IETF Related Standards
NETMOD, NETCONF, SFC and SPRING
Abstract
This chapter introduces the notion of other relevant and useful standards efforts going on in the industry. In particular, we focus here on the Internet Engineering Task Force’s efforts in this space, both failed and current. Here we define and describe what the NETMOD, NETCONF, SFC and SPRING working groups are up to and why it matters to NFV and SFC technology.
Keywords
IETF; NETMOD; NETCONF; SFC; SPRING; industry standards; working groups; internet engineering
Introduction
From the prior chapter on ETSI and the related exploration of NFV, you may have come away with the impression that standardization is currently stagnant or worse, an outdated artifact of the past. However, some traditional standards are actually making some headway around NFV. In particular, The Internet Engineering Task Force (IETF) is contributing actively in a number of areas. While it is a traditional standards organization that was formed in 1986 when many of those reading this book might not have even been born, it still remains relevant in new areas including NFV.
To recap a bit, the ETSI NFV “Phase 1” study we discussed earlier viewed the IETF relationship to NFV Standards as:
• The IETF RSerPool workgroup was identified in the draft ETSI Gap Analysis document (by the ETSI Reliability WG) as potential Standards providers for NFV (around resource management).
• The SFC workgroup was mentioned in the same analysis (by the ETSI Security WG), as well as the ConEx workgroup (in the context of security needs).
• While the FoRCES (workgroup) architecture was used in a PoC, it was not mentioned in the gap analysis.1
Further, there was a move to create a VNFPool workgroup. A Birds of a Feather (BoF) meeting was held,2 and was specifically driven by members of the ETSI community. Unfortunately, it did not succeed in forming a working group due to an apparently lack of a clear definition, overlap with other existing working groups and a general lack of community interest, perhaps due to a misunderstanding of what the proposed group was trying to achieve. This has unfortunately happened a number of times in the past at the IETF in areas related to SDN.3 The eventual outcome of that effort was the creation of the I2RS working group, which has since gone off in direction that no one seems to understand.
That experience aside, at present the IETF has several workgroups that are directly applicable to NFV either by virtue of adapting their charters, or by having been created later with a more clear or understandable focus. We particularly point to the work in the SFC, and Network Modeling (NETMOD) groups.
Other workgroups that are creating standards around transport, particularly those working on network overlays, have some overlap in the NFV space by virtue of being applicable to SDN and thus part of ETSI VIM. These include Network Virtualization Overlays (NVO3), LISP, MPLS (now called BESS), and Source Packet Routing in Networking (SPRING).4
The output of these groups and the efficacy of that output to actual NFV deployments varies. With that in mind, we will look specifically at the SFC and NETMOD workgroups in this chapter. We will pay particular attention to YANG modeling to describe interfaces to network systems. We will also look at the particular case of Segment Routing for IPv6 from SPRING as a practical tool that is in use in production NFV networks today.
Service Function Chaining
The IETF has had a recent history of tension between providing new solutions for evolving needs around SDN and NFV and the reuse/extension of existing paradigms like MPLS forwarding within these contexts. This has created some struggle for new working groups as their charters are continually pared back and work on solutions is dispersed amongst competing work groups. A recent attempt at reorganization will hopefully allow new workgroups to make faster progress, but the jury is still out on this attempt at renewed applicability in the new and evolving worlds of SDN and NFV.
The SFC workgroup is one of these new groups and its charter5 makes very clear that it will develop “a new approach to service delivery and operation.” The charter mandates documentation of a problem statement, architecture, generic SFC encapsulation, related control plane mechanisms, and management issues. The latter work on control plane extensions may be exported to appropriate workgroups and the management aspects need to be scoped (but may not drive actual recommendations under this charter). In addition, the workgroup decided to publish use cases—two of which were domain-specific (Data Center and Mobility) and the third a catch-all document (providing the use cases illustrated new requirements that were not found in the other use case documents).
The original goal was to deliver these work items by the end of 2015.
Problem Statement
The problem statement6 lists many of the challenges first covered in our more generic chapter on SFC and the problem of service creation (see Chapter 2: Service Creation and Service Function Chaining), including topological dependency, configuration complexity (there is hope that the modeling work in NETMOD and programmability of newer orchestration systems may provide abstractions that limit syntactic variation) and constrained HA of existing service deployment methodologies.
Some additional problem areas of interest include the consistent ordering of service functions (SFs) and application of service policies that are related and deal with the limited information we currently have for verification or triggering service policy.
SFC solutions are comprised of two main components: an overlay and an underlay. The overlay is a network virtualization scheme that can be thought of much like a network-based virtual private network from past network technologies such as MPLS layer 2 or layer 3 VPN. In these cases, an additional context demarcation is used to create a virtual context to effectively tunnel traffic across an otherwise agnostic substrate (ie, an IP/Ethernet/MPLS/ATM/Frame Relay network). The substrate can be referred to as the underlay.
NFV solutions all depend on the underlying transport mechanisms to deliver traffic between their endpoints. This is because the underlay must be able to encapsulate or tunnel the overlay traffic in order to transparently carry it from its source to its destination. This is the case whether the source and destination exist within the same underlay domain, or as is rapidly becoming more prevalent, overlays may span more than one type of underlay.
In all cases, this intrinsic dependency between the overlay on the underlying transport or underlay points out a key challenge:
transport-tied solutions may require sophisticated interworking and these have been shown to introduce a great deal of often unwanted, variation in implementations.
Basically the complications add difficulty in vendors interoperating with each others’ implementations. It is essentially an argument for the creation of a transport-independent and dynamic service overlay!
While we have also touched previously on the need for elasticity, more fine-grained traffic selection criteria and the need for vendor-interoperable solutions, the problem statement also notes the costs of limited end-to-end service visibility and per-function classification. This happens to also reinforce the arguments just given for an independent service overlay.
The problem statement document states three fundamental components that are the basis for SFC (and goals of SFC work):
• Create a topology and transport independent service overlay that provides service-specific information that aids in troubleshooting service failures (minimally, the preservation of path).
• Provide a classification mechanism that reduces or eliminates the need for per-function traffic classification, normalizes classification capability/granularity across all functions and equipment and enables the building of classification-keyed symmetric paths (where necessary).
• Provide the ability to pass “data plane” or inband metadata between functions (resulting from “antecedent classification,” provide by external sources or derived).
The last two components can be inter-related.
SFC Architecture
The SFC Architecture document7 defines The SFC as an “ordered set of abstract service functions.” The definition leaves room for services that require chain branching by stating that the order implied may not be a linear progression. There is stated support for cycles as well, and to accommodate these SFC control is going to be responsible for infinite loop detection/avoidance.
Additionally, the stateful nature of some functions and the services built from them drives a need for symmetry in SFCs. This symmetry can be “full” (meaning the entire chain is symmetric), or “hybrid” (meaning that only some functions require symmetry). The document provides a nonexhaustive list of potential methodologies to achieve/enforce symmetry, and we refer you to it if you are interested in reviewing all of these possible options.
It is worth noting that the SFC Architecture document also includes its own definition of terms that may not be entirely in sync with the ETSI definitions. This occurred despite it being strongly influenced by ETSI membership. It is also important to note that the architecture leaves interdomain chaining for future study. The document cleverly frees itself in a way that avoids having to standardize individual functions or the logic behind how a chain is selected or derived. These boundaries keep it from venturing into the function itself, and the particulars of management, orchestration, and policy of those functions while still providing the mechanisms and definitions for how to chain them together. In short, this was to avoid “boiling the ocean” of NFV and having to enumerate and define every combination and permutation of service function chains.
The Service Function Path (SFP) is the rough equivalent of the ETSI “forwarding graph” that we mentioned earlier in the ETSI chapter. It is defined in some of the most important verbiage in the document as:
a level of indirection between the fully abstract notion of service chain as a sequence of abstract service functions to be delivered, and the fully specified notion of exactly which SFF/SFs the packet will visit when it actually traverses the network.
The latter is described as the Rendered Service Path (RSP), which can again be a concise set of nodes to traverse but may also be less specific. SFC is a mechanism that allows for “loose coupling” between the service and the particulars of its instantiation.
Much of this text has a history in the early failure of a contingent in the work group to understand the value of an abstraction applied to a service like loadbalancing. It is this inherent approach to elasticity—a fundamental property of SFC, that avoids an explosion of explicit paths and the management of those paths, where the load balancing state can be locally maintained as a separate or integrated SF.
In defining the SF, which is the equivalent of the VNF in ETSI, care is taken to allow for an SF that can be either SFC encapsulation- aware or not. In this case, the SFC encapsulation is not passed to the function.
