CHAPTER 2
Tooling Up
WHAT’S IN THIS CHAPTER?
- Using the Jasmine unit-testing framework to prove the reliability of each component of your code
- Using a dependency-injection (DI) container to promote modularity, reusability, and testability
- Exploring how aspect-oriented programming (AOP) can make your code simpler and more reliable
- Exploring case studies in test-driven development
- Using JSLint to detect problems in your code before it ships
WROX.COM CODE DOWNLOADS FOR THIS CHAPTER
The wrox.com code downloads for this chapter are found at www.wrox.com/go/ reliablejavascript on the Download Code tab. The code is in the Chapter 2 download and organized in directories according to this chapter’s topics, with each directory holding one sample.
You can run a sample by copying its directory to your hard drive and double-clicking on the index.html file. Each sample’s ReadMe.txt file contains further instructions.
USING A TESTING FRAMEWORK
Assume for a moment that you’re working on a large team that’s building a travel reservation system. You’re responsible for the module that creates flight reservations, and one of the module functions should behave as follows: Given a passenger object and a flight object, createReservation will return a new object with the passengerInformation property set to the provided passenger object and the flightInformation property set to the provided flight object.
Simple enough, right? So simple, in fact, that there’s no harm in just going ahead and implementing the function, as shown in Listing 2-1.
Since your team has a requirement that no production code should be checked in without the appropriate (passing) unit tests, you’d write those now. You have the implementation of the function to refer to, so writing the tests for it is trivial. Listing 2-2 shows the tests that you might write with the code at hand.
These unit tests are written using the Jasmine testing framework. This book will feature Jasmine throughout, and you will see a more extensive introduction later in this chapter.
For the time being, all you have to keep in mind is that each it function call is an individual unit test (this example has two), and that each of those unit tests verifies that a single attribute of the object returned by the function has the proper value. The tests each verify the attribute value via a call to expect.
As you can see in Figure 2.1, the unit tests pass.
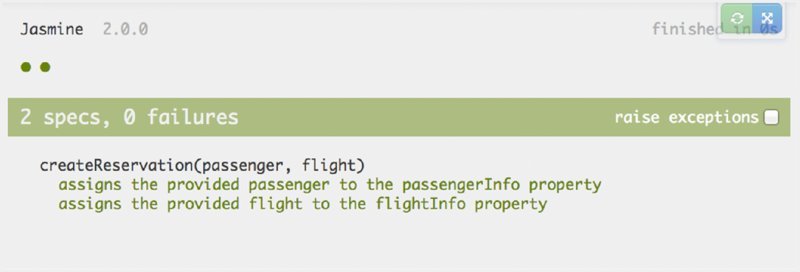
All of our samples retrieve the Jasmine files from a content distribution network (CDN), but it is also possible to download the files and include them from your local computer.
You’ve satisfied your team’s unit test requirement, so you check in the code and confidently move on to the next piece of functionality.
A few hours (or maybe days or weeks) later, you get an e-mail from Charlotte, a fellow team member, who is integrating your createReservation function into another area of the application. When she runs her suite of integration tests, all of the tests that exercise the createReservation function fail. “Impossible,” you respond, “All of the unit tests for that function pass!”
Closer inspection reveals that the unit tests are incorrect. The specification says that the attribute names of the returned reservation object should be passengerInformation and flightInformation, and Charlotte wrote her code expecting those attributes to be present. Unfortunately, in our hasty implementation of createReservation we used the attribute names passengerInfo and flightInfo.
Because the tests were written according to the function’s implementation rather than its specification, they verify the actual—incorrect—behavior of the function rather than the expected behavior of the function. Had they been written first, based solely on the specification, the attribute names probably would have been correct the first time.
We won’t dispute that the same mistake could happen if the function had been written using TDD, which would base the tests on the specification rather than the existing code. Our experience has shown that it is far less likely, however.
Identifying Incorrect Code
TDD identifies defects in code at the earliest possible time: the moment after they’re created. When following TDD, a test is written to verify a small piece of functionality, and then the functionality is implemented with the minimum amount of code possible.
Returning now to the createReservation function, you will see how a different outcome is assured by writing the tests first. As a reminder, the specification for the function as described earlier in the chapter is:
- Given a passenger object and a flight object,
createReservationwill return a new object with thepassengerInformationproperty set to the provided passenger object and theflightInformationproperty set to the provided flight object.
Listing 2-3 shows the first test to verify that the passengerInformation property is properly assigned.
Listing 2-4 shows your minimum implementation of createReservation that will cause the test to pass.
You then immediately execute the unit test and it fails (Figure 2.2). How did that happen?
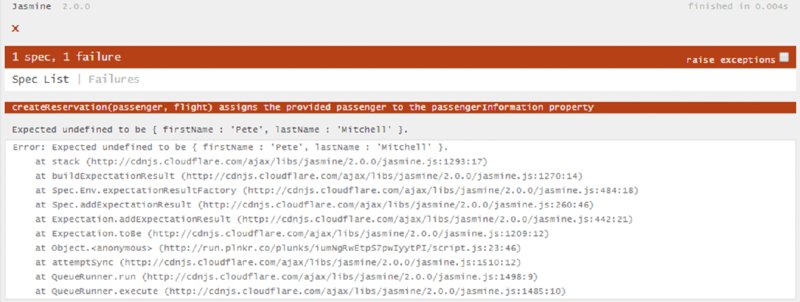
Ah! The attribute name in the returned object was incorrect; it was called passengerInfo instead of passengerInformation. You quickly change the name of the attribute to the specified passengerInformation, and now your test passes (Figure 2.3). Note that the figure also reflects a change to the it statement: You changed the it statement to also indicate that the passengerInformation property is being tested.

You can then follow the same process for assignment of the flightInformation attribute, yielding a createReservation function that is verified correct via unit tests.
The error of incorrectly naming an attribute in the returned object once again made its way into the implementation of the createReservation function. This time, however, you wrote your test first and based the test on the specification. This allowed you to immediately identify and address the error rather than waiting hours (or days, or weeks) for another developer running integration tests to alert you to the problem.
For a trivial function such as createReservation, this piecewise creation of tests and addition of functionality admittedly feels like a bit of overkill. It is easy to imagine other cases, however, where the iterative process of TDD could end up saving a significant amount of debugging time.
Suppose that you have to write a function that performs a multitude of computations on an array of data. You attempt to implement a large portion of the function all at once, and that portion contains an off-by-one error such that you omit the last piece of data from the computations.
When you verify the output of your function, the computed value will be incorrect, but you won’t know why it’s incorrect. It could be a mathematical error in one of the computations, or perhaps you’re not handling a case of numeric overflow. Had you written a simple test early on to verify that each and every element of the array is involved in the computation, you would have immediately caught the off-by-one error and likely would have had a working solution much sooner.
Designing for Testability
Writing tests first makes the testability of your code a primary concern rather than an afterthought. In our experience working with developers at all skill levels, there is a direct correlation between how easy code is to test and how well that code is tested. Additionally, we’ve found that code that is easy to test tends to be easier to maintain and extend. As we proposed in the first chapter, code that follows the principles of SOLID development lends itself quite well to testing. If you make testability a goal of your designs you will tend to write SOLID code.
For example, suppose every reservation created with the createReservation function should be submitted to a web service to be stored in a database.
If you’re not practicing TDD, you may simply extend createReservation by adding a call to jQuery.ajax(...) which sends the reservation to a web service endpoint via asynchronous JavaScript and XML (AJAX). The addition of this one simple function call, though, has increased the number of responsibilities the humble little createReservation function has, and has increased the effort required to properly unit test it.
You’ve already added the jQuery.ajax(...) call, you already have tests for some of the things the createReservation function does, and maybe you manually tested and verified that the reservation ends up in the database. It’s easy to decide that it’s just too much effort to write unit tests for that one little bit of functionality and move on to your next task. We’ve seen it happen many times, and admit to doing it many times ourselves.
Assuming you have committed yourself to TDD, instead of steaming ahead and updating createReservation, you would write a test to verify the new functionality. The first test verifies that the reservation is sent to the correct web service endpoint.
