Chapter 7
Dark Web Content Analyzing Techniques
Introduction
The dark web is home to content that is hidden from normal search engines. It can only be accessed through special software, and even then, it is not exactly given where one should begin looking for content. There are isolated listings of some of the websites that one can access on the dark net. These listings are commonly found on surface websites such as The Hidden Wiki and popular social networks such as Reddit. Even then, the listings are limited, and with time, most of the sites listed have either changed their hosting, been shut down by law enforcement officers, or ceased operating altogether. To the ordinary person, these listings are everything that the dark net has to offer. However, technical users and law enforcement agencies have special techniques that they use to analyze the content on dark nets. To analyze content on these dark nets, special tools and techniques are combined. The normal search engines using traditional crawling techniques cannot find the content on the dark web. They rely on web pages being hyperlinked with each other in order to be effectively crawled. This makes them unable to crawl the dark net which lacks hyperlinking and typically discourages indexing. This chapter will focus on the techniques that can be used to analyze the contents of the dark web.
It will cover this in the following topics:
-
Surface web versus deep web
-
Traditional web crawlers mechanism
-
Surfacing deep web content
-
Analysis of deep web sites.
Surface Web versus Deep Web
To understand how web content analysis is done, it is good to take the familiar example of how surface web indexing engines work. Their workings are normally through creating indexes of web pages that they have crawled. Web crawling is done through robots that have special automated scripts that browse the World Wide Web in a systematic way. Search engines continue to crawl the internet in order to grow or update their indices. This happens without much restrictions on the surface web. Since crawling takes some of the resources on the sites being crawled, there are some surface web sites that will discourage search engines from crawling them. They can do so by including some commands in the robot.txt file on the root folders of their websites. Due to the huge amounts of information being released to the internet today, it is increasingly challenging for search engines to crawl. Engines such as Google are yet to create a complete index of the surface web.
However, these search engines cannot crawl or analyze the deep web as they do the surface web. Crawling is most effective where web pages are hyperlinked. When the crawler gets to an external link to another page, it associates it with the page it is on. It will also jump to the linked websites creating a spider-like web of how the pages are linked. The crawler requires that the pages be static. This means that the content should not be dynamically generated. However, much of the internet is made up of hidden data that cannot be indexed by normal crawlers. Therefore, search engines do not have any data about them. The following are the characteristics that make much of the deep web data.
-
Dynamic—this is content generated as a response to queries. It is dependent on the inputs a user provides to specify some of the attributes of the data that they wish to view. When an input is given, there is an HTML page that is generated dynamically which is then returned as output.
-
Unlinked—the pages on the deep web are not hyperlinked to each other.
-
Non-textual content—these are contents particularly hard to index as they include multimedia files and non-HTML contents.
It is estimated that the deep web is close to 500 times of the total size of the surface web. Over 200,000 websites are said to exist on dark nets on the deep web. Their contents cannot be accessed since the normal search engines are not capable of crawling them (Figure 7.1).
