CHAPTER 9
Network Operations
This chapter covers the following official Network+ objectives:
 Given a scenario, use appropriate documentation and diagrams to manage the network.
Given a scenario, use appropriate documentation and diagrams to manage the network.
Compare and contrast business continuity and disaster recovery concepts.
Explain common scanning, monitoring, and patching processes and summarize their expected
outputs.
Given a scenario, use remote access methods.
Identify policies and best practices.
This chapter covers CompTIA Network+ objectives 3.1, 3.2, 3.3, 3.4, and 3.5. For more information on the official Network+ exam topics, see the “About the Network+ Exam” section in the Introduction.
This chapter focuses on two important parts of the role of a network administrator: documentation and the tools to use to monitor or optimize connectivity. Documentation, although not glamorous, is an essential part of the job. This chapter looks at several aspects of network documentation.
![]() Given a scenario, use appropriate documentation and diagrams to manage the network.
Given a scenario, use appropriate documentation and diagrams to manage the network.
![]() Identify policies and best practices.
Identify policies and best practices.
CramSaver
If you can correctly answer these questions before going through this section, save time by skimming the Exam Alerts in this section and then completing the Cram Quiz at the end of the section.
1. Which network topology focuses on the direction in which data flows within the physical environment?
2. In computing, what are historical readings used as a measurement for future calculations referred to as?
3. True or false: Both logical and physical network diagrams provide an overview of the network layout and function.
Answers
1. The logical network refers to the direction in which data flows on the network within the physical topology. The logical diagram is not intended to focus on the network hardware but rather on how data flows through that hardware.
2. Keeping and reviewing baselines is an essential part of the administrator’s role.
3. True. Both logical and physical network diagrams provide an overview of the network layout and function.
ExamAlert
Remember that this objective begins with “Given a scenario.” That means that you may receive a drag and drop, matching, or “live OS” scenario where you have to click through to complete a specific objective-based task.
Administrators have several daily tasks, and new ones often crop up. In this environment, tasks such as documentation sometimes fall to the background. It’s important that you understand why administrators need to spend valuable time writing and reviewing documentation. Having a well-documented network offers a number of advantages:
![]() Troubleshooting: When something goes wrong on the network, including the wiring, up-to-date documentation
is a valuable reference to guide the troubleshooting effort. The documentation saves
you money and time in isolating potential problems.
Troubleshooting: When something goes wrong on the network, including the wiring, up-to-date documentation
is a valuable reference to guide the troubleshooting effort. The documentation saves
you money and time in isolating potential problems.
![]() Training new administrators: In many network environments, new administrators are hired, and old ones leave. In
this scenario, documentation is critical. New administrators do not have the time
to try to figure out where cabling is run, what cabling is used, potential trouble
spots, and more. Up-to-date information helps new administrators quickly see the network
layout.
Training new administrators: In many network environments, new administrators are hired, and old ones leave. In
this scenario, documentation is critical. New administrators do not have the time
to try to figure out where cabling is run, what cabling is used, potential trouble
spots, and more. Up-to-date information helps new administrators quickly see the network
layout.
![]() Working with contractors and consultants: Consultants and contractors occasionally may need to visit the network to make recommendations
for the network or to add wiring or other components. In such cases, up-to-date documentation
is needed. If documentation is missing, it would be much more difficult for these
people to do their jobs, and more time and money would likely be required.
Working with contractors and consultants: Consultants and contractors occasionally may need to visit the network to make recommendations
for the network or to add wiring or other components. In such cases, up-to-date documentation
is needed. If documentation is missing, it would be much more difficult for these
people to do their jobs, and more time and money would likely be required.
![]() Inventory management: Knowing what you have, where you have it, and what you can turn to in the case of
an emergency is both constructive and helpful.
Inventory management: Knowing what you have, where you have it, and what you can turn to in the case of
an emergency is both constructive and helpful.
Quality network documentation does not happen by accident; rather, it requires careful planning. When creating network documentation, you must keep in mind who you are creating the documentation for and that it is a communication tool. Documentation is used to take technical information and present it in a manner that someone new to the network can understand. When planning network documentation, you must decide what you need to document.
Note
Imagine that you have just taken over a network as administrator. What information would you like to see? This is often a clear gauge of what to include in your network documentation.
All networks differ and so does the documentation required for each network. However, certain elements are always included in quality documentation:
![]() Network topology: Networks can be complicated. If someone new is looking over the network, it is critical
to document the entire topology. This includes both the wired and wireless topologies
used on the network. Network topology documentation typically consists of a diagram
or series of diagrams labeling all critical components used to create the network.
These diagrams utilize common symbols for components such as firewalls, hubs, routers,
and switches. Figure 9.1, for example, shows standard figures for, from left to right, a firewall, a hub,
a router, and a switch.
Network topology: Networks can be complicated. If someone new is looking over the network, it is critical
to document the entire topology. This includes both the wired and wireless topologies
used on the network. Network topology documentation typically consists of a diagram
or series of diagrams labeling all critical components used to create the network.
These diagrams utilize common symbols for components such as firewalls, hubs, routers,
and switches. Figure 9.1, for example, shows standard figures for, from left to right, a firewall, a hub,
a router, and a switch.

FIGURE 9.1 Diagram symbols for a firewall, a hub, a router, and a switch
![]() Wiring layout and rack diagrams: Network wiring can be confusing. Much of it is hidden in walls and ceilings, making
it hard to know where the wiring is and what kind is used on the network. This makes
it critical to keep documentation on network wiring up to date. Diagram what is on
each rack and any unusual configurations that might be employed.
Wiring layout and rack diagrams: Network wiring can be confusing. Much of it is hidden in walls and ceilings, making
it hard to know where the wiring is and what kind is used on the network. This makes
it critical to keep documentation on network wiring up to date. Diagram what is on
each rack and any unusual configurations that might be employed.
![]() IDF/MDF documentation: It is not enough to show that there is an intermediate distribution frame (IDF) and/or
main distribution frame (MDF) in your building. You need to thoroughly document any
and every free-standing or wall-mounted rack and the cables running between them and
the end user devices.
IDF/MDF documentation: It is not enough to show that there is an intermediate distribution frame (IDF) and/or
main distribution frame (MDF) in your building. You need to thoroughly document any
and every free-standing or wall-mounted rack and the cables running between them and
the end user devices.
![]() Server configuration: A single network typically uses multiple servers spread over a large geographic area.
Documentation must include schematic drawings of where servers are located on the
network and the services each provides. This includes server function, server IP address,
operating system (OS), software information, and more. Essentially, you need to document
all the information you need to manage or administer the servers.
Server configuration: A single network typically uses multiple servers spread over a large geographic area.
Documentation must include schematic drawings of where servers are located on the
network and the services each provides. This includes server function, server IP address,
operating system (OS), software information, and more. Essentially, you need to document
all the information you need to manage or administer the servers.
![]() Network equipment: The hardware used on a network is configured in a particular way—with protocols,
security settings, permissions, and more. Trying to remember these would be a difficult
task. Having up-to-date documentation makes it easier to recover from a failure.
Network equipment: The hardware used on a network is configured in a particular way—with protocols,
security settings, permissions, and more. Trying to remember these would be a difficult
task. Having up-to-date documentation makes it easier to recover from a failure.
![]() Network configuration, performance baselines, and key applications: Documentation also includes information on all current network configurations, performance
baselines taken, and key applications used on the network, such as up-to-date information
on their updates, vendors, install dates, and more.
Network configuration, performance baselines, and key applications: Documentation also includes information on all current network configurations, performance
baselines taken, and key applications used on the network, such as up-to-date information
on their updates, vendors, install dates, and more.
![]() Detailed account of network services: Network services are a key ingredient in all networks. Services such as Domain Name
Service (DNS), Dynamic Host Configuration Protocol (DHCP), Remote Access Services
(RAS), and more are an important part of documentation. You should describe in detail
which server maintains these services, the backup servers for these services, maintenance
schedules, how they are structured, and so on.
Detailed account of network services: Network services are a key ingredient in all networks. Services such as Domain Name
Service (DNS), Dynamic Host Configuration Protocol (DHCP), Remote Access Services
(RAS), and more are an important part of documentation. You should describe in detail
which server maintains these services, the backup servers for these services, maintenance
schedules, how they are structured, and so on.
![]() Standard operating procedures/work instructions: Finally, documentation should include information on network policy and procedures.
This includes many elements, ranging from who can and cannot access the server room,
to network firewalls, protocols, passwords, physical security, cloud computing use,
mobile device use, and so on.
Standard operating procedures/work instructions: Finally, documentation should include information on network policy and procedures.
This includes many elements, ranging from who can and cannot access the server room,
to network firewalls, protocols, passwords, physical security, cloud computing use,
mobile device use, and so on.
ExamAlert
Be sure that you know the types of information that should be included in network documentation.
Wiring and Port Locations
Network wiring schematics are an essential part of network documentation, particularly for midsize to large networks, where the cabling is certainly complex. For such networks, it becomes increasingly difficult to visualize network cabling and even harder to explain it to someone else. A number of software tools exist to help administrators clearly document network wiring in detail.
Several types of wiring schematics exist. They can be general, as shown in Figure 9.2, or they can be very specific, indicating the actual type of wiring used, the operating system on each machine, and so on. The more generalized they are, the less they need updating, whereas very specific schematics often need to be changed regularly. Table 9.1 represents another way of documenting data.
ExamAlert
For the exam, be familiar with the look of a general wiring schematic such as the one shown in Figure 9.2.

FIGURE 9.2 A general wiring schematic
Figure 9.2 provides a simplified look at network wiring schematics. Imagine how complicated these diagrams would look on a network with 1,000, 2,000, or even 6,000 computers. Quality network documentation software makes this easier; however, the task of network wiring can be a large one for administrators. Administrators need to ensure that someone can pick up the wiring documentation diagrams and have a good idea of the network wiring.
Caution
Reading schematics and determining where wiring runs are an important part of the administrator’s role. Expect to see a schematic on your exam.
Port locations should be carefully recorded and included in the documentation as well. SNMP can be used directly to map ports on switches and other devices; it is much easier, however, to use software applications that incorporate SNMP and use it to create ready-to-use documentation. A plethora of such programs are available; some are free and many are commercial products.
Troubleshooting Using Wiring Schematics
Some network administrators do not take the time to maintain quality documentation. This will haunt them when it comes time to troubleshoot some random network problems. Without any network wiring schematics, the task will be frustrating and time-consuming. The information shown in Figure 9.2 might be simplified, but you could use that documentation to evaluate the network and make recommendations.
Caution
When looking at a wiring schematic, pay close attention to where the cable is run and the type of cable used if the schematic indicates this. If a correct cable is not used, a problem could occur.
Note
Network wiring schematics are a work in progress. Although changes to wiring do not happen daily, they do occur when the network expands or old cabling is replaced. It is imperative to remember that when changes are made to the network, the schematics and their corresponding references must be updated to reflect the changes. Out-of-date schematics can be frustrating to work with.
Physical and Logical Network Diagrams
In addition to the wiring schematics, documentation should include diagrams of the physical and logical network design. Recall from Chapter 1, “Introduction to Networking Technologies,” that network topologies can be defined on a physical or a logical level. The physical topology refers to how a network is physically constructed—how it looks. The logical topology refers to how a network looks to the devices that use it—how it functions.
Network infrastructure documentation isn’t reviewed daily; however, this documentation is essential for someone unfamiliar with the network to manage or troubleshoot the network. When it comes to documenting the network, you need to document all aspects of the infrastructure. This includes the physical hardware, physical structure, protocols, and software used.
ExamAlert
You should be able to identify a physical and logical diagram. You need to know the types of information that should be included in each diagram.
The physical documentation of the network should include the following elements:
![]() Cabling information: A visual description of all the physical communication links, including all cabling,
cable grades, cable lengths, WAN cabling, and more.
Cabling information: A visual description of all the physical communication links, including all cabling,
cable grades, cable lengths, WAN cabling, and more.
![]() Servers: The server names and IP addresses, types of servers, and domain membership.
Servers: The server names and IP addresses, types of servers, and domain membership.
![]() Network devices: The location of the devices on the network. This includes the printers, hubs, switches,
routers, gateways, and more.
Network devices: The location of the devices on the network. This includes the printers, hubs, switches,
routers, gateways, and more.
![]() Wide-area network: The location and devices of the WAN and components.
Wide-area network: The location and devices of the WAN and components.
![]() User information: Some user information, including the number of local and remote users.
User information: Some user information, including the number of local and remote users.
As you can see, many elements can be included in the physical network diagram. Figure 9.3 shows a physical segment of a network.

FIGURE 9.3 A physical network diagram
Caution
You should recognize the importance of maintaining documentation that includes network diagrams, asset management, IP address utilization, vendor documentation, and internal operating procedures, policies, and standards.
Networks are dynamic, and changes can happen regularly, which is why the physical network diagrams also must be updated. Networks have different policies and procedures on how often updates should occur. Best practice is that the diagram should be updated whenever significant changes to the network occur, such as the addition of a switch or router, a change in protocols, or the addition of a new server. These changes impact how the network operates, and the documentation should reflect the changes.
Caution
There are no hard-and-fast rules about when to change or update network documentation. However, most administrators will want to update whenever functional changes to the network occur.
The logical network refers to the direction in which data flows on the network within the physical topology. The logical diagram is not intended to focus on the network hardware but rather on how data flows through that hardware. In practice, the physical and logical topologies can be the same. In the case of the bus physical topology, data travels along the length of the cable from one computer to the next. So, the diagram for the physical and logical bus would be the same.
This is not always the case. For example, a topology can be in the physical shape of a star, but data is passed in a logical ring. The function of data travel is performed inside a switch in a ring formation. So the physical diagram appears to be a star, but the logical diagram shows data flowing in a ring formation from one computer to the next. Simply put, it is difficult to tell from looking at a physical diagram how data is flowing on the network.
In today’s network environments, the star topology is a common network implementation. Ethernet uses a physical star topology but a logical bus topology. In the center of the physical Ethernet star topology is a switch. It is what happens inside the switch that defines the logical bus topology. The switch passes data between ports as if they were on an Ethernet bus segment.