You probably wouldn’t get much further than defining the behavior before you would ask yourself the question, “Should createReservation be responsible for communicating with a web service?”
describe('createReservation(passenger, flight)', {
// Existing tests
it('submits the reservation to a web service endpoint', function(){
// should createReservation be responsible for
// communicating with a web service?
});
});The answer to the question is: No, most likely not. If one doesn’t exist already, you would benefit from creating (and testing!) an object with the sole responsibility of web service communication.
By maximizing the testability of your code, you are able to identify violations of the SOLID principles. Many times, as in the example above, you can avoid violating them altogether.
Writing the Minimum Required Code
To review the basic TDD workflow, you write a test that will fail in order to verify a small piece of functionality, and then you write the minimum amount of code possible to make that new test pass. You then change the internal implementation details of the code under development, known as refactoring, to remove duplication.
Between only adding the minimum lines of code, and then refactoring to remove duplicate code, you can be certain that at the end of the process you have added the fewest lines of code possible. This is perfect, because there can be no defects in code you don’t write!
Safe Maintenance and Refactoring
Practicing TDD guarantees that you will have a robust unit test suite for the production code in your project. Up-to-date unit tests are an insurance policy against future regression defects. A regression defect is a defect that appears in code that worked correctly at some time in the past, but is no longer working properly; the quality and reliability of the code has regressed.
Like any other insurance policy, there’s a recurring cost that seems like a burden without benefit. In the case of unit-testing, the recurring cost is the development and maintenance of the unit test suite. Also like any other insurance policy, there comes a point when you are relieved that you paid that recurring cost. If you’re a homeowner, it may be a violent storm that knocks a tree onto your house causing a significant amount of damage (as happened to one of us).
You will feel a similar sense of relief when it comes time to extend or maintain production code that has a comprehensive unit test suite. You can make changes to a portion of the code (still following TDD, of course) and be confident that you have not unintentionally changed the behavior of other portions of the code.
Runnable Specification
A robust unit test suite, like one generated when practicing TDD, also acts as a runnable specification for the code that the suite tests. Jasmine, the unit test framework that we’ll introduce in a following section (and use throughout this book) uses a behavior-based test organization. Each individual test, or specification as Jasmine refers to them, begins with a natural-text statement about the behavior that the test is exercising and verifying. The default Jasmine test result formatter shows these statements to us for each test.
Once again using the createReservation function as an example, you can see that it’s possible to read the output of the Jasmine unit tests to get a complete picture of how the function behaves. It isn’t necessary to read the createReservation function to determine what it’s doing; the unit tests tell you! The sort of “runnable documentation” that unit tests provide is invaluable when adding developers to a project, or even when revisiting code that you wrote in the past.
Current Open-Source and Commercial Frameworks
While Jasmine is the JavaScript test framework that we prefer, it isn’t the only one out there. This section explores two popular alternatives: QUnit and D.O.H.
QUnit
The open-source QUnit framework was developed by the team that wrote the jQuery, jQuery UI, and jQuery Mobile JavaScript frameworks. QUnit may be run within non-browser environments, such as the node.js or Rhino JavaScript engines. QUnit tests may also be executed in the browser after including the requisite library JavaScript and CSS files in an HTML file.
Defining a QUnit test is a low-friction affair:
QUnit.test("This is a test", function(assert){
assert.equal(true, true, "Oh no, true is not true!");
});The only argument to a QUnit test function is a reference to the QUnit assertion object, which exposes eight assertions—including equal, as you can see in the preceding code snippet—for use within tests.
Tests can be grouped via the QUnit.module function, which causes the tests that follow to be grouped in the test results. All the tests that follow are in the module until another QUnit.module call is encountered or the end of the file is reached. We prefer Jasmine’s nesting of tests within a suite because we find it more explicit and intuitive.
QUnit.module("module 1");
QUnit.test("I'm in module 1", function(assert){
// Test logic
});
QUnit.module("module 2");
QUnit.test("I'm in module 2", function(assert){
// Test logic
});You can find out more about QUnit at http://qunitjs.com/.
D.O.H.
D.O.H., the Dojo Objective Harness, was created to help the creators and maintainers of the Dojo JavaScript Framework. D.O.H. does not have any dependencies on Dojo, however, so it may be used as a general-purpose JavaScript testing framework.
Like Jasmine and QUnit, D.O.H. supports browser-based test execution and non-browser–based execution (such as within the node.js or Rhino JavaScript engines).
D.O.H. unit tests are defined using the register function of the doh object. The register function accepts an array of JavaScript functions, which define simple tests, or objects, which define more complex tests that include setup and tear down (analogous to Jasmine’s beforeEach and afterEach, which you will see in the next section).
doh.register("Test Module", [
function simpleTest(){
doh.assertTrue(true)
},
{
name: "more complex",
setup: function(){
// code to set up the test before it runs
},
runTest: function(){
doh.assertFalse(false);
},
tearDown: function(){
// Code to clean up after the test executes
}
}
]);D.O.H. provides four built-in assertions (such as assertFalse).
While we enjoy the framework’s name (D’oh!), we find the Jasmine syntax for test organization and definition to be more clear and expressive.
You can explore the D.O.H. framework at http://dojotoolkit.org/reference-guide/1.10/util/doh.html#util-doh.
Introducing Jasmine
Jasmine is a library for creating JavaScript unit tests in a behavior-driven development (BDD) style.
In this section, we’ll describe the basics of the framework, but we highly recommend that you visit the Jasmine homepage at http://jasmine.github.io where you can find the library’s documentation—which is a runnable Jasmine test suite—for in-depth exposure.
Suites and Specs
Jasmine test suites are defined using the global describe function. The describe function accepts two arguments:
- A string, usually one that describes what is being tested
- A function, containing the implementation of the test suite
Test suites are implemented using specs, or individual tests. Each spec is defined using the global it function. Like the describe function, the it function takes two arguments:
- A string, usually one that describes the behavior being tested
- A function containing at least one expectation: an assertion that a state of the code is either true or false
Test suite implementations may also make use of the global beforeEach and afterEach functions. When included within a suite implementation, the beforeEach is executed before each of the tests in the suite. Conversely, the afterEach function is executed after each of the tests in the suite. The beforeEach and afterEach functions are useful for performing common setup and teardown, reducing duplication within a test suite.
In Listing 2-2, there were two tests that had exactly the same setup step. We noted at the time that we’d show how to remove this blatant violation of the DRY principle. Listing 2-5 shows how to do that using the beforeEach function.
For completeness, Listing 2-6 shows the implementation of createReservation that allows the refactored unit tests to pass.
Expectations and Matchers
Each of the tests contains an expect statement. Here’s the expect from the first createReservation unit test:
expect(testReservation.passengerInformation).toBe(testPassenger);The expect function takes the actual value generated by the code under test, in this case testReservation.passengerInformation, and compares it with the value that is expected. The expected value in the first unit test is testPassenger.
The comparison between the actual value and the expected value is performed using a matcher function. Matchers return either true to indicate that the comparison was successful, or false to indicate the comparison was not successful. A spec that contains one or more expectations with an unsuccessful matcher is considered failing. Conversely, a spec that contains only expectations with successful matchers is considered passing.
The example above used the toBe matcher, meaning—you guessed it—you expect testReservation.passengerInformation to be the same object as testPassenger.
Jasmine includes many built-in matchers, but if it doesn’t have the exact matcher you need, Jasmine supports creating custom matchers. Creating custom matchers can be an excellent way to DRY out the test code.
Spies
Jasmine’s spies are JavaScript functions that act as test doubles. A test double replaces the default implementation of a function or object with another, usually simpler, implementation during a test. Test doubles commonly reduce the complexity of unit-testing by removing dependency on external resources, such as web services.
Earlier in this section, you briefly contemplated extending the capabilities of the createReservation function to include direct communication with a web service to save the created reservation in a database. At the time, it was decided that web service communication did not fall within the responsibility of the function.