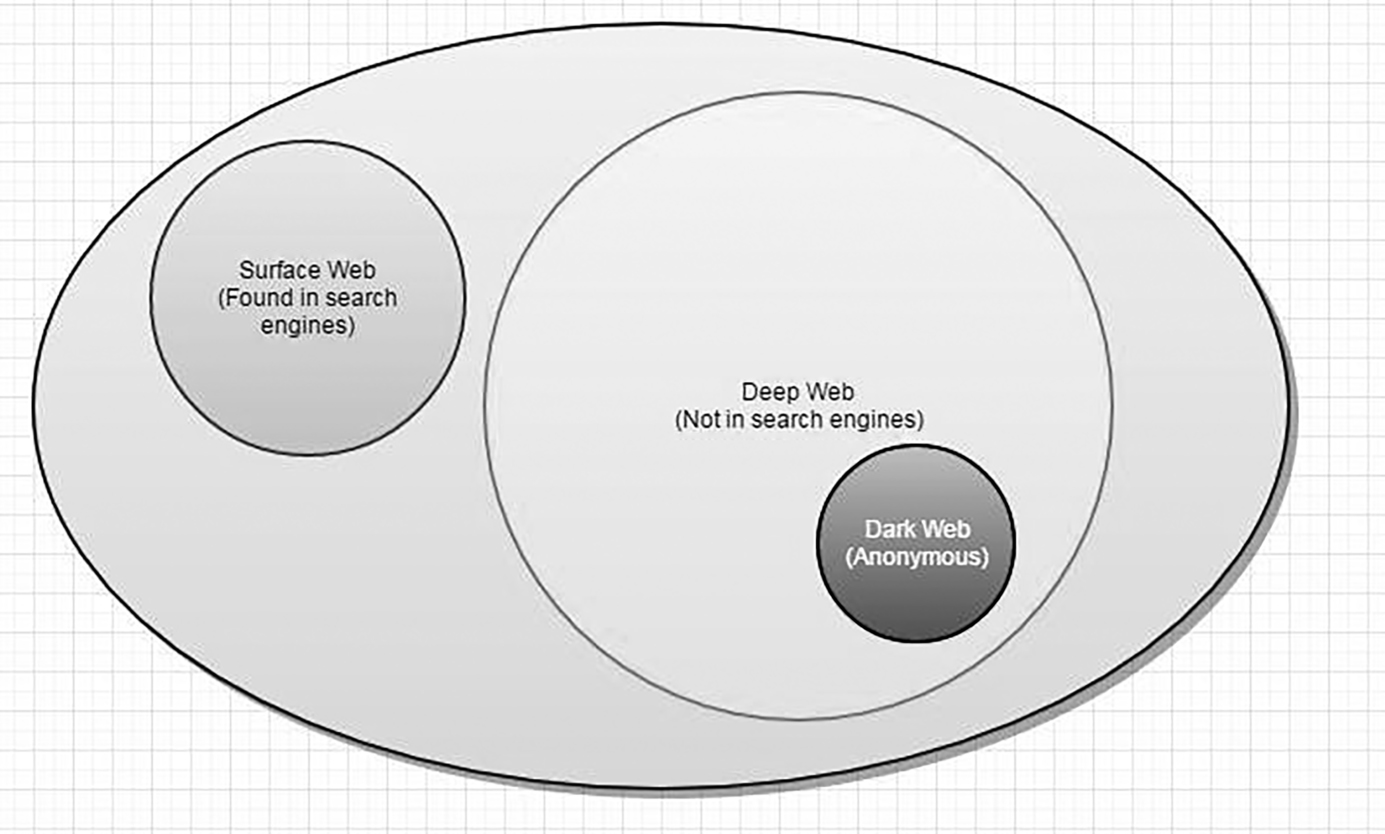
Figure 7.1 Illustration of the surface and deep web. (Source: https://cambiaresearch.com/articles/85/surface-web-deep-web-dark-web----whats-the-difference.)
Traditional Web Crawlers Mechanism
Traditional crawlers are the ones that are used to index surface websites. These include Yahoo Search, Google, and Bing. Their working is as shown in the figure below.
