Chapter 6. Hackers, Attackers, and Would-Be Bad Actors:
Thoughts on Security for Hybrid Cloud
All software, proprietary or open source, has long been a target for cyber hackers, attackers, and would-be bad actors. We want to ensure we set the right tone for this chapter: we aren’t suggesting that open source is inherently less secure than products built in a proprietary manner—not at all. But there is something to the old adage “You get what you pay for.” (And as we’ll explore later, there’s a world of difference between building systems for pet projects versus designing for the needs of enterprise.) Kate Compton makes the delightful comparison of “free” (open source) software to the curbside donations you might find after a move or when the college dormitories empty out come spring: “mattress-ware.” Sure, it’s free, but like with so many things in life you’re generally getting what you pay for. “Mattress-sourced” software might be the byproduct of an academic project or a developer’s Friday night whimsy. Making project code “open source” is a potential way to give new life to the project, but it comes with the expectation that there’s a fair bit of cleaning to do (of software bugs or literal bedbugs) before you would consider putting it “into production.” The point we want you to remember is that open source software for the enterprise requires much consideration and effort. You’re almost always better off partnering with an enterprise open source vendor.
One of the best parts about open source is the number of developers that can put eyeballs to software problems and the speed at which innovation can get to market with so many hands to keyboard. With that said, open source is not without its shortcomings. We’ve had firsthand experiences with getting open source projects up and running that date back to when Linux first came out decades ago, to standing up our first Hadoop instance in the early days (where it took months to properly get the full ecosystem working). The constant innovation is astonishing, but nevertheless it can wreak havoc on the stability of any company’s solutions—large or small. Often, you’ll find documentation is lacking. Finally, you need some pretty deep skills to support any open source project.
It’s also important to keep in mind that open source isn’t about a single solution; in fact, open source organizations don’t care if there are competing projects created for the same goals. What they do care about is ensuring that there is a sustainable development community behind the project. Quite simply, open source is about fostering open innovation through the commitment of a community; it’s not necessarily a standards-based organization.
It’s quite evident that the open source model has taken off. In fact, we’ll boldly tell you that most innovative companies are using enterprise open source software. Because of this, you’ll see a number of vendors integrate open source software into their product (like using Spark for data wrangling and cleansing), companies formed with committers of an open source project to offer paid support for it, and others that are a combination of both as they contribute to, make easier, and harden these open source solutions for the enterprise (like IBM).
What is enterprise hardening? It’s all the things a vendor can do that makes open source software more appropriate for enterprise deployment. It can take the form of “fit-and-finish” work like closing unused ports and firming up access controls, to enabling secure default configurations that make the project more secure, easier to install, more manageable, simpler to upgrade, and more.
Success can bring windfalls for your company, but it can just as easily lure in bad actors. Now more than ever, cybercriminals are wreaking havoc in the open source community and preying upon the very attributes that make open source technologies so attractive to developers: ease of access, modification, and redistribution. In this chapter we will explore some of the more common security concerns, dive a little deeper into container security, and give you some of our top recommendations to enhance your cybersecurity posture in a hybrid cloud model. This is not meant to be a comprehensive guide to hardening your hybrid multicloud environment, but it will put you on the right path and prime you to see the vulnerabilities (and opportunities) that may exist as you enable your business with cloud capabilities.
Just to Level Set: What’s This Open Source Stuff?
If you’re a business leader, chances are you’ve picked up on open source software (OSS), what it is, and why you should (must, really) care about it. To level set and get us all on the same page, here’s what open source means to us (and why it should matter to you).
OSS can be thought of as code that has been made publicly available by its original creator or authors. The concept behind OSS is a decentralized software development model that encourages open collaboration among a vast developer community. Often, developers will share their projects for peer review and further refinement by the community at large. This level of collaboration introduces a way of working that reaches far beyond typical proprietary software development methods. It provides for more flexible and less expensive up-front cost solutions that—for successful open source projects—outlast those solutions from proprietary software, precisely because they are built and maintained by software communities rather than a single company. Most OSS solutions began as a project in one of the many online code repositories, such as GitHub or GitLab. These repositories have large communities of developers that contribute code to existing projects, fork (open source lingo for taking a copy of something and then making it your own and taking it in a different direction—for example, MariaDB was forked from MySQL), and create new projects. The more developers engaged on a given project, the better the innovation pool becomes.
Note
Some open source projects go on to be wildly successful and become foundational to the enterprise. Linux and EnterpriseDB are great examples. Others never really take hold—there are literally thousands of open source database projects, and we’ve seen many customers start on one only to realize the open source project was abandoned by its original committers within a year. Finally, some projects take off like rocket ships (Hadoop), look like they’re set to change the world, and then peter out. The Kubernetes open source project is a fundamental anchor to cloud as a capability and we’re certain it will become an enterprise foundation building block.
As enterprises adopt agile development methodologies, OSS becomes increasingly valuable. In fact, the Linux kernel itself has seen a significant rise in adoption over the last decade and we expect even broader adoption with the growing popularity of Kubernetes (which we briefly talk about throughout this book, but go into detail in the Appendix). Each year we see an increasing number of commercial applications (distributed and sold under proprietary licensing) with embedded OSS as well. These trends show no sign of slowing—the trajectory toward broader adoption of OSS and community-led projects is a clear one.
With that out of the way, you might be asking yourself, “If everyone has access to the code, is OSS secure?” The answer isn’t always straightforward. We’ll suggest that OSS projects have the benefit of having an enormous base of developers committing code (particularly the more popular projects), which imparts a great deal of innovation, scrutiny, and expertise. However, not all OSS projects receive equal attention, which means they don’t all have thousands of developers reviewing the code for bugs and vulnerabilities in equal measure or have vast experience in enterprise enviroments. Generally speaking: your experience and quality-assurance levels may (and will) vary. You need to do your research before pulling any code down from your favorite repository. Let’s dive into what we mean by this.
Data Breaches, Exploits, and Vulnerabilities
You’d have to be asleep at the proverbial wheel if you haven’t seen the commonplace news about cyberattacks that have been launched over the last few years; as we’ve said throughout this book, they continue to increase at a steady (and alarming) pace. These attacks range in scope and severity: from data breaches and ransomware attacks at major financial institutions; to attacks on states, local governments, and federal agencies; and disturbingly, on health institutions (disproportionately targeted during the current COVID-19 pandemic). Because of their proliferation and integration into proprietary offerings, OSS technologies have become popular attack vectors for cybercriminals.
The Ponemon Institute’s “Cost of a Data Breach Report 2020” summarized a vast number of in-depth interviews conducted with 525+ organizations across 17 countries who all share a common thread—they all experienced data breaches between August 2019 and April 2020. As the pandemic boosted work-from-home patterns during on-and-off again lockdown protocols, Ponemon followed up with supplemental interviews with these same sample groups.
Ponemon’s report revealed that the average cost of data breaches has gone down (slightly)—likely representing established protocols and playbooks around handling such events. The report also shined a spotlight on the threat vectors where most attacks originate from and which types of breaches were shown to be increasingly on the rise. The study goes on to point out that the trend in malicious attacks has risen steadily over the last five years, making it the leading cause of security breaches today. As you can see in Figure 6-1, the third most common threat vector that often led to a data breach was “Vulnerabilities in third-party software,” including OSS code.
Note
One discovery that caught our attention (but seemed obvious after it did) was the use of OSS tools to carry out these attacks. OSS, it seems, is a sword that can cut both ways: like so many technological inventions, it can be used for tremendous good—but it can also be wielded as an instrument of ill intent and harm. A perfect example of this conundrum is the dark web. You get on the dark web using an open source browser that enables anonymous communications (called Tor) and law enforcement may use OSINT tools to find bits of information about the kind of interactions going on there.
