 evidence-based research
evidence-based researchMeta-analysis, research syntheses and systematic reviews |
CHAPTER 17 |
This new chapter introduces key issues in the more established field of meta-analysis and the more recent field of research syntheses and systematic reviews, as part of the push towards evidence-based educational practice. The chapter addresses issues in:
evidence-based research
meta-analysis
research syntheses and systematic reviews
As evidence-based education gathers pace (Coe, 1999), the fields of meta-evaluation and research syntheses come to take on increasing prominence as research methods in their own right. The use of meta-analysis and systematic reviews enables the cumulative effect of knowledge from educational research to be developed, as in, for example, medical sciences (Davies, 2000). Since the early days of reviews of research, gathering together a range of research studies and summarizing their main findings (‘narrative reviews’, e.g. in the journal Review of Educational Research), the field has advanced to include meta-analysis and research syntheses/systematic reviews, with the journal Research Synthesis Methods launched in 2009. This chapter introduces meta-analysis and research syntheses/systematic reviews.
In an age of evidence-based education, meta-analysis and research syntheses/systematic reviews are increasingly used methods of investigation, bringing together different studies to provide evidence to inform policy making and planning (Sebba, 1999; Thomas and Pring, 2004). That this is happening significantly is demonstrated in the establishment of:
the EPPI-Centre (Evidence for Policy and Practice Information and Co-ordinating Centre) at the University of London (http://eppi.ioe.ac.uk/cms/);
the Social, Psychological, Educational and Criminological Controlled Trials Register (SPECTR) (Milwain, 1998; Milwain et al., 1999), later transferred to the Campbell Collaboration (www.camp-bellcollaboration.org), a parallel to the Cochrane Collaboration in medicine (www.cochrane.org/index0.htm), which undertakes systematic reviews and meta-analyses of, typically, experimental evidence in medicine;
the Curriculum, Evaluation and Management (CEM) centre at the University of Durham (www.cemcentre.org/);
the UK Centre for Evidence-based Policy (from the UK’s Economic and Social Research Council) (www.esrcsocietytoday.ac.uk/ESRCInfoCentre/research/resources/centre_for_evidence_based_policy.aspx);
the Evidence Network at King’s College, London (www.evidencenetwork.org/);
the What Works Clearinghouse in the USA (http://ies.ed.gov/ncee/wwc/ and http://ies.ed.gov/ncee/wwc/reports/), with recommendations made for practice (e.g. http://ies.ed.gov/ncee/wwc/publications/practiceguides/">http://ies.ed.gov/ncee/wwc/publications/practiceguides/);
the UK government’s ‘Research Informed Practice Site’ (www.standards.dcsf.gov.uk/research/themes/).
‘Evidence’ here typically comes from randomized controlled trials (RCTs) of one hue or another (Tymms, 1999; Coe et al., 2000; Thomas and Pring, 2004: 95), with their emphasis on careful sampling, control of variables, both extraneous and included, and measurements of effect size. It also comes from systematic reviews of qualitative research. The cumulative evidence from these sources is intended to provide a reliable body of knowledge on which to base policy and practice (Coe et al., 2000). Such accumulated data, it is claimed, delivers evidence of ‘what works’, though Morrison (2001) suggests that this claim is suspect.
The roots of evidence-based practice lie in medicine, where the advocacy by Cochrane (1972) for randomized controlled trials together with their systematic review and documentation led to the foundation of the Cochrane Collaboration (Maynard and Chalmers, 1997), which is now worldwide. The careful, quantitative-based research studies that can contribute to the accretion of an evidential base are seen to be a powerful counter to the often untried and under-tested schemes that are injected into practice.
More recently evidence-based education has entered the worlds of social policy, social work (MacDonald, 1997) and education (Fitz-Gibbon, 1997). At the forefront of educational research in this area are the EPPI-Centre (Evidence for Policy and Practice Information and Co-ordinating Centre) at the University of London, and the Curriculum, Evaluation and Management Centre at the University of Durham, where the work of Fitz-Gibbon and Tymms shows how indicator systems can be used with experimental methods to provide clear evidence of causality and a ready answer to Fitz-Gibbon’s own question: how do we know what works? (Fitz-Gibbon, 1999: 33).
