I’ll now talk more about character classes or what are sometimes called
bracketed expressions. Character classes help you match
specific characters, or sequences of specific characters. They can be just
as broad or far-reaching as character shorthands—for example, the character
shorthand \d will match the same
characters as:
0-9
But you can use character classes to be even more specific than that. In this way, they are more versatile than shorthands.
Try these examples in whatever regex processor you prefer. I’ll use Rubular in Opera and Reggy on the desktop.
To do this testing, enter this string in the subject or target area of the web page:
! " # $ % & ' ( ) * + , - . /
0 1 2 3 4 5 6 7 8 9
: ; < = > ? @
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
[ \ ] ^ _ `
a b c d e f g h i j k l m n o p q r s t u v w x y z
{ | } ~You don’t have to type all that in. You’ll find this text stored in the file ascii-graphic.txt in the code archive that comes with this book.
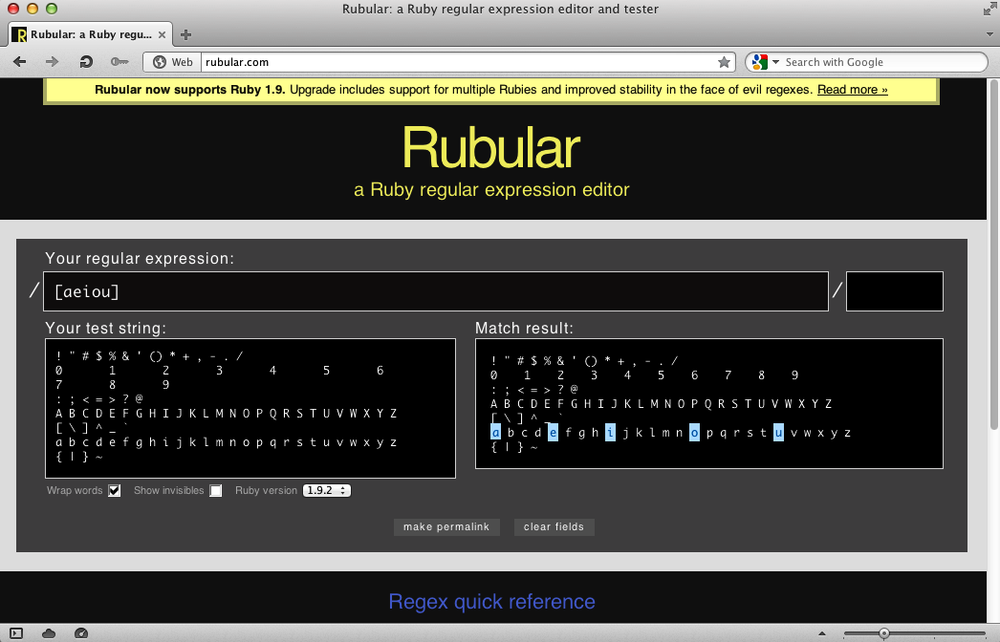
To start out, use a character class to match a set of English characters—in this case, the English vowels:
[aeiou]
The lowercase vowels should be highlighted in the lower text area (see Figure 5-1). How would you highlight the uppercase vowels? How would you highlight or match both?