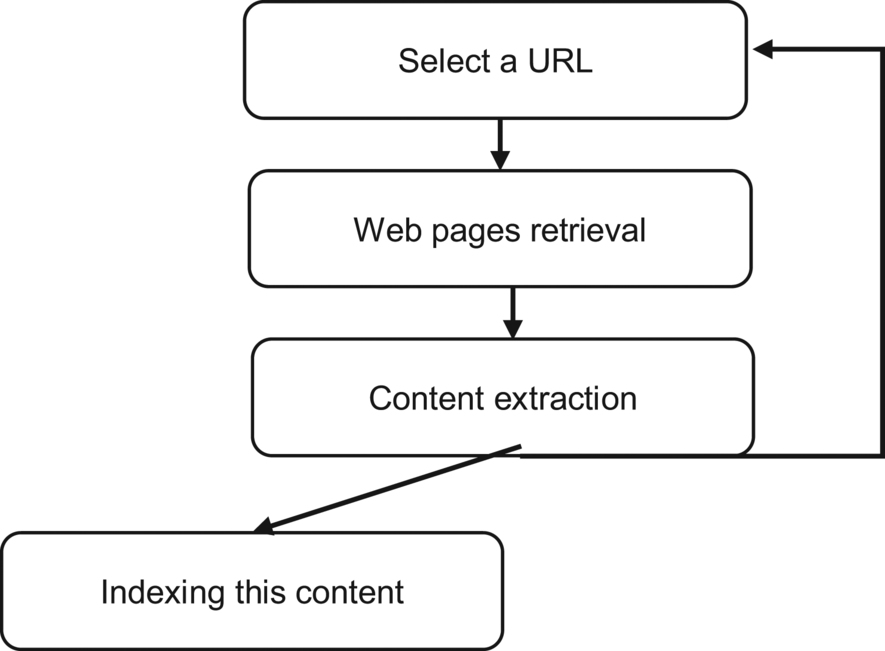
The crawler starts with a URL. This URL could have been found on another website that was being crawled. The crawler will retrieve all the web pages in that URL. The retrieved web pages will be used for the extraction of content and hyperlinks that they contain. The extracted data are sent to an indexer which indexes them based on certain categories. These may include the keywords they contain, the pages that they are linked to, the authors, and much more. After the indexing is done, the hyperlinks from the URLs are used as the inputs for a similar process. These crawlers are not equipped with mechanisms that can enable them to distinguish web pages that have forms or semi-structured data. They can only do loops to capture data in forms.
Surfacing Deep Web Content
To analyze content in the deep web, one needs to access it. To access this data, one has to surface it. The following is a process that can be used to surface content from the dark net:
-
Finding the sources
-
Selecting the data from the sources
-
Sending the selected data to an analysis system.
The data in the dark net includes content from databases, servers on the internet, and dynamic websites. In the process of analyzing information from the dark net, data sources may be integrated or bundled together. However, this integration might not be effective in some cases due to four reasons. The first one is that there may be the addition of redundant data. The second reason why the integration might be bad is that irrelevant data may be added to the data repository by the integration system. This, in turn, will reduce the quality of the results returned by the data integration system. The third reason is that adding more data to the integration system may lead to the inclusion of low-quality data. Lastly, there is a high cost of including data to the integration system. These costs are associated with sourcing the data and processing it so that it can be included in the repository and the integration system.
Schema Matching for Sources
With the completion of the previous step, the data is surfaced and the analysis process begins. Schema matching is whereby the extracted data is matched for relevance to a search keyword or phrase. A schema is developed with the required data, and the dark net sites that return data relevant to the schema are the ones retrieved. This eases the burden and reduces the cost of extracting web pages from the dark net just to process them. The schemas ensure that processing efforts are concentrated on data sources that have relevant data.
Data Extraction
Once the schema match is done and the relevant data source has been identified, it is time for the data to be retrieved. Different techniques are used to retrieve data from the deep web. For the convenience of costs and time, entire websites are not extracted. Only sections that contain data that is of interest are extracted.
Data Selection
Even in the normal surface web searches, there are hundreds or thousands of results of pages that can be retrieved from the internet. All these have relevant data based on the keywords used in the search operation. However, not all of these search results are of high relevance. Some may also be of low quality. The same is observed in the deep web. When a search is done based on some keywords, there may be hundreds or thousands of deep web sources that have been found to have related data. However, they also differ in quality. Therefore, they need to be ranked. On the surface web, the ranking is done on a rather competitive basis and that is why many websites invest in search engine optimization. However, the deep web does not have SEO (search engine optimization) since website owners do not expect that their websites will be found using search engines. Therefore, it is the burden of the search engine or search technique to find out how to index the extracted data. The following is a set of steps used to do a basic ranking:
-
Defining quality dimensions—the quality parameters for relevance of a search action are defined. They may be keywords, phrases, headings, or size of content, among other things. This helps filter out low-quality results from search operations.
-
Defining the quality assessment model—other criteria for defining quality sources are designed here.
-
Ranking the sources on quality basis depending on a certain threshold—based on the quality dimensions and assessment model, the retrieved sources are ranked.
Analysis of Deep Web Sites
Analysis of the deep web is complex and tiresome. It involves the following separate processes.
