 defining validity
defining validityValidity and reliability |
CHAPTER 10 |
This chapter discusses validity and reliability in quantitative, qualitative, naturalistic and mixed methods research. It suggests that both of these terms can be applied to these different types of research, though how validity and reliability are addressed in different approaches varies. The chapter indicates how validity and reliability are addressed, using different instruments for data collection. The chapter proceeds in several stages:
defining validity
validity in quantitative and qualitative research
types of validity
triangulation
validity in mixed methods research
ensuring validity
reliability
reliability in quantitative and qualitative research
validity and reliability in interviews, experiments, questionnaires, observations, tests and life histories
There are many different types of validity and reliability. Threats to validity and reliability can never be erased completely; rather the effects of these threats can be attenuated by attention to validity and reliability throughout a piece of research.
It is suggested that reliability is a necessary but insufficient condition for validity in research; reliability is a necessary precondition of validity, and validity may be a sufficient but not necessary condition for reliability. Brock-Utne (1996: 612) contends that the widely held view that reliability is the sole preserve of quantitative research has to be exploded, and this chapter demonstrates the significance of her view.
Validity is an important key to effective research. If a piece of research is invalid then it is worthless. Validity is thus a requirement for both quantitative and qualitative/naturalistic research.
Whilst earlier versions of validity were based on the view that it was essentially a demonstration that a particular instrument in fact measures what it purports to measure, or that an account accurately represents ‘those features that it is intended to describe, explain or theorise’ (Winter, 2000: 1), more recently validity has taken many forms. For example, in qualitative data validity might be addressed through the honesty, depth, richness and scope of the data achieved, the participants approached, the extent of triangulation and the disinterestedness or objectivity of the researcher (Winter, 2000). In quantitative data validity might be improved through careful sampling, appropriate instrumentation and appropriate statistical treatments of the data. It is impossible for research to be 100 per cent valid; that is the optimism of perfection. Quantitative research possesses a measure of standard error which is inbuilt and which has to be acknowledged. In qualitative data the subjectivity of respondents, their opinions, attitudes and perspectives together contribute to a degree of bias. Validity, then, should be seen as a matter of degree rather than as an absolute state (Gronlund, 1981). Hence at best we strive to minimize invalidity and maximize validity.
There are several different kinds of validity, e.g.
catalytic validity
concurrent validity
consequential validity
construct validity
content validity
criterion-related validity
convergent and discriminant validity
cross-cultural validity
cultural validity
descriptive validity
ecological validity
evaluative validity
external validity
face validity
internal validity
interpretive validity
jury validity
predictive validity
systemic validity
theoretical validity.
It is not our intention in this chapter to discuss all these terms in depth. Rather the main types of validity will be addressed. The argument will be made that, whilst some of these terms are more comfortably the preserve of quantitative methodologies, this is not exclusively the case. Indeed, validity is the touchstone of all types of educational research. That said, it is important that validity in different research traditions is faithful to those traditions; it would be absurd to declare a piece of research invalid if it were not striving to meet certain kinds of validity, e.g. generalizability, replicability, controllability. Hence the researcher will need to locate discussions of validity within the research paradigm that is being used. This is not to suggest, however, that research should be paradigm-bound, that is a recipe for stagnation and conservatism. Validity and reliability have different meanings in quantitative and qualitative research, and it is important not only to indicate these clearly, but for the researcher to demonstrate fidelity to the approach in which she or he is working and to abide by the principles of validity and reliability they require. We address this in the chapter here, locating different interpretations of validity and reliability within the different paradigms. Hammersley (1992a: 39) argues that there are only two paradigms – quantitative and qualitative – and that these are more or less mutually exclusive. However, one of the purposes of the opening three chapters of this book was to indicate the multiplicity of paradigms. Our reference to quantitative and qualitative paradigms here is for simple, heuristic purposes.
In much quantitative research, validity must be faithful to its premises of positivism and positivist principles, e.g.
controllability
replicability
predictability
the derivation of laws and universal statements of behaviour (i.e. generalizability)
context-freedom
fragmentation and atomization of research
randomization of samples
neutrality/objectivity
observability.
It must also ensure that the types of validity discussed below are satisfactorily addressed. In many cases this involves being faithful to the assumptions underpinning the statistics used, the construct and content validity of the measures used, the careful sampling, and the avoidance of a range of threats to internal and external validity outlined later in this chapter.
Much qualitative research abides by principles of validity that are very different from those of positivism and quantitative methods. Validity in qualitative research has several principles (Lincoln and Guba, 1985; Bogdan and Biklen, 1992):
the natural setting is the principal source of data;
context-boundedness and ‘thick description’;
data are socially situated, and socially and culturally saturated;
the researcher is part of the researched world;
as we live in an already interpreted world, a doubly hermeneutic exercise (Giddens, 1979) is necessary to understand others’ understandings of the world; the paradox here is that the most sufficiently complex instrument to understand human life is another human (Lave and Kvale, 1995: 220), but that this risks human error in all its forms;
holism in the research;
the researcher – rather than a research tool – is the key instrument of research;
the data are descriptive;
there is a concern for processes rather than simply with outcomes;
data are analysed inductively rather than using a priori categories;
data are presented in terms of the respondents rather than researchers;
seeing and reporting the situation through the eyes of participants – from the native’s point of view (Geertz, 1974);
respondent validation is important;
catching meaning and intention are essential.
Indeed Maxwell (1992) argues that qualitative researchers need to be cautious not to be working within the agenda of the positivists in arguing for the need for research to demonstrate concurrent, predictive, convergent, criterion-related, internal and external validity. The discussion below indicates that this need not be so. He argues, with Guba and Lincoln (1989), for the need to replace positivist notions of validity in qualitative research with the notion of authenticity. Maxwell, echoing Mishler (1990), suggests that ‘understanding’ is a more suitable term than ‘validity’ in qualitative research. We, as researchers, are part of the world that we are researching, and we cannot be completely objective about that, hence other people’s perspectives are equally as valid as our own, and the task of research is to uncover these. Validity, then, attaches to accounts, not to data or methods (Hammersley and Atkinson, 1983); it is the meaning that subjects give to data and inferences drawn from the data that are important. ‘Fidelity’ (Blumenfeld-Jones, 1995) requires the researcher to be as honest as possible to the self-reporting of the researched.
The claim is made (Agar, 1993) that in qualitative data collection the intensive personal involvement and in-depth responses of individuals secure a sufficient level of validity and reliability. This claim is contested by Hammersley (1992b: 144) and Silverman (1993: 153), who argue that these are insufficient grounds for validity and reliability, and that the individuals concerned have no privileged position on interpretation. (Of course, neither are actors ‘cultural dopes’ who need a sociologist or researcher to tell them what is ‘really’ happening!) Silverman argues that, whilst immediacy and authenticity make for interesting journalism, ethnography must have more rigorous notions of validity and reliability. This involves moving beyond selecting data simply to fit a preconceived or ideal conception of the phenomenon or because they are spectacularly interesting (Fielding and Fielding, 1986). Data selected must be representative of the sample, the whole data set, the field, i.e. they must address content, construct and concurrent validity.
Hammersley (1992a: 50–1) suggests that validity in qualitative research replaces certainty with confidence in our results, and that, as reality is independent of the claims made for it by researchers, our accounts will only be representations of that reality rather than reproductions of it. Lincoln and Guba (1985) suggest that key criteria of validity in qualitative research are: (a) credibility (replacing the quantitative concepts of internal validity); (b) transferability (replacing the quantitative concept of external validity); (c) dependability (replacing the quantitative concept of reliability); and (d) confirmability (replacing the quantitative concept of objectivity).
Lincoln and Guba (1985) argue that, within these criteria of validity, rigour can be achieved by careful audit trails of evidence, member checking/respondent validation (confirmation by participants) when coding or categorizing results, peer debriefing, negative case analysis, ‘structural corroboration’ (triangulation, discussed below) and ‘referential material adequacy’ (adequate reference to standard materials in the field). Trustworthiness, they suggest, can be addressed in the credibility, fittingness, auditability and confirmability of the data (see also Morse et al., 2002).
Whereas quantitative data, particularly in the positivist tradition, place great store by both external validity and internal validity, the emphasis in much qualitative research is on internal validity, and, in many cases, external validity is an irrelevance for qualitative research (Winter, 2000: 8) – it does not seek to generalize but only to represent the phenomenon being investigated, fairly and fully. (Of course, some qualitative research, e.g. Miles and Huberman (1994) does move towards generalizability, and, indeed, Chapter 1 indicated that qualitative data could be ‘quantitized’. It is possible, but the overwhelming feature of qualitative research is its concern with the phenomenon or situation in question, and not generalizability.) Hence issues such as random sampling, replicability, alpha coefficients of reliability, isolation and control of variables, and predictability simply do not matter in much qualitative research.
Maxwell (1992) argues for five kinds of validity in qualitative methods that explore his notion of ‘understanding’:
descriptive validity (the factual accuracy of the account, that it is not made up, selective, or distorted (cf. Winter, 2000: 4)); in this respect validity subsumes reliability; it is akin to Blumenfeld-Jones’s (1995) notion of ‘truth’ in research – what actually happened (objectively factual) and to Glaser and Strauss’s (1967) term ‘credibility’;
interpretive validity (the ability of the research to catch the meaning, interpretations, terms, intentions that situations and events, i.e. data, have for the participants/subjects themselves, in their terms); it is akin to Blumenfeld-Jones’s (1995) notion of ‘fidelity’ – what it means to the researched person or group (subjectively meaningful); interpretive validity has no clear counterpart in experimental/positivist methodologies;
theoretical validity (the theoretical constructions that the researcher brings to the research (including those of the researched)); theory here is regarded as explanation. Theoretical validity is the extent to which the research explains phenomena; in this respect is it akin to construct validity (discussed below); in theoretical validity the constructs are those of all the participants;
generalizability (the view that the theory generated may be useful in understanding other similar situations); generalizing here refers to generalizing within specific groups or communities, situations or circumstances (internal validity) and, beyond, to specific outsider communities, situations or circumstance (external validity); internal validity has greater significance here than external validity;
evaluative validity (the application of an evaluative, judgmental stance towards that which is being researched, rather than a descriptive, explanatory or interpretive framework). Clearly this resonates with critical-theoretical perspectives, in that the researcher’s own evaluative agenda might intrude.
To this one can add Auerbach and Silverstein’s (2003) category of transparency, i.e. how far the reader can understand, and is informed of, the processes by which the interpretation made is actually reached.
Validity in qualitative research depends on the purposes of the participants, the actors, and the appropriateness of the data collection methods used to catch those purposes (Winter, 2000: 7).
Differences in the meanings and criteria for validity in quantitative and qualitative are summarized in Table 10.1. Clearly the criteria are not the exclusive preserve of each of the two main types of research here (quantitative and qualitative). The intention of Table 10.1 is heuristic and to indicate emphases only.
Onwuegbuzie and Leech (2006b 239–46) set out many steps that researchers can take in order to ensure validity in qualitative research (several of which derive from Lincoln and Guba, 1985; see also Teddlie and Tashakkori, 2009: 295–7). These include:
prolonged engagement in the field (to gather rich and sufficient data);
persistent observation (to identify key relevant issues and to separate these from comparative irrelevancies);
triangulation (discussed later in this chapter);
leaving an audit trail (documentation and records used in the study that include: raw data; records of analysis and data reduction; reconstructions and syntheses of data; ‘process notes’ (on how the research and analysis are proceeding); notes on ‘intentions and dispositions’ of the researcher as the study proceeds; information concerning the development of instruments for data collection);
member checking/informant feedback (respondent validation, discussed below);
weighting the evidence (ensuring that correct attention is paid to higher quality data (e.g. those data gathered from long engagement, detailed study and trusted participants) and less attention is paid to low quality data);
checking for representativeness (ensuring that unsupported generalizability of the findings is avoided);
checking for researcher effects/clarifying researcher bias (how far the personal biases, assumptions or values of the researcher, or how far the researcher’s personal characteristics (e.g. clothing, appearance, sex, age, ethnicity) affect the research);
making contrast/comparisons (e.g. between subgroups, sites, literature);
theoretical sampling (following the data and where they lead, rather than leading the data, and ensuring that the research addresses all the required aspects of the theory);
checking the meaning of outliers (rather than ignoring outliers and exceptions, researchers should examine to see what leverage into an understanding of the phenomenon in question is provided by outliers);
using extreme cases (e.g. to identify what is missing in the majority of cases);
ruling out spurious relations (avoiding attributing causality or association where none exists);
replicating a finding (identifying how far the findings might apply to other groups);
referential adequacy (how well referenced are the findings to benchmark or significant literature);
following up surprises (avoiding/ignoring surprise results);
structural relationships (looking for consistency between the findings – with each other and with literature);
peer debriefing (external evaluation of the research, its conduct and findings);
rich and thick description (providing detail to support and corroborate findings);
the modus operandi approach (specifically looking for possible sources of invalidity in the research);
assessing rival explanations (looking for alternative interpretations and explanations of the data);
negative case analysis (examining disconfirming cases to see if the hypotheses or findings need to be amended in light of them);
confirmatory data analysis (conducting qualitative replication studies where possible);
effect sizes (avoiding simply ‘binarizing’ matters (e.g. strong/weak; present/absent; positive/negative) and replacing these with indications of size/power or strength of the findings).
TABLE 10.1 COMPARING VALIDITY IN QUANTITATIVE AND QUALITATIVE RESEARCH
Bases of validity in quantitative research |
|
Bases of validity in qualitative research |
Controllability |
↔ |
Natural |
Isolation, control and manipulation of required Variables |
↔ |
Thick description and high detail on required or important aspects |
Replicability |
↔ |
Uniqueness |
Predictability |
↔ |
Emergence, unpredictability |
Generalizability |
↔ |
Uniqueness |
Context-freedom |
↔ |
Context-boundedness |
Fragmentation and atomization of research |
↔ |
Holism |
Randomization of samples |
↔ |
Purposive sample/no sampling |
Neutrality |
↔ |
Value-ladenness of observations/double hermeneutic |
Objectivity |
↔ |
Confirmability |
Observability |
↔ |
Observability and non-observable meanings and intentions |
Inference |
↔ |
Description, inference and explanation |
‘Etic’ research |
↔ |
‘Emic’ research |
Internal validity |
↔ |
Credibility |
External validity |
↔ |
Transferability |
Reliability |
↔ |
Dependability |
Observations |
↔ |
Meanings |
This comprehensive list of ways of striving to ensure validity in qualitative research has similarities in some places with those of quantitative research (e.g. replication, researcher bias, external evaluation, representativeness, suitable generalizability, theoretical sampling triangulation, transparency, etc.). This suggests that whilst there may be different canons of validity between quantitative and qualitative research, and whilst there may be different interpretations of the meaning of ‘validity’ in different kinds of research, nevertheless there is some common ground between them; they are not mutually exclusive.
In the following sections, which describe types of validity, where it is useful to separate the interpretations of that form of validity in quantitative and qualitative research, this has been done. In some cases (e.g. catalytic, consequential validity), as the issues remain the same regardless of the types of research, this separation has not been done. The scene is set by considerations of internal and external validity, and then the remaining types of validity are considered in alphabetical order of the titles of each type.
Both qualitative and quantitative methods can address internal and external validity. Internal validity seeks to demonstrate that the explanation of a particular event, issue or set of data which a piece of research provides can actually be sustained by the data. In some degree this concerns accuracy, which can be applied to quantitative and qualitative research. The findings must describe accurately the phenomena being researched. Onwuegbuzie and Leech (2006b: 234) define internal validity as the ‘truth value, applicability, consistency, neutrality, dependability, and/or credibility of interpretations and conclusions within the underlying setting or group’.
Internal validity in quantitative research
The following summaries adapted from Campbell and Stanley (1963), Bracht and Glass (1968) and Lewis-Beck (1993) distinguish between ‘internal validity’ and ‘external validity’. Internal validity is concerned with the question, do the experimental treatments, in fact, make a difference in the specific experiments under scrutiny? External validity, on the other hand, asks the question, given these demonstrable effects, to what populations or settings can they be generalized?
