Chapter 2. Evolution of Cloud
In the first chapter, we introduced you to the thrivers, divers, and new arrivers; we boldly declared the mantra of this book (“Cloud is a capability, not a destination.”), and gave you a guide to digital transformation. In this chapter, we’ll discuss the evolution of cloud, where it’s going, and some things to keep in mind as you begin (or continue) your capability journey.
Are You on the Intranet, Internet, or Extranet? Nah—Just Internet
To get a feeling for what we’re talking about, consider the ubiquitous phrase: the internet. At one time, many would subdivide internet technologies into an access control list of sorts. There was talk of the EXTRAnet: a controlled private network limited to vendors, partners, suppliers, or other authorized groups. Today, most would say an extranet provides access from outside the firewall to resources inside the firewall for a value chain based on membership. For example, when you return equipment to a store that sends your broken item back to the manufacturer who deals with the warranty claim, the store is likely to log in to the manufacturer’s site and open a ticket, but that’s about it. Even so, bringing your items to the store is a necessary step because the store has access that the customer doesn’t.
At work we used the intRAnet: an internet that was behind a firewall and dedicated to providing information and services within an organization, usually to the exclusion of access to outsiders. In other words, if you didn’t work at the company, you had no access to it. This intranet would have department operational manuals, performance reviews, sensitive documents, code repos: all the stuff used to run your business that is nobody else’s business.
Then it started. A rallying cry around a set number of standards by groups like the Internet Engineering Task Force (IETF) or the World Wide Web Consortium (W3C). Communities ratified all kinds of standards, from documents (HTML), to fetching those documents (HTTP), to the concept of time, and all parts in between; soon enough, things just became referred to as the INTERnet. Think about it, when was the last time you used a word other than internet to describe these kinds of networks? When was the last time you heard someone at work say, “I found it on our intranet?” Answer: you were probably dancing the Macarena and weren’t embarrassed doing it. (Sure, there will be some roles where this differentiation matters, but this isn’t how business talks and it isn’t how most people think.) The bottom line: intranet, extranet, and internet just became internet.
Are You on a Private Cloud, Public Cloud, or Community Cloud? Nah—Just Cloud
History has a way of repeating itself. Think “cloud.” Cloud-talk today centers around terms like public clouds, community clouds, and private clouds; but work has started on a bunch of standards that have started to evolve and unify the patterns.
We think cloud will follow the same naming path as the internet and will settle on hybrid cloud (again, cloud as a capability not a destination), or just cloud for short. We’re already seeing technologies that support cloud computing in general (just like those that supported internet technologies). Think of the standardized open source technologies (many of which we cover in this book) such as Jenkins, Terraform, Ansible, Docker, and Kubernetes (K8s), all supported by major vendors for the orchestration and management of cloud native applications. These are the technologies that are creating integrated hybrid clouds.
With this in mind, we want to officially anoint our book’s mantra (you’ll hear it time and time again through the book); say it with us: “Cloud is a capability, not a destination!” If we can agree that cloud is a capability, then it’s perfectly aligned to where IT wants (and needs) to go: decentralized, flexible, performant, open, and secure.
Just like the “prevent defense” (an American football defense that’s happy to let the offense move downfield but holds defenders further back to try to prevent a major score) we think prevents a win, a “one location and vendor cloud fits all” approach won’t work either. Believe us, we’ve seen it fail, we’ve even seen some overzealous competitor sales (and IBM) reps try to push it. It often doesn’t work and it’s not the right tone for your business. Companies need the flexibility to run their workloads across any platform without having to rewrite everything as they go.
History Repeats Itself: From Granularity of Terms to General Terms
This is why our book’s mantra, “Cloud is a capability, not a destination,” encompasses a mindset shift you (and the organizations you work for) have to make to fully exploit the opportunities that those servers in the cloud offer. We’ve seen success in the cloud—mostly companies producing greenfield apps; that’s great if you’re a startup or building net new in a roll your own (RYO) fashion. But what about established investments? Many of these companies looked at the cloud as a pure cost-saving opportunity, and while some had success (most in limited fashions that didn’t nearly match the promises), others were left unpleasantly surprised. While the cloud can offer you some cost savings (cloud toe dippers typically start with archive or test), it all depends on the running workloads, data gravity, and your business. But cloud can’t just be about cost savings—in fact, over time it’ll prove to be more about agility than cost savings. Sure, that capability has potential to reduce the obvious costs, but it’s about putting your business in the best position possible to deliver.
But here is the cold hard truth: we estimate that a mere 20% of the potential value from cloud computing is being realized today by mature enterprises via the public cloud. As you will learn about in this book, cloud is more than cost savings; it’s a renovation opportunity that delivers flexibility. When you think about it the right way, you’ll start to think beyond “lifting and shifting” as-is applications to the cloud. For example, releasing software frequently to users is usually a time-consuming and painful process. Continuous integration and continuous delivery (CI/CD) can help organizations become more agile by automating and streamlining the steps involved in going from an idea, a change in the market, a challenge (like COVID-19), or a business requirement to ever-increasing value delivered to the customer.
Adoption of cloud being a capability and not a destination opens up your world to rethinking how applications are built, delivering continuous streams of improvement to engage your user base (think about how often apps get updated on your iPhone), and so much more. We believe this mantra will have you look at the technologies that support the cloud (Kubernetes, Docker, Jenkins, Terraform, and oh so many more) and appreciate how they make for agile organizations and encompass the entire end-to-end lifecycle of an idea, pivot, or change of course you need for your business.
So how do you access the 80% of value that’s yet to be unlocked? You embrace a hybrid strategy and all its components (on-premises, public cloud, multicloud, distributed cloud). In fact, don’t just embrace it—demand it. When vendors come knocking, talk about capability. Discuss the ability to dynamically access and move capacity that your business needs regardless of location. Not just on-premises or in a public cloud—but taking an app from one cloud provider and seamlessly running it on another; remember, we want the ultimate flexibility here. Start to think about breaking down the monoliths and containerizing those apps with a fundamental change to the operating model.
Building a hybrid cloud strategy and playbook is essential if you want to unleash the full potential of your cloud; in fact, studies suggest such a strategy can deliver 2.5x more value than a public-only strategy (the 20% of current captured cloud value we alluded to earlier).
Cloud is cloud—it’s an operational model and this shift from a place to an operational model will deliver superpowers to the organizations you serve; it’s about opening doors to more sources of value, including:
Infrastructure cost efficiencies
Business continuity and acceleration
Increased developer (and IT) productivity
Security and regulatory compliance
Flexibility to seize opportunities and drive value
Our definition of cloud (hybrid meaning multiple places and vendors) means there is lots of choice in the marketplace.
As practitioners in the field and running businesses, we’ve made some mistakes along the way, have the scar tissue to prove it, and offer you this list of characteristics that any vendor should demonstrate:
Industry expertise
Proven security
Confidential Computing and Zero Trust architectures
Build once and run anywhere with consistency
Capture the world’s innovation
Hybrid Cloud’s “Chapter 2”: Distributed Cloud
Cloud service providers (CSPs) are forever innovating, learning from their own (or other people’s) past mistakes, identifying new challenges, and pushing the boundaries of what is possible. With the rampant growth of hybrid cloud, several pesky challenges have surfaced like weeds, threatening to choke out the potential held by this new computing paradigm. How can customers tap into the capabilities of public cloud, without needing to actually be deployed on public cloud? How can one public cloud vendor’s capabilities be introduced on-premises, brought to the edge (especially with the onset of 5G), or even made available on other public clouds—running in a manner that is not only consistent, but also not overwhelming from a management perspective?
Enter another term for your repertoire: distributed cloud. A distributed cloud is a public cloud computing approach that replicates the power of your favorite CSP on infrastructure outside of that CSP’s datacenters. Essentially, you’re extending the public cloud to on-premises, private cloud, and edge environments. Distributed cloud is offered as a service by major cloud providers, and includes IBM Cloud Satellite, AWS Outposts, Google Anthos, and Azure Stack; each of these is unique in their own way, but all are focused on the idea of extending public cloud capabilities to customer environments. Throughout this book, we stress our mantra multiple times: cloud is a capability, not a destination! With a distributed cloud (a subset of hybrid cloud), companies can bring the capabilities of cloud that they need to an environment of their choosing. When done correctly, distributed cloud removes the challenges of running in different locations and occludes the needless details from you. Essentially, it makes running cloud services within your on-premises datacenter just as easy and seamless as running those same services in a public cloud datacenter.