Echoing Anderson and Biddle (1991), Fitz-Gibbon suggests that policy makers shun evidence in the development of policy and that practitioners, in the hurlyburly of everyday activity, call upon tacit knowledge rather than the knowledge which is derived from randomized controlled trials. However, in a compelling argument (1997: 35–6), she suggests that evidence-based approaches are necessary in order to: (a) challenge the imposition of unproven practices; (b) solve problems and avoid harmful procedures; (c) create improvement that leads to more effective learning. Further, such evidence, she contends, should examine effect sizes rather than statistical significance.
Meta-analysis argues that effect size, rather than statistical significance, should be calculated (Coe, 2000). This is useful, as the notion of effect size breaks the perceived stranglehold of statistical significance (Carver, 1978; Thompson, 1994, 1996, 1998, 2001, 2002; Thompson and Snyder, 1997; Coe, 2000), and replaces it with a more discerning, differentiated notion. It is commonplace to observe that statistical significance is easier to achieve with large samples than with small samples (Fitz-Gibbon, 1997: 118; Kline, 2004); effect size, as a more subtle function of sample size, is a more exact measure and feeds straightforwardly into the aggregation of data for meta-analyses (see, for example, Glass et al., 1981; Lipsey, 1992; Coe, 2000, 2002). Whilst effect size might be a less blunt instrument than statistical significance, nevertheless it does raise the issue of the transferability of data from small samples into the larger picture as discussed above, i.e. the problem of generalizability of small samples does not disappear.
Whilst the nature of information in evidence-based education might be contested by researchers whose sympathies (for whatever reason) lie outside randomized controlled trials, the message from Fitz-Gibbon (1996) will not go away: the educational community needs evidence on which to base its judgements and actions. The development of indicator systems worldwide attests to the importance of this, be it through assessment and examination data, inspection findings, national and international comparisons of achievement, or target setting. Rather than being a shot in the dark, evidence-based education suggests that policy formation should be informed, and policy decision making should be based on the best information to date rather than on hunch, ideology or political will. It is bordering on the unethical to implement untried and untested recommendations in educational practice, just as it is unethical to use untested products and procedures on hospital patients without their consent.
The study by Bhadwal and Panda (1991) is typical of research undertaken to explore the effectiveness of classroom methods. Often as not, such studies fail to reach the light of day, particularly when they form part of the research requirements for a higher degree. Meta-analysis is, simply, the analysis of other analyses. It involves aggregating and combining the results of comparable studies into a coherent account to discover main effects. This is often done statistically, though qualitative analysis is also advocated. Among the advantages of using meta-analysis, Fitz-Gibbon (1985: 46) cites the following:
Humble, small-scale reports which have simply been gathering dust may now become useful.
Small-scale research conducted by individual students and lecturers will be valuable since meta-analysis provides a way of coordinating results drawn from many studies without having to coordinate the studies themselves.
For historians, a whole new genre of studies is created – the study of how effect sizes vary over time, relating this to historical changes.
McGaw (1997: 371) suggests that quantitative meta-analysis replaces intuition, which is frequently reported narratively (Wood, 1995: 389), as a means of synthesizing different research studies transparently and explicitly (a desideratum in many synthetic studies (Jackson, 1980)), particularly when they differ very substantially. Narrative reviews, suggest Jackson (1980), Cook et al. (1992: 13) and Wood (1995: 390) are prone to:
lack comprehensiveness, being selective and only going to subsets of studies;
misrepresentation and crude representation of research findings;
over-reliance on significance tests as a means of supporting hypotheses, thereby overlooking the point that sample size exerts a major effect on significance levels, and overlooking effect size;
reviewers’ failure to recognize that random sampling error can play a part in creating variations in findings amongst studies;
overlook differing and conflicting research findings;
reviewers’ failure to examine critically the evidence, methods and conclusions of previous reviews;
overlook the extent to which findings from research are mediated by the characteristics of the sample;
overlook the importance of intervening variables in research;
unreplicability because the procedures for integrating the research findings have not been made explicit.