There are several kinds of threat to internal validity in quantitative research, for example (many of these apply strongly, though not exclusively, to experimental research):
History Frequently in educational research, events other than the intervention treatments occur during the time between pre-test and post-test observations (e.g. in a longitudinal survey, experiment, action research). Such events produce effects that can mistakenly be attributed to differences in treatment.
Maturation Between any two observations subjects change in a variety of ways. Such changes can produce differences that are independent of the research. The problem of maturation is more acute in protracted educational studies than in brief laboratory experiments.
Statistical regression Like maturation effects, regression effects increase systematically with the time interval between pre-tests and post-tests (e.g. in action research, experiments or longitudinal research). Statistical regression occurs in educational (and other) research due to the unreliability of measuring instruments and to extraneous factors unique to each group, e.g. in an experiment. Regression means, simply, that subjects scoring highest on a pre-test are likely to score relatively lower on a post-test; conversely, those scoring lowest on a pretest are likely to score relatively higher on a posttest. In short, in pre-test/post-test situations, there is regression to the mean. Regression effects can lead the educational researcher mistakenly to attribute post-test gains and losses to low scoring and high scoring respectively.
Testing Pre-tests at the beginning of research (e.g. experiments, action research, observational research) can produce effects other than those due to the research treatments. Such effects can include sensitizing subjects to the true purposes of the research and practice effects which produce higher scores on post-test measures.
Instrumentation Unreliable tests or instruments can introduce serious errors into research (e.g. testing, surveys, experiments). With human observers or judges or changes in instrumentation and calibration, error can result from changes in their skills and levels of concentration over the course of the research.
Selection Bias may be introduced as a result of differences in the selection of subjects for the comparison groups or when intact classes are employed as experimental or control groups. Selection bias, moreover, may interact with other factors (history, maturation, etc.) to cloud even further the effects of the comparative treatments.
Experimental mortality The loss of subjects through dropout often occurs in long-running research (e.g. experiments, longitudinal research, action research) and may result in confounding the effects of the variables, for whereas initially the groups may have been randomly selected, the residue that stays the course is likely to be different from the unbiased sample that began it.
Instrument reactivity The effects that the instruments of the study exert on the people in the study (e.g. observational research, action research, experiments, case studies) (see also Vulliamy et al., 1990).
Selection-maturation interaction Where there is a confusion between the research design effects and the variable’s effects.
Type I and Type II errors Failure to find something (e.g. a difference between groups) when it exists, and finding something (e.g. a difference between groups) when nothing exists, respectively.
A Type I error is committed where the researcher rejects the null hypothesis when it is in fact true (akin to convicting an innocent person (Mitchell and Jolley, 1988: 121)); this can be addressed by setting a more rigorous level of significance (e.g. ρ < 0.01 rather than ρ < 0.05). A Type II error is committed where the null hypothesis is accepted when it is in fact not true (akin to finding a guilty person innocent (Mitchell and Jolley, 1988: 121)). Boruch (1997: 211) suggests that a Type II error may occur if: (a) the measurement of a response to the intervention is insufficiently valid; (b) the measurement of the intervention is insufficiently relevant; (c) the statistical power of the experiment is too low; (d) the wrong population was selected for the intervention.
A Type II error can be addressed by reducing the level of significance (e.g. ρ < 0.20 or ρ < 0.30 rather than ρ < 0.05). Of course, the more one reduces the chance of a Type I error the more chance there is of committing a Type II error, and vice versa. In qualitative data a Type I error is committed when a statement is believed when it is, in fact, not true, and a Type II error is committed when a statement is rejected when it is in fact true.
Internal validity in qualitative research
In ethnographic research internal validity can be addressed in several ways (LeCompte and Preissle, 1993: 338):
using low-inference descriptors;
using multiple researchers;
using participant researchers;
using peer examination of data;
using mechanical means to record, store and retrieve data.
In ethnographic, qualitative research there are several overriding kinds of internal validity (LeCompte and Preissle, 1993: 323–4):
confidence in the data;
the authenticity of the data (the ability of the research to report a situation through the eyes of the participants);
the cogency of the data;
the soundness of the research design;
the credibility of the data;
the auditability of the data;
the dependability of the data;
the confirmability of the data.
The writers provide greater detail on the issue of authenticity, arguing for the following:
fairness (that there should be a complete and balanced representation of the multiple realities in, and constructions of, a situation);
ontological authenticity (the research should provide a fresh and more sophisticated understanding of a situation, e.g. making the familiar strange, a significant feature in reducing ‘cultural blindness’ in a researcher, a problem which might be encountered in moving from being a participant to being an observer (Brock-Utne, 1996: 610));
educative authenticity (the research should generate a new appreciation of these understandings);
catalytic authenticity (the research gives rise to specific courses of action);
tactical authenticity (the research should bring benefit to all involved – the ethical issue of ‘beneficence’).
Hammersley (1992b: 71) suggests that internal validity for qualitative data requires attention to:
plausibility and credibility;
the kinds and amounts of evidence required (such that the greater the claim that is being made, the more convincing the evidence has to be for that claim);
clarity on the kinds of claim made from the research (e.g. definitional, descriptive, explanatory, theory generative).
Lincoln and Guba (1985: 219, 301) suggest that credibility in naturalistic enquiry can be addressed by:
prolonged engagement in the field;
persistent observation (in order to establish the relevance of the characteristics for the focus);
triangulation (of methods, sources, investigators and theories);
peer debriefing (exposing oneself to a disinterested peer in a manner akin to cross-examination, in order to test honesty, working hypotheses and to identify the next steps in the research);
negative case analysis (in order to establish a theory that fits every case, revising hypotheses retrospectively);
member checking (respondent validation to assess intentionality, to correct factual errors, to offer respondents the opportunity to add further information or to put information on record; to provide summaries and to check the adequacy of the analysis).
Whereas in positivist research, history and maturation are viewed as threats to the validity of the research, ethnographic research simply assumes that this will happen; ethnographic research allows for change over time – it builds it in. Internal validity in ethnographic research is also addressed by the reduction of observer effects by having the observers sample both widely and staying in the situation for such a long time that their presence is taken for granted. Further, by tracking and storing information clearly, it is possible for the ethnographer to eliminate rival explanations of events and situations.
Onwuegbuzie and Leech (2006b: 235–7) identify twelve kinds of threat to internal validity in qualitative research:
1 Ironic legitimation (how far the research recognizes and is able to work with multiple realities and interpretations of the same situation, even if they are simultaneously contradictory).
2 Paralogical legitimation (how far the research is able to catch and address paradoxes in the claims to validity).
3 Rhizomatic legitimation (how much the research loses data when mapping of data rather than describing takes place).
4 Voluptuous legitimation (how far the interpretation placed on the data exceeds the capability of the researcher to support that interpretation from the data).
5 Descriptive validity (the accuracy of the account given by the researcher).
6 Observational bias (inadequate sampling of words, observations or behaviours in the study).
7 Researcher bias (discussed earlier).
8 Reactivity (how far the research alters the situation being researched or the participants in the research, e.g. the Hawthorne effect (discussed below) and the novelty effect).
9 Confirmation bias (the tendency for a piece of research to confirm existing findings or hypotheses (e.g. a circular argument)).
10 Illusory confirmation (the tendency to find relationships (e.g. between people, behaviours or events) when, in fact, they do not exist).
11 Causal error (inferring causal relations when none exist or where no evidence has been provided of their existence).
12 Effect size (avoiding taking numerical effect sizes and qualitizing them, when such a step would enrich the analysis; failure to take into account effect sizes and the meaningfulness that they could bring to the interpretation of the data).
External validity refers to the degree to which the results can be generalized to the wider population, cases, settings, times or situations, i.e. to the transferability of the findings. The issue of generalization is problematical. For positivist researchers generalizability is a sine qua non, whilst this is far less the case in naturalistic research. For one school of thought, generalizability through stripping out contextual variables is fundamental, whilst, for another, generalizations that say little about the context have little that is useful to say about human behaviour (Schofield, 1990). For positivists variables have to be isolated, controlled and samples randomized, whilst for ethnographers human behaviour is infinitely complex, irreducible, socially situated and unique.
External validity in quantitative research
External validity in quantitative research concerns generalizability, typically how far we can generalize from a sample to a population.
Bogdan and Biklen (1992: 45) argue that positivist researchers are more concerned to derive universal statements of general social processes rather than to provide accounts of the degree of commonality between various social settings (e.g. schools and classrooms).
Threats to external validity are likely to limit the degree to which generalizations can be made from the particular – often experimental – conditions to other populations or settings. Below, we summarize a number of factors (adapted from Campbell and Stanley, 1963; Bracht and Glass, 1968; Hammersley and Atkinson, 1983; Vulliamy, 1990; Lewis-Beck, 1993; Onwuegbuzie and Johnson, 2006b) that jeopardize external validity.
Failure to describe independent variables explicitly Unless independent variables are adequately described by the researcher, future replications of the research conditions are virtually impossible.
Lack of representativeness of available and target populations Whilst those participating in the research may be representative of an available population, they may not be representative of the population to which the researcher seeks to generalize her findings, i.e. poor sampling and/or randomization.
Hawthorne effect Medical research has long recognized the psychological effects that arise out of mere participation in drug experiments, and placebos and double-blind designs are commonly employed to counteract the biasing effects of participation. Similarly, so-called Hawthorne effects threaten to contaminate research treatments in educational research when subjects realize their role as guinea pigs.
Inadequate operationalizing of dependent variables Dependent variables that the researcher operationalizes must have validity in the non-research setting to which she wishes to generalize her findings. A paper and pencil questionnaire on career choice, for example, may have little validity in respect of the actual employment decisions made by undergraduates on leaving university.
Sensitization/reactivity to experimental/research conditions As with threats to internal validity, pretests may cause changes in the subjects’ sensitivity to the intervention variables and thus cloud the true effects of the treatment.
Interaction effects of extraneous factors and experimental/research treatments All the above threats to external validity represent interactions of various clouding factors with treatments. As well as these, interaction effects may also arise as a result of any or all those factors, see threats to internal validity below.
Invalidity or unreliability of instruments The use of instruments which yield data in which confidence cannot be placed (see below on tests).
Ecological validity, and its partner, the extent to which behaviour observed in one context can be generalized to another. Hammersley and Atkinson (1983: 10) comment on the serious problems that surround attempts to relating inferences from responses gained under experimental conditions, or from interviews, to everyday life.
Multiple treatment validity Applying several treatments simultaneously or in sequence may cause interaction effects between these treatments, such that it is difficult, if not impossible, to isolate the effects of particular treatments.
External validity in qualitative research
Generalizability in naturalistic research is interpreted as comparability and transferability (Lincoln and Guba, 1985; Eisenhart and Howe, 1992: 647). These writers suggest that it is possible to assess the typicality of a situation, the participants and settings, to identify possible comparison groups, and to indicate how data might translate into different settings and cultures (see also LeCompte and Preissle, 1993: 348). Schofield (1996: 200) suggests that it is important in qualitative research to provide a clear, detailed and in-depth description so that others can decide the extent to which findings from one piece of research are generalizable to another situation, i.e. to address the twin issues of comparability and translatability. Indeed, qualitative research can be generalizable, his paper argues (p. 209), by studying the typical (for its applicability to other situations – the issue of transferability (LeCompte and Preissle, 1993: 324)) and by performing multi-site studies (e.g. Miles and Huberman, 1984), though it could be argued that this is injecting a degree of positivism into non-positivist research. Lincoln and Guba (1985: 316) caution the naturalistic researcher against this; they argue that it is not the researcher’s task to provide an index of transferability; rather, they suggest, researchers should provide sufficiently rich data for the readers and users of research to determine whether transferability is possible. In this respect transferability requires thick description.
Bogdan and Biklen (1992: 45) argue that in qualitative research we are more interested not with the issue of whether the findings are generalizable in the widest sense but with the question of the settings, people and situations to which they might be generalizable.
In naturalistic research threats to external validity include (Lincoln and Guba, 1985: 189, 300):
selection effects (where constructs selected in fact are only relevant to a certain group);
setting effects (where the results are largely a function of their context);
history effects (where the situations have been arrived at by unique circumstances and, therefore, are not comparable);
construct effects (where the constructs being used are peculiar to a certain group).
Onwuegbuzie and Leech (2006b: 237–8) identify several threats to external validity in qualitative research that lie in the following fields:
1 Catalytic validity (how far the research empowers the research community, or the effects of a piece of research).
2 Action validity (how much use is made of the research findings by stakeholders and decision makers).
3 Investigation validity (the ethical rigour, expertise, quality control and, indeed, personality of the researcher).
4 Interpretive validity (how far the research catches the meanings and interpretations of the participants in the study).
5 Evaluative validity (how far an evaluative structure (rather than a descriptive, interpretive or explanatory structure) can be applied to the research).
6 Consensual validity (how far the ‘competent others’ agree on the interpretations made by the research).
7 Population generalizability/ecological generalizability/temporal generalizability (how successfully have the researchers kept within the bounds of generalizability/non-generalizability of their findings).
8 Researcher bias (as for internal validity in qualitative research).
9 Reactivity (as for internal validity in qualitative research).
10 Order bias (where the order of the questions posed in an interview/observation/questionnaire affects the dependability of the results).
11 Effect size (as for internal validity in qualitative research).
Catalytic validity embraces the paradigm of critical theory discussed in Chapter 2. Put neutrally, catalytic validity simply strives to ensure that research leads to action, echoing the paradigm of participatory research in Chapter 2. However, the story does not end there, for discussions of catalytic validity are substantive; like critical theory, catalytic validity suggests an agenda. Lather (1986, 1991) and Kincheloe and McLaren (1994) suggest that the agenda for catalytic validity is to help participants to understand their worlds in order to transform them. The agenda is explicitly political, for catalytic validity suggests the need to expose whose definitions of the situation are operating in the situation. Lincoln and Guba (1986) suggest that the criterion of ‘fairness’ should be applied to research, meaning that it should (a) augment and improve the participants’ experience of the world, and (b) that it should improve the empowerment of the participants. In this respect the research might focus on what might be (the leading edge of innovations and future trends) and what could be (the ideal, possible futures) (Schofield, 1990: 209).
Catalytic validity – a major feature in feminist research which, Usher (1996) suggests, needs to permeate all research – requires solidarity in the participants, an ability of the research to promote emancipation, autonomy and freedom within a just, egalitarian and democratic society (Masschelein, 1991), to reveal the distortions, ideological deformations and limitations that reside in research, communication and social structures (see also LeCompte and Preissle, 1993). Validity, it is argued (Mishler, 1990; Scheurich, 1996), is no longer an ahistorical given, but contestable, suggesting that the definitions of valid research reside in the academic communities of the powerful. Lather (1986) calls for research to be emancipatory and to empower those who are being researched, suggesting that catalytic validity, akin to Freire’s notion of ‘conscientization’, should empower participants to understand and transform their oppressed situation.
Validity, it is proposed (Sheurich, 1996), is but a mask that in fact polices and sets boundaries to what is considered to be acceptable research by powerful research communities; discourses of validity in reality are discourses of power to define worthwhile knowledge.
How defensible it is to suggest that researchers should have such ideological intents is, perhaps, a moot point, though not to address this area is to perpetuate inequality by omission and neglect. Catalytic validity reasserts the centrality of ethics in the research process, for it requires researchers to interrogate their allegiances, responsibilities and self-interestedness (Burgess, 1989).
Partially related to catalytic validity is consequential validity, which argues that the ways in which research data are used (the consequences of the research) are in keeping with the capability or intentions of the research, i.e. the consequences of the research do not exceed the capability of the research and the action-related consequences of the research are both legitimate and ful-filled. Clearly, once the research is in the public domain the researcher has little or no control over the way in which it is used. However, and this is often a political matter, research should not be used in ways in which it was not intended to be used, for example by exceeding the capability of the research data to make claims, by acting on the research in ways that the research does not support (e.g. by using the research for illegitimate epistemic support), by making illegitimate claims by using the research in unacceptable ways (e.g. by selection, distortion), and by not acting on the research in ways that were agreed, i.e. errors of omission and commission.
A clear example of consequential validity is formative assessment. This is concerned with the extent to which students improve as a result of feedback given, hence if there is insufficient feedback for students to improve, or if students are unable to improve as a result of – a consequence of – the feedback, then the formative assessment has little consequential validity.