With character classes, you can also match a range of characters:
[a-z]
This matches the lowercase letters a through z. Try matching a smaller range of those characters, something like a through f:
[a-f]
Of course, you can also specify a range of digits:
[0-9]
Or an even smaller range such as 3, 4, 5, and 6:
[3-6]
Now expand your horizon. If you wanted to match even numbers in the range 10 through 19, you could combine two character classes side by side, like this:
\b[1][24680]\b
Or you could push things further and look for even numbers in the range 0 through 99 with this (yes, as we learned in high school, zero by itself is even):
\b[24680]\b|\b[1-9][24680]\b
If you want to create a character class that matches hexadecimal digits, how would you do it? Here is a hint:
[a-fA-F0-9]
You can also use shorthands inside of a character class. For example, to match whitespace and word characters, you could create a character class like this:
[\w\s]
Which is the same as:
[_a-zA-Z \t\n\r]
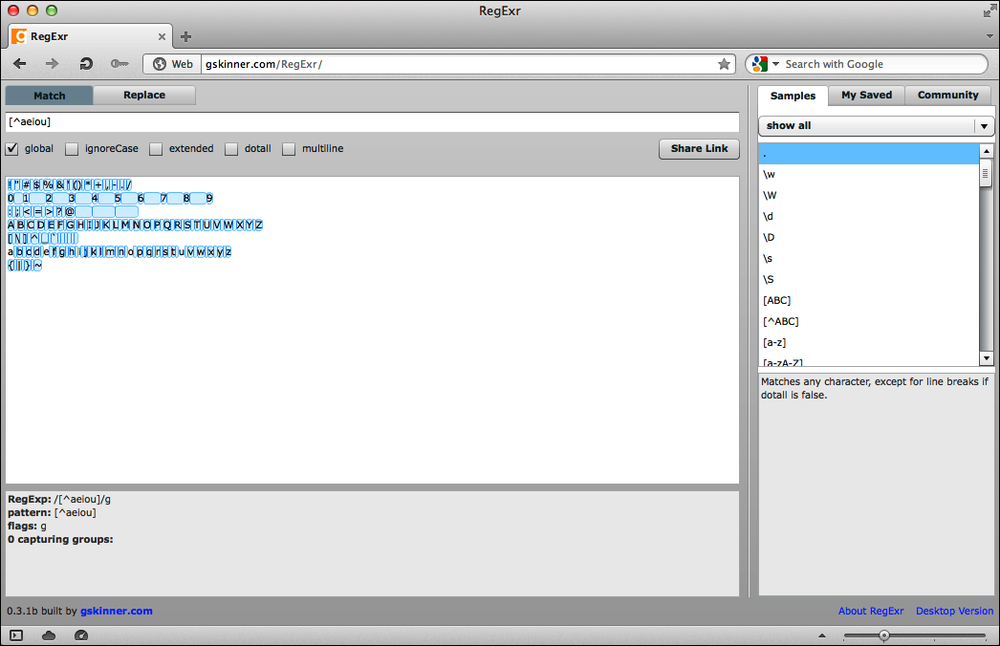
You have already seen syntax a number of times, so I’ll be brief. A negated character class matches characters that do not match the content of the class. For example, if you didn’t want to match vowels, you could write (try it in your browser, then see Figure 5-2):
[^aeiou]
In essence, the caret (^)
at the beginning of the class means “No, I don’t want these characters.” (The caret
must appear at the beginning.)
Character classes can act like sets. In fact, one other name for a character class is a character set. This functionality is not supported by all implementations. But Java supports it.
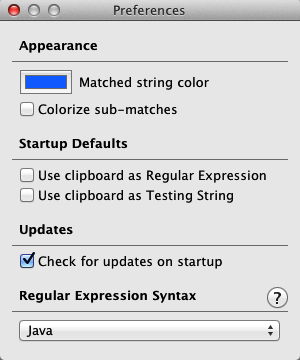
I’ll now show you a Mac desktop application called Reggy (see Technical Notes). Under Preferences (Figure 5-3), I changed the Regular Expression Syntax to Java, and in Font (under Format), I changed the point size to 24 points for readability.
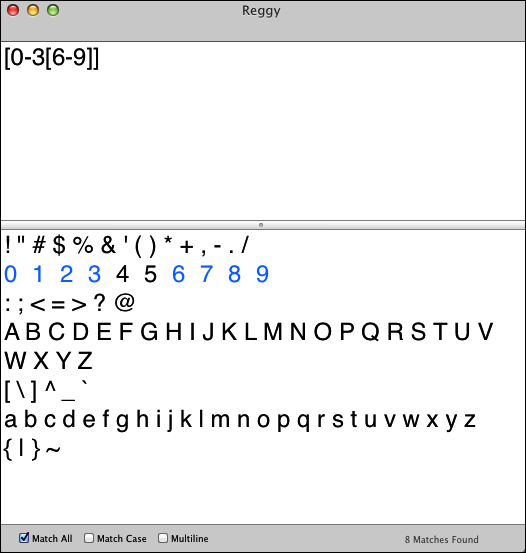
If you wanted a union of two character sets, you could do it like this:
[0-3[6-9]]
The regex would match 0 through 3 or 6 through 9. Figure 5-4 shows you how this looks in Reggy.
To match a difference (in essence, subtraction):
[a-z&&[^m-r]]

which matches all the letters from a to z, except m through r (see Figure 5-5).
POSIX or Portable Operating System Interface is a family of standards maintained by IEEE. It includes a regular expression standard, (ISO/IEC/IEEE 9945:2009), which provides a set of named character classes that have the form:
[[:xxxx:]]where xxxx is a name, such as digit or word.
To match alphanumeric characters (letters and digits), try:
[[:alnum:]]
Figure 5-6 shows the alphanumeric class in Rubular.