Charlotte, one of the other members on your team, has created a ReservationSaver JavaScript object encapsulating the ability to submit a reservation to a web service via a call to its saveReservation function. You’d like to extend the createReservation function to accept an instance of ReservationSaver as an argument and ensure the ReservationSaver’s saveReservation function is executed.
Because the saveReservation function communicates with a web service, your test needs to save the reservation and then somehow query the database and ensure that the reservation was added, right? Thankfully, no; you don’t have to do that, nor would you want to. Doing so would make your unit tests depend on the presence and correct functionality of external systems: the web service and the database.
Jasmine spies allow you to replace the complex implementation of saveReservation with a simpler version that removes the dependence on the external systems. For reference, here’s the ReservationSaver object that Charlotte created:
function ReservationSaver(){
this.saveReservation = function(reservation){
// Complex code that interacts with a web service
// to save the reservation
}
}For reasons that will become clear in the next section, “Using a Dependency-Injection Framework,” the createReservation function has been updated to accept an instance of a ReservationSaver. Providing the ReservationSaver as an argument allows you to write the test that ensures that the reservation is saved like this:
describe('createReservation', function(){
it('saves the reservation', function(){
var saver = new ReservationSaver();
// testPassenger and testFlight have been set up
// in the beforeEach for this suite.
createReservation(testPassenger, testFlight, saver);
// How do we make sure saver.saveReservation(...) was called?
});
});As it’s currently written, the test is providing the default, complex implementation of the ReservationSaver object to the createReservation function. However, you don’t want to do this because doing so adds a dependency on an external system and makes the present function difficult to test. Here’s where the power of Jasmine spies becomes evident.
Before calling createReservation, you can create a spy on the saveReservation function. Spies, among other things, allow you to verify that a particular function was executed. This capability is perfect for this first test.
You tell Jasmine to spy on a particular function using the spyOn global function. The spyOn function accepts an instance of an object as its first argument and the name of the function that should be spied on as its second argument. Thus, to create a spy on the saveReservation, you update the test like this:
it('saves the reservation', function(){
var saver = new ReservationSaver();
spyOn(saver, 'saveReservation');
// testPassenger and testFlight have been set up
// in the beforeEach for this suite.
createReservation(testPassenger, testFlight, saver);
// How do we make sure saveReservation was called?
});By creating the spy, you’ve replaced the saver object’s implementation of saveReservation with a function that does nothing related to the saving of a reservation at all. It does, however, keep track of each time the function is called as well as the arguments provided with each invocation. Jasmine also provides matchers for spies that can be used to create expectations that, among other things, verify that a particular spy was invoked one or more times. Adding that expectation to your test makes it complete:
it('saves the reservation', function(){
var saver = new ReservationSaver();
spyOn(saver, 'saveReservation');
// testPassenger and testFlight have been set up
// in the beforeEach for this suite.
createReservation(testPassenger, testFlight, saver);
expect(saver.saveReservation).toHaveBeenCalled();
});Because you’ve added an argument to the createReservation function, you must update the two existing tests. You don’t want any of your tests to execute the default implementation of the saveReservation function, so in Listing 2-7, you’ll refactor the new test to move creation of the ReservationSaver and its associated spy into the suite’s beforeEach function.
At this point, only the new test is failing. A minor refactor of the createReservation function yields a passing test suite in Listing 2-8.
USING A DEPENDENCY-INJECTION FRAMEWORK
You may remember from Chapter 1 that dependency inversion is one of the five pillars of SOLID development, and that dependency injection is part of the mechanism of bringing it about. In this section, you will develop a framework that brings both flexibility and discipline to dependency injection.
What Is Dependency Injection?
There’s a JavaScript conference coming up, and you’ve volunteered to help construct its website. This will be the biggest JavaScript conference ever, with every session so jam-packed that attendees must reserve their seats. Your job is to write the client-side code to make reservations possible.
You’ll need to call the conference’s web service to work with the database. Being well-versed in the principles of object-oriented programming, your first step was to encapsulate that service in a ConferenceWebSvc object. You have also created a JavaScript object, Messenger, that shows fancy popup messages. We pick up the story from there.
Each attendee is allowed to register for 10 sessions. Your next task is to write a function that lets the attendee attempt to register for one session, and then display either a success message or a failure message. Your first version might look something like Listing 2-9. (We apologize for the synchronous nature of the calls to ConferenceWebSvc. Better ideas are coming in Chapters 5 and 6. Also, we are using the “new” keyword to create objects even though some authorities don’t like it, so we cover the worst case.)
This code appears to be beautifully modular, with ConferenceWebSvc, Messenger, and Attendee each having a single responsibility. Attendee.reserve is so simple that it hardly needs to be unit-tested, which is a good thing because it can’t be unit-tested! Behind ConferenceWebSvc sit HTTP calls. How can you unit-test something that requires HTTP? Remember that unit tests are supposed to be fast and stand on their own. Also, Messenger will require the OK button on each message to be pressed. That is not supposed to be the job of a unit test on your module. Unit-testing is one of the keys to creating reliable JavaScript, and you don’t want to drift into system testing until all the units are ready.
The problem here is not with the Attendee object, but with the code it depends upon. The solution is dependency injection. Instead of burdening the code with hard-coded dependencies on ConferenceWebSvc and Messenger, you can inject them into Attendee. In production, you will inject the real ones, but for unit-testing you can inject substitutes, which could be fakes (objects with the appropriate methods but fake processing) or Jasmine spies.
// Production:
var attendee = new Attendee(new ConferenceWebSvc(), new Messenger(), id);
// Testing:
var attendee = new Attendee(fakeService, fakeMessenger, id);
This style of dependency injection (DI), which does not use a DI framework, is called “poor man’s dependency injection,” which is ironic because the best professional DI frameworks are actually free. Listing 2-10 shows the Attendee object with poor man’s dependency injection.
Making Your Code More Reliable with Dependency Injection
You have just seen how dependency injection allows unit-testing that would otherwise be impossible. Code that has been tested, and can continue to be tested in an automated test suite, will obviously be more reliable.
There is another, more subtle benefit to DI. You typically have more control over injected spies or fakes than over real objects. Thus, it is easier to produce error conditions and other exotica. What’s easier is more likely to get done, so you’ll find that your tests cover more contingencies.
Finally, DI promotes code reuse. Modules that have hard-coded dependencies tend not to be reused because they drag in too much baggage. The original Attendee module could never have been reused on the server side because of its hard-coded use of Messenger. The DI version allows you to use any messenger that has success and failure methods.
Mastering Dependency Injection
Dependency injection is not difficult. In fact, it makes life much easier. To become a DI Jedi, just keep these things in mind.
Whenever you’re coding an object, and it creates a new object, ask yourself the following questions. If the answer to any one of them is “Yes,” then consider injecting it instead of directly instantiating it.
- Does the object or any of its dependencies rely on an external resource such as a database, a configuration file, HTTP, or other infrastructure?
- Should my tests account for possible errors in the object?
- Will some of my tests want the object to behave in particular ways?
- Is the object one of my own, as opposed to one from a third-party library?
Choose a good dependency-injection framework to help you and become intimately familiar with its API. The next section will help you get started.
Case Study: Writing a Lightweight Dependency-Injection Framework
The dependency injection you’ve seen so far is hard-coded. It’s an improvement on the Big Ball of Mud style of programming, but still not ideal. Professional dependency-injection frameworks work like this:
- Soon after application startup, you register your injectables with a DI container, identifying each one by name and naming the dependencies it has, in turn.
- When you need an object, you ask the container to supply it.
- The container instantiates the object you requested, but first it recursively instantiates all its dependencies, injecting them into the respective objects as required.
In frameworks that use dependency injection heavily, such as AngularJS, the process can seem almost magic and too good to be true. In fact, it’s so magic that it can be hard to understand. To learn how these frameworks function, let’s build a DI container.
This will also serve as a case study in test-driven development. You will see how building the code bit by bit, in response to tests, makes for reliable JavaScript.
You want your container to do just two things: accept registrations for injectables and their dependencies, and supply objects on request. Suppose you code the register function first. It will take three arguments:
- The name of the injectable.
- An array of the names of its dependencies.