We recommend following Ponemon’s security work to continue to learn information about data breaches after reading this book. They’ve been doing it a long time and have become one of our most trusted sources for data breach information. We’ll also note that data breach reports are out of date the moment they are published; the numbers keep going up, so it’s worth keeping up with the newest reports.
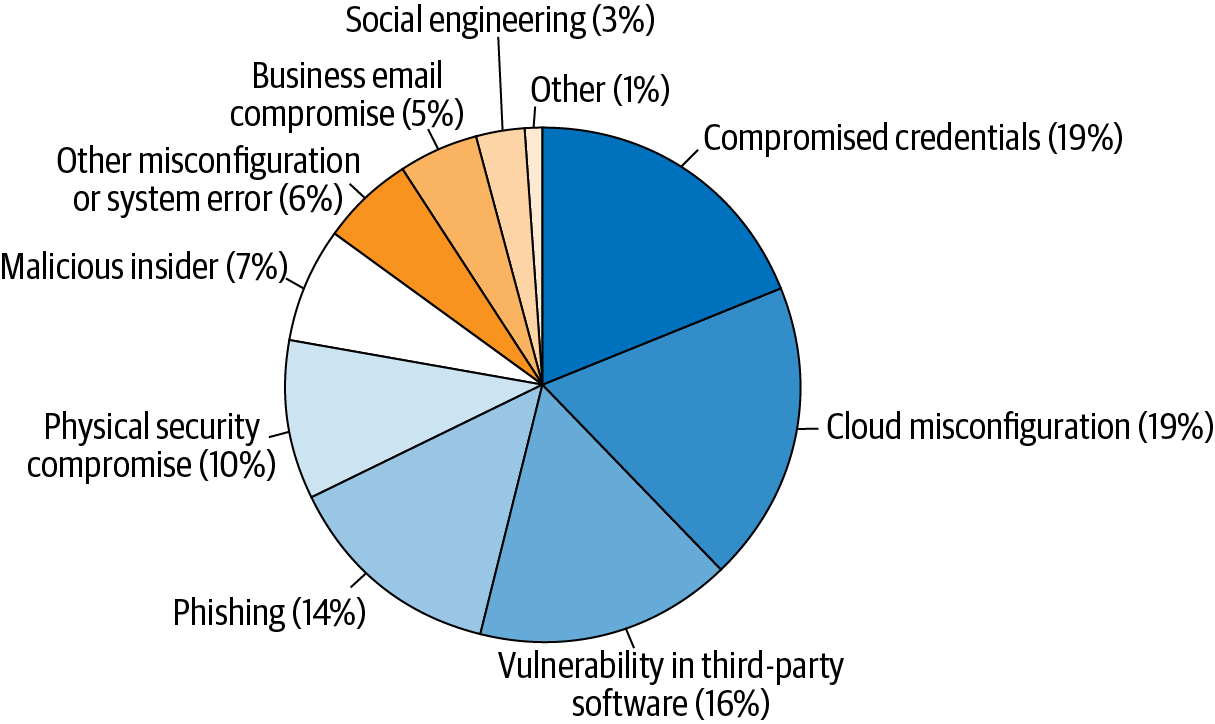
Figure 6-1. Ponemon’s “Cost of a Data Breach Report 2020” and popular threat vectors used for data breaches
Hackers Don’t Care Where You Work: Public Cloud and Security
Digital transformation goes hand and hand with the rise of cloud computing; in fact, it acts as an accelerator for cloud as organizations seek to modernize their IT infrastructures and apps. Looking to take advantage of the flexibility and potential cost savings of moving workloads to a cloud service provider (CSP), some organizations often view the public cloud as being more secure. They may feel that CSPs are better equipped to provide more elaborate security controls and policies, which might prevent attacks from the outside world, either because of a concentration of knowledge or economies of scale applied to such operations.
To quote Thomas Gray, author of “Ode on a Distant Prospect of Eton College”: “ignorance is bliss, ’tis folly to be wise.” The reality is that malicious attacks against misconfigured cloud environments (look back to Figure 6-1) have been and remain one of the leading causes of data breaches, tied for first with stolen or compromised credentials. One could surmise that these two leading causes go hand in hand: a malicious attack on a misconfigured cloud environment leading to compromised credentials. CSPs may be better equipped to withstand an attack provided they’ve invested in the proper tools, processes, and skills, but there are other risks and variables you need to consider before hosting your business applications and data in a public cloud.
For starters, placing all of your trust into another entity doesn’t relieve you from the responsibility of safeguarding any personally identifiable information (PII), sensitive personal information (SPI), or IP assets that you may have been entrusted with. Passing the buck on to someone else is not a strategy. Being a good data steward should still be a top priority for every organization. This means becoming familiar with and taking an active role in reviewing security controls, policies, threat awareness, and audit report reviews of any CSP you choose to partner with. Think about even the most basic example: access control lists (ACLs) for database authorizations. Misconfigured ACLs follow you to any cloud destination. Now think back to the concepts we discussed in Chapter 2 where we referenced how some public cloud administrators can access your encryption keys—that makes a security posture more complex (and potentially more exposed), doesn’t it?
In the context of public cloud, an additional concern is that your organization could potentially become collateral damage in a targeted attack against another company (or the public cloud vendor itself) that could leave your data assets inadvertently exposed. This is becoming especially concerning with the rise of attacks on public cloud infrastructures, where cybercriminals are finding new ways to exploit vulnerabilities on the surface in order to gain access to the underlying cloud platform. Once breached, attackers can gain access to move laterally across public cloud environments from tenant to tenant.
Security professionals often talk about an attack surface—all the potential points of entry where unauthorized access can be obtained. If you were to think of this in the physical context of a home or office building, think about doors, windows, ventilation systems—any conceivable point of entry would come to mind. Attack vectors describe methods used to breach the surfaces of IT estates: compromised credentials, software vulnerabilities, rogue insiders, misconfiguration, phishing, ransomware, and so on. Attack surfaces and attack vectors have steadily increased over the last few years, and public clouds (as well as hybrid cloud deployment models) have contributed to much of that increase. While we’ve not seen a 2021 year in review report yet, we think it’s a pretty safe bet to suggest there will be spikes in these methods of attack given the massive shift toward working from home and moving to CSP infrastructures.
Many of the common attack vectors that existed with traditional IT infrastructure deployments still apply (in a modern cloud and hybrid cloud deployment model), but the attack surface itself has increased. Take APIs as one example. There are hundreds—potentially thousands—of publicly exposed APIs that a single CSP may host. These APIs, by design, regularly serve up application logic and data. If not properly secured, they can lend themselves to malicious remote code execution (RCE), yielding a point of entry to a now-compromised system. If this goes undetected, this can lead not only to a single attack, but potentially multiple attacks. In the cyber underground and black markets, such access can be sold repeatedly before a data breach event actually takes place. Now think back to Chapter 2 where we talked about how applications are composed by stitching together various microservices—you might aggregate those from multiple vendors and (in many cases) those built by and hosted by your own organization…this gets more complex in the cloud, not less.
The Ponemon report also details the average cost and frequency of malicious data breaches associated with their root cause vector (Figure 6-2). Digging into these, we found some pretty telling facts within those findings.