In addition to data flow, logical diagrams may include additional elements, such as the network domain architecture, server roles, protocols used, and more. Figure 9.4 shows how a logical topology may look in the form of network documentation.

FIGURE 9.4 A logical topology diagram
Caution
The logical topology of a network identifies the logical paths that data signals travel over the network.
Baselines
Baselines play an integral part in network documentation because they let you monitor the network’s overall performance. In simple terms, a baseline is a measure of performance that indicates how hard the network is working and where network resources are spent. The purpose of a baseline is to provide a basis of comparison. For example, you can compare the network’s performance results taken in March to results taken in June, or from one year to the next. More commonly, you would compare the baseline information at a time when the network is having a problem to information recorded when the network was operating with greater efficiency. Such comparisons help you determine whether there has been a problem with the network, how significant that problem is, and even where the problem lies.
To be of any use, baselining is not a one-time task; rather, baselines should be taken periodically to provide an accurate comparison. You should take an initial baseline after the network is set up and operational, and then again when major changes are made to the network. Even if no changes are made to the network, periodic baselining can prove useful as a means to determine whether the network is still operating correctly.
All network operating systems (NOSs), including Windows, Mac OS, UNIX, and Linux, have built-in support for network monitoring. In addition, many third-party software packages are available for detailed network monitoring. These system-monitoring tools provided in a NOS give you the means to take performance baselines, either of the entire network or for an individual segment within the network. Because of the different functions of these two baselines, they are called a system baseline and a component baseline.
To create a network baseline, network monitors provide a graphical display of network statistics. Network administrators can choose a variety of network measurements to track. They can use these statistics to perform routine troubleshooting tasks, such as locating a malfunctioning network card, a downed server, or a denial-of-service (DoS) attack.
Note
Graphing, and the process of seeing data visually, can be much more helpful in identifying trends than looking at raw data and log files.
Collecting network statistics is a process called capturing. Administrators can capture statistics on all elements of the network. For baseline purposes, one of the most common statistics to monitor is bandwidth usage. By reviewing bandwidth statistics, administrators can see where the bulk of network bandwidth is used. Then they can adapt the network for bandwidth use. If too much bandwidth is used by a particular application, administrators can actively control its bandwidth usage. Without comparing baselines, however, it is difficult to see what is normal network bandwidth usage and what is unusual.
Caution
Remember that baselines need to be taken periodically and under the same conditions to be effective. They are used to compare current performance with past performance to help determine whether the network is functioning properly or if troubleshooting is required.
Policies, Procedures, Configurations, and Regulations
Well-functioning networks are characterized by documented policies, procedures, configurations, and regulations. Because they are unique to every network, policies, procedures, configurations, and regulations should be clearly documented.
Policies
By definition, policies refer to an organization’s documented rules about what is to be done, or not done, and why. Policies dictate who can and cannot access particular network resources, server rooms, backup media, and more.
Although networks might have different policies depending on their needs, some common policies include the following:
![]() Network usage policy: Defines who can use network resources such as PCs, printers, scanners, and remote
connections. In addition, the usage policy dictates what can be done with these resources
after they are accessed. No outside systems will be networked without permission from
the network administrator.
Network usage policy: Defines who can use network resources such as PCs, printers, scanners, and remote
connections. In addition, the usage policy dictates what can be done with these resources
after they are accessed. No outside systems will be networked without permission from
the network administrator.
![]() Internet usage policy: This policy specifies the rules for Internet use on the job. Typically, usage should
be focused on business-related tasks. Incidental personal use is allowed during specified
times.
Internet usage policy: This policy specifies the rules for Internet use on the job. Typically, usage should
be focused on business-related tasks. Incidental personal use is allowed during specified
times.
![]() Bring your own device (BYOD) policy: This policy specifies the rules for employees’ personally owned mobile devices (smartphones,
laptops, tablets, and so on) that they bring into the workplace and use to interact
with privileged company information and applications. Two things the policy needs
to address are onboarding and offboarding. Onboarding the mobile device is the procedures gone through to get it ready to go on the network
(scanning for viruses, adding certain apps, and so forth). Offboarding is the process of removing company-owned resources when it is no longer needed (often
done with a wipe or factory reset). Mobile device management (MDM) and mobile application management (MAM) tools (usually third party) are used to administer and leverage both employee-owned
and company-owned mobile devices and applications.
Bring your own device (BYOD) policy: This policy specifies the rules for employees’ personally owned mobile devices (smartphones,
laptops, tablets, and so on) that they bring into the workplace and use to interact
with privileged company information and applications. Two things the policy needs
to address are onboarding and offboarding. Onboarding the mobile device is the procedures gone through to get it ready to go on the network
(scanning for viruses, adding certain apps, and so forth). Offboarding is the process of removing company-owned resources when it is no longer needed (often
done with a wipe or factory reset). Mobile device management (MDM) and mobile application management (MAM) tools (usually third party) are used to administer and leverage both employee-owned
and company-owned mobile devices and applications.
ExamAlert
For the exam, be familiar with onboarding and offboarding.
![]() Email usage policy: Email must follow the same code of conduct as expected in any other form of written
or face-to-face communication. All emails are company property and can be accessed
by the company. Personal emails should be immediately deleted.
Email usage policy: Email must follow the same code of conduct as expected in any other form of written
or face-to-face communication. All emails are company property and can be accessed
by the company. Personal emails should be immediately deleted.
![]() Personal software policy: No outside software should be installed on network computer systems. All software
installations must be approved by the network administrator. No software can be copied
or removed from a site. Licensing restrictions must be adhered to.
Personal software policy: No outside software should be installed on network computer systems. All software
installations must be approved by the network administrator. No software can be copied
or removed from a site. Licensing restrictions must be adhered to.
![]() Password policy: Detail how often passwords must be changed and the minimum level of security for
each (number of characters, use of alphanumeric character set, and so on).
Password policy: Detail how often passwords must be changed and the minimum level of security for
each (number of characters, use of alphanumeric character set, and so on).
![]() User account policy: All users are responsible for keeping their password and account information secret.
All staff are required to log off and sometimes lock their systems after they finish
using them. Attempting to log on to the network with another user account is considered
a serious violation.
User account policy: All users are responsible for keeping their password and account information secret.
All staff are required to log off and sometimes lock their systems after they finish
using them. Attempting to log on to the network with another user account is considered
a serious violation.
![]() International export controls: A number of laws and regulations govern what can and cannot be exported when it comes
to software and hardware to various countries. Employees should take every precaution
to make sure they are adhering to the letter of the law.
International export controls: A number of laws and regulations govern what can and cannot be exported when it comes
to software and hardware to various countries. Employees should take every precaution
to make sure they are adhering to the letter of the law.
![]() Data loss prevention: Losses from employees can quickly put a company in the red. It should be understood
that it is every employee’s responsibility to make sure all preventable losses are
prevented.
Data loss prevention: Losses from employees can quickly put a company in the red. It should be understood
that it is every employee’s responsibility to make sure all preventable losses are
prevented.
![]() Incident response policies: When an incident occurs, all employees should understand it is their responsibility
to be on the lookout for it and report it immediately to the appropriate party.
Incident response policies: When an incident occurs, all employees should understand it is their responsibility
to be on the lookout for it and report it immediately to the appropriate party.
![]() Non Disclosure Agreements (NDAs): NDAs are the oxygen that many companies need to thrive. Employees should understand
the importance of them to continued business operations and agree to follow them to
the letter, and spirit, of the law.
Non Disclosure Agreements (NDAs): NDAs are the oxygen that many companies need to thrive. Employees should understand
the importance of them to continued business operations and agree to follow them to
the letter, and spirit, of the law.
![]() Safety procedures and policies: Safety is everyone’s business, and all employees should know how to do their job
in the safest manner while also looking out for other employees and customers alike.
Safety procedures and policies: Safety is everyone’s business, and all employees should know how to do their job
in the safest manner while also looking out for other employees and customers alike.
![]() Ownership policy: The company owns all data, including users’ email, voice mail, and Internet usage
logs, and the company reserves the right to inspect these at any time. Some companies
even go so far as controlling how much personal data can be stored on a workstation.
Ownership policy: The company owns all data, including users’ email, voice mail, and Internet usage
logs, and the company reserves the right to inspect these at any time. Some companies
even go so far as controlling how much personal data can be stored on a workstation.
This list is just a snapshot of the policies that guide the behavior for administrators and network users. Network policies should be clearly documented and available to network users. Often, these policies are reviewed with new staff members or new administrators. As they are updated, they are rereleased to network users. Policies are regularly reviewed and updated.
Note
You might be asked about network policies. Network policies dictate network rules and provide guidelines for network conduct. Policies are often updated and reviewed and are changed to reflect changes to the network and perhaps changes in business requirements.
Password-Related Policies
Although biometrics and smart cards are becoming more common, they still have a long way to go before they attain the level of popularity that username and password combinations enjoy. Usernames and passwords do not require any additional equipment, which practically every other method of authentication does; the username and password process is familiar to users, easy to implement, and relatively secure. For that reason, they are worthy of more detailed coverage than the other authentication systems previously discussed.
Note
Biometrics are not as ubiquitous as username/password combinations, but they are coming up quickly. Some smartphones, for example, offer the ability to use a fingerprint scanner and/or gestures to access the system instead of username and password. Features such as these are expected to become more common with future releases.
Passwords are a relatively simple form of authentication in that only a string of characters can be used to authenticate the user. However, how the string of characters is used and which policies you can put in place to govern them make usernames and passwords an excellent form of authentication.
Password Policies
All popular network operating systems include password policy systems that enable the network administrator to control how passwords are used on the system. The exact capabilities vary between network operating systems. However, generally they enable the following:
![]() Minimum length of password: Shorter passwords are easier to guess than longer ones. Setting a minimum password
length does not prevent a user from creating a longer password than the minimum; however,
each network operating system has a limit on how long a password can be.
Minimum length of password: Shorter passwords are easier to guess than longer ones. Setting a minimum password
length does not prevent a user from creating a longer password than the minimum; however,
each network operating system has a limit on how long a password can be.
![]() Password expiration: Also known as the maximum password age, password expiration defines how long the
user can use the same password before having to change it. A general practice is that
a password be changed every 30 days. In high-security environments, you might want
to make this value shorter, but you should generally not make it any longer. Having
passwords expire periodically is a crucial feature because it means that if a password
is compromised, the unauthorized user will not indefinitely have access.
Password expiration: Also known as the maximum password age, password expiration defines how long the
user can use the same password before having to change it. A general practice is that
a password be changed every 30 days. In high-security environments, you might want
to make this value shorter, but you should generally not make it any longer. Having
passwords expire periodically is a crucial feature because it means that if a password
is compromised, the unauthorized user will not indefinitely have access.
![]() Prevention of password reuse: Although a system might cause a password to expire and prompt the user to change
it, many users are tempted to use the same password again. A process by which the
system remembers the last 10 passwords, for example, is most secure because it forces
the user to create completely new passwords. This feature is sometimes called enforcing
password history.
Prevention of password reuse: Although a system might cause a password to expire and prompt the user to change
it, many users are tempted to use the same password again. A process by which the
system remembers the last 10 passwords, for example, is most secure because it forces
the user to create completely new passwords. This feature is sometimes called enforcing
password history.
![]() Prevention of easy-to-guess passwords: Some systems can evaluate the password provided by a user to determine whether it
meets a required level of complexity. This prevents users from having passwords such
as password, 12345678, their name, or their nickname.
Prevention of easy-to-guess passwords: Some systems can evaluate the password provided by a user to determine whether it
meets a required level of complexity. This prevents users from having passwords such
as password, 12345678, their name, or their nickname.
ExamAlert
You must identify an effective password policy. For example, a robust password policy would include forcing users to change their passwords on a regular basis.
Password Strength
No matter how good a company’s password policy, it is only as effective as the passwords created within it. A password that is hard to guess, or strong, is more likely to protect the data on a system than one that is easy to guess, or weak.
If you are using only numbers and letters—and the OS is not case sensitive—36 possible combinations exist for each entry, and the total number of possibilities is 366. That might seem like a lot, but to a password-cracking program, it’s not much security. A password that uses eight case-sensitive characters, with letters, numbers, and special characters, has so many possible combinations that a standard calculator cannot display the actual number.
There has always been a debate over how long a password should be. It should be sufficiently long that it is hard to break but sufficiently short that the user can easily remember it (and type it). In a normal working environment, passwords of eight characters are sufficient. Certainly, they should be no fewer than six characters. In environments in which security is a concern, passwords should be 10 characters or more.
Users should be encouraged to use a password that is considered strong. A strong password has at least eight characters; has a combination of letters, numbers, and special characters; uses mixed case; and does not form a proper word. Examples are 3Ecc5T0h and e1oXPn3r. Such passwords might be secure, but users are likely to have problems remembering them. For that reason, a popular strategy is to use a combination of letters and numbers to form phrases or long words. Examples include d1eTc0La and tAb1eT0p. These passwords might not be quite as secure as the preceding examples, but they are still strong and a whole lot better than the name of the user’s pet.
Procedures
Network procedures differ from policies in that they describe how tasks are to be performed. For example, each network administrator has backup procedures specifying the time of day backups are done, how often they are done, and where they are stored. A network is full of a number of procedures for practical reasons and, perhaps more important, for security reasons.
Administrators must be aware of several procedures when on the job. The number and exact type of procedures depends on the network. The network’s overall goal is to ensure uniformity and ensure that network tasks follow a framework. Without this procedural framework, different administrators might approach tasks differently, which could lead to confusion on the network.
Network procedures might include the following:
![]() Backup procedures: Backup procedures specify when they are to be performed, how often a backup occurs,
who does the backup, what data is to be backed up, and where and how it will be stored.
Network administrators should carefully follow backup procedures.
Backup procedures: Backup procedures specify when they are to be performed, how often a backup occurs,
who does the backup, what data is to be backed up, and where and how it will be stored.