Figure 2-1 gives you a rough idea of how a distributed cloud works. You start with an underlying foundation of providers—be they rooted on public clouds, on-premises environments, or edge locations. Building on that, you have a standard layer of distributed cloud hosts (simply referred to as hosts); this layer is essentially compute power. Upon a standardized layer of hosts, organizations can leverage services from the public cloud, or even build their own custom applications; quite simply, distributed cloud brings the power of a CSP right to your doorstep and gives you all the placement control you could ask for.
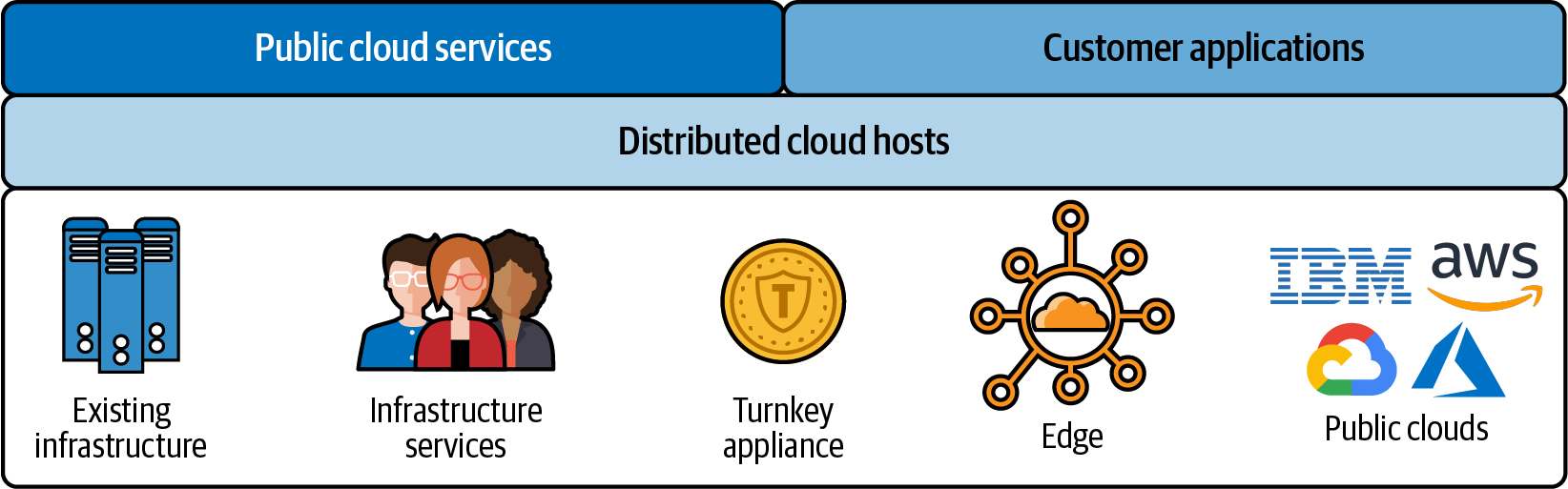
Figure 2-1. Distributed cloud
Distributed Cloud On-Premises
Unification of your technology stack is table stakes for any successful hybrid cloud strategy. For example, imagine using VMware workloads on-premises, but container-based Kubernetes in the cloud. In preparation for a potential spike in traffic, your team would be unable to rapidly utilize the elasticity of Kubernetes in the cloud. Translating from VMs to containers is simply inefficient and difficult! Instead, one ideal solution is to begin implementing Kubernetes on-premises and modernize the VMware workloads to run as containers on K8s instead. Here’s where things start to get tricky. In the public cloud, customers are able to readily utilize managed services to easily create and run Kubernetes clusters. They can use tools like Terraform with provider plug-ins that integrate with a CSP to automate the creation of one or many clusters with minimal effort.
Tip
Let’s clarify what we mean by the term managed service, as it has become overloaded with a lot of assumptions (and potential baggage). In this context, we’re referring to services that CSPs manage for you, while still providing you administrative access and control. For example, managed Kubernetes services automate the process of upgrading clusters (done by the CSPs) but allow you to choose when and which version for the actual operation.
You can probably guess where we’re going with this: the on-premises and private cloud experience is nowhere near as streamlined as a managed Kubernetes service. Organizations will need to train an operations team to handle the deployment and management of Kubernetes clusters. In addition, they’ll need to hire and train a site reliability engineering (SRE) team to ensure high availability and—in the worst-case scenario—respond to late-night critical situations (crit-sits).
Here’s where a distributed cloud offering shines. These organizations can continue to leverage the power of their CSP while running on-premises. We think IBM has done something quite special with its cloud strategy that truly puts the hybrid into hybrid cloud. First, the Red Hat OpenShift Container Platform is truly write once, run anywhere. (Remember how Java was “write once, test everywhere”? It’s not like that.) Second, a product called IBM Cloud Satellite runs inside a customer’s datacenter or out at the edge; each Cloud Satellite location is connected using IBM Cloud Satellite Link to provide connectivity to a consistent and centralized control plane (this is important) hosted on the IBM Cloud. For example, let’s say your business enabled the use of IBM Cloud Satellite for all of your environments, including on-premises. As an operations engineer, when it comes time to create a new OpenShift cluster on-premises, you’d first start by logging in to the control plane. When it comes time to choose which datacenter to deploy the cluster into, you select an on-premises “Satellite location.” (This Satellite location could be on any CSP too!)
By extending the power of cloud to on-premises environments, your hybrid cloud operations are optimized. Your operations teams no longer need to worry about learning how to deploy a cluster on-premises, as they can just use the managed public cloud approach. This demonstrates the true power of distributed cloud—the cloud is used as a capability, not a destination; what’s more, the capabilities all have a consistent management interface which is essential to flatten time to adoption curves and keep things simple.
Living on the Edge: Distributed Cloud
Data is everywhere around us. Many times, we get so caught up with focusing on data being processed in our datacenters that we forget where a heck of a lot of data is actually created—by humans like us. Every time we open our phone, walk into a supermarket, buy a movie ticket, or pour a drink at a fountain station, we’re generating data. Generally, this data is captured, sent off to some datacenter for processing, stored in some database, and more data is sent back. However, it’s not always reasonable to wait for the data to go all the way back to a datacenter. Imagine you’re in a self-driving car and that car is processing thousands of photos per second (video is nothing more than a bunch of still-frame pictures stitched together). Meanwhile the car is applying computer vision algorithms, along with data analysis from the advanced driver assistance system (ADAS) sensors, radar, and lidar. How safe would you feel if that car was sending data to a datacenter for processing (think back to your last dropped call)? For the driver, the latency (and risk) would simply be too high.
Edge computing provides a number of advantages—and it’s not just speed. It also allows businesses to scale more effectively by placing data collection and processing closer to the edge, rather than having to scale out expensive centralized datacenters. In addition, security is a major advantage as data never has to leave the edge—this can be critical for compliance with regulations like GDPR. Furthermore, some industries have regulations that state if you “land” that data (store it in the datacenter) it becomes subject to all kinds of data-retention rules.
One of the key challenges with edge computing is rapid growth, as each edge location will have its own set of workloads, microservices, and databases. Customers need a unified strategy to manage the multiple locations consistently. Distributed cloud shines again for edge use cases, where you can register your edge locations and manage them as if they were any other cloud datacenter. This means utilizing the power of the cloud, including DevOps toolchains, security policies, and advanced machine learning services all within your edge locations.