This leads us to now introduce the concept of the Service Function Forwarder (SFF) as seen in Fig. 4.1. The SFF can be integrated with the function or standalone. It forwards traffic from one or more attached SFs or proxies, transports packets to the next SFF on return from the SF in the SFP which is a typical overlay function, or terminating the SFP by stripping of the SFC encapsulation as its final operation.
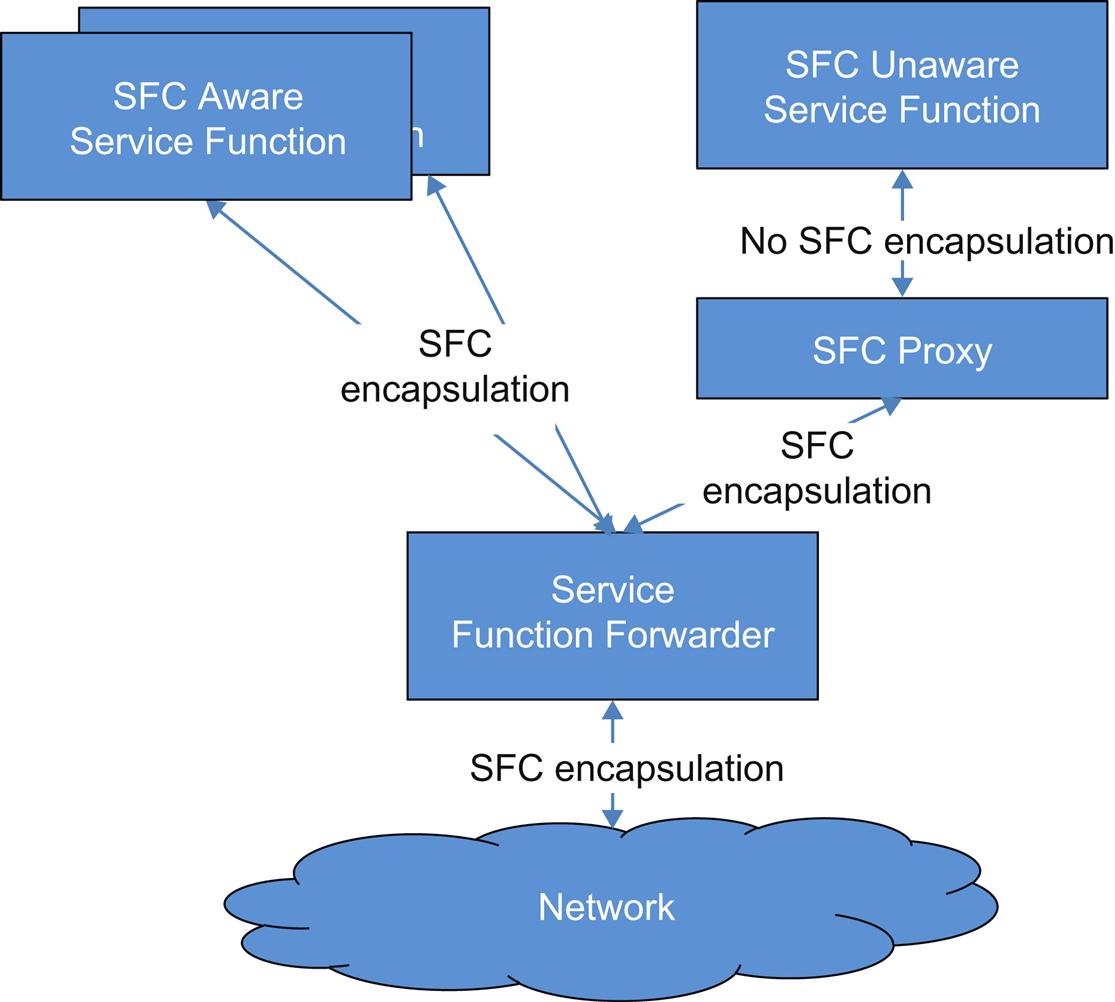
Because the SFF can have more than one SF, the architecture has to accommodate the potential private interconnection of those SFs. The coordination of this with the SFF is out of scope. The SF can naturally belong to more than one SFP, and this is a common method of “templatizing” or reusing the function.
The document mentions that the SFF “may be stateful,” creating and maintaining flow-centric information which can be leveraged in maintaining symmetry, handling proxy tasks or just ensuring uniform treatment. When we talk about creating a service overlay, the expected mechanism leverages the mapping of a service path ID (SPI) to next-hop(s), which is a construct above the normal network-level lookup.
This aligns with the second architectural principle (Section 3 of the document) that the realization of SFPs is separated from normal packet handling.
The other architectural goals outlined in the document echo some of those in the problem statement with a few additions. Most of these are around independence in the architecture:
• Independence from the SFs details—no IANA registry to catalog them.
• Independence of individual SFCs—that changing one SFC has no impact on another.
• Independence from any particular policy mechanism to resolve local policy or provide local classification criteria.
In allowing the SF to be SFC encapsulation-agnostic or unaware, the concept of the SFC Proxy is introduced (Fig. 4.2). At the lowest level, the proxy handles decapsulation/encapsulation tasks for the SF. Since a proxy can handle more than one function at a time, it would also select that function from information in the encapsulation and perform a transfer via a mapping on a more traditional local attachment circuit.
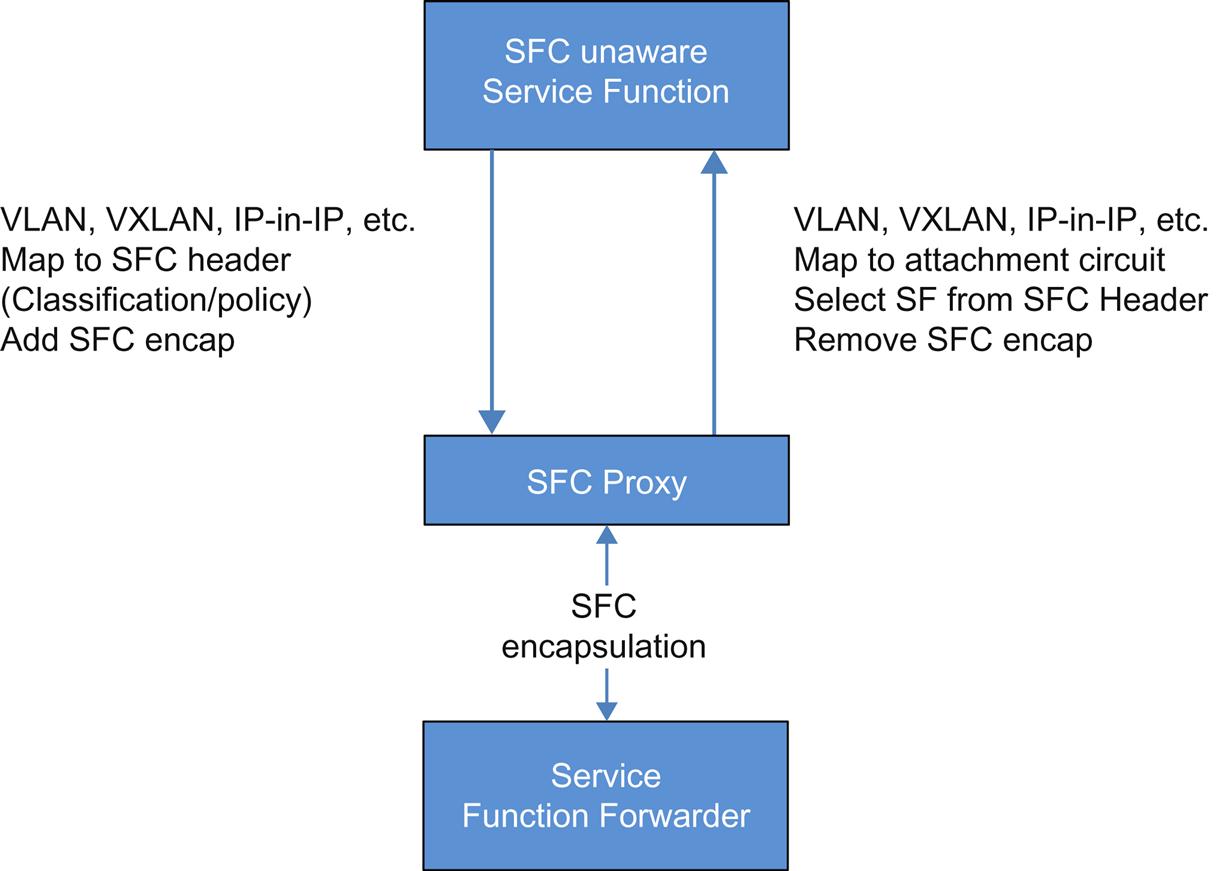
When traffic is returned, a reverse mapping enables the proxy to reapply the encapsulation. If the function has altered the packet it may need to be reclassified which the proxy can do locally or send to a default classification capable node.