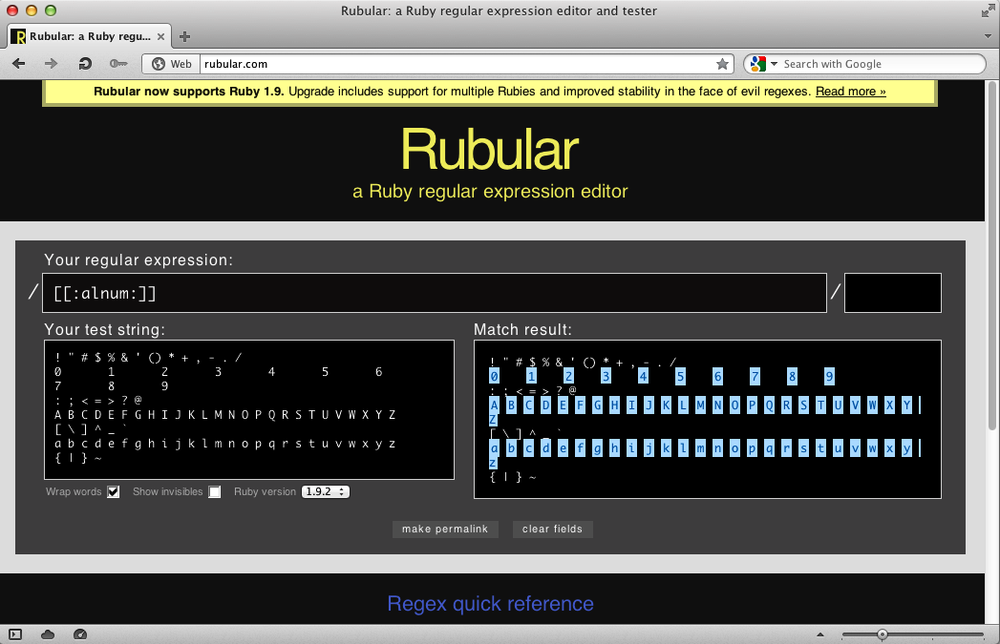
An alternative for this is simply the shorthand \w. Which is easier to type, the POSIX character
class or the shorthand? You know where I’m going: The least amount of
typing wins. I admit I don’t use POSIX classes very often. But they’re
still worth knowing about.
For alphabetic characters in either upper- or lowercase, use:
[[:alpha:]]
If you want to match characters in the ASCII range, choose:
[[:ascii:]]
Of course, there are negated POSIX character classes as well, in the form:
[[:^xxxx:]]So if you wanted to match non-alphabetic characters, you could use:
[[:^alpha:]]
To match space and tab characters, do:
[[:space:]]
Or to match all whitespace characters, there’s:
[[:blank:]]
There are a number of these POSIX character classes, which are shown in Table 5-1.
Table 5-1. POSIX character classes
| Character Class | Description |
|---|---|
[[:alnum:]] | |
[[:alpha:]] | |
[[:ascii:]] | |
[[:blank:]] | |
[[:ctrl:]] | |
[[:digit:]] | |
[[:graph:]] | |
[[:lower:]] | |
[[:print:]] | |
[[:punct:]] | |
[[:space:]] | |
[[:upper:]] | |
[[:word:]] | |
[[:xdigit:]] |
The next chapter is dedicated to matching Unicode and other characters.
How to create a character class or set with a bracketed expression
How to create one or more ranges within a character class
How to match even numbers in the range 0 through 99
How to match a hexadecimal number
How to use character shorthands within a character class
How to negate a character class
How to perform union, and difference with character classes
What POSIX character classes are
The Mac desktop application Reggy can be downloaded for free at http://www.reggyapp.com. Reggy shows you what it has matched by changing the color of the matched text. The default is blue, but you can change this color in Preferences under the Reggy menu. Under Preferences, choose Java under Regular Expression Syntax.
The Opera Next browser, currently in beta, can be downloaded from http://www.opera.com/browser/next/.
Rubular is an online Ruby regular expression editor created by Michael Lovitt that supports both versions 1.8.7 and 1.9.2 of Ruby (see http://www.rubular.com).
Read more about even numbers, of which zero is one, at http://mathworld.wolfram.com/EvenNumber.html.
The Java (1.6) implementation of regular expressions is documented at http://docs.oracle.com/javase/6/docs/api/java/util/regex/Pattern.html.
You can find out more about IEEE and its family of POSIX standards at http://www.ieee.org.