A quantitative method for synthesizing research results has been developed by Glass et al. (1978, 1981) and others (e.g. Hedges and Olkin, 1985; Hedges, 1990; Rosenthal, 1991) to supersede narrative intuition. Meta-analysis, essentially the ‘analysis of analysis’, is a means of quantitatively (a) identifying generalizations from a range of separate and disparate studies, and (b) discovering inadequacies in existing research such that new emphases for future research can be proposed. It is simple to use and easy to understand, though the statistical treatment that underpins it is somewhat complex. It involves the quantification and synthesis of findings from separate studies on some common measure, usually an aggregate of effect size estimates, together with an analysis of the relationship between effect size and other features of the studies being synthesized. Statistical treatments are applied to attenuate the effects of other contaminating factors, e.g. sampling error, measurement errors and range restriction. Research findings are coded into substantive categories for generalizations to be made (Glass et al., 1981), such that consistency of findings is discovered that through the traditional means of intuition and narrative review would have been missed.
Fitz-Gibbon (1985: 45) explains the technique by suggesting that in meta-analysis the effects of variables are examined in terms of their effect size, that is to say, in terms of how much difference they make rather than only in terms of whether or not the effects are statistically significant at some arbitrary level such as 5 per cent. Because with effect sizes it becomes easier to concentrate on the educational significance of a finding rather than trying to assess its importance by its statistical significance, and we may finally see statistical significance kept in its place as just one of many possible threats to internal validity. The move towards elevating effect size over significance levels is very important (see also Chapter 34), and signals an emphasis on ‘fitness for purpose’ (the size of the effect having to be suitable for the researcher’s purposes) over arbitrary cut-off points in significance levels as determinants of utility.
The term ‘meta-analysis’ originated in 1976 (Glass, 1976) and early forms of meta-analysis used calculations of combined probabilities and frequencies with which results fell into defined categories (e.g. statistically significant at given levels), though problems of different sample sizes confounded rigour (e.g. large samples would yield significance in trivial effects, whilst important data from small samples would not be discovered because they failed to reach statistical significance) (Light and Smith, 1971; Glass et al., 1981; McGaw, 1997: 371). Glass (1976) and Glass et al. (1981) suggested three levels of analysis: (a) primary analysis of the data; (b) secondary analysis, a reanalysis using different statistics; (c) meta-analysis, analysing results of several studies statistically in order to integrate the findings. Glass et al. (1981) and Hunter et al. (1982) suggest several stages in the procedure:
Step 1: Identify the variables for focus (independent and dependent).
Step 2: Identify all the studies which feature the variables in which the researcher is interested. Step 3: Code each study for those characteristics that might be predictors of outcomes and effect sizes (e.g. age of participants, gender, ethnicity, duration of the intervention).
Step 4: Estimate the effect sizes through calculation for each pair of variables (dependent and independent variable) (see Glass, 1977), weighting the effect size by the sample size.
Step 5: Calculate the mean and the standard deviation of effect sizes across the studies, i.e. the variance across the studies.
Step 6: Determine the effects of sampling errors, measurement errors and range of restriction.
Step 7: If a large proportion of the variance is attributable to the issues in Step 6, then the average effect size can be considered an accurate estimate of relationships between variables.
Step 8: If a large proportion of the variance is not attributable to the issues in Step 6, then review those characteristics of interest which correlate with the study effects.
Cook et al. (1992: 7–12) set out a four-stage model for an integrative review as a research process, covering:
problem formulation (where a high-quality meta-analysis must be rigorous in its attention to the design, conduct and analysis of the review);
data collection (where sampling of studies for review has to demonstrate fitness for purpose);
data retrieval and analysis (where threats to validity in non-experimental research – of which integrative review is an example – are addressed). Validity here must demonstrate fitness for purpose, reliability in coding and attention to the methodological rigour of the original pieces of research;
analysis and interpretation (where the accumulated findings of several pieces of research should be regarded as complex data points that have to be interpreted by meticulous statistical analysis).
Fitz-Gibbon (1984: 141–2) sets out four steps in conducting a meta-analysis:
Step 1: Finding studies (e.g. published/unpublished reviews) from which effect sizes can be computed.
Step 2: Coding the study characteristics (e.g. date, publication status, design characteristics, quality of design, status of researcher).
