File-fuzzing attacks either the file header or specific strings inside the file format. These attacks generate overflow or reconstruct the files by stretching the format rule; for example, attacking the file header with a simple byte flipper to corrupt the file so values such as size, flags, and internal structures trigger unexpected bugs in the application. Two of the main tools available to achieve file fuzzing are FileFuzz (labs.idefense.com/software/fuzzing.php) from iDefense, and PaiMei (pedram.redhive.com/code/paimei/) from Pedram.
When file fuzzers implement a string overflow strategy, they simply replace a string inside the file. This attack works only when the target parser is working with null-terminated strings. If by looking into the binary format you realize the string is not null-terminated nor has a common terminator, try to use another method for generating test cases.
PaiMei is a reverse-engineering framework consisting of multiple extensible components, as shown in Figure 22-2. The framework can essentially be thought of as a reverse engineer's Swiss Army knife. It has readily been proven effective for a wide range of both static and dynamic tasks such as fuzzer assistance, code coverage tracking, data flow tracking, and more.
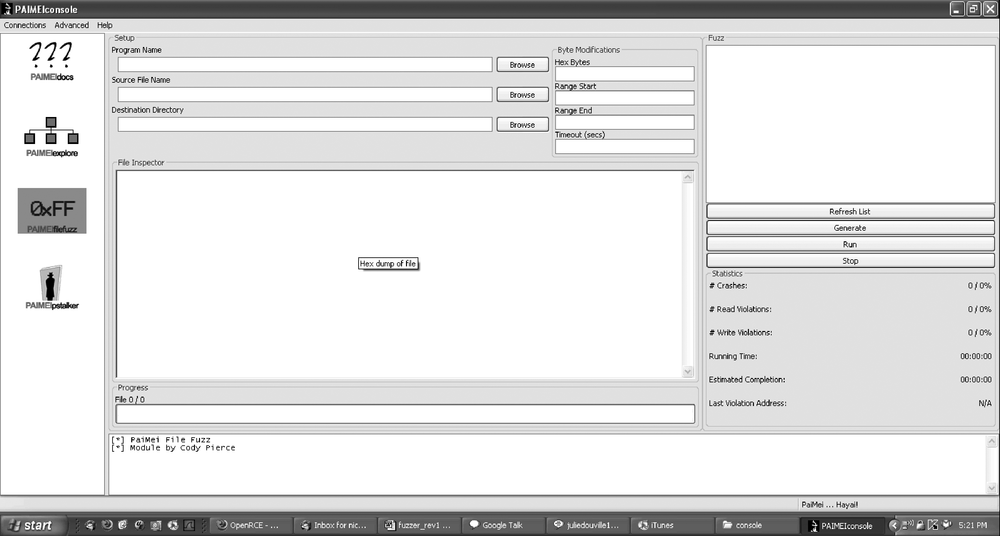
PaiMei is still in its infancy, yet its interface is easy to follow and use. It is one of the most promising reversing toolkits, but I won't spend too much time talking about it since it will probably change by the time you read this. For more timely information, go to http://pedram.redhive.com/code/paimei/.
FileFuzz is a graphical Windows-based file format fuzzing tool. FileFuzz was designed to automate the launching of applications and detection of exceptions created by fuzzed file formats. The great thing with FileFuzz and software like it is that almost everything is automated into a two-step process: generating test cases and running them. See Figure 22-3 for an example.
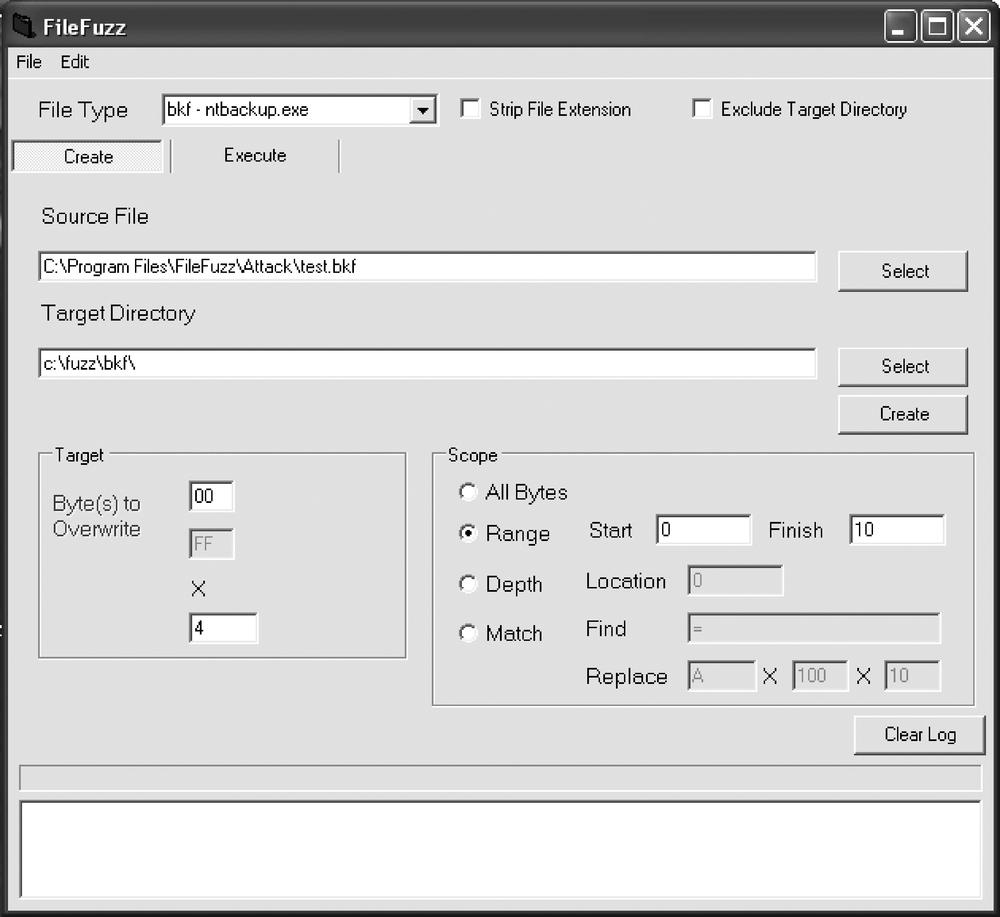
Using FileFuzz is rather simple:
To generate the test cases, begin with a basic file-type sample.
The generated test cases can be either bit flipped (all, range, location) or string-replaced.
To run the test, just switch to the execute part and start fuzzing.
Tip
FileFuzz also traces exceptions automatically in the application, so there is no need to attach your own debugger to follow what is occurring.
File fuzzing is not as thorough as block-based fuzzing, so it is possible that most tests cases are rejected by the application before even being processed. But FileFuzz is an easy and fast way to generate and run several test cases. It's a brute-force approach to fuzzing. While it might not provide the best results, the human time needed to achieve these results is so small that it can be (and usually is) worth it. If it takes too much time to play around with it to fit a specific case, change tools. The goal of fuzzing is to find the most bugs with the least amount of effort. If it takes too much effort, you're headed in the wrong direction.