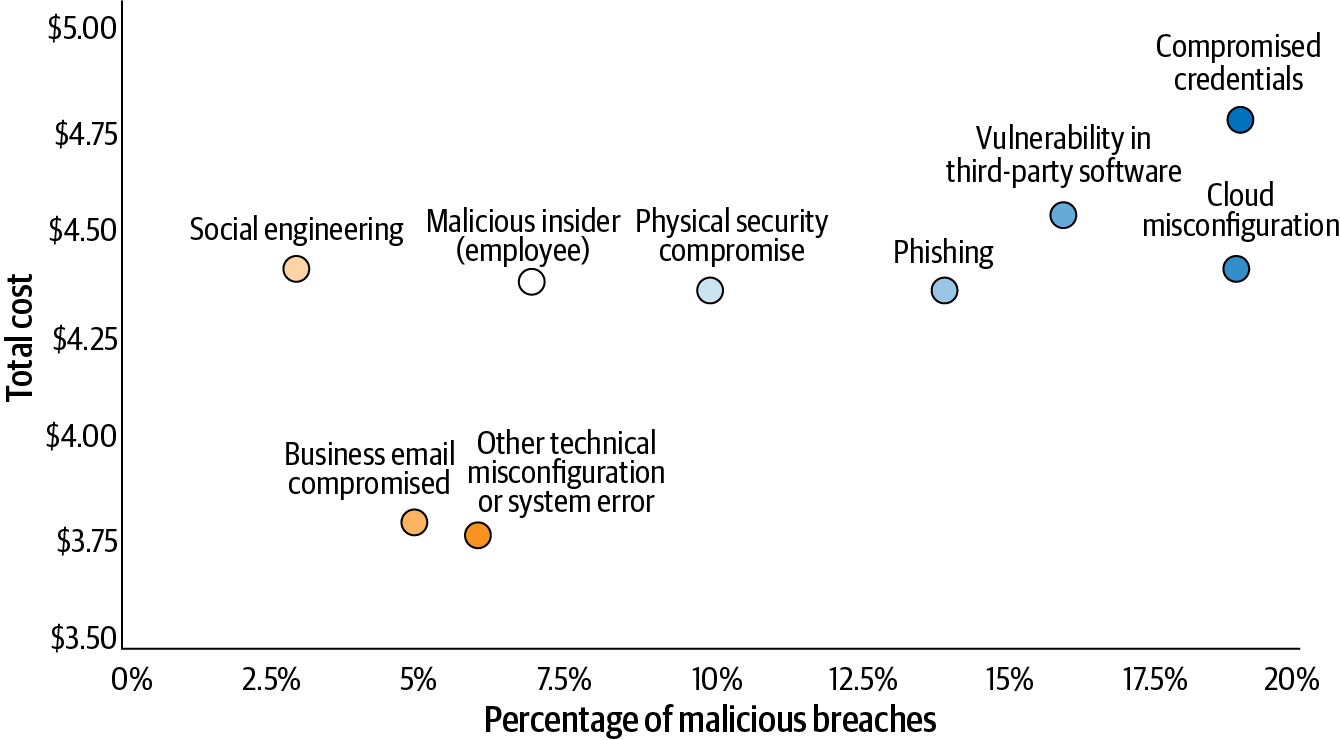
Figure 6-2. Average cost and frequency of malicious data breaches by root cause vector
Let’s say you’re breached because of a misconfiguration or system error...that will cost (on average) $3.86 million to manage. What we highlighted earlier warrants repeating here: Ponemon’s report noted how cloud misconfiguration tied for the most common threat vector along with compromised credentials.
But there’s something else that really caught our attention (and should catch yours too): the average cost of a data breach associated with a cloud misconfiguration is $4.41 million—that’s a 14% premium to deal with a configuration breach based on the destination!
Our book is about using cloud as a capability in multiple destinations. We’re not detailing these findings with you to push you one way or another, but rather to dispel some of the common myths and pitfalls we’ve seen clients fall into around cloud destinations and their instincts (like an instant cost-savings button). Whether looking at public clouds, private clouds, or the hybrid model we’re sure you’ll put to use, security is security and there are nuances you need to be familiar with for any destination. From access to your encryption keys to costs and more, flush them out and choose the appropriate cloud destination for supporting the workloads (and capabilities) your business needs.
Finally, something to keep in mind while studying Figure 6-2 is that misconfigurations often lead to compromised credentials. Any attacker who is seeking to exploit misconfigured cloud systems, in order to gain access and further compromise the system, will almost certainly begin by looking for ways to illicitly obtain credentialed access to the system. The holy grail for an attacker is to move laterally through a victim’s network by utilizing compromised credentials, elevating privileges, and going undetected to either steal as much data or inflict as much damage as possible.
A Case Study in Exploitable OSS
Arguably, one of the most prolific data breaches of the last decade began with bad actors exploiting a remote code execution vulnerability in a common OSS development tool for web applications known as the Apache Struts Web Framework (a tool used by thousands of websites globally).
Note
Details of this vulnerability can be found under the CVE-2017-5638 record listed on the National Vulnerability Database (NVD) and by referencing US Government Accountability Office (GAO) report GAO-18-559.
The Common Vulnerabilities and Exposures (CVE) report for this breach goes into all kinds of techy details about the code and the exploitation itself. All you need to know is that this vulnerability allowed an attacker to send malicious code wrapped in a content-type header and tricked a web service into executing its malicious code. Once exposed, this vulnerability permitted an open door into an otherwise protected network perimeter (we cover perimeter security later in this chapter).
Over time, news of this data breach caught the attention of media outlets, federal government agencies, and business leaders around the globe—but most shocking of all was the way that an OSS vulnerability exposed one of the world’s largest consumer credit reporting agencies to attack. At the time of the attack, this agency (which we won’t name here) collected and aggregated information on over 800 million individual consumers and more than 88 million businesses worldwide. Until this breach, a majority of consumers entrusted these agencies with their most sensitive and confidential information.
According to the NVD, the vulnerability in Apache Struts was first discovered in March 2017 and given the highest possible severity rating (10/10) because of the ubiquity of Struts and the fact that this vulnerability could be exploited without credentials, essentially making this a very easy attack vector. The good news is the community rallied around the vulnerability and created a remediation. The bad news? Hackers started exploiting the vulnerability on unpatched servers just days later.
Here’s what you need to know: there are lots of security fixes available but not yet implemented—this is one of the issues with the “roll your own” (RYO) approach to open source and befalls many open source practitioners. It’s hard as a developer to keep up when fixes don’t come pre-packaged and maintained by someone else for you. Regardless of whether you are using open source or proprietary software, it’s essential to maintain great security hygiene. Our experiences tell us that all in all, it’s harder to do this without a partner and solely relying on your team and stock open source software.
But there’s another lesson here: criminals are rewarded when you don’t have good security hygiene (think of the “1234” password on an ATM card). The CVE and NVD are publicly accessible resources that can be used for good or bad. Hackers will use it to look at easy attack vectors on vulnerable code (the bad) and you can use it to keep abreast of issues and create linkages to vulnerability scanning tools that can immediately warn you of these kinds of vulnerabilities (the good).
The agency in this example lacked both good security hygiene and these linkages and it resulted in over 40% of the US population discovering that their SPI (names, SSNs, addresses, driver license numbers, etc.) had been compromised in the breach—some even had credit card numbers compromised.
Over four months elapsed from the initial intrusion to when the breach was finally discovered, after the organization updated a digital certificate during a network inspection (which had expired 10 months earlier). Once updated and upon restart of the network scanning tool, administrators began seeing abnormal activity and initiated further investigations.
Note
One strange anecdote about this data breach is that none of the compromised data seems to have made its way to the dark web. In many recorded cases where a data breach has occurred, the attacker did so for financial gain and immediately sought to sell the compromised data on the dark web—often to the highest bidder. However, in this breach there has been no evidence of the 143 million plus records resurfacing. This raises the question—what was the motive behind this high-profile attack? Fast forward to February 2020 and reports began to surface that the US Department of Justice was able to link a nation state to this data breach, charging them with computer fraud, economic espionage, and wire fraud. Their motive? Presumably it was an effort to build a massive data lake of information on American citizens that contained PII and SPI classified data, including financial information on high-ranking government officials. (Source: https://oreil.ly/ekojL.)
This data breach, though large in scale, contains a number of mishaps that could have been prevented: usernames and passwords had been stored in the clear (without encryption), vulnerabilities in OSS applications were not immediately patched once identified, and there were what appears to have been relaxed security policies that allowed unabated lateral movement between systems and databases. We’ll talk more about the importance of proactively mitigating these risks and a concept called Zero Trust security later in this chapter (since we only briefed touched on it in Chapter 2). Each of these blind spots are commonplace in many organizations that are embarking on their digital transformation. Today, Chief Information Security Officers are dealing with IT environments far more complex than from even five years ago, so much so that standard perimeter security methods alone will prove to be grossly inadequate in the years ahead.