Step 3: Measuring the effect sizes (e.g. locating the experimental group as a z-score in the control group distribution) so that outcomes can be measured on a common scale, controlling for ‘lumpy data’ (non-independent data from a large data set).
Step 4: Correlating effect sizes with context variables (e.g. to identify differences between well-controlled and poorly controlled studies).
Effect size (e.g. Cohen’s d and eta squared) are the preferred statistics over statistical significance in metaanalyses, and we discuss this in Part 5. Effect size is a measure of the degree to which a phenomenon is present or the degree to which a null hypothesis is not supported. Wood (1995: 393) suggests that effect size can be calculated by dividing the significance level by the sample size. Glass et al. (1981: 29, 102) calculate the effect size as:
(mean of experimental group – mean of control group)
Standard deviation of the control group
Hedges (1981) and Hunter et al. (1982) suggest alternative equations to take account of differential weightings due to sample size variations. The two most frequently used indices of effect sizes are standardized mean differences and correlations (Glass et al., 1981: 373), though nonparametric statistics, e.g. the median, can be used. Lipsey (1992: 93–100) sets out a series of statistical tests for working on effect sizes, effect size means and homogeneity. It is clear from this that Glass and others assume that meta-analysis can only be undertaken for a particular kind of research – the experimental type – rather than for all types of research; this might limit its applicability.
Glass et al. (1981) suggest that meta-analysis is particularly useful when it uses unpublished dissertations, as these often contain weaker correlations than those reported in published research, and hence act as a brake on misleading, more spectacular generalizations. Meta-analysis, it is claimed (Cooper and Rosenthal, 1980), is a means of avoiding Type II errors (failing to find effects that really exist), synthesizing research findings more rigorously and systematically, and generating hypotheses for future research. However Hedges and Olkim (1980) and Cook et al. (1992: 297) show that Type II errors become more likely as the number of studies included in the sample increases.
Further, Rosenthal (1991) has indicated a method for avoiding Type I errors (finding an effect that, in fact, does not exist) that is based on establishing how many unpublished studies that average a null result would need to be undertaken to offset the group of published statistically significant studies. For one example he shows a ratio of 277:1 of unpublished to published research, thereby indicating the limited bias in published research.
Meta-analysis is not without its critics (e.g. Wolf, 1986; Elliott, 2001; Thomas and Pring, 2004). Wolf (1986: 14–17) suggests six main areas:
1 It is difficult to draw logical conclusions from studies that use different interventions, measurements, definitions of variables and participants.
2 Results from poorly designed studies take their place alongside results from higher quality studies.
3 Published research is favoured over unpublished research.
4 Multiple results from a single study are used, making the overall meta-analysis appear more reliable than it is, since the results are not independent.
5 Interaction effects are overlooked in favour of main effects.
6 Meta-analysis may have ‘mischievous consequences’ (p. 16) because its apparent objectivity and precision may disguise procedural invalidity in the studies.
Wolf (1986) provides a robust response to these criticisms, both theoretically and empirically. He also suggests (pp. 55–6) a ten-step sequence for carrying out meta-analyses rigorously, including, inter alia:
1 Make clear the criteria for inclusion and exclusion of studies.
2 Search for unpublished studies.
3 Develop coding categories that cover the widest range of studies identified.
4 Look for interaction effects and examine multiple independent and dependent variables separately.
5 Test for heterogeneity of results and the effects of outliers, graphing distributions of results.
6 Check for inter-rater coding reliability.
7 Use indicators of effect size rather than statistical significance.
8 Calculate unadjusted (raw) and weighted tests and effects sizes in order to examine the influence of sample size on the results found.
9 Combine qualitative and quantitative reviewing methods.
10 Report the limitations of the meta-analyses conducted.
One can add to this the need to specify the research questions being asked, the conceptual frameworks being used, the review protocols being followed, the search and retrieval strategies being used, and the ways in which the syntheses of the findings from several studies are brought together (Thomas and Pring, 2004: 54–5).
Gorard (2001b: 72–3) suggests a four-step model for conducting meta-analysis:
Step 1: Collect all the appropriate studies for inclusion.
Step 2: Weight each study ‘according to its size and quality’.