Network administrators should carefully follow backup procedures.
![]() Procedures for adding new users: When new users are added to a network, administrators typically have to follow certain
guidelines to ensure that the users have access to what they need, but no more. This
is called the principle of least privilege.
Procedures for adding new users: When new users are added to a network, administrators typically have to follow certain
guidelines to ensure that the users have access to what they need, but no more. This
is called the principle of least privilege.
![]() Privileged user agreement: Administrators and authorized users who have the ability to modify secure configurations
and perform tasks such as account setup, account termination, account resetting, auditing,
and so on need to be held to high standards.
Privileged user agreement: Administrators and authorized users who have the ability to modify secure configurations
and perform tasks such as account setup, account termination, account resetting, auditing,
and so on need to be held to high standards.
![]() Security procedures: Some of the more critical procedures involve security. Security procedures are numerous
but may include specifying what the administrator must do if security breaches occur,
security monitoring, security reporting, and updating the OS and applications for
potential security holes.
Security procedures: Some of the more critical procedures involve security. Security procedures are numerous
but may include specifying what the administrator must do if security breaches occur,
security monitoring, security reporting, and updating the OS and applications for
potential security holes.
![]() Network monitoring procedures: The network needs to be constantly monitored. This includes tracking such things
as bandwidth usage, remote access, user logons, and more.
Network monitoring procedures: The network needs to be constantly monitored. This includes tracking such things
as bandwidth usage, remote access, user logons, and more.
![]() Software procedures/system life cycle: All software must be periodically monitored and updated. Documented procedures dictate
when, how often, why, and for whom these updates are done. When assets are disposed
of, asset disposal procedures should be followed to properly document and log their
removal.
Software procedures/system life cycle: All software must be periodically monitored and updated. Documented procedures dictate
when, how often, why, and for whom these updates are done. When assets are disposed
of, asset disposal procedures should be followed to properly document and log their
removal.
![]() Procedures for reporting violations: Users do not always follow outlined network policies. This is why documented procedures
should exist to properly handle the violations. This might include a verbal warning
upon the first offense, followed by written reports and account lockouts thereafter.
Procedures for reporting violations: Users do not always follow outlined network policies. This is why documented procedures
should exist to properly handle the violations. This might include a verbal warning
upon the first offense, followed by written reports and account lockouts thereafter.
![]() Remote-access and network admission procedures: Many workers remotely access the network. This remote access is granted and maintained
using a series of defined procedures. These procedures might dictate when remote users
can access the network, how long they can access it, and what they can access. Network admission control (NAC)—also referred to as network access control—determines who can get on the network and is usually based on 802.1X guidelines.
Remote-access and network admission procedures: Many workers remotely access the network. This remote access is granted and maintained
using a series of defined procedures. These procedures might dictate when remote users
can access the network, how long they can access it, and what they can access. Network admission control (NAC)—also referred to as network access control—determines who can get on the network and is usually based on 802.1X guidelines.
Change Management Documentation
Change management procedures might include the following:
![]() Document reason for a change: Before making any change at all, the first question to ask is why. A change requested by one user may be based on a misunderstanding of what technology
can do, may be cost prohibitive, or may deliver a benefit not worth the undertaking.
Document reason for a change: Before making any change at all, the first question to ask is why. A change requested by one user may be based on a misunderstanding of what technology
can do, may be cost prohibitive, or may deliver a benefit not worth the undertaking.
![]() Change request: An official request should be logged and tracked to verify what is to be done and
what has been done. Within the realm of the change request should be the configuration
procedures to be used, the rollback process that is in place, potential impact identified,
and a list of those who need to be notified.
Change request: An official request should be logged and tracked to verify what is to be done and
what has been done. Within the realm of the change request should be the configuration
procedures to be used, the rollback process that is in place, potential impact identified,
and a list of those who need to be notified.
![]() Approval process: Changes should not be approved on the basis of who makes the most noise, but rather
who has the most justified reasons. An official process should be in place to evaluate
and approve changes prior to actions being undertaken. The approval can be done by
a single administrator or a formal committee based on the size of your organization
and the scope of the change being approved.
Approval process: Changes should not be approved on the basis of who makes the most noise, but rather
who has the most justified reasons. An official process should be in place to evaluate
and approve changes prior to actions being undertaken. The approval can be done by
a single administrator or a formal committee based on the size of your organization
and the scope of the change being approved.
![]() Maintenance window: After a change has been approved, the next question to address is when it is to take
place. Authorized downtime should be used to make changes to production environments.
Maintenance window: After a change has been approved, the next question to address is when it is to take
place. Authorized downtime should be used to make changes to production environments.
![]() Notification of change: Those affected by a change should be notified after the change has taken place. The
notification should not be just of the change but should include any and all impact
to them and identify who they can turn to with questions.
Notification of change: Those affected by a change should be notified after the change has taken place. The
notification should not be just of the change but should include any and all impact
to them and identify who they can turn to with questions.
![]() Documentation: One of the last steps is always to document what has been done. This should include
documentation on network configurations, additions to the network, and physical location
changes.
Documentation: One of the last steps is always to document what has been done. This should include
documentation on network configurations, additions to the network, and physical location
changes.
These represent just a few of the procedures that administrators must follow on the job. It is crucial that all these procedures are well documented, accessible, reviewed, and updated as needed to be effective.
Configuration Documentation
One other critical form of documentation is configuration documentation. Many administrators believe they could never forget the configuration of a router, server, or switch, but it often happens. Although it is often a thankless, time-consuming task, documenting the network hardware and software configurations is critical for continued network functionality.
Note
Organizing and completing the initial set of network documentation is a huge task, but it is just the beginning. Administrators must constantly update all documentation to keep it from becoming obsolete. Documentation is perhaps one of the less-glamorous aspects of the administrator’s role, but it is one of the most important.
Regulations
The terms regulation and policy are often used interchangeably; however, there is a difference. As mentioned, policies are written by an organization for its employees. Regulations are actual legal restrictions with legal consequences. These regulations are set not by the organizations but by applicable laws in the area. Improper use of networks and the Internet can certainly lead to legal violations and consequences. The following is an example of network regulation from an online company:
“Transmission, distribution, uploading, posting or storage of any material in violation of any applicable law or regulation is prohibited. This includes, without limitation, material protected by copyright, trademark, trade secret or other intellectual property right used without proper authorization, material kept in violation of state laws or industry regulations such as social security numbers or credit card numbers, and material that is obscene, defamatory, libelous, unlawful, harassing, abusive, threatening, harmful, vulgar, constitutes an illegal threat, violates export control laws, hate propaganda, fraudulent material or fraudulent activity, invasive of privacy or publicity rights, profane, indecent or otherwise objectionable material of any kind or nature. You may not transmit, distribute, or store material that contains a virus, ‘Trojan Horse,’ adware or spyware, corrupted data, or any software or information to promote or utilize software or any of Network Solutions services to deliver unsolicited email. You further agree not to transmit any material that encourages conduct that could constitute a criminal offense, gives rise to civil liability or otherwise violates any applicable local, state, national or international law or regulation.”
ExamAlert
For the exam and for real-life networking, remember that regulations often are enforceable by law.
Labeling
One of the biggest problems with documentation is in the time that it takes to do it. To shorten this time, it is human nature to take shortcuts and use code or shorthand when labeling devices, maps, reports, and the like. Although this can save time initially, it can render the labels useless if a person other than the one who created the labels looks at them or if a long period of time has passed since they were created and the author cannot remember what the label now means.
To prevent this dilemma, it is highly recommended that standard labeling rules be created by each organization and enforced at all levels.
You have been given a physical wiring schematic that shows the following:
|
Description |
Installation Notes |
|
Category 5E 350 MHz plenum-rated cable |
Cable runs 50 feet from the MDF to the IDF. Cable placed through the ceiling and through a mechanical room. Cable was installed 01/15/2018, upgrading a nonplenum cable. |
|
Category 5E 350 MHz nonplenum cable |
Horizontal cable runs 45 feet to 55 feet from the IDF to a wall jack. Cable 6 replaced Category 5e cable February 2018. Section of cable run through ceiling and over fluorescent lights. |
|
Category 6a UTP cable |
Patch cable connecting printer runs 15 feet due to printer placement. |
|
8.3-micron core/125-micron |
Connecting fiber cable runs 2 kilometers cladding single mode between the primary and secondary buildings. |
1. Given this information, what cable recommendation might you make, if any?
 A. Nonplenum cable should be used between the IDF and MDF.
A. Nonplenum cable should be used between the IDF and MDF.
B. The horizontal cable run should use plenum cable.
C. The patch cable connecting the printer should be shorter.
D. Leave the network cabling as is.
2. You have been called in to inspect a network configuration. You are given only one network diagram, shown in the following figure. Using the diagram, what recommendation might you make?
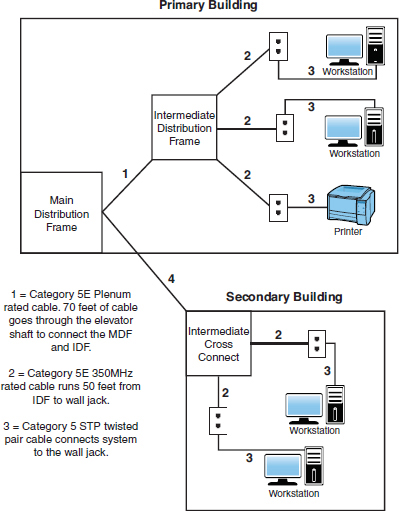
A. Cable 1 does not need to be plenum rated.
B. Cable 2 should be STP cable.
C. Cable 3 should be STP cable.
D. None. The network looks good.
3. Hollis is complaining that the network cabling in her office is outdated and should be changed. What should she do to have the cabling evaluated and possibly changed?
A. Tell her supervisor that IT needs to get on the ball.
B. Tell your supervisor that IT needs to get on the ball.
C. Purchase new cabling at the local electronics store.
D. Complete a change request.
Cram Quiz Answers
1. B. In this scenario, a section of horizontal cable runs through the ceiling and over fluorescent lights. This cable run might be a problem because such devices can cause EMI. Alternatively, plenum cable is used in this scenario. STP may have worked as well.
2. B. In this diagram, Cable 1 is plenum rated and should be fine. Cable 3 is patch cable and does not need to be STP rated. Cable 2, however, goes through walls and ceilings. Therefore, it would be recommended to have a better grade of cable than regular UTP. STP provides greater resistance to EMI.
3. D. An official change request should be logged and tracked to verify what is to be done and what has been done. Within the realm of the change request should be the configuration procedures to be used, the rollback process that is in place, potential impact identified, and a list of those that need to be notified.
Business Continuity and Disaster Recovery
![]() Compare and contrast business continuity and disaster recovery concepts.
Compare and contrast business continuity and disaster recovery concepts.
![]() Identify policies and best practices.
Identify policies and best practices.
CramSaver
If you can correctly answer these questions before going through this section, save time by skimming the Exam Alerts in this section and then completing the Cram Quiz at the end of the section.
1. What is the difference between an incremental backup and a differential backup?
2. What are hot, warm, and cold sites used for?
3. True or false: Acceptable use policies define what controls are required to implement and maintain the security of systems, users, and networks.
Answers
1. With incremental backups, all data that has changed since the last full or incremental backup is backed up. The restore procedure requires several backup iterations: the media used in the latest full backup and all media used for incremental backups since the last full backup. An incremental backup uses the archive bit and clears it after a file is saved to disk. With a differential backup, all data changed since the last full backup is backed up. The restore procedure requires the latest full backup media and the latest differential backup media. A differential backup uses the archive bit to determine which files must be backed up but does not clear it.
2. Hot, warm, and cold sites are designed to provide alternative locations for network operations if a disaster occurs.
3. False. Security policies define what controls are required to implement and maintain the security of systems, users, and networks. Acceptable use policies (AUPs) describe how the employees in an organization can use company systems and resources: both software and hardware.
Even the most fault-tolerant networks can fail, which is an unfortunate fact. When those costly and carefully implemented fault-tolerance strategies fail, you are left with disaster recovery.
Disaster recovery can take many forms. In addition to disasters such as fire, flood, and theft, many other potential business disruptions can fall under the banner of disaster recovery. For example, the failure of the electrical supply to your city block might interrupt the business functions. Such an event, although not a disaster per se, might invoke the disaster recovery methods.
The cornerstone of every disaster recovery strategy is the preservation and recoverability of data. When talking about preservation and recoverability, you must talk about backups. Implementing a regular backup schedule can save you a lot of grief when fault tolerance fails or when you need to recover a file that has been accidentally deleted. When it’s time to design a backup schedule, you can use three key types of backups: full, differential, and incremental.
Backups
Full Backups
The preferred method of backup is the full backup method, which copies all files and directories from the hard disk to the backup media. There are a few reasons why doing a full backup is not always possible. First among them is likely the time involved in performing a full backup.
ExamAlert
During a recovery operation, a full backup is the fastest way to restore data of all the methods discussed here, because only one set of media is required for a full restore.
Depending on the amount of data to be backed up, however, full backups can take an extremely long time when you are backing up and can use extensive system resources. Depending on the configuration of the backup hardware, this can considerably slow down the network. In addition, some environments have more data than can fit on a single medium. This makes doing a full backup awkward because someone might need to be there to change the media.
The main advantage of full backups is that a single set of media holds all the data you need to restore. If a failure occurs, that single set of media should be all that is needed to get all data and system information back. The upshot of all this is that any disruption to the network is greatly reduced.
Unfortunately, its strength can also be its weakness. A single set of media holding an organization’s data can be a security risk. If the media were to fall into the wrong hands, all the data could be restored on another computer. Using passwords on backups and using a secure offsite and onsite location can minimize the security risk.
Differential Backups
Companies that don’t have enough time to complete a full backup daily can use the differential backup. Differential backups are faster than a full backup because they back up only the data that has changed since the last full backup. This means that if you do a full backup on a Saturday and a differential backup on the following Wednesday, only the data that has changed since Saturday is backed up. Restoring the differential backup requires the last full backup and the latest differential backup.
