Chapter 3. “Cloud Chapter 2”: The Path to Cloud Native
Throughout this book we talk about all the value that awaits organizations that put their cloud capabilities to work inside a hybrid cloud architecture, and the “cheated” value return (or disappointment) for most enterprise cloud projects today. We insinuated a new chapter of cloud computing was here (the 2.0 moniker is tiring): “Cloud Chapter 2” (notice the quotes...we’re not talking about a chapter in the book). “Cloud Chapter 2” is all about cloud as a capability, and underpinning those capabilities are a bunch of Star Trek–sounding open source projects and a very large ecosystem. Kubernetes (and the enterprise hardened and tailored Red Hat OpenShift Container Platform version of it), Ansible, and Docker are the main ones. But like any great Emmy award winning movie, there is a large (and we mean very large) supporting cast of technology that can be leveraged (with just as interesting names—Fluentd, Grafana, Jenkins, Istio, Tekton, and oh so many more).
At times we struggled writing this book because we really wanted to keep its focus on the business user. Make no mistake about it, the Kubernetes ecosystem (and the software itself) can be very confusing because it’s so capable—but it is both a strength and a potential weakness. Business users are sure to get lost in the never-ending layers and components that allow you to expose this service to your broader technology stack, or the multiple ways in which to manage a deployment. Not to mention that Kubernetes is very CLI (command-line interface) oriented—another hurdle for the less programmer-minded of us to overcome. What’s more, there are loads of resources that detail how Kubernetes works (free and paid for) by people that can do just as good (or better) of a job than we can in describing it to you. We’re big fans of what Leon Katsnelson and his team are doing at CognitiveClass.ai with their Kubernetes education.
In this chapter we’ll talk about some concepts and technologies that we build on throughout this book. We purposely wrote this chapter so you could get a feel for the path to cloud-native where applications leverage all the capability of the cloud. We don’t talk about all the technologies in this chapter—in fact, we left out quite a few. That was on purpose. However, we wrote Appendix: Speaking Kubernetes and Other Strange-Sounding Names to teach you how to speak Kubernetes (and some other technologies in its ecosystem) for that purpose, so feel free to jump to it at any time to get some details on many of the technologies that are part of the Cloud “Chapter 2” renaissance.
Eras of Application Development
Throughout this book we talk about application modernization hand-in-hand with cloud capabilities. As you’re now aware, the reason why so many organizations can’t capture the full value of the cloud is because they have significant investments in existing applications that have been the backbone of their companies for years. Typically, these applications are siloed, difficult to connect to other systems, and expensive to update and maintain, and thus they often get tagged with the word legacy.
A quick note here for our readers—perception and reality are not always the same. In the context of what many refer to as legacy applications or systems, we’ve seen many vendors (including IBM) who have done a lot over the last two decades to modernize both the software and the hardware systems, making them fully cloud native (or at least give the ability to front their legacy applications as cloud native). This means you don’t have to “rip and replace” all legacy systems or processes when your point of view is cloud as a capability. You end up with opportunities to modernize that you may not have considered before. Got a COBOL copybook running on IBM Z? Grab an integration services platform (we’d like to recommend one of the containerized flavors) and wrap it up with REST API—that makes it callable like any other modern cloud native service. Developers that want to invoke that COBOL copybook (perhaps to pull from its output) simply call the API with the input parameters it expects and that returns the data to the app—they don’t even know it’s a COBOL copybook (what some would call legacy) piece of code. That’s the whole point!
That said, the word legacy describes a style in which these apps were built (and used) and thus application modernization seeks to take applications through a series of transformations that make them truly cloud native; this allows them to accrue all the benefits of cloud (the capability), and of course you can decide where to run them (the destination). When you think about cloud as a destination, these systems can operate just like “clouds” with front-ended APIs. In fact, this is the preferred architecture for many mission-critical and data-sensitive workloads (hence the title of the book, Cloud without Compromise), a true hybrid cloud approach.
To keep it simple, we consider a modernized app one that is easily updated, connects seamlessly with other apps, is easy to scale, and is built for the cloud (the capability). Think back to those thrivers, divers, and new arrivers we talked about in Chapter 1—the very experiences we detailed there showcase who’s running in a legacy mindset and who’s running modernized (even if they have some legacy applications they depend on).
When we work with clients, we like to get a quick feel for just where they are on their cloud journey. It would be easy for us to ask to look at their cloud contracts or see what SaaS properties they are subscribed to. But that’s not what we do—we go right to the app dev teams and classify their application-building approach (the Acumen Curves we talked about in Chapter 2 would serve as a tremendous harness for this conversation) as monoliths, service-oriented architectures (SOAs), or microservices. These classifications don’t just represent how apps are built, but how they interact and leverage the infrastructure where they run (which has everything to do with being cloud native—the industry term you will often hear when describing apps that are built for the cloud). Here’s the promise: if you want to automate, if you want to be agile, if you want to modernize, if you want true DevSecOps, if you want to write once and deploy anywhere, if you want all the capabilities that cloud brings and the freedom to choose the destination, you need to understand how architecture, infrastructure, and the way apps are built and delivered have evolved over time—not to mention what they are (a collection of services)—and that’s the primer we cover in this chapter.