Step 3: List the outcome measures used.
Step 4: Select a method for aggregation, based on the nature of the data collected (e.g. counting those studies in which an effect appeared and those in which an effect did not appear, or calculating the average effect size across the studies).
Subjectivity can enter into meta-analysis. Since so much depends upon the quality of the results that are to be synthesized, there is the danger that adherents may simply multiply the inadequacies of the database and the limits of the sample (e.g. trying to compare the incomparable). Hunter et al. (1982) suggest that sampling error and the influence of other factors has to be addressed, and that it should account for less than 75 per cent of the variance in observed effect sizes if the results are to be acceptable and able to be coded into categories. The issue is clear here: coding categories have to declare their level of precision, their reliability (e.g. inter-coder reliability – the equivalent of inter-rater reliability, see Chapter 10) and validity (McGaw, 1997: 376–7).
To the charge that selection bias will be as strong in meta-analysis – which embraces both published and unpublished research – as in solely published research, Glass et al. (1981: 226–9) argue that it is necessary to counter gross claims made in published research with more cautious claims found in unpublished research.
Because the quantitative mode of (many) studies demands only a few common variables to be measured in each case, explains Tripp (1985), the accumulation of the studies tends to increase sample size much more than it increases the complexity of the data in terms of the number of variables. Meta-analysis risks attempting to synthesize studies which are insufficiently similar to each other to permit this with any legitimacy (Glass et al., 1981: 22; McGaw, 1997: 372) other than at an unhelpful level of generality. The analogy here might be to try to keep together oil and water as ‘liquids’; metaanalysts would argue that differences between studies and their relationships to findings can be coded and addressed in meta-analysis. Eysenck (1978) suggests that early meta-evaluation studies mixed apples with oranges. Morrison asks:
How can we be certain that meta-analysis is fair if the hypotheses for the separate experiments were not identical, if the hypotheses were not operationalisations of the identical constructs, if the conduct of the separate RCTs (e.g. time frames, interventions and programmes, controls, constitution of the groups, characteristics of the participants, measures used) were not identical?
(Morrison, 2001:78)
Though Smith and Glass (1977), Glass et al. (1981: 218–20), Slavin (1995) and Evans et al., (2000) address these kinds of charges, it remains the case (McGaw, 1997) that there is a risk in meta-analysis of dealing indiscriminately with a large and sometimes incoherent body of research literature. Evans et al., (2000: 221) argue that, nonetheless, weak studies can add up to a strong conclusion and that the differences in the size of experimental effects between high-validity and low-validity studies are surprisingly small (p. 226) (see also Glass et al., 1981:220–6).
It is unclear, too, how meta-analysis differentiates between ‘good’ and ‘bad’ research – e.g. between methodologically rigorous and poorly constructed research (Cook et al, 1992: 297). Smith and Glass (1977) and Levačić and Glatter (2000) suggest that it is possible to use study findings, regardless of their methodological quality, though Glass and Smith (1978) and Slavin (1984a, 1984b), in a study of the effects of class size, indicate that methodological quality does make a difference.
Further, Wood (1995: 296) suggests that meta-analysis oversimplifies results by concentrating on overall effects to the neglect of the interaction of intervening variables. To the charge that because metaanalyses are frequently conducted on large data sets where multiple results derive from the same study (i.e. that the data are nonindependent) and are therefore unreliable, Glass et al. (1981) indicate how this can be addressed by using sophisticated data analysis techniques (pp. 153–216). Finally, a practical concern is the time required not only to use the easily discoverable studies (typically large-scale published studies) but to include the smaller-scale unpublished studies; the effect of neglecting the latter might be to build in bias in the meta-analysis.