Imagine a furniture company with distribution centers across the world. Chances are that similar workloads are required to run in every distribution center, such as inventory management, employee clock-ins, IoT sensors for temperature and humidity, and outgoing shipment tracking. Instead of having an operations team handle each distribution center as a unique (but connected) environment—which can quickly get very expensive—why not use a distributed cloud approach to manage all these edge locations centrally? With a distributed cloud offering, you can create abstractions that enable you to simplify the management of grouped locations. This allows you to roll out application services, compliance policies, and security rules across multiple environments at once.
Distributed Cloud for Multicloud
The primary advantage of distributed cloud is that you can extend the benefits of a public cloud anywhere. Naturally, if you want to run all of your workloads on a specific vendor’s cloud, so be it. But the reality (in our experience of having worked thousands of customer engagements over the years) is that no medium-to-large enterprise is running on a single cloud.
Tip
Flexera’s “Cloud Computing Trends: 2021 State of the Cloud Report” noted that organizations are using (on average) 2.6 public and 2.7 private clouds and they’re experimenting with an additional 1.1 public clouds and 2.2 private clouds.
Organizations everywhere want to retain the ability to choose the right cloud provider for their workloads (some public clouds are purpose built for finance and insurance), but this can be a real conundrum for many: at a minimum, maintaining multiple cloud environments will be taxing on administration resources. Ops teams will need to firmly understand the differences between each CSP, including methods for automation, deployments, pricing, auto-scaling, and more. Deploying a simple Kubernetes cluster on AWS forces you to learn their specific approach with Amazon Elastic Kubernetes Service (EKS)—unique datacenters, user interface (UI) flows, automation paths, and more. The same approach on IBM Cloud requires you to use IBM Cloud Kubernetes Service (IKS), with a different set of steps that essentially results in the same challenges we just surfaced for AWS; and on it goes. In the end, you have Kubernetes in both clouds that operates the same, but the process to get there is very different, which in turn is a recipe for higher costs, more status meetings, and an overall tax on an organization’s agility.
Distributed cloud enables you to simplify these differences with one consistent experience. You start by choosing one CSP as your home base, and then leverage the infrastructure as a service (IaaS) offerings of other CSPs to run your workloads. This means regardless of which cloud provider you’re using, you can deploy consistently across all of them.
Let’s give an example of how this works. Start by picking one distributed cloud offering as your central management environment (like IBM Cloud Satellite). Next you set out to run some workloads on AWS but they are consistently managed from the control plane that sits on the IBM Cloud. You spin up AWS IaaS resources like some EC2 instances (these are essentially VMs). Finally, you register these instances as a “Satellite location,” which enables you to extend IBM Cloud to datacenters in AWS! You can now provision Red Hat OpenShift on IBM Cloud, a managed OpenShift offering, directly on AWS datacenters. You might be wondering, “What’s the point?” Let’s assume you happened to have databases or other services running directly on AWS; you can now network them with your OpenShift cluster with ease. In addition, you gain consistency with a standard way of deploying OpenShift, whether it’s on IBM Cloud or AWS.
A Caveat to Distributed Cloud
Moving forward with any one particular cloud requires buy-in. Distributed cloud offerings come with the assumption that you will use one cloud to drive all of your workloads. To be fair, all CSPs require some extent of buy-in—each cloud has its own quirks and features, whether it’s datacenters, capabilities, or cost. With distributed cloud you gain freedom in the choice of infrastructure provider but are limited to choosing one primary cloud provider to manage your services. For some, this distinction is acceptable, because they would prefer to build skills with one cloud provider rather than many; but think back to the Flexera report. In addition, extending public cloud to on-premises is a no-brainer. Of course, you don’t have to manage every workload with a distributed cloud, but now the more capabilities that are left outside, the more liability there is for managing one-off environments.
Distributed Cloud: The Ultimate Unification Layer
Hybrid cloud emerged as a necessity, not because it’s the ideal approach. Customers may have data residency requirements forcing them to run on-premises, subscribed-to software as a service (SaaS) properties requiring them to run in a vendor-specific environment, legacy applications that are too difficult to move to the cloud, or data gravity considerations. Amidst these challenges, the benefits of utilizing the cloud are impossible to deny (cloud the capability), and are exactly why customers will thrive in hybrid cloud environments for years to come. When the challenges of hybrid cloud result from division, distributed cloud aims to solve them with unity.
Although we are strong proponents of technologies like Kubernetes and containers that support a hybrid cloud strategy, even a well-architected hybrid cloud can feel broken at times. For developers, a hybrid cloud environment means multiple environments with differing technology stacks to code and test against. For operations teams, a hybrid cloud leads to more environments that are prone to failure, more late-night pager duties, and more challenging approaches to integration. For security teams, hybrid cloud means a larger surface area for attack and complex security policies that are unique to the environment. Distributed cloud starts to fix these DevSecOps problems by offering the ultimate unification layer—one public cloud control point to rule them all.
Industry Expertise in Mission-Critical Business Processes
Downtime means no time…for you to serve your clients. We’re certain this isn’t new to you, so we’re not going to hit you with the cost per hour of downtime. That said, the number of times a call dropped or a VOIP call was garbled during the planning of this book on a web conference really hits home our point: your business is solely going to depend on a well-ingrained culture of mission-critical thinking and planning.
But there are other considerations we want you to think about in this area:
- You are unique
Every client we’ve ever talked to, on any project (cloud, AI, you name it), is starting from a different place. You need to be able to start from your place, wherever you are; there are no one-size-fits-all recommendations here. We suggest you tier your projects into value drivers and requirements, such as Platinum, Gold, Silver, and so on, but also differentiate between projects that are “low-hanging fruit,” projects that require thoughtful execution to modernize, and projects that don’t need to be modernized at all but could greatly benefit from the capability offered by cloud.
- Demand experience
Never underestimate the difference that industry and business domain expertise can make. Look for proven reference architectures and scalable assets—your partners should show their experience redesigning processes and workflow transformations for your industry—and yes, ask for names. This will help speed the work of business transformation and provide a scorecard that compares your organization to others that partner has worked with.
- Look to the experts
When one person is teaching, two people are learning—engage with a vendor that has a rich education ecosystem (that extends beyond certification) and experts that can make your team smarter. As they do this, the vendor can learn not just about your architecture, but about your team’s skill—your partner should be able to help here.
- Leverage the ecosystem
An extended strong technology partner ecosystem will help deliver added value to industry-specific business process transformation. We’ve always been fans of true partnerships. But that partnership should extend into the open source community, and reward those that come to open source communities to feed the soil versus those that just come to grab the fruit (today’s marketplace has examples of both).
Proven Security, Compliance, and Governance
Collectively, the world is doing a poor job at protecting information and preventing malware attacks. Add to this the ever-expanding set of regulations around data governance (for example, the European Union’s GDPR was the starting point, California’s Consumer Protection Act soon followed, and things are set to become even more dizzying with EU proposals on the usage of AI in its region). We tell our kids all the time, “You lose trust in buckets and gain it in droplets.” Technology partners should be no different. Your partner and their platform have to showcase and build trust into every interaction, with a robust portfolio of data protection and security services—all embedded into a cloud run-anywhere architecture, positioned to protect your processes, applications, and cloud services, while managing compliance requirements.
But it’s also very important to understand industry-specific cloud requirements to make it truly hybrid. As the cloud compute market matures, we’re seeing companies asking for services that match the specific needs of an industry or workload. Consider a bank trying to leverage the public cloud with sensitive data. Such a cloud journey will require the appeasement of risk analysts who will seek (more and more) Confidential Computing environments. If you want financial information on the cloud, you need to find a vendor who will guarantee that at no time does anybody at the cloud provider have access to the hardware security module (HSM) encryption keys—that bank needs full lifecycle management over their data—including keeping its own keys.
Things to look for here include automated and auditable processes, a consistent security and controls posture across all applications or services, and capabilities for the highest levels of cloud security and monitoring (which we’ll discuss next).
Confidential Computing and Zero Trust Architectures
Let’s start with this sound piece of advice we freely offer to anyone that will listen: where there is data, there is potential for breaches and unauthorized access. And here’s a dirty little secret no one wants to admit…very (and we mean very) few organizations know where all their security holes are, but almost all of them know there are walls they won’t look around the corners of because they don’t want to go to the board and tell them what needs changing.
