In this chapter, we will cover the most generic version of neural networks, feedforward neural networks. Feedforward neural networks are a group of artificial neural networks in which the connections between neurons do not form a cycle. Connections between neurons are unidirectional and move in only forward direction from input layer through hidden layers and to output later. In other words, the reason these networks are called feedforward is that the flow of information takes place in the forward direction.
which we will cover in Chapter 8, are improved versions of feedforward neural networks in which bidirectionality is added. Therefore, they are not considered feedforward anymore.
Feedforward neural networks are mainly used for supervised learning tasks. They are especially useful in analytical applications and quantitative studies where traditional machine learning algorithms are also used.
Feedforward neural networks are very easy to build, but they are not scalable in computer vision and natural language processing (NLP) problems. Also, feedforward neural networks do not have a memory structure which is useful in sequence data. To address the scalability and memory issues, alternative artificial neural networks such as convolutional neural networks and recurrent neural networks are developed, which will be covered in the next chapters.
You may run into different names for feedforward neural networks such as artificial neural networks, regular neural networks, regular nets, multilayer perceptron, and some others. There is unfortunately an ambiguity, but in this book, we always use the term feedforward neural network.
Deep and Shallow Feedforward Neural Networks
Every feedforward neural network must have two layers: (i) an input layer and (ii) an output layer. The main goal of a feedforward neural network is to approximate a function using (i) the input values fed from the input layer and (ii) the final output values in the output layer by comparing them with the label values.
Shallow Feedforward Neural Network
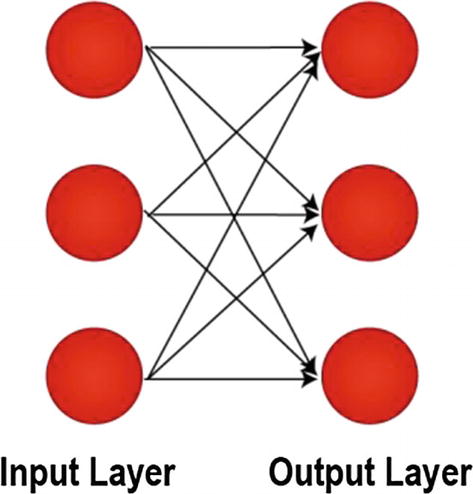
Shallow Feedforward Neural Network or Single-Layer Perceptron
The output values in a shallow feedforward neural network are computed directly from the sum of the product of its weights with the corresponding input values and some bias. Shallow feedforward neural networks are not useful to approximate nonlinear functions. To address this issue, we embed hidden layers between input and output layers.
Deep Feedforward Neural Network
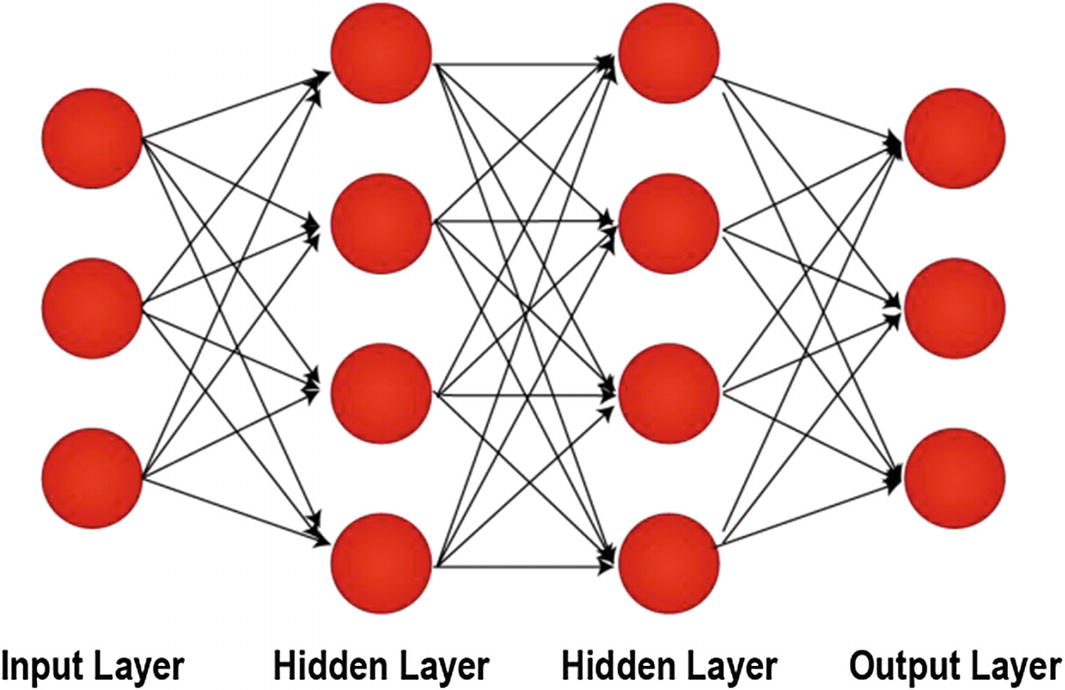
Deep Feedforward Neural Network or Multilayer Perceptron
Every neuron in a layer is connected to the neurons in the next layer and utilizes an activation function.
indicates that a feedforward neural network can approximate any real-valued continuous functions on compact subsets of Euclidean space. The theory also implies that when given appropriate weights, neural networks can represent all the potential functions.