In the Beginning: Monoliths and Waterfalls
Past civilizations used to mark their territories using a single enormously large block of stone (or metal) called a monolith. To IT people, a monolithic app (an application architecture approach) is used to describe a software app where all aspects of the app (user interface, data access code, and so on) are combined and compiled as one giant program and run in one place. If you recall, we’ve talked about how cloud native applications are composed of discrete blocks of logic (microservices)—this is the opposite.
If we think back to early in our careers in the dev labs, this is how apps were built (and many enterprise legacy apps are still built this way today). These apps ran on physical servers and used a waterfall development approach (each phase of a project must complete before the next phase—you’ll often hear the traditional synonym used for this approach to development).
If monolithic is the application architecture, the delivery is typically waterfall and the infrastructure are typically physical servers sitting on-premises and managed by you—likely overprovisioned, underutilized, inefficient, and buried in red tape. Unless, of course, you start applying the premise of this book and turning those servers into a cloud capability! You know you’re managing a monolithic project if your app project plan has distinct phases (like “Test”), and you deliver updates at well-defined and year (or multiple years) gap intervals. If you got a design wrong, you can’t go back to the current release. On and on it goes.
SOA Is the SOS to Your Monolith
Despite popular belief that it stands for “Save Our Souls,” SOS is actually a Morse code distress signal that isn’t an abbreviation for anything. The popularized definition was simply retrofitted to suit the existing code—ironically, this is the opposite of what those that build monolithic apps have to deal with, these souls need the ability to change the base without great cost. Service-oriented architecture (SOA) was a big buzzword a number of years ago and looking back, it’s evident SOA was an architectural epoch on the way to microservices (which are more cloud native).
SOA is a development style and the start of the era of application composition (versus building). It’s a discrete unit of functionality that is updated independently of other services. For example, a service might pull a client record and use more pronoun-sensitive phraseology on an AI-generated summary. SOA objects are self-contained and you don’t need to know how they work inside, only how to invoke them and how to handle the message that comes back (likely data in the JSON format). SOA objects might just do one thing (like in our example), or they could pipeline a number of tasks to do many things. SOA is typically deployed in distributed architectures. You might imagine an application using a number of web services, all talking to each other or resources like a database.
We feel SOAs were unsung heroes in the push to virtual machines (VMs) because they really showcased how inefficient it would be to order a new server to host a new service. Put simply, more flexibility means more utilization. SOA is also where agile takes hold, because this is where applications with coupled services are stitched together to make a full-fledged service where it’s easy to iterate for feature enhancements and so on. SOA was a path to cloud native, but things had to get smaller—micro-small.
Microservices: What SOA Would Be If It Was Version 2.0
The microservices architecture is an iteration over SOA that more loosely couples (it’s distributed in nature) services for application development. Microservices is a great name because the function unit (the service) gets more granular and more focused (it does one thing—it’s micro) when compared to SOA. The protocols that support the communications and invocation of services gets more lightweight in the microservices architecture compared to SOA as well. While it’s outside the scope of this book to detail SOA plumbing, it relied on heavyweight XML communications; microservices use a more lightweight API-focused architecture.
Just remember: microservices get more fine-grained in terms of function (they shrink the size of the service when compared to SOA) and their protocols (the way they operate and communicate) get more lightweight too. With microservices, you also run in a cloud native environment that delivers even more granular and dynamic infrastructure runtimes than traditional VMs.
You can see a good way to scorecard the “modernness” of your applications (Architecture, Infrastructure, and Delivery) in Figure 3-1. As you look at each epoch (each row for each modernization characteristic), you can’t help but notice that as you move down each pillar, the result is ever-more agility, independence of function (which means easy to update on the fly), more elasticity and capacity control (cloud), a better DevSecOps delivery mechanism (we talk about the Sec(urity) in DevSecOps in Chapter 6), and faster time to value.