To demonstrate this form of validity the instrument must show that it fairly and comprehensively covers the domain or items that it purports to cover (Carmines and Zeller, 1979: 20). It is unlikely that each issue will be able to be addressed in its entirety simply because of the time available or respondents’ motivation to complete, for example, a long questionnaire. If this is the case, then the researcher must ensure that the elements of the main issue to be covered in the research are both a fair representation of the wider issue under investigation (and its weighting) and that the elements chosen for the research sample are themselves addressed in depth and breadth. Careful sampling of items is required to ensure their representativeness. For example, if the researcher wished to see how well a group of students could spell 1,000 words in French but decided only to have a sample of 50 words for the spelling test, then that test would have to ensure that it represented the range of spellings in the 1,000 words – maybe by ensuring that the spelling rules had all been included or that possible spelling errors had been covered in the test in the proportions in which they occurred in the 1,000 words.
A construct is an abstract; this separates it from the previous types of validity which dealt in actualities – defined content. In this type of validity agreement is sought on the ‘operationalized’ forms of a construct, clarifying what we mean when we use this construct. Hence in this form of validity the articulation of the construct is important; is my understanding of this construct similar to that which is generally accepted to be the construct? For example, let us say that I wished to assess a child’s intelligence (assuming, for the sake of this example, that it is a unitary quality). I could say that I construed intelligence to be demonstrated in the ability to sharpen a pencil. How acceptable a construction of intelligence is this? Is not intelligence something else (e.g. that which is demonstrated by a high score in an intelligence test)? To establish construct validity I would need to be assured that my construction of a particular issue agreed with other constructions or theories of the same underlying issue, e.g. intelligence, creativity, anxiety, motivation.
Construct validity, then, concerns the extent to which a particular measure or instrument for data collection conforms to the theoretical context in which it is located.
Demonstrating construct validity means not only confirming the construction with that given in relevant literature, but requires me to look for counter examples which might falsify my construction. When I have balanced confirming and refuting evidence I am in a position to demonstrate construct validity. I can stipulate what I take this construct to be. In the case of conflicting interpretations of a construct, I might have to acknowledge that conflict and then stipulate the interpretation that I shall use.
Construct validity in quantitative research
Construct validity in quantitative research can be achieved through correlations with other measures of the issue or by rooting my construction in a wide literature search which teases out the meaning of a particular construct (i.e. a theory of what that construct is) and its constituent elements.
Campbell and Fiske (1959), Brock-Utne (1996) and Cooper and Schindler (2001) suggest that construct validity is addressed by convergent and discriminant techniques. Convergent techniques imply that different methods for researching the same construct should give a relatively high inter-correlation, whilst discriminant techniques suggest that using similar methods for researching different constructs should yield relatively low inter-correlations, i.e. that the construct in question is different from other potentially similar constructs. Such discriminant validity can also be yielded by factor analysis, which clusters together similar issues and separates them from others.
Construct validity in qualitative research
In qualitative/ethnographic research construct validity must demonstrate that the categories that the researchers are using are meaningful to the participants themselves (Eisenhart and Howe, 1992: 648), i.e. that they reflect the way in which the participants actually experience and construe the situations in the research, that they see the situation through the actors’ eyes.
Convergent and discriminant validity are two sides of the same coin, and are both facets of construct validity. Convergent validity is demonstrated when two related or similar factors or elements of a particular construct are shown (e.g. by measures or indicators) to be related or similar to each other, i.e. the results converge or are consistent with each other. Convergent validity is demonstrated when factors that should be related to each other are found, by indicators, actually to be related. Measures of correlation, regression or factor analysis are often used in quantitative research to demonstrate convergent validity. In qualitative research, where convergent validity is required to be shown, the researcher (e.g. using N-Vivo analysis and ‘proximity searches’, see Chapter 30) will be able to show, by collating and collecting together data from people, groups, samples and subsamples, whether convergence has been found.
By contrast, discriminant (divergent) validity requires two or more unrelated items, attributes, elements or factors to be shown, e.g. by measurement, to be unrelated to, or different from, each other, i.e. difference is found where it should be found. In quantitative research, statistics such as difference-testing (e.g. t-tests, chi-square tests, analysis of variance, collinearity diagnostics) are calculated. In qualitative research where discriminant validity is required to be shown, the researcher can examine negative cases, deviant cases and compare data from subgroups of people, samples and subsamples, cases and factors, to determine if, indeed, differences are found to exist in terms of key factors, constructs, sub-elements or issues.
Convergent and discriminant validity can be addressed powerfully by mixed methods research. Here one can examine whether a set of data from one method accords with the data found by another method which focused on the same issues, variables or constructs. For example, the researcher could investigate to see whether the findings on, say, social class uptake of higher education in terms of cost-benefit to working-class students yield similar results from both qualitative and quantitative data. If they do, and if this was either predicted or supported by the literature, then one could suggest that intended convergent validity has been demonstrated. By contrast, let us say that the researcher hypothesized that family income and social class upward mobility aspirations for working-class students were not significantly related (the former being an index of wealth and the latter being an index of culture), and the data found two different, discordant results, then discriminant validity has been shown.
Convergent and discriminant validity draw on triangulation of methods, instruments, samples and theories. These are important features of test construction (we return to them in Chapter 24).
This form of validity endeavours to relate the results of one particular instrument to another external criterion. Within this type of validity there are two principal forms: predictive validity and concurrent validity.
Criterion-related validity in quantitative research
Predictive validity is achieved if the data acquired at the first round of research correlate highly with data acquired at a future date. For example, if the results of examinations taken by 16 year olds correlate highly with the examination results gained by the same students when aged 18, then we might wish to say that the first examination demonstrated strong predictive validity.
A variation on this theme is encountered in the notion of concurrent validity. To demonstrate this form of validity the data gathered from using one instrument must correlate highly with data gathered from using another instrument. For example, suppose I wished to research a student’s problem-solving ability. I might observe the student working on a problem, or I might talk to the student about how she is tackling the problem, or I might ask the student to write down how she tackled the problem. Here I have three different data-collecting instruments – observation, interview and documentation respectively. If the results all agreed – concurred – that, according to given criteria for problem-solving ability, the student demonstrated a good ability to solve a problem, then I would be able to say with greater confidence (validity) that the student was good at problem-solving than if I had arrived at that judgement simply from using one instrument.
Concurrent validity is very similar to its partner – predictive validity – in its core concept (i.e. agreement with a second measure); what differentiates concurrent and predictive validity is the absence of a time element in the former; concurrence can be demonstrated simultaneously with another instrument.
An important partner to concurrent validity, which is also a bridge into later discussions of reliability, is triangulation, and this is discussed later in this chapter.
A considerable body of educational and psychological research seeks to understand the extent to which there are similarities and differences between cultures and their members. Matsumoto and Yoo (2006) identify four main phases of cross-cultural research:
The first phase consists of making comparatively coarse cross-cultural comparisons of similarities and differences between cultures, though there is no attempt to demonstrate empirically that differences found between groups are the result of cultural factors (pp. 234–5) and what are the elements of the culture that have given rise to the differences.
The second phase of ‘identifying meaningful dimensions of cultural variability’ (p. 235) identifies important dimensions of culture, and tests across cultures for the applicability, universality, extent and strength of these, for example Hofstede’s (1980) well-known dimensions of individualism-collectivism (see also Triandis, 1994), power-distance, uncertainty avoidance, masculinity-femininity and later long-term to short-term orientation (Hofstede and Bond, 1984). These studies have been criticized (Matsumoto and Yoo, 2006) for the assumption that: (a) countries are the same as cultures; (b) individual behaviour is the same as group behaviour (the ecological fallacy, discussed later); (c) there is a single or main culture in a culture (i.e. overlooking differences within countries as well as between countries); and (d) attributing the causes of differences found between cultures to cultural sources rather than to other factors (e.g. economic factors, psychological factors).
The third phase involves cultural studies in which theoretical models of culture and their influence on individuals were used to explain differences found between cultures (e.g. Markus and Kitayama (1991) on cognition, emotion and motivation, Nisbett (2005) on thought processes and cognition). This phase has been criticized for the limited empirical testing of ‘cultural ingredients’ (Matsumoto and Yoo, 2006).
The fourth phase consists of establishing ‘linkages’ between empirical research on cultural variables and the models that hypothesize such linkages (p. 236).
It appears, then, that for cross-cultural research to demonstrate validity, it is important to ensure that appropriate models of cross-cultural features and phenomena are developed, that make clear their causal rootedness in cultural variables (rather than, for example psychological, economic or personality variables), that these models are operationalized into specific variables that constitute elements of culture, and that these are then tested empirically.
A major question to be faced by the cross-cultural researcher is the extent to which an instrument which has been developed, tested and validated in one country (e.g. a commercially produced instrument) can be used in another culture or country. Are there sufficient similarities between the cultures or cultural properties (e.g. cultural ‘universals’) to enable the same instrument to be applied meaningfully in the other culture, given the particularities, uniqueness and sensitivities of each culture (e.g. Hilton and Skrutkowski, 2002; Sumathipala and Murray, 2006). This section addresses this topic, as it raises a prime matter of validity.
In conducting cross-cultural research another fundamental issue to be addressed is in whose terms, constructs and definitions the researcher is working. This rehearses the ‘emic’/‘etic’ discussion in Chapter 11, i.e. does the researcher use his/her own constructs, definitions, variables and elements of culture (‘etic’ views), or those that arise from the participants themselves (‘emic views’) (Hammerlsey, 2006: 6). Whose ‘definition of the situation’ drives the research? Are participants sufficiently aware of their own culture to be able to articulate it or, if the researcher uses/imposes her or his own construction of culture, is this a form of ‘symbolic violence’ to participants (Hammerlsey, 2006: 6)? In practice these may not be mutually exclusive, for the researcher can conduct pilot research (e.g. ethnographic research) to establish the categories, items and variables that are relevant, important and meaningful to participants, and then convert these into measurement scales for further investigation. ‘Emic’ research may be essential in cross-cultural research, as it is the locals who know more about their environment than an outside researcher (cf. Brock-Utne, 1996: 607) and who may know which are the important questions to ask in any environment (indeed Brock-Utne (1996: 610) argues for the researcher being a local rather than an outsider, as a local researcher will have more experience of, and hence more insight into, the local culture, though, of course, this should not blind the local researcher to the situation). Brock-Utne gives a fascinating example of the interpretation of riddles in an African society; the outsider expatriate interprets them as entertainment and amusement, whereas the locals saw them as essential teaching and educational tools and promoters of cognitive development (pp. 610–12).
Items that are present in one culture may not be present in another, or may have different relevance, meanings or importance (Banville et al., 2000: 374). Banville et al. (2000) suggest the use of a team of experts in both cultures to work in parallel in order to establish the ‘etic’ constructs, and then they formulate questions for study that are subsequently operationalized into ‘emic’ constructs for each culture. This, they aver, avoids the danger of imposing one ‘emic’ culture from one culture as an ‘etic’ construct on another culture (p. 375) (see also Aldridge and Fraser, 2000: 127). Essentially the authors are arguing for ensuring the relevance of the instrument for all the target cultures, by including ‘emic’ and ‘etic’ elements.
To address meaningfulness and relevance in cross-cultural research is important: whilst a construct or element of culture may be found in two cultures, it may have different meanings, weight or significance in the two cultures, i.e. the presence of a factor may not be sufficient in cross-cultural research. This introduces us to several concerns in cross-cultural research about validity.
Threats to validity in cross-cultural research may lie in many areas, for example:
Failure to operationalize elements of cultures into researchable variables.
Problems of whose construction of ‘culture’ to adopt: ‘emic’ and/or ‘etic’ research.
False attribution of causality for differences found between groups to cultural factors rather than non-cultural factors (e.g. economic factors, affluence, demography, biological features of people, climate, personality, religion, educational practices, personal/subjective perceptions of the research, contextual but non-cultural variables (Alexander, 2000; Matsumoto and Yoo, 2006)).
The ecological fallacy: the error of the ecological fallacy is made where ‘relationships that are found between aggregated data (e.g. mean scores) are assumed to apply to individuals, i.e. one infers an individual or particular characteristic from a generalization. It assumes that the individuals in a group exhibit the same features of the whole group taken together (a form of stereotyping)’ (Morrison, 2009: 62). The caution here is to avoid assuming that what one finds at a group level is necessarily the same as that which one would find at an individual level.
The directions of causality, for example, whether culture influences individual behaviour or vice versa, or both.
Sampling (e.g. a lot of cross-cultural research involves using groups of university students, or – as in the case of Hofstede (1980) – individual companies, hence it is dangerous to generalize more widely from these. Further, some studies do not have samples that are matched in terms of size or characteristics of the sample).
Instrument problems: different groups may not understand, or have different understandings of, the language/issues/instruments that are used for gathering data.
Problems of convergent validity (where several items that are supposed to be measuring the same construct or variable do not yield strong inter-correlations).
Problems of discriminant validity (where items that are supposed to be measuring different constructs or variables yield strong inter-correlations).
Problems of equivalence (where the same meaning and significance is given to concepts, constructs, language, sampling, methods in different cultures, such that meaningful comparisons can be made between cultures):
problems of conceptual equivalence (where items are unrelated or relatively unimportant or meaningless to one or more groups) (e.g. Aldridge and Fraser, 2000: 111);
problems of psychological equivalence, where the psychological connotations or referents in the original language may be different from those in the translated language, giving rise to differences in results that are attributable to factors other than cultural (Liu, 2002; Riordan and Vandenburg, 1994);
problems of meaning equivalence: using similar words in the two languages but which connote different interpretations or meanings;
failure of the instruments to take account of the different frames of reference of the different cultural groups (Riordan and Vandenburg, 1994);
failure of groups to understand the measures, instruments, language, meaning or research, i.e. the same items may be interpreted differently by different groups;
failure to accord equal significance to items (factors might be found to be present in different cultures, but some cultures accord those factors much more importance than others (e.g. in measures of personality such as the Big Five factors of personality (Matsumoto and Yoo, 2006: 240));
failure to accord equal relevance and meaning to the same construct or item in different cultures;
measurement equivalence;
linguistic equivalence (where translated versions of an instrument carry the same meaning as in the original, and which will be understood in the same way by members of different cultures).
Response bias, in which members of different cultures respond in systematically different ways to items, elements, constructs or scales in the instrument in ways that are meaningful to their own cultures, situations or contexts (Riordan and Vandenburg, 1994; Aldridge and Fraser, 2000: 127) (e.g. (a) some cultures may give more weight to socially desirable responses or to responses that make the participants look good (Liu, 2002: 82); (b) some cultures may give more weight to categories of ‘agree’ rather than ‘disagree’ in responses; (c) some cultures may consider it undesirable to use extreme ends of a measurement scale (e.g. ‘strongly agree’, ‘strongly disagree’) or, indeed, some cultures may deliberately value the use of extreme categories (e.g. those that emphasize status, masculinity and power) (Matsumoto and Yoo, 2006)).
Preparation of participants – giving advance organizers or suggestions to participants before administering an instrument (‘priming’) (Matsumoto and Yoo, 2006) – may give rise to different responses.
Problems with the researcher who may not speak the language(s) of the participants, or whose participants may be insufficiently articulate or literate to engage in respondent validation.
To address problems of validity in cross-cultural research there are several techniques that researchers can use. For instruments such as questionnaires, a common practice is to use ‘back translation’, undertaken by bilinguals or those with a sound ability in the second as well as the first language (cf. Brislin, 1970; Vallerand et al., 1992; Banville et al., 2000; Cardinal et al., 2003). Here the original version of the instrument (say a questionnaire in English) is translated into the other language required (say Chinese). Then the Chinese version is given to a third party who does not have sight of the original English version, and that third party translates the Chinese version back into English. The two English versions (the original and the resultant back-translation) are then compared to check whether the meanings (and, in a few cases, the exact language) are the same. If the meanings in the two English versions are the same then the Chinese version is said to be acceptable; if the meanings in the two English versions are discrepant then there is said to be a problem in the Chinese, and the Chinese translation is revisited to make changes to it.
Liu (2002) suggests that translators should be familiar not only with both languages, but also with the subject matter, and, if possible, instrumentation. Banville et al. (2000) report the use of professional translators instead of simply back-translation, in order to ensure discriminability of similar items in translation. Further, they indicate that translation should precede the conduct of the empirical research and that translated instruments should be piloted to determine their suitability for the target population.
A variant of this, to ensure even greater validity and reliability of the translated version, is to have more than one person doing the translation into the new language (each person is unknown to the other) and similarly for the back translation into English, as this avoids possible bias in having only a single translator at each stage (Banville et al., 2000: 379). In this instance, the two translators at each stage should compare their translations and discuss any differences found in meaning or language.
Aldridge and Fraser (2000) draw attention to the fact that there may be no equivalent words in the target translated language, and this may mean that there have to be rewordings of the original language in order to reach a compromise statement in the instrument (e.g. a questionnaire) that fits both languages. Whilst back-translation keeps the original language as the language of reference, ‘decentring’ suggests that, in fact compromises may have to be made in both the original and the translated language, in order to ensure communality or equivalence of meaning, i.e. the original and the translated language are equally important (Liu, 2002: 81) and must be user-friendly to all groups. Liu also suggests that it is useful to keep the original language in active rather than passive voice, simple and short sentences, avoiding colloquialisms, idioms and using specific terms and familiar rather than abstruse words (see also Hilton and Skrutkowski, 2002).
Banville et al. (2000) provide a useful seven-step approach from Vallerand (1989) to translating and using instruments in cross-cultural research:
Step 1: Prepare a preliminary version of the instrument using the back-translation technique.
Step 2: Evaluate the preliminary versions (to check that the back-translated version is acceptable, or to adjudicate between different versions of the back-translated items) and prepare an experimental version of the instrument using a committee of experts (three to five persons) to conduct such a review, thereby avoiding possible bias by a single researcher (see also Vallerand et al., 1992; Liu, 2002: 82).
Step 3: Pre-test the experimental version using a random survey approach, to check the clarity of the instructions and the appropriateness of the instrument.
Step 4: Evaluate the content and concurrent validity of the instrument using bilingual participants to check whether they are answering both versions in the same way, and to check the appropriateness of the instrument (using between 20 and 30 participants). Participants answer both versions of the instrument (i.e. both languages). Content validity to be assessed qualitatively (expert review) and concurrent validity to be assessed quantitatively (t-tests).
Step 5: Conduct a reliability analysis to check for internal validity and stability over time (looking for high reliability coefficients: Cronbach alphas), and to check the suitability of the instrument. Remove items with low reliability.
Step 6: Evaluate the construct validity of the instruments (through factor analysis, inter-scale correlations and to test the hypothesis that stems from theory).
Step 7: Establish norms of the scales/measures by selecting the population from which the sample will be drawn, by statistical indices, and by calculating means standard deviations and z-scores, used with a large number of people in order to establish the stability of the norms.
Step 4 uses bilingual participants to undertake both versions (both languages), so that their two sets of answers can be compared to look for discrepancies (see also Liu, 2002: 81–2). This may not be feasible for sole researchers, who may not have access to a sufficiently large group of bilingual participants, but may only have access to people who can translate rather than be fully bilingual and expert in both cultures. For an example of the use of this technique see Cothran et al. (2005).
In order to avoid the risk of bias in cross-cultural research, the researcher can also use a multi-instrument approach with different sized samples for different instruments (Aldridge and Fraser, 2000; Aldridge et al., 1999; Sumathipala and Murray, 2006). A multi-method approach provides triangulation and concurrent validity and gives a closer, more authentic meaning to the phenomenon or culture (particularly when qualitative data combine with quantitative data).
Qualitatively speaking, the researcher has to ensure: (a) that the meanings, definitions constructs that are being used are understood similarly by the members of the different cultures being investigated (the equivalence issue); (b) that these are given sufficient relevance, meaningfulness and weight in the different cultures for them to be suitable for investigation (or, indeed, the research may be intended to discover the relevance, meaningfulness and weight of these in the different cultures); (c) that the research includes items that are meaningful, relevant and significant to participants; and (d) the research draws on both ‘emic’ and ‘etic’ analysis and constructs as appropriate.
Quantitatively speaking, there are several ways in which the cross-cultural validity of measures can be addressed. We discuss these below. Essentially the purpose is to test the instrument on the different cultures to see if the reliability, items, clusters of items into factors, and suitability of the items are acceptable in both cultures; an instrument that is suitable, reliable and valid in one culture may not be in the other (Cothran et al., 2005: 194).
Factor analysis enables the researcher to examine the factor structure of the instrument. A suitable instrument for cross-cultural research should ensure that: (a) the same factors are extracted from the same instrument with the different groups of participants; (b) the same variables are included onto these factors with the different groups of participants; (c) the same loadings (e.g. weightings) of each variable are loaded onto each factor (see Chapter 37, which discusses factor loadings). One has to exercise discretion here, as, clearly the results will not be identical for each group of participants. However, if there are gross discrepancies found between factors, variables included, and loadings of each variable, then the researcher will need to consider whether the instrument is sufficiently valid to use, or whether some items will need to be excluded or replaced.
Inter-correlations of variables (alphas) (discussed later in this chapter: reliability) can be conducted to see whether: (a) the item-to-whole reliability correlation coefficient is the same for the different groups of participants; (b) the overall reliability level (the alpha) is sufficiently high for items to be included (see Chapter 36). A suitable instrument will ensure that the coefficient of correlation for each item to the whole is sufficiently high (e.g. ≥ 0.67), or the overall alphas for the sections of the instrument are sufficiently high (e.g. ≥ 0.67) to be retained. Items that show low correlations should be considered for removal. Hence the researcher will need to test his/her instrument in the groups concerned (e.g. groups of members of different cultures) in order to conduct such pilot testing. In this case it is advisable to include no fewer than 30 people in each of the pilot groups.
Items that the researcher hypothesizes should be strongly correlated (i.e. convergent validity: measuring the same construct, factor or trait (Rohner and Katz, 1970: 1069)) should have high correlation coefficients. Items that the researcher hypothesizes should have very low correlation coefficients (i.e. discriminant validity: measuring unrelated constructs, factors or traits (Rohner and Katz, 1970: 1069)) should have low correlation coefficients. Alternatively instead of using correlations, the researcher can conduct difference testing (e.g. t-tests, see Chapter 36) to discover: (a) whether items that he/she hypothesizes should be similar to each other (convergent validity) in reality show no statistically significant difference; and (b) whether items that he/she hypothesizes should be different from each other (discriminant validity) in reality are statistically significantly different from each other (see Keet et al., 1997 for an example of using correlational analysis, t-tests and factor analysis to establish validity in cross-cultural research).
Watkins (2007: 305–6) suggests that meta-analysis can be used to examine the cross-cultural relevance of variables to the participating groups. This is a statistical procedure in which the researcher selects and combines empirical studies that satisfy criteria for inclusion in respect of the hypotheses under investigation (e.g. they are quantitative, include relevant variables, include scales and measures that can be combined from different studies, include identified samples and include correlational analysis of items). Then the researcher calculates average correlations and effect sizes from the studies (bearing in mind the likely different sample sizes), and then judges whether the correlations and effect sizes found are sufficiently strong for items to be retained in the researcher’s own research (see Glass et al., 1981 for how to conduct a meta-analysis).
Cross-cultural validity, like other forms of research, has to be cautious in making generalizations from small samples, in avoiding claims about whole cultures or countries from limited or selective samples, and in imposing instruments from one culture onto another – however well they might be translated. Matsumoto and Yoo (2006) suggest that cross-cultural data are ‘nested’ (p. 246), i.e. there are data at several levels: individual, group, cultures, societies, ecologies. This points us to the statistical technique of multilevel modelling, which we introduce in Chapter 37.
Related to cross-cultural research and ecological validity (see below) is cultural validity (Morgan, 1999). This is particularly an issue in cross-cultural, intercultural and comparative kinds of research, where the intention is to shape research so that it is appropriate to the culture of the researched, and where the researcher and the researched are members of different cultures. Cultural validity is defined as ‘the degree to which a study is appropriate to the cultural setting where research is to be carried out’ (Joy, 2003: 1) (see also Stutchbury and Fox, 2009: 494). Cultural validity, Morgan (1999) suggests, applies at all stages of the research, and affects its planning, implementation and dissemination. It involves a degree of sensitivity to the participants, cultures and circumstances being studied. Morgan (2005: 1) writes that:
cultural validity entails an appreciation of the cultural values of those being researched. This could include: understanding possibly different target culture attitudes to research; identifying and understanding salient terms as used in the target culture; reviewing appropriate target language literature; choosing research instruments that are acceptable to the target participants; checking interpretations and translations of data with native speakers; and being aware of one’s own cultural filters as a researcher.
(Morgan, 2005: 1)
Joy (2003: 1) presents 12 important questions that researchers in different cultural contexts may face, to ensure that research is culture-fair and culturally sensitive:
1 Is the research question understandable and of importance to the target group?
2 Is the researcher the appropriate person to conduct the research?
3 Are the sources of the theories that the research is based on appropriate for the target culture?
4 How do researchers in the target culture deal with the issues related to the research question (including their method and findings)?
5 Are appropriate gatekeepers and informants chosen?
6 Are the research design and research instruments ethical and appropriate according to the standards of the target culture?
7 How do members of the target culture define the salient terms of the research?
8 Are documents and other information translated in a culturally appropriate way?
9 Are the possible results of the research of potential value and benefit to the target culture?
10 Does interpretation of the results include the opinions and views of members of the target culture?
11 Are the results made available to members of the target culture for review and comment?
12 Does the researcher accurately and fairly communicate the results in their cultural context to people who are not members of the target culture?
In education, ecological validity is particularly important and useful in charting how policies are actually happening ‘at the chalk face’ (Brock-Utne, 1996: 617). It concerns examining and addressing the specific characteristics of a particular situation, for example how policies are actually impacting in practice (p. 617) rather than simply having surveys, interviews, observations and questionnaires that reproduce the ‘rhetoric of policies’ (p. 617), i.e. that assume that policies are implemented in the ways intended or in the ways that the powerful groups intended (those at ‘the top of the hierarchy of credibility’) (p. 618).
Ecological validity requires the specific factors of research sites – schools, universities, regions, etc. – to be included and taken into account in the research. In this respect it is far more sympathetic to qualitative research and ‘thick description’ (Geertz, 1973) than those forms of quantitative, positivist research variables that seek to isolate, control out and manipulate variables in contrived settings. The ethical tension is raised in ecological validity between the need to provide rich descriptions of characteristics of a situation or institution and the increased likelihood that this will lead to the situation or institution being able to be identified and anonymity breached (Brock-Utne, 1996: 618).
For qualitative, naturalistic research a fundamental premise is that the researcher deliberately does not try to manipulate variables or conditions, and that the situations in the research occur naturally. The intention here is to give accurate portrayals of the realities of social situations in their own terms, in their natural or conventional settings.
For ecological validity to be demonstrated it is important to include and address in the research as many as possible of the characteristics and factors of a given situation. The difficulty with this is that the more characteristics are included and described, the harder it is to abide by central ethical tenets of much research – non-traceability, anonymity and non-identifiability.
Ecological validity is also a form of external validity; it concerns the extent to which characteristics of one situation or behaviour observed in one setting can be transferred or generalized to another situation. This blends fidelity to one specific set of circumstances with the extent to which that situation can apply to others.
Triangulation may be defined as the use of two or more methods of data collection in the study of some aspect of human behaviour. The use of multiple methods, or the multi-method approach as it is sometimes called, contrasts with the ubiquitous but generally more vulnerable single-method approach that characterizes so much of research in the social sciences. In its original and literal sense, triangulation is a technique of physical measurement: maritime navigators, military strategists and surveyors, for example, use (or used to use) several locational markers in their endeavours to pinpoint a single spot or objective. By analogy, triangular techniques in the social sciences attempt to map out, or explain more fully, the richness and complexity of human behaviour by studying it from more than one standpoint and, in so doing, by making use of both quantitative and qualitative data. Triangulation is a powerful way of demonstrating concurrent validity, particularly in qualitative research (Campbell and Fiske, 1959).
The advantages of the mixed-method approach in social research are manifold and we examine two of them. First, whereas the single observation in fields such as medicine, chemistry and physics normally yields sufficient and unambiguous information on selected phenomena, it provides only a limited view of the complexity of human behaviour and of situations in which human beings interact. It has been observed that as research methods act as filters through which the environment is selectively experienced, they are never atheoretical or neutral in representing the world of experience (Smith, 1975). Exclusive reliance on one method, therefore, may bias or distort the researcher’s picture of the particular slice of reality she is investigating. She needs to be confident that the data generated are not simply artefacts of one specific method of collection (Lin, 1976). Such confidence can be achieved, as far as nomothetic research is concerned, when different methods of data collection yield substantially the same results. (Where triangulation is used in interpretive research to investigate different actors’ viewpoints, the same method, e.g. accounts, will naturally produce different sets of data.)
Further, the more the methods contrast with each other, the greater the researcher’s confidence. If, for example, the outcomes of a questionnaire survey correspond to those of an observational study of the same phenomena, the more the researcher will be confident about the findings. Or, more extreme, where the results of a rigorous experimental investigation are replicated in, say, a role-playing exercise, the researcher will experience even greater assurance. If findings are artefacts of method, then the use of contrasting methods considerably reduces the chances of any consistent findings being attributable to similarities of method (Lin, 1976).
We come now to a second advantage: some theorists have been sharply critical of the limited use to which existing methods of enquiry in the social sciences have been put. One writer, for example, comments, ‘Much research has employed particular methods or techniques out of methodological parochialism or ethnocentrism. Methodologists often push particular pet methods either because those are the only ones they have familiarity with, or because they believe their method is superior to all others’ (Smith, 1975). The use of triangular techniques, it is argued, will help to overcome the problem of ‘method-boundedness’, as it has been termed; indeed Gorard and Taylor (2004) demonstrate the value of combining qualitative and quantitative methods.
In its use of mixed methods, triangulation may utilize either normative or interpretive techniques; or it may draw on methods from both these approaches and use them in combination.
We have just seen how triangulation is characterized by a mixed-method approach to a problem in contrast to a single-method approach. Denzin (1970) has, however, extended this view of triangulation to take in several other types as well as the mixed-method kind which he terms ‘methodological triangulation’, including:
time triangulation: this type attempts to take into consideration the factors of change and process by utilizing cross-sectional and longitudinal designs. Kirk and Miller (1986) suggest that diachronic reliability seeks stability of observations over time, whilst synchronic reliability seeks similarity of data gathered in the same time;
space triangulation: this type attempts to overcome the parochialism of studies conducted in the same country or within the same subculture by making use of cross-cultural techniques;
combined levels of triangulation: this type uses more than one level of analysis from the three principal levels used in the social sciences, namely, the individual level, the interactive level (groups), and the level of collectivities (organizational, cultural or societal);
theoretical triangulation: this type draws upon alternative or competing theories in preference to utilizing one viewpoint only;
investigator triangulation: this type engages more than one observer, data are discovered independently by more than one observer (Silverman, 1993: 99);
methodological triangulation: this type uses either (a) the same method on different occasions, or (b) different methods on the same object of study.
Many studies in the social sciences are conducted at one point only in time, thereby ignoring the effects of social change and process. Time triangulation goes some way to rectifying these omissions by making use of cross-sectional and longitudinal approaches. Cross-sectional studies collect data at one point in time; longitudinal studies collect data from the same group at different points in the time sequence. The use of panel studies and trend studies may also be mentioned in this connection. The former compare the same measurements for the same individuals in a sample at several different points in time; and the latter examine selected processes continually over time. The weaknesses of each of these methods can be strengthened by using a combined approach to a given problem.
Space triangulation attempts to overcome the limitations of studies conducted within one culture or subculture. As one writer says, ‘Not only are the behavioural sciences culture-bound, they are sub-culture-bound. Yet many such scholarly works are written as if basic principles have been discovered which would hold true as tendencies in any society, anywhere, anytime’ (Smith, 1975). Cross-cultural studies may involve the testing of theories among different people, as in Piagetian and Freudian psychology; or they may measure differences between populations by using several different measuring instruments. We have addressed cultural validity earlier.
Social scientists are concerned in their research with the individual, the group and society. These reflect the three levels of analysis adopted by researchers in their work. Those who are critical of much present-day research argue that some of it uses the wrong level of analysis, individual when it should be societal, for instance, or limits itself to one level only when a more meaningful picture would emerge by using more than one level. Smith extends this analysis and identifies seven possible levels: the aggregative or individual level, and six levels that are more global in that ‘they characterize the collective as a whole, and do not derive from an accumulation of individual characteristics’ (Smith, 1975). The six include:
group analysis (the interaction patterns of individuals and groups);
organizational units of analysis (units which have qualities not possessed by the individuals making them up);
institutional analysis (relationships within and across the legal, political, economic and familial institutions of society);
ecological analysis (concerned with spatial explanation);
cultural analysis (concerned with the norms, values, practices, traditions and ideologies of a culture); and
societal analysis (concerned with gross factors such as urbanization, industrialization, education, wealth, etc.).
Where possible, studies combining several levels of analysis are to be preferred. Researchers are sometimes taken to task for their rigid adherence to one particular theory or theoretical orientation to the exclusion of competing theories. Indeed Smith (1975) recommends the use of research to test competing theories.
Investigator triangulation refers to the use of more than one observer (or participant) in a research setting. Observers and participants working on their own each have their own observational styles and this is reflected in the resulting data. The careful use of two or more observers or participants independently, therefore, can lead to more valid and reliable data (Smith, 1975), checking divergences between researchers leading to minimal divergence, i.e. reliability.
In this respect the notion of triangulation bridges issues of reliability and validity. We have already considered methodological triangulation earlier. Denzin (1970) identifies two categories in his typology: ‘within methods’ triangulation and ‘between methods’ triangulation. Triangulation within methods concerns the replication of a study as a check on reliability and theory confirmation. Triangulation between methods involves the use of more than one method in the pursuit of a given objective. As a check on validity, the between methods approach embraces the notion of convergence between independent measures of the same objective (Campbell and Fiske, 1959).
Of the six categories of triangulation in Denzin’s typology, four are frequently used in education. These are: time triangulation with its longitudinal and cross-sectional studies; space triangulation as on the occasions when a number of schools in an area or across the country are investigated in some way; investigator triangulation as when two observers independently rate the same classroom phenomena; and methodological triangulation. Of these four, methodological triangulation is the one used most frequently and the one that possibly has the most to offer.
Triangular techniques are suitable when a more holistic view of educational outcomes is sought (e.g. Mortimore et al.’s (1988) search for school effectiveness), or where a complex phenomenon requires elucidation. Triangulation is useful when an established approach yields a limited and frequently distorted picture. Finally, triangulation can be a useful technique where a researcher is engaged in case study, a particular example of complex phenomena (Adelman et al., 1980).
Triangulation is not without its critics. For example, Silverman (1985) suggests that the very notion of triangulation is positivistic, and that this is exposed most clearly in data triangulation, as it is presumed that a multiple data source (concurrent validity) is superior to a single data source or instrument. The assumption that a single unit can always be measured more than once violates the interactionist principles of emergence, fluidity, uniqueness and specificity (Denzin, 1997: 320). Further, Patton (1980) suggests that even having multiple data sources, particularly of qualitative data, does not ensure consistency or replication. Fielding and Fielding (1986) hold that methodological triangulation does not necessarily increase validity, reduce bias or bring objectivity to research.
With regard to investigator triangulation Lincoln and Guba (1985: 307) contend that it is erroneous to assume that one investigator will corroborate another, nor is this defensible, particularly in qualitative, reflexive enquiry. They extend their concern to include theory and methodological triangulation, arguing that the search for theory and methodological triangulation is epistemologically incoherent and empirically empty (see also Patton, 1980). No two theories, it is argued, will ever yield a sufficiently complete explanation of the phenomenon being researched.
These criticisms are trenchant, but they have been answered equally trenchantly by Denzin (1997).
In naturalistic enquiry, Lincoln and Guba (1985: 315) suggest that triangulation is intended as a check on data, whilst member checking, an element of credibility, is to be used as a check on members’ constructions of data.
Though each of the methods in mixed methods research (quantitative and qualitative) have to conform to their specific validity requirements, where research integrates quantitative and qualitative methods, there is an argument for identifying specific validity requirements for mixed methods research. Indeed Onwuegbuzie and Johnson (2006) argue that the term ‘validity’ be replaced by ‘legitimation’ in mixed methods research, and they identify nine main types of legitimation (discussed below). These nine methods, the authors aver (p. 52) constitute an attempt to overcome problems in mixed methods research of:
a representation (using largely or only words and pictures to catch the dynamics of lived experiences and unfolding, emergent situations);
b legitimation (ensuring that the results are dependable, credible, transferable, plausible, confirmable and trustworthy);
c integration (using and combining quantitative and qualitative methods, each with their own, sometimes antagonistic, canons of validity, e.g. quantitative data may use large random samples whilst qualitative data may use small, purposive samples and yet they may have to be placed on an equal footing (p. 54)).
The nine types of legitimation in mixed methods research identified by Onwuegbuzie and Johnson (2006: 57) are:
1 Sample integration (how far different kinds and sizes of sample in combination, or the same samples in quantitative and qualitative research, can enable high-quality inferences to be made).
2 Inside-outside (how far researchers use, combine and balance both insiders’ views (‘emic’ research) and outsiders’ views (‘etic’ research) in the research in describing and explaining).
3 Weakness minimization (how far any weaknesses that stem from one approach are compensated by the strengths of the other approach, together with suitably weighting such strengths and weaknesses).
4 Sequential (how far one can minimize order effects (quantitative to qualitative and vice versa) in ‘meta-inferences’ made from data collection and analysis, such that one could reverse the order of the inferences made, or the order of the quantitative and qualitative data, without loss of power to the ‘metainferences’).
5 Conversion (how far qualitizing numerical data or quantitizing qualitative data can assist in yielding robust ‘meta-inferences’).
6 Paradigmatic mixing (how successful is the combination of the ontological, epistemological, axiological, methodological and rhetorical beliefs and practices in yielding useful results, particularly if the paradigms are in tension with each other).
7 Commensurability (how far any ‘meta-inferences’ made from the data catch a ‘mixed worldview’ (i.e. rejecting the incommensurability of paradigms) that is enabled by ‘Gestalt switching’ and integration of paradigms and their methodologies).
8 Multiple validities (fidelity to the canons of validity for each of the quantitative and qualitative data gathered).
9 Political (how accepted by the audiences are the ‘meta-inferences’ stemming from the combination of quantitative and qualitative methods).
It is very easy to slip into invalidity; it is both insidious and pernicious as it can enter at every stage of a piece of research. The attempt to build out invalidity is essential if the researcher is to be able to have confidence in the elements of the research plan, data acquisition, data processing analysis, interpretation and its ensuing judgement.
At the design stage threats to validity can be minimized by:
choosing an appropriate timescale;
ensuring that there are adequate resources for the required research to be undertaken;
selecting an appropriate methodology for answering the research questions;
selecting appropriate instrumentation for gathering the type of data required;
using an appropriate sample (e.g. one which is representative, not too small or too large);
demonstrating internal, external, content, concurrent and construct validity; ‘operationalizing’ the constructs fairly;
ensuring reliability in terms of stability (consistency, equivalence, split-half analysis of test material);
selecting appropriate foci to answer the research questions;
devising and using appropriate instruments (for example, to catch accurate, representative, relevant and comprehensive data (King et al., 1987); ensuring that readability levels are appropriate; avoiding any ambiguity of instructions, terms and questions; using instruments that will catch the complexity of issues; avoiding leading questions; ensuring that the level of test is appropriate, e.g. neither too easy nor too difficult; avoiding test items with little discriminability; avoiding making the instruments too short or too long; avoiding too many or too few items for each issue);
avoiding a biased choice of researcher or research team (e.g. insiders or outsiders as researchers).
There are several areas where invalidity or bias might creep into the research at the stage of data gathering; these can be minimized by:
reducing the Hawthorne effect (see the accompanying website);
minimizing reactivity effects (respondents behaving differently when subjected to scrutiny or being placed in new situations, for example, the interview situation – we distort people’s lives in the way we go about studying them (Lave and Kvale, 1995: 226));
trying to avoid drop-out rates amongst respondents;
taking steps to avoid non-return of questionnaires;
avoiding having too long or too short an interval between pre-tests and post-tests;
ensuring inter-rater reliability;
matching control and experimental groups fairly;
ensuring standardized procedures for gathering data or for administering tests;
building on the motivations of the respondents;
tailoring the instruments to the concentration span of the respondents and addressing other situational factors (e.g. health, environment, noise, distraction, threat);
addressing factors concerning the researcher (particularly in an interview situation); for example, the attitude, gender, race, age, personality, dress, comments, replies, questioning technique, behaviour, style and non-verbal communication of the researcher.
At the stage of data analysis there are several areas where invalidity lurks; these might be minimized by:
using respondent validation;
avoiding subjective interpretation of data (e.g. being too generous or too ungenerous in the award of marks), i.e. lack of standardization and moderation of results;
reducing the halo effect, where the researcher’s knowledge of the person or knowledge of other data about the person or situation exerts an influence on subsequent judgements;
using appropriate statistical treatments for the level of data (e.g. avoiding applying techniques from interval scaling to ordinal data or using incorrect statistics for the type, size, complexity, sensitivity of data);
recognizing spurious correlations and extraneous factors which may be affecting the data (i.e. tunnel vision);
avoiding poor coding of qualitative data;
avoiding making inferences and generalizations beyond the capability of the data to support such statements;
avoiding the equating of correlations and causes;
avoiding selective use of data;
avoiding unfair aggregation of data (particularly of frequency tables);
avoiding unfair telescoping of data (degrading the data);
avoiding Type I and/or Type II errors.
At the stage of data reporting invalidity can show itself in several ways; the researcher must take steps to minimize this by, for example:
avoiding using data selectively and unrepresentatively (for example, accentuating the positive and neglecting or ignoring the negative);
indicating the context and parameters of the research in the data collection and treatment, the degree of confidence which can be placed in the results, the degree of context-freedom or context-boundedness of the data (i.e. the level to which the results can be generalized);
presenting the data without misrepresenting its message;
making claims which are sustainable by the data;
avoiding inaccurate or wrong reporting of data (i.e. technical errors or orthographic errors);
ensuring that the research questions are answered; releasing research results neither too soon nor too late.
Having identified where invalidity lurks, the researcher can take steps to ensure that, as far as possible, invalidity has been minimized in all areas of the research.
Reliability is essentially a synonym for dependability, consistency and replicability over time, over instruments and over groups of respondents. It is concerned with precision and accuracy; some features, e.g. height, can be measured precisely, whilst others, e.g. musical ability, cannot. For research to be reliable it must demonstrate that if it were to be carried out on a similar group of respondents in a similar context (however defined), then similar results would be found. Guba and Lincoln (1994) suggest that the concept of reliability is largely positivist. Whilst it may be true that widely held views of reliability seem to adhere to positivism rather than to qualitative research, it is not exclusively so; qualitative research has to be as reliable as positivist research, though in different ways: the canons of reliability and the types of reliability differ in quantitative and qualitative research. Similarly, it is simply not the case that qualitative research, per se, guarantees reliability or that it is an irrelevance in qualitative research (Brock-Utne, 1996: 613). Reliability, as a precondition or sine qua non of validity (Brock-Utne, 1996: 614), is relevant to both quantitative and qualitative research.
In positivist and quantitative research (the two terms are different, as some qualitative research can also be positivist in seeking trends, patterns, predictability and control (e.g. Miles and Huberman, 1994)), there are three principal types of reliability: stability, equivalence and internal consistency (Carmines and Zeller, 1979). Here reliability concerns the research situation (e.g. the context of, or the conditions for, a test), factors affecting the researcher or participants, and the instruments for data collection themselves.
In this form reliability is a measure of consistency over time and over similar samples. A reliable instrument for a piece of research will yield similar data from similar respondents over time. A leaking tap which each day leaks one litre is leaking reliably whereas a tap which leaks one litre some days and two litres on others is not. In the experimental and survey models of research this would mean that if a test and then a re-test were undertaken within an appropriate time span, then similar results would be obtained. The researcher has to decide what an appropriate length of time is; too short a time and respondents may remember what they said or did in the first test situation, too long a time and there may be extraneous effects operating to distort the data (for example, maturation in students, outside influences on the students). A researcher seeking to demonstrate this type of reliability will have to choose an appropriate timescale between the test and re-test. Correlation coefficients can be calculated for the reliability of pre-and post-tests, using formulae which are readily available in books on statistics and test construction.
In addition to stability over time, reliability as stability can also be stability over a similar sample. For example, we would assume that if we were to administer a test or a questionnaire simultaneously to two groups of students who were very closely matched on signiificant characteristics (e.g. age, gender, ability, etc. – whatever characteristics are deemed to have a significant bearing on the responses), then similar results (on a test) or responses (to a questionnaire) would be obtained. The correlation coefficient on this form of the test/re-test method can be calculated either for the whole test (e.g. by using the Pearson statistic or a t-test) or for sections of the questionnaire (e.g. by using the Spearman or Pearson statistic as appropriate or a t-test). The statistical significance of the correlation coefficient can be found and should be 0.05 or higher if reliability is to be guaranteed. This form of reliability over a sample is particularly useful in piloting tests and questionnaires.
In using the test/re-test method, care has to be taken to ensure (Cooper and Schindler, 2001: 216):
the time period between the test and re-test is not so long that situational factors may change;
the time period between the test and re-test is not so short that the participants will remember the first test;
the participant may have become interested in the field and may have followed it up him/herself between the test and the re-test times.
Within this type of reliability there are two main sorts. Reliability may be achieved, first, through using equivalent forms (also known as ‘alternative forms’) of a test or data-gathering instrument. If an equivalent form of the test or instrument is devised and yields similar results, then the instrument can be said to demonstrate this form of reliability. For example, the pre-test and post-test in an experiment are predicated on this type of reliability, being alternate forms of instrument to measure the same issues. This type of reliability might also be demonstrated if the equivalent forms of a test or other instrument yield consistent results if applied simultaneously to matched samples (e.g. a control and experimental group or two random stratified samples in a survey). Here reliability can be measured through a t-test, through the demonstration of a high correlation coefficient and through the demonstration of similar means and standard deviations between two groups.
Second, reliability as equivalence may be achieved through inter-rater reliability. If more than one researcher is taking part in a piece of research then, human judgement being fallible, agreement between all researchers must be achieved, through ensuring that each researcher enters data in the same way. This would be particularly pertinent to a team of researchers gathering structured observational or semi-structured interview data where each member of the team would have to agree on which data would be entered in which categories. For observational data, reliability is addressed in the training sessions for researchers where they work on video material to ensure parity in how they enter the data.
At a simple level one can calculate the inter-rater agreement as a percentage:
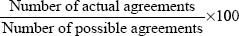
Robson (2002: 341) sets out a more sophisticated way of measuring inter-rater reliability in coded observational data, and his method can be used with other types of data.
Whereas the test/re-test method and the equivalent forms method of demonstrating reliability require the tests or instruments to be done twice, demonstrating internal consistency demands that the instrument or tests be run once only through the split-half method.
Let us imagine that a test is to be administered to a group of students. Here the test items are divided into two halves, ensuring that each half is matched in terms of item difficulty and content. Each half is marked separately. If the test is to demonstrate split-half reliability, then the marks obtained on each half should be correlated highly with the other. Any student’s marks on the one half should match his or her marks on the other half. This can be calculated using the Spearman-Brown formula:
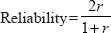
where
r = the actual correlation between the halves of the
instrument.
This calculation requires a correlation coefficient to be calculated, e.g. a Spearman rank order correlation or a Pearson product moment correlation.
Let us say that using the Spearman-Brown formula the correlation coefficient is 0.85; in this case the
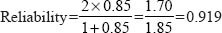
Given that the maximum value of the coefficient is 1.00 we can see that the reliability of this instrument, calculated for the split-half form of reliability, is very high indeed.
This type of reliability assumes that the test administered can be split into two matched halves; many tests have a gradient of difficulty or different items of content in each half. If this is the case and, for example, the test contains 20 items, then the researcher, instead of splitting the test into two by assigning items one to ten to one half and items 11 to 20 to the second half may assign all the even-numbered items to one group and all the odd-numbered items to another. This would move towards the two halves being matched in terms of content and cumulative degrees of difficulty.
An alternative measure of reliability as internal consistency is the Cronbach alpha, frequently referred to simply as the alpha coefficient of reliability, or simply the alpha. The Cronbach alpha provides a coefficient of inter-item correlations, that is, the correlation of each item with the sum of all the other relevant items, and is useful for multi-item scales. This is a measure of the internal consistency amongst the items (not, for example, the people). We address the alpha coefficient and its calculation in Part 5.
Reliability, thus construed, makes several assumptions, e.g. that instrumentation, data and findings should be controllable, predictable, consistent and replicable. This presupposes a particular style of research, typically within the positivist paradigm. Cooper and Schindler (2001: 218) suggest that in this paradigm reliability can be improved by: minimizing any external sources of variation: standardizing and controlling the conditions under which the data collection and measurement take place; training the researchers in order to ensure consistency (inter-rater reliability); widening the number of items on a particular topic; excluding extreme responses from the data analysis (e.g. outliers, which can be done with SPSS).
Whilst we discuss reliability in qualitative research here, the suitability of the term for qualitative research is contested (e.g. Winter, 2000; Stenbacka, 2001; Golafshani, 2003). Lincoln and Guba (1985) prefer to replace ‘reliability’ with terms such as ‘credibility’, ‘neutrality’, ‘confirmability’, ‘dependability’, ‘consistency’, ‘applicability’, ‘trustworthiness’ and ‘transferability’, in particular the notion of ‘dependability’.
LeCompte and Preissle (1993: 332) suggest that the canons of reliability for quantitative research may be simply unworkable for qualitative research. Quantitative research assumes the possibility of replication; if the same methods are used with the same sample then the results should be the same. Typically quantitative methods require a degree of control and manipulation of phenomena. This distorts the natural occurrence of phenomena (see earlier: ecological validity). Indeed the premises of naturalistic studies include the uniqueness and idiosyncrasy of situations, such that the study cannot be replicated – that is their strength rather than their weakness.
On the other hand, this is not to say that qualitative research need not strive for replication in generating, refining, comparing and validating constructs. Indeed LeCompte and Preissle (1993: 334) argue that such replication might include repeating:
the status position of the researcher;
the choice of informant/respondents;
the social situations and conditions;
the analytic constructs and premises that are used;
the methods of data collection and analysis.
Further, Denzin and Lincoln (1994) suggest that reliability as replicability in qualitative research can be addressed in several ways:
stability of observations (whether the researcher would have made the same observations and interpretation of these if they had been observed at a different time or in a different place);
parallel forms (whether the researcher would have made the same observations and interpretations of what had been seen if s/he had paid attention to other phenomena during the observation);
inter-rater reliability (whether another observer with the same theoretical framework and observing the same phenomena would have interpreted them in the same way).
Clearly this is a contentious issue, for it is seeking to apply to qualitative research the canons of reliability of quantitative research. Purists might argue against the legitimacy, relevance or need for this in qualitative studies.
In qualitative research reliability can be regarded as a fit between what researchers record as data and what actually occurs in the natural setting that is being researched, i.e. a degree of accuracy and comprehensiveness of coverage (Bogdan and Biklen, 1992: 48). This is not to strive for uniformity; two researchers who are studying a single setting may come up with very different findings but both sets of findings might be reliable. Indeed Kvale (1996: 181) suggests that in interviewing there might be as many different interpretations of the qualitative data as there are researchers. A clear example of this is the study of the Nissan automobile factory in the UK, where Wickens (1987) found a ‘virtuous circle’ of work organization practices that demonstrated flexibility, teamwork and quality consciousness, and where Garrahan and Stewart (1992), investigating the same practices, found a ‘vicious circle’ of exploitation, surveillance and control. Both versions of the same reality coexist because reality is multilayered. What is being argued for here is the notion of reliability through an eclectic use of instruments, researchers, perspectives and interpretations (echoing the comments earlier about triangulation) (see also Eisenhart and Howe, 1992).
Brock-Utne (1996) argues that qualitative research, being holistic, strives to record the multiple interpretations of, intention in and meanings given to situations and events. Here the notion of reliability is construed as dependability (Lincoln and Guba, 1985: 108–9; Anfara et al., 2002), recalling the earlier discussion on internal validity. For them, dependability involves member checks (respondent validation), debriefing by peers, triangulation, prolonged engagement in the field, persistent observations in the field, reflexive journals, negative case analysis and independent audits (identifying acceptable processes of conducting the enquiry so that the results are consistent with the data). Audit trails enable the research to address the issue of confirmability of results, in terms of process and product (Golafshani, 2003: 601). These are a safeguard against the charge levelled against qualitative researchers, namely, that they respond only to the ‘loudest bangs or the brightest lights’.
Dependability raises the important issue of respondent validation (see also McCormick and James, 1988). Whilst dependability might suggest that researchers need to go back to respondents to check that their findings are dependable, researchers also need to be cautious in placing exclusive store on respondents, for, as Hammersley and Atkinson (1983) suggest, they are not in a privileged position to be sole commentators on their actions.
Bloor (1978) suggests three means by which respondent validation can be addressed:
researchers attempt to predict what the participants’ classifications of situations will be;
researchers prepare hypothetical cases and then predict respondents’ likely responses to them;
researchers take back their research report to the respondents and record their reactions to that report.
Kleven (1995) suggests that qualitative research can address reliability in part by asking three questions, particularly in observational research:
1 Would the same observations and interpretations have been made if observations had been conducted at different times? (The ‘stability’ version of reliability.)
2 Would the same observations and interpretations have been made if other observations had been conducted at the time? (The ‘parallel forms’ version of reliability.)
3 Would another observer, working in the same theoretical framework, have made the same observations and interpretations? (The ‘inter-rater’ version of reliability.)
The debate on reliability in quantitative and qualitative research rehearses the paradigm wars discussed in the opening chapters: quantitative measures are criticized for combining sophistication and refinement of process with crudity of concept (Ruddock, 1981) and for failing to distinguish between educational and statistical significance (Eisner, 1985); qualitative methodologies, whilst possessing immediacy, flexibility authenticity, richness and candour, are criticized for being impressionistic, biased, commonplace, insignificant, ungeneralizable, idiosyncratic, subjective and short-sighted (Ruddock, 1981). This is an arid debate; rather the issue is one of fitness for purpose. For our purposes here we need to note that criteria of reliability in quantitative methodologies differ from those in qualitative methodologies. In qualitative methodologie reliability includes fidelity to real life, context-an situation-specificity, authenticity, comprehensiveness, detail, honesty, depth of response and meaningfulness to the respondents.
TABLE 10.2 COMPARING RELIABILITY IN QUANTITATIVE AND QUALITATIVE RESEARCH
Bases of reliability in quantitative research |
|
Bases of reliability in qualitative research |
Reliability |
Dependability |
|
Demonstrability |
↔ |
Trustworthiness |
Stability |
↔ |
Stability |
Isolation, control and manipulation of required variables |
↔ |
Fidelity to the natural situation and real life |
Identification, control and manipulation of key variables |
↔ |
Thick description and high detail on required or important aspects |
Singular, objective truths |
↔ |
Multiple interpretations/perceptions |
Replicability |
↔ |
Replicability |
Parallel forms |
↔ |
Parallel forms |
Generalizability |
↔ |
Generalizability |
Context-freedom |
↔ |
Context-specificity |
Objectivity |
↔ |
Authenticity |
Coverage of domain |
↔ |
Comprehensiveness of situation |
Verification of data and analysis |
↔ |
Honesty and candour |
Answering research questions |
↔ |
Depth of response |
Meaningfulness to the research |
↔ |
Meaningfulness to respondents |
Parsimony |
↔ |
Richness |
Objectivity |
↔ |
Confirmability |
Fidelity to ‘etic’ research |
↔ |
Fidelity to ‘emic’ research |
Internal consistency |
↔ |
Credibility |
Generalizability |
↔ |
Transferability |
Parallel forms |
↔ |
Parallel forms |
Inter-rater reliability |
↔ |
Inter-rater reliability |
Accuracy |
↔ |
Accuracy |
Precision |
↔ |
Accuracy |
Replication |
↔ |
Replication |
Neutrality |
↔ |
Multiple interests represented |
Consistency |
↔ |
Consistency |
Theoretical relevance |
↔ |
Applicability |
Triangulation |
↔ |
Triangulation |
Alternative forms (equivalence) |
|
|
Split-half |
|
|
Inter-item correlations (alphas) |
|
|
We summarize some similarities and differences between reliability in quantitative and qualitative research in Table 10.2. This table shows that, whilst there are some areas of reliability that are exclusive to quantitative research (split-half testing, equivalent forms and Cronbach alphas), many features of reliability apply, mutatis mutandis, to both quantitative and qualitative research. Further, Table 10.2 also shows that there are some features that were found in validity (Table 10.1) that also appear in reliability (e.g. content validity that appears as coverage of domain and comprehensiveness, and concurrent validity that appears as triangulation). This suggests some blurring of the edges between validity and reliability in the literature.
In interviews, inferences about validity are made too often on the basis of face validity (Cannell and Kahn, 1968), that is, whether the questions asked look as if they are measuring what they claim to measure. One cause of invalidity is bias, defined as ‘a systematic or persistent tendency to make errors in the same direction, that is, to overstate or understate the “true value” of an attribute’ (Lansing et al., 1961). One way of validating interview measures is to compare the interview measure with another measure that has already been shown to be valid. This kind of comparison is known as ‘convergent validity’. If the two measures agree, it can be assumed that the validity of the interview is comparable with the proven validity of the other measure.
Perhaps the most practical way of achieving greater validity is to minimize the amount of bias as much as possible. The sources of bias are the characteristics of the interviewer, the characteristics of the respondent and the substantive content of the questions. More particularly, these will include:
the attitudes, opinions and expectations of the interviewer;
a tendency for the interviewer to see the respondent in her/his own image;
a tendency for the interviewer to seek answers that support her/his preconceived notions;
misperceptions on the part of the interviewer of what the respondent is saying;
misunderstandings on the part of the respondent of what is being asked.
Studies have also shown that race, religion, gender, sexual orientation, status, social class and age in certain contexts can be potent sources of bias, i.e. interviewer effects (Lee, 1993; Scheurich, 1995). Interviewers and interviewees alike bring their own, often unconscious, experiential and biographical baggage with them into the interview situation. Indeed Hitchcock and Hughes (1989) argue that because interviews are interpersonal, humans interacting with humans, it is inevitable that the researcher will have some influence on the interviewee and, thereby, on the data. Fielding and Fielding (1986: 12) make the telling comment that even the most sophisticated surveys only manipulate data that at some time had to be gained by asking people! Interviewer neutrality is a chimera (Denscombe, 1995).
Lee (1993) indicates the problems of conducting interviews perhaps at their sharpest, where the researcher is researching sensitive subjects, i.e. research that might pose a significant threat to those involved (be they interviewers or interviewees). Here the interview might be seen as an intrusion into private worlds, or the interviewer might be regarded as someone who can impose sanctions on the interviewee, or as someone who can exploit the powerless; the interviewee is in the searchlight that is being held by the interviewer (see also Scheurich, 1995). Indeed Gadd (2004) reports that an interviewee may reduce his/her willingness to ‘open up’ to an interviewer if the dynamics of the interview situation are too threatening, taking the role of the ‘defended subject’. The issues also embrace transference and counter-transference, which have their basis in psychoanalysis. In transference the interviewees project onto the interviewer their feelings, fears, desires, needs and attitudes that derive from their own experiences (Scheurich, 1995). In counter-transference the process is reversed.
One way of controlling for reliability is to have a highly structured interview, with the same format and sequence of words and questions for each respondent (Silverman, 1993), though Scheurich (1995: 241–9) suggests that this is to misread the infinite complexity and open-endedness of social interaction. Controlling the wording is no guarantee of controlling the interview. Oppenheim (1992: 147) argues that wording is a particularly important factor in attitudinal questions rather than factual questions. He suggests that changes in wording, context and emphasis undermine reliability, because it ceases to be the same question for each respondent. Indeed he argues that error and bias can stem from alterations to wording, procedure, sequence, recording, rapport, and that training for interviewers is essential to minimize this. Silverman (1993) suggests that it is important for each interviewee to understand the question in the same way. He suggests that the reliability of interviews can be enhanced by: careful piloting of interview schedules; training of interviewers; inter-rater reliability in the coding of responses; and the extended use of closed questions.
On the other hand Silverman (1993) argues for the importance of open-ended interviews, as this enables respondents to demonstrate their unique way of looking at the world – their definition of the situation. It recognizes that what is a suitable sequence of questions for one respondent might be less suitable for another, and open-ended questions enable important but unanticipated issues to be raised.
Oppenheim (1992: 96–7) suggests several causes of bias in interviewing:
biased sampling (sometimes created by the researcher not adhering to sampling instructions);
poor rapport between interviewer and interviewee;
changes to question wording (e.g. in attitudinal and factual questions);
poor prompting and biased probing;
poor use and management of support materials (e.g. show cards);
alterations to the sequence of questions;
inconsistent coding of responses;
selective or interpreted recording of data/transcripts;
poor handling of difficult interviews.
One can add to this the issue of ‘acquiescence’ (Break-well, 2000: 254): the tendency that respondents may have to say ‘yes’, regardless of the question or, indeed, regardless of what they really feel or think.
There is also the issue of leading questions. A leading question is one which makes assumptions about interviewees or ‘puts words into their mouths’, i.e. where the question influences the answer perhaps illegitimately. For example (Morrison, 1993: 66–7) the question ‘when did you stop complaining to the headteacher?’ assumes that the interviewee had been a frequent complainer, and the question ‘how satisfied are you with the new mathematics scheme?’ assumes a degree of satisfaction with the scheme. The leading questions here might be rendered less leading by rephrasing, for example: ‘how frequently do you have conversations with the headteacher?’ and ‘what is your opinion of the new mathematics scheme?’ respectively.
In discussing the issue of leading questions we are not necessarily suggesting that there is not a place for them. Indeed Kvale (1996: 158) makes a powerful case for leading questions, arguing that they may be necessary in order to obtain information that the interviewer suspects the interviewee might be withholding. Here it might be important to put the ‘burden of denial’ onto the interviewee (e.g. ‘when did you last stop beating your wife?’). Leading questions, frequently used in police interviews, may be used for reliability checks with what the interviewee has already said, or may be deliberately used to elicit particular non-verbal behaviours that give an indication of the sensitivity of the interviewee’s remarks.
Hence reducing bias includes careful formulation of questions so that the meaning is crystal clear; thorough training procedures so that an interviewer is more aware of the possible problems; probability sampling of respondents; and sometimes matching interviewer characteristics with those of the sample being interviewed. Oppenheim (1992: 148) argues, for example, that interviewers seeking attitudinal responses have to ensure that people with known characteristics are included in the sample – the criterion group. We need to recognize that the interview is a shared, negotiated and dynamic social moment.
The notion of power is significant in the interview situation, for the interview is not simply a data collection situation but a social and frequently a political situation. Literally the word ‘inter-view’ is a view between people, mutually, not the interviewer extracting data, one-way, from the interviewee. Power can reside with interviewer and interviewee alike (Thapar-Björkert and Henry, 2004), though Scheurich (1995: 246) argues that, typically, more power resides with the interviewer: the interviewer generates the questions and the interviewee answers them; the interviewee is under scrutiny whilst the interviewer is not. Kvale (1996: 126), too, suggests that there are definite asymmetries of power as the interviewer tends to define the situation, the topics and the course of the interview.
Cassell (in Lee, 1993) suggests that elites and powerful people might feel demeaned or insulted when being interviewed by those with a lower status or less power. Further, those with power, resources and expertise might be anxious to maintain their reputation, and so will be more guarded in what they say, wrapping this up in well-chosen, articulate phrases. Lee (1993) comments on the asymmetries of power in several interview situations, with one party having more power and control over the interview than the other. Interviewers need to be aware of the potentially distorting effects of power, a significant feature of critical theory, as discussed in Chapter 2.
Neal (1995) draws attention to the feelings of powerlessness and anxieties about physical presentation and status on the part of interviewers when interviewing powerful people. This is particularly so for frequently lone, low-status research students interviewing powerful people; a low-status female research student might find that an interview with a male in a position of power (e.g. a university vice-chancellor, a senior politician or a senior manager) might turn out to be very different from an interview with the same person if conducted by a male university professor where it is perceived by the interviewee to be more of a dialogue between equals (see also Gewirtz and Ozga, 1993, 1994). Ball (1994b) comments that when powerful people are being interviewed, interviews must be seen as an extension of the ‘play of power’ – with its gamelike connotations. He suggests that powerful people control the agenda and course of the interview, and are usually very adept at this because they have both a personal and professional investment in being interviewed (see also Batteson and Ball, 1995; Phillips, 1998).
The effect of power can be felt even before the interview commences, notes Neal (1995), where she instances being kept waiting, and subsequently being interrupted, being patronized and being interviewed by the interviewee (see also Walford, 1994b). Indeed Scheurich (1995) suggests that many powerful interviewees will rephrase or not answer the question. Connell et al. (1996) argue that a working-class female talking with a multinational director will be very different from a middle-class professor talking to the same person. Limerick et al. (1996) comment on occasions where interviewers have felt themselves to be passive, vulnerable, helpless and indeed manipulated. One way of overcoming this is to have two interviewers conducting each interview (Walford, 1994c: 227). On the other hand, Hitchcock and Hughes (1989) observe that if the researchers are known to the interviewees and they are peers, however powerful, then a degree of reciprocity might be taking place, with interviewees giving answers that they think the researchers might want to hear.
The issue of power has not been lost on feminist research (e.g. Thapar-Björkert and Henry, 2004), that is research that emphasizes subjectivity, equality, reciprocity, collaboration, non-hierarchical relations and emancipatory potential (catalytic and consequential validity) (Neal, 1995), echoing the comments about research that is influenced by the paradigm of critical theory. Here feminist research addresses a dilemma of interviews that are constructed in the dominant, male paradigm of pitching questions that demand answers from a passive respondent.
Limerick et al. (1996) suggest that, in fact, it is wiser to regard the interview as a gift, as interviewees have the power to withhold information, to choose the location of the interview, to choose how seriously to attend to the interview, how long it will last, when it will take place, what will be discussed – and in what and whose terms – what knowledge is important, even how the data will be analysed and used (see also Thapar-Björkert and Henry, 2004). Echoing Foucault, they argue that power is fluid and is discursively constructed through the interview rather than being the province of either party.
Miller and Cannell (1997) identify some particular problems in conducting telephone interviews, where the reduction of the interview situation to just auditory sensory cues can be particularly problematical. There are sampling problems, as not everyone will have a telephone. Further, there are practical issues, for example, the interviewee can only retain a certain amount of information in her/his short-term memory, so bombarding the interviewee with too many choices (the non-written form of ‘show cards’ of possible responses) becomes unworkable. Hence the reliability of responses is subject to the memory capabilities of the interviewee – how many scale points and descriptors, for example, can an interviewee retain in her head about a single item? Further, the absence of non-verbal cues is significant, e.g. facial expression, gestures, posture, the significance of silences and pauses (Robinson, 1982), as interviewees may be unclear about the meaning behind words and statements. This problem is compounded if the interviewer is unknown to the interviewee.
Miller and Cannell report important research evidence to support the significance of the non-verbal mediation of verbal dialogue. As discussed earlier, the interview is a social situation; in telephone interviews the absence of essential social elements could undermine the salient conduct of the interview, and hence its reliability and validity. Non-verbal paralinguistic cues affect the conduct, pacing and relationships in the interview and the support, threat, confidence felt by the interviewees. Telephone interviews can easily slide into becoming mechanical and cold. Further, the problem of loss of non-verbal cues is compounded by the asymmetries of power that often exist between interviewer and interviewee; the interviewer will need to take immediate steps to address these issues (e.g. by putting interviewees at their ease).
On the other hand, Nias (1991) and Miller and Cannell (1997) suggest that the very factor that interviews are not face to face may strengthen their reliability, as the interviewee might disclose information that may not be so readily forthcoming in a face-to-face, more intimate situation. Hence, telephone interviews have their strengths and weaknesses, and their use should be governed by the criterion of fitness-for-purpose. They tend to be shorter, more focused and useful for contacting busy people (Harvey, 1988; Miller, 1995).
In his critique of the interview as a research tool, Kitwood (1977) draws attention to the conflict it generates between the traditional concepts of validity and reliability. Where increased reliability of the interview is brought about by greater control of its elements, this is achieved, he argues, at the cost of reduced validity. He explains,
In proportion to the extent to which ‘reliability’ is enhanced by rationalization, ‘validity’ would decrease. For the main purpose of using an interview in research is that it is believed that in an interpersonal encounter people are more likely to disclose aspects of themselves, their thoughts, their feelings and values, than they would in a less human situation. At least for some purposes, it is necessary to generate a kind of conversation in which the ‘respondent’ feels at ease. In other words, the distinctively human element in the interview is necessary to its ‘validity’. The more the interviewer becomes rational, calculating, and detached, the less likely the interview is to be perceived as a friendly transaction, and the more calculated the response also is likely to be.
(Kitwood, 1977)
Kitwood suggests that a solution to the problem of validity and reliability might lie in the direction of a ‘judicious compromise’.
A cluster of problems surround the person being interviewed. Tuckman (1972), for example, has observed that, when formulating her questions, an interviewer has to consider the extent to which a question might influence the respondent to show herself in a good light; or the extent to which a question might influence the respondent to be unduly helpful by attempting to anticipate what the interviewer wants to hear; or the extent to which a question might be asking for information about a respondent that she is not certain or likely to know herself. Further, interviewing procedures are based on the assumption that the person interviewed has insight into the cause of her behaviour. An insight of this kind may be rarely achieved and, when it is, it is after long and difficult effort, usually in the context of repeated clinical interviews.
In educational circles interviewing might be a particular problem in working with children. Simons (1982) and McCormick and James (1988) comment on particular problems involved in interviewing children, for example:
establishing trust;
overcoming reticence;
maintaining informality;
avoiding assuming that children ‘know the answers’;
overcoming the problems of inarticulate children;
pitching the question at the right level;
choice of vocabulary;
non-verbal cues;
moving beyond the institutional response or receiving what children think the interviewer wants to hear;
avoiding the interviewer being seen as an authority spy or plant;
keeping to the point;
breaking silences on taboo areas and those which are reinforced by peer-group pressure;
children being seen as of lesser importance than adults (maybe in the sequence in which interviews are conducted, e.g. the headteacher, then the teaching staff, then the children).
These are not new matters. The studies by Labov in the 1960s showed how students reacted very strongly to contextual matters in an interview situation (Labov, 1969). The language of children varied according to the ethnicity of the interviewee, the friendliness of the surroundings, the opportunity for the children to be interviewed with friends, the ease with which the scene was set for the interview, the demeanour of the adult (e.g. whether the adult was standing or sitting), the nature of the topics covered. The differences were significant, varying from monosyllabic responses by children in unfamiliar and uncongenial surroundings to extended responses in the more congenial and less threatening surroundings – more sympathetic to the children’s everyday world. The language, argot and jargon (Edwards, 1976), social and cultural factors of the interviewer and interviewee all exert a powerful influence on the interview situation.
The issue is also raised here (Lee, 1993) of whether there should be a single interview that maintains the detachment of the researcher (perhaps particularly useful in addressing sensitive topics), or whether there should be repeated interviews to gain depth and to show fidelity to the collaborative nature of research (a feature, as was noted above, which is significant for feminist research (Oakley, 1981)).
Kvale (1996: 148–9) suggests that a skilled interviewer should:
know her subject matter in order to conduct an informed conversation;
structure the interview well, so that each stage of the interview is clear to the participant;
be clear in the terminology and coverage of the material;
allow participants to take their time and answer in their own way;
be sensitive and empathic, using active listening and being sensitive to how something is said and the non-verbal communication involved;
be alert to those aspects of the interview which may hold significance for the participant;
keep to the point and the matter in hand, steering the interview where necessary in order to address this;
check the reliability, validity and consistency of responses by well-placed questioning;
be able to recall and refer to earlier statements made by the participant;
be ready to clarify, confirm and modify the participants’ comments with the participant.
Walford (1994c: 225) adds to this the need for the interviewer to have done her homework when interviewing powerful people, as such people could well interrogate the interviewer – they will assume up-to-dateness, competence and knowledge in the interviewer. Powerful interviewees are usually busy people and will expect the interviewer to have read the material that is in the public domain.
The issues of reliability do not reside solely in the preparations for and conduct of the interview; they extend to the ways in which interviews are analysed. For example Lee (1993) and Kvale (1996: 163) comment on the issue of ‘transcriber selectivity’. Here transcripts of interviews, however detailed and full they might be, remain selective, since they are interpretations of social situations. They become decontextualized, abstracted, even if they record silences, intonation, non-verbal behaviour, etc. The issue, then, is how useful they are to researchers overall rather than whether they are completely reliable.
One of the problems that has to be considered when open-ended questions are used in the interview is that of developing a satisfactory method of recording replies. One way is to summarize responses in the course of the interview. This has the disadvantage of breaking the continuity of the interview and may result in bias because the interviewer may unconsciously emphasize responses that agree with her expectations and fail to note those that do not. It is sometimes possible to summarize an individual’s responses at the end of the interview. Although this preserves the continuity of the interview, it is likely to induce greater bias because the delay may lead to the interviewer forgetting some of the details. It is these forgotten details that are most likely to be the ones that disagree with the interviewer’s own expectations.
As we have seen, the fundamental purpose of experimental design is to impose control over conditions that would otherwise cloud the true effects of the independent variables upon the dependent variables.
Clouding conditions that threaten to jeopardize the validity of experiments have been identified by Campbell and Stanley (1963), Bracht and Glass (1968) and Lewis-Beck (1993), conditions that are of greater consequence to the validity of quasi-experiments (more typical in educational research) than to true experiments in which random assignment to treatments occurs and where both treatment and measurement can be more adequately controlled by the researcher.
Threats to internal validity were introduced earlier in this chapter, and comprise:
history
maturation
statistical regression
testing
instrumentation
selection
experimental mortality
instrument reactivity
selection-maturation interaction.
Several threats to external validity were discussed earlier in this chapter (Section 10.4) and the reader is advised to review these.
An experiment can be said to be internally valid to the extent that, within its own confines, its results are credible (Pilliner, 1973); but for those results to be useful, they must be generalizable beyond the confines of the particular experiment; in a word, they must be externally valid also (see also Morrison (2001) for a critique of randomized controlled experiments and the problems of generalizability). Pilliner points to a lopsided relationship between internal and external validity (these terms have been discussed earlier in the chapter). Without internal validity an experiment cannot possibly be externally valid. But the converse does not necessarily follow; an internally valid experiment may or may not have external validity. Thus, the most carefully designed experiment involving a sample of Welsh-speaking children is not necessarily generalizable to a target population which includes non-Welsh-speaking subjects.
It follows, then, that the way to good experimentation in schools, or indeed any other organizational setting, lies in maximizing both internal and external validity.
Validity of postal questionnaires can be seen from two viewpoints (Belson, l986). First, whether respondents who complete questionnaires do so accurately, honestly and correctly; and second, whether those who fail to return their questionnaires would have given the same distribution of answers as did the returnees. The question of accuracy can be checked by means of the intensive interview method, a technique consisting of 12 principal tactics that include familiarization, temporal reconstruction, probing and challenging. The interested reader should consult Belson (1986: 35–8).
The problem of non-response (the issue of ‘volunteer bias’ as Belson calls it) can, in part, be checked on and controlled for, particularly when the postal questionnaire is sent out on a continuous basis. It involves follow-up contact with non-respondents by means of interviewers trained to secure interviews with such people. A comparison is then made between the replies of respondents and non-respondents. Further, Hudson and Miller (1997) suggest several strategies for maximizing the response rate to postal questionnaires (and, thereby to increase reliability). They involve:
including stamped addressed envelopes;
multiple rounds of follow-up to request returns (maybe up to three follow-ups);
stressing the importance and benefits of the questionnaire;
stressing the importance of, and benefits to, the client group being targeted (particularly if it is a minority group that is struggling to have a voice);
providing interim data from returns to non-returners to involve and engage them in the research;
checking addresses and changing them if necessary;
following up questionnaires with a personal telephone call;
tailoring follow-up requests to individuals (with indications to them that they are personally known and/or important to the research – including providing respondents with clues by giving some personal information to show that they are known) rather than blanket generalized letters;
features of the questionnaire itself (ease of completion, time to be spent, sensitivity of the questions asked, length of the questionnaire);
invitations to a follow-up interview (face to face or by telephone);
encouragement to participate by a friendly third party;
understanding the nature of the sample population in depth, so that effective targeting strategies can be used.
The advantages of the questionnaire over interviews, for instance, are: it tends to be more reliable; it encourages greater honesty because it is anonymous (though, of course, dishonesty and falsification might not be able to be discovered in a questionnaire); it is more economical than the interview in terms of time and money; and there is the possibility that it may be mailed. Its disadvantages, on the other hand, are: there is often too low a percentage of returns; the interviewer is unable to answer questions concerning both the purpose of the interview and any misunderstandings experienced by the interviewee, for it sometimes happens in the case of the latter that the same questions have different meanings for different people; if only closed items are used, the questionnaire may lack coverage or authenticity; if only open items are used, respondents may be unwilling to write their answers for one reason or another; questionnaires present problems to people of limited literacy; and an interview can be conducted at an appropriate speed whereas questionnaires are often filled in hurriedly. There is a need, therefore, to pilot questionnaires and refine their contents, wording, length, etc. as appropriate for the sample being targeted.
One central issue in considering the reliability and validity of questionnaire surveys is that of sampling. An unrepresentative, skewed sample, one that is too small, can easily distort the data, and indeed, in the case of very small samples, prohibit statistical analysis (Morrison, 1993). The issue of sampling was covered in Chapter 8.
There are questions about two types of validity in observation-based research. In effect, comments about the subjective and idiosyncratic nature of the participant observation study are about its external validity. How do we know that the results of this one piece of research are applicable to other situations? Fears that observers’ judgements will be affected by their close involvement in the group relate to the internal validity of the method. How do we know that the results of this one piece of research represent the real thing, the genuine product? In Chapter 8 on sampling, we refer to a number of techniques (quota sampling, snowball sampling, purposive sampling) that researchers employ as a way of checking on the representativeness of the events that they observe and of cross-checking their interpretations of the meanings of those events.
In addition to external validity, participant observation also has to be rigorous in its internal validity checks. There are several threats to validity and reliability here, for example:
the researcher, in exploring the present, may be unaware of important antecedent events;
informants may be unrepresentative of the sample in the study;
the presence of the observer might bring about different behaviours (reactivity and ecological validity);
the researcher might ‘go native’, becoming too attached to the group to see it sufficiently dispassionately.
To address this Denzin (1989) suggests triangulation of data sources and methodologies. Chapter 23 discusses the principal ways of overcoming problems of reliability and validity in observational research in naturalistic enquiry. In essence it is suggested that the notion of ‘trustworthiness’ (Lincoln and Guba, 1985) replaces more conventional views of reliability and validity, and that this notion is devolved on issues of credibility, confirmability, transferability and dependability. Chapter 23 indicates how these areas can be addressed.
If observational research is much more structured in its nature, yielding quantitative data, then the conventions of intra-and inter-rater reliability apply. Here steps are taken to ensure that observers enter data into the appropriate categories consistently (i.e. intra-and inter-rater reliability) and accurately. Further, to ensure validity, a pilot must have been conducted to ensure that the observational categories themselves are appropriate, exhaustive, discrete, unambiguous and effectively operationalize the purposes of the research.