Digging further into cloud native and containerization, the risks persist. In 2020 there were 240 CVE records associated with the Linux kernel and 29 for Kubernetes that had been identified. Of the 29 associated with Kubernetes, almost one third were given a base severity score of high, but only one was given a base severity score of critical. Keep in mind this represents only two key OSS components out of what are likely hundreds that could be running in your “cloud the capability” environment. It’s not something that organizations should gamble on—for exactly the reasons demonstrated by the case study we just examined. A full list of those CVEs can be found at https://cve.mitre.org/about/index.html or in the National Vulnerability Database at https://nvd.nist.gov/vuln/search.
Did You Leave the Container Door Open?
Using privileged escalation to escape running pods. Moving laterally through a cluster and across tenants. Man-in-the-middle attacks against public services leading to leaked credentials. Remote execution commands executed against exposed APIs with malicious intent. What do these exploits have in common? Each vulnerability has surfaced within Kubernetes (K8s) and the underlying Linux kernel. The good news is that almost all of these vulnerabilities were discovered by the developer community and received fixes almost immediately. The challenge for security teams is to spot these holes and apply patches to them using vulnerability scanners and remediation procedures as part of a well-defined and automated playbook for tackling security threats.
You may be asking yourself: “Why spend the time discussing these examples if only some of them have led to real-life data breaches?” We can’t emphasize enough that securing workloads from unauthorized access, whether it is from internal or external threats, is critical. You can invest time and resources into nailing down the user experience design (UX), only to lose your customer’s data to a breach. If that happens, the UX for these customers won’t be great no matter how wonderful your designs are—not to mention your company’s reputation in the aftermath. Security is critical and no organization is fully immune to cyberattacks.
So where should you focus your company’s efforts to secure modern enterprise IT estates (cloud, distributed, or hybrid), which often have physical boundaries? Focus on what you can control: data. This also happens to be your most prized asset, and you should control access to the data relentlessly. It’s the one asset that your business likely cannot survive without (and would fetch a shocking ransom to get back if lost or compromised). Let’s explore a few areas where you can prioritize on protecting your data assets in the next section. We are going to cover a lot of ground here and since this is a book on hybrid cloud, we will begin with what should be the foundation of all hybrid cloud deployments—the Zero Trust security model (a concept we first introduced you to in Chapter 2, but will delve deeper into here).
Zero Trust in a Hybrid Cloud World
There is no doubt about it: digital transformation and the move to hybrid cloud is changing the way that companies do business. Now more than ever, data and resources are increasingly accessible to anyone—and with that ease of access comes the perilous responsibility of ensuring that only the right person (at the right time) is granted the right level of access to both data and resources. How that level of access is defined will vary business to business, team to team; however, we might suggest that the appropriate level is only what a user (or application) needs to complete their task for that moment in time, and not one rung higher up the ladder than is necessary. There is a common security design principle that best describes what we mean here—the principle of least privilege (POLP). This is the idea that any user, program, or process should have only the bare minimum privileges necessary to perform the intended function.
What was once considered “outside” of the network is now “inside” the network, a traditional IT network perimeter line that is further blurred by multicloud architectures. Many companies subscribe to multiple services: software as a service, platform as a service, infrastructure as a service, and so on. More often than not, a business places its trust for its most-prized assets (its data) in someone else’s hands. In short, the traditional ways of managing IT security—which has largely focused on building a perimeter wall and keeping bad actors out—is no longer sufficient. Are firewalls and other network barriers still important? Absolutely. However, the best security practices will always assume that those barriers can and will be breached. The concept of “don’t trust anything or anyone, and always verify” could mean the difference between a minor event and a major breach—it can also mean the difference between the destination choices you have for your cloud applications.
By definition, Zero Trust is an IT security model that emphasizes strict identity and integrity verification on every person and device attempting to access data or services—regardless of if they are inside an established network perimeter or or on the outside. Quite simply, it means trust no one.
Every attempt to access a service or data must be verified before being authorized. This applies to all networked devices irrespective of their connectivity to a managed corporate network. The Zero Trust security model serves to protect sensitive data, critical services, and devices while enabling end-user productivity. This is a major paradigm shift in IT security where although trust was once implicit within the internal network, the Zero Trust model is now seeing a marked uptick in adoption. This is particularly critical in an era where cloud services have blurred the perimeter lines and employees work from home on an increasing (or in some cases permanent) basis.
Context is key to applying a Zero Trust security model and it relies upon an established governance model for sharing context between security tools. Having shared contextual awareness is key to protecting the connections between users, data, and resources. Figure 6-3 gives a highly simplified side-by-side comparison of the traditional IT and Zero Trust security models.
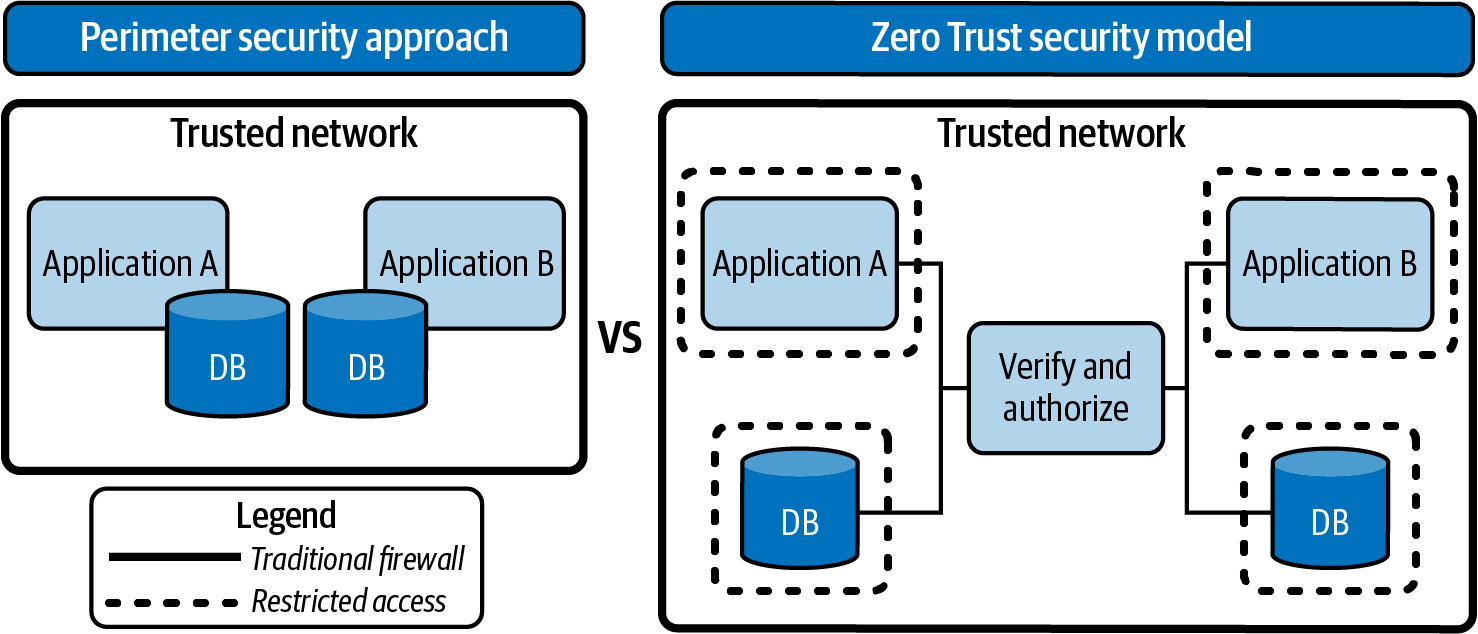
Figure 6-3. Traditional perimeter security versus Zero Trust security model
In Figure 6-3 you can see the importance of having perimeter security as the main line of defense to malicious network attacks no matter the approach you take—that’s a given. The Zero Trust approach is based on establishing firewalls within a network to establish a “safe zone.” Communications between users, applications, databases, servers, and other devices within this safe zone are considered secure. Identity and access management (IAM) methods and tools often exist within this model, prioritizing protection of network perimeters (and everything encapsulated within it). With the Zero Trust security model, you will see that the network perimeter still exists; however, new lines of defense have been established for each application, database, and server (the dashed lines surrounding the architecture pieces in Figure 6-3). The Zero Trust approach employs the notion that all requests for access must be verified before being authorized.