Meta-analysis is an attempt to overcome the problems of small samples (see Maynard and Chalmers’s (1997) review of the Cochrane Collaboration in medicine), yet the issue of sampling is complex. RCTs frequently use aggregated and averaged, rather than individual, data (Clarke and Dawson, 1999: 130), which might risk overlooking the distribution or spread of data or the possibilities of following up on individuals. In RCTs in the field of medicine, the issue of generalizability from the sample has been recognized as problematical (Clarke and Dawson, 1999: 131). The authors suggests that, here, in order to ensure that causality is clear, patients suffering from more than one illness might be deliberately excluded from the RCT. This results, characteristically, in small or very small samples, and, in this case, there are limits to generalizability, typicality and representativeness. The same problem can apply to education – in order to establish clear causality, the reduction of the sample to a subset might lead to very small samples. RCTs are inherently reductionist in their sampling. The results of the RCTs may be ‘true’ but trivially so, i.e. unable to be generalized to any wider population or circumstance. The problem here for RCTs is that, in terms of sampling, big is not necessarily beautiful, but neither is small! The simple accretion of results from RCTs through meta-analysis is, of course, a way of validating them, as is the prolongation of the duration of the RCT, but this is blind to the other consequences and activities taking place all around the RCT. A treatment for cancer in multiple RCTs might show it to be effective in reducing cancer, and hence might justify its use; however it might bring a host of other effects which, on balance, and in the eyes of the sufferers, are worse than the cancer.
The issue of sampling is compounded by questions of ethics. For example, in medicine, ethical questions can be raised about the process of randomization, wherein control groups might be denied access to treatment (e.g. the teacher’s attention or access to resources), or where participants might be subjected to potentially hazardous treatments. Fitz-Gibbon and Morris (1987) suggest that one way of addressing this is through the notion of drawing the sample from ‘borderline cases’ only for the control group: patients in greatest need of treatment/intervention are not deprived of it, and it is only those patients who are at the borders of needing treatment that are randomly assigned to control or experimental groups (Clarke and Dawson, 1999: 129). Whilst the borderline method might make for ethical practice, it limits the generalizability of the results. Further, if informed consent is to be obtained from participants, then this might skew the sampling to volunteers, who may or may not be representative of the wider population.
Randomization may not be appropriate in some circumstances. For example, let us imagine a situation where some form of punishment were to be tried in schools for a particular offence. How would one justify not making this a required punishment for all those in the school who committed the particular offence in question? It would contradict natural justice (Wilkins, 1969; see also Clarke and Dawson, 1999: 98) for some offenders to be exempted, in the interests of an experiment.
Clarke and Dawson (1999: 130) draw attention to the fact that in health care treatments may produce adverse reactions, in which case patients are withdrawn from the experiment. Others might simply leave the experiment. That this contributes to ‘experimental mortality’ or attrition rates has been long recognized (Campbell and Stanley, 1963). Less clear in education, however, is how the problem has been, or might be, addressed (cf. Rossi and Freeman, 1993). This might undermine putative parity between the control and experimental groups, a parity which, from earlier arguments about the range of participants and characteristics within and between groups, is already suspect. As the constitution of the groups changes, however slightly (and chaos theory reminds us that small changes can result in massive effects), so the dynamics of the situation change, and the consistency and comparability of the research protocol, conditions, contexts and contents are undermined. To address this involves identifying not only the exact factors on which assignation of the sample to control and experimental groups will take place, but also a recognition of significant ways in which the two groups differ. The judgement then becomes about the extent to which the dissimilarities between the two groups might outweigh their similarities (see the earlier discussion).
Further, in connection with changes to the sample, there is an ‘arrow of time’ (Prigogine and Stengers, 1985) that argues that situations evolve irreversibly and that to overlook this by holding time and situations constant in RCTs is to misrepresent reality. Though Campbell and Stanley’s (1963) influential work on RCTs discusses the threats to internal validity caused by history and maturation (p. 5), and they suggest that randomization can overcome these (pp. 13–14), there is a nagging worry that the importance of these factors -of the people involved in the RCT – might be underestimated. How these can be addressed in education is an open question.
If meta-analysis is to be fair, in the traditions of natural science, it will need to gather and evaluate alternative, rival explanations and data that might refute the hypotheses under investigation. This is, as proponents of RCTs might agree, standard in scientific methodology. Though the advocates of meta-analysis in education (e.g. Fitz-Gibbon, 1984, 1985) suggest the need to utilize both published and unpublished research, there are serious practical problems in that published research may only report ‘successes’ and unpublished research may be difficult to locate, or ownership and release of data may be prohibited or restricted.
