4
La recherche qui trouve
Dans les salles de travaux pratiques des lycées, il est fréquent que des enseignants arrangent les résultats des expériences menées par les élèves pour obtenir des résultats plus convaincants. Pour étudier, par exemple, le phototropisme végétal en faisant germer des graines à proximité d’une source lumineuse, nombre d’enseignants de biologie se sentent tenus de prendre soin, avant que les élèves ne découvrent le résultat de l’« expérience », d’arracher les quelques inévitables germes qui ont eu le mauvais goût de se diriger non pas vers la lampe, mais à son exact opposé. Pour étudier telle ou telle réaction qui modifie l’acidité, mesurée avec des indicateurs colorés, certains de leurs collègues de chimie veillent à ajouter quelques gouttes de soude ou d’acide dans les solutions remises aux élèves, pour être bien certains qu’ils observeront le changement de couleur signant l’évolution du pH. La volonté d’obtenir une expérience édifiante, à défaut d’être didactique, peut, à la rigueur, passer pour une excuse à ce genre de pratiques, fort répandues. Il est en revanche injustifiable que nombre de chercheurs en fassent de même, arrangeant le compte rendu de leurs expériences de manière qu’elles semblent aussi robustes que des travaux pratiques.
Pour le béotien qui l’aborde, la littérature scientifique étonne en effet par son étonnante efficacité. Exceptionnels sont les articles qui décrivent un échec, une fausse piste, une impasse. Tout se passe comme si les chercheurs n’avaient toujours que de bonnes idées. Supposées interroger la nature, leurs expériences ont presque toujours le bon goût de confirmer l’hypothèse qui avait conduit à leur élaboration. N’est-il pas étrange que les chercheurs tombent ainsi toujours dans le mille ? Que les hypothèses qu’ils formulent se trouvent presque toujours validées par leurs expériences ? D’un joueur gagnant à tous les coups, on suspecterait à juste titre l’honnêteté. Comment croire que les scientifiques ne posent à la nature que de bonnes questions susceptibles d’idoines réponses ?
Histoire de p
Lorsqu’il conduit une série d’expériences, un chercheur teste le plus souvent une hypothèse. Il mesure n nombre de fois tel ou tel phénomène et cherche à savoir si son hypothèse permet de rendre compte des n résultats obtenus. Cependant, il ne peut exclure que les variations du phénomène qu’il observe soient liées au hasard. Sans guère discuter des fondements de cet usage, la communauté scientifique admet le plus souvent qu’un résultat est considéré comme pertinent si l’on peut calculer qu’il y a moins d’une chance sur vingt qu’il soit dû au hasard. Les scientifiques notent cette probabilité statistique p. Ce seuil de p < 0,05 (1 sur 20) est parfaitement arbitraire. On pourrait tout aussi bien choisir un sur cent ou un sur mille… C’est néanmoins la convention admise pour qu’un résultat soit jugé digne d’intérêt. Notons au passage que cet usage entraîne automatiquement qu’au moins une étude scientifique sur vingt est fausse ou du moins décrit un phénomène qui n’en est peut-être pas un.
Deux psychologues nord-américains ont eu l’astucieuse idée d’étudier les valeurs de p rapportées dans les expériences décrites dans quelque 3 557 publications parues en 2008 dans trois revues respectées dans le domaine de la psychologie expérimentale25. Ils ont observé que les valeurs de p comprises entre 0,045 et 0,050, soit juste sous le seuil retenu pour faire d’une expérience une observation digne d’être publiée, sont surreprésentées. Avec un pic particulièrement net entre 0,04875 et 0,05000, qui incite fortement à penser que les données ont été arrangées pour passer juste sous le seuil fatidique, à la manière de ces candidats au baccalauréat repêchés par un jury charitable qui obtiennent si souvent la note moyenne de 10,01.
