
(a) a practice item – repeating known knowledge,
(b) an application item – applying known knowledge, (c) a synthesis item – bringing together and integrating diverse areas of knowledge);
Tests |
CHAPTER 24 |
The field of testing is so extensive that the comments that follow must needs be of an introductory nature and the reader seeking a deeper understanding will need to refer to specialist texts and sources on the subject. Limitations of space permit no more than a brief outline of a small number of key issues to do with tests and testing. This includes:
 what are we testing?
what are we testing?
parametric and non-parametric tests
norm-referenced, criterion-referenced and domain-referenced tests
commercially produced tests and researcher-produced tests
constructing a test
software for preparation of a test
devising a pre-test and post-test
ethical issues in testing
computerized adaptive testing
Since the spelling test of Rice (1897), the fatigue test of Ebbinghaus (1897) and the intelligence scale of Binet (1905), the growth of tests has proceeded at an extraordinary pace in terms of volume, variety, scope and sophistication. In tests, researchers have at their disposal a powerful method of data collection, an impressive array of tests for gathering data of a numerical rather than verbal kind. In considering testing for gathering research data, several issues need to be borne in mind, not the least of which is why tests are being used at all:
What are we testing (e.g. achievement, aptitude, attitude, personality, intelligence, social adjustment, etc.)?
Are we dealing with parametric or non-parametric tests?
Are they norm-referenced or criterion-referenced?
Are they available commercially for researchers to use or will researchers have to develop home-produced tests?
Do the test scores derive from a pre-test and post-test in the experimental method?
Are they group or individual tests?
Do they involve self-reporting or are they administered tests?
Let us unpack some of these issues.
There is a myriad of tests, to cover all aspects of a student’s life and for all ages (young children to old adults), for example:
ability
achievement
anxiety
aptitude
attainment
attitudes and values
behavioural disorders
competence-based assessment
computer-based assessment
creativity
critical thinking
cross-cultural adjustment
depression
diagnostic assessment
diagnosis of difficulties
higher order thinking
intelligence
interest inventories
introversion and extraversion
language proficiency tests
learning disabilities
locus of control
motivation and interest
neuropsychological assessment
performance
performance in school subjects
personality
potential
projective tests
reading readiness
self-esteem
social adjustment
spatial awareness
special abilities and disabilities
stress and burnout
university entrance tests
verbal and non-verbal reasoning
The Handbook of Psychoeducational Assessment (Saklofske et al, 2001) includes sections on ability assessment, achievement assessment, behaviour assessment, cross-cultural cognitive assessment and neuropsychological assessment. The Handbook of Psychological and Educational Assessment of Children: Intelligence, Aptitude and Achievement (Reynolds and Kamphaus, 2003) provides a clear overview of, inter alia:
the history of psychological and educational assessment;
a practical model of test development;
legal and ethical issues in the assessment of children;
measurement and design issues in the assessment of children;
intelligence testing, both verbal and non-verbal;
memory testing;
neuropsychological and biological perspectives on the assessment of children;
assessment of academic skills;
criterion-referenced testing;
diagnostic assessment;
writing abilities and instructional needs;
assessment of learning disabilities;
bias in aptitude assessment;
assessment of culturally and linguistically diverse children;
assessment of creativity;
assessment of language impairment;
assessment of psychological and educational needs of children with severe mental retardation and brain injury;
computer-based assessment.
The purpose in providing this comprehensive list is to indicate not only that there is a copious amount of assessment and testing material available but that it covers a very wide spectrum of topics. The Eighteenth Mental Measurements Yearbook (Spies et al, 2010) and Tests in Print VII (Murphy et al., 2010) are useful sources of published tests, as are specific publishers such as Harcourt Assessment and John Wiley. The American Psychological Association also produces on its website Finding Information about Psychological Tests: (www.apa.org/science/programs/testing/find-tests.aspx) and the British Psychological Society (www.bps.org.uk; www.psychtesting.org.uk and www.psychtesting.org.uk/directories/directories_home.cfm) produces lists of tests and suppliers. Standard texts that detail copious tests, suppliers and websites include: Gronlund and Linn (1990); Kline (2000); Loewenthal (2001); Saklofske et al. (2001); Reynolds and Kamphaus (2003); and Aiken (2003). The British Psychological Society also produces a glossary of terms connected with testing, at www.psychtesting.org.uk/download$.cfm?file_uuid=AlFBEA7D–1143-DFD0–7EAB-C510 B9DlDClA&siteName=ptc
Parametric tests are designed to represent the wide population, e.g. of a country or age group. They make assumptions about the wider population and the characteristics of that wider population, i.e. the parameters of abilities are known. They assume (Morrison, 1993):
that there is a normal curve of distribution of scores in the population (the bell-shaped symmetry of the Gaussian curve of distribution seen, for example, in standardized scores of IQ or the measurement of people’s height or the distribution of achievement on reading tests in the population as a whole),
that there are continuous and equal intervals between the test scores, and, with tests that have a true zero (see Chapter 34), the opportunity for a score of, say, 80 per cent to be double that of 40 per cent; this differs from the ordinal scaling of rating scales discussed earlier in connection with questionnaire design where equal intervals between each score could not be assumed.
Parametric tests will usually be published tests which are commercially available and which have been piloted and standardized on a large and representative sample of the whole population. They usually arrive complete with the backup data on sampling, reliability and validity statistics which have been computed in the devising of the tests. Working with these tests enables the researcher to use statistics applicable to interval and ratio levels of data.
On the other hand, non-parametric tests make few or no assumptions about the distribution of the population (the parameters of the scores) or the characteristics of that population. The tests do not assume a regular bell-shaped curve of distribution in the wider population; indeed the wider population is perhaps irrelevant as these tests are designed for a given specific population – a class in school, a chemistry group, a primary school year group. Because they make no assumptions about the wider population, the researcher must work with non-parametric statistics appropriate to nominal and ordinal levels of data. Parametric tests, with a true zero and marks awarded, are the stock-in-trade of classroom teachers – the spelling test, the mathematics test, the end-of-year examination, the mock examination.
The attraction of non-parametric statistics is their utility for small samples because they do not make any assumptions about how normal, even and regular the distributions of scores will be. Furthermore, computation of statistics for non-parametric tests is less complicated than that for parametric tests. Non-parametric tests have the advantage of being tailored to particular institutional, departmental and individual circumstances. They offer teachers a valuable opportunity for quick, relevant and focused feedback on student performance.
Parametric tests are more powerful than non-parametric tests because they not only derive from standardized scores but enable the researcher to compare sub-populations with a whole population (e.g. to compare the results of one school or local education authority with the whole country, for instance in comparing students’ performance in norm-referenced or criterion-referenced tests against a national average score in that same test). They enable the researcher to use powerful statistics in data processing (see Chapters 34–8), and to make inferences about the results. Because non-parametric tests make no assumptions about the wider population a different set of statistics is available to the researcher (see Part 5). These can be used in very specific situations – one class of students, one year group, one style of teaching, one curriculum area – and hence are valuable to teachers.
A norm-referenced test compares students’ achievements relative to other students’ achievements (e.g. a national test of mathematical performance or a test of intelligence which has been standardized on a large and representative sample of students between the ages of six and 16). A criterion-referenced test does not compare student with student but, rather, requires the student to fulfil a given set of criteria, a predefined and absolute standard or outcome (Cunningham, 1998). For example, a driving test is usually criterion-referenced since to pass it requires the ability to meet certain test items – reversing round a corner, undertaking an emergency stop, avoiding a crash, etc. regardless of how many others have or have not passed the driving test. Similarly many tests of playing a musical instrument require specified performances – e.g. the ability to play a particular scale or arpeggio, the ability to play a Bach Fugue without hesitation or technical error. If the student meets the criteria, then he or she passes the examination.
A criterion-referenced test provides the researcher with information about exactly what a student has learned, what she can do, whereas a norm-referenced test can only provide the researcher with information on how well one student has achieved in comparison to another, enabling rank orderings of performance and achievement to be constructed. Hence a major feature of the norm-referenced test is its ability to discriminate between students and their achievements – a well constructed norm-referenced test enables differences in achievement to be measured acutely, i.e. to provide variability or a great range of scores. For a criterion-referenced test this is less of a problem, the intention here is to indicate whether students have achieved a set of given criteria, regardless of how many others might or might not have achieved them, hence variability or range is less important here.