Confidential Computing is a computing technology that isolates sensitive data in a protected CPU enclave during processing. The contents of the enclave—the data being processed, and the techniques used to process it—are accessible only to authorized programming code, and invisible and unknowable to anything or anyone else, including a cloud provider! As companies rely more and more on public and hybrid cloud services, data privacy in the cloud is imperative. The primary goal of Confidential Computing is to provide greater assurance to companies that their data in the cloud is protected and confidential. For years cloud providers have offered encryption services for protecting data at rest (in storage and databases) and data in transit (moving over a network connection). Confidential Computing eliminates the remaining data security vulnerability by protecting data in use—that is, during processing or runtimes using trusted execution environments (TEEs) that are hardware assisted for the most protection you can get.
Many people think that Zero Trust is about making a system and its users more trusted, but that’s not it at all. Zero Trust is about eliminating trust. Its genesis comes from the notion that for all the years we’ve been talking about security, we assume that everyone inside an organization are actors that should be trusted; but what if those actors are imposters or there’s an internal identity theft? Zero Trust involves removing trust from your data, assets, applications, and services for the most critical areas to your organization and creating a microperimeter around it. Bottom line: Zero Trust operates on the notion that trust is a vulnerability and no one should be trusted.
We think Confidential Computing and Zero Trust are set to become a brand-new bar of requirements for CSPs and will become ubiquitous to core computing concepts. These concepts are applied to the protection of all data (be it in motion or at rest, on-premises or not) within TEEs (the stuff in the cloud where your apps are running) and the surface areas where those applications run. Why the infrastructure assist? Quite simply, doing it in the software is pretty much putting your hand up and saying, “I’ll put a best effort into security, but with budgets the way they are, we’ll cut a corner here or there.” (It hurts us more to write that than hear it.)
But even traditional protection approaches need to be challenged. Why don’t we just encrypt all data and not worry about it? Seems simple enough, right? Nope. It’s not that people don’t care about data security, it’s just really hard. It requires an appetite and resource commitments to get it right and do it right—and that’s more than likely going to require application changes, unless you’re using a true secure enclave technology. Application changes, performance impact, technical challenges…all reasons why many aren’t adopting an “encrypt everything” strategy. It’s no wonder why Ponemon noted that of all the data breaches in 2018, a mere 4% (on average) of them were deemed “secure” (all of the data was encrypted, which makes all of the stolen data useless.) The bottom line: consumability is the biggest issue in the security market.
Note
We’d be remiss to not suggest you look into true secure enclave technologies like Secure Service Containers that run hardware assisted on LinuxONE and IBM Z, which solve a lot of the friction around an encrypt everything strategy, all with the simplicity of a “light switch” to turn it on with next to zero performance impact and no changes to your applications.
There are cultural issues at play too. We say this (partially) tongue-in-cheek, but application developers really don’t like security folks. Why? Because performance means different things to different people:
Performance to a database administrator (DBA) means, “How fast does it take to run the transaction and is it within my service level agreement (SLA)?”
Performance to an AI practitioner means, “How accurate is my AI and how are its predictions (AI nerds call this generalization) on real world data the model has never seen before?”
Performance to an application developer means, “How fast can I build this application so I can move on to the next project in my queue?”
What does performance mean to security personnel? Nothing—unless it’s how fast can I detect an intrusion or something like that. It’s not on their measurement scope or in their ethos. Think about it: every single concern in the preceding list means nothing to a security professional. That’s why the Chief Security Officer’s division is also sometimes affectionately nicknamed “The Department of No!”
One thing is a certainty to us—in no way, shape, or form do we see any signs of the world doing a better job at protecting data. In a cloud virtualized and containerized world, you’ll have lots (and we mean lots) of virtual machines running beside each other, and if in the public cloud, perhaps beside someone you don’t even know. The question you have to ask is, “Are the virtual machines protected from each other?” or “What about container contents, are they protected?”
But it’s more than that. If you’re storing data in a public cloud provider, you must differentiate between the concepts of operational assurances and technical assurances when it comes to the protection of your data. This is a big deal and quite frankly not enough decision makers are even using this lexicon.
Let’s assume you have some sort of sensitive data (be it medical, financial, intellectual property, and so on). Operational assurance is basically your cloud provider saying to you, “I promise to not access your data.” They’ll back that up with comments about operational protocols and procedures that ultimately add up to a giant promise that administrators will not access your data. While that’s much appreciated, it may not be enough for you to pass a regulatory hurdle or have the confidence to replatform your apps. It may be OK for certain apps, but think about the ones that run the core of your business or hold the most sensitive data about your business and its clients.
What’s more, the number of insider breaches is growing like crazy, and you just don’t hear nearly as much about these breaches as you do external hackers. Internal breaches could be of malicious intent, but they can also be the work of inadvertent actors (folks exposing data they didn’t mean to). Heck, think about bringing in an external vendor to apply maintenance to fix some disk…there is an extensive list of “trusted” actors who could access your data.
In other words, we don’t think an operational model of trust is going to be enough if you’re looking to capture the 80% of the remaining cloud value that’s sitting there. The question you need to be asking (at least for certain apps) is “Can you access my data?” not “Will you access my data?” You don’t want operational assurances—you need technical assurances. True answers will sound like, “Umm…we want to help you, but because of the technology we’re using we can’t.” In these scenarios, even if law enforcement served a signed bench warrant, the CSP still couldn’t share usable data because they can’t see it and because of the way the security profile is managed. See the difference? The answer posture changes from “won’t” to “can’t.” (It’s fair to note that laws, expectations, and legal authorities have yet to catch up here and the future of data privacy will be an interesting space for years to come.)
Build Once and Run Anywhere with Consistency
This means you’re not rewiring or refactoring code solely because you want to run a portion of your business on Azure and moved it from another vendor (or vice versa). You also want to vet ease of integration and a consistent application development lifecycle. Think about your experiences with Java—it was marketed as a write once and run anywhere proposition that when put into practice became write once and test everywhere. That’s not what you’re looking for here and you’ll have to dig well beneath the veneer of websites and marketing brochures to flush this out. Open source technologies (like Linux, containers, and Kubernetes) will be key to this, but the goal is a consistent set of cloud services across any cloud or any location. If your application containerizes a certain vendor’s database and wants to run it elsewhere, that’s your prerogative to do so, one that must be free of friction or a “tax.”
Capture the World’s Innovation
Your cloud strategy should enable access to a wide range of innovations and technologies; your vendors are Sherpas to the unprecedented pace and quality of innovations in our world. Those innovations come from emerging technologies built by the vendor, but they are equally integrated or friendly to the unmatched pace and quality of innovations from the open source community.
From quantum computing (which will most certainly be a hybrid cloud platform—after all, some quantum computers operate within one of the coldest places in the universe, which is why you don’t want one in your office), to leading-edge AI networks, to edge computing, and blockchain, technologies fronted with APIs and exposed for usage is what will propel your business to transform.
Perhaps one vendor captures a certain area of innovation better than another (one is exceptional at natural language processing, another at visual recognition, and so on); that’s the very essence of what we’re getting at and spending the time to ensure these items remain top of mind. In the end, you’ll want to deploy the right systems (x86, OpenPOWER, IBM Z, LinuxONE—you choose) and cloud (AWS, Azure, Google Cloud, IBM—you choose) to specifically meet your business needs, not what the vendor is profiting from.
Cloud Solely for Savings Could Leave You with Cravings: A Trend of Repatriation
We alluded to this earlier, but we think it warrants some more musings. Today, there’s a huge swath of companies who raced to the cloud while seeking cost savings–only to find themselves still hunting for savings. Just like when organizations went all-in on Hadoop, using cloud as a destination isn’t always the right answer either. This is exactly why cloud should be thought of as a capability (and not as a destination): be it on-premises, public, or on the edge. We’ll say it in a more direct way: not all applications are suited for public cloud, but almost all applications benefit by being cloud enabled.
