CHAPTER 10
Looking for
the Edge
Finding Historical Patterns
in Markets
Science is the great antidote to the poison of enthusiasm and superstition.—Adam Smith
Traders commonly refer to having an edge in markets. What this means is that they have a positive expectancy regarding the returns from their trades. Card counting can provide an edge to a poker player, but how can traders count the cards of their markets and put probabilities on their side? One way of accomplishing this is historical investigation. While history may not repeat exactly in markets, we can identify patterns that have been associated with a directional edge in the past and hypothesize that these will yield similar tendencies in the immediate future. By knowing market history, we identify patterns to guide trade ideas.
So how can we investigate market history to uncover such patterns? This has been a recurring topic of reader interest on the TraderFeed blog. If you’re going to mentor yourself as a trader, your efforts will be greatly aided by your ability to test the patterns you trade. After all, if you know the edge associated with what you’re trading, you’re most likely to sustain the confidence needed to see those trades through.
A thorough presentation of testing market ideas would take a book in itself, but this chapter should get you started. Armed with a historical database and Excel, you can greatly improve your ability to find worthy market hypotheses to guide your trading. Let’s get started . . .
LESSON 91: USE HISTORICAL PATTERNS IN TRADING
A trading guru declares that he has turned bearish because the S&P 500 Index has fallen below its 200-day average. Is this a reasonable basis for setting your trading or investing strategy? Is there truly an edge to selling the market when it moves below its moving averages?
The only way we can determine the answer is through investigation. Otherwise, investing and trading become little more than exercises in faith and superstition. Because markets have behaved in a particular way in the past does not guarantee that they will act that way now. Still, history provides the best guide we have. Markets, like people, will never be perfectly predictable. But if we’ve observed people over time in different conditions, we can arrive at some generalizations about their tendencies. Similarly, a careful exploration of markets under different historical conditions can help us find regularities worth exploiting.
As it turns out, moving average strategies—so often touted in the popular trading press—are not so robust. As of my writing this, since 1980, the average 200-day gain in the S&P 500 Index following occasions when we’ve traded above the 200-day moving average has been 8.68 percent. When we’ve been below the 200-day moving average, the next 200 days in the S&P 500 Index have returned 7.32 percent. That’s not a huge difference, and it’s hardly grounds to turn bearish on a market. When David Aronson tested more than 6,000 technical indicators for his excellent book, Evidence-Based Technical Analysis, he found a similar lack of robustness: not a single indicator emerged as a significant predictor of future market returns.
Investigate before you invest: Common trading wisdom is uncommonly wrong.
One way that historical patterns aid our self-coaching is by helping us distinguish myth from fact. “The trend is your friend” we commonly hear. My research on the blog, however, has consistently documented worse returns following winning days, weeks, and months than following losing ones. It is not enough to accept market wisdom at face value: just as you would research the reliability of a vehicle before making a purchase, it makes sense to research the reliability and validity of trading strategies.
There are traders who make the opposite mistake and trade mechanically from historical market patterns. I have seen an unusual proportion of these traders blow up. Market patterns are relative to the historical period that we study. If I examine the past few years of returns in a bull market, I will find significant patterns that will completely vanish in a bear market. If I include many bull and bear markets in my database, I will go back so far in time that I will be studying periods that are radically different from the current one in terms of who and what are moving markets. Automated, algorithmic strategies have completely reshaped market patterns, particularly over short time periods. If you study precomputer-era markets you would miss this influence altogether. Select a look-back period for historical analysis that is long enough to cover different markets but not so lengthy as to leave us with irrelevant data is as much art as science.
My approach to trading treats historical market patterns as qualitative research data. In a nutshell, qualitative research is hypothesis-generating research, not hypothesis-testing research. I view the patterns of markets as sources of trading hypotheses, not as fixed conclusions. The basic hypothesis is that the next trading period will not differ significantly from the recent past ones. If a pattern has existed over the past X periods, we can hypothesize that it will persist over the next period. Like any hypothesis, this is a testable proposition. It is an idea backed by support, not just faith or superstition, but it is not accepted as a fixed truth to be traded blindly.
Historical testing yields hypotheses for trading, not conclusions.
For this reason, I do not emphasize the use of inferential statistics in the investigation of historical patterns. I am looking for qualitative differences much as a psychologist might look for various behavior patterns in a person seeking therapy. In short, I’m looking to generate a hypothesis, not test one. The testing, in the trading context, is reflected in my trading results: if my returns significantly exceed those expected by chance, we can conclude that I am trading knowledge, not randomness.
When we adopt a qualitative perspective, the issue of look-back period becomes less thorny. As long as we consider the results of historical investigations to be nothing more than hypotheses, we can draw our ideas from the past few weeks, months, years, or decades of trading. The basic hypothesis remains the same: that the next time period will not differ significantly from the most recent ones. With that in mind, we can frame multiple hypotheses derived from different patterns over different time frames. One hypothesis, for example, might predicate buying the market based on strong action at the close of the prior day, with the anticipation of taking out the previous day’s R1 pivot level. A second hypothesis might also entail buying the market based on a pattern of weakness during the previous week’s trading. When multiple independent patterns point in the same direction, we still don’t have a certain conclusion, but we do have a firm hypothesis.
When independent patterns point to similar directional edges, we have especially promising hypotheses for trading.
Of course, if we generate enough hypotheses, some are going to look promising simply as a matter of chance. We could look at all combinations of Dow stocks, day of week, and week of year and the odds are good that we’d find some pattern for some stock that looks enticing, such as (to invent one possibility) IBM tends to rise on the first Wednesday of months during the summer season. Good hypotheses need to make sense; you should have some idea of why they might be valid. It makes sense, for instance, to buy after a period of weakness because you would benefit from short covering and an influx of money from the sidelines. It doesn’t make sense to buy a stock on alternate Thursdays during months that begin with M—no matter what the historical data tell you.
When you’re first learning to generate good hypotheses, your best bet is to keep it simple and get your feel for the kinds of patterns that are most promising. Many of your initial candidates will emerge from investigations of charts. Perhaps you’ll notice that it has been worth selling a stock when it rises on unusually high volume, or that markets have tended to bounce following a down open that follows a down day. Such ideas are worth checking out historically. What patterns have you noticed in your trading and observation? Write down these patterns and keep them simple: these patterns will get you started in our qualitative research.
COACHING CUE
Several newsletters do an excellent job of testing historical patterns and can provide you with inspiration for ideas of your own. Check out the contributions of Jason Goepfert, Rob Hanna, and Rennie Yang in Chapter 9, along with their links. All three are experienced traders and investigators of market patterns.
LESSON 92: FRAME GOOD HYPOTHESES WITH THE RIGHT DATA
In the previous lesson, I encouraged you to keep hypotheses simple. This is not just for your learning; in general, we will generate the most robust hypotheses if we don’t try to get too fancy and add many conditions to our ideas. Ask a question that is simple and straightforward, such as, “What typically happens the week following a very strong down week?” This question is better than asking, “What typically happens the week following a very strong down week during the month of March when gold has been up and bonds have been down?” The latter question will yield a small sample of matching occasions—perhaps only three over many years—so that it would be difficult to generalize from these. While I will occasionally look at patterns with a small N simply as a way to determine if the current market is behaving in historically unusual ways, it is the patterns that have at least 20 occurrences during a look-back period that will merit the greatest attention. The more conditions we add to a search, the more we limit the sample and make generalization difficult.
