The ultimate goal of a successful attack is, invariably, to take control of a host. Host monitoring is the de facto last line of defense.
Because anything that is done to gain access to a machine ends up changing that machine in some way or another, it is a good idea to read logs and look at binary files for tell-tale signs that could reveal malicious activities. This is called local monitoring. Another advantage of local monitoring is the flattening of local versus remote activity. In effect, everything, regardless of attack vector (local or remote), appears in the same logfiles.
This chapter presents how host-monitoring tools can effectively help you identify suspicious activities using file integrity checkers and log-monitoring parsers. At the end of the chapter, large environment centralized management systems are shown to be invaluable, as they allow the correlation of events from many source devices, making the most relevant events stand out from the pack.
An attacker attempting to take control of a host inevitably leaves traces, be it file permissions, file attributes, file size, or binary signatures. File integrity checkers are tools that report such changes and allow tracing those changes over time. Because of their ability to alert you about changes on any part of the filesystem, file integrity checkers are sometimes used to track changes in situations where multiple administrators have to concurrently manage sensitive servers.
Using a file integrity checker is most appropriately done by setting up a workflow process. File integrity checking compares a baseline or known state to the current situation of a given filesystem. My best advice is to plan a deployment strategy before jumping on the bandwagon of file integrity checking, especially in an environment where multiple hosts are to be monitored. Figure 20-1 shows a typical workflow. Note that baselining and managing changes are mostly manual tasks, while checking can be automated. When checking occurs, the file integrity checker simply compares file attributes to the baseline. Automating that step is as easy as creating a cronjob to start it.
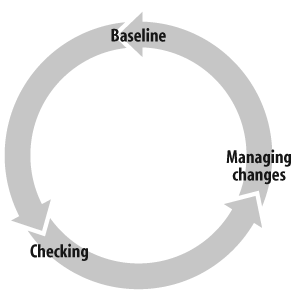
Once your workflow is established, file integrity works only if you exercise it on a regular basis. If not, you are at risk of slowly drifting away from the baseline that makes each check report bigger and harder to decipher than its predecessor. The time interval appropriate to reconcile your file integrity database depends on the host you want to monitor. In my experience, a stable production server running any flavor of daily automatic upgrade tool (yum updates, up2date, Windows update, and so on) needs reconciling at least once a week. Of course, daily reports should still be read on a daily basis to fully benefit from integrity checking.
Tip
Manually reconcile your file integrity database at least once a week for production servers.
A filesystem's state is the collection of its file's attributes and content taken at a given time. Storing attributes is trivial, but storing a full-size file snapshot for later verification is a waste of storage space. Instead, what you really want to know is whether the file content changed since the last time you checked. Checksums could actually be useful in providing the solution to this problem, but it is unfortunately too easy for a malicious user to manipulate the source file and obtain a checksum collision with the original file.
In Table 20-1, notice the variety of characteristics that file integrity checkers track. Especially interesting in host security are file permissions, ownership, and cryptographic hashes. Forensic investigators would also consider the file last content change (mtime) and last inode change time (ctime); this is useful in following a hacker's trail. Table 20-1 shows the most commonly monitored attributes.
Table 20-1. List of most commonly monitored attributes
Abbreviation | Attributes | Comments |
|---|---|---|
P | Permissions | User and group rights assigned to access a given file. |
I | inode | A number that uniquely identifies a file system object on a given device. Should not change for a given file unless the file was first deleted then recreated. |
N | Number of hard links to the file | Number of times a given physical file (inode) is referenced by the filesystem from different path names. |
U | user | Owner of the file. |
G | group | Group ownership of the file. |
S | size | File size in bytes. |
B | Block count | File size in blocks. |
M | mtime | Last file content change. |
A | atime | Last access time. |
C | ctime | Last inode or file permission change time. |
md5 | md5 hash | Various cryptographic hashes. |
sha1 | sha-1 hash | |
rmd160 | ripemd160 hash | |
Tiger | tiger hash |