Chapter 5. Shift Left
Application modernization is a pivotal moment for information technology, clearly demarcating this generation from those that will follow. In fact, we think it’s the only way that organizations can truly capture all the value the hybrid cloud has to offer.
Using containers and orchestration, applications can at last be engineered to realize the “write once, run anywhere” paradigm. For developers, enterprise, and business of all sizes—this means truly unconstrained portability of apps and services. Being able to abstract the process of designing and building applications from the environment(s) they need to run on achieves three goals at once: it unshackles the creativity of developers (who can focus on writing better code with the best tools at their fingertips); it drastically shrinks the time to market for new cloud native (and modernized) apps; and it slashes administrative upkeep that would otherwise be needed to maintain and refactor these apps for new environments over time.
A hybrid multicloud architecture is what makes this level of application portability feasible. The question of where to run applications has shifted from “Here or there?” to one of “Here, and where else?” The plurality of vendors that a business can purchase cloud services from shows that cloud, as it exists today, has transformed from a destination into a set of capabilities. This holds especially true for vendors that offer cloud footprints that can operate across public cloud, private cloud, and on-premises. Modern containerized apps that follow the axiom of “write once, run anywhere” are able to migrate fluidly across a wide range of hybrid multicloud architectures—and do so in a consistent, repeatable fashion that lends itself well to enterprise.
To “shift left,” as developers put it, is to loop back on old processes, identify shortcomings within the old ways of doing things, and steadily iterate on those designs to improve them through experience over time. Plenty of lessons are learned each year within the IT marketplace, and the pandemic years are certainly no exception. The disruption underway from this monumental shift in computing, as we enter the new decade, cannot be understated. How can a business have confidence that its choice of technology partner in this new paradigm is the correct one?
Monolithic and Microservices
Today, rapid application deployment is a must-have for companies to meet consumer demands or challenges. As you’re likely well aware, the quick delivery of capabilities via software to support ever-changing requirements is no easy task.
A real-life example: one of us built a model based on Python’s scikit-image library and our script suddenly broke after updating the library to the latest-and-greatest release. Why? The latest version would not accept the visualize=true option in our code. Suddenly we had to spell it as visualise=true (note the s). We’re not sure what Commonwealth English teacher turned open source committer was behind this, but it illustrates the point perfectly: change within the open source community is constant, and in turn these changes can impact (or even break) an enterprise’s services just as quickly.
One thing we can unanimously agree on: the faster that a development team can improve their existing applications or find errors in their code, the more time they can otherwise invest in new skills, or use to make better apps.
Separating the Old from the New
A handy way to conceptualize and separate “modernized” applications from those applications that came before is “monolithic” (the old) versus “microservice” (the new) approaches to application design. If both of these terms are new to you, excellent, you’re in the right place. If on the other hand you have familiarity with service-oriented architectures, you may be asking yourself how the new approaches to application design are any different than the old—after all, don’t they both use services in the end? Indulge us for a moment as we set out to demonstrate exactly why microservices are anything but yet-another flavor of service-oriented design.
For simplicity, let’s generalize (generously so) that legacy applications existing within many enterprise organizations today can be described as “monolithic”: large, often enormously complex applications, written in a single programming language and frequently running on a single machine. You can see an abstract example of such a monolithic application housed inside a virtual machine (running atop an enterprise hypervisor) in Figure 5-1.
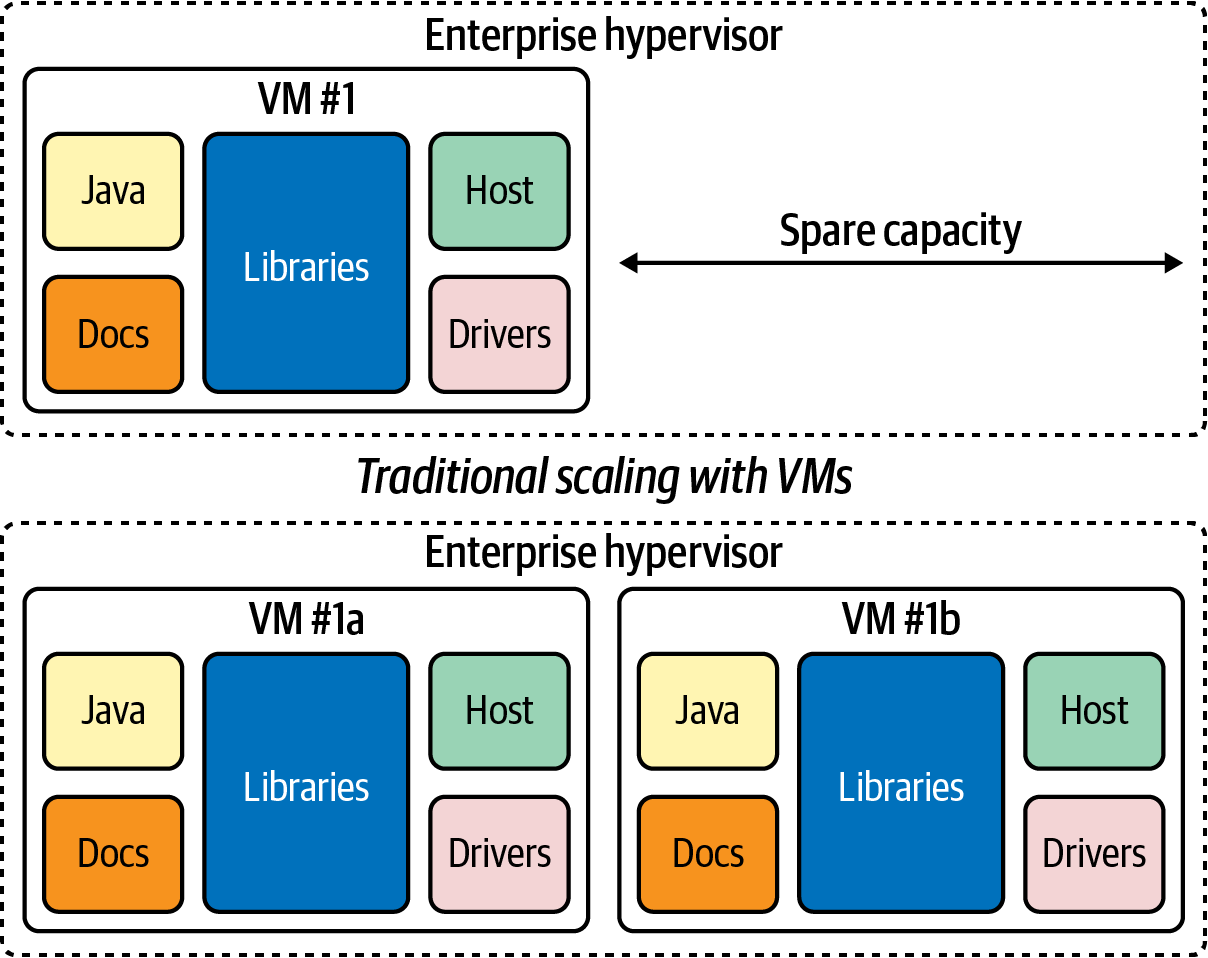
Figure 5-1. Traditional linear approach to scaling up monolithic applications, which is effective, but costly: replicate the virtual machine (and its contents) from the top to what is shown on the bottom with VMs #1a and #1b—both of which are essentially clones of the original VM #1
There are caveats to this, of course—there may be segments of code written in different languages and monolithic applications are not impossible to adapt to distributed systems (although some exceptional feats of engineering may be required). But the reason these are exceptions to the rule (and not the norm) is exactly the reason why we consider monolithic applications to be “legacy” (or at least not modernized). It is precisely because monolithic code is difficult to maintain and challenging to scale that many enterprise organizations are reluctant to modify these apps—not to mention that many of these apps are the backbone of the business and these days a business’s risk tolerance is zero. And therein lies the rub: those businesses that are stuck maintaining legacy code are unable to embrace open source innovations, and those organizations unable to scale their mission-critical services are left behind in a marketplace moving increasingly toward hybrid multicloud environments.