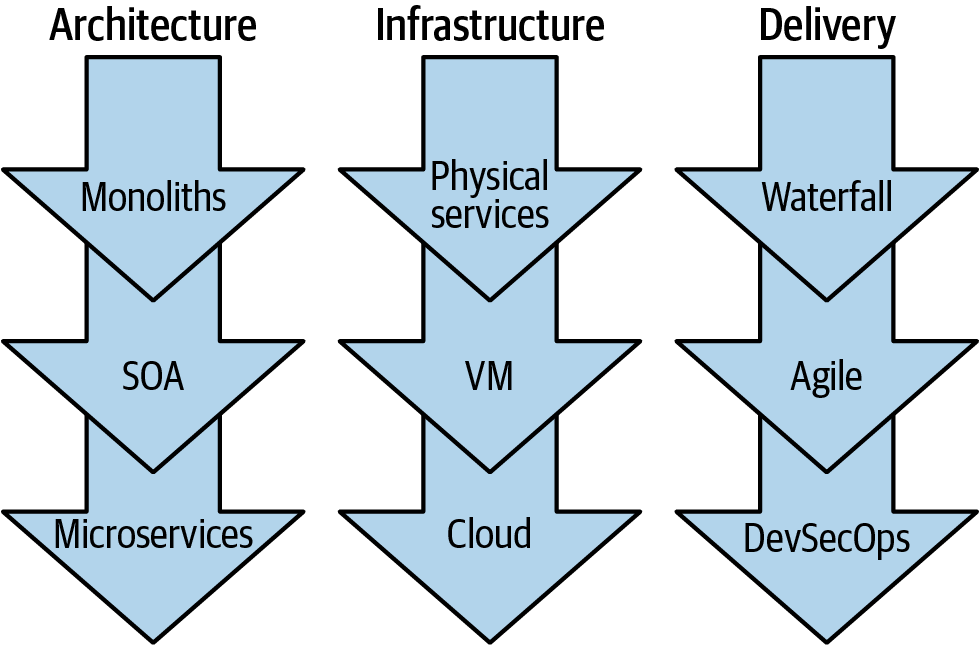
Figure 3-1. The epochs of application modernization: further down in each pillar is more modernized and cloud native
If we think about the conversations we’re having with clients today, there is always someone saying they are doing a DevOps transformation; someone else is doing a cloud transformation; and yet another group is talking about microservices. If you’re new to all of this and listening in, you might very well conclude that there are three separate transformations going on here—and that’s “true”—for those clients that are spinning their wheels. If success is your navigational heading, you need transformation across three key areas (architecture, infrastructure, and delivery) under a single culture and mantra that permeates throughout the entire organization. If you build a new microservice, you’re going to need some place to host and run that service (unless you’re doing function as a service, which we talk about in Chapter 4). Your microservice’s runtime must be resilient and dynamically scalable (you may need a lot of these small things, or hardly any at all)—this is all screaming for cloud the capability (which is a big change from SOA). Map these characteristics back to the monolithic architecture. How did you scale distributed or nondistributed monolithic apps on your server? You’d get a new server (scaled up) or rebuild your app to scale out.
The theme in modern application development is speed. Speed of scale, speed of delivery, and so on. The very nature of speed is the DevSecOps delivery nuance—bringing together the speed developers love (they think project to project), and the resiliency and assuredness that operations seek (they think about things like service level agreements, upgrades, patching, and security). By and large, the transitions outlined in Figure 3-1 are getting away from a yearly delivery project plan and moving you toward continuous delivery instead.
First “Pass” on PaaS
To truly appreciate the rise of containers (which we talk about in the next section), we wanted to ensure you had at least a brief understanding of first-generation platform as a service (PaaS) capabilities. So let’s get started with the world’s first foray into PaaS.
In the pursuit of speed—faster development, more agile delivery, and unimpeded elasticity—is it possible to go too far? Absolutely. That’s exactly what happened during the tumultuous state of the cloud near the start of the last decade. Cloud service providers (CSPs) were shaping the cloud landscape, going beyond IaaS and iterating on the first generation of PaaS capabilities.
As businesses finally began to take advantage of the elasticity of cloud and IaaS to run their SOA-based applications on VMs, the industry began to reinvent itself yet again. This is par for the course in the world of IT—after all, change is the only thing that remains constant in this world. You either evolve or fall behind.
As your attention moves down each modernized app characteristic in Figure 3-1, you’re likely to notice a pattern—the movement from physical services, to VMs, to the cloud also results in a change of responsibilities more and more away from your control. Clients eager to move from traditional IT and on-premises datacenters began to embrace IaaS. They rejoiced in the seemingly unlimited elasticity of the cloud, while adopting a flexible mode of consumption allowing them to pay for only what they use. Clients with existing applications were willing to relinquish complete control and autonomy of their infrastructure for these advantages. In addition, this paved the way for those new arrivers to run production-grade applications with a significantly reduced barrier of entry.
Naturally, CSPs continued to apply this same philosophy as consumers continued to embrace the cloud (the destination). CSPs began to offer the first generation of PaaS capabilities like Heroku, IBM Bluemix (now IBM Cloud Foundry Public), Google App Engine, and AWS Elastic Beanstalk. We (the customers) were all told to focus on what really matters—writing code—and let their cloud handle the rest. This meant moving further up the traditional IT stack and handing off control of our runtimes, middleware, and operating systems.