More recently an outgrowth of criterion-referenced testing has been the rise of domain-referenced tests (Gipps, 1994: 81). Here considerable significance is accorded to the careful and detailed specification of the content or the domain which will be assessed. The domain is the particular field or area of the subject that is being tested, for example, light in science, two-part counterpoint in music, parts of speech in English language. The domain is set out very clearly and very fully, such that the full depth and breadth of the content are established. Test items are then selected from this very full field, with careful attention to sampling procedures so that representativeness of the wider field is ensured in the test items. The student’s achievements on that test are computed to yield a proportion of the maximum score possible, and this, in turn, is used as an index of the proportion of the overall domain that she has grasped. So, for example, if a domain has 1,000 items and the test has 50 items, and the student scores 30 marks from the possible 50 then it is inferred that she has grasped 60 per cent ({30 ÷ 50} x 100) of the domain of 1,000 items. Here inferences are being made from a limited number of items to the student’s achievements in the whole domain; this requires careful and representative sampling procedures for test items.
There is a battery of tests in the public domain which cover a vast range of topics and which can be used for evaluative purposes (references are indicated at the start of this chapter).
Most schools will have used published tests at one time or another. There are several attractions to using published tests:
they are objective;
they have been piloted and refined;
they have been standardized across a named population (e.g. a region of the country, the whole country, a particular age group or various age groups) so that they represent a wide population;
they declare how reliable and valid they are (mentioned in the statistical details which are usually contained in the manual of instructions for administering the test);
they tend to be parametric tests, hence enabling sophisticated statistics to be calculated;
they come complete with instructions for administration;
they are often straightforward and quick to administer and to mark;
guides to the interpretation of the data are usually included in the manual;
researchers are spared the task of having to devise, pilot and refine their own test.
On the other hand Howitt and Cramer (2005) suggest that commercially produced tests are expensive to purchase and to administer; they are often targeted to special, rather than general, populations (e.g. in psychological testing), and they may not be exactly suited to the purpose required. Further, several commercially produced tests have restricted release or availability, hence the researcher might have to register with a particular association or be given clearance to use the test or to have copies of it. For example, Harcourt Assessment and McGraw-Hill publishers not only hold the rights to a worldwide battery of tests of all kinds but require registration before releasing tests. In this example Harcourt Assessment also has different levels of clearance, so that certain parties or researchers may not be eligible to have a test released to them because they do not fulfil particular criteria for eligibility.
Published tests by definition are not tailored to institutional or local contexts or needs; indeed their claim to objectivity is made on the grounds that they are deliberately supra-institutional. The researcher wishing to use published tests must be certain that the purposes, objectives and content of the published tests match the purposes, objectives and content of the evaluation. For example, a published diagnostic test might not fit the needs of the evaluation to have an achievement test, a test of achievement might not have the predictive quality which the researcher seeks in an aptitude test, a published reading test might not address the areas of reading that the researcher is wishing to cover, a verbal reading test written in English might contain language which is difficult for a student whose first language is not English. These are important considerations. A much-cited text on evaluating the utility for researchers of commercially available tests is produced by the American Psychological Association (1999) in the Standards for Educational and Psychological Testing (www.apa.org/science/programs/testing/standards.aspx).
The golden rule for deciding to use a published test is that it must demonstrate fitness for purpose. If it fails to demonstrate this, then tests will have to be devised by the researcher. The attraction of this latter point is that such a ‘home-grown’ test will be tailored to the local and institutional context very tightly, i.e. that the purposes, objectives and content of the test will be deliberately fitted to the specific needs of the researcher in a specific, given context. In discussing fitness for purpose Cronbach (1949) and Gronlund and Linn (1990) set out a range of criteria against which a commercially produced test can be evaluated for its suitability for specific research purposes.
Researchers should be cautious, perhaps, in considering whether to employ commercially produced tests, particularly in the case of having to use them with individuals and groups that are different from those in which the test was devised, as many tests show cultural bias. Further, there is the issue of the language medium of the test – for example using the Wechsler tests of intelligence (in English medium) with students who are not native speakers of English or who do not know about certain aspects of English culture turns the test away from a test on intelligence and towards a test of English language ability and English cultural knowledge.
Many commercially produced tests might be available in languages other than the original, but not only should the translations be checked to see if they are correct but the cultural significance of the test items themselves should be checked to see that they hold the same meaning and connotations in the target language as they do in the original language. It is often dangerous to import tests developed in one language and one culture into another language and another culture, as there are problems of validity, bias and reliability.
Against these advantages of course there are several important considerations in devising a ‘homegrown’ test. Not only might it be time-consuming to devise, pilot, refine and then administer the test but, because much of it will probably be non-parametric, there will be a more limited range of statistics which may be applied to the data than in the case of parametric tests.
The scope of tests and testing is far-reaching; no areas of educational activity are untouched by them. Achievement tests, largely summative in nature, measure achieved performance in a given content area. Aptitude tests are intended to predict capability, achievement potential, learning potential and future achievements. However, the assumption that these two constructs – achievement and aptitude – are separate has to be questioned (Cunningham, 1998); indeed it is often the case that a test of aptitude for, say, geography, at a particular age or stage will be measured by using an achievement test at that age or stage. Cunningham (1998) has suggested that an achievement test might include more straightforward measures of basic skills whereas aptitude tests might put these in combination, e.g. combining reasoning (often abstract) and particular knowledge, i.e. achievement and aptitude tests differ according to what they are testing.
Not only do the tests differ according to what they measure, but, since both can be used predictively, they differ according to what they might be able to predict. For example, because an achievement test is more specific and often tied to a specific content area, it will be useful as a predictor of future performance in that content area but will be largely unable to predict future performance out of that content area. An aptitude test tends to test more generalized abilities (e.g. aspects of ‘intelligence’, skills and abilities that are common to several areas of knowledge or curricula), hence it is able to be used as a more generalized predictor of achievement. Achievement tests, Gronlund (1985) suggests, are more linked to school experiences whereas aptitude tests encompass out-of-school learning and wider experiences and abilities. However Cunningham (1998), in arguing that there is a considerable overlap between the two types, is suggesting that the difference is largely cosmetic. An achievement test tends to be much more specific and linked to instructional programmes and cognate areas than an aptitude test, which looks for more general aptitudes (Hanna, 1993) (e.g. intelligence or intelligences (Gardner, 1993)).
Researchers considering constructing a test of their own will need to be aware of classical test theory (CTT) and Item Response Theory (IRT). Classical test theory assumes that there is a ‘true score’, which is the score which an individual would obtain on that test if the measurement was made without error and the expected score that would be gained over an infinite number of independent test administrations. It is the score that would be found by calculating the mean score that the individual test-taker would obtain on that same test if that person took it on an infinite number of occasions.
However, CTT recognizes that, in fact, errors do arise in the real world, due to, for example, cultural and socio-economic backgrounds and bias in the test, administration and marking of the test, and attitudes to the test by the test-takers. Hence tests provide an ‘observed score’ rather than a ‘true score’; the observed score (X) is the true score (T) plus the error (E) (X = T+E). A true score in CTT depends on the contents of the test rather than the characteristics of the test-taker, and the difficulty of the items might depend on the characteristics of the sample (a sampling issue) rather than on the item itself, i.e. it may be difficult to compare the results of different test-takers on different tests. Readers are advised to review classical test theory and reliability in connection with this formula and the calculation of the error (e.g. Kline, 2005).