Qualification of a Deep Web Site Search Analysis
The surface web has a familiar problem of content replication and duplicate sites. These can severely affect the quality of search results since the same content can be listed over and over in repeating search results. The approach by surface web search engines is to punish websites that have identical content. Therefore, if a search engine has a near match of all the content that is in a certain website, the new content is ranked lower. The deep web has a similar problem when it comes to content analysis after searching the servers of this part of the web. There may be tens of thousands of results but a fraction of those may be duplicate listings. Therefore, an inspection needs to be done so that the duplicates are removed from the search results. The unique sources are then to be passed for the next stage of analysis. The next stage is a check to determine whether the listings are actually sites.
Unlike most results on the surface web, some part of the results from the deep web are filled with non-HTML content. The deep web is a stash of lots of content kept out of the public. Most of them are not websites, and some of these contents have to be filtered out. Ultimately, one ends up with actual websites that are hits of search queries. This analysis is not simple and not very accurate; thus, the algorithms used keep on being updated on what qualifies a search result as relevant.
Analysis of the Number of Deep Web Websites
It is important for some people and institutions such as law agencies to keep abreast with the sites that are on the deep web. If new drug marketplaces or child porn websites are opened, it ultimately falls down to the law enforcement agencies to find out these sites deep in the darkness of the dark net. Monitoring the number of dark net websites, therefore, helps to note when there are new sites that have to be inspected. When an overall number of deep web sites is mentioned, it is not from a wild guess. It is due to a special type of analysis that can be used to determine the number of websites that are in this part of the internet. One of the techniques used to estimate the number of active websites on the deep web is called overlap analysis. Overlap analysis is based on search engines that already exist on the deep web or custom-built search engines for crawling the deep web.
The technique does analysis based on the coverage of the search engines. Pairwise comparisons are done based on the number of search results retrieved from two sources and the number of shared results that overlap (Figure 7.2).
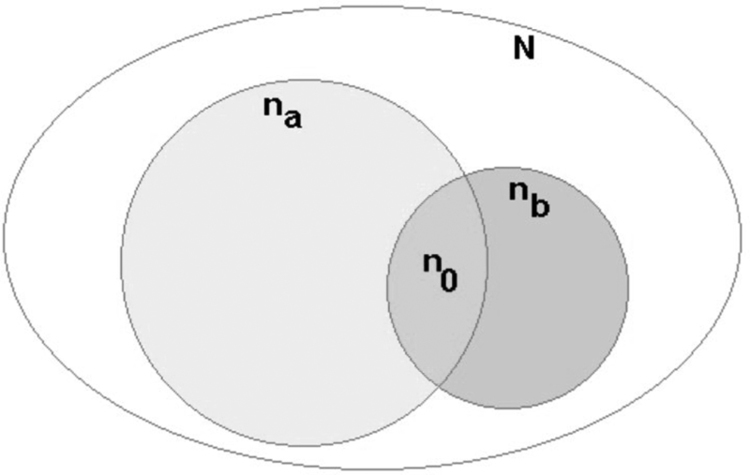
Figure 7.2 A diagrammatic representation of overlap analysis.
In the figure above, na and nb are the listings from two sources. N is the estimated total size of the population, that is, the number of websites. N0 is the degree of overlap between the listings of the search results. An estimation of the total population of the deep web can, therefore, be arrived at by dividing na/(n0/nb). This might be seen as vague; thus, we might have to consider a simpler explanation. For instance, assume that the total population is known to be 100, and let us see whether overlap analysis will give us the same figure. If the search listings from two sources show that they both contain 50 items in the total population and that an average of 25 items is shared by these sources, hence are unique, it follows that 25 items should not be listed by either. Therefore, they should have 25 unique items. To get to the total population we have to perform the following: 50/(25/50). The end result here is 100 which is the total population we had earlier said. The division from the overlap analysis has arrived at the same figure. However, it is more complex in the actual deep web to do this due to the procedures involved in determining the listings from two sources and the number of listings that are shared or unshared by them.