The simplest patterns will tend to be the most robust.
Of course, the number of occurrences in a look-back period will partly depend on the frequency of data that you investigate. With 415 minutes in a trading day for stock index futures, you would have 8,300 observations of one-minute patterns in a 20-day period. If you were investigating daily data, the same number of observations would have to cover a period exceeding 30 years. Databases with high frequency data can become unwieldy in a hurry and require dedicated database applications. The simple historical investigations that I conduct utilize database functions in a flat Excel file. When I investigate a limited number of variables over a manageable time frame, I find this to be adequate to my needs. Clearly, a system developer who is going to test many variables over many time frames would need a relational database or a dedicated system-testing platform, such as TradeStation. The kind of hypothesis-generating activities covered in this chapter are most appropriate for discretionary traders who would like to be a bit more systematic and selective in their selection of market patterns to trade—not formal system developers.
Before you frame hypotheses worthy of historical exploration, you need to create your data set. This data set would include a range of variables over a defined time period. The variables that you select would reflect the markets and indicators that you typically consult when making discretionary trading decisions. For instance, if you trade off lead-lag relationships among stock market sectors, you’ll need to include sector indexes/ETFs in your database. If you trade gap patterns in individual stocks, you’ll need daily open-high-low-close prices for each issue that you trade at the very least. Some of the patterns I track in my own trading involve the number of stocks making new highs or lows; this is included in my database with separate columns on a sheet dedicated to each.
As you might suspect, a database can get large quickly. With a column in a spreadsheet for each of the following: date, open price, high price, low price, closing price, volume, rate of change, and several variables (indicators) that you track, you can have a large sheet for each stock or futures contract that you trade—particularly if you are archiving intraday data. I strongly recommend that beginners at this kind of historical investigation get their feet wet with daily data. This process will keep the data sets manageable and will be helpful in framing longer timeframe hypotheses that can supplement intraday observation and judgment. Many good swing patterns can be found with daily data and clean, affordable data are readily available.
Some of the most promising historical patterns occur over a period of several days to several weeks.
There are several possible sources for your historical database. Many real-time platforms archive considerable historical data on their servers. You can download these data from programs such as e-Signal and Real Tick (two vendors I’ve personally used) and update your databases manually at the end of the trading day. The advantage of this solution is that it keeps you from the expense of purchasing historical data from vendors. It also enables you to capture just the data you want in the way you want to store them. This is how I collect most of my intraday data for stock index futures and such variables as NYSE TICK. My spreadsheet is laid out in columns in ways that I find intuitive. The entire process of updating a sheet, including built in charts, takes a few minutes at most.
A second way you can go, which I also use, is to purchase historical data from a vendor. I obtain daily data from Pinnacle Data (
www.pinnacledata.com), which includes an online program for updating that is idiot-proof. Many of their data fields go back far in market history, and many of them cover markets and indicators that I would not be able to easily archive on my own. The data are automatically saved in Excel sheets, with a separate sheet for each data element. That means that you have to enter the different sheets and pull out all the data relevant to a particular hypothesis and time frame. The various fields can be copied onto a single worksheet that you can use for your historical investigations (more on this later). Among the data that I find useful from Pinnacle Data are advance-decline information; new highs/lows; volume (including up/down volume); interest rates; commodity and currency prices; and weekly data. These data are general market data, not data for individual equities. When I collect individual equity data, I generally find the historical data from the real-time quotation platforms to be adequate to my needs.
For the collection of clean intraday data, I’ve found TickData (
www.tickdata.com) to be a particularly valuable vendor. The data management software that accompanies the historical data enables you to place the data in any time frame and store them as files within Excel. This is a great way to build a historical database of intraday information quickly, including price data for stocks and futures and a surprising array of indicator data.
If you go with a historical data vendor, you’ll have plenty of data for exploration and the updating process will be easy. Manual updating of data from charting platforms is more cumbersome and time-consuming, but obviously cheaper if you’re already subscribing to the data service. It is important thing that you obtain the data you most want from reliable sources in user-friendly ways. If the process becomes too cumbersome, you’ll quickly abandon it.
As your own trading coach, you want to make the learning process stimulating and enjoyable; that is how you’ll sustain positive motivation. Focus on what you already look at in your trading and limit your initial data collection to those elements. Price, volume, and a few basic variables for each stock, sector, index, or futures contract that you typically look at will be plenty at first. Adding data is never a problem. The key is to organize the information in a way that will make it easy for you to pull out what you want, when you want it. As you become proficient at observing historical patterns, you’ll be pleasantly surprised at how this process prepares you for recognizing the patterns as they emerge in real time.
COACHING CUE
Consider setting up separate data archives for daily and weekly data, so that you can investigate patterns covering periods from a single day to several weeks. You’d be surprised how many hypotheses can be generated from simple open-high-low-close price data alone. How do returns differ after an up day versus a down day? What happens after a down day in which the day’s range is the highest of the past 20 days? What happens after three consecutive up or down days? How do the returns differ following a down day during a down week versus a down day during an up week? You can learn quite a bit simply by investigating price data.
LESSON 93: EXCEL BASICS
In this lesson, I’ll go over just a few essentials of Excel that I employ in examining historical market data. If you do not already have a basic understanding of spreadsheets (how cells are named, how to copy information and paste it into cells, how to copy data from one cell to another, how to create a chart of the data in a sheet, how to write simple formulas into cells), you’ll need a beginning text for Excel users. All of the things we’ll be reviewing here are true basics; we won’t be using workbooks linking multiple sheets, and we won’t be writing complex macros. Everything you need to formulate straightforward hypotheses from market data can be accomplished with these basics.
So let’s get started. Your first step in searching for market patterns and themes is to download your historical data into Excel. Your data vendors will have instructions for downloading data; generally this will involve copying the data from the charting application or from the data vendors’ servers and pasting them into Excel. If, for instance, you were using e-Signal (
www.esignal.com) as a real-time data/charting application, you would activate the chart of the data you’re interested in by clicking on that chart. You then click on the menu item Tools and then click on the option for Data Export. A spreadsheet-like screen will pop up with the chart data included. Along the very top row, you can check the boxes for the data elements you want in your spreadsheet. If there are data in the chart that you don’t need for your pattern search, you simply uncheck the boxes for those columns.
On that spreadsheet screen in e-Signal, if you click on the button for Copy to Clipboard, you will place all of the selected data on the Windows clipboard, where the data elements are stored as alphanumeric text. You then open a blank sheet in Excel, click on the Excel menu item for Edit, and select the option for Paste. That will place the selected data into your Excel spreadsheet.
If you had wanted more historical data than popped up in the e-Signal spreadsheet-like screen, you would have to click your chart and drag your mouse to the right, moving view of the data into the past. Move it back as far as you need and then go through the process of clicking on Tools, selecting Data Export, etc. If you need more historical data than e-Signal (or your current charting/data vendor) carries on their servers, that’s when you’ll need to subscribe to a dedicated historical data source such as Pinnacle Data (
www.pinnacledata.com).
If you need data going back many years for multiple indicators or
instruments, you’ll want to download data from a historical data
vendor who has checked the data for completeness and accuracy.