The researcher will have to judge the place and significance of test data, not forgetting the problem of the Hawthorne effect operating negatively or positively on students who have to undertake the tests. There is a range of issues which might affect the reliability of the test – for example, the time of day, the time of the school year, the temperature in the test room, the perceived importance of the test, the degree of formality of the test situation, ‘examination nerves’, the amount of guessing of answers by the students (the calculation of standard error which the tests demonstrate feature here), the way that the test is administered, the way that the test is marked, the degree of closure or openness of test items. Hence the researcher who is considering using testing as a way of acquiring research data must ensure that it is appropriate, valid and reliable (Carmines and Zeller, 1979; Linn, 1993; Borsboom et al., 2004).
Wolf (1994) suggests four main factors that might affect reliability: the range of the group that is being tested, the group’s level of proficiency, the length of the measure (the longer the test the greater the chance of errors), and the way in which reliability is calculated. Fitz-Gibbon (1997: 36) argues that, other things being equal, longer tests are more reliable than shorter tests. Additionally there are several ways in which reliability might be compromised in tests. Feldt and Brennan (1993) suggest four types of threat to reliability:
individuals (e.g. their motivation, concentration, forgetfulness, health, carelessness, guessing, their related skills, e.g. reading ability, their usedness to solving the type of problem set, the effects of practice);
situational factors (e.g. the psychological and physical conditions for the test – the context);
test marker factors (e.g. idiosyncrasy and subjectivity);
instrument variables (e.g. poor domain sampling, errors in sampling tasks, the realism of the tasks and relatedness to the experience of the testees, poor question items, the assumption or extent of unidi-mensionality in item response theory, length of the test, mechanical errors, scoring errors, computer errors).
There are several threats to reliability in tests and examinations, particularly tests of performance and achievement, for example (Cunningham, 1998; Airasian, 2001) with respect to examiners and markers:
errors in marking (e.g. attributing, adding and transfer of marks);
inter-rater reliability (different markers giving different marks for the same or similar pieces of work);
inconsistency in the marker (e.g. being harsh in the early stages of the marking and lenient in the later stages of the marking of many scripts);
variations in the award of grades for work that is close to grade boundaries (some markers placing the score in a higher or lower category than other markers);
the halo effect, wherein a student who is judged to do well or badly in one assessment is given undeserved favourable or unfavourable assessment respectively in other areas.
With reference to the students and teachers themselves, there are several sources of unreliability:
Motivation and interest in the task has a considerable effect on performance. Clearly, students need to be motivated if they are going to make a serious attempt at any test that they are required to undertake, where motivation is intrinsic (doing something for its own sake) or extrinsic (doing something for an external reason, e.g. obtaining a certificate or employment or entry into higher education). The results of a test completed in a desultory fashion by resentful pupils are hardly likely to supply the researcher with reliable information about the students’ capabilities (Wiggins, 1998). Motivation to participate in test-taking sessions is strongest when students have been helped to see its purpose, and where the examiner maintains a warm, purposeful attitude toward them during the testing session (Airasian, 2001).
The relationship (positive to negative) between the assessor and the testee exerts an influence on the assessment. This takes on increasing significance in teacher assessment, where the students know the teachers personally and professionally – and vice versa – and where the assessment situation involves face-to-face contact between the teacher and the student. Both test-takers and test-givers mutually influence one another during examinations, oral assessments and the like (Harlen, 1994). During the test situation, students respond to such characteristics of the evaluator as the person’s sex, age and personality.
The conditions – physical, emotional, social – exert an influence on the assessment, particularly if they are unfamiliar. Wherever possible, students should take tests in familiar settings, preferably in their own classrooms under normal school conditions. Distractions in the form of extraneous noise, walking about the room by the examiner and intrusions into the room, all have significant impact upon the scores of the test-takers, particularly when they are younger pupils (Gipps, 1994). An important factor in reducing students’ anxiety and tension during an examination is the extent to which they are quite clear about what exactly they are required to do. Simple instructions, clearly and calmly given by the examiner, can significantly lower the general level of tension in the test-room. Teachers who intend to conduct testing sessions may find it beneficial in this respect to rehearse the instructions they wish to give to pupils before the actual testing session. Ideally, test instructions should be simple, direct and as brief as possible.
The Hawthorne effect, wherein, in this context, simply informing a student that this is an assessment situation will be enough to disturb her/his performance – for the better or the worse (either case not being a fair reflection of her/his usual abilities).
Distractions (including superfluous information).
Students respond to the tester in terms of their perceptions of what s/he expects of them (Haladyna, 1997; Tombari and Borich, 1999; Stiggins, 2001).
The time of the day, week, month will exert an influence on performance. Some students are fresher in the morning and more capable of concentration (Stiggins, 2001).
Students are not always clear on what they think is being asked in the question; they may know the right answer but not infer that this is what is required in the question.
The students may vary from one question to another – a student may have performed better with a different set of questions which tested the same matters. Black (1998) argues that two questions which, to the expert, may seem to be asking the same thing but in different ways, to the students might well be seen as completely different questions.
Students (and teachers) practise test-like materials, which, even though scores are raised, might make them better at taking tests although the results might not indicate increased performance.
A student may be able to perform a specific skill in a test but not be able to select or perform it in the wider context of learning.
Cultural, ethnic and gender background affect how meaningful an assessment task or activity is to students, and meaningfulness affects their performance.
Students’ personalities may make a difference to their test performance.
Students’ learning strategies and styles may make a difference to their test performance.
Marking practices are not always reliable, markers may be too generous, marking by effort and ability rather than performance.
The context in which the task is presented affects performance: some students can perform the task in everyday life but not under test conditions.
With regard to the test items themselves, there may be problems (e.g. test bias), e.g.
The task itself may be multidimensional, for example, testing ‘reading’ may require several components and constructs. Students can execute a mathematics operation in the mathematics class but they cannot perform the same operation in, for example, a physics class; students will disregard English grammar in a science class but observe it in an English class. This raises the issue of the number of contexts in which the behaviour must be demonstrated before a criterion is deemed to have been achieved (Cohen et al., 2004). The question of transferability of knowledge and skills is also raised in this connection. The context of the task affects the student’s performance.
The validity of the items may be in question.
The language of the assessment and the assessor exerts an influence on the testee, for example if the assessment is carried out in the testee’s second language or in a ‘middle-class’ code (Haladyna, 1997).
The readability level of the task can exert an influence on the test, e.g. a difficulty in reading might distract from the purpose of a test which is of the use of a mathematical algorithm.
The size and complexity of numbers or operations in a test (e.g. of mathematics) that might distract the testee who actually understands the operations and concepts.
The number and type of operations and stages to a task – a student might know how to perform each element, but when they are presented in combination the size of the task can be overwhelming.
The form and presentation of questions affects the results, giving variability in students’ performances.
A single error early on in a complex sequence may confound the later stages of the sequence (within a question or across a set of questions), even though the student might have been able to perform the later stages of the sequence, thereby preventing the student from gaining credit for all she or he can, in fact, do.
Questions might favour boys more than girls or vice versa.
Essay questions favour boys if they concern impersonal topics and girls if they concern personal and interpersonal topics (Haladyna, 1997; Wedeen et al., 2002).
Boys perform better than girls on multiple choice questions and girls perform better than boys on essay-type questions (perhaps because boys are more willing than girls to guess in multiple-choice items), and girls perform better in written work than boys.
Questions and assessment may be culture-bound: what is comprehensible in one culture may be incomprehensible in another.
The test may be so long, in order to ensure coverage, that boredom and loss of concentration may impair reliability.
Hence specific contextual factors can exert a significant influence on learning and this has to be recognized in conducting assessments, to render an assessment as unthreatening and natural as possible.
Harlen (1994: 140–2) suggests that inconsistency and unreliability in teacher-and school-based assessment may derive from differences in: (a) interpreting the assessment purposes, tasks and contents, by teachers or assessors; (b) the actual task set, or the contexts and circumstances surrounding the tasks (e.g. time and place; (c) how much help is given to the test-takers during the test; (d) the degree of specificity in the marking criteria; (e) the application of the marking criteria and the grading or marking system that accompanies it; (f ) how much additional information about the student or situation is being referred to in the assessment.
She advocates the use of a range of moderation strategies, both before and after the tests, including:
statistical reference/scaling tests;
inspection of samples (by post or by visit);
group moderation of grades;
post hoc adjustment of marks;
accreditation of institutions;
visits of verifiers;
agreement panels;
defining marking criteria;
exemplification;
group moderation meetings.
Whilst moderation procedures are essentially post hoc adjustments to scores, agreement trials and practice marking can be undertaken before the administration of a test, which is particularly important if there are large numbers of scripts or several markers.
The issue here is that the results as well as the instruments should be reliable. Reliability is also addressed by:
calculating coefficients of reliability, split-half techniques, the Kuder-Richardson formula, parallel/equivalent forms of a test, test/re-test methods, the alpha coefficient;
calculating and controlling the standard error of measurement;
increasing the sample size (to maximize the range and spread of scores in a norm-referenced test), though criterion-referenced tests recognize that scores may bunch around the high level (in mastery learning for example), i.e. that the range of scores might be limited, thereby lowering the correlation coefficients that can be calculated;
increasing the number of observations made and items included in the test (in order to increase the range of scores);
ensuring effective domain sampling of items in tests based on item response theory (a particular issue in Computer Adaptive Testing, introduced below (Thissen, 1990));
ensuring effective levels of item discriminability and item difficulty.
Reliability not only has to be achieved but be seen to be achieved, particularly in ‘high stakes’ testing (where a lot hangs on the results of the test, e.g. entrance to higher education or employment). Hence the procedures for ensuring reliability must be transparent. The difficulty here is that the more one moves towards reliability as defined above, the more the test will become objective, the more students will be measured as though they are inanimate objects, and the more the test will become decontextualized.
An alternative form of reliability which is premised on a more constructivist psychology, emphasizes the significance of context, the importance of subjectivity and the need to engage and involve the testee more fully than a simple test. This rehearses the tension between positivism and more interpretive approaches outlined in the first chapter of this book. Objective tests, as described in this chapter, lean strongly towards the positivist paradigm, whilst more phenomenological and interpretive paradigms of social science research will emphasize the importance of settings, of individual perceptions, of attitudes, in short, of ‘authentic’ testing (e.g. by using non-contrived, non-artificial forms of test data, for example portfolios, documents, course work, tasks that are stronger in realism and more ‘hands on’). Though this latter adopts a view which is closer to assessment rather than narrowly ‘testing’, nevertheless the two overlap, both can yield marks, grades and awards, both can be formative as well as summative, both can be criterion-referenced.
With regard to validity, it is important to note here that an effective test will ensure adequate:
Content validity (e.g. adequate and representative coverage of programme and test objectives in the test items, a key feature of domain sampling) is achieved by ensuring that the content of the test fairly samples the class or fields of the situations or subject matter in question. Content validity is achieved by making professional judgements about the relevance and sampling of the contents of the test to a particular domain. It is concerned with coverage and representativeness rather than with patterns of response or scores. It is a matter of judgement rather than measurement (Kerlinger, 1986). Content validity will need to ensure several features of a test (Wolf, 1994): (a) test coverage (the extent to which the test covers the relevant field); (b) test relevance (the extent to which the test items are taught through, or are relevant to, a particular programme); (c) programme coverage (the extent to which the programme covers the overall field in question).
Criterion-related validity (where a high correlation coefficient exists between the scores on the test and the scores on other accepted tests of the same performance) is achieved by comparing the scores on the test with one or more variables (criteria) from other measures or tests that are considered to measure the same factor. Wolf (1994) argues that a major problem facing test devisers addressing criterion-related validity is the selection of the suitable criterion measure. He cites the example of the difficulty of selecting a suitable criterion of academic achievement in a test of academic aptitude. The criterion must be: (a) relevant (and agreed to be relevant); (b) free from bias (i.e. where external factors that might contaminate the criterion are removed); (c) reliable – precise and accurate; (d) capable of being measured or achieved.
Construct validity (e.g. the clear relatedness of a test item to its proposed construct/unobservable quality or trait, demonstrated by both empirical data and logical analysis and debate, i.e. the extent to which particular constructs or concepts can give an account for performance on the test) is achieved by ensuring that performance on the test is fairly explained by particular appropriate constructs or concepts. As with content validity, it is not based on test scores, but is more a matter of whether the test items are indicators of the underlying, latent construct in question. In this respect construct validity also subsumes content and criterion-related validity. It is argued (Loevinger, 1957) that in fact construct validity is the queen of the types of validity because it is sub-sumptive and because it concerns constructs or explanations rather than methodological factors. Construct validity is threatened by (a) under-representation of the construct, i.e. the test is too narrow and neglects significant facets of a construct, (b) the inclusion of irrelevancies – excess reliable variance.
Concurrent validity (where the results of the test concur with results on other tests or instruments that are testing/assessing the same construct/performance – similar to predictive validity but without the time dimension. Concurrent validity can occur simultaneously with another instrument rather than after some time has elapsed).
Face validity (that, superficially, the test appears – at face value – to test what it is designed to test).
Jury validity (an important element in construct validity, where it is important to agree on the conceptions and operationalization of an unobservable construct).
Predictive validity (where results on a test accurately predict subsequent performance – akin to criterion-related validity).
Consequential validity (where the inferences that can be made from a test are sound).
Systemic validity (Fredericksen and Collins, 1989) (where programme activities both enhance test performance and enhance performance of the construct that is being addressed in the objective. Cunningham (1998) gives an example of systemic validity where, if the test with the objective of vocabulary performance leads to testees increasing their vocabulary, then systemic validity has been addressed).
To ensure test validity, then the test must demonstrate fitness for purpose as well as addressing the several types of validity outlined above. The most difficult for researchers to address, perhaps, is construct validity, for it argues for agreement on the definition and operationalization of an unseen, half-guessed-at construct or phenomenon. The community of scholars has a role to play here. For a full discussion of validity see Messick (1993). To conclude this chapter, we turn briefly to consider validity and reliability in life history accounts.
Three central issues underpin the quality of data generated by life history methodology. They are to do with representativeness, validity and reliability. Plummer (1983) draws attention to a frequent criticism of life history research, namely that its cases are atypical rather than representative. To avoid this charge, he urges intending researchers to ‘work out and explicitly state the life history’s relationship to a wider population’ by way of appraising the subject on a continuum of representativeness and non-representativeness.
Reliability in life history research hinges upon the identification of sources of bias and the application of techniques to reduce them. Bias arises from the informant, the researcher and the interactional encounter itself. Box 10.1, adapted from Plummer (1983), provides a checklist of some aspects of bias arising from these principal sources.
BOX 10.1 PRINCIPAL SOURCES OF BIAS IN LIFE HISTORY RESEARCH
Source: informant
Is misinformation (unintended) given?
Has there been evasion?
Is there evidence of direct lying and deception?
Is a ‘front’ being presented?
What may the informant ‘take for granted’ and hence not reveal?
How far is the informant ‘pleasing you’?
How much has been forgotten?
How much may be self-deception?
Source: researcher
Attitudes of researcher: age, gender, class, race, religion, politics, etc.
Demeanour of researcher: dress, speech, body language, etc.
Personality of researcher: anxiety, need for approval, hostility, warmth, etc.
Scientific role of researcher: theory held (etc.), researcher expectancy.
Source: the interaction
The encounter needs to be examined. Is bias coming from:
The physical setting – ‘social space’?
The prior interaction?
Non-verbal communication?
Vocal behaviour?
Source: Adapted from Plummer, 1983: 103, table 5.2
Several validity checks are available to intending researchers. Plummer (1983) identifies the following:
1 The subject of the life history may present an autocritique of it, having read the entire product.
2 A comparison may be made with similar written sources by way of identifying points of major divergence or similarity.
3 A comparison may be made with official records by way of imposing accuracy checks on the life history.
4 A comparison may be made by interviewing other informants.
Essentially, the validity of any life history lies in its ability to represent the informant’s subjective reality, that is to say, his or her definition of the situation.
 Companion Website
Companion WebsiteThe companion website to the book includes PowerPoint slides for this chapter, which list the structure of the chapter and then provide a summary of the key points in each of its sections. In addition there is further information on the original Hawthorne experiments and measuring inter-rater reliability. These resources can be found online at www.routledge.com/textbooks/cohen7e.