Implementing a Zero Trust security model in a modern cloud architecture is shown in Figure 6-4. Such an implementation often includes a mixture of hybrid cloud, distributed and multicloud, and traditional on-premises services. With multiple technology services spread across multiple datacenters, networks, and providers, the number of perimeters increases—and so too does the number of potential holes in those defenses. The traditional perimeter security approach is simply not enough. Like we said earlier, a vulnerability allowing access to one network can quickly bleed over into other cloud infrastructures.
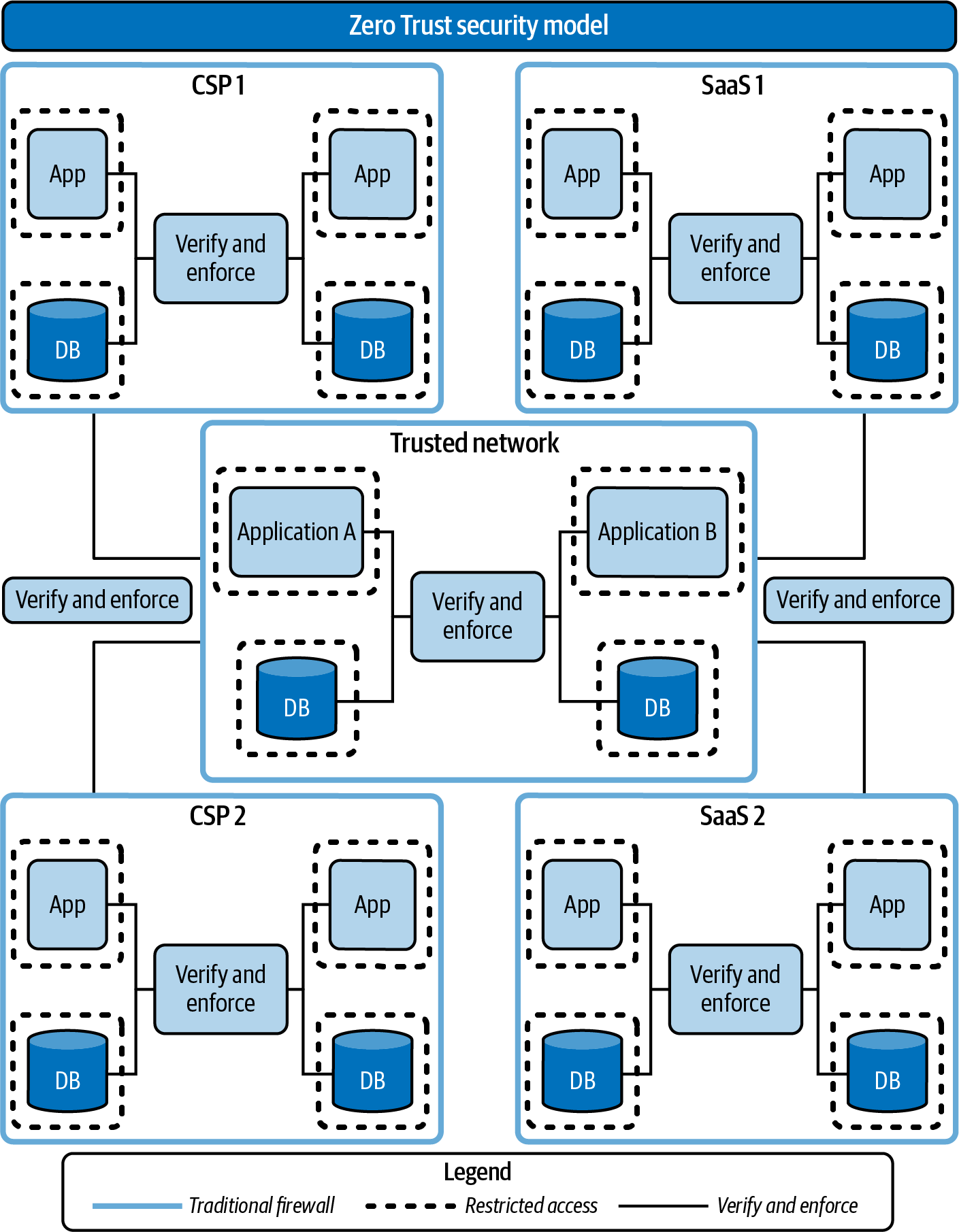
Figure 6-4. Verification and enforcement of permissions and access control is critical: in a hybrid multicloud architecture, the integrity of these checks must be maintained between applications and databases, between Software as a Service (SaaS) providers, and between cloud providers, as well as between the aforementioned endpoints and trusted networks
Implementing a Zero Trust security model will limit risk exposure by restricting access, which in turn limits the ability for a threat to move laterally throughout a network.
A key element to implementing Zero Trust security in a Linux-based hybrid cloud enterprise architecture is Security-Enhanced Linux (SELinux). Linux systems have a very tight approach to access control; however, escalating privileges to root (the superuser of Linux operating systems—a “go to” move for many to get things done like a data scientist using pip to add a Python package to a server) access could easily compromise the entire system if not properly implemented. In order to provide an extra layer of security to IT environments within the US government, the United States National Security Agency (NSA) created a series of improvements to the Linux kernel using Linux Security Modules. That work was released under the GNU General Public License (GPL) in the year 2000 and was adopted upstream in 2003. SELinux was born out of this set of security modifications provided by the NSA and was adopted by various Linux variants, including Red Hat Enterprise Linux (RHEL).