Monolithic applications can be modular in design, which is why the often-cited description of microservices being “modular” is not always the most helpful way of distinguishing the two design paradigms. A monolithic application usually has a presentation component (HTTP requests responded to with HTML or JSON/XML in turn), a database component (data access objects), business logic, application integration, and plenty of other services. The application might be written entirely in the same language, or it could be split up into pieces—especially with service-oriented architectures, which tend to deploy these monolithic applications across a number of different machines. However, it is still monolithic in design. This will become apparent when we compare how a microservice is constructed and managed later in this chapter.
Microservices Dance to a Different Fiddle
Microservices are often described as the “deconstruction of the monolith,” which is a fair assessment of their mission, but may leave you with misconceptions about the methods used to achieve this end state. For example, “deconstruction” implies breaking down into smaller, “simpler” pieces (from a business logic perspective); however, microservices architecture sometimes adds complexity, by the mere fact that the composed application is now a distributed service across smaller networked pieces. But what deconstruction provides the developer and business is the decomposition of one unwieldy and large application into more manageable chunks of services.
Each of these services, by nature of the way that they are designed, can be developed and worked on (scaled and kept available too...more on that in a bit) independently of one another (now you’re starting to see the benefits). This is a tremendous change from the way developers are forced to work on monolithic applications: mainly, having to tackle the entire stack of code at once. The result is that future improvements and refinements to microservices-based applications can be much more strategic (“modular” in the true sense of the word) and collaborative across different teams. As long as you publish the external API of the microservice in a way that other teams or services can dialog with it, teams can work on different components of an application independently of one another.
The extensibility of microservices also means that, for each microservice component within a composed application, developers can use the languages and technologies that they want to use—the tools best suited for the focused task at hand—rather than be constrained by the legacy programming languages that at minimum large parts of the monolith would otherwise have needed to maintain. This approach broadens the aperture of open source innovations that can be introduced into a microservices-based application and in turn opens the doors to exciting new workloads your application can tackle.
Scaling: One of These Things Is Not Like the Other
If you manage a set of enterprise apps, scaling up those applications generally means (we’re purposely keeping it really simply here) making the application’s resource requirements bigger: give it more memory, additional CPU cycles, greater network bandwidth, and so on all the way down the infrastructure stack.
We can already imagine those of you with programming backgrounds shouting at this page, “It doesn’t quite work that way!” You’re correct, it’s not that simple. But for the sake of delineating the differences between monolithic and microservice approaches to scale, let’s maintain the notion that in order to scale legacy applications you need only throw more resources at it.
The bottom line: for enterprise organizations maintaining such monolithic applications, the calculus for scaling is a simple one. If you need additional scale, you give the application access to a larger machine. Yes, you can scale out your applications across multiple distributed machines, but that’s particularly challenging—and requires more technical chops, so it’s not for everyone.
To contrast with the monolithic app, we sketched out Figure 5-2 to illustrate a simplified abstraction of three microservices, each in turn deployed on independent Compute Nodes (servers) from one another. Collectively, they form an application powered by microservices. The color-coded blocks represent modular elements within the microservice that can be modified or developed, scaled, and kept available independently of other elements (stacked blocks of the same color-coded service in turn represent replicas—or copies—of the same microservice). Note the variety of tasks performed by this array of microservices. And yet despite the complexity of the overall application, each microservice is performing only a single (and uniquely essential) task.
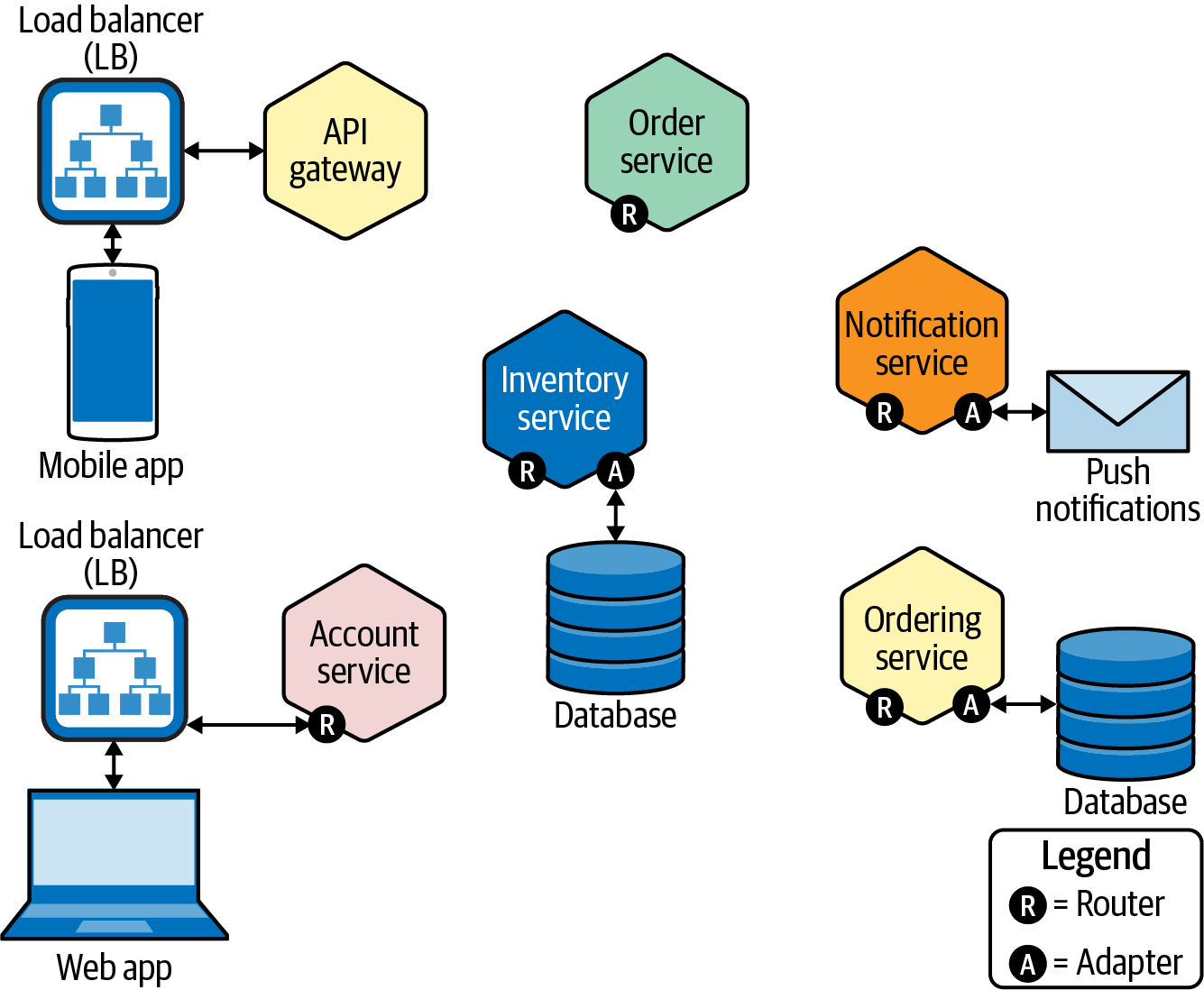
Figure 5-2. A generalized view of how microservices might be arranged across separate Compute (worker) Nodes
In a microservices-based architecture, you scale up by adding more components (or more copies of the same component) to the overall stack. This concept is known as “horizontal scaling,” in contrast to the more “vertical” scaling approach used by many monolithic applications. And yet, you could easily make the argument that the two approaches to scaling aren’t that substantially different to one another. After all, isn’t the solution—throwing more resources and hardware at the bottleneck—essentially the same for both monolithic and microservice applications?