- A function whose return value is the injectable object. In other words, when you ask the container for an instance of the injectable, it will call this function and return whatever the function returns. The container will also pass instances of the requested object’s dependencies to this function, but you can hold off on figuring this out until later tests.
TDD works best when you code the absolute minimum at every stage, so you might start by coding only an empty version of register. Because this function is an asset that can be shared by all instances of DiContainer, you would make it part of DiContainer’s prototype. (See Listing 2-11.)
To make the code as reliable as possible, you’d want to verify that those arguments were passed and are of the right types. Laying that solid foundation is often a good first test, for then your subsequent tests can rely on it. Listing 2-12 shows such a test.
A few things to note about the test so far:
- The “subject under test,” container, is created in a
beforeEach. This gives you a fresh instance for each test, so one test cannot pollute the results of another. - The text arguments to the two nested
describes and theitconcatenate to form something that reads like a sentence: “DiContainer register (name,dependencies,func) throws if any argument is missing or the wrong type.” - Although TDD purists might insist on a separate test for each of the elements of badArgs, in practice placing such a burden on the developer will mean that he will test fewer conditions than he ought. If one expectation and one description cover all the tests, then it might be acceptable to group them like this.
When you run the test, it fails (Figure 2.4).
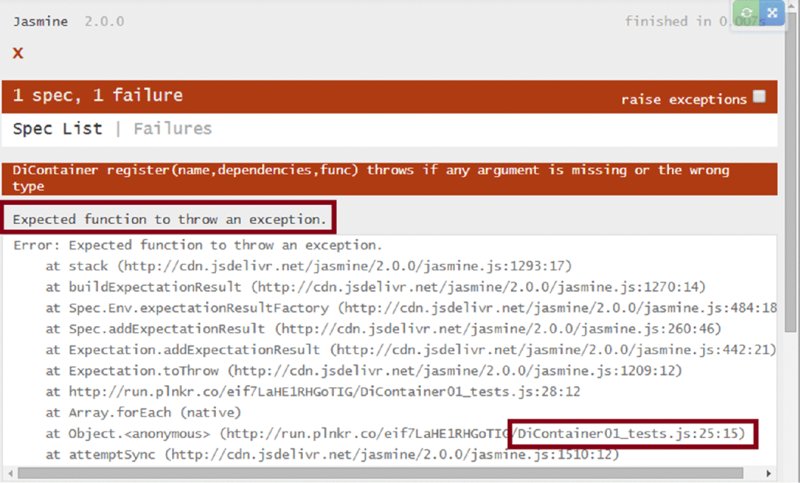
You can remedy the failure by adding the argument-checking functionality to DiContainer .register. Instead of the empty function, you now have the code in Listing 2-13.
The test now passes (Figure 2.5).
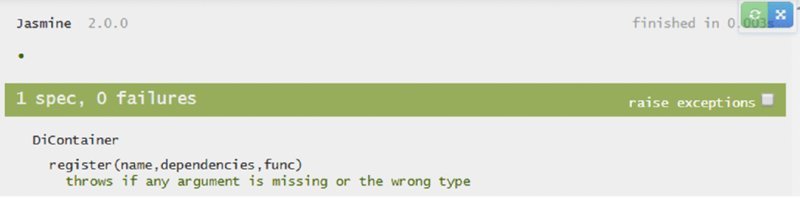
If you read the listing closely, you may have noticed that the message is placed in the prototype, exposing it to the public. This technique allows you to make your tests tighter. Instead of just expecting the function toThrow(), you can make it more exact and therefore more reliable by changing the.toThrow() expectation to the following:
.toThrowError(container.messages.registerRequiresArgs);The register function still doesn’t do anything, but it will be hard to test how well it puts things in the container if you can’t get them out again, so you turn your attention to the other half of the picture: the get function. It needs only one parameter: the name of what it’s getting.
Again, it’s a good idea to start with the argument-checking. We find that code is more reliable if the error-checking tests are done as early as possible. If they’re left until “all the real code is done” it’s too easy to move on to other things. Listing 2-14 is a good start.
The test fails spectacularly because you don’t even have a get function yet. As always with TDD, you code the absolute minimum to remedy the present error, as you can see in Listing 2-15.
What do you know!? The test passes! In TDD, it’s okay for a test to pass “by coincidence.” If you’re thorough with your future tests, the situation will rectify itself. This is where you must have the courage of your TDD convictions. If you were to code anything now, your code would be ahead of your tests.
At last you’re ready to make get(name)fulfill its destiny, as expressed in the test in Listing 2-16.
The test also demonstrates a minor point of technique. By using the variables name and returnFromRegisteredFunction, you keep the test DRY (their values being represented only once) and make the expectation self-documenting.
For the test to pass, you must make register store the registration and make get retrieve it. The relevant parts of DiContainer are now as in Listing 2-17. For clarity, we have replaced what we’ve already discussed with ellipses comments.
The new test passes (Figure 2.6), but now the earlier test, which passed without writing any code, fails. In TDD, it is not unusual for these supposedly lucky breaks to quickly rectify themselves.
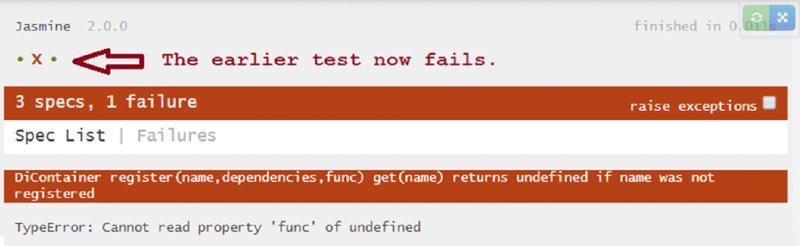
You can make all the tests pass by making get handle the undefined case more intelligently (Listing 2-18).
Now you are in a position to make get supply dependencies to the object it returns (Listing 2-19). Your test consists of registering a main object and two dependencies. The main object will return the sum of its dependencies’ return values.
And the implementation to make the test pass is in Listing 2-20.
The change was to add dependencies to the registrations[name] object in the register function, and then access registration.dependencies in the get function.
The final requirement is to supply dependencies recursively. Although you might suspect this works already, the wise test-driven developer takes nothing for granted. This final test is in DiContainer_tests.js, in this chapter’s downloads. The completed library is DiContainer.js.
We hope this exercise has communicated the spirit of test-driven development, as well as given some insight into how typical JavaScript DI containers work.
Using a Dependency-Injection Framework
Earlier in this chapter, you developed a module that allowed an attendee to reserve a seat at a JavaScript conference. You got it to the point where you were injecting Attendee’s dependencies into its constructor, but in a hard-coded manner:
var attendee = new Attendee(new ConferenceWebSvc(), new Messenger(), id);Now that you have a proper DI container, you can avoid hard-coding the dependencies each time you construct an object. Most large JavaScript applications start with a setup (configuration) routine. That is a good place to set up the dependency injection as well.
Suppose your application is managed under a global called MyApp. In the configuration, you would find something that looks like Listing 2-21.
There is an advanced but important point in the way Attendee is placed in DiContainer. The registration is not for a function to produce an Attendee, but for a function to produce a factory that produces an Attendee. This is because Attendee requires a parameter in addition to its dependencies, namely the attendeeId. It would be possible to code the DI container so that you could do this:
var attendee = MyApp.diContainer.get('Attendee', attendeeId);but then Attendees could not be supplied as recursive dependencies of other objects. (Those other objects could not, in general, be expected to pass an attendeeId all the way from the top of the chain, which is where it would have to originate.)
With that factory in place you can, deep in the application, get an Attendee from the DI container, as you see in Listing 2-22.
Current Dependency-Injection Frameworks
There are two dependency-injection frameworks that enjoy widespread adoption and are being kept current: AngularJS and RequireJS. Each is free and open source, and each has its unique strengths.
RequireJS
RequireJS uses a syntax very much like the DiContainer in this chapter. (Yes, we cheated.) Where DiContainer has a register function, RequireJS has define, which it supplies as a global. The DiContainer get(moduleName) becomes RequireJS’s require(moduleUrl).