Differential backups know what files have changed since the last full backup because they use a setting called the archive bit. The archive bit flags files that have changed or have been created and identifies them as ones that need to be backed up. Full backups do not concern themselves with the archive bit because all files are backed up, regardless of date. A full backup, however, does clear the archive bit after data has been backed up to avoid future confusion. Differential backups notice the archive bit and use it to determine which files have changed. The differential backup does not reset the archive bit information.
Incremental Backups
Some companies have a finite amount of time they can allocate to backup procedures. Such organizations are likely to use incremental backups in their backup strategy. Incremental backups save only the files that have changed since the last full or incremental backup. Like differential backups, incremental backups use the archive bit to determine which files have changed since the last full or incremental backup. Unlike differentials, however, incremental backups clear the archive bit, so files that have not changed are not backed up.
ExamAlert
Both full and incremental backups clear the archive bit after files have been backed up.
The faster backup time of incremental backups comes at a price—the amount of time required to restore. Recovering from a failure with incremental backups requires numerous sets of media—all the incremental backup media sets and the one for the most recent full backup. For example, if you have a full backup from Sunday and an incremental for Monday, Tuesday, and Wednesday, you need four sets of media to restore the data. Each set in the rotation is an additional step in the restore process and an additional failure point. One damaged incremental media set means that you cannot restore the data. Table 9.2 summarizes the various backup strategies.
|
Backup Type |
Advantage |
Disadvantage |
Data Backed Up |
Archive Bit |
|
Full |
Backs up all data on a single media set. Restoring data requires the fewest media sets. |
Depending on the amount of data, full backups can take a long time. |
All files and directories are backed up. |
Does not use the archive bit, but resets it after data has been backed up. |
|
Differential |
Faster backups than a full backup. |
The restore process takes longer than just a full backup. Uses more media sets than a full backup. |
All files and directories that have changed since the last full backup. |
Uses the archive bit to determine the files that have changed, but does not reset the archive bit. |
|
Incremental |
Faster backup times |
Requires multiple disks; restoring data takes more time than the other backup methods. |
The files and directories that have changed since the last full or incremental backup. |
Uses the archive bit to determine the files that have changed, and resets the archive bit. |
ExamAlert
Review Table 9.2 before taking the Network+ exam.
Snapshots
In addition to the three types of backups previously discussed, there are also snapshots. Whereas a backup can take a long time to complete, the advantage of a snapshot—an image of the state of a system at a particular point in time—is that it is an instantaneous copy of the system. This is often accomplished by splitting a mirrored set of disks or by creating a copy of a disk block when it is written in order to preserve the original and keep it available.
Snapshots are popular with virtual machine implementations. You can take as many snapshots as you want (provided you have enough storage space) in order to be able to revert a machine to a “saved” state. Snapshots contain a copy of the virtual machine settings (hardware configuration), information on all virtual disks attached, and the memory state of the machine at the time of the snapshot. This makes the snapshots additionally useful for virtual machine cloning, allowing the machine to be copied once—or multiple times—for testing.
ExamAlert
Think of a snapshot as a photograph, which is where the name came from, of a moment in time of any system.
Backup Best Practices
Many details go into making a backup strategy a success. The following are issues to consider as part of your backup plan:
![]() Offsite storage: Consider storing backup media sets offsite so that if a disaster occurs in a building,
a current set of media is available offsite. The offsite media should be as current
as any onsite and should be secure.
Offsite storage: Consider storing backup media sets offsite so that if a disaster occurs in a building,
a current set of media is available offsite. The offsite media should be as current
as any onsite and should be secure.
![]() Label media: The goal is to restore the data as quickly as possible. Trying to find the media
you need can prove difficult if it is not marked. Furthermore, this can prevent you
from recording over something you need to keep.
Label media: The goal is to restore the data as quickly as possible. Trying to find the media
you need can prove difficult if it is not marked. Furthermore, this can prevent you
from recording over something you need to keep.
![]() Verify backups: Never assume that the backup was successful. Seasoned administrators know that checking
backup logs and performing periodic test restores are part of the backup process.
Verify backups: Never assume that the backup was successful. Seasoned administrators know that checking
backup logs and performing periodic test restores are part of the backup process.
![]() Cleaning: You need to occasionally clean the backup drive. If the inside gets dirty, backups
can fail.
Cleaning: You need to occasionally clean the backup drive. If the inside gets dirty, backups
can fail.
ExamAlert
A backup strategy must include offsite storage to account for theft, fire, flood, or other disasters.
Using Uninterruptible Power Supplies
No discussion of fault tolerance can be complete without a look at power-related issues and the mechanisms used to combat them. When you design a fault-tolerant system, your planning should definitely include uninterruptible power supplies (UPSs). A UPS serves many functions and is a major part of server consideration and implementation.
On a basic level, a UPS, also known as a battery backup, is a box that holds a battery and built-in charging circuit. During times of good power, the battery is recharged; when the UPS is needed, it’s ready to provide power to the server. Most often, the UPS is required to provide enough power to give the administrator time to shut down the server in an orderly fashion, preventing any potential data loss from a dirty shutdown.
Why Use a UPS?
Organizations of all shapes and sizes need UPSs as part of their fault tolerance strategies. A UPS is as important as any other fault-tolerance measure. Three key reasons make a UPS necessary:
![]() Data availability: The goal of any fault-tolerance measure is data availability. A UPS ensures access
to the server if a power failure occurs—or at least as long as it takes to save a
file.
Data availability: The goal of any fault-tolerance measure is data availability. A UPS ensures access
to the server if a power failure occurs—or at least as long as it takes to save a
file.
![]() Protection from data loss: Fluctuations in power or a sudden power-down can damage the data on the server system.
In addition, many servers take full advantage of caching, and a sudden loss of power
could cause the loss of all information held in cache.
Protection from data loss: Fluctuations in power or a sudden power-down can damage the data on the server system.
In addition, many servers take full advantage of caching, and a sudden loss of power
could cause the loss of all information held in cache.
![]() Protection from hardware damage: Constant power fluctuations or sudden power-downs can damage hardware components
within a computer. Damaged hardware can lead to reduced data availability while the
hardware is repaired.
Protection from hardware damage: Constant power fluctuations or sudden power-downs can damage hardware components
within a computer. Damaged hardware can lead to reduced data availability while the
hardware is repaired.
Power Threats
In addition to keeping a server functioning long enough to safely shut it down, a UPS safeguards a server from inconsistent power. This inconsistent power can take many forms. A UPS protects a system from the following power-related threats:
![]() Blackout: A total failure of the power supplied to the server.
Blackout: A total failure of the power supplied to the server.
![]() Spike: A short (usually less than 1 second) but intense increase in voltage. Spikes can
do irreparable damage to any kind of equipment, especially computers.
Spike: A short (usually less than 1 second) but intense increase in voltage. Spikes can
do irreparable damage to any kind of equipment, especially computers.
![]() Surge: Compared to a spike, a surge is a considerably longer (sometimes many seconds) but
usually less intense increase in power. Surges can also damage your computer equipment.
Surge: Compared to a spike, a surge is a considerably longer (sometimes many seconds) but
usually less intense increase in power. Surges can also damage your computer equipment.
![]() Sag: A short-term voltage drop (the opposite of a spike). This type of voltage drop can
cause a server to reboot.
Sag: A short-term voltage drop (the opposite of a spike). This type of voltage drop can
cause a server to reboot.
![]() Brownout: A drop in voltage that usually lasts more than a few minutes.
Brownout: A drop in voltage that usually lasts more than a few minutes.
Many of these power-related threats can occur without your knowledge; if you don’t have a UPS, you cannot prepare for them. For the cost, it is worth buying a UPS, if for no other reason than to sleep better at night.
Alternatives to UPS
Power management is not limited only to the use of UPSs. In addition, to these devices, you should employ power generators to be able to keep your systems up and running when the electrical provider is down for an extended period of time. Redundant circuits and dual power supplies should also be used for key equipment.
Hot, Warm, and Cold Sites
A disaster recovery plan might include the provision for a recovery site that can be quickly brought into play. These sites fall into three categories: hot, warm, and cold. The need for each of these types of sites depends largely on the business you are in and the funds available. Disaster recovery sites represent the ultimate in precautions for organizations that need them. As a result, they do not come cheaply.
The basic concept of a disaster recovery site is that it can provide a base from which the company can be operated during a disaster. The disaster recovery site normally is not intended to provide a desk for every employee. It’s intended more as a means to allow key personnel to continue the core business functions.
In general, a cold recovery site is a site that can be up and operational in a relatively short amount of time, such as a day or two. Provision of services, such as telephone lines and power, is taken care of, and the basic office furniture might be in place. But there is unlikely to be any computer equipment, even though the building might have a network infrastructure and a room ready to act as a server room. In most cases, cold sites provide the physical location and basic services.
Cold sites are useful if you have some forewarning of a potential problem. Generally, cold sites are used by organizations that can weather the storm for a day or two before they get back up and running. If you are the regional office of a major company, it might be possible to have one of the other divisions take care of business until you are ready to go. But if you are the only office in the company, you might need something a little hotter.
For organizations with the dollars and the desire, hot recovery sites represent the ultimate in fault-tolerance strategies. Like cold recovery sites, hot sites are designed to provide only enough facilities to continue the core business function, but hot recovery sites are set up to be ready to go at a moment’s notice.
A hot recovery site includes phone systems with connected phone lines. Data networks also are in place, with any necessary routers and switches plugged in and turned on. Desks have installed and waiting desktop PCs, and server areas are replete with the necessary hardware to support business-critical functions. In other words, within a few hours, the hot site can become a fully functioning element of an organization.
The issue that confronts potential hot-recovery site users is that of cost. Office space is expensive in the best of times, but having space sitting idle 99.9 percent of the time can seem like a tremendously poor use of money. A popular strategy to get around this problem is to use space provided in a disaster recovery facility, which is basically a building, maintained by a third-party company, in which various businesses rent space. Space is usually apportioned according to how much each company pays.
Sitting between the hot and cold recovery sites is the warm site. A warm site typically has computers but is not configured ready to go. This means that data might need to be upgraded or other manual interventions might need to be performed before the network is again operational. The time it takes to get a warm site operational lands right in the middle of the other two options, as does the cost.
ExamAlert
A hot site mirrors the organization’s production network and can assume network operations at a moment’s notice. Warm sites have the equipment needed to bring the network to an operational state but require configuration and potential database updates. A cold site has the space available with basic services but typically requires equipment delivery.
High Availability and Recovery Concepts
When an incident occurs, it is too late to consider policies and procedures then; this must be done well ahead of time. Business continuity should always be of the utmost concern. Business continuity is primarily concerned with the processes, policies, and methods that an organization follows to minimize the impact of a system failure, network failure, or the failure of any key component needed for operation. Business continuity planning (BCP) is the process of implementing policies, controls, and procedures to counteract the effects of losses, outages, or failures of critical business processes. BCP is primarily a management tool that ensures that critical business functions (CBFs) can be performed when normal business operations are disrupted.
Critical business functions refer to those processes or systems that must be made operational immediately when an outage occurs. The business can’t function without them, and many are information intensive and require access to both technology and data. When you evaluate your business’s sustainability, realize that disasters do indeed happen. If possible, build infrastructures that don’t have a single point of failure (SPOF) or connection. If you’re the administrator for a small company, it is not uncommon for the SPOF to be a router/gateway, but you must identify all critical nodes and critical assets. The best way to remove an SPOF from your environment is to add in redundancy.
Know that every piece of equipment can be rated in terms of mean time between failures (MTBF) and mean time to recovery (MTTR). The MTBF is the measurement of the anticipated or predicted incidence of failure of a system or component between inherent failures, whereas the MTTR is the measurement of how long it takes to repair a system or component after a failure occurs.
Some technologies that can help with availability are the following:
![]() Fault tolerance is the capability to withstand a fault (failure) without losing data. This can be
accomplished through the use of RAID, backups, and similar technologies. Popular fault-tolerant
RAID implementations include RAID 1, RAID 5, and RAID 10.
Fault tolerance is the capability to withstand a fault (failure) without losing data. This can be
accomplished through the use of RAID, backups, and similar technologies. Popular fault-tolerant
RAID implementations include RAID 1, RAID 5, and RAID 10.
![]() Load balancing is a technique in which the workload is distributed among several servers. This feature
can take networks to the next level; it increases network performance, reliability,
and availability. A load balancer can be either a hardware device or software specially
configured to balance the load.
Load balancing is a technique in which the workload is distributed among several servers. This feature
can take networks to the next level; it increases network performance, reliability,
and availability. A load balancer can be either a hardware device or software specially
configured to balance the load.
ExamAlert
Remember that load balancing increases redundancy and therefore data availability. Also, load balancing increases performance by distributing the workload.
![]() NIC teaming is the process of combining multiple network cards for performance and redundancy
(fault tolerance) reasons. This can also be called bonding, balancing, or aggregation.
NIC teaming is the process of combining multiple network cards for performance and redundancy
(fault tolerance) reasons. This can also be called bonding, balancing, or aggregation.
![]() Port aggregation is the combining of multiple ports on a switch; it can be done one of three ways:
auto, desirable, or on.
Port aggregation is the combining of multiple ports on a switch; it can be done one of three ways:
auto, desirable, or on.
![]() Clustering is a method of balancing loads and providing fault tolerance.
Clustering is a method of balancing loads and providing fault tolerance.
Use vulnerability scanning and penetration testing to find the weaknesses in your systems before others do. Make sure that end user awareness and training is a priority when it comes to identifying problems and that you stress adherence to standards and policies. Those policies should include the following:
![]() Standard business documents: Many of these have been discussed in previous chapters, but they include service-level agreements (SLAs), memorandums of understanding (MOUs), master license agreements (MLAs), and statements of work (SOWs). An SLA, in particular, is an agreement between you or your company and a service
provider, typically a technical support provider. SLAs are also usually part of network
availability and other agreements. They stipulate the performance you can expect or
demand by outlining the expectations a vendor has agreed to meet. They define what
is possible to deliver and provide the contract to make sure what is delivered is
what was promised.