Not quite. We can understand why monolithic applications do not scale well when we look at how it is that developers and programmers go about deconstructing monolithic apps. As we made the argument for previously, an enterprise application “in the old days” was probably written all in the same language. It would have used libraries that were tightly integrated inside of the application. At the same time, there would have been components that existed outside the monolith application—the presentation layer, the database layer, and so on—that are connected by some client or port-adapter mechanism to the monolith.
If you want to scale up a monolithic application, you have to replicate it outright in its entirety—this includes needing to scale everything else that the monolith was dependent on to run (including components like external ports, adapters, and so on). Every copy of the monolithic application would require a replica of its own for each of these external dependencies.
So, what do we want you to take away from all this if you’re a business leader looking to bolster your technical chops? When you’re scaling a monolithic application, you need to scale all of the enterprise components together alongside it. This approach is often rife with wasted resource allocation and complex interdependencies. Certain subcomponents perhaps did not need to be scaled—individually they may have been “keeping up” with demand just fine—but the overall complexity of the monolithic application required that these underutilized components be replicated all the same.
How do microservices approach resource scaling differently? Recall back to the depiction in Figure 5-2 and the matched groupings. Each of these groups are the microservice equivalent to the components (libraries, frameworks, and so on) we described for the monolithic application. There are, however, two key differences. First, external dependencies exist for microservices just as they do for monoliths, but they often communicate over RESTful APIs rather than adapters and are therefore easily modified. Second, the stacked groups of microservice components can be scaled independently of one another, as opposed to the wholesale all-or-nothing approach for scaling monolithic application stacks.
An expanded view of our generalized microservice application is shown in Figure 5-3. This depiction revisits the same application we saw in Figure 5-2, only this time scaled up to meet the increasing demand on some of its microservice components. You can see that stacked tiles represent redundant (replica) copies of a particular microservice application or function. Notice that some tiles have more replicas than others—this reflects the way that microservice applications can scale only the components that need to be scaled, independently of the other components.
When you want to scale up a microservices-based application, you simply replicate the individual components (the shaded tiles in Figure 5-3) that need to be scaled—and only those components. Think back to the Uber app example we talked about in Chapter 2. It’s likely the case that the microservices that provide arrival estimation need more scale (as they are under much heavier demand) than those microservices that provide loyalty point inquiries.
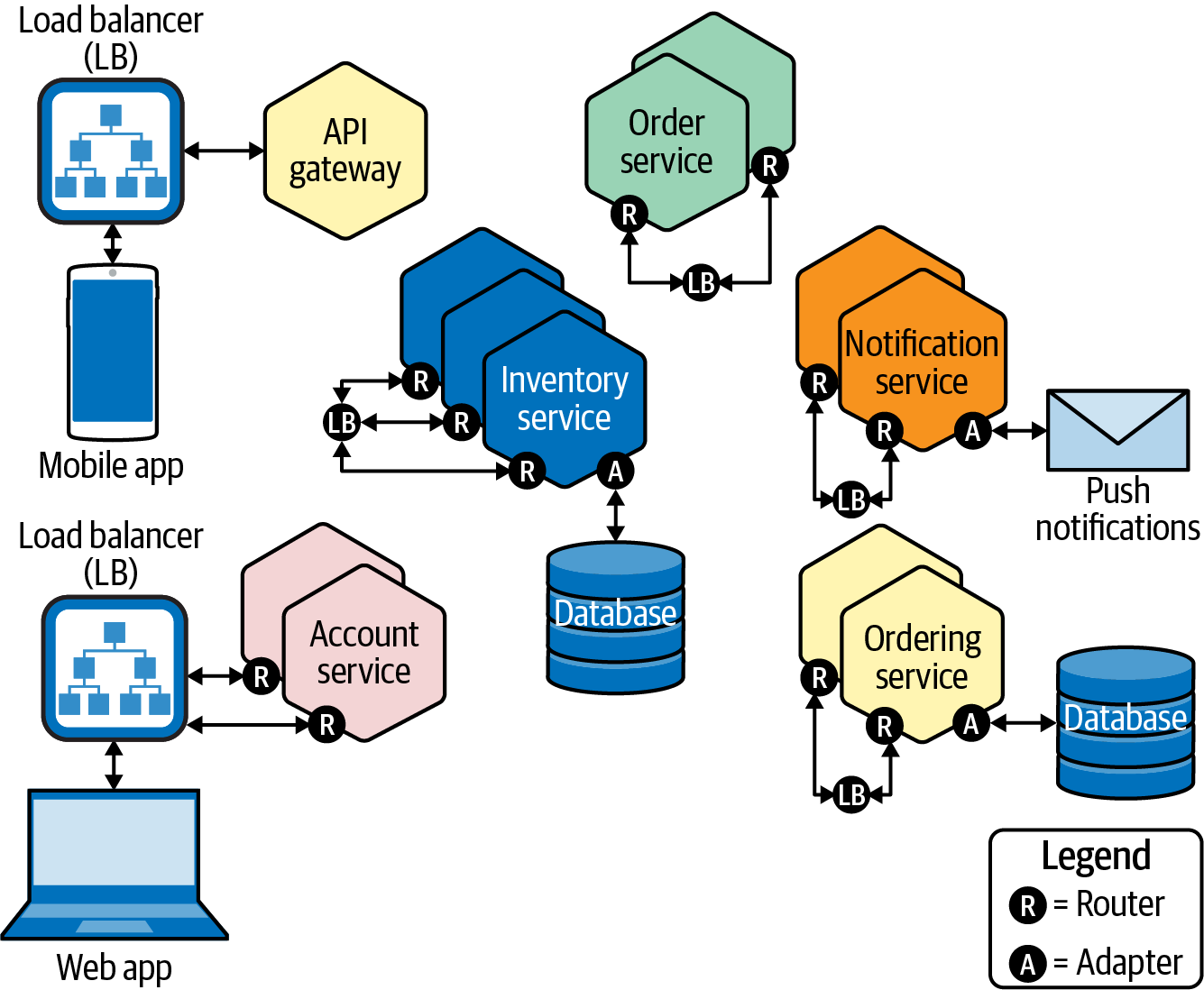
Figure 5-3. Microservices-based applications can scale individual components, independently of one another if need be
Don’t overlook this point: the very nature of microservices means that an administrator can be selective in the components they scale (rather than the total approach of monolithic applications), which in turn cuts down on overprovisioning and unnecessary wasted system resources. Microservice components can be treated as separate units and scaled (up or down) independently of each other depending on the component of the app it supports. You can imagine how this modular approach to design, deployment, and scaling lends itself well to a “containerized” worldview that we talked about in Chapter 3.
Teams managing these individual microservice components can therefore work independently of each other, as well. Microservice components can be written in distinct languages from each other, or any mix of languages within the same microservice. As long as that microservice sits behind a well-recognized and documented API interface (such as REST), other components of the microservice application (and external applications) can easily communicate with the component.
Imagine a scenario where a developer has recently been introduced to a team—or perhaps volunteers their programming expertise to an open source community project—and offers to reimplement some component of the microservice application in a much better way than it is currently. The original component was written in PHP, but our astute programmer would much prefer to use Python in order to take advantage of its more efficient programming structures. If this were a monolithic application, this approach to rewriting a component in a different language from the core application language would likely be a nonstarter (or at least significantly more complex to implement). With microservice design, it’s no impediment whatsoever! Our programmer is free to select a new language that is much more conducive to their expertise and to the workload that the microservice needs to carry.
Orchestration: Amplifying the Challenges of Scale
One of the design considerations for scaling up microservice applications is that the components themselves should be “stateless” in design. Stateless essentially means that, in the event one of the microservices were to fail (due to hardware loss or other reason), then work can be assigned to any of that microservice’s replicas without additional instructions or fiddling around with other instances. If a microservice were to be “lost,” then the application will realize it did not get a response to its request and in turn hand off that same request to another copy of the microservice. All of this is managed by handing work to load balancers, which then pick from a pool of the same microservices and hands work off to one of them based on the type of workload. In other words, if microservices go down, any of their replicas should be capable of picking up the slack immediately and the application should carry on without interruption.