By contrast, Item Response Theory (IRT) is based on the principle that it is possible to measure single, specific latent traits, abilities, attributes that, themselves, are not observable, i.e. to determine observable quantities of unobservable quantities (e.g. Hambleton, 1993). The theory/model assumes a relationship between a person’s possession or level of a particular attribute, trait or ability and his/her response to a test item. IRT is also based on the view that it is possible:
to identify objective levels of difficulty of an item, e.g. the Rasch model (Wainer and Mislevy, 1990);
to devise items that will be able to discriminate effectively between individuals;
to describe an item independently of any particular sample of people who might be responding to it, i.e. is not group-dependent (i.e. the item difficulty and item discriminability are independent of the sample);
to describe a testee’s proficiency in terms of his or her achievement of an item of a known difficulty level;
to describe a person independently of any sample of items that has been administered to that person (i.e. a testee’s ability does not depend on the particular sample of test items);
to specify and predict the properties of a test before it has been administered;
for traits to be unidimensional (single traits are specifiable, e.g. verbal ability, mathematical proficiency) and to account for test outcomes and performance in terms of that unidimensional trait, i.e. for an item to measure a single, undimensional trait;
for a set of items to measure a common trait or ability;
for a testee’s response to any one test item not to affect his or her response to another test item;
that the probability of the correct response to an item does not depend on the number of testees who might be at the same level of ability;
that it is possible to identify objective levels of difficulty of an item;
that a statistic can be calculated that indicates the precision of the measured ability for each testee, and that this statistic depends on the ability of the testee and the number and properties of the test items.
In devising a test the researcher will have to consider not only the foundations of the test (e.g. in CTT or IRT) but also:
the purposes of the test (for answering evaluation questions and ensuring that it tests what it is supposed to be testing, e.g. the achievement of the objectives of a piece of the curriculum);
the type of test (e.g. diagnostic, achievement, aptitude, criterion-referenced, norm-referenced);
the objectives of the test (cast in very specific terms so that the content of the test items can be seen to relate to specific objectives of a programme or curriculum);
the content of the test (what is being tested and what the test items are);
the construction of the test, involving item analysis in order to clarify the item discriminability and item difficulty of the test (see below);
the format of the test – its layout, instructions, method of working and of completion (e.g. oral instructions to clarify what students will need to write, or a written set of instructions to introduce a practical piece of work);
the nature of the piloting of the test;
the validity and reliability of the test;
the provision of a manual of instructions for the administration, marking and data treatment of the test (this is particularly important if the test is not to be administered by the researcher or if the test is to be administered by several different people, so that reliability is ensured by having a standard procedure).
In planning a test the researcher can proceed through the following headings.
The purposes of a test are several, for example to diagnose a student’s strengths weaknesses and difficulties, to measure achievement, to measure aptitude and potential, to identify readiness for a programme (Gronlund and Linn (1990) term this ‘placement testing’ and it is usually a form of pre-test, normally designed to discover whether students have the essential prerequisites to begin a programme, e.g. in terms of knowledge, skills, understandings). These types of tests occur at different stages. For example, the placement test is conducted prior to the commencement of a programme, and will identify starting abilities and achievements – the initial or ‘entry’ abilities in a student. If the placement test is designed to assign students to tracks, sets or teaching groups (i.e. to place them into administrative or teaching groupings), then the entry test might be criterion-referenced or norm-referenced; if it is designed to measure detailed starting points, knowledge, abilities and skills then the test might be more criterion-referenced as it requires a high level of detail. It has its equivalent in ‘baseline assessment’ and is an important feature if one is to measure the ‘value-added’ component of teaching and learning: one can only assess how much a set of educational experiences has added value to the student if one knows that student’s starting point and starting abilities and achievements.
Formative testing is undertaken during a programme, and is designed to monitor students’ progress during that programme, to measure achievement of sections of the programme, and to diagnose strengths and weaknesses. It is typically criterion-referenced.
Diagnostic testing is an in-depth test to discover particular strengths, weaknesses and difficulties that a student is experiencing, and is designed to expose causes and specific areas of weakness or strength. This often requires the test to include several items about the same feature, so that, for example, several types of difficulty in a student’s understanding will be exposed; the diagnostic test will need to construct test items that will focus on each of a range of very specific difficulties that students might be experiencing, in order to identify the exact problems that they are having from a range of possible problems. Clearly this type of test is criterion-referenced.
Summative testing is the test given at the end of the programme, and is designed to measure achievement, outcomes or ‘mastery’. This might be criterion-referenced or norm-referenced, depending to some extent on the use to which the results will be put (e.g. to award certificates or grades, to identify achievement of specific objectives).
The test specifications include:
which programme objectives and student learning outcomes will be addressed;
which content areas will be addressed;
the relative weightings, balance and coverage of items;
the total number of items in the test;
the number of questions required to address a particular element of a programme or learning outcomes;
the exact items in the test.
To ensure validity in a test it is essential to ensure that the objectives of the test are fairly addressed in the test items. Objectives, it is argued (Mager, 1962; Wiles and Bondi, 1984), should: (a) be specific and be expressed with an appropriate degree of precision; (b) represent intended learning outcomes; (c) identify the actual and observable behaviour which will demonstrate achievement; (d) include an active verb; (e) be unitary (focusing on one item per objective).
The test must measure what it purports to measure. It should demonstrate several forms of validity (e.g. construct, content, concurrent, predictive, criterion-related), discussed later.
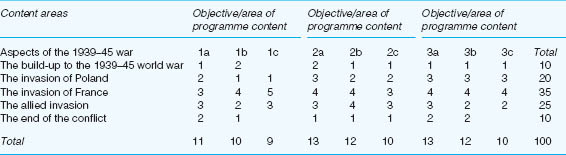
One way of ensuring that the objectives are fairly addressed in test items can be done through a matrix frame that indicates the coverage of content areas, the coverage of objectives of the programme and the relative weighting of the items on the test. Such a matrix is set out in Table 24.1 taking the example from a secondary school history syllabus.
Table 24.1 indicates the main areas of the programme to be covered in the test (content areas); then it indicates which objectives or detailed content areas will be covered (la–3c) – these numbers refer to the identified specifications in the syllabus; then it indicates the marks/percentages to be awarded for each area. This indicates several points:
the least emphasis is given to the build-up to and end of the war (10 marks each in the ‘total’ column);
the greatest emphasis is given to the invasion of France (35 marks in the ‘total’ column);
there is fairly even coverage of the objectives specified (the figures in the ‘total’ row only vary from 9–13);
greatest coverage is given to objectives 2a and 3a, and least coverage is given to objective 1c;
some content areas are not covered in the test items (the blanks in the matrix).
Hence we have here a test scheme that indicates relative weightings, coverage of objectives and content, and the relation between these two latter elements. Gronlund and Linn (1990) suggest that relative weightings should be addressed by first assigning percentages at the foot of each column, then by assigning percentages at the end of each row, and then completing each cell of the matrix within these specifications. This ensures that appropriate sampling and coverage of the items are achieved. The example of the matrix refers to specific objectives as column headings; of course these could be replaced by factual knowledge, conceptual knowledge and principles, and skills for each of the column headings. Alternatively they could be replaced with specific aspects of an activity, for example (Cohen et al., 2004: 339): designing a crane, making the crane, testing the crane, evaluating the results, improving the design. Indeed these latter could become content (row) headings, as shown in Table 24.2. Here one can see that practical skills will carry fewer marks than recording skills (the column totals), and that making and evaluating carry equal marks (the row totals).
This exercise also enables some indication to be gained on the number of items to be included in the test, for instance in the example of the history test above the matrix is 9 × 6 = 54 possible items, and in the ‘crane’ activity above the matrix is 5 × 4 = 20 possible items. Of course, there could be considerable variation in this, for example more test items could be inserted if it were deemed desirable to test one cell of the matrix with more than one item (possible for cross-checking), or indeed there could be fewer items if it were possible to have a single test item that serves more than one cell of the matrix. The difficulty in matrix construction is that it can easily become a runaway activity, generating very many test items and, hence, leading to an unworkably long test – typically the greater the degree of specificity required, the greater the number of test items there will be. One skill in test construction is to be able to have a single test item that provides valid and reliable data for more than a single factor.
Having undertaken the test specifications, the researcher should have achieved clarity on (a) the exact test items that test certain aspects of achievement of objectives, programmes, contents, etc.; (b) the coverage and balance of coverage of the test items; and (c) the relative weightings of the test items.
