Chapter 6
Identity and Access Control
Chapter 6 deals with two sides of the same coin: identity management and access control. The essence of information risk mitigation is ensuring that only the right people and processes can read, view, use, change, or remove any of our sensitive information assets, or use any of our most important information-based business processes. We also require the ability to prove who or what touched what information asset and when, and what happened when they did. We'll see how to authenticate that a subject user (be that a person or a software process) is who they claim to be; use predetermined policies to decide if they are authorized to do what they are attempting to do; and build and maintain accounting or audit information that shows us who asked to do what, when, where, and how. Chapter 6 combines decades of theory-based models and ideas with cutting-edge how-to insight; both are vital to an SSCP on the job.
Identity and Access: Two Sides of the Same CIANA+PS Coin
At the heart of all information security (whether Internet-based or not) is the same fundamental problem. Information is not worth anything if it doesn't move, get shared with others, and get combined with other information to make decisions happen. But to keep that information safe and secure, to meet all of our company's CIANA+PS needs, we usually cannot share that information with just anybody! The flip side of that also tells us that in all likelihood, any one person will not have valid “need to know” for all of the information our organization has or uses. Another way to think about that is that if you do not know who is trying to access your information, you don't know why to grant or deny their attempt.
Each one of the elements of the CIANA+PS security paradigm—which embraces confidentiality, integrity, availability, nonrepudiation, authentication, privacy, and safety—has this same characteristic. Each element must look at the entire universe of people or systems, and separate out those we trust with access to our information from those we do not, while at the same time deciding what to let those trusted people or systems do with the information we let them have access to.
What do we mean by “have access to” an object? In general, access to an object can consist of being able to do one or more of the following kinds of functions:
- Read part or all of the contents of the object
- Read metadata about the object, such as its creation and modification history, its location in the system, or its relationships with other objects
- Write to the object or its metadata, modifying it in whole or part
- Delete part or all of the object, or part or all of its metadata
- Load the object as an executable process (as an executable program, a process, process thread, or code injection element such as a dynamic link library [DLL file])
- Receive data or metadata from the object, if the object can perform such services
(i.e., if the object is a server of some kind)
- Read, modify, or delete security or access control information pertaining to the object
- Invoke another process to perform any of these functions on the object
- And so on…
This brings us right to the next question: who, or what, is the thing that is attempting to access our information, and how do we know that they are who they claim to be? It used to be that this identity question focused on people, software processes or services, and devices. The incredible growth in Web-based services complicates this further, and we've yet to fully understand what it will mean with Internet of Things (IoT) devices, artificial intelligences, and robots of all kinds joining our digital universal set of subjects—that is, entities requesting access to objects.
Our organization's CIANA+PS needs are at risk if unauthorized subjects—be they people or processes—can execute any or all of those functions in ways that disrupt our business logic:
- Confidentiality is violated if any process or person can read, copy, redistribute, or otherwise make use of data we deem private, or of competitive advantage worthy of protection as trade secrets, proprietary, or restricted information.
- Integrity is lost if any person or process can modify data or metadata, or execute processes out of sequence or with bad input data.
- Authorization—the granting of permission to use the data—cannot make sense if there is no way to validate to whom or what we are granting that permission.
- Nonrepudiation cannot exist if we cannot validate or prove that the person or process in question is in fact who they claim to be and that their identity hasn't been spoofed by a man-in-the-middle kind of attacker.
- Availability rapidly dwindles to zero if nothing stops data or metadata from unauthorized modification or deletion.
- Privacy can be violated (or our systems fail to be compliant with privacy requirements) if data can be moved, copied, viewed, or used in unauthorized ways
- Safety can be compromised if data or metadata can be altered or removed
The increasing use of remote collaboration technologies in telemedicine highlights these concerns. If clinical workers cannot trust that the patient they think they are treating, the lab results they believe they are reading, and the rest of that patient's treatment record have all been protected from unauthorized access, they lose the confidence they need to know that they are diagnosing and treating the right patient for the right reasons.
One more key ingredient needs to be added as we consider the vexing problems of managing and validating identities and protecting our information assets and resources from unauthorized use or access: the question of trust. In many respects, that old adage needs to be updated: it's not what you know, but how you know how much you can trust what you think you know, that becomes the heart of identity and access management concerns.
Identity Management Concepts
Identity management actually starts with the concept of an entity, which is a person, object, device, or software unit that can be uniquely and unambiguously identified. Each entity, whether it be human or nonhuman, can also have many different identities throughout the existence of that entity. Many of these identities are legitimate, lawful, and in fact necessary to create and use; some may not be.
Let's illustrate with a human being, for example. Most human names are quite common, even at the level of the full form of all parts of that name. On top of this, many information systems such as credit reporting agencies carry different versions of the names of individuals, through errors, abbreviations, or changes in usage. This can happen if I choose to use my full middle name, its initial, or no use of it at all on an account application or transaction. To resolve the ambiguity, it often takes far more data:
- Biometric data, such as fingerprints, retina scans, gait, facial measurements, and voiceprints
- DNA analysis
- Historical data regarding places of residence, schooling, or employment
- Circumstances of birth, such as place, parents, attending physician, or midwife
- Marriage, divorce, or other domestic partnership histories, as well as information regarding any children (naturally parented, foster, adopted, or other)
- Photographic and video images or recordings
For any given human, that can amount to a lot of data—far too much data to make for a useful, practical way to control access to a facility or an information system. This gives rise defining an identity as:
- A label or data element assigned to an entity, by another entity,
- for the purpose of managing and controlling that entity's access to, use of, or enjoyment of the systems, facilities, or information,
- which are under the administrative control of the identity-granting entity.
Note the distinctions here: entities are created, identities are assigned. And the process of granting permissions to enter, use, view, modify, learn from, or enjoy the resources or assets controlled by the identity-granting organization is known as entitlement. To add one further definition, a credential is a document or dataset that attests to the correctness, completeness, and validity of an identity's claim to be who and what that identity represents, at a given moment in time, and for the purposes associated with that identity.
We need a way to associate an identity, in clear and unambiguous ways, with exactly one such person, device, software process or service, or other subject, whether a part of our system or not. In legal terms, we need to avoid the problems of mistaken identity, just because of a coincidental similarity of name, location, or other information related to two or more people, processes, or devices. It may help if we think about the process of identifying such a subject:
- A person (or a device) offers a claim as to who or what it is.
- The claimant offers further supporting information that attests to the truth of that claim.
- We verify the believability (the credibility or trustworthiness) of that supporting information.
- We ask for additional supporting information, or we ask a trusted third party to authenticate that information.
- Finally, we conclude that the subject is whom or what it claims to be.
So how do we create an identity? It's one thing for your local government's office of vital records to issue a birth certificate when a baby is born, or a manufacturer to assign a MAC address to an Internet-compatible hardware device. How do systems administrators manage identities?
Identity Provisioning and Management
The identity management lifecycle describes the series of steps in which a subject's identity is initially created, initialized for use, modified as needs and circumstances change, and finally retired from authorized use in a particular information system. These steps are typically referred to as provisioning, review, and revocation of an identity:
- Provisioning starts with the initial claim of identity and a request to create a set of credentials for that identity; typically, a responsible manager in the organization must approve requests to provision new identities. (This demonstrates separation of duties by preventing the same IT provisioning clerk from creating new identities surreptitiously.) Key to this step is identity proofing, which separately validates that the evidence of identity as submitted by the applicant is truthful, authoritative, and current. Once created, the identity management functions have to deploy that identity to all of the access control systems protecting all of the objects that the new identity will need access to. Depending on the size of the organization, the complexity of its IT systems, and even how many operating locations around the planet the organization has, this “push” of a newly provisioned identity can take minutes, hours, or maybe even a day or more. Many larger organizations will use regularly scheduled update and synchronization tasks, running in the background, to bring all access control subsystems into harmony with each other. An urgent “right-now” push of this information can force a near-real-time update, if management deems it necessary.
- Review is the ongoing process that checks whether the set of access privileges granted to a subject are still required or if any should be modified or removed. Individual human subjects are often faced with changes in their job responsibilities, and these may require that new privileges be added and others be removed. Privilege creep happens when duties have changed and yet privileges that are no longer actually needed remain in effect for a given user. For example, an employee might be temporarily granted certain administrative privileges in order to substitute for a manager who has suddenly taken medical retirement, but when the replacement manager is hired and brought on board, those temporary privileges should be reduced or removed.
- Revocation is the formal process of terminating access privileges for a specific identity in a system. Such revocation is most often needed when an employee leaves the organization (whether by death, retirement, termination, or by simply moving on to other pastures). Employment law and due diligence dictate that organizations have policies in place to handle both preplanned and sudden departures of staff members, to protect systems and information from unauthorized access after such departure. Such unplanned departures might require immediate actions be taken to terminate all systems privileges within minutes of an authorized request from management.
Ongoing Manual Provisioning
Provisioning happens throughout the life of an identity within a particular system. Initially, it may require a substantial proofing effort, as examined earlier. Once the new identity has been created and enabled within the system, it will probably need changes (other than revocation or temporary suspension) to meet the changing needs of the organization and the individual, and some of these changes can and should be allocated to the identity holder themselves to invoke on an as-needed basis. Password changes, updates to associated physical addresses, phone numbers, security challenge questions, and other elements are often updated by the end users (entities using the assigned identities) directly, without requiring review, approval, or action by security personnel or access control administrators. Organizations may, of course, require that some of these changes be subject to approval or require other coordinated actions to be taken.
Just-in-Time Provisioning and Identity
The initial creation of an identity can also be performed right at the moment when an entity first requests access to a system's resources. This just-in-time identity (JIT identity, not JITI) is quite common on websites, blogs, and email systems where the system owner does not require strong identity proofing as part of creating a new identity. To support this, standardized identity assurance levels (IALs) have been created and are in widespread use, reflecting the degree of proofing required to support the assertion of an identity by an applicant. These levels are:
- IAL1: This is the lowest level of identity assertion, for which no effort is expended nor required to validate the authenticity of the information provided by an applicant.
- IAL2: This level requires that an online identity authentication service be able to validate the applicant's claim to use of an identity. This might be done by creating an account by using one's preexisting social media account (at LinkedIn, Facebook, or other).
- IAL3: This most stringent of IAL levels requires physical verification of the documents submitted by the applicant to prove their claim to an identity. These may be government-issued identity documents (which may also be required to be apostilled or otherwise authenticated as legitimate documents).
Just-in-time identity can also play a powerful role in privilege management, in which an identity that has elevated privileges associated with it is not actually granted use of these privileges until the moment they are needed. Systems administrators, for example, generally do not require root or superuser privileges to read their internal email or access trouble ticket systems. A common example of this is the super user do or sudo command in Unix and Linux systems, or the User Account Control feature on Windows-based systems. These provide ways to enforce security policies that prevent accidental and some malicious attempts to perform specific operations such as installing new software, often by requiring a second, specific confirmation by the end user.
The identity management lifecycle is supported by a wide range of processes and tools within a typical IT organization. At the simplest level, operating systems have built-in features that allow administrators to create, maintain, and revoke user identities and privileges. Most OS-level user creation functions can also create roaming profiles, which can allow one user identity to have access privileges on other devices on the network, including any tailoring of those privileges to reflect the location of the user's device or other conditions of the access request. What gets tricky is managing access to storage, whether on local devices or network shared storage, when devices and users can roam around. This can be done at the level of each device using built-in OS functions, but it becomes difficult if not impossible to manage as both the network and the needs for control grow. At some point, the organization needs to look at ways to manage the identity lifecycle for all identities that the organization needs to care about. This will typically require the installation and use of one or more servers to provide the key elements of identity and access control.
Identity and AAA
SSCPs often need to deal with the “triple-A” of identity management and access control, which refers to authentication, authorization, and accounting. As stated earlier, these are all related to identities, and are part of how our systems decide whether to grant access (and with which privileges) or not—so in that sense they sit on the edge of the coin between the two sides of our CIANA+PS coin. Let's take a closer look at each of these important functions.
Authentication is where everything must start. Authentication is the act of examining or testing the identity credentials provided by a subject that is requesting access, and based on information in the access control list, either granting (accepts) access, denying it, or requesting additional credential information before making an access determination:
- Multifactor identification systems are a frequent example of access control systems asking for additional information: the user completes one sign-on step, and is then challenged for the second (or subsequent) factor.
- At the device level, access control systems may challenge a user's device (or one automatically attempting to gain access) to provide more detailed information about the status of software or malware definition file updates, and (as you saw in Chapter 5, “Communications and Network Security”) deny access to those systems not meeting criteria, or route them to restricted networks for remediation.
Once an identity has been authenticated, the access control system determines just what capabilities that identity is allowed to perform. Authorization requires a two-step process:
- Assigning privileges during provisioning. Prior to the first access attempt, administrators must decide which permissions or privileges to grant to an identity, and whether additional constraints or conditions apply to those permissions. The results of those decisions are stored in access control tables or access control lists in the access control database.
- Authorizing a specific access request. After authenticating the identity, the access control system must then determine whether the specifics of the access request are allowed by the permissions set in the access control tables.
At this point, the access request has been granted in full; the user or requesting subject can now go do what it came to our systems to do. Yet, in the words of arms control negotiators during the Cold War, trust, but verify. This is where our final A comes into play. Accounting gathers data from within the access control process to monitor the lifecycle of an access, from its initial request and permissions being granted through the interactions by the subject with the object, to capturing the manner in which the access is terminated. This provides the audit trail by which we address many key information security processes, each of which needs to ascertain (and maybe prove to legal standards) who did what to which information, using which information:
- Software or system anomaly investigation
- Systems hardening, vulnerability mitigation, or risk reduction
- Routine systems security monitoring
- Security or network operations center ongoing, real-time system monitoring
- Digital forensics investigations
- Digital discovery requests, search warrants, or information requested under national security letters
- Investigation of apparent violations of appropriate use policies
- Incident response and recovery
- The demands of law, regulation, contracts, and standards for disclosure to stakeholders, authorities, or the public
Obviously, it's difficult if not impossible to accomplish many of those tasks if the underlying audit trail wasn't built along the way, as each access request came in and was dealt with.
Before we see how these AAA functions are implemented in typical information systems, we need to look further into the idea of permissions or capabilities.
Access Control Concepts
Access control is all about subjects and objects (see Figure 6.1). Simply put, subjects try to perform an action upon an object; that action can be reading it, changing it, executing it (if the object is a software program), or doing anything to the object. Subjects can be anything that is requesting access to or attempting to access anything in our system, whether data or metadata, people, devices, or another process, for whatever purpose. Subjects can be people, software processes, devices, or services being provided by other Web-based systems. Subjects are trying to do something to or with the object of their desire. Objects can be collections of information, or the processes, devices, or people that have that information and act as gatekeeper to it. This subject-object relationship is fundamental to your understanding of access control. It is a one-way relationship: objects do not do anything to a subject. Don't be fooled into thinking that two subjects interacting with each other is a special case of a bidirectional access control relationship. It is simpler, more accurate, and much more useful to see this as two one-way subject-object relationships. It's also critical to see that every task is a chain of these two-way access control relationships.

FIGURE 6.1 Subjects and objects
As an example, consider the access control system itself as an object. It is a lucrative target for attackers who want to get past its protections and into the soft underbellies of the information assets, networks, and people behind its protective moat. In that light, hearing these functions referred to as datacenter gatekeepers makes a lot of sense. Yet the access control system is a subject that makes use of its own access control tables, and of the information provided to it by requesting subjects. (You, at sign-on, are a subject providing a bundle of credential information as an object to that access control process.)
Subjects and Objects—Everywhere!
Let's think about a simple small office/home office (SOHO) LAN environment, with an ISP-provided modem, a Wi-Fi router, and peer-to-peer file and resource sharing across the half a dozen devices on that LAN. The objects on this LAN would include:
- Each hardware device, and its onboard firmware, configuration parameters, and device settings, and its external physical connections to other devices
- Power conditioning and distribution equipment and cabling, such as an UPS
- The file systems on each storage device, each computer, and each subtree and each file within each subtree
- All of the removable storage devices and media, such as USB drives, DVDs, and CDs used for backup or working storage
- Each installed application on each device
- Each defined user identity on each device, and the authentication information that goes with that user identity, such as username and password
- Each person who is a user, or is attempting to be a user (whether as guest or otherwise)
- Accounts at all online resources used by people in this organization, and the access information associated with those accounts
- The random-access memory (RAM) in each computer, as free memory
- The RAM in each computer allocated to each running application, process, process thread, or other software element
- The communications interfaces to the ISP, plain old telephone service, or other media
- And so on…
Note that third item: on a typical Windows 10 laptop, with 330 GB of files and installed software on a 500 GB drive, that's only half a million files—and each of those, and each of the 100,000 or so folders in that directory space, is an object. Those USB drives, and any cloud-based file storage, could add similar amounts of objects for each computer; mobile phones using Wi-Fi might not have quite so many objects on them to worry about. A conservative upper bound might be 10 million objects.
What might our population of subjects be, in this same SOHO office?
- Each human, including visitors, clients, family, and even the janitorial crew
- Each user ID for each human
- Each hardware device, including each removable disk
- Each mobile device each human might bring into the SOHO physical location with them
- Each executing application, process, process thread, or other software element that the operating system (of the device it's on) can grant CPU time to
- Any software processes running elsewhere on the Internet, which establish or can establish connections to objects on any of the SOHO LAN systems
- And so on…
That same Windows 10 laptop, by the way, shows 8 apps, 107 background processes, 101 Windows processes, and 305 services currently able to run—loaded in memory, available to Windows to dispatch to execute, and almost every one of them connected by Windows to events so that hardware actions (like moving a mouse) or software actions (such as an Internet Control Message Protocol packet hitting our network interface card will wake them up and let them run. That's 521 pieces of executing code. And as if to add insult to injury, the one live human who is using that laptop has caused 90 user identities to be currently active. Many of these are associated with installed services, but each is yet another subject in its own right.
Multiply that SOHO situation up to a medium-sized business, with perhaps 500 employees using its LANs, VPNs, and other resources available via federated access arrangements, and you can see the magnitude of the access control management problem.
Data Classification and Access Control
Next, let's talk layers. No, not layers in the TCP/IP or OSI 7-layer reference model sense! Instead, we need to look at how permissions layer onto each other, level by level, much as those protocols grow in capability layer by layer.
Previously, you learned the importance of establishing an information classification system for your company or organization. Such systems define broad categories of protection needs, typically expressed in a hierarchy of increasing risk should the information be compromised in some way. The lowest level of such protection is often called unclassified, or suitable for public release. It's the information in press releases or in content on public-facing webpages. Employees are not restricted from disclosing this information to almost anyone who asks. Next up this stack of classification levels might be confidential information, followed by secret or top secret (in military parlance). Outside of military or national defense marketplaces, however, we often have to deal with privacy-related information, as well as company proprietary data.
For example, the US-CERT (Computer Emergency Readiness Team) has defined a schema for identifying how information can or cannot be shared among the members of the US-CERT community. The Traffic Light Protocol (TLP) can be seen at www.us-cert.gov/tlp and appears in Figure 6.2. It exists to make sharing of sensitive or private information easier to manage so that this community can balance the risks of damage to the reputation, business, or privacy of the source against the needs for better, more effective national response to computer emergency events.

FIGURE 6.2 US-CERT Traffic Light Protocol for information classification and handling
Note how TLP defines both the conditions for use of information classified at the different TLP levels, but also any restrictions on how a recipient of TLP-classified information can then share that information with others.
Each company or organization has to determine its own information security classification needs and devise a structure of categories that support and achieve those needs. They all have two properties in common, however, which are called the read-up and write-down problems:
- Reading up refers to a subject granted access at one level of the data classification stack, which then attempts to read information contained in objects classified at higher levels.
- Writing down refers to a subject granted access at one level that attempts to write or pass data classified at that level to a subject or object classified at a lower level.
Shoulder-surfing is a simple illustration of the read-up problem, because it can allow an unauthorized person to masquerade as an otherwise legitimate user. A more interesting example of the read-up problem was seen in many login or sign-on systems, which would first check the login ID, and if that was correctly defined or known to the system, then solicit and check the password. This design inadvertently confirms the login ID is legitimate; compare this to designs that take both pieces of login information, and return “user name or password unknown or in error” if the input fails to be authenticated.
Writing classified or proprietary information to a thumb drive, and then giving that thumb drive to an outsider, illustrates the write-down problem. Write-down also can happen if a storage device is not properly zeroized or randomized prior to its removal from the system for maintenance or disposal.
Having defined our concepts about subjects and objects, let's put those read-up and write-down problems into a more manageable context by looking at privileges or capabilities. Depending on whom you talk with, a subject is granted or defined to have permission to perform certain functions on certain objects. The backup task (as subject) can read and copy a file, and update its metadata to show the date and time of the most recent backup, but it does not (or should not) have permission to modify the contents of the file in question, for example. Systems administrators and security specialists determine broad categories of these permissions and the rules by which new identities are allocated some permissions and denied others.
Bell-LaPadula and Biba Models
Let's take a closer look at CIANA+PS, in particular the two key components of confidentiality and integrity. Figure 6.3 illustrates a database server containing proprietary information and an instance of a software process that is running at a level not approved for proprietary information. (This might be because of the person using the process, the physical location or the system that the process is running on, or any number of other reasons.) Both the server and the process act as subjects and objects in their different attempts to request or perform read and write operations to the other. As an SSCP, you'll need to be well acquainted with how these two different models approach confidentiality and integrity:
- Protecting confidentiality requires that we prevent attempts by the process to read the data from the server, but we also must prevent the server from attempting to write data to the process. We can, however, allow the server to read data inside the process or associated with it. We can also allow the process to write its data, at a lower classification level, up into the server. This keeps the proprietary information safe from disclosure, while it assumes that the process running at a lower security level can be trusted to write valid data up to the server.
- Protecting integrity by contrast requires just the opposite: we must prevent attempts by a process running at a lower security level from writing into the data of a server running at a higher security level.

FIGURE 6.3 Bell-LaPadula (a) vs. Biba access control models (b)
The first model is the Bell-LaPadula model, developed by David Bell and Leonard LaPadula for the Department of Defense in the 1970s, as a fundamental element of providing secure systems capable of handling multiple levels of security classification. Bell-LaPadula emphasized protecting the confidentiality of information—that information in a system running at a higher security classification level must be prevented from leaking out into systems running at lower classification levels. Shown in Figure 6.3(a), Bell-LaPadula defines these controls as:
- The simple security property (SS) requires that a subject may not read information at a higher sensitivity (i.e., no “read up”).
- The * (star) security property requires that a subject may not write information into an object that is at a lower sensitivity level (no “write-down”).
The discretionary security property requires that systems implementing Bell-LaPadula protections must use an access matrix to enforce discretionary access control
Remember that in our examples in Figure 6.2, the process is both subject and object, and so is the server! This makes it easier to see that the higher-level subject can freely read from (or be written into) a lower-level process; this does not expose the sensitive information to something (or someone) with no legitimate need to know. Secrets stay in the server.
Data integrity, on the other hand, isn't preserved by Bell-LaPadula; clearly, the lower-security-level process could disrupt operations at the proprietary level by altering data that it cannot read. The other important model, developed some years after Bell-LaPadula, was expressly designed to prevent this. Its developer, Kenneth Biba, emphasized data integrity over confidentiality; quite often the non-military business world is more concerned about preventing unauthorized modification of data by untrusted processes, than it is about protecting the confidentiality of information. Figure 6.3(b) illustrates Biba's approach:
- The simple integrity property requires that a subject cannot read from an object which is at a lower level of security sensitivity (no “read-down”).
- The * (star) Integrity property requires that a subject cannot write to an object at a higher security level (no “write-up”).
Quarantine of files or messages suspected of containing malware payloads offers a clear example of the need for the “no-read-down” policy for integrity protection. Working our way down the levels of security, you might see that “business vital proprietary,” privacy-related, and other information would be much more sensitive (and need greater integrity protection) than newly arrived but unfiltered and unprocessed email traffic. Blocking a process that uses privacy-related data from reading from the quarantined traffic could be hazardous! Once the email has been scanned and found to be free from malware, other processes can determine if its content is to be elevated (written up) by some trusted process to the higher level of privacy-related information.
As you might imagine, a number of other access models have been created to cope with the apparent and real conflicts between protecting confidentiality and assuring the integrity of data. You'll probably encounter Biba and Bell-LaPadula on the SSCP exam; you may or may not run into some of these others:
- The Clark-Wilson model considers three things together as a set: the subject, the object, and the kind of transaction the subject is requesting to perform upon the object. Clark-Wilson requires a matrix that only allows transaction types against objects to be performed by a limited set of trusted subjects.
- The Brewer and Nash model, sometimes called the “Chinese Wall” model, considers the subject's recent history, as well as the role(s) the subject is fulfilling, as part of how it allows or denies access to objects.
- Non-interference models, such as Gogun-Meseguer, use security domains (sets of subjects), such that members in one domain cannot interfere with (interact with) members in another domain.
- The Graham-Denning model also use a matrix to define allowable boundaries or sets of actions involved with the secure creation, deletion, and control of subjects, and the ability to control assignment of access rights.
All of these models provide the foundational theories or concepts behind which access control systems and technologies are designed and operate. Let's now take a look at other aspects of how we need to think about managing access control.
Role-Based
Role-based access control (RBAC) grants specific privileges to subjects regarding specific objects or classes of objects based on the duties or tasks a person (or process) is required to fulfill. Several key factors should influence the ways that role-based privileges are assigned:
- Separation of duties takes a business process that might logically be performed by one subject and breaks it down into subprocesses, each of which is allocated to a different, separate subject to perform. This provides a way of compartmentalizing the risk to information security. For example, retail sales activities will authorize a sales clerk to accept cash payments from customers, put the cash in their sales drawer, and issue change as required to the customer. The sales clerk cannot initially load the drawer with cash (for making change) from the vault, or sign off the cash in the drawer as correct when turning the drawer in at the end of their shift. The cash manager on duty performs these functions, and the independent counts done by sales clerk and cash manager help identify who was responsible for any errors.
- Need to know, and therefore need to access, should limit a subject's access to information objects strictly to those necessary to perform the tasks defined as part of their assigned duties, and no more.
- Duration, scope or extent of the role should consider the time period (or periods) the role is valid over, and any restrictions as to devices, locations, or factors that limit the role. Most businesses, for example, do not routinely approve high-value payments to others after business hours, nor would they normally consider authorizing these when submitted (via their approved apps) from a device at an IP address in a country with which the company has no business involvement or interests. Note that these types of attributes can be associated with the subject (such as role-based), the object, or the conditions in the system and network at the time of the request.
Role-based access has one strategic administrative weakness. Privilege creep, the unnecessary, often poorly justified, and potentially dangerous accumulation of access privileges no longer strictly required for the performance of one's duties, can inadvertently put an employee and the organization in jeopardy. Quality people take on broader responsibilities to help the organization meet new challenges and new opportunities; and yet, as duties they previously performed are picked up by other team members, or as they move to other departments or functions, they often retain the access privileges their former jobs required. To contain privilege creep, organizations should review each employee's access privileges in the light of their currently assigned duties, not only when those duties change (even temporarily!) but also on a routine, periodic basis.
Attribute-Based
Attribute-based access control (ABAC) systems combine multiple characteristics (or attributes) about a subject, an object, or the environment to authorize or restrict access. ABAC uses Boolean logic statements to build as complex a set of rules to cover each situation as the business logic and its information security needs dictate. A simple example might be the case of a webpage designer who has limited privileges to upload new webpages into a beta test site in an extranet authorized for the company's community of beta testers but is denied (because of their role) access to update pages on the production site. Then, when the company prepares to move the new pages into production, they may need the designer's help in doing so and thus (temporarily) require the designer's ability to access the production environment. Although this could be done by a temporary change in the designer's subject-based RBAC access privileges, it may be clearer and easier to implement with a logical statement such as:
IF (it's time for move to production) AND (designer-X) is a member of (production support team Y) THEN (grant access to a, b, c…)
Attribute-based access control can become quite complex, but its power to tailor access to exactly what a situation requires is often worth the effort. As a result, it is sometimes known as externalized, dynamic, fine-grained, or policy-based access control or authorization management.
Subject-Based
Subject-based access control looks at characteristics of the subject that are not normally expected to change over time. For example, a print server (as a subject) should be expected to have access to the printers, the queue of print jobs, and other related information assets (such as the LAN segment or VLAN where the printers are attached); you would not normally expect a print server to access payroll databases directly! As to human subjects, these characteristics might be related to age, their information security clearance level, or their physical or administrative place in the organization. For example, a middle school student might very well need separate roles defined as a student, a library intern, or a software developer in a computer science class, but because of their age, in most jurisdictions they cannot sign contracts. The webpages or apps that the school district uses to hire people or contract with consultants or vendors, therefore, should be off limits to such a student.
Object-Based
Object-based access control uses characteristics of each object or each class of objects to determine what types of access requests will be granted. The simplest example of this is found in many file systems, where objects such as individual files or folders can be declared as read-only. More powerful OS file structures allow a more granular approach, where a file folder can be declared to have a set of attributes based on classes of users attempting to read, write, extend, execute, or delete the object. Those attributes can be further defined to be inherited by each object inside that folder, or otherwise associated with it, and this inheritance should happen with every new instance of a file or object placed or created in that folder.
Rule-Based Access Control
Rule-based access control (RuBAC), as the name suggests, uses systems of formally expressed rules that direct the access control system in granting or denying access to objects. These rules can be as simple or as complex as the organization's security policies might require and are normally constructed using Boolean logic or other set theory constructs. Elegant in theory, RuBAC can be hard to scale to large enterprises with many complex, overlapping use cases and conditions; they can also be hard to maintain and debug as a result. One common use for RuBAC is to selectively invoke it for special cases, such as for the protection of organizational members or employees (and the organization's data and systems) when traveling to or through higher-risk locations.
Risk-Based Access Control
Risk-based access control (which so far does not have an acronym commonly associated with it) is more of a management approach to overall access control system implementation and use. As you saw in previous chapters, the actual risk context that an organization or one of its systems faces can change on a day-to-day basis. Events within the organization and in the larger marketplaces and communities it serves can suggest that the likelihood of previously assessed risks might dramatically increase (or decrease) and do so quickly. Since all security controls introduce some amount of process friction (such as additional processing time, identity and authorization challenges, or additional reviews by managers), a risk-based access control system provides separate adjustable sensitivity controls for different categories of security controls. When risk managers (such as an organization's chief information security officer or chief risk officer) decide an increase is warranted, one such control might increase the frequency and granularity of data backups, while another might lower the threshold on transactions that would trigger an independent review and approval. Risk-based access control systems might invoke additional attributes to test or narrow the limits on acceptable values for those attributes; in some cases, such risk-based decision making might turn off certain types of access altogether.
Mandatory vs. Discretionary Access Control
One question about access control remains: now that your system has authenticated an identity and authorized its access, what capabilities (or privileges) does that subject have when it comes to passing along its privileges to others? The “write-down” problem illustrates this issue: a suitably cleared subject is granted access to read a restricted, proprietary file; creates a copy of it; and then writes it to a new file that does not have the restricted or proprietary attribute set. Simply put, mandatory (or nondiscretionary) access control uniformly enforces policies that prohibit any and all subjects from attempting to change, circumvent, or go around the constraints imposed by the rest of the access control system. Specifically, mandatory or nondiscretionary access prevents a subject from:
- Passing information about such objects to any other subject or object
- Attempting to grant or bequeath its own privileges to another subject
- Changing any security attribute on any subject, object, or other element of the system
- Granting or choosing the security attributes of newly created or modified objects (even if this subject created or modified them)
- Changing any of the rules governing access control
Discretionary access control, on the other hand, allows the systems administrators to tailor the enforcement of these policies across their total population of subjects. This flexibility may be necessary to support a dynamic and evolving company, in which the IT infrastructure as well as individual roles and functions are subject to frequent change, but it clearly comes with some additional risks.
Network Access Control
Connecting to a network involves performing the right handshakes at all of the layers of the protocols that the requesting device needs services from. Such connections either start at Layer 1 with physical connections, or start at higher layers in the TCP/IP protocol stack. Physical connections require either a cable, fiber, or wireless connection, and in all practicality, such physical connections are local in nature: you cannot really plug in a Cat 6 cable without being there to do it. By contrast, remote connections are those that skip past the Physical layer and start the connection process at higher layers of the protocol stack. These might also be called logical connections, since they assume the physical connection is provided by a larger network, such as the Internet itself.
Let's explore these two ideas by seeing them in action. Suppose you're sitting at a local coffee house, using your smartphone or laptop to access the Internet via their free Wi-Fi customer network. You start at the Physical layer (via the Wi-Fi), which then asks for access at the Data Link layer. You don't get Internet services until you've made it to Layer 3, probably by using an app like your browser to use the “free Wi-Fi” password and your email address or customer ID as part of the logon process. At that point, you can start doing the work you want to do, such as checking your email, using various Transport layer protocols or Application layer protocols like HTTPS. The connection you make to your bank or email server is a remote connection, isn't it? You've come to their access portal by means of traffic carried over the Internet, and not via a wire or wireless connection.
Network access control is a fundamental and vital component of operating any network large or small. Without network access control, every resource on your network is at risk of being taken away from you and used or corrupted by others. The Internet connectivity you need, for business or pleasure, won't be available if your neighbor is using it to stream their own videos; key documents or files you need may be lost, erased, corrupted, or copied without your knowledge. “Cycle-stealing” of CPU and GPU time on your computers and other devices may be serving the needs of illicit crypto-currency miners, hackers, or just people playing games. You lock the doors and windows of your house when you leave because you don't want uninvited guests or burglars to have free and unrestricted access to the network of rooms, hallways, storage areas, and display areas for fine art and memorabilia that make up the place you call home. (You do lock up when you leave home, don't you?) By the same token, unless you want to give everything on your network away, you need to lock it up and keep it locked up, day in and day out.
Network access control (NAC) is the set of services that give network administrators the ability to define and control what devices, processes, and persons can connect to the network or to individual subnetworks or segments of that network. It is usually a distributed function involving multiple servers within a network. A set of NAC protocols define ways that network administrators translate business CIANA+PS needs and policies into compliance filters and settings. Some of the goals of NAC include:
- Mitigation of non-zero day attacks (that is, attacks for which signatures or behavior patterns are known)
- Authorization, authentication, and accounting of network connections
- Encryption of network traffic, using a variety of protocols
- Automation and support of role-based network security
- Enforcement of organizational security policies
- Identity management
At its heart, network access control is a service provided to multiple devices and other services on the network; this establishes many client-server relationships within most networks. It's important to keep this client-server concept in mind as we dive into the details of making NAC work.
A quick perusal of that list of goals suggests that an organization needs to define and manage all of the names of people, devices, and processes (all of which are called subjects in access control terms) that are going to be allowed some degree of access to some set of information resources, which we call objects. Objects can be people, devices, files, or processes. In general, an access control list (ACL) is the central repository of all the identities of subjects and objects, as well as the verification and validation information necessary to authenticate an identity and to authorize the access it has requested. By centralized, we don't suggest that the entire ACL has to live on one server, in one file; rather, for a given organization, one set of cohesive security policies should drive its creation and management, even if (especially if!) it is physically or logically is segmented into a root ACL and many subtree ACLs.
Network access control is an example of the need for an integrated, cohesive approach to solving a serious problem. Command and control of the network's access control systems is paramount to keeping the network secure. Security operations center (SOC) dashboards and alarm systems need to know immediately when attempts to circumvent access control exceed previously established alarm limits so that SOC team members can investigate and respond quickly enough to prevent or contain an intrusion.
IEEE 802.1X Concepts
IEEE 802.1X provides a port-based standard by which many network access control protocols work, and does this by defining the Extensible Authentication Protocol (EAPOL). Also known as “EAP over LAN,” it was initially created for use in Ethernet (wired) networks, but later extended and clarified to support wired and wireless device access control, as well as the Fiber Distributed Data Interface (ISO standard 9314-2). Further extensions provide for secure device identity and point-to-point encryption on local LAN segments.
This standard has seen implementations in every version of Microsoft Windows since Windows XP, Apple Macintosh systems, and most distributions of Linux.
EAPOL defines a four-step authentication handshake, the steps being initialization, initiation, negotiation, and authentication. We won't go into the details here, as they are beyond the scope of what SSCPs will typically encounter (nor are they detailed on the exam), but it's useful to know that this handshake needs to use what the standard calls an authenticator service. This authenticator might be a RADIUS client (more on that in a minute), or almost any other IEEE 802.1X-compatible authenticators, of which many can function as RADIUS clients.
Let's look a bit more closely at a few key concepts that affect the way NAC as systems, products, and solutions is often implemented.
- Preadmission vs. postadmission reflects whether designs authenticate a requesting endpoint or user before it is allowed to access the network, or deny further access based on postconnection behavior of the endpoint or user.
- Agent vs. agentless design describes whether the NAC system is relying on trusted agents within access-requesting endpoints to reliably report information needed to support authentication requests, or whether the NAC does its own scanning and network inventory, or uses other tools to do this. An example might be a policy check on the verified patch level of the endpoint's operating system; a trusted agent, part of many major operating systems, can report this. Otherwise, agentless systems would need to interrogate, feature by feature, to check if the requesting endpoint meets policy minimums.
- Out-of-band vs. inline refers to where the NAC functions perform their monitoring and control functions. Inline solutions are where the NAC acts in essence as a single (inline) point of connection and control between the protected side of the network (or threat surface!) and the unprotected side. Out-of-band solutions have elements of NAC systems, typically running as agents, at many places within the network; these agents report to a central control system and monitoring console, which can then control access.
- Remediation deals with the everyday occurrence that some legitimate users and their endpoints may fail to meet all required security policy conditions—for example, the endpoint may lack a required software update. Two strategies are often used in achieving remediation:
- Quarantine networks provide a restricted IP subnetwork, which allows the endpoint in question to have access only to a select set of hosts, applications, and other information resources. This might, for example, restrict the endpoint to a software patch and update management server; after the update has been successfully installed and verified, the access attempt can be reprocessed.
- Captive portals are similar to quarantine in concept, but they restrict access to a select set of webpages. These pages would instruct the endpoint's user how to perform and validate the updates, after which they can retry the access request.
RADIUS Authentication
Remote Authentication Dial-In User Service (RADIUS) provides the central repository of access control information and the protocols by which access control and management systems can authenticate, authorize, and account for access requests. Its name reflects its history, but don't be fooled—RADIUS is not just for dial-in, telephone-based remote access to servers, either by design or use. It had its birth at the National Science Foundation, whose NSFNet was seeing increasing dial-up customer usage and requests for usage. NSF needed the full AAA set of access control capabilities—authenticate, authorize, and accounting—and in 1991 asked for industry and academia to propose ways to integrate its collection of proprietary, in-house systems. From those beginnings, RADIUS has developed to where commercial and open source server products exist and have been incorporated into numerous architectures. These server implementations support building, maintaining, and using that central access control list that we discussed earlier.
Without going into the details of the protocols and handshakes, let's look at the basics of how endpoints, network access servers, and RADIUS servers interact and share responsibilities:
- The network access server is the controlling function; it is the gatekeeper that will block any nonauthorized attempts to access resources in its span of control.
- The RADIUS server receives an authentication request from the network access server—which is thus a RADIUS client—and either accepts it, challenges it for additional information, or rejects it. (Additional information might include PINs, access tokens or cards, secondary passwords, or other two-factor access information.) Tokens can be either synchronous or asynchronous, depending upon whether the token uses system time information or an algorithm to determine the dynamic (per-use) part of the token.
- The network access server (if properly designed and implemented) then allows access, denies it, or asks the requesting endpoint for the additional information requested by RADIUS.
RADIUS also supports roaming, which is the ability of an authenticated endpoint and user to move from one physical point of connection into the network to another. Mobile device users, mobile IoT, and other endpoints “on the move” typically cannot tolerate the overhead and wall-clock time consumed to sign in repeatedly, just because the device has moved from one room or one hotspot to another.
RADIUS, used by itself, had some security issues. Most of these are overcome by encapsulating the RADIUS access control packet streams in more secure means, much as HTTPS (and PKI) provide very secure use of HTTP. When this is not sufficient, organizations need to look to other AAA services such as Terminal Access Controller Access-Control System Plus (TACACS+) or Microsoft's Active Directory.
Once a requesting endpoint and user subject have been allowed access to the network, other access control services such as Kerberos and Lightweight Directory Access Protocol (LDAP) are used to further protect information assets themselves. For example, as a student you might be granted access to your school's internal network, from which other credentials (or permissions) control your use of the library, entry into online classrooms, and so forth; they also restrict your student logon from granting you access to the school's employee-facing HR information systems.
A further set of enhancements to RADIUS, called Diameter, attempted to deal with some of the security problems pertaining to mobile device network access. Diameter has had limited deployment success in the 3G (third-generation) mobile phone marketplace, but inherent incompatibilities still remain between Diameter and network infrastructures that fully support RADIUS.
TACACS and TACACS+
The Terminal Access Controller Access Control System (TACACS, pronounced “tack-axe”) grew out of early Department of Defense network needs for automating authentication of remote users. By 1984, it started to see widespread use in Unix-based server systems; Cisco Systems began supporting it and later developed a proprietary version called Extended TACACS (XTACACS) in 1990. Neither of these were open standards. Although they have largely been replaced by other approaches, you may see them still being used on older systems.
TACACS+ was an entirely new protocol based on some of the concepts in TACACS. Developed by the Department of Defense as well, and then later enhanced, refined, and marketed by Cisco Systems, TACACS+ splits the authentication, authorization, and accounting into separate functions. This provides systems administrators with a greater degree of control over and visibility into each of these processes. It uses TCP to provide a higher-quality connection, and it also provides encryption of its packets to and from the TACACS+ server. It can define policies based on user type, role, location, device type, time of day, or other parameters. It integrates well with Microsoft's Active Directory and with LDAP systems, which means it provides key functionality for single sign-on (SSO) capabilities. TACACS+ also provides greater command logging and central management features, making it well suited for systems administrators to use to meet the AAA needs of their networks.
Implementing and Scaling IAM
The most critical step in implementing, operating, and maintaining identity management and access control (IAM) systems is perhaps the one that is often overlooked or minimized. Creating the administrative policy controls that define information classification needs, linking those needs to effective job descriptions for team members, managers, and leaders alike, has to precede serious efforts to plan and implement identity and access management. As you saw in Chapters 3 and 4, senior leaders and managers need to establish their risk tolerance and assess their strategic and tactical plans in terms of information and decision risk. Typically, the business impact analysis (BIA) captures leadership's deliberations about risk tolerance and risk as it is applied to key objectives, goals, outcomes, processes, or assets. The BIA then drives the vulnerability assessment processes for the information architecture and the IT infrastructure, systems, and apps that support it.
Assuming your organization has gone through those processes, it's produced the information classification guidelines, as well as the administrative policies that specify key roles and responsibilities you'll need to plan for as you implement an IAM set of risk mitigation controls:
- Who determines which people or job roles require what kind of access privileges for different classification levels or subsets of information? Who conducts periodic reviews, or reviews these when job roles are changed?
- Who can decide to override classification or other restrictions on the handling, storage, or distribution of information?
- Who has organizational responsibility for implementing, monitoring, and maintaining the chosen IAM solution(s)?
- Who needs to be informed of violations or attempted violations of access control and identity management restrictions or policies?
Choices for Access Control Implementations
Two more major decisions need to be made before you can effectively design and implement an integrated access control strategy. Each reflects in many ways the decision-making and risk tolerance culture of your organization, while coping with the physical realities of its information infrastructures. The first choice is whether to implement a centralized or decentralized access control system:
- Centralized access control is implemented using one system to provide all identity management and access control mechanisms. This system is the one-stop-shopping point for all access control decisions; every request from every subject, throughout the organization, comes to this central system for authentication, authorization, and accounting. Whether this system is a cloud-hosted service, or operates using a single local server or a set of servers, is not the issue; the organization's logical space of subjects and objects is not partitioned or segmented (even if the organization has many LAN segments, uses VPNs, or is geographically spread about the globe) for access control decision-making. In many respects, implementing centralized access control systems can be more complex, but use of systems such as Kerberos, RADIUS, TACACS, and Active Directory can make the effort less painful. Centralized access control can provide greater payoffs for large organizations, particularly ones with complex and dispersed IT infrastructures. For example, updating the access control database to reflect changes (temporary or permanent) in user privileges is done once, and pushed out by the centralized system to all affected systems elements.
- Decentralized access control segments the organization's total set of subjects and objects (its access control problem) into partitions, with an access control system and its servers for each such partition. Partitioning of the access control space may reflect geographic, mission, product or market, or other characteristics of the organization and its systems. The individual access control systems (one per partition) have to coordinate with each other, to ensure that changes are replicated globally across the organization. Windows Workgroups are examples of decentralized access control systems, in which each individual computer (as a member of the workgroup) makes its own access control decisions, based on its own local policy settings. Decentralized access control is often seen in applications or platforms built around database engines, in which the application, platform, or database uses its own access control logic and database for authentication, authorization, and accounting. Allowing each Workgroup, platform, or application to bring its own access control mechanisms to the party, so to speak, can be simple to implement, and simple to add each new platform or application to the organization's IT architecture; but over time, the maintenance and update of all of those disparate access control databases can become a nightmare.
The next major choice that needs to be made reflects whether the organization is delegating the fine-grained, file-by-file access control and security policy implementation details to individual to users or local managers, or is retaining (or enforcing) more global policy decisions with its access control implementation:
- Mandatory access control (MAC) denies individual users (subjects) the capability to determine the security characteristics of files, applications, folders, or other objects within their IT work spaces. Users cannot make arbitrary decisions, for example, to share a folder tree if that sharing privilege has not been previously granted to them. This implements the mandatory security policies as defined previously, and results in highly secure systems.
- Discretionary access control (DAC) allows individual users to determine the security characteristics of objects, such as files, folders, or even entire systems, within their IT work spaces. This is perhaps the most common access control implementation methodology, as it comes built-in to nearly every modern operating system available for servers and endpoint devices. Typically, these systems provide users the ability to grant or deny the privileges to read, write (or create), modify, read and execute, list contents of a folder, share, extend, view other metadata associated with the object, and modify other such metadata.
Having made those decisions, based on your organization's administrative security policies and information classification strategies, and with roles and responsibilities assigned, you're ready to start your IAM project.
“Built-in” Solutions?
Almost every device on your organization's networks (and remember, a device can be both subject and object) has an operating system and other software (or firmware) installed on it. For example, Microsoft Windows operating systems provide policy objects, which are software and data constructs that the administrators use to enable, disable, or tune specific features and functions that the OS provides to users. Such policies can be set at the machine, system, application, user, or device level, or for groups of those types of subjects. Policy objects can enforce administrative policies about password complexity, renewal frequency, allowable number of retries, lockout upon repeated failed login attempts, and the like. Many Linux distributions, as well as Apple's operating systems, have very similar functions built into the OS. All devices ship from the factory with most such policy objects set to “wide open,” you might say, allowing the new owner to be the fully authorized systems administrator they need to be when they first boot up the device. As administrator/owners, we're highly encouraged to use other built-in features, such as user account definitions and controls, to create “regular” or “normal” user accounts for routine, day-to-day work. You then have the option of tailoring other policy objects to achieve the mix of functionality and security you need.
For a small home or office LAN, using the built-in capabilities of each device to implement a consistent administrative set of policies may be manageable. But as you add functionality, your “in-house sysadmin” job jar starts to fill up quickly. That new NAS or personal cloud device probably needs you to define per-user shares (storage areas), and specify which family users can do what with each. And you certainly don't want the neighbors next door to be able to see that device, much less the existence of any of the shares on it! If you're fortunate enough to have a consistent base of user devices—everybody in the home is using a Windows 10 or macOS Mojave laptop, and they're all on the same make and model smartphone—then you think through the set of policy object settings once and copy (or push) them to each laptop or phone. At some point, keeping track of all of those settings overwhelms you. You need to centralize. You need a server that can help you implement administrative policies into technical policies, and then have that server treat all of the devices on your network as clients.
Before we look at a client-server approach to IAM, let's look at one more built-in feature in the current generation of laptops, tablets, smartphones, and phablets, which you may (or may not) wish to utilize “straight from the shrink wrap.”
Other Protocols for IAM
As organizations scale out their IT and OT infrastructures to include other resources and organizations, they need to be able to automate and control how these systems exchange identity, authentication, and authorization information with each other. RADIUS, as we've seen, provides one approach to delivering these sets of functions. Let's take a brief look at some of the others, which you may need to delve into more fully if your organization is using any of them.
LDAP
The Lightweight Directory Access Protocol (LDAP) is based on the International Telecommunications Union's Telecommunications Standardization Sector (ITU-T) X.500 standard, which came into effect in 1988. This is actually a set of seven protocols that together provide the interfaces and handshakes necessary for one system to query and retrieve information from another system's directory of subjects and objects. DAP, the original protocol, was constructed around the OSI 7-Layer protocol stack, and thus other implementations of the same functions were needed to support TCP/IP's protocol stack; LDAP has proven to be the most popular in this respect. It works in conjunction with other protocol suites, notably X.509, to establish trust relationships between clients and servers (such as confirmation that the client reached the URL or URI that they were intending to connect with). We'll look at this process in more detail in Chapter 12, “Cross-Domain Challenges.”
SAML and XACML
The Security Assertions Markup Language (SAML), published by OASIS, is a community-supported open standard for using extensible markup language (XML) to make statements or assertions about identities. These assertions are exchanged between security domains such as access control systems belonging to separate organizations, or between access control systems and applications platforms. SAML 2.0, the current version, was published in 2005, with a draft errata update released in 2019. As an XML-based language, SAML is human-readable; SAML assertions flow via HTTP (HTTPS preferably) over the Internet. These assertions provide information about an identity and any conditions that may apply to it.
XACML, the Extensible Access Control Markup Language, was designed to support SAML's basic authentication processes, and as such the two languages (and the rules for using them) are very strongly related. XACML is not bound to SAML, however; it can just as easily be used with other access control systems, especially when security policies require a finer level of detail than normally supported by SAML alone.
OAuth
The IETF created the Open Authorization (OAuth) process as a way of supporting applications to gain third-party access and use of an HTTP service. It's built around four basic roles:
- Resource owners are entities that can grant (or deny) access to their resources by a third party. These entities may be servers, systems, or humans (who are then known as end users in OAuth terms).
- Resource servers are the devices hosting the resources in question. For OAuth to function, these servers have to be able to receive and act upon an OAuth access token, to then allow (or deny) access to a protected resource on that server.
- Client applications are programs which are making the request to access a protected resource; they are doing this on behalf of, and with the authorization of, the resource owner. (Note that in this context, the word “client” does not imply anything about where this application is hosted, or what its general functions might be.)
- Authorization servers are responsible for authenticating the requesting client application, validating it by generating access tokens which are then passed to the resource servers for their use.
OAuth eliminated the need to send usernames and passwords to the third party system. OAuth 2.0, the current version (since 2012), has been made transport-dependent: it uses TLS, which forces it to be used via HTTPS rather than the unsecure HTTP. The access tokens are encrypted during transit as an additional precaution.
SCIM
The system for cross-domain identity management (SCIM) provides protocols used by cloud-based systems, applications, and services to streamline and automate the provisioning of identities across multiple applications. Larger-scale applications platforms, such as Salesforce, Microsoft's O365, and Slack, use SCIM. As a system based around Microsoft's Active Directory, it relies on the initial user provisioning process creating a specific type of AD record, which has a SCIM connector associated with it. This leads to that new user now having access to all SCIM-enabled applications. When the user no longer requires any of those access privileges (such as when they leave the organization), one action in the central directory to terminate that user's ID leads to terminating their access to all of those SCIM applications.
Multifactor Authentication
As mentioned at the start of this chapter, authentication of a subject's claim to an identity may require multiple steps to accomplish. We also have to separate this problem into two categories of identities: human users, and everything else. First, let's deal with human users. Traditionally, users have gained access to systems by using or presenting a user ID (or account ID) and a password to go with it. The user ID or account ID is almost public knowledge—there's either a simple rule to assign one based on personal names or they're easily viewable in the system, even by nonprivileged users. The password, on the other hand, was intended to be kept secret by the user. Together, the user ID and password are considered one factor, or subject-supplied element in the identity claim and authentication process.
In general, each type of factor is something that the user has, knows, or is; this applies to single-factor and multifactor authentication processes:
- Things the user has: These would normally be physical objects that users can reasonably be expected to have in their possession and be able to produce for inspection as part of the authentication of their identity. These might include identification cards or documents, electronic code-generating identity devices (such as key fobs or apps on a smartphone), or machine-readable identity cards. Matching of scanned images of documents with approved and accepted ones already on file can be done manually or with image-matching utilities, when documents do not contain embedded machine-readable information or OCR text.
- Information the user knows: Users can know personally identifying information such as passwords, answers to secret questions, or details of their own personal or professional life. Some of this is presumed to be private, or at least information that is not widely known or easily determined by examining other publicly available information.
- What the user is: As for humans, users are their physical bodies, and biometric devices can measure their fingerprints, retinal vein patterns, voice patterns, and many other physiological characteristics that are reasonably unique to a specific individual and hard to mimic. Each type of factor, by itself, is subject to being illicitly copied and used to attempt to spoof identity for systems access.
Use of each factor is subject to false positive errors (acceptance of a presented factor that is not the authentic one) or false negative errors (rejection of authentic factors), and can be things that legitimate users may forget (such as passwords, or leaving their second-factor authentication device or card at home). As you add more factors to user sign-on processes, you add complexity and costs. User frustration can also increase with additional factors being used, leading to attempts to cheat the system.
There is also a potential privacy concern with all of these factors. In order for authentication systems to work, the system has to have a reference copy of the documents, the information, or the biometric measurements. Access to these reference copies needs to be controlled and accounted for, for any number of legal and ethical reasons. It might seem obvious that the reference copies be stored in an encrypted form, and then have the endpoint device that accepts this information encrypt it for transmission to the identity management system for comparison with the encrypted copies on file. This may make it difficult or impossible to determine whether the endpoint's data has an acceptable amount of error in it (the document was not properly aligned with the scanner, or the finger was not aligned the same way on the fingerprint reader). As an SSCP, you do not need to know how to solve these problems, but you should be aware of them and take them into consideration as you plan for identity authentication.
All of the foregoing applies whether your systems are using single-factor or multifactor authentication processes.
Multifactor authentication requires the use of more than one factor in authenticating the legitimacy of the claimed identity. The underlying presumption is that with more factors being checked, the likelihood that the subject's claim to the identity is invalid decreases.
Three cautions may be worth some attention at this point with regard to the use of built-in biometric and image identification systems in the current generations of laptops, phablets, and smartphones.
First, these may be challenging to scale, if your organization needs to allow for roaming profiles (which enable the same user to log on from different devices, perhaps even in different locations around the world).
Second, there's the risk that a third party could compel or inveigle your user into using the biometrics to complete an access attempt. Legally, a growing number of jurisdictions have the authority to compel someone to unlock devices in their possession, such as when crossing borders. Pickpockets, too, have been known to steal someone's smartphone, immediately try to unlock it, and turn and point the camera at its owner to complete the photo-based authentication challenge. Although many businesses may never have to worry about these concerns, the one that you work for (or help create) just might.
Finally, we must consider that as with any instrumentation or control system and process, errors do happen. The false negative, false rejection, or Type 1 error, happens when a legitimate, trusted access request by a subject is denied in error. Type 2 errors, also known as false acceptance or false positive errors, occur when an unauthorized or unrecognized subject is mistakenly allowed access. Biometric authentication technologies, for example, must frequently cope with errors induced by their users' physical health, ambient noise, lighting, or weather conditions, or electrical noise that affects the sensors at the endpoint device. The important question becomes how much error in today's measurements you can tolerate, when compared to the on-file (baseline) biometric data, before you declare that the readings do not match the baseline:
- Tolerate too little error, which increases your false rejection rate (FRR), and you increase the chance of false negatives or Type 1 errors (denying legitimate access requests).
- Tolerate too much error, which increases your false acceptance rate (FAR), and you increase the chance of false positives or Type 2 errors (accepting as a match, and thereby allowing access that should have been denied).
Figure 6.4 illustrates the general concept of FAR and FRR, showing how increasing the sensitivity of a sensor (such as a biometric device) may lower the false acceptance rate but raise the false rejection rate. Note that FAR and FRR apply equally to any sensor or measurement technology; errors are present in everything.

FIGURE 6.4 Crossover error rate (where FAR equals FRR)
This visualization of FAR and FRR is often over-emphasized, and caution is advised when talking about a crossover error point or rate measure. This figure is a control's-eye view, you might say: it only sees the risk management issue from the point of view of the device and its operator. Organizational managers need to look at a much larger trade space, one that looks at all of the access control techniques being used and then considers FAR and FRR in aggregate. Figure 6.5 illustrates this problem.

FIGURE 6.5 Overall access control system error rates trade space
From management's perspective, every step increase in FRR introduces friction into legitimate, necessary, value-creating activities: work done by employees or members of the organization, or business conducted with customers, prospects, or suppliers, can take longer. Since FAR and FRR are inversely related, every step increase in protecting the organization against intruders gaining access due to errors in the IAM systems causes friction that hinders those legitimate user activities. The intrusion might happen, think these managers; the friction will happen, every time, as soon as the risk-based sensitivity control is turned up.
As a result, the sweet spot on the trade space is generally not where the CER point is indicated; instead, it is somewhere to either side, reflecting the organization's larger sense of risk tolerance and costs. They may also adjust where the best FAR-versus-FRR operating point is based on the asset or process involved.
Server-Based IAM
In the vast majority of IT infrastructures, companies and organizations turn to server-based identity management and access control systems. They scale much more easily than node-by-node, device-by-device attempts at solutions, and they often provide significantly greater authentication, authorization, and accounting functions in the bargain. Although seemingly more complex, they are actually much easier to configure, operate, maintain, and monitor. Let's take a closer look.
Conceptually, an identity management and access control system provides a set of services to client processes, using a centralized repository to support authentication of identity claims and grant or deny access, and accounting for successful and unsuccessful attempts at access. Different systems designs may use one server or multiple servers to perform those functions. These servers can of course either be dedicated hardware servers, be job streams that run on hardware servers along with other jobs (such as print sharing or storage management), or be running on virtual machines in a public, private, or hybrid cloud environment. In any case, careful attention must be paid to how those servers are connected to each other, to the rest of your networks and systems, and to the outside world.
In particular, notice that different access control systems are modeled around different transmission protocols. As you saw in Chapter 5, UDP and TCP deliver very different error detection and correction opportunities for systems designers. RADIUS is an example of an access control system built around UDP, and so its basic flow of control and data is prone to data loss or error. TACACS, and systems based on its designs, are built around TCP, which provides better control over error detection and retransmission.
On the other hand, different access control designs provide different mixes of authentication, authorization, and accountability functionality. RADIUS implementations tend to provide richer accounting of access activities than TACACS, for example.
Server-based IAM systems (integrated or not) may also make use of multiple information repositories, as well as multiple servers performing some or all of the AAA tasks. This is particularly helpful in enterprise architectures, where an organization might have business units in multiple locations around the globe. Performance, reliability, and availability would dictate a local IAM server and repository, which synchronizes with the repositories at other locations as often as business logic requires it to.
Integrated IAM systems
As organizations grow more complex in their information needs, they usually need more powerful ways to bring together different aspects of their identity management and access control systems. A typical mid-sized company might need any number of specific platforms for logically separated tasks, such as human resources management, finance and accounting, customer relations management, and inventory. In the past, users had to first sign on to their local client workstation, then sign on to the corporate intranet, and then present yet another set of credentials to access and use each software platform and the data associated with it. Each application might have been built by different vendors, and each might be using different approaches to end-user identification authentication and access authorization. When the business further expands and needs to share information resources or provide (limited subsets of) platform access to partners, clients, or vendors, its identity and access management functions become more complicated. We need to share authorization information across related but separate applications, platforms, and systems, including systems that aren't under our direct control or management.
One approach is to use a directory system as the repository for identity authentication and access authorization information (or credentials), and then ensure that each time an application needs to validate an access request or operation, it uses that same set of credentials. This would require a server for that repository, and an interface by which client systems can request such services. The International Telecommunications Union (ITU) first published the X.500 Directory Specification in the late 1980s, and since then it has become the standard used by almost all access control and identity management systems. It included a full-featured Directory Access Protocol (DAP), which needed all of the features of the OSI 7-layer protocol stack. Broader use of X.500 by TCP/IP implementations was spurred by the development at MIT of LDAP.
Single Sign-On
Single sign-on (SSO) was the first outgrowth of needing to allow one user identity with one set of authenticated credentials to access multiple, disparate systems to meet organizational needs. SSO is almost taken for granted in the IT world—cloud-based service providers that do not support an SSO capability often find that they are missing a competitive advantage without it. On the one hand, critics observe that if the authentication servers are not working properly (or aren't available), then the SSO request fails and the user can do nothing. This may prompt some organizations to ensure that each major business platform they depend on has its own sign-on capability, supported by a copy of the central authentication server and its repository. SSO implementations also require the SSO server to internally store the authenticated credentials and reformat or repackage them to meet the differing needs of each platform or application as required. Because of this, SSO is sometimes called reduced sign-on.
OpenID Connect
We started this chapter with the need to separate the entity from the identities (yes, plural) that it uses and to further separate those identities from the credentials that attest to the validity of those identities in particular contexts (such as accessing resources). In recent years it's become apparent that web-based identity systems must carry these concepts forward in their implementations and use.
OpenID Connect, developed by the OpenID Foundation, provides for a separation of the entity layer from the identity layer. OpenID Connect builds on the standards and toolkits provided by its predecessor, OpenID 2.0 and has moved to using Java technologies (specifically JSON and its JSON Web Token, or JWT), which make OpenID Connect both more interoperable with other systems and more developer-friendly.
Identity as a Service (IDaaS)
A number of third-party solutions now provide cloud-based as ways of obtaining subscription-based identity management and access control capabilities. Some of these product offerings are positioned toward larger organizations, with 500 or more users' worth of identity and access information needing to be managed. When the vendors in question have well-established reputations in the identity and access management marketplace, then using IDaaS may be a worthwhile alternative to developing and fielding your own in-house solutions (even if your chosen server architectures end up being cloud-based). This marketplace is almost 10 years old at this writing, so there should be a rich vein of lessons learned to pore over as you and your organization consider such an alternative.
IDaaS should not be confused with digital identity platforms, such as provided by using a Microsoft, Google, or other account. These digital identity platforms can provide alternate ways to authenticate a user, but you should be cautious: you're trusting that digital identity platform has done its job in proofing the identity information provided by the user to the degree that your information security needs require.
Federated IAM
Generally speaking, a federated system is one built up from stand-alone systems that collaborate with each other in well-defined ways. In almost every industry, federations of businesses, nonprofit or civic organizations, and government agencies are created to help address shared needs. These federations evolve over time as needs change, and many of them fade away when needs change again. Federated identity management and access control systems can serve the needs of those organizational federations when they require identities to be portable across the frontiers between their organizations and their IT infrastructures.
Federated identity management systems provide mechanisms for sharing identity and access information, which makes identity and access portable, allowing properly authorized subjects to access otherwise separate and distinct security domains. Federated access uses open standards, such as the OASIS Security Assertion Markup Language (SAML), and technologies such as OAuth, OpenID, various security token approaches, Web service specifications, Windows Identity Foundation, and others. Microsoft's Active Directory Federated Services (ADFS), which runs on Windows Server systems, can provide SSO capabilities across a mixed environment of Windows and non-Windows systems, for example, by using SAML 2.0-compliant federation services as partners. Federated access systems typically use Web-based SSO for user access (which is not to be confused with SSO within an organization's systems). Just as individual platform or system access is logically a subset of SSO, SSO is a subset of federated access.
One outgrowth of federated IAM approaches has been to emphasize the need for better, more reliable ways for entities to be able to assert their identity as a part of an e-business transaction or operation. Work to develop an identity assurance framework is ongoing, and there are efforts in the US, UK, and a few other nations to develop standards and reference models to support this.
Session Management
We've now got most of the building blocks in place to look more closely at what happens in the Session layer, or Layer 5, of the OSI 7-Layer internetworking model. From a user's perspective, a session consists of all the activities that they conduct with a server, between (and including) their initial connection or login to that server and ending with (and including) their termination of that session.
Looking at this in integrated identity and access management terms, a session is defined as:
- The set of activities performed by systems elements,
- that work together to ensure that the logical connection between user and server remains uninterrupted,
- while assuring the protection of all resources used throughout the session.
You'll note that this definition leaves the purpose of the session, or the accomplishment of the user's purposes, goals, or objectives, purely to the application layer to address. Session management helps create a session, keeps it running safely and securely, and tears it down when the session is ended or expires; what happens during the session is not, in general, the session manager's concern. It can also provide for tracking and keeping secure the various service requests made by a subject.
Session management requires coordination between the IAM elements on all servers and client devices involved in the session; normally, these will use X.509 certificates as a way of passing standardized data regarding identities. (We'll look at these and most of the other cryptologic functions needed in session management in more detail in Chapter 7, “Cryptography”). Briefly, the steps in session management are as follows:
- The subject must identify themselves and be authenticated. The initial sign-on menu process (executing as part of a web page or an app on the user's device) gathers up various user ID information. This typically includes:
- The subject's login ID fields, including password
- The user's originating IP or device address (MAC or private/temporary IPv6 address)
- Physical geolocation data, if available
- User ID or entity ID information, for the entity (if any) that is initiating this request on the subject's behalf
- This data is sent to an identity or authentication server for validation.
- A session identifier is generated and appended to the subject data. Session IDs tend to be long strings of random values; most banking systems, for example, use a 30-character session ID. The session ID should be unique enough that it can be used to unambiguously identify a particular session, conducted during a particular time, and initiated by or involving a particular subject.
- If validated by the server, the server responds to the requesting subject's device with an access token. This token contains an expiration date and time, which will force a timeout and termination of the session unless the subject asks for the session to be extended.
- The session token is then passed by the subject to the server(s) that will be performing the services being requested during the session.
- IAM systems on the server(s) and other security functions monitor the conduct of session activities and may request that session management terminate a session if such is required by security policies.
- At successful conclusion, the session is terminated.
Many systems use cookies to keep track of the conduct of a session, and these often store the session ID as part of one or more cookies. Attackers who can capture a session cookie as it is transmitted to the subject's device, or recover it from temporary storage on that device, may be able to resubmit that session ID, which allows the attacker to impersonate the subject and reconnect to the server. This session replay attack is quite common, thanks to less-than-secure implementations of session management functions by many web apps. It rates second place on the Open Web Application Security Project's (OWASP's) Top Ten list of vulnerabilities, where it's shown as broken or vulnerable authentication and session management.
Kerberos
Named after the three-headed watchful guard dog of Greek mythology, this approach for indirect authentication (using the services of a third party) has become a de facto standard across much of the industry. Microsoft has made it a mainstay of its systems, and it is used by many Linux platforms as well. It is built into many applications platforms and other products and provides a broad base for single sign-on (SSO) capabilities. It also uses encryption processes (which we'll look at in Chapter 7), but it uses them to provide authentication in a different way than other systems. Kerberos uses a ticket as its access control token, which when combined with a session key provides the authentication to the servers controlling the resources the subject seeks to access. This can be summarized in its six-step process model, shown here:
- Step 1: The subject requests access, which results in a request for a ticket granting service to generate the ticket granting ticket (TGT). This is generally done on the subject's behalf by a combination of applications and system software running on the subject's device. The TGT request is sent to the domain controller or other server acting as the Kerberos server for the system.
- Step 2: The Kerberos server interrogates the access control system (via the domain controller) and either declines the request or approves it and replies with the TGT and a session key. This is sent to the subject.
- Step 3: The subject uses the authentication received in step 2 to send a ticket request to the Kerberos server.
- Step 4: The Kerberos server responds with the ticket and the session key.
- Step 5: The subject contacts the resource server and requests the desired service; the authentication information provided in step 4 (the ticket) is provided to the server.
- Step 6: The server approves (or disapproves) the access and replies to the subject.
One of the distinctive features of Kerberos is that it provides its own key distribution center (KDC), and this means that the KDC can be a single point of failure in federated systems using Kerberos. The KDC must also be kept secured and isolated from any other non-Kerberos-related tasks. (Sadly, exploits against print services, turned on by default in many as-shipped copies of Windows Server and other server systems, provide a common backdoor into some Kerberos and other SSO architectures.) As with other SSO architectures, options exist to provide redundant or distributed support to critical single-point functions like the KDC, but at added complexity (and potentially bringing other risks to the system as a result).
Credential Management
Earlier we looked at the common definition of a credential as a formal authentication that an identity is what it claims to be. More formally, security professionals talk about credentials as being a binding (or encapsulation) of all the relevant data about an identity and an authenticator, which is created to support the subject's assertion that their claim to that identity is valid and meets or exceeds the authentication criteria of the system(s) the subject wants to use that identity with. Credentials can take many forms:
- Documents issued by competent authorities, such as government-issued identification or licenses
- Physical cards with embedded processors and memory, such as common access cards or smart cards
- Software apps and encapsulated data, installed on smartphones or other devices
- Other security tokens, which might be key fob–sized devices that will be used by the subject during identity authentication processes
- Cryptographic keys, typically in the form of public-private key pairs
Credentials have their own lifecycle. They are usually generated by a credential service provider (CSP), while credential management systems (CMSs) facilitate the transfer and use of credentials in providing access. The credential lifecycle, first published by NIST as part of the US government's Federal Identity, Credential, and Access Management (FICAM) Architecture in 2009, consists of the following steps:
- Sponsorship starts when an authorized entity supports a claimant's request for a credential to be issued by a CSP.
- Enrollment is performed by the claimant providing supporting information (for identity proofing) to the CSP. This data is captured and made part of the credential record.
- Credential production involves the generation of the credential, in whatever form was requested (or supported by the CMS being used). This includes any provisioning processes necessary to initially inform the CMS of the new credential.
- Issuance releases the credential to the subject for their use.
- Credential lifecycle management includes subsequent update, revocation, re-issuance, re-enrollment, suspension, expiration, or other actions as required.
As identity as a service became more widespread, NIST, ISO, and others worked to update these process models to better reflect the use of cryptography in the generation, sharing, authentication, and use of credentials. The cryptographic details will be looked at in Chapter 7; as a credential management process, Figure 6.6, taken from NIST SP 800-63, outlines the updated model.
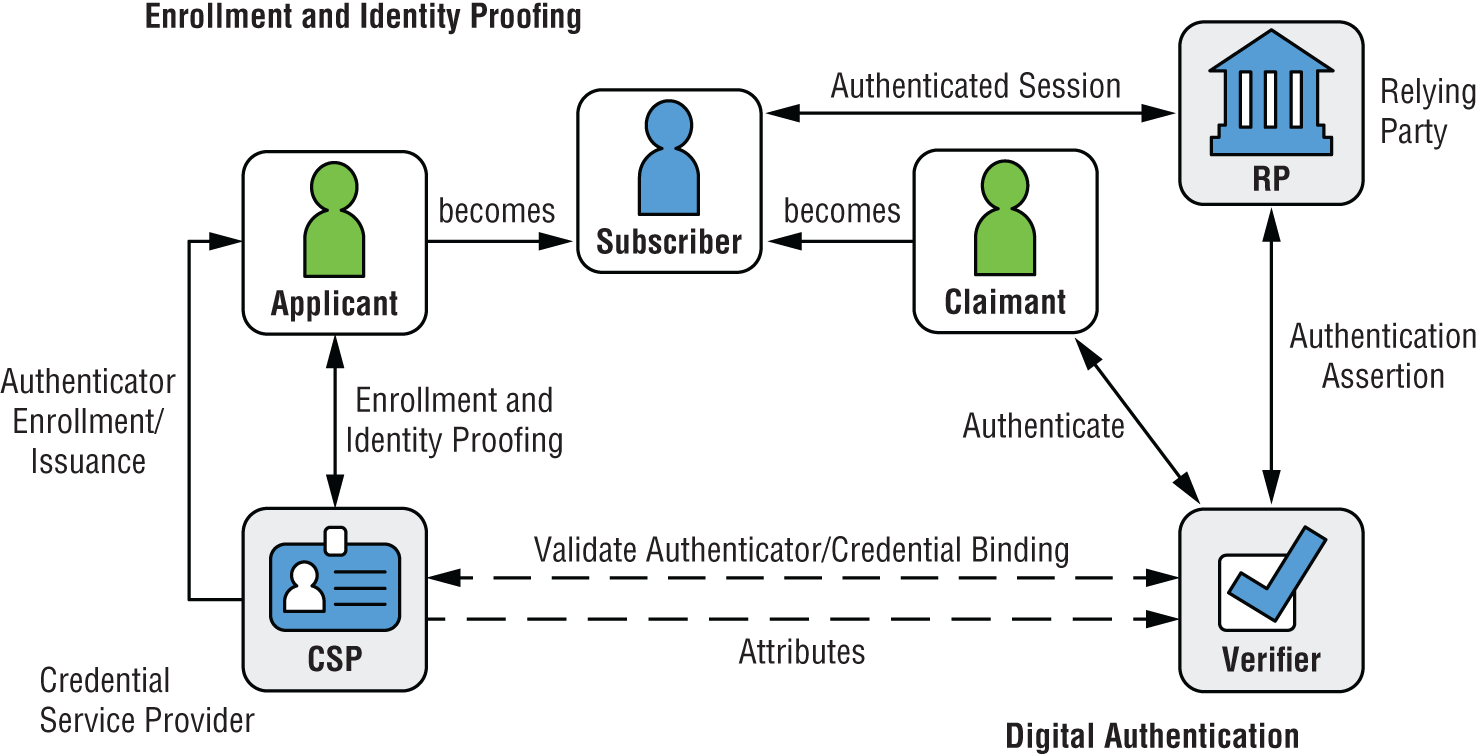
FIGURE 6.6 Digital identity and credentials process model (from NIST SP 800-63)
This figure shows the same entity—the subject or user—taking on three different roles or functions throughout the process. Let's start on the left side of the figure with the applicant. As an applicant, the user enrolls with a credential services provider such as LinkedIn, Facebook, or Office 365. That CSP issues the applicant their authenticator for the credential being issued to them. This enables the applicant to change roles, morphing into a subscriber of that CSP. At some time later, the user desires to use that credential to connect to a service provider, such as their online bank or a merchant. The user now takes on the role of being a claimant.
This server, known as a relying party, takes the authentication information provided by the claimant and passes it to a verifier for third-party verification. That verification service interrogates the CSP, which returns validation that the authentication and credential are properly bound and may provide other attributes if need be. The verifier passes this back to the relying party, which can now make the final decision to establish a secure session with the subscriber-claimant.
As you might suspect, there's a lot of details below the level of this model that make it all work, but we won't go into those.
Trust Frameworks and Architectures
One of the key considerations in federating access between or across systems is the way that trust relationships do or do not transfer. One example might be a humanitarian relief operation that involves a number of nonprofit, nongovernmental organizations (NGOs) from different countries, sharing a consolidated planning, coordination, and information system platform operated by a major aid agency. Some of the NGOs might trust aid agency employees with shared access to their information systems; others might not. There might also be local organizations, working with some of the NGOs, who are not known to the international aid agency; even host nation government agencies might be a part of this puzzle. The aid agency might wish to grant only a limited set of accesses to some of the NGOs and their staff and maybe no access at all to a few of the NGOs. This demonstrates several types of trust relationships:
- One-way trust relationships exist where organization A trusts its users and trusts the users of organization B, but while B trusts its own people as users, it does not fully trust the users in organization A and must limit their access to B's systems and information resources.
- Two-way trust relationship exist when both organizations have the same level of trust in all of the users in the other's domain. This does not have to be as high a level of trust as what they repose in their own people but just a symmetric or matching degree of trust.
- Transitive trust happens when organization A trusts organization B, and B trusts C, and because of that A can trust C.
As the complexity of the relationships between organizations, their systems and platforms, and the domains of user subjects (and objects) associated with those platforms increases, trust relationships can start to matrix together sometimes in convoluted ways. This could quickly overwhelm efforts by each organization's systems administrators to manage locally. Federated approaches to identity and access management are not by themselves simple, but they can be easier to manage, especially when the social or organizational context and trust relationships are not simple and straightforward. Federated systems also allow for much quicker, cleaner disconnects, such as when the relief operation ends or when one agency's systems are found to be less secure than can be tolerated by others in the federation.
Solutions to situations like this might contain elements of the following:
- Advanced firewall technologies
- Gateways and proxies as interface control points
- VLANs and restricted VLANs
- Public access zones
- Extranets for datacenter access
- Extensive Authentication Protocol (EAP)
- Allowed listing of applications, with application visibility and control functions to monitor and enforce allowed listing policies
- Multifactor authentication of subjects
- Behavior and posture monitoring, such as enforcing device update status and using remediation or quarantine to enforce updates or limit access
- Network segmentation to include zero trust architectures where required
This last needs some explanation and discussion.
User and Entity Behavior Analytics (UEBA)
The number-one priority in keeping any system secure, safe, and available is detecting when an intrusion or an attack is underway. This demands that the security team and the total set of end users, administrators, and support staff be able to recognize when something out of the ordinary is happening. Discriminating between business normal, abnormal but reasonable, and possibly suspicious behaviors or events requires organizations and their people to have a deep understanding of their normal business processes, as well as good situational awareness of changes in the real world (internal or external) that are legitimately driving change in their systems' and users' behaviors.
As we've seen throughout this chapter, users can be both human and nonhuman entities; entities, we've also seen, are capable of having multiple identities associated with them (and not all of those are necessarily either legitimate or properly authenticated for our systems).
Modeling techniques are often used to take many observations of similar events (such as user behaviors) and attempt to deduce or infer a set of general statements about those behaviors. Modeling can also be done by predicting future system behaviors and then observing subsequent events to see if the predictions hold true.
Over the last few years, user and entity behavioral analysis (UEBA) has become one of the major innovations in the security profession. It's being used in detecting new types and patterns of financial crime, smuggling, racketeering, and many other disciplines; its use in information systems security has made UEBA something of a household word. UEBA systems operationalize an organization's approach to separating out the possibly suspicious from the abnormal (or the normal) events by applying machine learning techniques to three distinct but related sets of knowledge:
- Threat typologies: These are behavior patterns that signal with high confidence that an intrusion, attack, or other hazardous set of events is taking place.
- Allowed typologies: These patterns reflect the designed-in use cases for the system and its subsystems; they describe or model the way things are supposed to work.
- User session histories: Data is collected over time from a wide variety of security and operational sensors, logging agents, or other monitoring elements throughout the system.
The first two of these knowledge bases are curated content—as collections of patterns or templates, they are subject to ongoing review and assessment. Human analysts and modelers (both from security and other functional areas of the organization) can choose to add newly detected examples of either type of behaviors to their respective collections. The threat typologies are often derived in the first instance from current CVE and attack pattern findings published at MITRE's ATT&CK framework website. Vendors of UEBA-based access control and security systems generally do this as part of making their systems and services more valuable to customers. Allowed typologies must be generated by people or organizations with deep, broad, and current understanding of how their business logic and systems are supposed to be put to use. This should reflect how they were designed to be used, and how their users are coached, trained, and guided to use them. In-house analysts will often add new patterns (to any or all of these knowledge bases) to reflect known or anticipated changes in market dynamics, the overall risk context of the organization, or changes in the organization's products and services.
When a UEBA system is first installed, it has to undergo a period of initial training. This training has to happen whether the learning components of that UEBA system are part of its artificial intelligence or its natural (human-hosted) intelligence capabilities. Once that training period is over, the same operational data gathering system that feeds the user session history knowledge base can now use the knowledge base as part of its real-time monitoring, analysis, and incident detection activities. These features come together in integrated UEBA-enabled security systems, as shown in Figure 6.7.

FIGURE 6.7 UEBA security in operation (conceptual)
Suppose this system is being used to monitor and protect the security information and event management (SIEM) system in your organization. Your SOC team, like many other functional groups in the organization, probably has some of its members who must be able to perform a variety of privileged and nonprivileged SIEMs-related tasks remotely—the SOC manager or CISO, for example, might need to be able to gain real-time insight and provide real-time direction when they're at home, or on travel status, as part of an incident response process. In this example, your SOC manager, Emba, has traveled to a distant city to attend an information security conference; he gets an urgent SMS notification from the SIEM that several IoCs have been detected and that human analysts have confirmed them as highly likely to be correct. Emba logs in remotely, and this triggers the UEBA watchdogs into action.
- Initial login data is captured and compared both to UEBA data and to travel status updates to the access control system. The green light is given to allow Emba to connect to the SIEM and begin his work on the incident.
- Emba suspects the data is indicating an insider threat may be the culprit; he attempts to access assets that have PII and other data pertaining to specific individuals who've been behaving oddly recently. This requires a temporary elevation of privilege, which is checked (by the IAM and UEBA systems), and since all looks good, this access is allowed.
- Emba then concludes that a pre-scripted set of containment and response actions did not execute correctly, and he attempts to restart it. This requires superuser privileges, which as a remotely requested activity is modeled as risky. Additional challenges and tests by IAM and UEBA work to resolve this and finally allow it to proceed.
- The script Emba has restarted then needs to shut down and restart security-sensitive assets, such as perimeter firewalls or a bastion server. But wait: Emba has signed in using his mobile phone, but he's done so using a VPN and the mobile phone data services available in the area of the conference hotel. The system detects the constant changes of IP addresses (or IPv6 privacy addresses), and given the elevated risk of these actions, the system determines it cannot with high confidence know that the entity “Emba” is who it claims to be, nor are his mobile phone, VPN client, and browser software (instances of these apps, that is) what they claim that they are. It denies the request and alerts security personnel.
- At this point, on-scene security personnel request direct voice/video contact with Emba to attempt to confirm that he is in fact their SOC manager, and not a very sophisticated attacker. (Ideally, the crew and their boss have sufficient prior rapport that they can also not be fooled by a deep fake of Emba's voice, speech, or video appearance.)
This hypothetical example indicates the challenges that even the most advanced security techniques and the most proficient, skillful, and knowledgeable security analysts must face every day: the most stressing situations are ones that are highly dynamic and often quite unique. They may have elements—small sets of behaviors—that can be defined, studied, or modeled in advance. But the whole attack will come as a series of surprises, reflecting the attacker's skill and preparation as much as the misperceptions and mistaken choices they make during each step of the attack.
UEBA is an approach to adding capability to your identity management and access control systems, to your network security, and to every other aspect of your organization's business processes. It is another of those rapidly evolving “hot topics” in information systems security. More than 20 of the industry-leading vendors providing these types of capabilities offer purchase, lease, or subscription plans that bring this type of security within the price reach of smaller businesses and organizations. As a security professional, you don't have to become a machine learning expert to put these systems to work; instead, your security-focused operational analysis and troubleshooting perspectives and skills can help you get the organization started on a UEBA pathway.
Zero Trust Architectures
From some perspectives, the normal conventions for designing and implementing network security implicitly or explicitly assume that once a subject has been granted access to the network, they are trusted to do what they were granted access to do. This is a little bit like registering as a hotel guest, and the key card you're given lets you use the elevator to access the floors the guest rooms are on or go into the fitness center. Your key card will not, however, let you into other guests' rooms or into areas restricted to the staff. Even in the hotel, the question must be asked: do you have legitimate business on floors where your room is not located?
Zero trust network design and access control reflect the need to counter the more advanced persistent threats and the increasing risk of data exfiltration associated with many of them. This shifts the security focus from the perimeter to step-by-step, node-by-node movement and action within the organization's information infrastructure. Instead of large, easily managed networks or segments, zero trust designs seek to micro-segment the network. Fully exploiting the capabilities of attribute-based access control, the zero trust approach promises to more effectively contain a threat, whether an outsider or insider, and thus limit the possibility of damage or loss. In August 2020, NIST published SP 800-207, Zero Trust Architecture, to focus attention and bring together ongoing development of the concept. It establishes a working definition of zero trust architecture (ZTA) as a concept, and some general deployment models applying it to workflows, security processes, and systems design and implementation for industrial control, enterprise information systems, and other domains. ISO 27001 has not been updated to reflect zero trust architectures specifically, but many experts are quick to point out that implementing ZTA is fully consistent with existing ISO standards such as 27001.
You might at first think that zero trust architectures, and their attitude of “never trust, always verify,” are incompatible with federated identity management and access control systems. Federated systems seem to encourage us to make one giant, trusting community of collaboration and sharing, with which we can break down the walls between companies, departments, and people; how can zero trust play a role in this? It does this by increasing the levels of decision assurance within the organization. Zero trust architectures add to the CIANA+PS payback via:
- Ensuring that all accesses to all objects, by all subjects, are fully authenticated and authorized each time; this limits the opportunity for a process to misbehave and start corrupting other data or processes.
- Combining attributes about subjects, objects, and types of access (and the business task being performed) with time of day, location, or other environmental or context information; this limits the exposure to abnormal events.
- Adopting and enforcing a least-privilege strategy ensures that step by step, task by task, subjects and the processes they run are doing just what they need to and nothing else.
- Segmenting the network and infrastructure into clearly defined zones of trust, and inspecting, verifying, and logging both the traffic crossing that demarcation point and blocked attempts to cross it.
- Increasing the use of additional authentication methods, such as those needed to thwart credential-based attacks.
Never trust, always authenticate access requests fully, and always track and account for all activity, authorized or not. Analyze and assess those accounting records; seek the anomalies and investigate them.
This may sound like rampant paranoia, but the truth is, the advanced persistent threats are not just “out there” somewhere. They are probably already in your systems. Perhaps now's the time to replace “trust, but verify” with constant vigilance as your watchwords.
Summary
Two major themes tie everything in this chapter together with Chapter 5's deep dive into network architectures and the protocol stacks that make them work. The first of those themes is the need to systematically and rigorously manage and control the creation, maintenance, and use of identities as they relate to subjects claiming the right to access our systems and our information. Identities are not, of course, the subjects, no more than you are your name. Nor are you the information needed to authenticate your claim that you are you when you try to access your online bank or your employer's information system. That brings us to the second of those themes, which involves the “triple A” of authenticating a claim to an identity by a subject, authorizing that subject's access to an object, and keeping detailed accounting records of every activity involved in that process and in the subject's use of the object.
Three forces have come together to make the SSCP's job even more demanding when it comes to this combined set of topics we call identity and access management. Organizations have grown in complexity internally and externally, as they take on both temporary and long-term relationships with partners, vendors, clients, and others in their markets. This combines with the natural tendency to want more data, better data, to support more decisions made more quickly, resulting in ever more complex patterns of information access and use within the organization and across its federated ecosystem of other, hopefully like-minded organizations and individuals. Finally, we have to acknowledge the growing sophistication of the advanced persistent threat actors, and their willingness and ability to take months to infiltrate, scout out valuable information assets to steal a copy of, and then complete their attack by exfiltrating their prize. All three of these trends are forcing us to take on more complex, powerful, flexible approaches to network security, identity management, and access control.
Exam Essentials
- Compare and contrast single-factor and multifactor authentication. Typically, these refer to how human users gain access to systems. Each factor refers to something that the user has, knows, or is. Users can have identification cards or documents, electronic code-generating identity devices (such as key fobs or apps on a smartphone), or machine-readable identity cards. Users can know personally identifying information such as passwords, answers to secret questions, or details of their own personal or professional life. Users are their physical bodies, and biometric devices can measure their fingerprints, retinal vein patterns, voice patterns, or many other physiological characteristics that are reasonably unique to a specific individual and hard to mimic. Each type of factor, by itself, is subject to being illicitly copied and used to attempt to spoof identity for systems access. Use of each factor is subject to false positive errors (acceptance of a presented factor that is not the authentic one) and false negative errors (rejection of authentic factors), and they can be things that legitimate users may forget (such as passwords or leaving their second-factor authentication device or card at home). As you add more factors to user sign-on processes, you add complexity and costs. User frustration can also increase with additional factors being used, leading to attempts to cheat the system.
Explain the advantages and disadvantages of single sign-on architectures. Initially, the design of systems and platform applications required users to present login credentials each time they attempted to use each of these different systems. This is both cumbersome and frustrating to users and difficult to manage from an identity provisioning and access control perspective. SSO (single sign-on) allows users to access an organization's systems by only having to do one sign-on—they present their authentication credentials once. It uses an integrated identity and access control management (IAM) systems approach to bring together all information about all subjects (people or processes) and all objects (people, processes, and information assets, including networks and computers) into one access control list or database. SSO then generates a ticket or token, which is the authorization of that subject's access privileges for that session. This can be implemented with systems like XTACACS, RADIUS, Microsoft Active Directory, and a variety of other products and systems, depending on the degree of integration the organization needs. SSO eliminates the hassle of using and maintaining multiple, platform-specific or system-specific sign-on access control lists; it does bring the risk that once into the system, users can access anything, including things outside of the scope, purview, or needs of their authorized duties and privileges. Properly implemented access control should provide that next level of “need to know” control and enforcement.
Explain why we need device authentication for information security, and briefly describe how it works. Access to company or organizational information assets usually requires physical and logical access, typically via the Physical, Data Link, and Network layers of a protocol stack such as TCP/IP. The CIANA+PS needs of the organization will dictate what information needs what kinds of protection, and in most cases, this means that only trusted, authorized subjects (people, processes, or devices) should be authorized to access this information. That requires that the subject first authenticate its identity. Device authentication depends on some hardware characteristic, such as a MAC address, and may also depend on authentication of the software, firmware, or data stored on the device; this ensures that trusted devices that do not have required software updates or malware definition file updates, for example, are not allowed access. Further constraints might restrict even an authorized device from attempting to access the system from new, unknown, and potentially untrustworthy locations, times of day, etc. The authentication process requires the device to present such information, which the access control system uses to either confirm the claimed identity and authorize access, request additional information, or deny the request.
Compare and contrast single sign-on and federated access. SSO, by itself, does not bridge one organization's access control systems with those of other organizations, such as strategic partners, subcontractors, or key customers; this requires a federated identity and access management approach. Just as individual platform or system access is logically a subset of SSO, SSO is a subset of federated access. Federated identity management systems provide mechanisms for sharing identity and access information, which makes identity and access portable, allowing properly authorized subjects to access otherwise separate and distinct security domains. Federated access uses open standards, such as the OASIS Security Assertion Markup Language (SAML), and technologies such as OAuth, OpenID, various security token approaches, Web service specifications, Windows Identity Foundation, and others. Federated access systems typically use Web-based SSO for user access.
Explain what is meant by the evolution of identity and its impact on information security. Traditionally, identity in information systems terms was specific to human end users needing access to systems objects (such as processes, information assets, or other users); this was user-to-applications access, since even a system-level application (such as a command line interpreter) is an application program per se. This has evolved to consider applications themselves as subjects, for example, and in Web service or service-oriented architectures (SOA), this involves all layers of the protocol stack. Privacy and the individual civil rights of users also are driving the need to provide a broad, integrated approach to letting users manage the information about themselves, particularly the use of personally identifying information (PII) as part of identity and access management systems. Fortunately, this evolution is occurring at a time when open and common standards and frameworks, such as the Identity Assurance Framework, are becoming more commonly used and are undergoing further development. The concept of identity will no doubt continue to involve as we embrace both the Internet of Things and greater use of artificial intelligence systems and robots.
Describe what internetwork trust architectures are and how they are used. When two or more organizations need their physically and logically separate networks to collaborate together, this requires some form of sharing of identity and access control information. Internetwork trust architectures are the combination of systems, technologies, and processes used by the two organizations to support this interorganizational collaboration. This will typically require some sort of federated access system.
Explain what a zero trust network is and its role in organizational information security.
Zero trust network design and access control reflect the need to counter the more advanced persistent threats and the increasing risk of data exfiltration associated with many of them. This shifts the security focus from the perimeter to step-by-step, node-by-node movement and action within the organization's information infrastructure. Instead of large, easily managed networks or segments, zero trust designs seek to micro-segment the network. Fully exploiting the capabilities of attribute-based access control, the zero trust approach promises to more effectively contain a threat, whether an outsider or insider, and thus limit the possibility of damage or loss. It's sometimes called the “never trust, always verify” approach, and for good reason.
Explain how one-way, two-way, and transitive trust relationships are used in a chain of trust. It's simplest to start with one-way trust: node A is the authoritative source of trusted information about a topic, and since the builders of node B know this, node B can trust the information it is given by node A. This would require that the transmission of information from node A to B meets nonrepudiation and integrity requirements. Two-way trust is actually the overlap of two separate one-way trust relationships: node A is trusted by node B, which in turn is trusted by node A. Now, if node C trusts node B, then transitivity says that node C also trusts node A. This demonstrates a simple chain of trust: node A is trusted by B, which is trusted by C. This chain of trust concept is fundamental to certificates, key distribution, integrated and federated access control, and a host of other processes critical to creating and maintaining the confidentiality, integrity, authorization, nonrepudiability, and availability of information.
One-way and two-way trust are most often applied to domains of users: organization A trusts its users and trusts the users of its strategic partner B, but organization B does not have the same level of trust for organization A's users. This often happens during mergers, temporary partnerships or alliances, or the migration of subsets of an organization's users from one set of platforms to another.
- Describe the use of an extranet and important information security considerations with using extranets. An extranet is a virtual extension to an organization's intranet (internal LAN) system, which allows outside organizations to have a greater degree of collaboration, information sharing, and use of information and systems of both organizations. For example, a parts wholesaler might use an extranet to share wholesale catalogs, or filtered portions thereof, with specific sets of key customers or suppliers. Extranets typically look to provide application-layer shared access and may do this as part of a SOA approach. Prior to the widespread adoption of VPN technologies, organizations needed significant investment in additional hardware, network systems, software, and personnel to design, deploy, maintain, and keep their extranets secure. In many industries, the use of industry-focused applications provided as a service (SaaS or PaaS cloud models, for example) can take on much of the implementation and support burden of a traditional extranet. As with any network access, careful attention to identity management and access control is a must!
Explain the role of third-party connections in trust architectures. In many trust architectures, either one of the parties is the anchor of the trust chain, and thus issues trust credentials for others in the architecture to use, or a trusted third party, not actually part of the architecture per se, is the provider of this information. One such role is that of a credential service provider (CSP), which (upon request) generates and provides an object or data structure that establishes the link between an identity and its associated attributes, to a subscriber to that CSP. Other examples of third parties are seen in the ways that digital certificates and encryption keys are generated, issued, and used.
Describe the key steps in the identity management or identity provisioning lifecycle. In an information systems context, an identity is a set of credentials associated with (or bound to) an individual user, process, device, or other entity. The lifecycle of an identity reflects the series of events as the entity joins the organization, needs to be granted access to its information systems, and how those needs change over time; finally, the entity leaves the organization (or no longer exists), and the identity needs to be terminated to reflect this. Typically, these steps are called provisioning, review, and revocation. Provisioning creates the identity and distributes it throughout the organization's identity and access control systems and data structures, starting with management's review and approval of the access request, the identifying information that will be used, and the privileges requested. Pushing the identity out to all elements of the organization's systems may take a few minutes to a number of hours; often, this is done as part of overnight batch directory and integrated access management system updates. Review should be frequent and be triggered by changes in assigned roles as well as changes in organizational needs. Privilege creep, the accumulation of access privileges beyond that strictly required, should be avoided. When the employee (or entity) is no longer required by the organization to have access—when they are fired or separated from the organization, for example—their identity should first be blocked from further use, and then finally removed from the system after any review of their data or an audit of their access accounting information.
Explain the role of authentication, authorization, and accounting in identity management and access control terms. These three processes (the “AAA” of access control) are the fundamental functions of an access control system. Authentication examines the identity credentials provided by a subject that is requesting access, and based on information in the access control list, either grants (accepts) access, denies it, or requests additional credential information, such as an additional identification factor. Next, the access control system authorizes (grants permission to) the subject, allowing the subject to have access to various other objects in the system. Accounting is the process of keeping logs or other records that show access requests, whether those were granted or not, and a history of what resources in the system that subject then accessed. Accounting functions may also be carried out at the object level, in effect keeping a separate set of records as to which subjects attempted access to a particular object, when, and what happened as a result. Tailoring these three functions allows the SSCP to meet the particular CIANA+PS needs of the organization by balancing complexity, cost, and runtime resource utilization.
Explain the role of identity proofing in identity lifecycle management. Proofing an identity is the process of verifying the correctness and the authenticity of the supporting information used to demonstrate that a person (or other subject) is in fact the same entity that the supporting information claims that they are. For example, many free email systems require an applicant to provide a valid credit or debit card, issued in the applicant's name, as part of the application process. This is then tested (or “proofed”) against the issuing bank, and if the card is accepted by that bank, then at least this one set of supporting identity information has been found acceptable. The degree of required information security dictates the degree of trust placed in the identity (and your ability to authenticate it), and this then places a greater trust in the proofing of that identity. For individual (human) identities, a growing number of online identity proofing systems provide varying levels of trust and confidence to systems owners and operators that job applicants, customers, or others seeking access to their systems are who (or what) they claim to be.
Compare and contrast discretionary and nondiscretionary access control policies. Mandatory (also called nondiscretionary) policies are rules that are enforced uniformly across all subjects and objects within a system's boundary. This constrains subjects granted such access (1) from passing information about such objects to any other subject or object; (2) attempting to grant or bequeath its own privileges to another subject; (3) changing any security attribute on any subject, object, or other element of the system; (4) granting or choosing the security attributes of newly created or modified objects (even if this subject created or modified them); and (5) changing any of the rules governing access control. Discretionary access policies are also uniformly enforced on all subjects and objects in the system, but depending on those rules, such subjects or objects may be able to do one or more of the tasks that are prohibited under a mandatory policy.
Explain the different approaches that access control systems use to grant or deny access. Role-based access control (RBAC) systems operate with privileges associated with the organizational roles or duties assigned, typically to individual people. For example, a new employee working in the human resources department would not be expected to need access to customer-related transaction histories. Similarly, chief financial officers (CFOs) may have to approve transactions above a certain limit, but they probably should not be originating transactions of any size (using separation of duties to preclude a whaling attack, for example). Attribute-based access control systems look at multiple characteristics (or attributes) of a subject, an object, or the environment to authorize or restrict access. That said, CFOs might be blocked from authorizing major transactions outside of certain hours, on weekends, or if logged on from an IP address in a possibly untrustworthy location. Subject-based access control is focused on the requesting subject and applying roles or attributes as required to grant or deny access. Subject-based and object-based access control systems associate attributes and constraint checking against them with each subject and with each object, respectively.
Describe the different privileges that access control systems can authorize to subjects. Subjects attempt to do something with or to an object, learn something about it, or request a service from it. Access control has to compare the privileges already assigned to the subject with the conditions, constraints or other factors pertaining to the object and type of access requested, to determine whether to grant access or deny it. These privileges may involve requests to read data from it, or read metadata kept in the system about the object; modify its contents, or the metadata; delete or extend it (that is, request that additional systems resources, such as space in memory or in storage, be allocated to it); load it as an executable process or thread for execution by a CPU; assign privileges or attributes to it; read, change, or delete access control system criteria, conditions, or rules associated with the object; pass or grant permissions to the object; copy or move it to another location; or even ask for historical information about other access requests made about that object. In systems that implement subject ownership of objects, passing ownership is also a privilege to control. Each of these kinds of operations may be worth considering as a privilege that the access control system can either grant or deny.
Describe the key attributes of the reference monitor in access control systems. In abstract or conceptual terms, the reference monitor is a subject (a system, machine, or program) that performs all of the functions necessary to carry out the access control for an information system. Typically, it must be resistant to tampering, must always be invoked when access is requested or attempted, and must be small enough to allow thorough analysis and verification of its functions, design, and implementation in hardware, software, and procedures. It can be placed within hardware, operating systems, applications, or anywhere we need it to be, as long as such placement can meet those conditions. The security kernel is the reference monitor function within an operating system; the trusted computing base is the hardware and firmware implementation of the reference monitor (and other functions) in a processor or motherboard.
Explain how Biba and Bell-LaPadula, as access control models, contribute to information security. Each of these models is focused on a different information security attribute or characteristic. Bell-LaPadula was designed to meet the Department of Defense's need for systems that could handle multiple levels of classified information; it focuses on confidentiality by providing restrictions on “read up”—that is, accessing information at a higher level than the process is cleared for—or “write-down” of classified information into a process or environment at a lower security level. Biba is focused on protecting data integrity, and so it restricts higher-level tasks from reading from lower-level tasks (to prevent the higher-level task from possibly being contaminated with incorrect data or malware), while allowing reads from lower-level to higher-level tasks.
Explain Type 1 and Type 2 errors and their impacts in an identity management and access control context. Type 1 errors are false negatives, also called a false rejection, which incorrectly identify a legitimate subject as an intruder; this can result in delays or disruptions to users getting work done or achieving their otherwise legitimate system usage accomplished. Type 2 errors are false positives or false acceptances, in which unknown subjects, or authorized users or subjects exceeding their privileges, are incorrectly allowed access to systems or objects. Type 2 errors can allow unauthorized subjects (users or tasks) to access system information resources, take action, exfiltrate data, or take other harmful actions.
Explain the roles of remediation and quarantine in network access control. Network access control systems can be programmed to inspect or challenge (interrogate) devices that are attempting to connect to the network, which can check for a deficiency such as software updates not applied, malware definitions not current, or other conditions. Systems with otherwise legitimate, trusted credentials that fail these checks can be routed to remediation servers, which only allow the user access to and execution/download of the required fixes. For network access control, quarantine (which is also called captive portals) is similar in concept but deals with client systems attempting an HTTP or HTTPS connection that fails such tests. These are restricted to a limited set of webpages that provide instructions on how to remediate the client's shortcomings.
Describe the use of TACACS, RADIUS, and other network access control technologies. Network access control systems use authentication methods to validate that a subject (device or user) is whom or what they claim to be and that they are authorized to conduct access requests to sets of systems resources, and to account for such access requests, authorization, and resource use. Different access control technologies do these “AAA” tasks differently, achieving different levels of information security. Access control systems need a database of some sort that contains the information about authorized subjects, their privileges, and any constraints on access or use; this is often called an access control list (ACL). (Keep separate in your mind that routers and firewalls are often programmed with filter conditions and logic, as part of access control, by means of ACLs contained in the router's control memory. Two kinds of ACLs, two different places, working different aspects of the same overall problem.)
Terminal Access Controller Access Control System (TACACS) was an early attempt to develop network access capabilities, largely for Unix-based systems. (The “terminal” meant either a “dumb” CRT-keyboard terminal, a very thin client, or a remote card reader/printer job entry system.) XTACACS, or extended TACACS, was a Cisco proprietary extension to TACACS. TACACS+ grew out of both efforts, as an entirely new set of protocols that separate the authentication, authorization, and accounting functions, which provides greater security and control.
Remote Authentication Dial-In User Service (RADIUS) started with trying to control access to hosts by means of dial-in connections, typically using dumb terminals and thin clients. It works with (not in place of) a network access control server, which maintains the ACL information, to validate the request, deny it, or ask for additional information from the requestor. RADIUS has continued to be popular and effective, especially as it supports roaming for mobile end-user devices. An enhanced version of RADIUS, called Diameter, never gained momentum in the marketplace.
- Explain the uses of just-in-time identity and manual provisioning in IAM. Just-in-time (JIT) identity provides two different capabilities to systems operators. The first allows for new users to create identities on a system without manual intervention or action by administrators; this is often used for generating user IDs and accounts on wikis, blogs, and community resource pages. This might perhaps be more correctly called just-in-time identity provisioning. The second use case provides for on-demand privilege elevation, when a user attempts to access an object that requires higher privileges than they are currently using; privileges are immediately lowered back to the starting level immediately upon completion or termination of the task in question. This restricts the privileges used by any and all users to the minimum necessary for each task they are performing.
- Compare and contrast rule-based access control with attribute-based access control. Both of these models provide for the use of a detailed, fine-grained comparison of conditions associated with a subject, the object it is attempting to access, current conditions of the system, or other characteristics. Rule-based models provide for Boolean or set theoretic formulas to be expressed (the rules), which taken together as a logical chain must all evaluate as true to enable the access to proceed. Attribute-based models work in similar ways, but use parameter tables or lists to express these conditions. Comparing the two, RuBac's rule sets are harder to initially configure, demonstrate, and maintain than ABACs are. RuBACs are also harder to scale as the population of subjects, objects, or their interactions grows. ABAC is also proving to be simpler to add more dynamic attributes to than RuBac systems have been known to be.
- Explain the need for session management, and describe its operation. In IAM terms, a session is the set of activities conducted by a user during their connection with systems resources. Session management provides the protocols and processes that ensure the secure and continuous conduct of these activities, from initial connection through logout, the connection being dropped, a timeout, or other termination of the session. Generally, a session ID must be created and assigned, which is a long pseudorandom string (typically 30 characters) used to uniquely identify a session with the user it supports. X.509 certificate processes are used to coordinate the exchange of identity information by the session management functions and the applications involved in the session. Exploitable vulnerabilities can exist if the session management implementation does not properly construct, use, and protect session and token cookies, which can lead to compromise of a session ID and a subsequent replay attack.
- Describe Kerberos and explain its use. Kerberos is an indirect authentication system that has become a de facto standard across the information security world. It uses a ticket-based security token as its mechanism for validating a user's identity claim to access a service provider. A six-step protocol starts with the subject (user) requesting a ticket granting ticket (TGT); if this is confirmed (steps 1 and 2), the subject uses that TGT as part of a ticket request sent to the Kerberos server; if granted, the server sends back a session key in the form of a ticket (steps 3 and 4). The subject then provides that ticket to the service provider they desire access to (step 5), which then approves or disapproves of the access (step 6).
- Describe the concept of a zero trust architecture. More than just a microsegmentation of networks, a zero trust architecture (ZTA) is one that applies authentication and authorization processes to nearly every attempt by an identity or a process to access resources in any manner. Without this, identities can often identify resources on other systems elements (with scanners or other techniques) and attempt to move laterally, within their privilege level, to access resources without any further authorization or authentication being performed. Without a zero trust approach, once on the LAN, a user can access every device and port on it; ZTAs will segment organizational LANs into smaller and smaller security subdomains, requiring authorization (and possibly authentication) at each attempt to transit a ZTA boundary device such as a router. ZTAs also segment (or microsegment) data, software, and other assets into smaller units, as a means of establishing stronger need to know constraints. User and entity behavior analytics (UEBA) and more robust attribute-based access control (ABAC) are often part of ZTA implementations.
- Explain user and entity behavior analytics (UEBA) and its use. This security process uses a combination of known hostile behavior patterns, approved or permitted behavior patterns, and recent behavior histories as a learning baseline; this baseline is compared in real time (or in analysis of previously captured data) to identify behaviors that may be suspicious. These can cause heightened surveillance and analysis, trigger alarms to security management functions and operators, or interdict the suspicious behavior and attempt to contain it. UEBA systems are often used with access control systems, SIEM, SOAR, and managed security services. Using a variety of machine learning and other techniques, UEBA is becoming a primary replacement for more traditional security log file capture, management, and analysis methods.
Review Questions
- Which statement about single-factor vs. multifactor authentication is most correct?
- Single-factor is easiest to implement but with strong authentication is the hardest to attack.
- Multifactor requires greater implementation, maintenance, and management, but it can be extremely hard to spoof as a result.
- Multifactor authentication requires additional hardware devices to make properly secure.
- Multifactor authentication should be reserved for those high-risk functions that require extra security.
- Multifactor authentication means that our systems validate claims to subject identity based on:
- Third-party trusted identity proofing services
- Digital identity platforms
- Some aspect of what the subject is, knows, or has
- Two different biometric measurements
- In access control authentication systems, which is riskier, false positive or false negative errors?
- False negatives, because they lead to a threat actor being granted access
- False positives, because they lead to a threat actor being granted access
- False negatives, because they lead to legitimate subjects being denied access, which impacts business processes
- False positives, because they lead to legitimate subjects being denied access, which impacts business processes
- Your IT department head wants to implement SSO, but some of the other division heads think it adds too much risk. She asks for your advice. Which statement best helps her address other managers' concerns?
- They're right; by bridging multiple systems together with one common access credential, you risk opening everything to an attacker.
- Yes and no; single sign-on by itself would be risky, but thorough and rigorous access control at the system, application, and data level, tied to job functions or other attributes, should provide one-stop login but good protection.
- Single sign-off involves very little risk; you do, however, need to ensure that all apps and services that users could connect to have timeout provisions that result in clean closing of files and task terminations.
- Since support for single sign-on is built into the protocols and operating systems you use, there's very little risk involved in implementation or managing its use.
- What's the most secure way to authenticate device identity prior to authorizing it to connect to the network?
- MAC address allowed listing
- Multifactor authentication that considers device identification, physical location, and other attributes
- Verifying that the device meets system policy constraints as to software and malware updates
- Devices don't authenticate, but the people using them do.
- Which statement about federated access systems is most correct?
- SSO and federated access provide comparable capabilities and security.
- By making identity more portable, federated access allows multiple organizations to collaborate, but it does require greater attention to access control for each organization and its systems.
- Once you've established the proper trust architecture, federated access systems are simple to implement and keep secure.
- Most federated access systems need to use a digital identity platform or IDaaS to provide proper authentication.
- Which statement about extranets and trust architectures is most correct?
- Proper implementation of federated access provides safe and secure ways to bring an extranet into an organization's overall network system; thus an internetwork trust architecture is not needed.
- Extranets present high-risk ways for those outside of an organization to collaborate with the organization and thus need to be kept separate from the trust architecture used for other internetwork activities.
- Extranets provide extensions to an organization's intranet and thus need to use the same trust architecture as implemented in the main organizational network.
- Trust architectures are the integrated set of capabilities, connections, systems, and devices that provide different organizations safe, contained, and secure ways to collaborate together by sharing networks, platforms, and data as required; thus, extranets are an example of a trust architecture.
- What role should zero trust architectures play in your organization's information security strategy, plans, and programs?
- None just yet; this is a theoretical concept that is still being developed by the IETF and government-industry working groups.
- If you've done your threat modeling and vulnerability assessment correctly, you don't need the added complexity of a zero trust architecture.
- By guiding you to micro-segment your networks and systems into smaller, finer-grain zones of trust, you focus your attention on ensuring that any attempts to cross a connection between such zones has to meet proper authentication standards.
- Since the protocols you need to support zero trust do not work on IPv4, you need to wait to include zero trust architectures until you've transitioned your systems to IPv6.
- Which statement about trust relationships and access control is most correct?
- One-way trust relationships provide the infrastructure for SSO architectures.
- Transitive trust relationships are similar to trust chains but for individual users rather than digital certificates.
- Trust relationships describe the way different organizations are willing to trust each other's domain of users when developing federated access arrangements.
- Transitive trust relationships cannot be supported by federated access technologies.
- Which set of steps correctly shows the process of identity management?
- Proofing
- Provisioning
- Review
- Revocation
- Deletion
- 1, 2, 3, 4, and then 5
- 2, 3, 4
- 1, 2, 4, 5
- 2, 3, 5
- Which statements about AAA in access control are correct? (Choose all that apply.)
- Accounting provides the authorization to access resources as part of chargeback systems.
- Analysis, auditing, and accounting are the services provided by an access control system's server.
- Authorization checks to see if an identity has the right(s) to access a resource, while authentication validates that the identity is what it claims to be. Accounting tracks everything that is requested, approved, or denied.
- Authentication checks to see if an identity has been granted access privileges, using the access control tables in the central repository; authorization validates the identity is allowed to access the system. Accounting keeps track of all requests, approvals, and denials.
- Which of the following are allowed under mandatory access control policies?
- Passing information about the object to another subject
- Changing or creating new security attributes for an object or another subject
- Granting privileges to another subject
- None of these are allowed under mandatory access control policies.
- Which of the following statements are true about discretionary access control policies? (Choose all that apply.)
- Subjects cannot be allowed to pass information about the object to another subject.
- Changing or creating new security attributes for an object or another subject can only be done by the access control system.
- Subjects can change rules pertaining to access control but only if this is uniformly permitted across the system for all subjects.
- Subjects can be permitted to pass on or grant their own privileges to other subjects.
- Which form of access control depends on well-defined and up-to-date job descriptions?
- Role-based
- Subject-based
- Object-based
- Attribute-based
- Which form of access control is probably best for zero trust architectures to use?
- Role-based
- Subject-based
- Object-based
- Attribute-based
- What kinds of privileges should not be part of what your mandatory access control policies can grant or deny to a requesting subject? (Choose all that apply.)
- Any privilege relating to reading from, writing to, modifying, or deleting the object in question, if it was created or is owned by the requesting subject
- Reading or writing/modifying the metadata associated with an object
- Modifying access control system constraints, rules, or policies
- Reading, writing, deleting, or asking the system to load the object as an executable task or thread and run it
- Which statements about a reference monitor in an identity management and access control system are correct?
- It should be tamper-resistant.
- Its design and implementation should be complex so as to defeat reverse engineering attacks.
- It's an abstract design concept, which is not actually built into real hardware, operating systems, or access control implementations.
- It is part of the secure kernel in the accounting server or services provided by strong access control systems.
- A key employee seems to have gone missing while on an overseas holiday trip. What would you recommend that management do immediately, with respect to identity management and access control, for your federated access systems? Choose the most appropriate statement.
- Deprovision the employee's identity.
- Suspend all access privileges for the employee's identity, except for email, in case the employee tries to use it to contact the company for help.
- Suspend all access privileges for the employee's identity, and notify all federated systems partners to ensure that they take similar steps.
- Suspend all access privileges for devices normally used by the employee, such as their laptop, phablet, or phone (employee-owned, company-provided, or both). If possible, quickly establish a captive portal or quarantine subnet to route access attempts from these devices to.
- What is the role of third parties in identity management and access control? (Choose all that apply.)
- Third parties are those who have access to your systems via federated access, and as such, are part of your trust architectures.
- Credential service can be provided by third parties or by internal services as part of your systems.
- Identity proofing can be provided by external third parties.
- Identity as a service, usually via a cloud or Web-based service, is provided by numerous third parties.
- Which statement about subjects and objects is not correct?
- Subjects are what users or processes require access to in order to accomplish their assigned duties.
- Objects can be people, information (stored in any fashion), devices, processes, or servers.
- Objects are the data that subjects want to access in order to read it, write to it, or otherwise use it.
- Subjects are people, devices, or processes.
- John has talked with his IT director about getting an upgrade to their network access control tools that will allow them to implement remediation and quarantine measures. His director thinks this is unnecessary because their enterprise antimalware system provides for quarantine. Is John's director correct? Which of the following should John share with his director?
- No, because malware quarantine moves infected files into safe storage where they cannot be executed or copied by users; network access control quarantine prevents devices that are not up-to-date with software updates or other features from connecting to the Internet without performing required updates.
- Yes, because both kinds of technologies can support quarantine of suspect or questionable systems.
- No, because network access quarantine prevents HTTP or HTTPS connection attempts from systems that do not meet policy requirements by restricting them to webpages with update instructions; malware quarantine puts infected or suspected files out of reach of users to prevent inadvertent or deliberate execution or read attempts on them.
- Yes, because the antimalware system will prevent devices that are infected from accessing any systems resources, whether files, other CPUs, or other nodes on the network.
- Your IT director has asked you for a recommendation about which access control standard your team should be looking to implement. He's suggested either Diameter or XTACACS, as they used those in his last job. Which of the following gives you the best information to use in replying to your boss?
- The standard is IEEE 802.1X; Diameter and XTACACS are implementations of the standard.
- Diameter is an enhanced RADIUS and has been quite successful.
- XTACACS replaced TACACS+, which could be a good solution for you.
- RADIUS is the standard to work with.
- Why do we need IPSec?
- Now that IPv6 is here, we don't, since its built-in functions replace IPsec, which was for IPv4.
- Since more and more apps are moving to PKI for encryption of data on the move, we no longer need IPSec.
- IPSec provides key protocols and services that use encryption to provide confidentiality, authentication, integrity, and nonrepudiation at the packet level; without it, many of the Layer 2, 3, and 4 protocols are still unprotected from attack.
- Since IPv6 encrypts all traffic at all layers, once you've transitioned your systems to IPv6, you won't need IPSec, except for those legacy IPv4 systems you communicate with.