The resiliency of microservices to failure is as much a byproduct of their design (which has built-in redundancies and tolerance for failure) as it is a result of the way that microservices manage “state.” We won’t go into the full details of how they achieve that in this book, but in essence the way that administrators and applications update a microservice is by modifying its state. Contrast this with having to explicitly tell a microservice what to do: with stateful applications, these instructions are passed implicitly. Directions such as “I want you to be at this state and look like that” are relayed without explicit instructions on how to achieve that end state, yet the RESTful API endpoints of the microservice are able to act upon them accordingly. This is different from assuming (or having to figure out for yourself) what state a microservice is in and directly instructing it on what actions to take.
If microservices could speak, their conversations (and their underlying design philosophy) would sound something like this: “Tell me what state you want me in, and I’ll make the changes necessary to get there; regardless of the state I’m in at the time, I will make whatever changes are necessary to eventually get to the state that you want.” This notion of microservices understanding the state they are in, and systems that are able to course-correct to regain this state if necessary, is incredibly useful when you start to consider microservices in the context of containers and orchestration engines.
These concepts are new to many of us—how many of you picking up this book expected to get into discussions about the behavior of applications? It’s perfectly alright to feel awash in the possibilities. But know this: these behaviors are fundamental to understanding the essence of all that untapped value we keep telling you that’ll remain locked away without a modernized hybrid cloud strategy.
Figure 5-4 depicts orchestration: coordination and communication amongst the nodes and an application’s component (microservice) replicas. It is the same application we were just examining previously in Figures 5-2 and 5-3, but now distributed properly across separate hosts. Naturally, the more infrastructure hosts that your app is deployed across, the more fault-tolerant your app becomes and the less disastrous any potential hardware failure will be.
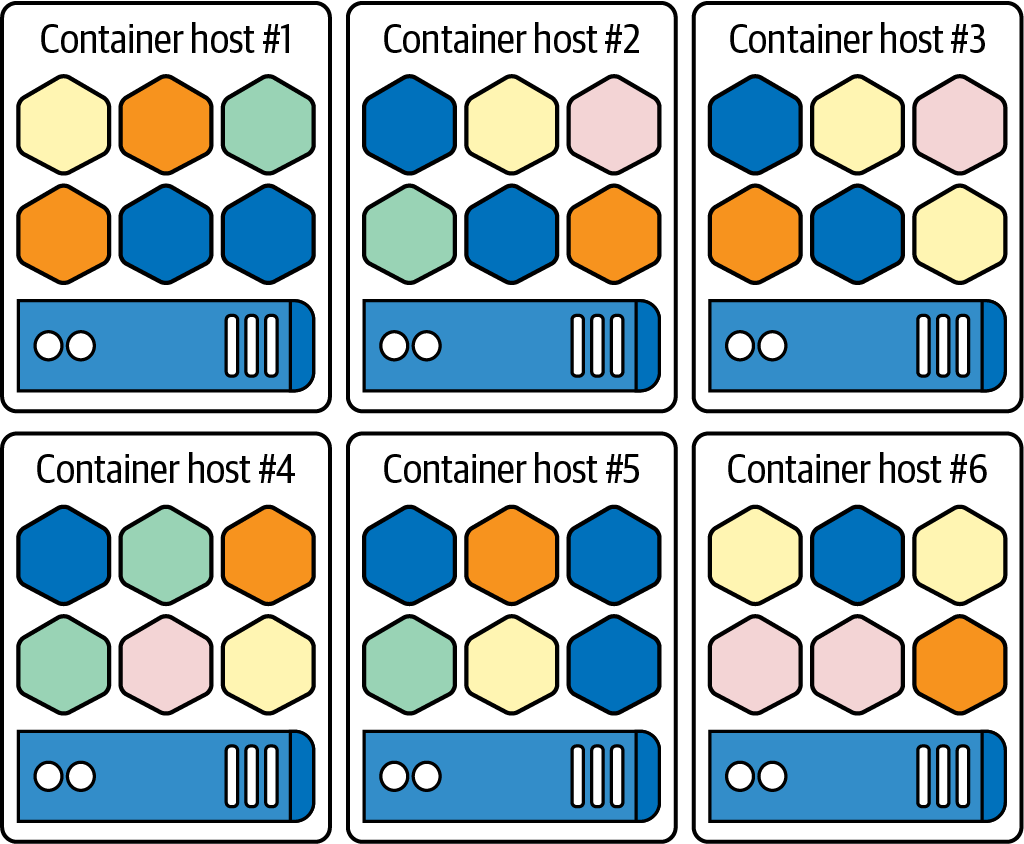
Figure 5-4. Redistributing the same microservices-based application from Figure 5-3 across multiple container hosts: this lends greater resiliency to failure and provides further opportunities for scaling resources as required
Think about it: imagine putting all the same microservices on a single host; while it might scale with the right hardware, if that host were to go down, you would lose all access to those microservices. That’s why we advise you to use a pattern that distributes those microservices across hosts in the best manner possible so that they are load-balanced and redundant across multiple servers. The loss of a single physical host would potentially take out multiple microservices, but wouldn’t break the application. As the microservices are distributed across other functional hosts, the application continues to run.
In a properly orchestrated Kubernetes (K8s) environment, such as Red Hat OpenShift, there are actively running components that recognize when a microservice has been lost and will immediately deploy additional replicas in response. The platform understands how many replica copies should exist at any one time, and should that number be less than expected, the orchestration platform will act to bring more online automatically. Here’s the point: you have to distribute microservices across hosts first so that your application remains resilient to failure, and afterwards (on a properly orchestrated platform) can leave the busywork of maintaining that application state to the orchestration layer.
Write Once, Run Anywhere
Up to this point, we’ve examined what distinguishes a modernized microservices-based application from a monolithic legacy application. But what does it take to achieve this? And more importantly: is the process of modernizing applications worth the time and cost of doing so? In Chapter 2, we gave you a framework to help figure that out (the Cloud Acumen Curve); here, we’ll give you the rubric for deciding how to place your project along that curve. There are three main stages to approaching container modernization: replatform, repackage, and refactor.
Three Stages of Approaching Modernization Incrementally
We’ll start with the “How?”—because the value associated with this process becomes readily apparent once you understand the multitude of ways that applications can be modernized. For each incremental step along the journey of application modernization—from legacy to replatform, repackage, and refactor—there are increasing benefits to users and consumers alike, as marked on the scorecards in Figure 5-5.
A common misconception we often hear from clients is the impression that application modernization is a zero-sum game: the notion that a business must choose to either modernize or stick with the monolith, with no middle ground. Like we said earlier in this chapter, the reality is far different! In truth, applications can be modernized incrementally over time. The pace at which your organization shifts toward microservices-based applications can depend on many factors: the technical staffing and proficiency of skills within your IT department; the complexity and volume of legacy applications that need to be modernized; or even the comfort and level of risk your organization is willing to sustain as you migrate mission-critical workloads toward a new (but ultimately beneficial) paradigm.