“ModuleUrl??” you say. Yes—what makes RequireJS special is that you use the locations of your scripts as module names. For example, you could put your AttendeeFactory in the RequireJS container like this:
define(['./Service', './Messenger'], function(service, messenger) {
return function(attendeeId) {
return new Attendee(service, messenger, attendeeId);
}
});Instead of depending on the module names (['Service', 'Messenger']), AttendeeFactory depends on the relative URLs (['./Service', './Messenger']).
So how about the name of the thing we’re defining ('AttendeeFactory')? There’s no need for it because the URL of the file in which this code appears (probably ./AttendeeFactory.js) doubles as the module name. This feature of RequireJS has the added benefit of automatically avoiding naming collisions. It also implies that “one module per file” is the normal way of doing things in RequireJS.
It is possible to explicitly name your modules (using the same syntax as DiContainer.register), but to do so is not in the full spirit of this library.
RequireJS ties DI modules to URLs to allow it to optimize how it loads your scripts. In fact, RequireJS started out as just one of several proposals before the CommonJS committee to solve the problem of how to get modules from the server to the browser (Transport C at http://wiki.commonjs.org/wiki/Modules/Transport). Their proposal was never formally accepted by CommonJS, but it seems to be the only one left standing and is widely used.
You can check out its many additional features at http://requirejs.org.
AngularJS
Compared to RequireJS, Google’s AngularJS is the new kid on the block, but it is taking the JavaScript world by storm. Although DI is at the very center of AngularJS, AngularJS is much more than a DI container. It is a complete, “opinionated” framework for building single-page applications (SPAs).
Dependency injection appears in AngularJS in a variety of ways. There are many functions along the lines of DiContainer.register, each suitable for different types of objects. For example, some AngularJS objects, called services, are by nature singletons, and the AngularJS framework ensures this with a service registration function that causes the same identical object to be injected each time one is requested. If that’s not the behavior you want, there’s a factory function that does just what the name implies. You can even register constants for dependency injection with the constant function.
Although AngularJS is an opinionated framework, many of its important features are under your control. In fact, if you don’t like the dependency injector, you can inject one of your own.
Not that you’ll have any time left to learn how to do that! Compared to RequireJS, Knockout, JQuery, or most other JavaScript libraries, AngularJS has a very long learning curve. However, once you’ve ascended most of it, everything will make complete sense and you will wonder what took you so long. AngularJS is very well designed, and if you’re looking for a total solution for your SPA, you couldn’t do much better.
The goodness is at https://angularjs.org.
USING AN ASPECT TOOLKIT
Aspect-oriented programming (AOP) is a way of gathering code that will be useful to more than one object (although it is not within the Single Responsibility of any of them) and distributing that code to the objects in a non-obtrusive way.
In the lingo of AOP, the pieces of code thus distributed are called advices, and the issues the advices address are called aspects or cross-cutting concerns. For an example, let’s return to the JavaScript conference from the last section.
Case Study: Caching with and without AOP
You’ll recall that you had volunteered to help write the conference’s website. To help defer costs, the organizers of the conference have partnered with a travel-services company to sell airplane tickets. Your job is to call their web service to obtain a bargain airfare based on the logged-in attendee’s preferred home airport. The ticket will be featured in an ad on the website.
You want the ad to appear without delay, but it involves a relatively time-consuming call to the web service. You decide to cache the featured ticket as long as the user does not change his preferred airport.
In fact, there may be a lot of things you want to cache on this website. Caching has become a cross cutting concern—a prime candidate for aspect-oriented programming. Let’s see how it plays out.
Implementing Caching without AOP
First, Listing 2-23 shows the function without caching. To increase the happiness of readers who prefer not to use the “new” keyword, we have used a different module-creation pattern than in the previous section.
Now you want to add caching. You could do so as in Listing 2-24 (without AOP).
That works, but you have more than doubled the lines of code in getSuggestedTicket. What’s more, the new code has nothing to do with the function’s core responsibility.
Wouldn’t it be nice if you could add the feature without modifying getSuggestedTicket at all? And even change the caching strategy later—expiring the cached result after 10 minutes, for example? Wouldn’t it be even better if you could chain additional features (storing the user’s preferences in a cookie, for example) just as unobtrusively?
That is what aspect-oriented programming does for you. With the AOP framework you’ll see shortly, you could have kept the original code and just added this in the application’s startup logic:
Aop.around('getSuggestedTicket', cacheAspectFactory());In this line of code, cacheAspectFactory() returns a completely reusable caching function that can intercept any call and, if its arguments have been seen before, return the same result.
Making Your Code More Reliable with AOP
It’s easy to see how AOP produces more reliable code. First, it keeps your functions simple. They execute their Single Responsibility, and that is all. Simplicity begets reliability.
Second, it keeps your code DRY. The obvious point here is that multiple occurrences of the code represent multiple places that someone could later break, and multiple opportunities to get out of sync. But there’s a more subtle point: You also don’t want to repeat the code that connects the new functionality (caching) to the old (getting a ticket).
Consider all the logic in Listing 2-24 that was devoted to weaving the caching aspect into the code. Every time a developer follows this pattern, there is a chance he will make a mistake. Because of this, if you’re serious about test-driven development, each time will require the full complement of unit tests. Those tests will look a lot like each other—more repetition!
Third, it allows you to centralize the configuration of your application. If you create one function whose Single Responsibility is configuring your aspects, you have only one place to consult when you want an overview of your bells and whistles. More importantly, if you are hunting a bug and want to defoliate its habitat, you can easily turn off features such as caching. You can also turn on features such as argument checking. There may even be an aspect that you want to turn on and off according to an end-user’s preferences.
Case Study: Building the Aop.js Module
Aspect-oriented programming consists of sticking functions together in new ways. What could be better-suited for such an enterprise than JavaScript? We would like to showcase a particularly elegant framework from Fredrik Appelberg and Dave Clayton, available for free at https://github.com/davedx/aop. Simply named Aop.js, it is a marvel of concision, compressed to an elegant minimum with every tool of the JavaScripter’s art.
Take a few minutes to look over Listing 2-25. Don’t worry if it’s impenetrable at first. That is exactly our hope. You will use test-driven development (TDD) to make it all clear shortly.
Amazing, right? Also perhaps a little hard to digest all at once?
In the “Using a Dependency-Injection Framework” section of this chapter, you used TDD to build a reliable component from scratch. In this section, you will use TDD as an aid to understand existing code. In fact, when we discovered Aop.js, this is exactly what we did. We re-built most of it using TDD, gaining intimate knowledge of each line as we went.
One characteristic of TDD is that you don’t code all the features of the application in one go. You add a test, code just enough to pass that test, possibly refactor, and repeat. Many developers wonder how such an incremental approach can possibly produce elegant code. We hope the following demonstration will put those fears to rest. Along the way, you’ll encounter some features of JavaScript that make gems like Aop.js possible.
At its heart, AOP intercepts the execution of a function (the target), causing it to be preceded, followed, or surrounded by another function (the advice). You might concentrate on the “surround” case, for the others are just special cases of it. Following Fredrik’s and Dave’s lead, you will create a function, around, in an Aop object. The source is in the AOP directory of this chapter’s download. See the remarks at the beginning of the chapter for details.
You could start with a bare version of this function, as you see in Listing 2-26.
Your first test, in Listing 2-27, is that Aop.around causes the original function to be replaced by the advice.
You created a target object, targetObj, that has a bare function, targetFn. You also have an advice function that just sets a flag, executedAdvice, when it executes. If you tie it all together with Aop.around,('targetFn', advice, targetObj), you would expect that a call to the target will cause the advice to execute. Of course, this test fails (Figure 2.7) because Aop.around still does nothing.