Standard business documents: Many of these have been discussed in previous chapters, but they include service-level agreements (SLAs), memorandums of understanding (MOUs), master license agreements (MLAs), and statements of work (SOWs). An SLA, in particular, is an agreement between you or your company and a service
provider, typically a technical support provider. SLAs are also usually part of network
availability and other agreements. They stipulate the performance you can expect or
demand by outlining the expectations a vendor has agreed to meet. They define what
is possible to deliver and provide the contract to make sure what is delivered is
what was promised.
![]() Acceptable use policy: Acceptable use policies (AUPs) describe how the employees in an organization can use company systems and resources:
both software and hardware. This policy should also outline the consequences for misuse.
In addition, the policy (also known as a use policy) should address installation of personal software on company computers and the use
of personal hardware, such as USB devices.
Acceptable use policy: Acceptable use policies (AUPs) describe how the employees in an organization can use company systems and resources:
both software and hardware. This policy should also outline the consequences for misuse.
In addition, the policy (also known as a use policy) should address installation of personal software on company computers and the use
of personal hardware, such as USB devices.
![]() Network policies: Similar to AUPs, these describe acceptable uses for the network resources.
Network policies: Similar to AUPs, these describe acceptable uses for the network resources.
![]() Security policies: Security policies define what controls are required to implement and maintain the security of systems,
users, and networks. This policy should be used as a guide in system implementations
and evaluations. One of particular note is a consent to monitoring policy in which employees and other network users acknowledge that they know they’re being
monitored and consent to it.
Security policies: Security policies define what controls are required to implement and maintain the security of systems,
users, and networks. This policy should be used as a guide in system implementations
and evaluations. One of particular note is a consent to monitoring policy in which employees and other network users acknowledge that they know they’re being
monitored and consent to it.
![]() BYOD policies: Bring your own device (BYOD) policies define what personally owned mobile devices (laptops, tablets, and smartphones)
employees are allowed to bring to their workplace and use. Mobile device management (MDM) and mobile application management (MAM) systems can be used to help enterprises manage and secure the use of those mobile
devices in the workplace.
BYOD policies: Bring your own device (BYOD) policies define what personally owned mobile devices (laptops, tablets, and smartphones)
employees are allowed to bring to their workplace and use. Mobile device management (MDM) and mobile application management (MAM) systems can be used to help enterprises manage and secure the use of those mobile
devices in the workplace.
ExamAlert
As you study for the exam, three topics to pay attention to are adherence to standards and policies, vulnerability scanning, and penetration testing.
All these policies are important, but those that relate to first responders and deal with data breaches are of elevated importance.
1. Which two types of backup methods clear the archive bit after the backup has been completed? (Choose two.)
A. Full
B. Differential
C. Incremental
D. GFS
2. You come to work on Thursday morning to find that the server has failed and you need to restore the data from backup. You finished a full backup on Sunday and incremental backups on Monday, Tuesday, and Wednesday. How many media sets are required to restore the backup?
A. Four
B. Two
C. Three
D. Five
3. Which of the following recovery sites might require the delivery of computer equipment and an update of all network data?
A. Cold site
B. Warm site
C. Hot site
D. None of the above
4. As part of your network administrative responsibilities, you have completed your monthly backups. As part of backup best practices, where should the media be stored?
A. In a secure location in the server room
B. In a secure location somewhere in the building
C. In an offsite location
D. In a secure offsite location
5. As network administrator, you have been tasked with designing a disaster recovery plan for your network. Which of the following might you include in a disaster recovery plan?
A. RAID 5
B. Offsite media storage
C. Mirrored hard disks
D. UPS
6. Which type of recovery site mirrors the organization’s production network and can assume network operations on a moment’s notice?
A. Warm site
B. Hot site
C. Cold site
D. Mirrored site
7. Which of the following are used to find weaknesses in your systems before others do? (Choose two.)
A. Data breachers
B. Vulnerability scanners
C. Penetration testers
D. First responders
8. Which of the following is a type of policy in which employees and other network users give consent to be monitored?
A. Consent to monitoring
B. Acceptable use
C. Memorandum of Understanding
D. Service-Level Agreement
Cram Quiz Answers
1. A, C. The archive bit is reset after a full backup and an incremental backup. Answer B is incorrect because the differential backup does not reset the archive bit. Answer D is wrong because GFS is a rotation strategy, not a backup method.
2. A. Incremental backups save all files and directories that have changed since the last full or incremental backup. To restore, you need the latest full backup and all incremental media sets. In this case, you need four sets of media to complete the restore process.
3. A. A cold site provides an alternative location but typically not much more. A cold site often requires the delivery of computer equipment and other services. A hot site has all network equipment ready to go if a massive failure occurs. A warm site has most equipment ready but still needs days or weeks to have the network up and running.
4. D. Although not always done, it is a best practice to store backups in a secure offsite location in case of fire or theft. Answer A is incorrect because if the server room is damaged by fire or flood, the backups and the data on the server can be compromised by the same disaster. Similarly, answer B is incorrect because storing the backups onsite does not eliminate the threat of a single disaster destroying the data on the server and backups. Answer C is incorrect because of security reasons. The offsite media sets must be secured.
5. B. Offsite storage is part of a disaster recovery plan. The other answers are considered fault-tolerance measures because they are implemented to ensure data availability.
6. B. A hot site mirrors the organization’s production network and can assume network operations at a moment’s notice. Answer A is incorrect because warm sites have the equipment needed to bring the network to an operational state but require configuration and potential database updates. Answer C is incorrect because cold sites have the space available with basic services but typically require equipment delivery. Answer D is incorrect because a mirrored site is not a valid option.
7. B, C. Use vulnerability scanning and penetration testing to find the weaknesses in your systems before others do. Answer A is incorrect because data breaches are invalid. Answer D is incorrect because first responders are typically those who are first on the scene after an incident.
8. A. A consent to monitoring policy is one in which employees and other network users acknowledge that they know they’re being monitored and consent to it. Answer B is incorrect because acceptable use policies describe how the employees in an organization can use company systems and resources. Answers C and D are incorrect because a Memorandum of Understanding and Service-Level Agreements are standard business documents.
![]() Explain common scanning, monitoring and patching processes and summarize their expected
outputs.
Explain common scanning, monitoring and patching processes and summarize their expected
outputs.
CramSaver
If you can correctly answer these questions before going through this section, save time by skimming the Exam Alerts in this section and then completing the Cram Quiz at the end of the section.
1. What can be used to capture network data?
2. True or false: Port scanners detect open and often unsecured ports.
3. True or false: Interface monitoring tools can be used to create “heat maps” showing the quantity and quality of wireless network coverage in areas.
4. True or false: Always test updates on a lab machine before rolling out on production machines.
5. What is it known as when you roll a system back to a previous version of a driver or firmware?
Answers
1. Packet sniffers can be used by both administrators and hackers to capture network data.
2. True. Port scanners detect open and often unsecured ports.
3. False. Wireless survey tools can be used to create heat maps showing the quantity and quality of wireless network coverage in areas.
4. True. Always test updates on a lab machine before rolling out on production machines.
5. This is known as downgrading and is often necessary when dealing with legacy systems and implementations.
When networks were smaller and few stretched beyond the confines of a single location, network management was a simple task. In today’s complex, multisite, hybrid networks, however, the task of maintaining and monitoring network devices and servers has become a complicated but essential part of the network administrator’s role. Nowadays, the role of network administrator often stretches beyond the physical boundary of the server room and reaches every node and component on the network. Whether an organization has 10 computers on a single segment or a multisite network with several thousand devices attached, the network administrator must monitor all network devices, protocols, and usage—preferably from a central location.
Given the sheer number and diversity of possible devices, software, and systems on any network, it is clear why network management is such a significant consideration. Despite that a robust network management strategy can improve administrator productivity and reduce downtime, many companies choose to neglect network management because of the time involved in setting up the system or because of the associated costs. If these companies understood the potential savings, they would realize that neglecting network management provides false economies.
Network management and network monitoring are essentially methods to control, configure, and monitor devices on a network. Imagine a scenario in which you are a network administrator working out of your main office in Spokane, Washington, and you have satellite offices in New York, Dallas, Vancouver, and London. Network management allows you to access systems in the remote locations or have the systems notify you when something goes awry. In essence, network management is about seeing beyond your current boundaries and acting on what you see.
Network management is not one thing. Rather, it is a collection of tools, systems, and protocols that, when used together, enables you to perform tasks such as reconfiguring a network card in the next room or installing an application in the next state.
Common Reasons to Monitor Networks
The capabilities demanded from network management vary somewhat among organizations, but essentially, several key types of information and functionality are required, such as fault detection and performance monitoring. Some of the types of information and functions that network management tools can provide include the following:
![]() Utilization: Once upon a time, it was not uncommon for a network to have to limp by with scarce
resources. Administrators would constantly have to trim logs and archive files to
keep enough storage space available to service print jobs. Those days are gone, and
any such hint of those conditions would be unacceptable today. To keep this from happening,
one of the keys is to manage utilization and stay on top of problems before they escalate.
Five areas of utilization to monitor are as follows:
Utilization: Once upon a time, it was not uncommon for a network to have to limp by with scarce
resources. Administrators would constantly have to trim logs and archive files to
keep enough storage space available to service print jobs. Those days are gone, and
any such hint of those conditions would be unacceptable today. To keep this from happening,
one of the keys is to manage utilization and stay on top of problems before they escalate.
Five areas of utilization to monitor are as follows:
![]() Bandwidth/throughput: There must be enough bandwidth to serve all users, and you need to be alert for bandwidth
hogs. You want to look for top talkers (those that transmit the most) and top listeners
(those that receive the most) and figure out why they are so popular.
Bandwidth/throughput: There must be enough bandwidth to serve all users, and you need to be alert for bandwidth
hogs. You want to look for top talkers (those that transmit the most) and top listeners
(those that receive the most) and figure out why they are so popular.
![]() Storage space: Free space needs to be available for all users, and quotas may need to be implemented.
Storage space: Free space needs to be available for all users, and quotas may need to be implemented.
![]() Network device CPU: Just as a local machine will slow when the processor is maxed out, so will the network.
Network device CPU: Just as a local machine will slow when the processor is maxed out, so will the network.
![]() Network device memory: It is next to impossible to have too much memory. Balance loads to optimize the resources
you have to work with.
Network device memory: It is next to impossible to have too much memory. Balance loads to optimize the resources
you have to work with.
![]() Wireless channel utilization: Akin to bandwidth utilization is channel utilization in the wireless realm. As a
general rule, a wireless network starts experiencing performance problems when channel
utilization reaches 50% of the channel capacity.
Wireless channel utilization: Akin to bandwidth utilization is channel utilization in the wireless realm. As a
general rule, a wireless network starts experiencing performance problems when channel
utilization reaches 50% of the channel capacity.
![]() Fault detection: One of the most vital aspects of network management is knowing if anything is not
working or is not working correctly. Network management tools can detect and report
on a variety of faults on the network. Given the number of possible devices that constitute
a typical network, determining faults without these tools could be an impossible task.
In addition, network management tools might not only detect the faulty device, but
also shut it down. This means that if a network card is malfunctioning, you can remotely
disable it. When a network spans a large area, fault detection becomes even more invaluable
because it enables you to be alerted to network faults and to manage them, thereby
reducing downtime.
Fault detection: One of the most vital aspects of network management is knowing if anything is not
working or is not working correctly. Network management tools can detect and report
on a variety of faults on the network. Given the number of possible devices that constitute
a typical network, determining faults without these tools could be an impossible task.
In addition, network management tools might not only detect the faulty device, but
also shut it down. This means that if a network card is malfunctioning, you can remotely
disable it. When a network spans a large area, fault detection becomes even more invaluable
because it enables you to be alerted to network faults and to manage them, thereby
reducing downtime.
ExamAlert
Most of this discussion involves your being alerted to some condition. Those alerts can generally be sent to you through email or SMS to any mobile device.
![]() Performance monitoring: Another feature of network management is the ability to monitor network performance.
Performance monitoring is an essential consideration that gives you some crucial information.
Specifically, performance monitoring can provide network usage statistics and user
usage trends. This type of information is essential when you plan network capacity
and growth. Monitoring performance also helps you determine whether there are any
performance-related concerns, such as whether the network can adequately support the
current user base.
Performance monitoring: Another feature of network management is the ability to monitor network performance.
Performance monitoring is an essential consideration that gives you some crucial information.
Specifically, performance monitoring can provide network usage statistics and user
usage trends. This type of information is essential when you plan network capacity
and growth. Monitoring performance also helps you determine whether there are any
performance-related concerns, such as whether the network can adequately support the
current user base.
![]() Security monitoring: Good server administrators have a touch of paranoia built into their personality.
A network management system enables you to monitor who is on the network, what they
are doing, and how long they have been doing it. More important, in an environment
in which corporate networks are increasingly exposed to outside sources, the ability
to identify and react to potential security threats is a priority. Reading log files
to learn of an attack is a poor second to knowing that an attack is in progress and
being able to react accordingly. Security information and event management (SIEM) products provide notifications and real-time analysis of security alerts and can
help you head off problems quickly.
Security monitoring: Good server administrators have a touch of paranoia built into their personality.
A network management system enables you to monitor who is on the network, what they
are doing, and how long they have been doing it. More important, in an environment
in which corporate networks are increasingly exposed to outside sources, the ability
to identify and react to potential security threats is a priority. Reading log files
to learn of an attack is a poor second to knowing that an attack is in progress and
being able to react accordingly. Security information and event management (SIEM) products provide notifications and real-time analysis of security alerts and can
help you head off problems quickly.
![]() Link status: You should regularly monitor link status to make sure that connections are up and
functioning. Breaks should be found and identified as quickly as possible to repair
them or find workarounds. A number of link status monitors exist for the purpose of
monitoring connectivity, and many can reroute (per a configured script file) when
a down condition occurs.