Think back to that autonomous car we talked about in the book’s Introduction. The term “path planning” is used by autonomous auto practitioners to describe how the self-driving car navigates (the actions it takes) on the road. Are you comfortable with high data latency to inference ratios? This refers to the time it takes to process camera, radar, and lidar data, send it up to the cloud, and receive a path planning instruction that says “Stop! There’s a person in front of you.” The bottom line: the cloud destination can hurt latency.
Let’s illustrate this with a simple example around Manufacturing 4.0 assembly lines. Manufacturing 4.0 is named to represent what many call the fourth industrial revolution—it’s the infusion of modern smart technology into traditional manufacturing and industrial practices for a better assembly line from a resiliency, quality, efficiency, and cost perspective. In automobile assembly lines, if a door assembly defect gets to the end of the line, the entire car has to be pulled off the line and reworked manually. In some cases, that means shipping the car to another facility. Fun fact: a car is manufactured every 30 to 60 seconds; this means that quality issue magnifies into huge money losses very quickly! But what about a smaller business? Material waste comes with a significant cost too (one small fabrication company we worked with loses ~$30,000 per month in ruined metals because of unrecoverable errors in production, such as a bad weld that results in a “blow through”).
Let’s assume you work in such a company, but your company is pretty forward thinking. You’ve got some snazzy on-the-line convolutional neural networks (CNNs—this is the class of AI algorithms well known for their computer vision properties), looking for defects in real time. You’ve been asked to cut costs and cloud (the destination kind) is how you’re told to do it. Your team performs their due diligence and meets with five CSPs recommended by your favorite analyst and issues a request for proposal (RFP) to each of them to help your organization save some money and get some workloads to “the cloud.”
Time passes—you look back at your accomplishments in the last year. You’re on the cloud and you discover the ROI isn’t quite what you expected. But heck, you’re on the cloud, right? Don’t worry: if this story sounds familiar to you or your business, you’re not alone (you’re going to hear why in a moment).
Just like Hadoop was not a one-size-fits-all answer to analytics in its heyday (which ultimately faded precisely because it was marketed as such, and that approach is why many associated projects failed to meet expectations), public cloud is not a one-size-fits-all answer either. Certain application and data gravity characteristics will help you decide where the destination goes; you focus on the application. That’s why cloud the capability matters so much, and it’s why a hybrid cloud strategy is so important. If you want to quickly spin up a monster GPU server to train those algorithms and converge an experimental model quickly, public cloud will very likely be a great answer (among other examples). But if you ran a small four-GPU server on the cloud for a year, nonstop, it’d cost you almost $100K, whereas you could likely buy one for $20K (or less, by the time you read this book).
One manufacturer we know implemented a computer vision solution that took tens of thousands of pictures a day, nonstop, and inferenced (this is AI fancy talk for scoring the algorithm—in this case analyzing the pictures) them to quickly identify quality escapes (defects). Public cloud? Likely not. In this scenario, it didn’t matter what public cloud option we looked at (Azure, AWS, or IBM) to support this scenario, those computer vision charges were based on usage (number of pictures looked at) and this led to drastically (that’s polite for crazy) more expensive public cloud solutions.
Our pro tip: always remember that public cloud pricing is utility pricing—the meter is running, just like how you’re billed for electricity in your home (and that can be a good or a bad thing as illustrated earlier). Running a nonstop application, or even a developer forgetting to shut down their test instances (one of us, whose name isn’t Chris, did that and cost his department $5,000), is like walking around your empty house with all the lights on and wondering aloud about all the money you could be saving. (If you have kids, this is a well-known feeling to you.)
Note
Enhanced data security is another example that has some rethinking a cloud destination definition versus capability. We won’t delve into those details here (loss of data control, who can access your encryption keys, governance and regulations are all at play here), but suffice to say that whether you’ve experienced a loss of control over your data, unexpected costs, or even high latency in application response times (data gravity is at play here), you’re not alone. The takeaway? Again, not all workloads are appropriate for a public cloud destination, but almost all apps are better served to be built as cloud (the capability) applications. This is why our personal experiences with clients have many asking us about hybrid clouds and the reevaluation of their decisions to blindly move all workloads with a one-strategy-fits-all approach to a CSP.
The IBM Institute for Business Value conducted an independent study with 1,100 executive interviews (across 10 countries and 18 industries) and found that nearly 51% of the respondents had plans to move at least some migrated workloads back from a public cloud service to on-premises, citing higher than expected costs and lack of data security as the primary drivers, as shown in Figure 2-2.
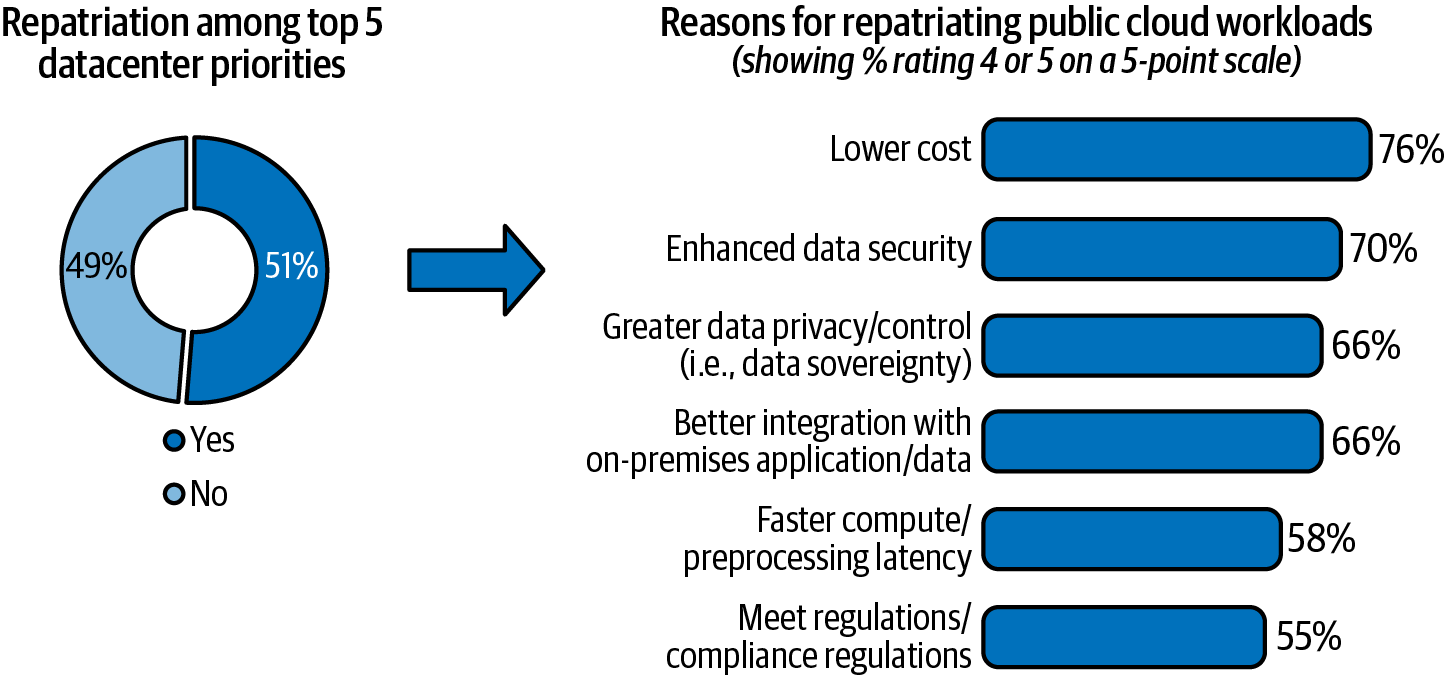
Figure 2-2. Lower costs and enhanced security are the top motivations for repatriating off-premises workloads to on-premises environments
Make sure you understand what we’re saying here. We are not advocating that any client should scrap their “public cloud first” strategies. In fact, it’s the opposite. Many that joined the pilgrimage to cloud are now drawing from their experiences and incorporating this knowledge into a newly defined “capability cloud first” strategy (what we call “Cloud Chapter 2”—an epoch of cloud computing, as opposed to a book chapter)—one with a broader aperture and appreciation for the capability aspects of the technology not solely focused on destination.