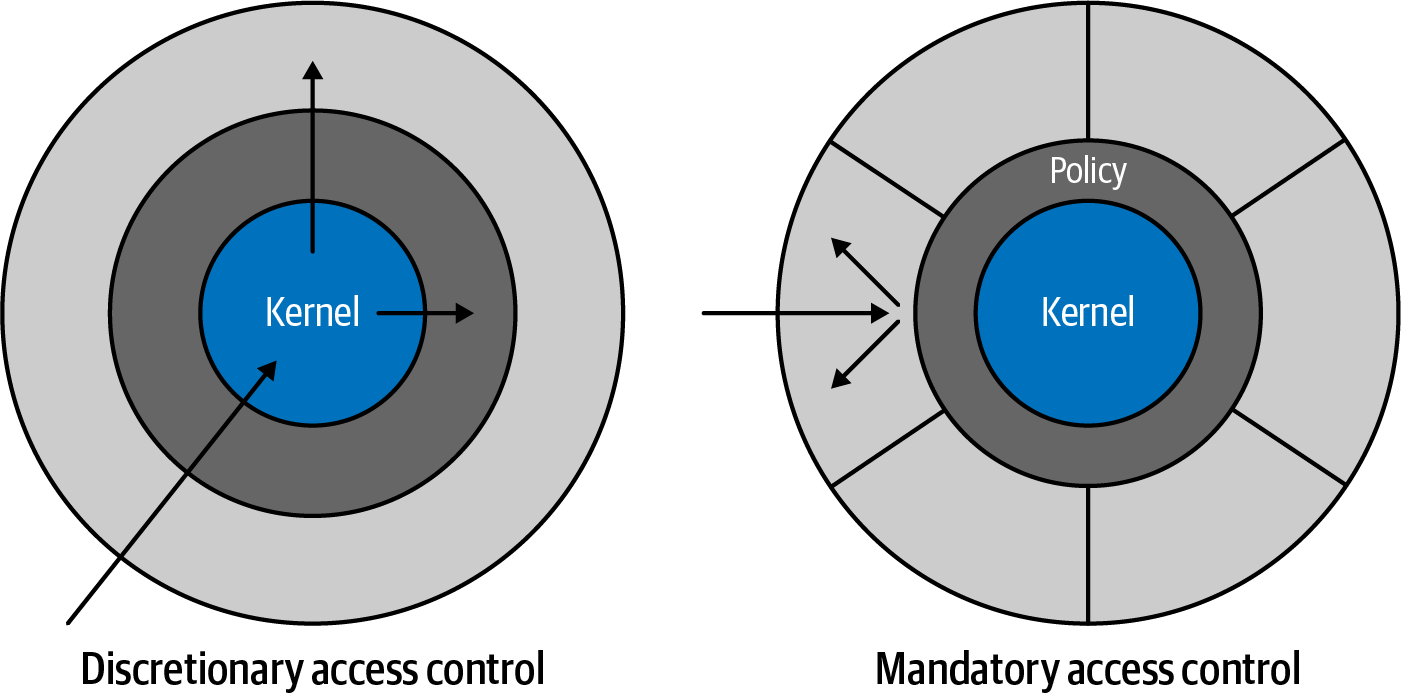
Figure 6-5. A security exploit that grants privileged access on a system using discretionary access control (DAC) will expose the entire system, while with mandatory access control (MAC), kernel policies (SELinux) block access even when running with privileged access, preserving the system integrity and firewalling the compromised service from the rest of the system
To understand the benefits of SELinux you need to understand how the traditional Linux access control system works. Linux’s traditional access control systems use a discretionary access control (DAC) system, which was defined by the Trusted Computer System Evaluation Criteria to provide access control that restricts access to objects based on the identity of the subjects (or groups which they are part of). If you are the owner of that object (or part of a group that owns that object), then you have control of that resource or object. Simple, right? Most of us are familiar with this model even with our own home laptops. But enterprise computing isn’t our home laptop.
Let’s explore a common IT scenario to illustrate: a service httpd running under an apache user where a user account becomes compromised. This then empowers the attacker to successfully escalate instructions and commands to root level (super powers on a Linux system) access by exploiting vulnerabilities in the httpd web server code. Not only are the contents of that service now compromised, but so too is the entire system—DAC provides access based on ownership. Since root is omnipotent (meaning unlimited powers) on a DAC model, it immediately has the highest level of ownership (and therefore access) possible. You can imagine the havoc that could be unleashed on such a compromised system. This is where SELinux shines and helps mitigate the risk of (or completely prevent) such scenarios from arising.
SELinux is an implementation of mandatory access control (MAC), which complements the traditional access control (DAC) but also enforces a specific set of control policies. There are different ways to deploy SELinux: a strict mode and a targeted mode. Strict mode denies all access by default such that every single object is required to have a policy set up beforehand in order to perform work. This makes enterprise use very restrictive and is the impetus for having an alternative targeted mode available as well. Think of the targeted mode as a “guards at the gate” approach, where you only protect the objects that could be exploited during a successful security breach; this follows a more prescriptive approach to security, rather than a blanket approach.
Let’s return to our previous example, where the object (service) that runs as the apache user is compromised and the attacker is able to escalate privileges to root access. With SELinux in place, administrators would have a set of policies in place to prevent even the root user (in the case it was hijacked) from inflicting any additional damage to the system. The apache hijack would only compromise the objects that the particular apache service would traditionally have access to, thereby restricting the pool of targets and limiting damage to the system. This is all possible because a set of rules were previously created that defined the objects that the web server has access to. Everything else that is not explicitly defined by the policy becomes untouchable, as the SELinux mechanism will enforce access control rigorously (even if root access is granted from that particular service). In other words, even if you’re a superhero with all the powers in the world at your disposal, SELinux has some Kryptonite in case a hero turns bad. In practice, the kernel must query and authorize against SELinux policies before each system call to know if the process has the correct permissions to perform a given operation. SELinux policies are, in a nutshell, a set of rules that authorize or forbid operations no matter who you are.
It’s also important to mention that DAC controls ownership plus permissions (like read, write, and execute). The users can change these permissions and, historically, the root user is omnipotent. With MAC, policies are predefined and locked in. Even if you try to change DAC permissions, if the policy was not written to enable access to an object, it will be blocked by SELinux.
For orchestrated multicloud environments, containers will continue to play a much bigger role. Having a secure, trusted platform foundation for containers is paramount to building a successful cloud implementation. As containers are nothing more than a process running on a Linux system, it shares the host kernel with other containerized processes. Each of these containerized processes are isolated from one another using kernel spaces. We won’t go too deep here, but the point we need to make is that container security is Linux security—which means that SELinux plays an important role when we are talking about containers as well.
Red Hat CoreOS, for example, is based on a trusted and mature Linux distribution known as Red Hat Enterprise Linux (RHEL) and inherits all of its robust security attributes as the basis for a secure operating system for container orchestration platforms. Each process on Red Hat CoreOS has an associated context and set of rules defining the scope of interactions permitted by the process. You might have wondered: “What does context mean in the scope of SELinux (and operating systems in general)? Essentially, when you have a file or directory that you want to create policies for, you typically require some sort of mechanism to label it (a way to map it to a set of SELinux policies). For example, for a file to be acted upon, it must belong to a specific label that identifies the SELinux policies governing permitted actions upon that file.
Let’s explore another scenario: a service running inside a container has a code bug that allows the attacker to gain shell access to that container. Thanks to cgroups, that kernel’s namespaces will restrict the attacker from observing or interacting with any other containers on the same CoreOS systems. However, if the attacker is able to take advantage of a kernel bug, they might be able to escape from that container environment—as multiple containers will be running as the same user. Having SELinux enabled (which Red Hat CoreOS activates by default) ensures that the Linux kernel restricts the attacker in this scenario from compromising any other containers running on that system. Each container carries a uniquely contextual security policy to deny cross-content access and prevent any further damage from occurring. In plain words, SELinux would prevent any further escalation. This is a big deal: think back to the Arriver’s Guide we introduced you to in Chapter 1 and the things containerization requires you to think about in a new way: security, resiliency, performance, and more.
Many attacks have been stopped or mitigated by simply having SELinux enabled, which is why having Red Hat CoreOS as a foundation for any hybrid multicloud platform is so beneficial—CVE-2016-9962 is one such example. On Red Hat systems with SELinux enabled, the dangers posed by hijacked containers with privileged access are greatly mitigated. SELinux prevents container processes from accessing host content, even in cases where those container processes manage to gain access to the actual file descriptors.
Another example: CVE-2017-7494 addressed a vulnerable Samba client.1 A malicious authenticated Samba client, having write access to the Samba share, could use this flaw to execute arbitrary code as root. When SELinux is enabled by default, the default security posture prevents the loading of modules from outside of Samba’s module directories and therefore mitigates the flaw. This is just one example of many. We could go on and on about the ways that SELinux technology plays a vital role in today’s IT environments. If nothing else, we hope our examples illustrate the benefits of kernel-level security and explain the rationale behind Red Hat’s strategy of embedding CoreOS at the center (where it has resided since the release of version 4 and onwards) of the Red Hat OpenShift Container Platform.
Beyond enabling Linux Security Modules for the Linux kernel itself, there are a number of additional solutions that provide value and can increase an organization’s security posture, such as the products behind the shield of IBM Security. It caters to the Zero Trust security model and thus offers contextually aware access control for identities and services, regardless of where those happen to reside (on-premises, off-premises, or a hybrid blend of the two). These tools offer a centralized approach and focus on understanding users, data, and resources in order to create coordinated security policies that are aligned with the initiatives of a business. By centralizing identity management and providing contextual awareness organizations can begin to automate the verification and enforcement procedures, enabling conditional access to data and services without friction.