In the section “Transport Derived SFF,” the SFC Architecture Document does show some of the remaining tension between MPLS advocacy (by some members) and the need to create a separate service overlay. In essence, it acknowledges that some members advocate using the transport path in the form most likely of an MPLS label stack, and makes it their responsibility or that of the associated control plane, to keep forwarding aligned with the path in the SFC encapsulation.
There are a series of additional topics of interest in the architecture that require more study and we encourage the reader to look further into this by visiting the IETF’s SFC Working Group page and joining its mailing list to follow ongoing discussions8:
• SFC Control Plane—is out of scope, but is envisioned to provide a domain-wide resource view, use policy to construct static or dynamic SFCs and propagate data plane forwarding and metadata specifications to the SFF(s).
• Operations and Management—because the scope is currently single domain, the document suggests that traditional concerns around MTU issues resulting from additional encapsulation via PMTUD9 or by setting link MTU high enough to accommodate SFC encapsulation are sufficient. Further, the document advocates the support of end-to-end Operations and Management (OAM) in-band but declares function validation such as application-level OAM to be clearly out-of-scope. Drafts have be submitted specifically to address OAM, but are still a work in progress.10
• Resilience—is a consideration, but SF state is the responsibility of the SF (multiple techniques exist and these are out-of-scope) and general resilience in the case of changing load are tied to monitoring and control functions (out-of-scope) and leverage of elasticity functions (operations).
NSH Header11
Perhaps the most controversial and important outcome of the SFC workgroup will be the SFC encapsulation. Typical of the IETF, there are two drafts—one submitted early and the other later. These two different approaches may or may not merge.
The dominant draft12 proposes an encapsulation comprised of a base header, SP header, and context headers (Fig. 4.3).

The base header includes version, reserved and enumerated flags (O to indicate an OAM packet and C for the presence of critical metadata), length (6 bits) in 4 byte words (setting maximum header length at 256 words), Next Protocol (IPv4, IPv6, and Ethernet values defined and an IANA registry will be allocated) and a Meta Data Type (MD Type) field.
The MD Type defines the type of metadata beyond the SP header. The values here will also require a new IANA register and two values are defined so far—0x1 indicating that fixed length context headers follow and 0x2 indicating the absence of these context headers.
The SP Header (Fig. 4.4) includes the SPI13 and the Service Index (SI).
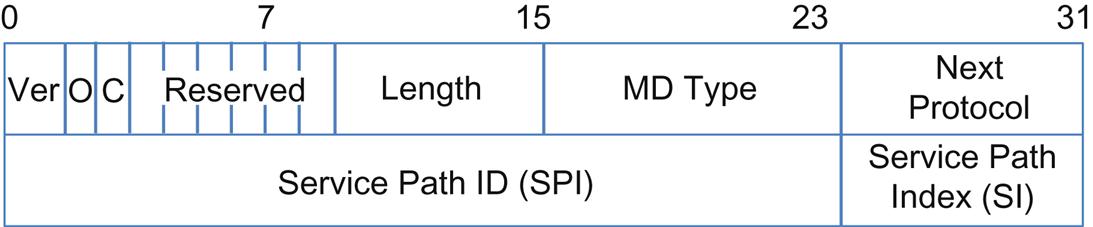
The SPI is a representative and not necessarily a canonical value (recall the separation of the idea of a “rendered” path) and the SI is an index in that path. As the packet progresses through the chain, the SI is decremented so that the SI can also be used as a loop detector/inhibitor. The idea behind the use of the fixed context headers in MD Type 0x1 comes from the desire to avoid a complex registry for metadata and its use is illustrated by examples.
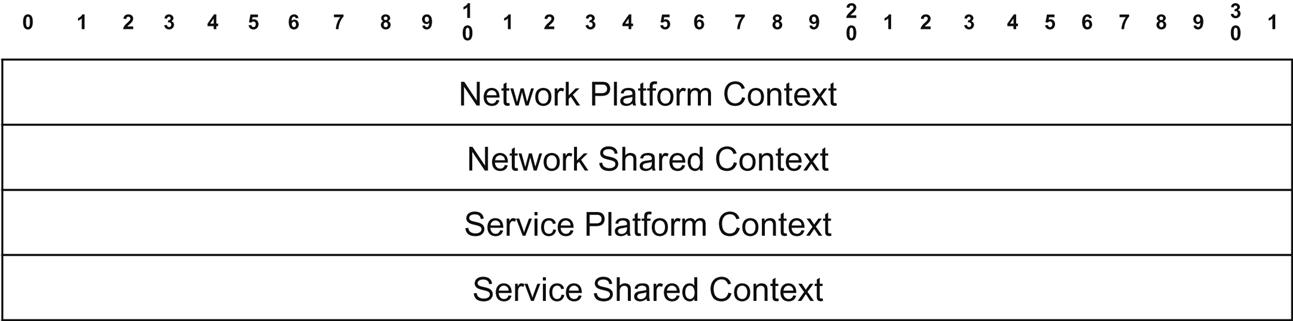
The guidelines given for these headers (Fig. 4.5) is that they have four parts (each 32 bits):
• Network Platform Context—platform-specific information to be shared between network nodes (eg, ingress port, forwarding context, or encapsulation).
• Network Shared Context—metadata relevant to any network node in the chain (eg, a classification result like appID, user identity, or tenant ID(s)).
• Service Platform Context—like the Network Platform Context but for service platforms (eg, identifier used for load balancing decisions).
• Service Shared Context—like the Network Shared Context but shared between service platforms and expected to be more finely grained (eg, appID).
A data center-oriented draft14 illustrates the potential use of the context headers in that environment (Fig. 4.6). The headers are designed to reflect a Data Center-specific usage and focus on application, tenant, or user identification central to DC service chains.

The suggested allocation for the Network Platform Context has a 4-bit wide Flag field with two defined flags (D bit signals whether the third word is Destination Class or Reserved and the F bit signals whether the fourth word is a Service Tag or Opaque). The Source Node ID is a domain unique identifier for the ingress node to the SFC and the Source Interface ID is the locally scoped to that node interface ID of ingress.
The Network Shared Context contains a unique Tenant ID assigned by the control plane. The enumeration of this is out-of-scope for the draft in question.
The Service Platform Context can have an optional Destination Class (signaled by the D bit), which is the result of the logical classification of the destination of the traffic. It also has a Source Class, with similar application to the source of traffic (eg, can represent an application, a group of users, a group of like endpoints). The information in these fields has many uses including Group Policy based networking enforcement.
Finally, the Service Shared Context can contain an optional Service Tag. The draft cites several uses including containing a flow ID, transaction, or application message unit. The flow ID could enable classification bypass, slow-path processing avoidance, and aid in flow programming. If the Service Tag is present, a reserved bit denoted as the A bit, enables acknowledgment of a Service Tag by a SF.
While certain aspects of the proposal are DC-specific such as tenancy, the others might have common application in other environments.
MD Type 2 allows for optional variable length context headers and variable length TLV metadata. MD Type 0x2 can be seen as a compromise around header length in deployments that did not want to include any metadata. They can also be leveraged for private metadata that does not fit the fixed context descriptions (Fig. 4.7).

The TLV Class field allows for both vendor and SDO TLV ownership and the definition of the Type field in this header is the responsibility of the Class owner. The Type does contain a critical (C) bit, to alert the function that the TLV is mandatory to process.15
Both methods of carrying metadata allow augmentation of the enclosed data by intervening SFs in the path.
The Lookup
The idea behind defining a conceptual separation between the SPI and a rendered path is to allow for elasticity and HA mechanisms in the path without having to have separate paths iterated for every service instance of a function. As the draft says, “the SPI provide a level of indirection between the service path/topology and the network transport.”
If the SPI/SI lookup in the SFF results in a single NextHop, then the path is “rendered.” If this happens at every SI, then the SPI IS the rendered path.
The examples of the SFF lookup tables given in the draft show both a centrally administered table (Fig. 4.8) and a split or localized lookup (Fig. 4.9). The latter suggests a split in which there are two tables that comprise the lookup, the SPI/SI that sets the next function SF and local resolution of the SF to an IP NextHop and encapsulation.