Link status: You should regularly monitor link status to make sure that connections are up and
functioning. Breaks should be found and identified as quickly as possible to repair
them or find workarounds. A number of link status monitors exist for the purpose of
monitoring connectivity, and many can reroute (per a configured script file) when
a down condition occurs.
![]() Interface monitoring: Just as you want to monitor for a link going down, you also need to know when there
are problems with an interface. Particular problems to watch for include errors, utilization
problems (unusually high, for example), discards, packet drops, resets, and problems
with speed/duplex. An interface monitoring tool is invaluable for troubleshooting problems here.
Interface monitoring: Just as you want to monitor for a link going down, you also need to know when there
are problems with an interface. Particular problems to watch for include errors, utilization
problems (unusually high, for example), discards, packet drops, resets, and problems
with speed/duplex. An interface monitoring tool is invaluable for troubleshooting problems here.
![]() Maintenance and configuration: Want to reconfigure or shut down the server located in Australia? Reconfigure a local
router? Change the settings on a client system? Remote management and configuration
are key parts of the network management strategy, enabling you to centrally manage
huge multisite locations.
Maintenance and configuration: Want to reconfigure or shut down the server located in Australia? Reconfigure a local
router? Change the settings on a client system? Remote management and configuration
are key parts of the network management strategy, enabling you to centrally manage
huge multisite locations.
![]() Environmental monitoring: It is important to monitor the server room, and other key equipment, for temperature
and humidity conditions. Humidity control prevents the buildup of static electricity
and when the level drops much below 50%, electronic components become vulnerable to
damage from electrostatic shock. Environmental monitoring tools can alert you to any dangers that arise here.
Environmental monitoring: It is important to monitor the server room, and other key equipment, for temperature
and humidity conditions. Humidity control prevents the buildup of static electricity
and when the level drops much below 50%, electronic components become vulnerable to
damage from electrostatic shock. Environmental monitoring tools can alert you to any dangers that arise here.
ExamAlert
For the exam, recognize the role humidity plays in controlling electrostatic shock.
![]() Power monitoring: A consistent flow of reliable energy is needed to keep a network up and running.
A wide array of power monitoring tools are available to help identify and log problems that you can then begin to resolve.
Power monitoring: A consistent flow of reliable energy is needed to keep a network up and running.
A wide array of power monitoring tools are available to help identify and log problems that you can then begin to resolve.
![]() Wireless monitoring: As more networks go wireless, you need to pay special attention to issues associated
with them. Wireless survey tools can be used to create heat maps showing the quantity and quality of wireless network
coverage in areas. They can also allow you to see access points (including rogues)
and security settings. These can be used to help you design and deploy an efficient
network, and they can also be used (by you or others) to find weaknesses in your existing
network (often marketed for this purpose as wireless analyzers).
Wireless monitoring: As more networks go wireless, you need to pay special attention to issues associated
with them. Wireless survey tools can be used to create heat maps showing the quantity and quality of wireless network
coverage in areas. They can also allow you to see access points (including rogues)
and security settings. These can be used to help you design and deploy an efficient
network, and they can also be used (by you or others) to find weaknesses in your existing
network (often marketed for this purpose as wireless analyzers).
Many tools are available to help monitor the network and ensure that it is properly functioning. Some tools, such as a packet sniffer, can be used to monitor traffic by administrators and those who want to obtain data that does not belong to them. The following sections look at several monitoring tools.
SNMP Monitors
An SNMP management system is a computer running a special piece of software called a network management system (NMS). These software applications can be free, or they can cost thousands of dollars. The difference between the free applications and those that cost a great deal of money normally boils down to functionality and support. All NMS applications, regardless of cost, offer the same basic functionality. Today, most NMS applications use graphical maps of the network to locate a device and then query it. The queries are built in to the application and are triggered by pointing and clicking. You can actually issue SNMP requests from a command-line utility, but with so many tools available, this is unnecessary.
Note
Some people call SNMP managers or NMSs trap managers. This reference is misleading, however, because an NMS can do more than just accept trap messages from agents.
Using SNMP and an NMS, you can monitor all the devices on a network, including switches, hubs, routers, servers, and printers, as well as any device that supports SNMP, from a single location. Using SNMP, you can see the amount of free disk space on a server in Jakarta or reset the interface on a router in Helsinki—all from the comfort of your desk in San Jose. Such power, though, brings with it some considerations. For example, because an NMS enables you to reconfigure network devices, or at least get information from them, it is common practice to implement an NMS on a secure workstation platform, such as a Linux or Windows server, and to place the NMS PC in a secure location.
Management Information Bases (MIB)
Although the SNMP trap system might be the most commonly used aspect of SNMP, manager-to-agent
communication is not a one-way street. In addition to reading information from a device
using the SNMP commands Get and Get Next, SNMP managers can issue the Set command. If you have a large sequence of Get Next commands to perform, you can use the Walk command to automatically move through them. The purpose of this command is to save
a manager’s time: you issue one command on the root node of a subtree and the command
“walks” through, getting the value of every node in the subtree.
To demonstrate how SNMP commands work, imagine that you and a friend each have a list
on which the following four words are written: four, book, sky, and table. If you,
as the manager, ask your friend for the first value, she, acting as the agent, can
reply “four.” This is analogous to an SNMP Get command. Now, if you ask for the next value, she would reply “book.” This is analogous
to an SNMP Get Next command. If you then say “set green,” and your friend changes the word book to green, you have performed the equivalent of an SNMP Set command. Sound simplistic? Well, if you can imagine expanding the list to include
100 values, you can see how you could navigate and set any parameter in the list,
using just those commands. The key, though, is to make sure that you and your friend
have the same list—which is where Management Information Bases (MIBs) come in.
SNMP uses databases of information called MIBs to define what parameters are accessible, which of the parameters are read-only, and which can be set. MIBs are available for thousands of devices and services, covering every imaginable need.
To ensure that SNMP systems offer cross-platform compatibility, MIB creation is controlled by the International Organization for Standardization (ISO). An organization that wants to create MIBs can apply to the ISO. The ISO then assigns the organization an ID under which it can create MIBs as it sees fit. The assignment of numbers is structured within a conceptual model called the hierarchical name tree.
Packet Sniffers
Packet sniffers are commonly used on networks and are also referred to as packet/network analyzers. They are either a hardware device or software that basically eavesdrops on transmissions traveling throughout the network, and can be helpful in performing packet flow monitoring. The packet sniffer quietly captures data and saves it to be reviewed later. Packet sniffers can also be used on the Internet to capture data traveling between computers. Internet packets often have long distances to travel, going through various servers, routers, and gateways. Anywhere along this path, packet sniffers can quietly sit and collect data. Given the capability of packet sniffers to sit and silently collect data packets, it is easy to see how they could be exploited.
You should use two key defenses against packet sniffers to protect your network:
![]() Use a switched network, which most today are. In a switched network, data is sent
from one computer system and is directed from the switch only to intended targeted
destinations. In an older network using traditional hubs, the hub does not switch
the traffic to isolated users but to all users connected to the hub’s ports. This
shotgun approach to network transmission makes it easier to place a packet sniffer
on the network to obtain data.
Use a switched network, which most today are. In a switched network, data is sent
from one computer system and is directed from the switch only to intended targeted
destinations. In an older network using traditional hubs, the hub does not switch
the traffic to isolated users but to all users connected to the hub’s ports. This
shotgun approach to network transmission makes it easier to place a packet sniffer
on the network to obtain data.
![]() Ensure that all sensitive data is encrypted as it travels. Ordinarily, encryption
is used when data is sent over a public network such as the Internet, but it may also
be necessary to encrypt sensitive data on a LAN. Encryption can be implemented in
a number of ways. For example, connections to web servers can be protected using the
Secure Sockets Layer (SSL) protocol and HTTPS. Communications to mail servers can also be encrypted using SSL.
For public networks, the IPsec protocol can provide end-to-end encryption services.
Ensure that all sensitive data is encrypted as it travels. Ordinarily, encryption
is used when data is sent over a public network such as the Internet, but it may also
be necessary to encrypt sensitive data on a LAN. Encryption can be implemented in
a number of ways. For example, connections to web servers can be protected using the
Secure Sockets Layer (SSL) protocol and HTTPS. Communications to mail servers can also be encrypted using SSL.
For public networks, the IPsec protocol can provide end-to-end encryption services.
Note
Chapter 10, “Network Security,” provides more information about encryption protocols.
Throughput Testing
In the networking world, throughput refers to the rate of data delivery over a communication channel. In this case, throughput testers test the rate of data delivery over a network. Throughput is measured in bits per second (bps). Testing throughput is important for administrators to make them aware of exactly what the network is doing. With throughput testing, you can tell whether a high-speed network is functioning close to its expected throughput.
A throughput tester is designed to quickly gather information about network functionality—specifically, the average overall network throughput. Many software-based throughput testers are available online—some for free and some for a fee. Figure 9.5 shows a software-based throughput tester.
FIGURE 9.5 A software throughput tester
As you can see, throughput testers do not need to be complicated to be effective. A throughput tester tells you how long it takes to send data to a destination point and receive an acknowledgment that the data was received. To use the tester, enter the beginning point and then the destination point. The tester sends a predetermined number of data packets to the destination and then reports on the throughput level. The results typically display in kilobits per second (Kbps), megabits per second (Mbps), or gigabits per second (Gbps). Table 9.3 shows the various data rate units.
|
Data Transfer |
Abbreviation |
Rate |
|
Kilobits per second |
Kbps or Kbit/s |
1,000 bits per second |
|
Megabits per second |
Mbps or Mbit/s |
1,000,000 bits per second |
|
Gigabits per second |
Gbps or Gbit/s |
1,000,000,000 bits per second |
|
Kilobytes per second |
KBps |
1,000 bytes per second, or 8 kilobits per second |
|
Megabytes per second |
MBps |
1,000,000 bytes per second, or 8 megabits per second |
|
Gigabytes per second |
GBps |
1,000,000,000 bytes per second, or 8 gigabits per second |
Administrators can periodically conduct throughput tests and keep them on file to create a picture of network performance. If you suspect a problem with the network functioning, you can run a test to compare with past performance to see exactly what is happening.
One thing worth mentioning is the difference between throughput and bandwidth. These terms are often used interchangeably, but they have different meanings. When talking about measuring throughput, you measure the amount of data flow under real-world conditions—measuring with possible electromagnetic interference (EMI) influences, heavy traffic loads, improper wiring, and even network collisions. Take all this into account, take a measurement, and you have the network throughput. Bandwidth, in contrast, refers to the maximum amount of information that can be sent through a particular medium under ideal conditions.
Note
Be sure that you know the difference between throughput and bandwidth.
Port Scanners
A port scanner is an application written to probe a host (usually a server) for open ports. This can be done by an administrator for legitimate purposes—to verify security policies on the network—or by attackers to find vulnerabilities to exploit. Port scanners are discussed in more detail in Chapter 11, “Network Troubleshooting.”
Vulnerability Scanners
In a vulnerability test, you run a software program that contains a database of known vulnerabilities against your system to identify weaknesses. It is highly recommended that you obtain such a vulnerability scanner and run it on your network to check for any known security holes. It is always preferable for you to find them on your own network before someone outside the organization does by running such a tool against you.
The vulnerability scanner may be a port scanner (such as Nmap: https://nmap.org/), a network enumerator, a web application, or even a worm, but in all cases it runs tests on its target against a gamut of known vulnerabilities.
Although Nessus and Retina are two of the better-known vulnerability scanners, SAINT and OpenVAS (which was originally based on Nessus) are also widely used.
ExamAlert
For the exam, CompTIA wants you to know that Nessus and Nmap are two popular vulnerability scanners.
Network Performance, Load, and Stress Testing
To test the network, administrators often perform three distinct types of tests:
![]() Performance tests
Performance tests
![]() Load tests
Load tests
![]() Stress tests
Stress tests
These test names are sometimes used interchangeably. Although some overlap exists, they are different types of network tests, each with different goals.
Performance Tests
A performance test is, as the name suggests, all about measuring the network’s current performance level. The goal is to take ongoing performance tests and evaluate and compare them, looking for potential bottlenecks. For performance tests to be effective, they need to be taken under the same type of network load each time, or the comparison is invalid. For example, a performance test taken at 3 a.m. will differ from one taken at 3 p.m.
Note
The goal of performance testing is to establish baselines for the comparison of network functioning. The results of a performance test are meaningless unless you can compare them to previously documented performance levels.
Load Tests
Load testing has some overlap with performance testing. Sometimes called volume or endurance testing, load tests involve artificially placing the network under a larger workload. For example, the network traffic might be increased throughout the entire network. After this is done, performance tests can be done on the network with the increased load. Load testing is sometimes done to see if bugs exist in the network that are not currently visible but that may become a problem as the network grows. For example, the mail server might work fine with current requirements. However, if the number of users in the network grew by 10%, you would want to determine whether the increased load would cause problems with the mail server. Load tests are all about finding a potential problem before it happens.
Performance tests and load tests are actually quite similar; however, the information outcomes are different. Performance tests identify the current level of network functioning for measurement and benchmarking purposes. Load tests are designed to give administrators a look into the future of their network load and to see if the current network infrastructure can handle it.
Note
Performance tests are about network functioning today. Load tests look forward to see whether performance may be hindered in the future by growth or other changes to the network.
Stress Tests
Whereas load tests do not try to break the system under intense pressure, stress tests sometimes do. They push resources to the limit. Although these tests are not done often, they are necessary and—for administrators, at least—entertaining. Stress testing has two clear goals:
![]() It shows you exactly what the network can handle. Knowing a network’s breaking point
is useful information when you consider network expansion.
It shows you exactly what the network can handle. Knowing a network’s breaking point
is useful information when you consider network expansion.
![]() It enables administrators to test their backup and recovery procedures. If a test
knocks out network resources, administrators can verify that their recovery procedures
work. Stress testing enables administrators to observe network hardware failure.
It enables administrators to test their backup and recovery procedures. If a test
knocks out network resources, administrators can verify that their recovery procedures
work. Stress testing enables administrators to observe network hardware failure.