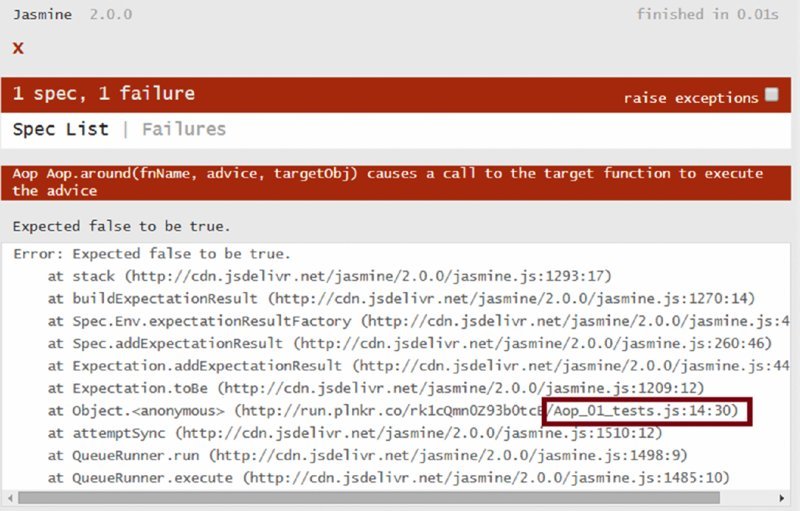
Next, you’d add just enough code to make it pass (Listing 2-28).
Next, you want to allow your advice to wrap a call to the target. This means that you must pass some information about the target to the advice. You can do so by passing an object to the advice, in which you store the original target function. In the Listing 2-29 tests, this object is called targetInfo and the function is in the fn property.
You could make a new target object for the new test, edit-copying from the first, but it might occur to you that one target could work for both tests. As you saw earlier in this chapter, you can refactor the target object up to the scope of the outer describe, where it is available to all tests. This small exertion will be amply repaid in future tests.
Because your tests will modify the target, you would re-initialize the target in a beforeEach that gets executed ahead of each test, as you can see in Listing 2-29.
This fails because the current implementation of Aop.around makes no effort at all to supply an object with an fn property that holds the target function. So, you add the new feature shown in Listing 2-30.
There are two things worth noting here. First, the call method. It is similar to Invoke in C# or Java. It calls the function (advice in this case) with the arguments given starting in the second parameter (just {fn: originalFn} here, but more could have been added). Its first parameter is the context in which the function should be called (its “this”). The context is important, but you have not yet written any test about it so you just use an empty object as a placeholder.
Call has a sister, apply, which expects the arguments to be in an array. If you want to write elegant JavaScript, you’ll want to make call and apply second nature.
Second, notice how the original function is captured in a variable, originalFn. Its value is set when Aop.around is called. That’s no surprise. The subtle marvel is that its value is still available to fnObj[fnName] after Aop.around has returned. (A C# or Java programmer might think that because originalFn is a local variable whose scope has exited, it, too, would have exited the stage.) This is an example of closure, another JavaScript feature to know and love if you want to follow in the footsteps of people like Fredrik Appelberg and Dave Clayton.
The Aop object is beginning to take shape.
You might suspect that Aop.around can wrap a target in multiple layers, but in true TDD fashion you want to be sure, so you add the test in Listing 2-31. Rather than creating two aspects that are nearly identical, you create a factory to produce them. It’s a relatively unimportant DRY moment, but these small points of beauty are what make a programmer’s day worthwhile, right?
All the tests pass and you are ready for the next feature: passing arguments to the target. So far, the advice doesn’t even know about the arguments. If it’s going to pass them along, you must provide them. You can just add an args property to the targetInfo object that the advice gets. TargetInfo will now be this shape:
{ fn: targetFunction, args: argumentsToPassToTarget }The earlier advices just called the target like this:
targetInfo.fn();but if you want to pass an array of arguments as if they were comma-separated on a call, you must use the apply function noted earlier:
targetInfo.fn.apply(this, targetInfo.args);These ideas appear in the new advice, argPassingAdvice, shown in Listing 2-32. The targetObj has also been enhanced to record the arguments it gets in the argsToTaget array. Programmers from other languages might be surprised that the arguments object provides the arguments passed to targetObj even though targetObj does not mention any arguments in its function() statement, but that’s yet another example of the flexibility of JavaScript.
When you run the test, it fails (Figure 2.8).
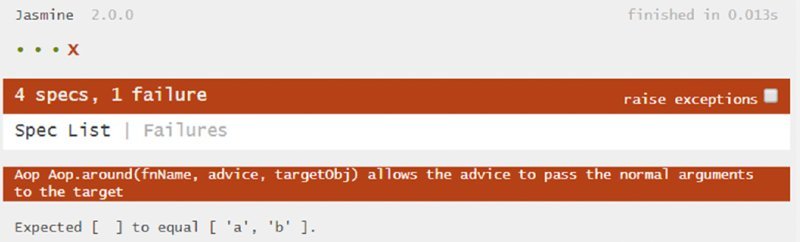
Each failure makes the test-driven developer happy because it means he gets to write more code. In this case, all you have to do is add args: arguments to the object passed to the advice (Listing 2-33).
Traditional developers may think in terms of tests that cover entire functions. You just saw an example of a test that covered one property, in one object, that was used in one line of code. Furthermore, that fraction of a fraction of a line of code was not even there before the test was written. This is test-driven development at its best. You are about to see another example.
You have just considered what goes into the target function; what about the return value that comes out of it? You want an advice to be able to pass that value back to the outside world if appropriate.
For that purpose, you add a return statement to your targetObj.targetFn. You can also make the argPassingAdvice return the value from its call to the target. None of the tests so far have counted on anything about return values, so they still pass, but what about the subject under test? Will it pass? Listing 2-34 shows a test that finds out. (Not shown: targetObj.targetFn has been changed to return a new variable, targetFnReturn.)
Another failure (Figure 2.9).
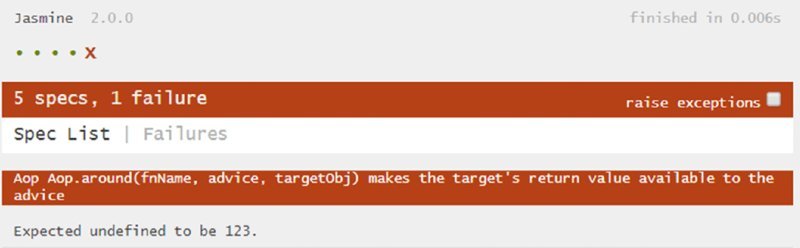
Because you have expected such a small increment of functionality, it is easy to add: just a return keyword in Aop.around, as in Listing 2-35.
The target is now wrapped, it gets the expected arguments, and you can obtain its return value. There is only one more thing to consider. In JavaScript, it’s all too easy to execute a function in a context it does not expect.
The tests in Listing 2-36 illustrate this idea.
First, within the target function there is an expectation that this is the value that pertained when the Target was created with new. However, if the call were to fail completely, expect(this) .toBe(self) would never execute and the test would seem to pass. To guard against that, the test concludes with an expectation that the function was called.
The second test is similar, but without such caution.Jasmine reports an error. You can fix it by replacing the old targetContext, which you had set to an empty object, with this (Listing 2-37).
The tests pass.
There is one more detail to attend to. In Listing 2-32, the advice had to do this to call the next advice in the chain (or the decorated function, if there were no more advices):
return targetInfo.fn.apply(this, targetInfo.args);This is less than ideal. Besides being a lot to type, it exposes the structure of targetInfo to consumers of Aop. Wouldn’t it be better to encapsulate that in a function? Following Fredrik and Dave, you can make a helper function, Aop.next, which calls the next aspect or target in the chain.
The comments in Listing 2-38 show how each step of development could proceed. Listing 2-39 shows the final suite of tests.
The tests pass and we now have a perfectly serviceable AOP component.
Referring back to Listing 2-25, you can probably envision the final step we could take toward Fredrik and Dave’s Aop.js masterpiece—namely to allow one call to Aop.around to affect multiple functions. You may have noticed that the parameters to Aop.around in their version were named differently:
Aop.around(pointcut, advice, namespaces)Where this chapter’s Aop.js has fnName, they have pointcut. A pointcut, in AOP terms, specifies the points at which an aspect may cut in and do its thing. In Aop.js, it is a JavaScript regular expression, so the plain name of a function, as in this chapter, is a special case.