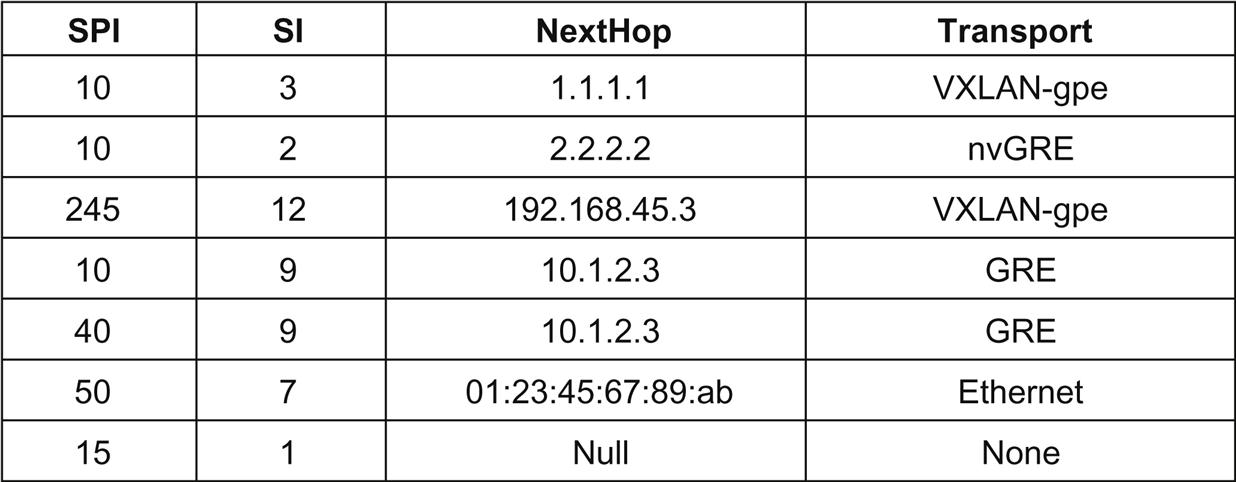

If the SPI/SI lookup in the SFF results in multiple NextHop(s), then the SFF can perform ECMP or weighted ECMP loading (assuming the SF is stateless).
For context-driven distribution, it is feasible that the SFF can do a secondary key lookup, integrate a more sophisticated load balancer or that the SF pointed to in the original lookup has an integrated load distribution function; this is called a composite function. In such cases, the SFF (or load distribution function, regardless of how it is integrated) can use one of the metadata/context fields as a secondary key (eg, mapping Application ID, User ID, to a path by local or centrally administered policy). This enables further load distribution that is locally transparently to the SP/chain.
Worked example
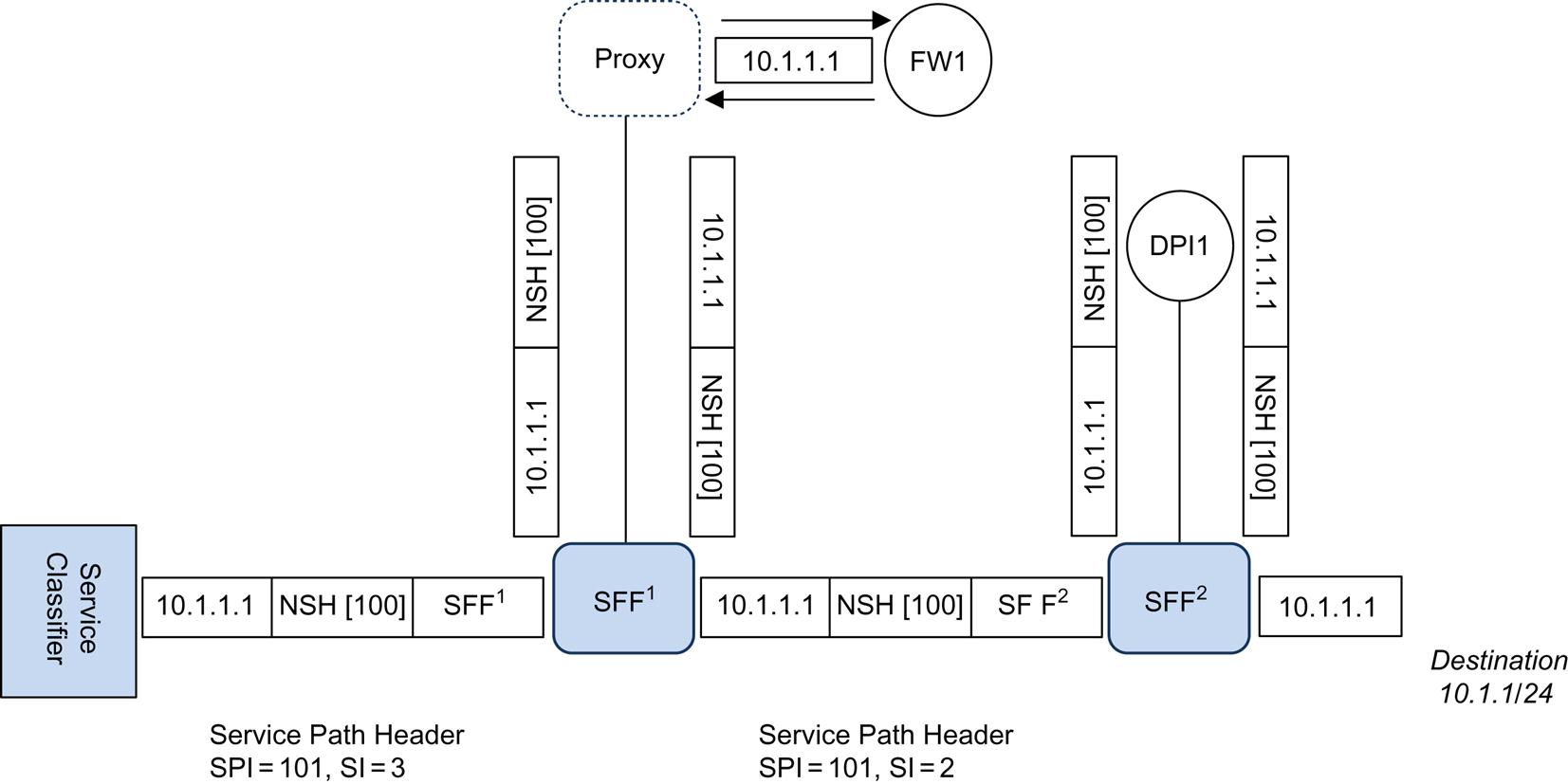
To understand how NSH is supposed to work, it may be best to follow/work an example. In Fig. 4.10, a service chain requiring the ordered traversal of Firewall, DPI, and Video Optimizer functions is depicted.

An SFC specific classifier or multi-purpose network node performs classification of a flow destined for 10.1.1.1/32 and based on that classification imposes the SFC NSH header. Though not shown, the classifier is also a SFF (SFF0). In that header the SPI is 100 and the index points to SFF1 and the Next Protocol Header would indicate IPv4 or Ethernet depending on the received encapsulation.
As an SFF, the classifier performs a SI decrement, does a lookup on the SPI index (which should now point at next SFF beyond “self”), which triggers the transport encapsulation of the frames to reach SFF1 and forwarding on that encapsulation.
The next SFF (SFF1) receives the encapsulated packet, does transport decapsulation, locates the NSH, identifies the local SF, and passes the packet with the NSH header to the function. On return, SFF1 repeats the process of SFF0—SI decrement, the lookup identifying SFF2 as the next hop for the transport encapsulation, etc.
At SFF3, on the return from the VOP function, the SI decrement operation will set the SI to “1,” which will trigger the NSH removal and the resumption of native forwarding. A SI of “0” has special significance—telling the SFF to drop the packet.
If, for some reason, the SF at any step reclassified the traffic in a way that altered the path, it would need to change the NSH base header to reflect the new path.
The SF, SFF, and SC Proxy can all update context information (the latter is most likely with imputed metadata).
In the case of the proxy illustration (Fig. 4.11), we have a simple service chain consisting of a Firewall and a DPI. The Firewall is nonencapsulation aware. Typically, the proxy function would be performed by the SFF, but it can be separate and is illustrated that way for convenience.
The proxy will strip off the NSH header and forward the packet on a local attachment circuit (eg, VLAN, tunnel). Ostensibly, the “direction” of attachment can be the trigger for the restoration of the header (eg, FW1 has two VLANs known to Proxy logically as “to FW1” and “from FW1”) on return.
The most significant aspects of NSH are the vendor community support for the concept16 there are a number of planned implementations and the ability for NICs to perform header offload handling (in the longer term).
Using metadata to enhance reliability
Since the NSH draft was published, creative proposals around the use of metadata to address some of the service management tasks associated with a service overlay have emerged. Examples include:
Source Packet Routing in Networking
The SPRING workgroup focuses on the insertion of an explicit or “source routed” path into the packet transport header and the mechanics of path traversal.
