Appendix. Speaking Kubernetes and Other Strange-Sounding Names
Open source software can be a fickle thing, with some projects blowing up like a viral TikTok trend, only to be forgotten a year later (OpenStack, we’re looking at you). However, there are certain open source projects born to solve critical problems and combined with a strong community that go on to become indispensable—they live on to power the world’s applications for decades to come. One of the first examples of this was Linux, which was born out of the need for a free operating system. Similarly, a number of projects revolutionized their respective areas—Jenkins for DevOps, NGINX for web servers, Eclipse for development environments...and the list goes on. Kubernetes revolutionized the container orchestration space and claimed its throne by defeating strong open source competitors, including Docker’s own Swarm and Apache Mesos. So how did Kubernetes (K8s) stand so far ahead?
So far, we’ve kept our terminology very neutral and generic and consciously avoided the special language that has grown up around Kubernetes. In this appendix we wanted you to learn K8s in the same way you would prepare as a tourist if you were stopping at a Greek island for the day. While you may not learn how to say “I’d like the lamb rare please, on a bed of orzo in an avgolemono stock,” you are certainly going to learn how to say “Efaresto” (Thanks), “Endaxi” (OK), “Kalosto” (Hello), or what to say when you take your first shot of Ouzo—“Stin ygeia sou” (To your health), which is ironic if you think about what you’re doing.
We’ll reiterate that the intention of this book is not to make you a Kubernetes practitioner. With that said, if you’re a manager (or strategist) who runs an organization responsible for cloud deployments, you will need to be familiar with the basic terminology—not only does it keep your seat at the table, but it will empower your leadership of those that live for the nitty-gritty details of making this all work. Trust us on this: while being a guru is going to resonate with your technology teams, showing some level of knowledge (and effort to acquire it) is a different universe than being that leader we’ve all worked for or seen in action before—the ones that literally know nothing about the technology but will drop the word “transformation” at every opportunity.
Figure A-1 shows a Kubernetes cluster followed by some key definitions that will serve you well to remember. (Check out the Kubernetes Standardized Glossary for a comprehensive, standardized list of K8s terminology. This glossary includes technical terms that are specific to Kubernetes, as well as more general terms that provide useful context.)
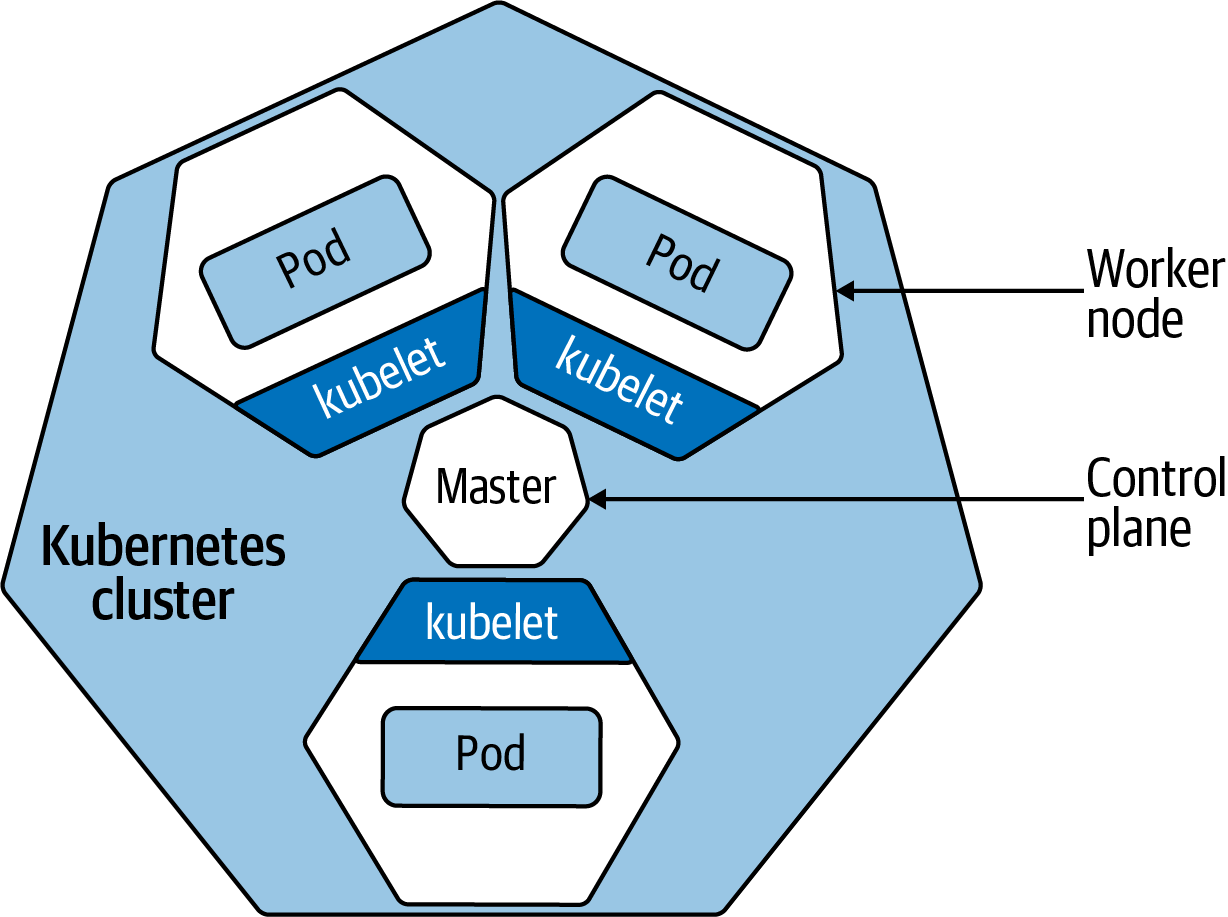
Figure A-1. The key components of a Kubernetes cluster
- Node
A node is a worker machine. It might be a physical or virtual machine, it might be running in the cloud—wherever it is, for the purposes of understanding K8s, you shouldn’t have to care. Each node has a Master Node that is responsible for scheduling pods in a cluster.