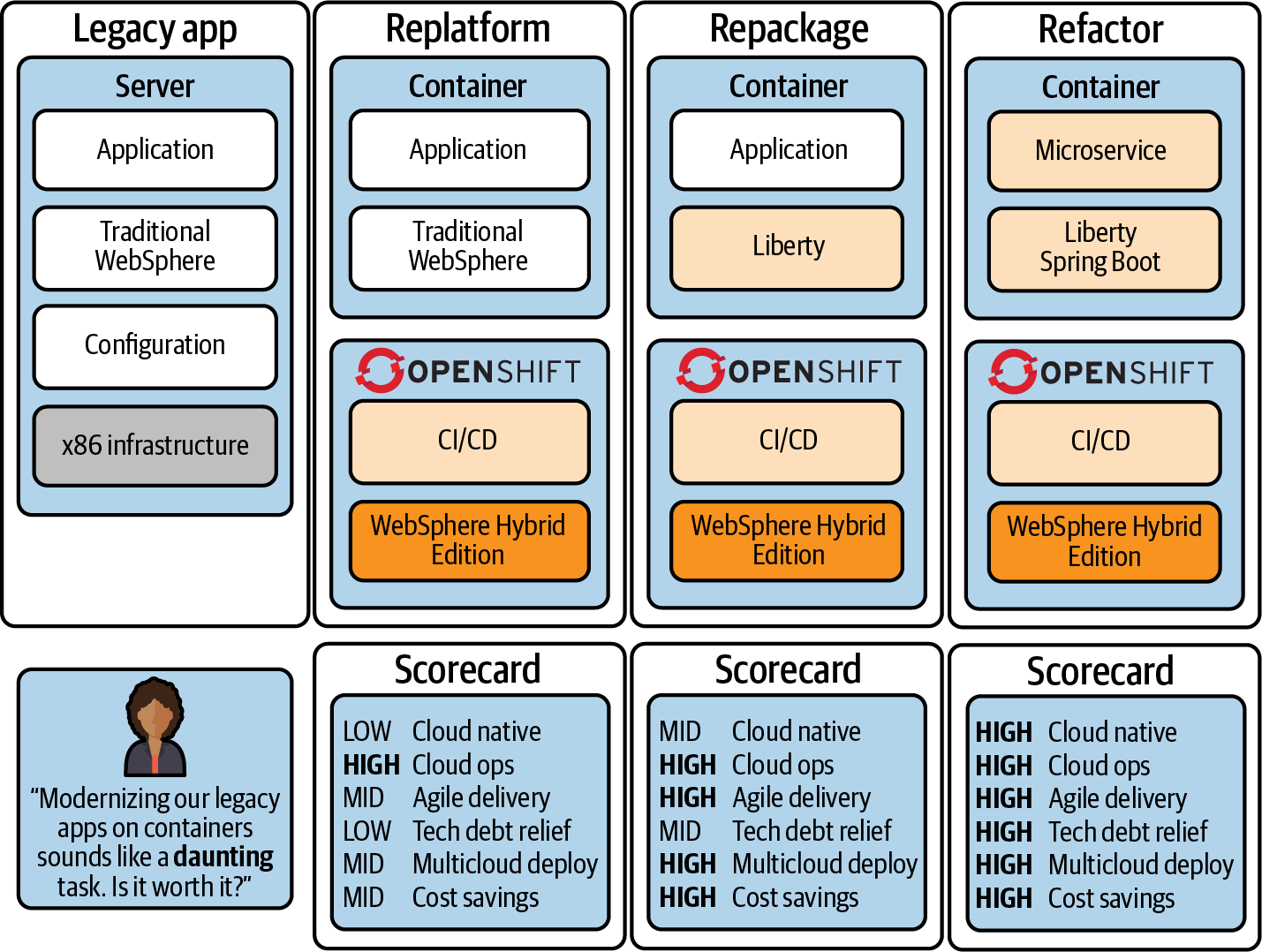
Figure 5-5. The stepwise, incremental journey from legacy applications to fully modernized microservices
Turn back and look at the incremental approach shown in Figure 5-5; it transitions from legacy monolithic applications on the left toward fully modernized applications on the right. Quite simply, the journey toward modernized applications exists on a gradient. For every step that a business makes along that journey, they in turn receive increasing benefits to their applications and to the business as a whole—as indicated by the scorecards along the bottom of Figure 5-5.
The first step toward modernizing applications simply is to replatform from legacy infrastructure toward platforms designed specifically for containers and Kubernetes orchestration, such as Red Hat OpenShift. Your choice of infrastructure matters here (as it does in all decisions made regarding your IT estate); therefore, selecting infrastructure that simplifies the process of modernizing code can pave the way for a smoother replatform experience. It’s important to note here that you’re not aiming to change the legacy app’s code in the replatform stage, but to merely migrate the monolith into a platform that supports containers and orchestration, as well as continuous integration and continuous delivery (CI/CD) pipelines.
The next phase is to repackage the application code. In this phase you have the opportunity to modernize the legacy code of which the monolith is composed. Several vendors in the marketplace today offer services for steering this transformational process in the right direction: first, by automatically assessing the level of effort required to modernize the legacy code with more modern and developer-friendly frameworks like Liberty and Spring Boot; and second, where possible, automatically performing the migration (or providing guidance on how to do so yourself).
The final phase in the journey is to refactor the application—the most modernized form as we’ve defined it, but by no means a requirement for organizations that want to simplify the maintenance and boost the value of their legacy applications (as we’ve seen demonstrated by the replatform and repackage phases). At this stage, the monolithic application has been refactored into more modular microservices; its code base likely reflects a myriad of open source languages that are tailored to the specific workloads of the app; and the experience of those maintaining the application has been simplified in terms of operations, integrated development environments, and tooling.
Comparing Legacy Applications, Containerized Applications, and Virtual Machines
It is a fitting time to now give containers their due and look at exactly what it is this technology enables and how it relates to the journey toward modernized applications that we’ve described so far.
Linux containers are the basic instrument—the atomic unit, if you will—of containerization technologies. As you learned about in Chapter 3, Docker is a specific flavor of this technology, which has become nearly synonymous with “containers” in general, but that’s merely owing to its popularity. Isolation technologies were developed and popularized first on Linux.
To an operating system, containers are like a process. You can conceptualize a container like you would a sandbox. It uses namespaces, control groups, Security-Enhanced Linux (SELinux), and other Linux security components to keep containerized code secured and isolated. Containerized applications can be remarkably portable: they can run—essentially unchanged—across a number of different cloud providers and types of infrastructure that support this technology.
To a developer, a container is a packaging method: it provides a way to package an application for delivery and ensures that all its dependencies and configuration information are passed along with it.
On the left of Figure 5-6, traditional legacy processes run on a single operating system (OS), atop hardware and hosts. They are dependent upon OS libraries, runtime libraries, and possibly special libraries that are required by particular applications. Regardless, it all runs as a stack on that specific host. Applications that are to be ported elsewhere have to be migrated alongside (inclusive) of the operating system and dependencies that application requires to run. This is what is sometimes described as the “heavyweight” nature of legacy applications (in contrast to the “lightweight” approach of containerized applications).
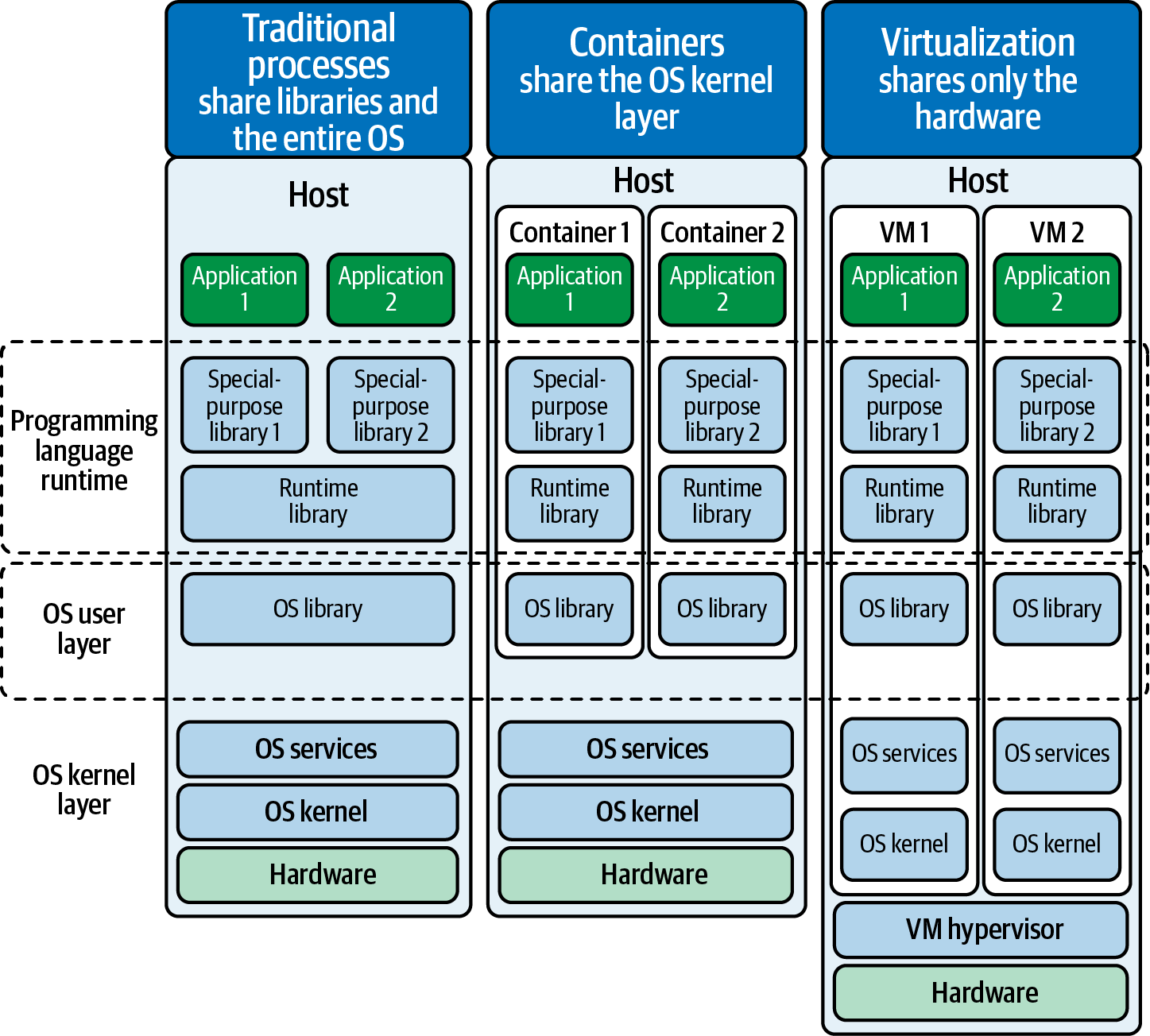
Figure 5-6. A full-stack perspective across legacy applications (left), containerized applications (center), and virtualized applications (right)
The far right of Figure 5-6 shows an example of the approach taken by enterprise organizations for years: virtualization. Using this strategy, a hypervisor is built into either the hardware directly or is running as a layer on top. This allows administrators to abstract different operating systems on virtual machines (VMs). In VMs, you are essentially running a full version of the operating system with every instance. This has the positive benefit of allowing every VM to potentially run a different version of unique operating systems from one another—but it also means that potentially every VM will need a bespoke approach to patching and maintenance. (By this way, this doesn’t even include the additional storage and resource constraints that running multiple VMs with separate OSes can put on a system!) On top of that are the OS libraries and runtime libraries that accompany every flavor of OS.
Herein lies the double-edged nature of virtual machines. You can have as many of them as your infrastructure is able to support and each VM can be tailored to a specific operating system environment. However, these resource requirements can be difficult to scope, costly to support, and particularly challenging to maintain. These flaws are further exacerbated when it comes to scaling VMs across multiple machines.
In the center of Figure 5-6, we showcase the modern approach toward improving on legacy applications while avoiding the pitfalls of virtual machines: containerization. In essence, containers have an OS and services that support the lifecycle of the container. The only contents that a container must supply are the runtime libraries, the application, and the application-specific dependencies that are needed to run that application. This means that all of the containers are running atop the same operating system: Linux.
A container engine runs containers. In the simplest terms, the container engine uses the kernel features of Linux in order to manage and start containers using things like Linux namespaces, control groups, and so on. To help you understand how all of these components come together to enable containers to work, we’ll dig into each of these concepts in turn.
Namespaces: What’s in a Name?
Namespaces are a Linux kernel feature that provides resource abstraction. They allow users to segregate different applications and set directives on whether those applications can see each other or share data. In effect, namespaces provide an isolation level for different types of resources. For example, if a user has two different namespaces for containers—each of which might have different process ID namespaces—then when that user inspects those containers, they will see completely distinct and isolated lists of process IDs. If they are sharing a namespace, that user will see the same list. For users looking to find ways to avoid containers interfering with one another (such as with network interfaces) or those looking to create filesystem constructs that are not seen by other containers, namespaces are the tool of choice.
Shared operating systems in general function because files and other objects (processes) have permissions to say who can run them, open a write to file, use a file, and so on. What permissions don’t tell you (or the operating system for that matter) is the context for how that object is supposed to be used.
Security-Enhanced Linux (SELinux) was mentioned earlier—it is fundamentally important to the way that Red Hat containers secure and isolate themselves from each other. SELinux provides a much more complete and comprehensive set of policies and tags that get applied to objects and processes, which essentially start to label them as, “What is this and what is it supposed to be used for?” Developers get to write the rules that say: “Processes with this tag can do X, Y, or Z to files or other objects that have tag A.” SELinux allows the administrator to set the minimum privilege required to work with objects, and to disallow (especially in situations of hacking or intrusion when a process is overtaken) processes from being used with something it was not designed to be used for.
For example, an Apache process with a tag httpd_t is illustrated in Figure 5-7. An SELinux configuration file exists on this container that states that “assets with tags can perform functions with assets of the same policy tags.” There is a policy that says that httpd_t services are allowed to work with files that have a tag of httpd_sys_content_t or httpd_log_t, but no others. The absence of a policy automatically disallows that interaction from taking place. There is no stated policy, for example, to allow httpd_t-tagged services to work with postgresql_db_t-tagged directories or files from /home/user; therefore, the Apache service is disallowed from interacting with the PostgreSQL database. Anything not explicitly set as a policy is fundamentally denied which enables the Zero Trust security model (we will discuss further in Chapter 6).
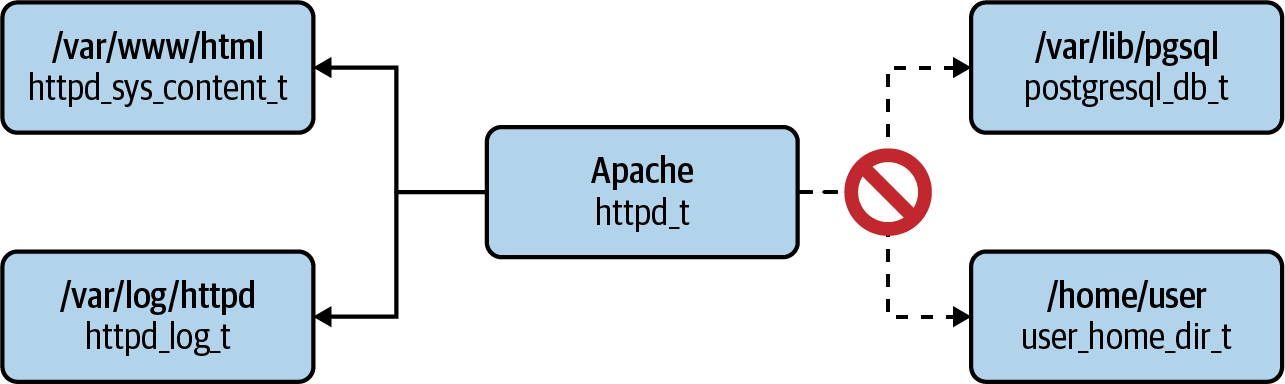
Figure 5-7. A depiction of SELinux “context” at work in securing an Apache HTTP server application with regard to permitted access routes (the /var/ directories on the left) and disallowed routes (Apache cannot access the PostgreSQL database on the right): context is set on every object across the system
One powerful feature within SELinux is mandatory access control, which may be a term familiar to those of you who have worked with security clearances before. People and objects are defined with security parameters, and these parameters dictate who is allowed to read top-secret documents and so forth. Mandatory access control, therefore, can be thought of as a labeling system. If your label (or pair of labels—the way in which you label is arbitrary, so long as you are consistent with how you do so) does not correspond to the level of access required by an object, you are disallowed from interacting (or perhaps even seeing) that object.