Since deep feedforward neural networks can approximate any linear or nonlinear function, they are widely used in real-world applications, both for classification and regression problems. In the case study of this chapter, we also build a deep feedforward neural network to have acceptable results.
Feedforward Neural Network Architecture
In a feedforward neural network, the leftmost layer is called the input layer, consisting of input neurons. The rightmost layer is called the output layer, consisting of a set of output neurons or a single output neuron. The layers in the middle are called hidden layers with several neurons ensuring nonlinear approximation.
In a feedforward neural network, we take advantage of an optimizer with backpropagation, activation functions, and cost functions as well as additional bias on top of weights. These terms are already explained in Chapter 3 and, therefore, omitted here. Please refer to Chapter 3 for more detail. Let’s take a deeper look at the layers of feedforward neural networks.
Layers in a Feedforward Neural Network
An input layer
An output layer
A number of hidden layers
Input Layer
Input layer is the very first layer of feedforward neural network, which is used to feed data into the network. Input layer does not utilize an activation function and its sole purpose to get the data into the system. The number of neurons in an input layer must be equal to the number of features (i.e., explanatory variables) fed into the system. For instance, if we are using five different explanatory variables to predict one response variable, our model’s input layer must have five neurons.
Output Layer
Output layer is the very last layer of the feedforward neural network, which is used to output the prediction. The number of neurons in the output layer is decided based on the nature of the problem. For regression problems, we aim to predict a single value, and therefore, we set a single neuron in our output layer. For classification problems, the number of neurons is equal to the number of classes. For example, for binary classification, we need two neurons in the output layer, whereas for multi-class classification with five different classes, we need five neurons in the output layer. Output layers also take advantage of an activation function depending on the nature of the problem (e.g., a linear activation for regression and softmax for classification problems).
Hidden Layer
Hidden layers are created to ensure the approximation of the nonlinear functions. We can add as many hidden layers as we desire, and the number of neurons at each layer can be changed. Therefore, as opposed to input and output layers, we are much more flexible with hidden layers. Hidden layers are appropriate layers to introduce bias terms, which are not neurons, but constants added to the calculations that affect each neuron in the next layer. Hidden layers also take advantage of activation functions such as Sigmoid, Tanh, and ReLU.
In the next section, we will build a deep feedforward neural network to show all these layers in action. Thanks to Keras Sequential API, the process will be very easy.