If you’re using Pinnacle Data, you can automatically update your entire database daily with its Goweb application. The program places all the updated data into Excel sheets that are stored on the C drive in a folder labeled Data. The IDXDATA folder within Data contains spreadsheets with each instrument or piece of data (S&P 500 Index open-high-low-close; number of NYSE stocks making 52-week highs) in its own spreadsheet. Once you open these sheets, you can highlight the data from the historical period you’re interested in, click on the Edit menu item in Excel, click on the Copy option, open a fresh, blank spreadsheet, click on Edit, and then click on the Paste option. By copying from the Pinnacle sheets and pasting into your own worksheets, you don’t modify your historical data files when you manipulate the data for your analyses.
Personally, I would not subscribe to a data/charting service that did not facilitate an easy downloading of data into spreadsheets for analysis. It’s also helpful to have data services that carry a large amount of intraday and daily data on their servers, so that you can easily retrieve all the data you need from a single source. In general, I’ve found e-Signal and Pinnacle to be reliable clean sources of data. There are others out there, however, and I encourage you to shop around.
When you download data for analysis, save your sheets in folders that will help you organize your findings and give the sheets names that you’ll recognize. Over time, you’ll perform many analyses; saving and organizing your work will prevent you from having to reinvent wheels later.
Once you have the data in your sheet, you’ll need to use formulas in Excel to get the data into the form you need to examine patterns of interest. Formulas in Excel will begin with an = sign. If, for example, you wanted to calculate an average value for the first 10 periods of price data (where the earliest data are in row 2 and later data below), you might enter into the cell labeled D11: “=average(C2:C11),” without typing the quotation marks. That will give you the simple average (mean) of the price data in cells C1 through C10. If you want to create a moving average, you could simply click on the D10 cell, click the Excel menu item for copy, left-click your mouse and drag from cell D11 down, and release. Your column D cells will update the average for each new cell in column C, creating a 10-period moving average.
As a rule, each column in Excel (labeled with the letters) will represent a variable of interest. Usually, my column A is date, column B is time (if I’m exploring intraday data), column C is open price, column D is high price, column E is low price, and column F is closing price. Column G might be devoted to volume data for each of those periods (if that’s part of what I’m investigating); columns H and above will be devoted to other variables of interest, such as the data series for another index or stock or the readings of a market indicator for that period. Each row of data is a time period, such as a day. Generally, my data are organized so that the earliest data are in row 2 and the later data fall underneath. I save row 1 for data labels, so that each column is labeled clearly: DATE, OPEN, HIGH, LOW, CLOSE, etc. You’ll see why this labeling is helpful when we get to the process of sorting the data.
Here are some simple statistical functions that I use frequently to examine data in a qualitative way. Each example assumes that we’re investigating the data in column C, from cells 1 through 10:
• =median(C2:C11) - The median value for the data in the formula.
• =max(C2:C11) - The largest value for the data in the formula.
• =min(C2:C11) - The smallest value for the data in the formula.
• =stdev(C2:C11) - The standard deviation for the data in the formula.
• =correl(C2:C11,D2:D11) - The correlation between the data in columns C and D, cells 1-10.
Much of the time, our analyses won’t be of the raw data, but will be of the changes in the data from period to period. The formula =(C3-C2) gives the difference from cell C2 to cell C3. If we want to express this difference as a percentage (so that we’re analyzing percent price changes from period to period), the formula would read = ((C3-C2)/C2)*100. This takes the difference of cells C3 and C2 as a proportion of the initial value (C2), multiplied by 100 to give a percentage.
When we want to update later cells with the percentage difference information, we don’t need to rewrite the formulas. Instead, as noted above, we click on the cell with the formula, click on the Excel menu item Edit, click on copy, then left click the cell below the one with the formula and drag down as far as we want the data. The spreadsheet will calculate price changes for each of the time periods that you selected by dragging. This means that if you save your formulas into worksheets, updating your data is as simple as downloading the fresh data from your vendor, pasting into the appropriate cells in your sheets, and copying the data from formulas for the cells representing the new data period. Once you’ve organized your sheets in this manner, it thus only takes a few minutes a day to completely update.
Once you create a spreadsheet with the appropriate formulas, updating your analyses is mostly a matter of pasting and copying. As a result, you can update many analyses in just a few minutes.
Once again, the basic formulas, arrangement of rows and columns, and copying of data will take some practice before you move on to actual analyses. I strongly encourage you to become proficient with downloading your data from your vendor/application and manipulating the data in Excel with copying, pasting, and formula writing before moving on. Once you have these skills, you’ll have them for life, and they will greatly aid your ability to generate promising trading hypotheses.
COACHING CUE
Trading platforms that support Dynamic Data Exchange (DDE) enable you to link spreadsheets to the platform’s data servers, so that the spreadsheets will populate in real time. This is helpful for tracking indicators as you trade, and it can also be a time-efficient way to archive data of interest. See Rennie Yang’s segment in Chapter 9 for an illustration of the use of DDE.
LESSON 94: VISUALIZE YOUR DATA
One of the best ways to explore data for possible relationships is to actually see the data for yourself. You can create simple charts in Excel that will enable you to see how two variables are related over time, identifying possible patterns that you might not have noticed from the spreadsheet rows and columns. For instance, when charting an indicator against a market average, you may notice divergence patterns that precede changes in market direction. Should you notice such patterns frequently, they might form the basis for worthwhile historical explorations.
Again, a basic introductory text for Excel users will cover the details of creating different kinds of charts, from column charts to line graphs to pie charts. You’ll also learn about the nuances of changing the colors on a chart, altering the graphics, and labeling the various lines and axes. In this lesson, I’ll walk you through a few basics that will get you started in your data exploration.
Many times, you can identify potential trading hypotheses by seeing relationships among data elements.
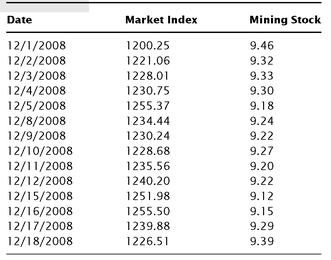
A simple chart to begin with will have dates in column A, price data in column B, and a second set of price data in column C (see
Table 10.1). This chart is helpful when you want to visualize how movements in the first trading instrument are related to movements in the second. For basic practice, here are some hypothetical data to type into Excel, with the data labels in the first row. Column A has the dates, column B contains closing prices for a market index, and column C has the closing prices for a mining stock.
To create the chart, highlight the data with your mouse, including the data labels, and click on the Excel menu item for Insert. You’ll select Chart and a menu of different kinds of charts will appear. You’ll click on Line and select the chart option at the top left in the submenu. That is a simple line chart. Then click Next, and you will see a small picture of your chart, the range of your data, and whether the series are in rows or columns. Your selection should be columns, because that is how you have your variables separated. Click Next again and you will see Step 3 of 4 in the Chart Wizard, allowing you to type in a chart title and labels for the X and Y axes. Go ahead and type in Market Index and Mining Stock for the title, Date for the Category (X) axis label, and Price for the Value (Y) axis label. Then click Next.
The Step 4 of 4 screen will ask you if you want the chart as an object in your spreadsheet, or if you want the chart to be on a separate sheet. Go ahead and select the option for “As new sheet.” Then click Finish.