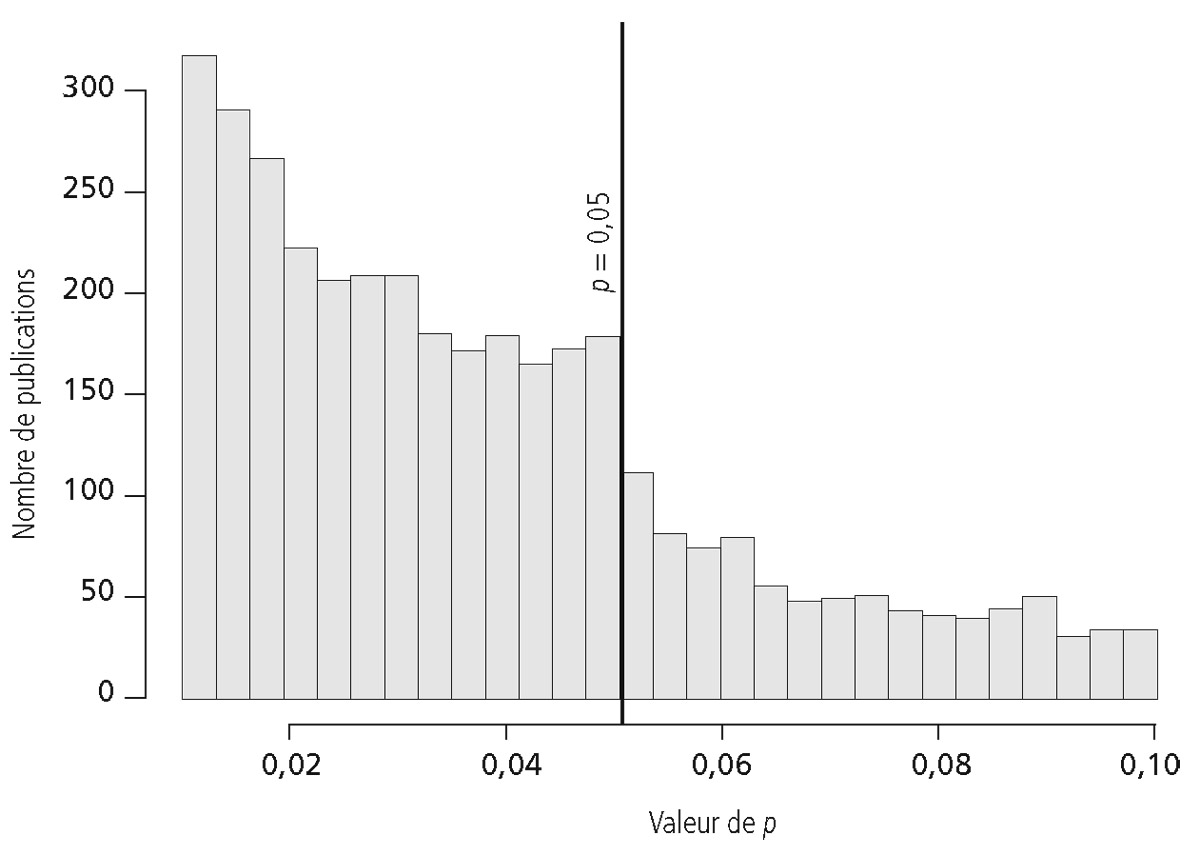
Distribution des valeurs de p dans plus de 3 000 publications en psychologie expérimentale parues en 2008. Le seuil de p < 0,05 (correspondant à moins d’une chance sur vingt que le résultat obtenu soit dû au hasard est considéré comme le critère pour que l’expérience soit jugée concluante). Il semble obnubiler les chercheurs, qui trouvent bien trop de résultats tout juste inférieurs au seuil. Ce graphe a été conçu par le statisticien Larry Wasserman à partir des données de Masicampo et Lalande, 2012.
Plusieurs manipulations sont possibles pour obtenir ce p juste inférieur à 0,05, sésame d’une future publication. On peut par exemple sélectionner de préférence les expériences jugées concluantes comme, on l’a lu au chapitre précédent, le fit sans doute Millikan dans son travail sur la mesure de la charge électrique de l’électron. On peut aussi décider d’arrêter la collecte de données quand les résultats obtenus ont le bon goût de permettre d’obtenir le fameux p < 0,05. Poursuivre risquerait en effet de s’en éloigner… Seulement 11 % des articles en psychologie expérimentale explicitent les raisons pour lesquelles les chercheurs ont choisi de limiter leurs expériences aux n cas décrits dans la publication26.