Because Segment Routing for IPv4 uses MPLS label mechanics to follow the transport path, it does not satisfy the NSH goal of path preservation. Attempts to add metadata to an MPLS transport stack would also face several challenges.17 Segment Routing for IPv6 (SRv6),18 however, does preserve the path and has been demonstrated (in IETF9019) to be capable of use in SFC.
The SRv6 proposal20 introduces a new IPv6 Routing Header type (very close to RFC2460, but with changes to make it more flexible and secure). The new header (SRH) is only inspected at each segment hop it is transparent to noncapable devices which only perform IPv6 forwarding on the frame.
The header (Fig. 4.12) consists of a number of housekeeping fields, a segment list, a policy list and the HMAC.
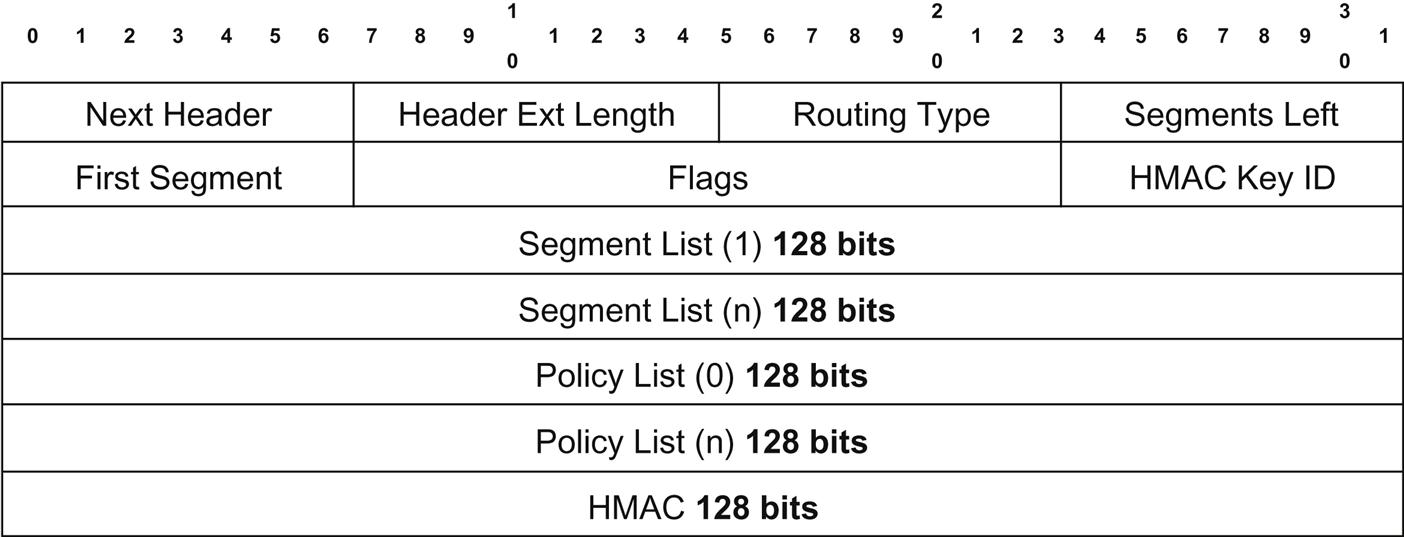
Next Header indicates the type of header immediately following SRH.
The Header Ext Length is an 8-bit unsigned integer that is the length of the header in 8-octet units.
Routing Type has to be assigned by IANA.
Segments Left is the index into the segment list (and functions similarly to the SI in SFC), pointing at the currently active segment.
First Segment is an offset into the SRH (not including the first 8 octets) in 16-octet units pointing to the last segment in the segment list (which is actually the first segment in the path).
Flags comprise of a 16-bit field that is split into four individual flags (each 1 bit): C—cleanup, P—protected (used in conjunction with FRR), 2 bits are Reserved and the remaining bits go to Policy Flags. Policy Flags are used to indicate/define the type of IPv6 addresses preserved/encoded in the Policy List. These 12 bits are subdivided into four (4) 3-bit fields to represent the contents of Policy List segments 1 through 4. The values defined are: 0x0—Not present, 0x1—SR Ingress, 0x2—SR Egress, and 0x3—Original Source Address.
The HMAC fields are used for security and are defined in a separate draft.21
The Segment List is a series of 128-bit IPv6 addresses encoded in the reverse order they would be traversed in the path (eg, last is in position 0 and first is in position “n”/last).
The Policy List as seen in the Flag section above, is an optional list of 128-bit IPv6 addresses that can be used for a variety of debugging and policy related operations.
The Segment List was also envisioned as being used in conjunction with MPLS, where each segment might represent up to four 32-bit labels.
The mechanics of forwarding are illustrated in Fig. 4.13. The transactions are shown linearly, but the individual nodes can be placed arbitrarily in the network with intervening, non-SRH aware IPv6 forwarders (the draft shows a more complex topology).
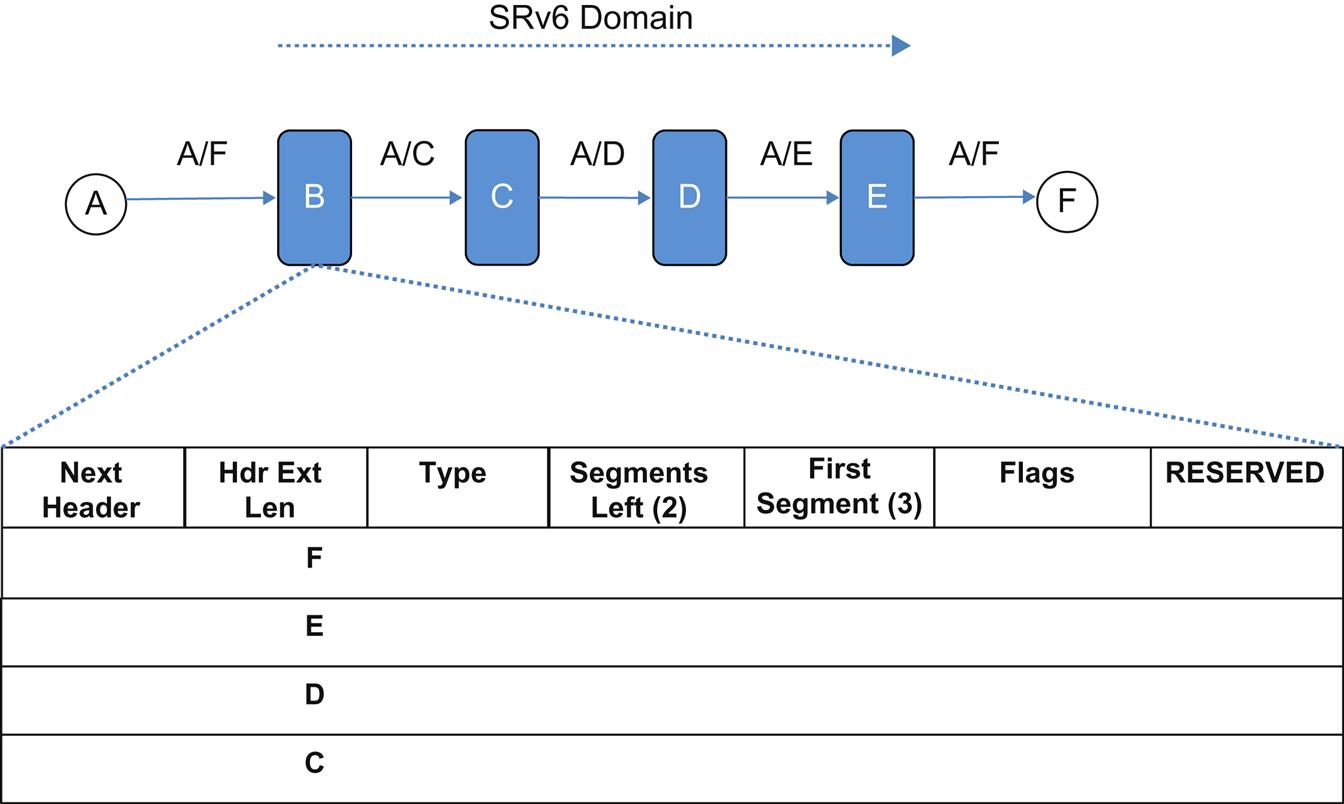
In the figure, Host A is sending to Host F. Through a number of potential mechanisms, B is programmed to impose the SRH on packets in such a flow (A could have imposed the SRH as well). The segment list B is to impose is “C, D, E,” which it does according to specification in reverse order. The Segments Left and First Segments are set “n – 1” (2), where N is the number of segments (3). The original Destination Address in the IPv6 header is replaced with the address of the first segment, and is place at the end of the segment list. The Flags are set to C (clean). The Policy Flags and Policy Segments could be set to reflect ingress/egress SR node (as in the draft), but this is not shown.