Stress tests assume that someday something will go wrong, and administrators will know exactly what to do when it happens.
Performance Metrics
Whether the testing being done is related to performance, load, or stress, you have to choose the metrics you want to monitor and focus on. Although a plethora of options are available, the most common four are the following:
![]() Error rate: This identifies the frequency of errors.
Error rate: This identifies the frequency of errors.
![]() Utilization: This shows the percentage of resources being utilized.
Utilization: This shows the percentage of resources being utilized.
![]() Packet drops: How many packets of data on the network fail to reach their destination.
Packet drops: How many packets of data on the network fail to reach their destination.
![]() Bandwidth/throughput: The capability to move data through a channel as related to the total capability
of the system to identify bottlenecks, throttling, and other issues.
Bandwidth/throughput: The capability to move data through a channel as related to the total capability
of the system to identify bottlenecks, throttling, and other issues.
Tracking Event Logs
In a network environment, all NOSs and most firewalls, proxy servers, and other network components have logging features. These logging features are essential for network administrators to review and monitor. Many types of logs can be used. The following sections review some of the most common log file types.
On a Windows Server system, as with the other operating systems, events and occurrences are logged to files for later review. Windows Server and desktop systems use Event Viewer to view many of the key log files. The logs in Event Viewer can be used to find information on, for example, an error on the system or a security incident. Information is recorded into key log files; however, you will also see additional log files under certain conditions, such as if the system is a domain controller or is running a DHCP server application.
Event logs refer generically to all log files used to track events on a system. Event logs are crucial for finding intrusions and diagnosing current system problems. In a Windows environment, for example, three primary event logs are used: Security, Application, and System.
Security Logs
A system’s Security log contains events related to security incidents, such as successful and unsuccessful logon attempts and failed resource access. Security logs can be customized, meaning that administrators can fine-tune exactly what they want to monitor. Some administrators choose to track nearly every security event on the system. Although this might be prudent, it can often create huge log files that take up too much space. Figure 9.6 shows a Security log from a Windows system.
FIGURE 9.6 A Windows Security log from Windows 10
Figure 9.6 shows that some successful logons and account changes have occurred. A potential security breach would show some audit failures for logon or logoff attempts. To save space and prevent the log files from growing too big, administrators might choose to audit only failed logon attempts and not successful ones.
Each event in a Security log contains additional information to make it easy to get the details on the event:
![]() Date: The exact date the security event occurred.
Date: The exact date the security event occurred.
![]() Time: The time the event occurred.
Time: The time the event occurred.
![]() User: The name of the user account that was tracked during the event.
User: The name of the user account that was tracked during the event.
![]() Computer: The name of the computer used when the event occurred.
Computer: The name of the computer used when the event occurred.
![]() Event ID: The event ID tells you what event has occurred. You can use this ID to obtain additional
information about the particular event. For example, you can take the ID number, enter
it at the Microsoft support website, and gather information about the event. Without
the ID, it would be difficult to find this information.
Event ID: The event ID tells you what event has occurred. You can use this ID to obtain additional
information about the particular event. For example, you can take the ID number, enter
it at the Microsoft support website, and gather information about the event. Without
the ID, it would be difficult to find this information.
To be effective, Security logs should be regularly reviewed.
Application Log
This log contains information logged by applications that run on a particular system rather than the operating system itself. Vendors of third-party applications can use the Application log as a destination for error messages generated by their applications.
The Application log works in much the same way as the Security log. It tracks both successful events and failed events within applications. Figure 9.7 shows the details provided in an Application log.

FIGURE 9.7 An Application log in Windows 10
Figure 9.7 shows that three types of events occurred: general application information events, a warning event, and error events. Vigilant administrators would likely want to check the event ID of both the event and warning failures to isolate the cause.
System Logs
System logs record information about components or drivers in the system, as shown in Figure 9.8. This is the place to look when you are troubleshooting a problem with a hardware device on your system or a problem with network connectivity. For example, messages related to the client element of Dynamic Host Configuration Protocol (DHCP) appear in this log. The System log is also the place to look for hardware device errors, time synchronization issues, or service startup problems.

FIGURE 9.8 A System log in Windows 10
Syslog
In addition to the specific logs mentioned previously, most UNIX/Linux-based systems include the capability to write messages (either directly or through applications) to log files via syslog. This can be done for security or management reasons and provides a central means by which devices that otherwise could not write to a central repository can easily do so (often by using the logger utility).
History Logs
History logs are most often associated with the tracking of Internet surfing habits. They maintain a record of all sites that a user visits. Network administrators might review these for potential security or policy breaches, but generally these are not commonly reviewed.
Another form of history log is a compilation of events from other log files. For instance, one History log might contain all significant events over the past year from the Security log on a server. History logs are critical because they provide a detailed account of alarm events that can be used to track trends and locate problem areas in the network. This information can help you revise maintenance schedules, determine equipment replacement plans, and anticipate and prevent future problems.
Note
Application logs and system logs can often be viewed by any user. Security logs can be viewed only by users who use accounts with administrative privileges.
Log Management
While discussing these logs, it becomes clear that monitoring them can be a huge issue. That is where log management (LM) comes in. LM describes the process of managing large volumes of system-generated computer log files. LM includes the collection, retention, and disposal of all system logs. Although LM can be a huge task, it is essential to ensure the proper functioning of the network and its applications. It also helps you keep an eye on network and system security.
Configuring systems to log all sorts of events is the easy part. Trying to find the time to review the logs is an entirely different matter. To assist with this process, third-party software packages are available to help with the organization and reviewing of log files. To find this type of software, enter log management into a web browser, and you will have many options to choose from. Some have trial versions of their software that may give you a better idea of how LM works.
Patch Management
All applications, including productivity software, virus checkers, and especially the operating system, release patches and updates often designed to address potential security weaknesses. Administrators must keep an eye out for these patches and install them when they are released.
Note
The various types of updates discussed in this section apply to all systems and devices, including mobile devices and laptops, as well as servers and routers. Special server systems (and services) are typically used to deploy mass updates to clients in a large enterprise network.
Discussion items related to this topic include the following:
![]() OS updates: Most operating system updates relate to either functionality or security issues.
For this reason, it is important to keep your systems up to date. Most current operating
systems include the capability to automatically find updates and install them. By
default, the automatic updates feature is usually turned on; you can change the settings
if you do not want this enabled.
OS updates: Most operating system updates relate to either functionality or security issues.
For this reason, it is important to keep your systems up to date. Most current operating
systems include the capability to automatically find updates and install them. By
default, the automatic updates feature is usually turned on; you can change the settings
if you do not want this enabled.
Note
Always test updates on a lab machine before rolling out on production machines.
![]() Firmware updates: Firmware updates keep the hardware interfaces working properly. Router manufacturers,
for example, often issue patches when problems are discovered. Those patches need
to be applied to the router to remove any security gaps that may exist.
Firmware updates: Firmware updates keep the hardware interfaces working properly. Router manufacturers,
for example, often issue patches when problems are discovered. Those patches need
to be applied to the router to remove any security gaps that may exist.
ExamAlert
Just as security holes can exist with operating systems and applications (and get closed through patches), they can also exist in firmware and be closed through updates.
![]() Driver updates: The main reason for updating drivers is when you have a piece of hardware that is
not operating correctly. The failure to operate can be caused by the hardware interacting
with software it was not intended to prior to shipping (such as OS updates). Because
the problem can be from the vendor or the OS provider, updates can be automatically
included (such as with Windows Update) or found on the vendor’s site.
Driver updates: The main reason for updating drivers is when you have a piece of hardware that is
not operating correctly. The failure to operate can be caused by the hardware interacting
with software it was not intended to prior to shipping (such as OS updates). Because
the problem can be from the vendor or the OS provider, updates can be automatically
included (such as with Windows Update) or found on the vendor’s site.
![]() Feature changes/updates: Not considered as critical as security or functionality updates, feature updates
and changes can extend what you could previously do and extend your time using the
hardware/software combination you have.
Feature changes/updates: Not considered as critical as security or functionality updates, feature updates
and changes can extend what you could previously do and extend your time using the
hardware/software combination you have.
![]() Major versus minor updates: Most updates are classified as major (must be done) or minor (can be done). Depending
on the vendor, the difference in the two may be telegraphed in the numbering: An update
of 4.0.0 would be a major update, whereas one of 4.10.357 would be considered a minor
one.
Major versus minor updates: Most updates are classified as major (must be done) or minor (can be done). Depending
on the vendor, the difference in the two may be telegraphed in the numbering: An update
of 4.0.0 would be a major update, whereas one of 4.10.357 would be considered a minor
one.
ExamAlert
As a general rule, the smaller the number of the update, the less significant it is.
![]() Vulnerability patches: Vulnerabilities are weaknesses, and patches related to them should be installed correctly
with all expediency. After a vulnerability in an OS, a driver, or a piece of hardware
has been identified, the fact that it can be exploited is often spread quickly: a
zero-day exploit is any attack that begins the very day the vulnerability is discovered.
Vulnerability patches: Vulnerabilities are weaknesses, and patches related to them should be installed correctly
with all expediency. After a vulnerability in an OS, a driver, or a piece of hardware
has been identified, the fact that it can be exploited is often spread quickly: a
zero-day exploit is any attack that begins the very day the vulnerability is discovered.
Note
If attackers learn of the weakness the same day as the developer, they have the ability to exploit it until a patch is released. Often, the only thing that you as a security administrator can do between the discovery of the exploit and the release of the patch is to turn off the system. Although this can be a costly undertaking in terms of productivity, it can be the only way to keep the network safe.
![]() Upgrading versus downgrading: Not all changing needs to be upgrading. If, for example, a new patch is applied that
changes the functionality of a hardware component to where it will no longer operate
as you need it to, you can consider reverting back to a previous state. This is known
as downgrading and is often necessary when dealing with legacy systems and implementations.
Upgrading versus downgrading: Not all changing needs to be upgrading. If, for example, a new patch is applied that
changes the functionality of a hardware component to where it will no longer operate
as you need it to, you can consider reverting back to a previous state. This is known
as downgrading and is often necessary when dealing with legacy systems and implementations.
ExamAlert
For the exam, know that removing patches and updates is considered downgrading.
Before installing or removing patches, it is important to do a configuration backup. Many vendors offer products that perform configuration backups across the network on a regular basis and allow you to roll back changes if needed. Free tools are often limited in the number of devices they can work with, and some of the more expensive ones include the capability to automatically analyze and identify the changes that could be causing any problems.
Cram Quiz
1. Which of the following involves pushing the network beyond its limits, often taking down the network to test its limits and recovery procedures?
A. Crash and burn
B. Stress test
C. Recovery test
D. Load test
2. You suspect that an intruder has gained access to your network. You want to see how many failed logon attempts there were in one day to help determine how the person got in. Which of the following might you do?
A. Review the History logs.
B. Review the Security logs.
C. Review the Logon logs.
D. Review the Performance logs.
3. Which utility can be used to write syslog entries on a Linux-based operating system?
A. memo
B. record
C. logger
D. trace
4. Which of the following is not a standard component of an entry in a Windows-based Security log?
A. Event ID
B. Date
C. Computer
D. Domain
E. User
5. You have just used a port scanner for the first time. On one port, it reports that there is not a process listening and access to this port will likely be denied. Which state is the port most likely to be considered to be in?
A. Listening
B. Closed
C. Filtered
D. Blocked
6. You are required to monitor discards, packet drops, resets, and problems with speed/duplex. Which of the following monitoring tools would assist you?
A. Interface
B. Power
C. Environmental
D. Application
7. By default, the automatic update feature on most modern operating systems is
A. Disabled
B. Turned on
C. Set to manual
D. Ineffective
8. What should you do if a weakness is discovered that affects network security, and no patch has yet been released?
A. Post information about the weakness on the vendor’s site.
B. Call the press to put pressure on the vendor.
C. Ignore the problem and wait for the patch.
D. Take the at-risk system offline.
Cram Quiz Answers
1. B. Whereas load tests do not try to break the system under intense pressure, stress tests sometimes do. Stress testing has two goals. The first is to see exactly what the network can handle. It is useful to know the network’s breaking point in case the network ever needs to be expanded. Second, stress testing allows administrators to test their backup and recovery procedures.
2. B. The Security logs can be configured to show failed or successful logon attempts as well as object access attempts. In this case, the administrator can review the Security logs and failed logon attempts to get the desired information. The failed logs will show the date and time when the failed attempts occurred.
3. C. The syslog feature exists in most UNIX/Linux-based distributions, and entries can be written using logger. The other options are not possibilities for writing syslog entries.
4. D. The standard components of an entry in a Windows-based Security log include the date, time, user, computer, and event ID. The domain is not a standard component of a log entry.
5. B. When a port is closed, no process is listening on that port and access to this port will likely be denied. When the port is open/listening, the host sends a reply indicating that a service is listening on the port. When the port is filtered or blocked, there is no reply from the host, meaning that the port is not listening or the port is secured and filtered.
6. A. An interface monitoring tool is invaluable for troubleshooting problems and errors that include utilization problems, discards, packet drops, resets, and problems with speed/duplex.
7. B. By default, the automatic update feature is usually turned on.
8. D. Often, the only thing that you as a security administrator can do, between the discovery of the exploit and the release of the patch, is to turn off the service. Although this can be a costly undertaking in terms of productivity, it can be the only way to keep the network safe.
Remote Access
![]() Given a scenario, use remote access methods.
Given a scenario, use remote access methods.
CramSaver
If you can correctly answer these questions before going through this section, save time by skimming the Exam Alerts in this section and then completing the Cram Quiz at the end of the section.
1. True or false: VPNs require a secure protocol to safely transfer data over the Internet.
2. What port does SSH for connections?
3. What port does Telnet use for connections?
Answers
1. True. VPNs require a secure protocol, such as IPsec or SSL, to safely transfer data over the Internet.
2. SSH uses port 22 and TCP for connections.
3. Telnet uses port 23 for connections.
ExamAlert
Remember that this objective begins with “Given a scenario.” That means that you may receive a drag and drop, matching, or “live OS” scenario where you have to click through to complete a specific objective-based task.