Il est fort probable que l’explosion des capacités de calcul, qui fait que n’importe quel ordinateur de bureau a aujourd’hui la puissance d’un supercalculateur des années 1970, ait contribué à amplifier cette tendance à arranger ses résultats pour qu’ils soient juste significatifs. Avant leur apparition dans le quotidien des laboratoires, le calcul de la fameuse valeur p se faisait à l’aide de tables listant, pour les différentes proportions possibles de valeurs expérimentales, les intervalles de p correspondants. Aujourd’hui, on n’obtient plus un intervalle mais, et en un clic, la valeur précise à plusieurs décimales près. Il en devient très simple, et si tentant, d’enlever quelques valeurs obtenues expérimentalement pour « voir ce que cela donne », et en particulier si p n’aurait pas l’heureuse initiative de passer soudainement sous 0,05. Une équipe de psychologues australiens a ainsi comparé les valeurs de p dans les articles publiés dans The Journal of Personality and Social Psychology en 1965 à ceux parus en 200527. Une bonne part des articles n’indique pas la fameuse valeur, se contentant d’affirmer p < 0,05. Si l’on recalcule, sur la base des résultats publiés, la valeur, on trouve que 38 % d’entre eux ont menti, la valeur moyenne étant de p = 0,545 ± 0,007. Est-il si important de savoir que les données rapportées ont 94,6 % de chances de ne pas être dues au hasard, et non plus 95 % ? Sans doute pas. Mais les auteurs relèvent que cette manière peu orthodoxe d’arrondir les chiffres est devenue de plus en plus fréquente durant les quarante années étudiées. De même, la propension à trouver des valeurs de p juste inférieures à 0,05 a explosé. Si elle existait déjà en 1965, elle est aujourd’hui devenue omniprésente. Difficile de croire que les chercheurs en psychologie aient en quarante ans à ce point progressé qu’ils ne puissent plus formuler que des hypothèses s’avérant pertinentes.
Des chercheurs de plus en plus perspicaces ?
Cette tendance à trouver de plus en plus de résultats tout juste significatifs ne concerne pas que la psychologie expérimentale. Le taux d’études réputées statistiquement significatives ne cesse de progresser dans bien d’autres disciplines. Le biologiste Marco Pautasso a eu l’idée malicieuse d’interroger différentes bases de données bibliographiques, pour dénombrer les articles dont le résumé contient les mots-clés « résultats non significatifs » ou « résultats significatifs ». Il a observé qu’entre 1990 et 2010 le ratio des premiers aux seconds a diminué, toutes disciplines confondues, de 20 %28 : pour 10 articles affirmant avoir observé un résultat significatif, on en trouvait 17 en 1990 admettant un résultat non significatif, mais plus que 13 aujourd’hui. Cette tendance s’observe dans différentes disciplines de la biologie, mais est particulièrement marquée en agronomie, dans les sciences de l’environnement et en nutrition, où les résultats significatifs sont devenus deux fois plus fréquents entre 1970 et 1990. En revanche, le ratio n’a pas évolué en chimie, en informatique, en science de l’ingénieur ou en physique.