Also, where this chapter’s Aop.js has fnObj, they have namespaces. In JavaScript, a namespace is just an object that contains other objects as properties. To avoid naming collisions, it is a good practice to put all of your application’s code in a namespace. You can build hierarchies of namespaces like this:
var MyApp = {};
MyApp.Encryption = {};
MyApp.WebServices = {};
MyApp.UI = {};
and then you can put your functions in namespaces:
MyApp.WebServices.amazon = function () {
// ...
getIsbn: function(title, author, pubYear) {
// ...
}
};The code developed so far in this chapter would only allow an aspect to be applied to one function, at the last level—for example, MyApp.WebServices.amazon.getIsbn. With the full Aop.js, we could apply it to every function that starts with “get” in multiple namespaces:
Aop.around(/^get/, advice, [ "MyApp.Encryption", "MyApp.WebServices" ]);Even without this enhancement, you have built the heart of Aop.js with test-driven development. Incidentally, the final version available in this chapter’s downloads, Aop.js, also has the before aspect and its tests. The test results in Figure 2.10 lay out all that Aop.js can do.
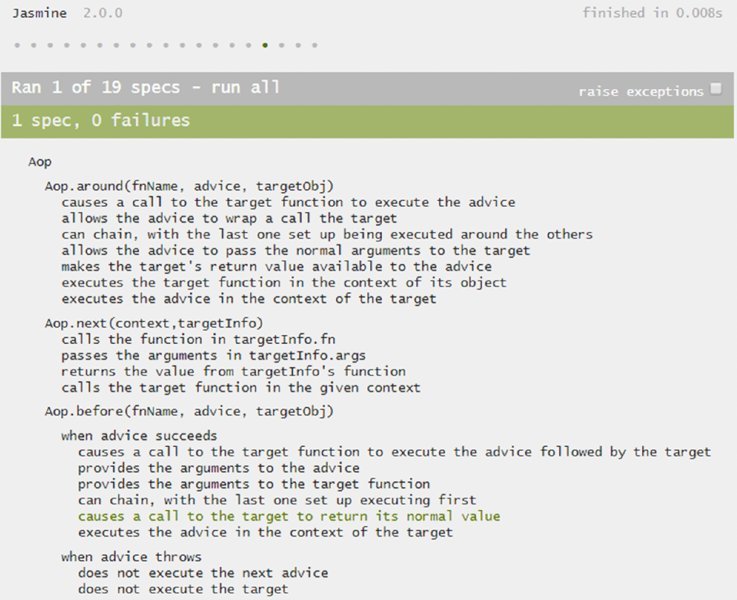
Other AOP Libraries
Although we like Aop.js, there are other choices such as AspectJS, AopJS jQuery plugin, and YUI’s Do Class.
AspectJS
With a name like AspectJS, you know this one will rank high in the search listings. It is one of the early entries in the JavaScript AOP sweepstakes, and very full-featured. It has capabilities such as suspending and resuming aspects—features which would be easy enough to add to Aop.js if you need them, but which are already in AspectJS. The drawback is that AspectJS is much heavier as a result.
Another huge drawback is that AspectJS does not appear to have been updated since 2008 (http://aspectjs.com/AJS_Release_History.htm). JavaScript itself is evolving and you may feel it makes sense to use tools that are keeping up.
AopJS jQuery Plugin
Although the AopJS jQuery plugin is relatively new and does not yet have high stats on GitHub, you will probably run across it just because it’s on the jQuery site (http://plugins.jquery.com/aop).
AopJS’s author has taken the time to provide both jQuery- and AngularJS-friendly syntax options, as well as easy chaining of aspects, as in this example from the documentation.
var myProxy = AOP.aspect(myFunction)
.before(myAdvice1)
.afterReturning(myAdvice2)
.afterThrowing(myAdvice3);The code does not have the concise elegance of Aop.js, but its capabilities are just a little more developed.
YUI’s Do Class
The folks at Yahoo!’s YUI project really know what they’re doing. One component of YUI is the Do class. It is very well documented at http://yuilibrary.com/yui/docs/api/classes/Do.html. Y.Do (Y is the namespace) is wonderful except for one thing: In August of 2014 Yahoo! announced that it was ceasing development of YUI.
Conclusion
Perhaps because AOP is so easy to implement in JavaScript, there aren’t many toolkits for it. It’s just not that big a problem. It seems that the heavyweight libraries have ceased development, leaving the minimalist alternatives that may never need updating.
In that world, it’s hard not to be drawn to Fredrik Appelberg and Dave Clayton’s Aop.js. Any module that does so much with only 50 lines of code including blanks and comments deserves to be not only adopted but loved.
For the remainder of this book, when we need AOP, we will use Aop.js.
USING A CODE-CHECKING TOOL
Code-checking tools perform static analysis, whereby they inspect the syntax and structure of source code without executing it. The purpose of the inspection is to find and report likely incorrect language usage that may lead to errors when the code is executed. Some static analysis tools also report deviations from coding style rules, and useful metrics like computational complexity.
These types of tools are generally referred to as linters to reflect their relation to the C programming language static code analysis tool, lint, which was developed in the late 1970s.
Throughout this section, we’ll refer to static analysis tools as linters, and the process of performing static analysis as linting.
Making Your Code More Reliable with Linting Tools
Linting serves an important purpose when programming in JavaScript. If you’re a developer coming from a compiled language like C# or Java, you’re accustomed to the compiler informing you of grievous syntax errors such as omitting a statement-terminating semicolon or forgetting a closing curly brace. As an interpreted language, JavaScript doesn’t have a compiler that complains when you’ve made a mistake. You won’t be aware of any syntax errors until the code is executed.
Since you have adopted TDD, you will have a test to exercise every bit of production code before you even write it, right? When practicing TDD, it may be enticing to skip the configuration and use of a linter because the unit tests guarantee that your code is functioning as it should.
Linters do not verify that code is correct. Your linter can’t tell you if the function you’ve written will return the correct value. It can tell you, however, that you’ve written code within your function that has a questionable format and may cause it to return an incorrect value.
Suppose you’ve been tasked with building an airline reservation system. The customer has requested that you implement functionality that will determine whether a particular passenger is eligible for a complimentary upgrade to a first class seat.
In order to be upgraded, a passenger needs to have flown a certain number of miles on the airline. For the purpose of this example, assume that a passenger object contains the passenger’s first and last names, and an array integer trip lengths. Here’s what a passenger would look like when created with the object-literal creation pattern:
var testPassenger = {
firstName: "Seth",
lastName: "Richards",
tripMileages: [
500,
600,
3400,
2500
]
};When calculating the miles a particular passenger has flown, you want to be able to reward members of the airline’s frequent flier program. To do so, you’ll provide a multiplier that will increase the mileage of each member’s flight to reward the passenger for his or her loyalty.
As the first step, you might create a function that will scale trip mileage by a multiplier. In test-driven fashion, Listing 2-40 shows unit tests that verify that the function behaves as expected.
Listing 2-41 shows an implementation of calculateUpgradeMileages that causes the unit tests to pass.
Finally, Figure 2.11 shows the Jasmine output of the unit tests.
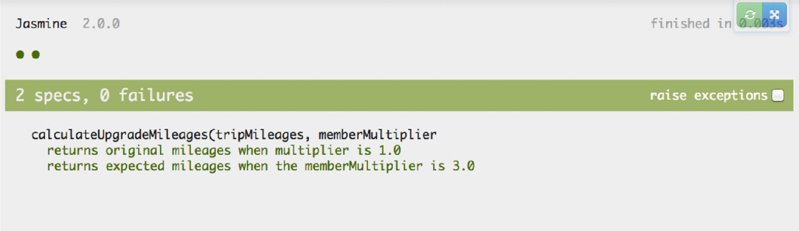
As you can see, the function returns the expected result and the tests pass. There is a potential problem in the code, however. Take a moment and see if you can identify the section of code in calculateUpgradeMileages that is troublesome. If it’s not immediately apparent to you, fear not because you have your linting tool to help.
Introducing JSHint
JSHint is an open-source static analysis tool that describes itself in the following way:
JSHint is a community-driven tool to detect errors and potential problems in JavaScript code and to enforce your team’s coding conventions.