“Cloud Chapter 2” offers organizations a much more refined, well-rounded, and effective cloud strategy that can be used to please renovators and innovators alike! It’s a blend of multicloud (vendors), hybrid cloud (location), and even has some workloads running on the edge! This may sound like a painful and costly retreat from what seemed at first to be a well-thought-out plan and in many instances, it very well could have been; at the same time, things are changing so fast. Remember what we said earlier: the world often overhypes the impact of new technologies in the first couple of years, but the danger follows from downplaying its impact over the years to come. Cloud will change the way businesses operate in the same way that AI will—and it’s why you’re reading this book.
But take a moment and think about the opportunity that “Cloud Chapter 2” has to offer. Unprecedented flexibility in choice of infrastructure, agility, continuous integration and continuous delivery (some call the second “d” deployment—technically they are different things, but we’ll assume them to be the same to keep things simple and just refer to it as CI/CD), cost savings, and more.
Are you one of those more forward-thinking organizations that invested precious resources (time, money, and effort) into building cloud native applications as opposed to the lift-and-shift approach that often shortchanges the full realization of cloud’s value? Your applications were refactored, containerized, and virtualized. Now you have to repatriate them for one reason or another (data gravity and performance, costs, governance, data control, and so on). Fear not, all is not lost. Not at all. There are opportunities here with a hybrid cloud strategy, starting with consolidation and extending all the way to more data security and control.
Before you talk to any vendor, evaluate your business and IT objectives, current and future plans, and data governance requirements. Ask: “What does the future look like for us?” Perhaps your business is just starting its AI journey? Are you trodding on an analytics path and pushing it to the edge in order to optimize your cold-chain custody transportation costs? Will you be using blockchain to evolve your food supply chain, from traceability (where the livestock came from) to transparency (where it came from, how it was transported, the record of the slaughterhouse that processed the meat, what the livestock was fed, who provided the feed, and so on). You know where you are now, but where are you trying to get to? As hard as it may be, try to anticipate how these ambitions may change over time and how cloud (the capability) can help.
By way of example: there’s no denying that data privacy is increasingly front of mind for every business and consumer, and more so with each passing year. If your organization handles data that’s considered to be personally identifiable information (or its subset, sensitive personally identifiable information), place your bets now that things are going to get more stringent, penalties are going to go up, and there will be less and less tolerance in the marketplace for accidental disclosures. Even if you’re an organization that doesn’t have any kind of sensitive information, you’ve got intellectual property that you want to preserve. This is just one of many considerations that need to be made when creating a winning cloud strategy—failure to do so will inevitably result in sunk costs, fines, penalties, or worse.
Be Ye a Renovator, Innovator, or Both? How You Spend Budget
There are certain ways to think about the initiatives your company is journeying on, projects you own, and even the ones you’re trying to sell or gain sponsorship for. In this section we want to share with you a ubiquitous framework we’ve developed that simplifies even the most complex of enterprises’ strategic transformation plans.
When it comes to budget planning, we recommend giving your projects one giant KISS! (Keep It Simple Silly—there’s another version of this acronym floating around). Every client we talk to is doing one of two things: spending money to save money or spending money to make money. When you spend it (money) to save it, you’re renovating and when you spend it to make it, you’re innovating. The best strategies will do both and leverage cost savings from renovating the IT landscape (spending money to save it) to partially fund the innovation (spending money to make it).
To illustrate this model, we’ll use something we call an Acumen Curve. You’ll find this simple framework handy for any strategic investment decisions your company is facing across almost any domain. For example, we developed a Data Acumen Curve (Figure 2-3) and use it to help clients put their data to work (after all, data is like a gym membership; if you don’t use it, you’ll get nothing but a recurring bill out of it). For one client, we created different categories for their project (for both renovation and innovation) and a plotted value curve on the expected outcomes if successful projects are aligned to business needs (that’s a key thing).
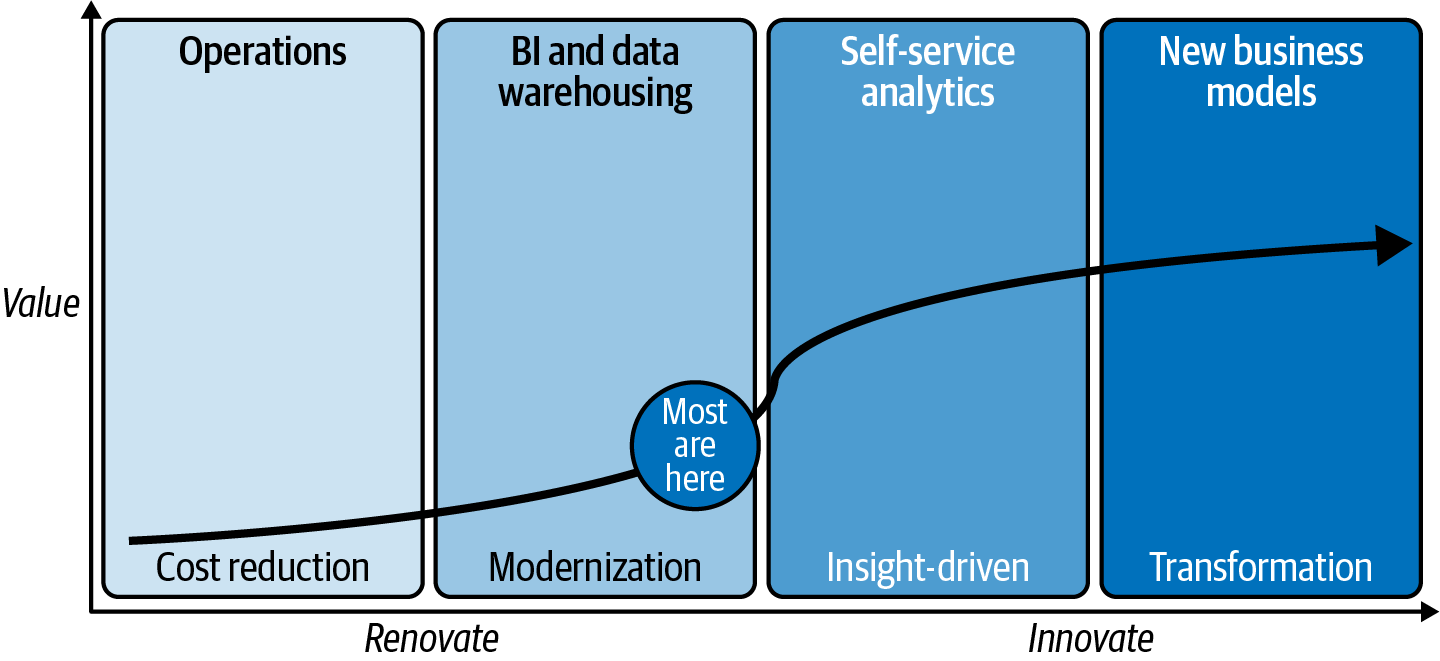
Figure 2-3. Data Acumen Curve: a terrific asset to include in any strategic planning project
You can see in Figure 2-3 the emergence of a natural border (it should be a friendly one) between renovating and innovating. This is important to understand because you should be able to derive downstream benefits of a renovation project. This will be even more profound in a Cloud Acumen Curve (which we’ll introduce next). There are some key takeaways here—and the similarities across any Acumen Curve will be uncanny:
- Strategies focused solely on cost reduction deliver shortchanged value
Today’s technology is about efficiency, automation, optimization, and more. If you’re focused only on cutting costs, the value returned won’t be enormous. Don’t get us wrong, smart cost cutting is a terrific strategy and you can forward the money saved toward more renovation and compound that value into innovation, but that is not the end game (despite so many being forced to play it as if it was). Governance is a great example. Most organizations scurry to implement regulatory compliance with the least possible work to comply approach—mainly, avoidance of fines (cost savings). However, this approach shortchanges the value of such a project because it misses the opportunity to create regulatory dividends from those compliance investments (data lineage, for example) to accelerate your analytics strategy. Some of us have been around analytics and AI for a long time and we can assure you, almost every governance project shortchanges its real value to the business.