Case Study | Fuel Economics with Auto MPG
Now that we covered the basics of feedforward neural networks, we can build a deep feedforward neural network to predict how many miles can a car travel with one gallon of gas. This term is usually referred to as miles per gallon (MPG). For this case study, we use one of the classic datasets: Auto MPG dataset. Auto MPG was initially used in the 1983 American Statistical Association Exposition. The data concerns prediction of city-cycle fuel consumption in miles per gallon in terms of three multivalued discrete and five continuous attributes. For this case study, we benefit from a tutorial written by François Chollet, the creator of Keras library.1
Let’s dive into the code. Please create a new Colab Notebook via https://colab.research.google.com.
Initial Installs and Imports
Please note that there will be some other imports, which will be shared in their corresponding sections.
Downloading the Auto MPG Data
Note that we retrieve the dataset from UCI Machine Learning Repository. UC Irvine provides an essential repository, along with Kaggle, in which you can access to a vast number of popular datasets.
Data Preparation
When we look at the UC Irvine’s Auto MPG page, we can see a list of attributes which represents all the variables in the Auto MPG dataset, which is shared here:
mpg: Continuous (response variable)
cylinders: Multivalued discrete
displacement: Continuous
horsepower: Continuous
weight: Continuous
acceleration: Continuous
model year: Multivalued discrete
origin: Multivalued discrete
car name: String (unique for each instance)
DataFrame Creation

The First Two Lines of the Auto MPG Dataset
Dropping Null Values

Null Value Counts in the Auto MPG Dataset
Handling Categorical Variables
Overview of the Auto MPG Dataset
is a special variable type that takes only the value 0 or 1 to indicate the absence or presence of a categorical effect. In machine learning studies, every category of a categorical variable is encoded as a dummy variable. But, omitting one of these categories as a dummy variable is a good practice, which prevents multicollinearity problem.

The First Two Lines of the Auto MPG Dataset with Dummy Variables
Splitting Auto MPG for Training and Testing
Now that we cleaned our dataset, it is time to split them into train and test sets. Train set is used to train our neural network (i.e., optimize the neuron weights) to minimize the errors. Test set is used as the never-been-seen observations to test the performance of our trained neural network.
Since our dataset is in the form of a Pandas DataFrame object, we can use sample attribute. We keep the 80% of the observations for training and 20% for testing. Additionally, we also split the label from the features so that we can feed the features as input. Then, check the results with labels.