What we have, then, in meta-analysis, holds out the possibility of combining studies to provide a clear message about accumulated data from RCTs. The confidence that can be placed in these data, however, is a matter for judgement.
It is the traditional pursuit of generalizations from each quantitative study which has most hampered the development of a database adequate to reflect the complexity of the social nature of education. The cumulative effects of ‘good’ and ‘bad’ experimental studies is graphically illustrated in Figure 17.1.
Glass and Smith (1978) and Glass et al. (1981: 35–44) identified 77 empirical studies of the relationship between class size and pupil learning. These studies yielded 725 comparisons of the achievements of smaller and larger classes, the comparisons resting on data accumulated from nearly 900,000 pupils of all ages and aptitudes studying all manner of school subjects. Using regression analysis, the 725 comparisons were integrated into a single curve showing the relationship between class size and achievement in general. This curve revealed a definite inverse relationship between class size and pupil learning. When the researchers derived similar curves for a variety of circumstances that they hypothesized would alter the basic relationship (for example, grade level, subject taught, pupil ability, etc.), virtually none of these special circumstances altered the basic relationship. Only one factor substantially affected the curve – whether the original study controlled adequately in the experimental sense for initial differences among pupils and teachers in smaller and larger classes. Adequate and inadequate control curves are set out in Figure 17.1.1
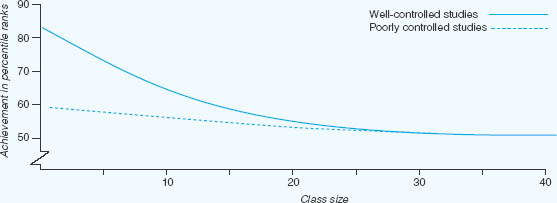
Regression lines for the regression of achievement (expressed in percentile ranks) onto class size for studies that were well-controlled and poorly controlled in the assignment of pupils to classes.
FIGURE 17.1 Class size and learning in well-controlled and poorly controlled studies
Source: Adapted from Glass and Smith, 1978
Whilst meta-analysis is one form of research synthesis, research syntheses and systematic reviews go broader, to include studies that are not solely randomized controlled trials. Research synthesis is an umbrella term which includes a range of styles of bringing together into a single expert review or report several studies and summaries on a particular topic. They often evaluate the quality of these studies, and draw conclusions that enable recommendations to be made for policy and practice.
Systematic reviews are a refinement of general research synthesis, by being more rigorous and less ‘narrative’ in character; they require the use of techniques to minimize bias, they follow protocols and criteria for searching for relevant primary, usually empirical, studies, their inclusion and exclusion, the standards for acceptable methodological rigour, their relevance to the topic in question, the scope of the studies included, team approaches to reviewing in order to reduce bias, the adoption of a consistent and clearly stated approach to combining information from across different studies, and the careful, relevant conclusions and recommendations drawn (Evans and Benefield, 2001: 529; Hemsley-Brown and Sharp, 2003). It is these criteria that separate them from the conventional ‘narrative reviews’, the latter being more wide-ranging and less explicit on their selection criteria (Evans and Benefield, 2001:529).
Systematic reviews may include, for example, surveys, qualitative research, ethnographies and narrative studies (for an introduction to qualitative researcher syntheses we refer readers to Howell Major and Savin-Baden, 2010). They can combine qualitative and quantitative studies, using, for example: narrative reviews and summaries, vote-counting reviews (counting how many results are statistically significant in one direction and how many show no effect (Davies 2000: 367)), best evidence syntheses (based on clear criteria and methodologies for selection of studies), meta-ethnographies (which summarize and synthesize evidence from ethnographic and interpretive, qualitative studies (Slavin, 1986)), thematic analyses, grounded theory, meta-study, realist synthesis, qualitative data analysis techniques from Miles and Huberman (1984) (e.g. within-site and cross-site analysis), content analyses, case surveys and qualitative comparative analysis (Davies, 2000; Dixon-Woods et al., 2005). Research syntheses seek to discover both consistencies in similar-appearing primary studies and also to account for the variability found between them (Cooper and Hedges, 1994: 4), leading to generalizations within the limits and contexts of the research studies used (Davies, 2000: 366).