- Cluster
A cluster is a collection of nodes running in a “datacenter” that runs containerized applications. The datacenter could be anything from your laptop or some Raspberry Pi in your house to a cloud provider running “Kubernetes as a Service.” If you’re creating a hybrid cloud, you will also have hybrid clusters, in which a single Kubernetes control plane manages nodes in different physical datacenters, including on-premises nodes and nodes running in some public cloud—that’s the whole cloud capability discussion we’ve been having throughout this book; when you think in this manner, your ability to modernize truly changes.
- Pod
A pod is a group of one or more related containers running on a cluster—it’s the smallest most basic deployable object in K8s. A pod is often a single container (like Docker, but it could be others), though it can be a group of containers that need to be run together. For example, a pod might be used to implement a single microservice.
- Role-based access control (RBAC)
RBAC is a management framework that allows administrators to declare business-defined access policies and permissions for your application. Access policies define specific roles with certain permissions (abilities); role bindings associate those roles with specific users. This is imperative for distribution of duty; you’re not just ensuring you are properly securing the administrative component of your Kubernetes cluster, but also being able to showcase these business rules, which goes a long way in pleasing auditors.
- Control plane
The control plane manages the cluster—think of it as a Kubernetes cluster’s nervous system. There are many components in the control plane; they’re responsible for scheduling, integrating with cloud servers, accepting commands through the user interface, storing all the cluster declarations and states, and more.
- kubectl
The open source command-line tool for submitting commands to the Kubernetes API Gateway, which routes commands to the control plane—this is a long way of saying it lets you run commands against the K8s cluster. You can use this tool to deploy apps, log diagnostic details for your cluster, manage the cluster, and more. Much like Terminal on macOS, you can do anything in the command line that you can in any management interface—and more.
The Perfect Open Source Project
In 2017, the Kubernetes project topped the GitHub charts for most-discussed repository, with the second highest project being OpenShift Origin, a distribution of Kubernetes by Red Hat often referred to as OKD. Kubernetes was and continues to be an exemplar of the perfect open source project, and it accomplished this in a few different ways.
Tip
In open source parlance, an upstream is the source repository and project where contributions happen and releases are made. (It might be easier to think of it like a river where the water flows downstream.) Contributions flow from upstream to downstream. In some cases, a project or product might have more than one upstream (like Hadoop relied on multiple upstream projects). OKD is the upstream Kubernetes distribution that is embedded in OpenShift. This distribution contains all the components within Red Hat OpenShift, which add developer- and operations-centric tooling on top of native K8s, and, like any other open source software, it can be used by anyone for free. A good analogy would be the Linux kernel. Kubernetes is like the Linux kernel in that the same Kubernetes can then run in a variety of distributions that support various developers’ needs.
Kubernetes is not a traditional all-inclusive PaaS system. In fact, its own documentation makes this declaration. Kubernetes provides the building blocks to build developer platforms, while allowing organizations to take advantage of its pluggable architecture to customize where it makes sense. This is one of the main reasons (the other being vendor agnosticism) why those same organizations that shied away from first-generation PaaS technologies like Cloud Foundry, Heroku, or App Engine eventually flocked to Kubernetes. With the building blocks of a PaaS, cloud providers like Google, IBM, Red Hat, Amazon, and Microsoft started working to provide a PaaS powered by Kubernetes.
How exactly does Kubernetes tread this line of providing a platform without forcing an opinionated approach to extensions like observability, storage, CI/CD, all the other components of a full-blown PaaS? It does so by providing a pluggable architecture for everything a user might want to configure. In fact, the Kubernetes documentation has an entire section of what Kubernetes is not. This includes the fact that Kubernetes doesn’t limit the type of supported applications, doesn’t deploy source code or build your app, doesn’t provide application services, doesn’t dictate logging solutions, and a load of other things K8s simply doesn’t do.
This list of what Kubernetes doesn’t do (when compared to traditional PaaS) might just leave you wondering how K8s became a leading platform in the first place. Kubernetes is a masterpiece in that it does exactly what it is expected to do really well: things like service discovery, automatic self-healing, configuration management, and more—capabilities that the standard user doesn’t want or even need to “shop around” for. For everything that a user might want to configure themselves, Kubernetes does not dictate the service to be used, but instead provides a pluggable architecture where services can insert themselves. For example, if you want to set up centralized logging for your Kubernetes clusters, you can use over 20 different tools, including Splunk, LogDNA, Fluentd, and Logstash. What if you don’t want to set up any of these tools? Well, Kubernetes conveniently has some barebones logging capabilities available out of the box as well! (Note that this is not always the case—Kubernetes doesn’t provide a built-in way to enable CI/CD, for example.)