What you’ll see is that the Wizard has recognized the date information from column A and placed it on the X-axis. The Wizard has also given us a single Y-axis and scaled it according to the high and low values in the data. Unfortunately, this leaves us unable to see much of the ups and downs in the mining stock data, since the price of the stock is much smaller than the price of the index.
To correct this problem, point your cursor at the line on the chart for your Market Index and right click. A menu will pop up, and you will select the option for Format Data Series. Click the tab for Axes and then click on the button for “Plot Series on Secondary Axis.” When you do that, the picture of the chart underneath the buttons will change, and you’ll notice now that you have two Y-axes: one for the Market Index price data and one for the Mining Stock data. You’ll be able to see their relative ups and downs much more clearly. Click on OK and you will see your new chart. If you’d like the Y-axes to have new labels, you can place your cursor on the center of the chart (away from the lines for the data) and right click. A menu will pop up, and you’ll select Chart Options. That will give you a screen enabling you to type in new labels for the Value (Y) axis (at left) and the Second value (Y) axis (at right).
If you right click on either of the two lines in the chart and, from the pop-up menu select Format Data Series, you’ll see a tab for Patterns. You can click the arrow beside the option for Weight and make the line thicker. You can click the arrow beside the option for Color and change the color of the line.
If you right-click on the X- or Y-axes, you’ll get a pop-up menu; click on Format Axis. If you select the tab for Font, you can choose the typeface, font style, and size of the print for the axis labels. If you select the tab for Scale, you can change the range of values for the axis. With a little practice, you can customize the look of your charts.
So what does your chart tell you? You can see that the Mining Stock is not moving in unison with the Market Index. When the index shows large rises or declines, the stock is tending to move in the opposite direction. By itself, over such a short period, that won’t tell you anything you’d want to hang your hat on, but it does raise interesting questions:
• Why is the mining stock moving opposite to the market index? Might the mining stock be moving in unison with the gold market instead?
• If the mining stock is moving with gold, is gold also moving opposite to the market index? If so, why might that be? Might there be a common influence on both of them: the strength of the U.S. dollar?
• Does this relationship occur over intraday time frames? Might we be able to identify some buy or sell signals in the mining stock when we see selling or buying in the broad market?
Reviewing charts that you create helps you see intermarket and intramarket relationships.
Many times, investigating relationships through charts leads you to worthwhile questions, which may then lead you to interesting and profitable trading ideas. The key is asking “Why?” What might be responsible for the relationship I am observing? Remember, in your own self-coaching, you want to be generating hypotheses, and there is no better way than plain old brainstorming. When you can actually see how the data are related to each other in graphical form, it is easier to accomplish that brainstorming. You won’t arrive at hard and fast conclusions, but you’ll be on your way toward generating promising trading ideas.
COACHING CUE
Plot charts of the S&P 500 Index (SPY) against the major sector ETFs from the S&P 500 universe as a great way to observe leading and lagging sectors, as well as divergences at market highs and lows. The sectors I follow most closely are: XLB (Materials); XLI (Industrials); XLY (Consumer Discretionary); XLP (Consumer Staples); XLE (Energy); XLF (Financial); XLV (Health Care); and XLK (Technology). If you want to bypass such charting, you can view excellent sector-related indicators and charts at the Decision Point site (
www.decisionpoint.com). Another excellent site for stock and sector charts is Barchart (
www.barchart.com).
LESSON 95: CREATE YOUR INDEPENDENT AND DEPENDENT VARIABLES
When I organize my spreadsheets, I generally place my raw data furthest to the left (columns A, B, C, etc.); transformations of the raw data into independent variables in the middle; and dependent variables furthest to the right. Let’s take a look at what this means.
Your independent variables are what we might call candidate predictors. They are variables that we think have an effect on the markets we’re trading. For example, let’s say that we’re investigating the impact of price change over the previous day of trading (independent variable) on the next day’s return for the S&P 500 Index (dependent variable). The raw data would consist of price data for the S&P 500 Index over the look-back period that we select. The independent variable would be a moving calculation of the prior day’s return. The dependent variable would be a calculation of the return over the next day. The independent variable is what we think might give us a trading edge; the dependent variable is what we would be trading to exploit that edge.
If I keep my raw data to the left in the spreadsheet, followed by transformations of the raw data to form the independent variable, and then followed by the dependent variable, I keep analyses clear from spreadsheet to spreadsheet.
Let’s set that up as an exercise. We’ll download data for the S&P 500 Index (cash close) for the past 1,000 trading days. That information will give us roughly four years of daily data. If I obtain the data from Pinnacle Data, I’ll open a blank sheet in Excel; click on the Excel menu item for File; click Open; go to the Data folder in the C drive; double-click on the IDXDATA folder; select All Files as the Files of type; and double-click the S&P 500 file. I’ll highlight the cells for the past 1,000 sessions; click on the Edit menu item in Excel; click on Copy; open a new, blank spreadsheet; then click the Edit menu item again; and click Paste, with the cursor highlighting the A2 cell. The data from the Pinnacle sheet will appear in my worksheet, leaving row A for data labels (Date, Open, High, Low, Close).
If you download your data from another source, your menu items to access the data will differ, but the result will be the same: you’ll copy the data from your source and paste them into the blank spreadsheet at cell A2, then create your data labels. As a result, your raw data will occupy columns A-E. (Column A will be Date; column B will be Open; column C will be High; column D will be Low; and column E will be Close.) Now, for the data label for column F (cell F1), you can type (without quotation marks): “SP(1).” This is your independent variable, the current day’s rate of change in the index. Your first entry will go into cell F3 and will be (again without quotations marks): “=((E3-E2)/E2)*100).” This is the percentage change in the index from the close of the session at A2 to the close of the session at A3.
Now let’s create our dependent variable in cell G7, with column G labeled SP+1 at G1. Your formula for cell G3 will be “=((E4-E3)/E3)*100).” This represents the next day’s percentage return for the index.
To complete your sheet, you would click and highlight the formula cells at F3 and G3; click on the Excel menu item for Edit; and select the option for Copy. You’ll see the F3 and G3 cells specially highlighted. Then, with your cursor highlighting cells F4 and G4, drag your mouse down the full length of the data set and release, highlighting all those cells. Click again on the Excel menu item for Edit, then select Paste. Your spreadsheet will calculate the formulas for each of the cells and the data portion of your spreadsheet will be finished. The raw data will be in columns A-E. The independent variable (our candidate predictor) will be in column F; and our variable of trading interest—the dependent variable—will reside in column G. Save this spreadsheet as Practice Sheet in an Excel folder. We’ll be using it for future lessons.
Note that we downloaded 1,000 days worth of data, but the actual number of data points in our sample is 998. We could not compute SP(1) from the first data point because we didn’t have the prior day’s close; hence we had to begin our formula in the third data row. We also could not compute SP+1 from the last data point because we don’t know tomorrow’s closing price. Thus our analyses can only use 998 of the data points of the 1,000 that we downloaded. If you want an even 1,000 data points, you’d have to download the last 1,002 values.