At first, these capabilities appeared to work like magic. You could simply write your application code in any of the many supported languages (like Node.js, Java, Swift, Python, Golang, or basically any language you could think of), then simply upload your code to the PaaS and have a running application on the web in a matter of minutes.
However, this technology came at a cost—the first generation of these PaaS solutions presented an opinionated (specific decisions and requirements made on the platform that will host your app) approach to IT. At least with IaaS, businesses were able to utilize VMs and ensure that their applications continued to run with little change required to the actual code. This was not the case with first generation PaaS. As much as companies may have wanted to, they couldn’t simply “lift-and-shift” their apps to these new PaaS capabilities like they had done with IaaS. In retrospect, there were three major factors preventing widespread adoption of these initial PaaS capabilities:
It required significant refactoring (developer talk for having to rewrite portions of an app to accommodate service and configuration parameters) of existing applications to adopt. Moving from monoliths to SOA was arguably a cakewalk when compared to the eventual transition to microservices. In 2011, Adam Wiggins (cofounder of Heroku) published the Twelve-Factor App (12factor.net). This document outlined a methodology to build modern, scalable, maintainable applications on a PaaS platform—essentially, microservices. To this day, these twelve factors continue to embody the best practices for building modern applications. However, for most companies in 2011, the Twelve-Factor App may as well have been written in an alien language—it was well ahead of its time.
PaaS platforms were so opinionated that an application running on one PaaS couldn’t be easily migrated to another. For example, consider what it was like to add a database service to Heroku versus Cloud Foundry (CF)—Heroku utilizes individual environment variables (
config vars), whereas Cloud Foundry uses a single environment variable (VCAP_SERVICES) in JSON format with all variables together. This meant that in order to migrate an application from Heroku to CF, you’d have to refactor the application itself, even when using the exact same database service in both environments! This leads to a terrible thing in the world of cloud—vendor lock-in. Clients who were burned in the early ages of cloud computing were not thrilled about the prospect of yet another technology that forced them to stay with a single CSP.First-generation PaaS platforms were asking for too much control and gave too many “not up for discussion” demands that made clients uncomfortable with relinquishing this much control over to the cloud. Companies were unwilling to adopt the public cloud model that PaaS required—this meant being forced to run on multitenant infrastructure on public cloud datacenters. Essentially, you had to drink the CSP-flavored Kool-Aid. In addition, clients began to find that the CSP-recommended approach (but it wasn’t really recommended at all…it was required) on things like service discovery, dependency management, security, and more didn’t always align with their requirements. In an opinionated PaaS, there was no room for change—you had to adopt the CSP’s approach.
Across all industries, the first generation of PaaS capabilities unfortunately led organizations to view the cloud as a lofty public cloud destination instead of as a powerful capability.
Lessons Learned: The Rise of Containers
In the early half of the last decade, it became increasingly clear that businesses were not adopting PaaS in the same way that they had with IaaS. CSPs learned some key lessons from this first generation of PaaS capabilities: avoid vendor lock-in at all costs, allow businesses to maintain a reasonable level of control over their stack, and do all this while giving developers the tools to maintain world-class agile DevOps practices.
It might surprise many to know (because of all the buzz around it) that containerization is not a new technology; it’s been around since the early 2000s but rose to greater prominence in 2013 with the release of Docker—and hasn’t stopped growing since. To understand why containers are so prominent today, we’ll start with the most apparent advantage—containers introduced an era of standardization that developers tend to take for granted today.
In 1937 the shipping container was invented by Malcom McLean—it had the effect of dropping shipping costs by 90% with this new standardized container. Just as the shipping industry was revolutionized by the use of containers, so too are the containers we’re talking about changing the software industry. Containers provide a standard way of packaging software, so it runs under a standard Linux-based operating system. The container package includes just the essential libraries, data, and configuration needed to run your app (containers are the minimalists of the IT society—more on that in a bit). A container just needs to be started with a standard command; it doesn’t require a complex set of commands, to say nothing of tracing back and installing a complex tree of dependencies. Containers enable automation and eliminate countless possibilities for making mistakes.
Looking back at the shipping industry, it’s easy to see the analogies. Loading a ship with 1,000 bushels of wheat, 750 casks of nails, 1,200 barrels of molasses, 150 sewing machines, and so on was a recipe for trouble. In the 1800s and early 1900s, each item had to be loaded by hand, packed carefully, and if something came loose during a storm, there was big trouble. Containers solved that problem: they come in standard sizes, they can be manipulated in standard ways, and they can be moved from ships to trucks, trains, or other vehicles without problems using a consistent set of tools (as opposed to all kinds of packages stuffed in a cargo net). That’s exactly what we want for software: we want standard commands to start or stop it with no complex incantations (a series of words said as a magic spell or charm—think Harry Potter); we want it to run on any kind of server without customization, and we want them all to look alike. Nobody should care whether a container contains a web server, a web application, middleware, or a database. Nobody should have to remember a paragraph-long command syntax that reads like geek haiku to get a service running—that command, with all its glorious options and parameters, should be embedded in the container. All that’s important is that the container can run.