As the packet progresses, the SRF aware nodes will swap the address in Segments Left with the IPv6 Destination Address and decrement Segments Left. When the packet gets to E, the Next Segment will be “0.” With the clean bit set, E will replace the IPv6 header Destination Address with F indicating the original destination, and strip the header.
A Demonstration
At IETF90, Cisco Systems, Ecole Polytechnique (Paris), UCL (LLN, Belgium), and Comcast collaborated on a demonstration that used interoperable SRv6 implementations for a specific application called hierarchical caching.
In the use case (illustrated in Fig. 4.14), content for an mpeg-DASH encoded video is encoded into chunks (of short duration). Those specific chunks are IPv6 addressed in the manifest of the video (where the address is usable as a consistent storage lookup mechanism, eg, hash). When the user makes a request for the content, a segment list that represents a series of anycast addresses—each representing a level in a cache hierarchy and ending with the content master—is imposed as part of a SRv6 header at the first provider upstream node from the set top box (based on a classification match).
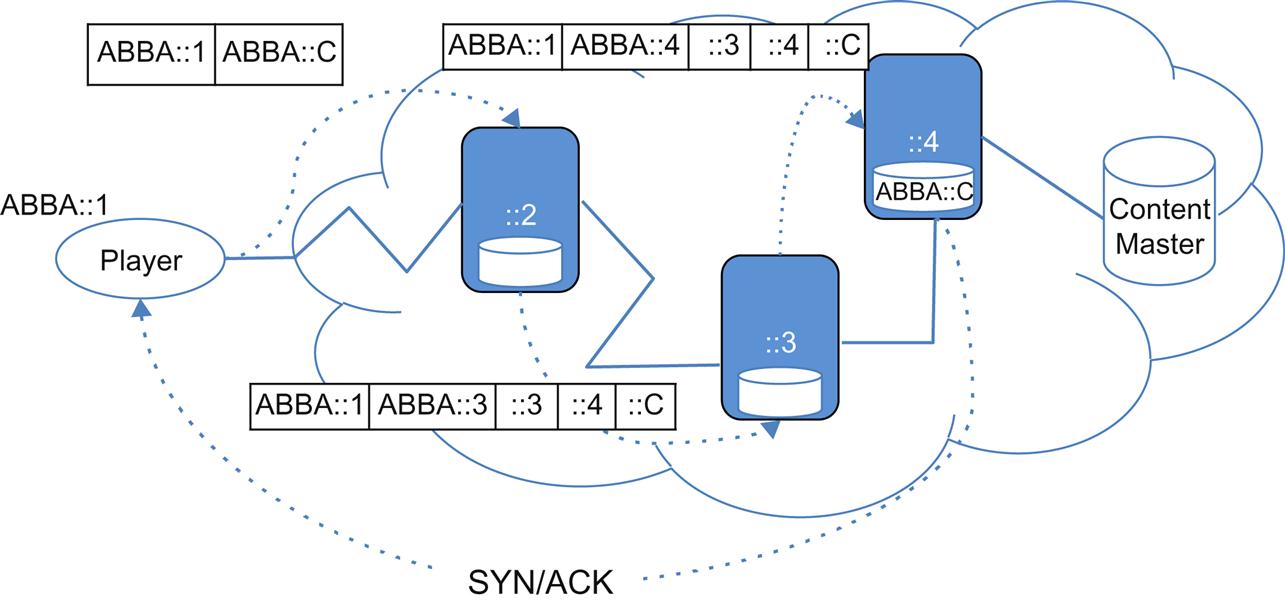
As the TCP/SYN packet reaches each level of the cache hierarchy in the path, the cache does a lookup in its content store (using a key value based on the innermost segment value22). If the content existed, respond with the appropriate ACK so that the session was established, otherwise the packet would progress to the next highest cache level by the SRv6 mechanism. At the highest level of the cache system, the content master, the chunk should always be available at an offset keyed to that chunk address.
The mechanisms for priming the cache or optimizing the cache were unchanged for the trial, such that over time the lowest level cache was populated.
Next for SRv6
Although SRv6 was originally intended as a traffic engineering mechanism, the use of SRv6 in the IETF demonstration shows how SRv6 can be used for a very specific service chaining application.
The reasons for resistance to reassigning transport headers to have significance in encoding metadata for service chaining, are tied to the variable, limited amount of space per encapsulation and interoperability problems this might create in networks that mix encapsulation in their overlays (thus the need for transport independence).23 These are still present in the use of SRv6 (even though there is arguably much more space to work with in the SRH than other encapsulations). The methodology cannot also be applied directly to IPv4 traffic, which presents a level of discontinuity that would have to be addressed for SRv6 to be seen as an SFC protocol.
As a final thought on SRv6, it is clear that it will need to coordinate closely with SFC to avoid the dissolution into transport-specific solutions. That is, to avoid the tendency toward these behaviors alluded to at the beginning of the SFC section of this chapter that could have doomed SFC to failure from the start. The authors of the SRv6 and NSH drafts are working to normalize their approaches to passing of metadata and rationalizing the transport path to the SP, which is hopefully moving things in the right direction. Only time will tell if this carries on, but we hope it does.
Network Modeling
The NETMOD workgroup was not explicitly mentioned in the ETSI Gap Analysis. However, we have included a discussion about what that working group is up to because we feel that this is a fairly significant oversight considering the explosion in not only the interest but the rapid use and deployment of model-driven APIs based on the Yang models this group is responsible for, as well as the Yang language used to create those models.
In 2014 the ETSI architecture’s numerous interfaces that were named but not defined in Phase 1 made no mention of this trend which actually began around that time, albeit slowly.24 This is also a massive oversight given how Yang, Network Configuration Protocol (NETCONF), and most recently RESTCONF are now poised to replace all traditional management protocols. They are even taking a run at replacing the good old command line interface (CLI) with model generated APIs.
The basic charter of the NETMOD Working Group25 is to define and maintain the Yang data modeling language.26 The NETMOD Working Group also defined a number of core data models as basic building blocks for other models to build upon such as RFC731727 as well as guidance about how to best build network data models.28
The Yang language can be used to specify network element data or service models, and recently has stretched to be used as an information modeling language for other uses. Within the context of NETMOD, Yang defines the model, but this model is not carried verbatim “on the wire”; instead, it is encoded using one of various available encoding schemes, but primarily XML today. That encoding is then carried as payload in one of the two officially supported network transport protocols. These are the NETCONF and RESTCONF protocols that contain functions for manipulating the encoded models.
The Yang Data Modeling Language
Yang is a data modeling language originally designed to specify network data models representing functions and features on network elements. The models also represented specific objects that could be read, changed or monitored using The NETCONF. The name Yang is actually an acronym from “Yet Another Next Generation.” The Yang data modeling language was developed by the NETMOD working group in the IETF and was first published as RFC6020 in 2010. However, the language and transport protocol had been in trial or experimental development and use for a number of years prior to that. The language and first transport protocols were designed as an effort to embrace the exact management capabilities expressed in proprietary CLIs, while leveraging many of the advances in standards-based management interfaces such as the Simple Network Management Protocol (SNMP)—and avoiding the shortcomings of those previous management protocols.
The data modeling language can be used to model both configuration data as well as the values of specific data of network elements (ie, the value of an interface counter at any point in time). Furthermore, Yang can be used to define the format of event notifications emitted by network elements. One important feature that was added to Yang that had not previously existed was an allowance for data modelers to specify remote procedure calls (RPCs) and their operation. These functions can then be invoked on network elements via the NETCONF protocol to invoke certain procedures or actions that say go beyond simply fetching the value of a system variable.
Yang is a modular language representing data structures in a tree format. This is convenient because it models how the CLIs on most network devices have always been designed—as a hierarchical tree of commands. The data modeling language contains a number of intrinsic data types such as strings and integers. These basic types can be used to build more complex types forming a very rich set of capabilities. One way more complex data structures can be represented is using groupings as another means of modeling more complex entities by building upon the basic ones. Yang data models can use XPath 1.029 expressions to define inter-node dependencies and references on the elements of a Yang data model.
To add some historical perspective on Yang, it is an evolution of a number of previous network modeling languages including CMIP, TL1, and the SNMP. It can be argued that SNMP was at the time, the most widely deployed management protocol. The data modeling language used to define SNMP’s data models is called The Structure of Management Information (SMI). SMI was based on a subset of The Abstract Syntax Notation One (ASN.1). In later versions of SNMP, the SMI Language was updated and extended and referred to as The SMIv2.