There are two considerations that are made during this type of analysis. The first one is that there should be accuracy in the determination of the number of listings from a source. The success of the whole analysis is pegged on this. If the number of listings is not arrived at correctly, the accuracy of the whole analysis procedure dips. The second consideration is how the listings are to be arrived at. They should be arrived at independently. In our example, our analysis violates the second rule; thus, the end result is on the lower side. This is because the listings used are search engine listings, and this should not be taken to mean independence. Searchable databases are in most cases linked to each other; thus, the independence of dark web search engines is questionable. However, when the two considerations are taken care of in a real scenario and with multiple pairwise comparisons, a more accurate number can be arrived at to show the number of sites on the deep web.
Deep Web Size Analysis
It might sound strange why there are estimates on the size of the deep web belittling the size of the surface web. It is said that 95% of the whole internet is the deep web while just a mere 5% is the surface web. The actual size of the deep web must, therefore, be very big. This is because surface web search engines such as Google already index billions of documents on the internet (web pages are documents too), and this is said to only be 5% of the internet. A common figure thrown around as the said size of the deep web is 3.4 TB. However, it is interesting to know how this estimation was arrived at owing to the fact that it is already a challenge to find the number of documents on the deep web. There is a type of analysis that is done to arrive at such figures which are mostly estimations.
To arrive at the estimated total size of this part of the internet, averages are used. The average sizes of the documents and data storage are used. A multiplier is then applied to come up with the estimated size of the deep web. Since the figures are enormous and the process of obtaining the average sizes is not simple, a lengthy process is used during the evaluation of the sizes of sample sites. In our previous example, there were 100 sites in the total population. To find out the total size of the population, we can first arrive at the average size of a sample of these sites and then apply a multiplier to arrive at a figure that we can say to be the total size of all our 100 sites.
In a real-world scenario, if there are 17,000 sites identified to be the population of the dark net, we can come up with the size of the whole dark net using this process. To begin with, we have to identify sample sites. With a 10% confidence interval and 95% confidence level, we can randomly select 100 websites. For the 100 samples, we can analyze the record count or document count of all these sites. For these sites, the total number of documents and their sizes could be used to get the average size of each page. When the average size of a page in one site is determined, the average could be used to determine the full size of the dark net site. When the full size of each dark net site is determined, an average can be calculated to show the average size of a dark net site. Using this figure, the full size of the dark net can be reached. All it takes is multiplying the average size of a site on the dark net with the total number of dark net sites.
Content Type Analysis
The media has been blamed for presenting a jaundiced view of the deep web. They often cover it as a dangerous part of the internet where all manner of crimes take place. From their perspective, it is the part of the internet where no one should try visiting or else they are hacked or their IP addresses are tracked and kidnappers send to them. Their uninformed view of this type of the web comes from the fact that they only cover it when law enforcement agencies have taken down drug black markets, arrested founders of illegal activity-related dark net sites, or taken down weapon-selling sites. Rarely will they cover this part of the internet in any other light. The fact is that the dark net is a vast space and has different types of contents. It would be unfair to demonize it based on media opinion. The dark net is a facilitator of many things, some of which the media is either unaware of or chooses to ignore when reporting about this hidden part of the internet.
However, it is a task to find out the types of content that exist on the dark net. This is because the content is purposefully meant to be hidden. To determine the type of content in the dark net, it is necessary for some analysis to be done. Since the dark net is big and there is not an exact number that can give the actual size, some cost-effective mechanisms have to be used to find the types of data and services available. The least costly way of analyzing the types of content on the deep web is through sampling. If there are presumed 17,000 dark net websites, an evaluation can be done on a sample of 700 sites. Through the samples, the type of data on each site can be analyzed and thus be used to categorize the dark net.
Figure 7.3 Alexa’s interface.
Site Popularity Analysis
It is possible to analyze the popularity of dark net websites based on the number of visitors, page views, and references that the site has. Alexa is a web-based system that keeps records of page visits, and up to date, it keeps analyzing sites on the dark net. Up to 71% of deep web sites are analyzed by Alexa, and it keeps updating their popularity. This is made possible by a universal power function that it runs on the internet that can record page views (Figure 7.3).
Log Analysis
However, analysis of the deep web is not only during the data retrieval process. The analysis is also done for malicious purposes such as to compromise the communication channels. Unlike the surface web, the connection between Tor clients and dark net servers is not convincingly safe. Traffic originating or destined to the dark web can be analyzed. There have been conceptual developments on how logs can be exploited to help analyze the deep web.