With a bit of practice, all of this will become second nature. It will take only a minute or two to open your data files, copy and paste the raw data, write your formulas, and copy the cells to complete your sheet. In this example, we are exploring how the prior day’s return is related to the next day’s return. We’re setting the spreadsheet up to ask the question, “Does it make sense to buy after an up day/sell after a down day; does it make sense to sell after an up day/buy after a down day; or does it make no apparent difference?” I call the independent variable the candidate predictor, because we don’t really know if it is related to our variable of interest. It’s also only a candidate because we’re not conducting the statistical significance tests that would tell us more conclusively that this is a significant predictor. Rather, we’re using the analysis much as we used the charting in the prior lesson: as a way to generate hypotheses.
Remember, in the current examples, we’re using historical relationship to describe patterns in markets, not to statistically analyze them. We’re generating, not testing, hypotheses.
If I had been interested in examining the relationship between the prior week’s price change with the next week’s return, the spreadsheet would look very similar, except the raw data would consist of weekly index data, rather than daily. In general, it’s neatest for analysis if you are investigating the impact of the prior period’s data on the next period. This ensures that all observations are independent; there are no overlapping data.
To see what I mean, consider investigating the relationship of the prior week’s (five-day) price change on the price change over the next five trading days utilizing daily market data. Your independent variable in column F would now look like “=((E7-E2)/E2)*100)”—price change over the past five days. The dependent variable in column G would be written as “=((E12-E7)/E7)*100”: the next five-day’s price change. Note, however, that as you copy those cells down the spreadsheet per the above procedure, that each observation at cells F8, F9, F10, and so on and G8, G9, G10, and so on, is not completely independent. The prior five-day return overlaps the values for F8, F9, and F10, and the prospective five-day return overlaps for cells G8, G9, and G10. This will always be the case when you’re using a smaller time period for your raw data than the period that you’re investigating for your independent and dependent variables.
Inferential statistical tests depend on each observation in the data set being independent, so it is not appropriate to include overlapping data when calculating statistical significance. For my purpose of hypothesis generation, I am willing to tolerate a degree of overlap, and so will use daily data to investigate relationships of up to 20 days in duration—particularly if the amount of overlap relative to the size of the entire data set is small. I would not, say, investigate the next 200 days’ return using daily data for a sample of 1,000 trading days. I wouldn’t have a particular problem using the daily data to investigate, for instance, the prior five-day price change on the next five-day return with a four-year look-back period.
Your findings will be most robust if your look-back period (the period that you are drawing data from) includes a variety of market conditions: rising, falling, range bound, high volatility, low volatility, and so on.
In general, my dependent variable will consist of prospective price change, because that is what I’m interested in as a trader. The independent variable(s) will consist of whatever my observations tell me might be meaningfully related to prospective price change. Normally, I look at dependent variables with respect to the next day’s return (to help with day trading ideas) and the next week’s return (to help with formulating swing hypotheses). If I want a sense of the market’s possible bigger picture, I’ll investigate returns over the next 20 trading days. Traders with different time frames may use different periods, including intraday. Overall, I’ve found the 1 to 20 day framework to be most useful in my investigations.
Once again, practice makes perfect. I would encourage you to become proficient at downloading your data and assembling your spreadsheets into variables before you try your hand at the actual historical investigations. Your results, after all, will only be as valid as the data you enter and the transformations you impose upon the data.
COACHING CUE
Note how, with the Practice Sheet assembled as in the above example, you can easily look at the next day’s average returns following opening gaps. Your independent variable would be the opening gap, which would be written as =((b3-e 2)/e2)*100 (the difference between today’s open and yesterday’s close as a percentage). The day’s price change would be =((e3-b3)/b3)*100 (the difference between today’s close and today’s open as a percentage). You would need to use stock index futures data or ETF data to get an accurate reflection of the market open; the cash index does not reflect accurate opening values, as not all stocks open for trading in the first minute of the session.
LESSON 96: CONDUCT YOUR HISTORICAL INVESTIGATIONS
Once you have your data downloaded and your independent and dependent variables calculated, you’re ready to take a look at the relationship between your two sets of variables. In the last lesson, you saved your spreadsheet of the S&P 500 Index data with the prior day’s price change in column F and the next day’s change in column G. Open that sheet, and we will get started with our investigation.
Your first step will be to copy the data from the sheet to a fresh worksheet. We will first copy the data to the Windows clipboard, then paste into the new sheet. This eliminates all formulas from the sheet, because the clipboard saves only alphanumeric text data. This process is necessary for the data manipulations that will be required for our investigation.
So, highlight all the cells in your sheet with the exception of the last row (the most recent day’s data). We don’t include that row in our analysis because there won’t be any data for the next day’s return. With the cells highlighted, click the Excel menu item for Edit, then select Copy. You’ll then exit out of the spreadsheet and instruct Windows to save the data to the clipboard. Open a fresh, blank sheet; click on cell A1; click the Excel menu item for Edit; and select Paste. Your data will be transferred to the new sheet, with no formulas included.
Once you’ve done this, you’ll delete the first row of data below the data labels, because there will be no data for the change from the prior day. When you delete the row by highlighting the entire row and clicking Edit and selecting Delete, the rows below will move up, so that there are no empty rows between the data labels and the data themselves.
You’ll now highlight all the data (including the first row of data labels), select the Excel menu item for Data; then select Sort; and select the option SP(1) in the Sort By drop down menu. You can click the button on the drop down menu for Descending: this will place your largest daily gain in the S&P 500 Index in the first row, the next largest in the second row, etc. The last row of data will be the day of the largest daily drop in the S&P 500 Index.
The Sort function separates your independent variables into high and low values, so that you can see how the dependent variables are affected.
Now we’re ready to explore the data. For the purpose of the illustration, I’ll assume that your data labels are in row 1 and that you have 999 rows of data (998 days of S&P data plus the row of labels). Below your bottom row in column G (say cell G1002), type in “=average(g2:g500)” (without the quotation marks) and hit Enter. In the cell below that (G1003), type in “=average(g501:g999)” and hit Enter. This gives you a general sense for whether next day returns have been better or worse following the half of the days in the sample that were strongest versus the half of days that were weakest. Note that you could analyze the next day returns roughly by quartiles simply by entering “=average(g2:g250)”; “=average(g251:g500)”; “=average(g501:g750)”; and “=average(g751:g999)”.
What your data will show is that next day returns tend to be most positive following weak days in the S&P 500 Index and most restrained following strong days in the Index. How much of a difference makes a difference for your trading? As I emphasized earlier in the chapter, I am not using this information to establish a statistically significant mechanical trading system. Rather, I’m looking qualitatively for differences that hit me between the eyes. These will be the most promising relationships for developing trading hypotheses. If the difference between average next day returns following an up day and a down day is the difference between a gain of 0.01 percent and 0.03 percent, I’m not going to get excited. If the average returns following the strong days are negative and those following the weak days are positive, that’s more interesting.
As you conduct many sortings, you’ll gain a good feel for differences that may form the basis for worthwhile hypotheses.
So how might I use the information? Perhaps I’ll drill down further, examine those quartiles, and find that returns are particularly muted following strong up days. If that’s the case, I will entertain the hypothesis of range-bound trading the morning following a strong daily rise in the S&P 500 Index. If I see that particularly weak days in the S&P 500 Index tend to close higher the next day, I may entertain the notion of an intraday reversal the day following a large drop. The data provide me with a heads up, a hypothesis—not a firm, fixed conclusion.