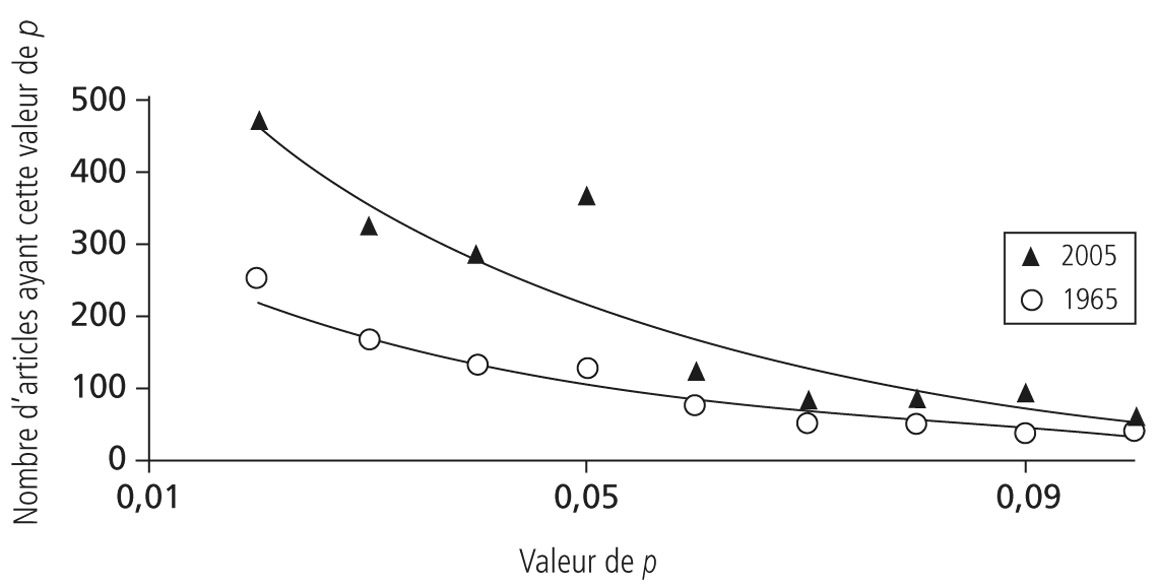
Distribution des valeurs de p rapportées dans les publications de 1965 et de 2005 du Journal of Personality and Social Psychology, une revue importante du domaine. Les chercheurs de 2005 semblent étonnamment plus performants que leurs aînés. Source : D’après Leggett et al., 2013.
Daniele Fanelli, dont on a déjà évoqué les importants travaux montrant qu’environ 2 % des chercheurs avaient au moins une fois fraudé, a affiné cette étude29. Son approche relève toujours de la bibliométrie. Mais au lieu de rechercher des mots-clés dans le résumé de l’article, il a eu la patience de parcourir quelque 4 600 articles parus depuis 1990 dans des domaines les plus variés, pris comme un échantillon aléatoire de la littérature scientifique, pour voir si l’hypothèse que les auteurs entendaient tester s’est trouvée confirmée par les résultats qu’ils décrivaient. Résultat : 70 % des articles parus en 1990 affirmaient avoir confirmé leur hypothèse, et 86 % en 2007. Presque toutes les disciplines étudiées, physique, biologie et sciences sociales, sont concernées par ces progrès exceptionnels de l’intelligence des chercheurs, dont les expériences confirmaient en 2007 leurs hypothèses dans 65 % (sciences de l’espace) à 100 % (biologie moléculaire et médecine clinique) des études. Saluons la remarquable sagacité des chercheurs asiatiques. Leurs 204 articles retenus dans l’étude de Fanelli ont atteint en 2007 les 100 % de résultats positifs, contre 85 % aux États-Unis et en Europe, la France ne se distinguant pas en la matière des autres pays de l’Union européenne. Mais peut-être les relecteurs des revues, pour la plupart anglo-saxonnes, se montrent-ils plus sévères lorsqu’ils examinent les manuscrits d’auteurs asiatiques, n’acceptant que les résultats exceptionnellement convaincants ? Légitime, l’hypothèse s’effondre lorsque l’on constate que le pourcentage de résultats positifs obtenus par les chercheurs américains est, avec le temps, toujours de dix points supérieur à celui de leurs collègues britanniques. Tous maîtrisent pourtant parfaitement l’anglais et sont également bien introduits dans les cénacles dirigeants des revues.