The original development of the NETCONF protocol in the IETF did not rely on models (or a modeling language to define those nonexistent models). Instead, the original protocol relied on an RPC paradigm. In this model, a client would encode an RPC using XML. These requests were sent to a server running on a network element. The server would respond with a reply encoded in XML. The contents of both the request and the response are described in an XML Document Type Definition (DTD) or an XML schema. This would allow the client or server to recognize the syntax constraints needed to complete the exchange of information between the two. However, this was not ideal, and so enhancements were made to tighten up the language insofar as to create a mechanism by which an effective programmable API could be created.
Even after these many enhancements had been made, it was clear that a data modeling language is needed to define data models manipulated by the NETCONF protocol. This created a language for defining the actual objects, their syntax, and their relationship with other objects in the system. This all could be specified prior to any exchange, which also made it easier to build the systems that were used to interact with the managed systems. Given the lineage the original authors of Yang had with the SNMP efforts, it should be unsurprising to find that the syntactic structure and the base type system of Yang was borrowed from SMIng (as are other successful elements of SNMP). When Yang was originally developed, it was tightly bound to the NETCONF protocol. That is to say, operations had to be supported by NETCONF, as well as the carriage of the data specified by the models. In this way, data model instances are serialized into XML and carried by NETCONF. This was recently relaxed to also include a RESTful variant of NETCONF called RESTCONF. Other attempts of late have also tried to extend an invitation to other transports such as ProtoBufs and a few others, as well as attempts to declare Yang a general information modeling language with little or no coupling to its underlying transport. These efforts have failed at the IETF to date, despite adoption in other places by network operators, as was done in the OpenConfig effort described later.
However, given the dramatic increase in model generation within multiple IETF workgroups (NETMOD, NETCONF, L3SM, LIME, I2NSF, and SUPA) and externally, the IESG moved to redistribute the Yang model workload and provide a coordination group30 (as at December 2014). The group is to coordinate modeling within the IETF and across other SDOs and Open Source initiatives. Additionally, they will provide an inventory of existing Yang models, tooling and help with compilation, and training and education.31
Currently, the NETMOD working group is almost complete with an effort to update Yang to version 1.1. This work is expected to be completed and published formally in early 2016.
An example using Yang is shown in Appendix A.
The NETCONF Protocol
As we mentioned earlier, Yang models are carried by several transport protocols. Yang primarily came from an evolution in The NETCONF, and for a time was very tightly bound to it. Today this is much less the case. NETCONF is a protocol developed at the IETF originally to carry configuration and state information to and from management network elements and network managers, as well as to manipulate that information. It was developed in the NETCONF Working Group32 and published in 2006 as RFC4741 and later updated to RFC6241. The NETCONF protocol is widely implemented by popular network devices such as routers and switches. Of late, it has found its way onto pretty much every other type of network element, real or virtual.
All of the operations of the NETCONF protocol are built on a series of basis RPC calls which are described below in some detail. The data carried within NETCONF is encoded using XML. As a first, the NETCONF requires that all of its protocol messages be exchanged using a secure underlying transport protocol such as Secure Sockets Layer (SSL).
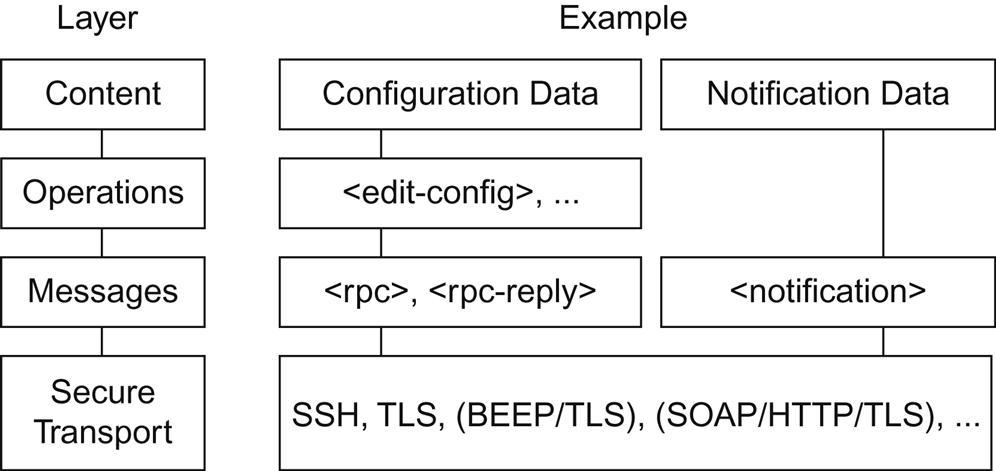
The NETCONF protocol can be partitioned into four logical layers that when used together, form the basis for all of the protocol’s operations including information data transportation:
1. The Content layer consists of configuration data and notification data.
2. The Operations layer defines a set of base protocol operations to retrieve and edit the configuration data.
3. The Messages layer provides a mechanism for encoding RPCs and notifications.
4. The Secure Transport layer provides a secure and reliable transport of messages between a client and a server.
Fig. 4.15 illustrates how these conceptual layers comprising the NETCONF protocol can be mapped to operations such as the modification of configuration information within a management element, or to create notifications that can be emitted by the same device and later processed by a management station.
Operations
The base NETCONF protocol defines some key operations that are used to satisfy the basic protocol requirements of fetching, setting, or deleting a device’s configuration. We have detailed these operations in Fig. 4.16.

The NETCONF functionality described in Fig. 4.16 can also be extended by implementing NETCONF capabilities. These comprise a set of additional protocol features that an implementation supports. When these are defined, they are exposed by either the client or server during the capability exchange portion of a session establishment. During this exchange, only these optional items are included as the mandatory protocol features are assumed by virtue of being mandatory to implement in a compliant implementation. Some optional capabilities such as :xpath and :validate are defined in RFC6241.
A capability to support subscribing and receiving asynchronous event notifications is published in RFC 5277. This document defines the <create-subscription> operation, which enables creating real time and replay subscriptions. Notifications are then sent asynchronously using the <notification> construct. It also defines the :interleave capability, which when supported with the basic :notification capability facilitates the processing of other NETCONF operations while the subscription is active.
Some additional capabilities that are interesting are two that are defined in RFC5717 to support partial locking of the running and one defined in RFC6022 that allows for the monitoring of the NETCONF protocol itself. The former is interesting as it allows multiple sessions to edit nonoverlapping subtrees within the running configuration. This is important because multiple managers can be manipulating the configuration of a device simultaneously. Without this capability, the only lock available is for the entire configuration, which has the obvious consequences. RFC6022 contains a data model that describes data stores, sessions, locks, and statistics contained in a NETCONF server. These things can be used to monitor and manage a NETCONF server much in the way previously was available for SNMP systems. Beyond that, a very important capability it defines are methods for NETCONF clients to discover data models supported by a device using the <get-schema> operation. This capability, while optional, has rapidly become a de facto standard feature demanded by not only network operators, but also those that create network management software and network controllers. When this capability is available, a device can be “discovered” dynamically and its model and capability contents read out at run time. This is an important distinction from previous models of operation that were very static, and assumed a device was shipped with a specific firmware image whose capabilities would not change inflight. That made sense in the previous world where vendor-specific hardware was deployed to run specific services and so forth. However, this new functionality is needed in the new world of virtualized machines and services, as those things can be rapidly changed. Another important reason for this is that the software that interacts with these components can change dynamically, and it better suits this new model of software to be able to dynamically read and interact with model changes of devices.
Message Layer
The NETCONF message layer provides a simple, transport-independent framing mechanism for encoding messages exchanged between a NETCONF client and server. There are really three types of messages described as:
Messages are really categorized as RPC Messages33 or as Event Notifications.34 As mentioned above, NETCONF messages are transmitted as what are referred to as a well-formed XML document. An RPC result is matched up with an RPC invocation using a message-id attribute. This is how a message exchange is essentially tracked. One advantage that NETCONF has over previous management protocols such as SNMP is that its messages can be pipelined, effectively allowing a client to send multiple invocations in parallel and simply wait for the responses.
Secure Transports
NETCONF messages are exchanged using a number of available secure transport protocols. A secure transport provides end point authentication, data integrity, confidentiality, and assurances that replay of message exchanges are not possible. It is mandatory for any compliance implement to implement the SSH Protocol.35 The Transport Layer Security (TLS) Protocol is also defined, albeit optionally, as an available secure transport.36 RFC 5539 defines a secure transport using TLS. Other secure transports were defined in the past, but are not declared as historic and are unused, so we will not mention them here.