The data might also help sharpen some of my trading practices. If I’m holding positions for intermediate-term swing positions, I might be more likely to add to a long position after a daily market dip than after a strong daily rise. I might be more likely to take partial profits on a short position following toward the end of a weak market day than toward the end of an up day.
And suppose we find no apparent differences whatsoever? This, too, is a finding. It would tell us that—at this time frame, for this time period—there is no evidence of trend or countertrend effects. This would help us temper our expectations following strong and weak market days. We would not assume that trends are our friends; nor would we be tempted to fade moves automatically. We would also know to look for potential edges elsewhere.
Keep a record of the relationships that you examine and what you find; this will guide future inquiries and prevent you from duplicating efforts later on.
If your analysis does not identify a promising relationship within the data, you’re limited only by your own creativity in exploring alternate hypotheses. For instance, you might look at how prior returns affect next returns for weekly or monthly data, rather than daily data. You might explore next day returns for a different instrument or market. Perhaps you’ll see greater evidence of trendiness in commodities or small stocks than in the S&P 500 Index.
Where your creativity can really kick in is in your selection of independent variables. The same basic spreadsheet format outlined above could be used to examine the relationship between the current day’s put-call ratio and the next day’s S&P 500 returns; the current day’s volume and next day returns; the current day’s financial sector performance and next day S&P 500 returns; the current day’s bond yield performance and next day returns. Once you have the spreadsheet analysis process mastered, it’s simply a matter of switching one set of variables for another. This way, you can investigate a host of candidate hypotheses in a relatively short period of time.
The key to making this work is the Sort command in Excel. This sorts your independent variable from high to low or low to high so that you can see what happens in your dependent variable as a result. Along with visualizing data in charts, sorting is a great way to get a feel for how variables may be related, highlighting important market themes. But save your original spreadsheet with the formulas—the one you had titled Practice Sheet in the previous lesson. We’re not finished with Excel tricks!
COACHING CUE
Here is one fruitful line of investigation: Take a look at next day returns as a function of weak up days versus strong up days. You can define weak versus strong with indicators such as the daily advance/decline ratio or the ratio of up volume to down volume. Limit your sort to the rising days in the sample and sort those based on market strength. What you’ll find for some markets is that very strong markets tend to continue their strength in the near term; weaker rising markets are more likely to reverse direction. Later, you can limit your sorting to the declining days and sort them by very weak and less weak markets. Many times, the patterns you see among the rising days are different from those that show up among the falling days.
LESSON 97: CODE THE DATA
Sometimes the independent variable you’re interested in is a categorical variable, not a set of continuous values. If I wanted to investigate the relationship between a person’s weight (independent variable) and their lung capacity (dependent variable), all of my data would be continuous. If, however, I wanted to investigate the relationship between gender (male/female) and lung capacity, I would now be looking at a categorical variable in relationship to a continuous one. Conversely, if I wanted to simply identify whether a person had normal versus subnormal lung capacity, I would wind up with a categorical breakdown for my dependent variable.
There are times in market analysis when we want to look at the data categorically, rather than in a continuous fashion. In my own investigations, I routinely combine categorical views with continuous ones. Here’s why:
If you reopen the spreadsheet we created, Practice Sheet, that examined current day returns in the S&P 500 Index as a function of the previous day’s performance, you’ll see that we had Date data in column A; open-highlow-close data in columns B-E; the present day’s price change in column F; and the next day’s price change in column G. For the analysis in the last lesson, we sorted the data based upon the present day’s price change and then examined the average price change for the next day as a function of strong versus weak days. Our dependent measure, next day’s price change, was continuous, and we compared average values to get a sense for the relationship between the independent and dependent variables.
Averages, however, can be misleading: a few extreme values can skew the result. These outliers can make the differences between two sets of averages look much larger than they really are. We can eliminate this possible source of bias by changing our dependent variable. We’ll keep the next day’s price change in column G, but now will add a dummy-coded variable in column H. This code will simply tell us whether the price change in column G is up or down. Thus, in cell H2, I would type in (without quotation marks): “=if(G2>0,1,0)” and hit Enter. This instructs the cell at H2 to return a “1” if the price change in cell G2 is positive; anything else—a zero or negative return—will return a “0.” I will then click on H2; click the Excel menu item for Edit; click Copy; click cell H3 and drag all the way down the length of the data; and then click Enter. The 0,1 dummy code will populate each of the column H cells.
We want to know whether the independent variable is associated with greater frequency of up/down days, as well as the magnitudes of change across those days.
Now we go through the same sorting procedure described in the previous lesson. We highlight all the cells in the worksheet—including the new column H—and click Edit and Copy. We exit the spreadsheet, instructing Excel to save changes and to save the highlighted data. We open a new sheet; click Edit; click Paste; and all the spreadsheet data—again minus the formulas—will appear on the sheet. Once again we sort the data by column F (current day’s price change) in descending order, as described in the previous lesson. Again we divide the data in half and, below the last entry in column G, we type in “=average(g2:g500)” and, below that, “=average(g501:g999).”
This, as noted in the previous lesson, shows us the magnitude of the average differences in next day’s returns when the current day is relatively strong (top half of price change) versus relatively weak (bottom half of the price change distribution).
In column H, next to the cells for the two averages in column G, we enter the formula “=sum(H2:H500)” and, below that, “=sum(H501:H999).” This tells us how many up days occurred following relatively strong days in the market and how many up days occurred following relatively weak days. Because we’re splitting the data in half, we should see roughly equal numbers of up days in the two sums if the current day’s performance is not strongly related to the next day’s price change. On the other hand, if we see considerably fewer up days following the strong market days than following the weak ones, we might begin to entertain a hypothesis.
If the average next day changes in column G look quite discrepant, but the number of winning days in the two conditions in column G are similar, that means that the odds of a winning day may not be significantly affected by the prior day’s return, but the size of that day might be affected. In general, I like to see clear differences in both criteria. Thus, if the average size of the next day’s return are higher following a falling day than a rising one and the odds of a rising day are higher, I’ll be most likely to use the observation to frame a possible market hypothesis.
Note that we can dummy code independent variables as well. If, for example, I wanted to see whether an up or down day (independent variable) tended to be followed by an up or down day (dependent variable), I could code column F (current day’s price change) with a code as above in column H and also code column G (next day’s price change) identically in column I. I would then copy the spreadsheet to a fresh sheet and sort the data based on column H, so that we’d separate the 1s from the 0s. We’d then examine the column I sum for the cells in column H that were 1s and compare with the column I sum for the cells in column H that were 0s.
Dummy coding is especially helpful if we want to examine the impact of events on prospective returns. For instance, we could code all Mondays with a 1; all Tuesdays with a 2, etc., and then sort the next day’s return based on the codings to tell us whether returns were more or less favorable following particular days of the week. Coding is also useful when we want to set up complex conditions among two or more independent variables and examine their relationship to future returns. This kind of coding gets a bit more complex and will form the basis for the next lesson.
COACHING CUE
If you include volume in your spreadsheet, you can code days with rising volume with a 1 and days with falling volume with a 0. This would then allow you to compare next day returns as a function of whether today’s rise or decline were on rising or falling volume. All you’d need to do is sort the data once based on the current day’s price change and then a second time separately for the rising and falling occasions as a function of the rising and declining volume.