Several protocols are associated with remote-control access that you should be aware of: Remote Desktop Protocol (RDP), Secure Shell (SSH), Virtual Network Computing (VNC), and Telnet. RDP is used in a Windows environment and is now called Remote Desktop Services (RDS). It provides a way for a client system to connect to a server, such as Windows Server, and, by using RDP, operate on the server as if they were local client applications. Such a configuration is known as thin client computing, whereby client systems use the resources of the server instead of their local processing power.
Windows products (server as well as client) have built-in support for Remote Desktop Connections. The underlying protocol used to manage the connection is RDP. RDP is a low-bandwidth protocol used to send mouse movements, keystrokes, and bitmap images of the screen on the server to the client computer. RDP does not actually send data over the connection—only screenshots and client keystrokes. RDP uses TCP and UDP port 3389.
SSH is a tunneling protocol originally created for UNIX/Linux systems. It uses encryption to establish a secure connection between two systems and provides alternative, security-equivalent applications for such utilities as Telnet, File Transfer Protocol (FTP), Trivial File Transfer Protocol (TFTP), and other communications-oriented applications. Although it is available with Windows and other operating systems, it is the preferred method of security for Telnet and other clear-text-oriented programs in the UNIX/Linux environment. SSH uses port 22 and TCP for connections.
Virtual Network Computing (VNC) enables remote login, in which clients can access their own desktops while being physically away from their computers. By default, it uses port 5900 and it is not considered overly secure.
Telnet enables sessions to be opened on a remote host and is one of the oldest TCP/IP protocols still in use today. On most systems, Telnet is blocked because of problems with security (it truly does not have any), and SSH is considered a secure alternative to Telnet that enables secure sessions to be opened on the remote host.
ExamAlert
Be sure that you know the ports associated with RDP (3389), Telnet (23), FTP (20, 21), VNC (5900), and SSH (22).
ExamAlert
The protocols described in this chapter enable access to remote systems and enable users to run applications on the system, using that system’s resources. Only the user interface, keystrokes, and mouse movements transfer between the client system and the remote computer.
Remote File Access
File Transfer Protocol (FTP) is an application that allows connections to FTP servers for file uploads and downloads. FTP is a common application that uses ports 20 and 21 by default. It is used to transfer files between hosts on the Internet but is inherently insecure. A number of options have been released to try to create a more secure protocol, including FTP over SSL (FTPS), which adds support for SSL cryptography, and SSH File Transfer Protocol (SFTP), which is also known as Secure FTP.
An alternative utility for copying files is Secure Copy (SCP), which uses port 22 by default and combines an old remote copy program (RCP) from the first days of TCP/IP with SSH.
On the opposite end of the spectrum from a security standpoint is the Trivial File Transfer Protocol (TFTP), which can be configured to transfer files between hosts without any user interaction (unattended mode). It should be avoided anywhere there are more secure alternatives.
VPNs
A virtual private network (VPN) encapsulates encrypted data inside another datagram that contains routing information. The connection between two computers establishes a switched connection dedicated to the two computers. The encrypted data is encapsulated inside Point-to-Point Protocol (PPP), and that connection is used to deliver the data.
A VPN enables users with an Internet connection to use the infrastructure of the public network to connect to the main network and access resources as if they were logged on to the network locally. It also enables two networks to be connected to each other securely.
To put it more simply, a VPN extends a LAN by establishing a remote connection using a public network such as the Internet. A VPN provides a point-to-point dedicated link between two points over a public IP network. For many companies, the VPN link provides the perfect method to expand their networking capabilities and reduce their costs. By using the public network (Internet), a company does not need to rely on expensive private leased lines to provide corporate network access to its remote users. Using the Internet to facilitate the remote connection, the VPN enables network connectivity over a possibly long physical distance. In this respect, a VPN is a form of wide-area network (WAN).
Note
Many companies use a VPN to provide a cost-effective method to establish a connection between remote clients and a private network. There are other times a VPN link is handy. You can also use a VPN to connect one private LAN to another, known as LAN-to-LAN internetworking. For security reasons, you can use a VPN to provide controlled access within an intranet. As an exercise, try drawing what the VPN would look like in these two scenarios.
Components of the VPN Connection
A VPN enables anyone with an Internet connection to use the infrastructure of the public network to dial in to the main network and access resources as if the user were locally logged on to the network. It also enables two networks to securely connect to each other.
Many elements are involved in establishing a VPN connection, including the following:
![]() VPN client: The computer that initiates the connection to the VPN server.
VPN client: The computer that initiates the connection to the VPN server.
![]() VPN server: Authenticates connections from VPN clients.
VPN server: Authenticates connections from VPN clients.
![]() Access method: As mentioned, a VPN is most often established over a public network such as the Internet;
however, some VPN implementations use a private intranet. The network used must be
IP based.
Access method: As mentioned, a VPN is most often established over a public network such as the Internet;
however, some VPN implementations use a private intranet. The network used must be
IP based.
![]() VPN protocols: Required to establish, manage, and secure the data over the VPN connection. Point-to-Point
Tunneling Protocol (PPTP) and Layer 2 Tunneling Protocol (L2TP) are commonly associated
with VPN connections. These protocols enable authentication and encryption in VPNs.
Authentication enables VPN clients and servers to correctly establish the identity
of people on the network. Encryption enables potentially sensitive data to be guarded
from the general public.
VPN protocols: Required to establish, manage, and secure the data over the VPN connection. Point-to-Point
Tunneling Protocol (PPTP) and Layer 2 Tunneling Protocol (L2TP) are commonly associated
with VPN connections. These protocols enable authentication and encryption in VPNs.
Authentication enables VPN clients and servers to correctly establish the identity
of people on the network. Encryption enables potentially sensitive data to be guarded
from the general public.
VPNs have become popular because they enable the public Internet to be safely used as a WAN connectivity solution.
ExamAlert
VPNs support analog modems, Integrated Services Digital Network (ISDN) wireless connections, and dedicated broadband connections, such as cable and digital subscriber line (DSL). Remember this for the exam.
VPN Pros and Cons
As with any technology, VPN has both pros and cons. Fortunately with VPN technology, these are clear cut, and even the cons typically do not prevent an organization from using VPNs in its networks. Using a VPN offers two primary benefits:
![]() Cost: If you use the infrastructure of the Internet, you do not need to spend money on
dedicated private connections to link remote clients to the private network. Furthermore,
when you use the public network, you do not need to hire support personnel to support
those private links.
Cost: If you use the infrastructure of the Internet, you do not need to spend money on
dedicated private connections to link remote clients to the private network. Furthermore,
when you use the public network, you do not need to hire support personnel to support
those private links.
![]() Easy scalability: VPNs make it easy to expand the network. Employees who have a laptop with wireless
capability can simply log on to the Internet and establish the connection to the private
network.
Easy scalability: VPNs make it easy to expand the network. Employees who have a laptop with wireless
capability can simply log on to the Internet and establish the connection to the private
network.
Table 9.4 outlines some of the advantages and potential disadvantages of using a VPN.
TABLE 9.4 Pros and Cons of Using a VPN
|
Advantage |
Description |
|
Reduced cost |
When you use the Internet, you do not need to rent dedicated lines between remote clients and a private network. In addition, a VPN can replace remote-access servers and long-distance dial-up network connections that were commonly used in the past by business travelers who needed access to their company intranet. This eliminates long-distance phone charges. |
|
Network scalability |
The cost to an organization to build a dedicated private network may be reasonable at first, but it increases exponentially as the organization grows. The Internet enables an organization to grow its remote client base without having to increase or modify an internal network infrastructure. |
|
Reduced support |
Using the Internet, organizations do not need to employ support personnel to manage a VPN infrastructure. |
|
Simplified |
With a VPN, a network administrator can easily add remote clients. All authentication work is managed from the VPN authentication server, and client systems can be easily configured for automatic VPN access. |
|
Disadvantage |
Description |
|
Security |
Using a VPN, data is sent over a public network, so data security is a concern. VPNs use security protocols to address this shortcoming, but VPN administrators must understand data security over public networks to ensure that data is not tampered with or stolen. |
|
Reliability |
The reliability of the VPN communication depends on the public network and is not under an organization’s direct control. Instead, the solution relies on an Internet service provider (ISP) and its quality of service (QoS). |
IPsec
The IP Security (IPsec) protocol is designed to provide secure communications between systems. This includes system-to-system communication in the same network, as well as communication to systems on external networks. IPsec is an IP layer security protocol that can both encrypt and authenticate network transmissions. In a nutshell, IPsec is composed of two separate protocols: Authentication Header (AH) and Encapsulating Security Payload (ESP). AH provides the authentication and integrity checking for data packets, and ESP provides encryption services.
ExamAlert
IPsec relies on two underlying protocols: AH and ESP. AH provides authentication services, and ESP provides encryption services.
Using both AH and ESP, data traveling between systems can be secured, ensuring that transmissions cannot be viewed, accessed, or modified by those who should not have access to them. It might seem that protection on an internal network is less necessary than on an external network; however, much of the data you send across networks has little or no protection, allowing unwanted eyes to see it.
Note
The Internet Engineering Task Force (IETF) created IPsec, which you can use on both IPv4 and IPv6 networks.
IPsec provides three key security services:
![]() Data verification: Verifies that the data received is from the intended source
Data verification: Verifies that the data received is from the intended source
![]() Protection from data tampering: Ensures that the data has not been tampered with or changed between the sending and
receiving devices
Protection from data tampering: Ensures that the data has not been tampered with or changed between the sending and
receiving devices
![]() Private transactions: Ensures that the data sent between the sending and receiving devices is unreadable
by any other devices
Private transactions: Ensures that the data sent between the sending and receiving devices is unreadable
by any other devices
IPsec operates at the network layer of the Open Systems Interconnect (OSI) reference model and provides security for protocols that operate at the higher layers. Thus, by using IPsec, you can secure practically all TCP/IP-related communications.
SSL/TLS/DTLS
Security is often provided by working with the Secure Sockets Layer (SSL) protocol and the Transport Layer Security (TLS) protocol. SSL VPN, also marketed as WebVPN and OpenVPN, can be used to connect locations that would run into trouble with firewalls and NAT when used with IPsec. It is known as an SSL VPN whether the encryption is done with SSL or TLS.
Note
SSL was first created for use with the Netscape web browser and is used with a limited number of TCP/IP protocols (such as HTTP and FTP). TLS is not only an enhancement to SSL, but also a replacement for it, working with almost every TCP/IP protocol. Because of this, TLS is popular with VPNs and VoIP applications. Just as the term Kleenex is often used to represent any paper tissue, whether or not it is made by Kimberly-Clark, SSL is often the term used to signify the confidentiality function, whether it is actually SSL in use or TLS (the latest version of which is 1.2).
The Datagram Transport Layer Security (DTLS) protocol is a derivation of SSL/TLS by the OpenSSL project that provides the same security services but strives to increase reliability.
The National Institute of Standards and Technology (NIST) publishes the Guide to SSL VPNs, which you can access at http://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication800-113.pdf.
Site-to-Site and Client-to-Site
The scope of a VPN tunnel can vary, with the two most common variations being site-to-site and client-to-site (also known as host-to-site). A third variation is host-to-host, but it is really a special implementation of site-to-site. In a site-to-site implementation, as the name implies, whole networks are connected together. An example of this would be divisions of a large company. Because the networks are supporting the VPN, each gateway does the work, and the individual clients do not need to have any VPN.
In a client-to-site scenario, individual clients (such as telecommuters or travelers) connect to the network remotely. Because the individual client makes a direct connection to the network, each client doing so must have VPN client software installed.
ExamAlert
Be sure that you understand that site-to-site and client-to-site are the two most common types of VPNs.
HTTPS/Management URL
HTTP Secure (HTTPS) is the protocol used for “secure” web pages that users should see when they must enter personal information such as credit card numbers, passwords, and other identifiers. It combines HTTP with SSL/TLS to provide encrypted communication. The default port is 443, and the URL begins with https:// instead of http://.
This is the common protocol used for management URLs to perform tasks such as checking server status, changing router settings, and so on.
Out-of-Band Management
When a dedicated channel is established for managing network devices, it is known as out-of-band management. A connection can be established via a console router, or modem, and this can be used to ensure management connectivity independent of the status of in-band network connectivity (which would include serial port connections, VNC, and SSH). Out-of-band management lets the administrator monitor, access, and manage network infrastructure devices remotely and securely, even when everything else is down.
Cram Quiz
1. Which of the following protocols is used in thin-client computing?
A. RDP
B. PPP
C. PPTP
D. RAS
2. Your company wants to create a secure tunnel between two networks over the Internet. Which of the following protocols would you use to do this?
A. PAP
B. CHAP
C. PPTP
D. SLAP
3. Because of a recent security breach, you have been asked to design a security strategy that will allow data to travel encrypted through both the Internet and intranet. Which of the following protocols would you use?
A. IPsec
B. SST
C. CHAP
D. FTP
Cram Quiz Answers
1. A. RDP is used in thin-client networking, where only screen, keyboard, and mouse input is sent across the line. PPP is a dialup protocol used over serial links. PPTP is a technology used in VPNs. RAS is a remote-access service.
2. C. To establish the VPN connection between the two networks, you can use PPTP. PAP and CHAP are not used to create a point-to-point tunnel; they are authentication protocols. SLAP is not a valid secure protocol.
3. A. IPsec is a nonproprietary security standard used to secure transmissions both on the internal network and when data is sent outside the local LAN. IPsec provides encryption and authentication services for data communications. Answer B is not a valid protocol. Answer C, Challenge Handshake Authentication Protocol (CHAP), is a remote-access authentication protocol. Answer D is incorrect because FTP is a protocol used for large data transfers, typically from the Internet.
What’s Next?
The primary goals of today’s network administrators are to design, implement, and maintain secure networks. This is not always easy, and is the topic of Chapter 10, “Network Security.” No network can ever be labeled “secure.” Security is an ongoing process involving a myriad of protocols, procedures, and practices.