The RESTCONF Protocol
REST (seen also as ReST) stands for Representational State Transfer. This type of protocol relies on a stateless client-server communications protocol. In reality this usually means the HTTP protocol is used. REST itself is an architecture style for designing networked applications, and specifically how they interact with each other. Specifically, REST is a style that specifies interactions between clients and servers be accomplished using a limited but well-defined number of actions, known as verbs. Because these verbs are limited, but have a well-defined specific meaning, the constrain and simplify the functionality of the interface. These verbs are defined as GET (ie, read), POST (ie, create), PUT (ie, update), and DELETE (ie, delete). Flexibility of the interface is achieved by assigning resources known as nouns or methods, to a unique universal resource identifier (URI). This description is contained in an XML file that can be fetched by a client. This page can also include the content that the client seeks. For example, a REST-like protocol might be one that is defined as running over HTTP for accessing data defined in Yang using data stores defined in NETCONF. An example of this is the RESTCONF protocol that was standardized by the IETF. This Standard describes how to map a Yang specification to a RESTful interface. The REST-like API is not intended to replace NETCONF, but rather provide an additional yet simplified interface that follows the REST principles just described, but remains compatible with a resource-oriented device abstraction as well as the already defined Yang models.
Like NETCONF before it, the RESTCONF protocol operates on a Yang model (ie, a conceptual data store defined by the YANG data modeling language). The NETCONF server lists each YANG module it supports under “/restconf/modules” in the top-level API resource type, using a structure based on the Yang module capability URI format. In this way a client can browse the supported list of modules by simply querying this portion of the data store. The conceptual data store contents, data-model-specific operations and notification events are identified by this set of YANG module resources. Similar to NETCONF, RESTCONF defines content as one of an operation resource, an event stream resource, or a data resource. All of these are defined using the Yang language.
The classification of data as configuration or nonconfiguration data is derived from the Yang “config” statement, and is an important distinction to make on the data store’s contents. Data ordering of either configuration or nonconfiguration data is stipulated through the use of the Yang “ordered-by” statement.
The Public Github Yang Repository
As we mentioned earlier in the chapter, many organizations have moved rapidly towards the adoption of Yang models as well as NETCONF and RESTCONF. To this end, many have taken on the task of development of Yang models. However, one interesting change from the past modes of development of these artifacts is the desire to build them with the collaboration and help of a wider community. To this end, many organizations including The IETF,37 Metro Ethernet Forum (MEF),38 Open Config,39 OpenDaylight,40 and The Institute of Electrical and Electronics Engineers (IEEE)41 have adopted the use of an open area on github.com that has been created for this purpose that we refer to as the Public Yang Repository or, more colloquially, “The Public Yang Repo.” In addition to those organizations, a number of vendors, including Cisco, Brocade, and Yumaworks, have elected to push their proprietary models here. One advantage to having these models all in one place is the simplicity of finding them all together. This not only encourages reuse of various components of models, but also help application builders find them without much fanfare.
The Public Yang Repo can be found by pointing your browser (or favorite github client) at https://github.com/YangModels/yang and looking through the models. A screen shot of the site’s home area is shown in Fig. 4.17.
Most anyone is welcome and encouraged to contribute models here, as well as collaborate with the community of people using the area. The community utilizes the canonical “committer” model of administering the site and moderating the check-ins of models, especially to the “standard” area which simply keeps the quality of the models high. For example, we maintain a set of “stable” models in the repository under most circumstances. In short, this means that the models compile with the industry standard pyang compiler.42 This at least ensures syntactic accuracy, but also does some “link” like checks on the models. We also periodically have others review the models in the repository to help improve them. Of course, those in the “standard” area are reflections of those found in some organization’s official standard area.
Conclusions
The bottom line is that, without SFC (its service layer abstraction and metadata passing), creating meaningful services puts a huge burden on orchestration.
We can admittedly build service chains without SFC using traditional methodologies like VLANs or transport tunnel overlays, but any elasticity means churning the underlay/overly to keep the transport path coherent with the SP. This is an extremely important point justifying the need for a service layer separate from transport: by integrating control over a flow in the NSH header, you do not have to worry about synchronizing protocol state (synchronization is implicit).
We can optimize a single VNF (eg, a vFW) and call it a service (“Security”), but to do so is incremental OPEX/CAPEX reduction (eg, optimization of the spend on an appliance). Will that contribute meaningfully to revenue generation? Complex services (more than a single “atom” of functionality) require SFC.
Further, the ability to share data between functions makes services intelligent, manageable, and (potentially) personal/customized. Without, it the services we build may be constrained to emulating existing services instead of imagining new ones.
SFC might need to be visited again as the concept of “composable” functions proliferates (a naiive vision in the early ETSI work but rapidly evolving as container, unikernel and “microservice” concepts are considered as replacements for the early “service-per-VM” ETSI model). Equivalents or functionality mappings for inter-process communication (not traversing the vSwitch between functions) may need to be developed.
There is still some tension in the IETF between transport-based service chaining solutions and the service overlay concept. Given the size of the existing IPv6 packet header (and its extensibility) the most potential for a merger of these views exists in SRv6.
It is clear that organizations such as the IETF play an important role in the development of some of the critical protocols and API in the area of VNF control and configuration such as NETCONF and RESTCONF. The IETF also plays a significant role in defining the Yang language which has rapidly become the industry standard for data modeling languages and model-driven API generation. However, it is important to also observe that other less traditional (and often open source) organizations—or even nonorganizations per se—are playing important roles too. To this end, we examined the growing community that has formed around The Public Yang Repo on github and highlighted the IETF’s own recognition of the need for interorganizational outreach and education. These organizations will continue to grow and play an important role in not only shaping how models are developed, but also in actually developing those models.
Appendix A
Example of Yang Model usage
The following example is taken from the Open Daylight Toaster tutorial and is shown here as an example of a Yang model that contains may of the important components found in any model. The toaster example is modeled after the canonical SNMP toaster MIB example found in many tutorials, and is also shipped with many of the popular toolkits. The general idea is to model a toaster that is controlled by SNMP, except in this case it is modeled with Yang and controlled with RESTCONF or NETCONF. Note that the example is slightly out-of-date in that the organizational information is not current, but it will suffice as an example. It is not our intent to create a full example of how to design and build Yang models here as many great tutorials exist online and in other places.
//This file contains a YANG data definition. This data model defines
//a toaster, which is based on the SNMP MIB Toaster example
module toaster {
//The yang version - today only 1 version exists. If omitted defaults to 1.
yang-version 1;
//a unique namespace for this toaster module, to uniquely identify it from other modules that may have the same name.
namespace
"http://netconfcentral.org/ns/toaster";
//a shorter prefix that represents the namespace for references used below
prefix toast;
//Defines the organization which defined / owns this .yang file.
organization "Netconf Central";
//defines the primary contact of this yang file.
contact
"Andy Bierman <andy@netconfcentral.org>";
//provides a description of this .yang file.
description
"YANG version of the TOASTER-MIB.";
//defines the dates of revisions for this yang file
revision "2009-11-20" {
description
"Toaster module in progress.";
}
//declares a base identity, in this case a base type for different types of toast.
identity toast-type {
description
"Base for all bread types supported by the toaster. New bread types not listed here nay be added in the future.";
}
//the below identity section is used to define globally unique identities
//Note - removed a number of different types of bread to shorten the text length.
identity white-bread {
base toast:toast-type; //logically extending the declared toast-type above.
description "White bread."; //free text description of this type.
}
identity wheat-bread {
base toast-type;
description "Wheat bread.";
}
//defines a new "Type" string type which limits the length
typedef DisplayString {
type string {
length "0 .. 255";
}
description
"YANG version of the SMIv2 DisplayString TEXTUAL-CONVENTION.";
reference
"RFC 2579, section 2.";
}
// This definition is the top-level configuration "item" that defines a toaster. The "presence" flag connotes there
// can only be one instance of a toaster which, if present, indicates the service is available.
container toaster {
presence
"Indicates the toaster service is available";
description
"Top-level container for all toaster database objects.";
//Note in these three attributes that config = false. This indicates that they are operational attributes.
leaf toasterManufacturer {
type DisplayString;
config false;
mandatory true;
description
"The name of the toaster's manufacturer. For instance, Microsoft Toaster.";
}
leaf toasterModelNumber {
type DisplayString;
config false;
mandatory true;
description
"The name of the toaster's model. For instance, Radiant Automatic.";
}
leaf toasterStatus {
type enumeration {
enum "up" {
value 1;
description
"The toaster knob position is up. No toast is being made now.";
}
enum "down" {
value 2;
description
"The toaster knob position is down. Toast is being made now.";
}
}
config false;
mandatory true;
description
"This variable indicates the current state of the toaster.";
}
} // container toaster
} // module toaster