer example than Russia’s abuse of Facebook for why society cannot rely on machine intelligence without human supervision and still expect to see a brighter future. Suggestion engines are not going away, and there is no choice but to create a cultural and legal framework of oversight in which they can be used responsibly. We’re optimistic that, given the chance, people can be smart enough to prevent the worst technological abuses without simply smashing all the machines.
Second, we can think of no better reason than this conversation why every citizen of the twenty-first century must understand some basic facts about artificial intelligence and data science. If education, as Thomas Jefferson said, is the cornerstone of democracy, then when it comes to digital technology, our democratic walls are falling down. Americans have debated the limits of commercial free speech almost since our birth as a country. But today we are way beyond a conversation about ads for sugary cereals on Saturday morning cartoons—far from the only example of a dubious marketing practice made utterly quaint by our new technology. There are so many unknowns that await us down the road. At a minimum, courts and legislatures should know more about their own blind spots, and stop dismissing details they don’t understand as “gobbledygook.” And citizens should participate in these discussions from a position of knowledge, rather than fear, of the basic technical details. Put simply, smart people who care about the world simply must know more about AI. That’s one reason we wrote this book.
The Bright Side for Science
Now for some good news about suggestion engines. The mathematical and algorithmic insights produced by the last decade of work on personalization are just starting to bleed over into other areas of science and technology. As that happens, a lot of good things are in store for us.
Take the case of patient-centered social networks—like Crohnology, for people with gastrointesintal disorders; Tiatros, for soldiers with post-traumatic stress disorder; or PatientsLikeMe, for pretty much anything. These networks run on personalization algorithms, too, just like Facebook. Patients see them as an important resource for suggestions about treatments and lifestyle changes, while researchers see them as a valuable repository of real-world medical data that can be used to make those suggestions even better.
Or consider the expanding statistical toolkit of neuroscientists, who can now routinely monitor the activity of hundreds of neurons at once as they try to understand how the brain processes information. Hardware advances will soon enable them to monitor thousands of neurons or more. As their data sets grow larger and larger, neuroscientists are increasingly turning to Netflix-style latent-feature models to find clusters of neurons that tend to fire together in response to some stimulus—the neurophysiological equivalent of liking the same TV show. This work could lead to new discoveries and pioneering treatments for some of our most common maladies, from autism to Alzheimer’s.
Perhaps the most exciting work of all is happening in cancer research, specifically something called “targeted therapy.” While cancer may be labeled according to body part, fundamentally it is a disease of your genome. Tumor genomes, moreover, vary widely. Even patients with the same kind of cancer may have tumors with different genetic subtypes, and researchers have discovered that these subtypes often respond to drugs in very different ways. It is now common for doctors to test a sample of a patient’s tumor for specific genes and proteins and to choose a cancer drug accordingly.
Over the years, cancer researchers have built large databases of genetic information on different tumor types, and they have joined forces with data scientists to mine those databases in search of patterns that can be exploited by targeted therapies. For example, about 60% of colorectal tumors have the wild-type (nonmutated) version of the KRAS gene. One particular cancer drug, cetuximab, is effective against these tumors but ineffective against the 40% that have a KRAS mutation.
That’s a simple pattern, involving just one gene. Other patterns, on the other hand, are very complex. They involve dozens or hundreds of genes related to one of the many intricate molecular signaling pathways that go awry in cancer cells. To handle that complexity, researchers are increasingly turning to big-data latent-feature models, of the kind pioneered in Silicon Valley over the last decade to power large-scale recommender systems. These models are being used to analyze genomic data for an explanation of why some cancer patients respond to a drug and others don’t. Just as Netflix uses the features in subscribers’ viewing profiles to target them with TV shows, cancer researchers hope to use the features in patients’ “genomic profiles” to target them with therapies—and maybe even design new ones for them, House of Cards style.
This idea is catching on. For example, in 2015, scientists at the National Cancer Institute announced that they had discovered two distinct subtypes of diffuse large B-cell lymphoma, based on latent genomic features. The scientists conjectured that the two subtypes, ABC and GCB, might respond differently to a particular drug, ibrutinib. So they enrolled 80 lymphoma patients in a clinical trial, took samples of their tumors to determine whether they were of subtype ABC or GCB, gave them all ibrutinib, and followed their progress over the ensuing months and years. The results were striking: ibrutinib was seven times more likely to work in patients with the ABC subtype.10
Given the long time horizon and billions of dollars required to develop and test a new cancer drug, this genomic-profiling strategy is far from mature. But as the ibrutinib trial shows, conditional probability is beginning to pay dividends in cancer research, and labs around the world are hard at work on the latest generation of targeted therapies.
Postscript
We hope this chapter has helped you to understand a bit more about the core idea behind companies like Netflix, Spotify, and Facebook: that, to a machine, “personalization” means “conditional probability.” We also hope you’ve come to appreciate that these modern AI systems represent just one step along a winding historical path of human ingenuity—a path that will surely lead to new wonders, but one fraught with new challenges, too.
To close this chapter, we’ll leave you with one last suggestion-engine story of our own. Over the summer of 2014, one of your authors (Scott) visited Ypres, a town in western Belgium whose strategic position loomed large in the early days of World War I. The German and Allied armies met outside Ypres in October of 1914. Both sides dug trenches, and a brutal years-long stalemate ensued:
Men marched asleep. Many had lost their boots
But limped on, blood-shod. All went lame; all blind;
Drunk with fatigue; deaf even to the hoots
Of gas-shells dropping softly behind.
—Wilfred Owen
By the end of the Third Battle of Ypres in 1917, nearly half a million soldiers were dead, and the town was a ruinous heap.
A century later, visiting the rebuilt Ypres is a solemn occasion, and on his visit in 2014, Scott found that sense of solemnity reinforced by a network of outdoor speakers piping classical music throughout the town center. It was a nice touch, and all the choices were conventionally tasteful … that is, until an unexpectedly modern bass line intruded. It wasn’t easy to identify the song at first, but the lyrics soon left no doubt. Whoever was behind the music in Ypres had chosen to play the 2006 hit “SexyBack,” by Justin Timberlake, throughout the town.
Maybe it had been intentional. Ypres had indeed brought the sexy back to its medieval streets, rebuilding brick by gorgeous brick after the Great War. Nonetheless, in light of all the classical songs, it seemed an odd choice. So when he visited the tourist office for a map of the surrounding battlefield memorials, Scott innocently asked the nice Flemish lady behind the desk whether she had any favorite music for the town speakers.
“Oh, no,” she said. “Actually, we just use Spotify.”
Even the best recommender systems make a bad suggestion once in a while.