Validity concerns the extent to which the test tests what it is supposed to test; it must measure what it purports to measure. It should demonstrate several forms of validity (see also Chapter 10):
construct validity (the extent to which the test measures a particular construct, trait, behaviour, evidenced through convergent validity and discriminant, divergent validity, and by correlating the test with other published tests with the same purposes and similar contents);
content validity (by adequate and representative coverage of the domain, field, tasks, behaviours, knowledge, etc., without interference from extraneous variables);
concurrent validity (the extent to which the test correlates with other tests in a similar field);
predictive validity (that it applies to the situation under consideration, e.g. that it accurately predicts final scores);
criterion-related validity (the extent to which the performance on the test enables the researcher to infer the individual’s performance on a particular criterion of interest, often calculated as a correlation between the score on a test and a score in another indication of the item that the test was intended to measure, e.g. a test of performance on a job-specific matter and the individual’s actual performance on that job-specific item in the real situation);
cultural validity (fairness to the language and culture of the individual test-takers, and avoidance of cultural bias: a feature of all research instruments, not solely tests);
consequential validity (that the results of the test are used fairly and ethically (discussed later in this chapter), and are only for the purpose of, and ways in which, the test was constructed).
Reliability concerns the degree of confidence that can be placed in the results and the data, which is often a matter of statistical calculation and subsequent test redesigning. Reliability is addressed through the forms and techniques set out in Chapter 10: test/re-test, parallel forms, split-half and internal consistency (Cronbach’s alpha).
Here the test is subject to item analysis. Gronlund and Linn (1990) suggest that an item analysis will need to consider:
the suitability of the format of each item for the (learning) objective (appropriateness);
the ability of each item to enable students to demonstrate their performance of the (learning) objective (relevance);
the clarity of the task for each item;
the straightforwardness of the task;
the unambiguity of the outcome of each item, and agreement on what that outcome should be;
the cultural fairness of each item;
the independence of each item (i.e. where the influence of other items of the test is minimal and where successful completion of one item is not dependent on successful completion of another);
the adequacy of coverage of each (learning) objective by the items of the test.
In moving to test construction the researcher will need to consider how each element to be tested will be operationalized: (a) what indicators and kinds of evidence of achievement of the objective will be required; (b) what indicators of high, moderate and low achievement there will be; (c) what will the students be doing when they are working on each element of the test; (d) what the outcome of the test will be (e.g. a written response, a tick in a box of multiple choice items, an essay, a diagram, a computation). Indeed the Task Group on Assessment and Testing in the UK (1988) suggest that attention will have to be given to the presentation, operation and response modes of a test: (a) how the task will be introduced (e.g. oral, written, pictorial, computer, practical demonstration); (b) what the students will be doing when they are working on the test (e.g. mental computation, practical work, oral work, written); and (c) what the outcome will be – how they will show achievement and present the outcomes (e.g. choosing one item from a multiple choice question, writing a short response, open-ended writing, oral, practical outcome, computer output). Operationalizing a test from objectives can proceed by stages:
identify the objectives/outcomes/elements to be covered;
break down the objectives/outcomes/elements into constituent components or elements;
select the components that will feature in the test, such that, if possible, they will represent the larger field (i.e. domain-referencing, if required);
recast the components in terms of specific, practical, observable behaviours, activities and practices that fairly represent and cover that component;
specify the kinds of data required to provide information on the achievement of the criteria;
specify the success criteria (performance indicators) in practical terms, working out marks and grades to be awarded and how weightings will be addressed;
write each item of the test.
Item analysis, Gronlund and Linn (1990: 255) aver, is designed to ensure that: (a) the items function as they are intended, for example, that criterion-referenced items fairly cover the fields and criteria and that norm-referenced items demonstrate item discriminability (discussed below); (b) the level of difficulty of the items is appropriate (see below: item difficulty); (c) the test is reliable (free of distractors – unnecessary information and irrelevant cues, see below: distractors) (see Millman and Greene, 1993). An item analysis will consider the accuracy levels available in the answer, the item difficulty, the importance of the knowledge or skill being tested, the match of the item to the programme and the number of items to be included. The foundation for item analysis lies in Item Response Theory, discussed earlier.
In constructing a test the researcher will need to undertake an item analysis to clarify the item discriminability and item difficulty of each item of the test. Item discriminability refers to the potential of the item in question to be answered correctly by those students who have a lot of the particular quality that the item is designed to measure and to be answered incorrectly by those students who have less of the particular quality that the same item is designed to measure. In other words, how effective is the test item in showing up differences between a group of students? Does the item enable us to discriminate between students’ abilities in a given field? An item with high discriminability will enable the researcher to see a potentially wide variety of scores on that item; an item with low discriminability will show scores on that item poorly differentiated. Clearly a high measure of discriminability is desirable, and items with low discriminability should be discarded.
Suppose the researcher wishes to construct a test of mathematics for eventual use with 30 students in a particular school (or with class A in a particular school). The researcher devises a test and pilots it in a different school or class B respectively, administering the test to 30 students of the same age (i.e. she matches the sample of the pilot school or class to the sample in the school which eventually will be used). The scores of the 30 pilot children are then split into three groups of ten students each (high, medium and low scores). It would be reasonable to assume that there will be more correct answers to a particular item amongst the high scorers than amongst the low scorers. For each item compute the following:
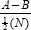
where
A = the number of correct scores from the high scoring group;
B = the number of correct scores from the low scoring group;
N = the total number of students in the two groups.
Suppose all ten students from the high scoring group answered the item correctly and two students from the low scoring group answered the item correctly. The formula would work out thus:
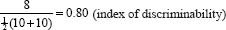
The maximum index of discriminability is 1.00. Any item whose index of discriminability is less than 0.67, i.e. is too undiscriminating, should be reviewed first to find out whether this is due to ambiguity in the wording or possible clues in the wording. If this is not the case, then whether the researcher uses an item with an index lower than 0.67 is a matter of judgement. It would appear, then, that the item in the example would be appropriate to use in a test. For a further discussion of item discriminability see Linn (1993) and Aiken (2003).
One can use the discriminability index to examine the effectiveness of distractors. This is based on the premise that an effective distractor should attract more students from a low scoring group than from a high scoring group. Consider the following example, where low and high scoring groups are identified:
|
A |
B |
c |
Top 10 students |
10 |
0 |
2 |
Bottom 10 students |
8 |
0 |
10 |
In example A, the item discriminates positively in that it attracts more correct responses (10) from the top ten students than the bottom ten (2) and hence is a poor distractor; here, also, the discriminability index is 0.20, hence is a poor discriminator and is also a poor distractor. Example B is an ineffective distractor because nobody was included from either group. Example C is an effective distractor because it includes far more students from the bottom ten students (10) than the higher group (2). However, in this case any ambiguities must be ruled out before the discriminating power can be improved.
Distractors are the stuff of multiple choice items, where incorrect alternatives are offered, and students have to select the correct alternatives. Here a simple frequency count of the number of times a particular alternative is selected will provide information on the effectiveness of the distractor: if it is selected many times then it is working effectively; if it is seldom or never selected then it is not working effectively and it should be replaced.
If we wish to calculate the item difficulty of a test, we can use the following formula:
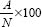
where
A = the number of students who answered the item correctly;
N = the total number of students who attempted the item.
Hence if 12 students out of a class of 20 answered the item correctly, then the formula would work out thus:
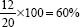
The maximum index of difficulty is 100 per cent. Items falling below 33 per cent and above 67 per cent are likely to be too difficult and too easy respectively. It would appear, then, that this item would be appropriate to use in a test. Here, again, whether the researcher uses an item with an index of difficulty below or above the cut-off points is a matter of judgement. In a norm-referenced test the item difficulty should be around 50 per cent (Frisbie, 1981). For further discussion of item difficulty see Linn (1993) and Hanna (1993).
Given that the researcher can only know the degree of item discriminability and difficulty once the test has been undertaken, there is an unavoidable need to pilot home-grown tests. Items with limited discriminability and limited difficulty must be weeded out and replaced, those items with the greatest discriminability and the most appropriate degrees of difficulty can be retained; this can only be undertaken once data from a pilot have been analysed.
Item discriminability and item difficulty take on differential significance in norm-referenced and criterion-referenced tests. In a norm-referenced test we wish to compare students with each other, hence item discriminability is very important. In a criterion-referenced test, on the other hand, it is not important per se to be able to compare or discriminate between students’ performance. For example, it may be the case that we wish to discover whether a group of students has learnt a particular body of knowledge, that is the objective, rather than, say, finding out how many have learned it better than others. Hence it may be that a criterion-referenced test has very low discriminability if all the students achieve very well or achieve very poorly, but the discriminability is less important than the fact than the students have or have not learnt the material. A norm-referenced test would regard such a poorly discriminating item as unsuitable for inclusion, whereas a criterion-referenced test would regard such an item as providing useful information (on success or failure).
With regard to item difficulty, in a criterion-referenced test the level of difficulty is that which is appropriate to the task or objective. Hence if an objective is easily achieved then the test item should be easily achieved; if the objective is difficult then the test item should be correspondingly difficult. This means that, unlike a norm-referenced test where an item might be reworked in order to increase its discriminability index, this is less of an issue in criterion-referencing. Of course, this is not to deny the value of undertaking an item difficulty analysis, rather it is to question the centrality of such a concern. Gronlund and Linn (1990: 265) suggest that where instruction has been effective the item difficulty index of a criterion-referenced test will be high.
In addressing the item discriminability, item difficulty and distractor effect of particular test items, it is advisable, of course, to pilot these tests and to be cautious about placing too great a store on indices of difficulty and discriminability that are computed from small samples.
In constructing a test with item analysis, item discriminability, item difficulty and distractor effects in mind, it is important also to consider the actual requirements of the test (Nuttall, 1987; Cresswell and Houston, 1991), for example:
are all the items in the test equally difficult;
which items are easy, moderately hard, hard, very hard;
what kinds of task each item is addressing (e.g. is it
(a) a practice item – repeating known knowledge,
(b) an application item – applying known knowledge, (c) a synthesis item – bringing together and integrating diverse areas of knowledge);
if not, what makes some items more difficult than the rest;
whether the items are sufficiently within the experience of the students;
how motivated students will be by the contents of each item (i.e. how relevant they perceive the item to be, how interesting it is).
The contents of the test will also need to take account of the notion of fitness for purpose, for example in the types of test items. Here the researcher will need to consider whether the kinds of data to demonstrate ability, understanding and achievement will be best demonstrated in, for example (Lewis, 1974; Cohen et al., 2004, chapter 16):
an open essay,
a factual and heavily directed essay;
short answer questions;
divergent thinking items;
completion items;
multiple choice items (with one correct answer or more than one correct answer);
matching pairs of items or statements;
inserting missing words;
incomplete sentences or incomplete, unlabelled diagrams;
true/false statements;
open-ended questions where students are given guidance on how much to write (e.g. 300 words, a sentence, a paragraph);
closed questions.
These items can test recall, knowledge, comprehension, application, analysis, synthesis and evaluation, i.e. different orders of thinking. These take their rationale from Bloom (1956) on hierarchies of thinking – from low order (comprehension, application), through middle order thinking (analysis, synthesis) to higher order thinking (evaluation, judgement, criticism). Clearly the selection of the form of the test item will be based on the principle of gaining the maximum amount of information in the most economical way. This is evidenced in the use of machine-scorable multiple choice completion tests, where optical mark readers and scanners can enter and process large-scale data rapidly.
In considering the contents of a test the test writer must also consider the scale for some kinds of test. The notion of a scale (a graded system of classification) can be created in two main ways (Howitt and Cramer, 2005: 203):
a list of items whose measurements go from the lowest to highest (e.g. an IQ test, a measure of sexism, a measure of aggressiveness), such that it is possible to judge where a student has reached on the scale by seeing the maximum level reached on the items;
the method of ‘summated scores’ in which a pool of items is created, and the student’s score is the total score gained by summing the marks for all the items.
Further, many psychological tests used in educational research will be unidimensional, that is, the items all measure a single element or dimension (Howitt and Cramer (2005: 204) liken this to weighing 30 people using ten bathroom scales, in which one would expect a high intercorrelation to be found between the bathroom scales). Other tests may be multidimensional, i.e. where two or more factors or dimensions are being measured in the same test (Howitt and Cramer (2005: 204) liken this to weighing 30 people using ten bathroom scales and then their heights using five different tape measures. Here one would expect a high intercorrelation to be found between the bathroom scale measures, a high intercorrelation to be found between the measurements from the tape measures, and a low intercorrelation to be found between the bathroom scale measures and the measurements from the tape measures, because they are measuring different things/dimensions).
Test constructors, then, need to be clear whether they are using a unidimensional or a multidimensional scale. Many texts, whilst advocating the purity of using a unidimensional test that measures a single construct or concept, also recognize the efficacy, practicality and efficiency in using multidimensional tests. For example, though one might regard intelligence casually as a unidimensional factor, in fact a stronger measure of intelligence would be obtained by regarding it as a multidimensional construct, thereby requiring multidimensional scaling. Of course, some items on a test are automatically unidimensional, for example age, hours spent on homework.
Further, the selection of the items needs to be considered in order to have the highest reliability. Let us say that we have ten items that measure students’ negative examination stress. Each item is intended to measure stress, for example:
Item 1 |
Loss of sleep at examination time; |
Item 2 |
Anxiety at examination time; |
Item 3 |
Irritability at examination time; |
Item 4 |
Depression at examination time; |
Item 5 |
Tearfulness at examination time; |
Item 6 |
Unwillingness to do household chores at examination time; |
Item 7 |
Mood swings at examination time; |
Item 8 |
Increased consumption of coffee at examination time; |
Item 9 |
Positive attitude and cheerfulness at examination time; |
Item 10 |
Eager anticipation of the examination. |
You run a reliability test (see Chapter 36 on SPSS reliability) of internal consistency and find strong intercor-relations between items 1–5 (e.g. around 0.85), negative correlations between items 9 and 10 and all the other items (e.g. –0.79), and a very low intercorrelation between items 6 and 8 and all the others (e.g. 0.26). Item-to-total correlations (one kind of item analysis in which the item in question is correlated with the sum of the other items) vary here. What do you do? You can retain items 1–5. For items 9 and 10 you can reverse the scoring (as these items looked at positive rather than negative aspects), and for items 6 and 8 you can consider excluding them from the test, as they appear to be measuring something else. Such item analysis is designed to include items that measure the same construct and to exclude items that do not. We refer readers to Howitt and Cramer (2005: chapter 12) for further discussion of this.
An alternative approach to deciding which items to retain or exclude from the list of ten items above is to use factor analysis (see Chapter 37), a method facilitated greatly by SPSS. Factor analysis will group together a cluster of similar items and keep that cluster separate from clusters of other items. So, for our example above, the factor analysis could have found, by way of illustration, three factors:
positive feelings (items 9 and 10);
negative psychological states (items 2, 3, 4, 5, 7);
physical, behavioural changes (items 1, 6, 8).
By looking at the factor loadings (see Chapter 37) the researcher would have to decide which were the most appropriate factors to retain, and, thereby, which items to include and exclude. As a general rule, items with low factor loadings (e.g. <0.3) should be considered for exclusion, as they do not contribute sufficiently to the factor. Factor analysis will indicate, also, whether the construct is unidimensional or multidimensional (if there is only one factor it is probably unidimensional).
Much of the discussion in this chapter assumes that the test is of the pen-and-paper variety. Clearly this need not be the case, for example tests can be written, oral, practical, interactive, computer-based, dramatic, diagrammatic, pictorial, photographic, involve the use of audio and video material, presentational and role-play, simulations. Oral tests, for example, can be conducted if the researcher feels that reading and writing will obstruct the true purpose of the test (i.e. it becomes a reading and writing test rather than, say, a test of mathematics). This does not negate the issues discussed in this chapter, for the form of the test will still need to consider, for example, reliability and validity, difficulty, discriminability, marking and grading, item analysis, timing. Indeed several of these factors take on an added significance in non-written forms of testing; for example: (a) reliability is a major issue in judging live musical performance or the performance of a gymnastics routine – where a ‘one-off’ event is likely; (b) reliability and validity are significant issues in group performance or group exercises – where group dynamics may prevent a testee’s true abilities from being demonstrated. Clearly the researcher will need to consider whether the test will be undertaken individually, or in a group, and what form it will take.
The test will need to address the intended and unintended clues that might be provided in it, for example (Morris et al., 1987):
the number of blanks might indicate the number of words required;
the number of dots might indicate the number of letters required;
the length of blanks might indicate the length of response required;
the space left for completion will give cues about how much to write;
blanks in different parts of a sentence will be assisted by the reader having read the other parts of the sentence (anaphoric and cataphoric reading cues).
Hanna (1993: 139–41) and Cunningham (1998) provide several guidelines for constructing short answer items to overcome some of these problems:
make the blanks close to the end of the sentence;
keep the blanks the same length;
ensure that there can be only a single correct answer;
avoid putting several blanks close to each other (in a sentence or paragraph) such that the overall meaning is obscured;
only make blanks of key words or concepts, rather than of trivial words;
avoid addressing only trivial matters;
ensure that students know exactly the kind and specificity of the answer required;
specify the units in which a numerical answer is to be given;
use short answers for testing knowledge recall.
With regard to multiple choice items there are several potential problems:
the number of choices in a single multiple choice item (and whether there is one or more right answer(s));
the number and realism of the distractors in a multiple choice item (e.g. there might be many distractors but many of them are too obvious to be chosen –there may be several redundant items);
the sequence of items and their effects on each other;
the location of the correct response(s) in a multiple choice item.
Gronlund and Linn (1990), Hanna (1993: 161–75), Cunningham (1998) and Aiken (2003) set out several suggestions for constructing effective multiple choice test items:
ensure that they catch significant knowledge and learning rather than low-level recall of facts;
frame the nature of the issue in the stem of the item, ensuring that the stem is meaningful in itself (e.g. replace the general ‘sheep’: (a) ‘are graminivorous, (b) are cloven footed, (c) usually give birth to one or two lambs at a time’ with ‘how many lambs are normally born to a sheep at one time?’);
ensure that the stem includes as much of the item as possible, with no irrelevancies;
avoid negative stems to the item;
keep the readability levels low;
ensure clarity and unambiguity;
ensure that all the options are plausible so that guessing of the only possible option is avoided;
avoid the possibility of students making the correct choice through incorrect reasoning;
include some novelty to the item if it is being used to measure understanding;
ensure that there can only be a single correct option (if a single answer is required) and that it is unambiguously the right response;
avoid syntactical and grammatical clues by making all options syntactically and grammatically parallel and by avoiding matching the phrasing of a stem with similar phrasing in the response;
avoid including in the stem clues as to which may be the correct response;
ensure that the length of each response item is the same (e.g. to avoid one long correct answer from standing out);
keep each option separate, avoiding options which are included in each other;
ensure that the correct option is positioned differently for each item (e.g. so that it is not always option 2);
avoid using options like ‘all of the above’ or ‘none of the above’;
avoid answers from one item being used to cue answers to another item – keep items separate.
The response categories of tests need to be considered, and we refer readers to our discussion of this topic in Chapter 20 on questionnaires (e.g. Likert scales, Guttman scales, semantic differential scales, Thurstone scales).
Morris et al. (1987: 161), Gronlund and Linn (1990), Hanna (1993: 147), Cunningham (1998) and Aiken (2003) also indicate particular problems in true/false questions:
ambiguity of meaning;
some items might be partly true or partly false;
items that polarize – being too easy or too hard;
most items might be true or false under certain conditions;
it may not be clear to the student whether facts or opinions are being sought;
as this is dichotomous, students have an even chance of guessing the correct answer;
an imbalance of true to false statements;
some items might contain ‘absolutes’ which give powerful clues, e.g. ‘always’, ‘never’, ‘all’, ‘none’.
To overcome these problems the authors suggest several points that can be addressed:
avoid generalized statements (as they are usually false);
avoid trivial questions;
avoid negatives and double negatives in statements;
avoid over-long and over-complex statements;
ensure that items are rooted in facts;
ensure that statements can be either only true or false;
write statements in everyday language;
decide where it is appropriate to use ‘degrees’ –’generally’, ‘usually’, ‘often’ – as these are capable of interpretation;
avoid ambiguities;
ensure that each statement only contains one idea;
if an opinion is to be sought then ensure that it is attributable to a named source;
ensure that true statements and false statements are equal in length and number.
Morris et al. (1987), Hanna (1993: 150–2), Cunningham (1998) and Aiken (2003) also indicate particular potential difficulties in matching items:
it might be very clear to a student which items in a list simply cannot be matched to items in the other list (e.g. by dint of content, grammar, concepts), thereby enabling the student to complete the matching by elimination rather than understanding;
one item in one list might be able to be matched to several items in the other;
the lists might contain unequal numbers of items, thereby introducing distractors – rendering the selection as much a multiple choice item as a matching exercise.
The authors suggest that difficulties in matching items can be addressed thus:
ensure that the items for matching are homogenous – similar – over the whole test (to render guessing more difficult);
avoid constructing matching items to answers that can be worked out by elimination (e.g. by ensuring that: (a) there are different numbers of items in each column so that there are more options to be matched than there are items; (b) students can avoid being able to reduce the field of options as they increase the number of items that they have matched; (c) the same option may be used more than once);
decide whether to mix the two columns of matched items (i.e. ensure, if desired, that each column includes both items and options);
sequence the options for matching so that they are logical and easy to follow (e.g. by number, by chronology);
avoid over-long columns and keep the columns on a single page;
make the statements in the options columns as brief as possible;
avoid ambiguity by ensuring that there is a clearly suitable option that stands out from its rivals;
make it clear what the nature of the relationship should be between the item and the option (on what terms they relate to each other);
number the items and letter the options.
With regard to essay questions, there are several advantages that can be claimed. For example, an essay, as an open form of testing, enables complex learning outcomes to be measured, it enables the student to integrate, apply and synthesize knowledge, to demonstrate the ability for expression and self-expression, and to demonstrate higher order and divergent cognitive processes. Further, it is comparatively easy to construct an essay title. On the other hand, essays have been criticized for yielding unreliable data (Gronlund and Linn, 1990; Cunningham, 1998), for being prone to unreliable (inconsistent and variable) scoring, neglectful of intended learning outcomes and prone to marker bias and preference (being too intuitive, subjective, holistic and time-consuming to mark). To overcome these difficulties the authors suggest that:
the essay question must be restricted to those learning outcomes that are unable to be measured more objectively;
the essay question must ensure that it is clearly linked to desired learning outcomes; that it is clear what behaviours the students must demonstrate;
the essay question must indicate the field and tasks very clearly (e.g. ‘compare’, ‘justify’, ‘critique’, ‘summarize’, ‘classify’, ‘analyse’, ‘clarify’, ‘examine’, ‘apply’, ‘evaluate’, ‘synthesize’, ‘contrast’, ‘explain’, ‘illustrate’);
time limits are set for each essay;
options are avoided, or, if options are to be given, ensure that, if students have a list of titles from which to choose, each title is equally difficult and equally capable of enabling the student to demonstrate achievement, understanding, etc.
marking criteria are prepared and are explicit, indicating what must be included in the answers and the points to be awarded for such inclusions or ratings to be scored for the extent to which certain criteria have been met;
decisions are agreed on how to address and score irrelevancies, inaccuracies, poor grammar and spelling;
the work is double-marked, blind and, where appropriate, without the marker knowing (the name of) the essay writer.
Clearly these are issues of reliability (see Chapter 10). The issue here is that layout can exert a profound effect on the test. For a general introduction to writing test items see Cohen and Wollack (2010) and http://cte. umdnj.edu/student_evaluation/evaluation_constructing.cfm">http://cte. umdnj.edu/student_evaluation/evaluation_constructing.cfm.
This will include (Gronlund and Linn, 1990; Hanna, 1993; Linn, 1993; Cunningham, 1998):
the nature, length and clarity of the instructions, e.g. what to do, how long to take, how much to do, how many items to attempt, what kind of response is required (e.g. a single word, a sentence, a paragraph, a formula, a number, a statement, etc.), how and where to enter the response, where to show the ‘working out’ of a problem, where to start new answers (e.g. in a separate booklet), is one answer only required to a multiple choice item, or is more than one answer required;
spread out the instructions through the test, avoiding overloading students with too much information at first, and providing instructions for each section as they come to it;
what marks are to be awarded for which parts of the test;
minimizing ambiguity and taking care over the read-ability of the items;
the progression from the easy to the more difficult items of the test (i.e. the location and sequence of items);
the visual layout of the page, for example, avoiding overloading students with visual material or words;
the grouping of items – keeping together items that have the same contents or the same format;
the setting out of the answer sheets/locations so that they can be entered onto computers and read by optical mark readers and scanners (if appropriate).
The layout of the text should be such that it supports the completion of the test and that this is done as efficiently and as effectively as possible for the student.
This refers to two areas: (a) when the test will take place (the day of the week, month, time of day), and (b) the time allowances to be given to the test and its component items. With regard to the former, in part this is a matter of reliability, for the time of day, week, etc. might influence how alert, motivated, capable a student might be. With regard to the latter, the researcher will need to decide what time restrictions are being imposed and why (for example, is the pressure of a time constraint desirable – to show what a student can do under time pressure (a speed test) – or an unnecessary impediment, putting a time boundary around something that need not be bounded – was Van Gogh put under a time pressure to produce the painting of sunflowers?) (see also Kohn, 2000).
Though it is vital that the student knows what the overall time allowance is for the test, clearly it might be helpful to a student to indicate notional time allowances for different elements of the test; if these are aligned to the relative weightings of the test (see the discussions of weighting and scoring) they enable a student to decide where to place emphasis in the test – she may want to concentrate her time on the high scoring elements of the test. Further, if the items of the test have exact time allowances, this enables a degree of standardization to be built into the test, and this may be useful if the results are going to be used to compare individuals or groups.
The awarding of scores for different items of the test is a clear indication of the relative significance of each item – the weightings of each item are addressed in their scoring. It is important to ensure that easier parts of the test attract fewer marks than more difficult parts of it, otherwise a student’s results might be artificially inflated by answering many easy questions and fewer more difficult questions (Gronlund and Linn, 1990). Additionally, there are several attractions to making the scoring of tests as detailed and specific as possible (Cresswell and Houston, 1991; Gipps, 1994; Aiken, 2003), awarding specific points for each item and sub-item, for example:
it enables partial completion of the task to be recognized – students gain marks in proportion to how much of the task they have completed successfully (an important feature of domain-referencing);
it enables a student to compensate for doing badly in some parts of a test by doing well in other parts of the test;
it enables weightings to be to be made explicit to the students;
it enables the rewards for successful completion of parts of a test to reflect considerations such as the length of the item, the time required to complete it, its level of difficulty, its level of importance;
it facilitates moderation because it is clear and specific;
it enables comparisons to be made across groups by item;
it enables reliability indices to be calculated (see discussions of reliability);
scores can be aggregated and converted into grades straightforwardly.
Ebel (1979) argues that the more marks that are available to indicate different levels of achievement (e.g. for the awarding of grades), the greater the reliability of the grades will be, though clearly this could make the test longer. Scoring will also need to be prepared to handle issues of poor spelling, grammar and punctuation – is it to be penalized, and how will consistency be assured here? Further, how will issues of omission be treated, e.g. if a student omits the units of measurement (miles per hour, dollars or pounds, metres or centimetres)?
Related to the scoring of the test is the issue of reporting the results. If the scoring of a test is specific then this enables variety in reporting to be addressed, for example, results may be reported item by item, section by section, or whole test by whole test. This degree of flexibility might be useful for the researcher, as it will enable particular strengths and weaknesses in groups of students to be exposed.
The desirability of some of the above points is open to question. For example, it could be argued that the strength of criterion-referencing is precisely its specificity, and that to aggregate data (e.g. to assign grades) is to lose the very purpose of the criterion-referencing (Gipps, 1994: 85). For example, if I am awarded a grade E for spelling in English, and a grade A for imaginative writing, this could be aggregated into a C grade as an overall grade of my English language competence, but what does this C grade mean? It is meaningless, it has no frame of reference or clear criteria, it loses the useful specificity of the A and E grades, it is a compromise that actually tells us nothing. Further, aggregating such grades assumes equal levels of difficulty of all items.
Of course, raw scores are still open to interpretation – which is a matter of judgement rather than exactitude or precision (Wiliam, 1996). For example, if a test is designed to assess ‘mastery’ of a subject, then the researcher is faced with the issue of deciding what constitutes ‘mastery’ – is it an absolute (i.e. very high score) or are there gradations, and if the latter, then where do these gradations fall? For published tests the scoring is standardized and already made clear, as are the conversions of scores into, for example, percentiles and grades.
Underpinning the discussion of scoring is the need to make it unequivocally clear exactly what the marking criteria are – what will and will not score points. This requires a clarification of whether there is a ‘checklist’ of features that must be present in a student’s answer.
Clearly criterion-referenced tests will have to declare their lowest boundary – a cut-off point – below which the student has been deemed to fail to meet the criteria. A compromise can be seen in those criterion-referenced tests which award different grades for different levels of performance of the same task, necessitating the clarification of different cut-off points in the examination. A common example of this can be seen in the GCSE examinations for secondary school pupils in the United Kingdom, where students can achieve a grade between A and F for a criterion-related examination.
The determination of cut-off points has been addressed by Nedelsky (1954), Angoff (1971), Ebel (1979) and Linn (1993). Angoff (1971) suggests a method for dichotomously scored items. Here judges are asked to identify the proportion of minimally acceptable persons who would answer each item correctly. The sum of these proportions would then be taken to represent the minimally acceptable score.
An elaborated version of this principle comes from Ebel (1979). Here a difficulty by relevance matrix is constructed for all the items. Difficulty might be assigned three levels (e.g. easy, medium and hard), and relevance might be assigned three levels (e.g. highly relevant, moderately relevant, barely relevant). When each and every test item has been assigned to the cells of the matrix the judges estimate the proportion of items in each cell that minimally acceptable persons would answer correctly, with the standard for each judge being the weighted average of the proportions in each cell (which are determined by the number of items in each cell). In this method judges have to consider two factors – relevance and difficulty (unlike Angoff, where only difficulty featured). What characterizes these approaches is the trust that they place in experts in making judgements about levels (e.g. of difficulty, or relevance or proportions of successful achievement), i.e. they are based on fallible human subjectivity.
Ebel (1979) argues that one principle in assignation of grades is that they should represent equal intervals on the score scales. Reference is made to median scores and standard deviations, median scores because it is meaningless to assume an absolute zero on scoring, and standard deviations as the unit of convenient size for inclusion of scores for each grade (see also Cohen and Holliday, 1996). One procedure is thus:
Step 1 |
Calculate the median and standard deviation of the scores. |
Step 2 |
Determine the lower score limits of the mark intervals using the median and the standard deviation as the unit of size for each grade. |
However, the issue of cut-off scores is complicated by the fact that they may vary according to the different purposes and uses of scores (e.g. for diagnosis, for certification, for selection, for program evaluation), as these purposes will affect the number of cut-off points and grades, and the precision of detail required. For a full analysis of determining cut-off grades see Linn (1993).
The issue of scoring takes in a range of factors, for example: grade norms, age norms, percentile norms and standard score norms (e.g. z-scores, T-scores, stanine scores, percentiles). These are beyond the scope of this book to discuss, but readers are referred to Cronbach (1970), Gronlund and Linn (1990), Cohen and Holliday (1996), Hopkins et al. (1996).
Piloting can be done in several ways:
a a small group of experts can examine the items in the test, their suitability, validity, relevance, possible cultural biases and sources of invalidity and unreliability, remoteness from the test-takers’ experiences;
b a small group of test-takers, asking them to give feedback on:
the clarity of the items, instructions and layout;
ambiguities or difficulties in wording;
readability levels and language problems for the target audience;
the type of question and its format (e.g. rating scale, multiple choice, open, closed, etc.);
response categories for closed questions and multiple choice items, and for the appropriateness of specific questions or stems of questions;
omissions, redundant and irrelevant items;
the clarity of the layout of the test;
the time taken to complete the test;
the complexity of the test items;
c a larger group of test-takers, to be able to gather sufficiently large-scale data to calculate reliability levels (alphas), item difficulty and item discriminability, to identify commonly misunderstood or non-completed items, and to check which items are consistently omitted or not reached (i.e. if the time was too short so that test-takers run out of time), and to be able to test out the marking scheme.