Now that we split our dataset into train and test sets, it is time to normalize our data. As mentioned in Chapter 3, feature scaling is an important part of the data preparation. Without feature scaling, a feature can adversely affect our model.
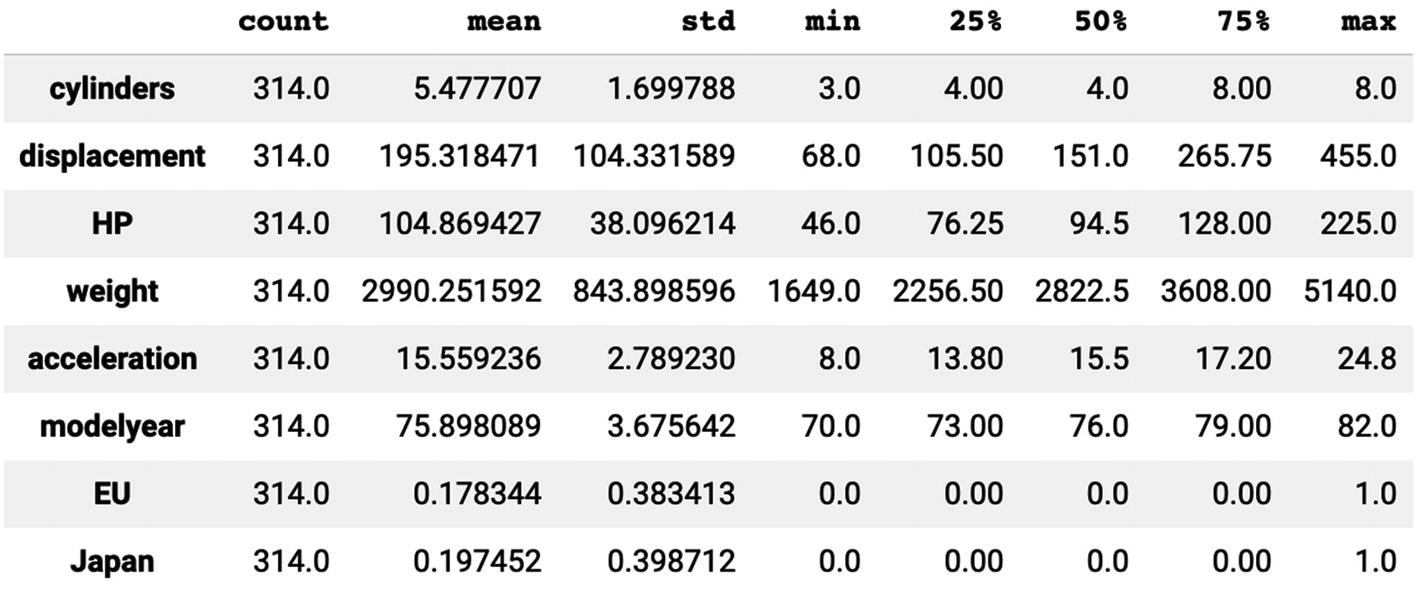
train_stats DataFrame for Train Set Statistics
Note that we do not normalize the label (y) values since their wide range doesn’t pose a threat for our model.
Model Building and Training
Now, our data is cleaned and prepared for our feedforward neural network pipeline. Let’s build our model and train it.
Tensorflow Imports
We already had some initial imports. In this part, we will import the remaining modules and libraries to build, train, and evaluate our feedforward neural network.
Sequential() is our API for model building, whereas Dense() is the layer we will use in our feedforward neural network. tf.docs module will be used for model evaluation.
Model with Sequential API
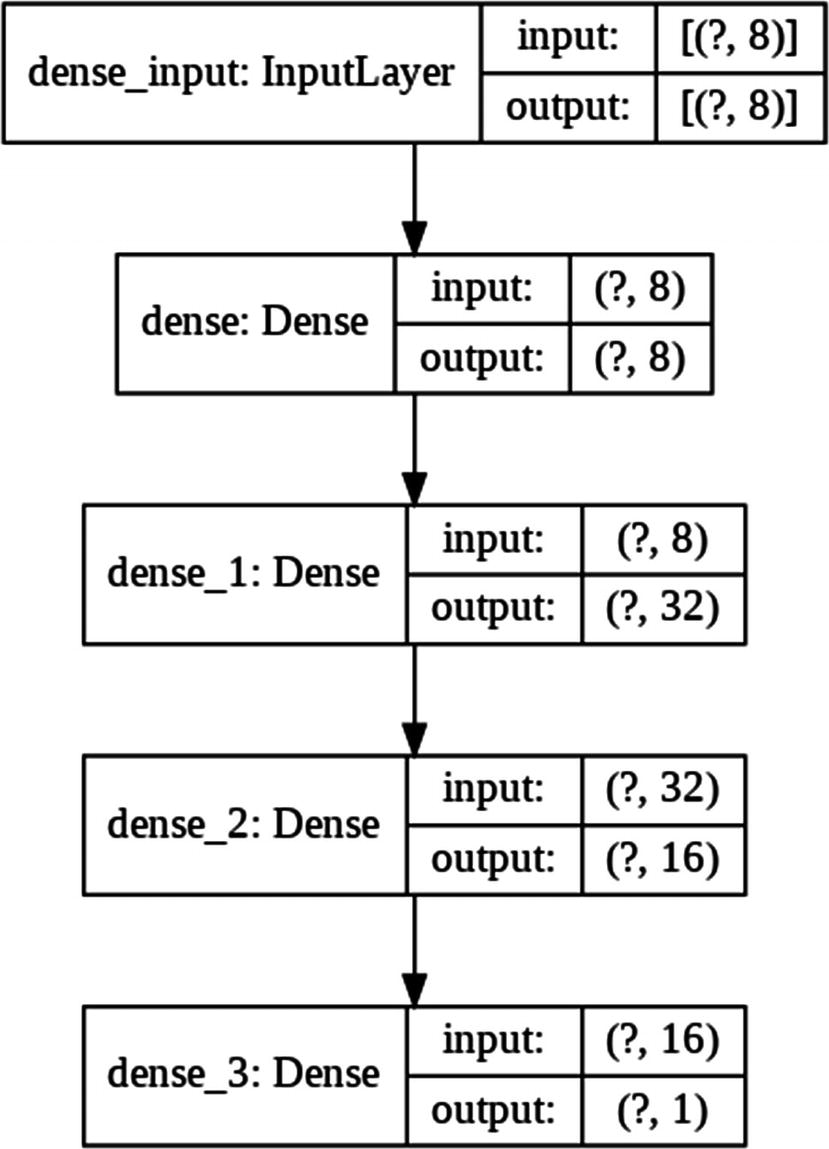
The Flowchart of the Feedforward Neural Network for Auto MPG
Model Configuration
We set aside 20% of our train set for validation. Therefore, our neural network will evaluate the model even before the test set. We set the epoch value to 1000, but it will stop early if it cannot observe a valuable improvement on the validation loss/cost. Finally, callbacks parameter will save valuable information for us to evaluate our model with plots and other useful tools.