Let’s face it: the current cybersecurity market is a crowded space with thousands of software vendors and OSS projects offering a plethora of tools. Many of these technologies still cater to traditional monolithic apps running on-premises, with a few new entrants that focus solely on the hybrid multicloud container market. They run the gamut from endpoint management to IAM, vulnerability scanning, threat detection, threat intelligence, and so much more. Many of these tools are often siloed or niche, making it incredibly difficult for security administrators and analysts to effectively perform their jobs. Many gaps exist in this often-segregated approach, which can alarmingly produce a false sense of security. Consider again the data breach example from earlier in this chapter: that organization felt they had all their bases covered. As soon as they were alerted to the vulnerability with Apache Struts, the security team scanned and patched all of their systems—or so they thought. The breach didn’t happen from a lack of skills alone. In fact, there was no evidence pointing to any one person’s inadequacies or incompetence. Rather, it was the tools and processes that supported the security apparatus that fell short. Placing heavy reliance on tooling is commendable, but having a well-established process for how they are managed is key.
Importance of Sec(urity) in DevSecOps
Let’s talk about DevOps and its role in ensuring a solid security strategy for deploying containers in a hybrid cloud environment. DevOps is a methodology that pulls together development processes, technology, and people with IT Operations. This is not to say that these historically disparate organizations now share only one unified toolset, process, or collection of resources. Not at all. DevOps is more about increasing the collaboration and transparency between the two groups. The end game is to build a cohesive system that is made of the people, processes, and technologies regardless of team or discipline. In the past, development teams have worked independently of IT Operations teams (and vice versa). In fact, each of these groups often created “silos within silos,” working independently of one another (and often pointing the blame to each other for anything that went wrong)—from the design phase, all the way to product release.
The DevOps methodology has in many ways simplified the entire development process. What would once have taken months or years to design, develop, package, and release now might only need days or weeks to implement. This has increased business agility dramatically, allowing companies to bring new services to market very quickly. These advances are particularly important in today’s economy, as it’s not always the biggest companies that succeed but rather (it seems more often than not) that success goes to the fastest and most innovative. Speed of innovation is a competitive differentiator that turns new market entrants into market incumbents.
There are downsides, however, to rapidly churning out new code in the form of rapid releases, updates, and patches. On occasion, a lengthy and sometimes egregious development process can lend itself well to catching bugs, defects, or other issues that could potentially lead to code vulnerabilities (and therefore risk to new adopters). Additionally, with longer production cycles IT security teams will generally have more time to prepare for and audit production rollouts. With DevOps practices, security teams are typically left out of the equation during the initial design and development phase. In the context of cloud native, leaving security out of DevOps can result in costly mistakes that are discovered much further downstream (potentially only after the damage has already been done).
In Chapter 5, we discussed the phrase “shift left” in the context of application development, but can it also be applied to security? The notion of incorporating both operations and security earlier into the development cycle is what we refer to as DevSecOps. The challenge for implementing the DevSecOps methodology can be a big culture shift, primarily due to IT security being viewed by many developers, operations staff, and business leaders as an inhibitor to speed and agility. Remember: speed of innovation drives business in today’s economy (and anything that applies friction to that velocity is often scorned). To make matters worse, a significant number of software developers have not been adequately trained in the concepts and best practices of security, creating a massive knowledge gap. Developers are often under tight deadlines to deliver and security often becomes someone else’s problem (or at least an afterthought). This mentality, whether it be a conscious effort to avoid delays in release cycles, or just a simple lack of understanding, can be a challenging cultural obstacle to overcome for many organizations.
We’ve found that by training development teams on the importance of adopting security principles and best practices, they are often able to move beyond the mindset or preconceived notions of security being an inhibitor to speed and innovation. Developers realize that their efforts to apply security best practices and collaboration with IT security teams early on in the project lifecycle can dramatically mitigate the risks and impacts of security vulnerabilities. These security holes, if exploited, have the potential to consume a developer’s time and resources in the future if ignored. Adopting a DevSecOps methodology early on in a project’s lifecycle will pay enormous dividends down the road.
When we speak with clients, one of the most common inhibitors preventing them from running production workloads in a container environment is the lack of acquired security skills. Many organizations that find themselves in this category believe that they can overcome the skills and process gaps through the use of tooling and automation (which can certainly help); yet simultaneously, they remain apprehensive because of unfounded concerns that the container security market is “too new.” Many such organizations are finding themselves leap-frogged by smaller, more agile companies who are willing to assume the risks and recognize the tremendous potential of containerization.
How do organizations overcome this stigma and risk apprehension? Our response is to look at what you already have in place from a technology perspective. What are the capabilities of the products you use today? Do those vendors have a strategy for how they will address container security at any stage in the lifecycle? Do they collaborate with other vendors to enrich their capabilities and add value for their clients? Do they have a well-established ecosystem of partners whom they work with to advance their products? You may find that many of the tools that you’ve already invested in either have plans to address these gaps or may in fact already address them. The key here is understanding that there are only a few security software vendors that can adequately address every phase of the lifecycle for container platforms. Others will come close; some will remain niche and you will be left to reconcile the pieces. This is why it is incredibly important to prioritize selection of vendors that are known collaborators with other companies in the market; focus on ones that build their solutions to open standards and seek to expand their offerings across the entire marketplace.
Container Security Visibility 101
Containers represent a new paradigm to IT security where traditional methods for securing the enterprise are no longer adequate (new worlds come with new rules, right?) What makes container security a challenge for IT organizations is linked to the very attributes that make containers so valuable. This paradox exists because:
Container images themselves are immutable (they can’t be changed—if you change a container image, you are essentially creating a new one), meaning any vulnerability within the container image will persist for the life of the image.
Containers are rapidly swapped and scaled, creating a lack of visibility into their attack surface.
Container configurations are vast—lots of knobs and dials raises the potential for misconfiguration (not to mention complexity is the top reason for outages).
Containers tend to be short-lived, making forensic investigations as well as compliance reporting a challenge.
At a high level, there are five key areas (shown in Figure 6-6) to focus on as you look to build out your container security strategy. It’s important to note that code scanning prior to the container build process is equally important.