Theoretically, it is possible to analyze the dark web using the NetFlow protocol. An attacker can analyze NetFlow records stored on routers that act as direct Tor nodes or are close to such nodes. These logs which may be retrieved from inside the Tor network and contain lots of information can be used to analyze the dark net. NetFlow records store the following data (Figure 7.4):

Figure 7.4 Types of data that can be retrieved from NetFlow. (Source: https://securelist.com/uncovering-tor-users-where-anonymity-ends-in-the-darknet/70673/.)
Netflow analysis has been said to be capable of analyzing traffic to and from Tor that can lead to the deanonymization of 81% of the dark net’s users. Netflow technology is commonly used by Cisco, which is the leading company in networking products and services. Netflow is used in Cisco routers, and it is used to collect the IP addresses of network traffic entering and exiting a router. Netflow is used primarily for admins to monitor congestion in routers. Apart from Cisco, Netflow is a standard that is run by many other manufacturers of networking devices. Therefore, the chances of coming across this technology in a dark net traffic flow are high.
In a research by Chakravarty, Netflow was used for active traffic analysis on the dark net in laboratory and real-world environments. The research, first of its kind, used an analysis method to find information about users accessing certain content on the dark net. The research created a perturbation on the server side of Tor and then observed where a similar perturbation would be observed at the client side. The observation was done through statistical correlation. The research came to a 100% success rate in laboratory environment, and when they applied the same analysis technique in the real world, the success rate was at 81%. The research was a demonstration that the dark net is not fully secure since it can be analyzed to deanonymize the users and content that they are accessing. The research showed that a persistent attacker on the Tor network could perform unlimited runs of traffic analysis through the creation of perturbation and observation of traffic at entry and exit routers, respectively. Figure 7.5 shows this traffic analysis technique.
The research was done with a setup of a server and website on the deep web. Visitors to the website downloaded a large file from the server. The server had an injected code that would allow the researcher to access the NetFlow of routers that it passed through. When the fetching of the NetFlow logs was happening, the server on the dark net was sending data through Tor’s anonymous network. This is where correlation analysis would come in. The end user would continue receiving data through the Tor network from the server for several minutes, and within this time, the NetFlow records of the router where the data was passing would be analyzed. The researcher would then be able to correlate the traffic flowing to an anonymous client with the logs of a certain router read from the Netflow. Not only would this reveal the client’s exit node, it would also reveal the type of content that they were accessing. The following is another representation of how this dark net analysis is done.
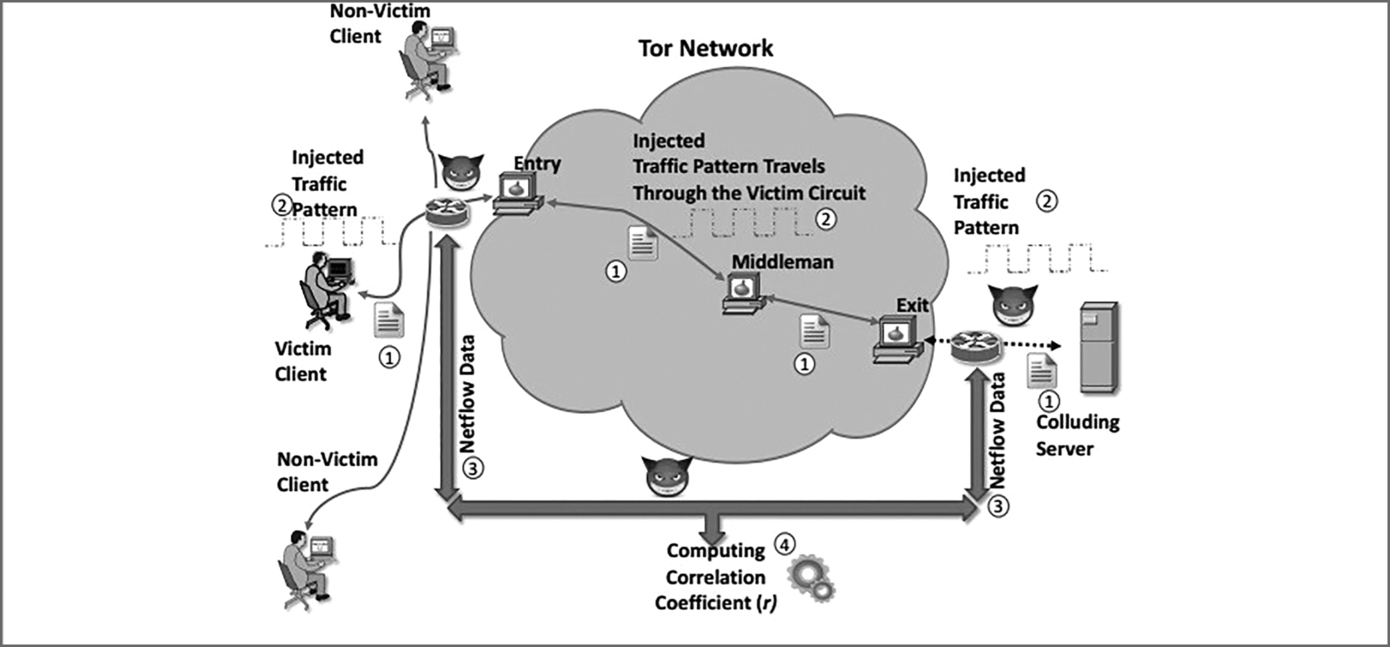