Another security feature is known as Control Groups or “cgroups,” another construct of the Linux operating system. Control Groups provide a way of setting up different collections of processes and determining rules for how resources are assigned to those groups. It is critical to explicitly set out these policies precisely because processes are capable of “spawning” child processes from parent processes. Control Groups ensure that these child processes are forced to share (and are limited to) the resource limits set on their parent processes. Limitations and caps can be set on aspects such as the bandwidth available to a process, the CPU cycle time that process can occupy, memory constraints, and much more. Control Groups in effect prevent rogue or hijacked processes from running rampant across your container platform resources.
At this stage, we’re ready to elevate the conversation another level: from containers to orchestration. Specifically, let’s talk more about Kubernetes and Red Hat OpenShift Container Platform (OCP).
Within OCP itself, Red Hat has put in tremendous amounts of work to rearchitect the platform in order to place Kubernetes at the very core of the offering itself. What you will see as we delve deeper into the platform is that OpenShift adds significant value (and prevents significant headache) compared to cooking up a Kubernetes orchestration platform in-house using open source components. We certainly won’t claim that it’s impossible to build your own Kubernetes orchestration platform—it began as an open source community project, after all! But after you look into the technical burden you’ll need to assume, the vulnerabilities that the open source tooling is exposed to, and the complexity of wrangling all of these components together, we are confident you’ll view the choice this way: “Sure, we could build our own—but why would we want to?”
Building an Operating System for Containers
Kubernetes retains the honors of the container orchestration layer for the Red Hat OpenShift platform. The features of K8s are vast. But for our purposes, we need only understand that these features include service discovery and load balancing—both of which are built into OCP natively. K8s also handles horizontal scaling (a replication controller concept), which can be used manually or be given parameters to work automatically—either from a command line or from a web console interface. Along the same line, K8s can actually check to see if containers exist; if they are down, it will restart them (similar to horizontal scaling: it knows there are supposed to be certain quantities of them, and it will clean up and replace those that fail).
Why does load balancing suit the distributed nature of containers so nicely? A requesting service only needs to know the target’s DNS name. This means that behind the scenes, an administrator can change the IP addresses and locations of that service (for example: a container could go down, be replicated, or be brought back online)—yet still map back to the original DNS name. As such, external applications or services can continue to reach out to the same DNS name consistently and not concern themselves with the potentially fluid and dynamically changing underpinnings of the containerized environment.
Kubernetes can recognize when underlying base images have changed, and update containers based on those changes. Afterwards, it can roll those out to production so that users tapping into your services are not detrimentally impacted by the rollout. If you take down services to replace them, users will complain that they cannot access the tooling they’ve come to depend on. Kubernetes does rollouts intelligently to ensure that it is only replacing a certain number of services at a time (instead of an all-or-nothing approach); furthermore, if rollouts of specific replacements fail, K8s knows how to recall those changes and bring back the previous iteration (without losing it for good). It’s a smart upgrade capability for your applications.
Kubernetes is designed for high availability and resiliency against failure—which happens more often than you might think in cloud and distributed systems. But a functional Kubernetes cluster also needs to be able to maintain state for the cluster and the applications running atop it, so OpenShift Container Platform also includes an etcd database (an open source distributed clustered key-value store used to hold and manage the critical information that distributed systems like K8s need to keep running). If certain nodes go up or down, you still have consistency in the configuration.
The purpose of this kind of store is that, for each of the resources making up the objects and entities belonging to the cluster, that definition for the “proper” state of these resources is maintained and stored in etcd. These include deployment configurations, build configurations, and more. The cluster uses that information to know how to restart application containers again, whatever the circumstance. This also applies to containers that are cluster services infrastructure. OpenShift Container Platform itself is built upon containerized services—it’s not just the applications that OpenShift users deploy that are containerized! OpenShift and Kubernetes run as containers themselves.
The operating system underlying all of this is CoreOS. With version 4 (and above) of OpenShift, Red Hat now uses the CoreOS container operating system in place of Red Hat Enterprise Linux (RHEL). It is a tightly integrated refinement of the RHEL operating system designed specifically for containers. Within that operating system, Red Hat has included the CRI-O engine, which is an Open Container Initiative (OCI)–compliant runtime that handles all of the container startup and management on top of CoreOS.
The most important concept introduced with CoreOS is the idea that the operating system is immutable (can’t be changed). When you boot up a CoreOS node, you cannot make changes on it. More specifically, any changes made on it are thrown away—so if you reboot the operating system again, you’ll receive the same level of consistency when it redeploys. The operating system itself underneath cannot be hacked or manipulated while it’s running. It also means that when you’re managing it, you’ll have to learn new techniques for how you are managing it. The entire operating system is updated as a single image, instead of using RPM packages. It is designed and tuned specifically for running containers. And everything, including system components, runs as containers on top. Red Hat OpenShift Container Platform knows how to perform updates to RHEL CoreOS, so there are proper procedures for maintaining the cluster itself.
Within Red Hat OpenShift, there are three types of load balancing working together: external, HAProxy, and internal. External load balancing depends on what types of load balancers and environments are available within your datacenter, and it performs the duties of managing access to the OpenShift API itself. HAProxy gives users and services an external-facing route to applications. Internal load balancing is handled using Netfilter rules (another Linux concept), which can be used for security and other path management between applications inside of the cluster; however, it has no control over outside users getting into the cluster. OCP understands how to perform automated scaling and does so by examining the amount of traffic coming in across the load balancers (“being handled” by the cluster); correspondingly, it adds or terminates containers as needed in order to handle the load.
OCP ships with logging and monitoring capabilities built in, which includes Prometheus (which we tell you all about in the Appendix). The combination of Prometheus and OpenShift’s alerting system gives administrators the ability to proactively respond to anything that happens within the cluster. They can keep track of the health and activity of the cluster and then take actions based on that information in a timely manner. OCP integrates the Elasticsearch/Kibana logging solution, which handles the aggregation of logs across all of the nodes and applications in the cluster. It also handles storage and retention of those logs.
Application management in OCP involves OpenShift Source-to-Image (S2I) for automatic build and deploy capabilities. Simply, Red Hat stores images that can be reused and can create configurations that automatically take source information, figure out what needs to be done with it, create a build set of instructions, and execute on those build instructions to deploy the application—all in one long flow. S2I can take any application that is source code (even when it comes from a Git repository or code from your local machine directory) and convert that code into a deployed containerized application. Once you’ve designed that workflow and performed it, the build config and the deployment config from that workflow are available to repeat the same containerized application again in the future.
Extensibility in K8s takes advantage of the orchestration layer’s fixed set of services, which includes an extension mechanism where providers like Red Hat can add features on top of the upstream K8s code. Red Hat provides package extensions that include Operators for ease of installation, updates, and management. Red Hat also has an Operator lifecycle manager that facilitates the discovery and installation of application and infrastructure components. Many other companies (not named Red Hat) have seen the advantages of using Operators and there has been momentum for standardization of publicly available Operators, resulting in OperatorHub.io, which was launched as a collaboration between IBM, Red Hat, Amazon, Google, and Microsoft.
It’s OK to Have an Opinion: Opinionated Open Source
So far we have discussed what it means to modernize applications, the technologies that make containerization possible, and the componentry underlying an orchestration platform such as Red Hat OpenShift. To pull these pieces together and take us home, let’s examine how each component—microservices, containers, and orchestration platform—enable modernized application services that are ready for the hybrid multicloud world.
Putting It All Together
As a way of thinking, Kubernetes defines a cluster’s state. Administrators and developers are keeping track of all the information in the etcd database. Kubernetes is running the controllers that monitor these resources, checking what their state is, and if the state is different from that which has been declared, it will take action to bring those resources to the state that they are supposed to be in.