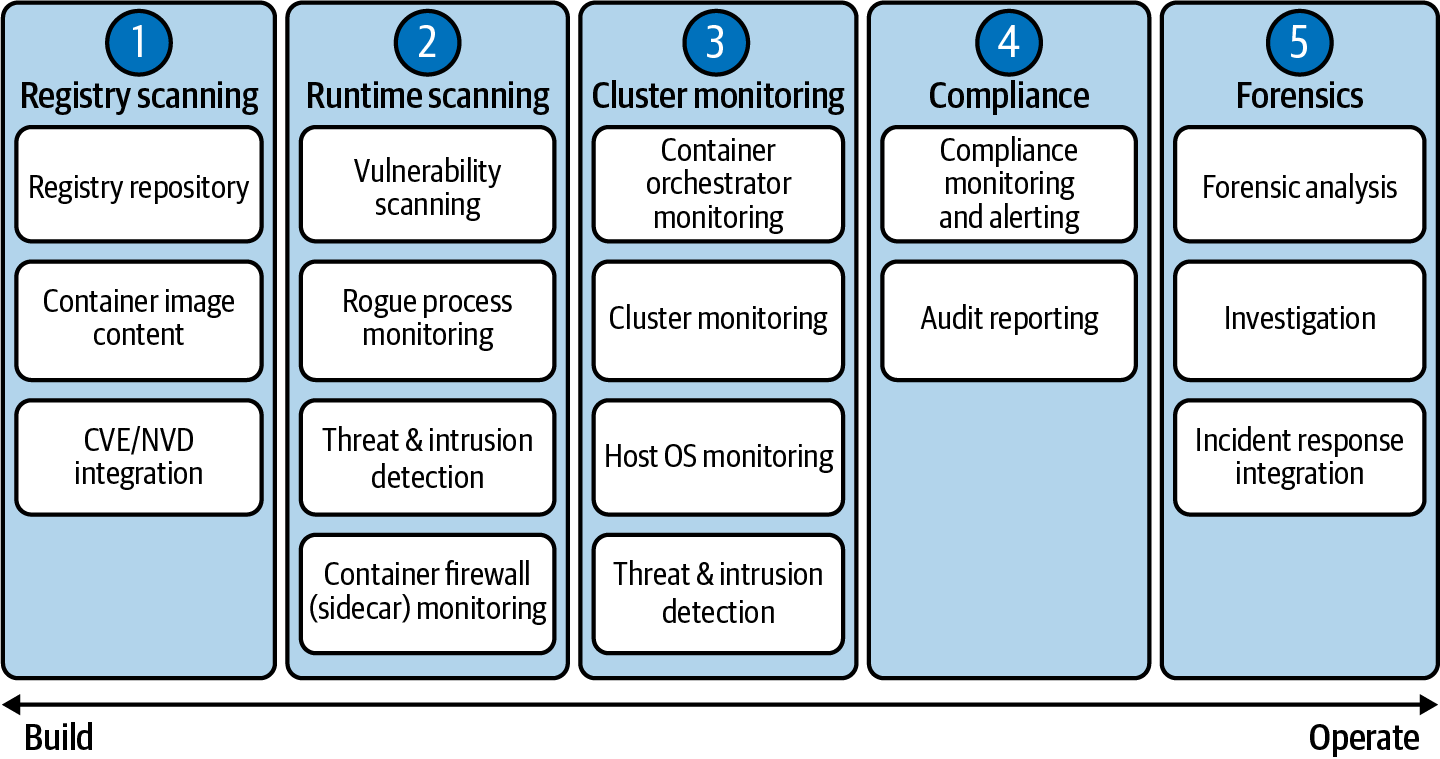
Figure 6-6. Gain security visibility across five key areas of your container deployments
Providing visibility into the health and security of your container environment is key to preventing, mitigating, and remediating cyber threats, so we’ve put together a basic checklist that will serve you well for years to come:
Registry and Container Image Vulnerability Scanning
Secure the repository itself
Securely store push/pull secrets
Scan image contents for known vulnerabilities and malicious code
Integrate with CVE/NVD for real-time vulnerability updates and establish known CVE baseline
Predictive analysis
Container Image Runtime Vulnerability Scanning
Container runtime scanning
Threat and intrusion detection
Container firewall (sidecar—some code on the side) monitoring
Anomalous execution
Predictive behavioral analysis
Integrate with CVE/NVD for real-time vulnerability updates and establish known CVE baseline
Container Orchestration and Cluster Monitoring
Misconfiguration and configuration drift monitoring
Threat and intrusion detection
Identity access
Privileged account monitoring
Container network monitoring
Pod monitoring
Predictive behavioral analysis
Compliance Monitoring and Reporting
Continuous access monitoring
Anomalous detection
Privileged account elevation detection
Configuration drift
Audit reporting across all
Predefined industry templates for internal and external regulatory compliance, including PCI-DSS, GLBA, SOX, NERC CIP, HIPAA, etc.
Forensics Analysis and Investigation
Post-event analysis
Integration to incident response
Placing emphasis on both registry and container image vulnerability scanning followed by container runtime vulnerability scanning and threat detection can help close a big gap. This is still an evolving market with many point products to choose from; choosing a point product for any one area may lead to gaps in the attack surface of your container environment—press whomever is selling you a solution to give you an end-to-end discussion on this topic.
Together, Red Hat and IBM have built an open ecosystem of technology partners to help close these gaps. Many of these ecosystem partners continue to focus on the areas where they are strong, while Red Hat and IBM seek to bring their solutions together into an integrated offering. For example, Red Hat Quay is a private container registry that allows organizations to store, build, and deploy container images. Red Hat’s Security Container Module is supported by Clair—an open source project that provides a tool to scan each layer of container images stored in Quay and delivers proactive alerts based on vulnerabilities such as configuration defects, embedded malware, and clear text secrets (passwords and API key licenses in configuration or code files) detected. Clair is configured to import known vulnerabilities from a number of sources, one being the CVE database mentioned earlier in this chapter (as well as the National Vulnerability Database). Our pro tip: provide vulnerability scanning early in the development lifecycle, as it raises awareness about potential vulnerabilities before code leaves the registry for deployment.
Runtime vulnerability assessments, container orchestration, and cluster monitoring provide exactly that level of proactive awareness. Having visibility into your Kubernetes orchestration engine and its configuration (including network, storage, and workload isolation settings) is imperative. Most containers are transient in nature, which quite simply means they tend to have a short life span. This makes it very difficult for traditional IT vulnerability scanning, threat detection, and intrusion detection tools to effectively work with a containerized environment.
Technologies such as StackRox (a Red Hat company) cater specifically to evaluation of containerized runtime environments by measuring baselines for process activity and providing runtime anomaly detection (and response) for anything that falls outside of those expected norms. StackRox can also monitor system-level events within containers and invoke prebuilt policies to detect privilege escalation, cryptomining activity, or other common exploits that might be running afoul within your Linux distributions and Kubernetes orchestration. There are a number of other capabilities provided by the StackRox platform, including compliance monitoring, network segmentation, risk profiling, and configuration management. Each of these capabilities is key to securing your enterprise container environment, giving you the tools to perform investigative analysis in the event of a breach (or to prove compliance if asked).
Finally, compliance monitoring, reporting, and forensics analysis are a critical capabilities for anyone—and also required by law for many industries under tight regulation. Whether implemented by regulation or due diligence, all organizations benefit from the ability to apply industry-specific compliance policies for their container-native environment and the ability to monitor any changes to the environment against that policy baseline. This also applies to scenarios where it’s necessary to provide evidence of compliance for auditing purposes using reporting capabilities provided by the tooling. Trust us on this: without this level of monitoring and reporting, fines will likely follow (not to mention brand erosion, loss of trust, and more).
With regards to forensics analysis and investigation, in the event of a breach it’s critical to quickly identify which systems have been impacted. This requires the ability to go back in time and retrace any potential anomalies that occurred, such as a privilege escalation, rogue containers, lateral movement between clusters, and so on. The Security Information and Event Management (SIEM) system must integrate several core areas when an incident occurs. There must be quick event correlation and historical analysis, and your incident response system must link known vulnerability attributes to identified suspicious behaviors. SIEM security teams provide tracking, insights, and visibility into security-related activities within IT environments.
Without this level of visibility, you can only assume that your entire container environment has been compromised (although in reality it may not have been—you just can’t be certain enough to discredit the possibility without full visibility). This can lead to unnecessary public disclosures, remediation, and discovery work—which is a waste of precious resources. Of course, the opposite can also be true: without the visibility provided by a combination of these capabilities, a breach may be missed entirely, leading to data loss. These become painful experiences for victim organizations and their end users—disasters that often could have been minimized or mitigated with the correct security strategy and tooling.
We began this chapter by discussing what OSS is and how cybercriminals (and on occasion nation state attackers) use exploits in software to expose vulnerabilities for financial gain (or for use against federal governments). The foundation for hybrid cloud is based on an open platform and new architectural model that many traditional IT security methods simply do not adequately address. To combat rising threats in containerized hybrid cloud environments, organizations need to take a new approach based on Zero Trust to protect systems and data, as well as a more collaborative approach to managing the software development lifecycle through a cohesive DevSecOps operating model.
1 Samba is a standard Windows interoperability suite of programs for Linux for file sharing and printer services.