JSHint is a fork of the JSLint project. JSLint was created and is maintained by Douglas Crockford. At the time they forked JSHint from JSLint, JSHint’s creators felt that JSLint had become “too opinionated” and that a linting tool driven by the JavaScript community was needed.
Using JSHint
You can copy-and-paste your JavaScript code into the JSHint homepage at http://www.jshint.com and the linter will execute automatically. While perhaps convenient for identifying a problem in a piece of sample code for a blog post (or book), using this mechanism to execute the linter is not suitable for development of a JavaScript solution with even limited complexity.
Because the calculateUpgradeMileages function is a piece of sample code for a book, you can use the online tool at http://www.jshint.com to find the questionable construct in the function.
Figure 2.12 shows what JSHint says about calculateUpgradeMileages.
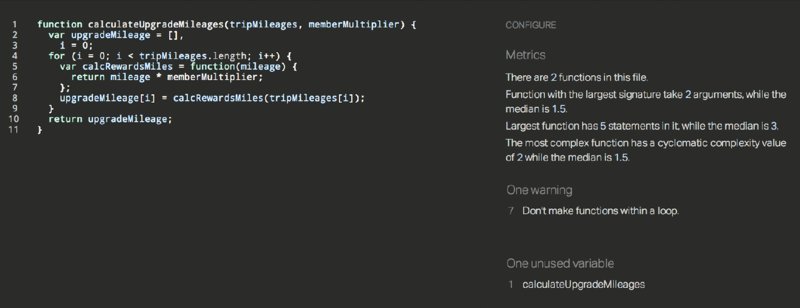
As you can see, JSHint provides the following warning:
Don't make functions within a loop.If you hadn’t noticed it before, JSHint is helpfully pointing out that you’ve declared a function within the loop that iterates over the list of mileages. Your unit tests pass, so in this case creation of a function inside a loop doesn’t result in a logic error. So what’s the problem?
Remember that JSHint identifies questionable constructs in JavaScript code. We can certainly agree that whether the result is logically correct or not, re-declaring a function during each iteration of a loop is questionable. At a minimum, it’s inefficient, and even though it didn’t in this example, it’s easy for the practice to result in incorrect and unreliable code.
Assume for a moment that you have a very good reason for placing your function within the loop. Each time you execute JSHint on your code, which should be very often, it will present that warning. Do you have to somehow make note that you (and the rest of the developers on your team) can safely ignore that particular warning for that particular line?
Thankfully, the answer is no. JSHint provides the ability to “relax” its rules globally via configuration, or locally via specially formatted comments.
Listing 2-42 shows the function again, this time with a comment that tells JSHint that you’re aware you’re creating a function inside a loop, and you’d like to relax the loopfunc rule:
The comment /*jshint loopfunc: true */, which precedes creation of the function, tells JSHint to relax its loopfunc rule until it encounters another comment that tells it to stop relaxing the rule. The comment that causes the rule to no longer be relaxed, /*jshint loopfunc: false*/, appears right after the function declaration.
Providing the updated code that relaxes the loopfunc rule to the JSHint website yields the results shown in Figure 2.13.
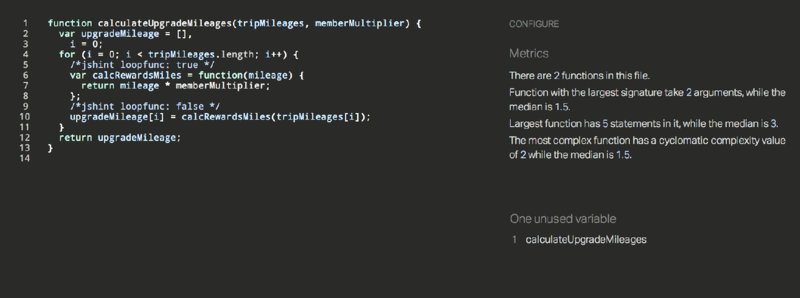
As you can see, JSHint makes note that you’ve relaxed the loopfunc rule and no longer warns about creation of a function within a loop.
In this example, you’ve disabled a single rule for the minimum number of lines necessary. It is possible to tell JSHint not to process any rules for a section of code. We recommend that this not be done unless absolutely necessary. If you’d suppressed the warning you were receiving by disabling all rules, it’s easy to imagine how a colleague maintaining or extending your code at some point in the future could be deprived of helpful linting warnings.
If You Don’t Run It, Bugs Will Come
Ideally, JSHint should be executed automatically any time you’ve made changes to your JavaScript code. Any manual mechanism could result in forgetting to run, or purposely not running, the linting tool. Linting is not something to be left to the end of a project, or even to the next build (your project has a repeatable, automated build process, right?). Your linter should provide continuous feedback as you’re developing so that the code issues it identifies are addressed as early as possible.
JSHint is distributed in multiple ways, including an npm module for use with the server-side JavaScript engine node.js. There are also plugins to automatically execute JSHint natively or via node.js on your JavaScript files for many popular text editors and integrated development environments (IDEs), such as VIM, Emacs, Sublime Text, TextMate, and Visual Studio.
If your favorite editor or IDE doesn’t have a JSHint plugin available, node.js task-execution packages such as Grunt and Gulp may be configured to watch for changes in your JavaScript files and automatically execute JSHint when a change is detected.
Alternatives to JSHint
JSHint is not the only JavaScript linting tool; it just happens to be the tool that provides the functionality that we require. Here are some alternatives to JSHint that you might want to consider if you’re choosing a linting tool for your project.
JSLint
JSLint is a mature JavaScript linting tool that was created and is maintained by Douglas Crockford. Mr. Crockford is a key figure in the JavaScript community, known for both his work on JSLint and his work to popularize JSON.
JSLint is available as an npm module for node.js, as well as a JavaScript file for use in browser-like environments.
The JSLint homepage can be found at http://www.jslint.com.
ESLint
ESLint is a relatively new open-source linting tool created by Nicholas Zakas in 2013. Even though it is a young project, it is full-featured and very capable. A feature unique to ESLint is its modularity. You may define your own custom linting rules and load them into the linter at run time. This is very useful if you would like to enforce a coding standard unique to your organization.
ESLint is available as an npm module for node.js. The ESLint homepage can be found at http://www.eslint.org.
Strict Mode
One more code-checking tool merits attention. Actually, it’s not an external tool, but a JavaScript setting that was introduced with ECMAScript 5. If you include the following in a scope (either the global scope or a function), the JavaScript interpreter will process certain features differently.
'use strict';With this directive in place, JavaScript will throw an error if you commit some common mistakes. These include using a variable without declaring it first, attempting to modify a read-only property, naming a variable with the reserved word arguments, and more.
When running on versions of JavaScript that do not support strict mode, the 'use strict' string will have no effect.
You will see an example of where strict mode can make a crucial difference in the “Default Binding and Strict Mode” section of Chapter 18. In the meantime, the listings in this book will use it just to get in the habit.
SUMMARY
In this chapter, we introduced some of our favorite techniques and tools for JavaScript development.
A unit-testing framework is absolutely essential for reliable software development. In this text, we will use Jasmine, which we have found easy to learn and very robust, but popular alternatives include QUnit and D.O.H.
As JavaScript applications become more complex, it becomes more important to keep their components clean and separate. Dependency injection is an important technique for doing just that. In this chapter, you worked through the test-driven development of a dependency-injection framework that will reappear in future chapters and may be useful in your own projects.
As another case study in TDD, you developed a toolkit for aspect-oriented programming. AOP allows you to enhance software components with common functionality such as caching, without changing those components at all. It’s another way to simultaneously keep your code DRY, fulfill the Single Responsibility Principle, and adhere to the Open/Closed Principle.
Code-checking tools, known as linters, promote reliability at the micro level by alerting you to syntax mistakes or violations of standards. JSHint, JSLint, and ESLint are some of the most popular. Strict mode is another good way to avoid mistakes at the syntax level.
In the next chapter, you will explore the rich variety of ways in which JavaScript can construct objects. It sounds like a simple topic, but you will see that it is anything but.