- Most haven’t bent the curve for maximum value
When you stop and take stock of where your organization truly is on an Acumen Curve, most will wake up and think “Wow, we have a long way to go!” We doubt few of the businesses that turned into divers, or had to contend with new arrivers, had any idea how truly broken their digital strategy was until COVID and disruption hit. That’s the point of these curves; you need to know ahead of time, not after the fact.
- Real value comes in the innovation phase
You can’t be a new arriver or thriver if all you’re doing is spending money to save or make it and not also reimagining the way you work. Take, for example, an AI project on our Data Acumen Curve (which we would place on the far-right quadrant in Figure 2-3). Do you layer AI on top of existing processes or rethink them from the ground up and redesign the workflow? Whether you are on a Data Acumen Curve or a Cloud Acumen Curve, most organizations today are unwilling to do the deep rethinking of their business models and workflows that will allow them to fully embrace the opportunities presented to them by an innovation investment. Be forewarned, you’ll miss out on the full gamut of potential benefits if your definition of the finish line is putting all your transformative innovations on top of existing business models and workflows. You should be thinking and planning how these models and workflows could (or should) change because of your AI and cloud innovations. We can’t stress enough how important this is. As you build your Acumen Curves, reimagine your business processes from the ground up with your new capabilities—we guarantee you that the impact will be greater for having done so.
We created a Cloud Acumen Curve (Figure 2-4) to help you get started. As you read this book, build your own and populate it with projects, expected outcomes, newfound superpowers your cloud journey will bring to the organization, and more.
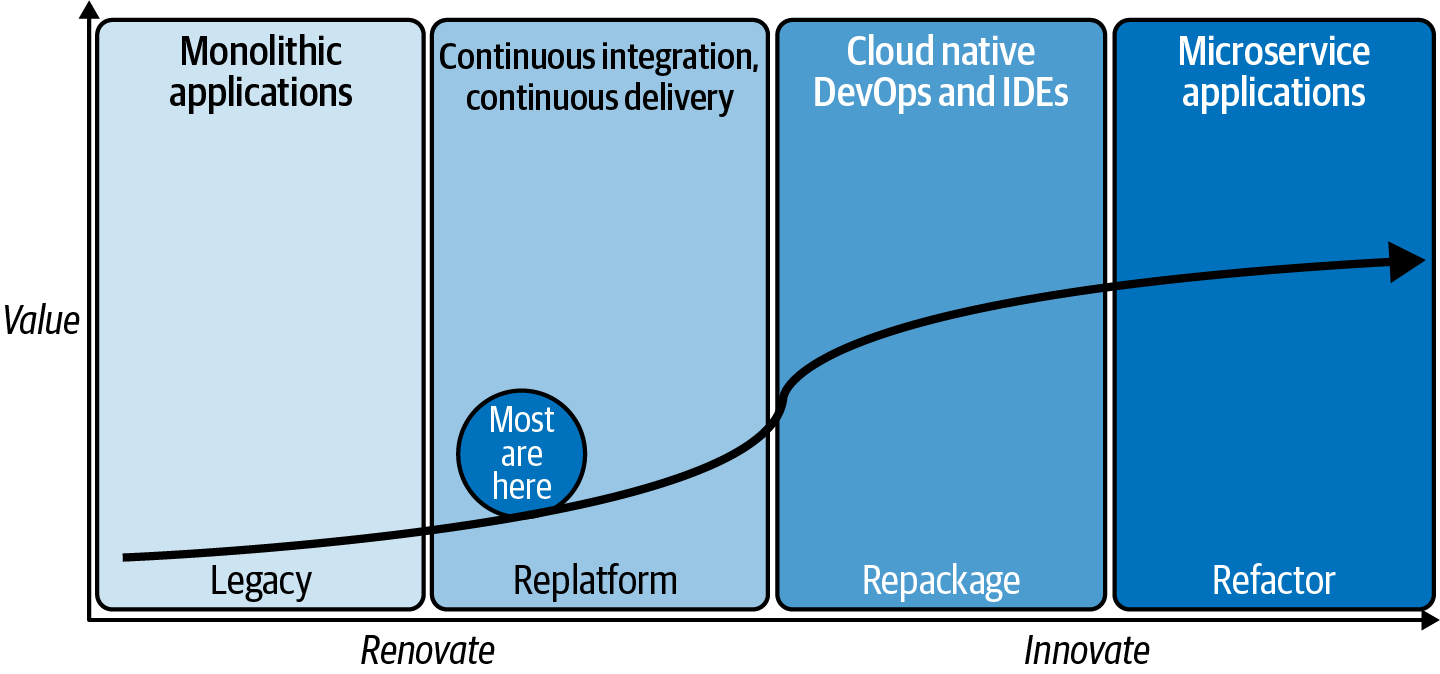
Figure 2-4. Cloud Acumen Curve: a framework for plotting value from the monoliths to microservices
You can see on this curve that the quadrants are different (don’t worry if you don’t fully understand the legacy, replatform, repackage, and refactor terms yet—we cover those in Chapter 5). Monolithic (legacy) apps refer to those applications where the entire application (from the interface to the inner workings) are combined into a single program that runs in one place. Uber’s app, on the other hand, is the opposite of a monolithic application: it is made up of perhaps dozens if not hundreds of microservices that have very discrete jobs—one for currency conversion, another for wait time estimates, another to calculate time to distance, others to suggest local Uber Eats partners and discounts at the final destination, and more. If Uber’s app wasn’t on the far right of Figure 2-4, they couldn’t roll out the near weekly updates we get on our mobile phones telling us about all the things they are doing to make our experience better.
Note
OK, we admit it. We share a guilty pleasure reading release notes from vendors whose personalities shine through in their update release notes (like Slack or Medium, among others). One of our favorites yet was Slack’s “We no longer show you in your own Quick Switcher results; if you want to talk to yourself, that’s fine, but you don’t need us for that.”
It’s important to remember that some apps should stay the way they are because you have “bigger fish to fry”; your business may be looking for quick wins rather than long-haul (albeit worthwhile) projects, while some apps are too critical to the business to entertain the expense or risk of changing just yet.
This naturally brings us to the middle phases on your journey to derive the most value you can from the cloud. This is where functions (like archive, Q/A, test), or greenfield applications have been replatformed to the cloud, and that’s the beginning of value drivers such as CI/CD. Of course, going back to the far-right of Figure 2-4, it’s enough to say that embracing a cloud native microservices approach will allow you to capitalize on the scalability and flexibility inherent to the cloud.
Mission-critical apps can replatform to the cloud, too. For example, we’ve seen businesses with critical functions (running on-premises on AIX and IBM i servers) become modernized and reap public cloud benefits such as pay-as-you-go billing, self-service provisioning, and flexible management, without having to change the code! This approach helps you grow at your own pace and start a cloud journey without heavy up-front costs, allows your workloads to run when and where you want, and more.
The takeaway? As you move farther and farther to the right of your Acumen Curve (allowing digital properties to sit where they make sense) you gain more and more cloud acumen, which delivers more and more value to your business. In Chapter 5 we’ll give you a scorecard you can apply to your Cloud Acumen Curve and see what phases unlock capabilities like agile delivery, tech debt relief, cloud operational models, and more.
There’s a final consideration we want to explicitly note here: how partnerships matter. Earlier in this chapter we talked about the kinds of things you want to look for from your cloud partners (you will have more than one, we can almost guarantee that). But what we didn’t articulate was the importance of a strategy. As you build out your cloud strategy, it is critical that it be open and portable: being able to build on one cloud property and move it to another either because of specific compute needs (resiliency, GPUs, quantum, and so on), vendor disagreement, or just having that option to negotiate better terms and pricing—flexibility is key! Quite simply, the assets you create should be able to be deployed anywhere across your landscape to fully realize the benefits of your hard work. We think by the time you’re done reading this book you’ll have great cloud acumen as a business leader and a framework to plan your journey, and also know what to look for, how to build teams, and the benefits you will come to realize from your efforts. If we’ve been successful in persuading you, we think you’ll end up with a Cloud Acumen Curve similar to what you see in Figure 2-5.