Les chercheurs ne se contentent pas de mener des expériences de plus en plus concluantes. Ils mènent aussi des travaux de plus en plus révolutionnaires ! Le terme « changement de paradigme » (paradigm shift) était inconnu des articles biomédicaux avant 1980. Sa fréquence dans les titres et résumés connaît depuis une croissance exponentielle. L’année 2015 a connu le nombre record de 813 changements de paradigme ! On se souvient que, pour le philosophe des sciences Thomas Kuhn, ces derniers marquent les révolutions scientifiques. La biologie et la médecine seraient donc en pleine ère des révolutions.
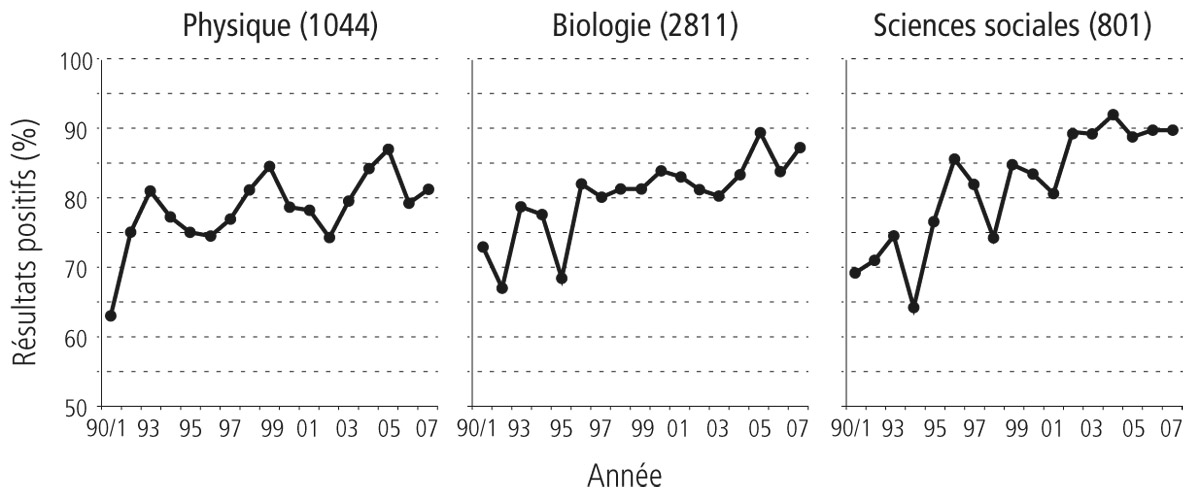
Évolution du pourcentage d’articles affirmant avoir confirmé leur hypothèse dans trois domaines entre 1990 et 2007. Plus qu’une progression de l’intelligence des chercheurs, nous sommes enclins à y voir leur propension croissante à ne publier que leurs résultats positifs, ou à rédiger ceux qui ne le sont pas de telle manière qu’ils le deviennent. Source : D’après Fanelli, 2012.
On ne publie que ce qui marche
Le lecteur l’aura compris : il n’y a aucune raison de croire à une telle progression de l’intelligence des chercheurs. Pourtant les constats bibliométriques de l’augmentation des valeurs de p juste significatives, de l’accroissement des résultats positifs, ou encore de la confirmation croissante des hypothèses, sont incontestables. Il doit donc exister un biais qui fait que la littérature scientifique ne publie, de plus en plus, qu’un certain type d’études. D’où peut-il provenir ?
Évacuons d’emblée les faux arguments. Peut-être les études scientifiques ont-elles pris une plus grande ampleur ? L’évolution est réelle dans le domaine biomédical. Là où une poignée de cas cliniques suffisait à faire, il y a trente ans, une publication, on demande aujourd’hui de vastes études rassemblant des centaines de patients. La puissance statistique des études s’est donc indéniablement accrue, et avec elle la probabilité de confirmer l’hypothèse originelle. Pourquoi pas ? Mais comment expliquer que la tendance à ne trouver presque que des résultats positifs concerne la totalité des disciplines, et non les seuls essais cliniques ? Quelques chercheurs se sont penchés sur l’évolution de la puissance statistique moyenne mise en œuvre dans les études d’écologie30 ou de psychologie31. Ils ont constaté qu’elle n’avait pas varié depuis trente ans.