The EPPI-Centre at the University of London indicates that systematic reviews are characterized by several criteria (http://eppi.ioe.ac.uk/cms/Default.aspx?tabid=67):
they use explicit, rigorous and transparent methods, which must be applied systematically;
they synthesize research studies, based on explicit criteria, in order to avoid bias;
they follow a standard set of stages;
they are accountable, able to be replicated and to be updated;
they are required to be relevant and useful to users;
they are intended to answer specific research questions;
they are evidence-based.
Based on these criteria, the EPPI-Centre indicates several stages that a systematic review must follow (http://eppi.ioe.ac.uk/cms/Default.aspx?tabid=89), including:
approaches to reviewing (including the involvement of users, different kinds of review, and methodological matters);
getting started (including setting the scope and methods of the review and ensuring quality in the review);
gathering and describing research (including locating and screening the studies for review, describing them and clarifying their scope);
appraising and synthesizing the data (including appraising their quality and relevance, synthesizing the findings, drawing conclusions and making recommendations, and reporting);
making use of the review (including disseminating the findings, with advice on how to use and apply the reports’ findings).
The Centre also provides ‘tools’ for undertaking systematic reviews (eppi.ioe.ac.uk/cms/Default.aspx?tabid=184).
The British Educational Research Association also publishes its own guidelines for the conduct of systematic reviews (www.bera.ac.uk/systematic-review/questions-conceptual-framework-and-inclusion-criteria/), which cover:
systematic review questions;
conceptual framework and inclusion/exclusion criteria; and
further reading.
Evans and Benefield (2001: 533–7) set out six principles for undertaking systematic reviews of evidence:
1 a clear specification of the research question which is being addressed;
2 a systematic, comprehensive and exhaustive search for relevant studies;
3 the specification and application of clear criteria for the inclusion and exclusion of studies (including data extraction criteria: published; unpublished; citation details; language; keywords; funding support; type of study (e.g. process- or outcome-focused, prospective or retrospective); nature of the intervention; sample characteristics; planning and processes of the study; outcome evaluation) and descriptive data on the studies (e.g. from funded or non-funded research, the type of study (process- or outcome-focused), the intervention made, the population and sampling, the design and planning of the intervention and the study, the evaluation of the outcome) (Evans and Benefield, 2001: 537);
4 evaluations of the quality of the methodology used in each study (e.g. the kind of experiment and sample; reporting of outcome measures);
5 the specification of strategies for reducing bias in selecting and reviewing studies;
6 transparency in the methodology adopted for reviewing the studies.
Cooper (2010) sets out a seven-step sequence for undertaking systematic reviews:
1 formulating the problem (including identifying the kinds of research evidence that will be relevant to answer the research question or hypothesis in the area of interest, looking at research designs in the studies used, the treatment of the main effects, drawing on qualitative and quantitative research, identifying the kind of research (e.g. descriptive or causal), judging the conceptual relevance of the studies, screening the studies);
2 searching the literature (including searching, locating and retrieving relevant literature, different kinds of literature, the status of the literature, addressing the adequacy of the literature);
3 gathering information from studies (including how to develop a coding guide, identifying predictor and outcome variables, research designs used, sampling, context, statistics used, effect sizes, using a coding guide);
4 evaluating the quality of studies (deciding which studies to include and exclude, identifying problems in the research studies used, evaluating the suitability of the research design for the research synthesis, evaluating the quality and rigour of the research);
5 analysing and integrating the outcomes of studies;
6 interpreting the evidence;
7 presenting the results.
Davies (2000: 373) cautions researchers to ensure that systematic reviews do not use evidence selectively to provide overwhelming evidence of ‘a positive effect of most educational interventions’, i.e. that they are a consequence of the methodology of the review in question, and to ensure that statistical significance does not override educational significance. His comments apply equally appropriately to meta-analysis and research syntheses. Examples of studies that use meta-evaluation and research syntheses can be found from the websites indicated at the start of this chapter, and also in the references given throughout the chapter.
 Companion Website
Companion WebsiteThe companion website to the book includes PowerPoint slides for this chapter, which list the structure of the chapter and then provide a summary of the key points in each of its sections. This resource can be found online at www.routledge.com/textbooks/cohen7e.