LESSON 98: EXAMINE CONTEXT
Philosopher Stephen Pepper coined the term contextualism to describe a worldview in which truth is a function of the context in which knowledge is embedded. A short-term price pattern might have one set of expectations in a larger bull market; quite another under bear conditions. A short-term reversal in the first hour of trading has different implications than one that occurs midday. To use an example from The Psychology of Trading, you understand Bear right! one way on the highway, quite another way in the Alaskan wilderness.
We can code market data for contexts and then investigate patterns specific to those contexts. What we’re really asking is, “Under the set of conditions that we find at present, what is the distribution of future expectations?” We’re not pretending that these will be universal expectations. Rather, they are contextual—applicable to our current situation.
Many of the most fruitful trading hypotheses pertain to certain kinds of markets—not to all markets, all the time.
Let’s retrieve the Practice Sheet historical daily data for the S&P 500 Index that we used in our previous lessons. To refresh memory: Column A in our spreadsheet consists of the Date; columns B through E are open-highlow-close data. Column F is the independent variable, the current day’s price change; entered into cell F22, it would be: “=((F22-F21)/F21)*100.” Column G will serve as our contextual variable. In G22, we enter the following:
= if(E22>average(E3:E21),1,0)
This will return to cell G23 a “1” if the current price is above the prior day’s simple 20-day moving average for the S&P 500 Index; a “0” if it is not above the average. The data label for cell G1 might be MA. Our dependent measure will be the next day’s price change. In cell H22, this would be “=((E23-E22)/E22)*100” and H1 would have the label SP+1.
To complete the sheet, we would highlight cell G22 and H22; click the Excel menu item for Edit; click Copy; highlight the cells below G23 for the full length of the data set; and hit Enter. We highlight and copy all the data in the sheet as before; save the sheet as Practice Sheet2; and instruct Windows to save the data to the clipboard for another application. We open a fresh spreadsheet; click on cell A1; click the Excel menu item for Edit; select Paste; and our sheet now fills with text data. Note that, in this case, we’ll have to eliminate rows 2 to 21, since they don’t have a value for the 20-day moving average. We’ll also eliminate the last row of data, because there are no data for the next day. You eliminate a row simply by highlighting the letter(s) for the row(s) at left; clicking the Excel menu item for Edit; selecting Delete. The row will disappear and the remaining data below will move into place.
Note that using a moving average as a variable of interest reduces the size of your data set, since the initial values will not have a moving average calculated. You need to take this into account when determining your desired sample size.
We now double sort the data to perform the contextual investigation. Let’s say that we’re interested in the expectations following a rising day in a market that is trading above versus below its 20-day moving average. We sort the data based on column F “SP(1)” as we did in our previous lesson, performing the sort on a Descending basis, so that the largest and positive price changes appear at the top of the sheet. Now we select only the data for the cells that show positive price change and copy those to another sheet. Our second sort will be based on column G (MA), again on a Descending Basis. This will separate the up days in markets trading above their 20-day moving average (those coded “1”) from all other days.
As before, we’ll examine the average next day’s return by calculating the average for the cells in column H that are coded in column G as “1” and comparing that to the average for the cells in column H that are coded in column G as “0.”
Thus, let’s say that there are 538 cells for up days; 383 of these are coded “1” in column G and 155 are coded “0.” You would compare “=average(H2:H384)” and “=average(H385:H539).” You could also code the cells in column H as either “1” or “0” in column I based on whether they are up or down “=if(H2>0,1,0)” and then compare “=sum(I2:I384)” and “=sum(I385:I539)” to see if there are notable differences in the number of up days following up days in markets that are above and below their moving averages.
Just for your curiosity, using cash S&P 500 data as the raw data, I found that the average next day change following an up day when we’re above the 20-day moving average to be -0.04 percent; the average next day change following an up day when we’re below the 20-day moving average was -0.18 percent. This is a good example of a finding that doesn’t knock my socks off, but is suggestive. I would want to conduct other investigations of what happens after rising days in falling markets before generating trading hypotheses that would have me shorting strength in a broader downtrend.
Many times you’ll see differences in the sorted data that are strong enough to warrant further investigation, but not strong enough to justify a trading hypothesis by itself.
This combination of coding and sorting can create a variety of contextual views of markets. For example, if we type in, “=if(E21=max(E2:E21), 1,0)” we can examine the context in which the current day is the highest price in the past 20 and see how that influences returns. If we include a second independent variable, such as the number of stocks making new 52-week highs and lows, we can examine how markets behave when new highs exceed new lows versus when new lows exceed new highs. For instance, if new highs go into column F and new lows into column G, we can code for “=if(F21>G21,1,0” in column H, place our dependent measure (perhaps the next day’s price change) in column I and sort based on the new high/low coding.
As mentioned earlier, it is wise to not create too many contextual conditions, because you will wind up with a very small sample of occasions that fit your query, and generalization will be difficult. If you obtain fewer than 20 occasions that meet your criteria, you may need to relax those criteria or include fewer of them.
As your own trading coach, you can utilize these contextual queries to see how markets behave under a variety of conditions. The movement of sectors, related asset classes—anything can be a context that affects recent market behavior. In exploring these patterns, you become more sensitive to them in real-time, aiding your selection and execution of trades.
COACHING CUE
If you’re interested in longer-term trading or investing, you can create spreadsheets with weekly or monthly data and investigate independent variables such as monthly returns on the next month’s returns; VIX levels on the next month’s volatility; sentiment data on the next month’s returns; price changes in oil on the next month’s returns, etc. You can also code data for months of the year (or beginning/end of the month) to investigate calendar effects on returns.
LESSON 99: FILTER DATA
Let’s say you want to analyze intraday information for the S&P 500 Index futures. Now your spreadsheet will look different as you download data from sources such as your real-time charting application. Your first column will be date, your second column will be time of day, and your next columns will be open, high, low, and closing prices. If you so select, the next column can be trading volume for that time period (one-minute, five-minute, hourly, and so on).
Suppose you want to see how the S&P 500 market has behaved at a certain time of day. What we will need to do is filter out that time of day from the mass of downloaded data and only examine that subset. Instead of sorting data, which has been a mainstay of our investigations to this point, we will use Excel’s filter function.
To illustrate how we might do this, we’ll start with a simple question. Suppose we want to know how trading volume for the current first half-hour of trading compares with the average trading volume for that corresponding half-hour over the prior 20 days of trading. This will give us a rough sense of market activity, which correlates positively with price volatility. The volume also gives a relative sense for the participation of large, institutional traders. If, say, we observe a break out of a range during the first 30 minutes of trading, it is helpful to know whether or not these large market-moving participants are on board.
Volume analyses can help you identify who is in the market.
For this investigation, we’ll examine half-hourly data for the S&P 500 emini contract. I obtain my intraday data from my quote platforms; in the current example, I’ll use e-Signal. To do this, we create a 30-minute chart of the ES futures contract; click on the chart and scroll to the right to move the chart backward in time. When we’ve covered the last 20 days or so, we click on the menu item Tools; select Data Export; then uncheck the boxes for the data that we won’t need. In this case, all we’ll need is Date, Time, and Volume. We click the button for Copy to Clipboard and open a fresh sheet in Excel. Once we click on the Excel menu item for Edit and select Paste, with the cursor at cell A2, we’ll populate the sheet with the intraday data. We can then enter names for the columns in row 1: Date; Time; and Volume. (If you’re downloading from e-Signal, those names will accompany the data and you can download the data with the cursor at A1).