The growth of projects in the Kubernetes ecosystem can largely be accredited to the Cloud Native Computing Foundation (CNCF). The CNCF provides a sustainable ecosystem for open source projects in the Kubernetes space. In addition, the CNCF provides certification programs for Kubernetes, such as the well-respected CKA (Certified Kubernetes Administrator) and CKAD (Certified Kubernetes Application Developer) certifications. But here’s a pro tip: if you’re going to be successful with K8s, you don’t just have to understand the technology, you have to also understand the ecosystem. We think it’s nearly impossible to go into production using Kubernetes alone. In the next few sections, we’ll cover some of the other open source projects in the Kubernetes ecosystem you need to know, most of which are part of the CNCF.
Day 1 on the Job: Helm Package Management
We’ve discussed application software as a series of components, implemented with containers, that provide services. So far, so good. But how does that all get installed? There are lots of components you’ll need to stitch together in order to build your application: different kinds of databases, unique services for monitoring your application and building dashboards (which we’ll discuss shortly), frameworks and platforms for web development, AI, and lots more. If you’ve ever managed an open source solution with lots of moving parts, the first thing you often ask is, “How do I get all the necessary components I need installed and running?” And if you’ve been through the ringer with some of these solutions like we have, you follow that question up with, “How do we automate the installation of our own software that relies on these components?”
The answer? Helm. Helm is Kubernetes’s package manager. Package managers are responsible for installing software. They figure out what dependencies are needed to install any new package and activate those dependencies in the appropriate order. In the Helm world, you package your apps into Helm Charts. Helm Charts are package descriptions (written in YAML) that describe dependencies, configuration details, and other information needed to install the package (your app) properly.
Throughout this book we’ve boldly declared that Kubernetes is the operating system for distributed computing—so let’s use that nuance to talk about Helm. Package managers are ubiquitous in programming languages and operating systems. If you’re a Python programmer, you manage the installation of libraries for file management, computer vision, numerics, and more, using pip. On operating systems you use things like yum and apt-get (in the Linux world) or homebrew (if you’re a Mac person). But it’s not just operating systems that seek to simplify the up and running and maintenance experience of solutions with lots of independent components. What a package manager is to an operating system or programming language is what Helm is to Kubernetes.
In April 2020, Helm moved from “incubating” to “graduated status” within the CNCF, proving that Helm has thriving adoption and a strong open-governance community. Helm finds popularity among operations teams for Day 1 (initial deployment phase) DevOps processes, where it is able to significantly simplify the number of resources an application on Kubernetes might require. For example, to deploy a frontend service and a backend service, expose a route (giving a service an externally reachable hostname), and set up a custom domain, you’ll need about four different Kubernetes resource configurations. These four configurations together create one application, so engineers can use Helm to consolidate them into a single “release.”
However, Helm has not found popularity among services with hefty Day 2 operations, which involve management of stateful (or other complex) workloads such as Quay container registries and MongoDB databases.
Day 2 on the Job: Kubernetes Operators to Save the Day
Stateful or complex workloads like databases have other requirements. They need to be backed up. Schemas need to be updated. And now you know what Operators do. Operators are a way of packaging code that performs periodic, stateful maintenance operations that are often handled by human operators. Operators can be complex. Upgrading a database schema, for example, typically requires unloading and reloading the data, or perhaps a shadow copy of the table and a database quiesce. That’s not necessarily simple work. And remember what we talked about earlier in this chapter—human error and complexity is a huge cause of downtime. There are many tasks that shouldn’t be performed by hand because they are complex or dangerous, or perhaps so rote in nature that they handcuff knowledge workers from high-order tasks. Operators are no different. Each of us stand to gain more resiliency and efficiency through automation.
You might be wondering how Operators are allowed to behave as a literal human operations engineer configuring Kubernetes. This is in part due to two major concepts in Kubernetes: control loop and Custom Resource Definitions (CRDs).
First, Kubernetes uses something called a control loop (see Figure A-2), which is the basis of self-healing Kubernetes resources. As we mentioned earlier, since Kubernetes is declarative (like a house thermostat), users can declare the state that they want with standard Kubernetes resources such as pods, deployments, and services (generally configured with YAML files). Kubernetes then applies the three simple phases of the control loop in Figure A-2 to make it all happen—observe, diff, and act.
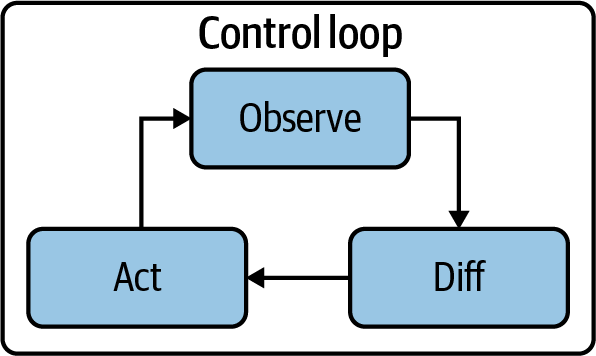
Figure A-2. The control loop: how Kubernetes Operators act like human operators
The first phase of the Kubernetes control loop is observe. This is where K8s is not just watching what’s going on in the cluster, but it’s making note of every single detail for any needed remediation to the declarative statements that serve as the “laws of intent” that govern the cluster. Next, K8s identifies what is different from the intended state of the ecosystem (what temperature and humidity did you want the house at)—this is referred to as the diff. Finally, if there’s any difference, K8s will act to remediate any differences between the declared state and the actual state within the cluster. Kubernetes is forever running the loop in Figure A-2—like a hamster forever running in a hamster wheel.
Let’s assume you created a deployment that demands three pods to be alive, but one of the pods eventually crashes? K8s to the rescue! You want three pods, and Kubernetes’ control loop is always trying to maintain the environment you set (like that house thermostat) so it will continually restart that pod to resolve the “difference” between the current and intended state. This is in essence how “self-healing” works.
Tip
Things like pods, deployments, and services are default resources in the Kubernetes API—all Kubernetes clusters support these resources. They are the building blocks of deploying applications on Kubernetes.
Kubernetes also allows you to augment the default Kubernetes API by supplying CRDs to extend the standard resources found in Kubernetes (pods, services, deployments, and so on). In turn, Kubernetes provides a frontend API for the extended resources you’ve defined—and these resources also follow the control loop. The ability for Operators to utilize CRDs allows developers to create large-scale resources that may encompass many standard Kubernetes resources. For example, once you’ve installed a MongoDB operator, it will create a CRD for a MongoDB database. As a user, you can create a resource referencing that CRD and deploy it to Kubernetes, much like any other standard resource. The CRD (and hence the Operator) is responsible for creating the many underlying Kubernetes resources that make up the MongoDB instance. This means less work for you!
The key advantage to Operators is that they can effectively offload the responsibility of maintaining a particular service in your Kubernetes cluster and thereby significantly reduce Day 2 operations costs. Contrast this with Helm. Whereas Helm allows users to perform Day 1 operations that deal with deploying many resources together, Operators take it a step further and allow for the continued management and maintenance of complex services running on Kubernetes. This is why you’ll find so many service providers beginning to develop Operators that Kubernetes administrators can implement to manage long-living services. This isn’t to say that Operators are replacing Helm—Helm is still a critical part of simplifying standard deployments and plays an important role in CI/CD pipelines. Helm is great for when you don’t need a sledgehammer to swat flies.
We’ve accomplished one of our major goals: turn infrastructure, along with the processes for managing infrastructure, into code. In a large, distributed system, that’s the only way these maintenance tasks can be performed repeatably and reliably. Ensure you understand this last paragraph because this is what the whole Kubernetes ecosystem is about. It’s the basis for modernization, agility, scalability, and more; it’s what drives automation into our processes, which results in efficiencies and frees up resources to drive the business.
The Infrastructure…Of Course!
So far, our discussion has been very virtual: there’s a cluster of machines (possibly virtualized) somewhere in the cloud (which could be public or on-premises) that do work for you. Kubernetes takes things like containers and runs them on those machines, all the while looking at what we declared the environment should look like, and it tries its hardest to make it that way. Great. But where do those machines come from? Cloud resources don’t appear magically just because you want them; public cloud providers all offer similar, but not equal, services; and there is no end to the different kinds of machines you can use in cloud computing. Are you better off scaling a NoSQL data model with lots of small, distributed servers? Or do you use one more powerful server and scale up, which is less complicated? Do you load up your server with lots of memory? Do GPUs help? TPUs? How do you select all of this?
To help guide you, we’re going to take advantage of the same ideas we’ve been using all along in this section and we mentioned in : infrastructure as code. That way, it’s standardized and repeatable. You don’t have to worry about the nightmare case where a system goes down and some person mistypes the number of virtual machine instances you need, where your app gets nicknamed molasses because the admin forgot a zero, or you get a giant bill because they typed too many of them.
Enter Terraform—an open source tool (developed by HashiCorp) for building, changing, and versioning infrastructure safely and efficiently. Think about the name: it’s about shaping the earth and putting the material you’re working with into a useful form. Or, if you’re inclined to sci-fi, think about “terraforming Mars”: assembling all of Mars’s resources to create a useable, livable environment. Terraform is essential to hybrid clouds because it really doesn’t care what kind of “earth” it’s forming. Yes, any cloud provider has their own way of specifying a configuration; but once you’ve told Terraform what resources you need, it takes over the process of figuring out how to acquire those resources. Describing what resources you need for AWS, Azure, GCP, IBM, and even your on-premises datacenter is a lot simpler than writing scripts (or tweaking dashboards) that do the work of acquiring those resources.
Terraform takes a page out of the Kubernetes book in its implementation—it’s declarative. This has a fundamental advantage that you can simply tell it what you want, and it will handle the painstaking process of making the individual API calls to create the infrastructure. A simple analogy would be setting your car’s GPS navigation to go to a destination versus simply calling a ride-sharing company. The prior requires that you control every turn, exit, and on-ramp, and even has the potential for error if you’re not familiar with the roads (or if the maps are out of date). This is akin to developing manual scripts to handle your infrastructure automation, or even worse, trying to figure out the interface nuances of the CSP you’ve chosen to work with every time you need to deploy something (and remember, enterprises today are using multiple CSPs!). However, with ride sharing, you simply input your final destination, get in the car, and the driver takes care of the rest. That’s why we like to think of Terraform as the Lyft/Uber of infrastructure automation.
It shouldn’t surprise you that Terraform has a public registry service: that is, a repository for public configuration modules as well as Terraform providers to make it easier to work with major CSPs. You can find modules that implement many common forms of infrastructure: for example, implementing a Kubernetes cluster on different public cloud providers. Your teams will almost certainly need to customize the modules (for example, to specify the number of nodes the application needs, or which zones to use), but almost all of the work has already been done.
Making the Network Tractable: Service Meshes
You probably realize that the picture we’ve been painting might seem a little too rosy. We’re talking about applications composed from many different services: frontends, databases, authentication, finance, shipping, manufacturing, and more. All of these services need to communicate with each other. They need the ability to find each other. And if you’ve thought about the implications of the cloud, you’ve realized that this is difficult. How can a service communicate with other services reliably if they’re starting and stopping all the time? If, the day after Black Friday, you only need hundreds of nodes, rather than thousands?
The eight Fallacies of Distributed Computing notes that the network is reliable, the network is secure, the network doesn’t change, and so on. We know, we’d be skeptical too. But Kubernetes shows us that the only realistic way to escape these fallacies is to embrace them. Rather than pretend that networks are reliable or tie your code up in knots trying to handle outages, introduce another layer (yes, every problem in computing can be solved by adding another abstraction) designed to solve these problems. And that’s why we need to start talking about service meshes.
It’s certainly true that, in the cloud, networking is hard. Programmers just want to be able to open a connection to a service. They don’t want to deal with services that appear and disappear almost at random, to find out what addresses those services live at, or to deal with issues like load balancing. (We’re exhausted just thinking about it!) And dealing with the network becomes even more complex when you need to think about security, authorization, monitoring, and A/B testing. Early cloud applications forced that on them. They couldn’t just call a network library; they suddenly had to understand how networks worked on a much deeper level.
This is where service meshes enter the picture. A service mesh is another set of services that takes the burden of networking away (abstracted) from your application code. Services no longer have to know the IP addresses of the services they need, open direct connections to those services, decide what to do when a service becomes unavailable, and so on. That is all managed by the service mesh. The services become “virtual services,” and the mesh takes responsibility for routing requests (for knowing which services are available and where they are located, knowing which services are allowed to access other services, and even understanding service versioning; for example, a service mesh can make a new version of a service available to a group of users for testing). You might want to think of the mesh as a gigantic proxy layer that manages all of these issues and forwards requests to the actual services, which only have to concern themselves with the business logic required to respond to these requests.
So we’re back where we want to be: the service doesn’t need to know about the network, and the programmer doesn’t need a deep understanding of network programming. All any service needs to know is the name of the other services it depends on. Services are exposed to each other through the service mesh, which understands resource discovery and routing, and keeps a close watch on where the actual services are, how many instances are running, the addresses of those instances, and so on.
But we get more in the bargain. Networking isn’t the only thing we don’t want our services to know about. Ideally, we’d rather not have them know about security (don’t get confused here, this doesn’t mean there isn’t any): poor implementations of issues like identity and authorization are the cause of much misery. Better to leave identity and authorization to specialists. Security can be managed by the service mesh, which can use other services to determine which users, services, and roles are trusted. We absolutely don’t want services to “know about” cryptography; no question about it, cryptography is important to security, but it is much easier to get cryptographic techniques wrong than to get them right, even if you’re using a well-known and correctly implemented library. Why not hand this off to the service mesh (and cryptographic protocols and implementations that can be changed via configuration, rather than by modifying the services)?
If all a service needs to know about is its business logic, and nothing more, then we finally have, in the cloud, what software developers have been striving to achieve for years: component-based distributed software systems. A new kind of service can be added without touching the rest of the system. Clients using the service may need to be updated—or perhaps not. In many cases, all that’s needed is a configuration change. Let’s say you’re an international business that’s expanding into South Africa. You decide to add a service that converts between US Dollars and Rand. Existing services that need currency exchange are already accessing other exchange services, which makes adding this new feature at most a configuration change. Adding the ability to take payments in cryptocurrency will probably require a new service too, but the rest of the application can remain the same; it just needs to know that Dogecoin is a new payment option.
Step back for a moment because we went through a lot of stuff there. We want to pause so you fully appreciate that we’ve achieved a high degree of cohesion: the ability to compose complex applications from components, all with minimal coupling between those components. And once we can do that, with the components packaged in standardized containers, we can deploy them anywhere: literally. On those Raspberry Pis in the broom closet, in a giant datacenter, on a cloud provider—or any combination. We can tell Kubernetes how many instances of the DogecoinExchangeService we want, tell the service mesh how to route the requests, and we’re up and running—without taking the application down for a second!
Again, we’ve been discussing service meshes in the abstract; we’ve talked about what a service mesh does rather than the specific software. While it’s not the only service mesh implementation, the dominant implementation in the Kubernetes ecosystem is Istio. Istio is an open source project started by IBM, Google, and Lyft; it incorporates Lyft’s Envoy project, which still exists on its own.
Testing, Integration, and Deployment
The ability to run an application in the cloud, in a way that’s independent of any cloud vendor—where your own datacenter or machine room can be one of those “vendors”—is a huge step forward. But there’s more to the problem than running the application. You need the ability to deploy it, you need the ability to integrate components together, and you need the ability to test in a modern way. What’s more, these capabilities all need to be automated—in part so they can be repeated reliably, but also so they can be performed repeatedly.
All of these capabilities come under the heading of CI/CD. The deployment scenarios of 20 or 30 years ago, when a “deployment” was very likely to be a break-the-world change, with the entire development and operations teams keeping their fingers crossed (probably with some of that vodka we talked about in the Preface to this book) and hoping nothing breaks, are a thing of the past for those that have embraced the very things we’ve been talking about all along in this book. We’ve discovered that the way to deploy software reliably is to deploy it frequently, where each deployment represents a minor change to a very small number of features. If each release represents a minor change, changes are easy to roll back; changes can be deployed to a small number of users for testing; and, most of all, short, reliable release cycles force you to commit your release process to software.
As we mentioned before, Kubernetes provides the building blocks of a PaaS—but it’s not an all-inclusive PaaS. One of the things Kubernetes explicitly doesn’t do is provide a native CI/CD process. In open source parlance, Kubernetes doesn’t have an opinion on CI/CD—which is coder talk for they don’t force you into a solution or template for this component; this can be good or bad. After all, developers definitely have formed their own opinions in this space, and DevOps processes tend to be custom fit to the team that implements them. This is one of the reasons that we think Kubernetes has become such an inflection point—K8s knows what it wants to do and it’s extremely good at doing it. For everything else, the open source community always finds a way (and more often than not, multiple ways—but that’s another story).
Tekton is an open source project that provides a strong framework to create cloud native CI/CD pipelines in a way that doesn’t depend on a cloud provider. It is an extension that runs on your Kubernetes cluster. It also integrates with the widely used open source tools for CI/CD, such as Jenkins (a free and open source automation server that helps with some of the tasks in the CI/CD lifecycle: building, testing, deploying, and so on). Tekton structures the deployment process as a set of pipelines, which execute some larger goal (such as deploying a project). Pipelines are composed of tasks, which are specific actions (such as running a test suite or compiling an application). You can create Deployment pipelines that minimize the time to cut over from an old version to a new version; or to deploy a new version to some servers but not others, for A/B testing; or to do small canary deployments to test the system against the real world. And if you need to, Tekton can also be used to roll back to an earlier release.
Tip
In software engineering speak, a canary deployment is a process whereby you make a staged release to a subset of your user community first so they can test it out and tell you what they think. If they “vote your new feature off the island,” you don’t roll it out and save yourself from irritating your entire customer base. You see this all the time with apps on the iPhone where the update description tells you that you will see the feature over time or you’ve updated a new app and was told of a new feature in the update notes, but you don’t see it.
But canary deployments are also used to understand how users will interact with potential changes like redesigning the interface and menu options. This affords an easy mechanism to “walk back” changes (it’s risk-averse) as opposed to other strategies (like Blue/Green), which make the changes in one step.
Monitoring and Observability
Whenever you deploy software, regardless of where it runs, you need to make sure that it runs reliably. You need to know that, at any time, the software is actually running, that it’s handling requests, and that it’s handling those requests in a reasonable amount of time. If the application is down, extremely slow, or malfunctioning in some other way, you need to know it. It doesn’t matter if this is a huge public-facing ecommerce application or some internal management dashboards; your staff needs to get it back online and (even more importantly) prevent it from ever going offline.
One thing we’ve learned in the last decade of IT operations is the importance of monitoring. Monitoring is relatively simple: you develop specific metrics (or health tests) and watch your applications to ensure that everything is running normally. A health check could be a simple network ping, a measurement of a physical parameter (like CPU temperature), or something more complex and application-focused, such as the number of transactions per second or the time users wait to get a response. Monitoring includes alerting (for example, generating pager alarms) and providing data for debugging and trend analysis (for example, forecasting resource requirements or cloud expenses).
Monitoring is valuable, but it isn’t the last word. The fundamental problem with monitoring is that you have to predict, in advance, what you will want to know. Sometimes, that’s not enough to tell you that your system is (or about to go) down, and it’s almost never enough to tell you what went wrong so you can bring the system back online. As modernized apps move to more and more distributed computing (the epochs we talked about in Chapter 3), and more and more components are part of an application’s composition, figuring out a root cause to a problem can be like trying to unravel the Gordian knot of cable wiring to charge that thing you bought off Amazon five years ago. It’s just not going to happen.
Observability could (perhaps should) be called the “next generation” of monitoring. It starts with a definition from control theory: “In control theory, observability is a measure of how well internal states of a system can be inferred by knowledge of its external outputs.” Observability means the ability to gather data about any aspect of your application when it’s running, so that you can infer what’s happening internally. That’s the kind of information you need for debugging. It’s all about the ability to find out what you need to know, because you can’t guess with full certainty what you will need to know in advance.
We think observability is going to become even a bigger deal in the years to come as more and more apps are redesigned for the loosely coupled style of distributed cloud native applications. We’ll use Figure A-3 to make our point.
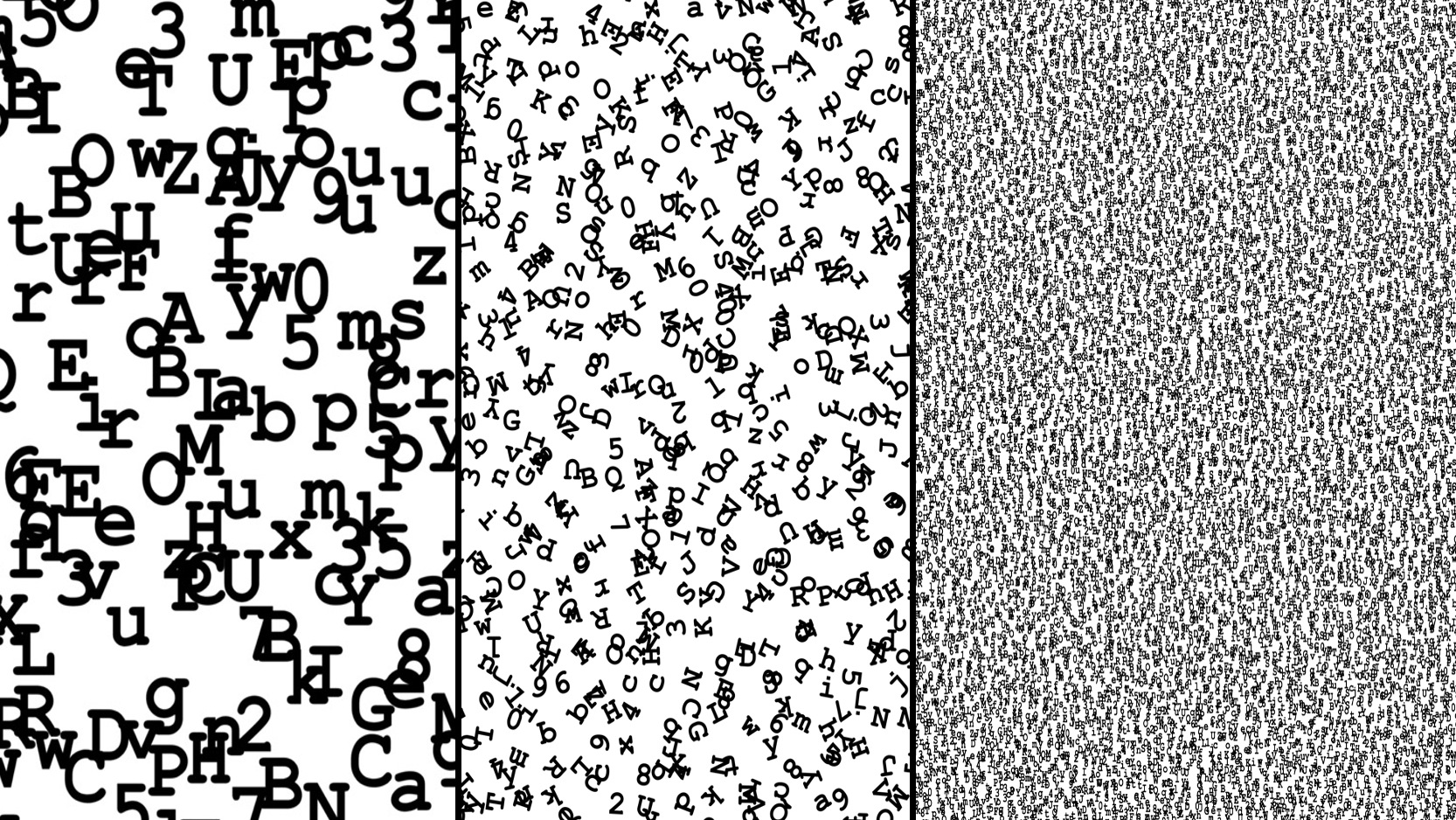
Figure A-3. Find the letter P: a depiction of the increasing complexity when moving from monoliths, to SOA, to microservices
Try to find the letter P (for problem). Easy on the left, harder in the middle, are you @$#~!$ kidding me on the right? That’s akin to figuring out what’s going on in your application stack from a monolith to service-oriented architecture (SOA) to microservices (cloud native). Think about it—if an app is composed of hundreds of microservices (some perhaps function as a service which run in under 10 seconds, if not milliseconds, then disappear because of their transient nature) how can you go from the mobile-native app sitting on your iPhone and trace that to the code running on the backend? Like we said, observability is a big deal that’s going to get bigger, and it’s why we’re really impressed with software pushing this to the forefront today (like Instana).
Next, we’re going to look briefly at some important tools for observability. We’ll also look at some technologies for creating dashboards, which are an important asset to any operations team: what does “observability” mean if you can’t actually observe what’s happening? What’s the point of having an observable system if you can’t react intelligently and efficiently?
Prometheus
Prometheus is an application for collecting real-time time-series data for generating alerts and metrics. It can collect data for an arbitrary number of metrics; each metric is multidimensional, meaning that it can be composed of several data streams of its own.
It may help to think of Prometheus as a data collector that incorporates a time-series database, indexed by metric names and key-value pairs (for specific dimensions). It has short-term memory-based storage, with long-term storage on local disk drives. It can be sharded to distribute load and it has a sophisticated query language.
Prometheus works by scraping (or pulling) data from the systems that it is monitoring. Sending data to Prometheus when it comes to scraping is simple: developers need to add a small amount of code that calls a client library to their applications. To monitor third-party software packages, an exporter converts any logs the package generates to the Prometheus format, and sends the converted data to Prometheus on request. Exporters are available for many commonly used third-party software packages; developers rarely need to write custom exporters.
Grafana
Prometheus has an expression browser that lets you query its database. Grafana’s expression browser is useful for taking a quick look at what’s happening with your systems...but it’s far from a final solution.
Grafana is often used with Prometheus to build dashboards. Grafana is another open source project, independent of Prometheus, but Prometheus includes Grafana integration. It’s simple to create a Prometheus data source for Grafana, and it’s also simple to create a graph that plots the data from that source because that’s the whole point of Grafana: to offer visualization and dashboarding services to a connected data source. Grafana also maintains a collection of freely reusable dashboards.
Alertmanager
Nobody appreciates waking up in the middle of the night because a system is down. But we all know it’s necessary. Downtime is expensive. Any enterprise system needs the ability to alert operators when human intervention is needed.
Alertmanager is the part of the Prometheus project that is responsible for determining when a human needs to be notified, and sending that notification in an appropriate way. Alerts can be sent via a system like PagerDuty or, if they don’t require immediate attention, via email or some other interface.
Alertmanager is responsible for minimizing alert duplication. Think about it…if your team is responsible for an application built on microservices, it’s possible for a single failure of a key component to cascade into hundreds if not thousands of alerts. In addition to de-duping alerts, Alertmanager can be configured to inhibit or suppress alerts that are caused by failures elsewhere in the system. Alertmanager can also silence alerts, for example, to avoid distracting the response team once it has been activated.
The Paradox of Choice: Red Hat OpenShift
For many, less is more. In the past few sections, we’ve touted Kubernetes as a platform with boundless potential and seemingly endless choices for configuration and customization. This is not exactly an advantage for many consumers who may be paralyzed by choice. Seriously, does the world really need 21 Pop-Tart (a breakfast pastry) flavors?
In his book The Paradox of Choice, Barry Schwartz argues that the freedom of choice has made us not freer, but rather more paralyzed—not happier, but more dissatisfied. Applied to Kubernetes, we have seen first-hand how some clients got intimidated by choice. We’ve said it before and we’ll say it again—the cloud is a capability, not a destination. The sooner we can dispel the notion that the cloud is a lofty, unattainable goal, the better.
But have no fear—there is a solution. Red Hat provides an open source distribution of Kubernetes called Origin Kubernetes Distribution (just pure K8s with none of the things that Red Hat does to make it more enterprise fulfilling and ready), but many people tend to gravitate to their flagship product—OpenShift Container Platform. Red Hat puts it succinctly: OpenShift is Kubernetes for the enterprise.
Red Hat is no newcomer to open source. It’s quite literally paved the way for open source in the enterprise, and in 2012 became the first one-billion dollar open source company. Red Hat is one of the largest code contributors to the Kubernetes project, second only to Google.
Here’s a simple example to show Red Hat’s commitment to open source and Kubernetes. In the early days of Kubernetes, basic role-based access control (RBAC) was not a priority for the project, which was a dealbreaker for many enterprises. Red Hat started implementing RBAC directly within the Kubernetes project, instead of as an added-value feature of OpenShift. This is the type of thing that makes Red Hat…well, Red Hat. Quite simply, the Red Had OpenShift Container Platform comes with opinions, tools, and features that make it hardened for the enterprise. It’s one of the special things that arise from IBM and Red Hat defining hybrid cloud.
Back to the matter at hand—how does Red Hat address this paradox of choice? As we’ve said before, Kubernetes provides the building blocks of an all-inclusive PaaS, without actually being one. Red Hat makes full use of these building blocks and has created a full-blown Kubernetes-powered PaaS. OpenShift is the best of Kubernetes with opinionated approaches for every capability we’ve talked about in the prior sections and more.
OpenShift comes embedded with Prometheus, Grafana, and Alertmanager for observability. It provides an embedded OperatorHub for installing additional services. It provides an enterprise-supported model for many open source capabilities such as Istio (OpenShift Service Mesh) and Tekton (OpenShift Pipelines). It embeds richer RBAC that goes above and beyond what is available in Kubernetes. The list goes on and on, and the support model that Red Hat provides on open source projects appeals to a number of enterprises that are faced with the paradox of choice.
Note
Red Hat OpenShift is different from the first generation of opiniated PaaS capabilities such as Heroku and Cloud Foundry for one major reason—although it provides recommended and supported extensions, it never dictates that you must use them. After all, OpenShift is Kubernetes underneath the covers and provides the same pluggable flexibility that Kubernetes offers.
No architect wants to be the one that decided to implement an open source project only for it to be eventually deprecated or unsupported. Although this is uncommon for mature projects (that became “CNCF graduated”), it does happen more than you might think. For example, Kubefed initially had large support as a multicluster tool for Kubernetes, but quickly lost traction and has remained in alpha for years.
Last but not least, one of the best perks of using OpenShift is the user interface. As practitioners will regularly say, learning to use Kubernetes can be extremely rewarding, but damn if it isn’t difficult to learn. This is partly due to the amount of CLI commands you need to learn—Kubernetes is primarily CLI-driven (we’re not casting shade on CLI or command-line tools; if you think vi is a productivity tool for word editing, have at it—but if you’re a graphic interface kind of person, OpenShift will help you out). The process of going from source code on GitHub to a running application can take a Kubernetes newbie upwards of a full-day of documentation hunting, trial-and-error, and banging their head. With the OpenShift management tool, a developer can quite literally click three buttons (we counted) to deploy from source code to a running application with an accessible route. This particular flow we’re referencing is called Source-to-Image (S2I), which OpenShift has open sourced by the way!