Figure 7.5 NetFlow-based traffic analysis against Tor: The client is forced to download a file from the server ①, while the server induces a characteristic traffic pattern ②. After the connection is terminated, the adversary obtains flow data corresponding to the server-to-client traffic ③ and computes their coefficient ④.
This analysis method threatens the anonymity of the dark web in future. If 81% of the users could be identified, Tor is, therefore, going to be insecure. A legal agency such as the FBI could set up servers on the dark net with catchy websites that have rigged content. If a user visits the site and downloads the Netflow malware file, their identity could be discovered within minutes (Figures 7.6 and 7.7).
Summary of the Chapter
This chapter has looked at how the deep web can be analyzed. It has given the difference between the surface and deep web that makes the deep web so difficult to index and analyze. The chapter has gone through the workings of a traditional web crawler, that is, the normal web crawler used by surface web search engines. It has shown that the simplistic nature of the surface web websites and their hyperlinked structure makes them easy to be crawled. When the crawler starts crawling a website, it will identify the linked pages and jump to them after it is done crawling the contents of the page that it is on. However, the deep web does not have this type of hyperlinking. It is therefore almost impossible for normal search engines to analyze and index the dark net sites. Analysis is therefore done systematically. The first step is to surface the deep web content. To surface it, a search has to be done, relevant data extracted, and then the essential data selected for analysis. The chapter has looked into the different types of analysis that can be done on deep web sites. These include content type analysis, site popularity analysis, size analysis, analysis of the number of websites, and finally log analysis. Log analysis has been covered differently since it is not a typical analysis technique. It is a technique used purposefully to compromise dark net websites. The analysis is done using log files retrieved from the NetFlow of compromised routers. The analysis finds out the users of the anonymous network and the types of content that they are accessing. The discussed types of analysis are the most common ones on the dark net.

Figure 7.6 Diagrammatic representation of log analysis.

Figure 7.7 Part of the paper by Chakravarty. (https://motherboard.vice.com/en_us/article/4x3qnj/how-the-nsa-or-anyone-else-can-crack-tors-anonymity.)
Questions
-
What are the characteristics of the surface web that make it easy to index?
-
Explain the mechanism used by traditional web crawlers to crawl the internet.
-
Explain the three steps used to surface content from the deep web.
-
Log analysis is a technique used to compromise dark nets, which networking equipment does it target to infiltrate the communication channel?
-
What is NetFlow?
-
Give two rivals of Cisco that also produce switches and routers.
-
How can an attacker find out the exit node being used by a Tor user during log analysis?
-
What is the current real-life success rate of log analysis?
Further Reading
The following are resources that can be used to gain more knowledge on this chapter: