I criteri editoriali
La costruzione dello stemma dei testimoni è dunque una operazione delicatissima e difficile, da fare con la massima prudenza. Si tratta però di uno strumento fondamentale per decidere su quali basi debba essere costituito il testo da stampare. L’alternativa è la scelta a caso di uno qualsiasi dei testimoni, in base a criteri del tutto estemporanei (la disponibilità, la datazione, la completezza, la chiarezza di lettura, ecc.). In effetti lo stemma non è, non dovrebbe essere, che la schematizzazione dei rapporti reali che intercorrono tra i testimoni che ci sono pervenuti. Poiché non c’è dubbio che i testimoni discendano dall’originale attraverso una catena di copie, solo l’individuazione delle loro relazioni ci mette in grado di sapere quale testimone è più vicino all’originale o comunque più rispettoso del suo dettato e quindi più affidabile. Il procedimento è del tutto analogo a quello attraverso il quale si ricostruiscono i rapporti genealogici all’interno di una famiglia.
Il guaio è che alcuni dei presupposti di questo procedimento sono quanto mai labili. Lasciamo da parte la circostanza che la stessa esistenza di un originale non può sempre essere data per scontata. Abbiamo però visto che l’apparentamento dei testimoni non può avvenire se non in base alla presenza in essi di errori comuni e che il concetto di errore è il più soggettivo che ci sia. E dobbiamo aggiungere che la linearità dei rapporti tra le copie è in se stessa opinabile. Si è detto che il copista di un’opera non breve poteva cambiare di antigrafo da un giorno all’altro. Ora aggiungo che accade spesso che a margine di un codice o nell’interlinea un lettore di un codice A aggiunga più o meno sistematicamente lezioni ricavate dal confronto con un’altra copia B e che successivamente chi trae una ulteriore copia da A scelga volta per volta se accettare la lezione originale di A o quella segnata a margine. In questi casi insorge contaminazione e, come ha scritto molto tempo fa Paul Maas, «contro la contaminazione non si è ancora scoperto alcun rimedio».
Da tempo sappiamo inoltre che il procedimento basato sugli errori è intrinsecamente dicotomico: una lezione è (almeno a nostro parere) o giusta o sbagliata. Ciò porta a individuare ogni snodo dello stemma codicum in forma binaria: da una parte i testimoni che hanno l’errore, dall’altra quelli che non lo hanno, che peraltro non costituiscono una famiglia se non sono uniti da un proprio errore comune. La logica ci impone questa conclusione[18]. Ma sappiamo già che lo stemma è un riassunto schematico di storia genealogica, sicché uno stemma che non ha che ramificazioni dicotomiche ci dà l’impressione che di norma i codici, a cominciare dagli originali, siano stati trascritti sempre e solo due volte e ne discendano dunque sempre due copie, quella che non ha l’errore e quella che lo ha. In effetti una percentuale altissima di stemmi costruiti dai filologi è a due rami e tutti i tentativi di giustificare come realistica questa circostanza lasciano a dire il vero insoddisfatti: è mai possibile che sia così raro che da un antigrafo discendano più di due famiglie?
Le osservazioni che ho fatto sembreranno distruttive. Ma alla ricostruzione stemmatica della storia della tradizione manoscritta possiamo adattare quello che Winston Churchill disse della democrazia: la stemmatica è un sistema pessimo, ma è il migliore tra quelli che conosciamo. Bisogna accontentarsi e vedere cosa se ne può ricavare.
Nella pratica filologica concreta è possibile che dallo stemma si traggano conclusioni molto diverse. L’uso più tradizionale è quello che posso esemplificare con uno schema classico. Siano tre i testimoni della nostra opera, rispettivamente A B C; siano questi i loro rapporti, stabiliti sulla base nel rinvenimento tanto di errori comuni a tutti e tre (e quindi riferibili a ω) quanto di errori comuni a A B (e quindi riferibili a β):
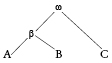
In questo caso metteremo a testo le lezioni comuni ad A B C, a meno che non siano riconosciute come errori dell’archetipo ω, nonché le lezioni sulle quali concordano A C oppure B C. Infatti le lezioni di A o di B che siano contraddette dall’accordo B C o A C devono essere considerate innovazioni del ramo testuale al quale appartengono i loro latori. Il procedimento può essere applicato meccanicamente fin quando non ci troviamo dinanzi a tre lezioni concorrenti, attestate ciascuna da un solo testimone; in questo caso non resta che giudicare la rispettiva qualità delle lezioni: la scelta meccanica lascia il posto al giudizio dell’editore.
Il procedimento che ho descritto è implacabile, ma produce un testo che è un mosaico di lezioni provenienti volta a volta da testimoni diversi. Il filologo sostiene che esso è il testo più vicino possibile al testo originale, ma gli si oppone che in realtà la sua ricostruzione produce un testo che non è mai esistito. Appare dunque preferibile un’altra via. Lo studio della tradizione non ci ha mostrato solo quali siano i rapporti tra i testimoni dimostrabili grazie agli errori comuni. Abbiamo anche potuto valutare la qualità della lezione tràdita da ciascuno di essi. Sulla base dello stemma disegnato sopra, C dovrebbe essere il codice più vicino a ω, ma tra ω e C possono esserci state innumerevoli copie, poi perdute, e il nostro esame può averci dato motivo di credere che il suo testo sia assai meno affidabile di quello di A. Potremo allora adottare come testo-base appunto il testo di A, riparando solo le corruttele di cui si possa mostrare che provengono da β e gli errori di archetipo, nonché gli errori manifesti del solo A.
Questo procedimento evita, o riduce, gli effetti della ricostruzione meccanica sull’assetto grafico del nostro testo. Se esso è stato composto in una lingua fortemente normalizzata, non sorgerebbero grossi problemi nell’inserire una lezione di C tra due lezioni di A: la forma linguistica sarebbe la stessa, le tessere del mosaico, per quanto provenienti da due fonti diverse, avrebbero almeno lo stesso colore. Ma le lingue con cui lavora la filologia moderna, e soprattutto quella medievale, sono debolmente o per nulla normalizzate, ed è lecito dubitare che il latino lo sarebbe assai meno se quello dei nostri testi non fosse uscito dalle mani dei grammatici e dei filologi. Se lavoriamo, ad esempio, con due codici uno dei quali toscano e l’altro veneto, oppure uno aragonese e l’altro leonese, uno piccardo e l’altro anglonormanno, come si fa ad inserire qualche lezione del primo nel testo del secondo, o viceversa? Il risultato è grottesco, a meno che non riscriviamo noi la forma, poniamo, veneta in toscano.
La veste linguistica di un testo dipende sostanzialmente dalle scelte del singolo copista, che non si riteneva vincolato al rispetto della veste del suo antigrafo, e men che meno di quella del suo originale, che del resto ignorava. Della veste linguistica reale dell’originale possiamo accertare qualcosa solo nel caso di testi in versi rimati, mai per i testi in prosa. Ricostruire la veste linguistica in base agli accordi stemmatici non ha senso, per quanto qualche volta sia stato fatto.
Se però seguiamo un manoscritto di base, che dovrà essere scelto anche in ragione di ciò che sappiamo sulla lingua dell’originale, il problema è semplificato. Il manoscritto di base non sarà seguito ciecamente, perché esso, come tutti gli altri, non sarà privo di errori. Ma lo studio della tradizione ci avrà indicato anche quali siano i testimoni, quanto più possibile a lui affini, che possono fornire lezioni corrette da sostituire a quelle erronee. Se non possiamo attingere l’originale, almeno dobbiamo risalire ad una forma testuale depurata dalle corruttele.