Compare the curve in Figure 2-5 to all the other curves you’ve seen in this chapter. It bends drastically in the renovation phase because you have a plan. Your organization creates downstream dividends from that plan and the work done in renovation drives innovation. We can’t stress enough how useful this model has been with the clients to whom we’ve been successful in delivering value. These acumen curves are how we get projects and conversations going, and how we hold each other accountable.
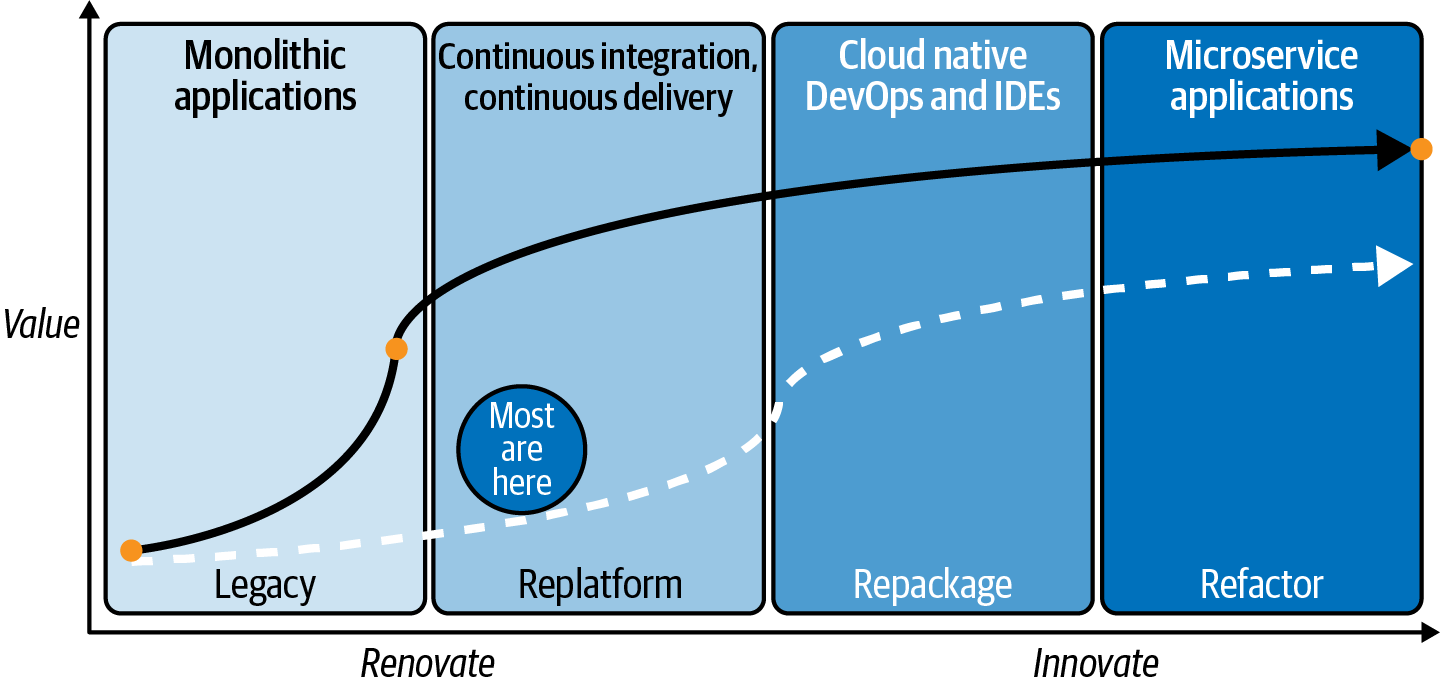
Figure 2-5. The kind of Cloud Acumen Curve you can build with the right strategy, requirements list, and partnerships
Adopting a “Learning Never Ends” Culture: A Cloud Success Secret Ingredient
What would you say if we told you that by exercising religiously for the next year, every day, you’d be fit for the rest of your life? You’d answer, “Ridiculous!” ([ri-dik-yuh-luhs]—causing or worthy or ridicule, preposterous, laughable). While the focus of this book is about redefining and expanding the aperture of the term “cloud,” arming you with questions to ask as you deploy your cloud strategies, and presenting you with architectures, gotchas, ideas, and points of views you perhaps never considered before, we’d be remiss if we didn’t share this secret success ingredient for organizations, their teams, and you as individuals. Learning never ends.
We could be writing a book about AI, cloud, or anything—those tech years like dog years we mentioned back in Chapter 1 feeds off a “learning never ends” culture. This is especially true in the cloud space because there’s so much open source technology at play whose names and versions are nothing short of dizzying. As world renowned golf instructor Steve Rodriguez of GOLFTEC says, “This is a skill you will forever be learning; don’t strive for perfect, just better.” Practice and focus breeds success in both.
The teams you lead (and you as leaders) have to instill a culture of learning to exploit all you can from cloud computing. That isn’t to say you rush in and jump on any new version or new technology, but capabilities and directional shifts are forever changing, and your goal can’t be to find out about them later. Perhaps these emerging technologies aren’t for your group…no problem. Or perhaps you want them pretested and “signed-off” (such as an enterprise-tested, hardened, and expanded Kubernetes platform like Red Hat OpenShift Container Platform). Keeping abreast of those compacted tech years is essential for organizations and personal careers.
As your leadership teams and employees build their cloud acumen skills, ensure they teach others along the way. Be it AI acumen, cloud acumen, blockchain acumen, or whatever—transformational shifts happen with culture changes at the top and knowledge becomes a thirst. It’s a great way to get everyone in the same mindset and expand the understanding of any undertaking. Cloud will create a mindset of “We can.” It will have developers thinking that continuous delivery is possible, that value can be added at almost any time to a subscription service; marketing will go into micro-campaigns focused on sprints; product designers are free to wildly create and deliver tiny features that can vastly change the client experience or reduce friction (and back out of those changes if the result misses the mark—A/B testing); and so much more.
How critical is learning for even the best employees, let alone your organization? Ever see the movie A Star Is Born (2018)? Music sensation Lady Gaga (the star that is born in the movie) and one of Hollywood’s top box-office draws, Bradley Cooper (a rugged worn-down boozing successful singer in the movie), are headliners in a story of love, success, and sadness. We won’t Siskel and Ebert the movie for you because the title kind of suggests the outcome, but we did learn something about this movie that so perfectly hits home the point we’re trying to make in this section. Consider this fun fact: Bradley Cooper played and sang everything live (no auto-tuning, no lip synching)—a demand made by Lady Gaga herself. Cooper worked with a voice coach to lower his speaking voice, spent over eighteen months on vocal lessons, six months on guitar lessons, and another six months on piano lessons, all to prepare for his role in the movie. All in all, it took Bradley Cooper years to fully prepare for his part (in a remake, at that) and just 42 days to film it all.
We think this Cooper story speaks volumes. If one of Hollywood’s most sought-after actors spends years building skills for 42 days of work, how important do you think preparation and learning is in the IT domain for your cloud organization?
Ready, Set, Cloud!
In this chapter we wanted to cast a different way of thinking and encourage you to challenge assumptions about your own notions of cloud, the vendors trying to sell you something, and the organizations you work for.
We talked about how 80% of cloud value is locked away (for those treating cloud as a destination) and the potential for 2.5x return on your cloud investments when you treat it as a capability (hybrid cloud). So how do you unlock the 80%? We recommend you tie business initiatives to the areas we discussed (some implicitly and some explicitly) so that you have supreme clarity over cloud capabilities and can articulate how your renovation or innovation strategies will deliver value for your business, namely:
Business acceleration
Developer productivity
Infrastructure cost efficiency
Regulatory compliance, security, and risk
Strategic optionality (the freedom to keep options open as much as possible while achieving your goals)
Thomas Edison once remarked, “Vision without execution is hallucination.” We think that sets the tone for our business practitioners’ book perfectly as we journey into more of the details. We want to give you tools, knowledge, ideas, and considerations that are going to help you execute on the cloud vision we outlined in this chapter.