Our next step is to highlight the entire data set that we want to cover. We click on the Excel menu item for Data; select Filter; and select AutoFilter. A set of small arrows will appear beside the column names. Click the arrow next to Time and, from the drop down menu, select the time that represents the start of the trading day. In my case, living in the Chicago area in Central Time, that would be 8:30 A.M. You’ll then see all the volume figures for the half-hour 8:30 A.M. to 9:00 A.M. Click on Edit; select Copy; open a blank sheet; click on Edit; and select Paste. This will put the 8:30 A.M. data on a separate sheet. If you have 20 values (the past 20 days), you can enter the formula “=average(c2:c21)” and you’ll see the average trading volume for the first half-hour of trading. Of course, you can filter for any time of day and see that half-hour’s average volume as well.
When you know the average trading volume for a particular time period, you can assess institutional participation in real time—particularly with respect to whether this volume picks up or slows down as a function of market direction.
The filter function is helpful when you want to pull out data selectively from a data set. Let’s say, for instance, that you had a column in which you coded Mondays as 1; Tuesday’s as 2; etc. You could then filter out the 1s in the historical data set and see how the market behaved specifically on Mondays. Similarly, you could code the first or last days of the month and filter the data to observe the returns associated with those.
In general, I find filtering most helpful for intraday analyses, when I want to see how markets behave at a particular time of day under particular conditions. Frankly, however, this is not where I find the greatest edges typically, and it’s not where I’d recommend that a beginner start with historical investigations. Should you become serious about investigating such intraday patterns, I strongly recommend obtaining a clean database from a vendor such as Tick Data. You can use their data management software to create data points at any periodicity and download these easily to Excel. Serious, longer-term investigations of historical intraday data need tools far stronger than Excel. Limits to the size of spreadsheets and the ease of maneuvering them make it impossible to use Excel for long-term investigations of high frequency data.
Still, when you want to see how markets behave in the short run—say, in the first hour of trading after a large gap open—investigations with intraday data and filtering can be quite useful. You’ll find interesting patterns of continuation and reversal to set up day-trading ideas or to help with the execution of longer timeframe trades.
COACHING CUE
Filtering can be useful for examining patterns of returns as a function of time of day. For instance, say the market is down over the past two hours: how do returns compare if those two hours are the first versus the last two hours of the day? How are returns over the next few hours impacted if the day prior to those two hours was down? Such analyses can be very helpful for intraday traders, particularly when you combine price change independent variables with such intraday predictors as NYSE TICK.
LESSON 100: MAKE USE OF YOUR FINDINGS
This chapter has provided only a sampling of the kinds of ways that you can use simple spreadsheets and formulas to investigate possible patterns in historical data. Remember: these are qualitative looks at the data; they are designed to generate hypotheses, not prove them. Manipulating data and looking at them from various angles is a skill just like executing trades. With practice and experience, you can get to the point where you investigate quite a few patterns all in the hour or two after market close or before they open.
The key is to identify what makes the current market unique or distinctive . Are we well below or above a moving average? Have there been many more new lows than highs or the reverse? Has one sector been unusually strong or weak? Have the previous days been strong or weak? It is often at the extremes—when indicators or patterns are at their most unusual—that we find the greatest potential edges. But sometimes those unique elements are hard to find. Very high or low volume; strong or weak put/call ratios; large opening gaps—all are good areas for investigations.
We find the greatest directional edges following extreme market events.
Once you have identified a pattern that stands out, this becomes a hypothesis that you entertain to start a trading day or week. If, say, I find that 40 of the last 50 occasions in which the market has been very weak with a high put/call ratio have shown higher prices 20 days later, this will have me looking for a near-term bottoming process. If, after that analysis, I notice that we’re making lower price lows but with fewer stocks and sectors participating in the weakness, this may add a measure of weight to my hypothesis. Eventually, I might get to the point where I think we’ve put in a price bottom and I’ll buy the market, giving myself a favorable risk/reward should the historical pattern play out.
But equally important, consider the scenario in which we see good historical odds of bouncing over a 20-day period, leading us to search for a near-term bottoming process. My fresh data, however, suggest that the market is weakening further: more stocks and sectors are making lows, not fewer. The historical pattern does not appear to be playing itself out. This, too, is very useful data. When markets buck their historical tendencies, something special may be at work. Some very good trades can proceed from the recognition that markets are not behaving normally.
This is the value of considering patterns as hypotheses and keeping your mind open to those hypotheses being supported or not. A historical pattern in markets is a kind of script for the market to follow; your job is to determine whether or not it’s following that script.
Our analyses only inform us of historical tendencies. If a market is not behaving in a manner that is consistent with its history, this alerts us to unique, situational forces at work.
All of this suggests that historical investigations are useful logical aids, but my experience is that their greatest value may be psychological. Day after day, week after week, and year after year of investigating patterns and running market results through Excel have given me a unique feel for patterns. It also has given me a keen sense for when patterns are changing: when historical precedents may no longer hold.
One routine that has been very helpful has been to isolate the last five or so instances of a potential pattern. If the market has behaved quite differently in the last several instances than it has historically, I entertain the possibility that we’re seeing a shift in market patterns. If I see the last few instances behaving abnormally across many different variables and time frames, those anomalies strengthen my sense of a market shift.
When I see how results have played out over the years, I become a less näïve trend follower. I don’t automatically assume that rising markets will continue to skyrocket or that falling markets will continue to plunge. I’ve developed tools for determining when trending markets are gaining and losing steam; these have been helpful in anticipating reversals. Seeing how these indicators behave under various market conditions over time—and actually quantifying their track record—has provided me with a measure of confidence in the ideas that I would not have in the absence of intimacy with the data.
Much of the edge in trading comes from seeing markets in unique ways, catching moves before they occur or early in their appearance. It is easy to become fixed in our views, with vision narrowed by looking at too few markets and patterns. As your own trading coach, you need to keep your mind open and fresh. Read, talk with experienced traders, follow a range of markets closely, test patterns historically, and know what’s happening globally: you’ll see things that never register on the radar of the average trader. You’ll be at your most creative when you have the broadest vision.
COACHING CUE
When you examine historical patterns, go into your data set and specifically examine the returns from the occasions that didn’t fit into the pattern. This will give you an idea of the kind of drawdowns you could expect if you were to trade the pattern mechanically. Many times, the exceptions to patterns end up being large moves; for instance, most occasions may show a countertrend tendency with a relative handful of very large trending moves. If you know this, you can look for those possible exceptions, study them, and maybe even identify and profit from them.
RESOURCES
My own interest in historical patterns owes a great deal to the work of Victor Niederhoffer. His Daily Speculations web site is a source of many testable ideas regarding market movements:
www.dailyspeculations.comTwo subscription services that do a fine job of testing trading ideas are the SentimenTrader site from Jason Goepfert (
www.sentimentrader.com) and the Market Tells letter from Rennie Yang (
www.markettells.com).
Henry, Rob, Jason, and Rennie all contributed segments to Chapter 9 of this book, offering insights into the relevance of testing ideas for self-coaching.