There are very many websites that researchers can visit to download software (either free or for inexpensive purchase) for test preparation, construction, layout, marking, and for collation and weighting of marks, for example:
www.centronsoftware.com/tcpage.html
www.bestshareware.net/test-construction-kit.htm
www.educational-software-directory.net/teacher/test-making (a website that links researchers to several software tools for test preparation).
Of course, these do not exonerate the researcher/test deviser from the thinking that goes into the test construction; rather, they follow from that thinking and preparation, and turn it into practical formats for administration either in hard copy or online. Further, the use of software and online testing can remove some of the burden of marking, data entry and analysis, as online tests can perform these calculations automatically (e.g. for closed/multiple choice items), and optical mark scanners can also be used to read in marks from hard copy into a computer file.
These kinds of software packages do not address validity and reliability, and the researcher will need to pilot and refine the test before final use.
The construction and administration of tests is an essential part of the experimental model of research, where a pre-test and a post-test have to be devised for the control and experimental groups. The pre-test and post-test must adhere to several guidelines:
The pre-test may have questions which differ in form or wording from the post-test, though the two tests must test the same content, i.e. they will be alternate forms of a test for the same groups.
The pre-test must be the same for the control and experimental groups.
The post-test must be the same for both groups.
Care must be taken in the construction of a post-test to avoid making the test easier to complete by one group than another.
The level of difficulty must be the same in both tests.
Test data feature centrally in the experimental model of research; additionally they may feature as part of a questionnaire, interview and documentary material.
A major source of unreliability of test data derives from the extent and ways in which students have been prepared for the test. These can be located on a continuum from direct and specific preparation, through indirect and general preparation, to no preparation at all. With the growing demand for test data (e.g. for selection, for certification, for grading, for employment, for tracking, for entry to higher education, for accountability, for judging schools and teachers) there is a perhaps understandable pressure to prepare students for tests. This is the ‘high-stakes’ aspect of testing (Harlen, 1994), where much hinges on the test results. At one level this can be seen in the backwash effect of examinations on curricula and syllabuses; at another level it can lead to the direct preparation of students for specific examinations. Preparation can take many forms (Mehrens and Kaminski, 1989; Gipps, 1994):
ensuring coverage, amongst other programme contents and objectives, of the objectives and programme that will be tested;
restricting the coverage of the programme content and objectives to those only that will be tested;
preparing students with ‘exam technique’;
practice with past/similar papers;
directly matching the teaching to specific test items, where each piece of teaching and content is the same as each test item;
practise on an exactly parallel form of the test;
telling students in advance what will appear on the test;
practise on, and preparation of, the identical test itself (e.g. giving out test papers in advance) without teacher input;
practise on, and preparation of, the identical test itself (e.g. giving out the test papers in advance), with the teacher working through the items, maybe providing sample answers.
How ethical it would be to undertake the final four of these is perhaps questionable, or indeed any apart from the first on the list. Are they cheating or legitimate test preparation? Should one teach to a test; is not to do so a dereliction of duty (e.g. in criterion- and domain-referenced tests) or giving students an unfair advantage and thus reducing the reliability of the test as a true and fair measure of ability or achievement? In high-stakes assessment (e.g. for public accountability and to compare schools and teachers) there is even the issue of not entering for tests students whose performance will be low (see, for example Haladyna et al., 1991). There is a risk of a correlation between the ‘stakes’ and the degree of unethical practice – the greater the stakes, the greater the incidence of unethical practice. Unethical practice, observes Gipps (1994), occurs where scores are inflated but reliable inference on performance or achievement is not, and where different groups of students are prepared differentially for tests, i.e. giving some students an unfair advantage over others. To overcome such problems, she suggests, it is ethical and legitimate for teachers to teach to a broader domain than the test, that teachers should not teach directly to the test, and the situation should only be that better instruction rather than test preparation is acceptable (Cunningham, 1998).
One can add to this list of considerations (Cronbach, 1970; Hanna, 1993; Cunningham, 1998) the view that:
tests must be valid and reliable (see Chapter 10);
the administration, marking and use of the test should only be undertaken by suitably competent/qualified people (i.e. people and projects should be vetted);
access to test materials should be controlled, for instance: test items should not be reproduced apart from selections in professional publication; the tests should only be released to suitably qualified professionals in connection with specific professionally acceptable projects;
tests should benefit the testee (beneficence);
clear marking and grading protocols should exist (the issue of transparency is discussed in Chapter 5);
test results are only reported in a way that cannot be misinterpreted;
the privacy and dignity of individuals should be respected (e.g. confidentiality, anonymity, non-traceability);
individuals should not be harmed by the test or its results (non-maleficence);
informed consent to participate in the test should be sought.
Whilst the use of tests in research is bound by the same ethical requirements as other forms of data collection (e.g. informed consent, non-maleficence, anonymity and confidentiality, rights to non-participation and withdrawal, etc.), a further major ethical issue concerns the use made of the test data (consequential validity). Here the test data should only be used for the purpose for which the test was constructed; too often test data become used for purposes other than these, and this is ethically highly questionable.
Computerized adaptive testing (Wainer, 1990; Aiken, 2003: 50–2; Wainer and Dorans, 2000) is the decision on which particular test items to administer, which is based on the subjects’ responses to previous items. It is particularly useful for large-scale testing, where a wide range of ability can be expected. Here a test must be devised that enables the tester to cover this wide range of ability; hence it must include some easy to some difficult items –too easy and it does not enable a range of high ability to be charted (testees simply getting all the answers right), too difficult and it does not enable a range of low ability to be charted (testees simply getting all the answers wrong). We find out very little about a testee if we ask a battery of questions which are too easy or too difficult for her. Further, it is more efficient and reliable if a test can avoid the problem for high ability testees of having to work through a mass of easy items in order to reach the more difficult items and for low ability testees of having to try to guess the answers to more difficult items. Hence it is useful to have a test that is flexible and that can be adapted to the testees. For example, if a testee found an item too hard the next item could adapt to this and be easier, and, conversely, if a testee was successful on an item the next item could be harder.
Wainer indicates that in an adaptive test the first item is pitched in the middle of the assumed ability range; if the testee answers it correctly then it is followed by a more difficult item, and if the testee answers it incorrectly then it is followed by an easier item. Computers here provide an ideal opportunity to address the flexibility, discriminability and efficiency of testing. Aiken (2003: 51) suggests that computer adaptive testing can reduce the number of test items present to around 50 per cent of those used in conventional tests. Testees can work at their own pace, they need not be discouraged but can be challenged, the test is scored instantly to provide feedback to the testee, a greater range of items can be included in the test and a greater degree of precision and reliability of measurement can be achieved; indeed test security can be increased and the problem of understanding answer sheets is avoided.
Clearly the use of computer adaptive testing has several putative attractions. On the other hand it requires different skills from traditional tests, and these might compromise the reliability of the test, for example:
the mental processes required to work with a computer screen and computer program differ from those required for a pen-and-paper test;
motivation and anxiety levels increase or decrease when testees work with computers;
the physical environment might exert a significant difference, e.g. lighting, glare from the screen, noise from machines, loading and running the software;
reliability shifts from an index of the variability of the test to an index of the standard error of the testee’s performance. The usual formula for calculating standard error assumes that error variance is the same for all scores, whereas in item response theory it is assumed that error variance depends on each testee’s ability – the conventional statistic of error variance calculates a single average variance of summed scores, whereas in item response theory this is at best very crude, and at worst misleading as variation is a function of ability rather than test variation and cannot fairly be summed (see Thissen (1990) for an analysis of how to address this issue);
having so many test items increases the chance of inclusion of poor items.
Computer adaptive testing requires a large item pool for each area of content domain to be developed (Flaugher, 1990), with sufficient numbers, variety and spread of difficulty. All items must measure a single aptitude or dimension, and the items must be independent of each other, i.e. a person’s response to an item should not depend on that person’s response to another item. The items have to be pre-tested and validated, their difficulty and discriminability calculated, the effect of distractors reduced, the capability of the test to address unidimensionality and/or multidimensionality clarified, and the rules for selecting items enacted.
 Companion Website
Companion WebsiteThe companion website to the book includes PowerPoint slides for this chapter, which list the structure of the chapter and then provide a summary of the key points in each of its sections. This resource can be found online at www.routledge.com/textbooks/cohen7e.