OpenShift Container Platform (OCP) runs on essentially two types of nodes: masters and workers. Master nodes run the API; provide the interface for the web console, command line, and many other API endpoints utilized for internal and external cluster communication; host the etcd database that maintains the state of the cluster; and execute all of the internal cluster services needed to maintain cluster operations. This list is not exhaustive, but for our purposes it gives a comprehensive idea of the importance of the Master nodes to a K8s cluster. Master nodes are configured so that they cannot be scheduled for end-user application pods. In other words, when you deploy applications and they are looking for nodes to be scheduled on, the Master nodes are specifically marked as being unavailable for use as general-purpose (Worker) nodes. Worker nodes, or Infrastructure nodes, can be scheduled as application pods for deployment of containers. Administrators can determine how many Worker nodes they expect will be needed to handle the resiliency and redundancy requirements for their applications (with consideration given to how many Worker nodes the cluster infrastructure can support, of course).
Administrators supply the compute nodes, networking infrastructure, and a sufficient amount of storage to supply the storage volumes and space for additional disks within containers—not just the space to run the containers themselves. Figure 5-8 illustrates the orientation of these services and technologies across the compute, network, and storage componentry of the OCP cluster. These variables need to be set up (or made available) before the cluster is provisioned, much like you would do for any datacenter.
Sitting atop the architecture stack depicted in Figure 5-8 are Worker nodes, on which teams schedule all of the user applications and containers that are to be built. You can easily scale Workers by adding more of them; furthermore, OpenShift can scale these Workers automatically for you should demand for services outpace what they are outputting at the time.
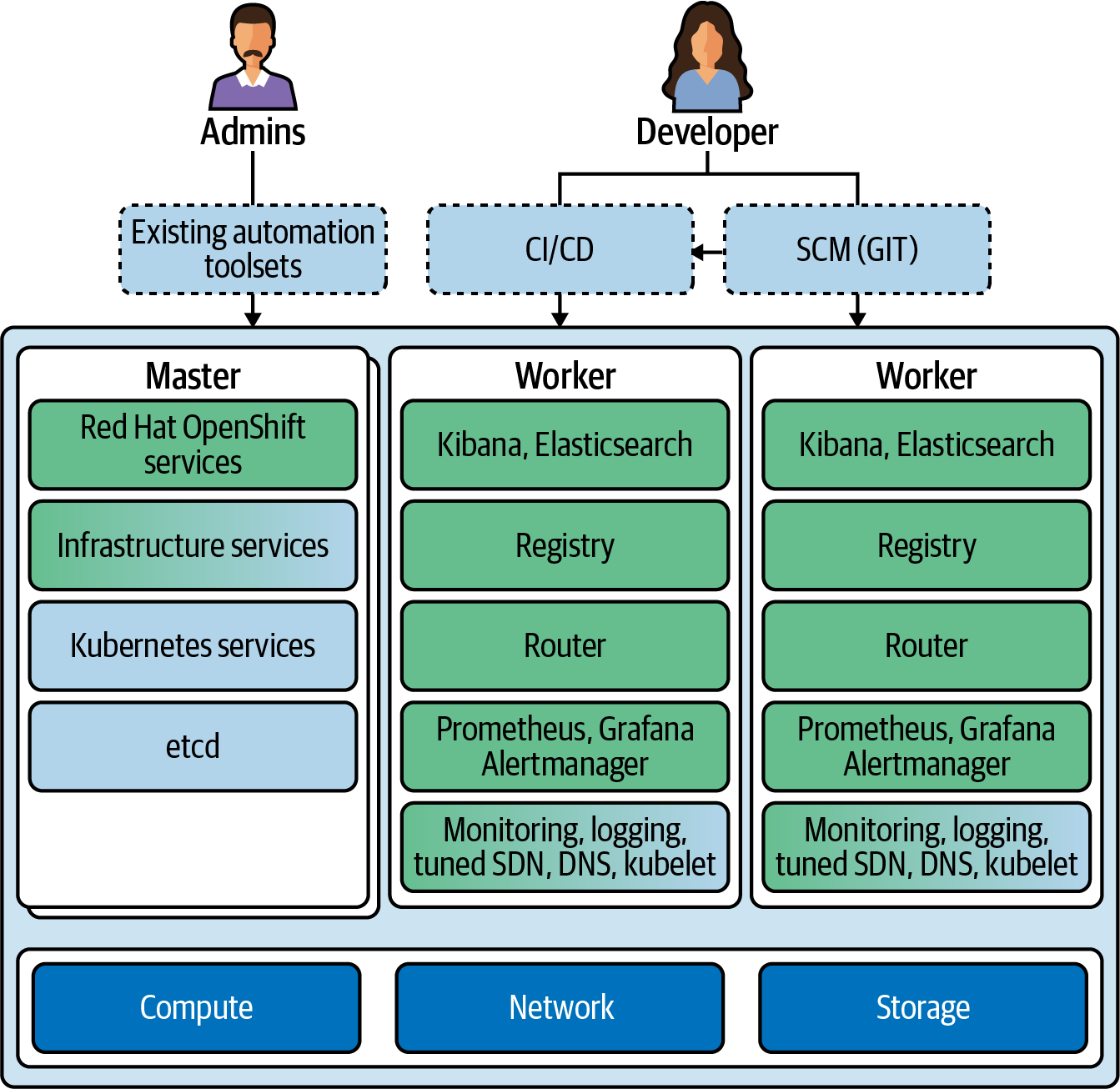
Figure 5-8. A simplified view of the OpenShift Container Platform stack and an abstraction of Kubernetes at the core of the platform
The Master node(s) are usually set up in groups of three for high availability and to achieve a cluster quorum. User workloads never run on the Master. An etcd service is running on the Master node, which keeps track of the state of everything in the cluster, including which users are logged in, where workloads live on the cluster, and so on. Master nodes also play host to the core Kubernetes components: Kubernetes API server (overseeing APIs to get at the cluster management services), Scheduler (for scheduling across nodes), and Cluster Management (handles the cluster’s state via the etcd database). On top of that we also have OpenShift services: OpenShift API server, Operator Lifecycle Management (integrated to give administrators access to automatic cluster upgrades), and Web Console. A number of internal and support Infrastructure Services also run on the Master, which make containers easier to run at scale, including monitoring, logging, SDN, DNS, and Kubelet. All of these come integrated and operational out of the box with the Red Hat OpenShift cluster.
OpenShift has a cluster management solution that includes Prometheus, Grafana, and Alertmanager. Each of these components has been enhanced based on work done by Red Hat’s own engineering team, which applied lessons learned and best practices from Red Hat’s experience managing OpenShift to improve the monitoring capabilities for its customers. These cluster management tools make it possible for administrators to understand the health and capacity of the overall OpenShift cluster and empowers them to take actions based on that information.
Logging capabilities are based on Fluentd, Elasticsearch, and Kibana—making it easy to visualize and corroborate log events. This is immensely valuable when you have applications that can scale to many, perhaps hundreds or thousands, of instances. In such a scenario, an administrator would do anything to avoid having to read through 100 disparate logs; they would much prefer having access to a single aggregated log per application. Many of the features described here also tie into OpenShift’s role-based access control (RBAC) features, allowing administrators to control who gets access to what services within the cluster. In the case of operational logs, administrators have the ability to control and make sure that the right individuals see the logs (and only the logs) that they are meant to have access to.
Regardless of whether people consuming this platform are administrators or developers, the web, command-line, and IDE integration tools support people working in whatever way they want or need to. As you can infer, all of the components we’ve discussed so far come together to simultaneously improve the quality of life of the administrator, while bolstering the security and stability of the platform as a whole. And, naturally, they accelerate the journey of businesses deployed on the platform toward fully modernized applications that are hardened for the challenges of hybrid multicloud computing.