Evaluating the Results
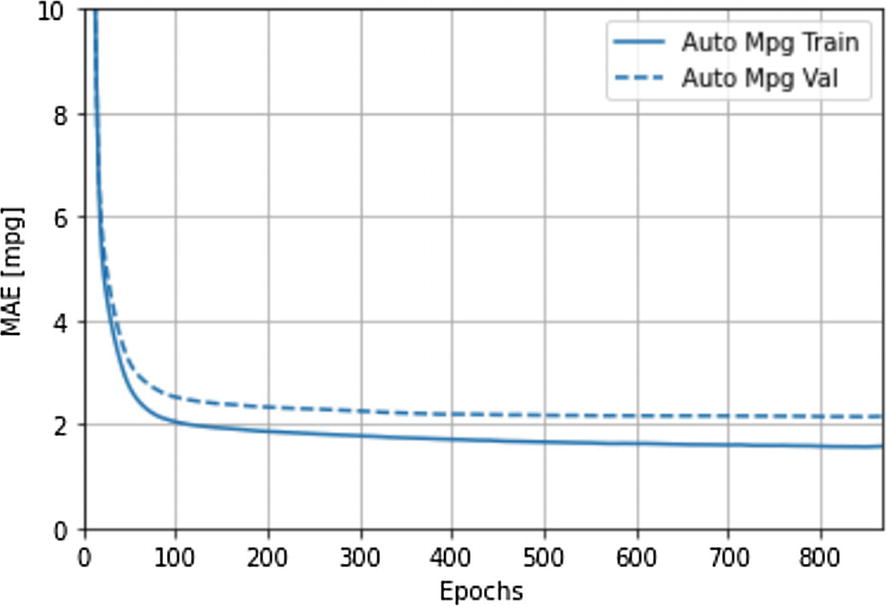
The Line Plot Showing Mean Absolute Error Values at Each Epoch

Evaluation Results for the Trained Model for Auto MPG
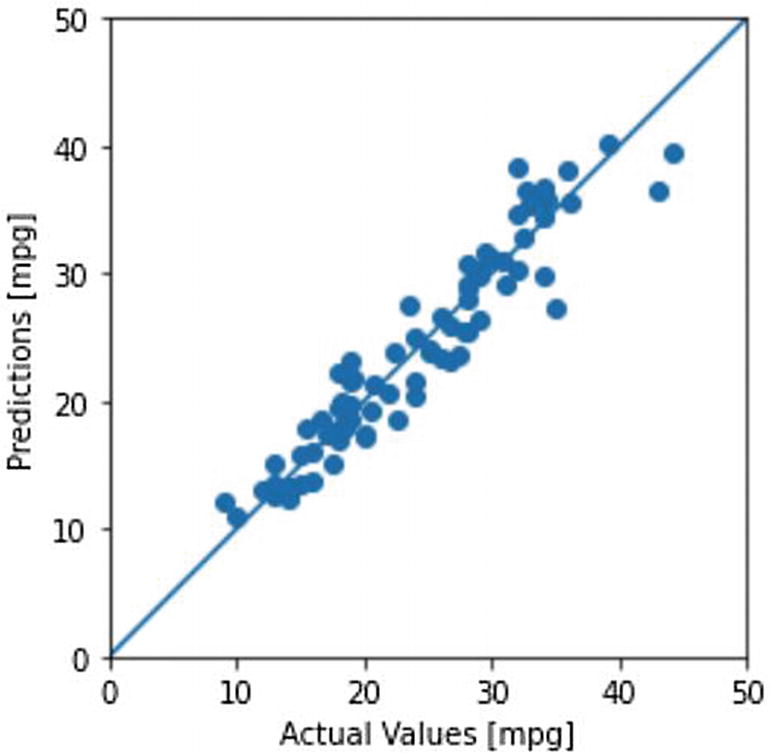
The Scatter Plot for Actual Test Labels vs. Their Prediction Values
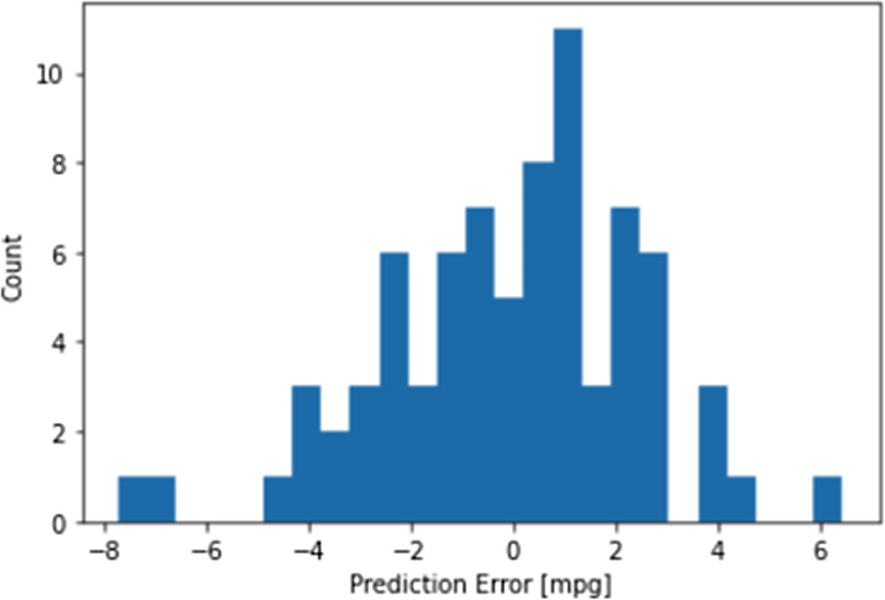
The Histogram Showing the Error Distribution of the Model Around Zero
Making Predictions with a New Observation
Both the scatter plot and the histogram we generated earlier show that our model is healthy, and our loss values are also in an acceptable range. Therefore, we can use our trained model to make new predictions, using our own dummy observation.

A Pandas DataFrame with Single Observation
Conclusion
Feedforward neural networks are artificial neural networks that are widely used in analytical applications and quantitative studies. They are the oldest artificial neural networks and often named as multilayer perceptron. They are considered as the backbone of the artificial neural network family. You can find them embedded at the end of a convolutional neural network. Recurrent neural networks are developed from feedforward neural networks, with added bidirectionality.
In the next chapter, we will dive into convolutional neural networks, a group of neural network family which are widely used in computer vision, image and video processing, and many alike.