Autre explication possible : les revues scientifiques n’accepteraient plus dans leurs colonnes que des résultats positifs. Cette hypothèse est autrement plus plausible. Tous les chercheurs déplorent la difficulté de publier un résultat « négatif ». Le terme en lui-même interroge. Qu’est-ce donc qu’un résultat négatif ? Tout résultat d’une recherche menée selon une méthodologie correcte n’est-il pas, en soi, digne d’être communiqué aux pairs ? Sans doute. Mais, autocensure ou anticipation du refus que leur opposeront peut-être les comités de lecture, la plupart des chercheurs ne publient pas les résultats des expériences qui n’ont pas donné de résultats nets. Les essais cliniques sont un des secteurs de la recherche les plus enclins à ne publier que leurs résultats positifs. Le mode de financement est, évidemment, en cause. Quel pourrait être l’intérêt d’une entreprise pharmaceutique à rendre public le fait que telle molécule n’a semblé avoir aucun effet contre telle maladie ? Ses concurrents apprendraient que c’est là une fausse piste et son image – ainsi que son cours en Bourse – en souffrirait.
L’agacement qu’éprouvent certains chercheurs devant leur difficulté à publier des résultats n’allant pas dans le sens de l’hypothèse formulée a même été à l’origine de la création, en 2002, du Journal of Negative Results in Biomedicine. Il ne publie qu’une dizaine d’articles par an. Son homologue The Journal of Negative Results, spécialisé dans l’écologie et la biologie évolutive, n’en publie qu’un ou deux, dans un domaine où les conflits d’intérêts sont pourtant bien moins prégnants. Si elles ont à ce jour échoué à convaincre les chercheurs de publier dans leurs colonnes, ces deux revues n’en ont pas moins le mérite de souligner, ne serait-ce que par leur titre provocateur, la difficulté de publier leurs résultats dits négatifs. Les revues les plus prestigieuses, telles que Nature et Science, ont en effet une prédilection pour les « belles histoires », ces expériences plus que parfaites susceptibles d’être de très nombreuses fois citées, souvent même sans en lire le détail. Ce travers est aussi indéniable que bien documenté.
Comment les chercheurs font-ils donc pour transformer leurs données expérimentales en résultats positifs dont sont si friandes les revues ? Une des solutions les plus simples est de réécrire l’histoire, ce que les anglophones décrivent comme le HARKing, « Hypothesing After the Results are Known » (formuler l’hypothèse une fois les résultats connus), jeu de mots sur le terme hark, qui signifie « écoutez-moi ». Supposons, en simplifiant le cheminement de la réflexion scientifique dans la pratique bien plus sinueuse, qu’un chercheur veuille tester l’hypothèse que le phénomène A est la cause du phénomène B. Et que ses données expérimentales montrent que A est la cause du phénomène C. Rien ne lui interdit d’écrire un article prétendant se demander si A entraîne C, et d’y répondre par l’affirmative. Minuscule mystification que les historiens de demain se chargeront d’identifier dans les archives d’aujourd’hui. Elle ne prête à guère d’autres conséquences que d’entretenir l’idée fallacieuse d’une recherche omnisciente, trouvant toujours ce qu’elle cherche. Mais pourquoi ne pas présenter toutes les hypothèses possibles ? Pourquoi ne pas présenter l’incertitude initiale, comme dans un film policier où la possibilité de plusieurs coupables génère le suspens ? Dans le langage scientifique, il s’agirait de présenter son étude en décrivant plusieurs hypothèses possibles, non en comparant celle de son choix à une hypothèse nulle. D’écrire non que l’on va prouver que le phénomène A cause le phénomène B, mais que l’on se demande si A cause B, C, D ou on ne sait quel autre. Certains chercheurs le font. L’étude de Daniele Fanelli que l’on a plus haut commentée montre hélas que ces articles ouverts à toutes les possibilités restent rares. Nouvelle illustration du fait que la science telle que la racontent les articles scientifiques n’a qu’un lointain rapport avec celle qui se pratique dans les laboratoires.