But Wait, Don’t VMs Do the Same Thing!?
A discerning reader might have created parallels between the advantages of containers and using VMs. VMs can also package up all the dependencies of an application and these incantations to get them started, and standardize workloads no matter the size. But there’s a catch! VMs require that you also package a “Guest Operating System (OS),” which is redundant for containers as they can utilize the underlying “Host OS.” Therein lies the genius of containers, allowing developers to create standardized packages of applications that are incredibly lightweight in comparison to their hefty VM counterparts. Let’s use Figure 3-2 to review this point.
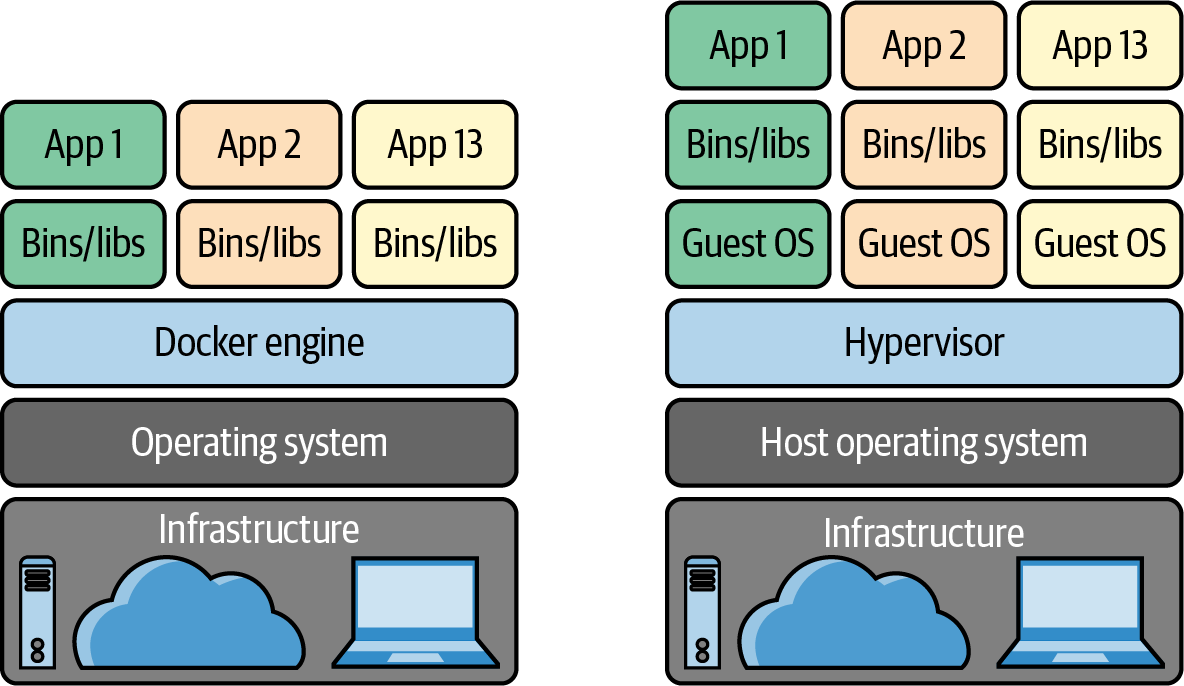
Figure 3-2. A comparison between packaging up an application using Docker (on the left) or a VM (on the right)
Imagine a team collaborating on developing a microservice where each team member develops, tests, and runs on a different operating system—Windows, macOS and Linux. Before containers, one potential approach to prevent unexpected differences from affecting the execution of the application would be to utilize VMs (the right side of Figure 3-2). This architecture has an unfortunate byproduct—it instantly kills developer productivity. Collaborating on code changes in a service when they need to be built into a VM each and every time is incredibly slow. Due to this, VMs were typically used by operations teams to run applications in production, rather than as a tool that developers used to collaborate on projects.
Containers solve this problem with lightweight, standardized packaging that allows applications to run anywhere. Developers can include the container builds as part of their local iterative development flow, eliminating the age-old problem of, “Well, it worked on my computer so it must be a you problem!” (This is the Java “write once, test everywhere” joke we joked about in Chapter 2.) In addition, sharing containers with your dev team is incredibly easy with container registries, which we’ll cover shortly. Lastly, container-based environments simply run more efficiently than VMs on the exact same hardware. Whereas a bulky VM essentially “quarantines” a set amount of memory and CPU usage to run, lightweight containers free up resources when they’re not being utilized. This greater efficiency translates to lower costs.
Beyond containers letting you architect your applications such that they are used in the most efficient manner possible, they change the landscape on startup times. If it took us days to get a traditional server going (once we got it in our office), then it took minutes with virtual machines and now we’re talking seconds—even subseconds—with containers.
Docker Brings Containers to the Masses
Container technology has been around for ages, with FreeBSD Jails available in 2000, cgroups being introduced in 2006, and LXC implementing the Linux container manager in 2008. So why weren’t people using them sooner?
In the early days, containers were a complex, commonly misunderstood, and difficult technology to utilize. No one knew how to practically use them! The rise of containers was popularized by Docker for two big reasons. First, Docker avoided vendor lock-in by supporting an open source model that runs on any environment (cloud or on premises); second, and more importantly, Docker brought containers to the masses with the Docker CLI, which instantly empowers developers to build containers with ease.
As you’re well aware of by now, Docker quickly became the standard for building and running containers. Docker’s Dockerfile describes how to build a container; its build command creates a container image; its run command creates (instantiate is the synonym for “create” in tech-speak) the container and runs the application packaged inside it (it actually combines two separate commands, create and run); and the stop command terminates the container. There are many more commands and subcommands (many of which have to do with managing resources and networking), but that’s the essence. It really is that simple.
Another reason behind Docker’s success was Docker Hub, which is a repository (cool people say repo) for container images. Docker Hub provides prebuilt containers for many commonly used applications. Docker Hub is particularly useful because containers are hierarchical: a container can reference a “parent,” and only add software and configuration that’s not included in the parent. For example, an application that needs a local MySQL database would be built on top of a standard MySQL container, and would only contain the application software, tools, or programs it needs, and any associated configuration files, but not another copy of MySQL. The MySQL container might, in turn, be built on top of other containers. So containers don’t just help developers package software; they help developers to build software in standard ways, by taking advantage of existing container hierarchies wherever possible. The ease of publishing Docker containers made it immensely easy for developers to collaborate and paved the way for streamlined CI/CD (continuous integration and continuous delivery).
For enterprise software, one drawback of Docker Hub is that it is public. It’s great that Docker Hub allows developers to share containers, but what if you provide an application or library that you only want to distribute within your company, or to a select group of business partners? Quay, a container repository designed for private use, solves this problem: it can be used to manage and distribute containers that can’t be shipped outside of your organization. Quay also includes a vulnerability scanner called Clair, which helps to ensure that your software is safe. The Quay project is now sponsored by Red Hat.
A Practical Understanding of Kubernetes
Think of how you regulate climate conditions in your house. You have a control interface (like a Nest thermostat) and perhaps you set the temperature of your house to 19oC (66oF) with 30% humidity. Your house’s climate systems constantly checks your declarative settings against the actual conditions using different sensors and mechanisms throughout the house. Behind that Nest thermostat is a control plane that can kick in air conditioning, the humidifier, heat, and so on—an ecosystem to bring your house to where you asked it to always remain; if anything gets out of sync from your definition of perfection, you have a system that remediates the situation.
With this analogy in mind, think of Kubernetes (say koo-br-neh-teez) as climate control for your operations. Why do we need a thermostat for our operational environments? Like we said earlier in this book, modern-day applications aren’t built but rather composed, and that composition is done through piecing together discrete functional parts composed of services and containers (which have shorter life spans than traditional virtual machine approaches). Today’s applications come with more capability and flexibility than ever, but with more moving parts that need to be managed (and that’s where things can go wrong). More moving parts means more complexity. Quite simply, Kubernetes provides a way to run and manage an entire ecosystem of distributed functions (like microservices), including how they interact and how they scale, in a framework that is completely standard and portable.
Today, human error is responsible for a whopping 50% of downtime. Now ask yourself this question, “What adds more to human error than anything?” Answer: Complexity! Specifically, the complexity of managing applications with more objects and greater churn introduces new challenges: configuration, service discovery, load balancing, resource scaling, and the discovery and fixing of failures. Managing all of this complexity by hand is next to impossible—imagine some poor operations (ops) person tasked with looking at the logs for an application composed of two hundred services! What’s more, clusters commonly run more than 1,000 containers, which makes updating these large clusters infeasible without automation.
Learning to pronounce the term Kubernetes (or K8s for short—the 8 is the number of letters after the K and before the s) is characteristic of learning how to actually use it—there’s a learning curve. Kubernetes is Greek for “helmsman” or “pilot”: the person who steers the ship. That helps: Kubernetes is the “pilot” that steers, or controls, large distributed systems. In the same way a Nest thermostat is climate orchestration for your house, Kubernetes container orchestration is a system to steer (or govern) your distributed systems so that they run correctly and safely.
Starting the Kubernetes Journey
Kelsey Hightower, the well-known Kubernetes developer advocate, has said, “The way it’s going Kubernetes will be the Linux of distributed systems. The technology is solid with an even stronger community.” While Kelsey is referring specifically to the open source community that has grown up around Kubernetes, we believe this statement could go much further. We’d be so bold as to say that Kubernetes is the operating system for distributed systems of containers regardless of the hardware architecture. What does an operating system like Linux, Windows, or iOS really do? It manages resources (CPU, memory, storage, communications, and so on) and that’s exactly what K8s does: it manages the resources of a cluster of nodes—each of which is running its own operating system.
Our bold statement about Kubernetes says both more, and less, than it seems. An operating system isn’t magic; it doesn’t create value out of nothing. It requires an ecosystem of tools; it requires developers who build applications to run on the operating system; and it requires administrators who know how to keep it running. It can handle a lot of the day-to-day work of running your distributed systems (the Day 2 stuff we touch on later in this chapter). We won’t pretend that getting Kubernetes configured correctly to manage your applications as you move to cloud native capabilities is an easy task. But it’s completely worthwhile—as worthwhile as using Microsoft Office or Apple Numbers to work with spreadsheets.
We’ve seen already how containers have become the standard way to package applications. We’ve known for a long time that we want to automate as much as possible—and to automate, we need to standardize. We don’t want to start each service we need with a different command; we want to be able to say, “Make this thing run, make sure it has all the resources it needs, I don’t care how.” That’s what containers let you do.
Kubernetes takes over the job of running containers, so you no longer have to start them manually. That eliminates a lot of mumbling over the keyboard when you need to run hundreds or thousands of containers. But it’s more than that. In a modern system, you might need several databases, an authentication service, a service that manages stock in the warehouse, a service that does billing, a service that queues orders to be shipped, a service that computes taxes, a service that manages currency exchange, and so on. Make your own list for your own business: it will be very extensive. And if your application is used heavily, you may need many copies of these services to handle the load. If you’re a retail business, you might see a 100x peak on Black Friday. If you’re a bank’s investment arm, you’ll see a peak on triple witching Friday (the simultaneous expiration of stock options, stock index futures, and stock index option contracts, all on the same day). If you’re an accounting firm, you’ll see a peak when tax forms are due. Handling those peaks is part (certainly not all, but part) of what the cloud is about. You don’t want permanently allocate resources to handle those 100x peaks; you cloud-enable your application and then allocate computing power as you need it whether it is in your datacenter or someone else’s datacenter. Need more compute? It’s just a few clicks away.
But you also don’t want some staff person trying to guess how many servers you need or writing some custom error-prone script to start new servers automatically. And that’s precisely what Kubernetes allows you to avoid. Instead, your operations team may say, “We need at least 3 copies of the backend database, at least 10 copies (and as many as 1,000—depending on the load) of the frontend and authentication services,” and so on. Kubernetes brings containers online to run the services you need, it watches the load and starts more copies of containers as needed, it scraps containers that are no longer needed (because the load is dropping), and it watches container health so it can scrap containers that aren’t working and start new replacements. There are a lot of pieces that go into this—and we’ll discuss them—but this is at the heart of what Kubernetes provides.
Kubernetes isn’t magic, of course; it needs to be configured, and there are plenty of people telling us that Kubernetes is too complex. And in some ways, they’re right—the complexity of K8s is a problem that the community will need to deal with in the coming years. But it’s important to realize one big advantage that Kubernetes gives you. It’s declarative, not procedural. A Kubernetes configuration isn’t a list of commands that need to be executed to bring the system into its desired state. It’s a description of that desired state (just like your Nest thermostat set at the temperature you want for your house): what services need to run, how many instances there need to be, how they’re connected, and so forth. Kubernetes determines what commands need to be executed to bring the system into that desired state, and what has to continue being done to keep the ecosystem in the desired state. Kubernetes is automation that allows you to deploy complex, distributed systems with hundreds of services and thousands of servers and have them run reliably and consistently with minimum human involvement. We will never claim that administrators or IT staff are no longer needed; but K8s imbues superpowers on those teams, allowing them to manage much more infrastructure than would have been possible in the past. Is Kubernetes a “heavy lift”? Possibly. But how does that compare to managing thousands of VMs, each running its own servers, manually?
Many important ideas fall out of this discussion. Applications are composed of containers and containers implement services. The application itself provides a uniform, consistent API to the rest of the world, even though Kubernetes may be starting and stopping containers on the fly. Think about the implications: a billing service may be accessing the accounts receivable service at the address http://ar2134.internal.aws.mycorp.com/. What happens when this server dies? Does the system crash or hang until the accounts receivable service reboots? This might have been what happened in the past. But with Kubernetes, the billing service only needs to look up the accounts receivable service—Kubernetes takes care of finding a running instance and routing the request through to that instance. The result is bedrock solidity somehow built on top of shifting sand, in spite of the odds!
This sort of routing can work because the containers themselves are immutable and interchangeable. As we said earlier, rather than bringing up a server—with a system administrator carefully coaxing it to life by installing and starting all the software components it needs (web servers, databases, and middleware)—you build standardized containers instead. If something goes wrong, kill one, start the other, and fix up the network so that clients never need to know that anything has happened.
In the DevOps community, people often have a “pets versus cattle” debate (some of you aren’t going to like the analogy they use) around the notion that how we treat pets versus cattle isn’t much different than how we should think about servers versus containers. Think of your house pet—it has a name and its own unique personality. Now think of a traditional server in your company that handles warranty claims. It’s not uncommon to “get to know” a server that has troubles. Just like if the family dog had issues, you’d take it to the vet for special care. What’s more, you’re likely to spend special time with your “IT pet”—we’re not talking about the Tamagotchi you spent hours on before you had social media to make time disappear with little to show for it. You patch it, turn up the log diagnostics to try and figure out what’s going on, and so on.
To DevOps, containers are cattle (remember how we said containers are “short lived”)—identically produced en masse. Because containers are easily produced and immutable (you can’t make configuration changes to them), you’re not going to care for and nurture a sick container with the same attentiveness you might give a server. If a container instance is malfunctioning, get rid of it and replace it with another. This is only possible because containers are immutable; and because they’re immutable, every instance is exactly the same. We don’t even have to think about the possibility that a new instance will fail because someone installed libSomeStrangeThing 3.9.2, which is incompatible with libSomeStrangeThing 3.9.1. Administrators do need to keep containers updated and scanned for vulnerabilities—we’ve all seen what happens when deployed software doesn’t receive security updates. But that’s another set of issues (which we talked about in Chapter 6), and much of this process can be automated, too.
Because Kubernetes can start and stop containers without worrying about what’s inside the containers, it can take whatever actions are needed to keep the system running. Think about just how radical an idea this truly is: Kubernetes is self-healing. Most of us can remember the era when distributed IT servers would crash and return to life an hour or so later. In many respects, that’s still true: distributed IT servers may be more reliable than they were even a decade ago, but they still crash, networks still fail, and the power still goes out. Building an enterprise system without taking outages into account is wishful thinking that could easily be fatal. When commerce went online, businesses immediately realized that the cost of being offline could easily be thousands or even millions of dollars per minute—and undoubtedly the COVID-19 pandemic has made offline costs even more significant—if not fatal—to your business.
It’s also important to realize that Kubernetes isn’t specific to any vendor’s cloud and will run on almost any hardware architecture—ranging from Raspberry Pi microcomputers, to the largest servers built on mainframes. For a few tens of dollars, you can build a Raspberry Pi cluster and keep it in the office broom closet; and once you’ve developed your application there, Kubernetes will (with very few changes) allow you to move that application to a cloud—to any cloud destination for that matter. Kubernetes will let you describe what zones you need, what processor capabilities you need (memory, GPU, TPU, and the like), and so on, so you don’t have to hardwire your software to specific configurations. It’s like we’re always saying: “Cloud is a capability, not a destination!” Kubernetes is the keystone that provides organizations the ability to run software anywhere, at any scale.
Finally, Kubernetes has been designed so that it can be extended and evolved with new features. Historically, Kubernetes has been tied to Docker (as the dominant container system of the time). Recently, the Kubernetes project announced that it is “deprecating” (IT talk for no longer enhancing, still supported, but perhaps not for long) Docker. Kubernetes has standardized on the OCI (Open Container Interface) container format and runtime engine. The OCI standard allows Kubernetes to evolve beyond Docker in several important ways, including the ability to use container registries other than Docker Hub and the ability to support other kinds of containers (and possibly even applications without containers). Read this carefully: deprecating Docker won’t be a barrier to current users. Docker’s container format complies with the OCI standard, too; therefore, you can still use Docker to build images that Kubernetes can run. And you can still use Docker to run those containers for development or testing. If you’re familiar with Docker, there’s no reason to stop using it—but there will now be other alternatives to explore—“let a thousand flowers bloom” goes the Apache open source slogan.
Time to Start Building
We’ve outlined critical cloud concepts to get you moving to cloud native—by now, we think you have a solid understanding of why we keep saying cloud is a capability not a destination. Think about it—shouldn’t reducing the bloat of VMs be desirable for any destination? See the problem with thinking that this tech is only for those on a public cloud? So what’s next? It’s time to start thinking about your application and how you’ll implement it in the cloud. Lift and shift—simply porting your application as is to a cloud provider—is probably the easiest solution, but it’s also the least productive, hardest to scale in the long run, and is going to come up short on all the value you could be getting from a cloud strategy. Rethinking and reimplementing mission-critical applications as a set of services gives your company the kind of flexibility that couldn’t be imagined a few years ago. Does your app need a new interface? Need to support a new kind of product? Are there other ways in which your software needs to evolve? Now is the time to think about reorganizing your applications so that new features and new product directions don’t require an entire rewrite. That’s where many IT groups fail. We want to get beyond failure.